


Article original : Rust Tutorial – Learn Multi-Scale Processing of Astronomical Images
Récemment, un effort massif a été consacré au développement de nouvelles techniques de traitement d'image. Et beaucoup d'entre elles sont dérivées de méthodes de traitement de signal numérique telles que les transformées de Fourier et les transformées en ondelettes.
Ces techniques ont non seulement permis une large gamme de techniques de traitement d'image telles que la réduction de bruit, le renforcement de la netteté et l'extension de la plage dynamique, mais ont également permis de nombreuses techniques utilisées en vision par ordinateur telles que la détection de contours, la détection d'objets, et ainsi de suite.
L'analyse multi-échelle est l'une des techniques les plus récentes (relativement parlant) qui a été adoptée dans une large gamme d'applications, en particulier dans les applications de traitement d'image et de données astronomiques. Cette technique, qui est basée sur la transformée en ondelettes, nous permet de diviser nos données en plusieurs signaux, qui s'additionnent tous pour former le signal final.
Nous pouvons ensuite effectuer notre travail de traitement ou d'analyse sur ces sous-signaux individuels, ce qui nous permet de faire des opérations ciblées qui n'affectent pas les autres sous-signaux.
Dans ce tutoriel, nous allons d'abord explorer en quoi consiste cette technique, à travers le prisme d'un algorithme particulier pour effectuer une analyse multi-échelle sur des images. Nous passerons ensuite à la manière dont nous pouvons implémenter ce que nous avons discuté dans la première partie dans le langage de programmation Rust et recréer les exemples que vous voyez dans la première moitié de l'article.
Avant de lire :
Prérequis pour la partie 1 :
La technique décrite est dérivée du concept des "Transformées en Ondelettes". Vous n'avez pas besoin de tout savoir à ce sujet, mais une compréhension très basique vous aidera à mieux saisir le matériel.
Puisque l'article se concentre sur le traitement et l'analyse d'images, une compréhension basique du fonctionnement des pixels en format numérique est utile, mais pas obligatoire.
Prérequis pour la partie 2 :
Ici, nous nous concentrons sur l'implémentation de l'algorithme en utilisant le langage de programmation Rust, sans entrer dans les détails du langage lui-même. Être à l'aise avec l'écriture de programmes Rust et la lecture de documentations de crates est donc requis.
Si ce n'est pas votre cas, vous pouvez toujours lire la partie 1 et apprendre la technique, puis peut-être voudrez-vous l'essayer dans un langage de votre choix. Si vous n'êtes pas familier avec Rust, je vous encourage fortement à apprendre les bases. Voici un cours interactif sur Rust qui peut vous aider à commencer.
Table des matières
- Partie 1 : Comprendre la technique et l'algorithme de traitement multi-échelle
- Partie 2 : Comment implémenter la transformée À Trous en Rust
- Conclusion
Partie 1 : Comprendre la technique et l'algorithme de traitement multi-échelle
Alors, que voulons-nous dire lorsque nous parlons de traitement ou d'analyse multi-échelle de certaines données ? Eh bien, nous voulons généralement dire décomposer les données d'entrée en plusieurs signaux, chacun représentant une échelle particulière d'information.
L'échelle, lorsqu'on parle d'analyse d'image, fait simplement référence à la taille des structures que nous examinons à un moment donné. Elle ignore tout le reste qui est soit plus petit, soit plus grand que l'échelle actuelle.
Qu'est-ce que le traitement d'image multi-échelle ?
Pour les images, les "échelles" font généralement référence à la taille en pixels de diverses structures ou détails dans l'image. Vous pourrez obtenir une compréhension intuitive en regardant l'exemple suivant :
 Messier 33, alias la galaxie du Triangle
Messier 33, alias la galaxie du Triangle
En supposant que notre compréhension naïve est correcte, nous pouvons dériver des images d'au moins les 3 échelles suivantes :
- Structures très petites, généralement de la taille d'un seul pixel. Cette couche, lorsqu'elle est séparée du reste de l'image, ne contiendra que le bruit et quelques étoiles nettes pour la plupart.
- Structures petites, généralement de quelques pixels de taille. Cette couche, lorsqu'elle est séparée, contiendra toutes les étoiles et les très fins détails dans les bras de la galaxie.
- Structures de grande et très grande échelle, généralement de 100 pixels de taille. Cette couche, lorsqu'elle est séparée, contiendra la taille et la forme générale de la galaxie au centre.
La question devient maintenant, pourquoi devons-nous faire tout cela en premier lieu ?
La réponse est simple : cela nous permet d'apporter des améliorations et des changements ciblés à une image.
Par exemple, la réduction de bruit sur l'image globale entraînera généralement une perte de netteté dans la galaxie. Mais puisque nous avons décomposé notre image en plusieurs échelles, nous pouvons facilement appliquer la réduction de bruit uniquement aux premières couches, car la plupart du bruit aléatoire qui est facile à éliminer ne réside que dans les couches de basse échelle.
Nous recombinons ensuite les couches de basse échelle avec réduction de bruit avec les couches de grande échelle non modifiées, et nous obtenons une sortie qui nous donne une réduction de bruit sans perte de qualité.
Une autre chose particulière à propos du bruit est qu'il est presque toujours présent dans une seule de ces couches, rendant le processus de réduction de bruit à la fois facile et non destructif.
