


Article original : Web Scraping with Google Sheets – How to Scrape Web Pages with Built-in Functions
Vous avez bien lu – vous pouvez pratiquer le web scraping sans quitter votre espace préféré : Google Sheets.
Google Sheets dispose de cinq fonctions intégrées qui vous aident à importer des données depuis d'autres feuilles et d'autres pages web. Nous allons passer en revue chacune d'entre elles, de la plus simple (la plus limitée) à la plus complexe (la plus puissante).
Les voici, et vous pouvez cliquer sur chaque fonction pour accéder directement à sa section dédiée. J'ai également réalisé une vidéo qui explique tout :
Raccourcis vers les sections
- Comment utiliser la fonction IMPORTRANGE
- Comment utiliser la fonction IMPORTDATA
- Comment utiliser la fonction IMPORTFEED
- Comment utiliser la fonction IMPORTHTML
- Comment utiliser la fonction IMPORTXML
Voici la feuille Google Sheets que nous utiliserons pour démontrer chaque fonction.
Si vous souhaitez la modifier, faites une copie en sélectionnant Fichier - Créer une copie lorsque vous l'ouvrez.
 capture d'écran de Google Sheets
capture d'écran de Google Sheets
Comment utiliser la fonction IMPORTRANGE
Il s'agit de la seule fonction qui importe une plage depuis une autre feuille plutôt que des données depuis une autre page web. Ainsi, si vous avez une autre feuille Google Sheets, vous pouvez lier les deux feuilles ensemble et importer les données dont vous avez besoin depuis une feuille vers l'autre.
Par exemple, voici une feuille contenant une série de données aléatoires sur les Samsung Galaxy.
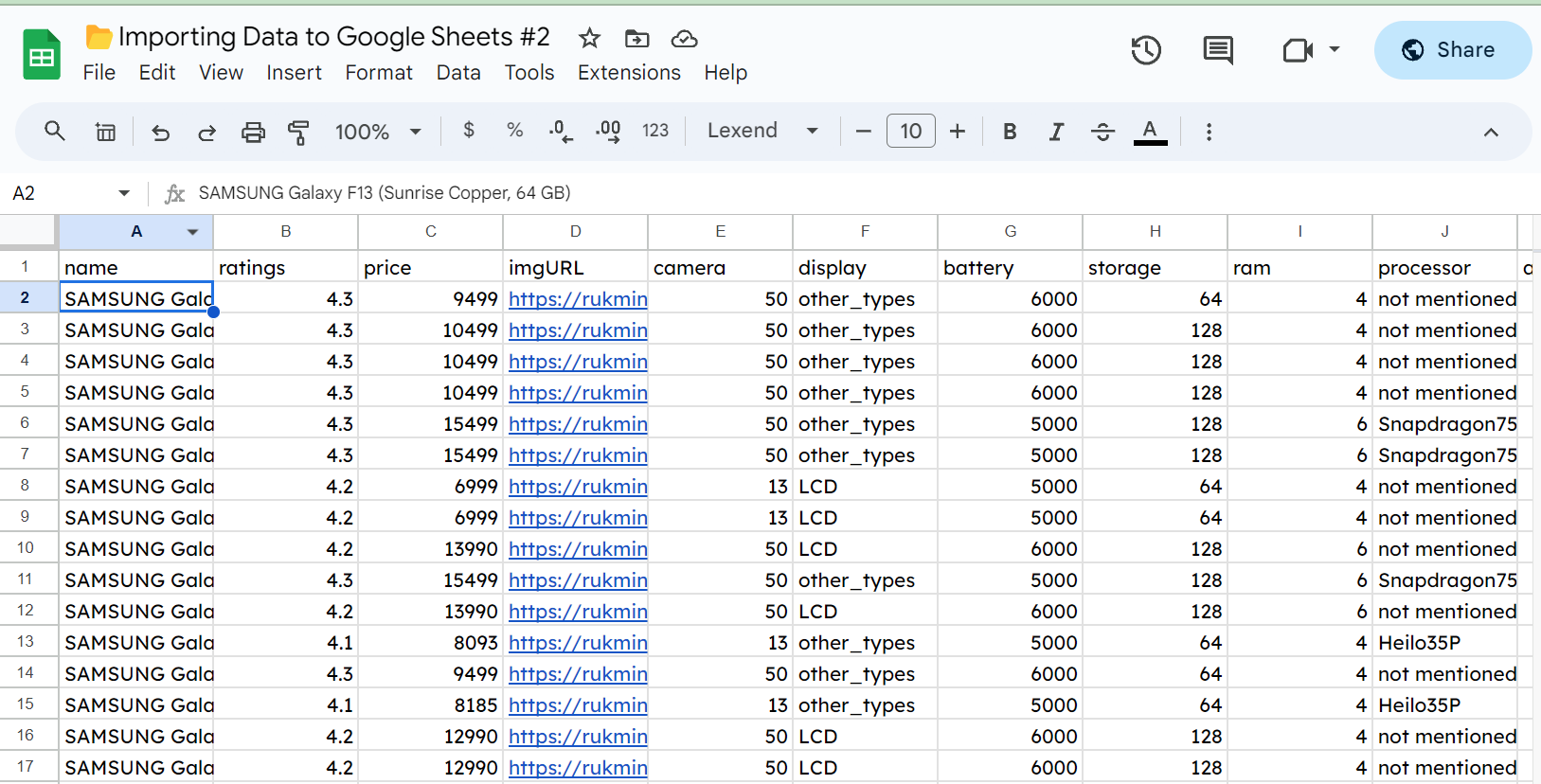
Vous pouvez voir que nous avons quelques centaines de lignes de données sur les téléphones. Si nous voulons importer ces données dans une autre feuille de calcul, nous pouvons utiliser IMPORTRANGE(). C'est la plus simple à utiliser des cinq fonctions que nous allons examiner. Tout ce dont elle a besoin est une URL pour une feuille Google Sheets et la plage que nous voulons importer.
