


Article original : What is a Greedy Algorithm? Examples of Greedy Algorithms
Selon le dictionnaire Oxford English Dictionary, "glouton" signifie avoir un désir excessif pour quelque chose sans considérer l'effet ou le dommage causé.
En informatique, un algorithme glouton est un algorithme qui trouve une solution aux problèmes dans le temps le plus court possible. Il choisit le chemin qui semble optimal à ce moment-là sans tenir compte de l'optimisation globale de la solution qui serait formée.
Edsger Dijkstra, un informaticien et mathématicien qui voulait calculer un arbre couvrant minimal, a introduit le terme "algorithme glouton". Prim et Kruskal ont proposé des techniques d'optimisation pour minimiser le coût des graphes.
De nombreux algorithmes gloutons ont été développés pour résoudre des problèmes de graphes. Un graphe est une structure composée d'arêtes et de sommets.
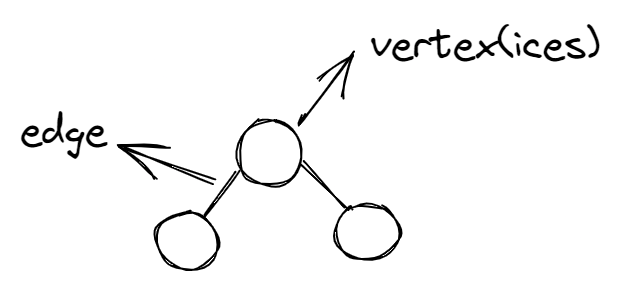
Diagramme d'un graphe simple
Algorithmes gloutons vs non gloutons
Un algorithme est glouton lorsque le chemin choisi est considéré comme la meilleure option en fonction d'un critère spécifique sans tenir compte des conséquences futures. Mais il évalue généralement la faisabilité avant de prendre une décision finale. La justesse de la solution dépend du problème et des critères utilisés.
Exemple : Un graphe a divers poids et vous devez déterminer la valeur maximale dans l'arbre. Vous commencez par rechercher chaque nœud et vérifier son poids pour voir s'il s'agit de la valeur la plus grande.
Il existe deux approches pour résoudre ce problème : l'approche gloutonne ou non gloutonne.
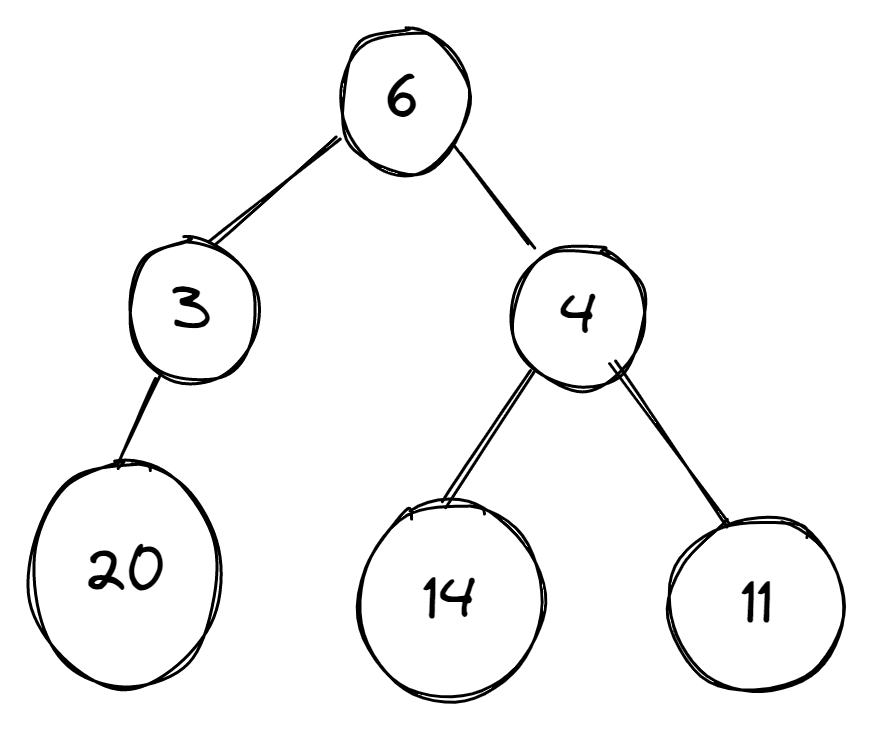
Exemple de graphe
Ce graphe se compose de différents poids et nous devons trouver la valeur maximale. Nous allons appliquer les deux approches sur le graphe pour obtenir la solution.
Approche gloutonne
Dans les images ci-dessous, un graphe a différents nombres dans ses sommets et l'algorithme est censé sélectionner le sommet avec le plus grand nombre.
En commençant par le sommet 6, il est ensuite confronté à deux décisions – lequel est le plus grand, 3 ou 4 ? L'algorithme choisit 4, puis est confronté à une autre décision – lequel est le plus grand, 14 ou 11. Il sélectionne 14, et l'algorithme se termine.
D'autre part, il y a un sommet étiqueté 20 mais il est attaché au sommet 3 que l'approche gloutonne ne considère pas comme le meilleur choix. Il est important de sélectionner des critères appropriés pour prendre chaque décision immédiate.
