

Article original : SQLAlchemy makes ETL magically easy
Par Peter Gleeson
L'un des aspects clés de tout flux de travail en science des données est l'approvisionnement, le nettoyage et le stockage des données brutes dans un format pouvant être utilisé en amont. Ce processus est communément appelé « Extract-Transform-Load » ou ETL pour faire court.
Il est important de concevoir des processus ETL efficaces, robustes et fiables, ou « pipelines de données ». Un pipeline inefficace rendra le travail avec les données lent et improductif. Un pipeline non robuste se brisera facilement, laissant des lacunes.
Pire encore, un pipeline de données non fiable contaminera silencieusement votre base de données avec de fausses données qui peuvent ne pas devenir apparentes avant que des dégâts ne soient causés.
Bien que cruciale, le développement ETL peut parfois être un processus lent et fastidieux. Heureusement, il existe des solutions open source qui facilitent grandement la vie.
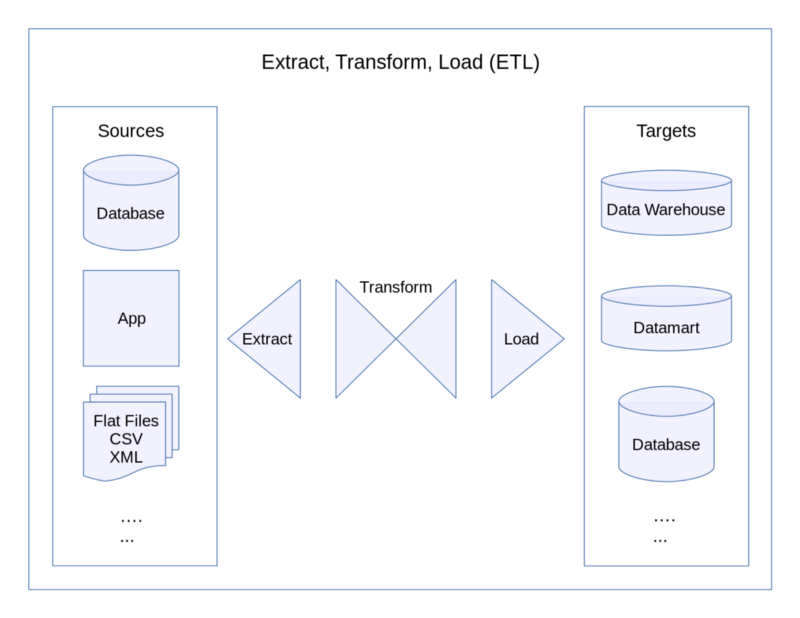
Qu'est-ce que SQLAlchemy ?
Une telle solution est un module Python appelé SQLAlchemy. Il permet aux ingénieurs de données et aux développeurs de définir des schémas, d'écrire des requêtes et de manipuler des bases de données SQL entièrement via Python.
Les fonctionnalités Object Relational Mapper (ORM) et Expression Language de SQLAlchemy atténuent certaines des idiosyncrasies apparentes entre différentes implémentations de SQL en vous permettant d'associer des classes et des constructions Python avec des tables de données et des expressions.
Ici, nous allons passer en revue quelques points forts de SQLAlchemy pour découvrir ce qu'il peut faire et comment il peut rendre le développement ETL plus fluide.
Installation
Vous pouvez installer SQLAlchemy en utilisant l'installateur de paquets pip.
$ sudo pip install sqlalchemy
En ce qui concerne SQL lui-même, il existe de nombreuses versions différentes disponibles, notamment MySQL, Postgres, Oracle et Microsoft SQL Server. Pour cet article, nous utiliserons SQLite.
SQLite est une implémentation open-source de SQL qui est généralement préinstallée avec Linux et Mac OS X. Elle est également disponible pour Windows. Si vous ne l'avez pas déjà sur votre système, vous pouvez suivre ces instructions pour vous lancer.
