


Article original : Asynchronous Programming in JavaScript for Beginners
Bonjour à tous ! Dans cet article, nous allons examiner un sujet clé en matière de programmation : la gestion de l'asynchronisme.
Nous commencerons par donner une base théorique sur ce qu'est l'asynchronisme et comment il se rapporte aux composants clés de JavaScript : le thread d'exécution, la pile d'appels et la boucle d'événements.
Ensuite, je vais présenter les trois façons dont nous pouvons gérer les tâches asynchrones en JavaScript : les callbacks, les promesses et async/await.
Ça a l'air amusant, non ? C'est parti !
Table des matières
Qu'est-ce que l'asynchronisme ?
Tout programme informatique n'est rien d'autre qu'une série de tâches que nous demandons à l'ordinateur d'exécuter. En JavaScript, les tâches peuvent être classées en types synchrones et asynchrones.
Les tâches synchrones sont celles qui s'exécutent séquentiellement, l'une après l'autre, et pendant leur exécution, rien d'autre n'est fait. À chaque ligne du programme, le navigateur attend que la tâche se termine avant de passer à la suivante.
On dit que ce type de tâches est "bloquant", car pendant leur exécution, elles bloquent le thread d'exécution (je vais expliquer ce que c'est dans un instant), l'empêchant de faire autre chose.
Les tâches asynchrones, en revanche, sont celles qui, pendant leur exécution, ne bloquent pas le thread d'exécution. Ainsi, le programme peut toujours effectuer d'autres tâches pendant que la tâche asynchrone est en cours d'exécution.
C'est pourquoi on dit que ce type de tâches est "non bloquant". Cette technique est particulièrement utile pour les tâches qui prennent beaucoup de temps à s'exécuter, car en ne bloquant pas le thread d'exécution, le programme est capable de s'exécuter plus efficacement.
Selon la documentation Mozilla :
La programmation asynchrone est une technique qui permet à votre programme de démarrer une tâche potentiellement longue et de toujours pouvoir répondre à d'autres événements pendant que cette tâche s'exécute, plutôt que d'avoir à attendre que cette tâche soit terminée. Une fois que cette tâche est terminée, votre programme est présenté avec le résultat.
Asynchronisme en JavaScript
Maintenant que nous avons une idée plus ou moins claire de ce qu'est l'asynchronisme, plongeons dans les choses compliquées et intéressantes – comment JavaScript rend cela possible.
L'un des premiers paradoxes apparents de JavaScript – et il y en a quelques-uns – que vous rencontrerez lors de l'apprentissage du langage est que JavaScript est un langage monothread.
"Monothread" signifie qu'il a un seul thread d'exécution. Cela signifie que les programmes JavaScript ne peuvent exécuter qu'une seule tâche à la fois.
Ce n'est pas le cas, par exemple, pour des langages comme Java ou Ruby, qui peuvent créer divers threads d'exécution et ainsi exécuter de nombreuses tâches simultanément.
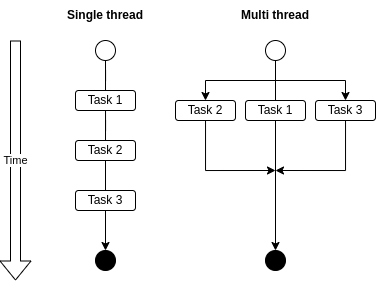
Visualisation de l'exécution monothread vs multithread
Et voici le paradoxe : si JavaScript ne peut exécuter qu'une seule tâche à la fois, comment se fait-il que les tâches synchrones puissent s'exécuter pendant que les tâches asynchrones se complètent "en arrière-plan" ? Comment se fait-il que les tâches asynchrones ne bloquent pas le thread d'exécution ? Comment sont-elles exécutées alors ?
Pour expliquer cela, nous devons brièvement décrire comment les navigateurs web exécutent le code JavaScript et certains de ses composants principaux : la pile d'appels, les Web APIs, la file d'attente des callbacks et la boucle d'événements.
Qu'est-ce que la pile d'appels ?
Comme vous le savez peut-être, une pile est un type de structure de données où les éléments sont ajoutés et supprimés selon un modèle LIFO (dernier entré, premier sorti). Les navigateurs utilisent quelque chose appelé la pile d'appels pour lire et exécuter chaque tâche contenue dans un programme JavaScript.
Commentaire : Si vous n'êtes pas familier avec les structures de données, vous pouvez consulter cet article que j'ai écrit il y a quelque temps.