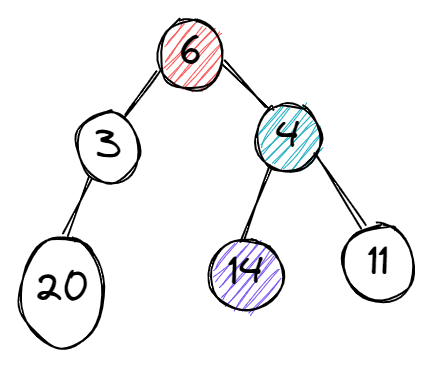
Le graphe exemple montrant l'approche gloutonne
Approche non gloutonne
L'approche "non gloutonne" vérifie toutes les options avant d'arriver à une solution finale, contrairement à l'approche "gloutonne" qui s'arrête une fois qu'elle obtient ses résultats.
En commençant par le sommet 6, il est ensuite confronté à deux décisions – lequel est le plus grand, 3 ou 4 ? L'algorithme choisit 4, puis est confronté à une autre décision – lequel est le plus grand, 14 ou 11. Il sélectionne 14 et le met de côté.
Ensuite, il relance le processus, en commençant par le sommet 6. Il sélectionne le sommet avec 3 et le vérifie. 20 est attaché au sommet 3 et le processus s'arrête. Maintenant, il compare les deux résultats – 20 et 14. 20 est plus grand, donc il sélectionne le sommet (3) qui porte le plus grand nombre et le processus se termine.
Cette approche considère de nombreuses possibilités pour trouver la meilleure solution.
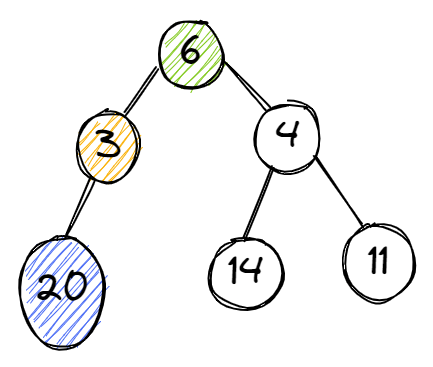
Le graphe exemple montrant l'approche non gloutonne
Caractéristiques d'un algorithme glouton
L'algorithme résout son problème en trouvant une solution optimale. Cette solution peut être une valeur maximale ou minimale. Il fait des choix basés sur la meilleure option disponible.
L'algorithme est rapide et efficace avec une complexité temporelle de O(n log n) ou O(n). Par conséquent, il est appliqué pour résoudre des problèmes à grande échelle.
La recherche de la solution optimale est effectuée sans répétition – l'algorithme s'exécute une seule fois.
Il est simple et facile à implémenter.
Comment utiliser les algorithmes gloutons
Avant d'appliquer un algorithme glouton à un problème, vous devez poser deux questions :
Avez-vous besoin de la meilleure option à ce moment-là pour le problème ?
Avez-vous besoin d'une solution optimale (soit une valeur minimale ou maximale) ?
Si votre réponse à ces questions est "Oui", alors un algorithme glouton est un bon choix pour résoudre votre problème.
Procédure