Si vous êtes plus un apprenant visuel, voyons cela en pratique en utilisant l'image que nous avons utilisée ci-dessus. Nous allons travailler avec la version en niveaux de gris suivante de cette image, où j'ai également ajouté du bruit gaussien aléatoire :
 Messier 33 alias la galaxie du Triangle, convertie en niveaux de gris et avec ajout de bruit gaussien
Messier 33 alias la galaxie du Triangle, convertie en niveaux de gris et avec ajout de bruit gaussien
En effectuant une séparation de couches basée sur l'échelle sur cette image, nous obtenons les résultats suivants. Notez que les résultats sont redimensionnés à une plage où ils peuvent être vus comme une image à des fins de représentation. La transformée réelle produit des valeurs de pixels qui n'ont pas de sens lorsqu'elles sont regardées indépendamment, mais toutes les techniques et calculs décrits dans ce tutoriel peuvent encore être appliqués en toute sécurité sans redimensionnement. Le processus de recomposition nous donne automatiquement la plage correcte :
 Décomposition À Trous à 9 niveaux. De haut en bas et de gauche à droite, nous avons des images aux échelles de pixels suivantes : 1, 2, 4, 8, 16, 32, 64, 128, 256 (puissances de 2)
Décomposition À Trous à 9 niveaux. De haut en bas et de gauche à droite, nous avons des images aux échelles de pixels suivantes : 1, 2, 4, 8, 16, 32, 64, 128, 256 (puissances de 2)
- Les première et deuxième couches contiennent le bruit et les étoiles. Dans cet exemple particulier, le bruit est mélangé avec les étoiles. Mais en utilisant les première et deuxième couches, nous pouvons facilement cibler les zones qui ne sont pas présentes dans la deuxième couche, car nous pouvons être sûrs que ce sont là que le bruit est présent dans la première couche.
- Avec la troisième couche, nous voyons toujours la luminance résiduelle des étoiles. Mais si vous regardez de près, nous voyons aussi très faiblement les bras de la galaxie commencer à apparaître.
- À partir de la quatrième couche, nous voyons la galaxie à différentes échelles et niveaux de détail, complètement sans les étoiles. Nous commençons par les détails les plus fins (détails à échelle relativement petite) et passons progressivement à des échantillons de plus en plus grandes échelles. À la fin, nous ne voyons qu'une forme vague là où se trouvait la galaxie.
À partir de là, nous pouvons appliquer sélectivement la réduction de bruit aux deux premières couches. Ensuite, nous pouvons recombiner toutes les couches pour créer l'image suivante qui a très peu de bruit tout en préservant la même quantité de détails dans les étoiles et les bras de la galaxie :
 Messier 33 alias la galaxie du Triangle, résultat de la recombinaison de toutes les couches mais avec réduction de bruit appliquée aux couches d'échelle de pixels 1 & 2
Messier 33 alias la galaxie du Triangle, résultat de la recombinaison de toutes les couches mais avec réduction de bruit appliquée aux couches d'échelle de pixels 1 & 2
Dans sa forme la plus basique, l'analyse multi-échelle implique de diviser votre image source, communément appelée "signal", en plusieurs "signaux" – chacun contenant les données pour une échelle particulière dans le signal source.
L'échelle, lorsqu'on parle de signal d'image ici, fait référence à la distance entre les pixels adjacents que nous prenons lors de la création de la couche à partir de l'image source.
En pratique, cette technique est utilisée comme l'une des premières étapes dans tous les types d'analyse de données astronomiques et de traitement d'image.
Par exemple, vous pouvez utiliser la technique pour détecter les emplacements des étoiles tout en ignorant les structures plus grandes beaucoup plus facilement que ce ne serait possible autrement.
La transformée en ondelettes À Trous
Tout ce que je vous ai montré précédemment, et tout ce que vous allez voir dans ce tutoriel, a été réalisé avec une décomposition et une recomposition en ondelettes en utilisant l'algorithme à trous pour les transformées en ondelettes discrètes.
Cet algorithme a été utilisé au fil des ans pour diverses applications. Mais il est devenu particulièrement important récemment dans les applications de traitement d'image astronomique, où différents objets et signaux dans une image peuvent être complètement séparés en fonction des échelles structurelles.
Voici comment fonctionne l'algorithme :
- Nous commençons avec l'image source d'entrée et le nombre de niveaux à décomposer en n.
- Pour chaque niveau n :
- Nous convoluons l'image avec notre fonction d'échelle (nous verrons ce que c'est dans un instant), où les pixels adjacents sont considérés comme étant à 2n unités de distance l'un de l'autre, ce qui nous donne le résultat resultn. C'est de là que vient le nom "À Trous", qui se traduit littéralement par "avec trous".
- La sortie de la couche outputn est ensuite calculée en utilisant input - resultn.
- Nous mettons ensuite à jour input pour qu'il soit égal à resultn. Cela est également connu sous le nom de données résiduelles qui servent de données source pour la couche suivante.
- Répétez les étapes ci-dessus pour tous les niveaux.
- À la fin, nous avons 9 couches d'ondelettes et 1 couche résiduelle. Les 10 couches sont nécessaires pour la recomposition.
Pour une approche plus mathématique de la compréhension de cet algorithme, je vous encourage à lire sur l'algorithme à trous ici.
Le processus de recomposition est très simple : nous devons simplement additionner toutes les 10 couches ensemble. Nous pouvons choisir d'appliquer un biais positif ou négatif à n'importe quelle couche, qui est un facteur par lequel multiplier les valeurs des pixels de la couche lors de la recomposition. Vous pouvez l'utiliser soit pour améliorer, soit pour diminuer les caractéristiques de cette couche particulière.
