

Article original : Who contributed the most to open source in 2017 and 2018? Let’s analyze GitHub’s data and find out.
Par Felipe Hoffa
Pour cette analyse, nous examinerons tous les PushEvents publiés par GitHub en 2017. Pour chaque utilisateur GitHub, nous devrons faire notre meilleure estimation pour déterminer à quelle organisation il appartient. Nous ne regarderons que les dépôts qui ont reçu au moins 20 étoiles cette année.
Voici les résultats que j'ai obtenus, que vous pouvez explorer dans mon rapport interactif Data Studio.
Comparaison des principaux fournisseurs de cloud
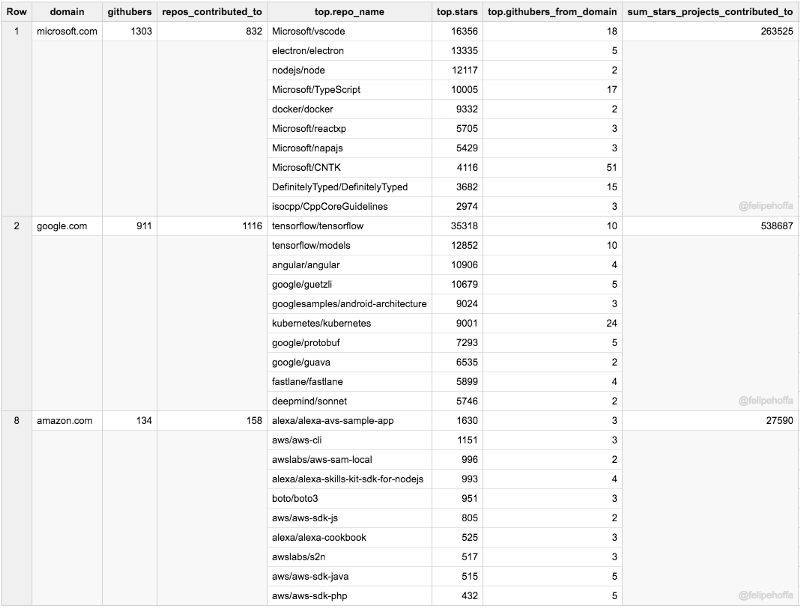
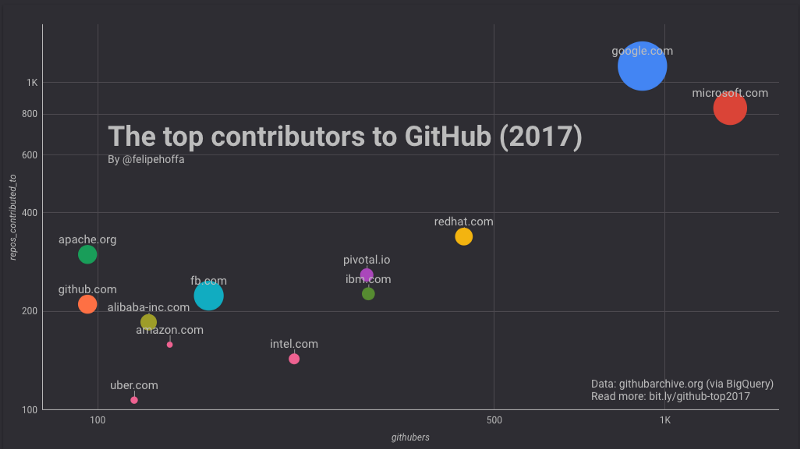
En examinant GitHub en 2017 :
- Microsoft semble avoir ~1 300 employés qui poussent activement du code vers 825 dépôts populaires sur GitHub.
- Google affiche ~900 employés actifs sur GitHub, qui poussent du code vers ~1 100 dépôts populaires.
- Amazon semble n'avoir que 134 employés actifs sur GitHub, poussant du code vers seulement 158 projets populaires.
- Tous les projets ne sont pas égaux : Bien que les Googlers contribuent à 25 % de dépôts en plus que Microsoft, ces dépôts ont accumulé beaucoup plus d'étoiles (530 000 contre 260 000). Le total des étoiles pour les dépôts Amazon en 2017 ? 27 000.
