
Article original : An in-depth introduction to SQOOP architecture
Par Jayvardhan Reddy
Apache Sqoop est un outil d'ingestion de données conçu pour transférer efficacement des données en masse entre Apache Hadoop et des bases de données structurées telles que les bases de données relationnelles, et vice-versa.
Dans le cadre de ce blog, je vais expliquer comment l'architecture fonctionne lors de l'exécution d'une commande Sqoop. Je couvrirai des détails tels que la génération de jar via Codegen, l'exécution du travail MapReduce, et les différentes étapes impliquées dans l'exécution d'une commande d'importation/exportation Sqoop.
Codegen
Comprendre Codegen est essentiel, car en interne, cela convertit notre travail Sqoop en un jar qui consiste en plusieurs classes Java telles que POJO, ORM, et une classe qui implémente DBWritable, étendant SqoopRecord pour lire et écrire les données des bases de données relationnelles vers Hadoop et vice-versa.
Vous pouvez créer un Codegen explicitement comme montré ci-dessous pour vérifier les classes présentes dans le jar.
sqoop codegen \ --connect jdbc:mysql://ms.jayReddy.com:3306/retail_db \ --username retail_user \ --password ******* \ --table products
Le jar de sortie sera écrit dans votre système de fichiers local. Vous obtiendrez un fichier Jar, un fichier Java et des fichiers Java qui sont compilés en fichiers .class :