Fonctions d'échelle
Les fonctions d'échelle sont des noyaux de convolution spécifiques qui nous aident à mieux représenter les données à une échelle particulière en fonction de notre cas d'utilisation. Il existe 3 fonctions d'échelle les plus couramment utilisées, qui sont présentées ci-dessous :



Les images ci-dessus montrent les 3 fonctions d'échelle les plus couramment utilisées dans l'algorithme À Trous, visualisées en utilisant une décomposition de niveau 3 de l'image de la galaxie du Triangle utilisée précédemment :
- B3 Spline est un noyau très lisse. Il est principalement utilisé pour l'isolation des structures à grande échelle. Si nous voulions accentuer notre galaxie, nous aurions utilisé ce noyau.
- Low-scale est un noyau très pointu, et est le meilleur pour travailler avec des structures à petite échelle.
- Le noyau d'interpolation linéaire nous donne le meilleur des deux mondes, et est donc utilisé lorsque nous devons travailler avec des structures à petite et grande échelle. C'est ce que nous avons utilisé dans tous nos exemples précédents.
Convolution des pixels à chaque échelle
J'ai mentionné dans l'algorithme qu'à chaque échelle, les pixels de l'image sont considérés comme étant à 2n unités de distance. Essayons de mieux comprendre cela en utilisant la visualisation suivante :
Considérons l'image suivante de 8px par 8px. Chaque pixel est étiqueté de 1 à 64, ce qui est leur index.
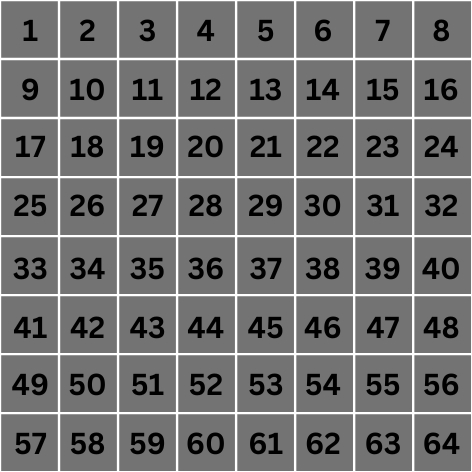 Une grille de pixels représentative d'une image de 8x8px
Une grille de pixels représentative d'une image de 8x8px
Nous allons nous concentrer sur une opération de convolution d'un des pixels du centre uniquement pour cet exemple, disons le pixel numéro 28.
Échelle 0 : À l'échelle 0, la valeur de 2n devient 1. Cela signifie que pour la convolution, nous considérerons les pixels qui sont à 1 unité de distance de notre pixel central cible. Ces pixels sont mis en évidence ci-dessous :
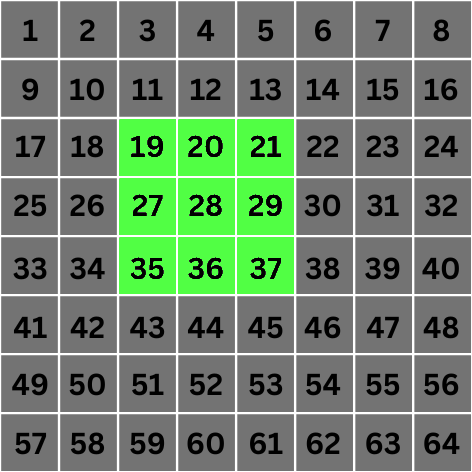 Grille de 8x8px avec les pixels impliqués dans la convolution pour le pixel numéro 28 mis en évidence à l'échelle 0
Grille de 8x8px avec les pixels impliqués dans la convolution pour le pixel numéro 28 mis en évidence à l'échelle 0
Échelle 1 : C'est là que les choses deviennent intéressantes. À l'échelle 1, la valeur de 2n devient 2. Cela signifie que pour la convolution, nous sauterons directement aux pixels qui sont à 2 emplacements de distance du pixel cible :
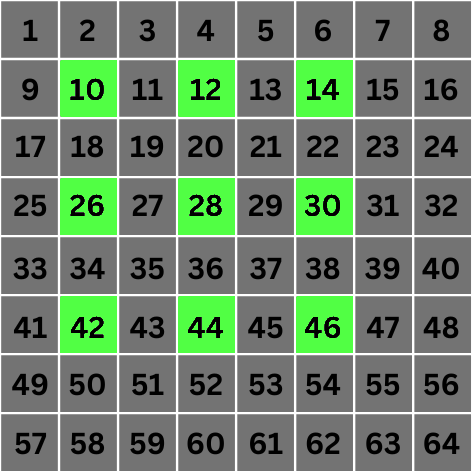 Grille de 8x8px avec les pixels impliqués dans la convolution pour le pixel numéro 28 mis en évidence à l'échelle 1
Grille de 8x8px avec les pixels impliqués dans la convolution pour le pixel numéro 28 mis en évidence à l'échelle 1
Comme vous pouvez le voir, nous avons créé des "trous" dans notre calcul de la valeur du pixel cible en sautant 2n - 1 pixels adjacents et en sélectionnant le 2nème pixel. C'est la base de l'algorithme.
Ce processus est répété pour chaque pixel de l'image, tout comme un processus de convolution régulier. Et chaque fois, nous considérons des distances croissantes entre les pixels pour le calcul des valeurs finales à des échelles croissantes.
Regardons juste une échelle de plus.
