


Article original : A Practical Guide to Regular Expressions – Learn RegEx with Real Life Examples
Qu'est-ce que les expressions régulières ?
Les expressions régulières, également connues sous le nom de regex, fonctionnent en définissant des motifs que vous pouvez utiliser pour rechercher certains caractères ou mots à l'intérieur de chaînes de caractères.
Une fois que vous avez défini le motif que vous souhaitez utiliser, vous pouvez effectuer des modifications, supprimer certains caractères ou mots, substituer une chose par une autre, extraire des informations pertinentes d'un fichier ou de toute chaîne contenant ce motif particulier, et ainsi de suite.
Pourquoi devriez-vous apprendre les regex ?
Les regex vous permettent de traiter du texte de manière à gagner beaucoup de temps. Cela peut également introduire une certaine amusement dans le processus.
L'utilisation des regex peut faciliter la localisation d'informations. Une fois que vous avez trouvé votre cible, vous pouvez effectuer des éditions, des remplacements ou des suppressions par lots, ou tout autre traitement dont vous avez besoin.
Quelques exemples pratiques d'utilisation des regex sont le renommage de fichiers par lots, l'analyse de logs, la validation de formulaires, la réalisation d'éditions massives dans une base de code et la recherche récursive.
Dans ce tutoriel, nous allons couvrir les bases des regex avec l'aide de ce site. Plus tard, je vous présenterai quelques défis regex que vous résoudrez en utilisant Python. Je vous montrerai également comment utiliser des outils comme sed et grep avec les regex.
Comme beaucoup de choses dans la vie, les expressions régulières sont l'une de ces choses que vous ne pouvez vraiment comprendre qu'en pratiquant. Je vous encourage à jouer avec les regex pendant que vous lisez cet article.
Table des matières
- Bases des Regex
- Comment utiliser les regex avec les outils en ligne de commande
- Regex avancées : Lookarounds
- Exemples pratiques de Regex
- Mots de la fin
Bases des Regex
Une expression régulière n'est rien d'autre qu'une séquence de caractères qui correspond à un motif. En plus d'utiliser des caractères littéraux (comme 'abc'), il existe certains métacaractères (*, +, ? et ainsi de suite) qui ont des buts spéciaux. Il existe également des fonctionnalités comme les classes de caractères qui peuvent vous aider à simplifier vos expressions régulières.
Avant d'écrire une regex, vous devrez apprendre tous les cas de base et les cas particuliers pour le motif que vous recherchez.
Par exemple, si vous voulez faire correspondre 'Hello World', voulez-vous que la ligne commence par 'Hello' ou peut-elle commencer par n'importe quoi ? Voulez-vous exactement un espace entre 'Hello' et 'World' ou peut-il y en avoir plus ? D'autres caractères peuvent-ils venir après 'World' ou la ligne doit-elle se terminer là ? Vous vous souciez de la sensibilité à la casse ? Et ainsi de suite.
Ce sont le genre de questions auxquelles vous devez avoir une réponse avant de vous asseoir pour écrire votre regex.
Correspondance exacte
La forme la plus basique de regex implique de faire correspondre une séquence de caractères de manière similaire à ce que vous pouvez faire avec Ctrl-F dans un éditeur de texte.

En haut, vous pouvez voir le nombre de correspondances, et en bas, une explication est fournie pour ce que la regex correspond caractère par caractère.
Ensemble de caractères
Les ensembles de caractères regex vous permettent de faire correspondre un caractère parmi un groupe de caractères. Le groupe est entouré de crochets [].
Par exemple, t[ah]i correspond à "tai" et "thi". Ici, 't' et 'i' sont fixes mais entre eux peut se trouver 'a' ou 'h'.
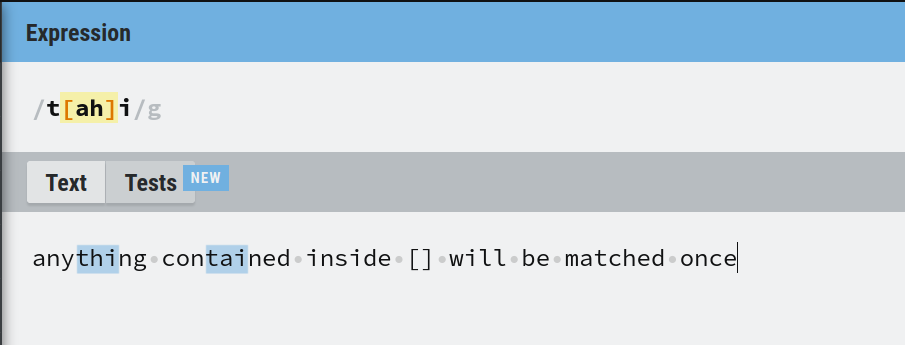
Correspondance de plages dans les regex
Parfois, vous pouvez vouloir faire correspondre un groupe de caractères qui sont séquentiels par nature, comme toute lettre majuscule anglaise. Mais écrire toutes les 26 lettres serait assez fastidieux.
Les regex résolvent ce problème avec des plages. Le "-" agit comme un opérateur de plage. Voici quelques plages valides :
| Plage | Correspondances |
| [A-Z] | lettres majuscules |
| [a-z] | lettres minuscules |
| [0-9] | Tout chiffre |
Vous pouvez également spécifier des plages partielles, comme [b-e] pour faire correspondre l'une des lettres 'bcde' ou [3-6] pour faire correspondre l'un des chiffres '3456'.
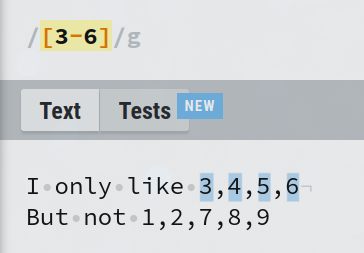
Vous n'êtes pas limité à spécifier une seule plage à l'intérieur d'un ensemble de caractères. Vous pouvez utiliser plusieurs plages et également les combiner avec tout autre caractère supplémentaire. Ici, [3-6u-w;] correspondra à l'un des '3456uvw' ou au point-virgule ';'.

