


Article original : Data Structures in JavaScript – With Code Examples
Bonjour à tous ! Dans cet article, nous allons examiner un sujet clé en informatique et en développement logiciel : les structures de données.
C'est définitivement un sujet incontournable pour toute personne travaillant dans le monde du développement logiciel, mais il peut être difficile à comprendre et même un peu intimidant lorsque l'on débute.
Dans cet article, je vais essayer de donner une explication simple des structures de données, ce qu'elles sont, quand elles sont utiles, et comment nous pouvons les implémenter en utilisant JavaScript.
C'est parti !
Table des matières
Qu'est-ce qu'une structure de données ?
En informatique, une structure de données est un format pour organiser, gérer et stocker des données de manière à permettre un accès et une modification efficaces.
Plus précisément, une structure de données est une collection de valeurs de données, les relations entre elles, et les fonctions ou opérations qui peuvent être appliquées à ces données.
Ces définitions peuvent sembler un peu abstraites au premier abord, mais réfléchissez-y. Si vous avez codé un peu, vous avez probablement utilisé des structures de données auparavant.
Avez-vous utilisé des tableaux et des objets ? Ce sont toutes des structures de données. Elles sont toutes une collection de valeurs qui se rapportent les unes aux autres, et peuvent être manipulées par vous. 😉
// Une collection des valeurs 1, 2 et 3
const arr = [1, 2, 3]
// Chaque valeur est liée à une autre, dans le sens où chacune est indexée dans une position du tableau
const indexOfTwo = arr.indexOf(2)
console.log(arr[indexOfTwo-1]) // 1
console.log(arr[indexOfTwo+1]) // 3
// Nous pouvons effectuer de nombreuses opérations sur le tableau, comme ajouter de nouvelles valeurs
arr.push(4)
console.log(arr) // [1,2,3,4]
JavaScript possède des structures de données primitives (intégrées) et non primitives (non intégrées).
Les structures de données primitives viennent par défaut avec le langage de programmation et vous pouvez les implémenter directement (comme les tableaux et les objets). Les structures de données non primitives ne viennent pas par défaut et vous devez les coder si vous voulez les utiliser.
Différentes structures de données existent car certaines d'entre elles sont mieux adaptées à certains types d'opérations. Vous pourrez probablement résoudre la plupart des tâches de programmation avec des structures de données intégrées, mais pour certaines tâches très spécifiques, une structure de données non primitive peut s'avérer utile.
Maintenant, passons en revue les structures de données les plus populaires, et voyons comment chacune d'elles fonctionne, dans quelles occasions elles sont utiles, et comment nous pouvons les coder en JavaScript.
Tableaux
Un tableau est une collection d'éléments stockés à des emplacements mémoire contigus.
Chaque élément peut être accédé par son index (position). Les tableaux commencent toujours à l'index 0, donc dans un tableau de 4 éléments, nous pourrions accéder au 3ème élément en utilisant le numéro d'index 2.
const arr = ['a', 'b', 'c', 'd']
console.log(arr[2]) // c
La propriété length d'un tableau est définie comme le nombre d'éléments qu'il contient. Si le tableau contient 4 éléments, nous pouvons dire que le tableau a une longueur de 4.
const arr = ['a', 'b', 'c', 'd']
console.log(arr.length) // 4
Dans certains langages de programmation, l'utilisateur ne peut stocker que des valeurs de même type dans un tableau et la longueur du tableau doit être définie au moment de sa création et ne peut pas être modifiée par la suite.
En JavaScript, ce n'est pas le cas, car nous pouvons stocker des valeurs de n'importe quel type dans le même tableau et la longueur de celui-ci peut être dynamique (elle peut croître ou diminuer autant que nécessaire).
const arr = ['store', 1, 'whatever', 2, 'you want', 3]
N'importe quel type de données peut être stocké dans un tableau, et cela inclut également les tableaux. Un tableau qui contient d'autres tableaux est appelé un tableau multidimensionnel.
const arr = [
[1,2,3],
[4,5,6],
[7,8,9],
]
En JavaScript, les tableaux viennent avec de nombreuses propriétés et méthodes intégrées que nous pouvons utiliser à différentes fins, telles que l'ajout ou la suppression d'éléments du tableau, le tri, le filtrage de ses valeurs, la connaissance de sa longueur, etc. Vous pouvez trouver une liste complète des méthodes de tableau ici. 😉
Comme je l'ai mentionné, dans les tableaux, chaque élément a un index défini par sa position dans le tableau. Lorsque nous ajoutons un nouvel élément à la fin du tableau, il prend simplement le numéro d'index qui suit le dernier élément précédent dans le tableau.
Mais lorsque nous ajoutons/suprimons un nouvel élément au début ou au milieu du tableau, les index de tous les éléments qui viennent après l'élément ajouté/supprimé doivent être changés. Cela a bien sûr un coût computationnel, et est l'une des faiblesses de cette structure de données.
Les tableaux sont utiles lorsque nous devons stocker des valeurs individuelles et ajouter/supprimer des valeurs à la fin de la structure de données. Mais lorsque nous devons ajouter/supprimer de n'importe quelle partie de celle-ci, il existe d'autres structures de données qui performant plus efficacement (nous en parlerons plus tard).
Objets (tables de hachage)
En JavaScript, un objet est une collection de paires clé-valeur. Cette structure de données est également appelée map, dictionnaire ou table de hachage dans d'autres langages de programmation.
