

Article original : Hyperparameter Optimization Techniques to Improve Your Machine Learning Model's Performance
Par Davis David
Lorsque vous travaillez sur un projet de machine learning, vous devez suivre une série d'étapes jusqu'à ce que vous atteigniez votre objectif.
L'une des étapes que vous devez effectuer est l'optimisation des hyperparamètres sur votre modèle sélectionné. Cette tâche intervient toujours après le processus de sélection du modèle, où vous choisissez le modèle qui offre de meilleures performances que les autres.
Qu'est-ce que l'optimisation des hyperparamètres ?
Avant de définir l'optimisation des hyperparamètres, vous devez comprendre ce qu'est un hyperparamètre.
En résumé, les hyperparamètres sont différentes valeurs de paramètres utilisées pour contrôler le processus d'apprentissage et qui ont un effet significatif sur les performances des modèles de machine learning.
Un exemple d'hyperparamètres dans l'algorithme Random Forest est le nombre d'estimateurs (_nestimators), la profondeur maximale (_maxdepth) et le critère (criterion). Ces paramètres sont ajustables (tunable) et peuvent affecter directement la qualité de l'entraînement d'un modèle.
Ainsi, l'optimisation des hyperparamètres est le processus consistant à trouver la bonne combinaison de valeurs d'hyperparamètres pour atteindre une performance maximale sur les données dans un laps de temps raisonnable.
Ce processus joue un rôle vital dans la précision de prédiction d'un algorithme de machine learning. Par conséquent, l'optimisation des hyperparamètres est considérée comme la partie la plus délicate de la construction de modèles de machine learning.
La plupart de ces algorithmes de machine learning sont fournis avec des valeurs par défaut pour leurs hyperparamètres. Mais les valeurs par défaut ne sont pas toujours performantes sur différents types de projets de Machine Learning. C'est pourquoi vous devez les optimiser afin d'obtenir la bonne combinaison qui vous donnera la meilleure performance.
Un bon choix d'hyperparamètres peut vraiment faire briller un algorithme.
Il existe des stratégies courantes pour optimiser les hyperparamètres. Examinons chacune d'elles en détail maintenant.
Comment optimiser les hyperparamètres
Grid Search
Il s'agit d'une méthode traditionnelle et largement utilisée qui effectue un réglage des hyperparamètres pour déterminer les valeurs optimales pour un modèle donné.
Le Grid Search fonctionne en essayant chaque combinaison possible de paramètres que vous souhaitez tester dans votre modèle. Cela signifie que la recherche complète prendra beaucoup de temps, ce qui peut devenir très coûteux en ressources de calcul.
Vous pouvez en savoir plus sur la mise en œuvre du Grid Search ici.
Random Search
Cette méthode fonctionne un peu différemment : des combinaisons aléatoires des valeurs des hyperparamètres sont utilisées pour trouver la meilleure solution pour le modèle construit.
L'inconvénient du Random Search est qu'il peut parfois manquer des points (valeurs) importants dans l'espace de recherche.
Vous pouvez en savoir plus sur la mise en œuvre du Random Search ici.
Techniques alternatives d'optimisation des hyperparamètres
Je vais maintenant vous présenter quelques techniques/méthodes alternatives et avancées d'optimisation des hyperparamètres. Celles-ci peuvent vous aider à obtenir les meilleurs paramètres pour un modèle donné.
Nous examinerons les techniques suivantes :
- Hyperopt
- Scikit Optimize
- Optuna
Hyperopt
Hyperopt est une puissante bibliothèque Python pour l'optimisation des hyperparamètres développée par James Bergstra.
Elle utilise une forme d'optimisation bayésienne pour le réglage des paramètres qui vous permet d'obtenir les meilleurs paramètres pour un modèle donné. Elle peut optimiser un modèle avec des centaines de paramètres à grande échelle.
Hyperopt possède quatre fonctionnalités importantes que vous devez connaître pour exécuter votre première optimisation.
Search Space
Hyperopt dispose de différentes fonctions pour spécifier des plages pour les paramètres d'entrée. Celles-ci sont appelées espaces de recherche stochastiques. Les options les plus courantes pour un espace de recherche sont :
- hp.choice(label, options) – Ceci peut être utilisé pour les paramètres catégoriels. Il renvoie l'une des options, qui doit être une liste ou un tuple.
Exemple :hp.choice("criterion", ["gini","entropy",]) - hp.randint(label, upper) – Ceci peut être utilisé pour les paramètres entiers. Il renvoie un entier aléatoire dans la plage (0, upper).
Exemple :hp.randint("max_features",50) - hp.uniform(label, low, high) – Ceci renvoie une valeur uniformément comprise entre
lowethigh.
Exemple :hp.uniform("max_leaf_nodes",1,10)
D'autres options que vous pouvez utiliser sont :
- hp.normal(label, mu, sigma) – Renvoie une valeur réelle distribuée normalement avec une moyenne mu et un écart-type sigma.
- hp.qnormal(label, mu, sigma, q) – Renvoie une valeur comme round(normal(mu, sigma) / q) * q.
- hp.lognormal(label, mu, sigma) – Renvoie une valeur tirée selon exp(normal(mu, sigma)).
- hp.qlognormal(label, mu, sigma, q) – Renvoie une valeur comme round(exp(normal(mu, sigma)) / q) * q.
Vous pouvez en savoir plus sur les options d'espace de recherche ici.
Juste une petite note : chaque expression stochastique optimisable possède un label (par exemple, n_estimators) comme premier argument. Ces labels sont utilisés pour renvoyer les choix de paramètres à l'appelant pendant le processus d'optimisation.
