

Article original : JVM Tutorial - Java Virtual Machine Architecture Explained for Beginners
Par Siben Nayak
Que vous ayez utilisé Java pour développer des programmes ou non, vous avez probablement entendu parler de la Machine Virtuelle Java (JVM) à un moment ou à un autre.
La JVM est le cœur de l'écosystème Java et permet aux logiciels basés sur Java de suivre l'approche "write once, run anywhere". Vous pouvez écrire du code Java sur une machine et l'exécuter sur n'importe quelle autre machine utilisant la JVM.
La JVM a été initialement conçue pour supporter uniquement Java. Cependant, avec le temps, de nombreux autres langages tels que Scala, Kotlin et Groovy ont été adoptés sur la plateforme Java. Tous ces langages sont collectivement connus sous le nom de langages JVM.
Dans cet article, nous allons en apprendre davantage sur la JVM, son fonctionnement et les différents composants qui la constituent.
#Qu'est-ce qu'une Machine Virtuelle ?
Avant de plonger dans la JVM, revisitons le concept de Machine Virtuelle (VM).
Une machine virtuelle est une représentation virtuelle d'un ordinateur physique. Nous pouvons appeler la machine virtuelle la machine invitée, et l'ordinateur physique sur lequel elle s'exécute est la machine hôte.
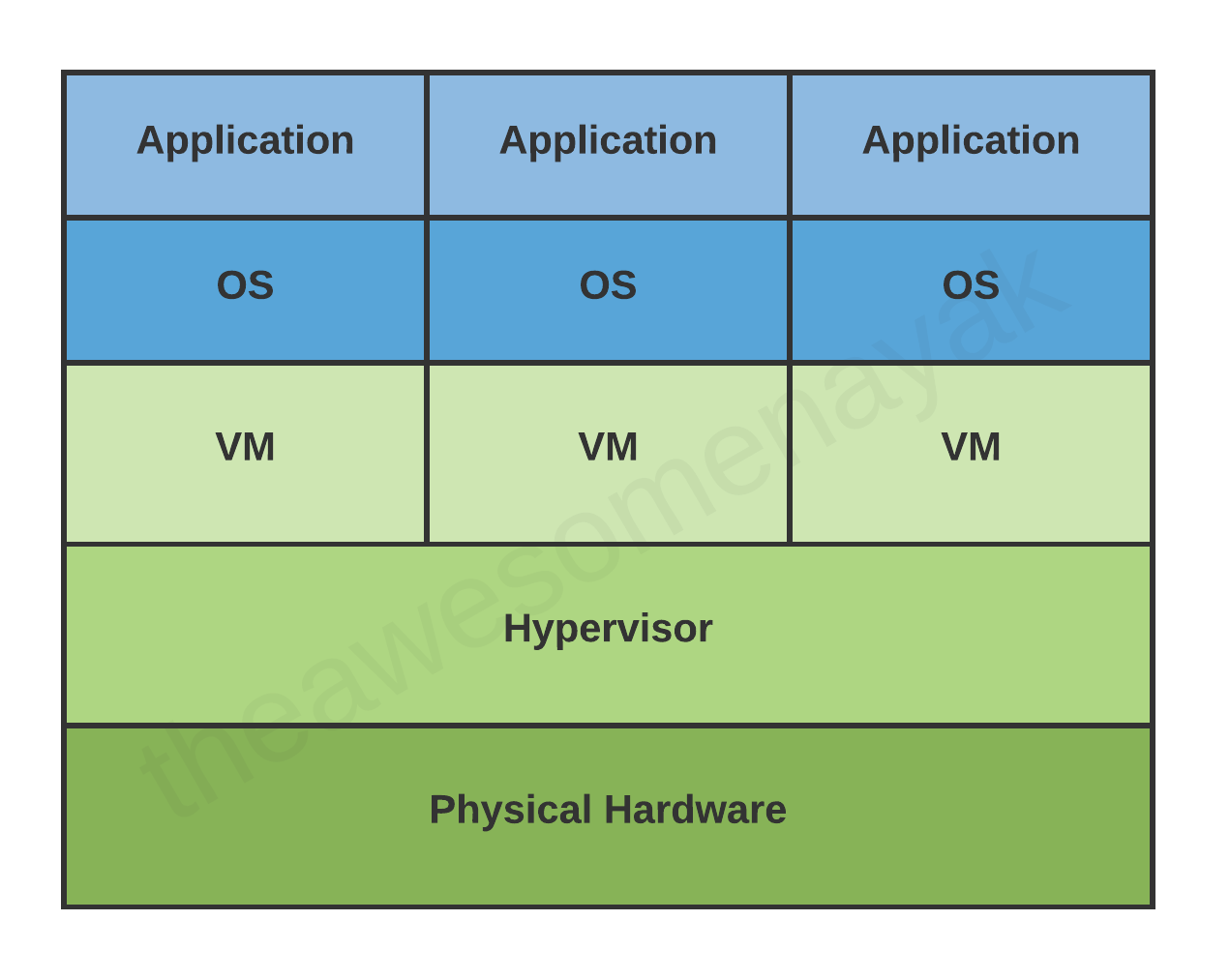
Une seule machine physique peut exécuter plusieurs machines virtuelles, chacune avec son propre système d'exploitation et ses applications. Ces machines virtuelles sont isolées les unes des autres.
