


Article original : Use these open-source tools for Data Warehousing
De nos jours, tout le monde parle des logiciels open-source. Cependant, cela reste encore peu courant dans le domaine de l'entreposage de données (DWH). Pourquoi ?
Pour cet article, j'ai choisi quelques technologies open-source et les ai utilisées ensemble pour construire une architecture de données complète pour un système d'entreposage de données.
J'ai opté pour Apache Druid pour le stockage des données, Apache Superset pour les requêtes, et Apache Airflow comme orchestrateur de tâches.
Druid — le stockage de données
Druid est un magasin de données open-source, orienté colonne, distribué et écrit en Java. Il est conçu pour ingérer rapidement de grandes quantités de données d'événements et fournir des requêtes à faible latence sur ces données.
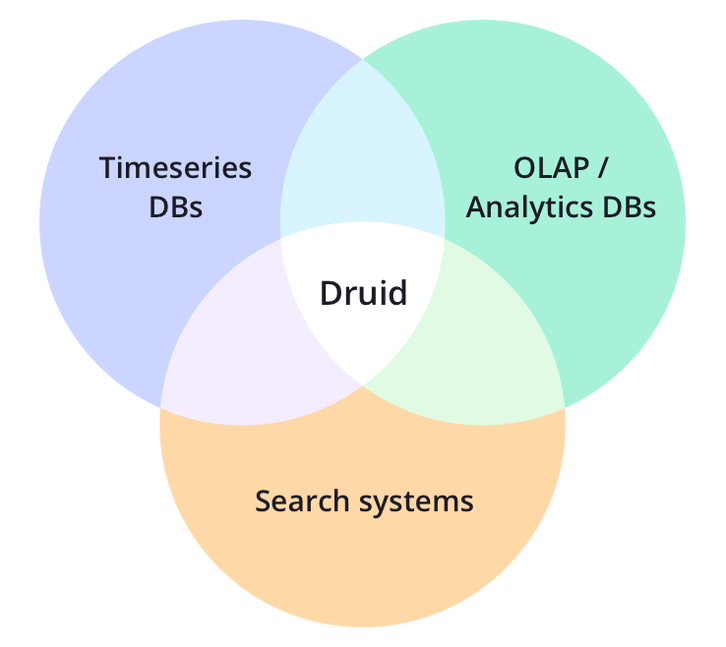
Pourquoi utiliser Druid ?
Druid possède de nombreuses fonctionnalités clés, notamment des requêtes OLAP en moins d'une seconde, l'ingestion de flux en temps réel, la scalabilité et une grande efficacité en termes de coûts.
En gardant à l'esprit la comparaison des technologies OLAP modernes, j'ai choisi Druid plutôt que ClickHouse, Pinot et Apache Kylin. Récemmment, Microsoft a annoncé qu'ils ajouteraient Druid à leur Azure HDInsight 4.0.
Pourquoi ne pas utiliser Druid ?
Carter Shanklin a écrit un article détaillé sur les limitations de Druid sur Horthonwork.com. Le principal problème réside dans son support des jointures SQL et des capacités SQL avancées.
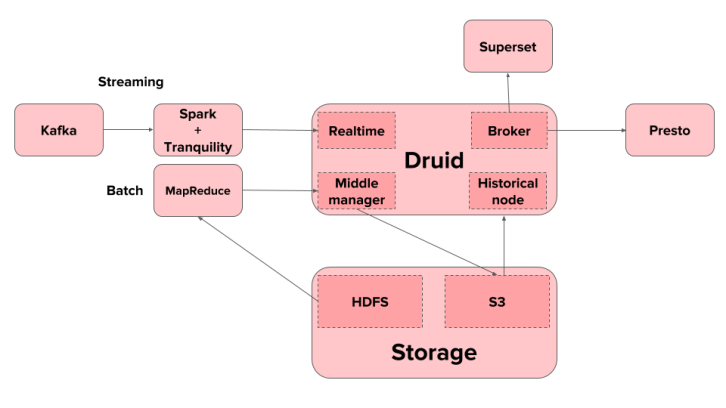
L'architecture de Druid
Druid est scalable grâce à son architecture en cluster. Vous avez trois types de nœuds différents — le Middle-Manager-Node, le Historical Node et le Broker.
L'avantage est que vous pouvez ajouter autant de nœuds que vous le souhaitez dans le domaine spécifique qui vous convient le mieux. Si vous avez beaucoup de requêtes à exécuter, vous pouvez ajouter plus de Brokers. Ou, si une grande quantité de données doit être ingérée par lots, vous ajouterez des middle managers, et ainsi de suite.
Une architecture simple est présentée ci-dessous. Vous pouvez en lire plus sur la conception de Druid ici.
Apache Superset — l'interface utilisateur
La manière la plus simple d'interroger Druid est via un outil léger et open-source appelé Apache Superset.
Il est facile à utiliser et dispose de tous les types de graphiques courants comme les graphiques à bulles, les comptes de mots, les cartes thermiques, les boîtes à moustaches et beaucoup d'autres.
