

Article original : What is DNS? Domain Name System, DNS Server, and IP Address Concepts Explained
Par Chloe Tucker
Introduction
À la fin de cet article, vous devriez avoir une meilleure compréhension de :
- Ce qu'est le DNS et ce qu'il fait
- Ce que font les serveurs DNS
- Comment les adresses du Protocole Internet (IP) fonctionnent dans le contexte du DNS
Concepts importants
Il y a quelques modèles mentaux essentiels à connaître lorsque l'on apprend le DNS, les serveurs DNS et les adresses IP. Passer en revue ces concepts maintenant, avant de commencer à apprendre le DNS, aidera à :
- donner un sens à tous les différents termes utilisés pour décrire le comportement qui s'inscrit dans ces modèles, et
- aider à la rétention de la mémoire.
Les modèles mentaux vous donnent un cadre de référence lorsque les choses deviennent un peu étranges et inhabituelles.
Alors, posons les bases.
- Requête et réponse. C'est lorsque la Chose 1 demande quelque chose à la Chose 2, et la Chose 2 répond à cette demande. Comme ceci :
 Requête et Réponse
Requête et Réponse
- Relations parent-enfant et graphes qui ressemblent à ceci (mais plus compliqués).
 Graphe d'arbre
Graphe d'arbre
- Messages. Ce n'est pas une requête et une réponse car il n'y a pas de réponse. Dans le monde du DNS, le formatage et le contenu des messages varient selon l'usage.
 Message
Message
- Relation client-serveur. En termes simples, un serveur est un dispositif logiciel ou matériel qui fournit des fonctionnalités pour d'autres dispositifs logiciels ou matériels, appelés « clients ».
Préparez-vous à entendre beaucoup parler de serveurs. Il s'avère qu'il y a énormément de serveurs qui entrent en jeu dans ce que nous appelons le DNS, et comment nous, en tant qu'êtres humains, l'utilisons lorsque nous nous connectons à Internet.
 Relation client-serveur
Relation client-serveur
Qu'est-ce que le DNS ?
Le Système de Noms de Domaine (DNS) associe les noms de domaine lisibles par les humains (dans les URLs ou les adresses email) aux adresses IP. Par exemple, le DNS traduit et associe le domaine freecodecamp.org à l'adresse IP 104.26.2.33.
Pour vous aider à comprendre pleinement cette description, cette section détaille :
- Le contexte historique du développement du DNS - quels problèmes résolvait-il ainsi que les adresses IP ?
- Les noms de domaine
- Les adresses IP
Contexte historique
En 1966, l'Agence pour les projets de recherche avancée (ARPA), une agence gouvernementale américaine, a fondé un réseau informatique appelé ARPAnet. En termes simples, pensez à ARPAnet comme la première itération de ce que nous connaissons aujourd'hui sous le nom d'Internet.
Les principaux objectifs d'ARPAnet incluaient
« (1) fournir une communication fiable même en cas de défaillance partielle de l'équipement ou du réseau, (2) pouvoir se connecter à différents types d'ordinateurs et de systèmes d'exploitation et (3) être un effort coopératif plutôt qu'un monopole contrôlé par une seule corporation. Afin de fournir une communication fiable en cas de défaillance de l'équipement, ARPANET a été conçu de sorte qu'aucun point ou lien ne soit plus critique qu'un autre. Cela a été accompagné par la construction de routes redondantes et l'utilisation du réacheminement à la volée des données si une partie du réseau tombait en panne. »
Les problèmes
Le DNS et le TCP/IP ont été cruciaux pour résoudre deux problèmes avec ARPAnet :
Pour ARPAnet, il y avait un seul emplacement (un fichier appelé HOSTS.TXT) qui contenait toutes les associations nom-adresse pour chaque hôte sur le réseau.
« HOSTS.TXT était maintenu par le Network Information Center de SRI (surnommé « le NIC ») et distribué à partir d'un seul hôte, SRI-NIC.[*] Les administrateurs d'ARPAnet envoyaient généralement leurs modifications au NIC par email, et téléchargeaient périodiquement par FTP vers SRI-NIC et récupéraient le fichier HOSTS.TXT actuel. Leurs modifications étaient compilées dans un nouveau fichier HOSTS.TXT une ou deux fois par semaine. »
Il y avait trois défis avec cette configuration :
- Trafic et charge - la distribution du fichier devenait trop lourde pour l'hôte responsable.