#Qu'est-ce que la Machine Virtuelle Java ?
Dans des langages de programmation comme C et C++, le code est d'abord compilé en code machine spécifique à la plateforme. Ces langages sont appelés langages compilés.
D'autre part, dans des langages comme JavaScript et Python, l'ordinateur exécute les instructions directement sans avoir à les compiler. Ces langages sont appelés langages interprétés.
Java utilise une combinaison des deux techniques. Le code Java est d'abord compilé en bytecode pour générer un fichier class. Ce fichier class est ensuite interprété par la Machine Virtuelle Java pour la plateforme sous-jacente. Le même fichier class peut être exécuté sur n'importe quelle version de JVM s'exécutant sur n'importe quelle plateforme et système d'exploitation.
Similaire aux machines virtuelles, la JVM crée un espace isolé sur une machine hôte. Cet espace peut être utilisé pour exécuter des programmes Java indépendamment de la plateforme ou du système d'exploitation de la machine.
#Architecture de la Machine Virtuelle Java
La JVM se compose de trois composants distincts :
- Chargeur de Classe
- Zone de Mémoire/Données d'Exécution
- Moteur d'Exécution
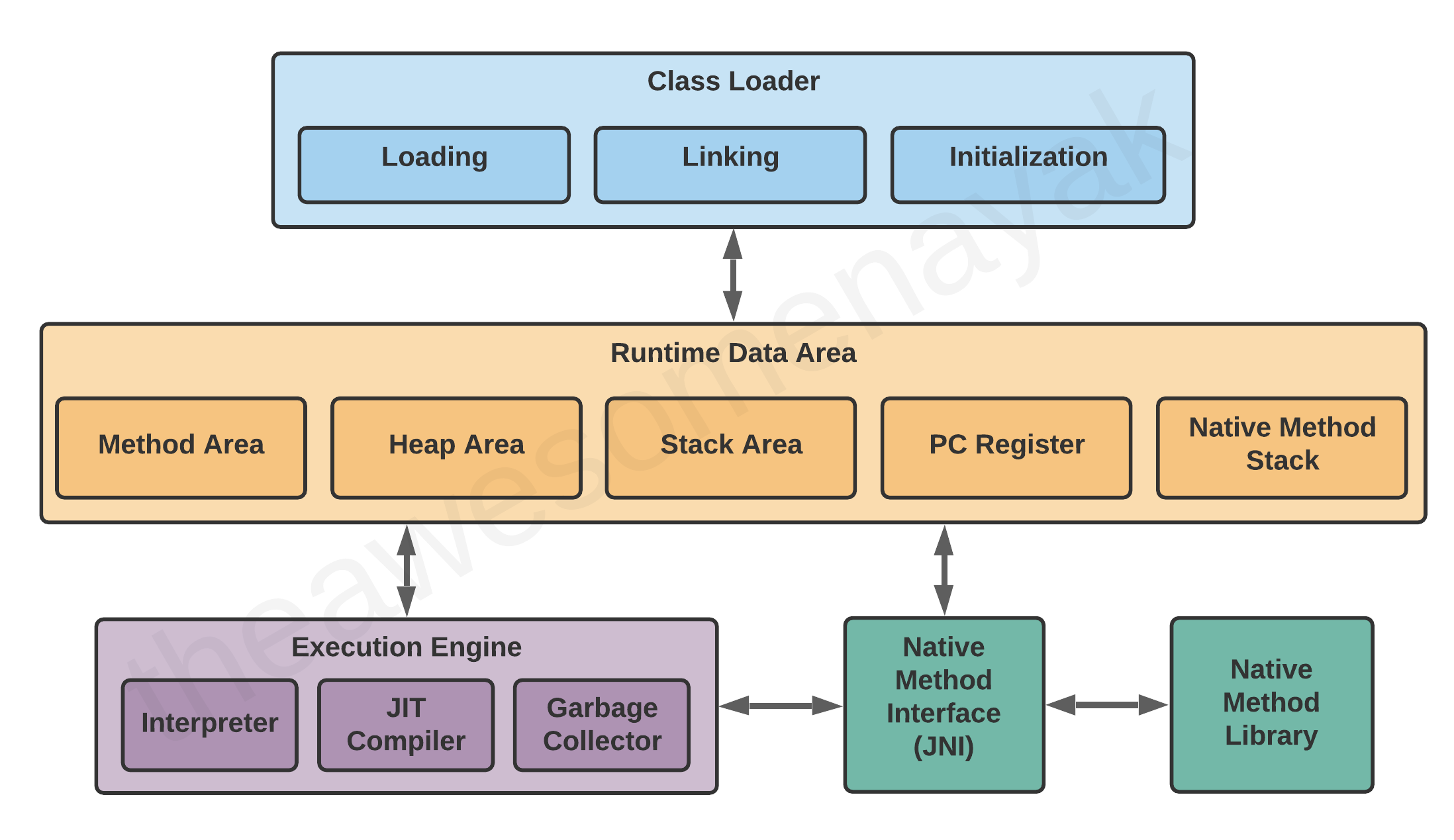
Examinons chacun d'eux plus en détail.
Chargeur de Classe
Lorsque vous compilez un fichier source .java, il est converti en bytecode sous forme de fichier .class. Lorsque vous essayez d'utiliser cette classe dans votre programme, le chargeur de classe la charge en mémoire principale.
La première classe à être chargée en mémoire est généralement la classe qui contient la méthode main().
Il y a trois phases dans le processus de chargement de classe : le chargement, la liaison et l'initialisation.
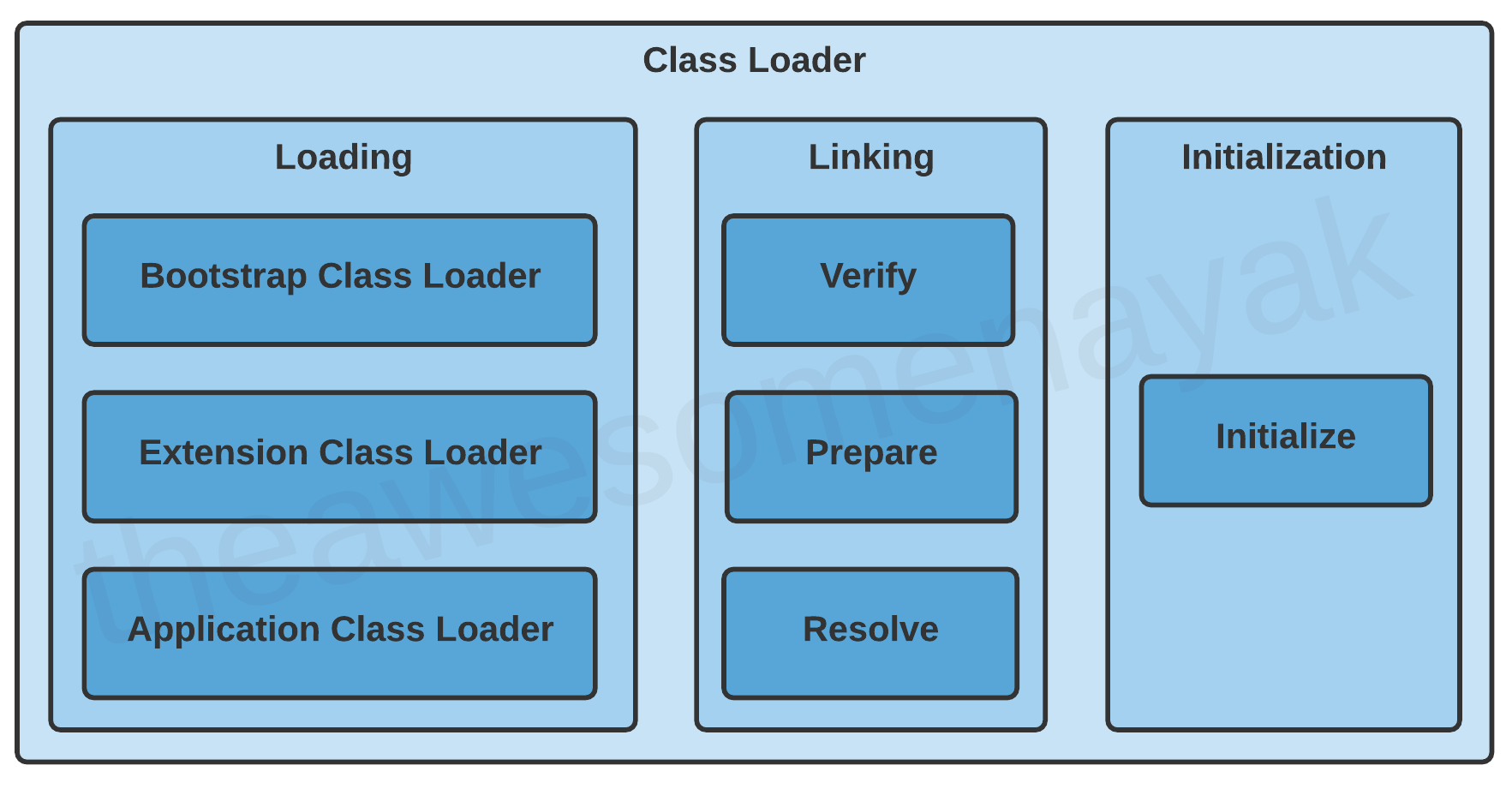
Chargement
Le chargement consiste à prendre la représentation binaire (bytecode) d'une classe ou d'une interface avec un nom particulier, et à générer la classe ou l'interface originale à partir de celle-ci.
Il y a trois chargeurs de classe intégrés disponibles en Java :
- Bootstrap Class Loader - C'est le chargeur de classe racine. Il est le superclasse de l'Extension Class Loader et charge les packages Java standard comme
java.lang,java.net,java.util,java.io, et ainsi de suite. Ces packages sont présents dans le fichierrt.jaret d'autres bibliothèques principales présentes dans le répertoire$JAVA_HOME/jre/lib. - Extension Class Loader - C'est la sous-classe du Bootstrap Class Loader et la superclasse de l'Application Class Loader. Il charge les extensions des bibliothèques Java standard qui sont présentes dans le répertoire
$JAVA_HOME/jre/lib/ext. - Application Class Loader - C'est le dernier chargeur de classe et la sous-classe de l'Extension Class Loader. Il charge les fichiers présents sur le classpath. Par défaut, le classpath est défini sur le répertoire courant de l'application. Le classpath peut également être modifié en ajoutant l'option de ligne de commande
-classpathou-cp.
La JVM utilise la méthode ClassLoader.loadClass() pour charger la classe en mémoire. Elle essaie de charger la classe en fonction d'un nom entièrement qualifié.
Si un chargeur de classe parent n'est pas en mesure de trouver une classe, il délègue le travail à un chargeur de classe enfant. Si le dernier chargeur de classe enfant n'est pas en mesure de charger la classe non plus, il lance NoClassDefFoundError ou ClassNotFoundException.