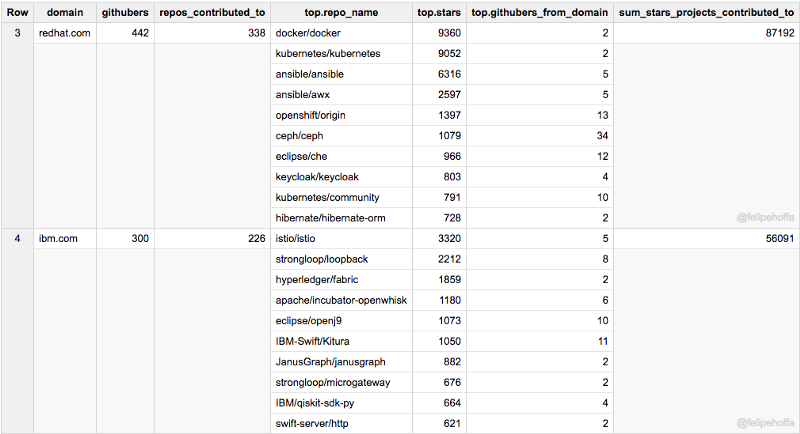
RedHat, IBM, Pivotal, Intel et Facebook
Si Amazon semble si loin derrière Microsoft et Google — quelles sont les entreprises entre les deux ? Selon ce classement, RedHat, Pivotal et Intel apportent d'excellentes contributions à GitHub :
Notez que le tableau suivant combine tous les domaines régionaux d'IBM — tandis que les régions individuelles apparaissent toujours dans les tableaux suivants.
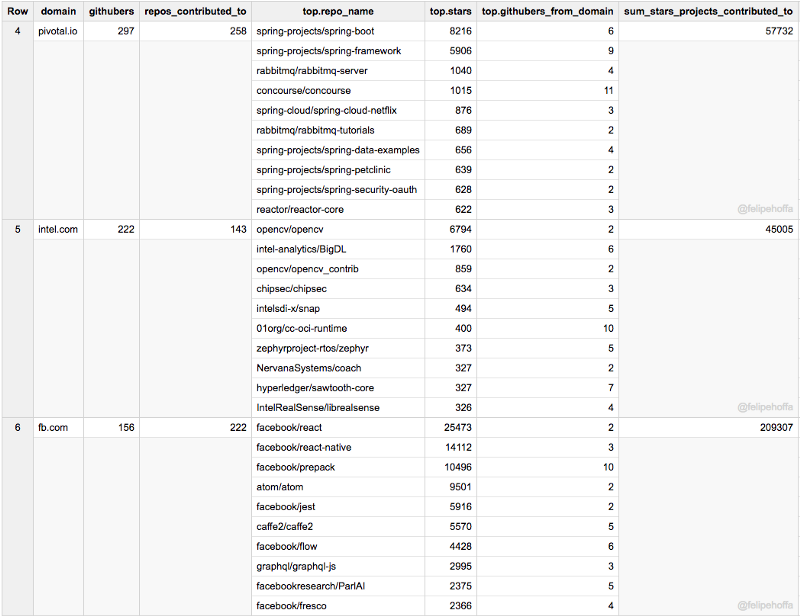
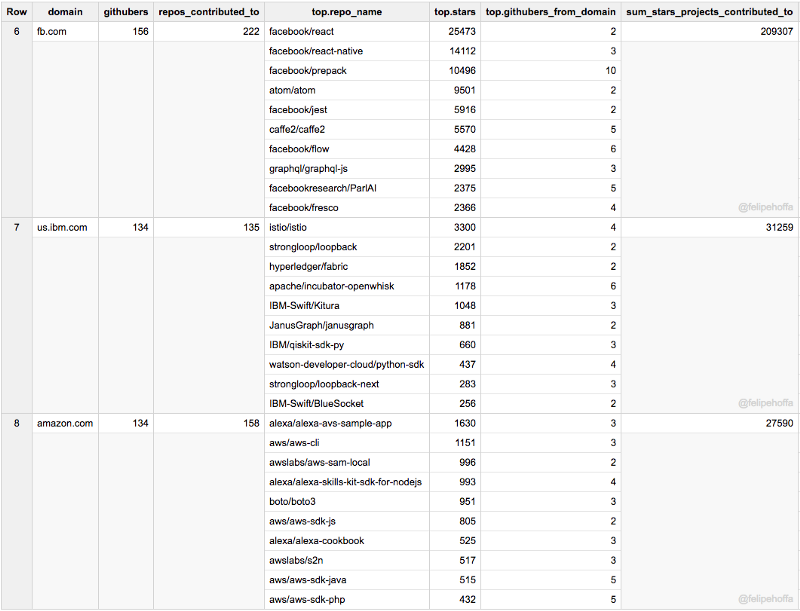
Facebook et IBM (US) ont un nombre similaire d'utilisateurs GitHub à Amazon, mais les projets auxquels ils contribuent ont accumulé plus d'étoiles (surtout Facebook) :
