

Article original : Finding Correlations in Non-Linear Data
Par Peter Gleeson
D'un point de vue signalétique, le monde est un endroit bruyant. Pour comprendre quoi que ce soit, nous devons être sélectifs avec notre attention.
Nous, les humains, sommes devenus assez bons, au cours de millions d'années de sélection naturelle, pour filtrer les signaux de fond. Nous apprenons à associer des signaux particuliers à certains événements.
Par exemple, imaginez que vous jouez au ping-pong dans un bureau animé.
Pour renvoyer le coup de votre adversaire, vous devez faire un grand nombre de calculs et de jugements complexes, en tenant compte de multiples signaux sensoriels concurrents.
Pour prédire le mouvement de la balle, votre cerveau doit échantillonner en permanence la position actuelle de la balle et estimer sa trajectoire future. Les joueurs plus avancés tiendront également compte de l'effet appliqué par l'adversaire.
Enfin, pour jouer votre propre coup, vous devez tenir compte de la position de votre adversaire, de votre propre position, de la vitesse de la balle et de l'effet que vous souhaitez appliquer.
Tout cela implique une quantité incroyable de calcul différentiel subconscient. Nous tenons pour acquis que, généralement parlant, notre système nerveux peut faire cela automatiquement (au moins après un peu de pratique).
Tout aussi impressionnant est la manière dont le cerveau humain attribue différentiellement de l'importance à chacun des nombreux signaux concurrents qu'il reçoit. La position de la balle, par exemple, est jugée plus pertinente que, disons, la conversation qui se déroule derrière vous, ou la porte qui s'ouvre devant vous.
Cela peut sembler si évident que cela ne mérite pas d'être mentionné, mais c'est un témoignage de notre capacité à apprendre à faire des prédictions précises à partir de données bruyantes.
Certes, une machine à l'état brut recevant un flux continu de données audiovisuelles aurait du mal à savoir quels signaux prédisent le mieux le cours optimal de l'action.
Heureusement, il existe des méthodes statistiques et computationnelles qui peuvent être utilisées pour identifier des motifs dans des données bruyantes et complexes.
Corrélation 101
Généralement, lorsque nous parlons de 'corrélation' entre deux variables, nous faisons référence à leur 'relation' dans un certain sens.
Les variables corrélées sont celles qui contiennent des informations l'une sur l'autre. Plus la corrélation est forte, plus une variable nous en dit sur l'autre.
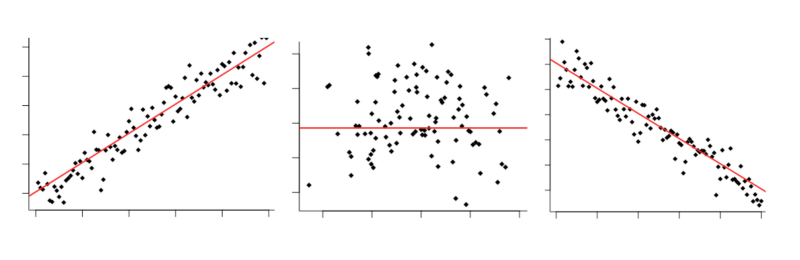 Vous avez peut-être déjà tout vu : Corrélation positive, zéro corrélation, corrélation négative
Vous avez peut-être déjà tout vu : Corrélation positive, zéro corrélation, corrélation négative
Vous avez peut-être déjà une certaine compréhension de la corrélation, de son fonctionnement et de ses limitations. En effet, c'est un peu un cliché de la science des données :
« La corrélation n'implique pas la causalité »
Cela est bien sûr vrai — il y a de bonnes raisons pour lesquelles même une forte corrélation entre deux variables n'est pas une garantie de causalité. La corrélation observée pourrait être due aux effets d'une troisième variable cachée, ou simplement entièrement due au hasard.
Cela dit, la corrélation permet de faire des prédictions sur une variable basée sur une autre. Il existe plusieurs méthodes qui peuvent être utilisées pour estimer la corrélation pour les données linéaires et non linéaires. Examinons comment elles fonctionnent.
Nous allons passer en revue les mathématiques et l'implémentation du code, en utilisant Python et R. Le code pour les exemples de cet article peut être trouvé ici.
Coefficient de corrélation de Pearson
Qu'est-ce que c'est ?
Le coefficient de corrélation de Pearson (PCC, ou Pearson's r) est une mesure de corrélation linéaire largement utilisée. C'est souvent la première enseignée dans de nombreux cours élémentaires de statistiques. Mathématiquement parlant, il est défini comme « la covariance entre deux vecteurs, normalisée par le produit de leurs écarts types ».
En savoir plus...
La covariance entre deux vecteurs appariés est une mesure de leur tendance à varier au-dessus ou en dessous de leurs moyennes ensemble. C'est-à-dire, une mesure de si chaque paire tend à être sur des côtés similaires ou opposés de leurs moyennes respectives.
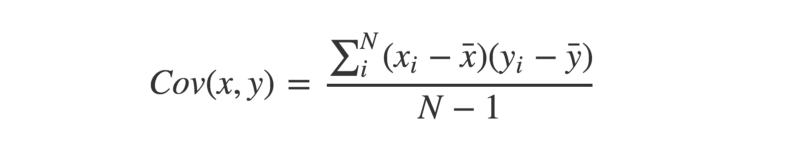
Voyons cela implémenté en Python :
def mean(x):
return sum(x)/len(x)
def covariance(x,y):
calc = []
for i in range(len(x)):
xi = x[i] - mean(x)
yi = y[i] - mean(y)
calc.append(xi * yi)
return sum(calc)/(len(x) - 1)
a = [1,2,3,4,5] ; b = [5,4,3,2,1]
print(covariance(a,b))
La covariance est calculée en prenant chaque paire de variables, et en soustrayant leurs moyennes respectives. Ensuite, multipliez ces deux valeurs ensemble.
- Si elles sont toutes deux au-dessus de leur moyenne (ou toutes deux en dessous), cela produira un nombre positif, car un positif × positif = positif, et de même un négatif × négatif = positif.
- Si elles sont de côtés différents de leurs moyennes, cela produit un nombre négatif (car positif × négatif = négatif).
Une fois que nous avons toutes ces valeurs calculées pour chaque paire, additionnez-les, et divisez par n-1, où n est la taille de l'échantillon. C'est la covariance de l'échantillon.
Si les paires ont tendance à être toutes deux du même côté de leurs moyennes respectives, la covariance sera un nombre positif. Si elles ont tendance à être de côtés opposés de leurs moyennes, la covariance sera un nombre négatif. Plus cette tendance est forte, plus la valeur absolue de la covariance est grande.
S'il n'y a pas de motif global, alors la covariance sera proche de zéro. Cela est dû au fait que les valeurs positives et négatives s'annuleront mutuellement.