Consultez l'onglet pour IMPORTRANGE dans la feuille Google Sheets ici, et vous verrez que dans la cellule A5, nous avons la fonction =IMPORTRANGE(B4,"data!a1:K"). Cela importe la plage A1:K depuis l'onglet data de notre deuxième feuille de calcul dont l'URL est dans la cellule B4.
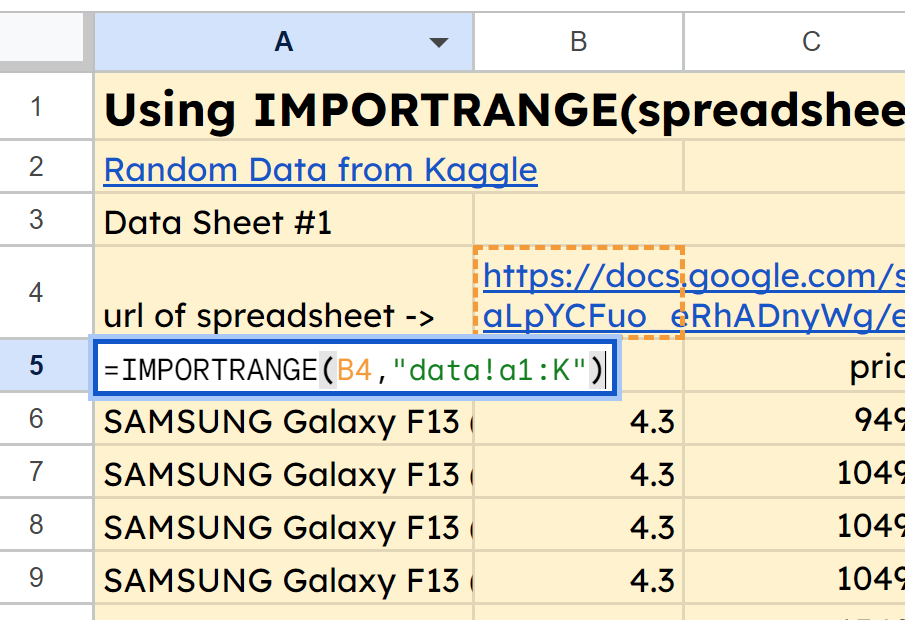 capture d'écran de la fonction IMPORTRANGE
capture d'écran de la fonction IMPORTRANGE
Une fois vos données importées dans votre feuille de calcul, vous pouvez faire l'une des deux choses suivantes.
- Laisser le lien via la fonction
IMPORTRANGE. Ainsi, si votre source de données va être mise à jour, vous obtiendrez les données mises à jour. - Copier et CTRL+SHIFT+V pour coller uniquement les valeurs. Ainsi, vous avez les données brutes dans votre nouvelle feuille de calcul et vous n'aurez pas à dépendre de quelque chose qui change avec l'URL à l'avenir.
Comment utiliser la fonction IMPORTDATA
C'est assez simple. Elle importera des données .csv ou .tsv depuis n'importe où sur Internet. Ces formats signifient respectivement Valeurs Séparées par des Virgules et Valeurs Séparées par des Tabulations.
Le format .csv est le type de fichier le plus couramment utilisé pour les données financières qui doivent être importées dans des feuilles de calcul et d'autres programmes.
Comme IMPORTRANGE, nous n'avons besoin que de quelques informations pour IMPORTDATA : l'URL où se trouve le fichier et le délimiteur. Il y a aussi une variable optionnelle pour la locale, mais j'ai trouvé qu'elle était inutile.
En fait, Google Sheets est assez intelligent – vous pouvez omettre le délimiteur, et il devinera généralement quel type de données (.csv ou .tsv) se trouve à l'URL.
Vous pouvez voir que j'ai trouvé un site de données gouvernementales de New York où se trouvent certaines données sur les numéros gagnants de la loterie. J'ai mis l'URL d'un fichier .csv dans A5, puis utilisé la fonction =IMPORTDATA(A5,",") pour importer les données depuis le fichier .csv.
 Capture d'écran de la fonction IMPORTDATA
Capture d'écran de la fonction IMPORTDATA
Vous pourriez également télécharger le fichier .csv puis sélectionner Fichier - Importer pour importer ces données. Mais dans le cas où vous n'avez pas les permissions de téléchargement ou souhaitez simplement les obtenir directement depuis un site, IMPORTDATA fonctionne très bien.
Comment utiliser la fonction IMPORTFEED
Cette fonction importe les données des flux RSS. Si vous êtes familier avec les podcasts, vous reconnaîtrez peut-être le terme. Chaque podcast a un flux RSS qui est un fichier structuré rempli de données XML.
En utilisant l'URL du flux RSS, IMPORTFEED extraira les données d'un podcast, d'un article de presse ou d'un blog à partir de ses informations RSS.