- Collisions de noms - chaque hôte devait avoir un nom unique, et il n'y avait pas d'autorité centralisée qui empêchait les utilisateurs du réseau d'ajouter un hôte avec un nom conflictuel (non unique), brisant ainsi « tout le système ».
- Cohérence - l'acte de mettre à jour le fichier et de s'assurer que tous les hôtes avaient la version la plus à jour est devenu impossible ou au moins très difficile.
En essence, HOSTS.TXT était un point de défaillance unique, donc tout le processus ne s'adaptait pas bien au-delà d'un certain nombre d'hôtes. ARPAnet avait besoin d'une solution décentralisée et évolutive. Le DNS était cette solution. Source
La communication hôte-à-hôte au sein du même réseau n'était pas suffisamment fiable. TCP/IP a aidé à résoudre ce problème.
- Le Protocole de Contrôle de Transmission (TCP) fournit des mesures d'assurance qualité pour le processus de transformation des messages (entre hôtes) en paquets. Le protocole TCP est orienté connexion, ce qui signifie qu'une connexion entre l'hôte source et l'hôte de destination doit être établie.
- Le Protocole Internet (IP) définit comment les messages (paquets) sont transportés entre l'hôte source et l'hôte de destination. Une adresse IP est un identifiant unique pour un chemin spécifique qui mène à un hôte sur un réseau.
- TCP et IP travaillent en étroite collaboration, c'est pourquoi ils sont généralement référencés comme « TCP/IP ».
- Bien que je ne m'étende pas sur ce sujet dans cet article, TCP et User Datagram Protocol (UDP) sont utilisés dans la couche de transport de données du DNS. UDP est plus rapide, beaucoup moins fiable, et ne nécessite pas de connexions ; TCP est plus lent, beaucoup plus fiable, mais nécessite des connexions. Ils sont utilisés selon les besoins et de manière appropriée dans le DNS ; il va sans dire que l'inclusion de TCP dans ARPAnet a été un ajout précieux à la couche de transport de données.
Au début des années 1980, le DNS et le TCP/IP (et donc, les adresses IP) étaient des procédures opérationnelles standard pour ARPAnet.
Cette histoire est très abrégée. Si vous souhaitez en apprendre davantage sur ces sujets, veuillez consulter la section Ressources à la fin de cet article.
Maintenant que nous avons un contexte historique, passons à l'apprentissage des noms de domaine et des adresses IP.
Noms de domaine
Dans le contexte du DNS, un nom de domaine fournit un moyen convivial pour pointer vers des ressources non locales. Cela pourrait être un site web, un système de messagerie, un serveur d'impression, ou tout autre serveur disponible sur Internet. Un nom de domaine peut être plus qu'un simple site web !
« L'objectif des noms de domaine est de fournir un mécanisme pour nommer les ressources de manière à ce que les noms soient utilisables dans différents hôtes, réseaux, familles de protocoles, internets et organisations administratives. »
Un nom de domaine est beaucoup plus facile à retenir et à entrer dans un terminal ou un navigateur Internet qu'une adresse IP.
Un nom de domaine fait partie d'un Localisateur de Ressource Uniforme (URL), mais les termes ne sont pas synonymes. Une URL est l'adresse web complète d'une ressource, tandis que le nom de domaine est le nom d'un site web et est un sous-composant de chaque URL.
Bien qu'il existe des distinctions techniques entre les URL et les noms de domaine, les navigateurs web les traitent généralement de la même manière, donc vous arriverez sur le site web si vous tapez l'adresse web complète ou simplement le nom de domaine.
Domaines de premier niveau et domaines de second niveau
Il y a deux parties à un domaine donné : le domaine de premier niveau (TLD) et le domaine de second niveau (SLD). Les parties d'un nom de domaine deviennent plus spécifiques en allant de la droite (fin) vers la gauche (début).
