


Article original : Data Visualization with Matplotlib – a Step by Step Guide
SEE est une belle série Apple TV qui dépeint une dystopie où les humains ont perdu la vue. Des centaines d'années plus tard, il était considéré comme un mythe que les gens aient jamais pu voir.
Jason Momoa est l'un des principaux acteurs et joue Baba Voss, un guerrier d'élite. La femme de Jason donne naissance à des jumeaux voyants, et des années plus tard, pendant la bataille, Baba Voss a parfois besoin de l'aide des enfants voyants. Ils l'ont aidé à mieux comprendre le terrain, même avec sa maîtrise du champ de bataille. On pourrait dire que ses enfants l'ont aidé à visualiser les choses.
Dans les temps anciens, avant les appareils numériques, la visualisation des données était également un mythe. Les premiers humains comprenaient le besoin de visualisation, ils avaient donc des ressources comme des cartes, des hiéroglyphes, de l'art rupestre, et ainsi de suite. Les témoins oculaires dessinaient généralement leurs chemins et autres informations pertinentes sur des pierres, du bois ou des parchemins.
Comme les enfants de Baba Voss, ces ressources facilitent la vie des humains en leur donnant une perspective visuelle sur les choses ou les environnements.
Alors, que signifie réellement la visualisation dans ce contexte ? Nous pouvons définir la visualisation comme "toute technique de création d'images, de diagrammes ou d'animations pour communiquer un message." (source)
Dans cet article, nous explorerons ce qu'est la visualisation de données et comment vous pouvez utiliser l'outil de visualisation de données Matplotlib pour explorer et analyser des données. Vous apprendrez à l'utiliser pour créer des graphiques qui aident les propriétaires d'entreprise et les parties prenantes à obtenir plus d'informations sur les données et à prendre des décisions éclairées.
Qu'est-ce que la visualisation de données ?
La visualisation de données fait référence à l'intégration de données et d'éléments visuels comme des images, des graphiques, des diagrammes, et ainsi de suite pour communiquer des messages à différentes parties prenantes.
Ces parties prenantes peuvent être des utilisateurs, des membres de l'équipe, des gestionnaires ou des membres exécutifs de haut niveau d'une organisation.
Les données dans ce contexte font référence à différentes entrées recueillies à partir de la base de données de l'organisation ou obtenues à partir de sources externes, comme des bases de données publiques ou des organisations privées, qui ont donné accès via leurs API.
Nous travaillerons avec un ensemble de données de licenciements d'employés qui contient des détails sur les employés qui ont été licenciés dans différentes industries de 2020 à 2022. Les colonnes de l'ensemble de données incluent les noms des entreprises, les lieux, les industries, le total des licenciements, le pourcentage de licenciements, la date, les pays et d'autres colonnes pertinentes.
Voici un aperçu du cadre de données :

Qu'est-ce que Matplotlib ?
Matplotlib est une bibliothèque Python populaire pour afficher des données et créer des graphiques statiques, animés et interactifs. Ce programme vous permet de dessiner des graphiques attrayants et informatifs comme des graphiques en ligne, des graphiques de dispersion, des histogrammes et des graphiques en barres.
Matplotlib est hautement personnalisable et flexible, ce qui en fait un choix privilégié pour les analystes de données et les scientifiques travaillant dans des domaines tels que la finance, la science, l'ingénierie et les sciences sociales.
Dans cet article, je vais vous montrer comment créer un graphique en barres, un graphique circulaire et un graphique en ligne pour expliquer comment vous pouvez faire de la visualisation de données en utilisant Matplotlib.
La première chose dont vous avez besoin est d'importer Matplotlib et d'autres bibliothèques pertinentes comme Pandas, Numpy et leurs sous-modules.
# Importe les packages
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import matplotlib.dates as mdates
from matplotlib.ticker import MaxNLocator
Dans le code ci-dessus, nous importons le package Pandas, qui analyse et manipule nos données. Nous avons importé Matplotlib et nous utiliserons le module Pyplot pour la visualisation des données.
Nous utiliserons le package Numpy importé dans la troisième ligne pour les calculs numériques. Nous travaillerons également avec le module de date pour les manipulations de date lors de la création de notre graphique. Le dernier module est le module ticker, qui définit les graduations sur les axes du graphique. Avec ces modules, vous pouvez analyser, manipuler, calculer et visualiser vos données.