Au premier abord, il pourrait sembler que la covariance est une mesure suffisante de la 'relation' entre deux variables. Cependant, regardez le graphique ci-dessous :
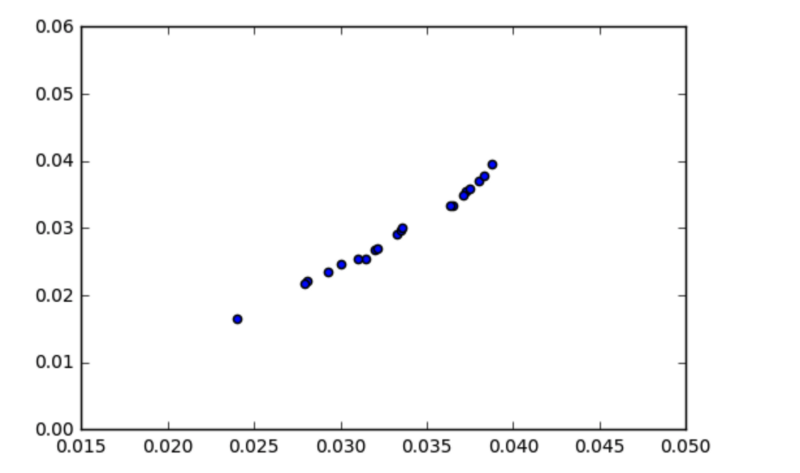 _Covariance = 0,00003. D'après une [question posée récemment sur stackexchange](https://stats.stackexchange.com/questions/320001/why-does-this-set-of-data-have-no-covariance" rel="noopener" target="blank" title=")
_Covariance = 0,00003. D'après une [question posée récemment sur stackexchange](https://stats.stackexchange.com/questions/320001/why-does-this-set-of-data-have-no-covariance" rel="noopener" target="blank" title=")
On dirait qu'il y a une forte relation entre les variables, n'est-ce pas ? Alors pourquoi la covariance est-elle si faible, à environ 0,00003 ?
La clé ici est de réaliser que la covariance est dépendante de l'échelle. Regardez les axes x et y — presque tous les points de données se situent entre la plage de 0,015 et 0,04. La covariance sera également proche de zéro, puisqu'elle est calculée en soustrayant les moyennes de chaque observation individuelle.
Pour obtenir une figure plus significative, il est important de normaliser la covariance. Cela se fait en la divisant par le produit des écarts types de chacun des vecteurs.
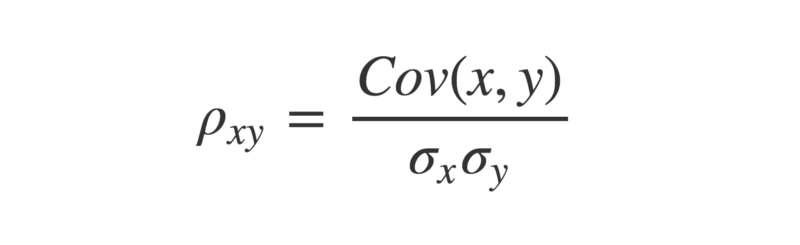 La lettre grecque rho est souvent utilisée pour désigner le r de Pearson
La lettre grecque rho est souvent utilisée pour désigner le r de Pearson
En Python :
import math
def stDev(x):
variance = 0
for i in x:
variance += (i - mean(x) ** 2) / len(x)
return math.sqrt(variance)
def Pearsons(x,y):
cov = covariance(x,y)
return cov / (stDev(x) * stDev(y))
La raison pour laquelle cela est fait est que l'écart type d'un vecteur est la racine carrée de sa variance. Cela signifie que si deux vecteurs sont identiques, alors multiplier leurs écarts types sera égal à leur variance.
Fait intéressant, la covariance de deux vecteurs identiques est également égale à leur variance.
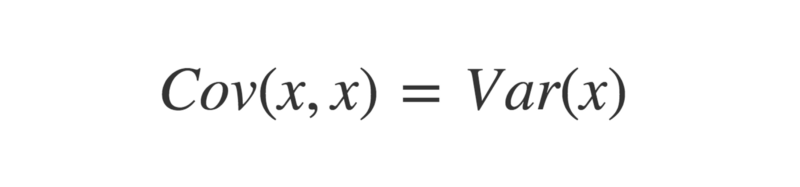
Par conséquent, la valeur maximale que la covariance entre deux vecteurs peut prendre est égale au produit de leurs écarts types, ce qui se produit lorsque les vecteurs sont parfaitement corrélés. C'est ce qui borne le coefficient de corrélation entre -1 et +1.
Dans quelle direction pointent les flèches ?
À titre accessoire, une manière beaucoup plus intéressante de définir le PCC de deux vecteurs vient de l'algèbre linéaire.
Tout d'abord, nous centrons les vecteurs, en soustrayant leurs moyennes de leurs valeurs individuelles.
a = [1,2,3,4,5] ; b = [5,4,3,2,1]
a_centered = [i - mean(a) for i in a]
b_centered = [j - mean(b) for j in b]
Maintenant, nous pouvons utiliser le fait que les vecteurs peuvent être considérés comme des 'flèches' pointant dans une direction donnée.
Par exemple, en 2-D, le vecteur [1,3] pourrait être représenté comme une flèche pointant 1 unité le long de l'axe x, et 3 unités le long de l'axe y. De même, le vecteur [2,1] pourrait être représenté comme une flèche pointant 2 unités le long de l'axe x, et 1 unité le long de l'axe y.
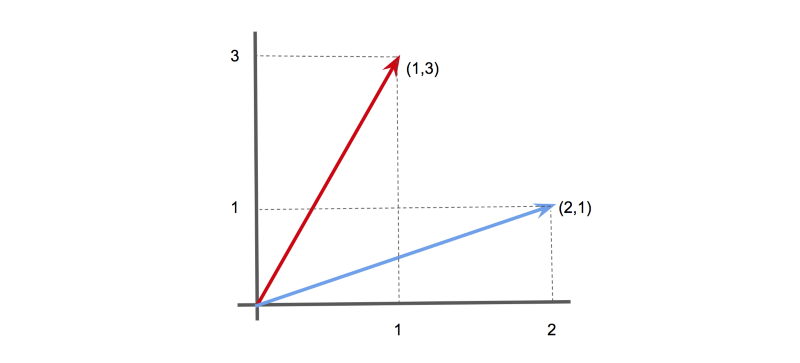 Deux vecteurs (1,3) et (2,1) représentés comme des flèches.
Deux vecteurs (1,3) et (2,1) représentés comme des flèches.
De même, nous pouvons représenter nos vecteurs de données comme des flèches dans un espace à n dimensions (bien que n'essayez pas de visualiser lorsque n > 3...)
L'angle θ entre ces flèches peut être calculé en utilisant le produit scalaire des deux vecteurs. Cela est défini comme :
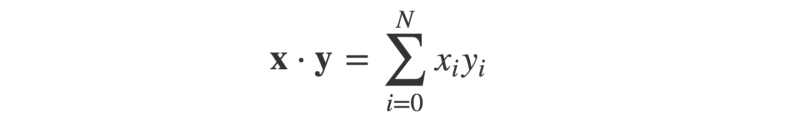
Ou, en Python :
def dotProduct(x,y):
calc = 0
for i in range(len(x)):
calc += x[i] * y[i]
return calc
Le produit scalaire peut également être défini comme :
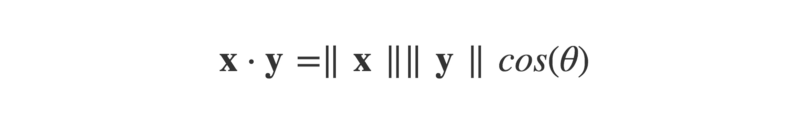
Où ||x|| est la magnitude (ou 'longueur') du vecteur x (pensez au théorème de Pythagore), et θ est l'angle entre les vecteurs flèches.
