


Article original : What is Microsoft Fabric? How to Build a Customer Segmentation Project
Microsoft Fabric est un outil d'analyse de données qui peut vous aider à rationaliser tous vos besoins et flux de travail en matière de données, de l'intégration des données à l'analyse et à l'ingénierie.
Dans ce guide, je vais expliquer en détail ce qu'est Microsoft Fabric, comment il fonctionne, et je vais vous guider à travers la construction d'un projet avec celui-ci. Si vous avez déjà une compréhension de la plateforme, vous pouvez passer à la section Projet Microsoft Fabric.
Voici ce que vous allez apprendre dans ce guide :
- Qu'est-ce que Microsoft Fabric ?
- Pourquoi vous devriez apprendre Microsoft Fabric
- Architecture et composants de Microsoft Fabric
- Comment commencer en construisant un projet simple
- Comment créer un espace de travail dans Microsoft Fabric
- Comment créer un Lakehouse dans Microsoft Fabric
- Comment utiliser les données de l'API Kaggle dans Microsoft Fabric
- Comment utiliser le Data Wrangler dans Microsoft Fabric
- Comment effectuer une segmentation client dans Microsoft Fabric
- Comment visualiser vos données de Lakehouse dans Power BI
Prérequis
Pour suivre ce guide, vous aurez besoin d'une licence Power BI. Vous pouvez en obtenir une gratuitement pour vous entraîner en utilisant le Programme Microsoft 365 Developer.
Il serait également utile d'avoir des connaissances en Microsoft Power BI et Python.
Qu'est-ce que Microsoft Fabric ?
Microsoft Fabric est une plateforme logicielle-as-a-service (SaaS) tout-en-un pour gérer tous vos besoins et flux de travail en matière d'analyse de données. Microsoft a construit cette plateforme de bout en bout pour gérer les données liées aux données, de votre stockage et migration de données à vos analyses de données en temps réel, projets de science des données et flux de travail d'ingénierie des données.
Mais comment cela fonctionne-t-il ?
Cet outil rassemble diverses nouvelles technologies et outils de données préexistants—Power BI, OneLake, Azure Data Factory, Data Activator, Power Query, Apache Spark, Synapse Data Warehouse, Synapse Data Engineering, Synapse Data Science, Synapse Real-Time Analytics, Azure Machine Learning, et divers connecteurs.
Pourquoi vous devriez apprendre Microsoft Fabric
Le meilleur aspect de Microsoft Fabric est sa simplicité en termes de fonctionnalité. En utilisant diverses technologies ensemble, vous pouvez tout faire en un seul endroit et vous concentrer davantage sur ce que vous pouvez faire avec, et moins sur les licences, les systèmes de support, les dépendances et comment intégrer toutes ces différentes plateformes.
Un autre avantage de la plateforme est la manière dont elle gère vos données. Cela vous permet de maintenir une source d'information unique et fiable. Avec OneLake de Microsoft Fabric, vous pouvez avoir un stockage de données unifié.
Microsoft Fabric intègre également le service Azure OpenAI dans sa couche. Ainsi, vous pouvez utiliser l'IA (Co-pilot) pour vous aider à découvrir rapidement des insights.
Enfin, comme il s'agit d'une plateforme tout-en-un, il y a un avantage en termes de coût, car il n'est pas nécessaire de souscrire à plusieurs fournisseurs.
Architecture de Microsoft Fabric
Considérez Microsoft Fabric comme votre domaine de données.
Tout comme chaque bien immobilier, Microsoft Fabric possède divers composants dans son architecture.
Commençons par examiner la terminologie que vous rencontrerez et que vous devrez comprendre lors de l'utilisation de l'architecture de Microsoft Fabric :
Expériences et charges de travail :
Celles-ci font référence aux diverses capacités de la plateforme. Chaque expérience sur la plateforme est adaptée avec un utilisateur spécifique en tête.
Voici quelques exemples des différentes expériences/charges de travail disponibles. Vous remarquerez que chacune d'entre elles est conçue pour un objectif, une tâche et un utilisateur spécifiques.
- Data Factory : Cette application offre aux utilisateurs plus de 150 connecteurs vers des Lakehouses, des entrepôts de données, des sources de données cloud et locales, et orchestrer des pipelines de données pour la transformation des données. Un Lakehouse ici fait référence à une plateforme de données pour stocker des données structurées et non structurées. Vous pouvez également copier vos données locales vers le cloud et les charger dans OneLake via la Data Factory.
- Synapse Data Engineering fait partie de l'expérience d'ingénierie des données sur la plateforme. Il possède des fonctionnalités intéressantes comme les Lakehouses, les pipelines de données intégrés et un moteur Spark.
- Synapse Data Warehouse vous fournit un moteur SQL unifié et serverless. Comme votre entrepôt de données "traditionnel", vous avez toutes les capacités de vos fonctionnalités T-SQL transactionnelles.
- Synapse Real-Time Analytics vous permet de diffuser des données à partir d'appareils IoT (Internet des objets), de télémétrie et de journaux. Vous pouvez également utiliser la charge de travail ici pour analyser des données semi-structurées en utilisant ses capacités de langage de requête Kusto (KQL), tout comme Azure Data Explorer.
- Synapse Data Science vous permet de construire, collaborer, entraîner et déployer des modèles de Machine Learning (ML) et d'IA entièrement scalables de bout en bout. Vous pouvez également effectuer vos expériences ML dans vos notebooks et journaliser vos modèles en utilisant la fonctionnalité de journalisation automatique de Fabric. Un outil à mentionner dans cette expérience est le Data Wrangler, une interface graphique de Fabric pour la transformation des données. Avec cet outil, vous pouvez nettoyer vos données en simplifiant en cliquant sur des boutons tandis que l'outil génère automatiquement le code Python pour vous. Il est similaire à Power Query.
- Business Intelligence avec Power BI vous aide à transformer rapidement vos données commerciales en rapports analytiques et tableaux de bord perspicaces.
- Data Activator vous permet de prendre en charge l'observabilité de vos données et de surveiller les charges de travail de manière non codée/low-code. Cela vous indique lorsque des points de données spécifiques atteignent un seuil ou correspondent à un motif. Vous pouvez également automatiser des actions particulières et lancer des flux Power Automates lorsque certaines conditions se produisent.
- Copilot dans Fabric vous fournit un service Azure OpenAI. Cela signifie que vous pouvez créer des rapports, décrire comment vous souhaitez ingérer vos données, résumer, explorer et transformer vos données en utilisant la capacité de langage naturel d'Azure OpenAI.
Espaces de travail
Les espaces de travail sont similaires à ceux de Power BI. Ici, vous pouvez partager et collaborer avec d'autres personnes et créer des rapports, des entrepôts de données, des Lakehouses, des tableaux de bord et des notebooks.
Unité de capacité (CU)
Une CU est la capacité de votre ressource à effectuer ou produire une sortie.
Maintenant, nous allons examiner les différents composants de l'architecture de Microsoft Fabric.
OneLake
OneLake est le dépôt central de données pour Microsoft Fabric qui stocke les données au format Delta Lake. Considérez-le comme OneDrive pour vos données. Ce dépôt vous permet d'explorer et de trouver des actifs de données dans votre organisation.
Une chose passionnante est Shortcuts, qui vous permet de partager ou de pointer vers des données dans d'autres emplacements dans OneLake sans déplacer ou dupliquer les données. Cela élimine tout cas de redondance de données.
Lakehouses vs Warehouses
Bien que les deux "maisons" contiennent des données, il existe certaines différences entre les Lakehouses et les Warehouses dans Microsoft Fabric.
