
Article original : Algorithmic problem solving: How to efficiently compute the parity of a stream of numbers
Par Kousik Nath
Énoncé du problème :
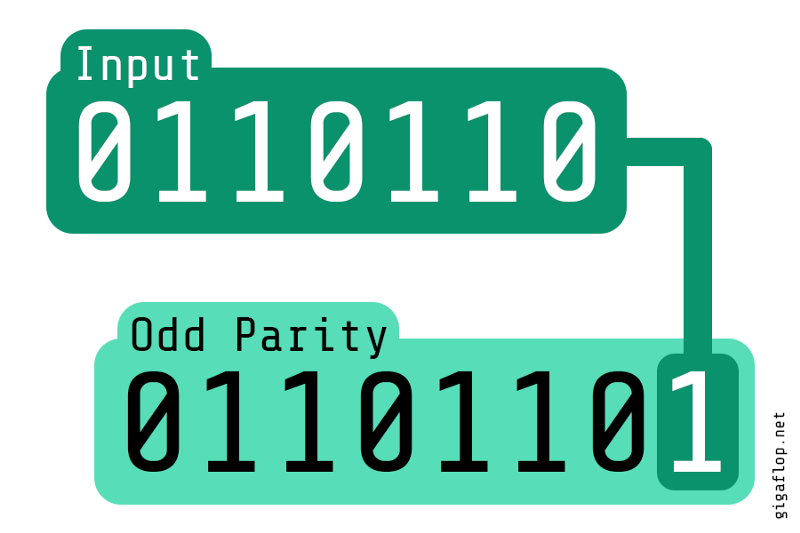
Vous recevez un flux de nombres (disons des nombres de type long), calculez la parité des nombres. Hypothétiquement, vous devez traiter une échelle énorme comme 1 million de nombres par minute. Concevez un algorithme en tenant compte d'une telle échelle. La parité d'un nombre est 1 si le nombre total de bits définis dans la représentation binaire du nombre est impair, sinon la parité est 0.
Solution :
Approche 1 - Force brute :
L'énoncé du problème indique clairement ce qu'est la parité. Nous pouvons calculer le nombre total de bits définis dans la représentation binaire du nombre donné. Si le nombre total de bits définis est impair, la parité est 1, sinon 0. La méthode naïve consiste donc à effectuer un décalage binaire vers la droite sur le nombre donné et à vérifier le bit le moins significatif (LSB) actuel pour suivre le résultat.

Dans l'extrait de code ci-dessus, nous parcourons tous les bits dans la boucle while un par un. Avec la condition ((no & 1) == 1), nous vérifions si le LSB actuel est 1 ou 0, si 1, nous faisons result ^= 1. La variable result est initialisée à 0. Ainsi, lorsque nous effectuons l'opération xor (^) entre la valeur actuelle de result et 1, le result sera défini à 1 si le result est actuellement 0, sinon 1.
S'il y a un nombre pair de bits définis, finalement le result deviendra 0 car le xor entre tous les 1 s'annulera mutuellement. S'il y a un nombre impair de 1, la valeur finale de result sera 1. no >>> 1 décale les bits de 1 vers la droite.
>>> est l'opérateur de décalage logique à droite en Java qui décale également le bit de signe (le bit le plus significatif dans un nombre signé). Il existe un autre opérateur de décalage à droite — >> qui est appelé opérateur de décalage arithmétique à droite [voir la référence 1 à la fin de la page]. Il ne décale pas le bit de signe dans la représentation binaire — le bit de signe reste intact à sa position. Enfin, result & 0x1 retourne 1 s'il y a parité ou 0 sinon.
Avantages :
- La solution est très facile à comprendre et à implémenter.
Inconvénients :
- Nous traitons tous les bits manuellement, donc cette approche est à peine efficace à grande échelle.
Complexité temporelle : O(n) où n est le nombre total de bits dans la représentation binaire du nombre donné.