Supposons que vous avez un problème avec un ensemble de nombres et que vous devez trouver la valeur minimale.
Vous commencez par définir la contrainte, qui dans ce cas est de trouver la valeur minimale. Ensuite, chaque nombre sera scanné et vérifié sur chaque contrainte qui sert de condition à remplir. Si la condition est vraie, le ou les nombres sont sélectionnés et retournés comme solution finale.
Voici une représentation sous forme de diagramme de ce processus :
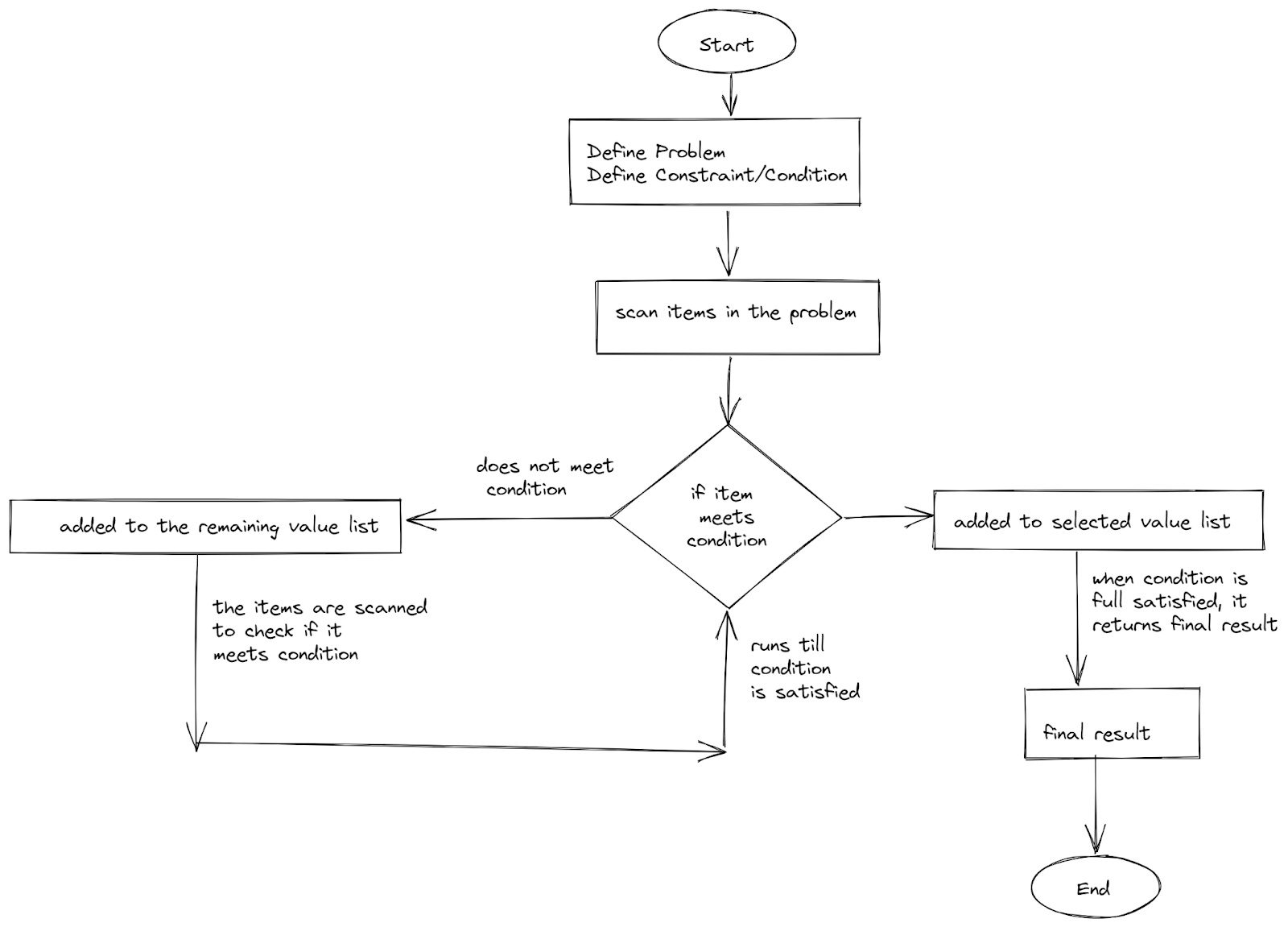
Diagramme montrant le processus de résolution d'un problème en utilisant des algorithmes gloutons
Exemples d'algorithmes gloutons
Problème 1 : Problème de sélection d'activités
Ce problème contient un ensemble d'activités ou de tâches qui doivent être accomplies. Chacune a une heure de début et une heure de fin. L'algorithme trouve le nombre maximum d'activités qui peuvent être faites dans un temps donné sans qu'elles ne se chevauchent.
Approche du problème
Nous avons une liste d'activités. Chacune a une heure de début et une heure de fin.
Tout d'abord, nous trions les activités et l'heure de début par ordre croissant en utilisant l'heure de fin de chacune.
Ensuite, nous commençons par choisir la première activité. Nous créons une nouvelle liste pour stocker l'activité sélectionnée.
Pour choisir la prochaine activité, nous comparons l'heure de fin de la dernière activité à l'heure de début de la prochaine activité. Si l'heure de début de la prochaine activité est supérieure à l'heure de fin de la dernière activité, elle peut être sélectionnée. Sinon, nous passons à la suivante.
Ce processus est répété jusqu'à ce que toutes les activités soient vérifiées. La solution finale est une liste contenant les activités qui peuvent être faites.
Le tableau ci-dessous montre une liste d'activités ainsi que les heures de début et de fin.
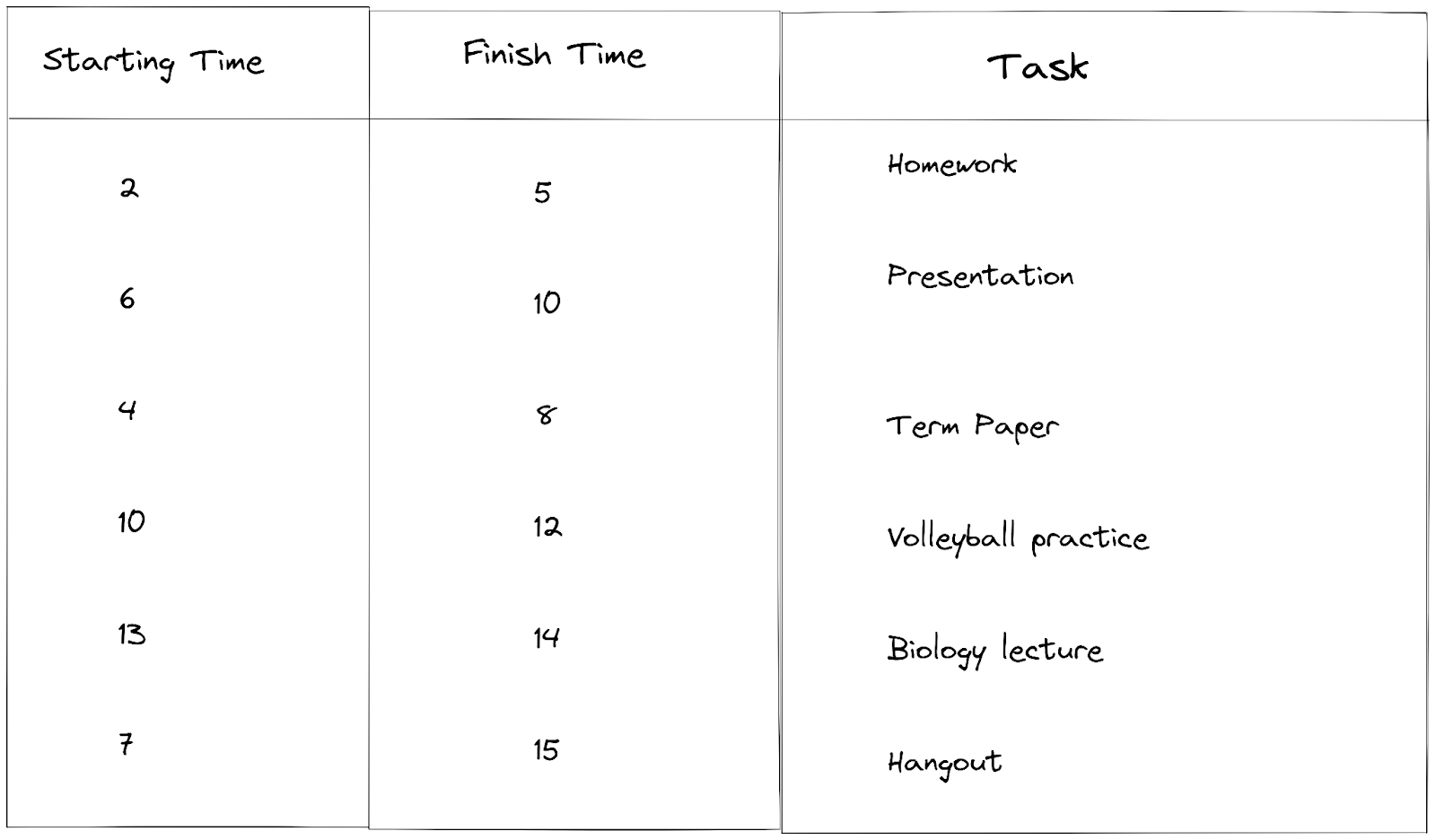
La première étape consiste à trier l'heure de fin par ordre croissant et à organiser les activités en conséquence.