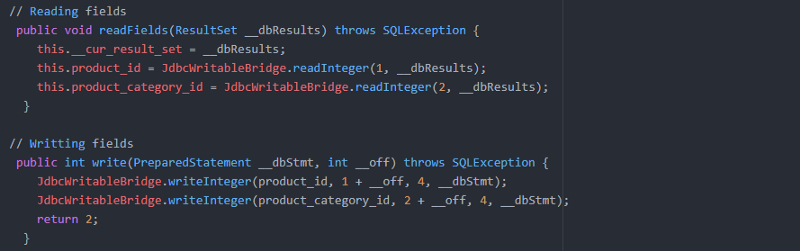
Examinons un extrait du code qui sera généré.
Classe ORM pour la table 'products' // Modèle objet-relationnel généré pour le mappage :
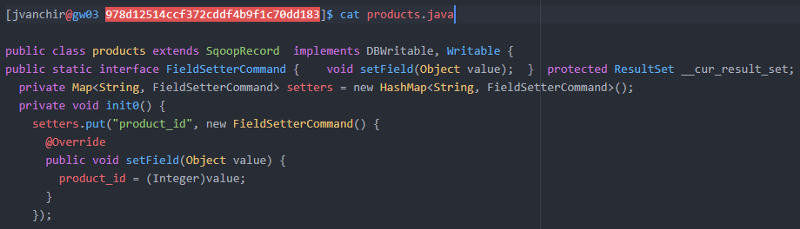
Méthodes Setter & Getter pour obtenir les valeurs :
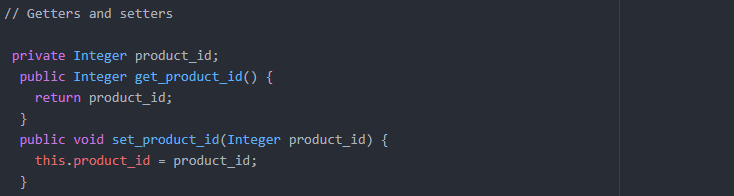
En interne, il utilise des instructions JDBC préparées pour écrire dans Hadoop et ResultSet pour lire les données de Hadoop.
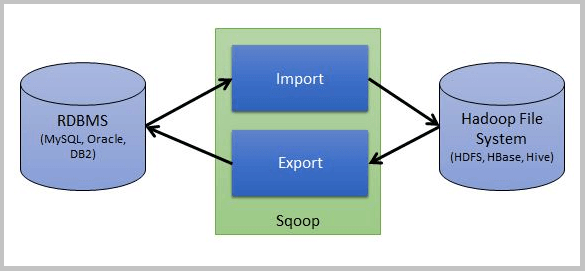
Importation Sqoop
Il est utilisé pour importer des données des bases de données relationnelles traditionnelles vers Hadoop.
Examinons un extrait de code pour cela.
sqoop import \ --connect jdbc:mysql://ms.jayReddy.com:3306/retail_db \ --username retail_user \ --password ******* \ --table products \ --warehouse-dir /user/jvanchir/sqoop_prac/import_table_dir \ --delete-target-dir
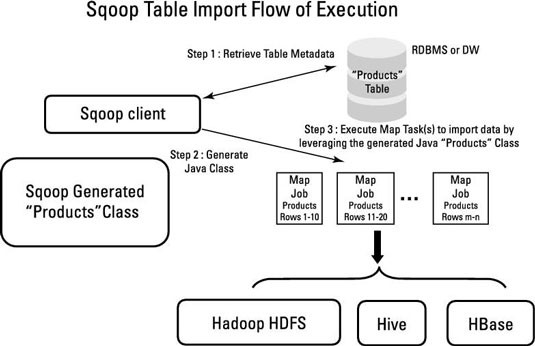
Les étapes suivantes se déroulent en interne lors de l'exécution de Sqoop.
Étape 1 : Lire les données de MySQL en streaming. Il effectue diverses opérations avant d'écrire les données dans HDFS.
Dans le cadre de ce processus, il générera d'abord du code (code MapReduce typique) qui n'est rien d'autre que du code Java. En utilisant ce code Java, il tentera d'importer.
- Générer le code. (Hadoop MR)
- Compiler le code et générer le fichier Jar.
- Soumettre le fichier Jar et effectuer les opérations d'importation
Lors de l'importation, il doit prendre certaines décisions sur la manière de diviser les données en plusieurs threads afin que l'importation Sqoop puisse être mise à l'échelle.
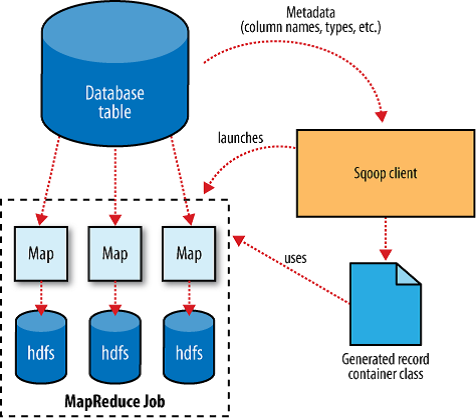
Étape 2 : Comprendre la structure des données et effectuer CodeGen
En utilisant l'instruction SQL ci-dessus, il récupérera un enregistrement ainsi que les noms des colonnes. En utilisant ces informations, il extraira les métadonnées des colonnes, le type de données, etc.
Étape 3 : Créer le fichier Java, le compiler et générer un fichier jar
Dans le cadre de la génération de code, il doit comprendre la structure des données et il doit appliquer cet objet aux données entrantes en interne pour s'assurer que les données sont correctement copiées dans la base de données cible. Chaque table unique a un fichier Java décrivant la structure des données.
Ce fichier jar sera injecté dans les binaires Sqoop pour appliquer la structure aux données entrantes.
Étape 4 : Supprimer le répertoire cible s'il existe déjà.
Étape 5 : Importer les données

Ici, il se connecte à un gestionnaire de ressources, obtient la ressource et démarre l'application master.
Pour effectuer une distribution égale des données parmi les tâches de mappage, il exécute en interne une requête de limite basée sur la clé primaire par défaut pour trouver le nombre minimum et maximum d'enregistrements dans la table. En fonction du nombre maximum, il le divise par le nombre de mappers et le divise entre chaque mapper.

Il utilise 4 mappers par défaut :
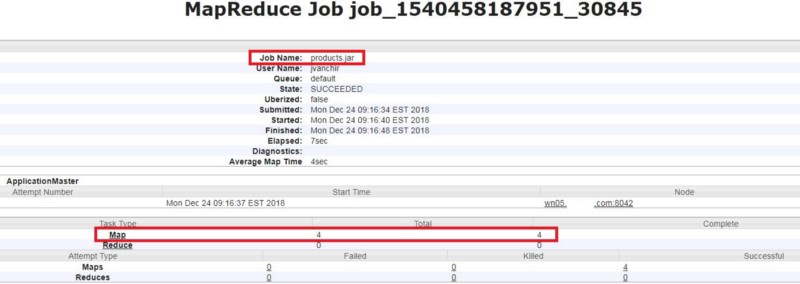
Il exécute ces travaux sur différents exécutants comme montré ci-dessous :