Comment créer un graphique en barres
Les graphiques en barres vous aident avec les valeurs catégorielles. C'est-à-dire, si vous voulez comparer différentes entités en quantité, un graphique en barres est un excellent moyen de le visualiser. Dans l'ensemble de données de licenciements, nous comparerons différentes entreprises qui ont licencié des employés selon le nombre d'employés licenciés.
plt.figure(figsize=(8, 6))
industry_val = df_layoffs.groupby('company')['total_laid_off'].sum().sort_values(ascending=False).head(10)
industry_val.plot(label="", kind='bar')
plt.show()
Le code ci-dessus est une façon de créer un graphique en barres. Il montre les 10 entreprises avec le plus grand nombre de licenciements.
Nous définissons d'abord la taille du graphique à 8 pouces par 6 pouces. Ensuite, nous regroupons nos données dans le dataframe par le total des employés licenciés par chaque entreprise. Nous les trions ensuite par ordre décroissant et sélectionnons les 10 entreprises avec le plus grand nombre de licenciements. Enfin, nous créons notre graphique en barres en utilisant les données sélectionnées. La dernière ligne (plt.show()) affiche le graphique qui est montré ci-dessous.
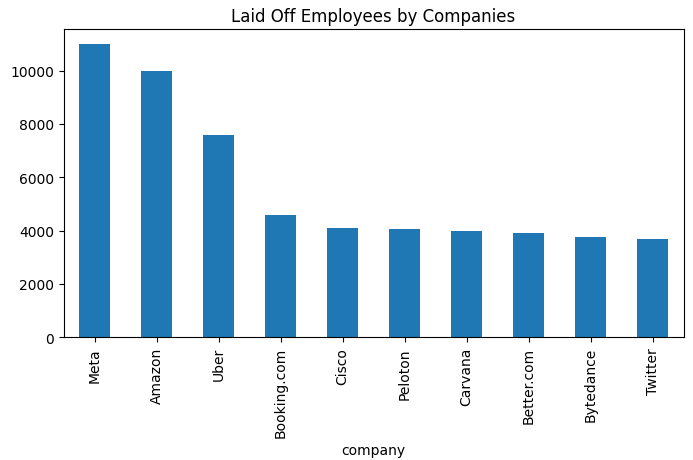
D'après le graphique ci-dessus, vous remarquerez que Meta et Amazon avaient le plus grand nombre d'employés licenciés tandis que Twitter avait le moins de licenciements.
Comment créer un graphique circulaire
Un graphique circulaire représente un secteur entier, chaque portion étant allouée selon sa taille à un sous-secteur. La colonne de l'industrie sera un ajustement parfait pour utiliser un graphique circulaire. Nous verrons quelle industrie a eu le plus et le moins de licenciements.
# Regrouper les données par industrie et sommer le total des employés licenciés
industry_val = df_layoffs.groupby('industry')['total_laid_off'].sum().sort_values(ascending=False).head()
# créer le graphique circulaire et afficher les labels et les valeurs à l'intérieur du graphique
plt.figure(figsize=(8, 6))
plt.pie(industry_val, labels=industry_val.index, autopct='%1.1f%%')
plt.title('Employés licenciés par industrie')
plt.show()
Tout d'abord, le code regroupe les données par industrie et fait la somme du nombre total d'employés licenciés pour chaque industrie. Il trie ensuite les industries par ordre décroissant en fonction du nombre total d'employés licenciés et sélectionne les valeurs les plus élevées à l'aide de la fonction head().
Ensuite, nous créons un graphique circulaire pour visualiser les données. La taille de chaque part du graphique représente la proportion d'employés licenciés dans cette industrie. Les étiquettes du graphique circulaire montrent les noms des industries. Les valeurs en pourcentage à l'intérieur des parts montrent la proportion d'employés licenciés dans cette industrie. Le graphique est intitulé "Employés licenciés par industrie".
Enfin, le graphique circulaire est affiché à l'aide de la fonction plt.show(). Comme nous l'avons fait dans le graphique en barres, la fonction plt.figure(figsize=(8, 6)) définit la taille du graphique à 8 pouces de large et 6 pouces de haut.

Le graphique ci-dessus montre la proportion de licenciements dans différentes industries. Le secteur des transports et le secteur de la consommation sont les industries les plus touchées, suivis par le commerce de détail, la finance et l'industrie alimentaire.
Comment créer un graphique en ligne
Les graphiques en ligne montrent les changements au fil du temps pour une entité. Avec notre ensemble de données, un graphique en ligne pourrait être utilisé pour montrer la tendance des licenciements au cours de l'année ou des deux dernières années. Cela dépend de ce que vous essayez de communiquer, mais nous travaillerons avec une analyse d'une année.