Correspondance de tout caractère non dans l'ensemble
Si vous préfixez l'ensemble avec un '^', l'opération inverse sera effectuée. Par exemple, [^A-Z0-9] correspondra à tout sauf aux lettres majuscules et aux chiffres.

Classes de caractères
Lors de l'écriture de regex, vous devrez souvent faire correspondre certains groupes comme des chiffres, et ce plusieurs fois dans la même expression.
Par exemple, comment feriez-vous pour faire correspondre un motif comme 'lettre-chiffre-lettre-chiffre' ?
Avec ce que vous avez appris jusqu'à présent, vous pouvez venir avec [a-zA-Z]-[0-9]-[a-zA-z]-[0-9]. Cela fonctionne, mais vous pouvez voir comment l'expression peut devenir assez désordonnée à mesure que la longueur du motif augmente.
Pour simplifier l'expression, des classes ont été attribuées à des groupes de caractères bien définis comme les chiffres. Le tableau suivant montre ces classes et leur expression équivalente avec des ensembles de caractères :
| Classe | Correspondances | Expression équivalente |
| . | tout sauf nouvelle ligne | [^\n\r] |
| \w | caractère de mot | [a-zA-Z0-9_] |
| \W | caractère non-mot | [^\w] |
| \d | chiffres | [0-9] |
| \D | non-chiffres | [^\d] |
| \s | espace, tabulation, nouvelles lignes | [ \t\r\n\f] |
| \S | caractères non-espace | [^\s] |
Les classes de caractères sont très pratiques et rendent vos expressions beaucoup plus propres. Nous les utiliserons abondamment tout au long de ce tutoriel, vous pouvez donc utiliser ce tableau comme point de référence et revenir ici si vous oubliez l'une des classes.
La plupart du temps, nous ne nous soucierons pas de toutes les positions dans un motif. La classe "." nous évite d'écrire tous les caractères possibles dans un ensemble.
Par exemple, t.. correspond à tout ce qui commence par t et à deux caractères quelconques ensuite. Cela peut vous rappeler l'opérateur LIKE de SQL qui utiliserait t%% pour accomplir la même chose.

Quantificateurs
Les mots "motif" et "répétition" vont de pair. Si vous voulez faire correspondre un nombre à 3 chiffres, vous pouvez utiliser \d\d\d. Mais que faire si vous devez faire correspondre 11 chiffres ? Vous pourriez écrire '\d' 11 fois, mais une règle générale lors de l'écriture de regex ou simplement de la programmation est que si vous vous retrouvez à répéter quelque chose plus de deux fois, vous ignorez probablement une fonctionnalité.
Dans les regex, vous pouvez utiliser des quantificateurs à cette fin. Pour faire correspondre 11 chiffres, vous pouvez simplement écrire l'expression \d{11}.
Le tableau ci-dessous liste les quantificateurs que vous pouvez utiliser dans les regex :
| Quantificateur | Correspondances |
| * | 0 ou plus |
| ? | 0 ou 1 |
| + | 1 ou plus |
| {n} | exactement n fois |
| {n, } | n ou plus fois |
| {n, m} | n à m fois inclusivement |
Dans cet exemple, l'expression can\s+write correspond à can suivi d'un ou plusieurs espaces, suivi de write. Mais vous pouvez voir que 'canwrite' n'est pas correspond car \s+ signifie qu'au moins un espace doit être correspond. Cela est utile lorsque vous recherchez dans du texte qui n'est pas rogné.
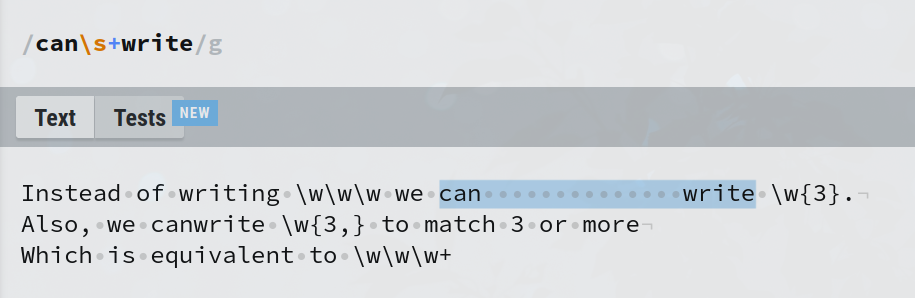
Pouvez-vous deviner ce que can\s?write correspondra ?
Groupes de capture
Les groupes de capture sont des sous-expressions enfermées dans des parenthèses (). Vous pouvez avoir autant de groupes de capture que vous le souhaitez, et même des groupes de capture imbriqués.
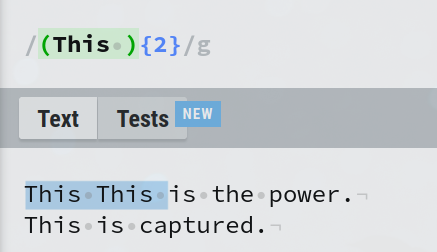
L'expression (The ){2} correspond à 'The ' deux fois. Mais sans un groupe de capture, l'expression The {2} correspondrait à 'The' suivi de deux espaces, car le quantificateur serait appliqué au caractère espace et non à 'The ' en tant que groupe.
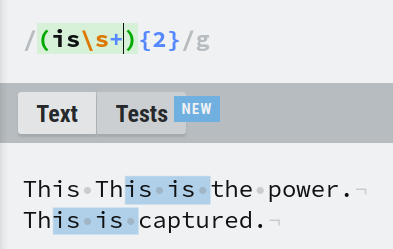
Vous pouvez faire correspondre n'importe quel motif à l'intérieur des groupes de capture comme vous le feriez avec n'importe quelle regex valide. Ici, (is\s+){2} correspond si elle trouve 'is' suivi d'un ou plusieurs espaces deux fois.
Comment utiliser le OU logique dans les regex
Vous pouvez utiliser "|" pour faire correspondre plusieurs motifs. This is (good|bad|sweet) correspond à 'This is ' suivi de l'un des 'good', 'bad' ou 'sweet'.

