


Article original : What are the SOLID Principles in C#? Explained With Code Examples
Les principes SOLID sont cinq principes de conception logicielle qui vous aident à écrire des logiciels de haute qualité, flexibles, maintenables, réutilisables, testables et lisibles. Si vous prévoyez de travailler avec des logiciels orientés objet, il est crucial de comprendre ces cinq principes.
Les principes SOLID ont été introduits par un ingénieur logiciel nommé Robert C. Martin (également connu sous le nom d'"Uncle Bob") au début des années 2000. Le but d'Uncle Bob était de promouvoir de bonnes pratiques de conception logicielle, en particulier en programmation orientée objet (POO), en abordant les problèmes courants auxquels les développeurs sont confrontés à mesure que les systèmes logiciels grandissent en taille et en complexité.
Voici les cinq principes SOLID :
En suivant ces principes, vous pouvez créer des conceptions logicielles plus faciles à comprendre, à maintenir et à étendre, conduisant à des logiciels de meilleure qualité, plus robustes et adaptables au changement.
Dans cet article, pour démontrer chaque principe, je vais d'abord vous montrer un mauvais exemple de code en C# qui viole le principe. Nous discuterons ensuite des problèmes que ce mauvais code cause, puis nous résoudreons ces problèmes en refactorisant le code pour satisfaire le principe.
Commençons par le...
Principe de responsabilité unique (SRP) en C
Une classe ne devrait avoir qu'une seule raison de changer, ce qui signifie qu'elle ne devrait avoir qu'une seule responsabilité ou but.
Ce principe encourage la création de classes plus focalisées et effectuant une seule tâche bien définie, plutôt que plusieurs tâches. Diviser les classes en unités plus petites et plus focalisées rend le code plus facile à comprendre, à maintenir et à tester.
Un exemple qui viole le SRP :
public class User
{
public string Username { get; set; }
public string Email { get; set; }
public void Register()
{
// Logique d'enregistrement de l'utilisateur, par exemple, sauvegarder dans la base de données...
// Envoyer une notification par email
EmailSender emailSender = new EmailSender();
emailSender.SendEmail("Welcome to our platform!", Email);
}
}
public class EmailSender
{
public void SendEmail(string message, string recipient)
{
// Logique d'envoi d'email
Console.WriteLine($"Sending email to {recipient}: {message}");
}
}
Dans cet exemple, la classe User gère les données de l'utilisateur (nom d'utilisateur et email), et contient la logique pour enregistrer un utilisateur. Cela viole le SRP car la classe a plus d'une raison de changer. Elle pourrait changer en raison de :
Modifications dans la gestion des données utilisateur - par exemple, ajouter plus de champs, tels que
firstName,gender,hobbies.Modifications de la logique d'enregistrement d'un utilisateur, par exemple, nous pourrions choisir de récupérer un utilisateur de la base de données par son nom d'utilisateur plutôt que par son email.
Pour adhérer au Principe de Responsabilité Unique, nous devrions séparer ces responsabilités en classes distinctes.
Refactorisation du code pour satisfaire le SRP :
public class User
{
public string Username { get; set; }
public string Email { get; set; }
}
public class EmailSender
{
public void SendEmail(string message, string recipient)
{
// Logique d'envoi d'email
Console.WriteLine($"Sending email to {recipient}: {message}");
}
}
public class UserService
{
public void RegisterUser(User user)
{
// Logique d'enregistrement de l'utilisateur...
EmailSender emailSender = new EmailSender();
emailSender.SendEmail("Welcome to our platform!", user.Email);
}
}
Dans le code refactorisé, la classe User est responsable uniquement de la représentation des données utilisateur. La classe UserService gère désormais l'enregistrement des utilisateurs, séparant les préoccupations liées à la gestion des données utilisateur de la logique d'enregistrement des utilisateurs. La classe UserService est responsable uniquement de la logique métier de l'enregistrement d'un utilisateur.
Cette séparation des responsabilités adhère au Principe de Responsabilité Unique, rendant le code plus facile à comprendre, à maintenir et à étendre.
Principe ouvert/fermé (OCP) en C
Les entités logicielles (classes, modules, fonctions, etc.) doivent être ouvertes à l'extension mais fermées à la modification.
