

Article original : An awesome guide on how to build RESTful APIs with ASP.NET Core
Par Evandro Gomes
Cet article servira de guide étape par étape sur la façon d'implémenter des API RESTful propres et maintenables.
Aperçu
RESTful n'est pas un terme nouveau. Il fait référence à un style architectural où les services web reçoivent et envoient des données depuis et vers des applications clientes. L'objectif de ces applications est de centraliser les données que différentes applications clientes utiliseront.
Choisir les bons outils pour écrire des services RESTful est crucial car nous devons nous soucier de l'évolutivité, de la maintenance, de la documentation et de tous les autres aspects pertinents. ASP.NET Core nous offre une API puissante et facile à utiliser, idéale pour atteindre ces objectifs.
Dans cet article, je vais vous montrer comment écrire une API RESTful bien structurée pour un scénario « presque » réel, en utilisant le framework ASP.NET Core. Je détaillerai les patterns et stratégies courants pour simplifier le processus de développement.
Je vous montrerai également comment intégrer des frameworks et des bibliothèques courants, tels qu'Entity Framework Core et AutoMapper, pour fournir les fonctionnalités nécessaires.
Prérequis
Je m'attends à ce que vous ayez des connaissances sur les concepts de programmation orientée objet.
Même si je vais couvrir de nombreux détails du langage de programmation C#, je vous recommande d'avoir des connaissances de base sur ce sujet.
Je suppose également que vous savez ce qu'est REST, comment fonctionne le protocole HTTP, ce que sont les points de terminaison d'API (endpoints) et ce qu'est le JSON. Voici un excellent tutoriel d'introduction à ce sujet. La dernière exigence est que vous compreniez le fonctionnement des bases de données relationnelles.
Pour coder avec moi, vous devrez installer .NET Core 2.2, ainsi que Postman, l'outil que je vais utiliser pour tester l'API. Je vous recommande d'utiliser un éditeur de code tel que Visual Studio Code pour développer l'API. Choisissez l'éditeur de code que vous préférez. Si vous choisissez cet éditeur, je vous recommande d'installer l'extension C# pour avoir une meilleure coloration syntaxique.
Vous trouverez un lien vers le dépôt Github de l'API à la fin de cet article pour vérifier le résultat final.
Le périmètre
Écrivons une API web fictive pour un supermarché. Imaginons que nous devions implémenter le périmètre suivant :
- Créer un service RESTful qui permet aux applications clientes de gérer le catalogue de produits du supermarché. Il doit exposer des points de terminaison pour créer, lire, modifier et supprimer des catégories de produits, telles que les produits laitiers et les cosmétiques, et également pour gérer les produits de ces catégories.
- Pour les catégories, nous devons stocker leurs noms. Pour les produits, nous devons stocker leurs noms, l'unité de mesure (par exemple, KG pour les produits mesurés au poids), la quantité dans l'emballage (par exemple, 10 si le produit est un paquet de biscuits) et leurs catégories respectives.
Pour simplifier l'exemple, je ne gérerai pas les produits en stock, l'expédition des produits, la sécurité ou toute autre fonctionnalité. Le périmètre donné est suffisant pour vous montrer comment fonctionne ASP.NET Core.
Pour développer ce service, nous avons essentiellement besoin de deux points de terminaison d'API : un pour gérer les catégories et un pour gérer les produits. En termes de communication JSON, nous pouvons imaginer les réponses comme suit :
Point de terminaison d'API : /api/categories
Réponse JSON (pour les requêtes GET) :
{
[
{ "id": 1, "name": "Fruits and Vegetables" },
{ "id": 2, "name": "Breads" },
… // Autres catégories
]
}
Point de terminaison d'API : /api/products
Réponse JSON (pour les requêtes GET) :
{
[
{
"id": 1,
"name": "Sugar",
"quantityInPackage": 1,
"unitOfMeasurement": "KG"
"category": {
"id": 3,
"name": "Sugar"
}
},
… // Autres produits
]
}
Commençons à écrire l'application.
Étape 1 — Création de l'API
Tout d'abord, nous devons créer la structure des dossiers pour le service web, puis nous devons utiliser les outils CLI .NET pour générer une API web de base. Ouvrez le terminal ou l'invite de commande (cela dépend du système d'exploitation que vous utilisez) et tapez les commandes suivantes, en séquence :
mkdir src/Supermarket.API
cd src/Supermarket.API
dotnet new webapi
Les deux premières commandes créent simplement un nouveau répertoire pour l'API et changent l'emplacement actuel vers le nouveau dossier. La dernière génère un nouveau projet suivant le modèle Web API, qui est le type d'application que nous développons. Vous pouvez en savoir plus sur cette commande et d'autres modèles de projet que vous pouvez générer en consultant ce lien.
Le nouveau répertoire aura désormais la structure suivante :
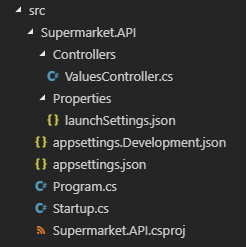
Aperçu de la structure
Une application ASP.NET Core consiste en un groupe de middlewares (petits morceaux de l'application attachés au pipeline de l'application, qui gèrent les requêtes et les réponses) configurés dans la classe Startup. Si vous avez déjà travaillé avec des frameworks comme Express.js auparavant, ce concept ne vous est pas nouveau.
Lorsque l'application démarre, la méthode Main, de la classe Program, est appelée. Elle crée un hôte web par défaut en utilisant la configuration de démarrage, exposant l'application via HTTP via un port spécifique (par défaut, le port 5000 pour HTTP et 5001 pour HTTPS).
Jetez un œil à la classe ValuesController à l'intérieur du dossier Controllers. Elle expose des méthodes qui seront appelées lorsque l'API recevra des requêtes via la route /api/values.
Ne vous inquiétez pas si vous ne comprenez pas une partie de ce code. Je détaillerai chacune d'elles lors du développement des points de terminaison d'API nécessaires. Pour l'instant, supprimez simplement cette classe, car nous n'allons pas l'utiliser.
Étape 2 — Création des modèles de domaine
Je vais appliquer certains concepts de conception qui garderont l'application simple et facile à maintenir.
Écrire du code qui peut être compris et maintenu par vous-même n'est pas si difficile, mais vous devez garder à l'esprit que vous travaillerez au sein d'une équipe. Si vous ne faites pas attention à la façon dont vous écrivez votre code, le résultat sera un monstre qui vous donnera, à vous et à vos coéquipiers, des maux de tête constants. Cela semble extrême, n'est-ce pas ? Mais croyez-moi, c'est la vérité.

Commençons par écrire la couche de domaine. Cette couche contiendra nos classes de modèles, les classes qui représenteront nos produits et catégories, ainsi que les interfaces de dépôts (repositories) et de services. J'expliquerai ces deux derniers concepts dans un instant.
À l'intérieur du répertoire Supermarket.API, créez un nouveau dossier appelé Domain. Dans le nouveau dossier domain, créez-en un autre appelé Models. Le premier modèle que nous devons ajouter à ce dossier est Category. Initialement, ce sera une simple classe Plain Old CLR Object (POCO). Cela signifie que la classe n'aura que des propriétés pour décrire ses informations de base.
La classe possède une propriété Id, pour identifier la catégorie, et une propriété Name. Nous avons également une propriété Products. Cette dernière sera utilisée par Entity Framework Core, l'ORM que la plupart des applications ASP.NET Core utilisent pour persister les données dans une base de données, afin de mapper la relation entre les catégories et les produits. Cela a également du sens en termes de programmation orientée objet, puisqu'une catégorie possède de nombreux produits associés.
Nous devons également créer le modèle de produit. Dans le même dossier, ajoutez une nouvelle classe Product.
Le produit possède également des propriétés pour l'Id et le nom. Il y a aussi une propriété QuantityInPackage, qui indique combien d'unités du produit nous avons dans un paquet (rappelez-vous l'exemple des biscuits du périmètre de l'application) et une propriété UnitOfMeasurement. Celle-ci est représentée par un type enum, qui représente une énumération des unités de mesure possibles. Les deux dernières propriétés, CategoryId et Category, seront utilisées par l'ORM pour mapper la relation entre les produits et les catégories. Cela indique qu'un produit a une, et une seule, catégorie.
Définissons la dernière partie de nos modèles de domaine, l'enum EUnitOfMeasurement.
Par convention, les enums n'ont pas besoin de commencer par un « E » devant leur nom, mais dans certaines bibliothèques et frameworks, vous trouverez ce préfixe comme moyen de distinguer les enums des interfaces et des classes.
Le code est vraiment simple. Ici, nous n'avons défini qu'une poignée de possibilités pour les unités de mesure, cependant, dans un système de supermarché réel, vous pourriez avoir beaucoup d'autres unités de mesure, et peut-être un modèle séparé pour cela.
Notez l'attribut Description appliqué sur chaque possibilité d'énumération. Un attribut est un moyen de définir des métadonnées sur les classes, interfaces, propriétés et autres composants du langage C#. Dans ce cas, nous l'utiliserons pour simplifier les réponses du point de terminaison de l'API des produits, mais vous n'avez pas à vous en soucier pour l'instant. Nous y reviendrons plus tard.
Nos modèles de base sont prêts à être utilisés. Nous pouvons maintenant commencer à écrire le point de terminaison de l'API qui va gérer toutes les catégories.
Étape 3 — L'API des catégories
Dans le dossier Controllers, ajoutez une nouvelle classe appelée CategoriesController.
Par convention, toutes les classes de ce dossier qui se terminent par le suffixe « Controller » deviendront des contrôleurs de notre application. Cela signifie qu'elles vont gérer les requêtes et les réponses. Vous devez faire hériter cette classe de la classe Controller, définie dans l'espace de noms (namespace) Microsoft.AspNetCore.Mvc.
Un espace de noms consiste en un groupe de classes, interfaces, enums et structs liés. Vous pouvez le voir comme quelque chose de similaire aux modules du langage Javascript, ou aux paquets (packages) de Java.
Le nouveau contrôleur doit répondre via la route /api/categories. Nous y parvenons en ajoutant l'attribut Route au-dessus du nom de la classe, en spécifiant un espace réservé qui indique que la route doit utiliser le nom de la classe sans le suffixe controller, par convention.