Encore une fois, vous devez comprendre l'importance des groupes de capture ici. Réfléchissez à ce que l'expression This is good|bad|sweet correspondrait ?

Avec un groupe de capture, good|bad|sweet est isolé de This is. Mais s'il n'est pas à l'intérieur d'un groupe de capture, toute la regex est un seul groupe. Donc l'expression This is good|bad|sweet correspondra si la chaîne contient 'This is good' ou 'bad' ou 'sweet'.
Comment référencer les groupes de capture
Les groupes de capture peuvent être référencés dans la même expression ou lors de l'exécution de remplacements comme vous pouvez le voir dans l'onglet Remplacement.
La plupart des outils et des langages vous permettent de référencer le n-ième groupe capturé avec '\n'. Sur ce site, '$n' est utilisé lors du référencement dans le remplacement. La syntaxe pour le remplacement variera en fonction des outils ou du langage que vous utilisez. Pour JavaScript, par exemple, c'est '$n', tandis que pour Python, c'est '\n'.
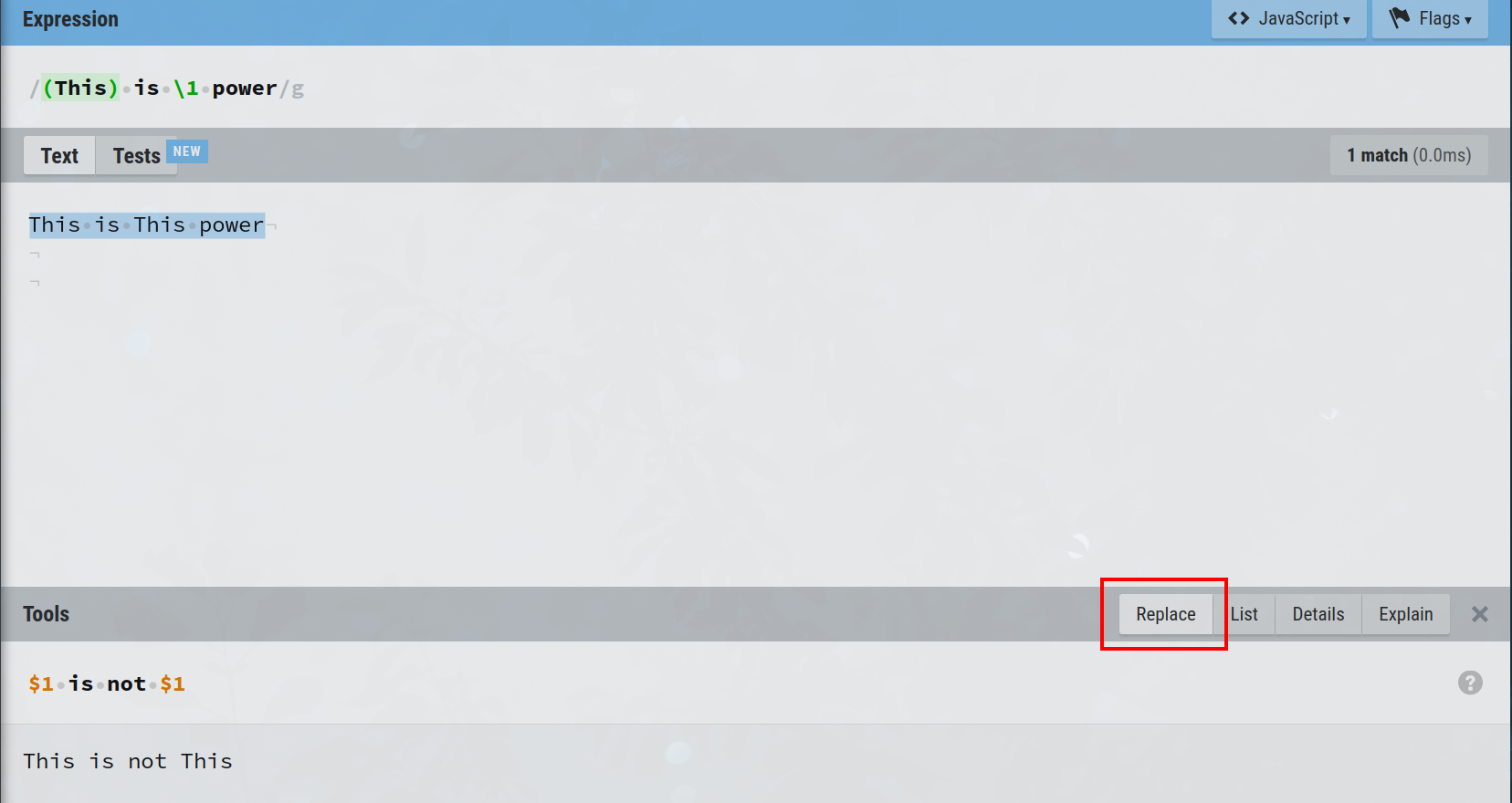
Dans l'expression (This) is \1 power, 'This' est capturé puis référencé avec '\1', correspondant effectivement à This is This power.
Comment nommer les groupes de capture
Vous pouvez nommer vos groupes de capture avec la syntaxe (?<name>pattern) et les référencer dans la même expression avec \k<name>.
Lors du remplacement, le référencement est effectué par $<name>. Il s'agit de la syntaxe pour JavaScript et elle peut varier selon les langages. Vous pouvez en apprendre davantage sur les différences ici. Notez également que cette fonctionnalité peut ne pas être disponible dans certains langages.
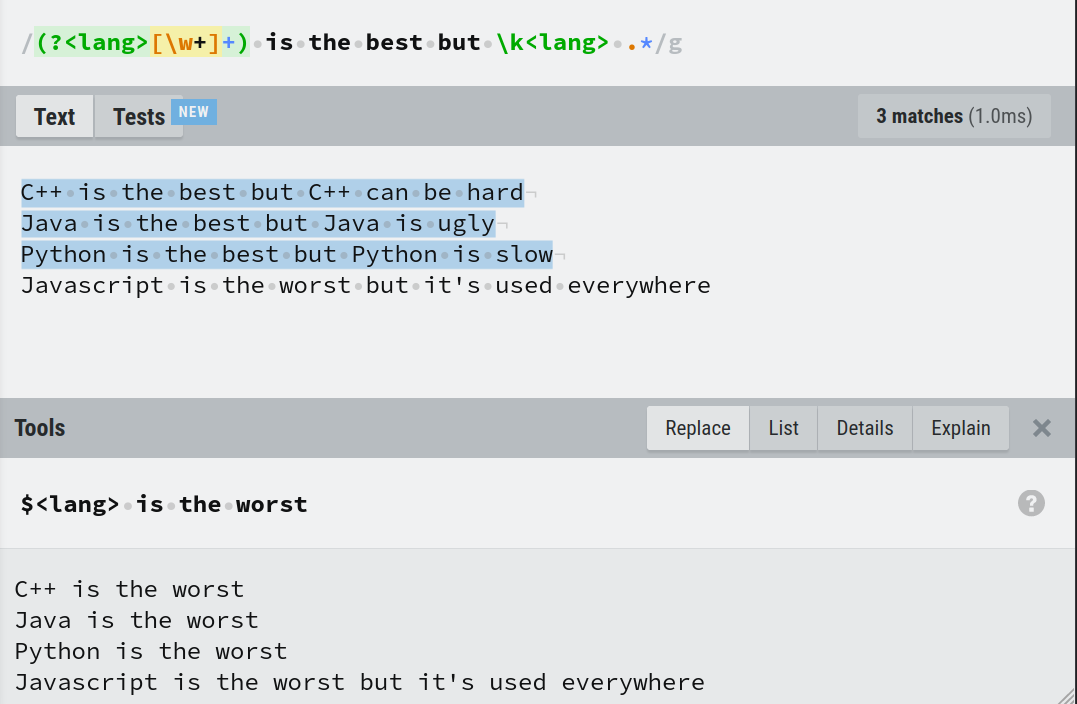
Dans l'expression (?<lang>[\w+]+) is the best but \k<lang> .*, le motif [\w+]+ est capturé avec le nom 'lang' et référencé avec \k<lang>. Ce motif correspondra à tout caractère de mot ou au caractère '+' une ou plusieurs fois. Le .* à la fin de la regex correspond à tout caractère 0 ou plusieurs fois. Et enfin, lors du remplacement, le référencement est effectué par $<lang>.
Comment utiliser les regex avec les outils en ligne de commande
Il existe de bons outils CLI disponibles qui vous permettent d'exécuter des regex depuis votre terminal. Ces outils vous font gagner encore plus de temps car vous pouvez facilement tester différentes regex sans écrire de code dans un langage puis le compiler ou l'interpréter.
Certains des outils bien connus sont grep, sed et awk. Regardons quelques exemples pour vous donner quelques idées sur la façon dont vous pouvez tirer parti de ces outils.
Recherche récursive avec grep
Vous pouvez exécuter la puissance des regex à travers grep. Grep peut rechercher des motifs dans un fichier ou effectuer une recherche récursive.
Si vous êtes sur Windows, vous pouvez installer grep en utilisant winget. Exécutez cette commande dans powershell :
winget install -e --id GnuWin32.Grep
Je vais vous montrer la solution à un défi que j'ai créé pour une compétition CTF à mon université.
Le fichier joint au défi est un fichier zip qui contient plusieurs niveaux de répertoires et beaucoup de fichiers. Le nom de la compétition était Coderush avec le format de drapeau coderush{flag is here}. Vous devez donc rechercher le motif coderush{.*} qui correspondra au format de drapeau coderush{any character here}.
Décompressez le fichier avec unzip ripG.zip et accédez-y avec cd ripG.
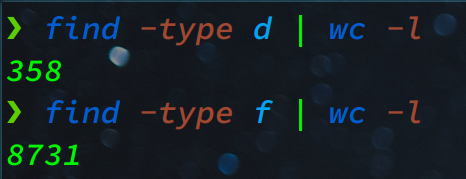
Il y a 358 répertoires et 8731 fichiers. Au lieu de rechercher le motif dans les fichiers un par un, vous pouvez employer grep comme ceci :
grep --color -R "coderush{.*}"
Le drapeau "-R" active la recherche récursive.