Il s'agit de la première fonction qui commence à avoir quelques options supplémentaires à sa disposition.
Tout ce qui est requis est l'URL d'un flux, et elle importera les données de ce flux. Cependant, nous pouvons spécifier quelques autres paramètres si nous le souhaitons. Les options incluent :
- [query] : cela spécifie quelles parties des données extraire du flux. Nous pouvons sélectionner parmi des options comme "feed " où le type peut être titre, description, auteur ou URL. Même chose avec "items " où le type peut être titre, résumé, URL ou créé.
- [headers] : cela inclura les en-têtes (TRUE) ou non (FALSE)
- [num_items] : cela spécifie combien d'éléments retourner lors de l'utilisation de Query. (La documentation indique que si cela n'est pas spécifié, tous les éléments actuellement publiés sont retournés, mais je n'ai pas trouvé cela être le cas. J'ai dû spécifier un nombre plus grand pour obtenir plus d'une douzaine ou plus).
Vous pouvez voir sur les captures d'écran ci-dessous que j'interroge l'un de mes flux pour extraire les titres des épisodes et les URL.
Tout d'abord, pour obtenir tous les titres, j'ai utilisé IMPORTFEED(A3, "items title", TRUE, 50) :
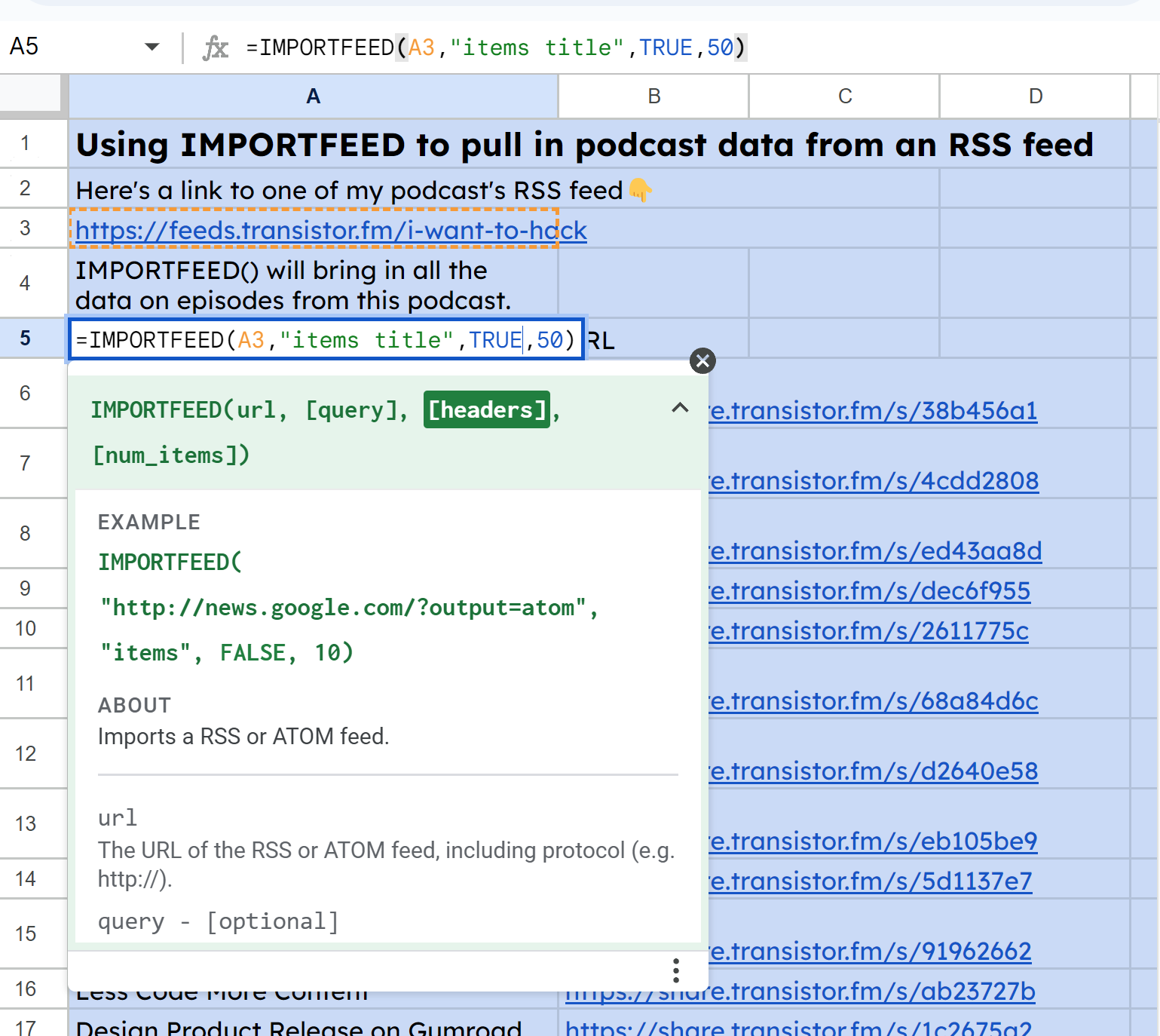 Capture d'écran de IMPORTFEED
Capture d'écran de IMPORTFEED
Ensuite, de manière similaire pour les URL, j'ai utilisé IMPORTFEED(A3, "items url", TRUE, 50) :
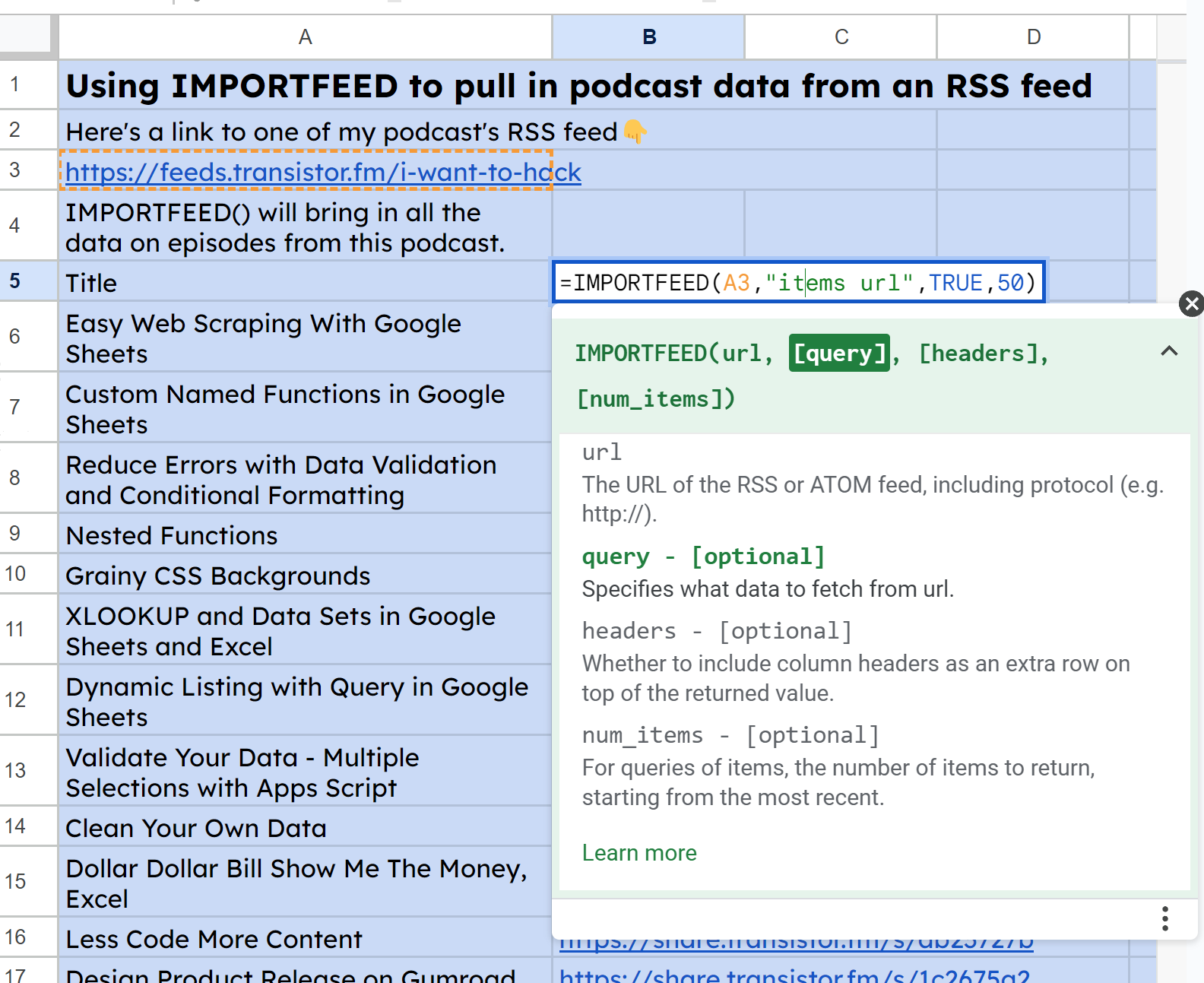 Capture d'écran de IMPORTFEED #2
