


Article original : Asynchronous vs Batch Data Processing in Distributed Systems – Explained with Examples
Les systèmes distribués traitent et stockent souvent d'énormes quantités de données. Le traitement efficace de ces données est généralement un effort continu, et la manière dont il est conçu affecte presque toujours l'expérience utilisateur finale d'un produit.
Deux modes populaires de traitement des données sont le traitement par lots et le traitement asynchrone. Nous en apprendrons davantage sur les deux dans cet article, ainsi que sur le moment d'utiliser chaque approche.
Table des matières
- Quand utilisons-nous le traitement par lots ?
- Exemple concret de traitement par lots des données
- Quand utilisons-nous le traitement asynchrone
- Exemple concret de traitement asynchrone des données
Traitement par lots des données
Qu'est-ce que le traitement par lots ?
Le traitement par lots, comme vous l'aurez peut-être deviné, attend qu'une certaine quantité de données soit accumulée, puis traite ce lot de données en une seule fois. En d'autres termes, cela signifie que dans la plupart des scénarios, nous attendrions qu'un certain nombre d'événements se produisent, puis nous traiterions les données.
Cela diffère du traitement asynchrone des données, où nous traitons un événement et ses données associées dès qu'il se produit. Plus d'informations à ce sujet bientôt.
Maintenant que vous en savez un peu plus sur le traitement par lots, il sera utile de voir quelques exemples concrets.
Quand utilisons-nous le traitement par lots ?
Le traitement par lots est utilisé dans de nombreux scénarios, tels que :
- Grand volume de données : Lorsque nous avons une très grande quantité de données, il est souvent plus efficace en termes de ressources de laisser les données s'accumuler sur une période de temps, puis de les traiter.
- Données non sensibles au temps : Puisque le traitement par lots attend que les données s'accumulent, il n'est généralement pas adapté au traitement de données très sensibles au temps. En revanche, il est possible de traiter des lots de données à intervalles de temps courts.
- Traitement planifié des données : Dans de nombreux cas, nous avons besoin qu'une grande quantité de données soit traitée à intervalles réguliers. Les sauvegardes et mises à jour automatiques du système, par exemple, sont généralement planifiées à des intervalles particuliers. Le traitement par lots peut être très utile dans de tels scénarios.
Exemple concret de traitement par lots des données
Un cas d'utilisation populaire du traitement par lots dans le monde réel est celui des transactions par carte de crédit.
De nombreuses institutions financières choisissent de régler les transactions par carte de crédit par lots plutôt que de les régler en temps réel. Comme le règlement des transactions n'est généralement pas très sensible au temps, cela donne aux systèmes le temps d'exécuter diverses autres analyses/tâches sur les transactions, telles que la détection de fraude, les conversions de devises, etc.
 Transactions par carte de crédit et traitement par lots
Transactions par carte de crédit et traitement par lots
Le diagramme ci-dessus montre un exemple de très haut niveau du cycle de vie d'une transaction par carte de crédit. Les étapes sont les suivantes :
- La transaction par carte de crédit a lieu au point de vente (POS).
- Une passerelle transmet la demande à un composant serverless qui écrit la transaction dans une base de données de staging où la transaction est stockée temporairement.
- À la fin de la journée de travail, les transactions dans la base de données de staging sont réconciliées et passent par la détection de fraude. C'est le composant où le traitement par lots a lieu (notez que nous avons attendu que certaines données s'accumulent et que nous avons traité une grande quantité de données).
À quoi ressemble le traitement par lots en code ?
Nous avons vu un exemple de système distribué dans l'exemple ci-dessus. À quoi ressemble le traitement par lots en code ?
Ci-dessous, vous verrez un code qui vous permet de traiter un lot de messages SQS :
import boto3
def process_batch_messages(sqs, queue_url):
partial_response = sqs.receive_message(
QueueUrl=queue_url
MaxNumberOfMessages=10 # Cela définit la taille maximale du lot à 10
WaitTimeSeconds=10 # Nous attendons un maximum de 10 secondes
)
if 'Messages' in partial_response:
messages = partial_response['Messages']
for each message in messages:
# faire quelque chose avec chaque message
# supprimer le message de la file d'attente après le traitement
sqs.delete_message(QueueUrl=queue_url, ReceiptHandle=message['ReceiptHandle'])
if __name__ == '__main__':
# Initialiser le client sqs
sqs = boto3.client(
'sqs',
aws_access_key_id='Votre identifiant de clé d'accès',
aws_secret_access_key='votre clé d'accès secrète',
region_name='Votre région AWS'
)
your_queue_url = 'votre-url-de-file-d-attente'
process_batch_messages(sqs, your_queue_url)
Le code ci-dessus attend le premier des deux événements : soit que 10 secondes se soient écoulées, soit qu'une taille de lot de 10 ait été atteinte dans la file d'attente.
Traitement asynchrone des données
Qu'est-ce que le traitement asynchrone ?
Le mot asynchrone est généralement défini comme "des événements qui ne sont pas coordonnés dans le temps". Comme le suggère la définition, le traitement asynchrone des données ne repose pas sur la coordination des événements de données, et ces événements sont traités au fur et à mesure qu'ils se produisent.
Cela signifie que dès qu'un événement se produit, l'événement est traité et les données correspondant à l'événement peuvent être stockées dans un sous-système, transmises à un autre composant du système, ou peuvent simplement conduire à un autre événement étant déclenché.
Quand utilisons-nous le traitement asynchrone ?
Vous utiliserez le traitement asynchrone des données (parfois également appelé async) dans divers scénarios.