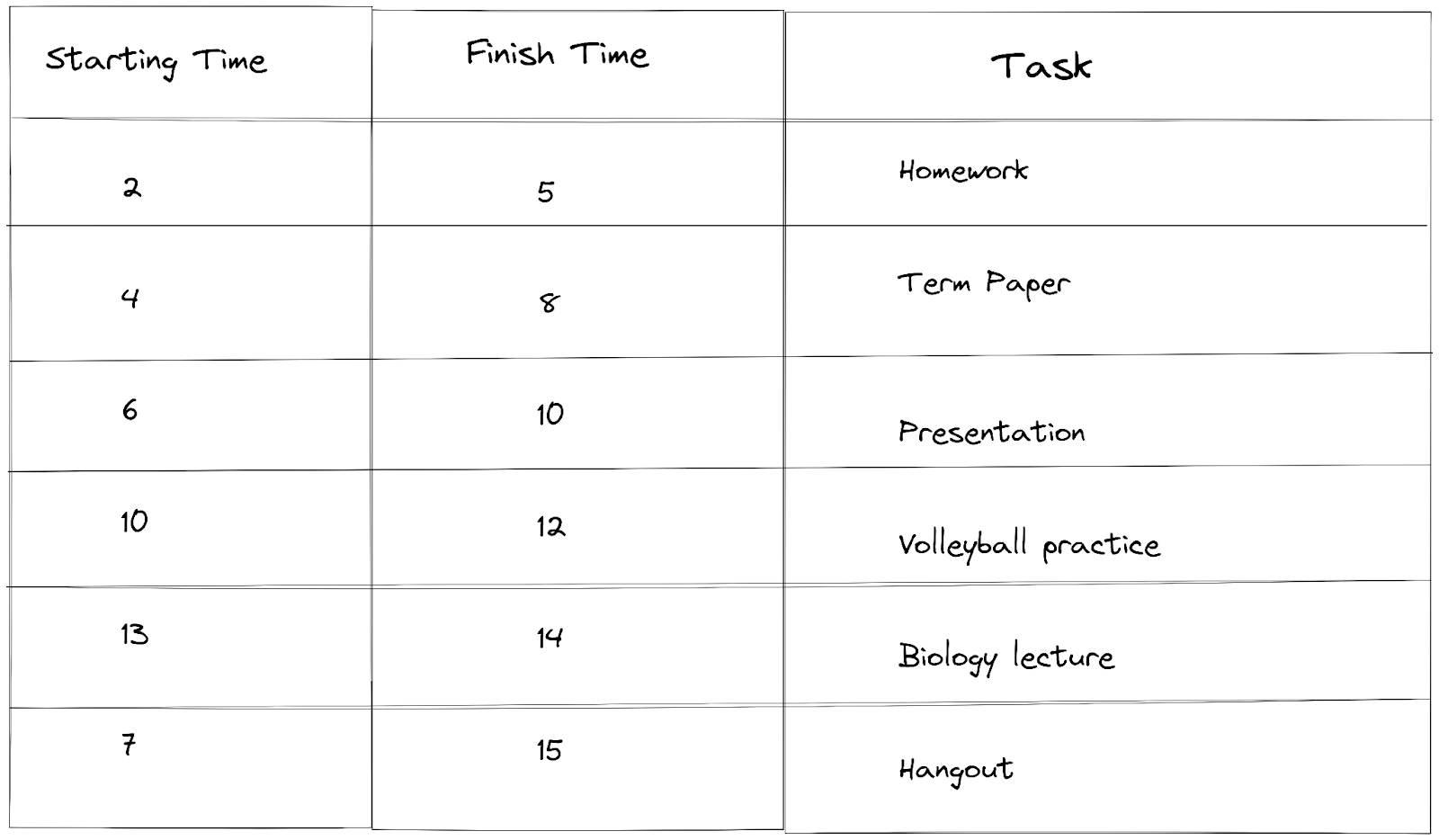
Après avoir trié les activités, nous sélectionnons la première activité et la stockons dans la liste des activités sélectionnées. Dans notre exemple, la première activité est "Devoirs".
En passant à l'activité suivante, nous vérifions l'heure de fin des "Devoirs" (5) qui était la dernière activité sélectionnée et l'heure de début du "Mémoire" (4). Pour choisir une activité, l'heure de début de l'activité suivante doit être supérieure ou égale à l'heure de fin. (4) est inférieur à (5), donc nous sautons l'activité et passons à la suivante.
