

Article original : What is Serialization?
Par George Offley
Lors d'une récente réunion de mise à jour de projet, mon équipe a discuté de la manière dont nous allions utiliser la sérialisation pour envoyer des données d'une application à une autre.
Un ingénieur qui cherchait à s'impliquer davantage dans des projets logiciels m'a dit qu'il n'était pas familier avec ce terme.
Il est facile de manquer des processus essentiels comme ceux-ci qui ne se présentent pas jusqu'à ce que vous vous lanciez dans des projets plus importants. C'était le cas pour cette personne, comme ce fut le cas pour moi à un moment donné.
Alors j'ai voulu en écrire. J'ai aidé mon collègue à apprendre la sérialisation ce jour-là, et vous allez l'apprendre aujourd'hui.
Qu'est-ce que la Sérialisation ?
La sérialisation est le processus dans lequel un service prend une structure de données, comme un dictionnaire en Python, l'emballe et la transmet à un autre service pour lecture. C'est la définition simple.
Imaginez que je dois envoyer un message à quelqu'un. Alors j'écris le texte sur un puzzle déjà assemblé. Je démonte les pièces, ajoute quelques instructions sur la manière de réassembler le puzzle, et je l'envoie.
Le destinataire du message reçoit alors les pièces du puzzle, les remet toutes ensemble, et maintenant il a mon message.
 Flux de base des événements de sérialisation
Flux de base des événements de sérialisation
La définition technique est un peu plus amusante. À savoir, la sérialisation est le processus de conversion d'un objet de données en un flux d'octets, et de sauvegarde de l'état de l'objet pour être stocké sur un disque ou transmis à travers un réseau. Cela réduit la taille de stockage nécessaire et facilite le transfert d'informations sur un réseau.
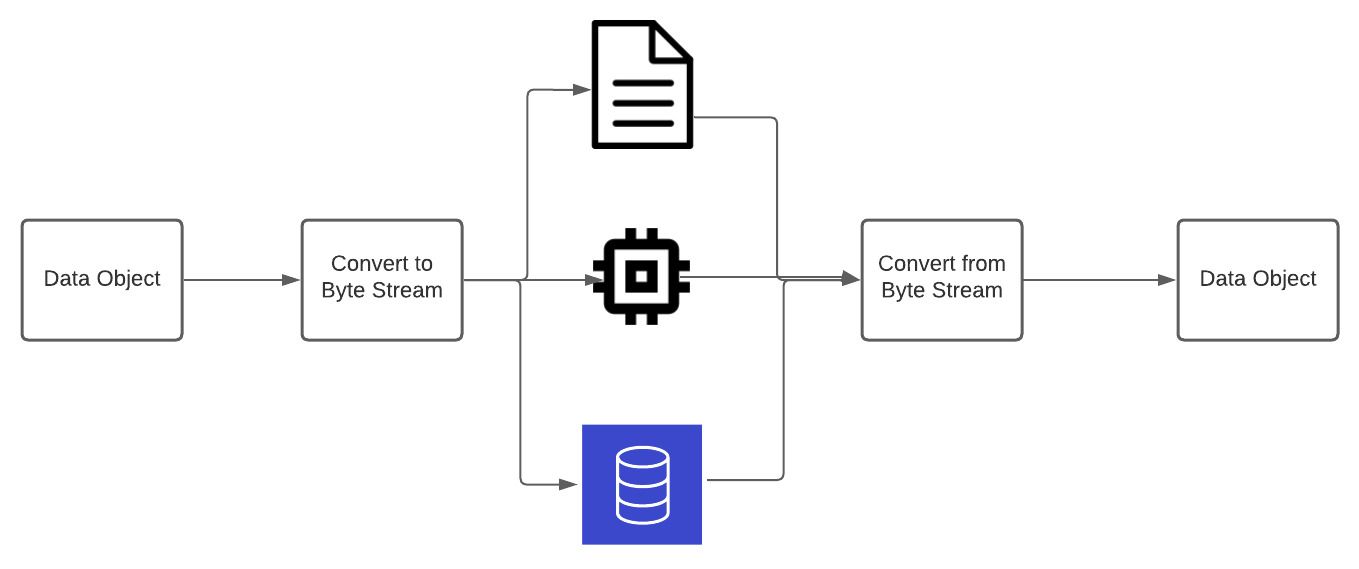 Processus de sérialisation
Processus de sérialisation
Marshaling et Sérialisation - quelles sont les différences ?
Le processus de marshaling pourrait venir à l'esprit. Le marshaling est le processus de transformation de la représentation mémoire d'un objet en une forme adaptée à la transmission.
Bien que le marshaling et la sérialisation soient loin d'être synonymes, il existe une différence cruciale. Par exemple, lors de la création d'un programme Golang pour lire des données JSON dans une structure de données Golang, vous pourriez utiliser le marshaling pour traduire les valeurs des clés JSON en valeurs des clés Golang.
