

Article original : A brief history of serverless (or, how I learned to stop worrying and start loving the cloud)
Par Himanshu Pant
Il était une fois…
Les débuts
Dans les bonnes vieilles années des années 1950, lorsque Elvis régnait sur les charts avec des tubes comme Jailhouse Rock, un paradigme informatique est apparu appelé mainframes, alias Big Iron (sans rapport avec Arnold Schwarzenegger).
IBM était le principal acteur dans ce domaine, avec une poignée d'autres petits fournisseurs donnant parfois du fil à retordre à Big Blue.
Ces premières machines étaient purement orientées vers le traitement par lots — M. John Appleseed pouvait perforer ses instructions (lire programmes) sur une carte perforée (voir ci-dessous), la passer à l'équipe des opérations et aller prendre un café, ou même partir pour la journée.

L'opérateur planifiait et exécutait les cartes perforées précédemment soumises.

Fait amusant : l'image ci-dessus représente un énorme 5 Mo de données sur 62 500 cartes perforées. Imaginez donc le nombre de cartes nécessaires pour capturer la base de code de Win 10 ou MacOS si nous utilisions encore cette technologie !
Une fois la sortie générée/imprimée, l'opérateur la collectait physiquement et la déposait dans le cubicle ou la boîte aux lettres physique de M. Appleseed. L'accès en ligne était principalement réservé aux ressources en ayant besoin, comme, par exemple, le personnel d'un comptoir de réservation d'une compagnie aérienne.
Donc, à tous ceux qui pleurent malgré avoir des IDE basés sur GUI pour faire leur développement logiciel, si vous pensez que votre travail est difficile — pensez à ces pionniers.
Il va sans dire que le processus ci-dessus n'était pas seulement lent, mais aussi extrêmement coûteux. Tellement que l'utilisation du système était mesurée et facturée en secondes sur le compte du client.
Les réécritures de code étaient extrêmement fastidieuses et chronophages. En fait, à y penser, cela peut être la raison des compétences exceptionnelles en codage des développeurs de cette époque, car comme l'a si bien dit un certain M. Real slim shady :

L'ère du PC
Ensuite est venue l'ère du PC, qui a démocratisé la technologie sous la forme de l'ordinateur personnel.
Le modèle de traitement a commencé à passer des systèmes centralisés basés sur les mainframes au modèle basé sur le client-serveur. La planification, l'acquisition et la maintenance des infrastructures sont devenues une partie vitale du développement logiciel, car le rythme des affaires a commencé à augmenter de manière exponentielle.
Il n'était donc pas inhabituel de voir le déploiement de logiciels sur un système basé sur le client-serveur accompagné de projections pour la croissance future du volume. Des provisions devaient être faites pour cela. Comme c'était le cas, le travail typique de l'ingénieur était difficile — mais cela nécessitait également qu'il soit un devin.

Ainsi, notre pauvre M. Appleseed avait beaucoup de choses à comprendre. Non seulement il devait comprendre ce que les équipes commerciales disaient sous forme de leurs exigences, mais il devait également apprendre tous les outils de codage, les normes, les meilleures pratiques et les innovations à suivre.
Il devait également prendre en compte des paramètres tels que les modèles d'utilisation du logiciel, la rapidité ou la lenteur de sa croissance future, et quel pourrait être le matériel optimal afin de trouver le bon équilibre entre performance et efficacité des coûts.
Les obstacles bureaucratiques dans toute organisation donnée faisaient que le pauvre ingénieur était toujours coincé entre le marteau et l'enclume.
En plus de passer des nuits blanches sur les exigences en constante évolution et les délais changeants, il devait également se contenter des caprices de l'acquisition d'infrastructures. Dans le monde des mainframes, la situation était un peu meilleure, car l'acquisition de matériel n'était pas si courante. Mais l'allocation des ressources était encore une corvée, ce qui causait beaucoup de maux de tête.
L'ère du Cloud
Le milieu des années 2000 a vu l'avènement d'un nouveau paradigme en informatique : « le cloud ». Il a changé la nature de l'informatique telle qu'elle était connue jusqu'à ce point.