Cela peut être déroutant au début. Par exemple, regardons « freecodecamp.org »
- URL : https://www.freecodecamp.org
- Nom de domaine : freecodecamp.com
- TLD : org
- SLD : freecodecamp
Dans les premiers jours d'ARPAnet, il y avait un nombre limité de TLD disponibles, incluant com, edu, gov, org, arpa, mil, et des domaines de code de pays à 2 lettres. Ces TLD étaient initialement réservés aux institutions participant à ARPAnet, mais certains sont devenus disponibles sur les marchés commerciaux plus tard.
Aujourd'hui, il y a une richesse comparative de TLD disponibles, incluant net, aero, biz, coop, info, museum, name, et autres.
Les domaines de second niveau sont les domaines disponibles pour l'achat individuel via des registrars de domaines (par exemple, Namecheap).
Adresses IP
Bien que les adresses IP soient liées au DNS dans leur fonction, le Protocole Internet lui-même est techniquement séparé du DNS. J'ai déjà fourni un contexte historique pour cette distinction, alors maintenant je vais expliquer comment les adresses IP fonctionnent.
Une adresse IP, comme mentionné précédemment, est un identifiant unique pour un chemin spécifique qui mène à un hôte sur un réseau. J'aimerais faire référence à l'analogie d'un numéro de téléphone et d'un téléphone : un numéro de téléphone ne représente pas le téléphone lui-même, c'est juste un moyen d'atteindre la personne avec le téléphone.
Cette analogie est raisonnablement appropriée (au moins, à un niveau superficiel), avec les adresses IP. Une adresse IP représente un point final, mais ce n'est pas le point final lui-même. Les attributions d'IP peuvent être fixes (permanentes) ou dynamiques (flexibles et peuvent être réattribuées).
Comme un nom de domaine, l'organisation des adresses IP suit une structure hiérarchique. Contrairement aux noms de domaine, les adresses IP deviennent plus spécifiques en allant de gauche à droite. Voici un exemple d'IPv4 ci-dessous :
 Ce diagramme montre que 129.144 est la partie réseau et 50.56 est la partie hôte d'une adresse IPv4.
Ce diagramme montre que 129.144 est la partie réseau et 50.56 est la partie hôte d'une adresse IPv4.
- Réseau : le numéro unique attribué à votre réseau
- Hôte : identifie l'hôte (machine) sur le réseau
Si une plus grande spécificité est nécessaire, les administrateurs réseau peuvent sous-réseauter l'espace d'adressage et déléguer des numéros supplémentaires.
Combien d'adresses IP existe-t-il ?
IPv4 était la toute première itération d'IP qu'ARPAnet utilisait en production. Déployé au début des années 80, c'est toujours la version IP la plus répandue. C'est un schéma 32 bits, et peut donc supporter un peu plus de 4 milliards d'adresses.
Mais attendez, est-ce suffisant ? Non.
IPv6 a un schéma 128 bits, ce qui lui permet de supporter 340 undécillions d'adresses. Il offre également des améliorations de performance par rapport à IPv4.
Exemple d'adresse IPv4 :
- 104.26.2.33 (freeCodeCamp)
Exemple d'adresse IPv6 :
- 2001:db8:a0b:12f0::1 (le format compressé et ne pointant pas vers freeCodeCamp)
Comment fonctionne le Système de Noms de Domaine ?
Alors, nous avons appris les noms de domaine ! Nous avons appris les adresses IP ! Maintenant, comment se rapportent-ils au Système de Noms de Domaine ?
Tout d'abord, ils s'intègrent dans l'espace de noms.
L'espace de noms de domaine
Comme le suggère le langage « domaine de premier niveau » et « domaine de second niveau », l'espace de noms est basé sur une hiérarchie
« ...avec la hiérarchie correspondant approximativement à la structure organisationnelle, et les noms utilisant "." comme caractère pour marquer la frontière entre les niveaux de hiérarchie. » Source.