# convertir la colonne de date en objet datetime
df_layoffs['date'] = pd.to_datetime(df_layoffs['date'])
# sélectionner les données pour une durée d'un an à partir du 1er janvier 2022
date_de_debut = pd.Timestamp('2022-01-01')
date_de_fin = date_de_debut + pd.DateOffset(years=1)
df_une_annee = df_layoffs.loc[(df_layoffs['date'] >= date_de_debut) & (df_layoffs['date'] < date_de_fin)]
# tracer les données sélectionnées
df_date = df_une_annee.groupby('date')['total_laid_off'].sum()
plt.figure(figsize=(10, 4))
plt.plot(df_date.index, df_date.values)
plt.xlabel('Date')
plt.ylabel('Total des licenciements')
plt.title('Tendance des licenciements pour 2022')
plt.xticks(rotation=45)
# définir le format des étiquettes de l'axe x pour afficher Mois-Année
format_date = mdates.DateFormatter('%b-%Y')
plt.gca().xaxis.set_major_formatter(format_date)
# Utiliser MaxNLocator pour réduire le nombre de xticks
locator = MaxNLocator(nbins=10)
plt.gca().xaxis.set_major_locator(locator)
plt.show()
En comparaison avec les graphiques en barres et les graphiques circulaires, ce code est beaucoup plus difficile. Mais voici une explication :
La première ligne du code convertit la colonne 'date' du DataFrame (df_layoffs) en un objet DateTime afin que les dates puissent être manipulées facilement.
# convertir la colonne de date en objet datetime
df_layoffs['date'] = pd.to_datetime(df_layoffs['date'])
Ensuite, nous sélectionnons les données pour une durée d'un an commençant le 1er janvier 2022. La date de début est définie comme un objet Timestamp, et la date de fin est définie comme un an à partir de la date de début en utilisant la fonction pd.DateOffset. La fonction loc est ensuite utilisée pour filtrer les lignes du DataFrame, en sélectionnant uniquement celles qui tombent dans cette durée d'un an. N'oubliez pas que nous travaillons avec les données d'une année.
# sélectionner les données pour une durée d'un an à partir du 1er janvier 2022
date_de_debut = pd.Timestamp('2022-01-01')
date_de_fin = date_de_debut + pd.DateOffset(years=1)
df_une_annee = df_layoffs.loc[(df_layoffs['date'] >= date_de_debut) & (df_layoffs['date'] < date_de_fin)]
Après cela, nous regroupons les données sélectionnées par date et calculons le nombre total de licenciements à chaque date en utilisant les fonctions groupby et sum. Cela est stocké dans un nouveau DataFrame appelé df_date.
# tracer les données sélectionnées
df_date = df_une_annee.groupby('date')['total_laid_off'].sum()
Ensuite, nous créons un graphique de la tendance des licenciements pour 2022 en utilisant la bibliothèque matplotlib. La taille du graphique est définie à (10, 4) en utilisant la fonction figure.
plt.figure(figsize=(10, 4))
L'axe x représente la date, et l'axe y représente le nombre total de licenciements. La fonction xlabel étiquette l'axe x comme 'Date', et la fonction ylabel étiquette l'axe y comme 'Total des licenciements'.
plt.plot(df_date.index, df_date.values)
plt.xlabel('Date')
plt.ylabel('Total des licenciements')
Le titre du graphique est défini à 'Tendance des licenciements pour 2022' en utilisant la fonction title.
plt.title('Tendance des licenciements pour 2022')
Les étiquettes de l'axe x sont tournées de 45 degrés en utilisant la fonction xticks pour éviter l'encombrement.
plt.xticks(rotation=45)
Le format des étiquettes de l'axe x est défini pour afficher le format Mois-Année en utilisant la fonction DateFormatter.
# définir le format des étiquettes de l'axe x pour afficher Mois-Année
format_date = mdates.DateFormatter('%b-%Y')
plt.gca().xaxis.set_major_formatter(format_date)
Enfin, le nombre de xticks sur le graphique est réduit en utilisant la fonction MaxNLocator, qui réduit le nombre de xticks à 10.