L'activité suivante "Présentation" a une heure de début de (6) et elle est supérieure à l'heure de fin (5) des "Devoirs". Nous la sélectionnons donc et l'ajoutons à notre liste d'activités sélectionnées.
Pour l'activité suivante, nous faisons la même vérification. L'heure de fin de la "Présentation" est (10), l'heure de début de la "Pratique de volleyball" est (10). Nous voyons que l'heure de début est égale à l'heure de fin, ce qui satisfait l'une des conditions, donc nous la sélectionnons et l'ajoutons à notre liste d'activités sélectionnées.
En continuant vers l'activité suivante, l'heure de fin de la "Pratique de volleyball" est (12) et l'heure de début du "Cours de biologie" est (13). Nous voyons que l'heure de début est supérieure à l'heure de fin, donc nous la sélectionnons.
Pour notre dernière activité, l'heure de début pour "Sortie" est (7) et l'heure de fin de notre dernière activité "Cours de biologie" est (14), 7 est inférieur à 14, donc nous ne pouvons pas sélectionner l'activité. Comme nous sommes à la fin de notre liste d'activités, le processus se termine.
Notre résultat final est la liste des activités sélectionnées que nous pouvons faire sans chevauchement de temps : {Devoirs, Présentation, Pratique de volleyball, Cours de biologie}.
Implémentation en code de l'exemple
La variable <data> stocke les heures de début de chaque activité, l'heure de fin de chaque activité, et la liste des tâches (ou activités) à effectuer.
La variable <selected_activity> est une liste vide qui stockera les activités sélectionnées qui peuvent être effectuées.
<start_position> montre la position de la première activité qui est l'index "0". Ce sera notre point de départ.
data = {
"start_time": [2 , 6 , 4 , 10 , 13 , 7],
"finish_time": [5 , 10 , 8 , 12 , 14 , 15],
"activity": ["Homework" , "Presentation" , "Term paper" , "Volleyball practice" , "Biology lecture" , "Hangout"]
}
selected_activity =[]
start_position = 0
Voici un tableau de dataframe montrant les données originales :
Original Info
start_time finish_time activity
0 2 5 Homework
1 6 10 Presentation
2 4 8 Term paper
3 10 12 Volleyball practice
4 13 14 Biology lecture
5 7 15 Hangout
Ensuite, nous trions l'heure de fin par ordre croissant et réorganisons l'heure de début et l'activité en conséquence. Nous ciblons les variables en utilisant les clés dans le dictionnaire.
tem = 0
for i in range(0 , len(data['finish_time'])):
for j in range(0 , len(data['finish_time'])):
if data['finish_time'][i] < data['finish_time'][j]:
tem = data['activity'][i] , data['finish_time'][i] , data['start_time'][i]
data['activity'][i] , data['finish_time'][i] , data['start_time'][i] = data['activity'][j] , data['finish_time'][j] , data['start_time'][j]
data['activity'][j] , data['finish_time'][j] , data['start_time'][j] = tem
Dans le code ci-dessus, nous avons initialisé <tem> à zéro. Nous n'utilisons pas la méthode intégrée pour trier l'heure de fin. Nous utilisons deux boucles pour l'organiser par ordre croissant. <i> et <j> représentent les index et vérifient si les valeurs de <data['finish_time'][i]> sont inférieures à <data['finish_time'][j]>.
Si la condition est vraie, <tem> stocke les valeurs des éléments dans la position <i> et échange l'élément correspondant.
Maintenant, nous imprimons le résultat final, voici ce que nous obtenons :
print("Start time: " , data['start_time'])
print("Finish time: " , data['finish_time'])
print("Activity: " , data['activity'])
# Résultats avant le tri
# Start time: [2, 6, 4, 10, 13, 7]
# Finish time: [5, 10, 8, 12, 14, 15]
# Activity: ['Homework', 'Presentation', 'Term paper', 'Volleyball practice', 'Biology lecture', 'Hangout']
# Résultats après le tri
# Start time: [2, 4, 6, 10, 13, 7]
# Finish time: [5, 8, 10, 12, 14, 15]
# Activity: ['Homework', 'Term paper', 'Presentation', 'Volleyball practice', 'Biology lecture', 'Hangout']
Et voici un tableau de dataframe montrant les données triées :
Sorted Info with respect to finish_time
start_time finish_time activity
0 2 5 Homework
1 4 8 Term paper
2 6 10 Presentation
3 10 12 Volleyball practice
4 13 14 Biology lecture
5 7 15 Hangout
Après avoir trié les activités, nous commençons par sélectionner la première activité, qui est "Homework". Elle a un index de départ de "0" donc nous utilisons <start_position> pour cibler l'activité et l'ajouter à la liste vide.
selected_activity.append(data['activity'][start_position])
La condition pour sélectionner une activité est que l'heure de début de l'activité suivante sélectionnée soit supérieure à l'heure de fin de l'activité précédente. Si la condition est vraie, l'activité sélectionnée est ajoutée à la liste <selected_activity>.
