

Article original : An introduction to web scraping using R
Par Hiren Patel
Avec le boom du commerce électronique, les entreprises sont passées en ligne. Les clients recherchent également des produits en ligne. Contrairement au marché hors ligne, un client peut comparer le prix d'un produit disponible à différents endroits en temps réel.
Par conséquent, la tarification compétitive est devenue l'élément le plus crucial d'une stratégie commerciale.
Afin de maintenir les prix de vos produits compétitifs et attractifs, vous devez surveiller et suivre les prix fixés par vos concurrents. Si vous connaissez la stratégie de tarification de vos concurrents, vous pouvez aligner votre stratégie de tarification en conséquence pour obtenir un avantage sur eux.
Ainsi, la surveillance des prix est devenue une partie vitale du processus de gestion d'une entreprise de commerce électronique.
Vous vous demandez peut-être comment obtenir les données nécessaires pour comparer les prix.
Les 3 meilleures façons d'obtenir les données nécessaires pour la comparaison des prix
1. Flux de données des marchands
Comme vous le savez peut-être, il existe plusieurs sites de comparaison de prix disponibles sur Internet. Ces sites concluent une sorte d'accord avec les entreprises, où ils obtiennent les données directement auprès d'elles et les utilisent pour la comparaison des prix.
Ces entreprises mettent en place une API ou utilisent FTP pour fournir les données. Généralement, une commission de référence est ce qui rend un site de comparaison de prix financièrement viable.
2. Flux de produits à partir d'API tierces
D'autre part, il existe des services qui offrent des données de commerce électronique via une API. Lorsqu'un tel service est utilisé, le tiers paie pour le volume de données.
3. Web Scraping
Le web scraping est l'une des méthodes les plus robustes et fiables pour obtenir des données web à partir d'Internet. Il est de plus en plus utilisé dans l'intelligence des prix car c'est un moyen efficace d'obtenir les données produits à partir des sites de commerce électronique.
Vous n'avez peut-être pas accès aux première et deuxième options. Par conséquent, le web scraping peut venir à votre secours. Vous pouvez utiliser le web scraping pour exploiter la puissance des données afin d'arriver à une tarification compétitive pour votre entreprise.
Le web scraping peut être utilisé pour obtenir les prix actuels pour le scénario de marché actuel, et le commerce électronique de manière plus générale. Nous utiliserons le web scraping pour obtenir les données d'un site de commerce électronique. Dans ce blog, vous apprendrez comment extraire les noms et les prix des produits d'Amazon dans toutes les catégories, sous une marque particulière.
L'extraction périodique de données d'Amazon peut vous aider à suivre les tendances du marché en matière de tarification et vous permettre de fixer vos prix en conséquence.
Table des matières
1. Web scraping pour la comparaison des prix
Comme le dit la sagesse du marché, le prix est tout. Les clients prennent leurs décisions d'achat en fonction du prix. Ils basent leur compréhension de la qualité d'un produit sur le prix. En bref, le prix est ce qui motive les clients et, par conséquent, le marché.
Par conséquent, les sites de comparaison de prix sont très demandés. Les clients peuvent facilement naviguer sur l'ensemble du marché en regardant les prix du même produit à travers les marques. Ces sites web de comparaison de prix extraient le prix du même produit à partir de différents sites.
En plus du prix, les sites de comparaison de prix extraient également des données telles que la description du produit, les spécifications techniques et les caractéristiques. Ils projettent l'ensemble des informations sur une seule page de manière comparative.
Cela répond à la question que l'acheteur potentiel a posée dans sa recherche. Maintenant, l'acheteur potentiel peut comparer les produits et leurs prix, ainsi que des informations telles que les caractéristiques, les options de paiement et de livraison, afin qu'il puisse identifier la meilleure offre disponible.
L'optimisation des prix a un impact sur l'entreprise dans le sens où de telles techniques peuvent augmenter les marges bénéficiaires de 10 %.
