
Article original : An introduction to aggregates in R: a powerful tool for playing with data
Par Satyam Singh Chauhan
La visualisation de données ne concerne pas seulement les couleurs et les graphiques. Il s'agit d'explorer les données et de visualiser la bonne chose.
Lors de la manipulation des données, l'outil le plus puissant qui s'avère utile est les Agrégats. Les Agrégats sont simplement le type de transformation que nous appliquons à toute donnée donnée.
Nous avons 11 fonctions d'agrégation disponibles :
- avg
La moyenne de toutes les valeurs numériques est calculée et retournée. - count
La fonction count retourne le nombre total d'éléments dans chaque groupe. - first
La première valeur de chaque groupe est retournée par la fonction first. - last
La dernière valeur de chaque groupe est retournée par la fonction last. - max
La valeur maximale de chaque groupe est retournée par la fonction max.
C'est très utile pour identifier les valeurs aberrantes également. - median
La médiane de toutes les valeurs numériques pour le groupe mentionné est retournée par la fonction median. - min
La valeur minimale de chaque groupe est retournée par la fonction min.
C'est très utile pour identifier les valeurs aberrantes également. - mode
Le mode de toutes les valeurs numériques pour le groupe mentionné est retourné par la fonction mode. - rms
Root Mean Square, la valeur rms pour toutes les valeurs numériques dans le groupe est retournée par la fonction rms. - sttdev
L'écart-type de toutes les valeurs numériques données dans le groupe est retourné par la fonction stddev. - sum
La somme de toutes les valeurs numériques est retournée par la fonction sum.
Exemples de base
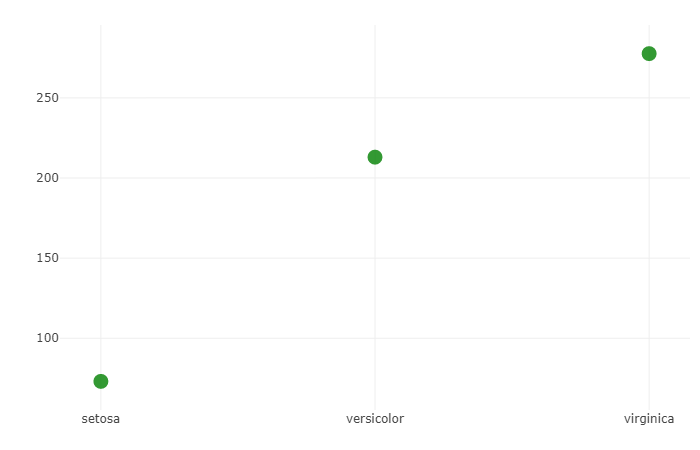
Graphique de dispersion visuel de base utilisant la fonction d'agrégation — sum
#Inclure la bibliothèque
library(plotly)
#Stocker le graphique dans une variable pour le manipuler plus facilement.
p <- plot_ly( type = 'scatter', y = iris$Petal.Length/iris$Petal.Width, x = iris$Species, mode = 'markers', marker = list( size = 15, color = 'green', opacity = 0.8 ), transforms = list( list( type = 'aggregate', groups = iris$Species, aggregations = list( list( target = 'y', func = 'sum', enabled = T ) ) ) ))
#Afficher le graphique
p
Que signifie cela ?
La fonction sum, comme mentionné ci-dessus, calcule la somme de chaque groupe.
Ainsi, ici les groupes sont catégorisés par espèces. Ce code utilise le jeu de données Iris qui comprend trois espèces différentes, setosa, veriscolor et virginica. Pour chaque espèce, il y a 50 observations dans le jeu de données. Ce jeu de données est disponible dans R (intégré) et peut être chargé directement.
Il existe "iris" et "iris3" - deux jeux de données sont disponibles. Vous pouvez choisir l'un d'eux pour exécuter ce code. Le jeu de données utilisé dans cet article est "iris".
Que fait exactement ce code ?
Ce code utilise la fonction sum et calcule la somme de toutes les longueurs des pétales de chaque groupe respectivement. Ensuite, la somme calculée est tracée sur l'axe x-y. Où l'axe x est l'espèce, l'axe y montre la sommation.
À partir de ce graphique, nous pouvons avoir une idée que la taille des pétales de setosa est la plus petite car la somme est la plus petite, mais ce n'est pas une preuve concluante. Pour obtenir une preuve concluante, nous pouvons utiliser la fonction avg.
La fonction sum est très adaptée pour presque tout le jeu de données. Par exemple, l'un des meilleurs endroits où cela peut être utilisé est dans le jeu de données de population. Dans le jeu de données de la population mondiale, nous pouvons agréger les pays selon les continents et trouver la somme de toute la population des pays qui s'y trouvent.