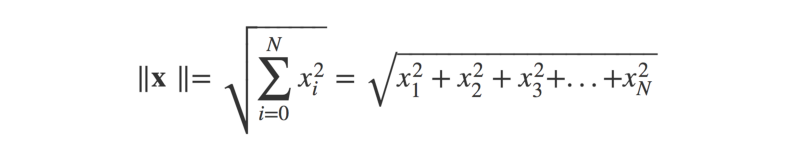
En tant que fonction Python :
def magnitude(x):
x_sq = [i ** 2 for i in x]
return math.sqrt(sum(x_sq))
Cela nous permet de trouver cos(θ), en divisant le produit scalaire par le produit des magnitudes des deux vecteurs.
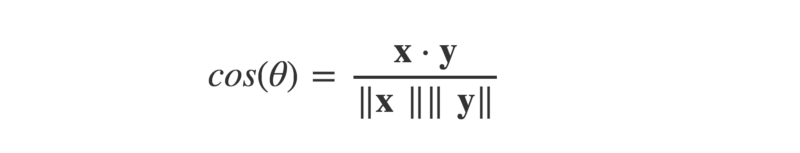
def cosTheta(x,y):
mag_x = magnitude(x)
mag_y = magnitude(y)
return dotProduct(x,y) / (mag_x * mag_y)
Maintenant, si vous connaissez un peu de trigonométrie, vous vous souviendrez peut-être que la fonction cosinus produit un graphique qui oscille entre +1 et -1.
 _[Source](http://cda.mrs.umn.edu/~mcquarrb/teachingarchive/Precalculus/Animations/SineCosineAnim.html" rel="noopener" target="blank" title=")
_[Source](http://cda.mrs.umn.edu/~mcquarrb/teachingarchive/Precalculus/Animations/SineCosineAnim.html" rel="noopener" target="blank" title=")
La valeur de cos(θ) variera en fonction de l'angle entre les deux vecteurs flèches.
- Lorsque l'angle est zéro (c'est-à-dire, les vecteurs pointent dans la même direction exacte), cos(θ) sera égal à 1.
- Lorsque l'angle est -180°, (les vecteurs pointent dans des directions exactement opposées), alors cos(θ) sera égal à -1.
- Lorsque l'angle est 90° (les vecteurs pointent dans des directions complètement indépendantes), alors cos(θ) sera égal à zéro.
Cela peut sembler familier — une mesure entre +1 et -1 qui semble décrire la relation entre deux vecteurs ? N'est-ce pas le r de Pearson ?
Eh bien — c'est exactement ce que c'est ! En considérant les données comme des vecteurs flèches dans un espace à haute dimension, nous pouvons utiliser l'angle θ entre eux comme une mesure de similarité.
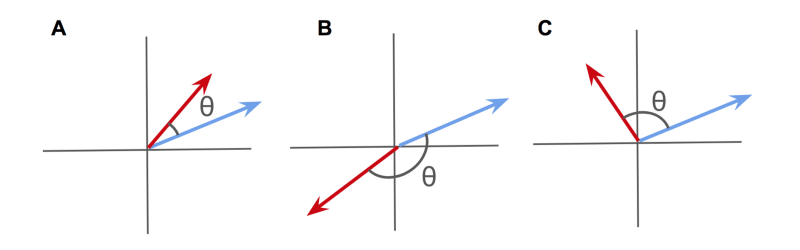 A) Vecteurs corrélés positivement ; B) Vecteurs corrélés négativement ; C) Vecteurs non corrélés
A) Vecteurs corrélés positivement ; B) Vecteurs corrélés négativement ; C) Vecteurs non corrélés
Le cosinus de cet angle θ est mathématiquement identique au coefficient de corrélation de Pearson.
Lorsque l'on les considère comme des flèches à haute dimension, les vecteurs corrélés positivement pointeront dans une direction similaire.
Les vecteurs corrélés négativement pointeront vers des directions opposées.
Et les vecteurs non corrélés pointeront à angle droit l'un par rapport à l'autre.
Personnellement, je pense que c'est une manière vraiment intuitive de comprendre la corrélation.
Significativité statistique ?
Comme c'est toujours le cas avec les statistiques fréquentistes, il est important de se demander à quel point une statistique de test calculée à partir d'un échantillon donné est réellement significative. Le r de Pearson n'est pas une exception.
Malheureusement, appliquer des intervalles de confiance à une estimation de PCC n'est pas entièrement direct.
Cela est dû au fait que le r de Pearson est borné entre -1 et +1, et donc n'est pas normalement distribué. Une estimation de PCC de, disons, +0,95 a seulement autant de place pour l'erreur au-dessus, mais beaucoup de place en dessous.
Heureusement, il existe une solution — en utilisant un truc appelé la Z-transformation de Fisher :
- Calculez une estimation du r de Pearson comme d'habitude.
- Transformez r→z en utilisant la Z-transformation de Fisher. Cela peut être fait en utilisant la formule z = arctanh(r), où arctanh est la fonction tangente hyperbolique inverse.
- Maintenant, calculez l'écart type de z. Heureusement, cela est simple à calculer, et est donné par SDz = 1/sqrt(n-3), où n est la taille de l'échantillon.
- Choisissez votre seuil de significativité, alpha, et vérifiez combien d'écarts types par rapport à la moyenne cela correspond. Si nous prenons alpha = 0,95, utilisez 1,96.
- Trouvez l'estimation supérieure en calculant z +(1,96 × SDz), et la borne inférieure en calculant z - (1,96 × SDz).
- Convertissez ces valeurs en r, en utilisant r = tanh(z), où tanh est la fonction tangente hyperbolique.
- Si les bornes supérieure et inférieure sont toutes deux du même côté de zéro, vous avez une significativité statistique !
Voici une implémentation en Python :
r = Pearsons(x,y)
z = math.atanh(r)
SD_z = 1 / math.sqrt(len(x) - 3)
z_upper = z + 1.96 * SD_z
z_lower = z - 1.96 * SD_z
r_upper = math.tanh(z_upper)
r_lower = math.tanh(z_lower)
Bien sûr, lorsqu'on dispose d'un grand ensemble de données de nombreuses variables potentiellement corrélées, il peut être tentant de vérifier chaque corrélation par paire. Cela est souvent appelé 'fouille de données' — fouiller l'ensemble de données pour trouver des relations apparentes entre les variables.
Si vous adoptez cette approche de comparaison multiple, vous devriez utiliser des seuils de significativité plus stricts pour réduire votre risque de découvrir des faux positifs (c'est-à-dire, trouver des variables non liées qui semblent corrélées purement par hasard).
Une méthode pour faire cela est d'utiliser la correction de Bonferroni.
Les petits caractères
Jusqu'à présent, tout va bien. Nous avons vu comment le r de Pearson peut être utilisé pour calculer le coefficient de corrélation entre deux variables, et comment évaluer la significativité statistique du résultat. Étant donné un ensemble de données non vues, il est possible de commencer à chercher des relations significatives entre les variables.
Cependant, il y a un piège majeur — le r de Pearson ne fonctionne que pour les données linéaires.