# Utiliser MaxNLocator pour réduire le nombre de xticks
locator = MaxNLocator(nbins=10)
plt.gca().xaxis.set_major_locator(locator)
Le graphique est ensuite affiché en utilisant la fonction show.
plt.show()
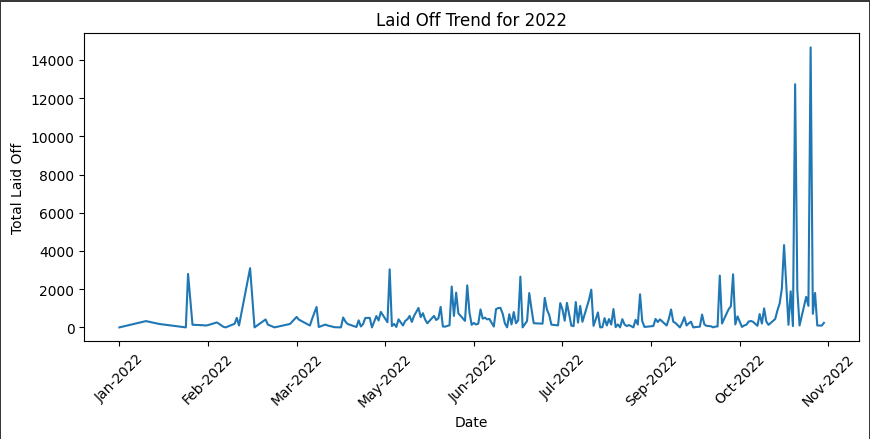
Le graphique ci-dessus montre les tendances et les schémas de licenciements pour 2022.
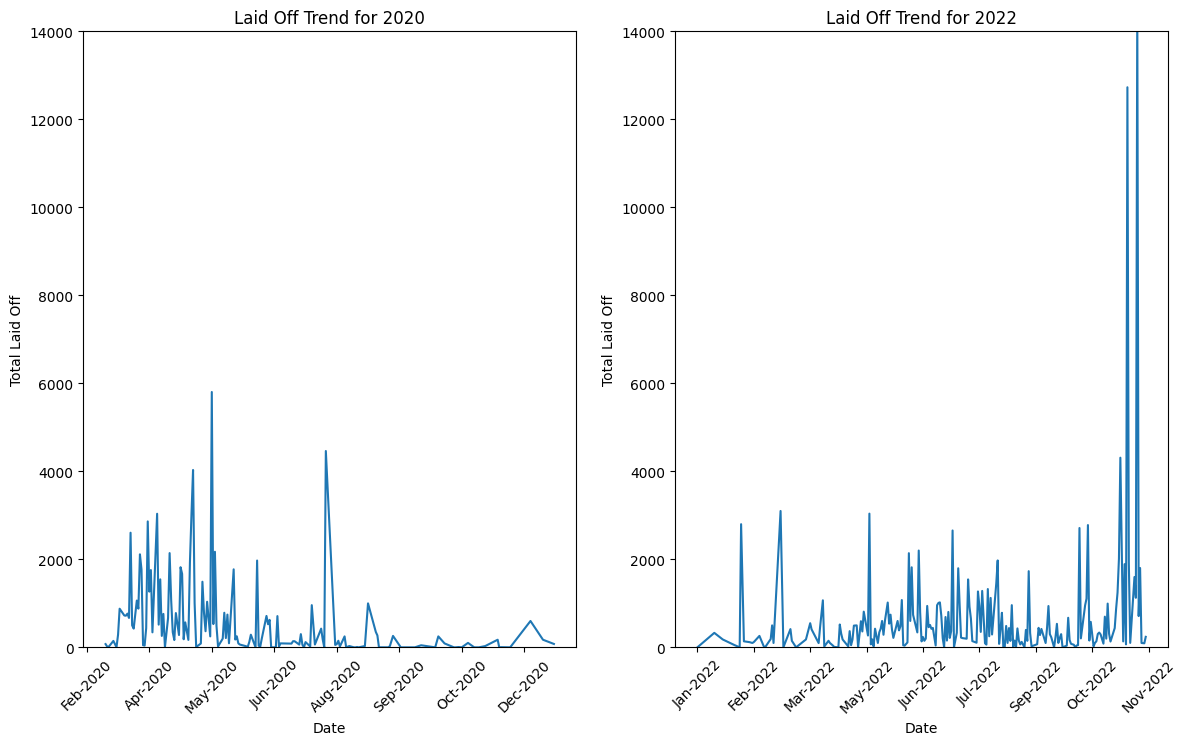
Vous pouvez également analyser la performance d'une entité sur différentes périodes. Le deuxième graphique montre une analyse des licenciements d'employés en 2020 par rapport à 2022.