Le commerce électronique est une question de tarification compétitive, et cela s'est étendu à d'autres domaines d'activité. Prenons le cas des voyages. Maintenant, même les sites web liés aux voyages extraient les prix des sites web des compagnies aériennes en temps réel pour fournir la comparaison des prix des différentes compagnies aériennes.
Le seul défi ici est de mettre à jour les données en temps réel et de rester à jour chaque seconde, car les prix changent constamment sur les sites sources. Les sites de comparaison de prix utilisent des tâches Cron ou au moment de la visualisation pour mettre à jour le prix. Cependant, cela dépendra de la configuration du propriétaire du site.
C'est là que ce blog peut vous aider — vous serez en mesure de travailler sur un script de scraping que vous pourrez personnaliser selon vos besoins. Vous pourrez extraire des flux de produits, des images, des prix et tous les autres détails pertinents concernant un produit à partir de nombreux sites web différents. Avec cela, vous pouvez créer votre base de données puissante pour un site de comparaison de prix.
2. Web scraping en R
La comparaison des prix devient fastidieuse car l'obtention de données web n'est pas si facile — il existe des technologies comme HTML, XML et JSON pour distribuer le contenu.
Ainsi, pour obtenir les données dont vous avez besoin, vous devez naviguer efficacement à travers ces différentes technologies. R peut vous aider à accéder aux données stockées dans ces technologies. Cependant, cela nécessite une compréhension approfondie de R avant de commencer.
Qu'est-ce que R ?
Le web scraping est une tâche avancée que peu de gens effectuent. Le web scraping avec R est certainement une programmation technique et avancée. Une compréhension adéquate de R est essentielle pour le web scraping de cette manière.
Pour commencer, R est un langage pour le calcul statistique et les graphiques. Les statisticiens et les data miners utilisent beaucoup R en raison de son logiciel statistique évolutif et de son accent sur l'analyse des données.
Une des raisons pour lesquelles R est un favori parmi cet ensemble de personnes est la qualité des graphiques qui peuvent être réalisés, y compris les symboles mathématiques et les formules lorsque cela est nécessaire.
R est merveilleux car il offre une grande variété de fonctions et de packages qui peuvent gérer les tâches de data mining.
rvest, RCrawler, etc. sont des packages R utilisés pour les processus de collecte de données.
Dans cette section, nous verrons quels types d'outils sont nécessaires pour travailler avec R afin de réaliser le web scraping. Nous le verrons à travers le cas d'utilisation du site web Amazon, d'où nous essaierons d'obtenir les données produits et de les stocker sous forme JSON.
Prérequis
Dans ce cas d'utilisation, la connaissance de R est essentielle et je suppose que vous avez une compréhension de base de R. Vous devez être conscient d'au moins une interface R, telle que RStudio. L'interface de base d'installation de R est correcte.
Si vous n'êtes pas conscient de R et des autres interfaces associées, vous devriez consulter ce tutoriel.
Maintenant, comprenons comment les packages que nous allons utiliser seront installés.
Packages :
1. rvest
Hadley Wickham a créé le package rvest pour le web scraping en R. rvest est utile pour extraire les informations dont vous avez besoin à partir des pages web.
Avec cela, vous devez également installer les packages selectr et 'xml2'.
Étapes d'installation :
install.packages('selectr')
install.packages('xml2')
install.packages('rvest')
rvest contient les fonctions de base pour le web scraping, qui sont assez efficaces. En utilisant les fonctions suivantes, nous essaierons d'extraire les données des sites web.
read_html(url): extrait le contenu HTML d'une URL donnéehtml_nodes(): identifie les conteneurs HTML.html_nodes("class"): appelle le nœud basé sur la classe CSShtml_nodes("#id"): appelle le nœud basé sur l'IDhtml_nodes(xpath="xpath"): appelle le nœud basé sur le xpath (nous couvrirons cela plus tard)html_attrs(): identifie les attributs (utile pour le débogage)html_table(): transforme les tableaux HTML en data frameshtml_text(): supprime les balises HTML et extrait uniquement le texte
2. stringr
stringr entre en jeu lorsque vous pensez à des tâches liées au nettoyage et à la préparation des données.
