

Article original : LangChain Tutorial – How to Build a Custom-Knowledge Chatbot
Par Shane Duggan
Vous avez peut-être lu au sujet du grand nombre d'applications d'IA qui ont été lancées au cours des derniers mois. Vous avez peut-être même commencé à en utiliser certaines.
Des outils d'IA tels que ChatPDF et CustomGPT AI sont devenus très utiles pour les gens – et pour de bonnes raisons. Les jours où vous deviez parcourir un document de 50 pages pour trouver une simple réponse sont révolus. À la place, vous pouvez compter sur l'IA pour faire le travail difficile.
Mais comment exactement tous ces développeurs créent-ils et utilisent-ils ces outils ? Eh bien, beaucoup d'entre eux utilisent un framework open source appelé LangChain.
Dans cet article, je vais vous présenter LangChain et vous montrer comment il est utilisé en combinaison avec l'API d'OpenAI pour créer ces outils révolutionnaires. J'espère inspirer l'un d'entre vous à en créer un vous-même. Alors, plongeons-nous dans le sujet !
Qu'est-ce que LangChain ?

LangChain est un framework open source qui permet aux développeurs d'IA de combiner des modèles de langage de grande taille (LLM) comme GPT-4 avec des données externes. Il est disponible en packages Python ou JavaScript (TypeScript).
Comme vous le savez peut-être, les modèles GPT ont été formés sur des données jusqu'en 2021, ce qui peut être une limitation significative. Et bien que les connaissances générales de ces modèles soient excellentes, pouvoir les connecter à des données et des calculs personnalisés ouvre de nombreuses portes. C'est exactement ce que fait LangChain.
Essentiellement, il permet à votre LLM de référencer des bases de données entières lorsqu'il génère ses réponses. Ainsi, vos modèles GPT peuvent maintenant accéder à des données à jour sous forme de rapports, de documents et d'informations de sites web.
Récemment, LangChain a connu une augmentation significative de popularité, surtout après le lancement de GPT-4 en mars. Cela est dû à sa polyvalence et aux nombreuses possibilités qu'il offre lorsqu'il est associé à un LLM puissant.
Comment fonctionne LangChain ?
Bien que vous puissiez penser que LangChain semble assez compliqué, il est en réalité assez accessible.
En bref, LangChain compose simplement de grandes quantités de données qui peuvent être facilement référencées par un LLM avec aussi peu de puissance de calcul que possible. Il fonctionne en prenant une grande source de données, par exemple un PDF de 50 pages, et en le décomposant en "morceaux" qui sont ensuite intégrés dans un Vector Store.
 Diagramme simple de la création d'un Vector Store
Diagramme simple de la création d'un Vector Store
Maintenant que nous avons des représentations vectorisées du grand document, nous pouvons utiliser cela en conjonction avec le LLM pour récupérer uniquement les informations dont nous avons besoin pour être référencées lors de la création d'une paire prompt-complétion.
Lorsque nous insérons un prompt dans notre nouveau chatbot, LangChain interrogera le Vector Store pour obtenir des informations pertinentes. Pensez-y comme un mini-Google pour votre document. Une fois les informations pertinentes récupérées, nous les utilisons en conjonction avec le prompt pour alimenter le LLM et générer notre réponse.
