


Article original : What is The C Programming Language? A Tutorial for Beginners
Ce tutoriel vous donnera un aperçu général des concepts de base du langage de programmation C.
Nous aborderons l'histoire du langage, pourquoi et où il est utilisé, le processus de compilation, et quelques concepts de programmation très basiques qui sont communs dans la plupart des langages de programmation populaires.
Ce n'est pas un guide complet du langage, mais il vous donnera plutôt une compréhension de haut niveau des concepts et idées importants de C en tant que débutant absolu en codage.
Chaque langage a sa propre syntaxe et des façons spécifiques de faire les choses, mais les concepts couverts ici sont communs et appliqués à tous les langages de programmation.
Avoir une compréhension de la manière dont les choses fonctionnent et de ces concepts universels peut vous mener loin dans votre parcours de codage. Cela facilite l'apprentissage d'une nouvelle technologie à long terme.
Ce tutoriel s'inspire fortement du matériel couvert dans les premières semaines du cours CS50 : Introduction à l'informatique que je recommande vivement à toute personne souhaitant approfondir l'informatique et la programmation, quel que soit son niveau d'expérience.
Table des matières
- L'histoire derrière les origines de C - Un aperçu
- Caractéristiques du langage et pourquoi envisager d'apprendre C
- Où est utilisé C ?
- Processus de compilation : Écrire-Compiler-Exécuter
- Hello world
- Variables et affectation
- Opérateurs
- Lectures supplémentaires
L'histoire du langage de programmation C
L'histoire du langage de programmation C est étroitement liée à l'histoire du développement du système d'exploitation Unix.
Si nous regardons en arrière pour comprendre ce qui a conduit au développement du système d'exploitation qui a changé le monde de l'informatique, nous verrons les étapes qui ont conduit au développement de C.
En termes simples, C a été dérivé du besoin de trouver et finalement créer un langage à appliquer sur le système d'exploitation Unix.
Projet MAC et MULTICS
Tout a commencé en 1965 lorsque le projet expérimental MAC a été achevé au MIT - le premier système de ce type. C'était le début de l'ère MULTICS. Il utilisait quelque chose appelé CTSS, ou Compatible Time Sharing System.
C'était une innovation clé à cette époque. Jusqu'à ce point, nous étions à l'ère des premiers mainframes, où des ordinateurs massifs, puissants et extrêmement coûteux occupaient des pièces entières.
Pour accomplir des tâches, les programmeurs écrivaient du code à la main. Ensuite, ils perforaient un jeu de cartes de ruban papier qui étaient codées avec le programme écrit à la main.
Ils faisaient cela en remettant les feuilles de papier sur lesquelles le programme était écrit aux opérateurs qui utilisaient une machine de perforation de clés qui perforait les trous de la carte et représentait les données et les instructions sur la carte.
Ensuite, ils alimentaient les cartes perforées à un lecteur de cartes perforées connecté à l'ordinateur central. Il convertissait alors les séquences des trous des cartes en informations numériques. Des tâches simples prenaient beaucoup de temps avec cette méthode et une seule personne pouvait utiliser chaque machine à la fois.
L'idée du partage de temps a tout changé. Au lieu d'utiliser des cartes, il attachait plusieurs consoles (qui à l'époque étaient des terminaux mécaniques appelés télétypes) à un ordinateur central. Cela permettait à de nombreuses personnes d'utiliser le même ordinateur simultanément.
Plus de 100 terminaux de machine à écrire répartis sur le campus du MIT pouvaient être attachés à un grand ordinateur central. Ce système supportait jusqu'à 30 utilisateurs distants en même temps, chacun utilisant l'un de ces terminaux.
Le système d'exploitation de l'ordinateur central multitâche et tournait autour des personnes qui voulaient effectuer des tâches informatiques à partir de leurs terminaux connectés et donnait quelques secondes à chacun.
Il fournissait ce qui semblait être un service continu, semblant charger et exécuter de nombreux programmes simultanément. Mais en réalité, il passait simplement par le programme de chaque utilisateur très rapidement. Cela donnait l'illusion qu'une personne avait tout l'ordinateur pour elle-même.
Ce système s'est avéré extrêmement efficace, productif et économique, économisant du temps et, à long terme, de l'argent, puisque ces ordinateurs étaient extrêmement coûteux.
Quelque chose qui aurait pu prendre des jours à compléter prenait maintenant beaucoup moins de temps. Et cela a commencé à permettre un plus grand accès à l'informatique.
Suite au succès du CTSS, le MIT a décidé qu'il était temps de construire sur ce système et de passer à l'étape suivante. Cette prochaine étape serait de créer un système de partage de temps plus avancé.
Mais ils imaginaient une entreprise plus ambitieuse que cela : ils voulaient construire un système qui servirait d'utilitaire informatique pour les programmeurs capable de supporter des centaines d'utilisateurs accédant au mainframe en même temps. Et il partagerait des données et des ressources entre eux.
Cela nécessiterait plus de ressources, alors ils se sont associés à General Electric et Bell Labs.
Ce nouveau projet a été nommé MULTICS, qui signifiait 'Multiplexed Information and Computing Service' et a été implémenté sur l'un des mainframes de General Electric, le GE 635.
Cette équipe a travaillé sur MULTICS pendant plusieurs années. Mais en 1969, Bell Labs a quitté le projet car il prenait trop de temps et était trop coûteux.
Bell Labs : Le Hub d'Innovation
Le retrait de Bell Labs du projet MULTICS a laissé certains employés frustrés et à la recherche d'alternatives.
Alors qu'ils travaillaient sur MULTICS, l'équipe a créé un environnement informatique sans précédent. Ils étaient habitués à travailler avec des systèmes de partage de temps et avaient vu leur efficacité. Ces programmeurs avaient une vaste connaissance des systèmes d'exploitation, et les innovations de ce projet leur donnaient envie de s'étendre davantage.
Un groupe dirigé principalement par Ken Thompson et Dennis Ritchie voulait utiliser l'informatique communautaire et créer un système de fichiers qu'ils pourraient partager. Il aurait les caractéristiques innovantes qu'ils aimaient de MULTICS mais ils l'implémenteraient de manière simple, plus petite et moins coûteuse.
Ils ont partagé leurs idées et ont commencé à itérer.
 _Ken Thompson et Dennis Ritchie, Source de l'image de Wikipedia_
_Ken Thompson et Dennis Ritchie, Source de l'image de Wikipedia_
Bell Labs a favorisé un environnement ouvert et favorable qui a permis l'expression créative et l'épanouissement des idées innovantes. Il était axé sur la recherche, et ils encourageaient la résolution de problèmes par la pensée indépendante pour les aider à améliorer leurs solutions initiales.
Grâce à de nombreuses discussions et expérimentations, ils ont fait les plus grandes percées et écrit l'histoire.
Alors qu'ils travaillaient encore sur MULTICS, Ken Thompson avait créé un jeu appelé Space Travel. Il l'avait initialement écrit sur MULTICS, sur le GE 635, mais lorsque Bell Labs s'est retiré, il a adapté le jeu à un programme Fortran pour le faire fonctionner sur le système d'exploitation GECOS qui fonctionnait sur le GE 635.
Il y avait de nombreux problèmes avec le jeu - il ne fonctionnait pas aussi bien sur GECOS que sur MULTICS et il avait besoin d'une machine différente et moins coûteuse pour le faire fonctionner.
Ken Thompson a essuyé un refus lorsqu'il a demandé un financement pour créer un système d'exploitation différent, puisque Bell Labs s'était déjà retiré d'un tel projet. Mais il a fini par trouver un vieux et peu utilisé mini-ordinateur DEC PDP-7 qu'il pouvait essayer - c'était le seul système disponible.
 Un DEC PDP-7, Source de l'image de Wikipedia
Un DEC PDP-7, Source de l'image de Wikipedia
Il a commencé à écrire son jeu sur ce système simple mais était limité par le logiciel de l'ordinateur. Alors qu'il travaillait dessus, il a fini par implémenter les bases du système de fichiers que son équipe avait envisagé.
Il a commencé avec un système de fichiers hiérarchique, un interpréteur de ligne de commande, et d'autres programmes utilitaires. En un mois, il avait créé un système d'exploitation avec un assembleur, un éditeur et un shell. C'étaient des fonctionnalités plus petites et plus simples de MULTICS. Ce système d'exploitation était la première version de Unix.
Les débuts de Unix avec le langage d'assemblage
Au début du projet, Ken Thompson ne pouvait pas programmer sur l'ordinateur DEC PDP-7. Les programmes DEC PDP-7 devaient être compilés et traduits sur le mainframe GE 635 plus puissant, puis la sortie était physiquement transférée sur le PDP-7 par bande papier.
Le DEC PDP-7 avait très peu de mémoire, seulement 8 Ko. Pour faire face à cette restriction, le système de fichiers, la première version du noyau Unix, et pratiquement tout le reste du projet étaient codés en Assemblage. L'utilisation de l'Assemblage permettait à Thompson de manipuler et de contrôler directement chaque partie de la mémoire de cet ordinateur.
Le langage d'assemblage est un langage de programmation de bas niveau qui utilise un code symbolique et est proche du langage natif de la machine, le binaire. Les instructions dans le code et chaque instruction dans le langage correspondent étroitement aux instructions machine spécifiques à l'architecture de l'ordinateur.
Il est dépendant de la machine et spécifique à la machine, ce qui signifie qu'un ensemble d'instructions a des résultats très différents d'une machine à l'autre. Les programmes écrits en langage d'assemblage sont écrits pour un type spécifique de processeur - donc un programme écrit en Assemblage ne fonctionnera pas sur une variété de processeurs.
Il était courant d'écrire des systèmes d'exploitation en utilisant le langage d'assemblage à l'époque. Et lorsqu'ils ont commencé à travailler sur Unix, ils n'avaient pas la portabilité à l'esprit.
Ils ne se souciaient pas de savoir si le système d'exploitation fonctionnait sur différents systèmes et architectures de machines. C'était une pensée qui est venue plus tard. Leur principale priorité était l'efficacité du logiciel.
Alors qu'ils travaillaient sur MULTICS, ils utilisaient des langages de programmation de haut niveau, comme PL/I au début et plus tard BCPL. Les programmeurs s'étaient habitués à utiliser des langages de haut niveau pour écrire des logiciels de type système d'exploitation, des utilitaires et des outils en raison des avantages qu'ils offraient (ils étaient relativement faciles à utiliser et à comprendre).
Lors de l'utilisation d'un langage de programmation de plus haut niveau, il y a une abstraction entre l'architecture de l'ordinateur et divers détails obscurs. Cela signifie qu'il est au-dessus du niveau de la machine et qu'il n'y a pas de manipulation directe de la mémoire du matériel.
Les langages de haut niveau sont plus faciles à lire, à apprendre, à comprendre et à maintenir, ce qui en fait un choix plus facile lors du travail en équipe. Les commandes ont une syntaxe de type anglais, et les termes et instructions semblent plus familiers et conviviaux par rapport au format symbolique de l'Assemblage.