Échelle 2 : C'est là que les choses deviennent encore plus intéressantes. À l'échelle 2, la valeur de 2n devient 4. Cela signifie que pour la convolution, nous sauterons directement aux pixels qui sont à 4 emplacements de distance du pixel cible :
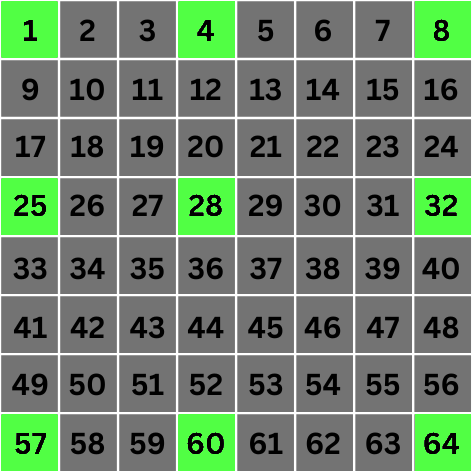 Grille de 8x8px avec les pixels impliqués dans la convolution pour le pixel numéro 28 mis en évidence à l'échelle 2
Grille de 8x8px avec les pixels impliqués dans la convolution pour le pixel numéro 28 mis en évidence à l'échelle 2
Attendez, quoi ? Pourquoi choisissons-nous les pixels 1, 4, 8, 25, & 57 ? 1 & 4 sont seulement à 3 emplacements de distance, 25 est seulement à 2 emplacements de distance, et 8 & 57 ne sont même pas alignés diagonalement avec le pixel cible. Que se passe-t-il ?
Gestion des conditions aux limites
Comme nous l'avons mentionné, ce processus est exécuté pour tous les pixels d'une image, nous devons également considérer les cas où les emplacements des pixels pour la convolution se trouvent en dehors de l'image.
Ce n'est pas un concept unique à cet algorithme. Pendant la convolution, cela est appelé une condition aux limites ou la gestion des pixels aux limites. Il existe diverses techniques pour traiter cela, et toutes impliquent d'étendre virtuellement l'image afin de donner l'impression que nous ne rencontrons pas la limite.
Certaines des techniques sont :
- Étendre autant que nécessaire en copiant la valeur de la dernière ligne/colonne
- Miroiter l'image sur tous les bords et coins
- Envelopper l'image autour des bords.
Dans notre exemple, nous employons la technique de "miroitage". Lors de l'implémentation d'un tel algorithme, nous n'avons pas besoin de créer réellement une image étendue. Toute gestion des limites est implémentable en utilisant uniquement des formules mathématiques de base.
Notre image étendue, avec les pixels corrects sélectionnés pour l'échelle 2, est la suivante :
 Image source étendue sur tous les bords et coins en utilisant la technique de miroitage. Toutes les régions estompées représentent les zones étendues.
Image source étendue sur tous les bords et coins en utilisant la technique de miroitage. Toutes les régions estompées représentent les zones étendues.
Encore une fois, l'extension est uniquement logique et est entièrement calculée à l'aide de formules, plutôt que d'étendre réellement l'image source puis de vérifier. Nous pouvons facilement voir qu'avec les images miroitées en place, notre règle de base de sélection des pixels qui sont à 2n emplacements de distance est toujours suivie.
Calcul du nombre maximum d'échelles possibles pour toute image donnée
Si vous y réfléchissez attentivement, vous verrez que le nombre maximum de couches dans lesquelles une image peut être décomposée peut être calculé en calculant le log2 de la largeur ou de la hauteur de l'image (selon la plus petite) et en supprimant la partie fractionnaire.
Dans notre image de 5x5, log2(5) ~= 2,32. Si nous supprimons la partie fractionnaire, il nous reste 2 couches. De même, pour une image de 1000x1000px, log21000 ~= 9,96, ce qui signifie que nous pouvons décomposer une image de 1000x1000 px en un maximum de 9 couches. Cela implique simplement que nos "trous" ne peuvent pas être plus grands que la largeur ou la hauteur.
Même avec l'extension de miroitage que nous avons utilisée ci-dessus, si les trous sont plus grands que la largeur de l'image, ils finiront toujours en dehors des régions étendues, surtout pour les pixels de coin ou de bordure, rendant impossible la convolution à cette échelle.
Notes de clôture
En réfléchissant un peu plus aux exemples et aux visualisations, vous pouvez clairement voir comment et pourquoi cet algorithme fonctionne, et comment il est capable de séparer les structures dans une image en fonction de leurs tailles. Les tailles de trous croissantes font en sorte que seules les structures plus grandes que le trou lui-même sont conservées pour toute couche donnée.
Un grand avantage de l'utilisation de cet algorithme est le coût de calcul. Puisque cela n'implique pas de transformées de Fourier ou d'ondelettes, le coût de calcul est assez faible, relativement parlant. Le coût en mémoire, cependant, est effectivement plus élevé. Mais le plus souvent, c'est un bon compromis.
Un autre avantage de cet algorithme, lorsqu'on le compare à d'autres algorithmes de transformée en ondelettes discrètes, est que la taille de l'image source est préservée tout au long du processus. Il n'y a pas de décimation ou de mise à l'échelle ici, ce qui fait de cet algorithme l'un des plus faciles à comprendre et à implémenter.
L'algorithme est utilisé dans presque tous les logiciels de traitement d'image astronomique tels que PixInsight, Siril, et bien d'autres.
Cet algorithme est également connu sous d'autres noms tels que Transformée en Ondelettes Stationnaires et Transformée Starlet.
Partie 2 : Comment implémenter la transformée À Trous en Rust
Maintenant, je vais vous montrer comment vous pouvez implémenter cet algorithme en Rust.