for pos in range(len(data['finish_time'])):
if data['start_time'][pos] >= data['finish_time'][start_position]:
selected_activity.append(data['activity'][pos])
start_position = pos
print(f"The student can work on the following activities: {selected_activity}")
# Résultats
# The student can work on the following activities: ['Homework', 'Presentation', 'Volleyball practice', 'Biology lecture']
Voici à quoi cela ressemble dans son ensemble :
data = {
"start_time": [2 , 6 , 4 , 10 , 13 , 7],
"finish_time": [5 , 10 , 8 , 12 , 14 , 15],
"activity": ["Homework" , "Presentation" , "Term paper" , "Volleyball practice" , "Biology lecture" , "Hangout"]
}
selected_activity =[]
start_position = 0
# tri des éléments par ordre croissant par rapport à l'heure de fin
tem = 0
for i in range(0 , len(data['finish_time'])):
for j in range(0 , len(data['finish_time'])):
if data['finish_time'][i] < data['finish_time'][j]:
tem = data['activity'][i] , data['finish_time'][i] , data['start_time'][i]
data['activity'][i] , data['finish_time'][i] , data['start_time'][i] = data['activity'][j] , data['finish_time'][j] , data['start_time'][j]
data['activity'][j] , data['finish_time'][j] , data['start_time'][j] = tem
# par défaut, la première activité est insérée dans la liste des activités à sélectionner.
selected_activity.append(data['activity'][start_position])
for pos in range(len(data['finish_time'])):
if data['start_time'][pos] >= data['finish_time'][start_position]:
selected_activity.append(data['activity'][pos])
start_position = pos
print(f"The student can work on the following activities: {selected_activity}")
# Résultats
# The student can work on the following activities: ['Homework', 'Presentation', 'Volleyball practice', 'Biology lecture']
Problème 2 : Problème du sac à dos fractionnaire
Un sac à dos a un poids maximum, et il ne peut contenir qu'un certain ensemble d'objets. Ces objets ont un poids et une valeur.
Le but est de remplir le sac à dos avec les objets qui ont les valeurs totales les plus élevées et ne dépassent pas la capacité de poids maximale.
Approche du problème
Il y a deux éléments à considérer : le sac à dos et les objets. Le sac à dos a un poids maximum et contient certains objets de grande valeur.
Scénario : Dans un magasin de bijoux, il y a des objets en or, en argent et en bois. L'objet le plus coûteux est l'or, suivi de l'argent et puis du bois. Si un voleur de bijoux vient dans le magasin, il prend de l'or car il fera le plus de profit.
Le voleur a un sac (sac à dos) dans lequel il peut mettre ces objets. Mais il y a une limite à ce que le voleur peut porter car ces objets peuvent devenir lourds. L'idée est de choisir l'objet qui rapporte le plus de profit et qui tient dans le sac (sac à dos) sans dépasser son poids maximum.
La première étape consiste à trouver le rapport valeur/poids de tous les objets pour savoir quelle fraction chacun occupe.
Nous trions ensuite ces rapports par ordre décroissant (du plus élevé au plus bas). De cette façon, nous pouvons choisir les rapports avec le nombre le plus élevé en premier, sachant que nous ferons un profit.
Lorsque nous choisissons le rapport le plus élevé, nous trouvons le poids correspondant et l'ajoutons au sac à dos. Il y a des conditions à vérifier.
Condition 1 : Si l'objet ajouté a un poids inférieur au poids maximum du sac à dos, d'autres objets sont ajoutés jusqu'à ce que la somme de tous les objets dans le sac soit égale au poids maximum du sac à dos.
Condition 2 : Si la somme des poids des objets dans le sac est supérieure à la capacité maximale du sac à dos, nous trouvons la fraction du dernier objet ajouté. Pour trouver la fraction, nous faisons ce qui suit :
Nous trouvons la somme des poids restants des objets dans le sac à dos. Ils doivent être inférieurs à la capacité maximale.
Nous trouvons la différence entre la capacité maximale du sac à dos et la somme des poids restants des objets et divisons par le poids du dernier objet à ajouter.
Fraction = (capacité maximale du sac à dos - somme des poids restants) / poids du dernier objet à ajouter
Pour ajouter le poids du dernier objet au sac à dos, nous multiplions la fraction par le poids.
Poids_ajouté = poids du dernier objet à ajouter * fraction
Lorsque nous additionnons les poids de tous les objets, il sera égal au poids maximum du sac à dos.
Exemple pratique :
Supposons que la capacité maximale du sac à dos est de 17, et qu'il y a trois objets disponibles. Le premier objet est de l'or, le deuxième objet est de l'argent, et le troisième objet est du bois.
Le poids de l'or est de 10, le poids de l'argent est de 6, et le poids du bois est de 2
la valeur (profit) de l'or est de 40, la valeur (profit) de l'argent est de 30, et la valeur (profit) du bois est de 6.
Ratio de l'or = valeur/poids = 40/10 = 4
Ratio de l'argent = valeur/poids = 30/6 = 5
Ratio du bois = valeur/poids = 6/2 = 3
Classement des ratios par ordre décroissant : 5, 4, 3.
Le ratio le plus grand est 5 et nous l'associons au poids correspondant "6". Il pointe vers l'argent.
Nous mettons d'abord l'argent dans le sac à dos et le comparons au poids maximum qui est de 17. 6 est inférieur à 17, donc nous devons ajouter un autre objet. En revenant aux ratios, le deuxième plus grand est "4" et il correspond au poids de "10" qui pointe vers l'or.
Maintenant, nous mettons l'or dans le sac à dos, ajoutons le poids de l'argent et de l'or, et le comparons avec le poids du sac à dos. (6 + 10 = 16). En le vérifiant par rapport au poids maximum, nous voyons qu'il est inférieur. Nous pouvons donc prendre un autre objet. Nous revenons à la liste des ratios et prenons le 3ème plus grand qui est "3" et il correspond à "2" qui pointe vers le bois.
