

Article original : What is Cached Data? What does Clear Cache Mean and What Does it Do?
Par Jeff M Lowery
D'abord, qu'est-ce qu'un cache ?
En termes généraux, un cache (prononcé "cash") est un type de dépôt. Vous pouvez penser à un dépôt comme un entrepôt de stockage. Dans le militaire, cela servirait à stocker des armes, de la nourriture et d'autres fournitures nécessaires pour mener à bien une mission.
 Un réseau de distribution militaire
Un réseau de distribution militaire
En informatique, ces "fournitures" sont appelées ressources, où les ressources sont des scripts, du code et du contenu de documents. Ces derniers sont parfois plus spécifiquement appelés "assets" tels que du texte, des données statiques, des médias et des hyperliens, mais ici je vais simplement utiliser le terme ressources.
La distinction entre un cache et d'autres types de dépôts
Le but principal d'un cache est d'accélérer la récupération des ressources des pages web, réduisant ainsi les temps de chargement des pages. Un autre aspect critique d'un cache est de s'assurer qu'il contient des données relativement fraîches.
Cet article couvrira deux méthodes prévalentes de mise en cache : la mise en cache du navigateur et les Content Delivery Networks (CDN).
Outre les caches, d'autres dépôts entrent en jeu dans les architectures web ; souvent, ceux-ci sont conçus pour contenir d'énormes quantités de données. Ils ne sont pas aussi axés, cependant, sur les performances de récupération.
Par exemple, Amazon Glacier est un dépôt de données conçu pour stocker des données à moindre coût, mais pas pour les récupérer rapidement. Une base de données SQL, en revanche, est conçue pour être flexible, à jour et rapide, mais elle est rarement bon marché et généralement pas aussi rapide qu'un cache.
Le Cache du Navigateur : un cache mémoire
Un cache mémoire stocke les ressources localement sur l'ordinateur où le navigateur est en cours d'exécution. Tant que le navigateur est actif, les ressources récupérées seront stockées dans la mémoire physique (RAM) de l'ordinateur, et éventuellement également sur le disque dur.
Plus tard, lorsque les exactes mêmes ressources sont nécessaires lors de la revisite d'une page web, le navigateur les récupérera à partir du cache au lieu du serveur distant. Comme le cache est stocké localement, dans une mémoire rapide, ces ressources sont récupérées plus rapidement, et la page se charge plus vite.
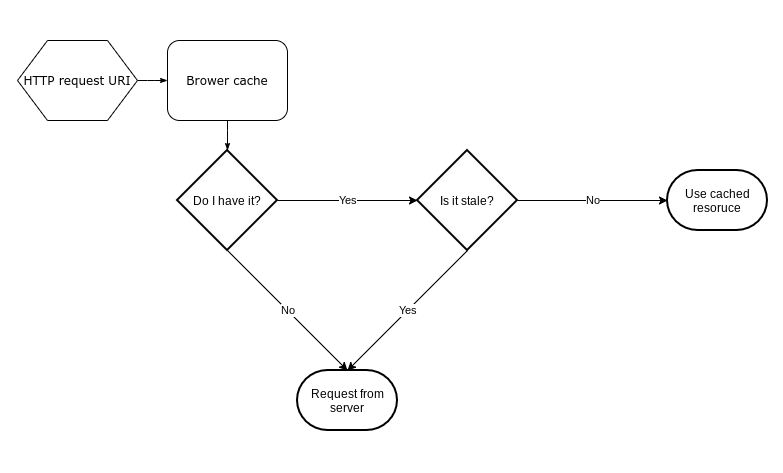
La vitesse de récupération des ressources est essentielle, mais il en va de même pour la nécessité que les ressources soient fraîches. Une ressource obsolète est une ressource qui est périmée et peut ne plus être valide.
Une partie du travail du navigateur consiste à identifier quelles ressources en cache sont obsolètes et à récupérer à nouveau celles qui le sont. Comme une page web a généralement de nombreuses ressources, il y aura généralement un mélange de versions obsolètes et fraîches dans le cache.
Comment le navigateur sait-il ce qui est obsolète dans le cache ?
La réponse n'est pas simple, mais il existe deux approches principales : le cache-busting et les champs d'en-tête HTTP.