Liaison
Après qu'une classe est chargée en mémoire, elle subit le processus de liaison. La liaison d'une classe ou d'une interface implique la combinaison des différents éléments et dépendances du programme ensemble.
La liaison comprend les étapes suivantes :
Vérification : Cette phase vérifie la correction structurelle du fichier .class en le vérifiant par rapport à un ensemble de contraintes ou de règles. Si la vérification échoue pour une raison quelconque, nous obtenons une VerifyException.
Par exemple, si le code a été construit en utilisant Java 11, mais est exécuté sur un système qui a Java 8 installé, la phase de vérification échouera.
Préparation : Dans cette phase, la JVM alloue de la mémoire pour les champs statiques d'une classe ou d'une interface, et les initialise avec des valeurs par défaut.
Par exemple, supposons que vous avez déclaré la variable suivante dans votre classe :
private static final boolean enabled = true;
Pendant la phase de préparation, la JVM alloue de la mémoire pour la variable enabled et définit sa valeur à la valeur par défaut pour un booléen, qui est false.
Résolution : Dans cette phase, les références symboliques sont remplacées par des références directes présentes dans le pool de constantes d'exécution.
Par exemple, si vous avez des références à d'autres classes ou variables constantes présentes dans d'autres classes, elles sont résolues dans cette phase et remplacées par leurs références réelles.
Initialisation
L'initialisation implique l'exécution de la méthode d'initialisation de la classe ou de l'interface (connue sous le nom de <clinit>). Cela peut inclure l'appel du constructeur de la classe, l'exécution du bloc statique et l'assignation de valeurs à toutes les variables statiques. C'est la phase finale du chargement de classe.
Par exemple, lorsque nous avons déclaré le code suivant plus tôt :
private static final boolean enabled = true;
La variable enabled a été définie à sa valeur par défaut de false pendant la phase de préparation. Dans la phase d'initialisation, cette variable se voit attribuer sa valeur réelle de true.
Note : la JVM est multithread. Il peut arriver que plusieurs threads essaient d'initialiser la même classe en même temps. Cela peut entraîner des problèmes de concurrence. Vous devez gérer la sécurité des threads pour vous assurer que le programme fonctionne correctement dans un environnement multithread.
Zone de Données d'Exécution
Il y a cinq composants à l'intérieur de la zone de données d'exécution :

Examinons chacun d'eux individuellement.
Zone de Méthode
Toutes les données au niveau de la classe telles que le pool de constantes d'exécution, les données de champ et de méthode, et le code pour les méthodes et les constructeurs, sont stockées ici.
Si la mémoire disponible dans la zone de méthode n'est pas suffisante pour le démarrage du programme, la JVM lance une erreur OutOfMemoryError.
Par exemple, supposons que vous avez la définition de classe suivante :
public class Employee {
private String name;
private int age;
public Employee(String name, int age) {
this.name = name;
this.age = age;
}
}
Dans cet exemple de code, les données au niveau du champ telles que name et age et les détails du constructeur sont chargés dans la zone de méthode.
La zone de méthode est créée au démarrage de la machine virtuelle, et il n'y a qu'une seule zone de méthode par JVM.
Zone de Tas (Heap)
Tous les objets et leurs variables d'instance correspondantes sont stockés ici. Il s'agit de la zone de données d'exécution à partir de laquelle la mémoire pour toutes les instances de classe et les tableaux est allouée.
Par exemple, supposons que vous déclarez l'instance suivante :
Employee employee = new Employee();
Dans cet exemple de code, une instance de Employee est créée et chargée dans la zone de tas.
Le tas est créé au démarrage de la machine virtuelle, et il n'y a qu'une seule zone de tas par JVM.
Note : Puisque les zones de Méthode et de Tas partagent la même mémoire pour plusieurs threads, les données stockées ici ne sont pas thread-safe.
Zone de Pile (Stack)
Chaque fois qu'un nouveau thread est créé dans la JVM, une pile d'exécution séparée est également créée en même temps. Toutes les variables locales, les appels de méthode et les résultats partiels sont stockés dans la zone de pile.