Vous pouvez en apprendre davantage sur grep et ses options de ligne de commande ici
Substitution avec sed
Vous pouvez utiliser sed pour effectuer des insertions, des suppressions, des substitutions sur des fichiers texte en spécifiant une regex. Si vous êtes sur Windows, vous pouvez obtenir sed ici. Ou si vous utilisez WSL, des outils comme grep et sed seront déjà disponibles.
Voici l'utilisation la plus courante de sed :
sed 's/pattern/replacement/g' filename
echo "${text}" | sed 's/pattern/replacement/g'
Ici, l'option "g" est spécifiée pour remplacer toutes les occurrences.
D'autres options utiles sont -n pour supprimer le comportement par défaut d'impression de toutes les lignes et utiliser p au lieu de g pour imprimer uniquement les lignes qui sont affectées par la regex.
Regardons le contenu de texts.txt.
Hello rand chars World 56 rand chars
Henlo 52 rand chars W0rld rand chars
GREP rand chars Henlo 62 rand chars
Henlo 10 rand chars Henlo rand chars
GREP rand chars Henlo 45 rand chars
Notre tâche est de remplacer Henlo number par Hello number uniquement dans les lignes où "GREP" est présent. Nous recherchons donc le motif Henlo ([0-9]+) qui correspondra à 'Henlo ' suivi de 1 ou plusieurs chiffres, et tous les chiffres sont capturés. Ensuite, notre chaîne de remplacement sera Hello \1 – le '\1' référence le groupe de capture contenant les chiffres.
Une façon d'accomplir cela serait d'utiliser grep pour extraire les lignes contenant "GREP", puis effectuer le remplacement avec sed.
grep "GREP" texts.txt | sed -En 's/Henlo ([0-9]+)/Hello \1/p'
L'option "-E" active les regex étendues, sans lesquelles vous devriez échapper les parenthèses.