Capture d'écran de IMPORTFEED #2
Comment utiliser la fonction IMPORTHTML
Maintenant, nous commençons à extraire des données directement depuis un site web. Cela prendra une URL puis un paramètre de requête où nous spécifions de rechercher soit un "tableau" soit une "liste".
Cela est suivi d'une valeur d'index représentant quel tableau ou liste rechercher s'il y en a plusieurs sur la page. Il est indexé à zéro, donc entrez zéro si vous recherchez le premier.
IMPORTHTML examine le code HTML sur un site web pour les éléments HTML <table> et <list>.
<!--Voici à quoi ressemble un tableau simple :-->
<table>
<thead>
<tr>
<th>en-tête de tableau 1</th>
<th>en-tête de tableau 2</th>
</tr>
</thead>
<tbody>
<tr>
<td>donnée de tableau ligne 1 cellule1</td>
<td>donnée de tableau ligne 1 cellule2</td>
</tr>
<tr>
<td>donnée de tableau ligne 2 cellule1</td>
<td>donnée de tableau ligne 2 cellule2</td>
</tr>
</tbody>
</table>
<!--Voici à quoi ressemble une liste ordonnée :-->
<ol>
<li>élément ordonné 1</li>
<li>élément ordonné 2</li>
<li>élément ordonné 2</li>
</ol>
<!--Voici à quoi ressemble une liste non ordonnée :-->
<ul>
<li>élément non ordonné 1</li>
<li>élément non ordonné 2</li>
<li>élément non ordonné 3</li>
</ul>
Dans la feuille d'exemple, j'ai l'URL de certaines statistiques sur les Barkley Marathons dans la cellule B3 et je fais ensuite référence à celle-ci dans la fonction de A4 : =IMPORTHTML(B3,"table",0).