Un objet JS typique ressemble à ceci :
const obj = {
prop1: "Je suis",
prop2: "un",
prop3: "objet"
}
Nous utilisons des accolades pour déclarer l'objet. Ensuite, nous déclarons chaque clé suivie d'un deux-points, et la valeur correspondante.
Une chose importante à mentionner est que chaque clé doit être unique au sein de l'objet. Vous ne pouvez pas avoir deux clés avec le même nom.
Les objets peuvent stocker à la fois des valeurs et des fonctions. En parlant d'objets, les valeurs sont appelées propriétés, et les fonctions sont appelées méthodes.
const obj = {
prop1: "Bonjour !",
prop3: function() {console.log("Je suis une propriété, mec !")
}}
Pour accéder aux propriétés, vous pouvez utiliser deux syntaxes différentes, soit object.property soit object["property"]. Pour accéder aux méthodes, nous appelons object.method().
console.log(obj.prop1) // "Bonjour !"
console.log(obj["prop1"]) // "Bonjour !"
obj.prop3() // "Je suis une propriété, mec !"
La syntaxe pour assigner de nouvelles valeurs est assez similaire :
obj.prop4 = 125
obj["prop5"] = "La nouvelle propriété du quartier"
obj.prop6 = () => console.log("encore un autre exemple")
console.log(obj.prop4) // 125
console.log(obj["prop5"]) // "La nouvelle propriété du quartier"
obj.prop6() // "encore un autre exemple"
Comme les tableaux, en JavaScript, les objets viennent avec de nombreuses méthodes intégrées qui nous permettent d'effectuer différentes opérations et d'obtenir des informations à partir d'un objet donné. Une liste complète peut être trouvée ici.
Les objets sont un bon moyen de regrouper des données qui ont quelque chose en commun ou qui sont d'une certaine manière liées. De plus, grâce au fait que les noms de propriétés sont uniques, les objets sont pratiques lorsque nous devons séparer des données en fonction d'une condition unique.
Un exemple pourrait être de compter combien de personnes aiment différents aliments :
const obj = {
amateursDePizza: 1000,
amateursDePates: 750,
amateursDasadoArgentin: 12312312312313123
}
Piles
Les piles sont une structure de données qui stocke des informations sous forme de liste. Elles permettent uniquement d'ajouter et de supprimer des éléments selon un modèle LIFO (dernier entré, premier sorti). Dans les piles, les éléments ne peuvent pas être ajoutés ou supprimés dans le désordre, ils doivent toujours suivre le modèle LIFO.
Pour comprendre comment cela fonctionne, imaginez une pile de papiers sur votre bureau. Vous ne pouvez ajouter plus de papiers à la pile qu'en les plaçant sur le dessus de tous les autres. Et vous ne pouvez retirer un papier de la pile qu'en prenant celui qui est sur le dessus de tous les autres. Dernier entré, premier sorti. LIFO. 😉

Une pile de papiers
Les piles sont utiles lorsque nous devons nous assurer que les éléments suivent le modèle LIFO. Voici quelques exemples d'utilisation des piles :
La pile d'appels de JavaScript.
La gestion des invocations de fonctions dans divers langages de programmation.
La fonctionnalité d'annulation/rétablissement offerte par de nombreux programmes.
Il existe plus d'une façon d'implémenter une pile, mais probablement la plus simple est d'utiliser un tableau avec ses méthodes push et pop. Si nous utilisons uniquement pop et push pour ajouter et supprimer des éléments, nous suivrons toujours le modèle LIFO et donc opérerons dessus comme une pile.
Une autre façon est de l'implémenter comme une liste, ce qui pourrait ressembler à ceci :
// Nous créons une classe pour chaque nœud dans la pile
class Node {
// Chaque nœud a deux propriétés, sa valeur et un pointeur qui indique le nœud qui suit
constructor(value){
this.value = value
this.next = null
}
}
// Nous créons une classe pour la pile
class Stack {
// La pile a trois propriétés, le premier nœud, le dernier nœud et la taille de la pile
constructor(){
this.first = null
this.last = null
this.size = 0
}
// La méthode push reçoit une valeur et l'ajoute au "haut" de la pile
push(val){
var newNode = new Node(val)
if(!this.first){
this.first = newNode
this.last = newNode
} else {
var temp = this.first
this.first = newNode
this.first.next = temp
}
return ++this.size
}
// La méthode pop élimine l'élément au "haut" de la pile et retourne sa valeur
pop(){
if(!this.first) return null
var temp = this.first
if(this.first === this.last){
this.last = null
}
this.first = this.first.next
this.size--
return temp.value
}
}
const stck = new Stack
stck.push("value1")
stck.push("value2")
stck.push("value3")
console.log(stck.first) /*
Node {
value: 'value3',
next: Node { value: 'value2', next: Node { value: 'value1', next: null } }
}
*/
console.log(stck.last) // Node { value: 'value1', next: null }
console.log(stck.size) // 3
stck.push("value4")
console.log(stck.pop()) // value4
Le big O des méthodes de pile est le suivant :
Insertion - O(1)
Suppression - O(1)
Recherche - O(n)
Accès - O(n)
Files d'attente
Les files d'attente fonctionnent de manière très similaire aux piles, mais les éléments suivent un modèle différent pour l'ajout et la suppression. Les files d'attente permettent uniquement un modèle FIFO (premier entré, premier sorti). Dans les files d'attente, les éléments ne peuvent pas être ajoutés ou supprimés dans le désordre, ils doivent toujours suivre le modèle FIFO.