Regardez les graphiques ci-dessous. Ils montrent clairement ce qui ressemble à une relation non aléatoire, mais le r de Pearson est très proche de zéro.
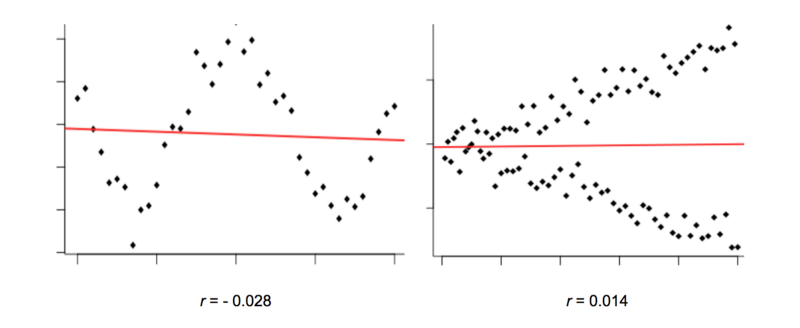
La raison en est que les variables dans ces graphiques ont une relation non linéaire.
Nous pouvons généralement visualiser une relation entre deux variables comme un 'nuage' de points dispersés de chaque côté d'une ligne. Plus la dispersion est large, plus les données sont 'bruyantes', et plus la relation est faible.
Cependant, le r de Pearson compare chaque point de données individuel avec un seul autre (les moyennes globales). Cela signifie qu'il ne peut considérer que des lignes droites. Il n'est pas très bon pour détecter des relations non linéaires.
Dans les graphiques ci-dessus, le r de Pearson ne révèle pas qu'il y a beaucoup de corrélation à discuter.
Pourtant, la relation entre ces variables est clairement non aléatoire, et cela les rend potentiellement utiles comme prédicteurs l'une de l'autre. Comment les machines peuvent-elles identifier cela ? Heureusement, il existe différentes mesures de corrélation disponibles pour nous.
Examinons quelques-unes d'entre elles.
Corrélation de distance
Qu'est-ce que c'est ?
La corrélation de distance présente certaines similitudes avec le r de Pearson, mais est en fait calculée en utilisant une notion de covariance plutôt différente. La méthode fonctionne en remplaçant nos concepts quotidiens de covariance et d'écart type (tels que définis ci-dessus) par des analogues de 'distance'.
Tout comme le r de Pearson, la 'corrélation de distance' est définie comme la 'covariance de distance' normalisée par l''écart type de distance'.
Au lieu d'évaluer comment deux variables tendent à co-varier en fonction de leur distance par rapport à leurs moyennes respectives, la corrélation de distance évalue comment elles tendent à co-varier en termes de leurs distances par rapport à tous les autres points.
Cela ouvre la possibilité de mieux capturer les dépendances non linéaires entre les variables.
Les détails...
Robert Brown était un botaniste écossais né en 1773. En étudiant le pollen des plantes sous son microscope, Brown a remarqué de minuscules particules organiques qui tremblaient au hasard à la surface de l'eau qu'il utilisait.
Peut-être ne pouvait-il pas soupçonner qu'une observation fortuite de sa part mènerait à l'immortalisation de son nom en tant que (re-)découvreur du mouvement brownien.
Encore moins pouvait-il savoir qu'il faudrait près d'un siècle avant qu'Albert Einstein ne fournisse une explication du phénomène — et prouve ainsi l'existence des atomes — la même année où il publia des articles sur E=MC², la relativité restreinte et aida à lancer le domaine de la théorie quantique.
Le mouvement brownien est un processus physique par lequel des particules se déplacent au hasard en raison de collisions avec les molécules environnantes.
Les mathématiques derrière ce processus peuvent être généralisées en un concept connu sous le nom de processus de Wiener. Parmi d'autres choses, le processus de Wiener joue un rôle important dans le modèle le plus célèbre des finances mathématiques, Black-Scholes.
Intéressamment, le mouvement brownien et le processus de Wiener s'avèrent pertinents pour une mesure de corrélation non linéaire développée au milieu des années 2000 grâce au travail de Gabor Szekely.
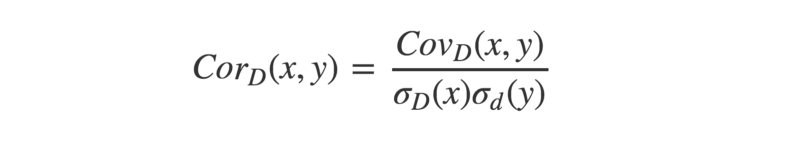
Passons en revue comment cela peut être calculé pour deux vecteurs x et y, chacun de longueur N.
- Tout d'abord, nous formons des matrices de distance N×N pour chacun des vecteurs. Une matrice de distance est exactement comme un tableau des distances routières dans un atlas — l'intersection de chaque ligne et colonne montre la distance entre les villes correspondantes. Ici, l'intersection entre la ligne i et la colonne j donne la distance entre les i-ème et j-ème éléments du vecteur.
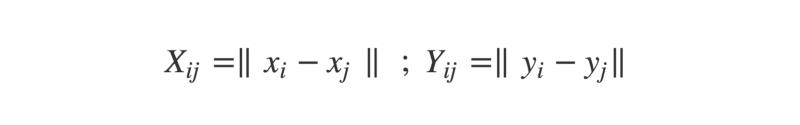
- Ensuite, les matrices sont 'double-centrées'. Cela signifie que pour chaque élément, nous soustrayons la moyenne de sa ligne et la moyenne de sa colonne. Ensuite, nous ajoutons la moyenne générale de toute la matrice.
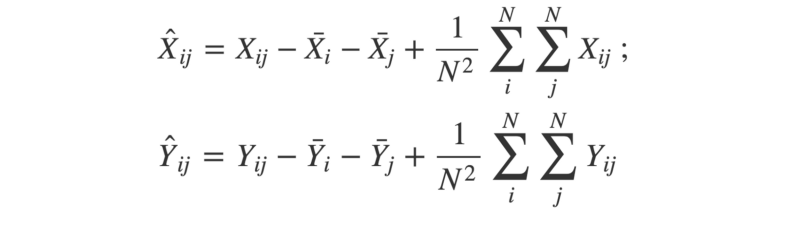 Les symboles 'chapeau' signifient 'double-centré' ; les symboles 'barre' signifient 'moyenne'
Les symboles 'chapeau' signifient 'double-centré' ; les symboles 'barre' signifient 'moyenne'
- Avec les deux matrices double-centrées, nous pouvons calculer le carré de la covariance de distance en prenant la moyenne de chaque élément dans X multiplié par son élément correspondant dans Y.
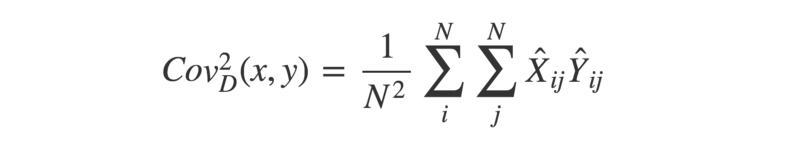
- Maintenant, nous pouvons utiliser une approche similaire pour trouver la 'variance de distance'. Souvenez-vous — la covariance de deux vecteurs identiques est équivalente à leur variance. Par conséquent, la variance de distance au carré peut être décrite comme ci-dessous :
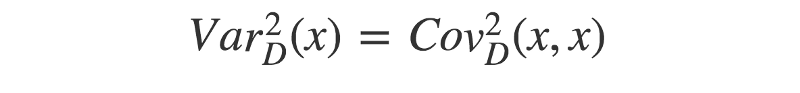
- Enfin, nous avons toutes les pièces pour calculer la corrélation de distance. Souvenez-vous que l'écart type (de distance) est égal à la racine carrée de la (variance de distance).