Objective Function
Il s'agit d'une fonction de minimisation qui reçoit les valeurs des hyperparamètres en entrée de l'espace de recherche et renvoie la perte (loss).
Cela signifie que pendant le processus d'optimisation, nous entraînons le modèle avec les valeurs d'hyperparamètres sélectionnées et prédisons la caractéristique cible. Ensuite, nous évaluons l'erreur de prédiction et la renvoyons à l'optimiseur.
L'optimiseur décidera quelles valeurs vérifier et itérera à nouveau. Vous apprendrez comment créer des fonctions objectifs dans l'exemple pratique.
fmin
La fonction fmin est la fonction d'optimisation qui itère sur différents ensembles d'algorithmes et leurs hyperparamètres, puis minimise la fonction objectif.
fmin prend cinq entrées, qui sont :
- La fonction objectif à minimiser
- L'espace de recherche défini
- L'algorithme de recherche à utiliser, tel que Random Search, TPE (Tree Parzen Estimators) et Adaptive TPE
Note :hyperopt.rand.suggestethyperopt.tpe.suggestfournissent la logique pour la recherche séquentielle de l'espace des hyperparamètres - Le nombre maximum d'évaluations
- Et l'objet trials (optionnel)
Exemple :
from hyperopt import fmin, tpe, hp, Trials
trials = Trials()
best = fmin(fn=lambda x: x ** 2,
space= hp.uniform('x', -10, 10),
algo=tpe.suggest,
max_evals=50,
trials = trials)
print(best)
Trials Object
L'objet Trials est utilisé pour conserver tous les hyperparamètres, la perte et d'autres informations. Cela signifie que vous pouvez y accéder après avoir exécuté l'optimisation.
De plus, les trials peuvent vous aider à sauvegarder des informations importantes et à les charger plus tard pour reprendre le processus d'optimisation. Vous en apprendrez plus à ce sujet dans l'exemple pratique ci-dessous.
from hyperopt import Trials
trials = Trials()
Maintenant que vous comprenez les fonctionnalités importantes de Hyperopt, nous allons voir comment l'utiliser. Vous suivrez ces étapes :
- Initialiser l'espace sur lequel effectuer la recherche
- Définir la fonction objectif
- Sélectionner l'algorithme de recherche à utiliser
- Exécuter la fonction hyperopt
- Analyser les sorties des évaluations stockées dans l'objet trials
Hyperopt en pratique
Dans cet exemple pratique, nous utiliserons le Mobile Price Dataset. Notre tâche est de créer un modèle qui prédira le niveau de prix d'un appareil mobile : 0 (bas prix), 1 (prix moyen), 2 (prix élevé) ou 3 (prix très élevé).
Installer Hyperopt
Vous pouvez installer hyperopt depuis PyPI en exécutant cette commande :
pip install hyperopt
Ensuite, importez les packages importants suivants, y compris hyperopt :
# importation des packages
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn import metrics
from sklearn.model_selection import cross_val_score
from sklearn.preprocessing import StandardScaler
from hyperopt import tpe, hp, fmin, STATUS_OK, Trials
from hyperopt.pyll.base import scope
import warnings
warnings.filterwarnings("ignore")
Dataset
Chargeons le jeu de données depuis le répertoire data. Pour obtenir plus d'informations sur le jeu de données, lisez ceci ici.
# chargement des données
data = pd.read_csv("data/mobile_price_data.csv")
Consultez les cinq premières lignes du jeu de données comme ceci :
# lecture des données
data.head()
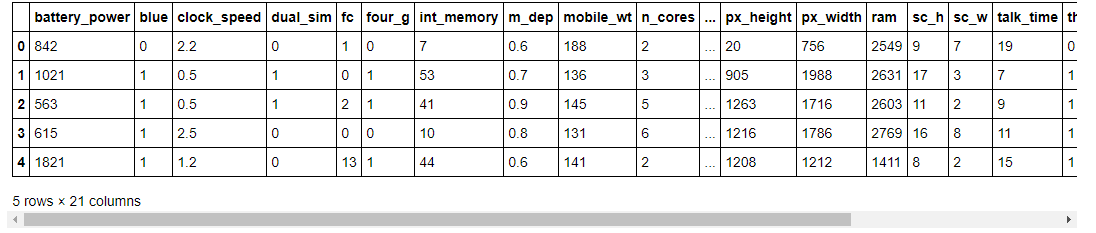 Cinq premières lignes
Cinq premières lignes
Comme vous pouvez le voir, dans notre jeu de données, nous avons différentes caractéristiques avec des valeurs numériques.
Regardons la forme (shape) du jeu de données.
# affichage de la forme
data.shape
Nous obtenons ce qui suit :
(2000, 21)
Dans ce jeu de données, nous avons 2000 lignes et 21 colonnes. Maintenant, comprenons la liste des caractéristiques que nous avons dans ce jeu de données.
# affichage de la liste des colonnes
list(data.columns)
['battery_power', 'blue', 'clock_speed', 'dual_sim', 'fc', 'four_g', 'int_memory', 'm_dep', 'mobile_wt', 'n_cores', 'pc', 'px_height', 'px_width', 'ram', 'sc_h', 'sc_w', 'talk_time', 'three_g', 'touch_screen', 'wifi', 'price_range']
Vous pouvez trouver la signification de chaque nom de colonne ici.
Division du jeu de données en caractéristique cible et caractéristiques indépendantes
Il s'agit d'un problème de classification. Nous allons donc maintenant séparer la caractéristique cible et les caractéristiques indépendantes du jeu de données. Notre caractéristique cible est price_range.