Approche 2 - Effacer tous les bits définis un par un :
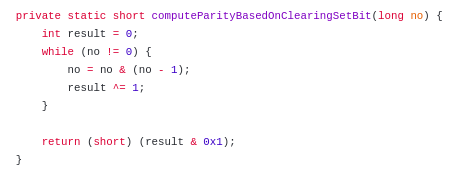
Il y a un goulot d'étranglement dans la solution ci-dessus : la boucle while elle-même. Elle parcourt simplement tous les bits un par un, devons-nous vraiment faire cela ? Notre préoccupation concerne les bits définis, donc nous ne tirons aucun avantage à parcourir les bits non définis ou les bits 0. Si nous pouvons simplement parcourir uniquement les bits définis, notre solution devient un peu plus optimisée. En calcul binaire, si nous avons un nombre n, nous pouvons effacer le bit défini le plus à droite avec l'opération suivante :
n = n & (n-1)
Prenons un exemple : disons n = 40, la représentation binaire en format 8 bits est : 00101000.
n = 0010 1000
n - 1 = 0010 0111
n & (n - 1) = 0010 0000
Nous avons réussi à effacer le bit défini le plus bas (4ème bit à partir de la droite). Si nous continuons à faire cela, le nombre n deviendra 0 à un certain moment. Sur la base de cette logique, si nous calculons la parité, nous n'avons pas besoin de scanner tous les bits. Plutôt, nous scannons seulement k bits où k est le nombre total de bits définis dans le nombre et k <= longueur de la représentation binaire. Voici le code :
Avantages :
- Simple à implémenter.
- Plus efficace que la solution par force brute.
Inconvénients :
- Ce n'est pas la solution la plus efficace.
Complexité temporelle :
O(k) où k est le nombre total de bits définis dans le nombre.
Approche 3 - Mise en cache :
Regardons à nouveau l'énoncé du problème, il y a définitivement une préoccupation concernant l'échelle. Nos solutions précédentes peuvent-elles servir des millions de requêtes ou y a-t-il encore une possibilité de faire mieux ?
Nous pouvons probablement rendre la solution plus rapide si nous pouvons stocker le résultat en mémoire — mise en cache. De cette manière, nous pouvons économiser quelques cycles CPU pour calculer le même résultat. Donc, si le nombre total de bits est 64, combien de mémoire avons-nous besoin pour stocker tous les nombres possibles ? 64 bits nous amèneront à avoir Math.pow(2, 64) nombres signés possibles (le bit le plus significatif est utilisé pour stocker uniquement le signe). La taille d'un nombre de type long est de 64 bits ou 8 octets, donc la taille totale de la mémoire requise est : 64 * Math.pow(2, 64) bits ou 134217728 TeraBytes. C'est trop et cela ne vaut pas la peine de stocker une quantité de données aussi énorme. Pouvez-vous faire mieux ?
Nous pouvons diviser le nombre de 64 bits en un groupe de 16 bits, récupérer la parité de ces groupes individuels de bits à partir du cache et les combiner. Cette solution fonctionne car 16 divise 64 en 4 parties égales et nous nous préoccupons simplement du nombre total de bits définis. Donc, tant que nous obtenons la parité de ces groupes individuels de bits, nous pouvons faire un xor de leurs résultats les uns avec les autres, puisque xor est associatif et commutatif. L'ordre dans lequel nous récupérons ces groupes de bits et les traitons n'a même pas d'importance.
Si nous stockons ces nombres de 16 bits sous forme d'entier, la mémoire totale requise est : Math.pow(2, 16) * 32 bits = 256 Kilo Bytes.

Dans l'extrait ci-dessus, nous décalons un groupe de 16 bits par i * WORD_SIZE où0 ≤ i ≤ 3 et effectuons une opération bitwise AND (&) avec un mask = 0xFFFF (0xFFFF = 1111111111111111) afin que nous puissions simplement extraire les 16 bits les plus à droite en tant que variables entières comme masked1, masked2, etc. Nous passons ces variables à une méthode checkAndSetInCache qui calcule la parité de ce nombre au cas où il n'est pas disponible dans le cache. À la fin, nous effectuons simplement une opération xor sur le résultat de ces groupes de nombres qui détermine la parité finale du nombre donné.