Commençons par gérer les requêtes GET. Tout d'abord, lorsque quelqu'un demande des données à /api/categories via le verbe GET, l'API doit renvoyer toutes les catégories. Nous pouvons créer un service de catégorie à cet effet.
Conceptuellement, un service est essentiellement une classe ou une interface qui définit des méthodes pour gérer une certaine logique métier. C'est une pratique courante dans de nombreux langages de programmation de créer des services pour gérer la logique métier, telle que l'authentification et l'autorisation, les paiements, les flux de données complexes, la mise en cache et les tâches qui nécessitent une interaction entre d'autres services ou modèles.
En utilisant des services, nous pouvons isoler la gestion des requêtes et des réponses de la logique réelle nécessaire pour accomplir les tâches.
Le service que nous allons créer initialement définira un comportement unique, ou méthode : une méthode de listage. Nous attendons de cette méthode qu'elle renvoie toutes les catégories existantes dans la base de données.
Par souci de simplicité, nous ne traiterons pas la pagination des données ou le filtrage dans ce cas. J'écrirai un article à l'avenir montrant comment gérer facilement ces fonctionnalités.
Pour définir un comportement attendu pour quelque chose en C# (et dans d'autres langages orientés objet, comme Java, par exemple), nous définissons une interface. Une interface indique comment quelque chose doit fonctionner, mais n'implémente pas la logique réelle du comportement. La logique est implémentée dans les classes qui implémentent l'interface. Si ce concept n'est pas clair pour vous, ne vous inquiétez pas. Vous le comprendrez dans un instant.
Dans le dossier Domain, créez un nouveau répertoire appelé Services. Là, ajoutez une interface appelée ICategoryService. Par convention, toutes les interfaces doivent commencer par la lettre majuscule « I » en C#. Définissez le code de l'interface comme suit :
Les implémentations de la méthode ListAsync doivent renvoyer de manière asynchrone une énumération de catégories.
La classe Task, encapsulant le retour, indique l'asynchronisme. Nous devons penser à une méthode asynchrone car nous devons attendre que la base de données termine une opération pour renvoyer les données, et ce processus peut prendre un certain temps. Notez également le suffixe « Async ». C'est une convention qui indique que notre méthode doit être exécutée de manière asynchrone.
Nous avons beaucoup de conventions, n'est-ce pas ? Personnellement, j'aime ça, car cela rend les applications faciles à lire, même si vous êtes nouveau dans une entreprise qui utilise la technologie .NET.
« — Ok, nous avons défini cette interface, mais elle ne fait rien. Comment peut-elle être utile ? »
Si vous venez d'un langage tel que Javascript ou d'un autre langage non fortement typé, ce concept peut sembler étrange.
Les interfaces nous permettent d'abstraire le comportement souhaité de l'implémentation réelle. En utilisant un mécanisme connu sous le nom d'injection de dépendances, nous pouvons implémenter ces interfaces et les isoler des autres composants.
Fondamentalement, lorsque vous utilisez l'injection de dépendances, vous définissez certains comportements à l'aide d'une interface. Ensuite, vous créez une classe qui implémente l'interface. Enfin, vous liez les références de l'interface à la classe que vous avez créée.
« — Cela semble vraiment déroutant. Ne pouvons-nous pas simplement créer une classe qui fait ces choses pour nous ? »
Continuons l'implémentation de notre API et vous comprendrez pourquoi utiliser cette approche.
Modifiez le code de CategoriesController comme suit :
J'ai défini une fonction constructeur pour notre contrôleur (un constructeur est appelé lorsqu'une nouvelle instance d'une classe est créée), et il reçoit une instance de ICategoryService. Cela signifie que l'instance peut être n'importe quoi qui implémente l'interface de service. Je stocke cette instance dans un champ privé en lecture seule _categoryService. Nous utiliserons ce champ pour accéder aux méthodes de notre implémentation de service de catégorie.
Au fait, le préfixe underscore est une autre convention courante pour désigner un champ. Cette convention, en particulier, n'est pas recommandée par le guide officiel des conventions de nommage de .NET, mais c'est une pratique très courante pour éviter d'avoir à utiliser le mot-clé « this » pour distinguer les champs de classe des variables locales. Personnellement, je pense que c'est beaucoup plus propre à lire, et beaucoup de frameworks et de bibliothèques utilisent cette convention.
Sous le constructeur, j'ai défini la méthode qui va gérer les requêtes pour /api/categories. L'attribut HttpGet indique au pipeline ASP.NET Core de l'utiliser pour gérer les requêtes GET (cet attribut peut être omis, mais il est préférable de l'écrire pour une meilleure lisibilité).
La méthode utilise notre instance de service de catégorie pour lister toutes les catégories, puis renvoie les catégories au client. Le pipeline du framework gère la sérialisation des données en un objet JSON. Le type IEnumerable<Category> indique au framework que nous voulons renvoyer une énumération de catégories, et le type Task, précédé du mot-clé async, indique au pipeline que cette méthode doit être exécutée de manière asynchrone. Enfin, lorsque nous définissons une méthode async, nous devons utiliser le mot-clé await pour les tâches qui peuvent prendre un certain temps.
Ok, nous avons défini la structure initiale de notre API. Maintenant, il est nécessaire d'implémenter réellement le service de catégories.
Étape 4 — Implémentation du service de catégories
Dans le dossier racine de l'API (le dossier Supermarket.API), créez-en un nouveau appelé Services. Ici, nous placerons toutes les implémentations de services. À l'intérieur du nouveau dossier, ajoutez une nouvelle classe appelée CategoryService. Modifiez le code comme suit :
C'est simplement le code de base pour l'implémentation de l'interface, mais nous ne gérons toujours aucune logique. Réfléchissons à la façon dont la méthode de listage devrait fonctionner.
Nous devons accéder à la base de données et renvoyer toutes les catégories, puis nous devons renvoyer ces données au client.
Une classe de service n'est pas une classe qui devrait gérer l'accès aux données. Il existe un pattern appelé Pattern Repository qui est utilisé pour gérer les données des bases de données.
Lors de l'utilisation du Pattern Repository, nous définissons des classes de dépôt (repository), qui encapsulent essentiellement toute la logique de gestion de l'accès aux données. Ces dépôts exposent des méthodes pour lister, créer, modifier et supprimer des objets d'un modèle donné, de la même manière que vous pouvez manipuler des collections. En interne, ces méthodes communiquent avec la base de données pour effectuer des opérations CRUD, isolant l'accès à la base de données du reste de l'application.
Notre service doit communiquer avec un dépôt de catégories pour obtenir la liste des objets.
Conceptuellement, un service peut « communiquer » avec un ou plusieurs dépôts ou d'autres services pour effectuer des opérations.
Il peut sembler redondant de créer une nouvelle définition pour gérer la logique d'accès aux données, mais vous verrez dans un instant qu'isoler cette logique de la classe de service est vraiment avantageux.
Créons un dépôt qui sera chargé d'intermédier la communication avec la base de données comme moyen de persister les catégories.
Étape 5 — Le dépôt de catégories et la couche de persistance
Dans le dossier Domain, créez un nouveau répertoire appelé Repositories. Ensuite, ajoutez une nouvelle interface appelée ICategoryRepository. Définissez l'interface comme suit :
Le code initial est fondamentalement identique au code de l'interface de service.
Ayant défini l'interface, nous pouvons revenir à la classe de service et finir d'implémenter la méthode de listage, en utilisant une instance de ICategoryRepository pour renvoyer les données.
Maintenant, nous devons implémenter la logique réelle du dépôt de catégories. Avant de le faire, nous devons réfléchir à la façon dont nous allons accéder à la base de données.
Au fait, nous n'avons toujours pas de base de données !
Nous utiliserons Entity Framework Core (je l'appellerai EF Core par simplicité) comme ORM de notre base de données. Ce framework est fourni avec ASP.NET Core comme ORM par défaut et expose une API conviviale qui nous permet de mapper les classes de nos applications aux tables de la base de données.
EF Core nous permet également de concevoir notre application d'abord, puis de générer une base de données en fonction de ce que nous avons défini dans notre code. Cette technique s'appelle code first. Nous utiliserons l'approche code first pour générer une base de données (dans cet exemple, en fait, je vais utiliser une base de données en mémoire, mais vous pourrez facilement la changer pour une instance SQL Server ou MySQL server, par exemple).
Dans le dossier racine de l'API, créez un nouveau répertoire appelé Persistence. Ce répertoire contiendra tout ce dont nous avons besoin pour accéder à la base de données, comme les implémentations de dépôts.
À l'intérieur du nouveau dossier, créez un nouveau répertoire appelé Contexts, puis ajoutez une nouvelle classe appelée AppDbContext. Cette classe doit hériter de DbContext, une classe qu'EF Core utilise pour mapper vos modèles aux tables de la base de données. Modifiez le code de la manière suivante :
Le constructeur que nous avons ajouté à cette classe est chargé de transmettre la configuration de la base de données à la classe de base via l'injection de dépendances. Vous verrez dans un instant comment cela fonctionne.
Maintenant, nous devons créer deux propriétés DbSet. Ces propriétés sont des ensembles (sets) (collections d'objets uniques) qui mappent les modèles aux tables de la base de données.
De plus, nous devons mapper les propriétés des modèles aux colonnes de table respectives, en spécifiant quelles propriétés sont des clés primaires, lesquelles sont des clés étrangères, les types de colonnes, etc. Nous pouvons le faire en surchargeant la méthode OnModelCreating, en utilisant une fonctionnalité appelée API Fluent pour spécifier le mapping de la base de données. Modifiez la classe AppDbContext comme suit :
Le code est intuitif.
Nous spécifions à quelles tables nos modèles doivent être mappés. De plus, nous définissons les clés primaires, à l'aide de la méthode HasKey, les colonnes de table, à l'aide de la méthode Property, et certaines contraintes telles que IsRequired, HasMaxLength, et ValueGeneratedOnAdd, le tout avec des expressions lambda de manière « fluente » (chaînage de méthodes).
Jetez un œil au morceau de code suivant :
builder.Entity<Category>()
.HasMany(p => p.Products)
.WithOne(p => p.Category)
.HasForeignKey(p => p.CategoryId);
Ici, nous spécifions une relation entre les tables. Nous disons qu'une catégorie possède de nombreux produits, et nous définissons les propriétés qui mapperont cette relation (Products, de la classe Category, et Category, de la classe Product). Nous définissons également la clé étrangère (CategoryId).