# division des données en caractéristiques et cible
X = data.drop("price_range", axis=1).values
y = data.price_range.values
Prétraitement du jeu de données
Ensuite, nous allons standardiser les caractéristiques indépendantes en utilisant la méthode StandardScaler de scikit-learn.
# standardisation des variables de caractéristiques
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
Définir l'espace des paramètres pour l'optimisation
Nous utiliserons trois hyperparamètres de l'algorithme Random Forest : _n_estimators, maxdepth et criterion.
space = {
"n_estimators": hp.choice("n_estimators", [100, 200, 300, 400, 500, 600]),
"max_depth": hp.quniform("max_depth", 1, 15, 1),
"criterion": hp.choice("criterion", ["gini", "entropy"]),
}
Nous avons défini différentes valeurs dans les hyperparamètres sélectionnés ci-dessus. Maintenant, nous allons définir la fonction objectif.
Définir une fonction à minimiser (Fonction Objectif)
Notre fonction que nous voulons minimiser s'appelle hyperparameter_tuning. L'algorithme de classification pour optimiser ses hyperparamètres est Random Forest.
J'utilise la validation croisée pour éviter le surapprentissage (overfitting), puis la fonction renverra une valeur de perte et son statut.
# définition de la fonction objectif
def hyperparameter_tuning(params):
clf = RandomForestClassifier(**params, n_jobs=-1)
acc = cross_val_score(clf, X_scaled, y, scoring="accuracy").mean()
return {"loss": -acc, "status": STATUS_OK}
N'oubliez pas que hyperopt minimise la fonction. C'est pourquoi j'ajoute le signe négatif à l'acc.
Ajuster le modèle
Enfin, nous allons d'abord instancier l'objet Trial, ajuster le modèle, puis afficher la meilleure perte avec ses valeurs d'hyperparamètres.
# Initialisation de l'objet trials
trials = Trials()
best = fmin(
fn=hyperparameter_tuning,
space = space,
algo=tpe.suggest,
max_evals=100,
trials=trials
)
print("Best: {}".format(best))
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████| 100/100 [10:30<00:00, 6.30s/trial, best loss: -0.8915] Best: {'criterion': 1, 'max_depth': 11.0, 'n_estimators': 2}.
Après avoir effectué l'optimisation des hyperparamètres, la perte est de - 0.8915. Cela signifie que la performance du modèle a une précision de 89,15% en utilisant _n_estimators = 300, maxdepth = 11 et criterion = "entropy" dans le classifieur Random Forest.
Analyser les résultats à l'aide de l'objet trials
L'objet trials peut nous aider à inspecter toutes les valeurs de retour qui ont été calculées pendant l'expérience.
(a) trials.results
Ceci affiche une liste de dictionnaires renvoyés par 'objective' pendant la recherche.
trials.results
[{'loss': -0.8790000000000001, 'status': 'ok'}, {'loss': -0.877, 'status': 'ok'}, {'loss': -0.768, 'status': 'ok'}, {'loss': -0.8205, 'status': 'ok'}, {'loss': -0.8720000000000001, 'status': 'ok'}, {'loss': -0.883, 'status': 'ok'}, {'loss': -0.8554999999999999, 'status': 'ok'}, {'loss': -0.8789999999999999, 'status': 'ok'}, {'loss': -0.595, 'status': 'ok'},.......]
(b) trials.losses()
Ceci affiche une liste de pertes (float pour chaque essai 'ok').
trials.losses()
[-0.8790000000000001, -0.877, -0.768, -0.8205, -0.8720000000000001, -0.883, -0.8554999999999999, -0.8789999999999999, -0.595, -0.8765000000000001, -0.877, .........]
(c) trials.statuses()
Ceci affiche une liste de chaînes de statut.
trials.statuses()
['ok', 'ok', 'ok', 'ok', 'ok', 'ok', 'ok', 'ok', 'ok', 'ok', 'ok', 'ok', 'ok', 'ok', 'ok', 'ok', 'ok', 'ok', 'ok', ..........]
Note : Cet objet trials peut être sauvegardé, transmis aux routines de traçage intégrées ou analysé avec votre propre code personnalisé.
Maintenant que vous savez comment implémenter Hyperopt, découvrons la deuxième technique alternative d'optimisation des hyperparamètres appelée Scikit-Optimize.
Scikit-Optimize
Scikit-optimize est une autre bibliothèque Python open-source pour l'optimisation des hyperparamètres. Elle implémente plusieurs méthodes pour l'optimisation séquentielle basée sur un modèle.
La bibliothèque est très facile à utiliser et fournit une boîte à outils générale pour l'optimisation bayésienne qui peut être utilisée pour le réglage des hyperparamètres. Elle offre également un support pour le réglage des hyperparamètres des algorithmes de machine learning proposés par la bibliothèque scikit-learn.
Scikit-optimize est construit au-dessus de Scipy, NumPy et Scikit-Learn.
Scikit-optimize possède au moins quatre fonctionnalités importantes que vous devez connaître pour exécuter votre première optimisation. Examinons-les en profondeur maintenant.
Space
scikit-optimize dispose de différentes fonctions pour définir l'espace d'optimisation qui contient une ou plusieurs dimensions. Les options les plus courantes pour choisir un espace de recherche sont :
- Real — Il s'agit d'une dimension d'espace de recherche qui peut prendre n'importe quelle valeur réelle. Vous devez définir la borne inférieure et la borne supérieure, et les deux sont incluses.
Exemple :Real(low=0.2, high=0.9, name="min_samples_leaf") - Integer — Il s'agit d'une dimension d'espace de recherche qui peut prendre des valeurs entières.
Exemple :Integer(low=3, high=25, name="max_features") - Categorical — Il s'agit d'une dimension d'espace de recherche qui peut prendre des valeurs catégorielles.