Druid fournit une API REST, et dans la dernière version également une API de requête SQL. Cela facilite son utilisation avec n'importe quel outil, qu'il s'agisse de SQL standard, d'un outil BI existant ou d'une application personnalisée.
Apache Airflow — l'orchestrateur
Comme mentionné dans Orchestrators — Planification et surveillance des flux de travail, il s'agit de l'une des décisions les plus critiques.
Par le passé, des outils ETL comme Microsoft SQL Server Integration Services (SSIS) et autres étaient largement utilisés. C'est là que se déroulaient la transformation, le nettoyage et la normalisation des données.
Dans les architectures plus modernes, ces outils ne suffisent plus.
De plus, le code et la logique de transformation des données sont beaucoup plus précieux pour les autres personnes compétentes en données de l'entreprise.
Je vous recommande vivement de lire un article de blog de Maxime Beauchemin sur Functional Data Engineering — un paradigme moderne pour le traitement de données par lots. Cela approfondit beaucoup plus la manière dont les pipelines de données modernes devraient être.
Consultez également The Downfall of the Data Engineer où Max explique la rupture des "silos de données" et bien plus encore.
Pourquoi utiliser Airflow ?
Apache Airflow est un outil très populaire pour cette orchestration de tâches. Airflow est écrit en Python. Les tâches sont écrites sous forme de graphes acycliques dirigés (DAGs). Ceux-ci sont également écrits en Python.
Au lieu d'encapsuler votre logique de transformation critique quelque part dans un outil, vous la placez là où elle appartient, à l'intérieur de l'orchestrateur.
Un autre avantage est l'utilisation de Python standard. Il n'est pas nécessaire d'encapsuler d'autres dépendances ou exigences, comme la récupération depuis un FTP, la copie de données de A à B, l'écriture d'un fichier batch. Vous faites cela et tout le reste au même endroit.
Fonctionnalités d'Airflow
De plus, vous obtenez un aperçu entièrement fonctionnel de toutes les tâches actuelles en un seul endroit.
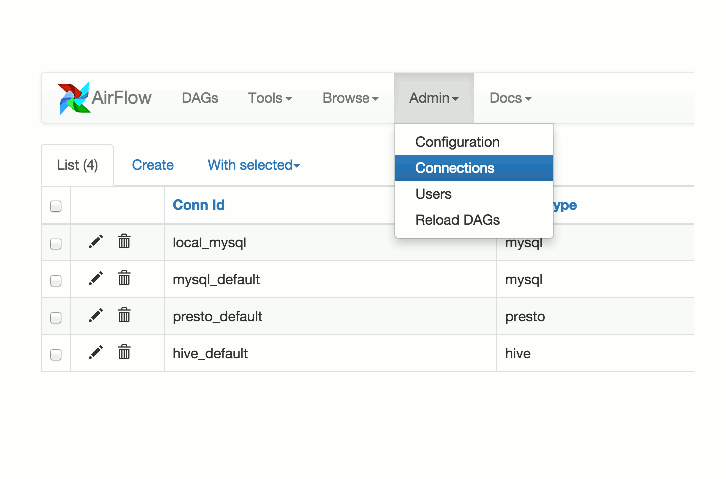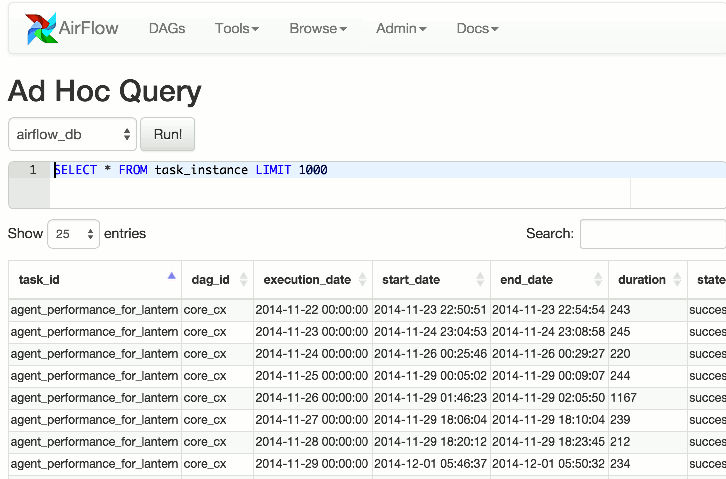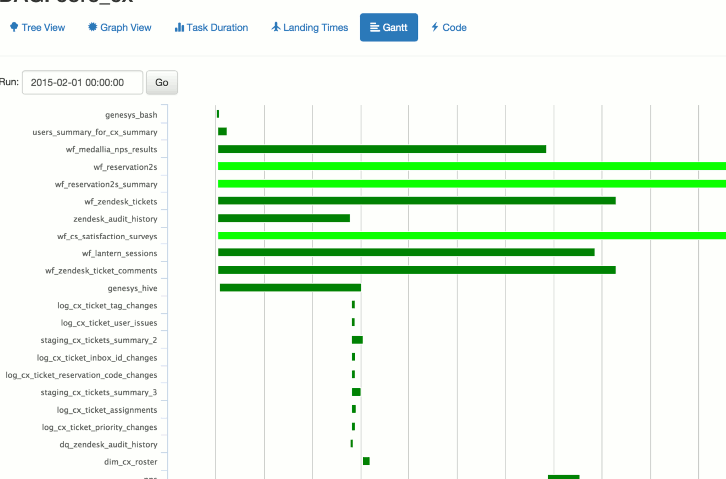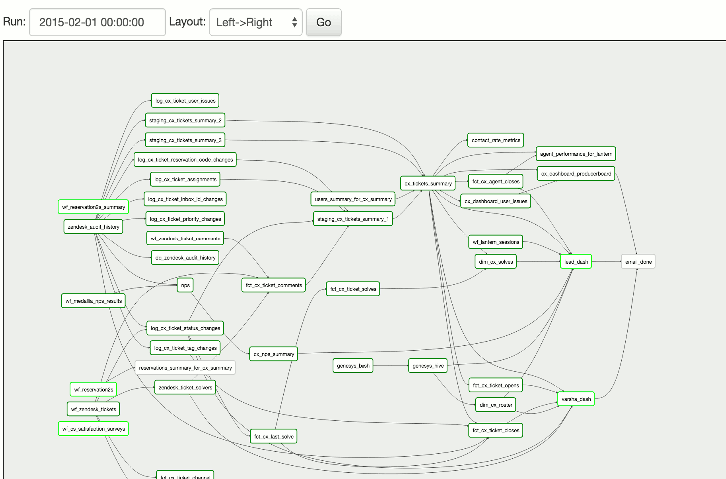
D'autres fonctionnalités pertinentes d'Airflow sont que vous écrivez des flux de travail comme si vous écriviez des programmes. Les travaux externes comme Databricks, Spark, etc. ne posent aucun problème.
Les tests de travaux passent par Airflow lui-même. Cela inclut le passage de paramètres à d'autres travaux en aval ou la vérification de ce qui s'exécute sur Airflow et la visualisation du code réel. Les fichiers de journalisation et autres métadonnées sont accessibles via l'interface web.