Ou vous pourriez simplement utiliser sed. Utilisez /pattern/ pour restreindre la substitution uniquement aux lignes où le motif est présent.
sed -En '/GREP/ s/Henlo ([0-9]+)/Hello \1/p' texts.txt
Regex avancées : Lookarounds
Les lookaheads et les lookbehinds (ensemble appelés lookarounds) sont des fonctionnalités des regex qui vous permettent de vérifier l'existence d'un motif sans l'inclure dans la correspondance.
Vous pouvez les considérer comme des assertions de largeur nulle – ils affirment l'existence d'un motif mais ne consomment aucun caractère dans la correspondance. Ces fonctionnalités sont très puissantes, mais elles sont également coûteuses en termes de calcul. Assurez-vous donc de surveiller les performances si vous les utilisez souvent.
Lookbehinds
Disons que vous voulez faire correspondre le mot 'linux', mais vous avez 2 conditions.
- Le mot 'GNU' doit apparaître avant 'linux'. Si une ligne contient 'linux' mais n'a pas 'GNU' avant, nous voulons ignorer cette ligne.
- Nous voulons faire correspondre uniquement
linuxet rien d'autre.
Nous savons déjà comment satisfaire la 1ère condition. GNU.* correspondra à 'GNU' suivi de n'importe quel nombre de caractères. Ensuite, nous faisons enfin correspondre le mot linux. Cela correspondra à tout GNU-any-characters-linux.
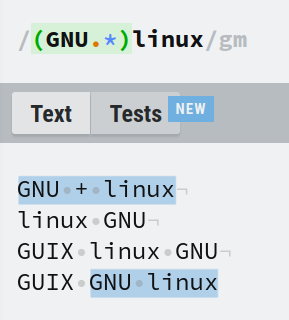
Mais comment empêcher la correspondance de GNU.* tout en maintenant la 1ère condition ?
C'est là qu'intervient le lookbehind positif. Vous pouvez marquer un groupe de capture comme un lookbehind positif en le préfixant avec ?<=. Dans cet exemple, l'expression devient (?<=GNU.*)linux.