Exemple :Categorical(["gini","entropy"],name="criterion")
Note : dans chaque espace de recherche, vous devez définir le nom de l'hyperparamètre à optimiser en utilisant l'argument name.
BayesSearchCV
La classe BayesSearchCV fournit une interface similaire à GridSearchCV ou RandomizedSearchCV, mais elle effectue une optimisation bayésienne sur les hyperparamètres.
BayesSearchCV implémente une méthode « fit » et une méthode « score », ainsi que d'autres méthodes courantes comme _predict(), predict_proba(), decisionfunction(), transform() et _inversetransform() si elles sont implémentées dans l'estimateur utilisé.
Contrairement à GridSearchCV, toutes les valeurs de paramètres ne sont pas essayées. Au lieu de cela, un nombre fixe de réglages de paramètres est échantillonné à partir des distributions spécifiées. Le nombre de réglages de paramètres essayés est donné par n_iter.
Notez que vous apprendrez à implémenter BayesSearchCV dans un exemple pratique ci-dessous.
Objective Function
Il s'agit d'une fonction qui sera appelée par la procédure de recherche. Elle reçoit les valeurs des hyperparamètres en entrée de l'espace de recherche et renvoie la perte (plus elle est basse, mieux c'est).
Cela signifie que pendant le processus d'optimisation, nous entraînons le modèle avec les valeurs d'hyperparamètres sélectionnées et prédisons la caractéristique cible. Ensuite, nous évaluons l'erreur de prédiction et la renvoyons à l'optimiseur.
L'optimiseur décidera quelles valeurs vérifier et itérera à nouveau. Vous apprendrez comment créer une fonction objectif dans l'exemple pratique ci-dessous.
Optimizer
Il s'agit de la fonction qui effectue le processus d'optimisation bayésienne des hyperparamètres. La fonction d'optimisation itère sur chaque modèle et l'espace de recherche à optimiser, puis minimise la fonction objectif.
Il existe différentes fonctions d'optimisation fournies par la bibliothèque scikit-optimize, telles que :
- dummy_minimize — Recherche aléatoire par échantillonnage uniforme dans les bornes données.
- forest_minimize — Optimisation séquentielle utilisant des arbres de décision.
- gbrt_minimize — Optimisation séquentielle utilisant des arbres boostés par gradient.
- gp_minimize — Optimisation bayésienne utilisant des processus gaussiens.
Note : nous implémenterons gp_minimize dans l'exemple pratique ci-dessous.
D'autres fonctionnalités que vous devriez apprendre sont les suivantes :
- Space Transformers
- Utils Functions
- Plotting Functions
- Machine learning extensions for model-based optimization
Scikit-optimize en pratique
Maintenant que vous connaissez les fonctionnalités importantes de scikit-optimize, regardons un exemple pratique. Nous utiliserons le même jeu de données appelé Mobile Price Dataset que celui utilisé avec Hyperopt.
Installer Scikit-Optimize
scikit-optimize nécessite la version de Python et les packages suivants :
- Python >= 3.6
- NumPy (>= 1.13.3)
- SciPy (>= 0.19.1)
- joblib (>= 0.11)
- scikit-learn >= 0.20
- matplotlib >= 2.0.0
Vous pouvez installer la dernière version avec cette commande :
pip install scikit-optimize
Ensuite, importez les packages importants, y compris scikit-optimize :
# importation des packages
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn import metrics
from sklearn.model_selection import cross_val_score
from sklearn.preprocessing import StandardScaler
from skopt.searchcv import BayesSearchCV
from skopt.space import Integer, Real, Categorical
from skopt.utils import use_named_args
from skopt import gp_minimize
import warnings
warnings.filterwarnings("ignore")
La première approche
Dans la première approche, nous utiliserons BayesSearchCV pour effectuer l'optimisation des hyperparamètres pour l'algorithme Random Forest.
Définir l'espace de recherche
Nous allons régler les hyperparamètres suivants du modèle Random Forest :
- n_estimators — Le nombre d'arbres dans la forêt.
- max_depth — La profondeur maximale de l'arbre.
- criterion — La fonction pour mesurer la qualité d'une division.
# définition de l'espace de recherche
params = {
"n_estimators": [100, 200, 300, 400],
"max_depth": (1, 9),
"criterion": ["gini", "entropy"],
}
Nous avons défini l'espace de recherche sous forme de dictionnaire. Il utilise les noms des hyperparamètres comme clés et la portée de la variable comme valeur.
Définir la configuration de BayesSearchCV
L'avantage de BayesSearchCV est que la procédure de recherche est effectuée automatiquement, ce qui nécessite une configuration minimale.
La classe peut être utilisée de la même manière que Scikit-Learn (GridSearchCV et RandomizedSearchCV).
# définition de la recherche
search = BayesSearchCV(
estimator=rf_classifier,
search_spaces=params,
n_jobs=1,
cv=5,
n_iter=30,
scoring="accuracy",
verbose=4,
random_state=42
)
Ajuster le modèle
Nous exécutons ensuite la recherche en passant les caractéristiques prétraitées et la caractéristique cible (price_range).
# exécution de la recherche
search.fit(X_scaled,y)
Vous pouvez trouver le meilleur score en utilisant l'attribut bestscore et les meilleurs paramètres en utilisant l'attribut bestparams de la recherche (search).