Suivis par Alibaba, Uber et Wix :
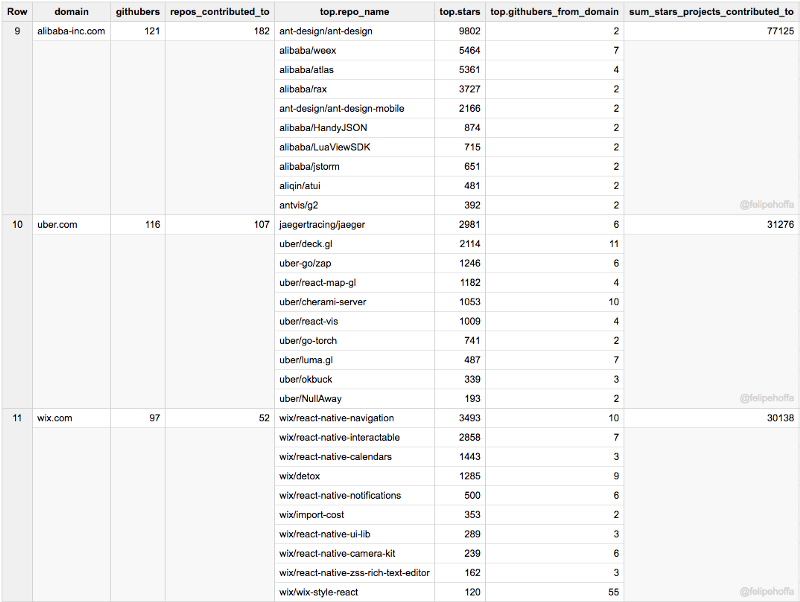
GitHub lui-même, Apache, Tencent :
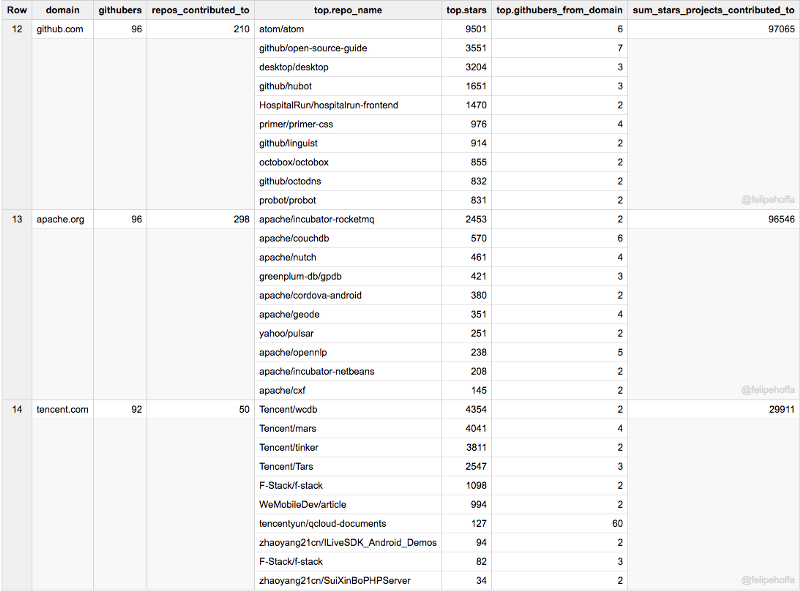
Baidu, Apple, Mozilla :
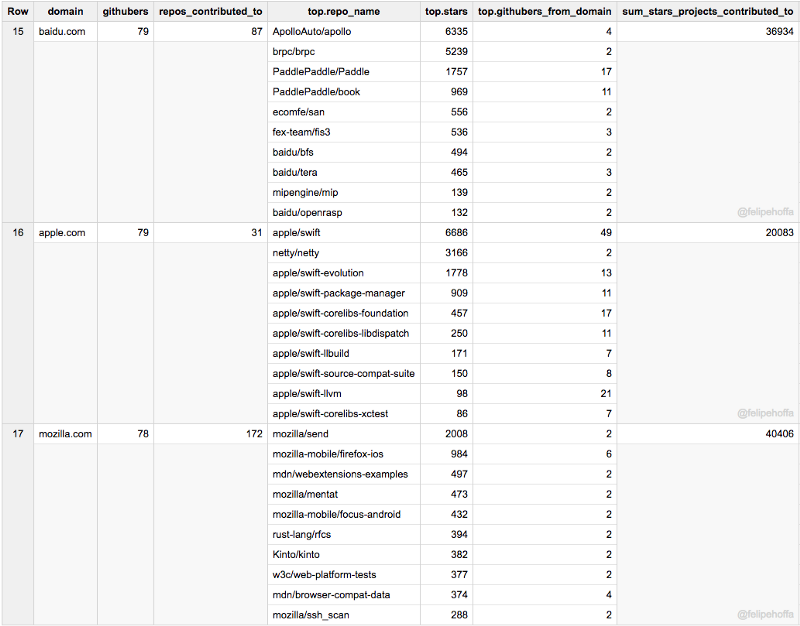
Oracle, Stanford, Mit, Shopify, MongoDb, Berkeley, VmWare, Netflix, Salesforce, Gsa.gov :
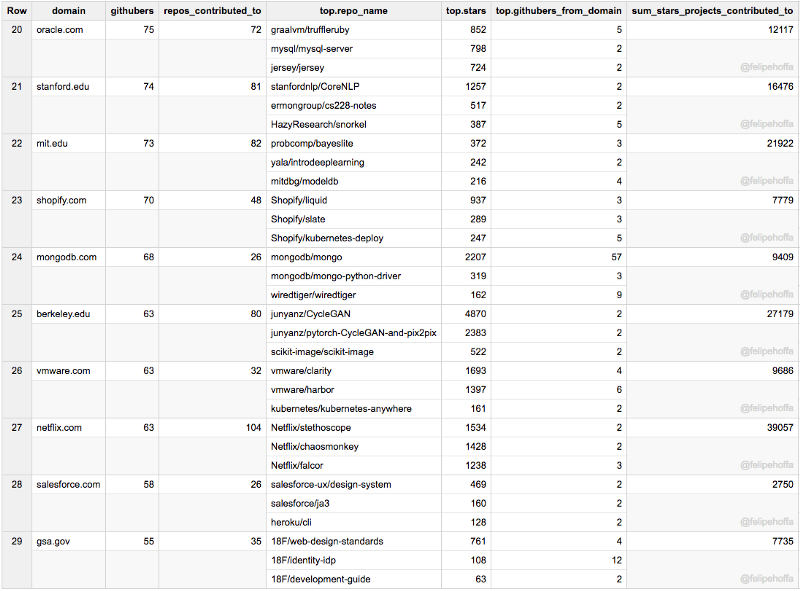
LinkedIn, Broad Institute, Palantir, Yahoo, MapBox, Unity3d, Automattic, Sandia, Travis-ci, Spotify :
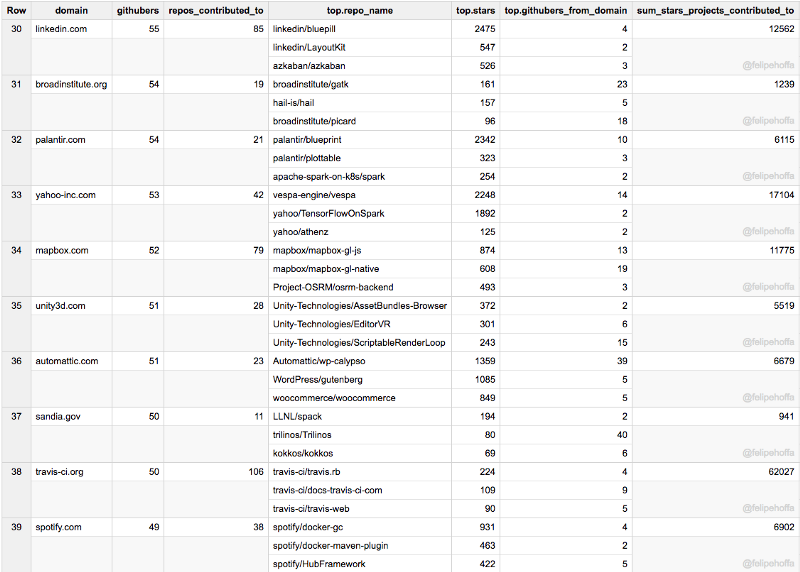