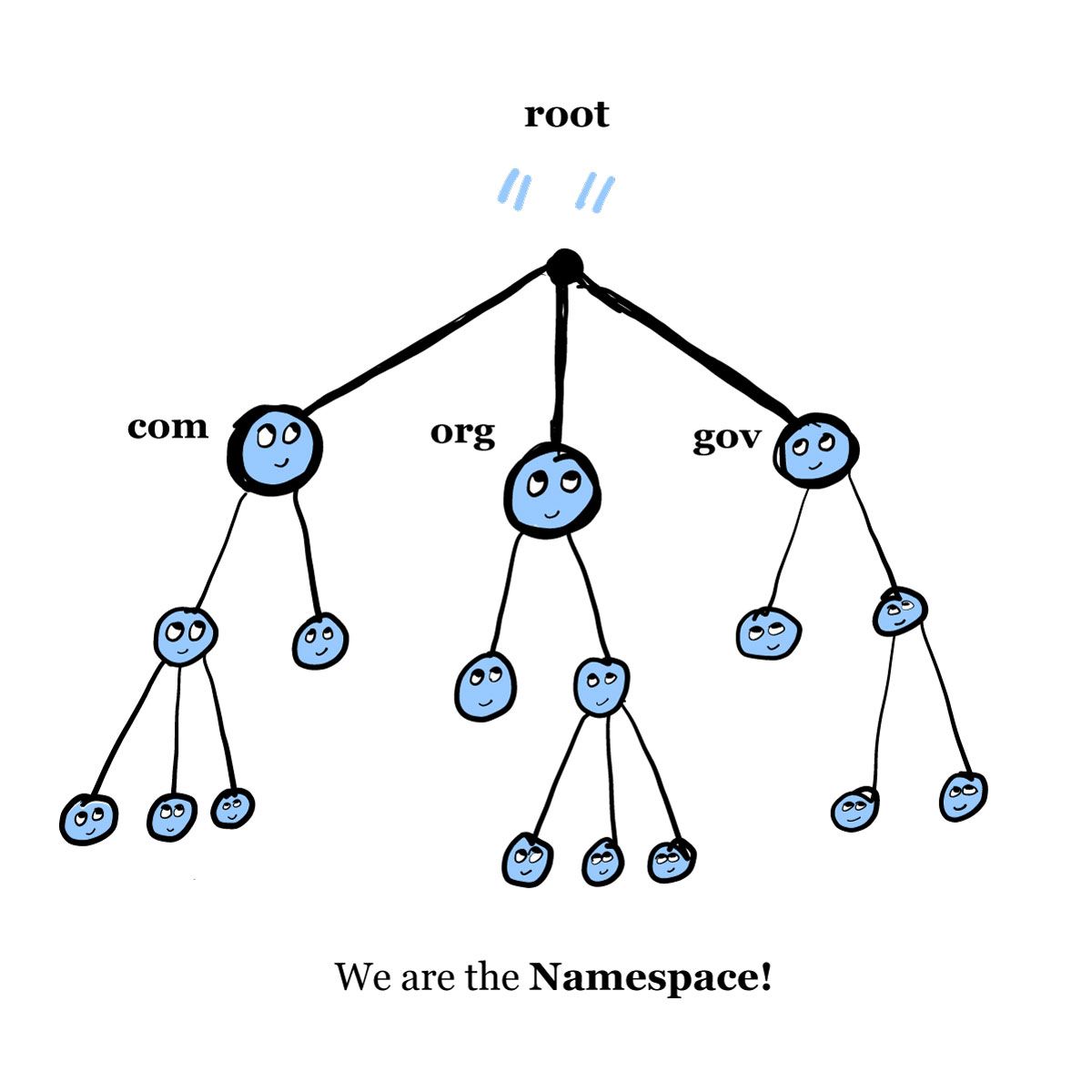
Ce graphe d'arbre, avec la racine en haut, illustre le mieux la structure :
 L'espace de noms
L'espace de noms
Décomposons cela, en commençant par le haut.
Le haut de ce graphe, noté avec un « . », est appelé la « racine ».
« Les serveurs de noms faisant autorité qui servent la zone racine du DNS, communément appelés les « serveurs racine », sont un réseau de centaines de serveurs dans de nombreux pays à travers le monde. Ils sont configurés dans la zone racine du DNS en tant que 13 autorités nommées. »
Le domaine racine a une étiquette de longueur nulle.
À partir de là, chaque nœud (point) dans le graphe a une étiquette unique pouvant aller jusqu'à 63 caractères de long.
Le premier niveau en dessous de la racine sont les TLD : les com, org, edu, et gov. Veuillez noter que ce graphe ne contient pas une liste complète des TLD.