Avantages :
- Au coût d'une mémoire relativement petite pour le cache, nous obtenons une meilleure efficacité puisque nous réutilisons un groupe de nombres de 16 bits à travers les entrées.
- Cette solution peut bien évoluer car nous servons des millions de nombres.
Inconvénients :
- Si cet algorithme doit être implémenté dans un appareil à mémoire ultra-faible, la complexité spatiale doit être bien réfléchie à l'avance afin de décider si cela vaut la peine d'accommoder une telle quantité d'espace.
Complexité temporelle :
O(n / WORD_SIZE) où n est le nombre total de bits dans la représentation binaire. Toutes les opérations de décalage à droite/gauche et bitwise &, |, ~, etc. sont des opérations au niveau du mot qui sont effectuées extrêmement efficacement par le CPU. Par conséquent, leur complexité temporelle est supposée être O(1).
Approche 4 - Utilisation des opérations XOR et de décalage :
Considérons cette représentation binaire de 8 bits : 1010 0100. La parité de ce nombre est 1. Que se passe-t-il lorsque nous effectuons un décalage à droite sur ce nombre de 4 et faisons un xor avec le nombre lui-même ?
n = 1010 0100
n >>> 4 = 0000 1010
n ^ (n >> 4) = 1010 1110
n = n ^ (n >>> 4) = 1010 1110 (n est simplement assigné au résultat)
Dans les 4 bits les plus à droite, tous les bits sont définis et sont différents dans n et n >>> 4. Concentrons-nous maintenant sur ces 4 bits les plus à droite : 1110, oublions les autres bits. Maintenant n est 1010 1110 et nous nous concentrons uniquement sur les 4 bits les plus bas, c'est-à-dire 1110. Faisons un décalage bitwise à droite sur n de 2.
n = 1010 1110
n >>> 2 = 0010 1011
n ^ (n >>> 2) = 1000 0101
n = n ^ (n >>> 2) = 1000 0101 (n est simplement assigné au résultat)
Concentrons-nous maintenant uniquement sur les 2 bits les plus à droite et oublions les 6 bits les plus à gauche. Faisons un décalage à droite du nombre de 1 :
n = 1000 0101
n >>> 1 = 0100 0010
n ^ (n >>> 1) = 1100 0111
n = n ^ (n >>> 1) = 1100 0111 (n est simplement assigné au résultat)
Nous n'avons plus besoin de décaler à droite, nous extrayons simplement le bit LSB qui est 1 dans le cas ci-dessus et retournons le résultat : result = (short) n & 1.
À première vue, la solution peut sembler un peu confuse, mais elle fonctionne. Comment ? Nous savons que 0 xor 1 ou 1 xor 0 est 1, sinon 0. Donc, lorsque nous divisons la représentation binaire d'un nombre en deux moitiés égales par longueur et que nous faisons un xor entre elles, toutes les paires de bits différents résultent en des bits définis dans le nombre xor.
Puisque la parité se produit lorsqu'un nombre impair de bits définis est présent dans la représentation binaire, nous pouvons utiliser l'opération xor pour vérifier si un nombre impair de 1 existe. Ainsi, nous décalons le nombre de la moitié du nombre total de chiffres, nous faisons un xor de ce nombre décalé avec le nombre original, nous assignons le résultat xor au nombre original et nous nous concentrons uniquement sur la moitié droite du nombre maintenant. Nous faisons donc simplement un xor de la moitié des nombres à la fois et réduisons notre portée de xor. Pour les nombres de 64 bits, nous commençons par faire un xor avec des moitiés de 32 bits, puis des moitiés de 16 bits, puis 8, 4, 2, 1 respectivement.