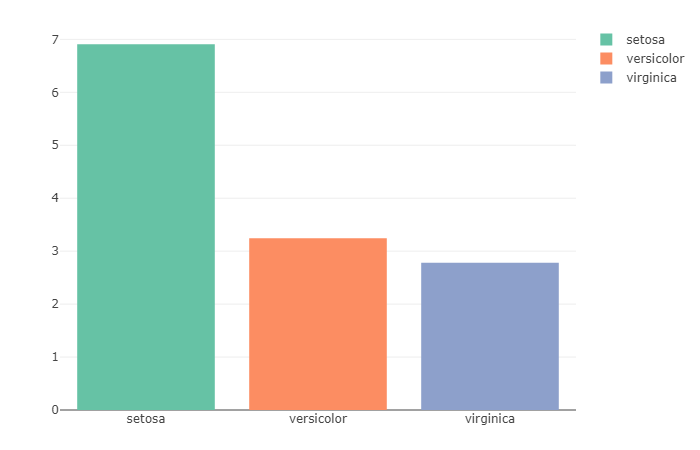
Fonction la plus utilisée — avg
#Inclure la bibliothèque
library(plotly)
#Stocker le graphique dans une variable pour le manipuler plus facilement.
q <- plot_ly( type = 'bar', y = iris$Petal.Length/iris$Petal.Width, x = iris$Species, color = iris$Species, transforms = list( list( type = 'aggregate', groups = iris$Species, aggregations = list( list( target = 'y', func = 'avg', enabled = T ) ) ) ))
#Afficher le graphique
q
Que signifie cela ?
Le jeu de données iris contient deux colonnes pour les pétales, Petal.Width et Petal.Length. De plus, il peut être utilisé pour calculer la moyenne du rapport entre Petal.Length et Petal.Width.
Que fait exactement ce code ?
Pour chaque observation, le rapport entre Petal.Length et Petal.Width est calculé avant que la moyenne de toutes les valeurs obtenues ne soit tracée. Comme nous pouvons l'observer à partir de ce graphique à barres, Setosa a le rapport maximal avec un rapport proche de 7, ce qui montre que la longueur des pétales dans Setosa est 7 fois plus longue que sa largeur. Alors que, d'autre part, virginica a le rapport le plus petit avec près de 3 fois la largeur.
Cette fonction est très flexible et surtout lorsqu'elle est utilisée très judicieusement pour obtenir le meilleur résultat. Par exemple, si nous considérons un autre jeu de données comme la Population, alors nous pouvons calculer le rapport moyen entre les naissances et les décès pour chaque pays.
Utilisons toutes les fonctions dans un seul graphique. Maintenant, nous allons tracer un graphique de dispersion pour chaque catégorie et nous allons utiliser toutes les fonctions. À ce graphique, nous allons ajouter un bouton à partir duquel nous pouvons sélectionner la fonction souhaitée pour faciliter notre travail et obtenir les résultats plus rapidement.
Agrégation de toutes les fonctions — toutes les fonctions en un seul graphique
#Inclure la bibliothèque
library(plotly)
#Stocker le graphique dans une variable pour le manipuler plus facilement.
s <- schema()
agg <- s$transforms$aggregate$attributes$aggregations$items$aggregation$func$values
l = list()
for (i in 1:length(agg)) { ll = list(method = "restyle", args = list('transforms[0].aggregations[0].func', agg[i]), label = agg[i]) l[[i]] = ll }
p <- plot_ly( type = 'scatter', x = iris$Species, y = iris$Sepal.Length / iris$Sepal.Width, mode = 'markers', marker = list( size = 20, color = 'orange', opacity = 0.8 ), transforms = list( list( type = 'aggregate', groups = iris$Species, aggregations = list( list( target = 'y', func = 'avg', enabled = T ) ) ) )) %>%layout( title = '<b>Plotly Aggregations par Satyam Chauhan</b><br>utiliser le menu déroulant pour changer l'agrégation<br><b>Rapport des sépales de longueur à largeur</b>', xaxis = list(title = 'Espèces'), yaxis = list(title = 'Rapport des sépales : Longueur/Largeur'), updatemenus = list( list( x = 0.2, y = 1.2, xref = 'paper', yref = 'paper', yanchor = 'top', buttons = l ) ))
#Afficher les graphiques
Que signifie cela ?
Nous créons une liste où tous les attributs de fonction d'agrégation sont stockés. Nous utilisons cette fonction pour expérimenter avec toutes les fonctions d'Agrégations dans R.
Quelques-uns des graphiques avec différents exemples sont montrés ci-dessous.