Pour commencer, un Lakehouse peut stocker tout type de données, qu'elles soient structurées ou non structurées. Cependant, elles sont stockées au format Delta par défaut. Le format Delta est une couche de stockage qui offre des transactions ACID (Atomicité, Cohérence, Isolation, Durabilité). Un Warehouse, en revanche, est plus adapté aux données structurées.
Les Lakehouses supportent également les Notebooks. Vous pouvez donc travailler avec divers langages, de PySpark à SQL et R. Les Warehouses, en revanche, n'utilisent que SQL.
Gardez à l'esprit, cependant, que Fabric vous fournit deux types de Warehouses : SQL Endpoint et Synapse Data Warehouse.
- SQL Endpoint est généré automatiquement lorsqu'un Lakehouse est créé. Cela signifie que vous pouvez avoir une expérience basée sur SQL et interroger les données du Lakehouse en utilisant le langage T-SQL.
- Synapse Data Warehouse est plus un moteur SQL traditionnel. Vous pouvez donc l'utiliser pour créer et interroger des données à partir de OneLake.
Comment commencer avec Microsoft Fabric – Un exemple de projet complet
Pour avoir un aperçu de la manière dont la plateforme Fabric fonctionne, nous allons construire un petit projet.
Nous allons créer un Lakehouse pour stocker un ensemble de données de centre commercial provenant de Kaggle en utilisant l'API Kaggle. Nous allons également transformer nos données en utilisant Data Wrangler. Ensuite, nous allons effectuer une segmentation client sur nos données en fonction du revenu annuel et du score de dépenses du client en utilisant l'algorithme de clustering KMeans. Cela nous permettra de regrouper les clients en diverses catégories comme les faibles revenus qui ne dépensent pas, les clients à revenus moyens, et les clients à hauts revenus qui ne dépensent pas beaucoup.
Commençons.
Comment activer Fabric
La première chose que nous devons faire est de nous connecter à Microsoft Power BI. Ici, nous allons activer les capacités de Microsoft Fabric pour notre espace de travail.
Pour ce faire, suivez ces étapes :
Tout d'abord, accédez aux paramètres de capacité dans le portail d'administration. Le portail d'administration est l'endroit où les administrateurs contrôlent et gèrent les diverses fonctionnalités de Power BI.
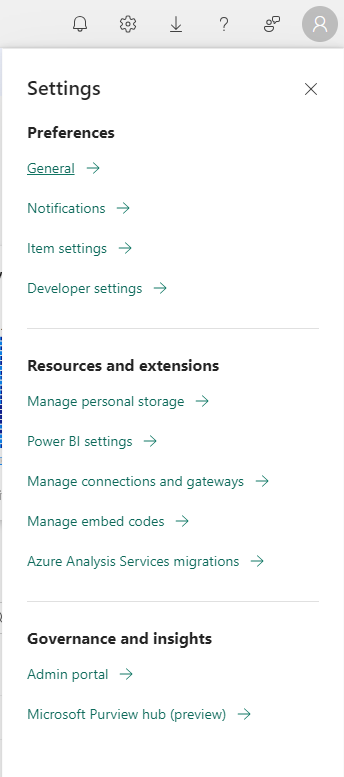
Ensuite, sous l'onglet Paramètres du locataire, recherchez l'onglet Microsoft Fabric.
Sous cet onglet, activez le bouton Les utilisateurs peuvent créer des éléments Fabric sur on. Une fois que vous avez fait cela, sélectionnez Appliquer.
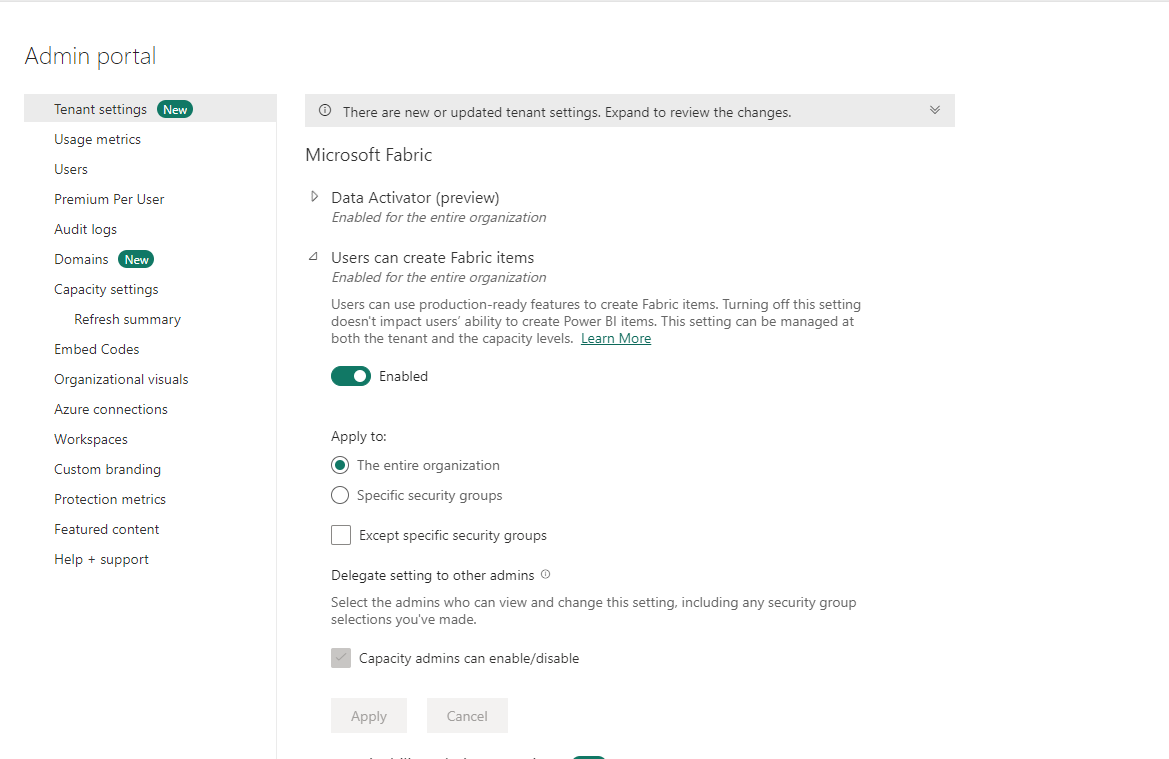
Maintenant, votre environnement sera configuré et les divers services devraient apparaître en bas à gauche de votre écran.

Comment créer un espace de travail dans Microsoft Fabric
Nous allons utiliser un ensemble de données de segmentation client de centre commercial de Kaggle pour cette démonstration. Ces données, comme mentionné dans Kaggle, ont été créées dans le but d'apprendre les concepts de segmentation client.
Parlons un peu de l'ensemble de données. Imaginez que vous avez un centre commercial de supermarché et que chaque client possède une carte de membre. Vous avez également un catalogue de données pour chaque client avec des informations de base comme leur identifiant client, leur âge, leur sexe, leur revenu annuel et leur score de dépenses.
Maintenant, nous voulons segmenter ces clients en divers groupes afin d'améliorer la fidélité des clients, de mieux comprendre les clients et de cibler plus efficacement notre stratégie marketing.
Pour y parvenir, nous utiliserons le score de dépenses attribué à chaque client pour définir leur pouvoir d'achat.
Pour commencer, vous devrez créer un nouvel espace de travail. Vous pouvez le faire en suivant ces étapes :
- Rendez-vous sur votre page d'accueil Microsoft Fabric.
- Sélectionnez espaces de travail et cliquez sur Nouvel espace de travail.
- Donnez un nom à votre espace de travail – je vais appeler le mien FabricMall.
- Cliquez sur Avancé pour voir les options déroulantes et sélectionnez Essai si vous utilisez votre essai Fabric.
- Cliquez sur Appliquer.
