
Article original : Clustering the Top 1%: Asset Analysis in R
Par Ben Weber
Le récent projet de réforme fiscale adopté aux États-Unis a soulevé de nombreuses questions sur la répartition des richesses dans le pays. Bien qu'il y ait eu beaucoup d'attention sur la manière dont le plan fiscal va impacter les revenus, moins d'attention a été portée sur la manière dont ce plan affecte les actifs des ménages riches.
L'objectif de cet article est de montrer comment le langage de programmation R peut être utilisé pour extraire des données de sources publiques afin de mieux comprendre le patrimoine net des ménages aisés aux États-Unis. En utilisant les données de l'enquête 2016 de la Réserve fédérale sur les finances des consommateurs, nous étudions les questions suivantes :
- À quel point les 1% et les 0,1% des ménages les plus riches sont-ils riches ?
- Existe-t-il différents types de millionnaires aux États-Unis ?
- Comment les allocations d'actifs diffèrent-elles selon les différents segments de patrimoine net ?
Pour répondre à ces questions, nous présentons des statistiques descriptives de ces données d'enquête et effectuons une analyse de regroupement sur les ménages aisés, que nous identifions comme des ménages avec un patrimoine net de plus de 1 000 000 USD.
Sur la base des données de l'enquête, notre analyse montre que le patrimoine net des 1% des ménages les plus riches aux États-Unis est de 10,4 M$ et que le patrimoine net des 0,1% des ménages les plus riches est de 43,2 M$. Cet article présente une analyse des différentes compositions d'actifs des millionnaires et montre comment les allocations d'actifs diffèrent entre les 10%, 1% et 0,1% des ménages les plus riches aux États-Unis. Le code source R utilisé pour produire tous les résultats et figures présentés dans cet article est disponible sous forme de Jupyter Notebook.
Configuration de l'environnement
Pour effectuer une analyse de regroupement sur les ménages aisés aux États-Unis, nous utilisons plusieurs packages disponibles dans la bibliothèque CRAN pour R. Pour l'analyse exploratoire des données, nous aimons utiliser le noyau R pour le notebook Jupyter, car il permet aux scientifiques des données de stocker facilement des notebooks sur GitHub et de partager des résultats avec d'autres équipes.
La configuration de cet environnement dépasse le cadre de cet article, mais j'ai précédemment détaillé notre motivation pour cette configuration dans cet article, et des détails supplémentaires pour configurer Jupyter avec le support R sont disponibles ici.
Nous sommes maintenant prêts à commencer à analyser les données de l'enquête pour mieux comprendre les actifs des ménages aisés aux États-Unis. Pour commencer, nous allons charger plusieurs bibliothèques qui nous aideront à analyser les données de l'enquête et à effectuer le regroupement.
Le bloc de code ci-dessous montre les bibliothèques qui doivent être chargées pour exécuter ce notebook. La bibliothèque readxl est nécessaire pour lire les données sources et les convertir en un data frame, les bibliothèques reldist et ENmisc sont utilisées pour calculer des distributions avec des ensembles de données pondérés, et les bibliothèques restantes sont utilisées pour l'analyse de regroupement.
library(readxl) # pour lire les fichiers xlsx library(reldist) # pour calculer les statistiques pondéréeslibrary(ENmisc) # pour les box plots pondéréslibrary(plotly) # pour les graphiques interactifslibrary(factoextra) # pour les cartes de facteurslibrary(FactoMineR) # Analyse en Composantes Principales (ACP)library(cluster) # Algorithmes de regroupement (CLARA)library(class) # pour KNN
Obtention des données
L'étape suivante consiste à télécharger les données depuis le site web de la Réserve fédérale. Les données de l'enquête sont disponibles sous forme de fichier xlsx zippé. Pour télécharger les données et les charger dans R sous forme de data frame pour analyse, nous utilisons le bloc de code ci-dessous. Comme il s'agit d'un fichier volumineux, nous veillons à ne pas le télécharger plusieurs fois. Le fichier résultant que nous décompressons fait environ 40 Mo et prend un certain temps à charger dans un data frame.
if (!file.exists("SCFP2016.xlsx")) { download.file( "https://www.federalreserve.gov/econres/files/scfp2016excel.zip", "SCFP2016.zip") unzip("scfp2016.zip")}
df <- read_excel("SCFP2016.xlsx")
Statistiques récapitulatives
Maintenant que nous avons chargé les données de l'enquête dans R, nous pouvons commencer à analyser l'allocation des actifs des ménages les plus riches aux États-Unis. Nous commencerons par quelques statistiques récapitulatives : combien de participants à l'enquête et combien de ménages sont représentés par cette enquête ? Compter le nombre de lignes dans le data frame répond à la première question (31,2k), et additionner les poids de tous les répondants à l'enquête répond à la deuxième question (126M).