(Re)lancer uniquement certaines parties du flux de travail et des tâches dépendantes est une fonctionnalité cruciale qui est disponible dès la création de vos flux de travail avec Airflow. Les travaux/tâches sont exécutés dans un contexte, le planificateur transmet les détails nécessaires et le travail est distribué à travers votre cluster au niveau de la tâche, et non au niveau du DAG.
Pour découvrir de nombreuses autres fonctionnalités, consultez la liste complète.
ETL avec Apache Airflow
Si vous souhaitez commencer avec Apache Airflow comme nouvel outil ETL, commencez par ces bonnes pratiques ETL avec Airflow partagées avec vous. Il contient des exemples simples d'ETL, avec du SQL standard, avec HIVE, avec Data Vault, Data Vault 2, et Data Vault avec des processus Big Data. Cela vous donne un excellent aperçu de ce qui est possible et de la manière dont vous pourriez l'aborder.
En même temps, il existe un conteneur Docker que vous pouvez utiliser, ce qui signifie que vous n'avez même pas besoin de configurer une infrastructure. Vous pouvez tirer le conteneur depuis ici.
Pour le dépôt GitHub, suivez le lien sur etl-with-airflow.
Conclusion
Si vous cherchez une architecture de données open-source, vous ne pouvez pas ignorer Druid pour des réponses OLAP rapides, Apache Airflow comme orchestrateur qui maintient votre lignée de données et vos plannings en ligne, ainsi qu'un outil de tableau de bord facile à utiliser comme Apache Superset.
Mon expérience jusqu'à présent est que Druid est extrêmement rapide et un choix parfait pour les remplacements de cubes OLAP de manière traditionnelle, mais nécessite encore un démarrage plus simple pour installer des clusters, ingérer des données, consulter les logs, etc. Si vous avez besoin de cela, jetez un œil à Impy qui a été créé par les fondateurs de Druid. Il crée tous les services autour de Druid dont vous avez besoin. Malheureusement, ce n'est pas open-source.
Apache Airflow et ses fonctionnalités en tant qu'orchestrateur sont quelque chose qui n'a pas encore beaucoup été adopté dans les environnements traditionnels de Business Intelligence. Je crois que ce changement vient très naturellement lorsque vous commencez à utiliser des technologies open-source et plus récentes.
Et Apache Superset est un moyen facile et rapide d'être opérationnel et de visualiser les données de Druid. Il existe de meilleurs outils comme Tableau, etc., mais ils ne sont pas gratuits. C'est pourquoi Superset s'intègre bien dans l'écosystème si vous utilisez déjà les technologies open-source mentionnées ci-dessus. Mais en tant qu'entreprise, vous pourriez vouloir investir dans cette catégorie car c'est ce que les utilisateurs voient à la fin de la journée.
Liens connexes :
Un service d'orchestration de flux de travail entièrement géré basé sur Apache Airflow
Intégration d'Apache Airflow et Databricks : Construction de pipelines ETL avec Apache Spark
Qu'est-ce que l'ingénierie des données et l'avenir de l'entreposage de données
Publié à l'origine sur www.sspaeti.com le 29 novembre 2018.