Essentiellement, la parité d'un nombre signifie la parité du xor des moitiés égales de la représentation binaire de ce nombre. Le cœur de l'algorithme est de se concentrer sur les 32 bits les plus à droite d'abord, puis 16, 8, 4, 2, 1 bits et d'ignorer les autres bits du côté gauche. Voici le code :

Avantages :
- Aucune espace supplémentaire n'utilise des opérations au niveau du mot pour calculer le résultat.
Inconvénients :
- Peut être un peu difficile à comprendre pour les développeurs.
Complexité temporelle :
O(log n) où n est le nombre total de bits dans la représentation binaire.
Voici le code complet fonctionnel :
import java.util.Arrays;
public class ParityOfNumber {
private static short computeParityBruteForce(long no) {
int result = 0;
while(no != 0) {
if((no & 1) == 1) {
result ^= 1;
}
no >>>= 1;
}
return (short) (result & 0x1);
}
private static short computeParityBasedOnClearingSetBit(long no) {
int result = 0;
while (no != 0) {
no = no & (no - 1);
result ^= 1;
}
return (short) (result & 0x1);
}
private static short computeParityWithCaching(long no) {
int[] cache = new int[(int) Math.pow(2, 16)];
Arrays.fill(cache, -1);
int WORD_SIZE = 16;
int mask = 0xFFFF;
int masked1 = (int) ((no >>> (3 * WORD_SIZE)) & mask);
checkAndSetInCache(masked1, cache);
int masked2 = (int) ((no >>> (2 * WORD_SIZE)) & mask);
checkAndSetInCache(masked2, cache);
int masked3 = (int) ((no >>> WORD_SIZE) & mask);
checkAndSetInCache(masked3, cache);
int masked4 = (int) (no & mask);
checkAndSetInCache(masked4, cache);
int result = (cache[masked1] ^ cache[masked2] ^ cache[masked3] ^ cache[masked4]);
return (short) (result & 0x1);
}
private static void checkAndSetInCache(int val, int[] cache) {
if(cache[val] < 0) {
cache[val] = computeParityBasedOnClearingSetBit(val);
}
}
private static short computeParityMostEfficient(long no) {
no ^= (no >>> 32);
no ^= (no >>> 16);
no ^= (no >>> 8);
no ^= (no >>> 4);
no ^= (no >>> 2);
no ^= (no >>> 1);
return (short) (no & 1);
}
public static void main(String[] args) {
long no = 1274849;
System.out.println("Représentation binaire du nombre : " + Long.toBinaryString(no));
System.out.println("Est Parité [computeParityBruteForce] : " + computeParityBruteForce(no));
System.out.println("Est Parité [computeParityBasedOnClearingSetBit] : " + computeParityBasedOnClearingSetBit(no));
System.out.println("Est Parité [computeParityMostEfficient] : " + computeParityMostEfficient(no));
System.out.println("Est Parité [computeParityWithCaching] : " + computeParityWithCaching(no));
}
}
Apprentissage de cet exercice :
- Bien que ce soit une connaissance de base, je veux mentionner que les opérations bitwise au niveau du mot sont constantes dans le temps.
- À grande échelle, nous pouvons appliquer la mise en cache en décomposant la représentation binaire en moitiés égales de taille de mot appropriée comme
16dans notre cas afin que nous puissions accommoder tous les nombres possibles en mémoire. Puisque nous devons traiter des millions de nombres, nous finirons par réutiliser des groupes de bits de16bits à partir du cache à travers les nombres. La taille du mot ne doit pas nécessairement être16, cela dépend de vos exigences et expériences. - Vous n'avez pas besoin de stocker la représentation binaire d'un nombre dans un tableau séparé pour opérer dessus, plutôt une utilisation astucieuse des opérations bitwise peut vous aider à atteindre votre objectif.
Références :
[1]. https://stackoverflow.com/questions/2811319/difference-between-and
[2]. https://gist.github.com/kousiknath/b0f5cd204369c5cd1669535cc9a58a53