Si vous préférez travailler avec du code plutôt qu'avec des notations mathématiques (après tout, il y a une raison pour laquelle les gens tendent à écrire des logiciels dans un langage et non dans l'autre...), alors consultez l'implémentation R ci-dessous :
set.seed(1234)
doubleCenter <- function(x){
centered <- x
for(i in 1:dim(x)[1]){
for(j in 1:dim(x)[2]){
centered[i,j] <- x[i,j] - mean(x[i,]) - mean(x[,j]) + mean(x)
}
}
return(centered)
}
distanceCovariance <- function(x,y){
N <- length(x)
distX <- as.matrix(dist(x))
distY <- as.matrix(dist(y))
centeredX <- doubleCenter(distX)
centeredY <- doubleCenter(distY)
calc <- sum(centeredX * centeredY)
return(sqrt(calc/(N^2)))
}
distanceVariance <- function(x){
return(distanceCovariance(x,x))
}
distanceCorrelation <- function(x,y){
cov <- distanceCovariance(x,y)
sd <- sqrt(distanceVariance(x)*distanceVariance(y))
return(cov/sd)
}
# Comparaison avec le r de Pearson
x <- -10:10
y <- x^2 + rnorm(21,0,10)
cor(x,y) # --> 0.057
distanceCorrelation(x,y) # --> 0.509
La corrélation de distance entre deux variables est bornée entre zéro et un. Zéro implique que les variables sont indépendantes, tandis qu'un score proche de un indique une relation dépendante.
Si vous préférez ne pas écrire vos propres méthodes de corrélation de distance à partir de zéro, vous pouvez installer le package energy de R, écrit par les chercheurs qui ont conçu la méthode. Les méthodes disponibles dans ce package appellent des fonctions écrites en C, offrant un grand avantage de vitesse.
Interprétation physique
L'un des résultats les plus surprenants concernant la formulation de la corrélation de distance est qu'elle présente une équivalence exacte avec la corrélation brownienne.
La corrélation brownienne fait référence à l'indépendance (ou à la dépendance) de deux processus browniens. Les processus browniens qui sont dépendants montreront une tendance à se 'suivre' mutuellement.
Une métaphore simple pour aider à saisir le concept de corrélation de distance est d'imaginer une flotte de bateaux en papier flottant à la surface d'un lac.
S'il n'y a pas de direction dominante du vent, alors chaque bateau dérivera au hasard — d'une manière qui est (en quelque sorte) analogue au mouvement brownien.
 Bateaux dérivant sans vent dominant
Bateaux dérivant sans vent dominant
S'il y a un vent dominant, alors la direction dans laquelle les bateaux dérivent dépendra de la force du vent. Plus le vent est fort, plus la dépendance est forte.
 Sous un vent dominant, les bateaux tendront à dériver dans la même direction
Sous un vent dominant, les bateaux tendront à dériver dans la même direction
De manière comparable, les variables non corrélées peuvent être considérées comme des bateaux dérivant sans vent dominant. Les variables corrélées peuvent être considérées comme des bateaux dérivant sous l'influence d'un vent dominant. Dans cette métaphore, le vent représente la force de la relation entre les deux variables.
Si nous permettons à la direction du vent dominant de varier à différents points du lac, alors nous pouvons introduire une notion de non-linéarité dans l'analogie. La corrélation de distance utilise les distances entre les 'bateaux' pour inférer la force du vent dominant.

Intervalles de confiance ?
Les intervalles de confiance peuvent être établis pour une estimation de la corrélation de distance en utilisant une technique de 'rééchantillonnage'. Un exemple simple est le rééchantillonnage bootstrap.
C'est un tour de passe-passe statistique astucieux qui nous oblige à 'reconstruire' les données en échantillonnant aléatoirement (avec remplacement) à partir de l'ensemble de données original. Cela est répété de nombreuses fois (par exemple, 1000), et chaque fois la statistique d'intérêt est calculée.
Cela produira une gamme de différentes estimations pour la statistique qui nous intéresse. Nous pouvons utiliser celles-ci pour estimer les bornes supérieure et inférieure pour un niveau de confiance donné.
Consultez le code R ci-dessous pour une fonction bootstrap simple :
set.seed(1234)
bootstrap <- function(x,y,reps,alpha){
estimates <- c()
original <- data.frame(x,y)
N <- dim(original)[1]
for(i in 1:reps){
S <- original[sample(1:N, N, replace = TRUE),]
estimates <- append(estimates, distanceCorrelation(S$x, S$y))
}
u <- alpha/2 ; l <- 1-u
interval <- quantile(estimates, c(l, u))
return(2*(dcor(x,y)) - as.numeric(interval[1:2]))
}
# Utiliser avec 1000 répétitions et un seuil alpha = 0,05
x <- -10:10
y <- x^2 + rnorm(21,0,10)
bootstrap(x,y,1000,0.05) # --> 0.237 à 0.546
Si vous souhaitez établir une significativité statistique, il existe un autre tour de rééchantillonnage disponible, appelé 'test de permutation'.
Cela est légèrement différent de la méthode bootstrap définie ci-dessus. Ici, nous gardons un vecteur constant et 'mélangeons' l'autre en rééchantillonnant. Cela approxime l'hypothèse nulle — qu'il n'y a pas de dépendance entre les variables.
La variable 'mélangée' est ensuite utilisée pour calculer la corrélation de distance entre elle et la variable constante. Cela est fait de nombreuses fois, et la distribution des résultats est comparée à la corrélation de distance réelle (obtenue à partir des données non mélangées).
La proportion de résultats 'mélangés' supérieurs ou égaux au résultat 'réel' est ensuite prise comme une valeur p, qui peut être comparée à un seuil de significativité donné (par exemple, 0,05).
Consultez le code pour voir comment cela fonctionne :
permutationTest <- function(x,y,reps){
estimates <- c()
observed <- distanceCorrelation(x,y)
N <- length(x)
for(i in 1:reps){
y_i <- sample(y, length(y), replace = T)
estimates <- append(estimates, distanceCorrelation(x, y_i))
}
p_value <- mean(estimates >= observed)
return(p_value)
}
# Utiliser avec 1000 répétitions
x <- -10:10
y <- x^2 + rnorm(21,0,10)
permutationTest(x,y,1000) # --> 0.036
Coefficient d'information maximale
Qu'est-ce que c'est ?
Le Coefficient d'Information Maximale (MIC) est une méthode récente pour détecter les dépendances non linéaires entre les variables, conçue en 2011. L'algorithme utilisé pour calculer le MIC applique des concepts de la théorie de l'information et de la probabilité aux données continues.
Plongeons...
La théorie de l'information est un domaine fascinant des mathématiques qui a été pionnier par Claude Shannon au milieu du vingtième siècle.