Pour les besoins de ce tutoriel, je vais supposer que vous êtes assez familier avec Rust et ses concepts de base, tels que les types de données, les itérateurs, et les traits, et que vous êtes à l'aise avec l'écriture de programmes qui utilisent ces concepts.
Je vais également supposer que vous comprenez ce que signifient la convolution et les noyaux de convolution dans ce contexte.
Prérequis
Nous allons avoir besoin de quelques dépendances. Avant d'en arriver là, créons rapidement un nouveau projet :
cargo new --lib atrous-rs
cd atrous-rs
Maintenant, ajoutons toutes les dépendances dont nous avons besoin. En fait, nous n'en avons besoin que de 2 :
cargo add image ndarray
image est une bibliothèque Rust que nous utiliserons pour travailler avec des images de tous les formats et encodages standard. Elle nous aide également à convertir entre divers formats et fournit un accès facile aux données de pixels sous forme de tampons.
ndarray est une bibliothèque Rust qui vous aide à créer, manipuler et travailler avec des tableaux 2D, 3D ou N-dimensionnels. Nous pourrions utiliser des Vectors imbriqués, mais utiliser un projet comme ndarray est meilleur dans ce cas car nous devons effectuer beaucoup d'opérations sur les valeurs individuelles ainsi que sur leurs voisins. Non seulement c'est beaucoup plus facile à faire avec ndarray, mais ils ont également des optimisations de performance intégrées pour de nombreuses opérations et types de CPU.
Bien que je vais couvrir les fonctions/traits/méthodes/types de données de base que nous utilisons à partir de ces crates, je ne vais pas entrer dans trop de détails pour eux. Je vous encourage à lire la documentation à la place.
Nous allons en fait passer directement à l'implémentation de l'algorithme, et revenir plus tard pour voir comment nous pouvons l'utiliser.
La transformée À Trous
Créez un nouveau fichier qui contiendra notre implémentation. Nommons-le transform.rs.
Commencez par ajouter la structure suivante, qui contiendra les informations dont nous avons besoin pour effectuer la transformation :
// transform.rs
use ndarray::Array2;
pub struct ATrousTransform {
input: Array2<f32>, // `Array2<f32>` est un tableau 2D où chaque valeur est de type `f32`. Cela contiendra nos données de pixels pour l'image d'entrée.
levels: usize, // Le nombre de niveaux ou d'échelles pour décomposer l'image
current_level: usize, // Niveau actuel que nous devons générer. Cela contient l'état de notre itérateur.
width: usize, // Largeur de l'image d'entrée
height: usize, // Hauteur de l'image d'entrée
}
Nous avons également besoin d'un moyen de créer cette structure facilement. Dans notre cas, nous voulons pouvoir la créer directement à partir de l'image d'entrée. De plus, l'image d'entrée peut être dans l'un des formats et encodages supportés, mais nous voulons un type de couleur cohérent pour implémenter les calculs, donc nous aurons également besoin de convertir l'image dans notre format attendu.
Il est utile d'extraire toute cette logique en utilisant le motif "constructeur" en Rust. Implémentons cela :
// transform.rs
use image::GenericImageView;
impl ATrousTransform {
pub fn new(input: &image::DynamicImage, levels: usize) -> Self {
let (width, height) = input.dimensions();
let (width, height) = (width as usize, height as usize);
// Crée un nouveau tableau 2D avec une taille appropriée pour chaque dimension pour contenir toutes les données de pixels de notre entrée. La méthode `zeros` prend un paramètre "shape", qui est un tuple de (rows_count, columns_count).
let mut data = Array2::<f32>::zeros((height, width));
// Convertit l'image en une image en niveaux de gris où chaque valeur de pixel est de type `f32`. Boucle sur tous les pixels de l'image d'entrée ainsi que leur emplacement 2D.
for (x, y, pixel) in input.to_luma32f().enumerate_pixels() {
// Place la valeur du pixel à l'emplacement approprié dans notre tableau de données. La syntaxe `[[]]` est utilisée pour fournir un index bidimensionnel tel que `[[row_index, col_index]]`
data[[y as usize, x as usize]] = pixel.0[0];
}
Self {
input: data,
levels,
current_level: 0,
width,
height
}
}
}
Cela prend en charge la conversion de l'image en niveaux de gris et la conversion des valeurs de pixels en f32. Si vous n'êtes pas déjà au courant, pour les images avec des valeurs de pixels en virgule flottante, les valeurs sont toujours normalisées. Cela signifie qu'elles sont toujours comprises entre 0 et 1 – 0 représentant le noir et 1 représentant le blanc.
Itérateurs et la transformée À Trous
Avant de continuer, réfléchissons à l'algorithme pendant une seconde. Nous devons être capables de générer des images à des échelles croissantes, jusqu'à ce que nous atteignions le nombre maximum de niveaux dont nous avons besoin.
Nous voulons que le consommateur de notre bibliothèque ait accès à toutes ces échelles, et puisse les manipuler et aussi les recombiner facilement une fois qu'il a terminé. Ils doivent être capables de filtrer les couches pour ignorer les structures à certaines échelles, les manipuler ou les "mapper" pour changer leurs caractéristiques, effectuer des opérations sur elles, ou même stocker chaque image si nécessaire.
Cela ressemble beaucoup aux itérateurs ! Les itérateurs nous donnent des méthodes comme filter, skip, take, map, for_each, et ainsi de suite, qui sont exactement tout ce dont nous avons besoin pour travailler avec nos couches avant la recomposition.