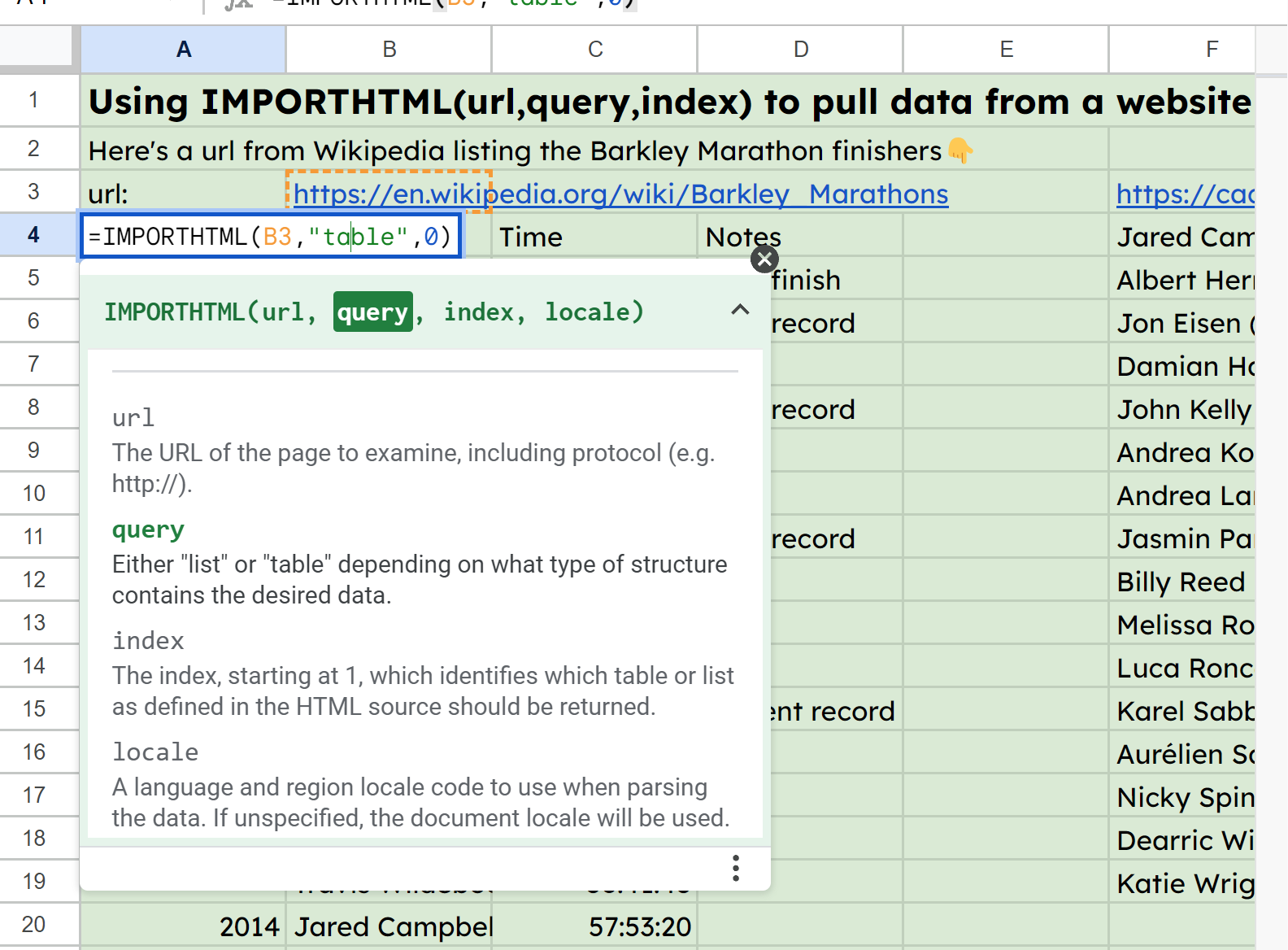 Capture d'écran de IMPORTHTML
Capture d'écran de IMPORTHTML
Pour information, freeCodeCamp a créé ScrapePark comme un endroit pour pratiquer le web scraping, vous pouvez donc l'utiliser pour IMPORTHTML et IMPORTXML qui suivent.
Comment utiliser la fonction IMPORTXML
Nous avons gardé le meilleur pour la fin. Cela examinera les sites web et extraira presque tout ce que nous voulons. C'est compliqué, cependant, car au lieu d'importer toutes les données de tableau ou de liste comme avec IMPORTHTML, nous écrivons nos requêtes en utilisant ce qu'on appelle XPath.
XPath est un langage d'expression utilisé pour interroger des documents XML. Nous pouvons écrire des expressions XPath pour que IMPORTXML extraie toutes sortes de choses d'une page HTML.
Il existe de nombreuses ressources pour trouver les expressions XPath appropriées. En voici une que j'ai utilisée pour ce projet.