# Combien de participants à l'enquête ?nrow(df)
# Combien de ménages l'enquête représente-t-elle ?floor(sum(df$WGT)))
# Quelle est la moyenne pondérée du patrimoine net des ménages ?floor(sum(df$NETWORTH*df$WGT)/sum(df$WGT)))
# quelle est la médiane du patrimoine net aux États-Unis ? reldist::wtd.quantile(df$NETWORTH, q=0.5, weight = df$WGT)
# qui sont les 1% ? reldist::wtd.quantile(df$NETWORTH, q=0.99, weight = df$WGT)
# top 0,1% des ménages à très haut patrimoine net reldist::wtd.quantile(df$NETWORTH, q=0.999, weight = df$WGT)
Pour répondre à des questions sur les moyennes, comme quelle est la moyenne du patrimoine net des ménages, nous devons utiliser des statistiques pondérées (puisque le poids d'un répondant à l'enquête peut être beaucoup plus grand que d'autres). Pour calculer la moyenne du patrimoine net, nous pouvons utiliser les fonctions intégrées de R, qui retourne une valeur de 690k $. Cependant, comme le patrimoine net est beaucoup plus proche d'une distribution log normale que normale, nous devrions utiliser d'autres approches.
Pour calculer la valeur médiane avec des réponses pondérées, nous utilisons la bibliothèque reldist, qui attribue plus de support aux répondants avec des poids plus élevés et moins de support aux répondants avec des poids plus faibles. Lorsque nous utilisons cette approche pour calculer la médiane pondérée, nous trouvons que le 50e percentile pour le patrimoine net des ménages aux États-Unis est de 97k $.
Le patrimoine net des 1% les plus riches est de 10,4 M$ et le patrimoine net des 0,1% les plus riches est de 43,2 M$. Nous utilisons la fonction wtd.quantile pour calculer ces statistiques descriptives, et l'exemple de code ci-dessus utilise les noms de fonctions entièrement quantifiés, en raison des collisions avec le package ENmisc.
Données démographiques
Les données de l'enquête fournissent un certain nombre de variables démographiques différentes qui peuvent être utilisées pour analyser le patrimoine net selon différents facteurs. Ces variables incluent la race, l'état matrimonial, le niveau d'éducation, le statut d'emploi, et d'autres. L'objectif de cet article est de montrer comment l'allocation des actifs varie selon le segment de patrimoine net, et l'analyse de l'impact de ces facteurs démographiques sur le patrimoine net est laissée comme exercice au lecteur.
# filtrer sur les âges 30 - 84, et regrouper en tranches de 5 ansdata <- df[df$AGE >= 30 & df$AGE < 85, ]ages <- floor(data$AGE/5.0)*5
# tracer le box plot pondéréwtd.boxplot(log10(1 + data$NETWORTH) ~ ages, data = data, weights = data$WGT, main = 'Patrimoine Net par Âge', xlab="Âge", ylab="Patrimoine Net (Log10)")
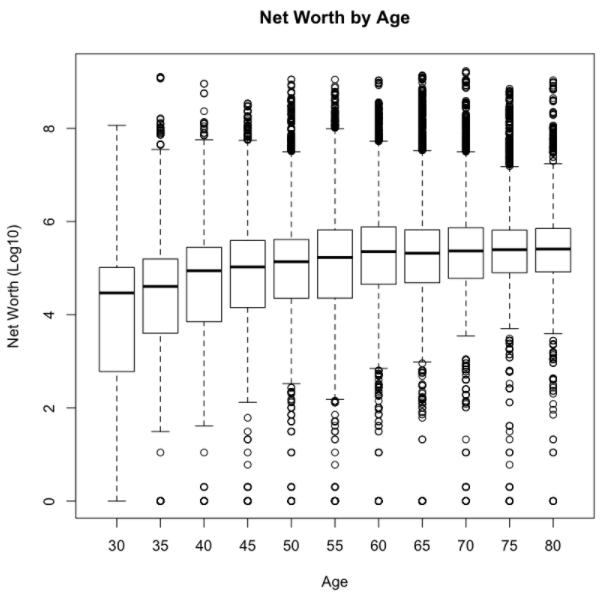
Une variable démographique que nous avons explorée est l'impact de l'âge sur le patrimoine net des ménages. Comme prévu, le patrimoine net médian augmente à mesure que le chef de ménage vieillit, avec un patrimoine net qui se stabilise autour de 60 ans.