Un concept clé est l'entropie — une mesure de l'incertitude dans une distribution de probabilité donnée. Une distribution de probabilité décrit les probabilités d'un ensemble donné de résultats associés à un événement particulier.
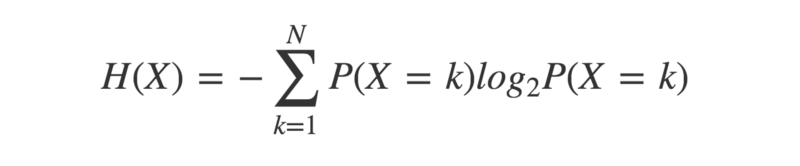 L'entropie d'une distribution de probabilité est moins « la somme de la probabilité de chaque résultat, multipliée par le logarithme de lui-même »
L'entropie d'une distribution de probabilité est moins « la somme de la probabilité de chaque résultat, multipliée par le logarithme de lui-même »
Pour comprendre comment cela fonctionne, comparez les deux distributions de probabilité ci-dessous :
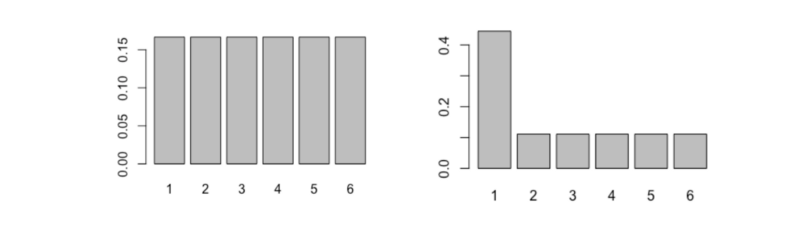 Les résultats possibles sont sur l'axe X ; leurs probabilités respectives sont sur l'axe Y
Les résultats possibles sont sur l'axe X ; leurs probabilités respectives sont sur l'axe Y
À gauche se trouve celle d'un dé à six faces équilibré, et à droite se trouve la distribution d'un dé à six faces moins équilibré.
Intuitivement, lequel pensez-vous avoir l'entropie la plus élevée ? Pour quel dé le résultat est-il le moins certain ? Calculons l'entropie et voyons ce que la réponse sera.
entropy <- function(x){
pr <- prop.table(table(x))
H <- sum(pr * log(pr,2))
return(-H)
}
dice1 <- 1:6
dice2 <- c(1,1,1,1,2:6)
entropy(dice1) # --> 2.585
entropy(dice2) # --> 2.281
Comme vous l'avez peut-être attendu, le dé le plus équilibré a l'entropie la plus élevée.
C'est parce que chaque résultat est aussi probable que n'importe quel autre, donc nous ne pouvons pas savoir à l'avance lequel favoriser.
Le dé déséquilibré nous donne plus d'informations — certains résultats sont beaucoup plus probables que d'autres — donc il y a moins d'incertitude sur le résultat.
Par ce raisonnement, nous pouvons voir que l'entropie sera la plus élevée lorsque chaque résultat est également probable. Ce type de distribution de probabilité est appelé une distribution 'uniforme'.
L'entropie croisée est une extension du concept d'entropie, qui prend en compte une deuxième distribution de probabilité.
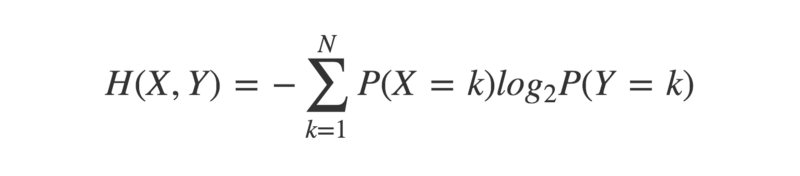
crossEntropy <- function(x,y){
prX <- prop.table(table(x))
prY <- prop.table(table(y))
H <- sum(prX * log(prY,2))
return(-H)
}
Cela a la propriété que l'entropie croisée entre deux distributions de probabilité identiques est égale à leur entropie individuelle. Lorsque l'on considère deux distributions de probabilité non identiques, il y aura une différence entre leur entropie croisée et leurs entropies individuelles.
Cette différence, ou 'divergence', peut être quantifiée en calculant leur divergence de Kullback-Leibler, ou KL-divergence.
La KL-divergence de deux distributions de probabilité X et Y est :
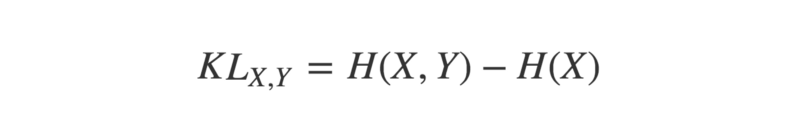 La KL-divergence des distributions de probabilité X et Y est égale à leur entropie croisée, moins l'entropie de X
La KL-divergence des distributions de probabilité X et Y est égale à leur entropie croisée, moins l'entropie de X
La valeur minimale de la KL-divergence entre deux distributions est zéro. Cela ne se produit que lorsque les distributions sont identiques.
KL_divergence <- function(x,y){
kl <- crossEntropy(x,y) - entropy(x)
return(kl)
}
Une utilisation de la KL-divergence dans le contexte de la découverte de corrélations est de calculer l'information mutuelle (MI) de deux variables.
L'information mutuelle peut être définie comme « la KL-divergence entre les distributions jointes et marginales de deux variables aléatoires ». Si celles-ci sont identiques, MI sera égal à zéro. Si elles sont différentes, alors MI sera un nombre positif. Plus les distributions jointes et marginales sont différentes, plus MI est élevé.
Pour mieux comprendre cela, prenons un moment pour revisiter certains concepts de probabilité.
La distribution conjointe des variables X et Y est simplement la probabilité de leur co-occurrence. Par exemple, si vous lanciez deux pièces X et Y, leur distribution conjointe refléterait la probabilité de chaque résultat observé. Supposons que vous lanciez les pièces 100 fois, et obtenez le résultat « pile, pile » 40 fois. La distribution conjointe refléterait cela.
P(X=P, Y=P) = 40/100 = 0,4
jointDist <- function(x,y){
N <- length(x)
u <- unique(append(x,y))
joint <- c()
for(i in u){
for(j in u){
f <- x[paste0(x,y) == paste0(i,j)]
joint <- append(joint, length(f)/N)
}
}
return(joint)
}
La distribution marginale est la distribution de probabilité d'une variable en l'absence de toute information sur l'autre. Le produit de deux distributions marginales donne la probabilité de la co-occurrence de deux événements sous l'hypothèse d'indépendance.
Pour l'exemple du lancer de pièces, supposons que les deux pièces produisent 50 piles et 50 faces. Leurs distributions marginales refléteraient cela.
P(X=P) = 50/100 = 0,5 ; P(Y=P) = 50/100 = 0,5
P(X=P) × P(Y=P) = 0,5 × 0,5 = 0,25
marginalProduct <- function(x,y){
N <- length(x)
u <- unique(append(x,y))
marginal <- c()
for(i in u){
for(j in u){
fX <- length(x[x == i]) / N
fY <- length(y[y == j]) / N
marginal <- append(marginal, fX * fY)
}
}
return(marginal)
}
Revenons à l'exemple du lancer de pièces, le produit des distributions marginales donnera la probabilité d'observer chaque résultat si les deux pièces sont indépendantes, tandis que la distribution conjointe donnera la probabilité de chaque résultat, tel qu'observé.