Pour comprendre cela, imaginez des personnes faisant la queue pour acheter de la nourriture. La logique ici est que si vous arrivez en premier dans la queue, vous serez le premier à être servi. Si vous arrivez en premier, vous serez le premier à sortir. FIFO. 😉

Une file de clients
Voici quelques exemples d'utilisation des files d'attente :
Tâches en arrière-plan.
Impression/traitement des tâches.
Comme pour les piles, il existe plus d'une façon d'implémenter une file d'attente. Mais probablement la plus simple est d'utiliser un tableau avec ses méthodes push et shift.
Si nous utilisons uniquement push et shift pour ajouter et supprimer des éléments, nous suivrons toujours le modèle FIFO et donc opérerons dessus comme une file d'attente.
Une autre façon est de l'implémenter comme une liste, ce qui pourrait ressembler à ceci :
// Nous créons une classe pour chaque nœud dans la file d'attente
class Node {
// Chaque nœud a deux propriétés, sa valeur et un pointeur qui indique le nœud qui suit
constructor(value){
this.value = value
this.next = null
}
}
// Nous créons une classe pour la file d'attente
class Queue {
// La file d'attente a trois propriétés, le premier nœud, le dernier nœud et la taille de la file d'attente
constructor(){
this.first = null
this.last = null
this.size = 0
}
// La méthode enqueue reçoit une valeur et l'ajoute à la "fin" de la file d'attente
enqueue(val){
var newNode = new Node(val)
if(!this.first){
this.first = newNode
this.last = newNode
} else {
this.last.next = newNode
this.last = newNode
}
return ++this.size
}
// La méthode dequeue élimine l'élément au "début" de la file d'attente et retourne sa valeur
dequeue(){
if(!this.first) return null
var temp = this.first
if(this.first === this.last) {
this.last = null
}
this.first = this.first.next
this.size--
return temp.value
}
}
const quickQueue = new Queue
quickQueue.enqueue("value1")
quickQueue.enqueue("value2")
quickQueue.enqueue("value3")
console.log(quickQueue.first) /*
Node {
value: 'value1',
next: Node { value: 'value2', next: Node { value: 'value3', next: null } }
}
*/
console.log(quickQueue.last) // Node { value: 'value3, next: null }
console.log(quickQueue.size) // 3
quickQueue.enqueue("value4")
console.log(quickQueue.dequeue()) // value1
Le big O des méthodes de file d'attente est le suivant :
Insertion - O(1)
Suppression - O(1)
Recherche - O(n)
Accès - O(n)
Listes chaînées
Les listes chaînées sont un type de structure de données qui stocke des valeurs sous forme de liste. Au sein de la liste, chaque valeur est considérée comme un nœud, et chaque nœud est connecté avec la valeur suivante dans la liste (ou null si l'élément est le dernier de la liste) par un pointeur.
Il existe deux types de listes chaînées, les listes chaînées simplement et les listes chaînées doublement. Les deux fonctionnent de manière très similaire, mais la différence est que dans les listes chaînées simplement, chaque nœud a un pointeur unique qui indique le nœud suivant de la liste. Alors que dans les listes chaînées doublement, chaque nœud a deux pointeurs, l'un pointant vers le nœud suivant et l'autre pointant vers le nœud précédent.
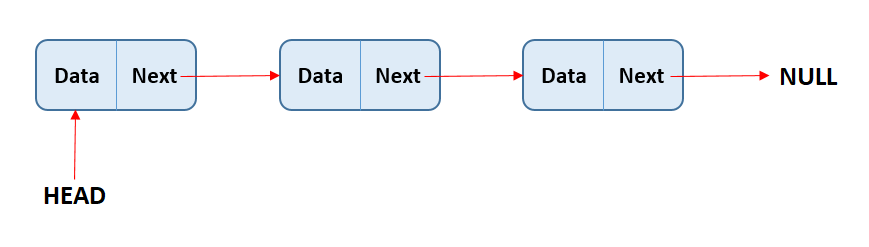
Dans une liste chaînée simplement, chaque nœud a un pointeur unique
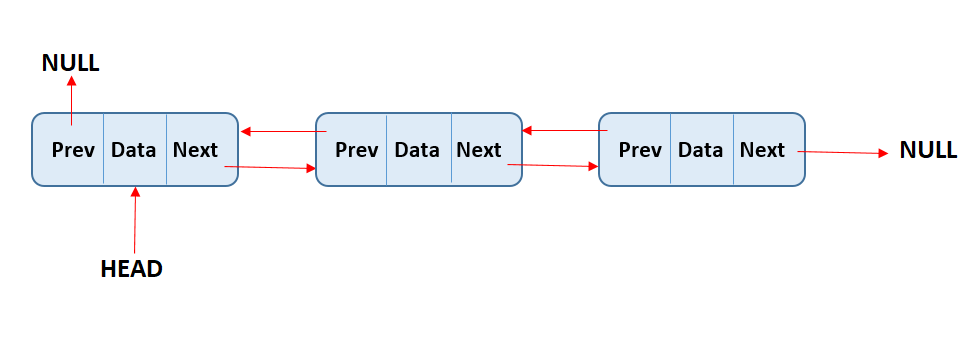
Dans une liste chaînée doublement, chaque nœud a deux pointeurs
Le premier élément de la liste est considéré comme la tête, et le dernier élément est considéré comme la queue. Comme pour les tableaux, la propriété length est définie comme le nombre d'éléments que la liste contient.