Chromium, UMich, Zalando, Esri, IBM (UK), SAP, EPAM, Telerik, UK Cabinet Office, Stripe :
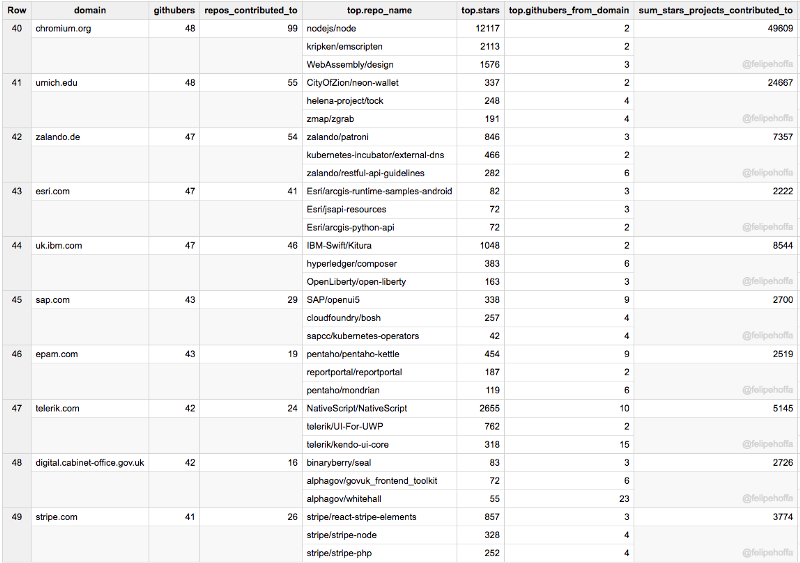
Cern, Odoo, Kitware, Suse, Yandex, IBM (Canada), Adobe, AirBnB, Chef, The Guardian :
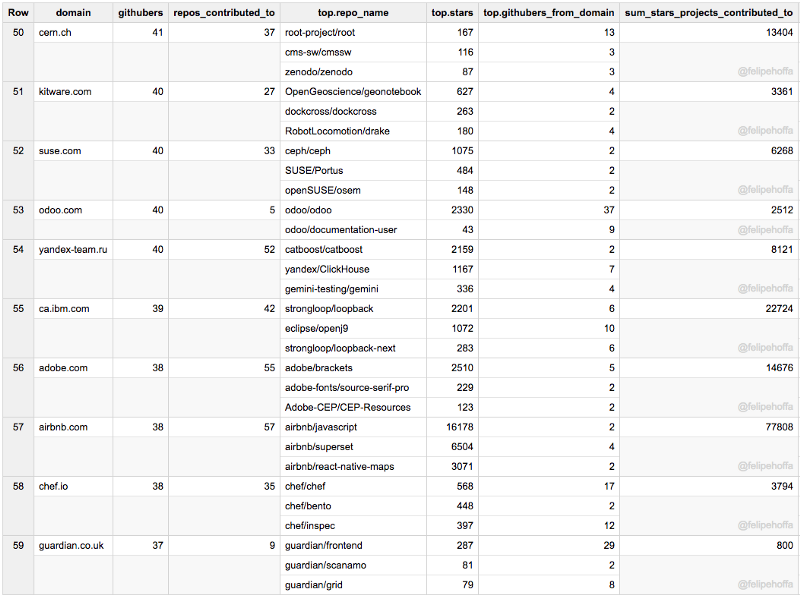
Arm, Macports, Docker, Nuxeo, NVidia, Yelp, Elastic, NYU, WSO2, Mesosphere, Inria
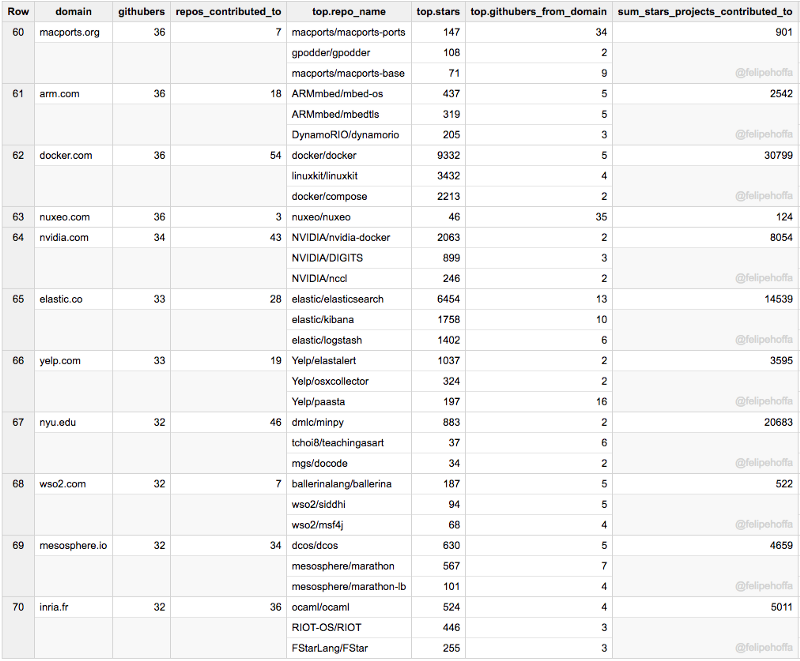
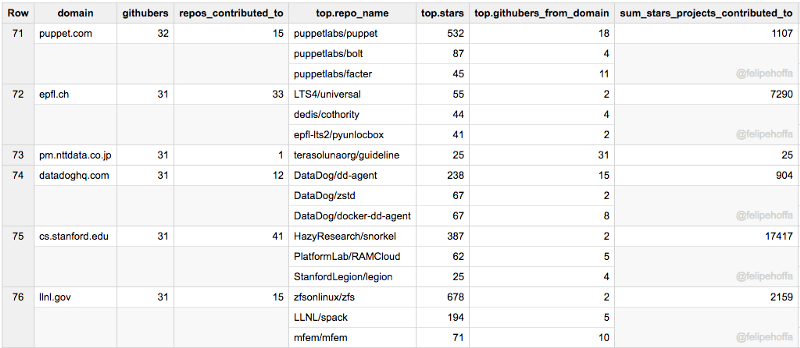
Puppet, Stanford (CS), DatadogHQ, Epfl, NTT Data, Lawrence Livermore Lab :
Ma méthodologie
Comment j'ai lié les utilisateurs GitHub aux entreprises