Cache-busting
 _Photo par [Unsplash](https://unsplash.com/@sarah_elizabeth?utm_source=ghost&utm_medium=referral&utm_campaign=api-credit">Sarah Shaffer / <a href="https://unsplash.com/?utm_source=ghost&utm_medium=referral&utmcampaign=api-credit)
_Photo par [Unsplash](https://unsplash.com/@sarah_elizabeth?utm_source=ghost&utm_medium=referral&utm_campaign=api-credit">Sarah Shaffer / <a href="https://unsplash.com/?utm_source=ghost&utm_medium=referral&utmcampaign=api-credit)
Le cache-busting est une technique côté serveur qui garantit que le navigateur ne récupère que des ressources fraîches. Il le fait indirectement.
Bien que le cache-busting puisse sembler dramatique, il ne casse rien et ne touche même pas ce qui est déjà en cache sur un navigateur. Tout ce que fait le cache-busting est de changer l'URI de la ressource originale de manière à ce qu'elle semble au navigateur que la ressource est complètement nouvelle. Comme elle semble nouvelle, elle ne sera pas dans le cache du navigateur. L'ancienne version de la ressource en cache sera toujours en cache, mais finira par se faner et mourir, sans jamais être accessible à nouveau.
Supposons que j'ai une page web située à www.foobar.com/about.html qui dit tout ce que vous voulez savoir sur foobar.com. Une fois que vous visitez cette page, elle et les ressources qui lui sont associées sont mises en cache par le navigateur.
Plus tard, foobar.com est racheté par la société Quxbaz, et le contenu de la page "à propos" subit des changements significatifs. Le cache du navigateur n'aura pas ce nouveau contenu, mais il peut encore croire que le contenu qu'il a est actuel et ne tentera jamais de le récupérer à nouveau.
Que faites-vous, en tant qu'administrateur web de Quxbaz, pour vous assurer que tout le nouveau contenu est poussé ?
Comme le navigateur s'appuie sur l'URI pour trouver les éléments dans le cache, si l'URI d'une ressource change, c'est comme si le navigateur ne l'avait jamais vue auparavant lorsqu'il va chercher cette ressource sur le serveur.
Ainsi, en changeant l'URI de la ressource de www.foobar.com/about.html à www.foobar.com/about2.html (ou à www.quxbaz.com/about.html), le navigateur ne trouvera aucune ressource en cache associée à cet URI, et effectuera une récupération complète depuis le serveur. La ressource peut être substantiellement la même que l'originale sous l'ancien URI, mais le navigateur ne le sait pas.
Vous n'avez pas à changer le nom de la page, cependant. Comme l'URI inclut également une chaîne de requête par définition, vous pouvez ajouter un paramètre de version à l'URI : www.foobar.com/about.html?v=2hef9eb1.
Dans ce cas, le paramètre de version v est défini avec une nouvelle valeur de hachage générée chaque fois que le contenu change, ou est déclenché par un autre processus, tel qu'un redémarrage du serveur. Le navigateur voit que la chaîne de requête a changé, et parce que les chaînes de requête peuvent affecter ce qui sera retourné, il récupérera une ressource à jour depuis le serveur.
Aucune de ces techniques ne fonctionnera si l'ancien URI est directement accessible depuis un marque-page. À moins que le navigateur n'ait été instruit de révalider l'URI sur la dernière requête en cache (ou que la ressource en cache ait expiré), il n'effectuera pas une récupération complète pour rafraîchir son cache. Cela nous amène au sujet suivant.
Champs d'en-tête HTTP
Chaque requête de ressource vient avec des méta-informations connues sous le nom d'en-tête. Inversement, chaque réponse a également des informations d'en-tête qui lui sont associées.
Dans certains cas, le navigateur voit les valeurs d'en-tête de la réponse et modifie les valeurs correspondantes dans les en-têtes de requête suivants. Parmi ces valeurs d'en-tête, il y a celles qui affectent la manière dont la mise en cache des ressources est effectuée sur le navigateur.
Requêtes HEAD et requêtes conditionnelles
Une requête HEAD est comme une requête GET ou POST tronquée. Au lieu de demander la ressource complète, une requête HEAD ne demande que les champs d'en-tête qui seraient autrement retournés sur une requête complète.
L'en-tête d'une ressource est généralement beaucoup plus petit (en nombre total d'octets) que les données de la ressource qui lui sont associées (le "corps" de la réponse). Les informations d'en-tête sont suffisamment informatives pour permettre au navigateur de déterminer la fraîcheur de la ressource dans son cache.