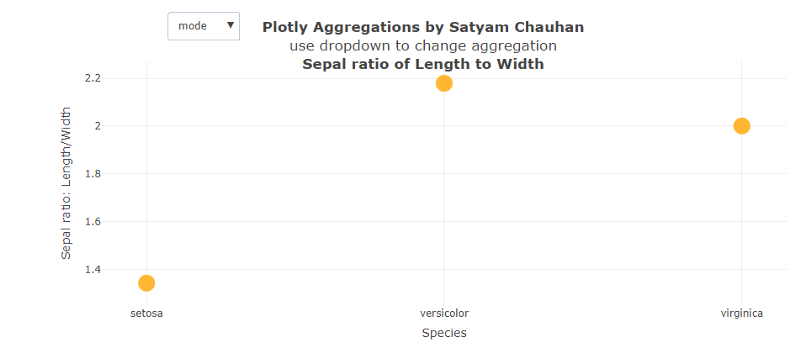
Que fait exactement ce code ?
Tout d'abord, une liste est créée comme mentionné précédemment, dans laquelle toutes les fonctions sont stockées. Après la création de la liste, l'axe y est défini comme le rapport entre Sepal.Length et Sepal.Width et l'axe x est défini comme Espèces.
Après avoir calculé le rapport, la fonction transform est appelée dans laquelle la fonction = 'avg' est mentionnée pour la phase de départ. Lorsque nous exécutons ce code et sélectionnons la fonction 'mode', nous obtenons Fig. 3 (ci-dessus), qui montre que le mode de setosa est le plus faible parmi les trois à environ 1,4. Le mode indique que le rapport 1,4 est répété le plus grand nombre de fois ou que cette valeur est la plus susceptible d'être échantillonnée. Le schéma différent que nous avons vu ici est que la valeur la plus élevée susceptible d'être échantillonnée provient de la catégorie veriscolor ayant un mode proche de 2,2.
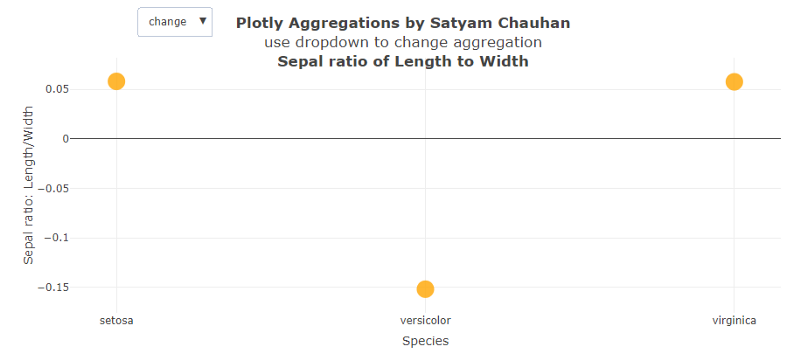
Dans la Fig. 4 ci-dessus, le changement de rapport entre la longueur et la largeur des sépales est tracé et nous obtenons des résultats très différents par rapport au reste des graphiques. Nous observons que le changement de Setosa et Virginica est le même et positif, tandis que dans le changement de rapport par espèce, veriscolor est presque négatif et est trois fois le changement de setosa et virginica.
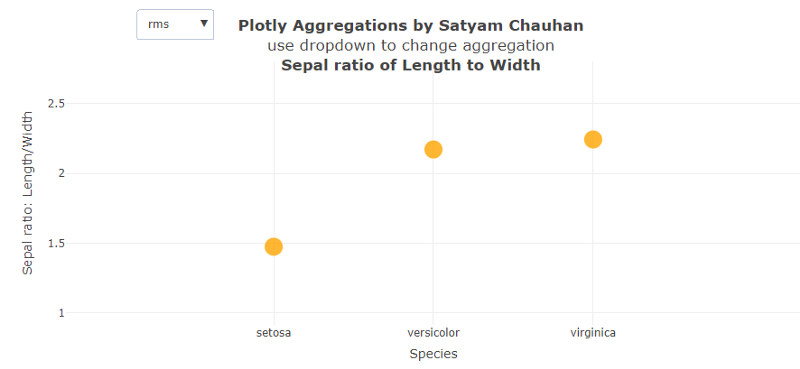
D'autre part, la figure de droite montre les valeurs rms de chaque espèce. Nous pouvons facilement voir que les espèces veriscolor et virginica ont presque la même valeur qui est significativement plus grande que la valeur rms de setosa.
Conclusion
Les fonctions d'agrégation sont l'un des outils les plus puissants que les développeurs peuvent demander. Elles peuvent vous fournir des modèles et des résultats auxquels vous ne vous attendriez pas. Pour analyser les données visuellement, vous devez manipuler les données, et pour cela, nous devons les manipuler et les transformer. Les fonctions d'agrégation le font pour vous, et ce sont l'une des fonctions les plus largement utilisées dans transform. Cet article n'est qu'un début. Vous pouvez certainement explorer davantage et appliquer davantage. C'est ce que font les explorateurs.