Les principales différences par rapport aux tableaux sont les suivantes :
Les listes n'ont pas d'index. Chaque valeur ne "connaît" que les valeurs auxquelles elle est connectée par des pointeurs.
Puisque les listes n'ont pas d'index, nous ne pouvons pas accéder aux valeurs de manière aléatoire. Lorsque nous voulons accéder à une valeur, nous devons toujours la chercher en itérant à travers la liste en commençant par sa tête ou sa queue.
Le bon côté de ne pas avoir d'index, c'est que l'insertion/suppression dans n'importe quelle partie de la liste est plus efficace qu'avec les tableaux. Nous devons simplement rediriger les pointeurs des valeurs "voisines", alors que dans les tableaux, les valeurs doivent être réindexées.
Comme toute structure de données, différentes méthodes sont implémentées afin d'opérer sur les données. Les plus courantes incluent : push, pop, unshift, shift, get, set, insert, remove, et reverse.
Commençons par voir comment implémenter une liste chaînée simplement, puis une liste chaînée doublement.
Liste chaînée simplement
Une implémentation complète d'une liste chaînée simplement pourrait ressembler à ceci :
// Nous créons une classe pour chaque nœud dans la liste
class Node{
// Chaque nœud a deux propriétés, sa valeur et un pointeur qui indique le nœud qui suit
constructor(val){
this.val = val
this.next = null
}
}
// Nous créons une classe pour la liste
class SinglyLinkedList{
// La liste a trois propriétés, la tête, la queue et la taille de la liste
constructor(){
this.head = null
this.tail = null
this.length = 0
}
// La méthode push prend une valeur en paramètre et l'assigne comme queue de la liste
push(val) {
const newNode = new Node(val)
if (!this.head){
this.head = newNode
this.tail = this.head
} else {
this.tail.next = newNode
this.tail = newNode
}
this.length++
return this
}
// La méthode pop supprime la queue de la liste
pop() {
if (!this.head) return undefined
const current = this.head
const newTail = current
while (current.next) {
newTail = current
current = current.next
}
this.tail = newTail
this.tail.next = null
this.length--
if (this.length === 0) {
this.head = null
this.tail = null
}
return current
}
// La méthode shift supprime la tête de la liste
shift() {
if (!this.head) return undefined
var currentHead = this.head
this.head = currentHead.next
this.length--
if (this.length === 0) {
this.tail = null
}
return currentHead
}
// La méthode unshift prend une valeur en paramètre et l'assigne comme tête de la liste
unshift(val) {
const newNode = new Node(val)
if (!this.head) {
this.head = newNode
this.tail = this.head
}
newNode.next = this.head
this.head = newNode
this.length++
return this
}
// La méthode get prend un numéro d'index en paramètre et retourne la valeur du nœud à cet index
get(index) {
if(index < 0 || index >= this.length) return null
const counter = 0
const current = this.head
while(counter !== index) {
current = current.next
counter++
}
return current
}
// La méthode set prend un numéro d'index et une valeur en paramètres, et modifie la valeur du nœud à l'index donné dans la liste
set(index, val) {
const foundNode = this.get(index)
if (foundNode) {
foundNode.val = val
return true
}
return false
}
// La méthode insert prend un numéro d'index et une valeur en paramètres, et insère la valeur à l'index donné dans la liste
insert(index, val) {
if (index < 0 || index > this.length) return false
if (index === this.length) return !!this.push(val)
if (index === 0) return !!this.unshift(val)
const newNode = new Node(val)
const prev = this.get(index - 1)
const temp = prev.next
prev.next = newNode
newNode.next = temp
this.length++
return true
}
// La méthode remove prend un numéro d'index en paramètre et supprime le nœud à l'index donné dans la liste
remove(index) {
if(index < 0 || index >= this.length) return undefined
if(index === 0) return this.shift()
if(index === this.length - 1) return this.pop()
const previousNode = this.get(index - 1)
const removed = previousNode.next
previousNode.next = removed.next
this.length--
return removed
}
// La méthode reverse inverse la liste et tous les pointeurs de sorte que la tête devienne la queue et la queue devienne la tête
reverse(){
const node = this.head
this.head = this.tail
this.tail = node
let next
const prev = null
for(let i = 0; i < this.length; i++) {
next = node.next
node.next = prev
prev = node
node = next
}
return this
}
}
Les méthodes des listes chaînées simplement ont les complexités suivantes :
Insertion - O(1)
Suppression - O(n)
Recherche - O(n)
Accès - O(n)
Listes chaînées doublement
Comme mentionné, la différence entre les listes chaînées doublement et simplement est que les listes chaînées doublement ont leurs nœuds connectés par des pointeurs avec à la fois la valeur précédente et la suivante. D'un autre côté, les listes chaînées simplement ne connectent leurs nœuds qu'avec la valeur suivante.
Cette approche de double pointeur permet aux listes chaînées doublement de performer mieux avec certaines méthodes par rapport aux listes chaînées simplement, mais au coût de consommer plus de mémoire (avec les listes chaînées doublement, nous devons stocker deux pointeurs au lieu d'un).