Le code ci-dessus montre comment afficher un box plot des données de l'enquête par âge, en utilisant le package ENmisc pour calculer les distributions pondérées. Les résultats de ce graphique montrent que le patrimoine net médian des ménages aux États-Unis est de 114k $ à 40 ans, 163k $ à 50 ans, et 243k $ à 60 ans.
Allocation des actifs
L'étape suivante dans le notebook est d'évaluer l'allocation des actifs des différents segments de patrimoine net. Pour cette analyse, nous définissons un segment basé sur la valeur log10 du patrimoine net du ménage. Cela signifie que tous les ménages à 5 chiffres sont regroupés ensemble, tous les ménages à 6 chiffres sont regroupés ensemble, et ainsi de suite.
# normaliser les actifs par le montant total financier et non financierhouseholds <- data.frame( LIQ = df$LIQ/assets, ... BUS = df$BUS/assets, OTHNFIN = df$OTHNFIN/assets
# diviser en segments de patrimoine net, et calculer les distributions moyennes nw <- floor(log10(households$netWorth))segment <- ifelse(nw == 4, " $10k", ifelse(nw == 5, " $100K", ifelse(nw == 6, " $1M", ifelse(nw == 7, " $10M", ifelse(nw == 8, " $100M", "$1B+")))))
results <- as.data.frame((aggregate(households,list(segment),mean)))
# tracer les résultatsplot <- plot_ly(results, x = ~Group.1, y = ~100*LIQ, type = 'bar', name = 'Liquide') %>% add_trace(y = ~100*CDS, name = 'Certificats de Dépôt') %>% add_trace(y = ~100*NMMF, name = 'Fonds Communs de Placement') %>% ... add_trace(y = ~100*BUS, name = 'Intérêts Commerciaux') %>% layout(yaxis = list(title = '% des Actifs', ticksuffix = "%"), xaxis = list(title = "Patrimoine Net"), title = "Allocation des Actifs par Patrimoine Net", barmode = 'stack')
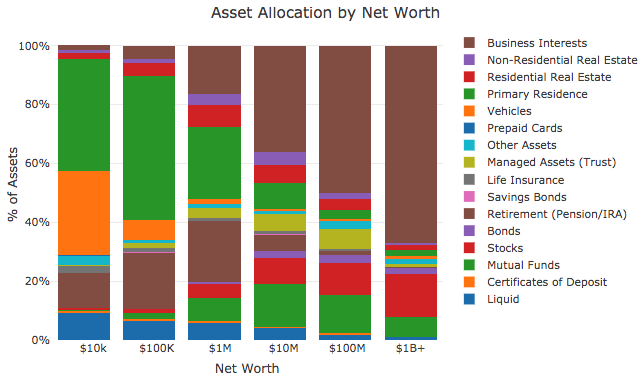
Le code ci-dessus calcule l'allocation des actifs par ménage, en divisant le montant des actifs d'un ménage, tels que les actions de l'entreprise (BUS) sur le nombre total d'actifs financiers et non financiers, à l'exclusion de la dette. Le motif "…" est utilisé pour indiquer que plusieurs lignes ont été exclues de l'extrait de code qui sont listées dans le notebook complet. Le deuxième bloc de code regroupe les ménages en différents segments de patrimoine net, et le troisième bloc trace les résultats comme montré ci-dessous.
Les résultats montrent que les riches, les ultra-riches et les milliardaires ont de grandes quantités d'actifs en actions d'entreprise (actions et options). Les riches n'ont qu'un petit pourcentage d'actifs dans les fonds de retraite, et ont plutôt des actifs en actions, fonds communs de placement, et immobilier résidentiel et commercial.