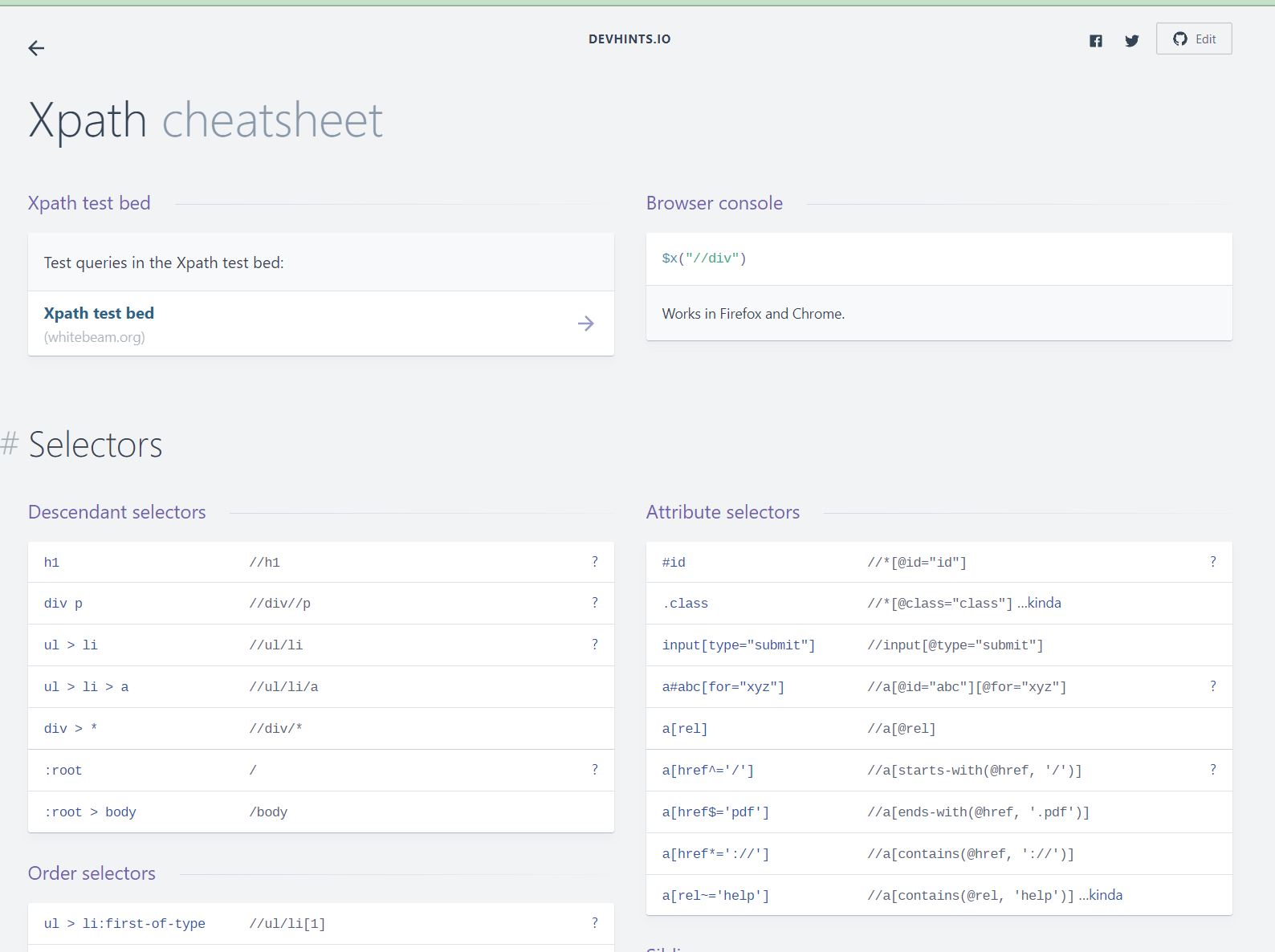 capture d'écran de l'aide-mémoire XPath
capture d'écran de l'aide-mémoire XPath
Dans la feuille pour IMPORTHTML, j'ai plusieurs exemples que je vous encourage à consulter.
Par exemple, en utilisant la fonction =IMPORTXML(A11,"//*[@class='post-card-title']"), nous pouvons importer tous les titres de mes articles car, en inspectant le HTML sur ma page d'auteur ici, j'ai trouvé qu'ils ont tous la classe post-card-title.