Consultez ce tutoriel si vous voulez apprendre à configurer des relations un-à-un et plusieurs-à-plusieurs à l'aide d'EF Core, ainsi que comment l'utiliser dans son ensemble.
Il existe également une configuration pour l'amorçage des données (seeding), via la méthode HasData :
builder.Entity<Category>().HasData
(
new Category { Id = 100, Name = "Fruits and Vegetables" },
new Category { Id = 101, Name = "Dairy" }
);
Ici, nous ajoutons simplement deux exemples de catégories par défaut. C'est nécessaire pour tester notre point de terminaison d'API une fois que nous l'aurons terminé.
Remarque : nous définissons manuellement les propriétés
Idici car le fournisseur en mémoire l'exige pour fonctionner. Je définis les identifiants sur de grands nombres pour éviter les collisions entre les identifiants générés automatiquement et les données d'amorçage.Cette limitation n'existe pas dans les vrais fournisseurs de bases de données relationnelles, donc si vous souhaitez utiliser une base de données telle que SQL Server, par exemple, vous n'avez pas à spécifier ces identifiants. Consultez ce ticket Github si vous voulez comprendre ce comportement.
Ayant implémenté la classe de contexte de base de données, nous pouvons implémenter le dépôt de catégories. Ajoutez un nouveau dossier appelé Repositories à l'intérieur du dossier Persistence, puis ajoutez une nouvelle classe appelée BaseRepository.
Cette classe est juste une classe abstraite dont tous nos dépôts hériteront. Une classe abstraite est une classe qui n'a pas d'instances directes. Vous devez créer des classes directes pour créer les instances.
Le BaseRepository reçoit une instance de notre AppDbContext via l'injection de dépendances et expose une propriété protégée (une propriété qui ne peut être accessible que par les classes enfants) appelée _context, qui donne accès à toutes les méthodes dont nous avons besoin pour gérer les opérations de base de données.
Ajoutez une nouvelle classe dans le même dossier appelée CategoryRepository. Maintenant, nous allons vraiment implémenter la logique du dépôt :
Le dépôt hérite de BaseRepository et implémente ICategoryRepository.
Remarquez à quel point il est simple d'implémenter la méthode de listage. Nous utilisons l'ensemble de base de données Categories pour accéder à la table des catégories, puis nous appelons la méthode d'extension ToListAsync, qui est chargée de transformer le résultat d'une requête en une collection de catégories.
EF Core traduit notre appel de méthode en une requête SQL, de la manière la plus efficace possible. La requête n'est exécutée que lorsque vous appelez une méthode qui transformera vos données en une collection, ou lorsque vous utilisez une méthode pour extraire des données spécifiques.
Nous avons maintenant une implémentation propre du contrôleur de catégories, du service et du dépôt.
Nous avons séparé les préoccupations, en créant des classes qui ne font que ce qu'elles sont censées faire.
La dernière étape avant de tester l'application est de lier nos interfaces aux classes respectives en utilisant le mécanisme d'injection de dépendances d'ASP.NET Core.
Étape 6 — Configuration de l'injection de dépendances
Il est temps pour vous de comprendre enfin comment ce concept fonctionne.
Dans le dossier racine de l'application, ouvrez la classe Startup. Cette classe est responsable de la configuration de toutes sortes de paramètres au démarrage de l'application.
Les méthodes ConfigureServices et Configure sont appelées au moment de l'exécution par le pipeline du framework pour configurer le fonctionnement de l'application et les composants qu'elle doit utiliser.
Jetez un œil à la méthode ConfigureServices. Ici, nous n'avons qu'une seule ligne, qui configure l'application pour utiliser le pipeline MVC, ce qui signifie essentiellement que l'application va gérer les requêtes et les réponses à l'aide de classes de contrôleurs (il se passe plus de choses ici en coulisses, mais c'est ce que vous devez savoir pour l'instant).
Nous pouvons utiliser la méthode ConfigureServices, en accédant au paramètre services, pour configurer nos liaisons de dépendances. Nettoyez le code de la classe en supprimant tous les commentaires et modifiez le code comme suit :
Regardez ce morceau de code :
services.AddDbContext<AppDbContext>(options => {
options.UseInMemoryDatabase("supermarket-api-in-memory");
});
Ici, nous configurons le contexte de base de données. Nous indiquons à ASP.NET Core d'utiliser notre AppDbContext avec une implémentation de base de données en mémoire, qui est identifiée par la chaîne passée en argument à notre méthode. Habituellement, le fournisseur en mémoire est utilisé lorsque nous écrivons des tests d'intégration, mais je l'utilise ici par souci de simplicité. De cette façon, nous n'avons pas besoin de nous connecter à une base de données réelle pour tester l'application.
La configuration de ces lignes configure en interne notre contexte de base de données pour l'injection de dépendances en utilisant une durée de vie limitée (scoped lifetime).
La durée de vie « scoped » indique au pipeline ASP.NET Core que chaque fois qu'il doit résoudre une classe qui reçoit une instance de AppDbContext comme argument de constructeur, il doit utiliser la même instance de la classe. S'il n'y a pas d'instance en mémoire, le pipeline créera une nouvelle instance et la réutilisera dans toutes les classes qui en ont besoin, au cours d'une requête donnée. De cette façon, vous n'avez pas besoin de créer manuellement l'instance de classe lorsque vous devez l'utiliser.
Il existe d'autres portées de durée de vie que vous pouvez consulter en lisant la documentation officielle.
La technique d'injection de dépendances nous offre de nombreux avantages, tels que :
- Réutilisabilité du code ;
- Meilleure productivité, car lorsque nous devons changer d'implémentation, nous n'avons pas besoin de nous soucier de changer cent endroits où vous utilisez cette fonctionnalité ;
- Vous pouvez facilement tester l'application puisque nous pouvons isoler ce que nous devons tester en utilisant des mocks (implémentations factices de classes) là où nous devons passer des interfaces comme arguments de constructeur ;
- Lorsqu'une classe doit recevoir plus de dépendances via un constructeur, vous n'avez pas à modifier manuellement tous les endroits où les instances sont créées (c'est génial !).
Après avoir configuré le contexte de base de données, nous lions également notre service et notre dépôt aux classes respectives.
services.AddScoped<ICategoryRepository, CategoryRepository>();
services.AddScoped<ICategoryService, CategoryService>();
Ici, nous utilisons également une durée de vie « scoped » car ces classes doivent utiliser en interne la classe de contexte de base de données. Il est logique de spécifier la même portée dans ce cas.
Maintenant que nous avons configuré nos liaisons de dépendances, nous devons apporter une petite modification à la classe Program, afin que la base de données amorce correctement nos données initiales. Cette étape n'est nécessaire que lors de l'utilisation du fournisseur de base de données en mémoire (voir ce ticket Github pour comprendre pourquoi).
Il était nécessaire de modifier la méthode Main pour garantir que notre base de données va être « créée » au démarrage de l'application puisque nous utilisons un fournisseur en mémoire. Sans ce changement, les catégories que nous voulons amorcer ne seront pas créées.
Avec toutes les fonctionnalités de base implémentées, il est temps de tester notre point de terminaison d'API.
Étape 7 — Test de l'API des catégories
Ouvrez le terminal ou l'invite de commande dans le dossier racine de l'API, et tapez la commande suivante :
dotnet run
La commande ci-dessus démarre l'application. La console affichera une sortie similaire à celle-ci :
info: Microsoft.EntityFrameworkCore.Infrastructure[10403]
Entity Framework Core 2.2.0-rtm-35687 initialized ‘AppDbContext’ using provider ‘Microsoft.EntityFrameworkCore.InMemory’ with options: StoreName=supermarket-api-in-memory
info: Microsoft.EntityFrameworkCore.Update[30100]
Saved 2 entities to in-memory store.
info: Microsoft.AspNetCore.DataProtection.KeyManagement.XmlKeyManager[0]
User profile is available. Using ‘C:\Users\evgomes\AppData\Local\ASP.NET\DataProtection-Keys’ as key repository and Windows DPAPI to encrypt keys at rest.
Hosting environment: Development
Content root path: C:\Users\evgomes\Desktop\Tutorials\src\Supermarket.API
Now listening on: https://localhost:5001
Now listening on: http://localhost:5000
Application started. Press Ctrl+C to shut down.
Vous pouvez voir qu'EF Core a été appelé pour initialiser la base de données. Les dernières lignes indiquent sur quels ports l'application s'exécute.
Ouvrez un navigateur et accédez à http://localhost:5000/api/categories (ou à l'URL affichée sur la sortie de la console). Si vous voyez une erreur de sécurité à cause du HTTPS, ajoutez simplement une exception pour l'application.
Le navigateur affichera les données JSON suivantes en sortie :
[
{
"id": 100,
"name": "Fruits and Vegetables",
"products": []
},
{
"id": 101,
"name": "Dairy",
"products": []
}
]
Ici, nous voyons les données que nous avons ajoutées à la base de données lorsque nous avons configuré le contexte de base de données. Cette sortie confirme que notre code fonctionne.
Vous avez créé un point de terminaison d'API GET avec très peu de lignes de code, et vous avez une structure de code qui est vraiment facile à modifier grâce à l'architecture de l'API.
Maintenant, il est temps de vous montrer à quel point il est facile de modifier ce code lorsque vous devez l'ajuster en fonction des besoins de l'entreprise.
Étape 8 — Création d'une ressource de catégorie
Si vous vous souvenez de la spécification du point de terminaison de l'API, vous avez remarqué que notre réponse JSON actuelle possède une propriété supplémentaire : un tableau de produits. Jetez un œil à l'exemple de la réponse souhaitée :
{
[
{ "id": 1, "name": "Fruits and Vegetables" },
{ "id": 2, "name": "Breads" },
… // Autres catégories
]
}
Le tableau de produits est présent dans notre réponse JSON actuelle car notre modèle Category possède une propriété Products, nécessaire à EF Core pour mapper correctement les produits d'une catégorie donnée.
Nous ne voulons pas de cette propriété dans notre réponse, mais nous ne pouvons pas modifier notre classe de modèle pour exclure cette propriété. Cela amènerait EF Core à générer des erreurs lorsque nous essayons de gérer les données des catégories, et cela briserait également la conception de notre modèle de domaine car il n'est pas logique d'avoir une catégorie de produits qui n'a pas de produits.