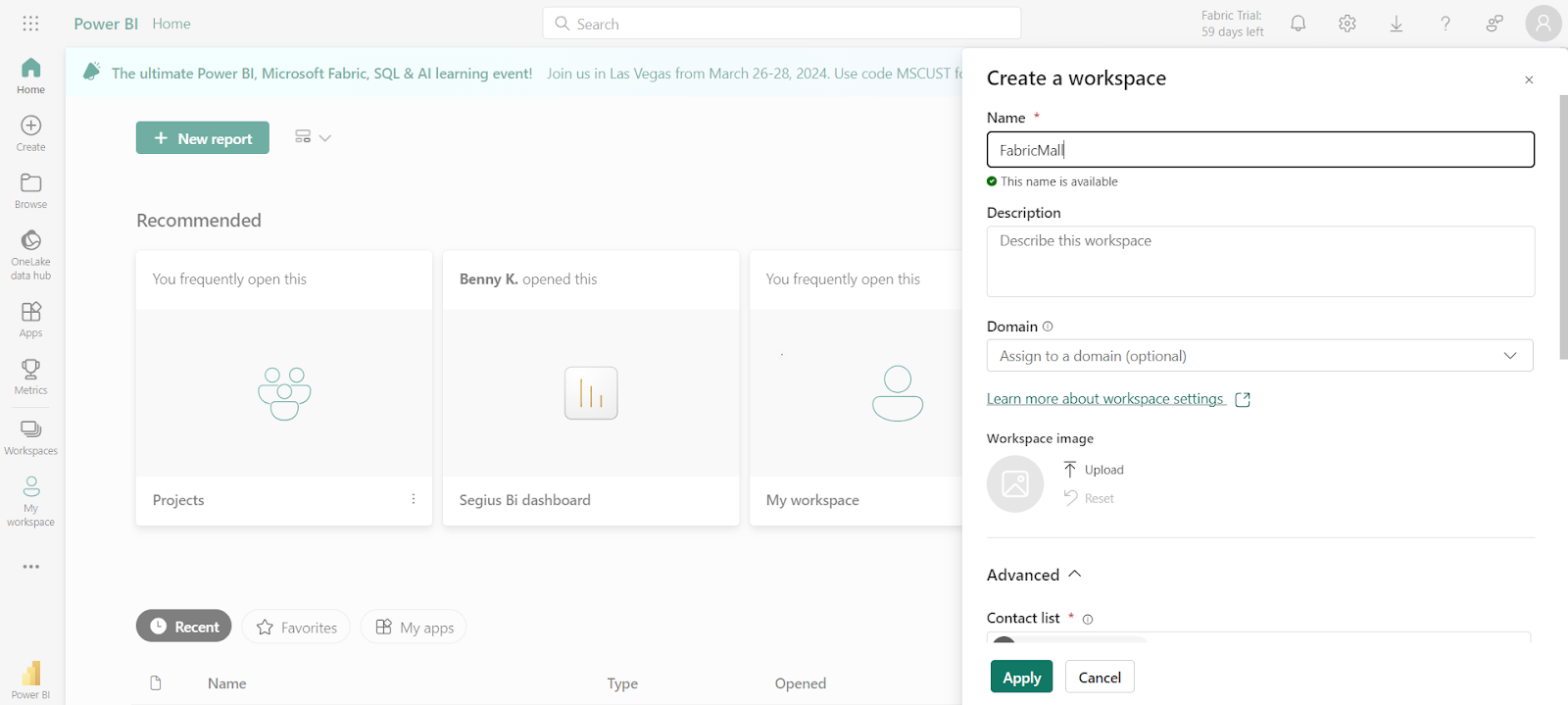
La prochaine chose que vous voulez faire est de créer un Lakehouse pour vos données.
Comment créer un Lakehouse dans Microsoft Fabric
Pour créer un Lakehouse, cliquez d'abord sur Nouveau dans votre espace de travail. Cela affichera une liste des diverses tâches que vous pouvez effectuer dans votre espace de travail.
Ensuite, sélectionnez Plus d'options et sélectionnez Lakehouse.
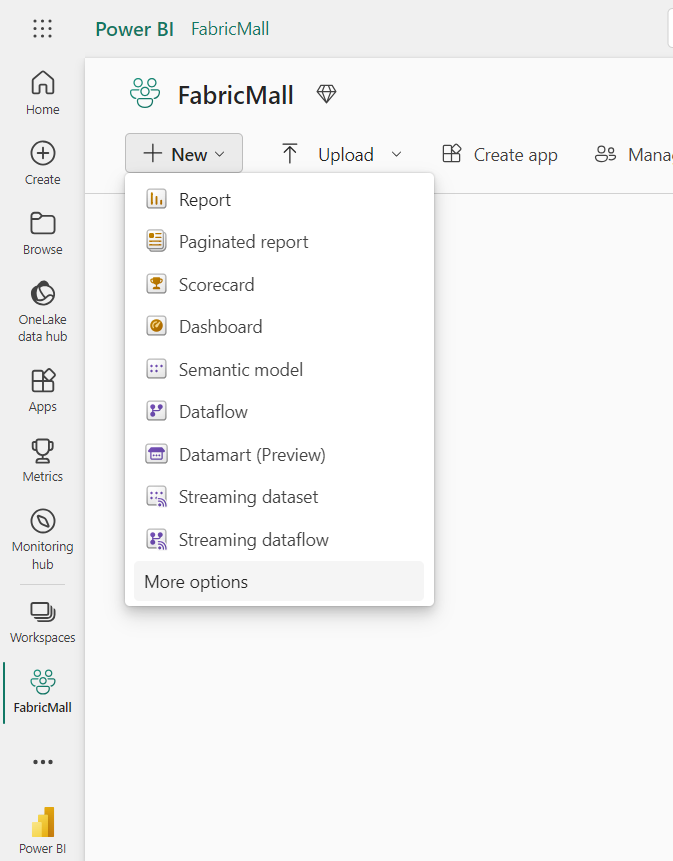
Ensuite, donnez-lui un nom, comme FabricMallLake, et cliquez sur Ouvrir le notebook.
Cliquez sur Nouveau notebook et Ouvrir. Vous pouvez renommer votre notebook dans le coin supérieur gauche de votre notebook. Le notebook est similaire à l'expérience Jupyter notebook.
Comment utiliser les données de l'API Kaggle dans Microsoft Fabric
Les notebooks nous permettent d'écrire, visualiser et exécuter du code. Dans le Notebook, nous allons utiliser Python pour effectuer une segmentation client sur nos données dans Microsoft Fabric.
Tout d'abord, importez Kaggle en utilisant la commande ci-dessous :
!pip install Kaggle
Ensuite, vous devrez importer votre système d'exploitation et vous connecter à l'API Kaggle.
import os
os.chdir('/lakehouse/default/Files')
os.environ['KAGGLE_USERNAME'] = 'bennyifeanyi'
os.environ['KAGGLE_KEY'] = '050019167fbe0027359cdb4b5eea50fe'
from kaggle.api.kaggle_api_extended import KaggleApi
api = KaggleApi()
api.authenticate()
api.dataset_download_file('vjchoudhary7/customer-segmentation-tutorial-in-python', 'Mall_Customers.csv')
Dans le code ci-dessus, os.chdir('/lakehouse/default/Files') représente notre chemin d'API de fichier. N'oubliez pas de remplacer le nom d'utilisateur et la clé API par les vôtres.
Maintenant, importez Pandas. Cela vous permettra de lire votre fichier.
import pandas as pd
df = pd.read_csv("/lakehouse/default/" + "Files/Mall_Customers.csv")
df.head()
Mais avant de commencer à segmenter nos clients, transformons nos données en explorant le data wrangler.