Si le traitement effectué dans un thread nécessite une taille de pile plus grande que ce qui est disponible, la JVM lance une erreur StackOverflowError.
Pour chaque appel de méthode, une entrée est faite dans la mémoire de pile qui est appelée le Cadre de Pile. Lorsque l'appel de méthode est terminé, le Cadre de Pile est détruit.
Le Cadre de Pile est divisé en trois sous-parties :
- Variables Locales - Chaque cadre contient un tableau de variables connu sous le nom de ses variables locales. Toutes les variables locales et leurs valeurs sont stockées ici. La longueur de ce tableau est déterminée à la compilation.
- Pile d'Opérandes - Chaque cadre contient une pile dernier entré, premier sorti (LIFO) connue sous le nom de sa pile d'opérandes. Cela agit comme un espace de travail d'exécution pour effectuer toute opération intermédiaire. La profondeur maximale de cette pile est déterminée à la compilation.
- Données de Cadre - Tous les symboles correspondant à la méthode sont stockés ici. Cela stocke également les informations de bloc catch en cas d'exceptions.
Par exemple, supposons que vous avez le code suivant :
double calculateNormalisedScore(List<Answer> answers) {
double score = getScore(answers);
return normalizeScore(score);
}
double normalizeScore(double score) {
return (score - minScore) / (maxScore - minScore);
}
Dans cet exemple de code, des variables comme answers et score sont placées dans le tableau des Variables Locales. La Pile d'Opérandes contient les variables et les opérateurs nécessaires pour effectuer les calculs mathématiques de soustraction et de division.

Note : Puisque la Zone de Pile n'est pas partagée, elle est intrinsèquement thread-safe.
Registres de Compteur de Programme (PC)
La JVM supporte plusieurs threads en même temps. Chaque thread a son propre registre PC pour contenir l'adresse de l'instruction JVM actuellement en cours d'exécution. Une fois l'instruction exécutée, le registre PC est mis à jour avec l'instruction suivante.
Piles de Méthodes Natives
La JVM contient des piles qui supportent les méthodes natives. Ces méthodes sont écrites dans un langage autre que Java, comme C et C++. Pour chaque nouveau thread, une pile de méthodes natives séparée est également allouée.
Moteur d'Exécution
Une fois que le bytecode a été chargé en mémoire principale et que les détails sont disponibles dans la zone de données d'exécution, l'étape suivante est d'exécuter le programme. Le Moteur d'Exécution gère cela en exécutant le code présent dans chaque classe.
Cependant, avant d'exécuter le programme, le bytecode doit être converti en instructions de langage machine. La JVM peut utiliser un interpréteur ou un compilateur JIT pour le moteur d'exécution.
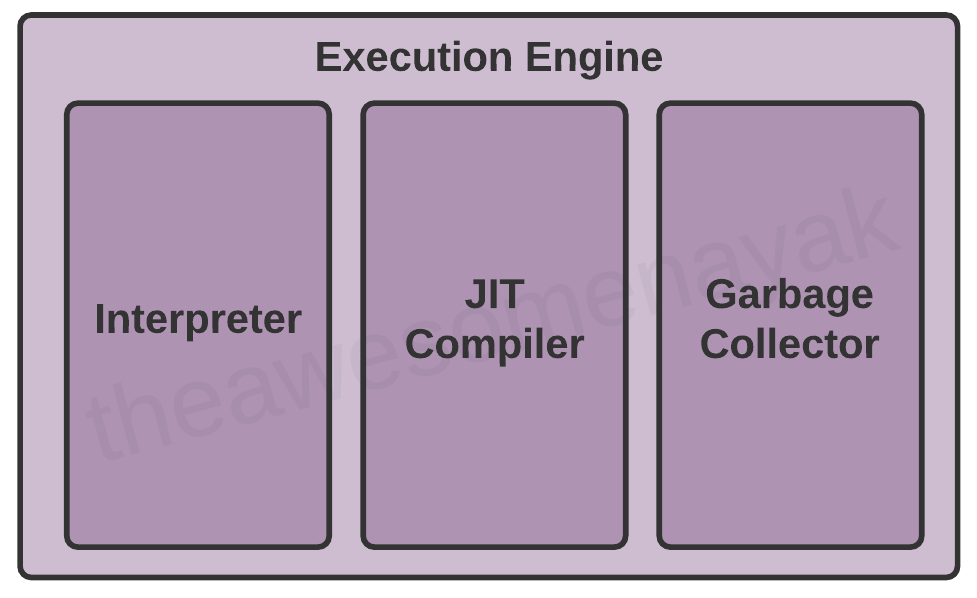
Interpréteur
L'interpréteur lit et exécute les instructions de bytecode ligne par ligne. En raison de l'exécution ligne par ligne, l'interpréteur est comparativement plus lent.