Pour renvoyer des données JSON contenant uniquement les identifiants et les noms des catégories du supermarché, nous devons créer une classe de ressource.
Une classe de ressource est une classe qui contient uniquement des informations de base qui seront échangées entre les applications clientes et les points de terminaison d'API, généralement sous forme de données JSON, pour représenter une information particulière.
Toutes les réponses des points de terminaison d'API doivent renvoyer une ressource.
C'est une mauvaise pratique de renvoyer la représentation réelle du modèle comme réponse car elle peut contenir des informations dont l'application cliente n'a pas besoin ou qu'elle n'a pas la permission d'avoir (par exemple, un modèle utilisateur pourrait renvoyer des informations sur le mot de passe de l'utilisateur, ce qui serait un gros problème de sécurité).
Nous avons besoin d'une ressource pour représenter uniquement nos catégories, sans les produits.
Maintenant que vous savez ce qu'est une ressource, implémentons-la. Tout d'abord, arrêtez l'application en cours d'exécution en appuyant sur Ctrl + C sur la ligne de commande. Dans le dossier racine de l'application, créez un nouveau dossier appelé Resources. Là, ajoutez une nouvelle classe appelée CategoryResource.
Nous devons mapper notre collection de modèles de catégories, qui est fournie par notre service de catégories, vers une collection de ressources de catégories.
Nous utiliserons une bibliothèque appelée AutoMapper pour gérer le mapping entre les objets. AutoMapper est une bibliothèque très populaire dans le monde .NET, et elle est utilisée dans de nombreux projets commerciaux et open source.
Tapez les lignes suivantes dans la ligne de commande pour ajouter AutoMapper à notre application :
dotnet add package AutoMapper
dotnet add package AutoMapper.Extensions.Microsoft.DependencyInjection
Pour utiliser AutoMapper, nous devons faire deux choses :
- L'enregistrer pour l'injection de dépendances ;
- Créer une classe qui indiquera à AutoMapper comment gérer le mapping des classes.
Tout d'abord, ouvrez la classe Startup. Dans la méthode ConfigureServices, après la dernière ligne, ajoutez le code suivant :
services.AddAutoMapper();
Cette ligne gère toutes les configurations nécessaires d'AutoMapper, telles que son enregistrement pour l'injection de dépendances et l'analyse de l'application au démarrage pour configurer les profils de mapping.
Maintenant, dans le répertoire racine, ajoutez un nouveau dossier appelé Mapping, puis ajoutez une classe appelée ModelToResourceProfile. Modifiez le code de cette façon :
La classe hérite de Profile, un type de classe qu'AutoMapper utilise pour vérifier comment nos mappings fonctionneront. Sur le constructeur, nous créons un mapping entre la classe de modèle Category et la classe CategoryResource. Étant donné que les propriétés des classes ont les mêmes noms et types, nous n'avons pas besoin d'utiliser de configuration spéciale pour elles.
La dernière étape consiste à modifier le contrôleur de catégories pour utiliser AutoMapper afin de gérer le mapping de nos objets.
J'ai modifié le constructeur pour recevoir une instance de l'implémentation IMapper. Vous pouvez utiliser ces méthodes d'interface pour utiliser les méthodes de mapping d'AutoMapper.
J'ai également modifié la méthode GetAllAsync pour mapper notre énumération de catégories vers une énumération de ressources à l'aide de la méthode Map. Cette méthode reçoit une instance de la classe ou de la collection que nous voulons mapper et, via des définitions de types génériques, elle définit vers quel type de classe ou de collection elle doit être mappée.
Notez que nous avons facilement modifié l'implémentation sans avoir à adapter la classe de service ou le dépôt, simplement en injectant une nouvelle dépendance (IMapper) au constructeur.
L'injection de dépendances rend votre application maintenable et facile à modifier puisque vous n'avez pas à casser toute votre implémentation de code pour ajouter ou supprimer des fonctionnalités.
Vous avez probablement réalisé que non seulement la classe de contrôleur mais toutes les classes qui reçoivent des dépendances (y compris les dépendances elles-mêmes) ont été automatiquement résolues pour recevoir les classes correctes selon les configurations de liaison.
L'injection de dépendances est incroyable, n'est-ce pas ?
Maintenant, redémarrez l'API à l'aide de la commande dotnet run et rendez-vous sur http://localhost:5000/api/categories pour voir la nouvelle réponse JSON.
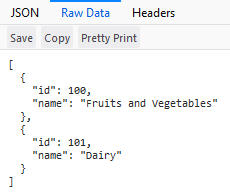
Nous avons déjà notre point de terminaison GET. Maintenant, créons un nouveau point de terminaison pour POST (créer) des catégories.
Étape 9 — Création de nouvelles catégories
Lorsqu'on traite de la création de ressources, nous devons nous soucier de beaucoup de choses, telles que :
- La validation des données et l'intégrité des données ;
- L'autorisation de créer des ressources ;
- La gestion des erreurs ;
- La journalisation (logging).
Je ne montrerai pas comment gérer l'authentification et l'autorisation dans ce tutoriel, mais vous pouvez voir comment implémenter facilement ces fonctionnalités en lisant mon tutoriel sur l'authentification par jeton web JSON (JWT).
De plus, il existe un framework très populaire appelé ASP.NET Identity qui fournit des solutions intégrées concernant la sécurité et l'enregistrement des utilisateurs que vous pouvez utiliser dans vos applications. Il comprend des fournisseurs pour travailler avec EF Core, comme un IdentityDbContext intégré que vous pouvez utiliser. Vous pouvez en savoir plus ici.
Écrivons un point de terminaison HTTP POST qui couvrira les autres scénarios (à l'exception de la journalisation, qui peut changer selon les différents périmètres et outils).
Avant de créer le nouveau point de terminaison, nous avons besoin d'une nouvelle ressource. Cette ressource mappera les données que les applications clientes envoient à ce point de terminaison (dans ce cas, le nom de la catégorie) vers une classe de notre application.
Puisque nous créons une nouvelle catégorie, nous n'avons pas encore d'ID, ce qui signifie que nous avons besoin d'une ressource qui représente une catégorie ne contenant que son nom.
Dans le dossier Resources, ajoutez une nouvelle classe appelée SaveCategoryResource :
Notez les attributs Required et MaxLength appliqués sur la propriété Name. Ces attributs sont appelés annotations de données (data annotations). Le pipeline ASP.NET Core utilise ces métadonnées pour valider les requêtes et les réponses. Comme les noms le suggèrent, le nom de la catégorie est obligatoire et a une longueur maximale de 30 caractères.
Définissons maintenant la forme du nouveau point de terminaison de l'API. Ajoutez le code suivant au contrôleur de catégories :
Nous indiquons au framework qu'il s'agit d'un point de terminaison HTTP POST à l'aide de l'attribut HttpPost.
Notez le type de réponse de cette méthode, Task<IActionResult>. Les méthodes présentes dans les classes de contrôleurs sont appelées actions, et elles ont cette signature car nous pouvons renvoyer plus d'un résultat possible après que l'application a exécuté l'action.
Dans ce cas, si le nom de la catégorie est invalide, ou si quelque chose ne va pas, nous devons renvoyer une réponse avec un code 400 (bad request), contenant généralement un message d'erreur que les applications clientes peuvent utiliser pour traiter le problème, ou nous pouvons avoir une réponse 200 (success) avec des données si tout se passe bien.
Il existe de nombreux types d'actions que vous pouvez utiliser comme réponse, mais généralement, nous pouvons utiliser cette interface, et ASP.NET Core utilisera une classe par défaut pour cela.
L'attribut FromBody indique à ASP.NET Core d'analyser les données du corps de la requête dans notre nouvelle classe de ressource. Cela signifie que lorsqu'un JSON contenant le nom de la catégorie est envoyé à notre application, le framework l'analysera automatiquement vers notre nouvelle classe.
Maintenant, implémentons notre logique de route. Nous devons suivre quelques étapes pour créer avec succès une nouvelle catégorie :
- Tout d'abord, nous devons valider la requête entrante. Si la requête est invalide, nous devons renvoyer une réponse « bad request » contenant les messages d'erreur ;
- Ensuite, si la requête est valide, nous devons mapper notre nouvelle ressource vers notre classe de modèle de catégorie à l'aide d'AutoMapper ;
- Nous devons maintenant appeler notre service, en lui demandant de sauvegarder notre nouvelle catégorie. Si la logique de sauvegarde est exécutée sans problème, elle doit renvoyer une réponse contenant les données de notre nouvelle catégorie. Sinon, elle doit nous donner une indication que le processus a échoué, et un message d'erreur potentiel ;
- Enfin, s'il y a une erreur, nous renvoyons un « bad request ». Sinon, nous mappons notre nouveau modèle de catégorie vers une ressource de catégorie et renvoyons une réponse de succès au client, contenant les données de la nouvelle catégorie.
Cela semble compliqué, mais il est vraiment facile d'implémenter cette logique en utilisant l'architecture de service que nous avons structurée pour notre API.
Commençons par valider la requête entrante.
Étape 10 — Validation du corps de la requête à l'aide du Model State
Les contrôleurs ASP.NET Core possèdent une propriété appelée ModelState. Cette propriété est remplie pendant l'exécution de la requête avant d'atteindre l'exécution de notre action. C'est une instance de ModelStateDictionary, une classe qui contient des informations telles que si la requête est valide et les messages d'erreur de validation potentiels.
Modifiez le code du point de terminaison comme suit :
Le code vérifie si l'état du modèle (dans ce cas, les données envoyées dans le corps de la requête) est invalide, en vérifiant nos annotations de données. Si ce n'est pas le cas, l'API renvoie un « bad request » (avec le code d'état 400) et les messages d'erreur par défaut fournis par nos métadonnées d'annotations.
La méthode ModelState.GetErrorMessages() n'est pas encore implémentée. C'est une méthode d'extension (une méthode qui étend la fonctionnalité d'une classe ou d'une interface déjà existante) que je vais implémenter pour convertir les erreurs de validation en chaînes simples à renvoyer au client.
Ajoutez un nouveau dossier Extensions à la racine de notre API, puis ajoutez une nouvelle classe ModelStateExtensions.