L'utilisation de langages de haut niveau signifie également écrire moins de code pour atteindre quelque chose, alors que les programmes en assembleur étaient extrêmement longs.
Thompson voulait utiliser un langage de haut niveau pour Unix dès le début, mais était limité par le DEC PDP-7.
À mesure que le projet progressait et que de plus en plus de personnes commençaient à y travailler, l'utilisation de l'Assemblage n'était pas idéale. Thompson a décidé qu'Unix avait besoin d'un langage de programmation système de haut niveau.
En 1970, ils ont réussi à obtenir un financement pour le DEC PDP-11 plus grand et plus puissant qui avait considérablement plus de mémoire.
Avec un langage de programmation de haut niveau rapide, structuré et plus efficace qui pouvait remplacer l'Assemblage, tout le monde pouvait comprendre le code et des compilateurs pouvaient être mis à disposition pour différentes machines.
Ils ont commencé à explorer différents langages pour écrire des logiciels système qu'ils pourraient utiliser pour implémenter Unix.
De B à C : Le besoin d'un nouveau langage
L'objectif était de créer des utilitaires - des programmes qui ajoutent des fonctionnalités - pour fonctionner sur Unix. Thompson a initialement tenté de créer un compilateur FORTRAN mais s'est ensuite tourné vers un langage qu'il avait utilisé auparavant, BCPL (Basic Combined Programming Language).
BCPL a été conçu et développé à la fin des années 1960 par Martin Richards. Son objectif principal était d'écrire des compilateurs et des logiciels système.
Ce langage était lent et avait de nombreuses restrictions, donc lorsque Thompson a commencé à l'utiliser en 1970 pour le projet Unix sur le DEC PDP-7, il a fait des ajustements et des modifications et a fini par écrire son propre langage, appelé B.
B avait de nombreuses caractéristiques de BCPL mais c'était un langage plus petit, avec une syntaxe moins verbeuse et un style plus simple. Il était encore lent et pas assez puissant pour supporter les utilitaires Unix, cependant, et ne pouvait pas tirer parti des fonctionnalités puissantes du PDP-11.
Dennis Ritchie a décidé d'améliorer ces deux langages précédents, BCPL et B. Il a pris des caractéristiques de chacun et a ajouté des concepts supplémentaires. Il a créé un langage plus puissant - C - aussi puissant et efficace que l'Assemblage. Ce nouveau langage a surmonté les limitations de ses prédécesseurs et pouvait utiliser la puissance de la machine de manière efficace.
Ainsi, en 1972, C est né, et le premier compilateur C a été écrit et implémenté pour la première fois sur la machine DEC PDP-11.
 _La célèbre photo de Thompson et Ritchie travaillant sur un PDP-11, Source de l'image Wikipedia_
_La célèbre photo de Thompson et Ritchie travaillant sur un PDP-11, Source de l'image Wikipedia_
Le langage de programmation C
En 1973, Dennis Ritchie a réécrit le code source d'Unix et la plupart des programmes et applications Unix en utilisant le langage de programmation C. Cela en a fait le langage d'implémentation standard du système d'exploitation.
Il a réimplémenté le noyau Unix en C, et presque tout le système d'exploitation (bien plus de 90 %) est écrit dans ce langage de haut niveau. Il mélange à la fois des fonctionnalités de lisibilité de haut niveau et des fonctionnalités de bas niveau, ce qui en fait le choix parfait pour écrire un système d'exploitation.
Vers la fin des années 1970, la popularité de C a commencé à augmenter et le langage a commencé à obtenir un soutien et une utilisation plus répandus. Jusqu'à ce point, C n'était toujours disponible que pour les systèmes Unix et les compilateurs n'étaient pas disponibles en dehors des laboratoires Bell.
Cette augmentation de popularité est venue non seulement de la puissance que C a donnée à la machine, mais aussi au programmeur. Il a également aidé que le système d'exploitation Unix gagnait la même popularité à un rythme encore plus rapide.
Unix se distinguait de ce qui l'avait précédé en raison de sa portabilité et de sa capacité à fonctionner sur une variété de machines, de systèmes et d'environnements différents.
C a rendu cette portabilité possible et, comme il était le langage du système Unix, il a gagné plus de notoriété - donc de plus en plus de programmeurs voulaient l'essayer.
En 1978, Brian Kernighan et Dennis Ritchie ont co-écrit et publié la première édition du livre 'Le langage de programmation C', également connu dans la communauté de programmation sous le nom de 'K&R'. Pendant de nombreuses années, ce texte a été la référence pour la description, la définition et la référence du langage C.
 [Page de couverture du livre, source de l'image Wikipedia](https://en.wikipedia.org/wiki/C(programminglanguage)#History)
[Page de couverture du livre, source de l'image Wikipedia](https://en.wikipedia.org/wiki/C(programminglanguage)#History)
Dans les années 1980, la popularité de C a explosé alors que différents compilateurs étaient créés et commercialisés. De nombreux groupes et organisations qui n'étaient pas impliqués dans la conception de C ont commencé à créer des compilateurs pour chaque système d'exploitation et chaque architecture d'ordinateur. C était maintenant disponible sur toutes les plateformes.
Alors que ces organisations créaient leurs propres compilateurs, elles ont commencé à changer les caractéristiques du langage pour s'adapter à chaque plateforme pour laquelle le compilateur était écrit.
Il existait diverses versions de C qui présentaient de légères différences entre elles. Lors de l'écriture des compilateurs, ces groupes ont proposé leurs propres interprétations de certains aspects du langage, basées sur la première édition du livre 'Le langage de programmation C'.
Avec toutes les itérations et ajustements, cependant, ce livre ne décrivait plus le langage tel qu'il était, et les changements apportés au langage ont commencé à poser des problèmes.
Le monde avait besoin d'une version commune de C, d'une norme pour le langage.
La norme C
Pour s'assurer qu'il existait une définition standard et indépendante de la machine du langage, l'ANSI (American National Standards Institute) a formé un comité en 1983. Ce comité a été nommé le comité X3J11, et sa mission était de fournir une définition claire et complète ainsi qu'une standardisation de C.
Après quelques années, en 1989, le travail du comité a été achevé et officialisé. Ils ont défini une norme commerciale pour le langage. Cette version du langage est connue sous le nom de 'ANSI C' ou C89.
C était utilisé dans le monde entier, donc un an plus tard, en 1990, la norme a été approuvée et adoptée par l'ISO, l'Organisation internationale de normalisation. La première version, C90, a été appelée ISO/IEC 9899:1990.
Depuis lors, de nombreuses révisions du langage ont eu lieu.
La deuxième version de la norme, C99, a été publiée en 1999 sous le nom de ISO/IEC 9899:1999 et a introduit de nouvelles fonctionnalités supplémentaires au langage. La troisième version, C11, a été publiée en 2011. La version la plus récente est la quatrième, C17, et est appelée ISO/IEC 9899:2018.
La continuation de C
C a tracé une voie pour la création de nombreux langages de programmation différents. De nombreux langages de programmation modernes de haut niveau que nous utilisons et aimons aujourd'hui sont basés sur C.
De nombreux langages créés après C voulaient résoudre des problèmes que C ne pouvait pas, ou surmonter certains des problèmes qui limitent C. Par exemple, l'enfant le plus populaire de C est son extension orientée objet C++ - mais Go, Java et JavaScript ont également été inspirés par C.
Caractéristiques du langage C et pourquoi vous devriez envisager d'apprendre C
C est un langage ancien, mais il reste populaire à ce jour, même après toutes ces années.
Il doit sa popularité à l'essor et au succès d'Unix, mais de nos jours, il est allé bien au-delà du simple fait d'être le langage 'natif' d'Unix. Il alimente désormais la plupart, sinon tous, des serveurs et systèmes du monde.
Les langages de programmation sont des outils que nous utilisons pour résoudre des problèmes informatiques spécifiques qui nous affectent à grande échelle.
Vous n'avez pas besoin de connaître C pour créer des pages web et des applications web. Mais cela s'avère utile lorsque vous souhaitez écrire un système d'exploitation, un programme qui contrôle d'autres programmes, ou un utilitaire de programmation pour le développement de noyau, ou lorsque vous souhaitez programmer des dispositifs embarqués ou toute application système. C excelle dans toutes ces tâches. Alors, examinons quelques raisons d'apprendre C.
Cela vous aide à comprendre comment fonctionne votre ordinateur
Malgré le fait que C soit un langage de programmation généraliste, il est principalement utilisé pour interagir avec les fonctions de bas niveau de la machine. En plus des raisons pratiques derrière l'apprentissage du langage, connaître C peut vous aider à comprendre comment l'ordinateur fonctionne réellement, ce qui se passe sous le capot, et comment les programmes s'exécutent et se lancent sur les machines.
Puisque C est considéré comme la base d'autres langages de programmation, si vous pouvez apprendre les concepts utilisés dans ce langage, il sera plus facile de comprendre d'autres langages plus tard.
Écrire du code C nous permet de comprendre les processus cachés qui se déroulent dans nos machines. Il nous permet de nous rapprocher du matériel sous-jacent de l'ordinateur sans nous embrouiller avec le langage d'assemblage. Il nous permet également de gérer une multitude de tâches de bas niveau tout en restant lisible comme les langages de haut niveau.
C est rapide et efficace
En même temps, nous ne perdons pas la fonctionnalité, l'efficacité et le contrôle de bas niveau de l'exécution du code que l'assemblage fournit.
Rappelez-vous que chaque processeur dans le matériel de chaque appareil a son propre code d'assemblage qui est unique à ce processeur. Il n'est pas du tout compatible avec tout autre processeur sur tout autre appareil.
L'utilisation de C nous offre une approche plus rapide, plus facile et globalement moins encombrante pour interagir avec l'ordinateur à son niveau le plus bas. En fait, il a un mélange de fonctionnalités de haut et de bas niveau. Et il nous aide à accomplir la tâche sans le tracas et la confusion du long code d'assemblage incompréhensible.
Ainsi, C est aussi proche que possible du matériel sous-jacent de l'ordinateur et est un excellent remplacement pour l'assemblage (l'ancienne norme pour écrire des systèmes d'exploitation) lorsque vous travaillez avec et implémentez des logiciels système.
C est puissant et flexible
Cette proximité avec le matériel signifie que le code C est écrit de manière explicite et précise. Il vous donne une image claire et un modèle mental de la manière dont votre code interagit avec l'ordinateur.
C ne cache pas la complexité avec laquelle une machine fonctionne. Il vous donne beaucoup de puissance et de flexibilité, comme la capacité d'allouer, de manipuler et d'écrire directement en mémoire.
Le programmeur fait une grande partie du travail lourd et le langage vous permet de gérer et de structurer la mémoire de manière efficace pour la machine, offrant des performances élevées, une optimisation et une vitesse. C permet au programmeur de faire ce qui doit être fait.