Déterminer l'organisation à laquelle appartient chaque utilisateur GitHub n'est pas facile — mais nous pouvons utiliser les domaines d'email qui apparaissent dans chaque message de commit contenu dans les PushEvents :
- Le même email peut apparaître pour plus d'un utilisateur, donc je n'ai considéré que les utilisateurs GitHub capables de pousser du code vers des projets GitHub avec plus de 20 étoiles pendant la période.
- Je n'ai compté que les utilisateurs GitHub avec plus de 3 pushes pendant la période.
- Les utilisateurs poussant du code vers GitHub peuvent afficher de nombreux emails différents sur leurs pushes — c'est une partie du fonctionnement de Git. Pour déterminer l'organisation pour chaque utilisateur, j'ai examiné l'email qui apparaît le plus fréquemment dans leurs pushes.
- Tout le monde n'utilise pas son email professionnel sur GitHub. Il y a beaucoup de gmail.com, users.noreply.github.com et d'autres fournisseurs d'hébergement d'email. Parfois, la raison en est l'anonymat et la protection de leurs boîtes mail professionnelles — mais si je ne pouvais pas voir leur domaine d'email, je ne pouvais pas les compter. Désolé.
- Parfois, les employés changent d'organisation. Je les ai assignés à celle qui a obtenu le plus de pushes selon ces règles.