Comment utiliser le Data Wrangler dans Microsoft Fabric
L'une des choses les plus excitantes à propos de ce notebook est que vous pouvez effectuer des tâches de nettoyage de données sans écrire de code en utilisant le Data Wrangler.
Pour ce faire, cliquez sur Données dans le ruban et sélectionnez Transformer DataFrame dans Data Wrangler.
Nous allons effectuer les transformations suivantes :
- Nous allons convertir la colonne genre en minuscules.
- Nous allons également renommer les colonnes avec des caractères spéciaux comme le signe dollar, les parenthèses et un tiret. Cela est dû au fait que j'ai remarqué que Fabric a du mal à gérer ces caractères pour le moment.
Pour effectuer ces transformations, suivez ces étapes :
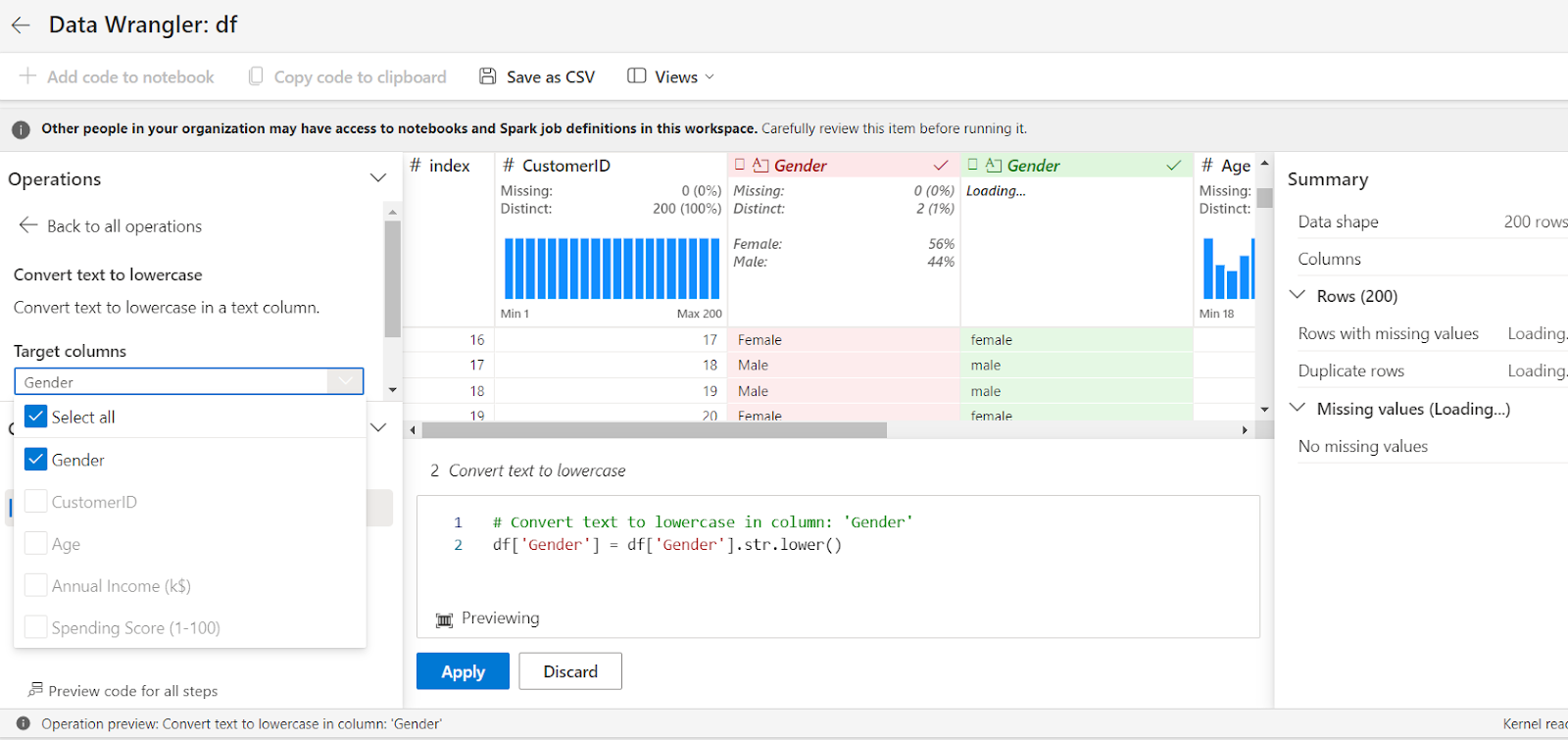
Sous l'onglet Opération, sélectionnez Convertir le texte en minuscules.
Choisissez la colonne – Genre dans cet exemple – et sélectionnez Appliquer. Cela convertira votre colonne Genre en minuscules et générera automatiquement les codes.
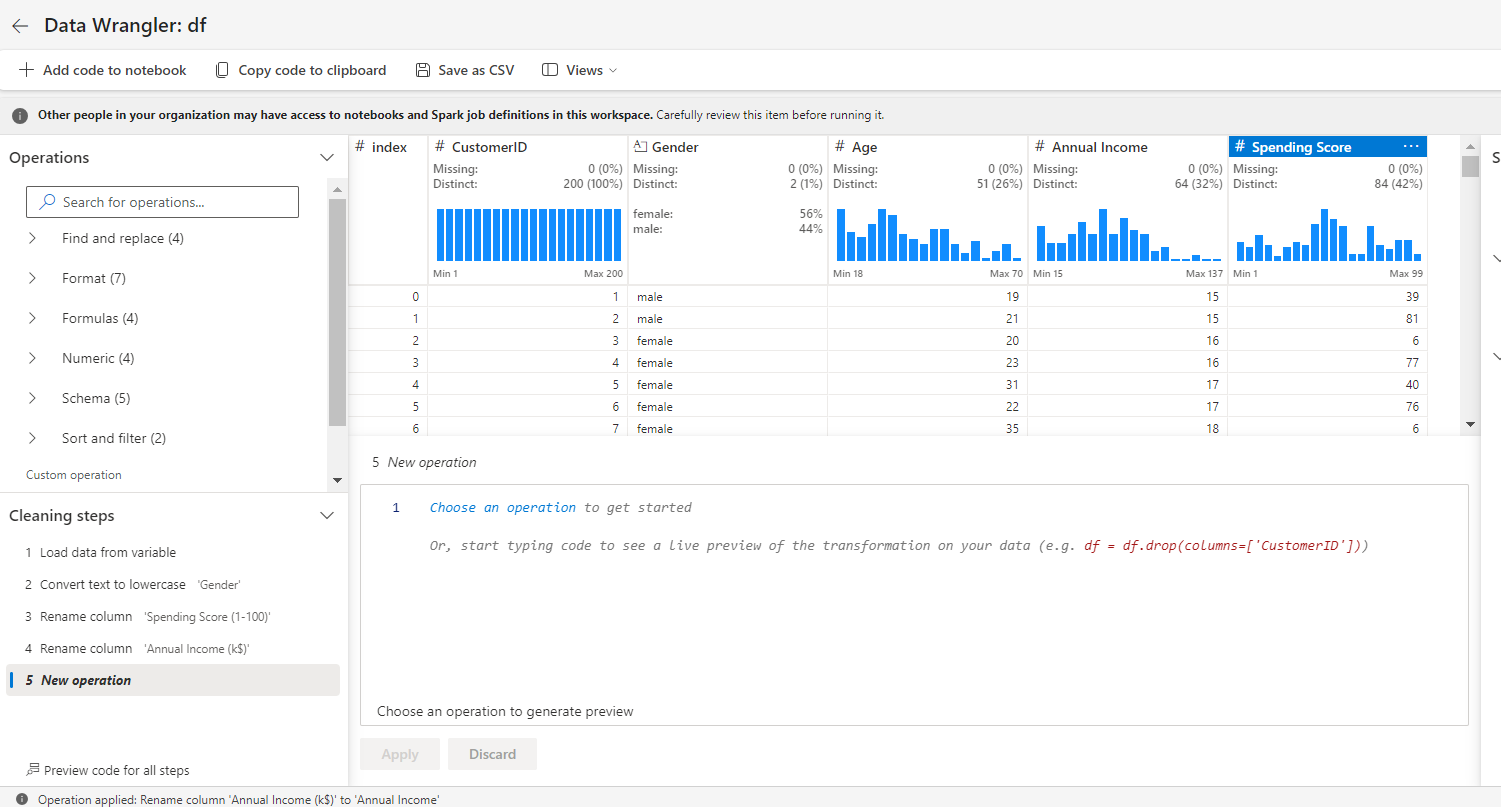
De même, sous l'onglet schéma, sélectionnez renommer les colonnes.