Une implémentation complète d'une liste chaînée doublement pourrait ressembler à ceci :
// Nous créons une classe pour chaque nœud dans la liste
class Node{
// Chaque nœud a trois propriétés, sa valeur, un pointeur qui indique le nœud qui suit et un pointeur qui indique le nœud précédent
constructor(val){
this.val = val;
this.next = null;
this.prev = null;
}
}
// Nous créons une classe pour la liste
class DoublyLinkedList {
// La liste a trois propriétés, la tête, la queue et la taille de la liste
constructor(){
this.head = null
this.tail = null
this.length = 0
}
// La méthode push prend une valeur en paramètre et l'assigne comme queue de la liste
push(val){
const newNode = new Node(val)
if(this.length === 0){
this.head = newNode
this.tail = newNode
} else {
this.tail.next = newNode
newNode.prev = this.tail
this.tail = newNode
}
this.length++
return this
}
// La méthode pop supprime la queue de la liste
pop(){
if(!this.head) return undefined
const poppedNode = this.tail
if(this.length === 1){
this.head = null
this.tail = null
} else {
this.tail = poppedNode.prev
this.tail.next = null
poppedNode.prev = null
}
this.length--
return poppedNode
}
// La méthode shift supprime la tête de la liste
shift(){
if(this.length === 0) return undefined
const oldHead = this.head
if(this.length === 1){
this.head = null
this.tail = null
} else{
this.head = oldHead.next
this.head.prev = null
oldHead.next = null
}
this.length--
return oldHead
}
// La méthode unshift prend une valeur en paramètre et l'assigne comme tête de la liste
unshift(val){
const newNode = new Node(val)
if(this.length === 0) {
this.head = newNode
this.tail = newNode
} else {
this.head.prev = newNode
newNode.next = this.head
this.head = newNode
}
this.length++
return this
}
// La méthode get prend un numéro d'index en paramètre et retourne la valeur du nœud à cet index
get(index){
if(index < 0 || index >= this.length) return null
let count, current
if(index <= this.length/2){
count = 0
current = this.head
while(count !== index){
current = current.next
count++
}
} else {
count = this.length - 1
current = this.tail
while(count !== index){
current = current.prev
count--
}
}
return current
}
// La méthode set prend un numéro d'index et une valeur en paramètres, et modifie la valeur du nœud à l'index donné dans la liste
set(index, val){
var foundNode = this.get(index)
if(foundNode != null){
foundNode.val = val
return true
}
return false
}
// La méthode insert prend un numéro d'index et une valeur en paramètres, et insère la valeur à l'index donné dans la liste
insert(index, val){
if(index < 0 || index > this.length) return false
if(index === 0) return !!this.unshift(val)
if(index === this.length) return !!this.push(val)
var newNode = new Node(val)
var beforeNode = this.get(index-1)
var afterNode = beforeNode.next
beforeNode.next = newNode, newNode.prev = beforeNode
newNode.next = afterNode, afterNode.prev = newNode
this.length++
return true
}
}
Le big O des méthodes des listes chaînées doublement est le suivant :
Insertion - O(1)
Suppression - O(1)
Recherche - O(n)
Accès - O(n)
Arbres
Les arbres sont des structures de données qui lient des nœuds dans une relation parent/enfant, dans le sens où il y a des nœuds qui dépendent ou proviennent d'autres nœuds.

Un arbre
Les arbres sont formés par un nœud racine (le premier nœud de l'arbre), et tous les nœuds qui proviennent de cette racine sont appelés enfants. Les nœuds au bas de l'arbre, qui n'ont pas de "descendants", sont appelés nœuds feuilles. Et la hauteur de l'arbre est déterminée par le nombre de connexions parent/enfant qu'il possède.
Contrairement aux listes chaînées ou aux tableaux, les arbres sont non linéaires, dans le sens où lors de l'itération de l'arbre, le flux du programme peut suivre différentes directions au sein de la structure de données et donc arriver à différentes valeurs.
Alors que dans les listes chaînées ou les tableaux, le programme ne peut itérer la structure de données que d'une extrémité à l'autre, en suivant toujours le même chemin.
Une exigence importante pour la formation d'un arbre est que la seule connexion valide entre les nœuds est de parent à enfant. La connexion entre frères et sœurs ou d'enfant à parent n'est pas autorisée dans les arbres (ces types de connexions forment des graphes, un type différent de structure de données). Une autre exigence importante est que les arbres doivent avoir une seule racine.
Voici quelques exemples d'utilisation des arbres en programmation :
Le modèle DOM.
L'analyse de situation en intelligence artificielle.
Les dossiers de fichiers dans les systèmes d'exploitation.
Il existe de nombreux types différents d'arbres. Dans chaque type d'arbre, les valeurs peuvent être organisées en suivant différents motifs qui rendent cette structure de données plus adaptée à utiliser lors de la confrontation à différents types de problèmes. Les types d'arbres les plus couramment utilisés sont les arbres binaires et les tas.
Arbres binaires
Les arbres binaires sont un type d'arbre dans lequel chaque nœud a un maximum de deux enfants.
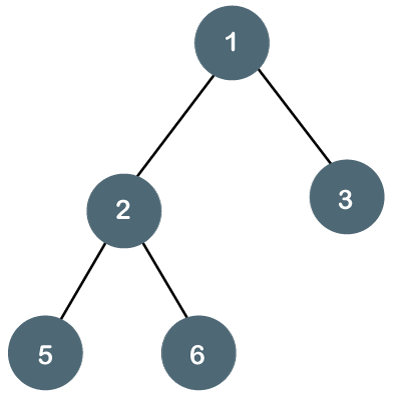
Un arbre binaire
Une situation clé dans laquelle les arbres binaires sont vraiment utiles est la recherche. Et pour la recherche, un certain type d'arbre binaire est utilisé, appelé arbres binaires de recherche (ABR).
Les ABR sont comme les arbres binaires mais les informations qu'ils contiennent sont ordonnées de manière à en faire une structure de données adaptée à la recherche.
