

Article original : Advanced Indexing Strategies in PostgreSQL
Par Faith Oyama
L'indexation dans PostgreSQL est un processus qui implique la création de structures de données optimisées pour rechercher et récupérer efficacement des données à partir de tables.
Un index est une copie d'une portion d'une table, organisée de manière à permettre à PostgreSQL de localiser et de récupérer rapidement les lignes qui correspondent à une condition de requête particulière.
Lorsqu'une requête est exécutée, PostgreSQL examine les index disponibles pour déterminer si l'un d'eux peut être utilisé pour satisfaire la condition de la requête. Si un index pertinent est trouvé, PostgreSQL l'utilise pour identifier rapidement les lignes correspondantes dans la table. Cela entraîne des requêtes significativement plus rapides, en particulier dans les situations où les tables sont grandes ou les conditions sont complexes.
PostgreSQL prend en charge plusieurs types d'index, notamment B-tree, hash, GiST, SP-GiST et BRIN. Chaque type d'index est conçu pour répondre à des types de requêtes et à des modèles d'accès aux données distincts.
En plus des types d'index standard, PostgreSQL permet aux utilisateurs de définir des index personnalisés en utilisant des fonctions définies par l'utilisateur.
Il est important de noter que la création d'un index nécessite un espace disque supplémentaire et peut avoir un impact sur les performances des opérations d'écriture, telles que INSERT, UPDATE et DELETE. Pour cette raison, il est essentiel de considérer les compromis et de choisir soigneusement les colonnes à indexer en fonction des requêtes que vous exécutez fréquemment et des modèles d'accès à vos données.
Index B-tree
L'index B-tree est le type d'index le plus couramment utilisé pour stocker et récupérer efficacement des données dans PostgreSQL. C'est le type d'index par défaut. Chaque fois que nous utilisons la commande CREATE INDEX sans spécifier le type d'index souhaité, PostgreSQL créera un index B-tree pour la table ou la colonne.
Un index B-tree est organisé sous forme de structure arborescente. L'index commence par un nœud racine, avec des pointeurs vers des nœuds enfants. Chaque nœud de l'arbre contient généralement plusieurs paires clé-valeur, où les clés sont utilisées pour l'indexation, et les valeurs pointent vers les données correspondantes dans la table.
Pour créer un index B-tree dans PostgreSQL, utilisez l'instruction CREATE INDEX. Voici la syntaxe :
CREATE INDEX index_name ON table_name;
Indexation sur une seule colonne
Pour créer un index B-tree basé sur une seule colonne de table au lieu de créer un index sur l'ensemble de la table, la syntaxe est la suivante.
CREATE INDEX index_name ON table_name (column_name);
index_name est le nom que vous souhaitez donner à l'index.
table_name est le nom de la table sur laquelle vous souhaitez créer l'index.
column_name est le nom de la ou des colonnes sur lesquelles vous souhaitez créer l'index.
Exemple :
Créons une table appelée "sales_info" et insérons quelques données fictives.
CREATE TABLE sales_info (
sales_id integer NOT NULL, email VARCHAR,
location VARCHAR, item_purchased VARCHAR,
price VARCHAR
);
Insérez des valeurs dans la table en utilisant l'instruction INSERT :
INSERT INTO sales_info (
sales_id, email, location, item_purchased,
price
)
VALUES
(
1, 'halie46@gmail.com', 'London',
'Headphone', '$50'
),
(
2, 'romaine21@gmail.com', 'Australia',
'Webcam', '$50'
),
(
3, 'frederique19@gmail.com', 'Canada',
'iPhone 14 pro', '$1259'
),
(
4, 'kenton_macejkovic80@hotmail.com',
'London', 'Wireless Mouse', '$20'
),
(
5, 'alexis62@hotmail.com', 'Switzerland',
'Dell Charger', '$15'
),
(
6, 'concepcion_kiehn@hotmail.com',
'Canada', 'Longitech Keyboard',
'$499'
);
Si nous créons un index B-tree sur la colonne sales_id en exécutant cette instruction :
CREATE INDEX idx_sales_id ON sales_info (sales_id);
Lorsque nous exécutons l'instruction SELECT, nous obtenons le temps d'exécution total de la requête ci-dessous.