Renommez Annual Income (k$) en AnnualIncome, et Spending Score (1-100) en SpendingScore.
Une fois que vous avez terminé la transformation, cliquez sur Ajouter le code au notebook.
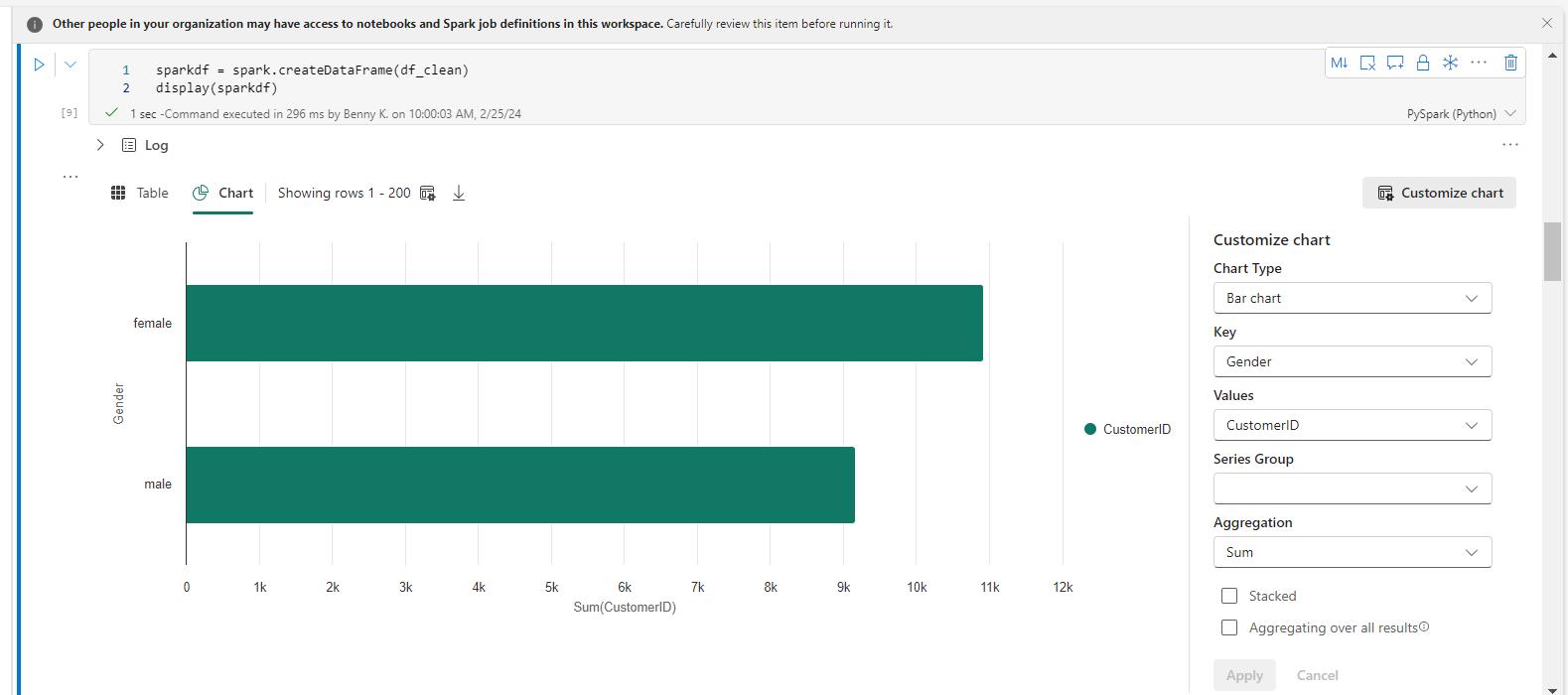
De retour dans le notebook, nous pouvons visualiser nos données en utilisant le code ci-dessous :
sparkdf = spark.createDataFrame(df_clean)
display(sparkdf)
Dans l'élément de graphique créé, sélectionnez Personnaliser le graphique. Choisissez les colonnes que vous voulez et sélectionnez Appliquer.
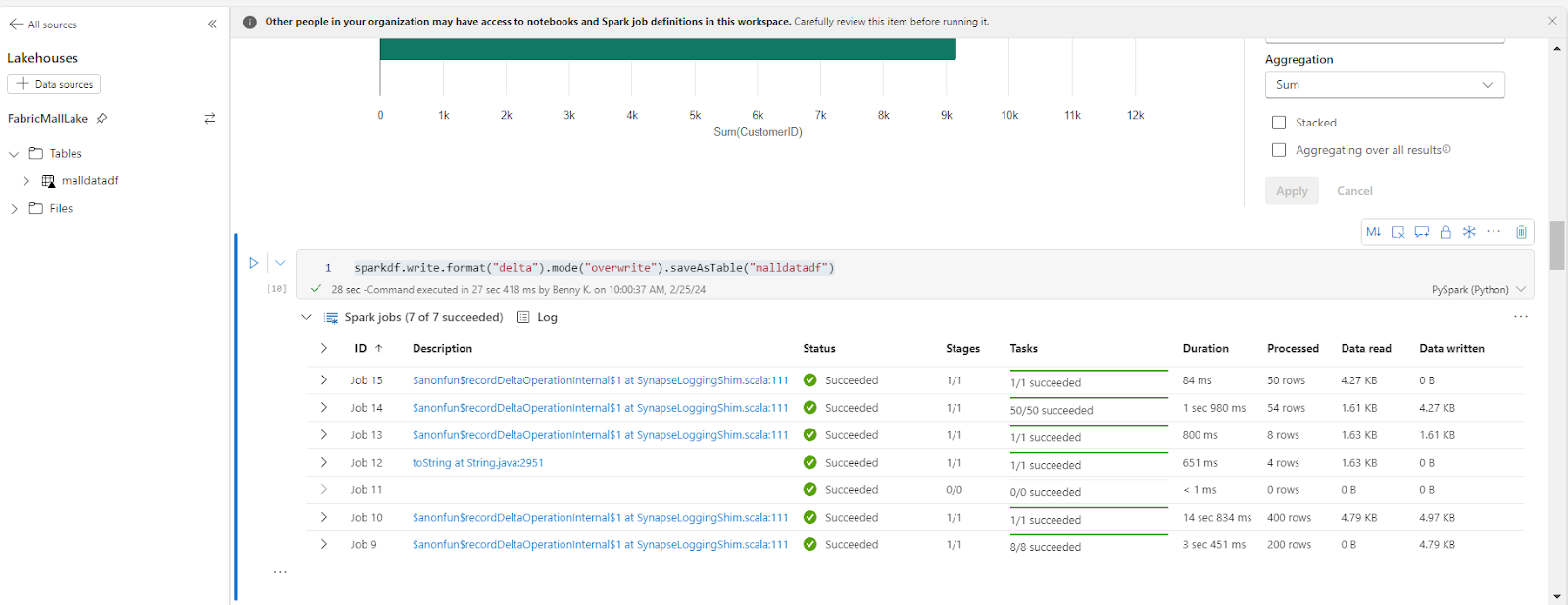
Une fois cela fait, nous pouvons sauvegarder les données dans le Lakehouse en utilisant le code ci-dessous :
sparkdf.write.format("delta").mode("overwrite").saveAsTable("malldatadf")
Comment effectuer une segmentation client dans Microsoft Fabric
Pour notre segmentation client, nous allons utiliser l'algorithme de clustering KMeans pour segmenter les clients en fonction de leur revenu annuel et de leur score de dépenses.