# affichage du meilleur résultat
print(search.best_score_)
print(search.best_params_)
Notez que la version actuelle de scikit-optimize (0.7.4) n'est pas compatible avec les dernières versions de scikit-learn (0.23.1 et 0.23.2). Ainsi, lorsque vous exécutez le processus d'optimisation en utilisant cette approche, vous pouvez obtenir des erreurs comme celle-ci :
TypeError: object.__init__() takes exactly one argument (the instance to initialize)
Vous pouvez trouver plus d'informations sur cette erreur sur leur compte GitHub.
- https://github.com/scikit-optimize/scikit-optimize/issues/928
- https://github.com/scikit-optimize/scikit-optimize/issues/924
- https://github.com/scikit-optimize/scikit-optimize/issues/902
J'espère qu'ils résoudront ce problème d'incompatibilité très bientôt.
La deuxième approche
Dans la deuxième approche, nous définissons d'abord l'espace de recherche en utilisant les méthodes d'espace fournies par scikit-optimize, qui sont Categorical et Integer.
# définition de l'espace des hyperparamètres à rechercher
search_space = list()
search_space.append(Categorical([100, 200, 300, 400], name='n_estimators'))
search_space.append(Categorical(['gini', 'entropy'], name='criterion'))
search_space.append(Integer(1, 9, name='max_depth'))
Nous avons défini différentes valeurs dans les hyperparamètres sélectionnés ci-dessus. Ensuite, nous définirons la fonction objectif.
Définir une fonction à minimiser (Fonction Objectif)
Notre fonction à minimiser s'appelle evaluate_model et l'algorithme de classification pour optimiser ses hyperparamètres est Random Forest.
J'utilise la validation croisée pour éviter le surapprentissage et la fonction renverra les valeurs de perte.
# définition de la fonction utilisée pour évaluer une configuration donnée
@use_named_args(search_space)
def evaluate_model(**params):
# configurer le modèle avec des hyperparamètres spécifiques
clf = RandomForestClassifier(**params, n_jobs=-1)
acc = cross_val_score(clf, X_scaled, y, scoring="accuracy").mean()
Le décorateur use_named_args() permet à votre fonction objectif de recevoir les paramètres sous forme d'arguments par mots-clés. Ceci est particulièrement pratique lorsque vous souhaitez définir les paramètres de l'estimateur de scikit-learn.
N'oubliez pas que scikit-optimize minimise la fonction, c'est pourquoi j'ajoute un signe négatif à l'acc.
Ajuster le modèle
Enfin, nous ajustons le modèle en utilisant la méthode gp_minimize (elle utilise l'optimisation basée sur les processus gaussiens) de scikit-optimize. Ensuite, nous affichons la meilleure perte avec ses valeurs d'hyperparamètres.
# exécution de l'optimisation
result = gp_minimize(
func=evaluate_model,
dimensions=search_space,
n_calls=30,
random_state=42,
verbose=True,
n_jobs=1,
)
Sortie :
Iteration No: 1 started. Evaluating function at random point.
Iteration No: 1 ended. Evaluation done at random point.
Time taken: 8.6910
Function value obtained: -0.8585
Current minimum: -0.8585
Iteration No: 2 started. Evaluating function at random point.
Iteration No: 2 ended. Evaluation done at random point.
Time taken: 4.5096
Function value obtained: -0.7680
Current minimum: -0.8585 …………….
Notez qu'il s'exécutera jusqu'à atteindre la dernière itération. Pour notre processus d'optimisation, le nombre total d'itérations est de 30.
Ensuite, nous pouvons afficher la meilleure précision et les valeurs des hyperparamètres sélectionnés que nous avons utilisés.
# résumé des résultats :
print('Best Accuracy: %.3f' % (result.fun))
print('Best Parameters: %s' % (result.x))
Best Accuracy: -0.882
Best Parameters: [300, 'entropy', 9]
Après avoir effectué l'optimisation des hyperparamètres, la perte est de -0.882. Cela signifie que la performance du modèle a une précision de 88,2% en utilisant _nestimators = 300, _maxdepth = 9 et criterion = “entropy” dans le classifieur Random Forest.
Notre résultat n'est pas très différent de celui de Hyperopt dans la première partie (précision de 89,15%).
Afficher les valeurs de la fonction
Vous pouvez afficher toutes les valeurs de la fonction à chaque itération en utilisant l'attribut func_vals de l'objet OptimizeResult (result).
print(result.func_vals)
Sortie :
array([-0.8665, -0.7765, -0.7485, -0.86 , -0.872 , -0.545 , -0.81 ,
-0.7725, -0.8115, -0.8705, -0.8685, -0.879 , -0.816 , -0.8815,
-0.8645, -0.8745, -0.867 , -0.8785, -0.878 , -0.878 , -0.8785,
-0.874 , -0.875 , -0.8785, -0.868 , -0.8815, -0.877 , -0.879 ,
-0.8705, -0.8745])
Tracer les traces de convergence
Nous pouvons utiliser la méthode plot_convergence de scikit-optimize pour tracer une ou plusieurs traces de convergence. Il suffit de passer l'objet OptimizeResult (result) dans la méthode plot_convergence.
# tracé de la convergence
from skopt.plots import plot_convergence
plot_convergence(result)

Le graphique montre les valeurs de la fonction à différentes itérations pendant le processus d'optimisation.
Maintenant que vous savez comment implémenter scikit-optimize, découvrons la troisième et dernière technique alternative d'optimisation des hyperparamètres appelée Optuna.
Optuna
Optuna est un autre framework Python open-source pour l'optimisation des hyperparamètres qui utilise la méthode bayésienne pour automatiser l'espace de recherche des hyperparamètres. Le framework a été développé par une société japonaise d'IA appelée Preferred Networks.
Optuna est plus facile à implémenter et à utiliser que Hyperopt. Vous pouvez également spécifier la durée du processus d'optimisation.