Maintenant, seul linux est correspond et rien d'autre.
Notez que les expressions (?<=GNU.*)linux et linux(?<=GNU.*) se comporteront exactement de la même manière. Dans la 2ème expression, bien que linux soit avant le lookbehind, il y a .* après 'GNU' qui correspond à linux. Cela signifie qu'il satisfait le lookbehind.
Pour simplifier, pensez au motif sans le lookbehind. Le motif GNU.* correspondra à 'GNU' et à tout ce qui suit, dans notre cas correspondant à linux.
Nous pouvons maintenant dériver une déclaration généralisée selon laquelle l'expression (?<=C)X correspondra au motif X – seulement si le motif C est venu avant X (et C ne doit pas être inclus dans la correspondance).
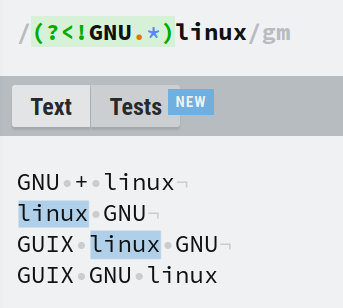
Vous pouvez également inverser la 1ère condition. Correspondre aux lignes qui contiennent le mot linux seulement si GNU n'est jamais venu avant. Cela s'appelle un lookbehind négatif. Le préfixe dans ce cas est ?<!. L'inverse de l'expression précédente serait (?<!GNU.*)linux.
Lookaheads
Les lookaheads sont également des assertions comme les lookbehinds, comme vous l'avez vu dans l'exemple précédent. La seule différence est que les lookbehinds font une assertion avant et les lookaheads font une assertion après.
Disons que vous avez ces deux conditions :
- Correspondre à
Helloseulement siWorldvient quelque part après. - Correspondre uniquement à Hello et rien d'autre.
Le préfixe pour un lookahead positif est ?=. L'expression Hello(?=.*World) répondra aux deux conditions. Cela est similaire à Hello.*World sauf que seul Hello sera correspond, tandis que Hello.*World correspondra à 'Hello', 'World' et tout ce qui se trouve entre les deux.
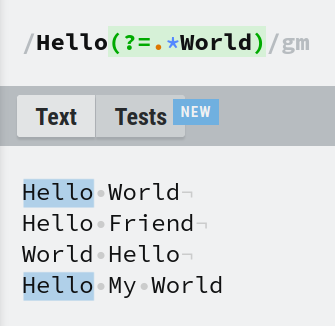
Similaire à l'exemple d'un lookbehind positif, les expressions Hello(?=.*World) et (?=.*World)Hello sont équivalentes. Parce que le .* avant 'World' correspond à Hello, satisfaisant la 1ère condition.
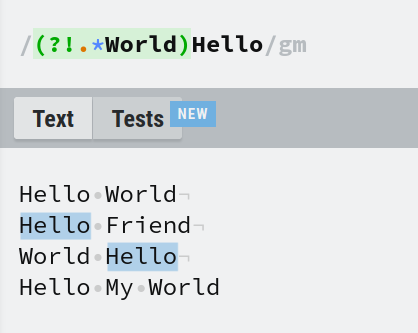
Un lookahead négatif est simplement le complément d'un lookbehind négatif. Vous pouvez l'utiliser en le préfixant avec ?!. (?!World)Hello correspondra à Hello seulement s'il n'y a pas de World nulle part après.
Voici un résumé de la syntaxe des lookarounds lorsque vous voulez faire correspondre le motif X avec l'assertion C.
| Opération | RegEx |
| positive lookahead | (?=C)X |
| negative lookahead | (?!C)X |
| positive lookbehind | (?<=C)X |
| negative lookbehind | (?<!C)X |
Exemples pratiques de Regex
Analyse de logs
Dans ce fichier de log, voici les lignes qui nous intéressent :
[1/10000] Train loss: 11.30368, Valid loss: 8.95446, Elapsed_time: 7.58941
[500/10000] Train loss: 0.96180, Valid loss: 0.20098, Elapsed_time: 82.48651
[1000/10000] Train loss: 0.04051, Valid loss: 0.11927, Elapsed_time: 156.86243
Notre tâche est d'extraire la perte d'entraînement et la perte de validation pour des fins telles que le traçage de la perte sur les époques. Nous devons extraire les valeurs de perte d'entraînement comme 11.30368, 0.96180, 0.04051 et les mettre dans un tableau.
Toutes les valeurs pertinentes sont préfixées par 'Train loss:', nous pouvons donc utiliser cela dans notre regex tel quel. Pour faire correspondre les nombres à virgule flottante, nous devons faire correspondre certains chiffres suivis d'un "." puis suivis de plus de chiffres. Vous pouvez faire cela avec \d+\.\d+. Parce que nous voulons garder une trace de ces nombres, ils doivent être à l'intérieur d'un groupe de capture.
Comme "." a un but spécial dans les regex, lorsque vous voulez faire correspondre un caractère ".", vous devez l'échapper avec une barre oblique inverse. Cela est applicable pour tous les caractères ayant un but spécial. Mais vous n'avez pas à l'échapper à l'intérieur d'un ensemble de caractères.
En mettant tout ensemble, l'expression pour extraire la perte d'entraînement est Train loss: (\d+\.\d+). Nous pouvons utiliser la même logique pour extraire la perte de validation avec Valid loss: (\d+\.\d+).
Voici une façon d'extraire ces informations en utilisant Python :
import re
f = open("log_train.txt", "r").read()
train_loss = re.findall(r'Train loss: (\d+\.\d+)', f)
valid_loss = re.findall(r'Valid loss: (\d+\.\d+)', f)
train_loss = [float(i) for i in train_loss]
valid_loss = [float(i) for i in valid_loss]
print("train_loss =", train_loss)
print("")
print("valid_loss =", valid_loss)
Lorsque qu'il y a un groupe de capture, re.findall recherche toutes les lignes et retourne les valeurs à l'intérieur du groupe de capture dans une liste.
Toute fonction regex ne retourne que des chaînes, donc les valeurs sont converties en floats et imprimées. Ensuite, vous pouvez les utiliser directement dans un autre script Python comme une liste de floats.
Voici le résultat :