Le clustering K-means est un algorithme d'apprentissage automatique non supervisé. Il regroupe des points de données similaires dans vos données en fonction d'observations sous-jacentes, de similitudes et de vecteurs d'entrée.
Nous allons le faire en important nos bibliothèques, en appliquant notre K-means en entraînant le modèle de clustering K-Means, et en visualisant les clusters de clients en fonction de leur revenu annuel et de leur score de dépenses.
Nous allons également inclure et montrer les centroïdes de chaque cluster, fournissant des insights sur la distribution des clients dans l'ensemble de données.
Les centroïdes ici font référence aux points centraux des clusters trouvés par notre algorithme. Cela est calculé comme la moyenne de tous les points de données dans ce cluster. Lorsque nous visualisons les clusters, le centroïde sera représenté par un symbole ou une couleur distincte.
Exécutez ce code pour y parvenir :
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MinMaxScaler
X = df_clean[['AnnualIncome', 'SpendingScore']]
# Normalisation des caractéristiques
scaler = MinMaxScaler()
X_scaled = scaler.fit_transform(X)
kmeans = KMeans(n_clusters=5, init='k-means++', random_state=42)
kmeans.fit(X_scaled)
plt.figure(figsize=(10, 8))
for cluster_label in range(5): # Boucle à travers chaque étiquette de cluster
cluster_points = X[kmeans.labels_ == cluster_label]
centroid = cluster_points.mean(axis=0) # Calcule le centroïde comme la position moyenne des points de données
plt.scatter(cluster_points['AnnualIncome'], cluster_points['SpendingScore'],
s=50, label=f'Cluster {cluster_label + 1}') # Trace les points pour le cluster actuel
plt.scatter(centroid[0], centroid[1], s=300, c='black', marker='*', label=f'Centroid {cluster_label + 1}') # Trace le centroïde
plt.title('Clusters de Clients')
plt.xlabel('Revenu Annuel (k$)')
plt.ylabel('Score de Dépenses (1-100)')
plt.legend()
plt.show()
Voici le résultat :
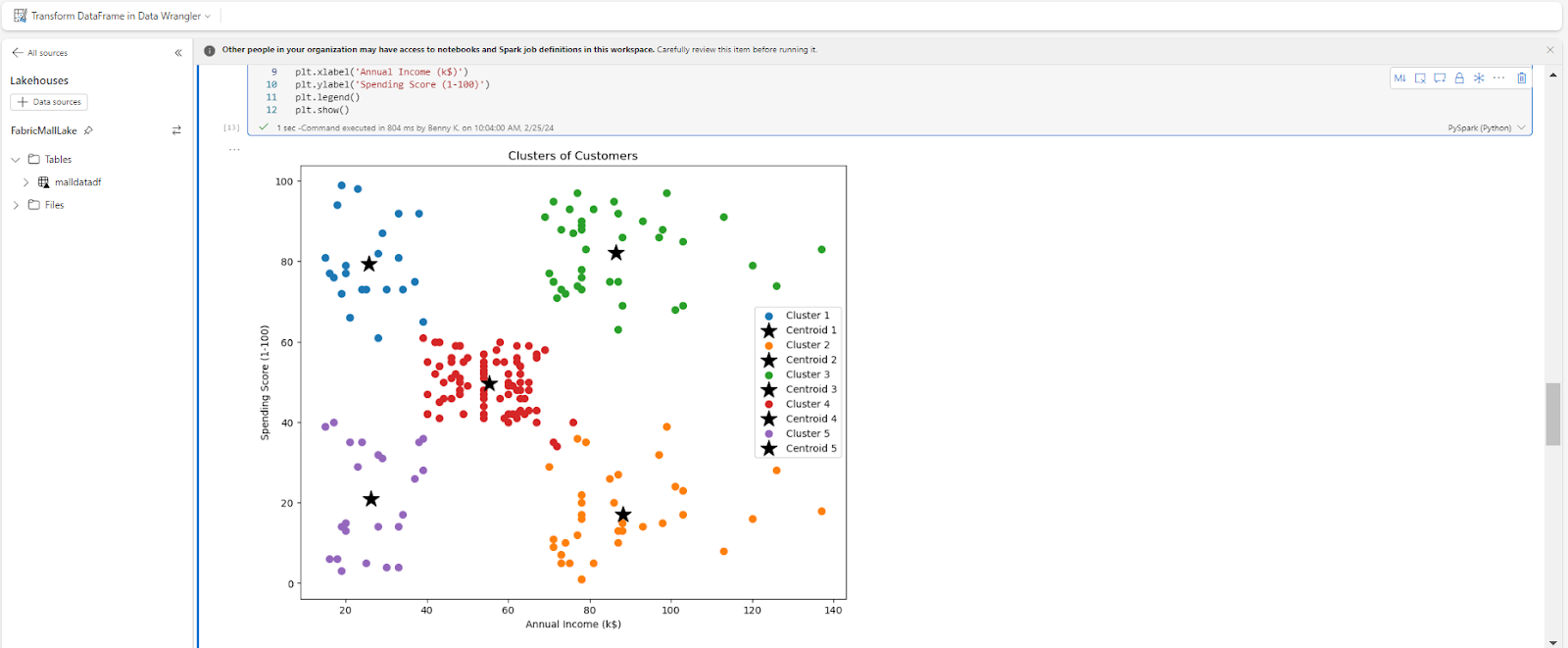
Le résultat de notre analyse montre que nos clients peuvent être regroupés en 5 clusters :
- Cluster 1 (Violet) sont des faibles revenus avec un faible score de dépenses.
- Cluster 2 (Bleu) sont des faibles revenus avec un score de dépenses élevé.
- Cluster 3 (Rouge) sont des clients à revenus moyens avec des scores de dépenses significatifs.
- Cluster 4 (Orange) sont des clients à revenus élevés qui ne dépensent pas beaucoup dans le centre commercial. Ils ne sont probablement pas satisfaits des services rendus.
- Cluster 5 (Vert) sont des clients à revenus élevés avec un score de dépenses élevé.