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
from matplotlib.ticker import MaxNLocator
# convertir la colonne de date en objet datetime
df_layoffs['date'] = pd.to_datetime(df_layoffs['date'])
# filtrer les données pour n'inclure que 2020 et 2022
df_filtered = df_layoffs[(df_layoffs['date'].dt.year == 2020) | (df_layoffs['date'].dt.year == 2022)]
# regrouper les données par année et calculer le total des licenciements
df_filtered['year'] = df_filtered['date'].dt.year
df_yearly = df_filtered.groupby(['year', 'date'])['total_laid_off'].sum().reset_index()
# créer des sous-graphiques et tracer les données pour chaque année dans des graphiques séparés
fig, axs = plt.subplots(ncols=2, figsize=(14, 8))
for i, year in enumerate(df_yearly['year'].unique()):
df_year = df_yearly.loc[df_yearly['year'] == year]
axs[i].plot(df_year['date'], df_year['total_laid_off'])
axs[i].set_xlabel('Date')
axs[i].set_ylabel('Total des licenciements')
axs[i].set_title(f'Tendance des licenciements pour {year}')
axs[i].xaxis.set_major_formatter(mdates.DateFormatter('%b-%Y'))
axs[i].tick_params(axis='x', rotation=45)
locator = MaxNLocator(nbins=10)
axs[i].xaxis.set_major_locator(locator)
# définir la limite de l'axe y à 0-14000 pour chaque sous-graphique
for ax in axs:
ax.set_ylim([0, 14000])
plt.show()
Passons en revue les différents composants du code ci-dessus.
La colonne 'date' dans le DataFrame est convertie en un objet datetime.
# convertir la colonne de date en objet datetime
df_layoffs['date'] = pd.to_datetime(df_layoffs['date'])
Ensuite, le code filtre les données pour n'inclure que les licenciements des années 2020 et 2022. Il regroupe ensuite les données filtrées par année et date et calcule le nombre total de licenciements pour chaque date.
# filtrer les données pour n'inclure que 2020 et 2022
df_filtered = df_layoffs[(df_layoffs['date'].dt.year == 2020) | (df_layoffs['date'].dt.year == 2022)]
# regrouper les données par année et calculer le total des licenciements
df_filtered['year'] = df_filtered['date'].dt.year
df_yearly = df_filtered.groupby(['year', 'date'])['total_laid_off'].sum().reset_index()
Nous créons ensuite deux sous-graphiques et traçons le nombre total de licenciements pour chaque année dans des graphiques séparés. Nous définissons les étiquettes de l'axe x au format de date 'MMM-YYYY' (par exemple, Jan-2022) et les faisons pivoter de 45 degrés. Nous définissons également l'étiquette de l'axe y à 'Total des licenciements' et le titre du graphique à 'Tendance des licenciements pour {year}' (par exemple, Tendance des licenciements pour 2020). Enfin, nous affichons les graphiques en utilisant la commande plt.show().
# créer des sous-graphiques et tracer les données pour chaque année dans des graphiques séparés
fig, axs = plt.subplots(ncols=2, figsize=(14, 8))
for i, year in enumerate(df_yearly['year'].unique()):
df_year = df_yearly.loc[df_yearly['year'] == year]
axs[i].plot(df_year['date'], df_year['total_laid_off'])
axs[i].set_xlabel('Date')
axs[i].set_ylabel('Total des licenciements')
axs[i].set_title(f'Tendance des licenciements pour {year}')
axs[i].xaxis.set_major_formatter(mdates.DateFormatter('%b-%Y'))
axs[i].tick_params(axis='x', rotation=45)
locator = MaxNLocator(nbins=10)
axs[i].xaxis.set_major_locator(locator)
plt.show()
Dans l'ensemble, le code est utilisé pour filtrer, regrouper et visualiser les données liées aux licenciements dans les entreprises, en se concentrant spécifiquement sur les tendances pour 2020 et 2022. Vous pouvez voir le résultat dans le graphique ci-dessous :
Conclusion
Nous avons commencé par discuter de ce qu'est la visualisation et de l'importance de la visualisation des données dans la transformation de chiffres bruts en informations et en sens commercial.
Ensuite, nous avons utilisé la bibliothèque Python populaire Matplotlib, qui est un outil de visualisation de données, pour créer des graphiques en barres, des graphiques circulaires et des graphiques en ligne. Il existe également d'autres cas d'utilisation non couverts dans cet article, comme les histogrammes, les graphiques de dispersion, les graphiques en boîte, et ainsi de suite.
En utilisant ces visualisations, nous pouvons donner un sens à nos données et prendre des mesures qui ne seraient pas possibles en regardant des chiffres bruts. La visualisation des données peut nous aider à obtenir de meilleurs résultats dans d'autres domaines tels que la finance, la science, l'ingénierie, etc. Pour des études plus approfondies, vous pouvez consulter la documentation officielle de matplotlib ici.
Merci d'avoir lu ! Veuillez me suivre sur LinkedIn où je publie également plus de contenu lié aux données.