Dans un nouveau répertoire, utilisez le terminal pour créer une nouvelle base de données :
$ mkdir sqlalchemy-demo && cd sqlalchemy-demo
$ touch demo.db
Définition d'un schéma
Un schéma de base de données définit la structure d'un système de base de données, en termes de tables, de colonnes, de champs et des relations entre eux. Les schémas peuvent être définis en SQL brut, ou via l'utilisation de la fonctionnalité ORM de SQLAlchemy.
Ci-dessous se trouve un exemple montrant comment définir un schéma de deux tables pour une plateforme de blogging imaginaire. L'une est une table d'utilisateurs, et l'autre est une table de posts téléchargés.
from sqlalchemy import *
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
from sqlalchemy.sql import *
engine = create_engine('sqlite:///demo.db')
Base = declarative_base()
class Users(Base):
__tablename__ = "users"
UserId = Column(Integer, primary_key=True)
Title = Column(String)
FirstName = Column(String)
LastName = Column(String)
Email = Column(String)
Username = Column(String)
DOB = Column(DateTime)
class Uploads(Base):
__tablename__ = "uploads"
UploadId = Column(Integer, primary_key=True)
UserId = Column(Integer)
Title = Column(String)
Body = Column(String)
Timestamp = Column(DateTime)
Users.__table__.create(bind=engine, checkfirst=True)
Uploads.__table__.create(bind=engine, checkfirst=True)
Tout d'abord, importez tout ce dont vous avez besoin depuis SQLAlchemy. Ensuite, utilisez create_engine(connection_string) pour vous connecter à votre base de données. La chaîne de connexion exacte dépendra de la version de SQL avec laquelle vous travaillez. Cet exemple utilise un chemin relatif vers la base de données SQLite créée précédemment.
Ensuite, commencez à définir vos classes de tables. La première dans l'exemple est Users. Chaque colonne de cette table est définie comme une variable de classe en utilisant Column(type) de SQLAlchemy, où type est un type de données (tel que Integer, String, DateTime, etc.). Utilisez primary_key=True pour désigner les colonnes qui seront utilisées comme clés primaires.
La table suivante définie ici est Uploads. C'est exactement la même idée — chaque colonne est définie comme précédemment.
Les deux dernières lignes créent effectivement les tables. Le paramètre checkfirst=True garantit que de nouvelles tables ne sont créées que si elles n'existent pas déjà dans la base de données.
Extraction
Une fois le schéma défini, la tâche suivante consiste à extraire les données brutes de leur source. Les détails exacts peuvent varier considérablement d'un cas à l'autre, selon la manière dont les données brutes sont fournies. Peut-être que votre application appelle une API interne ou tierce, ou peut-être devez-vous lire des données enregistrées dans un fichier CSV.
L'exemple ci-dessous utilise deux API pour simuler des données pour la plateforme de blogging fictive décrite ci-dessus. La table Users sera peuplée avec des profils générés aléatoirement sur randomuser.me, et la table Uploads contiendra des données inspirées de lorem ipsum grâce à JSONPlaceholder.
Le module Requests de Python peut être utilisé pour appeler ces API, comme montré ci-dessous :
import requests
url = 'https://randomuser.me/api/?results=10'
users_json = requests.get(url).json()
url2 = 'https://jsonplaceholder.typicode.com/posts/'
uploads_json = requests.get(url2).json()
Les données sont actuellement stockées dans deux objets (users_json et uploads_json) au format JSON. L'étape suivante consistera à transformer et charger ces données dans les tables définies précédemment.
Transformation
Avant que les données ne puissent être chargées dans la base de données, il est important de s'assurer qu'elles sont dans le bon format. Les objets JSON créés dans le code ci-dessus sont imbriqués et contiennent plus de données que nécessaire pour les tables définies.
Une étape intermédiaire importante consiste à transformer les données de leur format JSON imbriqué actuel en un format plat qui peut être écrit en toute sécurité dans la base de données sans erreur.