Avant d'approfondir, prenons une minute pour rafraîchir la définition du « cloud » donnée par le National Institute of Standards and Technology (NIST) :
L'informatique en nuage est un modèle permettant un accès réseau pratique et à la demande à un pool partagé de ressources informatiques configurables (par exemple, réseaux, serveurs, stockage, applications et services) qui peuvent être rapidement provisionnées et libérées avec un effort de gestion minimal ou une interaction avec le fournisseur de services. Cinq attributs majeurs définissent un système basé sur le cloud, à savoir :
a) Auto-service à la demande
b) Accès réseau large
c) Pooling de ressources
d) Élasticité rapide
e) Mesure du service
Les principaux facilitateurs de ce paradigme sont :
a) Réseaux WAN rapides
b) Serveurs de commodité puissants
c) Virtualisation haute performance pour le matériel de commodité
Notre cher M. Appleseed était maintenant heureux — après tout, il n'était plus à la merci de son ingénieur infrastructure pour obtenir des serveurs ou du stockage. D'un simple clic, il pouvait obtenir de la puissance de calcul, du stockage, une file d'attente et tout autre service.
Tout allait bien dans le monde informatique. Mais M. Appleseed, fidèle à sa nature humaine et étant une espèce entreprenante, a commencé à se demander comment il pouvait faciliter sa vie.
De plus, le monde devenait numérique à un rythme effréné avec des échelles inédites d'entreprises. Cela rendait la pratique de la pré-allocation de matériel un but autodestructeur. Toutes les interactions avec le monde numérique devenaient principalement basées sur des événements.
L'architecture Serverless
2015 (ou certains disent 2012) était le moment où ce paradigme informatique est apparu. Il y a eu un certain nombre d'interprétations proposées pour ce terme (serverless) et ses implications.
Une école de pensée l'attribue au Backend as a Service (BaaS). Par exemple, les services d'authentification offerts par des fournisseurs tiers comme Google ou Facebook.
L'autre école de pensée le lie à un concept dans lequel des applications avec une logique métier (lire : côté serveur) sont exécutées sur des conteneurs sans état, gérés entièrement par un fournisseur tiers, ce qui est connu sous le nom de Function as a Service (Faas).
Cet article se concentre sur la deuxième définition du concept, car elle a des implications intéressantes pour la manière dont les applications web sont architecturées.
La brève évolution du paradigme de l'informatique en nuage
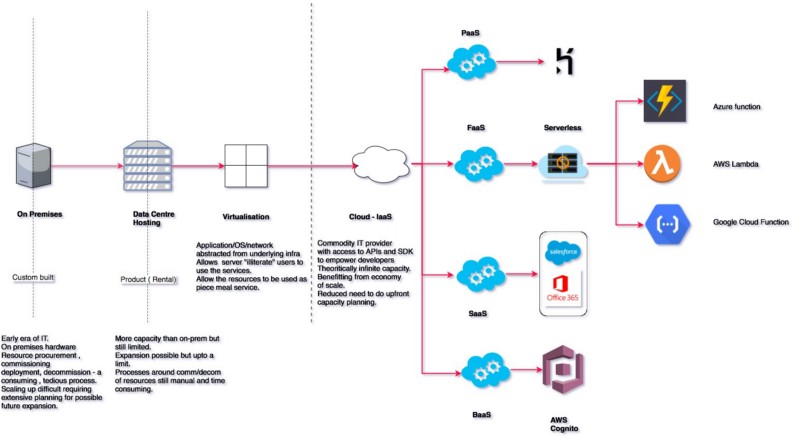
Au cœur, FaaS est un concept simple qui signifie que :
- L'équipe de développement ne doit pas s'inquiéter des aspects comme le serveur backend, sa maintenance, son acquisition ou sa mise à l'échelle (bien, dans une certaine mesure). Tout ce que l'équipe doit faire est de s'inquiéter de la logique de l'application.
- Le traitement est effectué sur des conteneurs de calcul qui sont sans état. Donc, en d'autres termes, après une unité logique de traitement, il n'y a pas de stockage des attributs de traitement par le système.
- Au lieu d'avoir un serveur avec des processus en cours d'exécution, par exemple cron, ici le traitement n'est initié qu'une fois que l'événement qualifiant se produit et est terminé lorsque le traitement est terminé ou que le temps défini s'est écoulé (selon ce qui se produit en premier).
Cela ne signifie pas qu'il n'y a aucun serveur dans le schéma des choses. Tout ce que cela signifie est que les serveurs et leur maintenance sont maintenant cachés au développeur.