Vous pourriez également utiliser sed, sauvegarder la sortie dans train_losses.txt, et lire depuis le fichier. D'abord, nous utilisons '/Train/' pour cibler uniquement les lignes avec 'Train' présent, puis nous appliquons la même regex qu'auparavant.
sed -En '/Train/ s/.*Train loss: ([0-9]+\.[0-9]+).*/\1/p' log_train.txt | tee train_losses.txt
".*" est ajouté au début et à la fin pour que sed corresponde au contenu de toutes les lignes pertinentes. Ensuite, toute la ligne est remplacée par la valeur du groupe de capture. La commande tee est utilisée pour rediriger la sortie de sed dans train_losses.txt tout en imprimant le contenu dans le terminal.
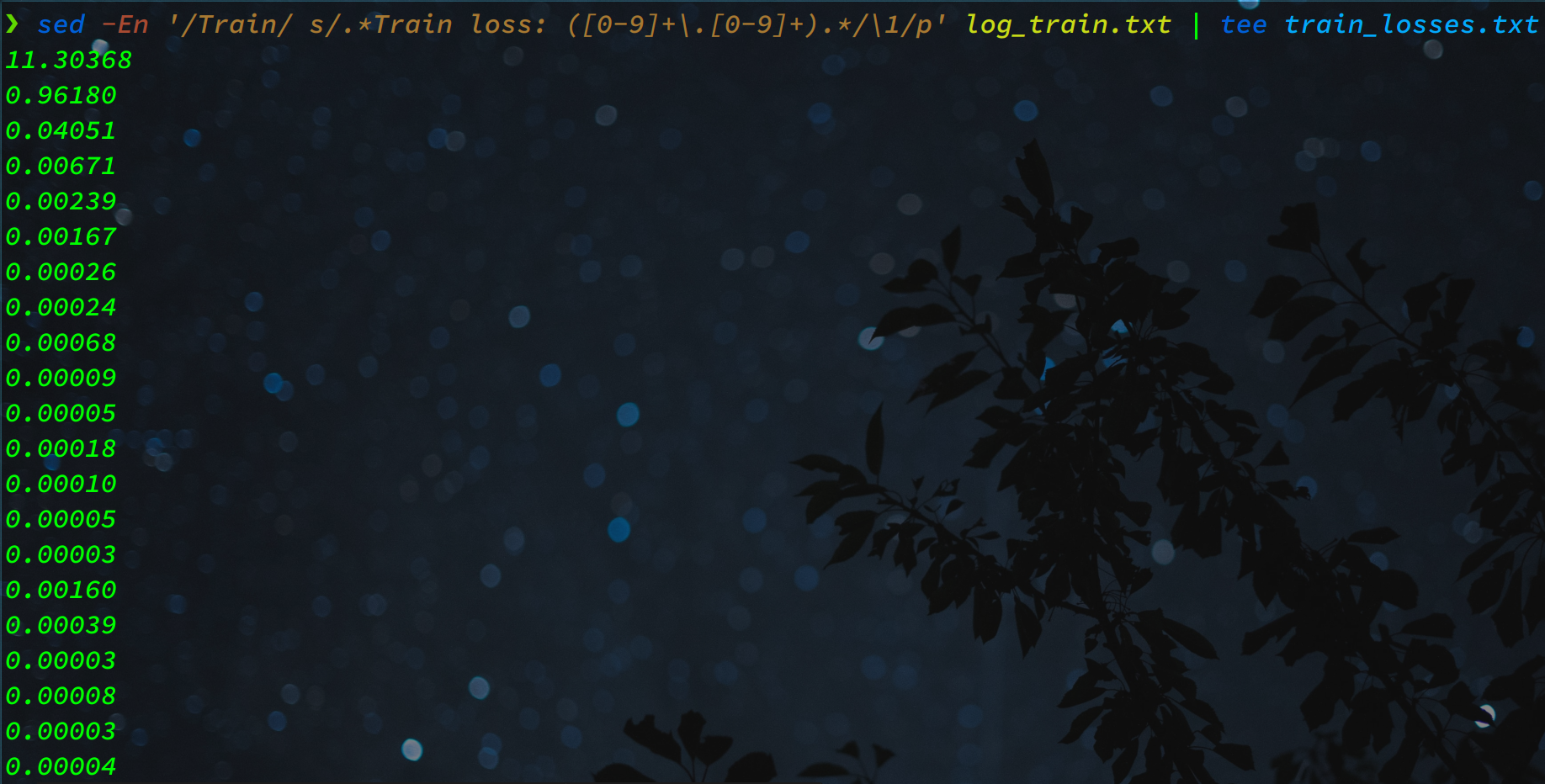
Prenez un moment pour réfléchir à ce dont vous auriez besoin pour extraire les époques. Vous devez extraire 500 de [500/10000] pour toutes ces lignes. Le tableau doit ressembler à [1, 500, 1000, 1500, ...]. Vous pouvez suivre la même approche que nous avons utilisée pour l'exemple précédent.
Notez que si vous voulez faire correspondre "[" ou "]", vous devez l'échapper. La réponse est donnée ici.
Renommage de fichiers en masse
Vous avez ces fichiers avec des valeurs aléatoires comme préfixes. Vous devez renommer tous les fichiers en 1.mp4, 2.mp4 et ainsi de suite. Voici comment les fichiers ont été générés.

C'est un scénario courant où vous avez une liste de fichiers qui ont leur numéro de séquence dans le nom, mais il y a aussi d'autres caractères que vous ne voulez pas.
Le motif doit correspondre à tout ce qui précède Episode, puis un underscore et ensuite le numéro et .mp4 à la fin.
La valeur pertinente est le numéro avant '.mp4' que nous mettrons à l'intérieur d'un groupe de capture. .*Episode_ correspondra à tout ce qui précède le numéro. Ensuite, nous pouvons capturer le numéro avec ([0-9]+) et également faire correspondre .mp4 avec \.mp4.
Donc, la regex finale est .*Episode_([0-9]+)\.mp4. Comme nous voulons garder le .mp4, la chaîne de remplacement sera \1.mp4.
Voici une façon de résoudre cela en utilisant sed.
for i in *.mp4; do
newname=$(echo $i | sed -En 's/.*Episode_([0-9]+)\.mp4/\1.mp4/p')
mv $i $newname
done;ls
Tout d'abord, le nouveau nom est enregistré dans une variable, puis la commande mv est utilisée pour renommer le fichier.

Pourrions-nous avoir simplement utilisé .* à la place de .*Episode_ ? Dans cet exemple, oui. Mais il pourrait y avoir des noms de fichiers comme Steins_Gate0.mp4 où le 0 fait partie du nom du film et vous ne vouliez pas vraiment renommer ce fichier, il est donc toujours préférable d'être aussi spécifique que possible.
Et si certains fichiers étaient nommés "Random_Episode6.mp4" ? La différence étant qu'il n'y a pas de underscore après Episode. Quel changement devrez-vous apporter ?
La réponse est que vous devrez ajouter un "?" après le "_" pour le rendre optionnel. La regex sera .*Episode_?([0-9]+)\.mp4.
Validation d'email
Il existe toutes sortes de regex compliquées pour valider les emails.
En voici une simple : ^[^@ ]+@[^@.]+\.\w+$. Elle correspond au format A@B.C
Le tableau ci-dessous décompose ce motif en morceaux plus petits :
| Motif | Correspondances |
^ | début de ligne |
[^@ ]+ | tout sauf "@" et le caractère espace |
@[^@.]+ | @ suivi de tout sauf "@" et "." caractères |
\.\w+ | "." suivi de caractères de mot |
$ | fin de ligne |
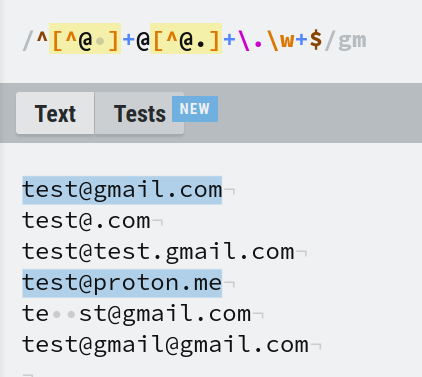
Sur le site regexr, vous pouvez activer le drapeau multiline depuis l'onglet Flags dans le coin supérieur droit. Le 'gm' à la fin indique que le drapeau multiline est activé.
Nous pouvons voir que les lignes 2,3,5,6 n'ont pas correspondu. Pouvez-vous trouver la raison et quelle partie de la regex est responsable de sa disqualification ?
La réponse est donnée ici
Contraintes de mot de passe
Vous pouvez également utiliser les regex pour imposer des contraintes. Ici, nous allons découvrir la puissance des lookaheads positifs.
Disons que nous voulons accepter une chaîne seulement s'il y a un chiffre dedans. Vous savez déjà comment trouver un chiffre avec la classe '\d'. Pour accomplir cela, nous pouvons utiliser [^\d]*\d. Cela correspondra à tout caractère non-chiffre 0 ou plusieurs fois puis correspondra à un chiffre.
Nous pouvons également utiliser l'expression .*\d pour correspondre à un chiffre. Donc, s'il n'y a pas de chiffre dans la chaîne, alors le lookahead échouera et aucun des caractères de cette chaîne ne sera correspond, retournant une chaîne vide "".
Lorsque nous utilisons un langage de programmation, nous pouvons vérifier si la regex a retourné une chaîne vide et déterminer que les contraintes ne sont pas satisfaites.
Nous allons créer une regex qui impose les critères suivants :
- Minimum 8 caractères et maximum 16 caractères.
- Au moins une lettre minuscule.
- Au moins une lettre majuscule.
- Au moins un chiffre.
Pour y parvenir, vous pouvez utiliser des lookaheads positifs. Voici la regex :
^(?=.*[a-z])(?=.*[A-Z])(?=.*\d).{8,16}$
Le tableau ci-dessous explique quelle partie de la regex impose quelle contrainte :
| Motif | Contrainte imposée |
.{8,16} | min 8 et max 16 caractères |
(?=.*[a-z]) | minimum une lettre minuscule |
(?=.*[A-Z]) | minimum une lettre majuscule |
(?=.*\d) | minimum un chiffre |