Dans les ABR, les valeurs sont ordonnées de sorte que chaque nœud qui descend du côté gauche de son parent doit avoir une valeur inférieure à celle de son parent, et chaque nœud qui descend du côté droit de son parent doit avoir une valeur supérieure à celle de son parent.

Un arbre binaire de recherche
Cet ordre dans ses valeurs rend cette structure de données idéale pour la recherche, puisque à chaque niveau de l'arbre, nous pouvons identifier si la valeur recherchée est supérieure ou inférieure au nœud parent, et à partir de cette comparaison, éliminer progressivement environ la moitié des données jusqu'à ce que nous atteignions notre valeur.
Lors de l'insertion ou de la suppression de valeurs, l'algorithme suivra les étapes suivantes :
Vérifier s'il y a un nœud racine.
Si oui, vérifier si la valeur à ajouter/supprimer est supérieure ou inférieure au nœud.
Si elle est inférieure, vérifier s'il y a un nœud à gauche et répéter l'opération précédente. Si ce n'est pas le cas, ajouter/supprimer le nœud à cette position.
Si elle est supérieure, vérifier s'il y a un nœud à droite et répéter l'opération précédente. Si ce n'est pas le cas, ajouter/supprimer le nœud à cette position.
La recherche dans les ABR est très similaire, sauf qu'au lieu d'ajouter/supprimer des valeurs, nous vérifions les nœuds pour l'égalité avec la valeur que nous recherchons.
La complexité big O de ces opérations est logarithmique (log(n)). Mais il est important de reconnaître que pour que cette complexité soit atteinte, l'arbre doit avoir une structure équilibrée afin que, à chaque étape de recherche, environ la moitié des données puisse être "éliminée". Si plus de valeurs sont stockées d'un côté ou de l'autre de l'arbre, l'efficacité de la structure de données est affectée.
Une implémentation d'un ABR pourrait ressembler à ceci :
// Nous créons une classe pour chaque nœud dans l'arbre
class Node{
// Chaque nœud a trois propriétés, sa valeur, un pointeur qui indique le nœud à sa gauche et un pointeur qui indique le nœud à sa droite
constructor(value){
this.value = value
this.left = null
this.right = null
}
}
// Nous créons une classe pour l'ABR
class BinarySearchTree {
// L'arbre n'a qu'une seule propriété qui est son nœud racine
constructor(){
this.root = null
}
// La méthode insert prend une valeur en paramètre et insère la valeur à sa place correspondante dans l'arbre
insert(value){
const newNode = new Node(value)
if(this.root === null){
this.root = newNode
return this
}
let current = this.root
while(true){
if(value === current.value) return undefined
if(value < current.value){
if(current.left === null){
current.left = newNode
return this
}
current = current.left
} else {
if(current.right === null){
current.right = newNode
return this
}
current = current.right
}
}
}
// La méthode find prend une valeur en paramètre et itère à travers l'arbre à la recherche de cette valeur
// Si la valeur est trouvée, elle retourne le nœud correspondant et si ce n'est pas le cas, elle retourne undefined
find(value){
if(this.root === null) return false
let current = this.root,
found = false
while(current && !found){
if(value < current.value){
current = current.left
} else if(value > current.value){
current = current.right
} else {
found = true
}
}
if(!found) return undefined
return current
}
// La méthode contains prend une valeur en paramètre et retourne true si la valeur est trouvée dans l'arbre
contains(value){
if(this.root === null) return false
let current = this.root,
found = false
while(current && !found){
if(value < current.value){
current = current.left
} else if(value > current.value){
current = current.right
} else {
return true
}
}
return false
}
}
Tas
Les tas sont un autre type d'arbre qui ont des règles particulières. Il existe deux principaux types de tas, les MaxHeaps et les MinHeaps. Dans les MaxHeaps, les nœuds parents sont toujours plus grands que leurs enfants, et dans les MinHeaps, les nœuds parents sont toujours plus petits que leurs enfants.
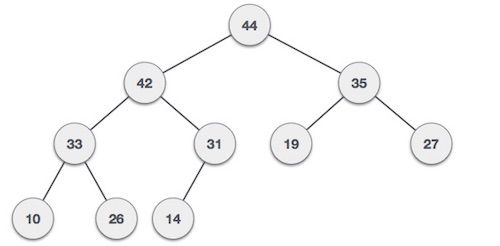
Un tas max
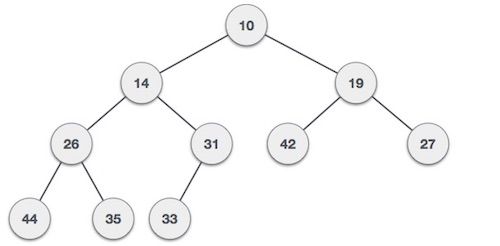
Un tas min
Dans cette structure de données, il n'y a aucune garantie entre frères et sœurs, ce qui signifie que les nœuds au même "niveau" ne suivent aucune règle autre que d'être plus élevés/plus bas que leur parent.
De plus, les tas sont aussi compacts que possible, ce qui signifie que chaque niveau contient tous les nœuds qu'il peut contenir sans espaces vides, et les nouveaux enfants sont placés dans les espaces de gauche de l'arbre en premier.
Les tas, et en particulier les tas binaires, sont fréquemment utilisés pour implémenter des files de priorité, qui à leur tour sont fréquemment utilisées dans des algorithmes bien connus tels que l'algorithme de recherche de chemin de Dijkstra.