Toutes les méthodes d'extension doivent être statiques, ainsi que les classes où elles sont déclarées. Cela signifie qu'elles ne gèrent pas de données d'instance spécifiques et qu'elles ne sont chargées qu'une seule fois au démarrage de l'application.
Le mot-clé this devant la déclaration du paramètre indique au compilateur C# de le traiter comme une méthode d'extension. Le résultat est que nous pouvons l'appeler comme une méthode normale de cette classe puisque nous incluons la directive using respective là où nous voulons utiliser l'extension.
L'extension utilise des requêtes LINQ, une fonctionnalité très utile de .NET qui nous permet d'interroger et de transformer des données à l'aide d'expressions chaînables. Les expressions ici transforment les méthodes d'erreur de validation en une liste de chaînes contenant les messages d'erreur.
Importez l'espace de noms Supermarket.API.Extensions dans le contrôleur de catégories avant de passer à l'étape suivante.
using Supermarket.API.Extensions;
Continuons l'implémentation de la logique de notre point de terminaison en mappant notre nouvelle ressource vers une classe de modèle de catégorie.
Étape 11 — Mapping de la nouvelle ressource
Nous avons déjà défini un profil de mapping pour transformer les modèles en ressources. Maintenant, nous avons besoin d'un nouveau profil qui fait l'inverse.
Ajoutez une nouvelle classe ResourceToModelProfile dans le dossier Mapping :
Rien de nouveau ici. Grâce à la magie de l'injection de dépendances, AutoMapper enregistrera automatiquement ce profil au démarrage de l'application, et nous n'aurons pas à modifier d'autre endroit pour l'utiliser.
Nous pouvons maintenant mapper notre nouvelle ressource vers la classe de modèle respective :
Étape 12 — Application du pattern Requête-Réponse pour gérer la logique de sauvegarde
Maintenant, nous devons implémenter la logique la plus intéressante : sauvegarder une nouvelle catégorie. Nous attendons de notre service qu'il le fasse.
La logique de sauvegarde peut échouer en raison de problèmes lors de la connexion à la base de données, ou peut-être parce qu'une règle métier interne invalide nos données.
Si quelque chose ne va pas, nous ne pouvons pas simplement lever une erreur, car cela pourrait arrêter l'API, et l'application cliente ne saurait pas comment gérer le problème. De plus, nous aurions potentiellement un mécanisme de journalisation qui enregistrerait l'erreur.
Le contrat de la méthode de sauvegarde, c'est-à-dire la signature de la méthode et le type de réponse, doit nous indiquer si le processus a été exécuté correctement. Si le processus se passe bien, nous recevrons les données de la catégorie. Sinon, nous devons recevoir, au moins, un message d'erreur indiquant pourquoi le processus a échoué.
Nous pouvons implémenter cette fonctionnalité en appliquant le pattern requête-réponse. Ce pattern de conception d'entreprise encapsule nos paramètres de requête et de réponse dans des classes afin d'encapsuler les informations que nos services utiliseront pour traiter une tâche et pour renvoyer des informations à la classe qui utilise le service.
Ce pattern nous offre certains avantages, tels que :
- Si nous devons modifier notre service pour recevoir plus de paramètres, nous n'avons pas à casser sa signature ;
- Nous pouvons définir un contrat standard pour nos requêtes et/ou réponses ;
- Nous pouvons gérer la logique métier et les échecs potentiels sans arrêter le processus de l'application, et nous n'aurons pas besoin d'utiliser des tonnes de blocs try-catch.
Créons un type de réponse standard pour nos méthodes de services qui gèrent les modifications de données. Pour chaque requête de ce type, nous voulons savoir si la requête est exécutée sans problème. Si elle échoue, nous voulons renvoyer un message d'erreur au client.
Dans le dossier Domain, à l'intérieur de Services, ajoutez un nouveau répertoire appelé Communication. Ajoutez-y une nouvelle classe appelée BaseResponse.
C'est une classe abstraite dont nos types de réponse hériteront.
L'abstraction définit une propriété Success, qui indiquera si les requêtes ont été complétées avec succès, et une propriété Message, qui contiendra le message d'erreur en cas d'échec.
Notez que ces propriétés sont obligatoires et que seules les classes héritées peuvent définir ces données car les classes enfants doivent transmettre ces informations via la fonction constructeur.
Conseil : ce n'est pas une bonne pratique de définir des classes de base pour tout, car les classes de base couplent votre code et vous empêchent de le modifier facilement. Préférez utiliser la composition plutôt que l'héritage.
Pour le périmètre de cette API, ce n'est pas vraiment un problème d'utiliser des classes de base, car nos services ne grandiront pas beaucoup. Si vous réalisez qu'un service ou une application va croître et changer fréquemment, évitez d'utiliser une classe de base.
Maintenant, dans le même dossier, ajoutez une nouvelle classe appelée SaveCategoryResponse.
Le type de réponse définit également une propriété Category, qui contiendra nos données de catégorie si la requête se termine avec succès.
Notez que j'ai défini trois constructeurs différents pour cette classe :
- Un constructeur privé, qui va passer les paramètres success et message à la classe de base, et définit également la propriété
Category; - Un constructeur qui ne reçoit que la catégorie en paramètre. Celui-ci créera une réponse réussie, en appelant le constructeur privé pour définir les propriétés respectives ;
- Un troisième constructeur qui ne spécifie que le message. Celui-ci sera utilisé pour créer une réponse d'échec.
Parce que C# prend en charge plusieurs constructeurs, nous avons simplifié la création de la réponse sans définir de méthode différente pour gérer cela, juste en utilisant différents constructeurs.
Nous pouvons maintenant modifier notre interface de service pour ajouter le nouveau contrat de méthode de sauvegarde.
Modifiez l'interface ICategoryService comme suit :
Nous allons simplement passer une catégorie à cette méthode et elle gérera toute la logique nécessaire pour sauvegarder les données du modèle, en orchestrant les dépôts et les autres services nécessaires pour le faire.
Notez que je ne crée pas de classe de requête spécifique ici car nous n'avons pas besoin d'autres paramètres pour effectuer cette tâche. Il existe un concept en programmation informatique appelé KISS — abréviation de Keep it Simple, Stupid (Garde ça simple, idiot). Fondamentalement, cela dit que vous devriez garder votre application aussi simple que possible.
Gardez cela à l'esprit lors de la conception de vos applications : n'appliquez que ce dont vous avez besoin pour résoudre un problème. Ne sur-concevez pas (over-engineer) votre application.
Nous pouvons maintenant terminer la logique de notre point de terminaison :
Après avoir validé les données de la requête et mappé la ressource vers notre modèle, nous la transmettons à notre service pour persister les données.
Si quelque chose échoue, l'API renvoie un « bad request ». Sinon, l'API mappe la nouvelle catégorie (incluant désormais des données telles que le nouvel Id) vers notre CategoryResource précédemment créée et l'envoie au client.
Maintenant, implémentons la logique réelle pour le service.
Étape 13 — La logique de base de données et le pattern Unit of Work
Puisque nous allons persister des données dans la base de données, nous avons besoin d'une nouvelle méthode dans notre dépôt.
Ajoutez une nouvelle méthode AddAsync à l'interface ICategoryRepository :
Maintenant, implémentons cette méthode dans notre classe de dépôt réelle :
Ici, nous ajoutons simplement une nouvelle catégorie à notre ensemble.
Lorsque nous ajoutons une classe à un DbSet<>, EF Core commence à suivre tous les changements qui arrivent à notre modèle et utilise ces données à l'état actuel pour générer des requêtes qui inséreront, mettront à jour ou supprimeront des modèles.
L'implémentation actuelle ajoute simplement le modèle à notre ensemble, mais nos données ne seront toujours pas sauvegardées.
Il existe une méthode appelée SaveChanges présente dans la classe de contexte que nous devons appeler pour exécuter réellement les requêtes dans la base de données. Je ne l'ai pas appelée ici car un dépôt ne devrait pas persister de données, c'est juste une collection d'objets en mémoire.
Ce sujet est très controversé, même entre développeurs .NET expérimentés, mais laissez-moi vous expliquer pourquoi vous ne devriez pas appeler SaveChanges dans les classes de dépôt.
Nous pouvons considérer un dépôt conceptuellement comme n'importe quelle autre collection présente dans le framework .NET. Lorsque vous traitez une collection en .NET (et dans de nombreux autres langages de programmation, tels que Javascript et Java), vous pouvez généralement :
- Y ajouter de nouveaux éléments (comme lorsque vous poussez des données vers des listes, des tableaux et des dictionnaires) ;
- Trouver ou filtrer des éléments ;
- Supprimer un élément de la collection ;
- Remplacer un élément donné, ou le mettre à jour.
Pensez à une liste du monde réel. Imaginez que vous écriviez une liste de courses pour acheter des choses dans un supermarché (quelle coïncidence, non ?).
Dans la liste, vous écrivez tous les fruits que vous devez acheter. Vous pouvez ajouter des fruits à cette liste, supprimer un fruit si vous renoncez à l'acheter, ou vous pouvez remplacer le nom d'un fruit. Mais vous ne pouvez pas sauvegarder des fruits dans la liste. Cela n'a pas de sens de dire une telle chose en français courant.
Conseil : lors de la conception de classes et d'interfaces dans des langages de programmation orientés objet, essayez d'utiliser le langage naturel pour vérifier si ce que vous faites semble correct.
Il est logique, par exemple, de dire qu'un homme implémente une interface de personne, mais il n'est pas logique de dire qu'un homme implémente un compte.
Si vous voulez « sauvegarder » la liste de fruits (dans ce cas, acheter tous les fruits), vous la payez et le supermarché traite les données de stock pour vérifier s'il doit acheter plus de fruits auprès d'un fournisseur ou non.
La même logique peut être appliquée lors de la programmation. Les dépôts ne devraient pas sauvegarder, mettre à jour ou supprimer des données. Au lieu de cela, ils devraient déléguer cela à une classe différente pour gérer cette logique.
Il y a un autre problème lors de la sauvegarde des données directement dans un dépôt : vous ne pouvez pas utiliser de transactions.
Imaginez que notre application dispose d'un mécanisme de journalisation qui stocke un nom d'utilisateur et l'action effectuée chaque fois qu'une modification est apportée aux données de l'API.