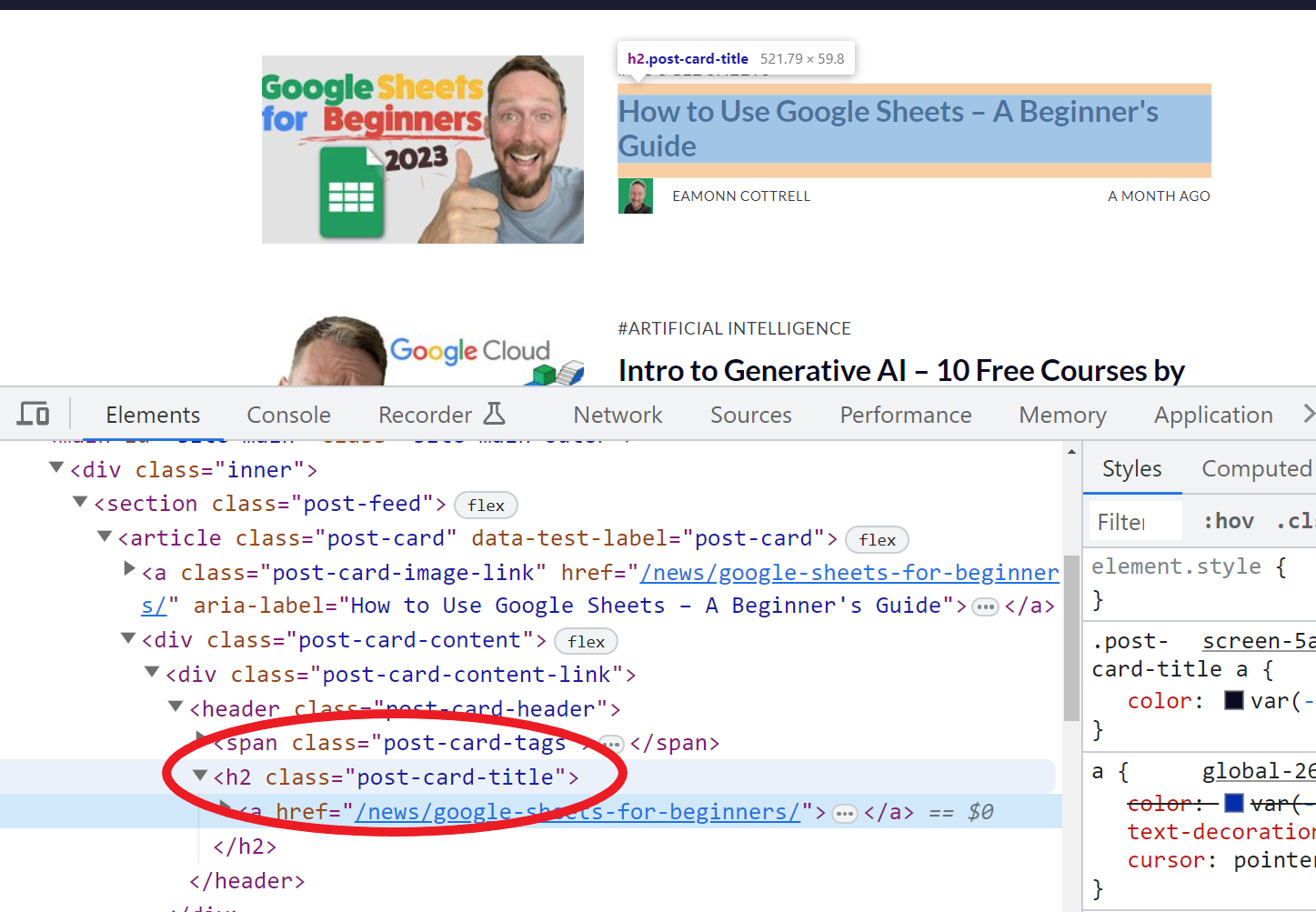 capture d'écran de l'inspection d'une page web avec les outils de développement
capture d'écran de l'inspection d'une page web avec les outils de développement
De la même manière, nous pouvons utiliser la fonction =IMPORTXML(A11,"//*[@class='post-card-title']//a/@href") pour récupérer le slug de l'URL de chacun de ces articles.
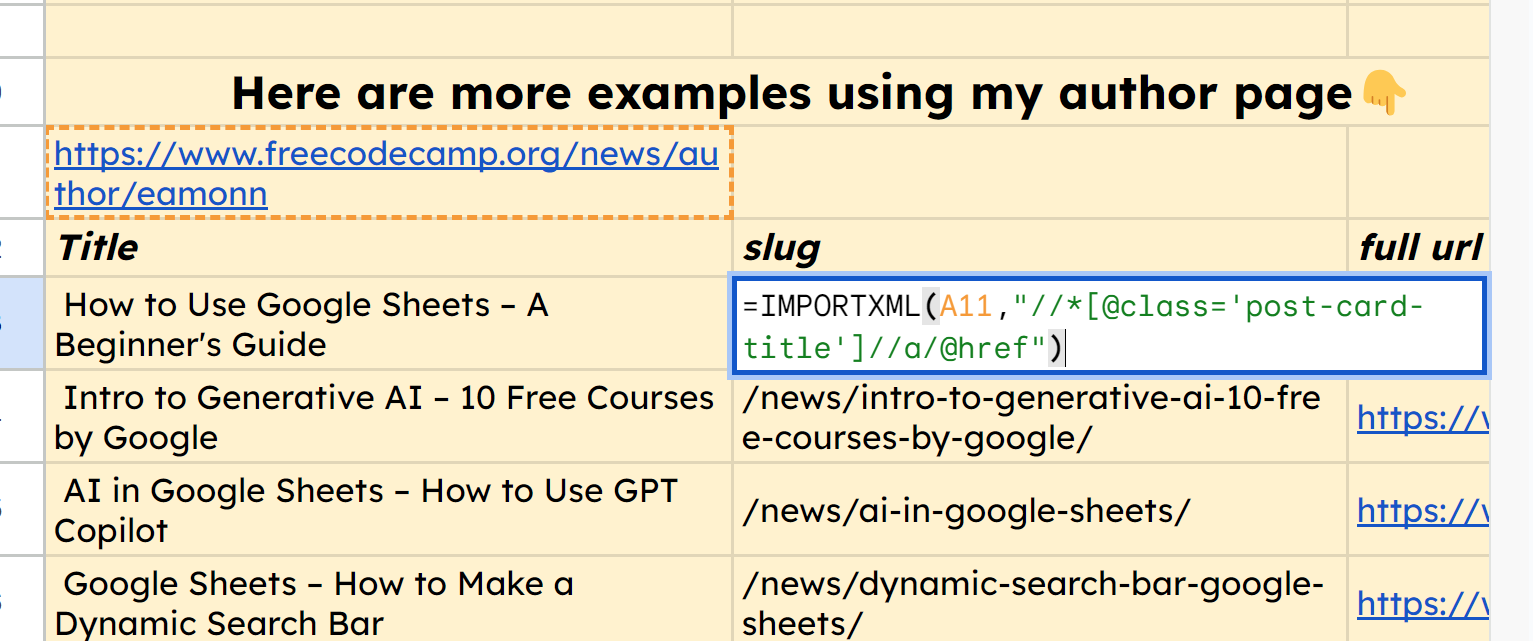 capture d'écran de IMPORTXML
capture d'écran de IMPORTXML
Vous remarquerez qu'il importe bien l'URL complète, donc en bonus, nous pouvons simplement préfixer le