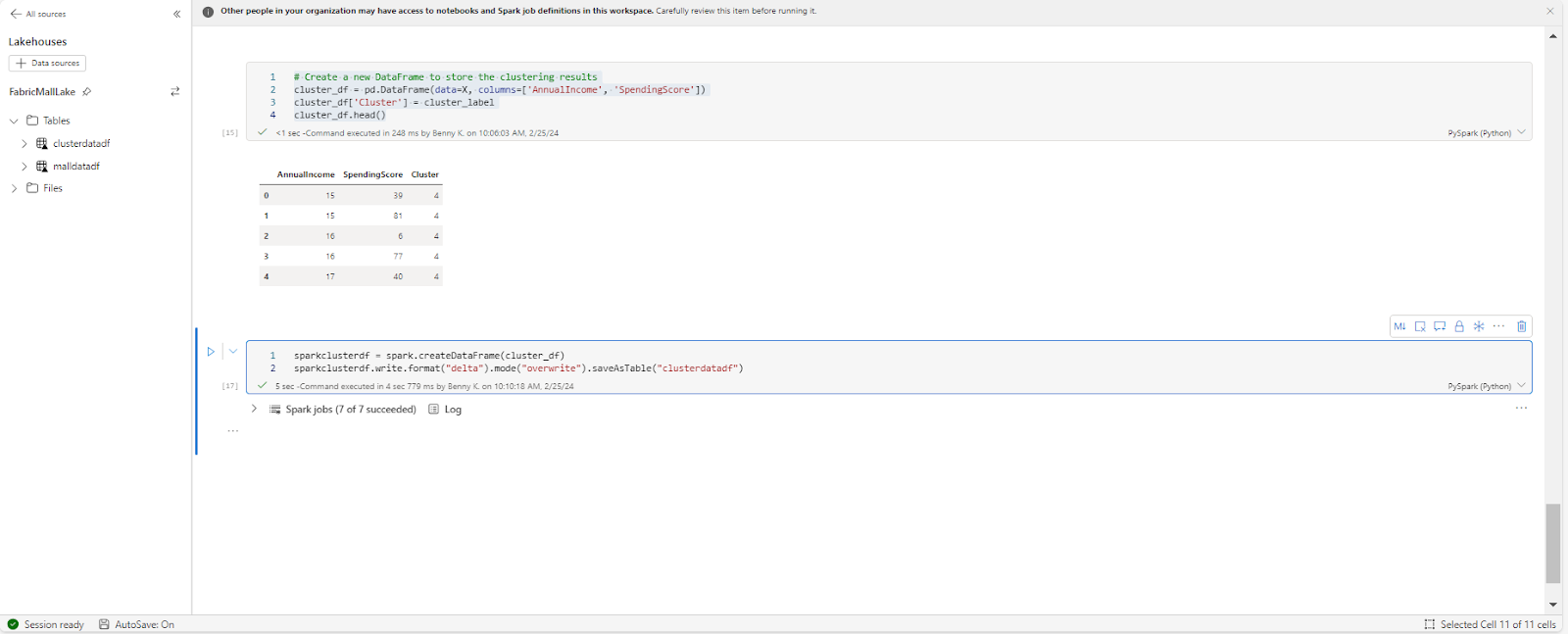
Nous pouvons également sauvegarder notre prédiction en tant que nouvel ensemble de données en utilisant ce code :
# Crée un nouveau DataFrame pour stocker les résultats de clustering
cluster_df = pd.DataFrame(data=X, columns=['AnnualIncome', 'SpendingScore'])
cluster_df['Cluster'] = cluster_label
sparkclusterdf = spark.createDataFrame(cluster_df)
sparkclusterdf.write.format("delta").mode("overwrite").saveAsTable("clusterdatadf")
Vous voulez jeter un coup d'œil au notebook ? Vous pouvez le télécharger depuis mon GitHub.
Comment visualiser les données de Lakehouse dans Power BI
Maintenant, nous pouvons décider de visualiser nos données sur un tableau de bord dans Fabric.
Retournez à l'espace de travail FabricMall et sélectionnez le type de modèle sémantique du Lakehouse FabricMallLake.
Ensuite, sélectionnez Gérer le modèle sémantique par défaut.
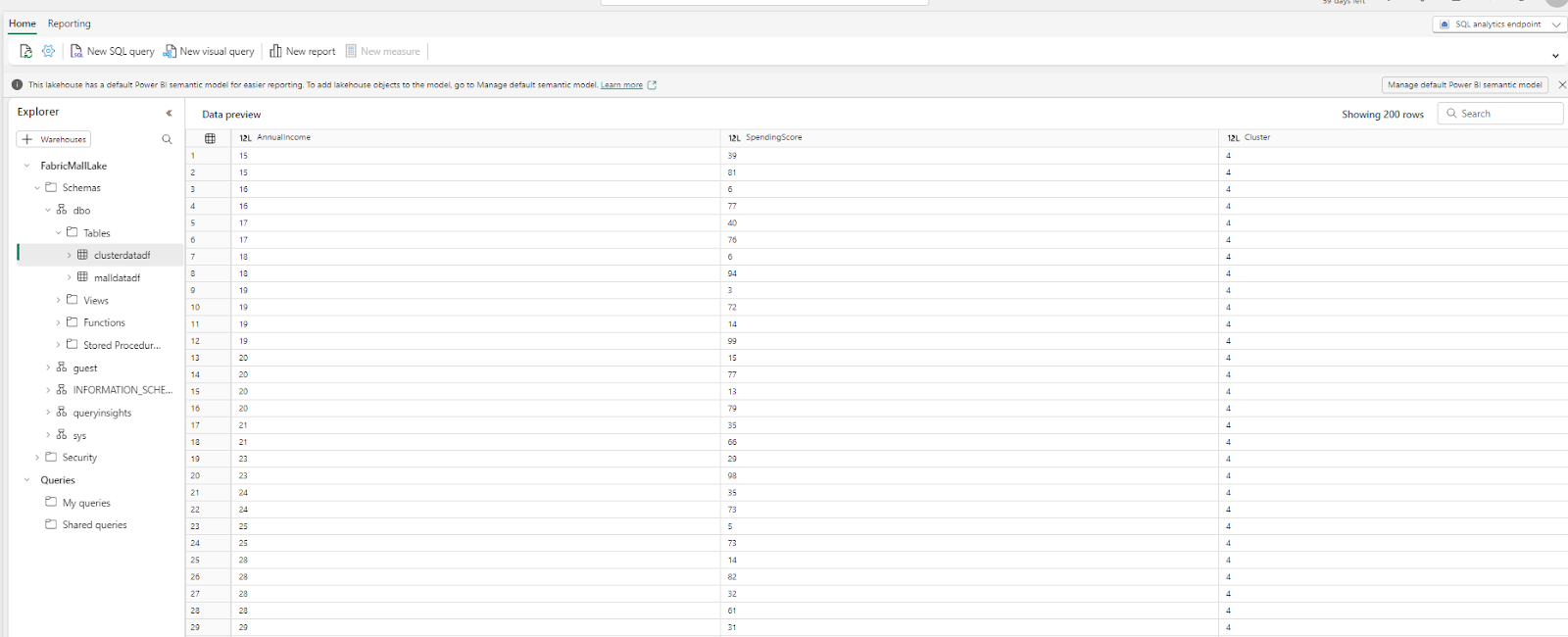
Choisissez votre ensemble de données, cliquez sur Confirmer, puis sélectionnez Nouveau Rapport.
Visualisons l'âge moyen dans nos données. Pour ce faire, cliquez sur la visualisation de carte et faites glisser l'âge dans cette carte. Cela créera automatiquement une visualisation montrant l'âge moyen dans votre ensemble de données.