Regroupement des millionnaires
Jusqu'à présent, nous avons examiné les statistiques globales des ménages riches, mais cela ne nous dit pas grand-chose sur les différents types de ménages aisés. Pour comprendre comment les actifs varient selon les ménages aisés, nous pouvons utiliser l'analyse de regroupement. L'une des façons les plus utiles de visualiser la différence entre les instances dans une population d'échantillon est d'utiliser des cartes de facteurs pour visualiser la variance dans la population.
# filtrer sur les ménages aisés, et afficher le nombre totalaffluent <- households[households$netWorth >= 1000000, ]cat(paste("Ménages aisés : ", floor(sum(affluent$weight))))
# tracer une carte de facteurs des actifs fviz_pca_var(PCA(affluent, graph = FALSE), col.var="contrib", gradient.cols = c("#00AFBB", "#E7B800", "#FC4E07"), repel = TRUE)+ labs(title ="Ménages aisés - Carte de facteurs des actifs")
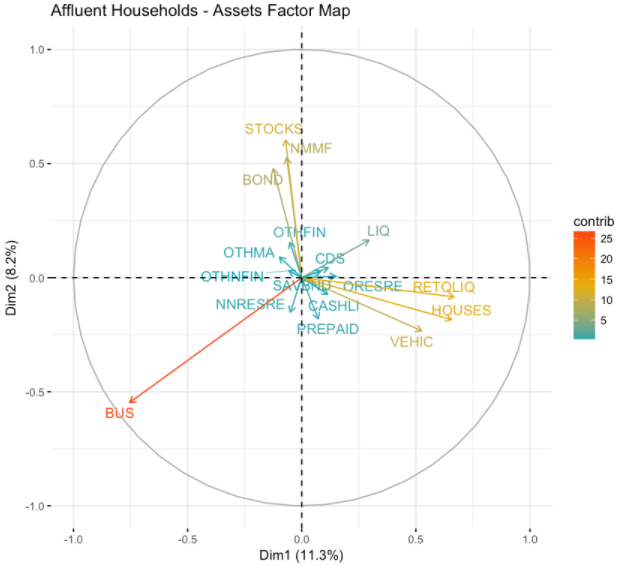
Le code ci-dessus filtre d'abord les répondants à l'enquête pour les ménages aisés, avec un patrimoine net de plus de 1 M USD, puis trace une carte de facteurs en utilisant l'analyse en composantes principales (ACP). La figure ci-dessous montre comment les différents actifs impactent la trajectoire de traçage d'un ménage à travers les deux composantes principales découvertes via l'ACP.
Les résultats tracés ci-dessous montrent qu'il existe quelques groupes d'actifs différents qui varient selon le patrimoine net aisé. Le facteur le plus significatif est l'équité commerciale. Certains autres regroupements de facteurs incluent les actifs d'investissement (ACTIONS, OBLIGATIONS) et les actifs immobiliers/fonds de retraite.
Combien de clusters utiliser ?
Nous avons maintenant montré des signes qu'il existe différents types de millionnaires, et que les actifs varient en fonction des segments de patrimoine net. Pour comprendre comment l'allocation des actifs diffère selon le segment de patrimoine net, nous pouvons utiliser l'analyse de clusters. Nous identifions d'abord les clusters parmi les répondants aisés à l'enquête, puis nous appliquons ces étiquettes à l'ensemble de la population des répondants à l'enquête.
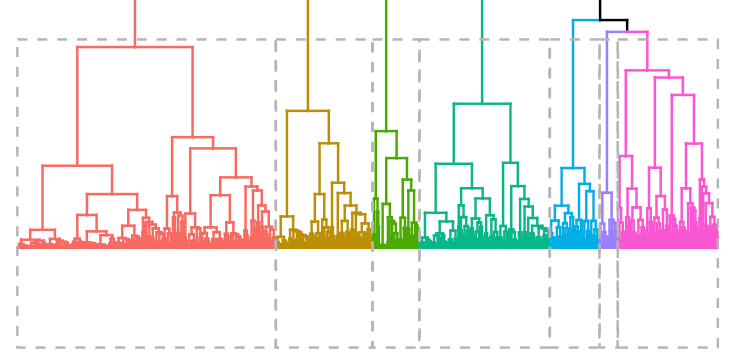
k <- 7res.hc <- eclust(households[sample(nrow(households), 1000), ], "hclust", k = k, graph = FALSE) fviz_dend(res.hc, rect = TRUE, show_labels = FALSE)
Pour déterminer combien de clusters utiliser, nous avons créé un dendrogramme de clusters en utilisant l'extrait de code ci-dessus, montré comme l'image d'en-tête de cet article. Nous avons également varié le nombre de clusters, k, jusqu'à obtenir le plus grand nombre de clusters distinctement identifiables.