C est portable, performant et indépendant de la machine
C est également hautement portable et indépendant de la machine. Même s'il est proche de la machine et a accès à ses fonctions de bas niveau, il a suffisamment d'abstraction de ces parties pour rendre la portabilité du code possible.
Comme les instructions d'assemblage sont spécifiques à la machine, les programmes ne sont pas portables. Un programme écrit sur une machine devrait être réécrit pour fonctionner sur une autre. Et cela est difficile à maintenir pour chaque architecture d'ordinateur.
C est universel et les programmes écrits en C peuvent être compilés et exécutés sur de nombreuses plateformes, architectures et une variété de machines sans perdre de performance. Cela fait de C un excellent choix pour créer des systèmes et des programmes où la performance compte vraiment.
C a inspiré la création de nombreux autres langages de programmation
De nombreux langages qui sont couramment utilisés aujourd'hui, comme Python, Ruby, PHP et Java, ont été inspirés par C. Ces langages modernes dépendent de C pour fonctionner et être efficaces. De plus, leurs bibliothèques, compilateurs et interpréteurs sont construits en C.
Ces langages cachent la plupart des détails sur la manière dont les programmes fonctionnent réellement sous le capot. En utilisant ces langages, vous n'avez pas à gérer l'allocation de mémoire et les bits et octets puisque qu'il y a plus de niveaux d'abstraction. Et vous n'avez pas besoin de ce niveau de contrôle granulaire avec des applications de haut niveau où l'interaction avec la mémoire est sujette aux erreurs.
Mais lorsque vous implémentez une partie d'un système d'exploitation ou d'un dispositif embarqué, connaître ces détails de bas niveau et la manipulation directe peut vous aider à écrire un code plus propre.
C est un langage assez compact
Bien que C puisse être assez cryptique et difficile à apprendre pour les débutants, c'est en réalité un langage assez petit et compact avec un ensemble minimal de mots-clés, de syntaxe et de fonctions intégrées. Vous pouvez donc vous attendre à apprendre et à utiliser toutes les fonctionnalités du langage lorsque vous explorez son fonctionnement.
Même si vous n'êtes pas intéressé par l'apprentissage de la programmation d'un système d'exploitation ou d'une application système, connaître les bases de C et la manière dont il interagit avec l'ordinateur vous donnera une bonne fondation des concepts et principes de l'informatique.
De plus, comprendre comment fonctionne la mémoire et est organisée est un concept fondamental de la programmation. Comprendre comment l'ordinateur se comporte à un niveau plus profond et les processus qui se déroulent peut vraiment vous aider à apprendre et à travailler avec n'importe quel autre langage.
Où est utilisé C ?
Il y a beaucoup de code C dans les appareils, produits et outils que des milliards d'entre nous utilisons dans notre vie quotidienne. Ce code alimente tout, des supercalculateurs du monde aux plus petits gadgets.
Le code C fait fonctionner les systèmes embarqués et les appareils intelligents de toutes sortes. Certains exemples sont les appareils ménagers comme les réfrigérateurs, les téléviseurs, les machines à café, les lecteurs DVD et les appareils photo numériques.
Votre tracker de fitness et votre montre intelligente ? Alimentés par C. Le système de suivi GPS dans votre voiture, et même les contrôleurs de feux de circulation ? Vous l'avez deviné - C. Et il y a de nombreux exemples de systèmes embarqués utilisés dans les industries industrielles, médicales, robotiques et automobiles qui fonctionnent avec du code C.
Un autre domaine où C est largement utilisé est le développement des systèmes d'exploitation et des noyaux. En plus d'Unix, pour lequel le langage a été créé, d'autres systèmes d'exploitation majeurs et populaires sont codés dans une certaine mesure en C.
Le noyau de Microsoft Windows est principalement scripté en C, tout comme le noyau Linux. La plupart des supercalculateurs sont alimentés par Linux, tout comme la plupart des serveurs Internet. Cela signifie que C alimente une grande partie de l'Internet.
Linux alimente également les appareils Android, donc le code C ne fait pas seulement fonctionner les supercalculateurs et les ordinateurs personnels, mais aussi les smartphones. Même OSX est codé dans une certaine mesure en C, ce qui fait que les ordinateurs Mac fonctionnent également avec C.
C est également populaire pour le développement d'applications de bureau et d'interfaces graphiques (GUI). La plupart des applications Adobe que nous utilisons pour l'édition vidéo et photo et la conception graphique (comme Photoshop, Adobe Illustrator et Adobe Premiere) sont codées avec C ou son successeur, C++.
Les compilateurs, interpréteurs et assembleurs pour une variété de langages sont conçus et construits avec C - en fait, ce sont quelques-unes des utilisations les plus courantes du langage.
De nombreux navigateurs et leurs extensions sont construits avec C, comme Google Chromium et le système de fichiers Google. Les développeurs utilisent également souvent C dans la conception de bases de données (MySql et Oracle sont deux des systèmes de bases de données les plus populaires construits en C), et il alimente des graphiques avancés dans de nombreux jeux informatiques.
À partir de cet aperçu général, nous pouvons voir que C et son dérivé C++ font fonctionner une grande partie de l'internet et du monde en général. De nombreux appareils et technologies que nous utilisons dans notre vie quotidienne sont écrits en ou dépendent de C.
Processus de compilation C : Écrire-Compiler-Exécuter
Qu'est-ce qu'un programme en C ?
Un programme informatique écrit en C est un ensemble lisible par l'homme et ordonné d'instructions qu'un ordinateur exécute. Il vise à fournir une solution à un problème informatique spécifique et à dire à l'ordinateur d'effectuer une certaine tâche avec une séquence d'instructions qu'il doit suivre.
Essentiellement, tous les programmes sont simplement des fichiers texte stockés sur le disque dur de votre ordinateur qui utilisent une syntaxe spéciale définie par le langage de programmation que vous utilisez.
Chaque langage a ses propres règles qui dictent ce que vous pouvez écrire et ce qui est considéré comme valide, et ce qui ne l'est pas.
Un programme a des mots-clés, qui sont des mots spécifiques réservés et faisant partie du langage. Il a également des morceaux littéraux de données comme des chaînes de caractères et des nombres. Et il a des mots qui suivent les règles du langage, que nous définissons et introduisons dans le langage qui n'existent pas déjà (comme des variables ou des méthodes).
Qu'est-ce qu'un compilateur ?
Les programmes sont écrits par nous et pour nous. Ils sont destinés à être compris par les humains.
Lorsque nous écrivons des programmes sous une forme lisible par l'homme, nous pouvons les comprendre - mais l'ordinateur peut ne pas en être capable. Les ordinateurs ne comprennent pas directement les langages de programmation, ils ne comprennent que le binaire. Les programmes doivent donc être traduits dans cette autre forme pour que l'ordinateur puisse réellement comprendre les instructions de notre programme.
Les programmes en langages de haut niveau peuvent être soit compilés, soit interprétés. Ils utilisent des morceaux spéciaux de logiciels appelés compilateurs et interpréteurs, respectivement.
Quelle est la différence entre un compilateur et un interpréteur ?
Les compilateurs et les interpréteurs sont tous deux des programmes, mais ils sont beaucoup plus complexes et agissent comme des traducteurs. Ils prennent un programme écrit sous une forme lisible par l'homme et le transforment en quelque chose que les ordinateurs peuvent comprendre. Et ils rendent possible l'exécution de programmes sur différents systèmes informatiques.
Les programmes compilés sont d'abord convertis en une forme lisible par la machine, ce qui signifie qu'ils sont traduits en code machine avant de s'exécuter. Le code machine est un langage numérique - des instructions binaires composées de séquences de 0 et de 1.
Cette compilation produit un programme exécutable, c'est-à-dire un fichier contenant le code en langage machine que le CPU (Unité Centrale de Traitement) pourra lire, comprendre et exécuter directement.
Après cela, le programme peut s'exécuter et l'ordinateur fait ce que le programme lui dit de faire. Les programmes compilés ont une correspondance plus forte avec le matériel sous-jacent et peuvent plus facilement manipuler le CPU et la mémoire de l'ordinateur.
Les programmes interprétés, en revanche, ne sont pas directement exécutés par la machine ni n'ont besoin d'être traduits en un programme en langage machine. Au lieu de cela, ils utilisent un interpréteur qui traduit et exécute automatiquement et directement chaque instruction et chaque ligne de code ligne par ligne pendant l'exécution.
C est un langage de programmation compilé. Cela signifie qu'il utilise un compilateur pour analyser le code source écrit en C et le transforme ensuite en un fichier binaire que le matériel de l'ordinateur peut exécuter directement. Cela sera spécifique pour chaque machine particulière.
Comment utiliser le compilateur GCC avec des exemples
Les systèmes Unix et de type Unix ont déjà un compilateur C intégré et installé. Cela signifie que Linux et MacOS ont un compilateur populaire intégré, appelé le compilateur GCC (ou GNU Compiler Collection).
Dans le reste de cette section, nous verrons des exemples utilisant ce compilateur et j'ai basé ces exemples sur un système Unix ou de type Unix. Donc, si vous avez un système Windows, assurez-vous d'activer le Sous-système Windows pour Linux.
Tout d'abord, assurez-vous d'avoir le compilateur GCC installé. Vous pouvez vérifier en ouvrant votre terminal et en tapant gcc --version dans l'invite qui se trouve généralement après le caractère $.
Si vous utilisez MacOS et n'avez pas installé les outils de développement en ligne de commande, vous obtiendrez une boîte de dialogue contextuelle vous demandant de les installer - donc si vous voyez cela, allez-y et faites-le.
Une fois que vous avez installé ceux-ci, ouvrez une nouvelle session de terminal et retapez la commande gcc --version. Si vous avez déjà installé les outils de ligne de commande, vous devriez obtenir la sortie ci-dessous :

Le terme compilation seul est une abstraction et une simplification, bien que dans la réalité, il y ait de nombreuses étapes qui se déroulent en coulisses. Ce sont les détails de plus bas niveau qui se produisent entre l'écriture, la compilation et l'exécution de notre programme C. La plupart se produisent même automatiquement, sans que nous nous en rendions compte.
Comment écrire du code source C
Pour développer des programmes C, nous devons d'abord avoir un type d'éditeur de texte. Un éditeur de texte est un programme que nous pouvons utiliser pour écrire notre code (appelé notre code source) dans un fichier texte.
Pour cela, vous pouvez utiliser un éditeur de texte en ligne de commande comme nano ou Vim si vous êtes à l'aise avec ceux-ci.
Vous pouvez également utiliser un IDE (Environnement de Développement Intégré), ou un éditeur de texte avec des fonctionnalités similaires à un IDE (un terminal intégré, la capacité d'écrire, de déboguer, d'exécuter et de lancer nos programmes tout en un seul endroit sans quitter l'éditeur, et bien plus encore).