Il y a quatre ensembles essentiels de fonctions dans stringr :
- Les fonctions stringr sont utiles car elles vous permettent de travailler autour des caractères individuels au sein des chaînes dans les vecteurs de caractères
- Il y a des outils d'espace blanc qui peuvent être utilisés pour ajouter, supprimer et manipuler les espaces blancs
- Il y a des opérations sensibles à la locale dont les opérations différeront d'une locale à l'autre
- Il y a des fonctions de correspondance de motifs. Ces fonctions reconnaissent quatre parties de la description du motif. Les expressions régulières sont les standards, mais il existe d'autres outils également
Installation
install.packages('stringr')
3. jsonlite
Ce qui rend le package jsonlite utile, c'est qu'il s'agit d'un parseur/générateur JSON optimisé pour le web.
Il est vital car il permet une cartographie efficace entre les données JSON et les types de données R cruciaux. En utilisant cela, nous sommes capables de convertir entre les objets R et JSON sans perte de type ou d'information, et sans avoir besoin de manipulation manuelle des données.
Cela fonctionne très bien pour interagir avec les API web, ou si vous souhaitez créer des moyens par lesquels les données peuvent voyager dans et hors de R en utilisant JSON.
Installation
install.packages('jsonlite')
Avant de nous lancer, voyons comment cela fonctionne :
Il doit être clair dès le départ que chaque site web est différent, car le codage qui entre dans un site web est différent.
Le web scraping est la technique d'identification et d'utilisation de ces motifs de codage pour extraire les données dont vous avez besoin. Votre navigateur rend le site web disponible pour vous à partir de HTML. Le web scraping consiste simplement à analyser le HTML mis à votre disposition par votre navigateur.
Le web scraping suit un processus défini qui fonctionne généralement comme suit :
- Accéder à une page à partir de R
- Indiquer à R où "regarder" sur la page
- Convertir les données dans un format utilisable dans R en utilisant le package rvest
Maintenant, passons à l'implémentation pour mieux comprendre.
3. Implémentation
Mettons-le en œuvre et voyons comment cela fonctionne. Nous allons extraire les données du site web Amazon pour la comparaison des prix d'un produit appelé "One Plus 6", un téléphone mobile.
Vous pouvez le voir ici.
Étape 1 : Chargement des packages nécessaires
Nous devons être dans la console, à l'invite de commande R pour démarrer le processus. Une fois que nous y sommes, nous devons charger les packages requis comme montré ci-dessous :
#chargement du package:> library(xml2)> library(rvest)> library(stringr)
Étape 2 : Lecture du contenu HTML d'Amazon
#Spécification de l'URL du site web à scraperurl <- 'https://www.amazon.in/OnePlus-Mirror-Black-64GB-Memory/dp/B0756Z43QS?tag=googinhydr18418-21&tag=googinkenshoo-21&ascsubtag=aee9a916-6acd-4409-92ca-3bdbeb549f80'
#Lecture du contenu html d'Amazonwebpage <- read_html(url)
Dans ce code, nous lisons le contenu HTML à partir de l'URL donnée, et assignons ce HTML à la variable webpage.
Étape 3 : Extraction des détails du produit d'Amazon
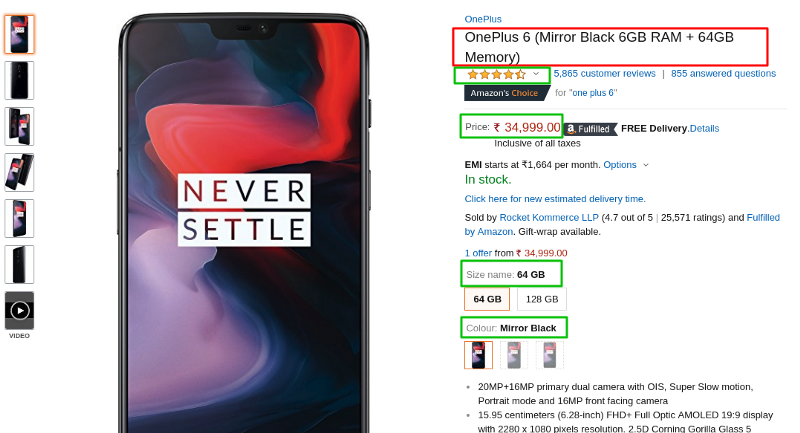
Maintenant, comme étape suivante, nous allons extraire les informations suivantes du site web :
Titre : Le titre du produit.