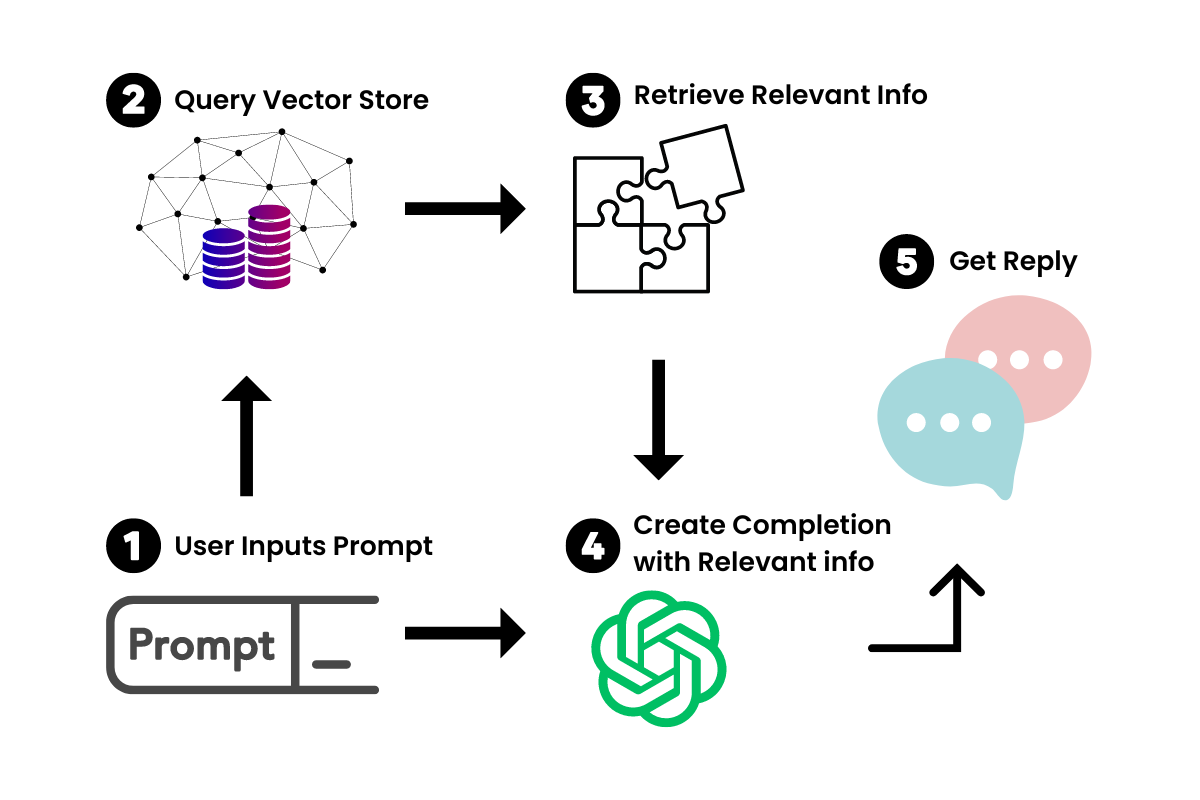 Comment LangChain fonctionne avec les LLM d'OpenAI
Comment LangChain fonctionne avec les LLM d'OpenAI
LangChain vous permet également de créer des applications qui peuvent effectuer des actions – telles que surfer sur le web, envoyer des e-mails et effectuer d'autres tâches liées aux API. Consultez AgentGPT, un excellent exemple de cela.
Il existe de nombreux cas d'utilisation possibles pour cela – en voici quelques-uns qui me viennent à l'esprit :
- Assistant IA personnel pour les e-mails
- Copain d'étude IA
- Analyse de données IA
- Chatbots de service client personnalisés pour les entreprises
- Assistant de création de contenu pour les réseaux sociaux
Et la liste continue. Je couvrirai des tutoriels de construction appropriés dans de futurs articles, alors restez à l'écoute pour cela.
Comment commencer avec LangChain
Une application LangChain se compose de 5 composants principaux :
- Modèles (LLM Wrappers)
- Prompts
- Chaines
- Embeddings et Vector Stores
- Agents
Je vais vous donner un aperçu de chacun, afin que vous puissiez avoir une compréhension de haut niveau de comment LangChain fonctionne. À l'avenir, vous devriez être en mesure d'appliquer les concepts pour commencer à créer vos propres cas d'utilisation et créer vos propres applications.
Je vais tout expliquer avec de courts extraits de code de Rabbitmetrics (Github). Il fournit d'excellents tutoriels sur ce sujet. Ces extraits devraient vous permettre de tout configurer et d'être prêt à utiliser LangChain.
Tout d'abord, configurons notre environnement. Vous pouvez installer 3 bibliothèques dont vous aurez besoin pour cela :
pip install -r requirements.txt
python-dotenv==1.0.0
langchain==0.0.137
pinecone-client==2.2.1
Pinecone est le Vector Store que nous allons utiliser en conjonction avec LangChain. Avec ceux-ci, assurez-vous de stocker vos clés API pour OpenAI, l'environnement Pinecone et l'API Pinecone dans votre fichier d'environnement. Vous pourrez trouver ces informations sur leurs sites web respectifs. Ensuite, nous chargeons simplement ce fichier d'environnement avec ce qui suit :
# Charger les variables d'environnement
from dotenv import load_dotenv,find_dotenv
load_dotenv(find_dotenv())
Maintenant, nous sommes prêts à commencer !
Modèles (LLM Wrappers)
Pour interagir avec nos LLM, nous allons instancier un wrapper pour les modèles GPT d'OpenAI. Dans ce cas, nous allons utiliser GPT-3.5-turbo d'OpenAI, car c'est le plus rentable. Mais si vous avez accès, n'hésitez pas à utiliser le plus puissant GPT4.
Pour importer ceux-ci, nous pouvons utiliser le code suivant :
# importer le schéma pour les messages de chat et ChatOpenAI afin d'interroger les modèles de chat GPT-3.5-turbo ou GPT-4
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI(model_name="gpt-3.5-turbo",temperature=0.3)
messages = [
SystemMessage(content="Vous êtes un expert en science des données"),
HumanMessage(content="Écrivez un script Python qui entraîne un réseau de neurones sur des données simulées")
]
response=chat(messages)
print(response.content,end='\n')
En essence, le SystemMessage fournit un contexte au module GPT-3.5-turbo qu'il référencera pour chaque paire prompt-complétion. Le HumanMessage fait référence à ce que vous taperiez dans l'interface ChatGPT – votre prompt.