Quelle modification devriez-vous apporter pour imposer au moins 5 lettres majuscules ?
Vous pourriez penser que (?=.*[A-Z]{5,}) fera le travail. Mais cette expression nécessite que les 5 lettres soient ensemble. Une chaîne comme rand-ABCDE-rand sera correspond, mais 0AxBCDxE0 ne sera pas correspond même si elle a 5 lettres majuscules (car elles ne sont pas adjacentes).
Encore une fois, les groupes de capture viennent à la rescousse. Nous voulons correspondre à 5 lettres majuscules n'importe où dans la chaîne. Nous savons déjà que nous pouvons correspondre à 1 lettre majuscule avec .*[A-Z]. Maintenant, nous allons les mettre à l'intérieur d'un groupe de capture et attacher un quantificateur de minimum 5. L'expression sera (.*[A-Z]){5,}.
Voici la réponse finale :
À la place de (?=.*[A-Z]), vous aurez besoin de (?=(.*[A-Z]){5,}). L'expression devient ^(?=.*[a-z])(?=(.*[A-Z]){5,})(?=.*\d).{8,16}$.

Vous pourriez également exiger que le mot de passe ne contienne pas certains mots pour renforcer les mots de passe.
Par exemple, nous voulons rejeter le mot de passe s'il contient pass ou 1234. Le lookahead négatif est l'outil pour ce travail. La regex serait ^(?!.*(pass|1234)).*$.
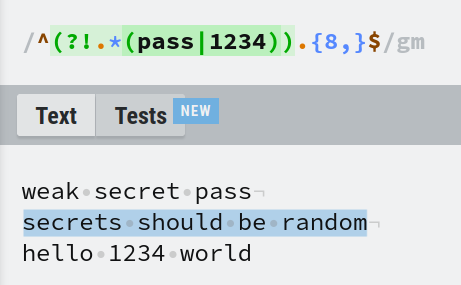
Dans cette regex, nous avons mis pass et 1234 à l'intérieur d'un groupe de capture et utilisé l'opérateur OU logique. Ce groupe de capture est imbriqué à l'intérieur d'un autre groupe de capture qui est préfixé avec ?!.*. Cela en fait un lookahead négatif qui correspond s'il y a au moins 8 caractères par .{8,} avec la condition que pass ou 1234 ne peuvent pas être présents n'importe où dans la chaîne.
Mots de la fin
J'espère que vous avez eu une bonne pratique en parcourant cet article. Ce n'est pas grave si vous oubliez certaines syntaxes. Ce qui est important, c'est de comprendre les concepts de base et d'avoir une bonne idée de ce qui est possible avec les regex. Ensuite, si vous oubliez un motif, vous pouvez simplement le rechercher sur Google ou consulter une feuille de triche.
Plus vous pratiquez, plus vous vous en sortirez sans aide extérieure. Finalement, vous serez capable d'écrire des regex super complexes et efficaces complètement hors ligne.
Il existe déjà quelques bonnes feuilles de triche pour les regex, donc j'ai voulu créer quelque chose de plus approfondi ici que vous pouvez consulter pour les concepts de base et les cas d'utilisation courants.
Si vous cherchez une feuille de triche, celle de QuickRef est utile. C'est un bon endroit pour rappeler la syntaxe et ils fournissent également un aperçu de base des fonctions liées aux regex dans divers langages de programmation.
La plupart des techniques regex sont les mêmes dans tous les langages de programmation et outils – mais certains outils peuvent offrir des fonctionnalités supplémentaires. Faites donc quelques recherches sur l'outil que vous utilisez pour choisir le meilleur pour vous.
Mon dernier conseil serait de ne pas forcer l'utilisation des regex juste parce que vous pouvez. La plupart du temps, un simple string.find() est suffisant pour faire le travail. Mais si vous vivez dans le terminal, vous pouvez vraiment faire beaucoup juste avec les regex, c'est sûr.
Si vous aimez ce type d'article, vous pouvez garder un œil sur mon blog ou Twitter.