Prix : Le prix du produit.
Description : La description du produit.
Évaluation : L'évaluation utilisateur du produit.
Taille : La taille du produit.
Couleur : La couleur du produit.
Cette capture d'écran montre comment ces champs sont disposés.
Ensuite, nous allons utiliser les balises HTML, comme le titre du produit et le prix, pour extraire les données en utilisant Inspecter l'élément.
Pour trouver la classe de la balise HTML, utilisez les étapes suivantes :
=> allez dans le navigateur chrome => go to cette URL => clic droit => inspecter l'élément
NOTE : Si vous n'utilisez pas le navigateur Chrome, consultez cet article.
Sur la base des sélecteurs CSS tels que la classe et l'id, nous allons extraire les données du HTML. Pour trouver la classe CSS du titre du produit, nous devons faire un clic droit sur le titre et sélectionner "Inspecter" ou "Inspecter l'élément".
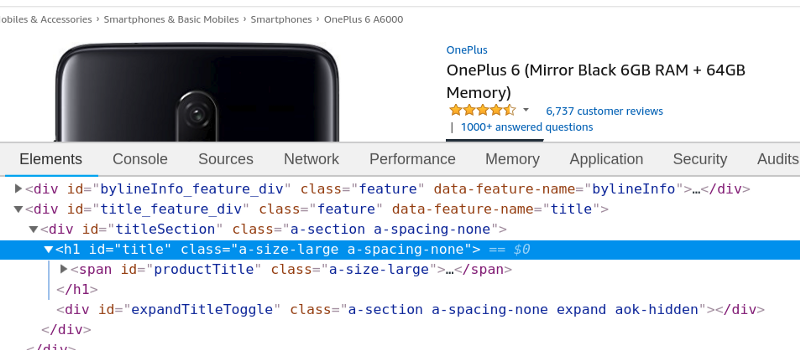
Comme vous pouvez le voir ci-dessous, j'ai extrait le titre du produit à l'aide de html_nodes dans lequel j'ai passé l'id du titre — h1#title — et webpage qui avait stocké le contenu HTML.
J'ai également pu obtenir le texte du titre en utilisant html_text et imprimer le texte du titre à l'aide de la fonction head().
#extraire le titre du produit> title_html <- html_nodes(webpage, 'h1#title')> title <- html_text(title_html)> head(title)
La sortie est affichée ci-dessous :

Nous avons pu obtenir le titre du produit en utilisant des espaces et \n.
L'étape suivante consisterait à supprimer les espaces et les nouvelles lignes à l'aide de la fonction str_replace_all() dans la bibliothèque stringr.
# supprimer tous les espaces et nouvelles lignesstr_replace_all(title, "[\\r\\n]" , "")
Sortie :
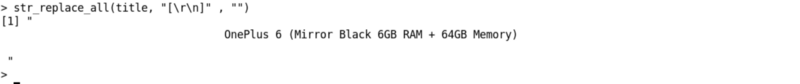
Maintenant, nous devons extraire les autres informations relatives au produit en suivant le même processus.