Un éditeur avec ces capacités est Visual Studio Code, en utilisant l'extension C/C++. Tout au long du reste de ce tutoriel, nous utiliserons VSCode.
De retour dans votre terminal, tapez les commandes ci-dessous pour créer un fichier où notre code C résidera.
`cd` # Nous amène à notre répertoire personnel, si nous n'y sommes pas déjà
`mkdir cprogram` # Crée un répertoire nommé cprogram
`cd cprogram` # nous navigue dans le répertoire cprogram que nous venons de créer
`touch hello.c` # crée un fichier nommé hello
`code .` # ouvre VSCODE dans le répertoire actuel
Nous avons donc créé un fichier texte brut, hello.c. Ce fichier contiendra du code écrit en langage C, ce qui signifie qu'il sera un programme C. Cela est indiqué par l'extension de fichier .c qui est une convention.
À l'intérieur, nous pouvons écrire n'importe quel programme C que nous souhaitons, en commençant par un programme très basique comme un programme qui affiche 'hello world' à l'écran.

Pour voir ce que fait notre code, nous devons exécuter le programme que nous venons d'écrire. Avant de l'exécuter, cependant, nous devons d'abord le compiler en tapant quelques commandes dans le terminal.
Nous pouvons continuer à utiliser la ligne de commande sur notre ordinateur ou nous pouvons utiliser le terminal intégré dans VSCode (en maintenant les touches control ~ enfoncées en même temps, une nouvelle fenêtre de terminal s'ouvre).
Jusqu'à présent, nous pouvons voir sur le panneau de gauche qu'il n'y a qu'un seul fichier dans notre répertoire cprogram, hello.c, qui contient notre code C.
Le terme 'compiler notre code C' ne se produit pas en une seule étape. Il implique également quelques actions plus petites qui se produisent automatiquement pour nous.
Pour rappel, lorsque nous parlons de compilation, nous entendons généralement que le compilateur prend notre code source en entrée (le code que nous avons écrit en C qui a une syntaxe similaire à l'anglais), et le traduit pour produire des instructions en code machine en sortie.
Ce code machine correspond directement aux instructions de notre code source, mais il est écrit de manière à ce que le CPU puisse le comprendre afin qu'il puisse exécuter les instructions.
Comment le code source C est transformé en code binaire
C'est l'idée générale - mais il y a 4 étapes plus petites impliquées qui se produisent entre-temps. Lorsque nous compilons notre code, nous le pré-traitons, le compilons, l'assemblons et le lions.
Ces étapes commencent à se produire lorsque nous tapons la commande gcc hello.c dans le terminal qui est le nom du compilateur et le fichier de code source, respectivement.
Si nous le voulions, nous pourrions alterner et personnaliser cette commande en tapant une commande plus spécifique comme gcc -o hello hello.c, où :
-osignifie 'sortir ce fichier'helloest le nom que nous spécifions nous-mêmes pour le fichier de programme exécutable que nous voulons sortir et qui sera créé, ethello.cest le fichier que le compilateurgccprendra en entrée (qui est le fichier où réside notre code source et que nous voulons compiler).
Pré-traitement en C
Un autre programme qui fait partie du compilateur effectue cette première étape - le préprocesseur. Le préprocesseur fait beaucoup de choses - par exemple, il agit comme un outil de 'recherche et remplacement' lorsqu'il parcourt notre code source à la recherche d'instructions spéciales et recherche des lignes commençant par un #.
Les lignes commençant par un #, comme #include, sont appelées directives de préprocesseur. Toute ligne commençant par un # indique au préprocesseur qu'il doit faire quelque chose. En particulier, il lui dit qu'il doit substituer cette ligne par autre chose automatiquement. Nous ne voyons pas ce processus, mais il se produit en coulisses.
Par exemple, lorsque le préprocesseur trouve la ligne #include <stdio.h> dans notre programme 'hello world' précédent, le #include dit littéralement au préprocesseur d'inclure, en copiant et collant, tout le code de ce fichier d'en-tête (qui est une bibliothèque externe, stdio.h) à la place de cette instruction dans notre propre code source. Il remplace donc la ligne #include <stdio.h> par le contenu réel du fichier stdio.h.
À l'intérieur de la bibliothèque <stdio.h>, il y a des prototypes de fonctions et des définitions ou des indices. De cette manière, toutes les fonctions sont définies de sorte que l'ordinateur les reconnaisse pendant le temps de compilation, et nous pouvons les utiliser dans notre programme.
Par exemple, la fonction printf(); est définie comme int printf(const char *format,…); à l'intérieur de <stdio.h>. Les mêmes étapes se produisent pour d'autres fichiers d'en-tête, c'est-à-dire des fichiers avec une extension .h.
Pendant l'étape de pré-traitement, nos commentaires dans notre code sont également supprimés et les macros sont développées et remplacées par leurs valeurs. Une macro est un fragment de code auquel un nom a été donné.
À ce stade, s'il n'y a pas d'erreurs dans notre code, il ne devrait y avoir aucune sortie dans le terminal, ce qui est un bon signe.
Nous ne voyons aucune sortie, mais un nouveau fichier a été créé avec une extension .i qui est toujours du code source C. Ce fichier inclut la sortie du pré-traitement, donc il est appelé code source pré-traité. Dans ce cas, un nouveau fichier, hello.i, est généré mais il ne sera pas visible dans notre éditeur.
Si nous exécutons la commande gcc -E hello.c :

Nous pourrons voir tout le contenu de ce fichier (qui est beaucoup) et la fin ressemble à quelque chose comme ceci :
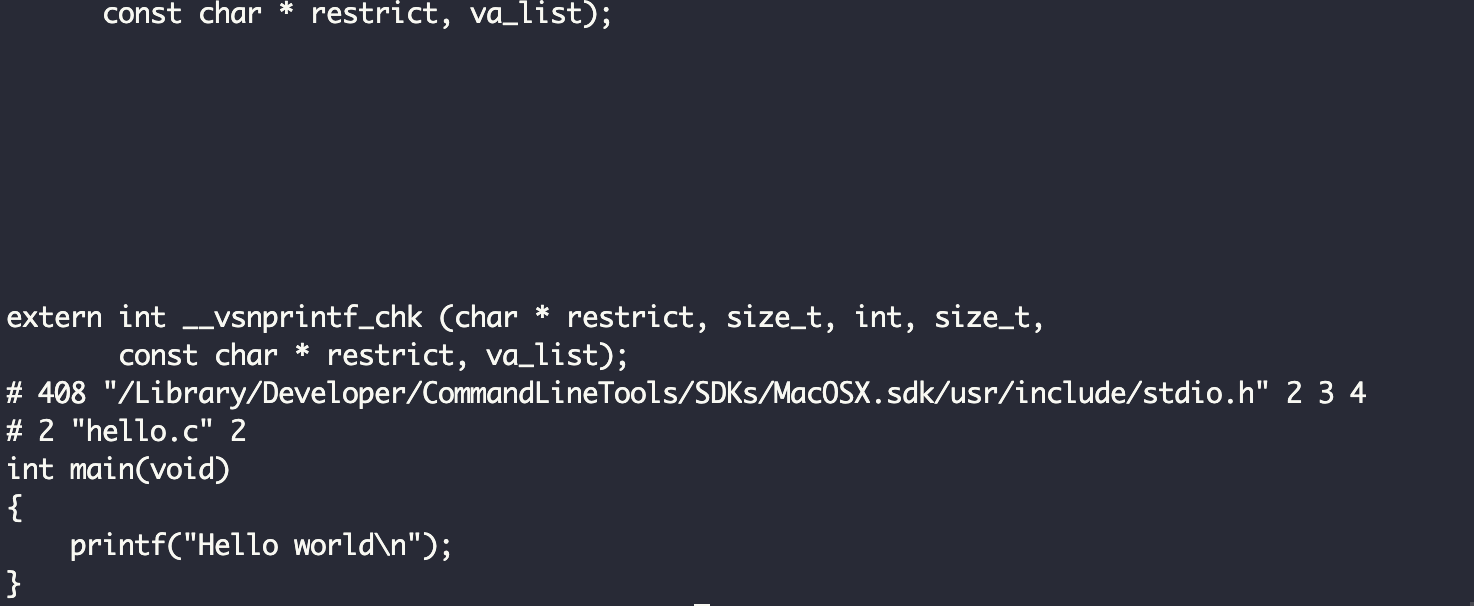
S'il y a des erreurs concernant la justesse de notre code ou si nous ne suivons pas la sémantique du langage, nous verrons quelques erreurs et la compilation prendra fin. Nous devrions corriger les erreurs et recommencer le processus depuis le début.
Compilation en C
Après l'étape de pré-traitement qui produit le code source C pré-traité, nous devons ensuite compiler le code. Cela implique de prendre le code qui est toujours du code source et de le changer en une autre forme intermédiaire. Nous utilisons un compilateur pour cette étape.
Pour rappel, un compilateur est un programme qui prend en entrée le code source et le traduit en quelque chose de plus proche du langage natif des ordinateurs.
Lorsque nous parlons de compilation, nous pouvons soit signifier l'ensemble du processus de traduction du code source en code objet (code machine), soit simplement une étape spécifique dans le processus de compilation complet.
L'étape dont nous parlons maintenant est lorsque la compilation convertit chaque instruction du programme de code source C pré-traité en un langage plus convivial pour l'ordinateur. Ce langage est plus proche du binaire que l'ordinateur peut réellement comprendre directement.
Ce langage intermédiaire est le code d'assemblage, un langage de programmation de bas niveau utilisé pour contrôler le CPU et le manipuler pour effectuer des tâches spécifiques et obtenir un accès proche à la mémoire de l'ordinateur. Vous vous souvenez du code d'assemblage de la section historique ?
Chaque CPU - le cerveau de l'ordinateur - a son propre ensemble d'instructions. Le code d'assemblage utilise des instructions et des commandes spécifiques qui correspondent directement à ces instructions et opérations de bas niveau qu'un CPU effectue et exécute.
Ainsi, dans cette étape du processus de compilation, chaque instruction du code source C pré-traité dans le fichier hello.i est traduite par le compilateur en l'instruction équivalente en langage d'assemblage à un niveau inférieur.