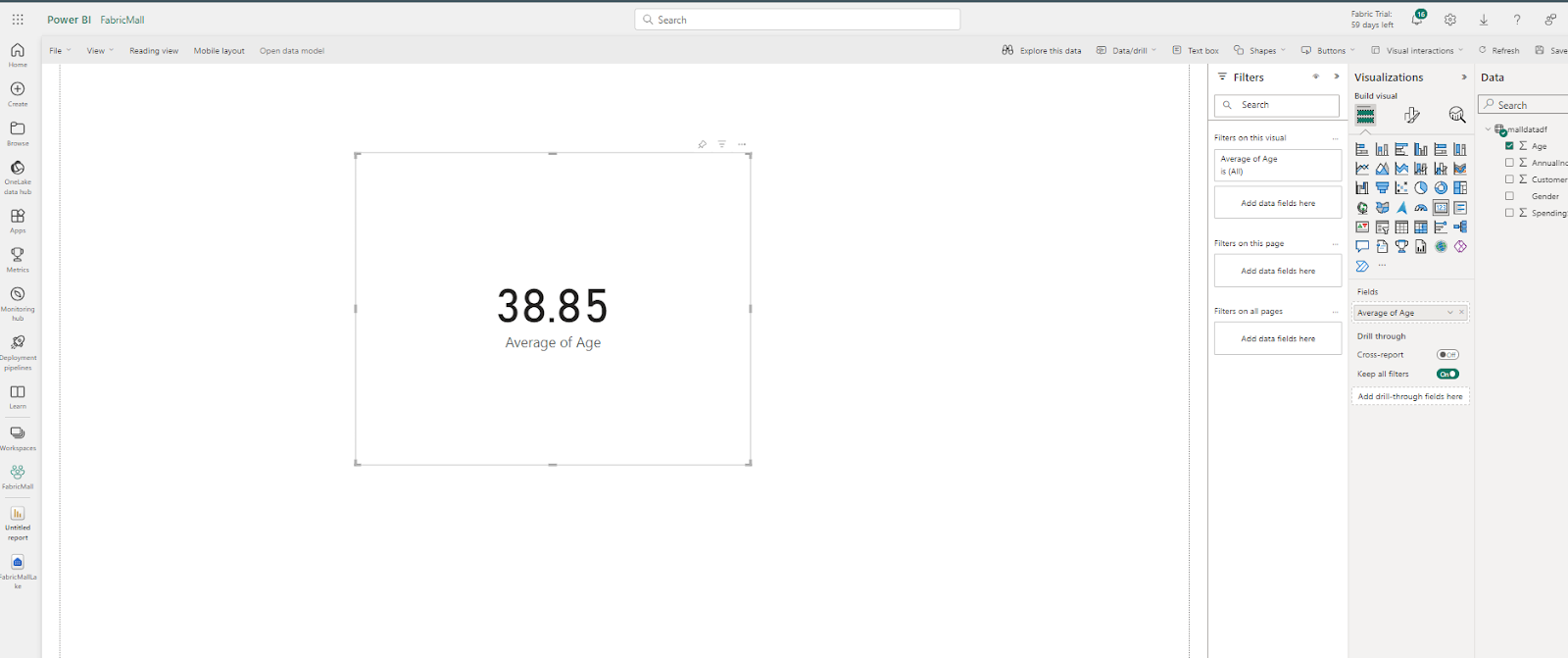
Tout comme dans Power BI Desktop, vous pouvez créer votre mesure, construire votre rapport et publier votre tableau de bord. Vous pouvez en apprendre davantage sur la création de visuels dans Power BI en utilisant cette vidéo gratuite freeCodeCamp YouTube data analysis video.
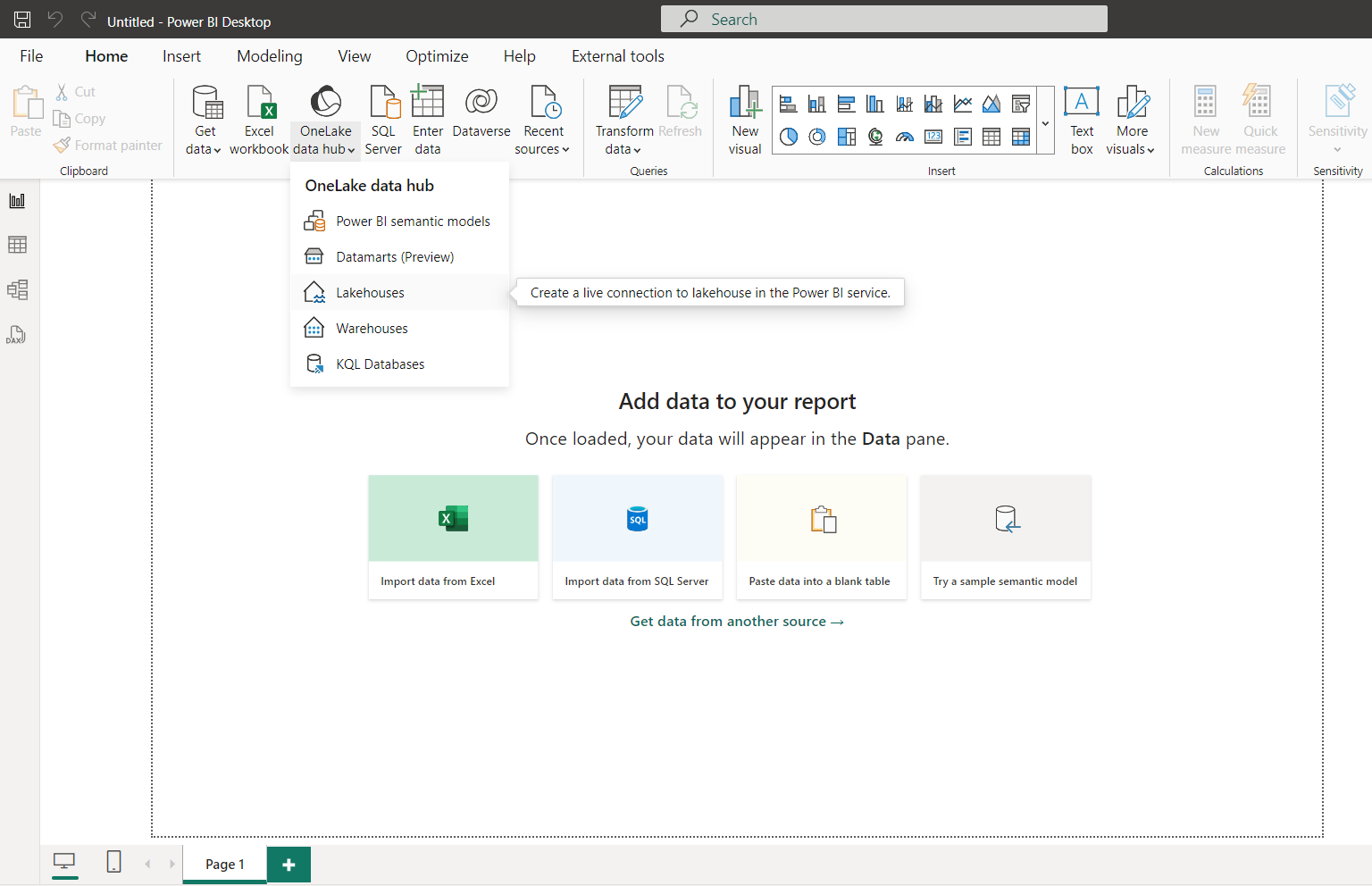
Alternativement, vous pouvez ouvrir Power BI Desktop et vous connecter à vos Lakehouses à partir du hub de données Onelake.
Où puis-je en apprendre davantage sur Microsoft Fabric ?
Bien que Microsoft Fabric soit une plateforme de données relativement nouvelle, j'espère que vous pouvez constater que cet outil vous aidera à simplifier la manière dont vous et votre équipe consommez, analysez et obtenez des insights à partir de vos données.
Pour en savoir plus, vous pouvez commencer par la documentation officielle de Fabric ou tout tutoriel YouTube utile comme le cours Fabric de Francis. Je vous conseille également de commencer par les tags de publication Fabric de freeCodeCamp si vous voulez une compilation de ressources.
Enfin, si vous êtes nouveau dans l'analyse de données, commencez votre voyage dès aujourd'hui avec le Bootcamp pour débutants en analyse de données de freeCodeCamp sur YouTube. Il couvre tout, de SQL, Tableau, Power BI et Python à Excel, Pandas et la construction de projets réels.
Si vous avez aimé lire cet article et/ou si vous avez des questions et souhaitez vous connecter, vous pouvez me trouver sur LinkedIn, Twitter et n'oubliez pas de consulter mes articles sur freeCodeCamp.