Ce principe promeut l'idée que le code existant doit pouvoir être étendu avec de nouvelles fonctionnalités sans modifier son code source. Il encourage l'utilisation de l'abstraction et du polymorphisme pour atteindre cet objectif, permettant au code d'être facilement étendu par l'héritage ou la composition.
(À propos, si vous ne comprenez pas ces concepts fondamentaux de la POO, tels que l'abstraction, le polymorphisme, l'héritage et la composition — alors consultez mon livre, Mastering Design Patterns in C#: A Beginner-Friendly Guide, Including OOP and SOLID Principles sur Amazon ou Gumroad.)
Considérons un exemple de hiérarchie de classes Shape qui calcule l'aire de différentes formes géométriques. Initialement, cela viole le Principe Ouvert/Fermé car l'ajout d'une nouvelle forme nécessite de modifier le code existant :
public enum ShapeType
{
Circle,
Rectangle
}
public class Shape
{
public ShapeType Type { get; set; }
public double Radius { get; set; }
public double Length { get; set; }
public double Width { get; set; }
public double CalculateArea()
{
switch (Type)
{
case ShapeType.Circle:
return Math.PI * Math.Pow(Radius, 2);
case ShapeType.Rectangle:
return Length * Width;
default:
throw new InvalidOperationException("Unsupported shape type.");
}
}
}
Dans cet exemple, la classe Shape a une méthode, CalculateArea(), qui calcule l'aire en fonction du type de forme. Ajouter une nouvelle forme, comme un triangle, nécessiterait de modifier la classe Shape existante, violant ainsi l'OCP.
Pour adhérer au Principe Ouvert/Fermé, nous devrions concevoir le système de manière à permettre l'extension sans modification. Refactorisons le code en utilisant l'héritage et le polymorphisme :
public abstract class Shape
{
public abstract double CalculateArea();
}
public class Circle : Shape
{
public double Radius { get; set; }
public override double CalculateArea()
{
return Math.PI * Math.Pow(Radius, 2);
}
}
public class Rectangle : Shape
{
public double Length { get; set; }
public double Width { get; set; }
public override double CalculateArea()
{
return Length * Width;
}
}
Dans ce code refactorisé, nous définissons une classe abstraite Shape avec une méthode abstraite CalculateArea(). Les classes concrètes de formes (Circle et Rectangle) héritent de la classe Shape et fournissent leurs propres implémentations de CalculateArea().
Ajouter une nouvelle forme, comme un triangle, impliquerait de créer une nouvelle classe — étendant la base de code — qui hérite de Shape et implémente CalculateArea(), sans modifier le code existant. Cela adhère à l'OCP en permettant l'extension sans modification.
Pouvoir ajouter des fonctionnalités sans modifier le code existant signifie que nous n'avons pas à nous soucier autant de casser le code existant fonctionnel et d'introduire des bugs.
Suivre l'OCP nous encourage à concevoir notre logiciel de manière à ajouter de nouvelles fonctionnalités uniquement en ajoutant du nouveau code. Cela nous aide à construire des logiciels faiblement couplés et maintenables.
Principe de substitution de Liskov (LSP) en C
Les objets d'une superclasse doivent être remplaçables par des objets de sa sous-classe sans affecter la correction du programme.
Ce principe garantit que les hiérarchies d'héritage sont bien conçues et que les sous-classes adhèrent aux contrats définis par leurs superclasses.
Les violations du LSP peuvent entraîner des comportements inattendus ou des erreurs lors de la substitution d'objets, rendant le code plus difficile à raisonner et à maintenir.
Considérons un exemple impliquant une classe Rectangle et une classe Square, qui héritent d'une classe commune Shape. Initialement, nous allons violer le LSP en n'adhérant pas au comportement attendu de ces classes. Ensuite, nous allons le corriger pour nous assurer que le principe est respecté.
public abstract class Shape
{
public abstract double Area { get; }
}
public class Rectangle : Shape
{
public virtual double Width { get; set; }
public virtual double Height { get; set; }
public override double Area => Width * Height;
}
public class Square : Rectangle
{
public override double Width
{
get => base.Width;
set => base.Width = base.Height = value;
}
public override double Height
{
get => base.Height;
set => base.Height = base.Width = value;
}
}
Maintenant, testons si Rectangle calcule correctement son aire :
// Program.cs
var rect = new Rectangle();
rect.Height = 10;
rect.Width = 5;
System.Console.WriteLine("Expected area = 10 * 5 = 50.");
System.Console.WriteLine("Calculated area = " + rect.Area);
Exécution du programme :
Expected area = 10 * 5 = 50.