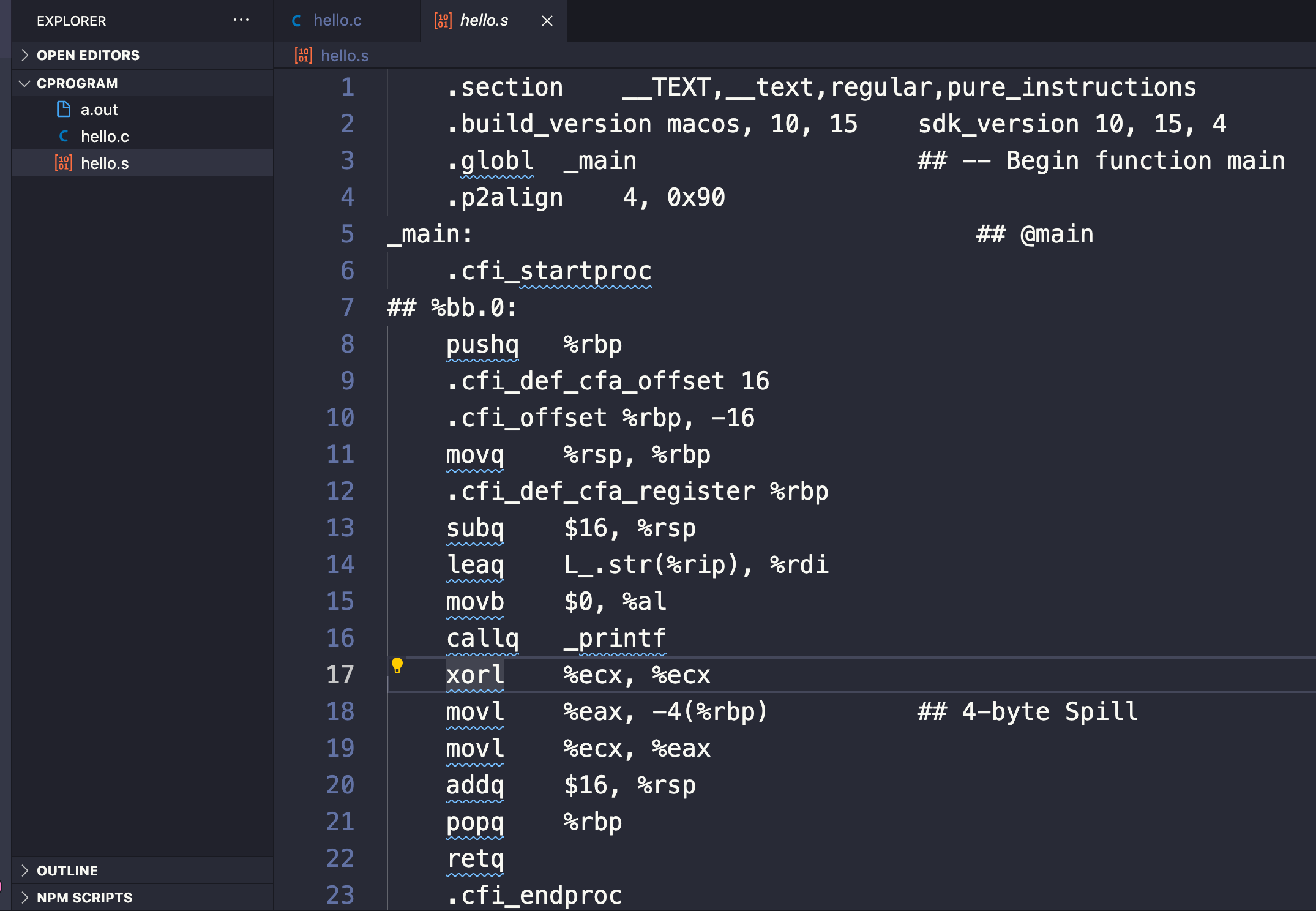
La sortie de cette action crée un fichier se terminant par .s (donc hello.s en coulisses) qui contient des instructions en assembleur.
En tapant la commande gcc -S hello.c, nous pouvons voir le contenu et les commandes d'assemblage quelque peu incompréhensibles du fichier hello.s que le compilateur a créé (mais qui n'était pas visible pour nous lorsque nous avons tapé gcc hello.c seul).
Si nous regardons de près, nous verrons quelques mots-clés et instructions familiers utilisés dans notre code source C comme main et printf :
Assemblage en C
L'assemblage signifie prendre le fichier hello.s contenant des instructions de code d'assemblage en entrée et, avec l'aide d'un autre programme qui est exécuté automatiquement dans le processus de compilation, l'assembler en instructions de code machine. Cela signifie qu'il aura en sortie des 0 et des 1 réels, ou des instructions au format binaire.
Cette étape se produit également en coulisses, et elle aboutit au langage final dans lequel les instructions de notre code source sont traduites. Et maintenant, l'ordinateur peut enfin comprendre ces instructions.
Chacune des commandes que nous avons écrites dans notre code source C a été transformée en instructions de langage d'assemblage et enfin en instructions binaires équivalentes. Tout cela s'est produit simplement avec la commande gcc. Ouf !
Le code que nous avons écrit est maintenant appelé code objet, que le CPU d'un ordinateur spécifique peut comprendre. Le langage est incompréhensible pour nous, les humains.
Les gens utilisaient pour coder en langage machine, mais c'était un processus très fastidieux. Tout symbole qui n'est pas un symbole de code machine (c'est-à-dire tout ce qui n'est pas des 0 et des 1) est difficile à comprendre. Coder directement dans un tel langage est extrêmement sujet aux erreurs.
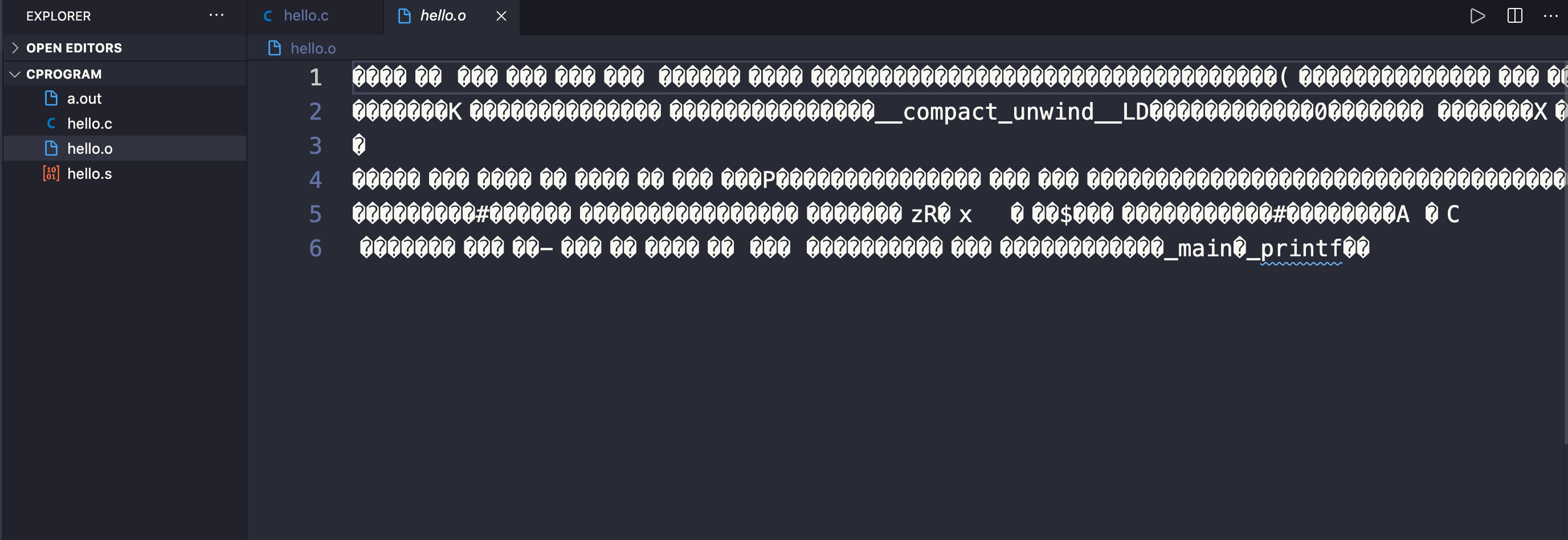
À ce stade, un autre fichier est créé avec une extension .o (pour objet) - donc dans notre cas, ce sera hello.o.
Nous pouvons voir le contenu réel du fichier objet contenant les instructions de niveau machine avec la commande gcc -c hello.c. Si nous faisons cela, nous verrons le contenu non lisible par l'homme de hello.o :
Liaison en C
Dans les images ci-dessus, vous avez peut-être remarqué un fichier a.out dans notre répertoire.
C'est l'étape et le fichier par défaut qui est créé lorsque nous tapons la commande du compilateur et notre nom de fichier, gcc hello.c dans notre cas.
Si nous avions utilisé la commande gcc -o hello hello.c mentionnée précédemment, nous aurions vu un programme exécutable nommé hello à la place de a.out.
Le a.out signifie sortie d'assemblage. Si nous tapons ls dans le terminal pour lister les fichiers dans notre répertoire, nous voyons que a.out a même l'air différent des autres :

La liaison est l'étape finale du processus de compilation où le fichier binaire final hello.o est lié avec tout le reste du code objet dans notre projet.
Ainsi, s'il y a d'autres fichiers contenant du code source C (comme des fichiers inclus dans notre programme qui implémentent des bibliothèques C déjà traitées et compilées, ou un autre fichier que nous avons écrit nommé, par exemple, filename.c en plus de hello.c), c'est à ce moment que le fichier objet filename.o sera combiné avec hello.o et les autres codes objets, les liant tous ensemble.
Cela forme un grand fichier exécutable avec le code machine combiné, a.out ou hello, qui représente notre programme.
Puisque nous avons enfin terminé la compilation, le programme est dans sa forme finale. Et maintenant, nous pouvons exécuter et lancer le fichier sur notre machine en tapant ./a.out. Cela signifie 'exécuter le fichier a.out qui se trouve dans le répertoire actuel', puisque ./ représente le dossier dans lequel nous nous trouvons. Nous voyons ensuite la sortie de notre programme dans le terminal :

Chaque fois que nous apportons des modifications à notre fichier de code source, nous devons répéter le processus de compilation depuis le début afin de voir les modifications lorsque nous exécutons le code à nouveau.
Comment écrire Hello World en C
Un programme hello world est très simple, mais c'est une tradition qui sert également de message de test lorsque vous commencez à apprendre à coder dans un nouveau langage de programmation.
Si vous exécutez votre programme "Hello World" avec succès, cela vous indique que votre système est correctement configuré.
 _'Hello world' conçu par Brian Kernighan à partir de la vente aux enchères d'algorithmes d'Artsy basé sur un mémorandum interne de 1974 des Bell Laboratories, "Programmation en C : Un tutoriel", qui contient la première version connue. Il a été réimprimé dans le livre populaire de 1978, Le langage de programmation C. Source de l'image et de la description de Wikipedia_
_'Hello world' conçu par Brian Kernighan à partir de la vente aux enchères d'algorithmes d'Artsy basé sur un mémorandum interne de 1974 des Bell Laboratories, "Programmation en C : Un tutoriel", qui contient la première version connue. Il a été réimprimé dans le livre populaire de 1978, Le langage de programmation C. Source de l'image et de la description de Wikipedia_
Un programme 'hello world' contient la syntaxe de base du langage et nous pouvons le décomposer en parties plus petites :
#include<stdio.h>
int main(void)
{
// imprimer hello world à l'écran
printf("Hello world\n");
}
Fichiers d'en-tête en C
Les fichiers d'en-tête sont des bibliothèques externes. Cela signifie qu'ils sont un ensemble de code déjà écrit par certains développeurs pour que d'autres développeurs l'utilisent.