Un avantage supplémentaire des itérateurs est qu'ils vous permettent de terminer le traitement de chaque couche avant de passer à la suivante. Si vous n'êtes pas sûr de pourquoi c'est le cas, je vous suggère de lire davantage sur le traitement d'une série d'éléments avec des itérateurs en Rust.
Nous allons implémenter le trait Iterator pour notre type ATrousTransform qui devrait produire une couche d'ondelettes comme sortie pour chaque itération.
Nous allons implémenter les parties les plus internes de l'algorithme en premier, puis construire à partir de là. Nous avons donc d'abord besoin d'un moyen de convoluer un tampon de données d'entrée avec la fonction d'échelle tout en veillant à ce que les pixels adjacents soient à 2n emplacements de distance, ce qui est la première étape de notre boucle.
Convolution
Nous devons définir notre noyau de convolution avant de pouvoir faire autre chose. Créez un nouveau fichier kernel.rs et ajoutez-le à lib.rs avec le contenu suivant :
// kernel.rs
#[derive(Copy, Clone)]
pub struct LinearInterpolationKernel {
values: [[f32; 3]; 3]
}
impl Default for LinearInterpolationKernel {
fn default() -> Self {
Self {
values: [
[1. / 16., 1. / 8., 1. / 16.],
[1. / 8., 1. / 4., 1. / 8.],
[1. / 16., 1. / 8., 1. / 16.],
]
}
}
}
Nous le définissons en utilisant une structure au lieu d'un tableau constant de tableaux car nous devons définir quelques petites méthodes utiles sur celui-ci liées à la gestion des index. Nous y reviendrons plus tard.
Créez un autre fichier convolve.rs. C'est là que tout le code pour gérer la convolution des pixels individuels ira. Nous allons définir un trait Convolution qui définira les méthodes nécessaires pour effectuer la convolution sur chaque pixel de la couche actuelle.
// convolve.rs
pub trait Convolution {
fn compute_pixel_index(
&self,
distance: usize,
kernel_index: [isize; 2],
target_pixel_index: [usize; 2]
) -> [usize; 2];
fn compute_convoluted_pixel(
&self,
distance: usize,
index: [usize; 2]
) -> f32;
}
Vous pourriez demander pourquoi nous avons besoin d'un trait ici au lieu d'un simple bloc impl. Nous travaillons uniquement avec des images en niveaux de gris dans cet article, mais vous pourriez vouloir l'étendre pour l'implémenter pour le RGB ou d'autres modes de couleur également.
Maintenant, vous devez implémenter ce trait pour votre structure ATrousTransform :
// convolve.rs
impl Convolution for ATrousTransform {
fn compute_pixel_index(
&self,
distance: usize,
kernel_index: [isize; 2],
target_pixel_index: [usize; 2]
) -> [usize; 2] {
let [kernel_index_x, kernel_index_y] = kernel_index;
// Calcule la distance réelle du pixel adjacent
// en multipliant leur position relative par
// la taille du trou.
let x_distance = kernel_index_x * distance as isize;
let y_distance = kernel_index_y * distance as isize;
let [x, y] = target_pixel_index;
// Calcule l'index du pixel adjacent dans l'image 2D
// en fonction de l'index du pixel actuel.
let mut x = x as isize + x_distance;
let mut y = y as isize + y_distance;
// Si l'index x est hors limites, considère x comme
// l'emplacement de la limite la plus proche
if x < 0 {
x = 0;
} else if x > self.width as isize - 1 {
x = self.width as isize - 1;
}
// Si l'index y est hors limites, considère y comme
// l'emplacement de la limite la plus proche
if y < 0 {
y = 0;
} else if y > self.height as isize - 1 {
y = self.height as isize - 1;
}
// L'index 2D final du pixel.
[y as usize, x as usize]
}
fn compute_convoluted_pixel(
&self,
distance: usize,
[x, y]: [usize; 2]
) -> f32 {
// Crée une nouvelle variable pour contenir le résultat de la convolution
// pour le pixel actuel.
let mut pixels_sum = 0.0;
let kernel = LinearInterpolationKernel::default();
// Itère sur la position relative des pixels par rapport au pixel central
// pour effectuer la convolution avec. En d'autres termes,
// ce sont les index des pixels voisins par rapport au
// pixel central.
for kernel_index_x in -1..=1 {
for kernel_index_y in -1..=1 {
// Obtient l'emplacement du pixel calculé qui correspond à
// la position actuelle dans le noyau
let pixel_index = self.compute_pixel_index(
distance,
[kernel_index_x, kernel_index_y],
[x, y]
);
// Obtient le facteur multiplicatif (valeur du noyau) pour
// cet emplacement relatif à partir du noyau.
let kernel_value = kernel.value_from_relative_index(
kernel_index_x,
kernel_index_y
);
// Multiplie la valeur du pixel par le facteur d'échelle du noyau
// et l'ajoute à la somme des pixels.
pixels_sum += kernel_value * self.input[pixel_index];
}
}
// Retourne la valeur du pixel calculé à partir du processus de convolution.
pixels_sum
}
}
Nous devons effectuer des calculs pour déterminer l'emplacement de chaque pixel en fonction de la position relative dans le noyau par rapport au pixel central, ainsi que pour nous assurer que la "taille du trou" est également prise en compte pour l'index final du pixel. Comme vous l'aurez peut-être remarqué, vous souhaitez également gérer les conditions aux limites lors du calcul des index.