Ma requête
#standardSQLWITHperiod AS ( SELECT * FROM `githubarchive.month.2017*` a),repo_stars AS ( SELECT repo.id, COUNT(DISTINCT actor.login) stars, APPROX_TOP_COUNT(repo.name, 1)[OFFSET(0)].value repo_name FROM period WHERE type='WatchEvent' GROUP BY 1 HAVING stars>20), pushers_guess_emails_and_top_projects AS ( SELECT * # , REGEXP_EXTRACT(email, r'@(.*)') domain , REGEXP_REPLACE(REGEXP_EXTRACT(email, r'@(.*)'), r'.*.ibm.com', 'ibm.com') domain FROM ( SELECT actor.id , APPROX_TOP_COUNT(actor.login,1)[OFFSET(0)].value login , APPROX_TOP_COUNT(JSON_EXTRACT_SCALAR(payload, '$.commits[0].author.email'),1)[OFFSET(0)].value email , COUNT(*) c , ARRAY_AGG(DISTINCT TO_JSON_STRING(STRUCT(b.repo_name,stars))) repos FROM period a JOIN repo_stars b ON a.repo.id=b.id WHERE type='PushEvent' GROUP BY 1 HAVING c>3 ))SELECT * FROM ( SELECT domain , githubers , (SELECT COUNT(DISTINCT repo) FROM UNNEST(repos) repo) repos_contributed_to , ARRAY( SELECT AS STRUCT JSON_EXTRACT_SCALAR(repo, '$.repo_name') repo_name , CAST(JSON_EXTRACT_SCALAR(repo, '$.stars') AS INT64) stars , COUNT(*) githubers_from_domain FROM UNNEST(repos) repo GROUP BY 1, 2 HAVING githubers_from_domain>1 ORDER BY stars DESC LIMIT 3 ) top , (SELECT SUM(CAST(JSON_EXTRACT_SCALAR(repo, '$.stars') AS INT64)) FROM (SELECT DISTINCT repo FROM UNNEST(repos) repo)) sum_stars_projects_contributed_to FROM ( SELECT domain, COUNT(*) githubers, ARRAY_CONCAT_AGG(ARRAY(SELECT * FROM UNNEST(repos) repo)) repos FROM pushers_guess_emails_and_top_projects #WHERE domain IN UNNEST(SPLIT('google.com|microsoft.com|amazon.com', '|')) WHERE domain NOT IN UNNEST(SPLIT('gmail.com|users.noreply.github.com|qq.com|hotmail.com|163.com|me.com|googlemail.com|outlook.com|yahoo.com|web.de|iki.fi|foxmail.com|yandex.ru|126.com|protonmail.com', '|')) # email hosters GROUP BY 1 HAVING githubers > 30 ) WHERE (SELECT MAX(githubers_from_domain) FROM (SELECT repo, COUNT(*) githubers_from_domain FROM UNNEST(repos) repo GROUP BY repo))>4 # second filter email hosters)ORDER BY githubers DESC
FAQ
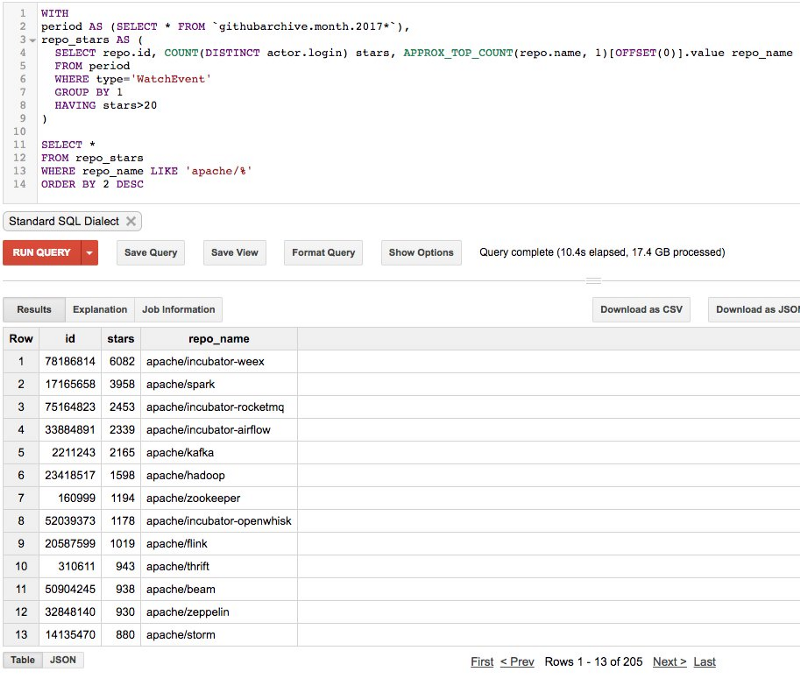
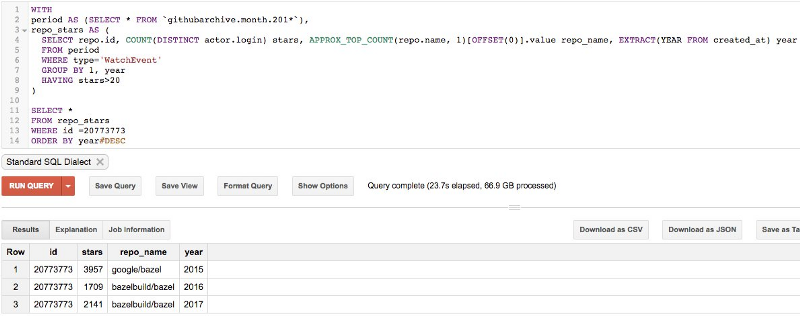
Si une organisation a 1 500 dépôts, pourquoi n'en comptez-vous que 200 ? Si un dépôt a 7 000 étoiles, pourquoi n'en affichez-vous que 1 500 ?