Imaginez maintenant que, pour une raison quelconque, vous ayez un appel à un service qui met à jour le nom d'utilisateur (ce n'est pas un scénario courant, mais considérons-le).
Vous conviendrez que pour changer le nom d'utilisateur dans une table d'utilisateurs fictive, vous devez d'abord mettre à jour tous les journaux pour indiquer correctement qui a effectué cette opération, n'est-ce pas ?
Imaginez maintenant que nous ayons implémenté la méthode de mise à jour pour les utilisateurs et les journaux dans différents dépôts, et qu'ils appellent tous les deux SaveChanges. Que se passe-t-il si l'une de ces méthodes échoue au milieu du processus de mise à jour ? Vous vous retrouverez avec une incohérence de données.
Nous ne devrions sauvegarder nos modifications dans la base de données qu'une fois que tout est terminé. Pour ce faire, nous devons utiliser une transaction, qui est essentiellement une fonctionnalité que la plupart des bases de données implémentent pour sauvegarder les données uniquement après la fin d'une opération complexe.
« — Ok, donc si nous ne pouvons pas sauvegarder les choses ici, où devrions-nous le faire ? »
Un pattern courant pour gérer ce problème est le Pattern Unit of Work. Ce pattern consiste en une classe qui reçoit notre instance AppDbContext comme dépendance et expose des méthodes pour démarrer, terminer ou abandonner des transactions.
Nous utiliserons une implémentation simple d'une unité de travail (unit of work) pour aborder notre problème ici.
Ajoutez une nouvelle interface à l'intérieur du dossier Repositories de la couche Domain appelée IUnitOfWork :
Comme vous pouvez le voir, elle n'expose qu'une méthode qui complétera de manière asynchrone les opérations de gestion des données.
Ajoutons maintenant l'implémentation réelle.
Ajoutez une nouvelle classe appelée UnitOfWork dans le dossier Repositories de la couche Persistence :
C'est une implémentation simple et propre qui ne sauvegardera toutes les modifications dans la base de données qu'après avoir fini de la modifier à l'aide de vos dépôts.
Si vous recherchez des implémentations du pattern Unit of Work, vous en trouverez des plus complexes implémentant des opérations de rollback.
Puisque EF Core implémente déjà le pattern repository et unit of work en coulisses, nous n'avons pas à nous soucier d'une méthode de rollback.
« — Quoi ? Alors pourquoi devons-nous créer toutes ces interfaces et classes ? »
Séparer la logique de persistance des règles métier offre de nombreux avantages en termes de réutilisabilité et de maintenance du code. Si nous utilisons EF Core directement, nous finirons par avoir des classes plus complexes qui ne seront pas si faciles à modifier.
Imaginez qu'à l'avenir vous décidiez de changer le framework ORM pour un autre, tel que Dapper, par exemple, ou si vous devez implémenter des requêtes SQL simples pour des raisons de performance. Si vous couplez votre logique de requêtes à vos services, il sera difficile de modifier la logique, car vous devrez le faire dans de nombreuses classes.
En utilisant le pattern repository, vous pouvez simplement implémenter une nouvelle classe de dépôt et la lier à l'aide de l'injection de dépendances.
Donc, fondamentalement, si vous utilisez EF Core directement dans vos services et que vous devez changer quelque chose, voici ce que vous obtiendrez :
Comme je l'ai dit, EF Core implémente les patterns Unit of Work et Repository en coulisses. Nous pouvons considérer nos propriétés DbSet<> comme des dépôts. De plus, SaveChanges ne persiste les données qu'en cas de succès pour toutes les opérations de base de données.
Maintenant que vous savez ce qu'est une unité de travail et pourquoi l'utiliser avec des dépôts, implémentons la logique réelle du service.
Grâce à notre architecture découplée, nous pouvons simplement passer une instance de UnitOfWork comme dépendance pour cette classe.
Notre logique métier est assez simple.
Tout d'abord, nous essayons d'ajouter la nouvelle catégorie à la base de données, puis l'API essaie de la sauvegarder, en enveloppant le tout dans un bloc try-catch.
Si quelque chose échoue, l'API appelle un service de journalisation fictif et renvoie une réponse indiquant l'échec.
Si le processus se termine sans problème, l'application renvoie une réponse de succès, en envoyant nos données de catégorie. Simple, n'est-ce pas ?
Conseil : Dans les applications du monde réel, vous ne devriez pas tout envelopper dans un bloc try-catch générique, mais vous devriez plutôt gérer séparément toutes les erreurs possibles.
Le simple fait d'ajouter un bloc try-catch ne couvrira pas la plupart des scénarios d'échec possibles. Assurez-vous d'implémenter correctement la gestion des erreurs.
La dernière étape avant de tester notre API est de lier l'interface de l'unité de travail à sa classe respective.
Ajoutez cette nouvelle ligne à la méthode ConfigureServices de la classe Startup :
services.AddScoped<IUnitOfWork, UnitOfWork>();
Maintenant, testons-le !
Étape 14 — Test de notre point de terminaison POST à l'aide de Postman
Démarrez à nouveau notre application en utilisant dotnet run.
Nous ne pouvons pas utiliser le navigateur pour tester un point de terminaison POST. Utilisons Postman pour tester nos points de terminaison. C'est un outil très utile pour tester les API RESTful.
Ouvrez Postman et fermez les messages d'introduction. Vous verrez un écran comme celui-ci :
Remplacez le GET sélectionné par défaut dans la zone de sélection par POST.
Tapez l'adresse de l'API dans le champ Enter request URL.
Nous devons fournir les données du corps de la requête à envoyer à notre API. Cliquez sur l'élément de menu Body, puis changez l'option affichée en dessous en raw.
Postman affichera une option Text sur la droite. Changez-la en JSON (application/json) et collez les données JSON suivantes ci-dessous :
{
"name": ""
}
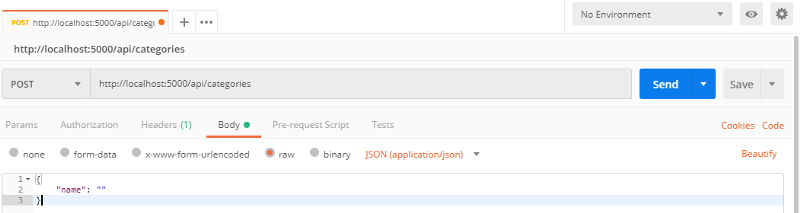
Comme vous le voyez, nous allons envoyer une chaîne de nom vide à notre nouveau point de terminaison.
Cliquez sur le bouton Send. Vous recevrez une sortie comme celle-ci :

Vous souvenez-vous de la logique de validation que nous avons créée pour le point de terminaison ? Cette sortie est la preuve qu'elle fonctionne !
Notez également le code d'état 400 affiché à droite. Le résultat BadRequest ajoute automatiquement ce code d'état à la réponse.
Maintenant, changeons les données JSON pour des données valides pour voir la nouvelle réponse :
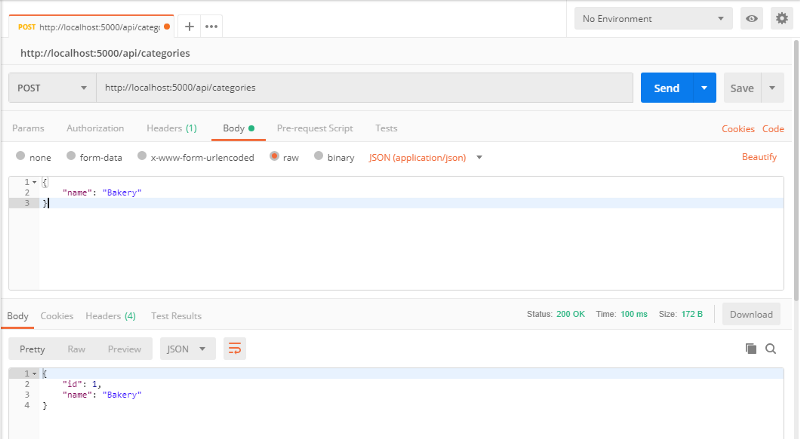
L'API a correctement créé notre nouvelle ressource.
Jusqu'à présent, notre API peut lister et créer des catégories. Vous avez appris beaucoup de choses sur le langage C#, le framework ASP.NET Core ainsi que les approches de conception courantes pour structurer vos API.
Continuons notre API de catégories en créant le point de terminaison pour mettre à jour les catégories.
À partir de maintenant, puisque je vous ai expliqué la plupart des concepts, j'accélérerai les explications et me concentrerai sur les nouveaux sujets pour ne pas vous faire perdre de temps. C'est parti !
Étape 15 — Mise à jour des catégories
Pour mettre à jour les catégories, nous avons besoin d'un point de terminaison HTTP PUT.
La logique que nous devons coder est très similaire à celle du POST :
- Tout d'abord, nous devons valider la requête entrante à l'aide du
ModelState; - Si la requête est valide, l'API doit mapper la ressource entrante vers une classe de modèle à l'aide d'AutoMapper ;
- Ensuite, nous devons appeler notre service, en lui demandant de mettre à jour la catégorie, en fournissant l'
Idde la catégorie respective et les données mises à jour ; - S'il n'y a pas de catégorie avec l'
Iddonné dans la base de données, nous renvoyons un « bad request ». Nous pourrions utiliser un résultatNotFoundà la place, mais cela n'a pas vraiment d'importance pour ce périmètre, puisque nous fournissons un message d'erreur aux applications clientes ; - Si la logique de sauvegarde est correctement exécutée, le service doit renvoyer une réponse contenant les données de la catégorie mise à jour. Sinon, il doit nous donner une indication que le processus a échoué, et un message indiquant pourquoi ;
- Enfin, s'il y a une erreur, l'API renvoie un « bad request ». Sinon, elle mappe le modèle de catégorie mis à jour vers une ressource de catégorie et renvoie une réponse de succès à l'application cliente.
Ajoutons la nouvelle méthode PutAsync dans la classe de contrôleur :
Si vous la comparez avec la logique POST, vous remarquerez que nous n'avons qu'une seule différence ici : l'attribut HttpPut spécifie un paramètre que la route donnée doit recevoir.