Pour l'exemple traité dans cet article, les données sont relativement simples et ne nécessiteront pas beaucoup de transformation. Le code ci-dessous crée deux listes, users et uploads, qui seront utilisées dans l'étape finale :
from datetime import datetime, timedelta
from random import randint
users, uploads = [], []
for i, result in enumerate(users_json['results']):
row = {}
row['UserId'] = i
row['Title'] = result['name']['title']
row['FirstName'] = result['name']['first']
row['LastName'] = result['name']['last']
row['Email'] = result['email']
row['Username'] = result['login']['username']
dob = datetime.strptime(result['dob'],'%Y-%m-%d %H:%M:%S')
row['DOB'] = dob.date()
users.append(row)
for result in uploads_json:
row = {}
row['UploadId'] = result['id']
row['UserId'] = result['userId']
row['Title'] = result['title']
row['Body'] = result['body']
delta = timedelta(seconds=randint(1,86400))
row['Timestamp'] = datetime.now() - delta
uploads.append(row)
L'étape principale ici consiste à itérer à travers les objets JSON créés précédemment. Pour chaque résultat, créez un nouvel objet dictionnaire Python avec des clés correspondant à chaque colonne définie pour la table pertinente dans le schéma. Cela garantit que les données ne sont plus imbriquées et ne conserve que les données nécessaires pour les tables.
L'autre étape consiste à utiliser le module datetime de Python pour manipuler les dates et les transformer en objets de type DateTime qui peuvent être écrits dans la base de données. Pour les besoins de cet exemple, des objets DateTime aléatoires sont générés en utilisant la méthode timedelta() du module DateTime de Python.
Chaque dictionnaire créé est ajouté à une liste, qui sera utilisée dans l'étape finale du pipeline.
Chargement
Enfin, les données sont dans un format qui peut être chargé dans la base de données. SQLAlchemy rend cette étape simple grâce à son API Session.
L'API Session agit un peu comme un intermédiaire, ou une « zone de maintien », pour les objets Python que vous avez soit chargés depuis la base de données, soit associés à celle-ci. Ces objets peuvent être manipulés dans la session avant d'être validés dans la base de données.
Le code ci-dessous crée un nouvel objet session, ajoute des lignes à celui-ci, puis les fusionne et les valide dans la base de données :
Session = sessionmaker(bind=engine)
session = Session()
for user in users:
row = Users(**user)
session.add(row)
for upload in uploads:
row = Uploads(**upload)
session.add(row)
session.commit()
L'usine sessionmaker est utilisée pour générer de nouvelles classes Session configurées. Session est une classe Python ordinaire qui est instanciée à la deuxième ligne en tant que session.
Ensuite, deux boucles qui itèrent à travers les listes users et uploads créées précédemment. Les éléments de ces listes sont des objets dictionnaires dont les clés correspondent aux colonnes données dans les classes Users et Uploads définies précédemment.
Chaque objet est utilisé pour instancier une nouvelle instance de la classe pertinente (en utilisant l'astuce pratique de Python some_function(**some_dict)). Cet objet est ajouté à la session actuelle avec session.add().
Enfin, lorsque la session contient les lignes à ajouter, session.commit() est utilisé pour valider la transaction dans la base de données.
Agrégation
Une autre fonctionnalité intéressante de SQLAlchemy est la possibilité d'utiliser son système Expression Language pour écrire et exécuter des requêtes SQL indépendantes du backend.
Quels sont les avantages de l'écriture de requêtes indépendantes du backend ? Pour commencer, elles rendent tout projet de migration futur beaucoup plus facile. Différentes versions de SQL ont des syntaxes quelque peu incompatibles, mais le langage d'expression de SQLAlchemy agit comme une lingua franca entre elles.
De plus, pouvoir interroger et interagir avec votre base de données de manière parfaitement Pythonique est un véritable avantage pour les développeurs qui préféreraient travailler entièrement dans le langage qu'ils connaissent le mieux. Cependant, SQLAlchemy vous permettra également de travailler en SQL simple, pour les cas où il est plus simple d'utiliser une requête pré-écrite.