Je vous encourage à prendre votre temps ici et à parcourir le code et les commentaires.
Implémentation de l'itérateur
Il est enfin temps d'implémenter le trait Iterator pour votre ATrousTransform :
// transform.rs
impl Iterator for ATrousTransform {
// Notre sortie est une image ainsi que le niveau actuel pour chaque
// itération. Le niveau actuel est un `Option` pour représenter
// la couche résiduelle finale après que les couches intermédiaires ont été
// générées.
type Item = (Array2::<f32>, Option<usize>);
fn next(&mut self) -> Option<Self::Item> {
let pixel_scale = self.current_level;
self.current_level += 1;
// Nous avons déjà généré toutes les couches. Retourne None pour
// sortir de l'itérateur.
if pixel_scale > self.levels {
return None;
}
// Nous avons généré toutes les couches intermédiaires, retourne la
// couche résiduelle.
if pixel_scale == self.levels {
return Some((self.input.clone(), None))
}
let (width, height) = (self.width, self.height);
// Distance entre les pixels adjacents pour la convolution (également
// appelée taille du "trou").
let distance = 2_usize.pow(pixel_scale as u32);
// Crée un nouveau tampon pour contenir les données calculées pour cette couche.
let mut current_data = Array2::<f32>::zeros((height, width));
// Itère sur chaque emplacement de pixel dans l'image 2D
for x in 0..width {
for y in 0..height {
// Définit le pixel actuel dans la couche actuelle à
// le résultat de la convolution sur le pixel actuel
// dans les données d'entrée.
current_data[[y, x]] = self.compute_convoluted_pixel(
distance,
[x, y]
);
}
}
// Crée la couche actuelle en soustrayant les pixels actuellement calculés
// de la couche précédente
let final_data = self.input.clone() - ¤t_data;
// Définit la couche d'entrée pour qu'elle soit égale à la couche actuellement calculée
// afin qu'elle puisse être utilisée comme la "couche précédente" dans la prochaine itération.
// Cela représente également nos données résiduelles pour chaque couche.
self.input = current_data;
// Retourne les données de la couche actuelle ainsi que les informations sur le niveau actuel.
Some((final_data, Some(self.current_level)))
}
}
Je vais souligner qu'il y a beaucoup de potentiel pour optimiser les performances ici, mais cela dépasse le cadre de cet article.
Nous allons enfin voir comment nous pouvons prendre toutes ces couches et reconstruire notre image d'entrée.
Recomposition
Comme je l'ai dit précédemment, reconstruire une image qui a été décomposée avec la transformée À Trous est aussi simple que de faire la somme de toutes les couches ensemble.
Nous allons définir un trait pour cela. Pourquoi nous avons besoin d'un trait ici devrait être clair une fois que vous regardez l'implémentation.
Créez un nouveau fichier recompose.rs avec le contenu suivant :
// recompose.rs
use image::{DynamicImage, ImageBuffer, Luma};
use ndarray::Array2;
pub trait RecomposableLayers: Iterator<Item = (Array2<f32>, Option<usize>)> {
fn recompose_into_image(
self,
width: usize,
height: usize,
) -> DynamicImage
where
Self: Sized,
{
// Crée un tampon de résultat pour contenir les données de pixels de notre image de sortie.
let mut result = Array2::<f32>::zeros((height, width));
// Pour chaque couche, ajoute les données de la couche à la valeur actuelle du tampon de résultat.
for layer in self {
result += &layer.0;
}
// Calcule les valeurs minimales et maximales d'intensité des pixels dans les données finales afin que
// nous puissions effectuer un "redimensionnement", qui normalise toutes les valeurs de pixels pour qu'elles soient
// comprises entre 0 et 1, comme cela est attendu pour les images en virgule flottante 32.
let min_pixel = result.iter().copied().reduce(f32::min).unwrap();
let max_pixel = result.iter().copied().reduce(f32::max).unwrap();
// Crée un nouveau `ImageBuffer`, qui est un type fourni par la crate `image` pour
// servir de tampon pour les données de pixels d'une image. Ici, nous créons un nouveau
// `Luma` ImageBuffer avec une valeur de pixel de type `u16`. Luma fait simplement référence
// aux niveaux de gris.
let mut result_img: ImageBuffer<Luma<u16>, Vec<u16>> =
ImageBuffer::new(width as u32, height as u32);
// Précalcule le dénominateur pour le calcul de mise à l'échelle afin que nous ne
// répétions pas cela inutilement pour chaque itération.
let rescale_ratio = max_pixel - min_pixel;
// Itère sur tous les pixels dans le `ImageBuffer` et le remplit en fonction des données
// du tampon `result` après avoir redimensionné la valeur.
for (x, y, pixel) in result_img.enumerate_pixels_mut() {
let intensity = result[(y as usize, x as usize)];
*pixel =
Luma([((intensity - min_pixel) / rescale_ratio * u16::MAX as f32) as u16]);
}
// Convertit le `ImageBuffer` en `DynamicImage` et le retourne
DynamicImage::ImageLuma16(result_img)
}
}
// Implémente ce trait pour tout ce qui implémente le trait Iterator
// avec le type d'élément donné
impl<T> RecomposableLayers for T where T: Iterator<Item = (Array2<f32>, Option<usize>)> {}
Si vous ne l'avez pas remarqué, puisque nous implémentons ce trait pour un générique, cela fonctionnera avec n'importe quel itérateur, tel que Filter, Map, et ainsi de suite. Si vous n'aviez pas utilisé un trait ici, vous auriez dû implémenter la même chose encore et encore pour chaque type d'itérateur intégré, et votre code n'aurait pas fonctionné avec des types tiers.