Un autre inconvénient de l'interpréteur est que lorsqu'une méthode est appelée plusieurs fois, chaque fois une nouvelle interprétation est nécessaire.
Compilateur JIT
Le compilateur JIT surmonte l'inconvénient de l'interpréteur. Le Moteur d'Exécution utilise d'abord l'interpréteur pour exécuter le bytecode, mais lorsqu'il trouve un code répété, il utilise le compilateur JIT.
Le compilateur JIT compile ensuite l'ensemble du bytecode et le transforme en code machine natif. Ce code machine natif est utilisé directement pour les appels de méthode répétés, ce qui améliore les performances du système.
Le compilateur JIT possède les composants suivants :
- Générateur de Code Intermédiaire - génère le code intermédiaire
- Optimiseur de Code - optimise le code intermédiaire pour de meilleures performances
- Générateur de Code Cible - convertit le code intermédiaire en code machine natif
- Profileur - trouve les points chauds (code qui est exécuté de manière répétée)
Pour mieux comprendre la différence entre l'interpréteur et le compilateur JIT, supposons que vous avez le code suivant :
int sum = 10;
for(int i = 0 ; i <= 10; i++) {
sum += i;
}
System.out.println(sum);
Un interpréteur récupérera la valeur de sum de la mémoire pour chaque itération dans la boucle, ajoutera la valeur de i à celle-ci, et l'écrira à nouveau en mémoire. Il s'agit d'une opération coûteuse car elle accède à la mémoire chaque fois qu'elle entre dans la boucle.
Cependant, le compilateur JIT reconnaîtra que ce code contient un HotSpot et effectuera des optimisations sur celui-ci. Il stockera une copie locale de sum dans le registre PC du thread et continuera à ajouter la valeur de i à celle-ci dans la boucle. Une fois la boucle terminée, il écrira la valeur de sum à nouveau en mémoire.
Note : un compilateur JIT prend plus de temps pour compiler le code que pour que l'interpréteur interprète le code ligne par ligne. Si vous allez exécuter un programme une seule fois, utiliser l'interpréteur est préférable.
Collecteur de Déchets (Garbage Collector)
Le Collecteur de Déchets (GC) collecte et supprime les objets non référencés de la zone de tas. Il s'agit du processus de récupération de la mémoire inutilisée à l'exécution automatiquement en les détruisant.
La collecte des déchets rend la mémoire Java efficace car elle supprime les objets non référencés de la mémoire de tas et libère de l'espace pour de nouveaux objets. Elle implique deux phases :
- Marquage - dans cette étape, le GC identifie les objets inutilisés en mémoire
- Balayage - dans cette étape, le GC supprime les objets identifiés lors de la phase précédente
La collecte des déchets est effectuée automatiquement par la JVM à intervalles réguliers et n'a pas besoin d'être gérée séparément. Elle peut également être déclenchée en appelant System.gc(), mais l'exécution n'est pas garantie.