Calculated area = 50
Parfait !
Maintenant, dans notre programme, la classe Square hérite de, ou étend, la classe Rectangle, car, mathématiquement, un carré est juste un type spécial de rectangle, où sa hauteur est égale à sa largeur. Pour cette raison, nous avons décidé que Square devrait étendre Rectangle — c'est comme dire « un carré est un (type spécial de) rectangle ».
Mais regardez ce qui se passe si nous substituons la classe Rectangle par la classe Square :
var rect = new Square();
rect.Height = 10;
rect.Width = 5;
System.Console.WriteLine("Expected area = 10 * 5 = 50.");
System.Console.WriteLine("Calculated area = " + rect.Area);
Expected area = 10 * 5 = 50.
Calculated area = 25
Oh là là, le LSP a été violé : nous avons remplacé l'objet d'une superclasse (Rectangle) par un objet de sa sous-classe (Square), et cela a affecté la correction de notre programme. En modélisant Square comme une sous-classe de Rectangle, et en permettant à la largeur et à la hauteur d'être définies indépendamment, nous violons le LSP. Lorsque nous définissons la largeur et la hauteur d'un Square, il devrait conserver sa forme carrée, mais notre implémentation permet une incohérence.
Corrigeons cela pour satisfaire le LSP :
public abstract class Shape
{
public abstract double Area { get; }
}
public class Rectangle : Shape
{
public double Width { get; set; }
public double Height { get; set; }
public override double Area => Width * Height;
}
public class Square : Shape
{
private double sideLength;
public double SideLength
{
get => sideLength;
set
{
sideLength = value;
}
}
public override double Area => sideLength * sideLength;
}
// Program.cs
Shape rectangle = new Rectangle { Width = 5, Height = 4 };
Console.WriteLine($"Area of the rectangle: {rectangle.Area}");
Shape square = new Square { SideLength = 5 };
Console.WriteLine($"Area of the square: {square.Area}");
Dans cet exemple corrigé, nous avons redessiné la classe Square pour définir directement la longueur du côté. Maintenant, un Square est correctement modélisé comme une sous-classe de Shape, et il adhère au Principe de Substitution de Liskov.
Comment cela satisfait-il le LSP ? Eh bien, nous avons une superclasse, Shape, et des sous-classes Rectangle et Square. Rectangle et Square maintiennent tous deux le comportement attendu correct d'une Shape — nous pouvons substituer un carré à un rectangle et l'aire sera toujours calculée correctement.
Principe de ségrégation des interfaces (ISP) en C
Les clients ne doivent pas être forcés de dépendre d'interfaces qu'ils n'utilisent pas.
Ce principe encourage la création d'interfaces fines qui contiennent uniquement les méthodes requises par les clients qui les utilisent. Il aide à prévenir la création d'interfaces "grosses" qui forcent les clients à implémenter des méthodes inutiles, conduisant à un code plus propre et plus maintenable.
Considérons un exemple impliquant des formes 2D et 3D, violant initialement l'ISP.
Violation de l'ISP :
public interface IShape
{
double Area();
double Volume(); // problème : les formes 2D n'ont pas de volume !
}
public class Circle : IShape
{
public double Radius { get; set; }
public double Area()
{
return Math.PI * Math.Pow(Radius, 2);
}
public double Volume()
{
throw new InvalidOperationException("Volume not applicable for 2D shapes.");
}
}
public class Sphere : IShape
{
public double Radius { get; set; }
public double Area()
{
return 4 * Math.PI * Math.Pow(Radius, 2);
}
public double Volume()
{
return (4.0 / 3.0) * Math.PI * Math.Pow(Radius, 3);
}
}
Dans cet exemple, nous avons une interface IShape représentant à la fois les formes 2D et 3D. Cependant, la méthode Volume() pose problème pour les formes 2D, comme Circle et Rectangle, car elles n'ont pas de volume. Cela viole l'ISP car les clients (classes utilisant l'interface IShape) peuvent être forcés de dépendre de méthodes dont ils n'ont pas besoin.
var circle = new Circle();
circle.Radius = 10;
System.Console.WriteLine(circle.Area());
System.Console.WriteLine(circle.Volume()); // Mon éditeur de texte ne signale pas de problème...
var sphere = new Sphere();
sphere.Radius = 10;
System.Console.WriteLine(sphere.Area());
System.Console.WriteLine(sphere.Volume());
Habituellement, si j'essaie d'appeler une méthode sur un objet qui n'existe pas, VS Code me dira que je fais une erreur. Mais ci-dessus, lorsque j'appelle circle.Volume(), VS Code est comme « pas de problème ». Et VS Code a raison, car l'interface IShape force Circle à implémenter une méthode Volume(), même si les cercles n'ont pas de volume.