Mais avec un chatbot à connaissances personnalisées, nous abstraisons souvent les composants répétitifs d'un prompt. Par exemple, si je créais une application de générateur de tweets, je ne voudrais pas continuer à taper "Écrivez-moi un tweet sur...". En fait, c'est ainsi que les outils d'écriture IA simples sont développés !
Alors, voyons comment nous pouvons abstraire cela avec des modèles de prompt.
Prompts
LangChain fournit des PromptTemplates qui vous permettent de changer dynamiquement les prompts avec l'entrée de l'utilisateur, de manière similaire à l'utilisation des regex.
# Importer le prompt et définir PromptTemplate
from langchain import PromptTemplate
template = """
Vous êtes un expert en science des données avec une expertise dans la construction de modèles de deep learning.
Expliquez le concept de {concept} en quelques lignes
"""
prompt = PromptTemplate(
input_variables=["concept"],
template=template,
)
# Exécuter le LLM avec PromptTemplate
llm(prompt.format(concept="autoencoder"))
llm(prompt.format(concept="regularization"))
Vous pouvez varier ceux-ci de différentes manières pour les adapter à votre cas d'utilisation. Si vous êtes familier avec l'utilisation de ChatGPT, cela devrait vous être confortable.
Chaines
Les chaînes vous permettent de prendre des PromptTemplates simples et de construire des fonctionnalités par-dessus. Essentiellement, les chaînes sont comme des fonctions composites qui vous permettent d'intégrer vos PromptTemplates et LLMs ensemble.
En utilisant les wrappers et PromptTemplates précédents, nous pouvons exécuter les mêmes prompts avec une seule chaîne qui prend un PromptTemplate et le compose avec un LLM :
# Importer LLMChain et définir la chaîne avec le modèle de langage et le prompt comme arguments.
from langchain.chains import LLMChain
chain = LLMChain(llm=llm, prompt=prompt)
# Exécuter la chaîne en spécifiant uniquement la variable d'entrée.
print(chain.run("autoencoder"))
En plus de cela, comme le suggère le nom, nous pouvons enchaîner ceux-ci ensemble pour créer des compositions encore plus grandes.
Par exemple, je peux prendre le résultat d'une chaîne et le passer dans une autre chaîne. Dans cet extrait, Rabbitmetrics prend la complétion de la première chaîne et la passe dans la deuxième chaîne pour l'expliquer à un enfant de 5 ans.
Vous pouvez ensuite combiner ces chaînes dans une chaîne plus grande et l'exécuter.
# Définir un deuxième prompt
second_prompt = PromptTemplate(
input_variables=["ml_concept"],
template="Transformez la description du concept de {ml_concept} et expliquez-la-moi comme si j'avais cinq ans en 500 mots",
)
chain_two = LLMChain(llm=llm, prompt=second_prompt)
# Définir une chaîne séquentielle en utilisant les deux chaînes ci-dessus : la deuxième chaîne prend la sortie de la première chaîne comme entrée
from langchain.chains import SimpleSequentialChain
overall_chain = SimpleSequentialChain(chains=[chain, chain_two], verbose=True)
# Exécuter la chaîne en spécifiant uniquement la variable d'entrée pour la première chaîne.
explanation = overall_chain.run("autoencoder")
print(explanation)
Avec les chaînes, vous pouvez créer un large éventail de fonctionnalités, ce qui rend LangChain si polyvalent. Mais là où il brille vraiment, c'est en l'utilisant en conjonction avec un Vector Store comme discuté précédemment. Introduisons ce composant.
Embeddings et Vector Stores
C'est ici que nous incorporons l'aspect des données personnalisées de LangChain. Comme mentionné précédemment, l'idée derrière les embeddings et les Vector Stores est de diviser les grandes données en morceaux et de stocker ceux-ci pour être interrogés lorsqu'ils sont pertinents.
LangChain dispose d'une fonction de division de texte pour cela :
# Importer l'utilitaire pour diviser les textes et diviser l'explication donnée ci-dessus en morceaux de document
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 100,
chunk_overlap = 0,
)
texts = text_splitter.create_documents([explanation])
La division de texte nécessite deux paramètres : la taille d'un morceau (chunk_size) et le chevauchement de chaque morceau (chunk_overlap). Avoir un chevauchement entre chaque morceau est important pour aider à identifier les morceaux adjacents pertinents.