La JVM contient 3 types différents de collecteurs de déchets :
- Serial GC - Il s'agit de l'implémentation la plus simple de GC, conçue pour les petites applications s'exécutant dans des environnements monotâches. Il utilise un seul thread pour la collecte des déchets. Lorsqu'il s'exécute, il entraîne un événement "stop the world" où l'ensemble de l'application est mis en pause. L'argument JVM pour utiliser le Serial Garbage Collector est
-XX:+UseSerialGC - Parallel GC - Il s'agit de l'implémentation par défaut de GC dans la JVM, également connue sous le nom de Throughput Collector. Il utilise plusieurs threads pour la collecte des déchets, mais met toujours l'application en pause lorsqu'il s'exécute. L'argument JVM pour utiliser le Parallel Garbage Collector est
-XX:+UseParallelGC. - Garbage First (G1) GC - G1GC a été conçu pour les applications multithreads qui disposent d'une grande taille de tas disponible (plus de 4 Go). Il partitionne le tas en un ensemble de régions de taille égale et utilise plusieurs threads pour les analyser. G1GC identifie les régions avec le plus de déchets et effectue la collecte des déchets sur cette région en premier. L'argument JVM pour utiliser le G1 Garbage Collector est
-XX:+UseG1GC
Note : Il existe un autre type de collecteur de déchets appelé Concurrent Mark Sweep (CMS) GC. Cependant, il a été déprécié depuis Java 9 et complètement supprimé dans Java 14 au profit de G1GC.
Interface Native Java (JNI)
Parfois, il est nécessaire d'utiliser du code natif (non-Java) (par exemple, C/C++). Cela peut être le cas lorsque nous devons interagir avec le matériel, ou pour surmonter les contraintes de gestion de la mémoire et de performance en Java. Java supporte l'exécution de code natif via l'Interface Native Java (JNI).
JNI agit comme un pont pour permettre aux packages de support pour d'autres langages de programmation tels que C, C++, etc. Cela est particulièrement utile dans les cas où vous devez écrire du code qui n'est pas entièrement supporté par Java, comme certaines fonctionnalités spécifiques à la plateforme qui ne peuvent être écrites qu'en C.
Vous pouvez utiliser le mot-clé native pour indiquer que l'implémentation de la méthode sera fournie par une bibliothèque native. Vous devrez également invoquer System.loadLibrary() pour charger la bibliothèque native partagée en mémoire et rendre ses fonctions disponibles pour Java.
Bibliothèques de Méthodes Natives
Les bibliothèques de méthodes natives sont des bibliothèques écrites dans d'autres langages de programmation, tels que C, C++ et assembleur. Ces bibliothèques sont généralement présentes sous forme de fichiers .dll ou .so. Ces bibliothèques natives peuvent être chargées via JNI.
#Erreurs Courantes de la JVM
- ClassNotFoundException - Cela se produit lorsque le Chargeur de Classe essaie de charger des classes en utilisant
Class.forName(),ClassLoader.loadClass()ouClassLoader.findSystemClass()mais qu'aucune définition pour la classe avec le nom spécifié n'est trouvée. - NoClassDefFoundError - Cela se produit lorsqu'un compilateur a compilé avec succès la classe, mais que le Chargeur de Classe n'est pas en mesure de localiser le fichier de classe à l'exécution.
- OutOfMemoryError - Cela se produit lorsque la JVM ne peut pas allouer un objet car elle est à court de mémoire, et qu'aucune mémoire supplémentaire ne peut être rendue disponible par le collecteur de déchets.
- StackOverflowError - Cela se produit si la JVM manque d'espace lors de la création de nouveaux cadres de pile lors du traitement d'un thread.
#Conclusion
Dans cet article, nous avons discuté de l'architecture de la Machine Virtuelle Java et de ses différents composants. Souvent, nous n'approfondissons pas les mécanismes internes de la JVM ou ne nous soucions pas de son fonctionnement tant que notre code fonctionne.
Ce n'est que lorsque quelque chose ne va pas et que nous devons ajuster la JVM ou corriger une fuite de mémoire que nous essayons de comprendre ses mécanismes internes.
C'est également une question d'entretien très populaire, tant pour les niveaux junior que senior pour les rôles backend. Une compréhension approfondie de la JVM vous aide à écrire un meilleur code et à éviter les pièges liés aux erreurs de pile et de mémoire.
Merci de m'avoir suivi jusqu'ici. J'espère que vous avez aimé l'article. Vous pouvez me retrouver sur LinkedIn où je discute régulièrement de technologie et de vie. Jetez également un coup d'œil à certains de mes autres articles et à ma chaîne YouTube. Bonne lecture. 👋