Les files de priorité sont un type de structure de données dans lequel chaque élément a une priorité associée et les éléments avec une priorité plus élevée sont présentés en premier.
Graphes
Les graphes sont une structure de données formée par un groupe de nœuds et certaines connexions entre ces nœuds. Contrairement aux arbres, les graphes n'ont pas de nœuds racine et feuille, ni de "tête" ou de "queue". Différents nœuds sont connectés les uns aux autres et il n'y a pas de connexion parent-enfant implicite entre eux.
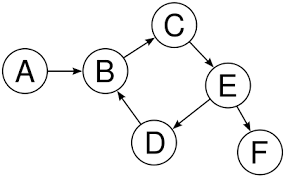
Un graphe
Les graphes sont des structures de données souvent utiles pour :
Les réseaux sociaux
La géolocalisation
Les systèmes de recommandation
Les graphes peuvent être classés en différents types selon les caractéristiques des connexions entre les nœuds :
Graphes non orientés et orientés
On dit qu'un graphe est non orienté s'il n'y a pas de direction implicite dans les connexions entre les nœuds.
Si nous prenons l'exemple d'image suivant, vous pouvez voir qu'il n'y a pas de direction dans la connexion entre le nœud 2 et le nœud 3. La connexion va dans les deux sens, ce qui signifie que vous pouvez parcourir la structure de données du nœud 2 au nœud 3, et du nœud 3 au nœud 2. Non orienté signifie que les connexions entre les nœuds peuvent être utilisées dans les deux sens.

Un graphe non orienté
Et comme vous l'avez peut-être deviné, les graphes orientés sont l'exact opposé. Réutilisons l'exemple d'image précédent, et voyons que ici il y a une direction implicite dans les connexions entre les nœuds.
Dans ce graphe particulier, vous pourriez parcourir du nœud A au nœud B, mais vous ne pouvez pas aller du nœud B au nœud A.
Un graphe orienté
Graphes pondérés et non pondérés
On dit qu'un graphe est pondéré si les connexions entre les nœuds ont un poids assigné. Dans ce cas, le poids signifie simplement une valeur qui est assignée à une connexion spécifique. C'est une information sur la connexion elle-même, et non sur les nœuds.
En suivant cet exemple, nous pouvons voir que la connexion entre les nœuds 0 et 4 a un poids de 7. Et la connexion entre les nœuds 3 et 1 a un poids de 4.

Un graphe pondéré
Pour comprendre l'utilisation des graphes pondérés, imaginez que vous souhaitez représenter une carte avec de nombreux endroits différents, et donner à l'utilisateur des informations sur le temps qu'il pourrait prendre pour aller d'un endroit à un autre.
Un graphe pondéré serait parfait pour cela, car vous pourriez utiliser chaque nœud pour enregistrer des informations sur l'emplacement, les connexions pourraient représenter les routes disponibles entre chaque lieu, et les poids représenteraient la distance physique d'un lieu à un autre.
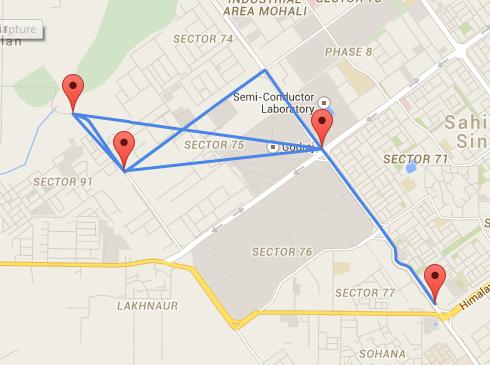
Les graphes pondérés sont largement utilisés dans les systèmes de géolocalisation
Et comme vous l'avez peut-être deviné une fois de plus, les graphes non pondérés sont ceux où les connexions entre les nœuds n'ont pas de poids assignés. Il n'y a donc aucune information particulière sur les connexions entre les nœuds, seulement sur les nœuds eux-mêmes.
Comment représenter les graphes
Lors du codage des graphes, il existe deux méthodes principales que nous pouvons utiliser : une matrice d'adjacence et une liste d'adjacence. Expliquons comment fonctionnent les deux et voyons leurs avantages et inconvénients.
Une matrice d'adjacence est une structure à deux dimensions qui représente les nœuds dans notre graphe et les connexions entre eux.
Si nous utilisons cet exemple...
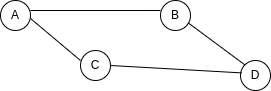
Notre matrice d'adjacence ressemblerait à ceci :
| - | A | B | C | D |
| A | 0 | 1 | 1 | 0 |
| B | 1 | 0 | 0 | 1 |
| C | 1 | 0 | 0 | 1 |
| D | 0 | 1 | 1 | 0 |
Vous pouvez voir que la matrice est comme un tableau, où les colonnes et les lignes représentent les nœuds dans notre graphe, et la valeur des cellules représente les connexions entre les nœuds. Si la cellule est 1, il y a une connexion entre la ligne et la colonne, et si elle est 0, il n'y en a pas.
Le tableau pourrait être facilement répliqué en utilisant un tableau à deux dimensions :
[
[0, 1, 1, 0]
[1, 0, 0, 1]
[1, 0, 0, 1]
[0, 1, 1, 0]
]
D'un autre côté, une liste d'adjacence peut être considérée comme une structure de paires clé-valeur où les clés représentent chaque nœud de notre graphe et les valeurs sont les connexions que ce nœud particulier possède.