Lorsque nous ajoutons le bois dans le sac à dos, le poids total est (6 + 10 + 2 = 18) mais cela est supérieur à notre poids maximum qui est de 17. Nous sortons le bois du sac à dos et il nous reste l'or et l'argent. La somme totale des deux est de 16 et la capacité maximale est de 17. Nous avons donc besoin d'un poids de 1 pour l'égaler. Maintenant, nous appliquons la condition 2 discutée ci-dessus pour trouver la fraction de bois qui peut tenir dans le sac à dos.
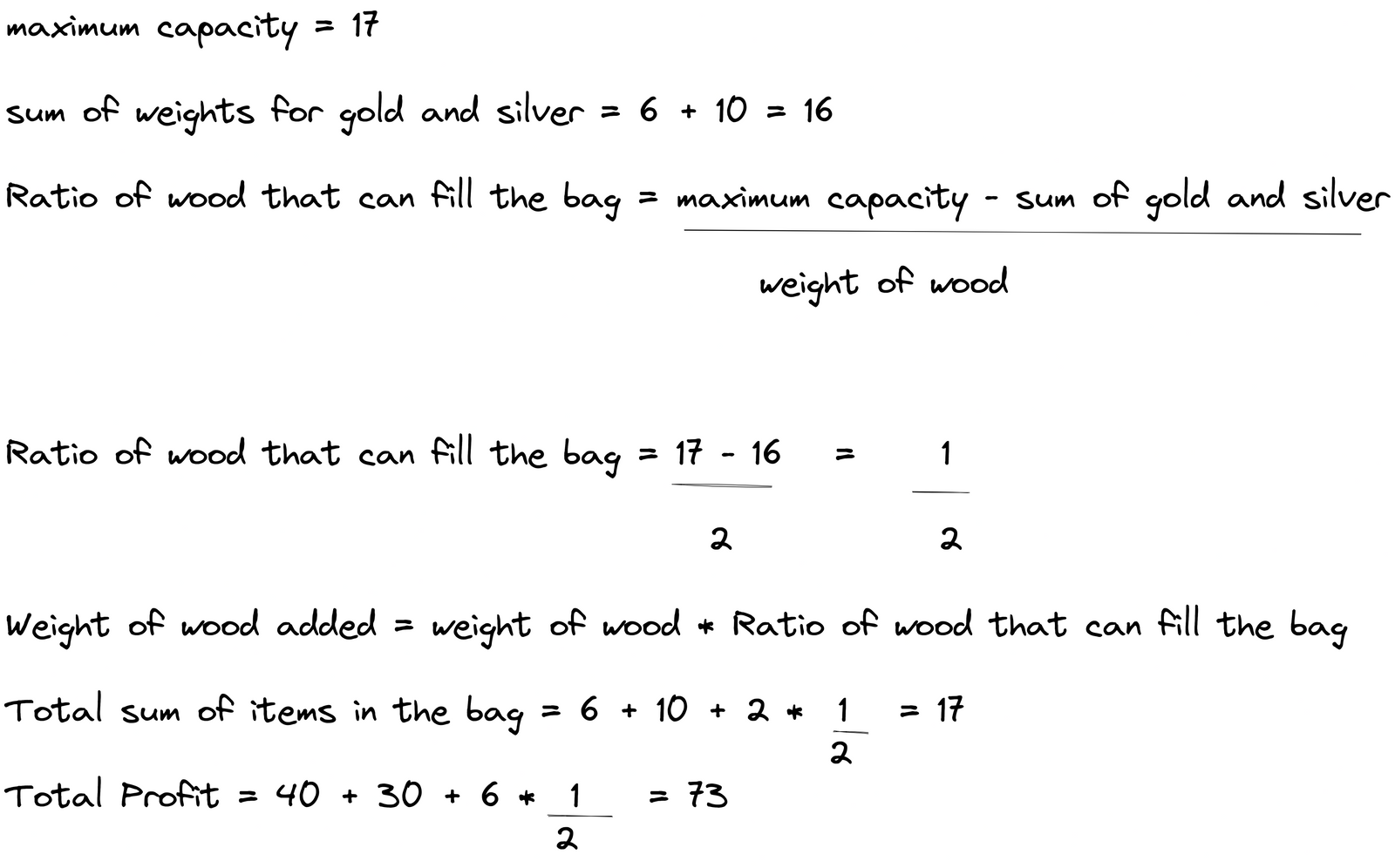
Explication du remplissage de l'espace restant dans le sac à dos avec un morceau fractionnaire de bois
Maintenant, le sac à dos est rempli.
Implémentation en code de l'exemple
La variable <data> stocke les poids de chaque objet et les profits. La variable <maximum_capacity> stocke le poids maximum du sac à dos. <selected_wt> est initialisée à 0, et elle stockera les poids sélectionnés à mettre dans le sac à dos. Enfin, <max_profit> est initialisée à 0, elle stockera les valeurs du poids sélectionné.
data = {
"weight": [10 , 6 , 2],
"profit":[40 , 30 ,6]
}
max_weight = 17
selected_wt = 0
max_profit = 0
Ensuite, nous calculons le rapport du profit au poids. Ratio = profit/poids :
ratio = [int(data['profit'][i] / data['weight'][i]) for i in range(len(data['profit']))]
Maintenant que nous avons le rapport, nous organisons les éléments par ordre décroissant, du plus grand au plus petit. Ensuite, les éléments en poids et profit sont organisés selon les positions du rapport trié.
