


Article original : What is DNS? Basics for Beginners
Lorsque vous accédez à un site web comme www.google.com, seriez-vous surpris d'apprendre que l'URL n'est pas vraiment l'adresse du site web ?
Il y a un certain travail "sous le capot" pour s'assurer que, lorsque vous tapez un nom convivial comme Google, il vous emmène vers le site web que vous attendez.
Alors, que se passe-t-il sous le capot ?
Qu'est-ce qu'une URL ?
Vous êtes peut-être familier avec ce qu'est une URL. C'est un simple lien vers un contenu sur le web. Les gens utilisent des URL quotidiennement pour partager des vidéos, des images, des sites, des articles - presque tout sur l'internet.
URL est un acronyme pour Uniform Resource Locator, et nous pouvons les décomposer en plusieurs "morceaux" plus petits. Voici ce qui compose une URL standard :
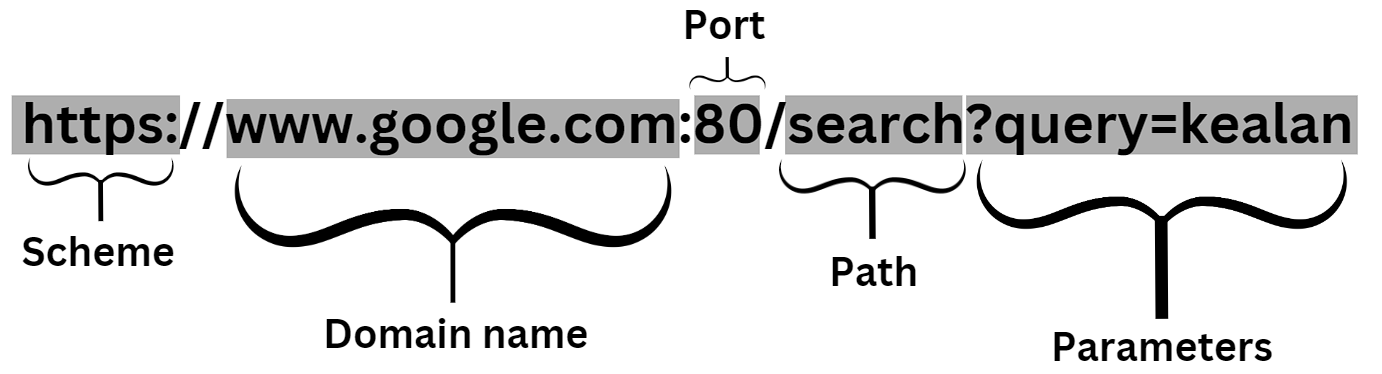 Anatomie d'une URL montrant le Schéma, le Nom de Domaine, le Chemin et les Paramètres
Anatomie d'une URL montrant le Schéma, le Nom de Domaine, le Chemin et les Paramètres
Une URL est simplement une adresse pour une ressource. Les ressources diffèrent comme nous l'avons discuté, mais ce sont simplement des pointeurs partout sur l'internet pour vous emmener vers le contenu que vous souhaitez voir.
Comme vous pouvez le voir dans le graphique ci-dessus, la décomposition d'une URL est souvent :
- Schéma : il s'agit du protocole qu'un navigateur utilise pour accéder à votre contenu. Normalement pour les sites web, c'est HTTP (non sécurisé), ou HTTPS (sécurisé).
- Nom de domaine : le nom du site web ("www.google.com" ici)
- Port : un port réseau (80 dans cet exemple)
- Chemin : un chemin vers une ressource particulière sur le serveur
- Paramètres : souvent des paires clé-valeur, pour servir des données supplémentaires au serveur web.
Qu'est-ce qu'une adresse IP ?
Les humains et les ordinateurs naviguent sur le web de manière très différente. Alors que la plupart des humains utilisent des URL comme nous venons de le discuter, pour communiquer entre ordinateurs, les ordinateurs utilisent le Protocole Internet (IP).
Le IP est un ensemble de règles qui acheminent et adressent les paquets de données (toutes les données que vous souhaitez voir) pour s'assurer qu'ils arrivent sur votre ordinateur.
Le Protocole Internet repose sur des appareils et des domaines, tous ayant leur propre adresse IP pour se connecter et identifier tous les différents segments (paquets !) de l'internet.
Une adresse IP est une série de nombres standardisés allant de 0 à 255 - séparés par des points.
Si vous voulez voir des adresses IP en action, et que vous êtes familier avec les terminaux, vous pouvez taper ping google.com dans le terminal de votre choix et vous pouvez voir l'adresse IP de Google.com.
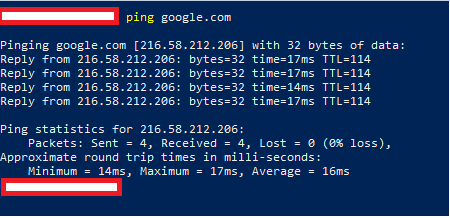 Capture d'écran d'un terminal PowerShell, montrant une commande ping vers 216.58.212.206, et 0% de perte de paquets.