Utilisation de la transformée À Trous
Après tout cela, il est enfin temps de reproduire le traitement que je vous ai montré pour l'image de la galaxie avec beaucoup de bruit. Créez un nouveau fichier main.rs avec le contenu suivant :
use image::{DynamicImage, ImageBuffer, Luma};
use atrous::recompose::RecomposableLayers;
use atrous::transform::ATrousTransform;
fn main() {
// Ouvre notre image bruyante
let image = image::open("m33-noise-lum.jpg").unwrap();
// Crée une nouvelle instance de la transformation avec 9 couches
let transform = ATrousTransform::new(&image, 9);
// Mappe sur chaque couche
transform.map(|(mut buffer, pixel_scale)| {
// Crée un nouveau tampon d'image pour contenir les données de pixels. Celui-ci
// sera peuplé à partir du tampon brut pour cette couche.
let mut new_buffer =
ImageBuffer::<Luma<u16>, Vec<u16>>::new(buffer.ncols() as u32, buffer.nrows() as u32);
// Itère sur tous les pixels du `ImageBuffer` pour le peupler. Nous
// convertissons également de `f32` pixels en `u16` pixels.
for (x, y, pixel) in new_buffer.enumerate_pixels_mut() {
*pixel = Luma([(buffer[[y as usize, x as usize]] * u16::MAX as f32) as u16])
}
// Si la couche actuelle est une couche de petite échelle (< 3),
// effectue une réduction de bruit
if pixel_scale.is_some_and(|scale| scale < 3) {
let mut image = DynamicImage::ImageLuma16(new_buffer).to_luma8();
// Le filtre bilatéral est un filtre de débroitage. Applique-le à l'image.
image = imageproc::filter::bilateral_filter(&image, 10, 10., 3.);
// Modifie le tampon brut pour contenir les valeurs de pixels mises à jour après
// le filtrage.
for (x, y, pixel) in image.enumerate_pixels() {
buffer[[y as usize, x as usize]] = pixel.0[0] as f32 / u8::MAX as f32;
}
// Retourne le tampon mis à jour.
(buffer, pixel_scale)
} else {
// Retourne le tampon non modifié pour les couches de plus grande échelle.
(buffer, pixel_scale)
}
})
// Appelle la méthode de recomposition sur l'itérateur
.recompose_into_image(image.width() as usize, image.height() as usize)
// Convertit la sortie en une image en niveaux de gris 8 bits
.to_luma8()
// Sauvegarde dans un fichier jpg
.save("noise-reduced.jpg")
.unwrap()
}
Vous devez également ajouter une nouvelle dépendance, imageproc, qui fournit des implémentations utiles de traitement d'image sur la base de la crate image.
cargo add imageproc
Pour que cela fonctionne, nous devons également modifier notre Cargo.toml pour définir explicitement les cibles binaires et de bibliothèque :
// Cargo.toml
[package]
name = "atrous-rs"
version = "0.1.0"
edition = "2021"
[[bin]]
name = "atrous"
path = "src/main.rs"
[lib]
name = "atrous"
path = "src/lib.rs"
# Voir plus de clés et leurs définitions à l'adresse https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
image = "0.25.1"
imageproc = "0.24.0"
ndarray = "0.15.6"
Vous pouvez télécharger l'image de test à partir d'ici. Déplacez-la dans le répertoire racine de votre projet, et exécutez cargo run --release. Une fois terminé, vous devriez avoir un nouveau fichier noise-reduced.jpg comme sortie de notre processus.
Et voilà.
Lectures complémentaires
Voici quelques-unes des ressources qui m'ont été très utiles lorsque j'apprenais cet algorithme et comment l'utiliser. Je vous encourage fortement à consulter ces ressources si vous souhaitez une compréhension plus technique de l'algorithme.
- L'algorithme à trous
- La transformée en ondelettes discrètes À Trous dans PixInsight
- Analyse d'images et de données astronomiques par Jean-Luc Starck et Fionn Murtagh
- Traitement d'images et de signaux parcimonieux : Ondelettes et analyse multirésolution géométrique associée par J.L. Starck, F. Murtagh, et J. Fadili
En outre, j'ai créé une bibliothèque Rust pour travailler avec la transformée À Trous. Elle correspond étroitement à ce que je vous ai montré ici, mais possède déjà certaines fonctionnalités supplémentaires, et en aura encore plus.
Des choses comme la gestion des images RGB et le travail avec les 3 noyaux différents sont déjà implémentées. Elle possède également une meilleure logique pour la gestion des conditions aux limites, où elle utilise la technique de pliage de l'image.
Je vais également bientôt travailler sur des améliorations de performance pour celle-ci.
Si vous souhaitez en savoir plus ou contribuer à la bibliothèque, n'hésitez pas à le faire. Le dépôt peut être trouvé ici : https://github.com/anshap1719/image-dwt
Conclusion
J'espère que vous avez apprécié le voyage jusqu'à présent. Si les techniques de traitement d'image ou leur implémentation en Rust sont quelque chose qui vous intéresse, alors restez à l'écoute pour plus d'articles, car ce sont les sujets que j'aime écrire.
De plus, n'hésitez pas à me contacter si vous avez des questions ou des opinions sur ce sujet.
Vous appréciez mon travail ?
Envisagez de m'offrir un café pour soutenir mon travail !
Jusqu'à la prochaine fois, bon codage et je vous souhaite un ciel dégagé !