Si vous préférez une approche quantitative, vous pouvez utiliser la fonction _fviznbclust, qui calcule le nombre optimal de clusters en utilisant une métrique de silhouette. Pour notre analyse, nous avons décidé d'utiliser 7 clusters.
clarax <- clara(affluent, k)fviz_cluster(clarax, stand = FALSE, geom = "point", ellipse = F)
Pour regrouper les ménages aisés en groupes uniques, nous avons utilisé l'algorithme CLARA. Une visualisation des différents clusters est montrée ci-dessous. Les résultats sont similaires à l'ACP et à l'approche de la carte des facteurs discutée ci-dessus.
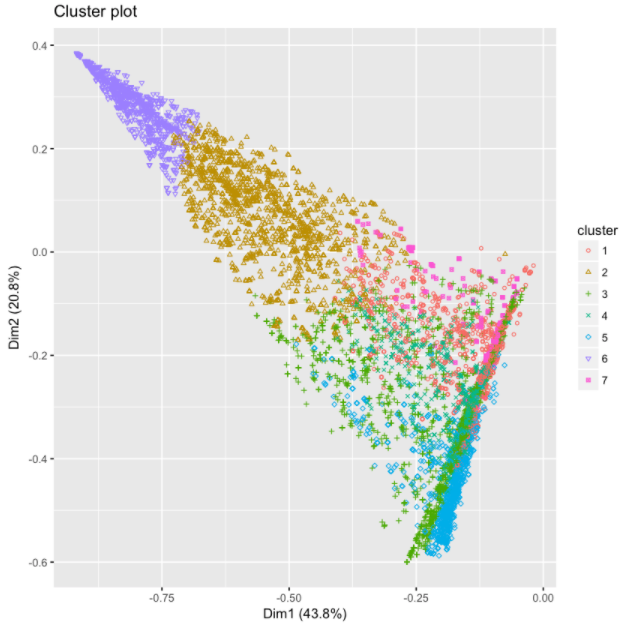
Descriptions des clusters
Maintenant que nous avons déterminé combien de clusters utiliser, il est utile d'inspecter les clusters et d'assigner des étiquettes qualitatives basées sur les ensembles de caractéristiques. L'extrait de code ci-dessous montre comment calculer les valeurs moyennes des caractéristiques pour les 7 clusters différents.
groups <- clarax$clusteringresults <- as.data.frame(t(aggregate(affluent,list(groups),mean))) results[2:18,]
Les résultats de ce bloc de code sont montrés ci-dessous. Sur la base de ces résultats, nous avons établi les descriptions de clusters suivantes :
- V1 : Actions/Obligations — 31% des actifs, suivis par la maison et les fonds communs de placement
- V2 : Diversifiés — 53% d'équité commerciale, 10% de maison et 9% dans d'autres biens immobiliers
- V3 : Immobilier résidentiel — 48% des actifs
- V4 : Fonds communs de placement — 50% des actifs
- V5 : Retraite — 48% des actifs
- V6 : Équité commerciale — 85% des actifs
- V7 : Immobilier commercial — 59% des actifs
À l'exception du cluster V7, contenant seulement 3% de la population, la plupart des clusters sont relativement équilibrés en taille. Le deuxième plus petit cluster représente 12% de la population tandis que le plus grand cluster représente 20%. Vous pouvez utiliser table(groups) pour montrer les tailles de population des clusters non pondérés.