domaine à chacun de ceux-ci. Voici la fonction pour la première ligne que nous pouvons faire glisser vers le bas pour obtenir toutes ces URL correctes : ="https://www.freecodecamp.org"&B13
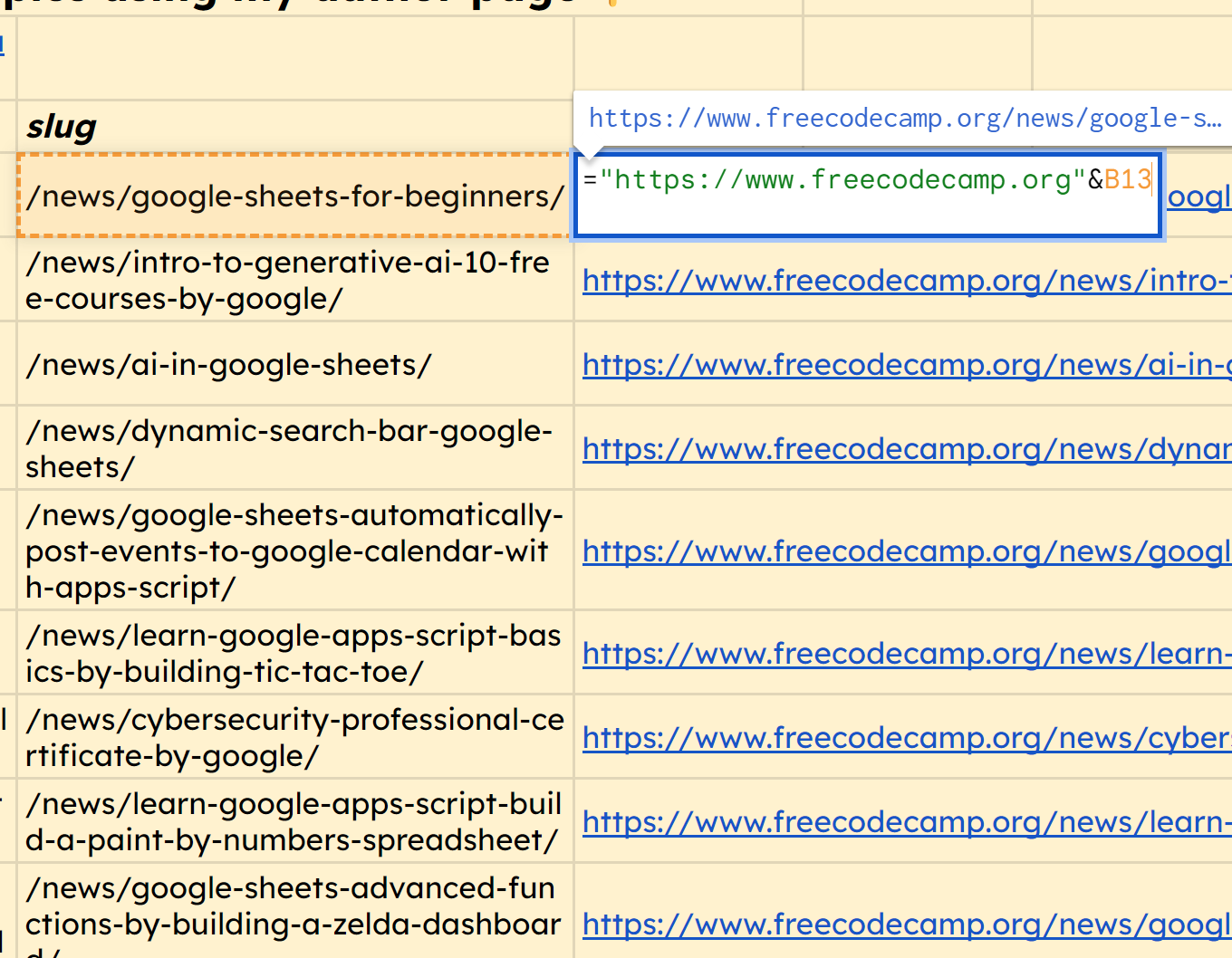 capture d'écran du préfixage du domaine au slug
capture d'écran du préfixage du domaine au slug
Suivez-moi
J'espère que cela vous a été utile ! J'ai moi-même beaucoup appris et j'ai apprécié réaliser la vidéo.
Vous pouvez me trouver sur YouTube : https://www.youtube.com/@eamonncottrell
Et j'ai une newsletter ici : https://got-sheet.beehiiv.com/