Le nombre par défaut de mappers peut être modifié en définissant le paramètre suivant :
Donc dans notre cas, il utilise 4 threads. Chaque thread traite des sous-ensembles mutuellement exclusifs, c'est-à-dire que chaque thread traite des données différentes des autres.
Pour voir les différentes valeurs, consultez ci-dessous :
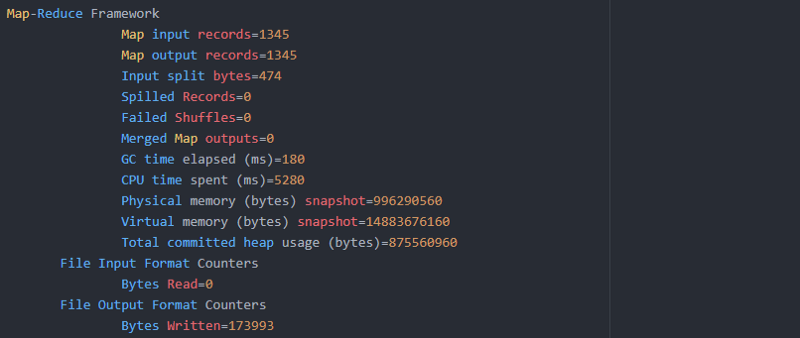
Opérations effectuées sous chaque nœud exécutant :

Dans le cas où vous effectuez une importation Sqoop Hive, une étape supplémentaire fait partie de l'exécution.
Étape 6 : Copier les données dans la table Hive

Exportation Sqoop
Cela est utilisé pour exporter des données de Hadoop vers des bases de données relationnelles traditionnelles.
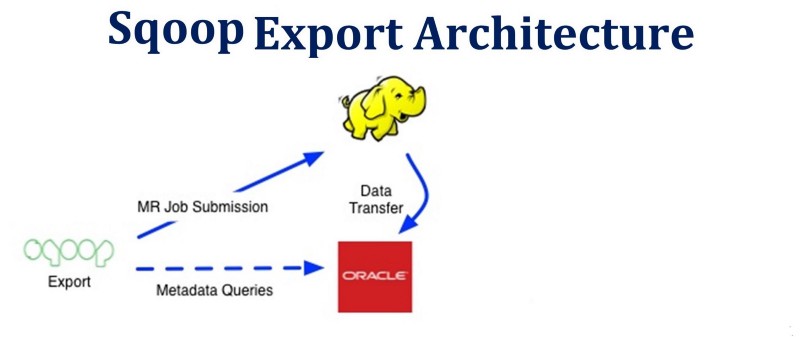
Examinons un extrait de code pour cela :
sqoop export \ --connect jdbc:mysql://ms.jayReddy.com:3306/retail_export \ --username retail_user \ --password ******* \ --table product_sqoop_exp \ --export-dir /user/jvanchir/sqoop_prac/import_table_dir/products
Lors de l'exécution de la commande ci-dessus, les étapes d'exécution (1-4) similaires à l'importation Sqoop ont lieu, mais les données sources sont lues à partir du système de fichiers (qui n'est rien d'autre que HDFS). Ici, il utilisera des limites basées sur la taille des blocs pour diviser les données et cela est pris en charge en interne par Sqoop.
Les divisions de traitement sont effectuées comme montré ci-dessous :

Après s'être connecté à la base de données respective vers laquelle les enregistrements doivent être exportés, il émettra une commande JDBC insert pour lire les données de HDFS et les stocker dans la base de données comme montré ci-dessous.
Maintenant que nous avons vu comment Sqoop fonctionne en interne, vous pouvez déterminer le flux d'exécution de la génération de jar à l'exécution d'une tâche MapReduce lors de la soumission d'un travail Sqoop.
Note : Les commandes exécutées liées à cet article sont ajoutées dans mon compte GIT.
De même, vous pouvez également lire plus ici :
- Architecture Hive en profondeur avec code.
- Architecture HDFS en profondeur avec code.
Si vous le souhaitez, vous pouvez me contacter sur LinkedIn - Jayvardhan Reddy.
Si vous avez aimé lire cet article, vous pouvez cliquer sur le bouton d'applaudissements et faire connaître cet article. Si vous souhaitez que j'ajoute autre chose, n'hésitez pas à laisser une réponse ?