Ils fournissent des fonctionnalités qui ne sont pas incluses dans le noyau du langage C. En ajoutant des fichiers d'en-tête à notre code, nous obtenons en retour une fonctionnalité supplémentaire que nous pouvons utiliser dans nos programmes.
Les fichiers d'en-tête comme include <stdio.h> se terminent par l'extension .h. En particulier, un fichier d'en-tête comme stdio.h est déjà intégré dans le compilateur.
La ligne include <stdio.h> est une instruction pour les fonctions pré-écrites dans le fichier de bibliothèque stdio.h qui indique à l'ordinateur d'accéder et de les inclure dans notre programme.
stdio.h nous donne la fonctionnalité standard input and standard output, ce qui signifie que nous pourrons obtenir des entrées et des sorties de l'utilisateur. Nous pouvons donc utiliser des fonctions d'entrée/sortie comme printf.
Si vous n'incluez pas le fichier stdio.h en haut de votre code, l'ordinateur ne comprendra pas ce qu'est la fonction printf.
Le programme principal en C
Voici le code :
int main(void)
{
}
C'est la fonction de départ principale d'un programme C. Les accolades ({}) sont le corps qui enveloppe tout le code qui doit être dans notre programme.
Cette ligne sert de modèle et de point de départ pour tous les programmes C. Elle indique à l'ordinateur où commencer à lire le code lorsqu'il exécute nos programmes.
Commentaires en C
Tout ce que nous écrivons après le // n'affectera pas la manière dont notre code s'exécute et l'ordinateur n'en tiendra pas compte pendant le temps de compilation et d'exécution.
Ces deux lignes indiquent que vous ajoutez des commentaires, qui sont des notes pour nous-mêmes et pour nos collègues. Les commentaires peuvent nous aider à nous souvenir et à rappeler aux autres ce que fait une certaine ligne de code ou pourquoi nous avons écrit ce code en premier lieu. Cela nous rappelle également quel est exactement le but de ce code lorsque nous y revenons le lendemain ou même des mois plus tard.
Sortie ou impression sur la console en C
printf("Hello world/n"); imprime la phrase 'Hello world' sur la console. Nous utilisons printf lorsque nous voulons dire quelque chose et voir la sortie à l'écran. Les caractères que nous voulons sortir doivent être entourés de guillemets doubles "" et de parenthèses ().
Le /n est un caractère d'échappement, ce qui signifie qu'il crée une nouvelle ligne et indique au curseur de se déplacer à la ligne suivante lorsqu'il le voit.
Le ; indique la fin de la phrase et la fin de cette ligne de code.
Variables en C
Voici comment nous définissons une variable en C :
Un élément de données qui peut prendre plus d'une valeur pendant l'exécution d'un programme.
En termes simples, vous pouvez penser aux variables comme une boîte nommée. Une boîte qui agit comme un lieu de stockage et un emplacement pour contenir différentes informations qui peuvent varier en contenu.
Chaque boîte a un nom unique qui agit comme une étiquette mise à l'extérieur qui est un identifiant unique, et l'information/contenu vit à l'intérieur. Le contenu est la valeur de la variable.
Les variables contiennent et pointent vers une valeur, vers certaines données utiles. Elles agissent comme une référence ou une abstraction de données littérales. Ces données sont stockées dans la mémoire de l'ordinateur et occupent une certaine quantité d'espace. Elles y vivent afin que nous puissions les récupérer plus tard et les utiliser dans nos programmes lorsque nous en avons besoin.
Comme le nom l'indique, ce vers quoi les variables pointent peut varier. Elles sont capables de prendre différentes valeurs au fil du temps à mesure que l'information change pendant la durée de vie du programme.
Affectation de variables en C
Le processus de nommage d'une variable est appelé affectation. Vous définissez une valeur spécifique qui se trouve à droite, à un nom de variable spécifique qui se trouve à gauche. Vous utilisez le = ou l'opérateur d'affectation pour faire cela.
Comme je l'ai mentionné, vous pouvez changer la valeur d'une variable, donc vous pouvez affecter et réaffecter des variables. Lorsque vous réaffectez une valeur, la nouvelle valeur pointe vers le nom de la variable. Donc la valeur peut être une nouvelle, mais le nom de la variable reste le même.
Comment déclarer vs initialiser une variable en C
Le langage de programmation C est un langage fortement typé statiquement, contrairement à de nombreux autres langages de programmation modernes.
Dans les langages à typage statique, vous devez déclarer explicitement vos variables comme étant d'un certain type de données. Ainsi, le compilateur sait pendant le temps de compilation si la variable est capable d'effectuer les actions pour lesquelles elle a été conçue et demandée.
Dans les langages à typage dynamique, une variable peut changer entre différents types de données sans avoir besoin de définir explicitement ce type de données.
Ainsi, lors de la déclaration d'une nouvelle variable dans le langage C, vous devez définir et spécifier de quel type elle est, et quel type de données sa valeur contient.
Le type d'une variable est le type de la valeur qu'elle contient. Cela permet au programme et plus tard au compilateur de savoir quel type d'informations il stocke.
Pour déclarer une variable, vous spécifiez le type de données et donnez un nom à la variable. Une étape facultative consiste à définir une valeur initiale. N'oubliez pas le point-virgule à la fin, qui termine l'instruction !
#include <stdio.h>
int main(void)
{
int n = 27;
// int est le type de données
// n est le nom
// n est capable de contenir des valeurs entières
// nombres entiers positifs/négatifs ou 0
// = est l'opérateur d'affectation
// 27 est la valeur
}
Quelle est la différence entre l'initialisation et la déclaration d'une variable ?
En résumé :
int n; // déclaration, créer une variable appelée n capable de contenir des valeurs entières
int n = 27; // initialisation, créer une variable appelée n et assigner une valeur, stocker un nombre dans cette variable
int n; est une déclaration de variable. Déclarer signifie que nous définissons un nom pour la variable et spécifions son type.
Nous n'avons pas nécessairement besoin de spécifier une valeur pour la variable tout de suite. Cela suffit, car déclarer une variable indique à l'ordinateur que nous voulons qu'une variable existe et que nous devons allouer un espace en mémoire pour elle. La valeur peut être et sera stockée plus tard.
Lorsque nous attribuons une valeur à la variable plus tard, il n'est pas nécessaire de spécifier à nouveau le type de données. Nous pouvons également déclarer plusieurs variables à la fois.
int name, age;
Si nous déclarons une variable et lui attribuons une valeur en même temps, cela s'appelle initialiser la variable.
int n = 27; est l'initialisation de la variable. Cela fait référence à l'attribution d'une valeur initiale que nous pouvons changer plus tard.
Si la nouvelle valeur est du même type de données, nous n'avons pas besoin d'inclure le type de données, seulement la nouvelle valeur. Si le type de données est différent, nous obtiendrons une erreur.
#include<stdio.h>
int main(void)
{
int age = 27;
age = 37;
// la nouvelle valeur de age est 37
}
Règles pour nommer les variables en C
- Les noms de variables doivent commencer soit par une lettre ou un tiret bas, par exemple
ageet_agesont valides. - Un nom de variable peut contenir des lettres (majuscules ou minuscules), des chiffres ou un tiret bas.
- Il ne peut y avoir d'autres symboles spéciaux qu'un tiret bas.
- Les noms de variables sont sensibles à la casse, par exemple
ageest différent deAge.
La portée d'une variable en C
La portée d'une variable fait référence à l'endroit où la variable peut être référencée et accessible. C'est essentiellement là où la variable vit et est valide et à quel point elle est visible pour le reste du programme.
Portée locale
Si une variable est déclarée dans un ensemble d'accolades, {}, comme par exemple une fonction spécifique, ce sera sa portée et nous ne pouvons pas y accéder et l'utiliser en dehors de ces accolades dans le reste du programme. Le reste du programme ne saura pas qu'elle existe.
Par conséquent, ce n'est pas une bonne idée de déclarer des variables de cette manière puisque leur portée et leur utilisation sont si limitées, ce qui peut conduire à des erreurs. Cette portée est appelée portée locale.
Portée globale
Si les variables sont déclarées en dehors des fonctions, elles ont une portée globale. Avoir une portée globale signifie qu'elles sont visibles dans tout le programme et peuvent être accessibles de n'importe où.
Mais gardez à l'esprit qu'il peut être difficile de les suivre. De plus, tout changement que nous leur apportons en cours de route peut devenir confus puisque cela peut se produire dans n'importe quelle partie et emplacement du programme.
Types de données en C
Les types de données spécifient sous quelle forme nous pouvons représenter et stocker des informations dans nos programmes C. Ils nous indiquent comment ces informations seront utilisées et quelles opérations peuvent être effectuées sur elles.
Les types de données déterminent également quel type de données nos variables peuvent contenir, car chaque variable en C doit déclarer le type de données qu'elle représente.
Il existe 6 types de données intégrés dans le langage. Mais vous pouvez convertir entre différents types, ce qui le rend moins fortement typé.
Chacun des types de données nécessite une allocation de mémoire différente et chaque type de données peut avoir des plages différentes jusqu'auxquelles ils peuvent stocker des valeurs.
L'ajout de mots-clés devant un nom de type modifie et apporte des changements au type. Ces mots-clés peuvent être soit unsigned soit signed.
Un mot-clé unsigned signifie que le type ne peut être que positif et non négatif, donc la plage de nombres commence à partir de 0. Un mot-clé signed vous permet de rendre un nombre négatif ou positif.
Examinons ces types de données plus en détail.
Le type de données char en C
Le type de données le plus basique en C est char. Vous l'utilisez pour stocker un seul caractère tel que les lettres du tableau ASCII comme 'a', 'Z', ou '!'. (Remarquez comment j'ai utilisé des guillemets simples entourant le caractère unique - vous ne pouvez pas utiliser de guillemets doubles dans ce cas.)
char vous permet également de stocker des nombres allant de [-128 à 127] et dans les deux cas utilise 1 octet de mémoire.
Un unsigned char peut prendre une plage de nombres de [0-255]
Le type de données int en C
int est un entier, un nombre entier, qui peut contenir une valeur positive ou négative ou 0 mais qui n'a pas de décimale.
C'est une valeur jusqu'à un certain nombre de bits. Lorsque vous déclarez un int, l'ordinateur alloue 4 octets de mémoire pour celui-ci. Plus spécifiquement, il utilise au moins 2 octets mais généralement 4. 4 octets de mémoire signifie qu'il alloue 32 bits (puisque 1 octet = 8 bits). Donc un int a 232 valeurs possibles - plus de 4 milliards d'entiers possibles.
La plage est de -231 à 231-1, spécifiquement de [-2,147,483,648 à 2,147,483,647].