Optuna possède au moins cinq fonctionnalités importantes que vous devez connaître pour exécuter votre première optimisation.
Search Spaces
Optuna propose différentes options pour tous les types d'hyperparamètres. Les options les plus courantes à choisir sont les suivantes :
- Paramètres catégoriels – utilise la méthode trials.suggest_categorical(). Vous devez fournir le nom du paramètre et ses choix.
- Paramètres entiers – utilise la méthode trials.suggest_int(). Vous devez fournir le nom du paramètre, la valeur basse et la valeur haute.
- Paramètres flottants – utilise la méthode trials.suggest_float(). Vous devez fournir le nom du paramètre, la valeur basse et la valeur haute.
- Paramètres continus – utilise la méthode trials.suggest_uniform(). Vous devez fournir le nom du paramètre, la valeur basse et la valeur haute.
- Paramètres discrets – utilise la méthode trials.suggest_discrete_uniform(). Vous devez fournir le nom du paramètre, la valeur basse, la valeur haute et le pas de discrétisation.
Méthodes d'optimisation (Samplers)
Optuna propose différentes manières d'effectuer le processus d'optimisation des hyperparamètres. Les méthodes les plus courantes sont :
- GridSampler – Il utilise une recherche par grille. Les essais suggèrent toutes les combinaisons de paramètres dans l'espace de recherche donné pendant l'étude.
- RandomSampler – Il utilise un échantillonnage aléatoire. Ce sampler est basé sur un échantillonnage indépendant.
- TPESampler – Il utilise l'algorithme TPE (Tree-structured Parzen Estimator).
- CmaEsSampler – Il utilise l'algorithme CMA-ES.
Objective Function
La fonction objectif fonctionne de la même manière que dans les techniques hyperopt et scikit-optimize. La seule différence est qu'Optuna vous permet de définir l'espace de recherche et l'objectif dans une seule fonction.
Exemple :
def objective(trial):
# Définition de l'espace de recherche
criterions = trial.suggest_categorical('criterion', ['gini', 'entropy'])
max_depths = trial.suggest_int('max_depth', 1, 9, 1)
n_estimators = trial.suggest_int('n_estimators', 100, 1000, 100)
clf = sklearn.ensemble.RandomForestClassifier(n_estimators=n_estimators,
criterion=criterions,
max_depth=max_depths,
n_jobs=-1)
score = cross_val_score(clf, X_scaled, y, scoring="accuracy").mean()
return score
Study
Une étude (study) correspond à une tâche d'optimisation (un ensemble d'essais). Si vous devez lancer le processus d'optimisation, vous devez créer un objet study et passer la fonction objectif à une méthode appelée optimize() et définir le nombre d'essais comme suit :
study = optuna.create_study()
study.optimize(objective, n_trials=100)
La méthode create_study() vous permet de choisir si vous souhaitez maximiser ou minimiser votre fonction objectif.
C'est l'une des fonctionnalités les plus utiles que j'apprécie dans Optuna, car vous avez la possibilité de choisir la direction du processus d'optimisation.
Notez que vous apprendrez à implémenter cela dans l'exemple pratique ci-dessous.
Visualization
Le module de visualisation d'Optuna propose différentes méthodes pour créer des figures pour le résultat de l'optimisation. Ces méthodes vous aident à obtenir des informations sur les interactions entre les paramètres et vous indiquent comment progresser.
Voici quelques-unes des méthodes que vous pouvez utiliser.
- plot_contour() – Cette méthode trace la relation entre les paramètres sous forme de graphique de contour dans une étude.
- plot_intermidiate_values() – Cette méthode trace les valeurs intermédiaires de tous les essais d'une étude.
- plot_optimization_history() – Cette méthode trace l'historique d'optimisation de tous les essais d'une étude.
- plot_param_importances() – Cette méthode trace l'importance des hyperparamètres et leurs valeurs.
- plot_edf() – Cette méthode trace la fonction de distribution empirique (EDF) de la valeur objective d'une étude.
Nous utiliserons certaines des méthodes mentionnées ci-dessus dans l'exemple pratique ci-dessous.
Optuna en pratique
Maintenant que vous connaissez les fonctionnalités importantes d'Optuna, dans cet exemple pratique, nous utiliserons le même jeu de données (Mobile Price Dataset) que celui utilisé dans les deux méthodes précédentes.
Installer Optuna
Vous pouvez installer la dernière version avec :
pip install optuna
Ensuite, importez les packages importants, y compris optuna :
# importation des packages
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn import metrics
from sklearn.model_selection import cross_val_score
from sklearn.preprocessing import StandardScaler
import joblib
import optuna
from optuna.samplers import TPESampler
import warnings
warnings.filterwarnings("ignore")
Définir l'espace de recherche et l'objectif dans une seule fonction
Comme je l'ai expliqué plus haut, Optuna vous permet de définir l'espace de recherche et l'objectif dans une seule fonction.
Nous définirons les espaces de recherche pour les hyperparamètres suivants du modèle Random Forest :
- n_estimators — Le nombre d'arbres dans la forêt.
- max_depth — La profondeur maximale de l'arbre.
- criterion — La fonction pour mesurer la qualité d'une division.
# définition de l'espace de recherche et de la fonction objectif
def objective(trial):
# Définition de l'espace de recherche
criterions = trial.suggest_categorical('criterion', ['gini', 'entropy'])
max_depths = trial.suggest_int('max_depth', 1, 9, 1)
n_estimators = trial.suggest_int('n_estimators', 100, 1000, 100)
clf = RandomForestClassifier(n_estimators=n_estimators,
criterion=criterions,
max_depth=max_depths,
n_jobs=-1)
score = cross_val_score(clf, X_scaled, y, scoring="accuracy").mean()
return score
Nous utiliserons la méthode trial.suggest_categorical() pour définir un espace de recherche pour criterion et trial.suggest_int() pour _maxdepth et _nestimators.