- Microservices : Les microservices impliquent souvent une demande qui nécessite une réponse immédiate. Comme ce traitement est effectué "par événement", cela nécessiterait un traitement asynchrone des données, donc dans la plupart des cas, les résultats sont retournés aux clients dans un très court laps de temps (faible latence).
- Interfaces utilisateur : Souvent, les composants des interfaces utilisateur nécessitent l'utilisation du traitement asynchrone des données. Par exemple, plusieurs récupérations de données peuvent être effectuées en arrière-plan à l'aide d'appels asynchrones lorsqu'un utilisateur utilise une application. Cela garantit que l'application fonctionne de manière fluide et réactive sans avoir besoin que les composants de l'interface utilisateur "gèlent".
- Systèmes nécessitant des réponses en temps réel : De nombreux systèmes interactifs nécessitent un traitement des données en temps réel. Au cours des dernières années, les appels vidéo et les réunions sont devenus de plus en plus populaires. Comme ces systèmes nécessitent des demandes et des réponses immédiates (et dans certains cas des flux de données étant traités), le traitement asynchrone des données est utilisé ici.
Exemple concret de traitement asynchrone des données
Les applications de chat sont un excellent exemple de traitement asynchrone des données. Ici, si un utilisateur 1 tape un message et l'envoie à l'utilisateur 2, le message doit être écrit dans les bases de données/systèmes requis, livré à l'utilisateur 2, et éventuellement lu par l'utilisateur 2 sans aucun délai.
Comme il s'agit d'un traitement en temps réel de l'événement qui s'est produit ici (l'événement étant qu'un message a été envoyé), il s'agit d'un exemple de traitement asynchrone des données.
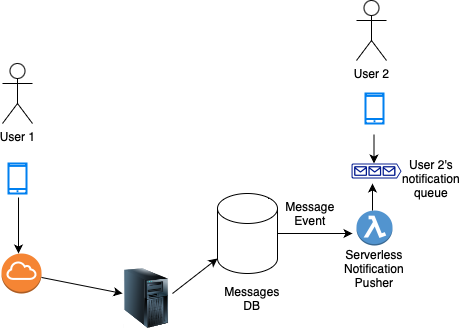 Échange de messages dans une application de chat
Échange de messages dans une application de chat
Dans le diagramme ci-dessus, nous voyons que l'utilisateur 1 envoie un message via son téléphone. Le message est acheminé vers un serveur de messages qui crée finalement une entrée dans une base de données de messages (Messages DB).
Maintenant que MessagesDB contient une entrée, un événement est déclenché et consommé par le Notification Pusher. Cela communique ensuite avec la file d'attente de notifications de l'utilisateur 2 pour placer une notification liée au message dans leur file d'attente de notifications.
Dès que l'appareil de l'utilisateur 2 est en ligne ou a accès à Internet, il reçoit une notification de message.
Notez que nous n'avons pas attendu que des données s'accumulent, ni n'avons traité ces données après un délai spécifique. Nous avons traité l'événement dès qu'il s'est produit. Il s'agit donc d'un exemple de traitement asynchrone des données.
À quoi ressemble le traitement asynchrone en code ?
Pouvons-nous modifier le code que nous avons vu dans la section sur le traitement par lots pour qu'il fonctionne pour le traitement asynchrone ? Rappelez-vous que nous avons dit "ce code attend le premier des deux événements : 10 secondes se sont écoulées, ou une taille de lot de 10 a été atteinte dans la file d'attente".
Si nous changeons la taille du lot à 1, nous traiterions effectivement un message dès qu'il est reçu.
import boto3
def process_async_messages(sqs, queue_url, batch_size):
partial_response = sqs.receive_message(
QueueUrl=queue_url
MaxNumberOfMessages=batch_size # Cela définit la taille maximale du lot
WaitTimeSeconds=10 # Nous attendons un maximum de 10 secondes
)
if 'Messages' in partial_response:
messages = partial_response['Messages']
for each message in messages:
# faire quelque chose avec chaque message
# supprimer le message de la file d'attente après le traitement
sqs.delete_message(QueueUrl=queue_url, ReceiptHandle=message['ReceiptHandle'])
if __name__ == '__main__':
# Initialiser le client sqs
sqs = boto3.client(
'sqs',
aws_access_key_id='Votre identifiant de clé d'accès',
aws_secret_access_key='votre clé d'accès secrète',
region_name='Votre région AWS'
)
your_queue_url = 'votre-url-de-file-d-attente'
process_async_messages(sqs, your_queue_url, 1)
Notez que dans le code ci-dessus, nous avons modifié process_batch_messages pour accepter un paramètre batch_size et renommé la méthode en process_async_messages. Cette méthode traite un message dès que la file d'attente reçoit un message (en supposant que la file d'attente ait reçu un message dans le délai d'attente de 10 secondes).
Résumé
Résumé du traitement par lots et asynchrone des données.
Le traitement par lots est un paradigme où vous attendez qu'une quantité de données s'accumule ou qu'un certain temps se soit écoulé avant que les données ne soient traitées.
Le traitement par lots est souvent utilisé dans des scénarios où vous avez de grands volumes de données, des données qui ne sont pas sensibles au temps, et des données qui peuvent être traitées selon un calendrier défini. L'exemple que nous avons discuté ci-dessus était celui d'une transaction par carte de crédit.
Le traitement asynchrone des données, en revanche, est utilisé pour traiter les données liées aux événements dès qu'ils se produisent.
Cette approche est souvent utilisée lors du traitement de données dans les microservices, les interfaces utilisateur, et en général avec les systèmes nécessitant un traitement en temps réel des requêtes-réponses. Nous avons examiné un exemple d'application de chat dans la discussion ci-dessus et appris comment le traitement asynchrone des données est applicable à ce scénario.