Il est facile de voir comment la violation de l'ISP peut introduire des bugs dans un programme — ci-dessus, tout semble bien, jusqu'à ce que nous exécutions le programme et qu'une exception soit levée.
Correction de l'ISP
public interface IShape2D
{
double Area();
}
public interface IShape3D
{
double Area();
double Volume();
}
public class Circle : IShape2D
{
public double Radius { get; set; }
public double Area()
{
return Math.PI * Math.Pow(Radius, 2);
}
}
public class Sphere : IShape3D
{
public double Radius { get; set; }
public double Area()
{
return 4 * Math.PI * Math.Pow(Radius, 2);
}
public double Volume()
{
return (4.0 / 3.0) * Math.PI * Math.Pow(Radius, 3);
}
}
Dans l'exemple corrigé, nous avons ségrégé l'interface IShape en deux interfaces plus petites et plus ciblées : IShape2D et IShape3D. Chaque classe de forme implémente désormais uniquement l'interface pertinente pour sa fonctionnalité.
Cela adhère au Principe de Ségrégation des Interfaces en s'assurant que les clients ne sont pas forcés de dépendre de méthodes qu'ils n'utilisent pas. Les clients peuvent désormais dépendre uniquement des interfaces dont ils ont besoin, favorisant une meilleure réutilisation du code et une plus grande flexibilité.
Ensuite, le cinquième et dernier principe SOLID...
Principe d'inversion des dépendances (DIP) en C
Les modules de haut niveau ne doivent pas dépendre des modules de bas niveau. Les deux doivent dépendre des abstractions.
L'inversion des dépendances est la stratégie de dépendre des interfaces ou des classes abstraites plutôt que des classes concrètes. Ce principe promeut le découplage entre les modules et encourage l'utilisation d'interfaces ou de classes abstraites pour définir les dépendances, permettant un code plus flexible et testable.
Commençons par un exemple violant le DIP, puis nous le corrigerons.
public class Engine // Engine est notre module "de bas niveau"
{
public void Start()
{
System.Console.WriteLine("Engine started.");
}
}
public class Car // Car est notre module "de haut niveau"
{
private Engine engine;
public Car()
{
this.engine = new Engine(); // Dépendance directe à la classe concrète Engine
}
public void StartCar()
{
engine.Start();
System.Console.WriteLine("Car started.");
}
}
Dans cet exemple :
La classe
Carcrée directement une instance de la classeEngine, conduisant à un couplage serré entre Car et Engine.Si la classe
Enginechange, cela peut affecter la classeCar, violant le Principe d'Inversion des Dépendances.
Le diagramme UML ci-dessous montre que Car dépend de Engine:
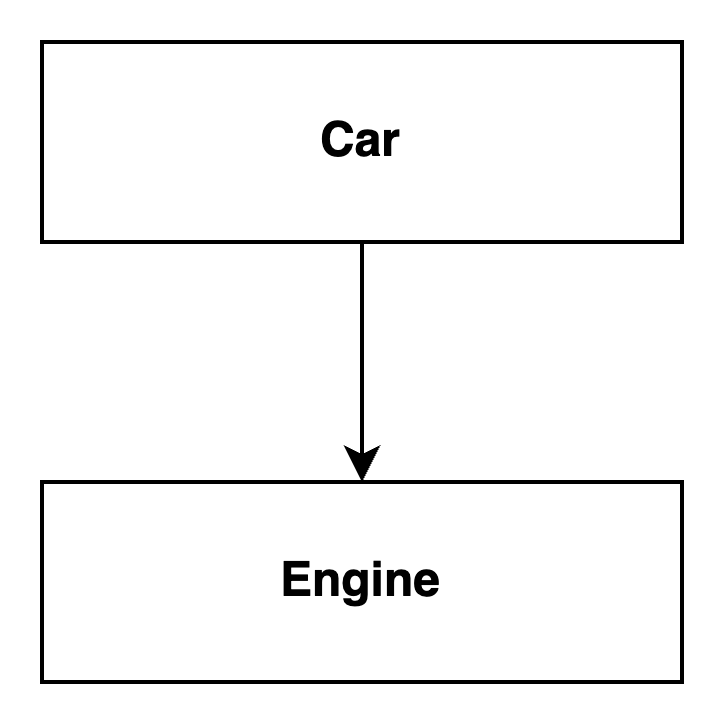
Mais que voulons-nous dire par classes "de haut niveau" et "de bas niveau" ?