De plus, nous utiliserons la validation croisée pour éviter le surapprentissage, puis la fonction renverra la précision moyenne.
Créer un objet Study
Ensuite, nous créons un objet study qui correspond à la tâche d'optimisation. La méthode create_study() nous permet de fournir le nom de l'étude, la direction de l'optimisation (maximize ou minimize) et la méthode d'optimisation que nous souhaitons utiliser.
# création d'un objet study
study = optuna.create_study(study_name="randomForest_optimization",
direction="maximize",
sampler=TPESampler())
Dans notre cas, nous avons nommé notre objet study randomForest_optimization. La direction de l'optimisation est maximize (ce qui signifie que plus le score est élevé, mieux c'est) et la méthode d'optimisation à utiliser est TPESampler().
Ajuster le modèle
Pour lancer le processus d'optimisation, nous devons passer la fonction objectif et le nombre d'essais dans la méthode optimize() de l'objet study que nous avons créé.
Nous avons fixé le nombre d'essais à 10 (mais vous pouvez changer ce nombre si vous souhaitez effectuer plus d'essais).
# passage de la fonction objectif à la méthode optimize()
study.optimize(objective, n_trials=10)
Sortie :

Ensuite, nous pouvons afficher la meilleure précision et les valeurs des hyperparamètres sélectionnés utilisés.
Pour afficher les meilleures valeurs d'hyperparamètres sélectionnées :
print(study.best_params)
Sortie : {‘criterion’: ‘entropy’, ‘max_depth’: 8, ‘n_estimators’: 700}
Pour afficher le meilleur score ou la meilleure précision :
print(study.best_value)
Sortie : 0.8714999999999999.
Notre meilleur score est d'environ 87,15%.
Tracer l'historique d'optimisation
Nous pouvons utiliser la méthode plot_optimization_history() d'Optuna pour tracer l'historique d'optimisation de tous les essais d'une étude. Il suffit de passer l'objet study optimisé dans la méthode.
optuna.visualization.plot_optimization_history(study)
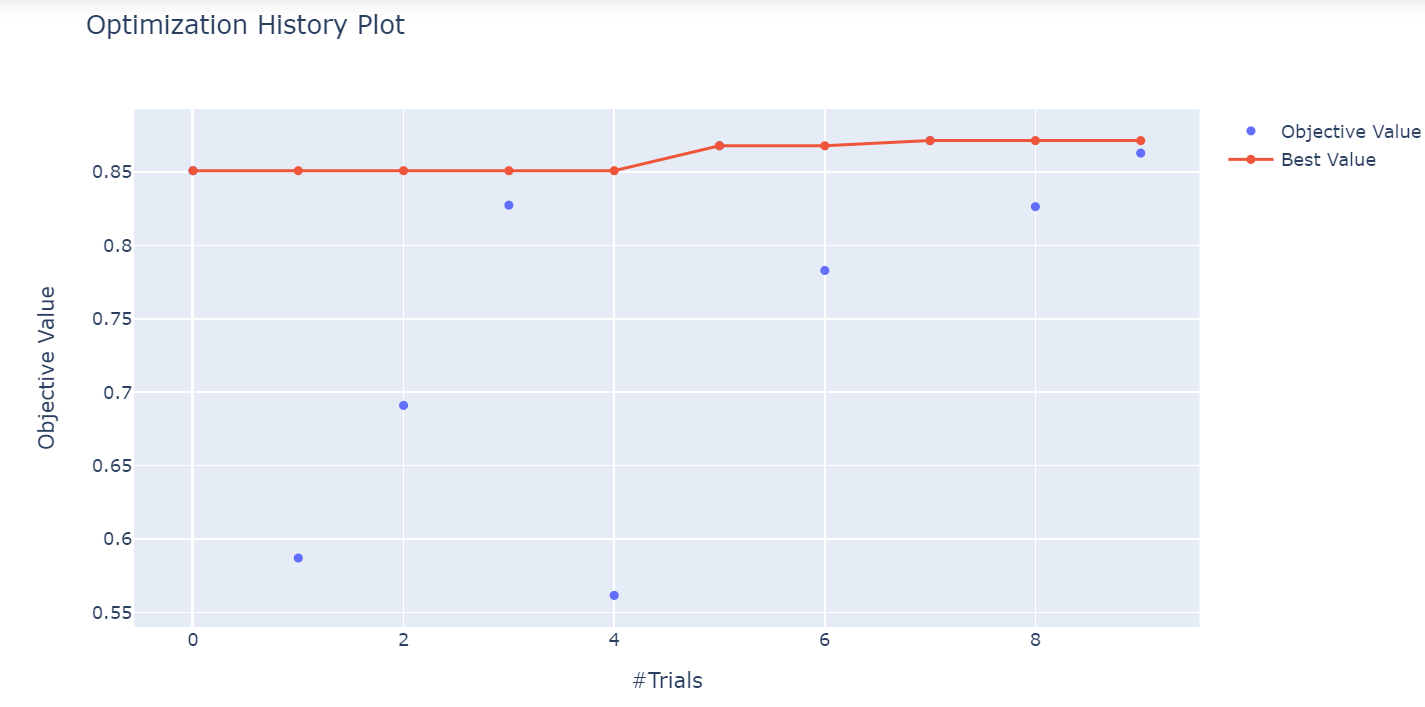
Le graphique montre les meilleures valeurs à différents essais pendant le processus d'optimisation.