Les requêtes HEAD sont souvent utilisées pour vérifier la validité d'une ressource serveur (c'est-à-dire, la ressource existe-t-elle toujours, et si oui, a-t-elle été mise à jour depuis que le navigateur y a accédé pour la dernière fois ?). Le navigateur utilisera ce qu'il a dans son cache si la requête HEAD indique que la ressource est valide, sinon il effectuera une requête GET ou POST complète et rafraîchira son cache avec ce qui est retourné.
Avec une requête conditionnelle, le navigateur envoie des champs dans l'en-tête décrivant la fraîcheur de sa ressource en cache. Cette fois, le serveur détermine si le cache du navigateur est toujours frais.
Si c'est le cas, le serveur retourne une réponse 304 avec uniquement les informations d'en-tête de la ressource, et aucun corps de ressource (les données). Si le cache du navigateur est déterminé comme étant obsolète, alors le serveur retournera une réponse complète 200 OK.
Ce mécanisme est plus rapide que l'utilisation des requêtes HEAD, car il élimine la possibilité d'avoir à émettre deux requêtes au lieu d'une.
Ce qui précède simplifie ce qui peut être un processus assez compliqué. Il y a beaucoup de réglages fins impliqués dans la mise en cache, mais tout est contrôlé par les champs d'en-tête, dont le plus important est cache-control.
Cache-Control
Lorsqu'il répond à une requête, le serveur envoie des champs d'en-tête au navigateur indiquant le comportement qu'il doit adopter lors de la mise en cache. Si je charge la page à https://en.wikipedia.org/wiki/Uniform_Resource_Identifier, la réponse contient ceci dans son enregistrement d'en-tête :
cache-control: private, s-maxage=0, max-age=0, must-revalidate
private signifie que seul le navigateur doit mettre en cache le contenu du document.
s-maxage et max-age sont définis à 0. La valeur s-maxage est pour les serveurs proxy avec des caches, tandis que max-age est destiné au navigateur. L'effet de la définition de max-age seul est que la ressource en cache expire immédiatement, mais elle peut encore être utilisée (même si elle est obsolète) lors des rechargements de page dans la même session de navigateur.
Une ressource obsolète peut être révalidée par une requête HEAD, qui peut être suivie d'une requête GET ou POST, selon la réponse. La directive must-revalidate ordonne au navigateur de révalider la ressource en cache si elle est obsolète.
Puisque max-age est défini à 0 dans ce cas, la ressource en cache est immédiatement obsolète une fois reçue. La combinaison des deux directives est équivalente à la directive unique no-cache.
Les deux paramètres garantissent que le navigateur révalide toujours la ressource en cache, qu'il soit encore dans la même session ou non.
Les directives de contrôle de cache sont très étendues et parfois déroutantes - elles constituent un sujet à part entière. Une liste complète documentée des directives peut être trouvée ici.
E-tag
Il s'agit d'un jeton que le serveur envoie et que le navigateur conserve jusqu'à la prochaine requête. Cela n'est utilisé que lorsque le navigateur sait que la durée de vie du cache de la ressource a expiré.
Les E-tags sont des valeurs de hachage générées par le serveur, qui utilisent souvent le nom de fichier physique de la ressource et la date de dernière modification sur le serveur comme graine. Lorsqu'un fichier de ressource est mis à jour, la date de modification change, et une nouvelle valeur de hachage est générée et envoyée dans l'en-tête de réponse à la requête.
Autres balises d'en-tête affectant la mise en cache
Les balises d'en-tête expires et last-modified sont presque obsolètes, mais sont encore envoyées par la plupart des serveurs pour la compatibilité avec les anciens navigateurs. Un exemple :
expires: Thu, 01 Jan 1970 00:00:00 GMT
last-modified: Sun, 01 Mar 2020 17:59:02 GMT
Ici, la date d'expiration est définie à la date zéro (historiquement, du système d'exploitation UNIX). Cela indique que la ressource expire immédiatement, tout comme max-age=0. Last-modified indique au navigateur quand la dernière mise à jour a été faite sur la ressource, ce qu'il peut ensuite utiliser pour décider s'il doit la récupérer à nouveau plutôt que d'utiliser la valeur en cache.
Forcer un rafraîchissement du cache depuis le navigateur
Qu'est-ce qu'un rechargement forcé ?
Un rechargement forcé force la récupération de toutes les ressources d'une page, qu'il s'agisse de contenu, de scripts, de feuilles de style ou de médias. Pratiquement tout, n'est-ce pas ?