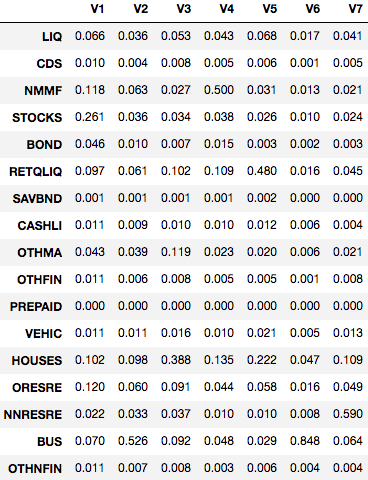
Populations de clusters par segments de patrimoine net
La dernière étape de cette analyse consiste à appliquer les différentes affectations de clusters à l'ensemble de la population, et à regrouper les populations par segments de patrimoine net. Comme nous avons entraîné les clusters uniquement sur les ménages aisés, nous devons utiliser un algorithme de classification pour étiqueter les ménages non aisés de la population. L'extrait de code ci-dessous utilise knn pour accomplir cette tâche.
Les blocs de code restants calculent le nombre de ménages classés dans chaque cluster, pour chacun des segments de patrimoine net.
# assigner tous les ménages à un cluster groups <- knn(train = affluent, test = households, cl = clarax$clustering, k = k, prob = T, use.all = T)
# déterminer combien de ménages sont dans chaque cluster clusters <- data.frame( c1 = ifelse(groups == 1, weights, 0), ... c7 = ifelse(groups == 7, weights, 0) )
# assigner chaque ménage à un cluster de patrimoine net nw <- floor(2*log10(nwHouseholds))/2results <- as.data.frame(t(aggregate(clusters,list(nw),sum)))
# calculer le nombre de ménages appartenant à chaque segmentresults$V1 <- results$V1/sum(ifelse(nw == 4, weights, 0))...results$V11 <- results$V11/sum(ifelse(nw == 9, weights, 0))
# tracer les résultats plot <- plot_ly(results, x = ~10^Group.1, y = ~100*c1, type = 'scatter', mode = 'lines', name = "Actions") %>% add_trace(y = ~100*c2, name = "Diversifiés") %>% ... add_trace(y = ~100*c7, name = "Immobilier Commercial") %>% layout(yaxis = list(title = '% des Ménages', ticksuffix = "%"), xaxis = list(title = "Patrimoine Net ($)", type = "log"), title = "Populations de Clusters par Patrimoine Net")
Les résultats de ce processus sont montrés dans la figure ci-dessous. Le graphique montre certains résultats évidents et certains résultats nouveaux : la propriété immobilière et les fonds de retraite constituent la majorité des actifs pour les ménages non aisés, il y a un mélange relativement équilibré de clusters autour de 2 M$ (à l'exclusion de l'immobilier commercial et de l'équité commerciale), et l'équité commerciale domine le patrimoine net pour les ménages ultra-riches, suivie par d'autres actifs d'investissement.
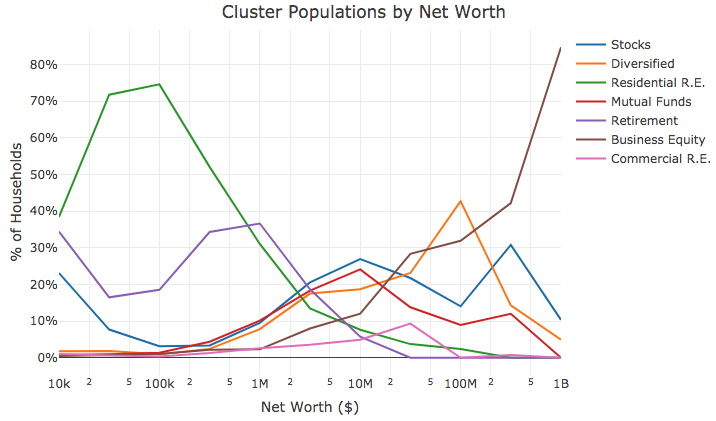
Résumé
Dans cet article, nous avons utilisé R pour télécharger et analyser les données de l'enquête 2016 de la Réserve fédérale sur les finances des consommateurs afin de comprendre à quel point les ménages les plus riches sont riches aux États-Unis, et pour regrouper les ménages aisés par allocation d'actifs. Nous avons identifié 7 groupes distincts de millionnaires, et montré comment la distribution des clusters varie en fonction du segment de patrimoine net. Veuillez garder à l'esprit que les résultats présentés proviennent de données d'enquête pondérées, et peuvent ne pas être représentatifs de l'ensemble de la population américaine.
Ben Weber est un scientifique principal des données chez Zynga. Nous recrutons !