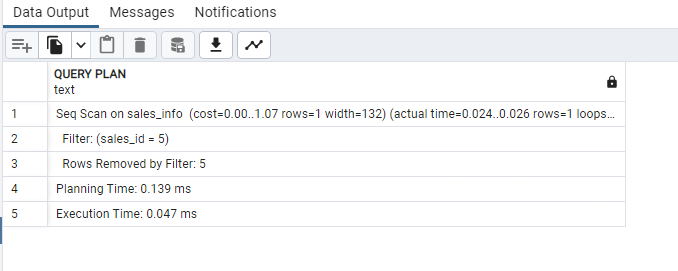
Le temps affiché peut sembler insignifiant, car la table avec laquelle nous travaillons est petite. Mais lorsque vous travaillez avec une grande quantité de données, cela améliorera considérablement les performances de vos requêtes.
Pour en savoir plus sur l'index B-Tree et les comportements des classes d'opérateurs B-Tree, consultez la documentation officielle ici.
Index de hachage
Les index de hachage sont conçus pour des recherches rapides clé-valeur. Lorsqu'une condition de requête nécessite des vérifications d'égalité sur des colonnes indexées, les index de hachage peuvent fournir une récupération extrêmement rapide, car la fonction de hachage détermine directement l'emplacement des données souhaitées. Les index de hachage sont les plus adaptés pour les comparaisons d'égalité, telles que les opérations = ou IN.
Comme les autres types d'index, les index de hachage doivent être maintenus lors des modifications de données (insertions, mises à jour et suppressions) pour garantir la cohérence des données. Mais la maintenance des index de hachage peut être plus coûteuse que celle des index B-tree en raison de la nécessité de résoudre les collisions et de réhasher les données.
Pour créer un index de hachage dans PostgreSQL, vous pouvez utiliser l'instruction CREATE INDEX avec la clause USING HASH. Par exemple :
CREATE INDEX hash_name ON table_name USING HASH (column_name);
Cette instruction crée un index de hachage nommé "hash_name" sur la colonne spécifiée de la table.
Point à noter ici : bien que les index de hachage soient disponibles dans PostgreSQL, ils ne sont pas adaptés aux requêtes de plage ou au tri. Les index B-tree sont généralement préférés pour de tels scénarios. Encore une fois, les index B-tree sont le type d'index par défaut et le plus couramment utilisé.
Les index de hachage ont des cas d'utilisation spécifiques et des limitations, et il est essentiel d'évaluer vos exigences et vos modèles de requête avant de décider du type d'index approprié pour votre base de données PostgreSQL.
Exemple :
Créez un index de hachage sur la table sales_info en utilisant HASH pour la colonne sales_id :
CREATE INDEX idx_sales_id ON sales_info USING HASH(sales_id);
Sélectionnez et filtrez les données en utilisant la clause WHERE :
EXPLAIN (ANALYZE)
Select
*
from
sales_info
WHERE
sales_id = 5;
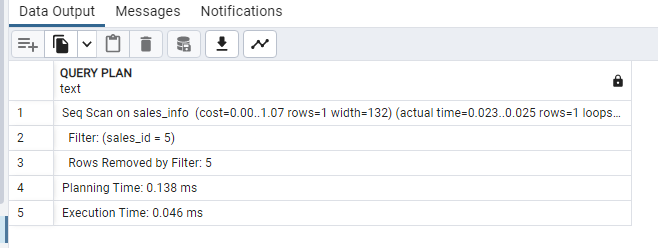
Consultez la documentation officielle si vous souhaitez approfondir les index de hachage.
Index GiST et SP-GiST
Les index GiST (Generalized Search Tree) et SP-GiST (Space-Partitioned Generalized Search Tree) sont des types d'index avancés dans PostgreSQL qui fournissent un support pour une large gamme de types de données et d'opérations de recherche.
Ils sont particulièrement utiles pour gérer des structures de données complexes et des données spatiales. Les index GiST sont ce que vous utilisez si vous souhaitez accélérer les recherches en texte intégral.
Création d'index GiST et SP-GiST :
Pour créer un index GiST ou SP-GiST dans PostgreSQL, vous pouvez utiliser l'instruction CREATE INDEX avec la clause USING GIST ou USING SPGIST, respectivement.