Je filtre pour la pertinence. Je ne compte que les étoiles données en 2017. Par exemple, Apache a >1 500 dépôts sur GitHub, mais seulement 205 ont reçu plus de 20 étoiles cette année.
Est-ce l'état de l'open source ?
Notez que l'analyse de GitHub n'inclut pas les principales communautés comme Android, Chromium, GNU, Mozilla, ni les fondations Apache ou Eclipse, et d'autres projets qui choisissent de mener la plupart de leurs activités en dehors de GitHub.
Vous avez été injuste envers mon organisation.
Je ne peux compter que ce que je peux voir. Veuillez remettre en question mes hypothèses et me dire comment vous mesureriez les choses de manière meilleure. Des requêtes fonctionnelles seraient le meilleur moyen.
Par exemple, voyez comment leur classement change lorsque je combine les domaines régionaux d'IBM en un seul avec une transformation SQL :
SELECT *, REGEXP_REPLACE(REGEXP_EXTRACT(email, r'@(.*)'), r'.*.ibm.com', 'ibm.com') domain
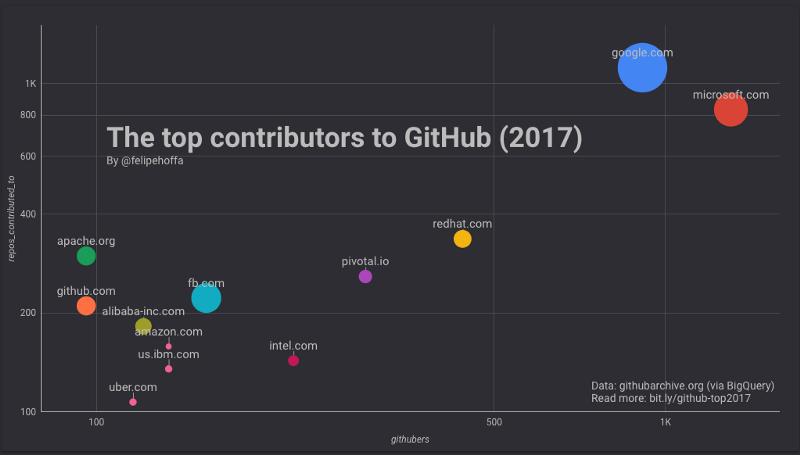
 La position relative d'IBM change significativement lorsque vous combinez leurs domaines d'email régionaux.
La position relative d'IBM change significativement lorsque vous combinez leurs domaines d'email régionaux.
Réactions
Quelques réflexions sur "les principaux contributeurs à GitHub 2017".
_Hier, Felipe Hoffa de l'équipe Google Dev Rel a publié une recherche intéressante sur l'utilisation des entreprises de... redmonk.com
Prochaines étapes
Je me suis déjà trompé — et cela se reproduira probablement. Veuillez examiner toutes les données brutes disponibles et remettre en question toutes mes hypothèses — ce sera intéressant de voir quels résultats vous obtiendrez.
Jouez avec le rapport interactif Data Studio.
Merci à Ilya Grigorik pour avoir maintenu GitHub Archive bien alimenté et rempli de données GitHub toutes ces années !
Vous voulez plus d'histoires ? Consultez mon Medium, suivez-moi sur twitter, et abonnez-vous à reddit.com/r/bigquery. Et essayez BigQuery — chaque mois, vous obtenez un téraoctet complet d'analyse gratuitement.
Mener avec des virgules — laid ou efficace ? Une enquête sur 320 Go de code SQL
_Gagner des arguments avec des données : Analysons 320 gigaoctets de code SQL open source pour déterminer si nous devons utiliser des virgules... hackernoon.comCertains codeurs aiment la chaleur — mais la plupart préfèrent les climats plus froids
_Précédemment, nous avons trouvé certaines des principales concentrations de codeurs open source autour d'endroits assez froids (Islande, Suède... hackernoon.com