Si les pièces sont réellement indépendantes, alors la distribution conjointe devrait être (approximativement) identique au produit des distributions marginales. Si elles sont dépendantes d'une certaine manière, alors il y aura une divergence.
Dans l'exemple, P(X=P,Y=P) > P(X=P) × P(Y=P). Cela suggère que les pièces tombent toutes deux sur pile plus souvent que ce qui serait attendu par hasard.
Plus la divergence entre les distributions conjointe et marginale est grande, plus il est probable que les événements soient dépendants d'une certaine manière. La mesure de cette divergence est définie par l'information mutuelle des deux variables.
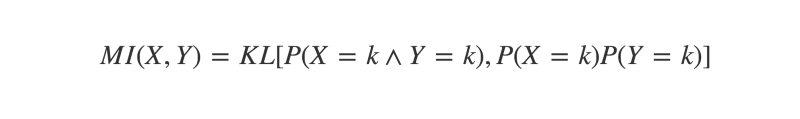 L'information mutuelle de X et Y est égale à « la divergence KL de leur distribution conjointe, et le produit de leurs distributions marginales »
L'information mutuelle de X et Y est égale à « la divergence KL de leur distribution conjointe, et le produit de leurs distributions marginales »
mutualInfo <- function(x,y){
joint <- jointDist(x,y)
marginal <- marginalProduct(x,y)
Hjm <- - sum(joint[marginal > 0] * log(marginal[marginal > 0],2))
Hj <- - sum(joint[joint > 0] * log(joint[joint > 0],2))
return(Hjm - Hj)
}
Une hypothèse majeure ici est que nous travaillons avec des distributions de probabilité discrètes. Comment pouvons-nous appliquer ces concepts aux données continues ?
Binning
Une approche consiste à quantifier les données (rendre les variables discrètes). Cela est réalisé par le binning (attribution de points de données à des catégories discrètes).
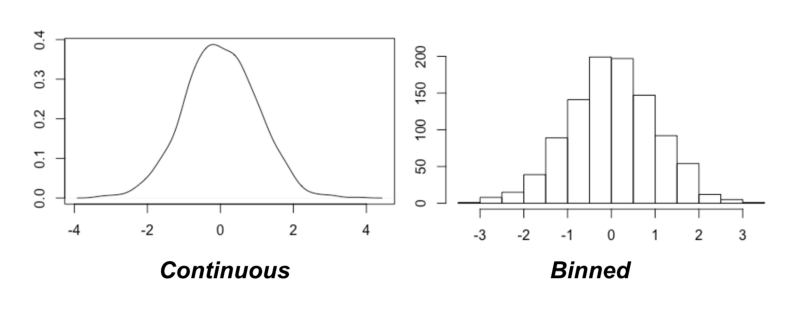
Le problème clé maintenant est de décider combien de bins utiliser. Heureusement, l'article original sur le Coefficient d'Information Maximale fournit une suggestion : essayez la plupart d'entre eux !
C'est-à-dire, essayez différents nombres de bins et voyez lequel produit le plus grand résultat d'information mutuelle entre les variables. Cela soulève deux défis, cependant :
- Combien de bins essayer ? Techniquement, vous pourriez quantifier une variable en n'importe quel nombre de bins, simplement en rendant la taille des bins de plus en plus petite.
- L'information mutuelle est sensible au nombre de bins utilisés. Comment comparez-vous équitablement l'IM entre différents nombres de bins ?
Le premier défi signifie qu'il est techniquement impossible d'essayer chaque nombre possible de bins. Cependant, les auteurs de l'article offrent une solution heuristique (c'est-à-dire, une solution qui n'est pas 'garantie parfaite', mais qui est une assez bonne approximation). Ils suggèrent également une limite supérieure au nombre de bins à essayer.
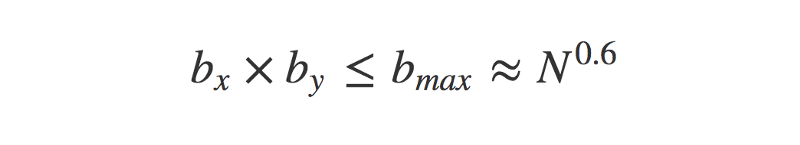 Le nombre maximum de bins à essayer est déterminé par la taille de l'échantillon, N
Le nombre maximum de bins à essayer est déterminé par la taille de l'échantillon, N
En ce qui concerne la comparaison équitable des valeurs d'IM entre différents schémas de binning, il y a une solution simple... normalisez-la ! Cela peut être fait en divisant chaque score d'IM par le maximum qu'il pourrait théoriquement prendre pour cette combinaison particulière de bins.
La combinaison de bins qui produit l'IM normalisée la plus élevée globalement est celle à utiliser.
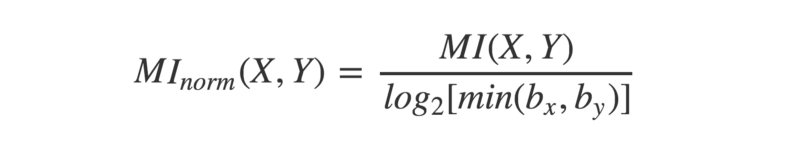 L'information mutuelle peut être normalisée en divisant par le logarithme du plus petit nombre de bins
L'information mutuelle peut être normalisée en divisant par le logarithme du plus petit nombre de bins
L'IM normalisée la plus élevée est ensuite rapportée comme le Coefficient d'Information Maximale (ou 'MIC') pour ces deux variables. Examinons un peu de code qui estimera le MIC de deux variables continues.
MIC <- function(x,y){
N <- length(x)
maxBins <- ceiling(N ** 0.6)
MI <- c()
for(i in 2:maxBins) {
for (j in 2:maxBins){
if(i * j > maxBins){
next
}
Xbins <- i; Ybins <- j
binnedX <-cut(x, breaks=Xbins, labels = 1:Xbins)
binnedY <-cut(y, breaks=Ybins, labels = 1:Ybins)
MI_estimate <- mutualInfo(binnedX,binnedY)
MI_normalized <- MI_estimate / log(min(Xbins,Ybins),2)
MI <- append(MI, MI_normalized)
}
}
return(max(MI))
}
x <- runif(100,-10,10)
y <- x**2 + rnorm(100,0,10)
MIC(x,y) # --> 0.751
Le code ci-dessus est une simplification de la méthode décrite dans l'article original. Une implémentation plus fidèle de l'algorithme est disponible dans le package R minerva. En Python, vous pouvez utiliser le module minepy.
Le MIC est capable de détecter tous types de relations linéaires et non linéaires, et a trouvé des utilisations dans une gamme d'applications différentes. Il est borné entre 0 et 1, avec des valeurs plus élevées indiquant une plus grande dépendance.
Intervalles de confiance ?
Pour établir des bornes de confiance sur une estimation de MIC, vous pouvez simplement utiliser une technique de bootstrap comme celle que nous avons vue précédemment.