for i in range(len(ratio)):
for j in range(i + 1 , len(ratio)):
if ratio[i] < ratio[j]:
ratio[i] , ratio[j] = ratio[j] , ratio[i]
data['weight'][i] , data['weight'][j] = data['weight'][j] , data['weight'][i]
data['profit'][i] , data['profit'][j] = data['profit'][j] , data['profit'][i]
Après que le poids et le profit soient triés, nous commençons à choisir les objets et à vérifier la condition. Nous parcourons la longueur du rapport pour cibler l'index de chaque objet dans la liste. Note : tous les objets dans le rapport sont organisés du plus grand au plus petit, donc le premier objet est la valeur maximale et le dernier objet est la valeur minimale.
for i in range(len(ratio)):
Le premier objet que nous sélectionnons a le rapport le plus élevé parmi les autres et il est à l'index 0. Maintenant que le premier poids est sélectionné, nous vérifions s'il est inférieur au poids maximum. Si c'est le cas, nous ajoutons des objets jusqu'à ce que le poids total soit égal au poids du sac à dos. Le deuxième objet que nous sélectionnons a le deuxième rapport le plus élevé parmi les autres et il est à l'index 1, l'arrangement est cet ordre de sélection.
Pour chaque poids sélectionné, nous l'ajoutons à la variable selected_wt et leurs profits correspondants à la variable max_profit.
if selected_wt + data['weight'][i] <= max_weight:
selected_wt += data['weight'][i]
max_profit += data['profit'][i]
Lorsque la somme des poids sélectionnés dans le sac à dos dépasse le poids maximum, nous trouvons la fraction du poids du dernier objet ajouté pour que le total des poids sélectionnés soit égal au poids maximum. Nous faisons cela en trouvant la différence entre le max_weight et la somme des poids sélectionnés divisée par le poids du dernier objet ajouté.
Le profit final réalisé à partir de la fraction transportée est ajouté à la variable max_profit. Ensuite, nous retournons le max_profit comme résultat final.
else:
frac_wt = (max_weight - selected_wt) / data['weight'][i]
frac_value = data['profit'][i] * frac_wt
max_profit += frac_value
selected_wt += (max_weight - selected_wt)
print(max_profit)
En mettant tout ensemble :
data = {
"weight": [10 , 6 , 2],
"profit":[40 , 30 ,6]
}
max_weight = 17
selected_wt = 0
max_profit = 0
# trouve le rapport
ratio = [int(data['profit'][i] / data['weight'][i]) for i in range(len(data['profit']))]
# trie le rapport par ordre décroissant, réorganise le poids et le profit dans l'ordre du rapport trié
for i in range(len(ratio)):
for j in range(i + 1 , len(ratio)):
if ratio[i] < ratio[j]:
ratio[i] , ratio[j] = ratio[j] , ratio[i]
data['weight'][i] , data['weight'][j] = data['weight'][j] , data['weight'][i]
data['profit'][i] , data['profit'][j] = data['profit'][j] , data['profit'][i]
# vérifie si le poids sélectionné avec le rapport le plus élevé est inférieur au poids maximum, si c'est le cas, il l'ajoute au sac à dos et stocke le profit, sélectionne l'élément suivant.
# sinon la somme des poids sélectionnés est supérieure au poids max, trouve la fraction
for i in range(len(ratio)):
if selected_wt + data['weight'][i] <= max_weight:
selected_wt += data['weight'][i]
max_profit += data['profit'][i]
else:
frac_wt = (max_weight - selected_wt) / data['weight'][i]
frac_value = data['profit'][i] * frac_wt
max_profit += frac_value
selected_wt += (max_weight - selected_wt)
print(f"Le profit maximum qui peut être réalisé à partir de chaque objet est : {round(max_profit , 2)} euros")
# Résultat
# Le profit maximum qui peut être réalisé à partir de chaque objet est : 73.0 euros
Applications des algorithmes gloutons
Il existe diverses applications des algorithmes gloutons. Certaines d'entre elles sont :
[Arbre couvrant minimal](https://en.wikipedia.org/wiki/Minimum_spanning_tree#:~:text=A%20minimum%20spanning%20tree%20(MST,minimum%20possible%20total%20edge%20weight.) est sans aucun cycle et avec le poids total des arêtes le plus faible possible. Cet arbre est dérivé d'un graphe non orienté connecté avec des poids.
Plus court chemin de Dijkstra est un algorithme de recherche qui trouve le chemin le plus court entre un sommet et d'autres sommets dans un graphe pondéré.
Problème du voyageur de commerce implique de trouver l'itinéraire le plus court qui visite différents endroits une seule fois et revient au point de départ.
Codage de Huffman attribue un code plus court aux symboles fréquemment rencontrés et un code plus long aux symboles moins fréquents. Il est utilisé pour encoder des données efficacement.
Avantages de l'utilisation d'un algorithme glouton
Les algorithmes gloutons sont assez simples à implémenter et faciles à comprendre. Ils sont également très efficaces et ont une complexité temporelle plus faible de O(N * logN).
Ils sont utiles pour résoudre des problèmes d'optimisation, en retournant une valeur maximale ou minimale.
Inconvénients/Limites de l'utilisation d'un algorithme glouton
Même si les algorithmes gloutons sont simples et utiles pour les problèmes d'optimisation, ils n'offrent pas toujours les meilleures solutions.
De plus, les algorithmes gloutons ne s'exécutent qu'une seule fois, donc ils ne vérifient pas la justesse du résultat produit.
Conclusion
Les algorithmes gloutons sont une approche simple pour résoudre des problèmes d'optimisation, en retournant une valeur minimale ou maximale.
Cet article a expliqué quelques exemples d'algorithmes gloutons et l'approche pour aborder chaque problème. En comprenant comment fonctionnent les problèmes d'algorithmes gloutons, vous pouvez mieux comprendre la programmation dynamique. Si vous avez des questions, n'hésitez pas à me contacter sur Twitter💙.