Tracer l'importance des hyperparamètres
Optuna fournit une méthode appelée plot_param_importances() pour tracer l'importance des hyperparamètres. Il suffit de passer l'objet study optimisé dans la méthode.
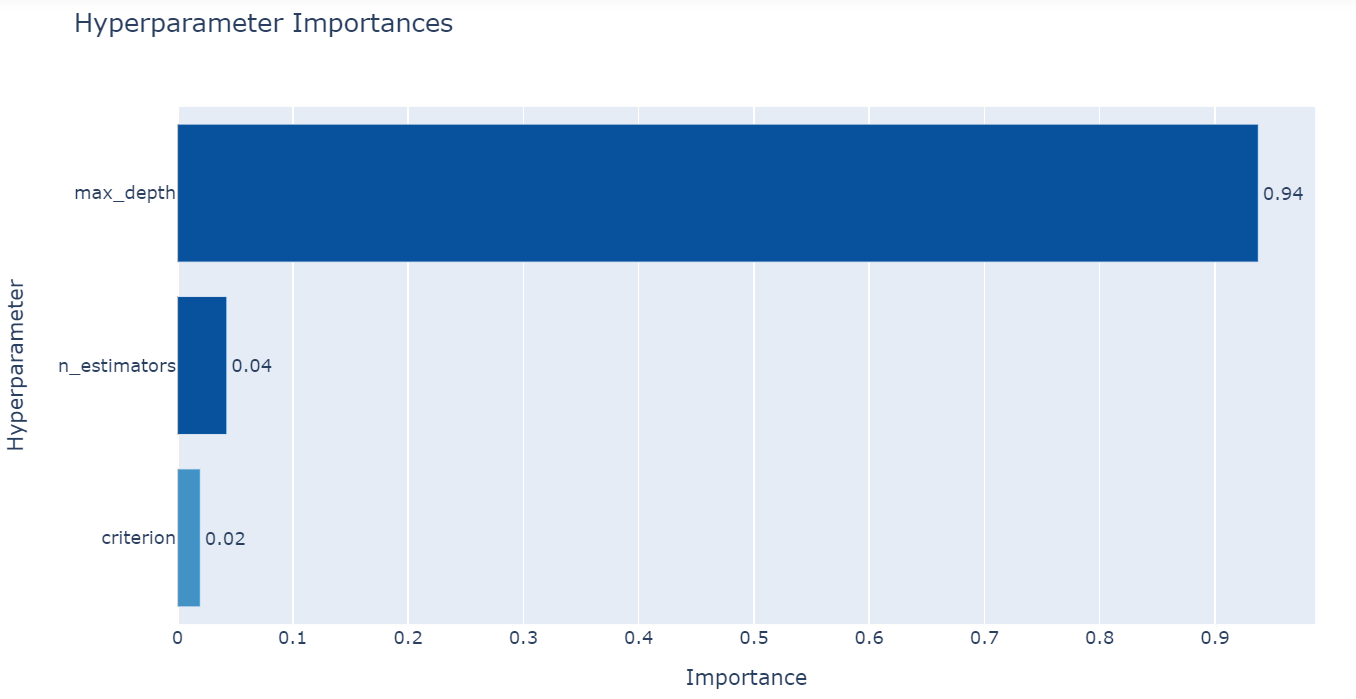
À partir de la figure ci-dessus, vous pouvez voir que max-depth est l'hyperparamètre le plus important.
Sauvegarder et charger les recherches d'hyperparamètres
Vous pouvez sauvegarder et charger les recherches d'hyperparamètres en utilisant le package joblib.
Tout d'abord, nous allons sauvegarder les recherches d'hyperparamètres dans le répertoire optuna_searches.
# sauvegarde de vos recherches d'hyperparamètres
joblib.dump(study, 'optuna_searches/study.pkl')
Ensuite, si vous souhaitez charger les recherches d'hyperparamètres depuis le répertoire optuna_searches, vous pouvez utiliser la méthode load() de joblib.
# chargement de vos recherches d'hyperparamètres
study = joblib.load('optuna_searches/study.pkl')
Conclusion
Félicitations, vous êtes arrivé à la fin de l'article !
Jetons un coup d'œil aux scores globaux et aux valeurs d'hyperparamètres sélectionnés par les trois techniques d'optimisation des hyperparamètres que nous avons abordées dans cet article.
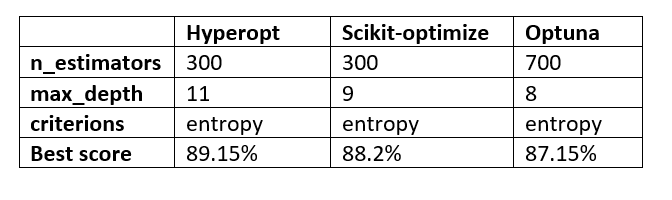
Les résultats présentés par chaque technique ne sont pas si différents les uns des autres. Le nombre d'itérations ou d'essais sélectionnés fait toute la différence.
Pour ma part, Optuna est facile à implémenter et constitue mon premier choix parmi les techniques d'optimisation des hyperparamètres. N'hésitez pas à me dire ce que vous en pensez !
Vous pouvez télécharger le jeu de données et tous les notebooks utilisés dans cet article ici :
https://github.com/Davisy/Hyperparameter-Optimization-Techniques
Si vous avez appris quelque chose de nouveau ou si vous avez apprécié la lecture de cet article, n'hésitez pas à le partager afin que d'autres puissent le voir. D'ici là, rendez-vous dans mon prochain article ! Vous pouvez également me joindre sur Twitter @Davis_McDavid