De plus, puisque l'unité physique de calcul est maintenant un conteneur, il n'est pas nécessaire d'avoir des serveurs en cours d'exécution avec des écouteurs d'événements en cours d'exécution pour effectuer un traitement. Des sources d'événements qualifiées pourraient être branchées dans le système et le service prendrait le relais.
Ce que le Serverless n'est PAS
« Qu'y a-t-il dans un nom ? Ce que nous appelons une rose sous un autre nom sentirait aussi bon. » — Juliette, Roméo et Juliette
Comme c'est le cas avec toute nouvelle innovation, plus souvent qu'autrement, des noms clinquants sont utilisés par les vendeurs pour reconditionner du vieux vin dans une nouvelle bouteille, pour ainsi dire, pour attirer plus de regards.
Dans le cas du serverless, cette confusion est plus répandue. Cela est dû au fait que le concept s'est développé en très peu de temps et en très proche proximité avec les autres concepts avec lesquels il peut être confondu.
Donc, ici, je tente de clarifier ce que le serverless est généralement (ou peut être) confondu. Je vais également donner mon avis.
Ce n'est PAS un Conteneur
« Une image de conteneur est un package léger, autonome et exécutable d'un logiciel qui inclut tout ce qui est nécessaire pour l'exécuter : code, runtime, outils système, bibliothèques système, paramètres. Disponible pour les applications basées sur Linux et Windows, le logiciel conteneurisé s'exécutera toujours de la même manière, indépendamment de l'environnement. Les conteneurs isolent le logiciel de son environnement, par exemple les différences entre les environnements de développement et de préproduction, et aident à réduire les conflits entre les équipes exécutant différents logiciels sur la même infrastructure. » — Docker.com
Le conteneur est une innovation récente en informatique. Google l'a popularisé en exécutant Gmail dessus. Les conteneurs sont utiles pour maintenir la fiabilité et l'homogénéité du logiciel s'exécutant sur divers environnements informatiques.
Par exemple, le code peut avoir été développé en Java 8, mais la production peut être en Java 9 — donc le code qui fonctionnait bien en développement peut commencer à générer des erreurs étranges en production.
En termes simples, le conteneur est l'ancienne VM (machine virtuelle) sous stéroïdes. Il n'a aucun des excès de graisse des versions individuelles des systèmes d'exploitation. Contrairement aux VM, où il y avait une copie séparée du système d'exploitation invité (ce qui rendait la VM lourde en ressources), les conteneurs partagent le noyau du système d'exploitation sous-jacent. Cela permet d'exécuter plusieurs conteneurs sur cette machine particulière par rapport aux VM.