Nous appellerons ce point de terminaison en spécifiant l' Id de la catégorie comme dernier fragment d'URL, comme /api/categories/1. Le pipeline ASP.NET Core analyse ce fragment vers le paramètre du même nom.
Nous devons maintenant définir la signature de la méthode UpdateAsync dans l'interface ICategoryService :
Passons maintenant à la logique réelle.
Étape 16 — La logique de mise à jour
Pour mettre à jour notre catégorie, nous devons d'abord renvoyer les données actuelles de la base de données, si elles existent. Nous devons également les mettre à jour dans notre DbSet<>.
Ajoutons deux nouveaux contrats de méthode à notre interface ICategoryRepository :
Nous avons défini la méthode FindByIdAsync, qui renverra de manière asynchrone une catégorie de la base de données, et la méthode Update. Notez que la méthode Update n'est pas asynchrone puisque l'API EF Core ne nécessite pas de méthode asynchrone pour mettre à jour les modèles.
Implémentons maintenant la logique réelle dans la classe CategoryRepository :
Enfin, nous pouvons coder la logique du service :
L'API essaie de récupérer la catégorie de la base de données. Si le résultat est null, nous renvoyons une réponse indiquant que la catégorie n'existe pas. Si la catégorie existe, nous devons définir son nouveau nom.
L'API essaie ensuite de sauvegarder les modifications, comme lorsque nous créons une nouvelle catégorie. Si le processus se termine, le service renvoie une réponse de succès. Sinon, la logique de journalisation s'exécute et le point de terminaison reçoit une réponse contenant un message d'erreur.
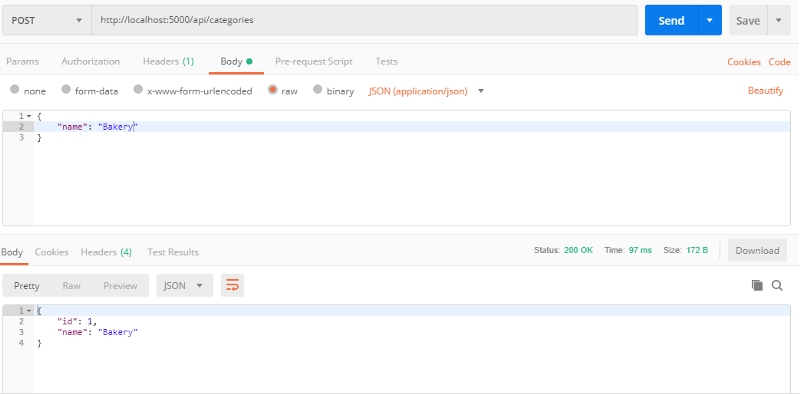
Maintenant, testons-le. Tout d'abord, ajoutons une nouvelle catégorie pour avoir un Id valide à utiliser. Nous pourrions utiliser les identifiants des catégories que nous avons amorcées dans notre base de données, mais je veux le faire de cette façon pour vous montrer que notre API va mettre à jour la bonne ressource.
Lancez à nouveau l'application et, à l'aide de Postman, POSTez une nouvelle catégorie dans la base de données :
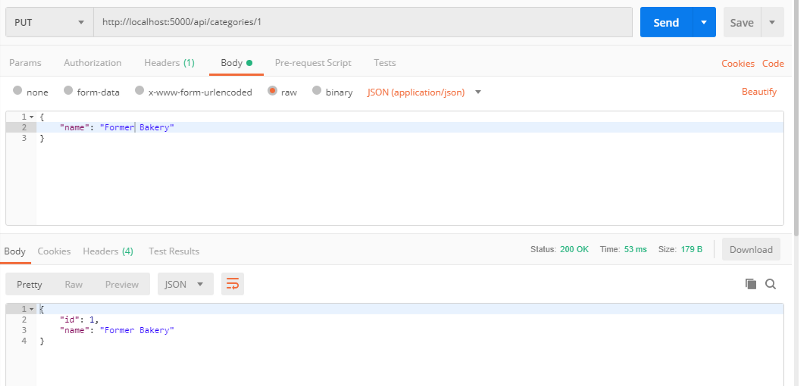
Ayant un Id valide en main, changez l'option POST en PUT dans la zone de sélection et ajoutez la valeur de l'ID à la fin de l'URL. Changez la propriété name pour un nom différent et envoyez la requête pour vérifier le résultat :
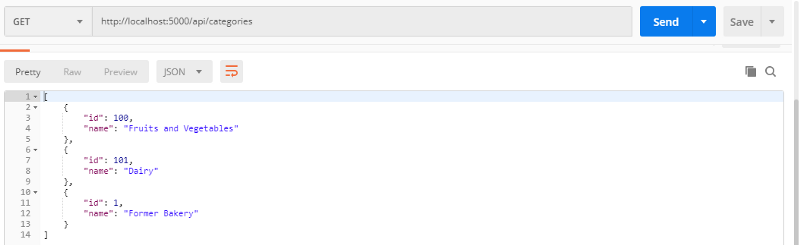
Vous pouvez envoyer une requête GET au point de terminaison de l'API pour vous assurer que vous avez correctement modifié le nom de la catégorie :
La dernière opération que nous devons implémenter pour les catégories est la suppression des catégories. Faisons-le en créant un point de terminaison HTTP Delete.
Étape 17 — Suppression de catégories
La logique de suppression des catégories est vraiment facile à implémenter puisque la plupart des méthodes dont nous avons besoin ont été construites précédemment.
Voici les étapes nécessaires pour que notre route fonctionne :
- L'API doit appeler notre service, en lui demandant de supprimer notre catégorie, en fournissant l'
Idrespectif ; - S'il n'y a pas de catégorie avec l'ID donné dans la base de données, le service doit renvoyer un message l'indiquant ;
- Si la logique de suppression est exécutée sans problème, le service doit renvoyer une réponse contenant les données de notre catégorie supprimée. Sinon, il doit nous donner une indication que le processus a échoué, et un message d'erreur potentiel ;
- Enfin, s'il y a une erreur, l'API renvoie un « bad request ». Sinon, l'API mappe la catégorie mise à jour vers une ressource et renvoie une réponse de succès au client.
Commençons par ajouter la logique du nouveau point de terminaison :
L'attribut HttpDelete définit également un modèle d' id.
Avant d'ajouter la signature DeleteAsync à notre interface ICategoryService, nous devons effectuer un petit refactoring.
La nouvelle méthode de service doit renvoyer une réponse contenant les données de la catégorie, de la même manière que nous l'avons fait pour les méthodes PostAsync et UpdateAsync. Nous pourrions réutiliser SaveCategoryResponse à cette fin, mais nous ne sauvegardons pas de données dans ce cas.
Pour éviter de créer une nouvelle classe avec la même forme pour répondre à ce besoin, nous pouvons simplement renommer notre SaveCategoryResponse en CategoryResponse.
Si vous utilisez Visual Studio Code, vous pouvez ouvrir la classe SaveCategoryResponse, placer le curseur de la souris au-dessus du nom de la classe et utiliser l'option Change All Occurrences pour renommer la classe :
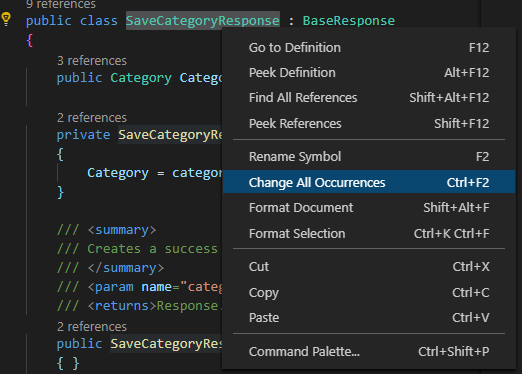
Assurez-vous de renommer également le nom du fichier.
Ajoutons la signature de la méthode DeleteAsync à l'interface ICategoryService :
Avant d'implémenter la logique de suppression, nous avons besoin d'une nouvelle méthode dans notre dépôt.
Ajoutez la signature de la méthode Remove à l'interface ICategoryRepository :
void Remove(Category category);
Et maintenant, ajoutez l'implémentation réelle dans la classe de dépôt :
EF Core exige que l'instance de notre modèle soit transmise à la méthode Remove pour comprendre correctement quel modèle nous supprimons, au lieu de simplement passer un Id.
Enfin, implémentons la logique dans la classe CategoryService :
Il n'y a rien de nouveau ici. Le service essaie de trouver la catégorie par ID, puis il appelle notre dépôt pour supprimer la catégorie. Enfin, l'unité de travail termine la transaction en exécutant l'opération réelle dans la base de données.
« — Hé, mais qu'en est-il des produits de chaque catégorie ? Ne devez-vous pas créer un dépôt et supprimer les produits d'abord, pour éviter les erreurs ? »
La réponse est non. Grâce au mécanisme de suivi d'EF Core, lorsque nous chargeons un modèle à partir de la base de données, le framework sait quelles relations le modèle possède. Si nous le supprimons, EF Core sait qu'il doit d'abord supprimer tous les modèles liés, de manière récursive.
Nous pouvons désactiver cette fonctionnalité lors du mapping de nos classes vers les tables de la base de données, mais cela sort du cadre de ce tutoriel. Jetez un œil ici si vous voulez en savoir plus sur cette fonctionnalité.
Il est maintenant temps de tester notre nouveau point de terminaison. Lancez à nouveau l'application et envoyez une requête DELETE à l'aide de Postman comme suit :
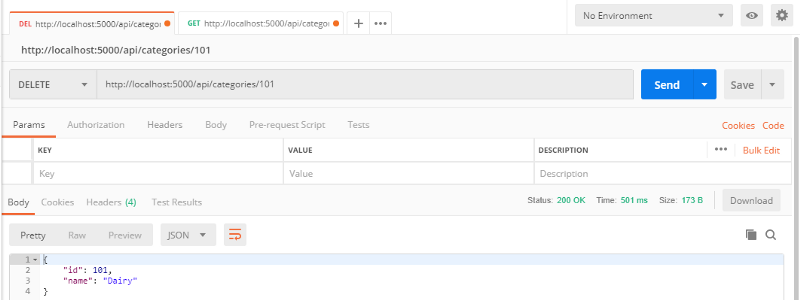
Nous pouvons vérifier que notre API fonctionne correctement en envoyant une requête GET :
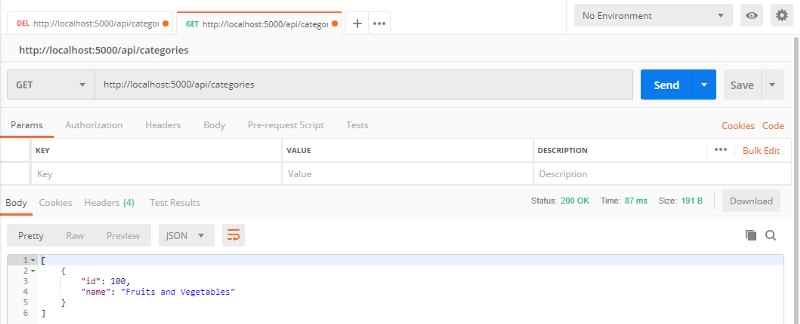
Nous avons terminé l'API des catégories. Il est maintenant temps de passer à l'API des produits.