En dessous des TLD se trouvent les SLD, les domaines de second niveau. Les enfants de chaque nœud sont appelés « sous-domaines », qui sont toujours considérés comme faisant partie du domaine parent. Par exemple, dans freecodecamp.org, freecodecamp (le SLD) est un sous-domaine de org (le TLD).
Selon la hiérarchie du site web, il peut y avoir des domaines de troisième, quatrième, cinquième niveau. Par exemple, dans hypothetical-subdomain.freecodecamp.org, hypothetical-subdomain est le domaine de troisième niveau, et le sous-domaine de freecodecamp. Et ainsi de suite, au moins jusqu'à 127 niveaux, ce qui est le maximum autorisé par le DNS.
Qui gère l'espace de noms ?
Ne serait-ce pas fou d'essayer d'avoir une seule personne ou organisation pour administrer tout ? Oui, ce serait le cas. Surtout parce que l'un des principaux objectifs de conception du DNS était de promouvoir une gestion distribuée et décentralisée du système dans son ensemble.
Je voudrais pouvoir vous dire que les personnes en charge s'appellent les « Rois de l'espace de noms », mais hélas.
Chaque domaine (ou sous-domaine) dans l'espace de noms de domaine est ou fait partie d'une zone, « une partie autonomement administrée de l'espace de noms ». Ainsi, l'espace de noms est divisé en zones.
La responsabilité de ces zones est gérée par délégation et administration.
Le processus d'attribution de la responsabilité des sous-domaines à d'autres entités est appelé délégation.
Par exemple, le Public Interest Registry administre le nom de domaine org, et ce depuis 2003. Le Public Interest Registry peut déléguer la responsabilité à d'autres parties pour gérer les sous-domaines de org, disons freecodecamp. Et ensuite, celui qui administre freecodecamp peut attribuer la responsabilité des sous-domaines de freecodecamp (par exemple, hypothethical-subdomain.freecodecamp.com) à une autre partie.
Si quelqu'un (une organisation, une équipe ou un individu) administre une zone, ce qu'il fait, c'est administrer le serveur de noms qui est responsable de la zone.
Cela nous amène à l'un des concepts les plus fondamentaux du Système de Noms de Domaine.
Serveurs de noms de domaine
« Les programmes qui stockent des informations sur l'espace de noms de domaine sont appelés serveurs de noms. »
À ce stade, penser à une relation client-serveur, au moins initialement, est utile. Les serveurs de noms de domaine sont le côté « serveur » de la relation client-serveur. Les serveurs de noms peuvent charger une, des centaines, voire des milliers de zones, mais ils ne chargent jamais l'intégralité de l'espace de noms. Une fois qu'un serveur de noms a chargé la totalité d'une zone, il est dit « faisant autorité » pour cette zone.
Pour comprendre pourquoi les serveurs de noms fonctionnent comme ils le font, il est utile de comprendre la partie « client » de la relation.
Résolveurs
Dans le DNS, le client (le demandeur d'informations) est appelé le « résolveur », ce qui peut sembler inversé au premier abord. Le serveur qui résout la demande ne serait-il pas appelé le « résolveur » ? Je le pensais aussi, mais ce n'est pas le cas. Mieux vaut simplement mémoriser cela et passer à autre chose.
Les résolveurs sont généralement inclus, de facto, dans la plupart des systèmes d'exploitation, de sorte que les applications installées sur le système d'exploitation n'ont pas à comprendre comment effectuer des requêtes DNS de bas niveau.
Les requêtes DNS et leurs réponses sont des types de messages DNS, et ont leur propre protocole de transport de données (généralement UDP). Les résolveurs sont responsables d'aider les applications installées sur le système d'exploitation à traduire les demandes de données liées au DNS en requêtes DNS.
En somme, les résolveurs sont responsables de l'emballage et de l'envoi des demandes de données. Une fois que le résolveur reçoit la réponse (si réponse il y a), il la transmet à l'application demandeur originale dans un format consommable par l'application demandeur.
Retour aux serveurs de noms
Maintenant que nous sommes un peu plus familiers avec le côté client de la relation, nous devons comprendre comment les serveurs de noms de domaine répondent aux requêtes des résolveurs.