- Un unsigned int a toujours la même taille qu'un int (4 octets) mais cela n'inclut pas les nombres négatifs dans la plage des valeurs possibles. Donc la plage est de 0 à 232-1, plus spécifiquement [0 à 4,294,969,295]
- Un short int a des valeurs plus petites qu'un int et alloue 2 octets de mémoire. Il permet des nombres dans une plage de [-32,768 à 32,767]
- Un unsigned short int utilise à nouveau 2 octets de mémoire et a une plage de nombres de [0 à 65,535]
- Un long int est pour lorsque nous devons utiliser un nombre plus grand. Il utilise au moins 4 octets de mémoire, mais généralement 8 octets avec des valeurs de [-2,147,483,648 à 2,147,483,647]
- Un unsigned long int a au moins 4 octets de mémoire avec une plage de [0 à 4,294,967,295]
- Un long long int est un entier avec plus de bits capable de compter des nombres plus élevés et plus grands par rapport aux ints et aux longs ints. Ils utilisent 8 octets au lieu de 4 et donc utilisent 64 bits. Cela permet une plage de -263 à 263-1, donc pour des nombres de [-9,223,372,036,854,775,808 à 9,223,372,036,854,775,807]
- Un unsigned long long utilise 8 octets et a une plage de nombres de [0 à 18,446,744,073,709,551,615]
Le type de données float en C
Les floats sont une valeur à virgule flottante qui est un nombre avec une décimale (également appelé nombre réel), avec une précision simple. Il alloue 4 octets de mémoire.
Le type de données double en C
Un double est une valeur à virgule flottante qui a des valeurs plus grandes que celle d'un float. Il peut contenir plus de mémoire - 8 octets - par rapport à un float, et est en double précision.
- Un long double est la plus grande taille par rapport aux floats et aux doubles, contenant au moins 10 octets de mémoire, mais peut même contenir jusqu'à 12 ou 16 octets.
Et enfin, le type void signifie essentiellement rien ou aucune valeur.
Codes de format en C
Les codes de format ou spécificateurs de format sont utilisés pour l'entrée et la sortie en C.
Ce sont un moyen d'indiquer au compilateur quel type de données il prend en entrée avec une variable, et quel type de données il produit en sortie lors de l'utilisation de la fonction printf(). Le f dans printf() signifie formaté.
Ils agissent comme un espace réservé de code de format et se substituent aux variables. Ils permettent au compilateur de savoir à l'avance de quel type ils sont lorsque la valeur de la sortie standard (c'est-à-dire ce que nous voulons imprimer) n'est pas déjà connue.
La syntaxe que nous utilisons est % spécificateur de format pour le type de données :
#include<stdio.h>
int main(void)
{
int age = 27;
printf("Mon âge est %i/n", age)
// imprime 27
// age est la variable que nous voulons utiliser
// %i est le spécificateur de format, un espace réservé pour une valeur entière
// nous séparons chaque argument avec une virgule
// dans la sortie %i est remplacé par la valeur de age
}
Il existe différents spécificateurs de format pour chaque type de données que nous avons discuté précédemment. En voici quelques-uns :
| Spécificateur de format | Type de données |
%c | char |
%c | unsigned char |
%i ou %d | int |
%u | unsigned int |
%hi ou %hd | short int |
%hu | unsigned short int |
%li ou %ld | long int |
%lu | unsigned long int |
%lli ou %lld | long long int |
%llu | unsigned long long int |
%f | float |
%lf | double |
%Lf | long double |
Opérateurs en C
Opérateurs arithmétiques en C
Les opérateurs arithmétiques sont des opérateurs mathématiques qui effectuent des fonctions mathématiques sur des nombres. Les opérations peuvent inclure l'addition, la soustraction, la multiplication et la division.
Les opérateurs les plus couramment utilisés sont :
+pour l'addition-pour la soustraction*pour la multiplication/pour la division%pour la division modulo (calculer le reste de la division)
Opérateur d'affectation en C
L'opérateur d'affectation, =, affecte une valeur à une variable. Il 'met' une valeur dans une variable.
En d'autres termes, il définit ce qui se trouve à droite du = comme étant la valeur de la variable à gauche du =.
Il existe des opérateurs d'affectation spécifiques pour mettre à jour une variable en modifiant la valeur.
En C, il existe diverses façons de mettre à jour les valeurs des variables. Par exemple, si nous voulons incrémenter la variable de 1, il y a trois façons possibles de le faire.
Il est d'abord utile de mentionner que l'incrémentation signifie prendre la valeur existante d'une variable, quelle que soit la valeur à droite, et ajouter 1. La nouvelle valeur est ensuite stockée dans la variable et mise à jour automatiquement.
La manière la plus simple d'incrémenter ou de mettre à jour est d'avoir une variable appelée x avec une valeur initiale de 5, donc :
x=5.
Pour ajouter 1 à la variable x, nous faisons x = x + 1 ce qui signifie x = 5 + 1.
La nouvelle valeur de x est maintenant 6, x=6.
Il existe un raccourci pour cette opération, utilisant une syntaxe spéciale qui incrémente les variables.
Au lieu d'écrire x = x +1, nous pouvons écrire x += 1.
Une manière encore plus courte est d'utiliser l'opérateur d'incrémentation, qui ressemble à nom_de_variable ++, donc dans notre cas x++.
Il en va de même pour la diminution, c'est-à-dire la décrémentation, d'une variable de 1.
Les trois façons de le faire sont :
x = x-1, x -= 1, x -- (en utilisant l'opérateur de décrémentation) respectivement.
Ce sont les façons d'incrémenter et de décrémenter une variable de 1 en C. Nous sommes capables de mettre à jour une variable en prenant sa valeur et en ajoutant, soustrayant, multipliant et divisant cette valeur par n'importe quel autre nombre et en définissant le résultat de cette opération comme la nouvelle valeur. Ces opérations seraient +=, -=, *=, et /= respectivement.
Ainsi, x = x * 5 ou le raccourci x *= 5 prendra la valeur de la variable x et la multipliera par 5 et la stockera dans x.
Opérateurs logiques en C
Nous utilisons les opérateurs logiques pour prendre des décisions en C. Le résultat d'une opération peut être soit vrai soit faux.
Il y a l'opérateur logique ET, &&. Les opérandes des deux côtés de && doivent être vrais pour que la condition soit vraie.
Il y a aussi l'opérateur logique OU, ||. Au moins un ou les deux opérandes des côtés droit et gauche de || doivent être vrais pour que la condition soit vraie.
Enfin, il y a le NON logique. Cela inverse la valeur de l'opérande. Si un opérande est vrai, alors l'opérateur NON rend la condition fausse et vice versa.
Opérateurs de comparaison en C
Les opérateurs de comparaison sont :
- Supérieur à
> - Supérieur ou égal à
>= - Inférieur à
< - Inférieur ou égal à
=<
Il y a aussi un opérateur de comparaison d'égalité, ==. Ne confondez pas cela avec =, l'opérateur d'affectation.
Nous utilisons == pour comparer deux valeurs et tester si elles sont égales ou non. Cet opérateur pose la question 'Ces deux valeurs sont-elles égales ?', alors que = affecte une valeur à une variable.
Lorsque nous utilisons l'opérateur de comparaison d'égalité et posons la question ci-dessus, il y a toujours une valeur de retour qui peut être soit vraie soit fausse, autrement connue sous le nom de valeur booléenne dans le contexte de la programmation informatique.
Enfin, il y a l'opérateur d'inégalité, !=, que nous utilisons pour tester si deux valeurs ne sont PAS égales.
Fonctions en C
Les fonctions sont des verbes, c'est-à-dire de petites actions. Elles font quelque chose. Elles accomplissent une tâche particulière et spécifique.
Elles encapsulent un comportement qui est destiné à être utilisé encore et encore. Le but des fonctions est d'avoir ce comportement écrit une seule fois quelque part afin que vous puissiez le réutiliser chaque fois que vous en avez besoin, à différents moments et à différents endroits dans un programme. Cela rend votre code plus simple et mieux organisé.
Les fonctions existent pour accomplir une tâche, servir un but particulier et être réutilisées. Et elles peuvent prendre des entrées et produire des sorties.
Arguments de fonction en C
Les entrées que les fonctions prennent sont appelées arguments. Une fonction peut avoir un ou plusieurs arguments.
Une fonction courante dans le langage de programmation C est printf();. Cela imprime quelque chose à l'écran. C'est une fonction utilisée pour dire quelque chose.
Les parenthèses () sont les entrées de la fonction, où les arguments vont - c'est-à-dire ce que nous voulons réellement dire et imprimer à l'écran. Ce qui se trouve entre les parenthèses est imprimé.
Dans printf("Hello world!"); , Hello world! est l'entrée de la fonction printf. Ici, nous appelons une fonction appelée printf et nous lui donnons un argument qui est une chaîne de caractères. Cela dit littéralement, imprime 'Hello world! 'à l'écran.
Sorties de fonction en C
Il existe deux types de sortie de fonction :
Premièrement, les sorties peuvent être simplement quelque chose de visuel, un effet visuel immédiat, quelque chose rapidement imprimé à l'écran.
Vous ne pouvez rien faire de plus avec cette sortie après l'effet. Comme dans le cas de printf("Hello world!"); , la sortie est la chaîne "Hello world!" imprimée à l'écran, et c'est tout. Vous ne pouvez pas utiliser cette chaîne d'une autre manière, car printf n'a pas de valeur de retour.
Ces types de fonctions sont connus sous le nom d'effets secondaires, ce qui signifie qu'ils ont un effet observable immédiat sans retourner de valeur.
De plus, une fonction comme printf est une invocation de fonction et dans la bibliothèque stdio est définie comme int printf(const char *format,...);.
Deuxièmement, la sortie peut être réutilisable et avoir une valeur de retour. Une valeur de retour est une valeur renvoyée au programmeur et stockée dans une variable pour une utilisation ultérieure.
Dans de tels cas, il n'y a pas d'effet immédiat - rien n'est imprimé à l'écran. La sortie est plutôt renvoyée à nous, stockée sous forme d'informations et enregistrée dans une variable.
Comment définir une méthode en C
Il y a trois choses que vous devez avoir dans la première ligne, la ligne de déclaration, lors de la définition d'une fonction.
1) Le type de retour
C'est le tout premier mot-clé utilisé, et comment une fonction commence indique la valeur de retour.
Par exemple, dans une fonction comme : void say_something(void), le premier void signifie que la fonction n'a pas de valeur de retour.
Dans un autre exemple avec une fonction différente, int main(void), nous spécifions et définissons son type de données de retour, dans ce cas un int. La sortie de la fonction sera un type de données int et sera renvoyée là où la fonction est appelée.
2) Le nom de la fonction
Le nom peut être n'importe quoi que nous voulons, bien qu'il soit préférable de nommer les méthodes en fonction de ce qu'elles sont censées faire.
3) Aucun ou un ou plusieurs arguments
Ce sont les entrées de la fonction, et le type de données de ces entrées.