Étape 18 — L'API des produits
Jusqu'à présent, vous avez appris à implémenter tous les verbes HTTP de base pour gérer les opérations CRUD avec ASP.NET Core. Passons au niveau supérieur en implémentant notre API de produits.
Je ne détaillerai pas à nouveau tous les verbes HTTP car ce serait exhaustif. Pour la dernière partie de ce tutoriel, je ne couvrirai que la requête GET, pour vous montrer comment inclure des entités liées lors de l'interrogation de données de la base de données et comment utiliser les attributs Description que nous avons définis pour les valeurs d'énumération EUnitOfMeasurement.
Ajoutez un nouveau contrôleur dans le dossier Controllers appelé ProductsController.
Avant de coder quoi que ce soit ici, nous devons créer la ressource produit.
Laissez-moi vous rafraîchir la mémoire en montrant à nouveau à quoi devrait ressembler notre ressource :
{
[
{
"id": 1,
"name": "Sugar",
"quantityInPackage": 1,
"unitOfMeasurement": "KG"
"category": {
"id": 3,
"name": "Sugar"
}
},
… // Autres produits
]
}
Nous voulons un tableau JSON contenant tous les produits de la base de données.
Les données JSON diffèrent du modèle de produit par deux choses :
- L'unité de mesure est affichée de manière plus courte, montrant seulement son abréviation ;
- Nous affichons les données de la catégorie sans inclure la propriété
CategoryId.
Pour représenter l'unité de mesure, nous pouvons utiliser une simple propriété de chaîne au lieu d'un type enum (au fait, nous n'avons pas de type enum par défaut pour les données JSON, nous devons donc le transformer en un type différent).
Maintenant que nous savons comment façonner la nouvelle ressource, créons-la. Ajoutez une nouvelle classe ProductResource dans le dossier Resources :
Nous devons maintenant configurer le mapping entre la classe de modèle et notre nouvelle classe de ressource.
La configuration du mapping sera presque la même que celle utilisée pour les autres mappings, mais ici nous devons gérer la transformation de notre enum EUnitOfMeasurement en une chaîne.
Vous souvenez-vous de l'attribut StringValue appliqué sur les types d'énumération ? Je vais maintenant vous montrer comment extraire cette information en utilisant une fonctionnalité puissante du framework .NET : l'API Reflection.
L'API Reflection est un ensemble puissant de ressources qui nous permet d'extraire et de manipuler des métadonnées. De nombreux frameworks et bibliothèques (y compris ASP.NET Core lui-même) utilisent ces ressources pour gérer de nombreuses choses en coulisses.
Voyons maintenant comment cela fonctionne en pratique. Ajoutez une nouvelle classe dans le dossier Extensions appelée EnumExtensions.
Cela peut paraître effrayant la première fois que vous regardez le code, mais ce n'est pas si complexe. Décomposons la définition du code pour comprendre comment il fonctionne.
Tout d'abord, nous avons défini une méthode générique (une méthode qui peut recevoir plus d'un type d'argument, dans ce cas, représenté par la déclaration TEnum) qui reçoit un enum donné comme argument.
Puisque enum est un mot-clé réservé en C#, nous avons ajouté un @ devant le nom du paramètre pour en faire un nom valide.
La première étape d'exécution de cette méthode consiste à obtenir les informations de type (la définition de la classe, de l'interface, de l'enum ou de la struct) du paramètre à l'aide de la méthode GetType.
Ensuite, la méthode obtient la valeur d'énumération spécifique (par exemple, Kilogram) en utilisant GetField(@enum.ToString()).
La ligne suivante trouve tous les attributs Description appliqués sur la valeur d'énumération et stocke leurs données dans un tableau (nous pouvons spécifier plusieurs attributs pour une même propriété dans certains cas).
La dernière ligne utilise une syntaxe plus courte pour vérifier si nous avons au moins un attribut de description pour le type d'énumération. Si c'est le cas, nous renvoyons la valeur Description fournie par cet attribut. Sinon, nous renvoyons l'énumération sous forme de chaîne, en utilisant le casting par défaut.
L'opérateur ?. (un opérateur conditionnel nul) vérifie si la valeur est null avant d'accéder à sa propriété.
L'opérateur ?? (un opérateur de coalescence nulle) indique à l'application de renvoyer la valeur à gauche si elle n'est pas vide, ou la valeur à droite sinon.
Maintenant que nous avons une méthode d'extension pour extraire les descriptions, configurons notre mapping entre modèle et ressource. Grâce à AutoMapper, nous pouvons le faire avec une seule ligne supplémentaire.
Ouvrez la classe ModelToResourceProfile et modifiez le code de cette façon :
Cette syntaxe indique à AutoMapper d'utiliser la nouvelle méthode d'extension pour convertir notre valeur EUnitOfMeasurement en une chaîne contenant sa description. Simple, n'est-ce pas ? Vous pouvez lire la documentation officielle pour comprendre la syntaxe complète.
Notez que nous n'avons défini aucune configuration de mapping pour la propriété category. Parce que nous avons précédemment configuré le mapping pour les catégories et parce que le modèle de produit possède une propriété category du même type et du même nom, AutoMapper sait implicitement qu'il doit la mapper en utilisant la configuration respective.
Ajoutons maintenant le code du point de terminaison. Modifiez le code de ProductsController :
Fondamentalement, la même structure définie pour le contrôleur de catégories.
Passons à la partie service. Ajoutez une nouvelle interface IProductService dans le dossier Services présent dans la couche Domain :
Vous devriez avoir réalisé que nous avons besoin d'un dépôt avant d'implémenter réellement le nouveau service.
Ajoutez une nouvelle interface appelée IProductRepository dans le dossier respectif :
Implémentons maintenant le dépôt. Nous devons l'implémenter presque de la même manière que nous l'avons fait pour le dépôt de catégories, sauf que nous devons renvoyer les données de catégorie respectives de chaque produit lors de l'interrogation des données.
EF Core, par défaut, n'inclut pas les entités liées à vos modèles lorsque vous interrogez des données car cela pourrait être très lent (imaginez un modèle avec dix entités liées, et toutes les entités liées ayant leurs propres relations).
Pour inclure les données des catégories, nous n'avons besoin que d'une seule ligne supplémentaire :
Notez l'appel à Include(p => p.Category). Nous pouvons chaîner cette syntaxe pour inclure autant d'entités que nécessaire lors de l'interrogation des données. EF Core va le traduire en une jointure (join) lors de l'exécution du select.
Nous pouvons maintenant implémenter la classe ProductService de la même manière que nous l'avons fait pour les catégories :
Lions les nouvelles dépendances en modifiant la classe Startup :
Enfin, avant de tester l'API, modifions la classe AppDbContext pour inclure certains produits lors de l'initialisation de l'application afin que nous puissions voir les résultats :
J'ai ajouté deux produits fictifs en les associant aux catégories que nous avons amorcées lors de l'initialisation de l'application.
C'est l'heure de tester ! Lancez à nouveau l'API et envoyez une requête GET à /api/products à l'aide de Postman :
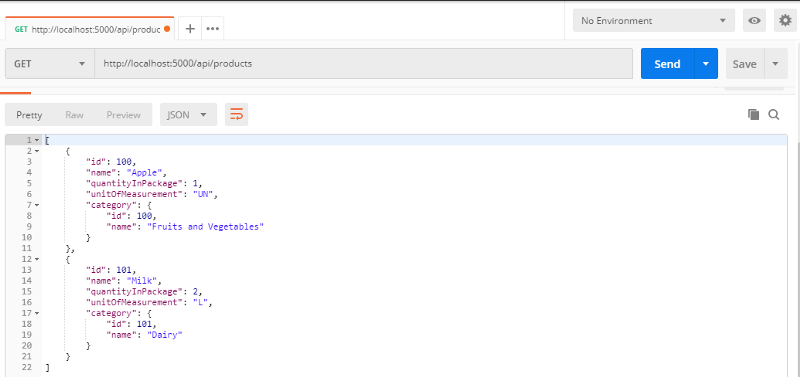 Voilà ! Voici nos produits
Voilà ! Voici nos produits
Et voilà ! Félicitations !
Vous avez maintenant une base sur la façon de construire une API RESTful à l'aide d'ASP.NET Core en utilisant une architecture découplée. Vous avez appris beaucoup de choses sur le framework .NET Core, comment travailler avec C#, les bases d'EF Core et AutoMapper et de nombreux patterns utiles à utiliser lors de la conception de vos applications.
Vous pouvez vérifier l'implémentation complète de l'API, contenant les autres verbes HTTP pour les produits, en consultant le dépôt Github :
evgomes/supermarket-api
_API RESTful simple construite avec ASP.NET Core 2.2 pour montrer comment créer des services RESTful en utilisant une architecture découplée et maintenable…_github.com
Conclusion
ASP.NET Core est un excellent framework à utiliser lors de la création d'applications web. Il est livré avec de nombreuses API utiles que vous pouvez utiliser pour créer des applications propres et maintenables. Considérez-le comme une option lors de la création d'applications professionnelles.
Cet article n'a pas couvert tous les aspects d'une API professionnelle, mais vous avez appris toutes les bases. Vous avez également appris de nombreux patterns utiles pour résoudre les problèmes auxquels nous sommes confrontés quotidiennement.
J'espère que vous avez apprécié cet article et qu'il vous a été utile. J'apprécie vos commentaires pour comprendre comment je peux l'améliorer.