La différence est que le marshaling pourrait être utilisé pour traduire des données. En revanche, la sérialisation envoie ou stocke des données dans un flux d'octets et les réassemble dans leur forme originale. Les deux font de la sérialisation, mais il y a une différence d'intention dans ces deux processus.
Vous pouvez voir cette structure que j'ai créée pour interagir avec les données Twitter ci-dessous comme un exemple de marshaling en action. En Golang, vous pouvez donner des indices appelés tags, convertissant facilement cet objet en données JSON en utilisant le service de marshaling intégré de Golang.
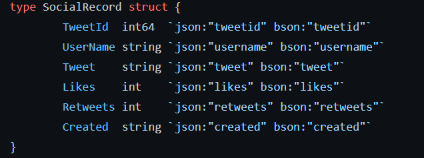 Struct Golang utilisant des tags JSON
Struct Golang utilisant des tags JSON
Qu'est-ce que l'Endianness ?
J'aimerais également aborder légèrement le sujet de l'endianness. L'endianness est un terme utilisé pour décrire l'ordre des octets en mémoire.
Vous pouvez penser à la mémoire comme un bloc où les bits de données sont stockés. Pour que la sérialisation fonctionne, le flux d'octets doit transférer des types de données indépendamment de l'endianness changeante d'un système à un autre.
Vous pouvez voir les différences entre little et big-endian ci-dessous. Il est essentiel que l'endianness corresponde d'un système à un autre ou soit convertie d'une manière ou d'une autre, car tous les systèmes n'ordonnent pas leurs bits de la même manière.
 Little et big-endian Courtesy of https://pvs-studio.com/en/blog/lessons/0019/
Little et big-endian Courtesy of https://pvs-studio.com/en/blog/lessons/0019/
Cas d'utilisation de la Sérialisation
Notre cas d'utilisation tire pleinement parti de ces fonctionnalités. Nous prévoyons de prendre certaines informations du matériel que nous scannons, d'emballer ces informations dans un flux d'octets, et de les envoyer via le réseau à un autre service qui reconstruira les données.
Le processus d'inversion du processus de sérialisation et de reconstruction des données dans leur forme originale est appelé désérialisation.
Il existe d'autres cas d'utilisation pour cela. Par exemple, les API REST ou les protocoles de messagerie tels que AMQP peuvent utiliser la sérialisation pour compresser et envoyer des données.
AMQP est un protocole de messagerie où vous envoyez des messages à un courtier AMQP, et le service récepteur "écoute" ce courtier pour un message. Les ingénieurs backend pourraient bien connaître cela, car cela est souvent utilisé pour envoyer des données d'un bout à l'autre dans des systèmes distribués.
De nombreux langages de programmation incluent la capacité de mettre en place facilement une certaine sérialisation. C'est donc un sujet indépendant du langage.
Exemple de Sérialisation
Donnons un exemple rapide. Ce code utilise la bibliothèque kombu pour envoyer des messages via AMQP. Nous utilisons cela pour envoyer des messages d'un logiciel à un autre via un réseau. Ce code est pour un service envoyant un message à un courtier AMQP :
def send_message(self, payload, sender_serializer):
...
try:
producer.publish(
{'payload': message},
...
serializer = 'json',
...
)
return
Notez la méthode publish. Nous passons la méthode de sérialisation en tant qu'argument afin que la bibliothèque sache comment sérialiser les données que nous passons.
Le message de données est converti en un flux d'octets, qui, si vous le regardez, ressemble simplement à une longue chaîne de lettres et de chiffres, et nous envoyons le message.
Le service correspondant utilisera la même méthode de sérialisation pour reconstruire les données dans leur état original. C'est une fonctionnalité significative car nous créons une suite d'outils qui doivent pouvoir s'envoyer des messages les uns aux autres pour qu'ils fonctionnent.
Formats de Données de Sérialisation
J'utilise JSON pour la sérialisation chaque fois que la tâche à accomplir l'exige. Cependant, vous pouvez également utiliser quelques autres.
JSON a beaucoup de surcharge, mais la lisibilité humaine le rend idéal pour moi. Vous pouvez également utiliser Protobufs, YAML, ou XML. Ce ne sont là que quelques-uns des formats d'objets de données que vous pouvez utiliser.
Conclusion
Je suis content d'avoir pu exprimer cela. J'ai pu arrêter de penser à cela, et, espérons-le, quelqu'un a appris quelque chose.
La sérialisation devient essentielle lorsque vous mettez en place votre pipeline de communication. Il est bon de connaître ce sujet pour aborder en toute confiance l'outil que vous utilisez avec les connaissances de base appropriées.
-George