Capture d'écran d'un terminal PowerShell, montrant une commande ping vers 216.58.212.206, et 0% de perte de paquets.
Vous pouvez tester cela davantage en tapant 216.58.212.206 directement dans votre navigateur et voir si cela vous emmène à Google.
Espérons que cet exemple met en lumière pourquoi nous utilisons des URL. Si les deux adresses (adresse IP et nom de domaine) vous ont emmené au même endroit, préféreriez-vous qu'on vous demande de retenir Google.com ou 216.58.212.206 ?
Notez que certaines adresses IP changent jour après jour (appelées adresses IP dynamiques) - donc l'adresse IP ci-dessus peut ne pas fonctionner, selon que l'adresse IP est dynamique ou statique.
Les adresses IP statiques sont celles qui ne changent pas - mais attribuer une seule adresse IP à chaque machine serait impraticable. Ce serait aussi un cauchemar logistique, car certaines personnes ne se connectent à un ordinateur qu'une fois par mois pour envoyer un e-mail, par exemple.
Nous pourrions très réalistement manquer d'adresses IP avec la technologie actuelle si nous donnions à chaque appareil une adresse IP unique (si vous voulez lire comment les adresses IP sont allouées en détail, lisez ici).
Qu'est-ce qu'un DNS ?
Si nous savons que les ordinateurs communiquent via le Protocole Internet et utilisent des adresses IP, comment transformons-nous google.com en le site web que nous utilisons si régulièrement ?
La réponse est d'utiliser un Système de Noms de Domaine (DNS). Le rôle du Système de Noms de Domaine est de transformer les noms de domaine lisibles par l'homme en adresses IP.
Il y a quatre serveurs spécifiques dont nous allons discuter.
DNS Recursor
Un DNS Recursor est comme un serveur dans un restaurant. Il agit comme une partie "tournée vers l'avant" du système pour recevoir les commandes (normalement des navigateurs) où le serveur se dirige ensuite vers l'arrière pour obtenir ce qui est nécessaire.
En réalité, ce n'est qu'un serveur qui reçoit des requêtes DNS des navigateurs et renvoie des informations.
Il y a 3 endroits différents où le DNS recursor peut généralement obtenir les informations en fonction de si des données ont été mises en cache :
- Serveur de noms racine
- Serveur de noms de domaine de premier niveau
- Serveur de noms faisant autorité
Alors discutons-les un par un.
Qu'est-ce qu'un serveur de noms racine ?
Le rôle principal du serveur de noms racine est de retourner le serveur de domaine de premier niveau (TLD).
C'est une étape importante pour mapper les noms d'hôtes en adresses IP.
Le serveur de noms racine agit essentiellement comme un catalogue qui pointe vers des emplacements plus spécifiques.
Qu'est-ce qu'un serveur de domaine de premier niveau (TLD) ?
Si le serveur de noms racine agit comme un catalogue, le serveur TLD agit comme une page dans un catalogue.
Le serveur TLD retourne généralement la dernière partie du nom d'hôte, comme com par exemple, dans "google.com".
Qu'est-ce qu'un serveur de noms faisant autorité ?
Ce serveur est comme une entrée de ligne sur la page spécifique du catalogue.
Le serveur de noms faisant autorité peut maintenant retourner l'adresse IP pour le nom d'hôte demandé depuis le navigateur, vers le DNS recursor - qui peut la renvoyer au navigateur.
Le DNS peut être super confus, et comprendre tout le processus peut prendre un peu de temps, alors attachons-le avec un dernier exemple.
Exemple de requête
Décomposons une requête d'exemple d'un utilisateur, et attachons ensemble ce processus assez complexe.
Chaque étape du flux commence à pointer de plus en plus près de l'adresse finale que l'utilisateur finira par atteindre.