Ici, nous allons étendre l'exemple de la plateforme de blogging fictive pour illustrer comment cela fonctionne. Une fois les tables de base Users et Uploads créées et peuplées, une étape suivante pourrait être de créer une table agrégée — par exemple, montrant combien d'articles chaque utilisateur a postés, et le moment où ils étaient actifs pour la dernière fois.
Tout d'abord, définissez une classe pour la table agrégée :
class UploadCounts(Base):
__tablename__ = "upload_counts"
UserId = Column(Integer, primary_key=True)
LastActive = Column(DateTime)
PostCount = Column(Integer)
UploadCounts.__table__.create(bind=engine, checkfirst=True)
Cette table aura trois colonnes. Pour chaque UserId, elle stockera le timestamp de leur dernière activité, et un compte du nombre de posts qu'ils ont téléchargés.
En SQL simple, cette table serait peuplée en utilisant une requête du type :
INSERT INTO upload_counts
SELECT
UserId,
MAX(Timestamp) AS LastActive,
COUNT(UploadId) AS PostCount
FROM
uploads
GROUP BY 1;
En SQLAlchemy, cela s'écrirait comme suit :
connection = engine.connect()
query = select([Uploads.UserId,
func.max(Uploads.Timestamp).label('LastActive'),
func.count(Uploads.UploadId).label('PostCount')]).\
group_by('UserId')
results = connection.execute(query)
for result in results:
row = UploadCounts(**result)
session.add(row)
session.commit()
La première ligne crée un objet Connection en utilisant la méthode connect() de l'objet engine. Ensuite, une requête est définie en utilisant la fonction select().
Cette requête est la même que la version SQL simple donnée ci-dessus. Elle sélectionne la colonne UserId de la table uploads. Elle applique également func.max() à la colonne Timestamp, qui identifie le timestamp le plus récent. Cela est étiqueté LastActive en utilisant la méthode label().
De même, la requête applique func.count() pour compter le nombre d'enregistrements qui apparaissent dans la colonne Title. Cela est étiqueté PostCount.
Enfin, la requête utilise group_by() pour regrouper les résultats par UserId.
Pour utiliser les résultats de la requête, une boucle for itère sur les objets de ligne retournés par connection.execute(query). Chaque ligne est utilisée pour instancier une instance de la classe de table UploadCounts. Comme précédemment, chaque ligne est ajoutée à l'objet session, et enfin la session est validée dans la base de données.
Vérification
Une fois que vous avez exécuté ce script, vous pouvez vouloir vous assurer que les données ont été correctement écrites dans la base de données demo.db créée précédemment.
Après avoir quitté Python, ouvrez la base de données dans SQLite :
$ sqlite3 demo.db
Maintenant, vous devriez pouvoir exécuter les requêtes suivantes :
SELECT * FROM users;
SELECT * FROM uploads;
SELECT * FROM upload_counts;
Et le contenu de chaque table sera imprimé dans la console ! En planifiant le script Python pour qu'il s'exécute à intervalles réguliers, vous pouvez être sûr que la base de données sera maintenue à jour.
Vous pourriez maintenant utiliser ces tables pour écrire des requêtes pour une analyse plus approfondie, ou pour construire des tableaux de bord à des fins de visualisation.
Pour aller plus loin
Si vous êtes arrivé jusqu'ici, alors espérons que vous aurez appris une ou deux choses sur la manière dont SQLAlchemy peut rendre le développement ETL en Python beaucoup plus simple !
Il n'est pas possible pour un seul article de rendre pleinement justice à toutes les fonctionnalités de SQLAlchemy. Cependant, l'un des principaux avantages du projet est la profondeur et le détail de sa documentation. Vous pouvez vous y plonger ici.
Sinon, consultez ce guide de référence si vous voulez commencer rapidement.
Le code complet de cet article peut être trouvé dans ce gist.
Merci d'avoir lu ! Si vous avez des questions ou des commentaires, veuillez laisser une réponse ci-dessous.