VM vs Conteneur
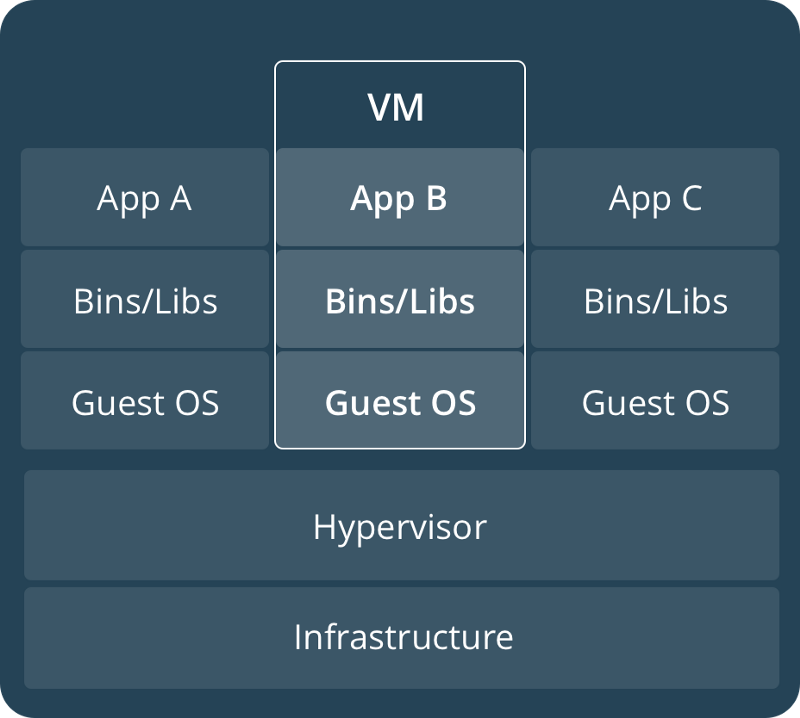
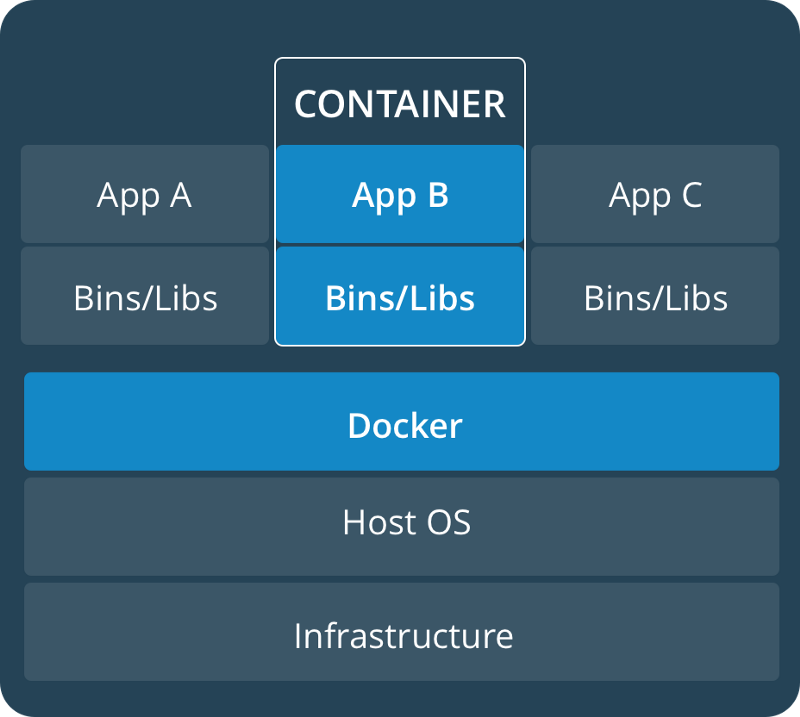
Les conteneurs résolvent une partie du problème : ils fournissent un environnement de production homogène, bien qu'au coût d'un effort de maintenance accru.
Cependant, pour être juste, les conteneurs sont généralement mieux adaptés à différents types de charges de travail (comme celles qui sont intrinsèquement plus complexes). Ils trouvent donc leur place dans les paysages informatiques d'entreprise où il y a déjà un monolithe en cours d'exécution et où l'organisation peut vouloir le porter rapidement sur le cloud.
La mise à l'échelle horizontale est un vecteur où le serverless vole la vedette aux conteneurs. Les fournisseurs de cloud modernes « théoriquement » offrent une capacité de mise à l'échelle illimitée pour leurs offres serverless. Et le meilleur de tout, cette mise à l'échelle est totalement transparente pour l'utilisateur.
L'informatique serverless est mieux alignée sur les opérations asynchrones basées sur les événements, tandis que les conteneurs semblent mieux adaptés aux charges de travail REQ/RESP synchrones.
Mais étant donné le rythme auquel les choses changent, les différences peuvent se diluer considérablement en peu de temps.
Ce n'est PAS du PaaS
« Platform as a service » (PaaS) est un modèle d'informatique en nuage dans lequel un fournisseur tiers fournit des outils matériels et logiciels — généralement ceux nécessaires au développement d'applications — aux utilisateurs via Internet. Un fournisseur PaaS héberge le matériel et le logiciel sur sa propre infrastructure. Par conséquent, le PaaS libère les utilisateurs de l'obligation d'installer du matériel et des logiciels en interne pour développer ou exécuter une nouvelle application. » — Techtarget
Tout comme les conteneurs, le PaaS diffère principalement en ce qui concerne le vecteur de mise à l'échelle. Cependant, aussi peu impliqués que les fournisseurs de PaaS puissent prétendre que leur offre est, elle nécessite toujours un certain effort de maintenance administrative, contrairement au serverless.
Avec le PaaS, il y a toujours une empreinte minimale en cours d'exécution dans le système qui sera active et engendrera des coûts. Cependant, avec le serverless, cela peut être réduit à zéro absolu.
Le PaaS peut encore être un bon choix étant donné son écosystème et ses outils plus avancés et son support de langage. Cependant, cela ne devrait pas être un obstacle étant donné le rythme élevé des avancées dans le domaine du serverless.