Les serveurs de noms répondent aux requêtes DNS par le biais de la résolution. La résolution est le processus par lequel les serveurs de noms trouvent des fichiers de données dans l'espace de noms. Selon le type de requête, les serveurs de noms répondent différemment à différentes requêtes, mais le but final est la résolution.
Types de requêtes
Type de requête ? Oui, il existe plusieurs types de requêtes DNS. Mais d'abord, qu'y a-t-il généralement dans une requête DNS ? C'est une demande d'informations, spécifiquement pour l'adresse IP associée à un nom de domaine.
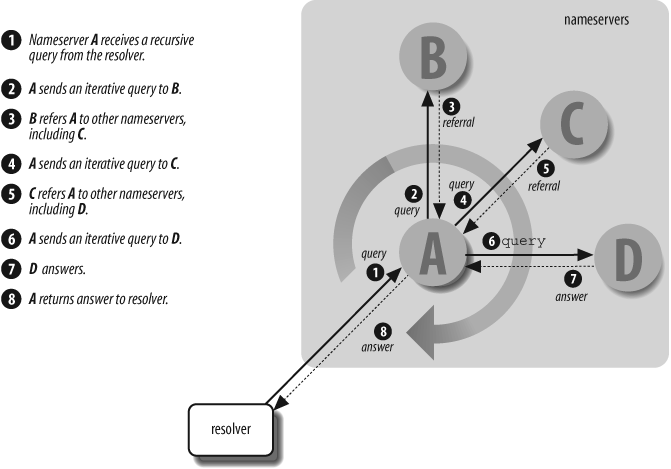
- Récursive : les requêtes récursives permettent à la requête d'être référée à plusieurs serveurs de noms pour être résolue. Si le premier serveur de noms interrogé ne possède pas les données souhaitées, alors ce serveur de noms envoie la requête au serveur de noms suivant le plus approprié, jusqu'à ce que le serveur de noms contenant les fichiers de données souhaités soit trouvé et envoie une réponse au résolveur.
- Itérative : les requêtes itératives nécessitent que le serveur de noms interrogé réponde soit avec les données souhaitées, soit avec une erreur. La réponse peut contenir l'adresse IP du serveur de noms le plus approprié pour envoyer la requête suivante ; le résolveur peut alors envoyer une autre requête à ce serveur de noms plus approprié.
Au cas où vous en auriez besoin, vous pouvez également interroger le nom de domaine, si tout ce que vous avez est l'adresse IP. Cela s'appelle une recherche DNS inverse.
Une fois que la requête atteint un serveur de noms qui contient les fichiers de données souhaités, alors la requête peut être résolue. Les serveurs de noms ont un certain nombre de fichiers de données associés à eux, tous ou certains d'entre eux peuvent être utilisés pour résoudre la requête.
Enregistrements de ressources (RR)
Ce sont les fichiers de données dans l'espace de noms de domaine. Ces fichiers de données ont des formats et des contenus spécifiques.
Les RR les plus courants :
- Enregistrement A : si vous n'avez entendu parler d'aucun autre RR sauf celui-ci, cela aurait du sens. C'est probablement le RR le plus connu et il contient l'adresse IP du domaine donné.
- Enregistrement CNAME : si vous n'avez entendu parler d'aucun autre RR sauf celui-ci et l'enregistrement A, cela aurait également du sens. Le « C » signifie « canonique », et est utilisé à la place d'un enregistrement A, pour attribuer un alias à un domaine.
- Enregistrement SOA : cet enregistrement contient des informations administratives sur le domaine, y compris l'adresse email de l'administrateur. Conseil : si vous administrez une zone, assurez-vous qu'il y a une adresse email valide ici, afin que les gens puissent vous contacter si nécessaire.
- D'autres types importants d'enregistrements de ressources (RR) sont PR, NS, SRV et MX. Lisez à leur sujet ici.
Mise en cache et temps de vie (TTL)
Lorsque le serveur de noms local reçoit une réponse à une requête, il met en cache ces données (les stocke en mémoire), de sorte que la prochaine fois qu'il reçoit la même requête, il peut simplement répondre à la requête directement plutôt que de passer par le processus de résolution original, plus long.