Classe de haut niveau : La classe de haut niveau est généralement celle qui représente la fonctionnalité principale ou la logique métier de l'application. Elle orchestrer l'interaction entre divers composants et est souvent plus abstraite par nature.
Dans cet exemple, la classe Car peut être considérée comme la classe de haut niveau. Elle représente la fonctionnalité principale liée au démarrage de la voiture et à sa conduite. La classe Car est concernée par le comportement global de la voiture, comme le contrôle de son mouvement.
Classe de bas niveau : La classe de bas niveau est généralement celle qui fournit une fonctionnalité ou des services spécifiques utilisés par la classe de haut niveau. Elle traite généralement des détails d'implémentation et est plus concrète par nature.
Dans cet exemple, la classe Engine peut être considérée comme la classe de bas niveau. Elle fournit la fonctionnalité spécifique liée au démarrage du moteur. La classe Engine encapsule les détails de fonctionnement du moteur, tels que l'allumage et la combustion.
En résumé, la classe Car est la classe de haut niveau, représentant la fonctionnalité principale de l'application liée au comportement de la voiture.
La classe Engine est la classe de bas niveau, fournissant une fonctionnalité spécifique liée au fonctionnement du moteur, qui est utilisée par la classe Car.
Correction du DIP :
Pour adhérer au Principe d'Inversion des Dépendances, nous introduisons une abstraction (interface) entre Car et Engine, permettant à Car de dépendre d'une abstraction plutôt que d'une implémentation concrète.
public interface IEngine
{
void Start();
}
public class Engine : IEngine
{
public void Start()
{
System.Console.WriteLine("Engine started.");
}
}
public class Car
{
private IEngine engine;
public Car(IEngine engine)
{
this.engine = engine;
}
public void StartCar()
{
engine.Start();
System.Console.WriteLine("Car started.");
}
}
Nous pouvons maintenant injecter n'importe quel type de moteur dans les implémentations de Car :
var engine = new Engine(); // implémentation concrète à "injecter" dans la voiture
var car = new Car(engine);
car.StartCar();
D'après le diagramme UML ci-dessous, nous pouvons voir que les deux objets dépendent désormais du niveau d'abstraction de l'interface. Engine a inversé sa dépendance sur Car.
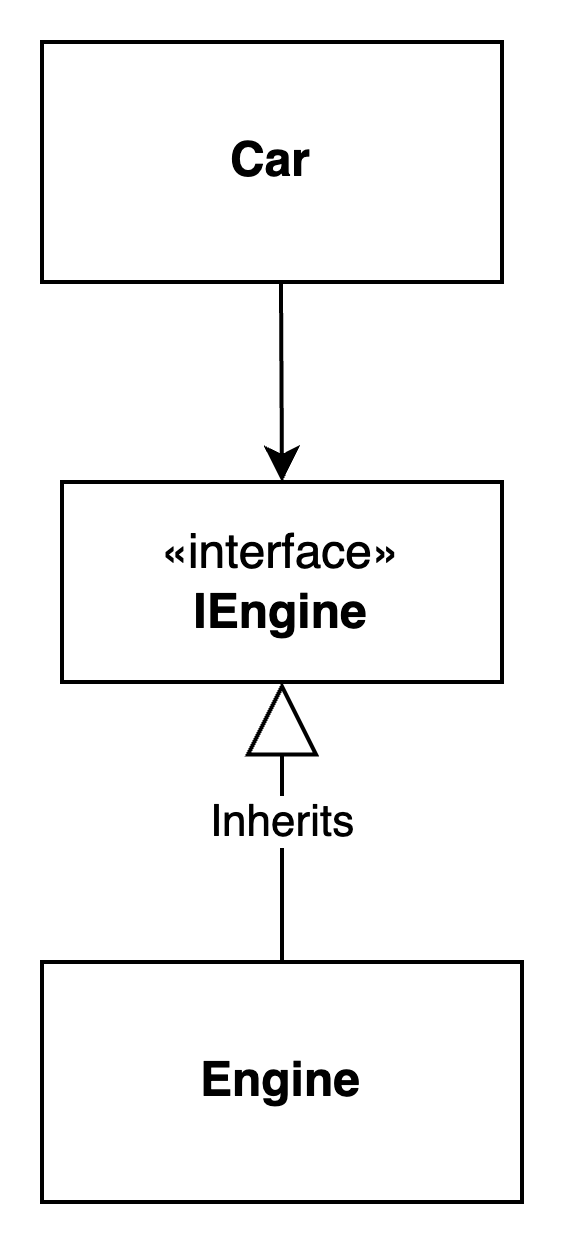
Dans cet exemple corrigé :
Nous définissons une interface
IEnginereprésentant le comportement d'un moteur.La classe
Engineimplémente l'interfaceIEngine.La classe
Cardépend désormais de l'interfaceIEngineplutôt que de la classe concrèteEngine.L'injection de dépendances est utilisée pour injecter l'implémentation
IEnginedans la classeCar, favorisant un couplage lâche. Maintenant, si nous voulons donner à une voiture un type de moteur différent, par exemple unFastEngine, nous pouvons l'injecter à la place.Maintenant, si l'implémentation du moteur change, cela n'affectera pas la classe
Cartant qu'elle adhère à l'interfaceIEngine.
L'injection de dépendances (DI) offre plusieurs avantages dans le développement logiciel :