Dans void say_something(void), le void à l'intérieur des parenthèses est un mot-clé pour l'argument et un espace réservé pour 'rien'. Cela signifie qu'il ne prend aucune entrée. Dans des cas comme celui-ci, l'argument est également appelé un paramètre.
Les paramètres sont essentiellement des variables déclarées dans la fonction, à l'intérieur des parenthèses comme le mot-clé void. Ils agissent comme un espace réservé pour accéder aux données d'entrée de la fonction, les arguments.
Les paramètres font référence à la valeur qui est passée dans la méthode. Cela signifie que lorsque nous appelons la fonction plus tard, nous lui passons les valeurs réelles, les arguments de la fonction.
Comment appeler une fonction en C
Nous pouvons appeler une fonction comme :
void say_hi(void)
{
printf("hello");
}
En écrivant le nom de la fonction, suivi de tout argument entre parenthèses et d'un point-virgule comme say_hi();. La fonction say_hi ne prend aucune entrée et n'a pas de valeur de retour. Lorsqu'elle est appelée, elle imprime simplement 'hello' à l'écran.
Une autre fonction comme :
int square(int n)
{
return n * n
}
est appelée de la même manière que l'exemple précédent. Dans ce cas, la fonction square prend une entrée et a une valeur de retour (les deux sont des int). L'entrée qu'elle prend est le paramètre appelé n, qui retourne un int lorsque la fonction est appelée.
Le mot return spécifie ce qui sera retourné, l'entrée n multipliée par elle-même.
Par exemple, lorsque la fonction est appelée square(3); , n agit comme une variable qui pointe vers le paramètre qui a été passé dans la fonction, comme 3. C'est comme si nous avions défini n = 3. La valeur qui est retournée est 9.
Les fonctions sont destinées à être réutilisées, donc nous pouvons l'utiliser chaque fois que nous souhaitons élever un nombre au carré :
#include <stdio.h>
int square(int x)
{
return x * x;
}
int main(void)
{
printf("%i\n", square(2));
printf("%i\n", square(4));
printf("%i\n", square(8));
}
Comment utiliser les expressions booléennes en C
Une expression booléenne est une expression qui évalue à l'une des deux valeurs, vrai ou faux. Elles tirent leur nom du mathématicien, philosophe et logicien George Boole.
 _George Boole Source de l'image Wikimedia_
_George Boole Source de l'image Wikimedia_
Nous utilisons les expressions booléennes pour comparer deux valeurs et elles sont particulièrement utiles dans le contrôle de flux.
Toute valeur non nulle est vraie et 0 est faux.
Nous pouvons combiner les expressions booléennes avec l'utilisation des différents opérateurs logiques, comme && (et), || (ou) et ! (non) mentionnés précédemment dans l'article.
Différentes combinaisons de valeurs et d'opérateurs conduisent à différents résultats de sortie, qui peuvent être exprimés dans une table de vérité, une table mathématique utilisée pour représenter des équations logiques qui résultent en 1 ou 0 ou leurs équivalents vrai ou faux.
Lorsque nous comparons deux valeurs booléennes en utilisant l'opérateur && (et), les deux valeurs doivent être égales à vrai pour que l'expression combinée soit vraie.
Par exemple, si quelqu'un nous demande "Voulez-vous une pizza et une salade ?", la seule façon pour que l'expression soit vraie est que nous voulions les deux, une pizza et une salade (donc notre réponse est oui aux deux). Si la réponse à l'une d'entre elles n'est pas vraie, alors toute l'expression est fausse.
Table de vérité pour &&
| Valeur A | Valeur B | Résultat |
| vrai | faux | faux |
| faux | vrai | faux |
| faux | faux | faux |
| vrai | vrai | vrai |
Contrairement à &&, l'opérateur || nous permet de prendre une action si une ou les deux valeurs sont vraies. Donc cet opérateur n'est pas exclusif, soit l'une des comparaisons doit être vraie pour que l'expression évalue à vrai ou même les deux.
Cela est assez unique en informatique, puisque dans notre exemple de question utilisé précédemment, si au lieu de ET nous le changions en OU, l'énoncé 'Voulez-vous une pizza ou une salade ?' ne signifie pas que vous voulez les deux. Vous voulez l'un ou l'autre, pas nécessairement les deux ensemble.
Table de vérité pour ||
| Valeur A | Valeur B | Résultat |
| vrai | faux | vrai |
| faux | vrai | vrai |
| faux | faux | faux |
| vrai | vrai | vrai |
Enfin, l'opérateur ! (non) est utilisé pour la négation, ce qui signifie qu'il transforme vrai en faux et faux en vrai.
!vrai est faux
!faux est vrai
Comment utiliser les instructions conditionnelles en C
Les instructions conditionnelles effectuent une action spécifique en fonction du résultat d'une comparaison qui a lieu. L'acte de faire une chose si une condition particulière est vraie et éventuellement une chose différente si cette condition particulière s'avère être fausse est appelé flux de contrôle.
Certaines parties du programme peuvent ne pas s'exécuter en fonction des résultats ou en fonction de certaines entrées de l'utilisateur. L'utilisateur peut emprunter différents chemins en fonction des diverses bifurcations qui surviennent pendant la vie d'un programme.
Les programmes avec des instructions conditionnelles utilisent principalement des blocs if. Les blocs if utilisent des expressions booléennes qui ne peuvent être que vraies ou fausses et ils prennent des décisions en fonction de ces valeurs résultantes. Nous désignons une instruction de bloc if en utilisant des accolades, {}, et l'indentation du code qui suit.
#include <stdio.h>
int main(void)
{
int x = 2;
int y = 3;
if (x < y)
// x < y est une expression booléenne, elle ne peut être que vraie ou fausse.
// Si ce qui est dans les parenthèses est vrai
//- dans ce cas, x est effectivement inférieur à y-
// exécuter le code qui suit
{
printf("x est inférieur à y");
// Parce que x < y est vrai, cette instruction sera imprimée
}
}
Une instruction if seule n'est pas très utile, surtout lorsque les programmes deviennent de plus en plus grands. Dans ce cas, l'instruction if est accompagnée d'une instruction else.
Cela signifie que 'si cette condition est vraie, faire ce qui suit, sinon faire ceci à la place'. Le mot-clé else est la solution lorsque la condition if est fausse et donc ne s'exécute pas.
int main(void)
{
int x = 1;
int y = 2;
if ( x > y)
{
printf("x est plus grand que y");
}
else
{
printf("x est inférieur à y");
// Parce que x > y est faux,
// ce bloc de code sera exécuté
// résultant en l'impression de l'instruction de la branche else
}
}
Si nous souhaitons choisir parmi plus de deux options et voulons avoir une plus grande variété d'instructions et d'actions, alors nous pouvons introduire une condition else if.
Cela signifie que 'Si cette condition est vraie, fais ceci. Si ce n'est pas le cas, fais ceci à la place. Cependant, si aucune des conditions ci-dessus n'est vraie, fais finalement ceci à la place.'
#include <stdio.h>
int main(void)
{
int x = 2;
int y = 2;
if(x < y)
// si cette condition est vraie, exécute ce bloc
{
printf("x est inférieur à y");
}
else if(x > y)
/ / si l'instruction ci-dessus était vraie, exécute ce bloc à la place
{
printf("x est supérieur à y");
}
else
// si ce bloc de code s'exécute
// c'est parce que x < y était faux
// et x > y aussi
// donc cela signifie x == y
{
printf("x est égal à y");
}
}
Comment utiliser les boucles en C
Une boucle est un comportement isolé ou un ensemble spécifique d'instructions qui sont répétées un certain nombre de fois, encore et encore, jusqu'à ce qu'une condition soit remplie. C'est la même action, le même code, qui est répété encore et encore.
Boucles While en C
Avant d'exécuter un code, les boucles while doivent vérifier une condition. Si elle est remplie, le code s'exécute. Sinon, le code ne prend aucune action. Ainsi, le code n'est pas garanti de s'exécuter même au moins une fois si une condition n'est pas remplie.
Il existe différents types de boucles while. L'une d'entre elles est une boucle infinie.
#include <stdio.h>
int main(void)
{
while(true)
{
printf("Hello world");
}
}
Le mot-clé while est utilisé avec une expression booléenne requise, true dans ce cas (qui reste toujours true).
Après avoir imprimé la ligne de code à l'intérieur des accolades, il vérifie en continu s'il doit exécuter le code à nouveau. Comme la réponse est toujours oui (puisque la condition qu'il doit vérifier est toujours vraie à chaque fois), il exécute le code encore et encore.
Dans cet exemple, la seule façon d'arrêter le programme et de sortir de la boucle sans fin est d'exécuter Ctrl + C dans le terminal.
Si la condition était false, il n'exécuterait jamais le code à l'intérieur des accolades.
Une autre boucle est une boucle qui répète quelque chose un certain nombre de fois.
#include <stdio.h>
int main(void)
{
int i = 0;
while(i < 10)
{
// tant que i est inférieur à 10, exécute ce code
printf("Hello world");
// puis incrémente
i++
// vérifie la condition à chaque fois
// une fois que le code dans les accolades est exécuté, vérifie si i est toujours inférieur à 10.
// Si oui, exécute le code + incrémente à nouveau et vérifie à nouveau
// la boucle se terminera finalement lorsque i atteindra 10
}
}
Boucles Do-while
#include <stdio.h>
int main(void)
{
int i = 10;
do {
printf("la valeur de i : %i\n", i);
i++;
}
while( i < 20 );
}
Comparé à la boucle while, la boucle do-while est garantie de s'exécuter au moins une fois et d'exécuter le code à l'intérieur des accolades au moins une fois.
Elle fait d'abord quelque chose puis vérifie une condition. Cela est utile lorsque nous voulons répéter quelque chose au moins une fois mais pour un nombre inconnu de fois.
Dans notre exemple, le code s'exécutera au moins une fois et l'instruction sera imprimée au moins une fois. Ensuite, la valeur est incrémentée. Il vérifie ensuite si la valeur est inférieure à 20, et si c'est le cas, il exécute le code à nouveau. Il cessera d'exécuter le code une fois que la valeur incrémentée à chaque fois ne sera plus inférieure à 20.
Ressources pour continuer à apprendre C
Cela marque la fin de cette introduction au langage de programmation C ! Bon travail pour être arrivé jusqu'à la fin.
J'espère que cela vous a donné un aperçu des 'pourquoi' et des 'comment' du langage et des fondamentaux que vous devez connaître pour commencer à écrire des programmes de base en C.
Si vous souhaitez approfondir, construire quelques projets et résoudre des problèmes en utilisant C, essayez CS50 Introduction à l'informatique.
Si vous aimez apprendre en lisant des livres, je recommande ceux ci-dessous :
Si vous aimez apprendre en regardant des vidéos et en codant en même temps, consultez la vidéo de tutoriel de programmation C pour débutants sur la chaîne YouTube de freeCodeCamp.
Merci d'avoir lu et bon codage !