Mais une fois que ces informations sont mises en cache, elles sont à la fois statiques et isolées, et risquent donc de devenir obsolètes. Par conséquent, tous les enregistrements de ressources ont ce qu'on appelle une valeur de temps de vie (TTL), qui dicte combien de temps ces données peuvent être mises en cache. Lorsque ce temps est écoulé (atteint zéro), le serveur de noms supprime l'enregistrement.
Note importante : le TTL ne s'applique pas aux serveurs de noms qui sont autoritaires pour la zone contenant l'enregistrement de ressource. Il ne s'applique qu'au serveur de noms qui a mis en cache cet enregistrement de ressource.
Une journée dans la vie d'une requête
Nous avons couvert beaucoup de terrain dans cet article, et cela a été lourd en concepts. Pour tout rassembler et le rendre réel, voici une journée (au sens figuré) dans la vie d'une requête.
Alors, pourquoi dois-je connaître tout cela ?
Il y a tant de raisons d'être familier avec les concepts liés au DNS et aux adresses IP.
- Tout d'abord, c'est l'épine dorsale de l'Internet, cette chose que beaucoup d'entre nous utilisons, pour laquelle nous développons des sentiments (amour/haine/vous-nommez), et que nous tenons pour acquise chaque jour. Il est important d'être familier avec les structures qui nous permettent d'accomplir de grandes choses aujourd'hui avec la technologie et l'Internet.
- Des personnes incroyablement intelligentes ont passé des décennies de leur vie à construire tout cela ! Reconnaissons et apprécions leurs contributions.
- Maintenant que j'ai exprimé les choses émouvantes, il est important d'être familier avec les concepts du DNS au cas où vous seriez responsable de quelque chose lié à l'infrastructure dans votre entreprise, votre équipe ou votre propre entreprise. Avoir un cadre de référence lorsque des problèmes importants surviennent vous permet d'agir plus rapidement et de trouver des solutions plus tôt.
Conclusion
À ce stade, vous devriez comprendre ce qu'est le DNS et ce qu'est un serveur de noms, ainsi que vous familiariser avec les concepts techniques liés aux adresses IP.
De nombreux livres ont été écrits sur le sujet et approfondissent le monde fascinant du DNS, et il y a tant de choses à apprendre. Les sujets qui n'ont pas été inclus dans cet article mais qui font partie du DNS ou qui y sont très liés incluent :
- Les implémentations de serveurs de noms
- Le transfert
- (Plus sur) les étiquettes de nœuds
- Les relations entre serveurs de noms primaires et secondaires
- Les algorithmes de retransmission
- L'équilibrage de charge
- De plus, d'autres sujets plus généraux sur le fonctionnement de l'Internet, comme :
- Le World Wide Web
- HTTP
- FTP
- Les couches de protocole de communication : couche de liaison, couche IP, couche de transport, couche Internet, etc.
Pour ceux d'entre vous qui lisent encore et veulent en apprendre davantage sur le DNS, je recommande avant tout « DNS et BIND, 5e éd. », écrit par Cricket Liu et publié par O'Reilly Media. C'est inestimable.
Je encourage également tout le monde à explorer les originales Request for Comments (RFC) liées ci-dessous. Non seulement il y a des points pour la lecture de sources primaires, mais ce sont également des documents exceptionnellement bien organisés et compréhensibles, ce qui explique pourquoi je les ai cités dans cet article.
Ressources
- RFC 1034 : DOMAIN NAMES - CONCEPTS AND FACILITIES
- RFC 1035 : DOMAIN NAMES - IMPLEMENTATION AND SPECIFICATION
- RFC 1122 : Requirements for Internet Hosts -- Communication Layers
- Plus sur les objectifs de conception du DNS, de Connected : An Internet Encyclopedia
- Comment l'Internet est né de l'ARPAnet à l'Internet, de The Conversation
- Cours vidéo sur l'apprentissage du DNS, par Cricket Liu, d'O'Reilly Media
Un peu sur moi
Je suis Chloe Tucker, une artiste et développeuse à Portland, Oregon. En tant qu'ancienne éducatrice, je recherche continuellement l'intersection de l'apprentissage et de l'enseignement, ou de la technologie et de l'art. Contactez-moi sur Twitter @_chloetucker et consultez mon site web à l'adresse chloe.dev.