Eh bien, certaines ressources peuvent ne pas être explicitement incluses sur une page. Au lieu de cela, elles peuvent être récupérées dynamiquement, généralement après que tout ce qui est explicite a été chargé.
Le navigateur ne sait pas à l'avance que cela va se produire, et lorsque cela arrive, les requêtes ultérieures (initiées par des scripts, généralement) utiliseront toujours des copies en cache de ces ressources si elles sont disponibles.
Qu'est-ce que "effacer le cache et rechargement forcé" ?
Cette opération efface l'ensemble du cache du navigateur, ce qui a le même effet qu'un rechargement forcé, mais provoque également la récupération des ressources chargées dynamiquement - après tout, il n'y a rien dans le cache, donc il n'y a pas de choix !
Réseaux de diffusion de contenu : un cache géolocalisé
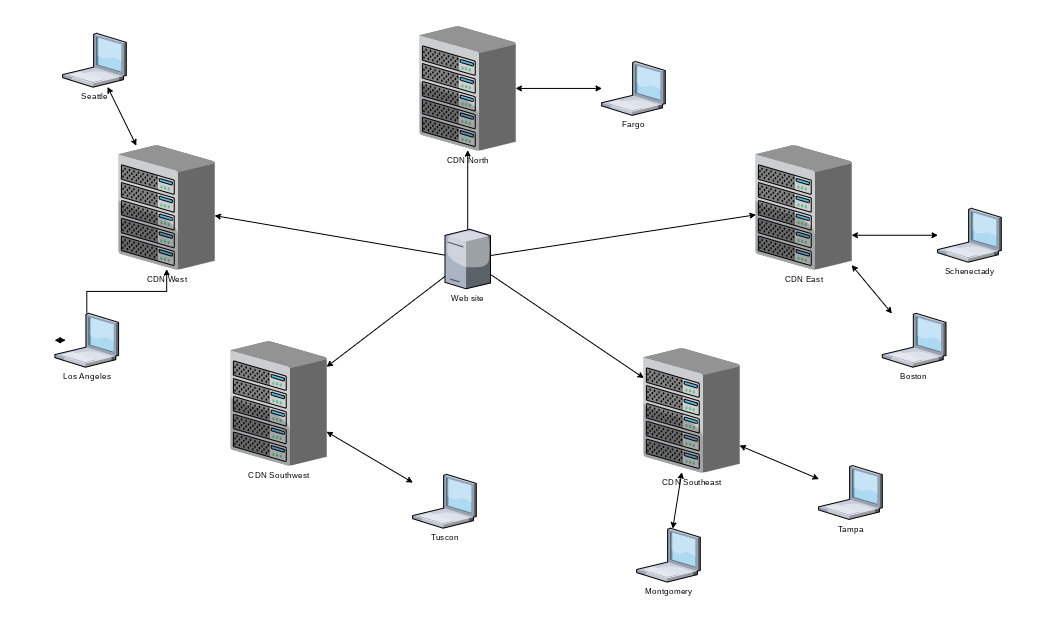
Un CDN est plus qu'un simple cache, mais la mise en cache est l'une de ses fonctions. Un CDN stocke des données dans des emplacements géographiquement distribués afin que les temps de trajet aller-retour vers et depuis un navigateur local géographiquement proche soient réduits.
Les requêtes du navigateur sont acheminées vers un CDN à proximité, réduisant ainsi la distance physique que les données de réponse doivent parcourir. Les CDN sont également capables de gérer de grandes quantités de trafic et offrent une sécurité contre certains types d'attaques.
Un CDN obtient ses ressources par le biais d'un Point d'Échange Internet (IXP), des nœuds qui font partie de l'épine dorsale d'Internet (en majuscules). Il y a des étapes à suivre pour configurer l'acheminement des requêtes vers un CDN au lieu du serveur hôte. L'étape suivante consiste à s'assurer que le CDN dispose du contenu actuel de votre site web.
À l'époque, la plupart des CDN prenaient en charge la méthode push : un site web poussait un nouveau contenu vers un hub CDN, qui était ensuite distribué aux nœuds géographiquement dispersés.
De nos jours, la plupart des CDN utilisent les protocoles de mise en cache décrits ci-dessus (ou similaires) pour 1) télécharger de nouvelles ressources, et 2) rafraîchir les ressources existantes. Le navigateur a toujours son cache, et rien de cela ne change. Tout ce qu'un CDN fait, c'est rendre ces transferts de nouvelles ressources plus rapides.