Pour généraliser la fonction bootstrap, nous pouvons tirer parti des capacités de programmation fonctionnelle de R, en passant la technique que nous voulons utiliser comme argument.
bootstrap <- function(x,y,func,reps,alpha){
estimates <- c()
original <- data.frame(x,y)
N <- dim(original)[1]
for(i in 1:reps){
S <- original[sample(1:N, N, replace = TRUE),]
estimates <- append(estimates, func(S$x, S$y))
}
l <- alpha/2 ; u <- 1 - l
interval <- quantile(estimates, c(u, l))
return(2*(func(x,y)) - as.numeric(interval[1:2]))
}
bootstrap(x,y,MIC,100,0.05) # --> 0.594 à 0.88
Résumé
Pour conclure ce tour d'horizon de la corrélation, testons chaque méthode différente contre une gamme de données générées artificiellement. Le code pour ces exemples peut être trouvé ici.
Bruit
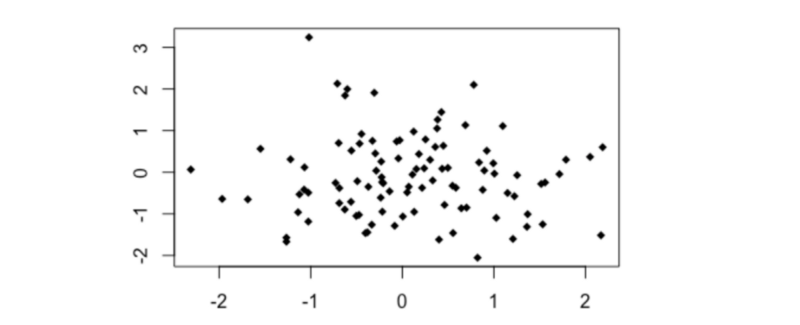
set.seed(123)
# Bruit
x0 <- rnorm(100,0,1)
y0 <- rnorm(100,0,1)
plot(y0~x0, pch = 18)
cor(x0,y0)
distanceCorrelation(x0,y0)
MIC(x0,y0)
- Pearson's r = - 0.05
- Distance Correlation = 0.157
- MIC = 0.097
Simple linéaire
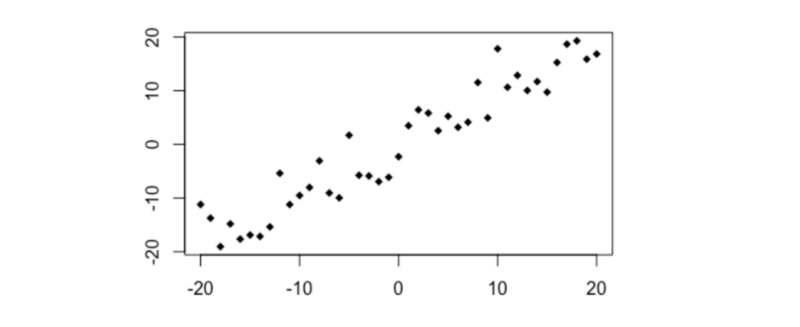
# Simple relation linéaire
x1 <- -20:20
y1 <- x1 + rnorm(41,0,4)
plot(y1~x1, pch =18)
cor(x1,y1)
distanceCorrelation(x1,y1)
MIC(x1,y1)
- Pearson's r =+0.95
- Distance Correlation = 0.95
- MIC = 0.89
Simple quadratique
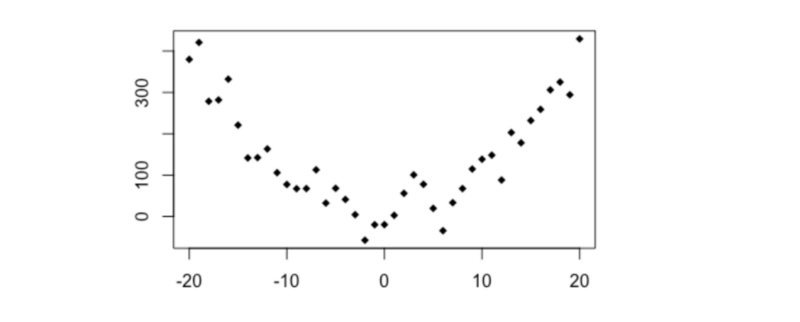
# y ~ x**2
x2 <- -20:20
y2 <- x2**2 + rnorm(41,0,40)
plot(y2~x2, pch = 18)
cor(x2,y2)
distanceCorrelation(x2,y2)
MIC(x2,y2)
- Pearson's r =+0.003
- Distance Correlation = 0.474
- MIC = 0.594
Trigonométrique
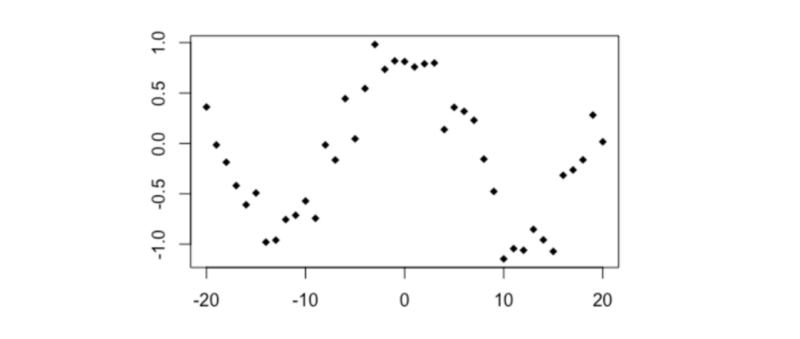
# Cosinus
x3 <- -20:20
y3 <- cos(x3/4) + rnorm(41,0,0.2)
plot(y3~x3, type='p', pch=18)
cor(x3,y3)
distanceCorrelation(x3,y3)
MIC(x3,y3)
- Pearson's r = - 0.035
- Distance Correlation = 0.382
- MIC = 0.484
Cercle
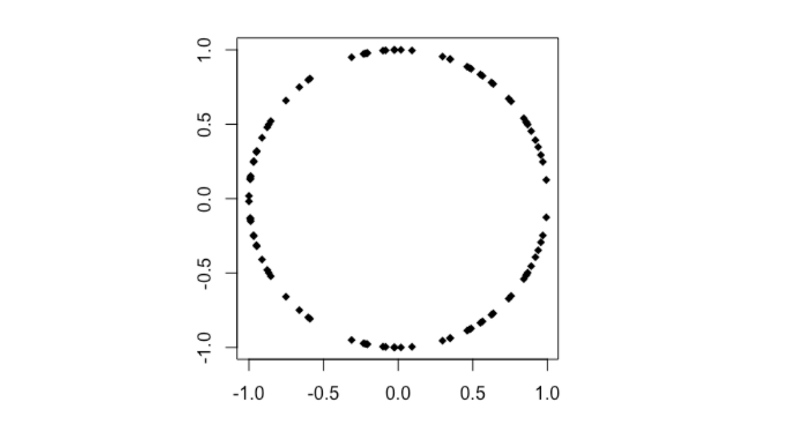
# Cercle
n <- 50
theta <- runif (n, 0, 2*pi)
x4 <- append(cos(theta), cos(theta))
y4 <- append(sin(theta), -sin(theta))
plot(x4,y4, pch=18)
cor(x4,y4)
distanceCorrelation(x4,y4)
MIC(x4,y4)
- Pearson's r < 0.001
- Distance Correlation = 0.234
- MIC = 0.218
Merci d'avoir lu !