Chacun de ces morceaux peut être récupéré comme suit :
texts[0].page_content
Après avoir obtenu ces morceaux, nous devons les transformer en embeddings. Cela permet au Vector Store de trouver et de retourner chaque morceau lorsqu'il est interrogé. Nous utiliserons le modèle d'embedding d'OpenAI pour cela.
# Importer et instancier les embeddings OpenAI
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(model_name="ada")
# Transformer le premier morceau de texte en un vecteur avec l'embedding
query_result = embeddings.embed_query(texts[0].page_content)
print(query_result)
Et enfin, nous devons avoir un endroit pour stocker ces embeddings vectorisés. Comme mentionné précédemment, nous utiliserons Pinecone pour cela. En utilisant les clés API du fichier d'environnement précédent, nous pouvons initialiser Pinecone pour stocker nos embeddings.
# Importer et initialiser le client Pinecone
import os
import pinecone
from langchain.vectorstores import Pinecone
pinecone.init(
api_key=os.getenv('PINECONE_API_KEY'),
environment=os.getenv('PINECONE_ENV')
)
# Télécharger les vecteurs vers Pinecone
index_name = "langchain-quickstart"
search = Pinecone.from_documents(texts, embeddings, index_name=index_name)
# Effectuer une simple recherche de similarité vectorielle
query = "Qu'est-ce qu'il y a de magique dans un autoencoder ?"
result = search.similarity_search(query)
print(result)
Et maintenant nous sommes capables d'interroger des informations pertinentes depuis notre Pinecone Vector Store ! Il ne reste plus qu'à combiner ce que nous avons appris pour créer notre cas d'utilisation spécifique – nous donnant notre "Agent" IA spécialisé.
Agents
Un agent est essentiellement une IA autonome qui prend des entrées et les complète en tant que tâches séquentielles jusqu'à ce que l'objectif final soit atteint. Cela implique que notre IA utilise d'autres API qui lui permettent de compléter des tâches telles que l'envoi d'e-mails ou la résolution de problèmes mathématiques. Utilisé en conjonction avec nos chaînes LLM + prompt, nous pouvons assembler une application IA appropriée.
Maintenant, expliquer cette partie sera extensif, alors voici un exemple simple de la façon dont un agent Python peut être utilisé dans LangChain pour résoudre un problème mathématique simple. Cet agent, dans ce cas, résout le problème en connectant notre LLM pour exécuter du code Python, et trouve les racines avec NumPy :
# Importer l'outil Python REPL et instancier l'agent Python
from langchain.agents.agent_toolkits import create_python_agent
from langchain.tools.python.tool import PythonREPLTool
from langchain.python import PythonREPL
from langchain.llms.openai import OpenAI
agent_executor = create_python_agent(
llm=OpenAI(temperature=0, max_tokens=1000),
tool=PythonREPLTool(),
verbose=True
)
# Exécuter l'agent Python
agent_executor.run("Trouver les racines (zéros) de la fonction quadratique 3 * x**2 + 2*x -1")
Un chatbot à connaissances personnalisées est essentiellement un agent qui enchaîne des prompts et des actions qui interrogent le stockage vectorisé, prennent les résultats et les enchaînent avec la question originale !
Si vous souhaitez en savoir plus sur les agents IA, ceci est une excellente ressource.
Autres variations
Même avec votre nouvelle compréhension de base du fonctionnement de LangChain, je suis sûr que vous avez déjà de nombreuses idées en tête.
Mais nous n'avons examiné qu'un seul modèle OpenAI jusqu'à présent, et c'est le GPT-3.5-turbo basé sur le texte. OpenAI dispose d'une gamme de modèles que vous pourriez utiliser avec LangChain – y compris la génération d'images avec Dall-E. En appliquant les mêmes concepts que nous avons discutés, nous pouvons créer des agents générateurs d'art IA, des agents constructeurs de sites web, et bien plus encore.
Prenez le temps d'explorer le paysage de l'IA et je suis convaincu que vous commencerez à avoir de plus en plus d'idées.
Conclusion
J'espère que vous avez appris un peu plus sur ce qui se passe derrière les scènes de tous ces nouveaux outils d'IA. Comprendre comment LangChain fonctionne est une compétence précieuse à avoir en tant que programmeur de nos jours et peut ouvrir les possibilités pour votre développement en IA.
Si vous avez aimé cet article et que vous souhaitez en savoir plus sur les nouveaux outils passionnants que les créateurs d'IA construisent, vous pouvez rester à jour avec ma Newsletter Byte-Sized AI. Il y a des tonnes d'histoires passionnantes sur ce que les gens construisent dans l'espace de l'IA, et j'adorerais que vous rejoigniez notre communauté.
Vous pouvez également me suivre sur Twitter, où nous pouvons également entrer en contact.
Autrement, commencez à expérimenter avec LangChain et créez quelques projets d'IA ingénieux.