Voici un exemple de création d'un index GiST sur une colonne de géométrie :
CREATE INDEX index_geometry ON table_name USING GIST (geometry_column);
Et voici un exemple de création d'un index SP-GiST sur une colonne tsvector :
CREATE INDEX index_text_search ON table_name USING SPGIST (tsvector_column);
Voici un aperçu des index GiST et SP-GiST dans PostgreSQL :
Index GiST :
- Les index GiST (Generalized Search Tree) sont des structures d'index polyvalentes qui supportent divers types de données au-delà des valeurs scalaires simples.
- Les index GiST permettent une recherche et une récupération efficaces pour des structures de données complexes telles que les objets géométriques, les documents textuels, les tableaux, et plus encore.
- Ils sont basés sur le concept d'arbres multidimensionnels, permettant des opérations de recherche flexibles.
- Les index GiST peuvent gérer différents prédicats de recherche, y compris l'égalité, la plage et les opérations spatiales comme les chevauchements, la contenance et les recherches basées sur la distance.
Index SP-GiST :
- Les index SP-GiST (Space-Partitioned Generalized Search Tree) sont une extension des index GiST qui améliorent davantage les capacités d'indexation.
- Les index SP-GiST sont conçus pour les types de données avec des caractéristiques de remplissage d'espace, tels que les données multidimensionnelles, les données de séries temporelles et les données de réseau.
- Ils partitionnent l'espace d'index en régions non chevauchantes, optimisant les performances de recherche pour des modèles d'accès spécifiques.
- Les index SP-GiST fournissent un support pour divers types de données, y compris les objets géométriques, la recherche de texte, et plus encore.
- Ils sont particulièrement efficaces pour l'indexation spatiale et peuvent gérer des requêtes spatiales complexes, y compris l'intersection, le voisin le plus proche et les opérations de clustering.
Consultez la documentation officielle sur les index GiST et SP-GiST pour plus d'informations.
Index BRIN
BRIN, ou Block Range Index, est un type d'index dans PostgreSQL conçu pour fournir une indexation efficace pour les grandes tables avec des données triées. L'index BRIN contient le minimum et le maximum dans un groupe de pages de base de données.
L'index BRIN est le moyen le plus simple d'optimiser pour la vitesse. Il est particulièrement utile pour les données qui présentent des caractéristiques séquentielles ou triées, telles que les données de séries temporelles ou les données avec un ordre naturel.
Voici un aperçu de l'index BRIN :
- Les index BRIN divisent la table en blocs logiques et stockent des informations de résumé sur chaque bloc.
- Chaque bloc contient une plage de valeurs, et l'index stocke les valeurs minimales et maximales dans chaque bloc.
- Au lieu de stocker des entrées d'index individuelles pour chaque ligne, les index BRIN stockent des résumés au niveau des blocs, ce qui les rend plus petits en taille par rapport aux autres types d'index.
- Les index BRIN fonctionnent bien lorsque les données sont triées ou lorsque les analyses séquentielles sont plus efficaces que les analyses d'index.
Pour créer un index BRIN dans PostgreSQL, vous utilisez l'instruction CREATE INDEX avec la clause USING BRIN.
Voici un exemple de création d'un index BRIN sur une colonne de timestamp :
CREATE INDEX timestamp ON table_name USING BRIN (column);
L'instruction ci-dessus crée un index BRIN sur la colonne de timestamp spécifiée de la table.
Voici quelques éléments à considérer lors de la création d'un index BRIN :
- Les index BRIN sont les plus efficaces lorsque les données sont triées ou présentent un ordre naturel.
- Ils peuvent ne pas être adaptés aux tables avec des données très non triées ou non séquentielles.
- Les index BRIN sont généralement utilisés pour les charges de travail intensives en lecture où les analyses séquentielles sont prévalentes.
- Une maintenance régulière et un réindexage périodique peuvent être nécessaires pour garantir des performances optimales.
Pour en savoir plus sur les index BRIN, vous pouvez consulter la documentation officielle.
Conclusion
Dans ce guide rapide, nous avons vu d'autres types d'index pris en charge par PostgreSQL en plus de l'index B-Tree.
Il n'est pas recommandé de créer un index à la volée juste avant d'exécuter une requête ponctuelle. La création d'un index bien conçu nécessite une planification et des tests minutieux.
Il est important de considérer que les index consomment de l'espace disque. De plus, chaque fois que de nouvelles lignes de données sont insérées ou que des lignes existantes sont mises à jour, la base de données met automatiquement à jour les entrées d'index correspondantes.