Prix du produit :
# extraire le prix du produit> price_html <- html_nodes(webpage, 'span#priceblock_ourprice')> price <- html_text(price_html)
# supprimer les espaces et nouvelles lignes> str_replace_all(title, "[\\r\\n]" , "")
# imprimer la valeur du prix> head(price)
Sortie :

Description du produit :
# extraire la description du produit> desc_html <- html_nodes(webpage, 'div#productDescription')> desc <- html_text(desc_html)
# remplacer les nouvelles lignes et espaces> desc <- str_replace_all(desc, "[\\r\\n\\t]" , "")> desc <- str_trim(desc)> head(desc)
Sortie :

Évaluation du produit :
# extraire l'évaluation du produit > rate_html <- html_nodes(webpage, 'span#acrPopover')> rate <- html_text(rate_html)
# supprimer les espaces et nouvelles lignes et tabulations > rate <- str_replace_all(rate, "[\\r\\n]" , "")> rate <- str_trim(rate)
# imprimer l'évaluation du produit> head(rate)
Sortie:
Taille du produit :
# Extraire la taille du produit> size_html <- html_nodes(webpage, 'div#variation_size_name')> size_html <- html_nodes(size_html, 'span.selection')> size <- html_text(size_html)
# supprimer la tabulation du texte> size <- str_trim(size)
# Imprimer la taille du produit> head(size)
Sortie :
Couleur du produit :
# Extraire la couleur du produit> color_html <- html_nodes(webpage, 'div#variation_color_name')> color_html <- html_nodes(color_html, 'span.selection')> color <- html_text(color_html)
# supprimer les tabulations du texte> color <- str_trim(color)
# imprimer la couleur du produit> head(color)
Sortie :
Étape 4 : Nous avons réussi à extraire les données de tous les champs qui peuvent être utilisés pour comparer les informations sur le produit à partir d'un autre site.
Compilons et combinons-les pour travailler sur un dataframe et inspecter sa structure.
#Combiner toutes les listes pour former un dataframeproduct_data <- data.frame(Title = title, Price = price,Description = desc, Rating = rate, Size = size, Color = color)
#Structure du dataframe str(product_data)
Sortie :

Dans cette sortie, nous pouvons voir toutes les données extraites dans les dataframes.
Étape 5 : Stocker les données au format JSON :
Une fois les données collectées, nous pouvons effectuer différentes tâches sur celles-ci, telles que comparer, analyser et obtenir des informations commerciales. Sur la base de ces données, nous pouvons envisager de former des modèles de machine learning.
Les données seraient stockées au format JSON pour un traitement ultérieur.
Suivez le code donné et obtenez le résultat JSON.
# Inclure la bibliothèque 'jsonlite' pour convertir au format JSON.> library(jsonlite)
# convertir le dataframe au format JSON> json_data <- toJSON(product_data)
# imprimer la sortie> cat(json_data)
Dans le code ci-dessus, j'ai inclus la bibliothèque jsonlite pour utiliser la fonction toJSON() afin de convertir l'objet dataframe au format JSON.
À la fin du processus, nous avons stocké les données au format JSON et les avons imprimées.
Il est possible de stocker les données dans un fichier csv ou dans une base de données pour un traitement ultérieur, si nous le souhaitons.
Sortie :

En suivant cet exemple pratique, vous pouvez également extraire les données pertinentes pour le même produit à partir de https://www.oneplus.in/6 et les comparer avec Amazon pour déterminer la valeur équitable du produit. De la même manière, vous pouvez utiliser les données pour les comparer avec d'autres sites web.
4. Note finale
Comme vous pouvez le voir, R peut vous donner un grand avantage pour extraire des données de différents sites web. Avec cette illustration pratique de la façon dont R peut être utilisé, vous pouvez maintenant l'explorer par vous-même et extraire des données produits d'Amazon ou de tout autre site web de commerce électronique.
Un mot d'avertissement pour vous : certains sites web ont des politiques anti-scraping. Si vous en abusez, vous serez bloqué et vous commencerez à voir des captchas au lieu des détails des produits. Bien sûr, vous pouvez également apprendre à contourner les captchas en utilisant différents services disponibles. Cependant, vous devez comprendre la légalité du scraping des données et ce que vous faites avec les données extraites.
N'hésitez pas à m'envoyer vos commentaires et suggestions concernant cet article !