Découplage : DI favorise le découplage entre les composants en supprimant les dépendances directes. Les composants s'appuient sur des abstractions plutôt que sur des implémentations concrètes, les rendant plus indépendants et plus faciles à maintenir.
Testabilité : L'injection de dépendances simplifie les tests unitaires en permettant aux composants d'être facilement remplacés par des implémentations mock ou stub pendant les tests. Cela permet des tests isolés des composants individuels sans dépendre de leurs dépendances.
Flexibilité : DI offre de la flexibilité dans la configuration et l'échange de dépendances à l'exécution. Il permet d'utiliser différentes implémentations de dépendances de manière interchangeable sans modifier le code client, facilitant la personnalisation et l'extensibilité à l'exécution.
Lisibilité et maintenabilité : En spécifiant explicitement les dépendances dans les paramètres du constructeur ou de la méthode, DI améliore la lisibilité du code et rend la base de code plus facile à comprendre. Il réduit également le risque de dépendances cachées, conduisant à un code plus maintenable et compréhensible.
Réutilisabilité : DI favorise la réutilisabilité des composants en les découplant de leurs contextes ou environnements spécifiques. Les composants peuvent être conçus pour être indépendants du framework ou de la plateforme de l'application, les rendant plus portables et réutilisables dans différents projets ou scénarios.
Évolutivité : DI simplifie la gestion des dépendances dans les applications à grande échelle en fournissant une approche standardisée pour la résolution des dépendances. Il aide à prévenir l'enfer des dépendances et facilite la gestion et l'évolutivité des systèmes complexes.
Globalement, l'injection de dépendances améliore la modularité, la testabilité et la maintenabilité des systèmes logiciels, contribuant à une meilleure qualité logicielle et à la productivité des développeurs.
Conclusion
Félicitations — vous comprenez maintenant les principes SOLID extrêmement importants. Ces principes vont vous éviter beaucoup de maux de tête au cours de votre carrière de développement logiciel, et vous guider vers la création de logiciels beaux, maintenables, flexibles et testables.
Si vous souhaitez faire passer vos compétences en développement logiciel au niveau supérieur et apprendre :
Les principes de la POO : encapsulation, abstraction, héritage, polymorphisme, couplage, composition, composition vs héritage, problème de la classe de base fragile.
Les 23 modèles de conception ("The Gang of Four Design Patterns") avec des exemples concrets.
Le langage de modélisation unifié (UML) : la manière standard de modéliser les classes et les relations entre elles.
Alors consultez mon livre :
Mastering Design Patterns in C#: A Beginner-Friendly Guide, Including OOP and SOLID Principles sur Amazon (également disponible sur Gumroad).
J'espère que cet article vous aide à devenir un meilleur développeur logiciel orienté objet !
Merci pour la lecture,
Danny 😊