En utilisant le même exemple de graphe, notre liste d'adjacence pourrait être représentée avec cet objet :
{
A: ["B", "C"],
B: ["A", "D"],
C: ["A", "D"],
D: ["B", "C"],
}
Vous pouvez voir que pour chaque nœud, nous avons une clé, et nous stockons toutes les connexions du nœud dans un tableau.
Alors, quelle est la différence entre les matrices d'adjacence et les listes ? Eh bien, les listes tendent à être plus efficaces lorsqu'il s'agit d'ajouter ou de supprimer des nœuds, tandis que les matrices sont plus efficaces lors de l'interrogation de connexions spécifiques entre les nœuds.
Pour voir cela, imaginez que nous voulons ajouter un nouveau nœud à notre graphe :
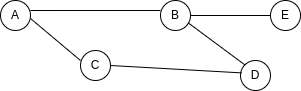
Pour représenter cela dans une matrice, nous devrions ajouter une toute nouvelle colonne et une toute nouvelle ligne :
| - | A | B | C | D | E |
| A | 0 | 1 | 1 | 0 | 0 |
| B | 1 | 0 | 0 | 1 | 1 |
| C | 1 | 0 | 0 | 1 | 0 |
| D | 0 | 1 | 1 | 0 | 0 |
| E | 0 | 1 | 0 | 0 | 0 |
Alors que pour faire la même chose dans une liste, ajouter une valeur aux connexions de B et une paire clé-valeur pour représenter E est suffisant :
{
A: ["B", "C"],
B: ["A", "D", "E"],
C: ["A", "D"],
D: ["B", "C"],
E: ["B"],
}
Maintenant, imaginez que nous voulons vérifier s'il y a une connexion existante entre le nœud B et E. Vérifier cela dans une matrice est très facile, car nous savons exactement la position dans la matrice qui représente cette connexion.
| - | A | B | C | D | E |
| A | 0 | 1 | 1 | 0 | 0 |
| B | 1 | 0 | 0 | 1 | 1 |
| C | 1 | 0 | 0 | 1 | 0 |
| D | 0 | 1 | 1 | 0 | 0 |
| E | 0 | 1 | 0 | 0 | 0 |
Mais dans une liste, nous n'avons pas cette information, nous devrions itérer sur tout le tableau qui représente les connexions de B et voir ce qu'il y a. Vous pouvez donc voir qu'il y a des avantages et des inconvénients pour chaque approche.
Une implémentation complète d'un graphe utilisant une liste d'adjacence pourrait ressembler à ceci. Pour garder les choses simples, nous représenterons un graphe non orienté et non pondéré.
// Nous créons une classe pour le graphe
class Graph{
// Le graphe n'a qu'une seule propriété qui est la liste d'adjacence
constructor() {
this.adjacencyList = {}
}
// La méthode addNode prend une valeur de nœud en paramètre et l'ajoute comme clé à la adjacencyList si elle n'était pas présente auparavant
addNode(node) {
if (!this.adjacencyList[node]) this.adjacencyList[node] = []
}
// La méthode addConnection prend deux nœuds en paramètres, et ajoute chaque nœud au tableau des connexions de l'autre.
addConnection(node1,node2) {
this.adjacencyList[node1].push(node2)
this.adjacencyList[node2].push(node1)
}
// La méthode removeConnection prend deux nœuds en paramètres, et supprime chaque nœud du tableau des connexions de l'autre.
removeConnection(node1,node2) {
this.adjacencyList[node1] = this.adjacencyList[node1].filter(v => v !== node2)
this.adjacencyList[node2] = this.adjacencyList[node2].filter(v => v !== node1)
}
// La méthode removeNode prend une valeur de nœud en paramètre. Elle supprime toutes les connexions à ce nœud présentes dans le graphe et supprime ensuite la clé du nœud de la liste d'adjacence.
removeNode(node){
while(this.adjacencyList[node].length) {
const adjacentNode = this.adjacencyList[node].pop()
this.removeConnection(node, adjacentNode)
}
delete this.adjacencyList[node]
}
}
const Argentina = new Graph()
Argentina.addNode("Buenos Aires")
Argentina.addNode("Santa fe")
Argentina.addNode("Córdoba")
Argentina.addNode("Mendoza")
Argentina.addConnection("Buenos Aires", "Córdoba")
Argentina.addConnection("Buenos Aires", "Mendoza")
Argentina.addConnection("Santa fe", "Córdoba")
console.log(Argentina)
// Graph {
// adjacencyList: {
// 'Buenos Aires': [ 'Córdoba', 'Mendoza' ],
// 'Santa fe': [ 'Córdoba' ],
// 'Córdoba': [ 'Buenos Aires', 'Santa fe' ],
// Mendoza: [ 'Buenos Aires' ]
// }
// }
Résumé
C'est tout, tout le monde. Dans cet article, nous avons introduit les principales structures de données utilisées en informatique et en développement logiciel. Ces structures sont la base de la plupart des programmes que nous utilisons dans la vie de tous les jours, il est donc vraiment bon de les connaître.
Même si ce sujet peut sembler un peu abstrait et intimidant au premier abord, je crois que nous pouvons mieux le comprendre en pensant simplement aux structures de données comme des moyens d'organiser les données pour mieux accomplir certaines tâches.
Comme toujours, j'espère que vous avez apprécié l'article et appris quelque chose de nouveau. Si vous le souhaitez, vous pouvez également me suivre sur LinkedIn ou Twitter.
À plus tard !