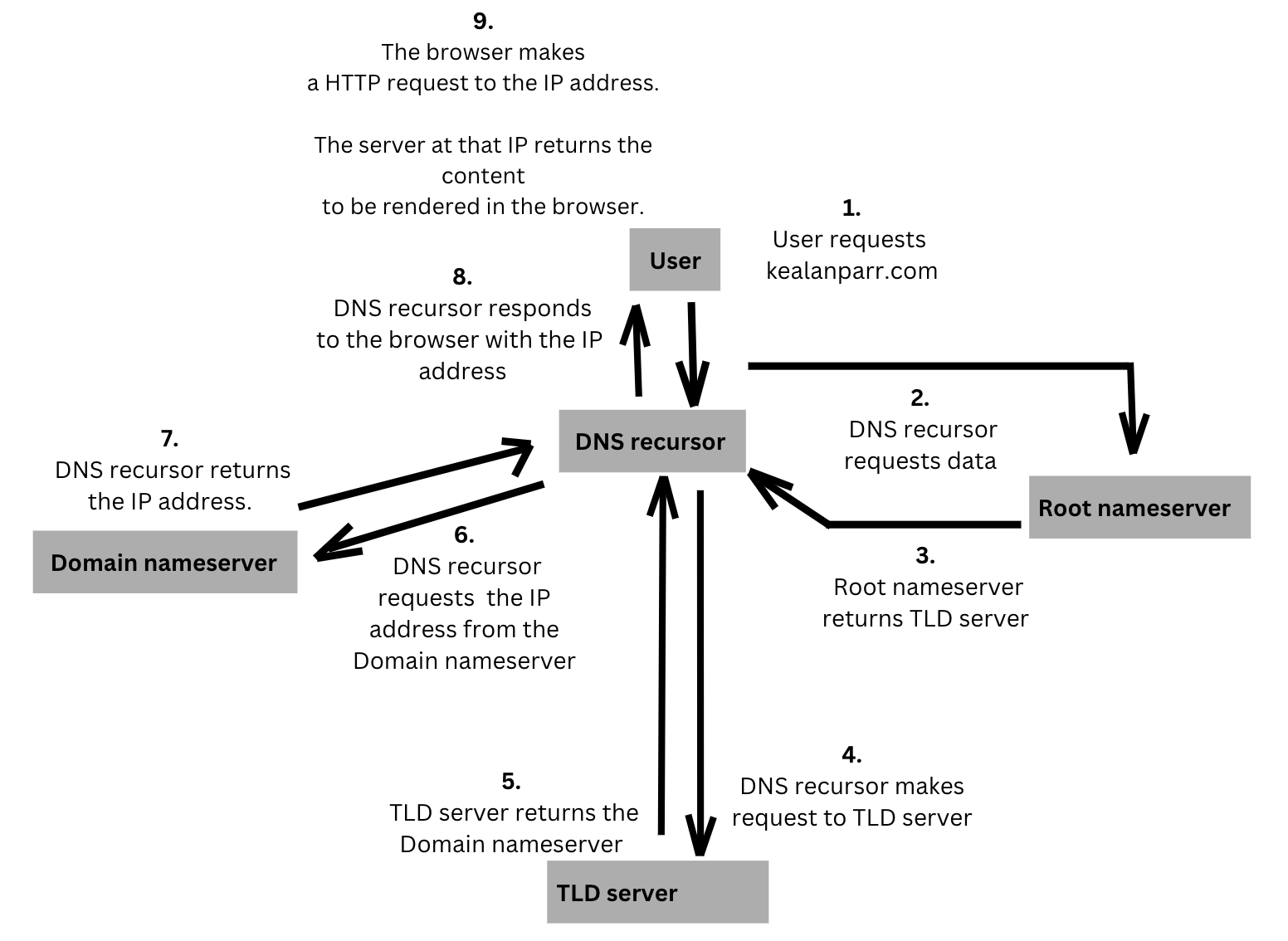 Diagramme montrant les étapes du processus de requête
Diagramme montrant les étapes du processus de requête
Décomposons ce qui se passe dans ce graphique :
Étape 1 :
Un utilisateur tape 'kealanparr.com' dans son navigateur, et la requête atteint le DNS recursor.
Étape 2 :
Le DNS recursor interroge ensuite un serveur de noms racine.
Étape 3 :
Le serveur de noms racine répond ensuite au DNS recursor avec l'adresse d'un serveur de domaine de premier niveau (TLD) tel que .com.
Étape 4 :
Le DNS recursor fait ensuite une requête au TLD .com.
Étape 5 :
Le serveur TLD .com répond ensuite avec l'adresse IP du serveur de noms du domaine, kealanparr.com.
Étape 6 :
Le DNS recursor envoie une requête au serveur de noms du domaine.
Étape 7 :
L'adresse IP pour kealanparr.com est ensuite retournée au résolveur depuis le serveur de noms de domaine.
Étape 8 :
Le DNS recursor répond à la requête du navigateur web avec l'adresse IP du domaine demandé.
Étape 9 :
À ce stade, la recherche DNS a retourné suffisamment de données pour que le navigateur fasse la requête pour la page web.
- Le navigateur fait une requête HTTP à l'adresse IP.
- Le serveur à cette IP retourne le contenu de la page web à rendre dans le navigateur.
Conclusion
J'espère que cet article vous a aidé à comprendre quelques principes de mise en réseau qui affectent les sites web que vous utilisez quotidiennement.
Les adresses IP, le DNS, et plus encore sont toutes des technologies que la plupart des gens utilisent quotidiennement mais qu'ils ne connaissent peut-être pas très bien.
Cloudflare a un article qui m'a été utile lors de mes recherches pour cet article, que vous pouvez lire ici.
Je tweete mes articles ici si vous souhaitez en lire davantage.