Le fonctionnement est assez simple. Lorsqu'une tâche doit être exécutée, elle est ajoutée à la pile d'appels. Une fois terminée, elle est supprimée de la pile d'appels. Cette même action est répétée pour chaque tâche jusqu'à ce que le programme soit entièrement exécuté.
Voyons cela avec un exemple simple. Si nous avions ces trois lignes de code :
console.log('tâche 1')
console.log('tâche 2')
console.log('tâche 3')
Notre pile d'appels ressemblerait à ceci :

Illustration d'un exemple de pile d'appels
La pile d'appels commence vide au début du programme.
La première tâche est ajoutée à la pile d'appels et exécutée.
La première tâche est supprimée de la pile d'appels une fois terminée.
La deuxième tâche est ajoutée à la pile d'appels et exécutée.
La deuxième tâche est supprimée de la pile d'appels une fois terminée.
La troisième tâche est ajoutée à la pile d'appels et exécutée.
La troisième tâche est supprimée de la pile d'appels une fois terminée. Fin du programme.
Facile, non ? Maintenant, regardons un exemple un peu plus compliqué avec ces lignes de code :
const multiply = (a, b) => a*b
const square = n => multiply(n, n)
const printSquare = n => console.log(square(n))
printSquare(4)
Ici, nous appelons printSquare(), qui appelle lui-même square(), qui appelle lui-même multiply(). Avec ce programme, notre pile d'appels pourrait ressembler à ceci :
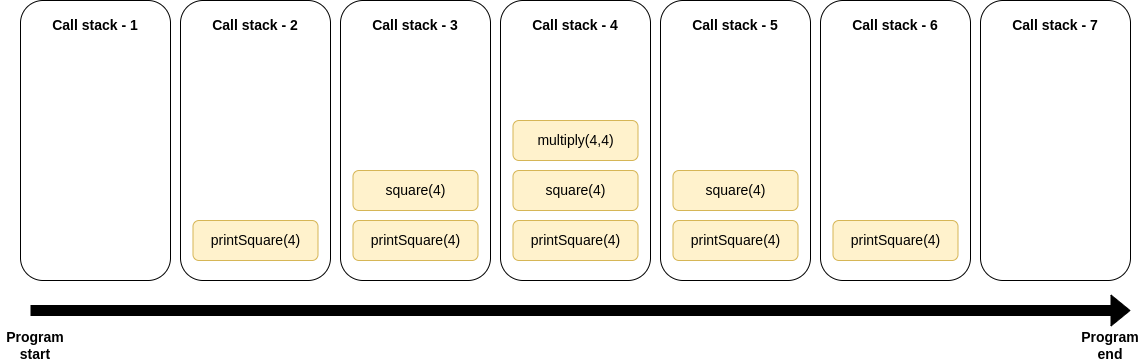
Un autre exemple plus complexe d'une pile d'appels
La pile d'appels commence vide au début du programme.
printSquare(4)est ajouté à la pile d'appels et exécuté.Comme
printSquare(4)appelle la fonctionsquare(4),square(4)est ajouté à la pile d'appels et exécuté également. Notez que comme l'exécution deprintSquare(4)n'est pas encore terminée, il est conservé sur la pile.Comme
square(4)appellemultiply(4,4),multiply(4,4)est ajouté à la pile d'appels et exécuté également.multiply(4,4)est supprimé de la pile d'appels une fois terminé.square(4)est supprimé de la pile d'appels une fois terminé.printSquare(4)est supprimé de la pile d'appels une fois terminé. Fin du programme.
Dans cet exemple, nous pouvons clairement voir le modèle LIFO que la pile d'appels utilise pour ajouter et supprimer des tâches.
L'important à noter ici est que les tâches ne sont pas supprimées de la pile avant d'être terminées. C'est ainsi que fonctionnent les callbacks synchrones.
Lorsque qu'une fonction appelle une autre fonction, le callback est ajouté à la pile et exécuté. Une fois l'exécution du callback terminée, il est supprimé de la pile et l'exécution de la fonction principale est terminée.
Web APIs, la file d'attente des callbacks et la boucle d'événements
Jusqu'à présent, tout va bien, non ? En utilisant la pile d'appels, JavaScript prend en compte chaque tâche, l'exécute, puis passe à la suivante. Assez simple.
Maintenant, regardons l'exemple suivant :
console.log('tâche1')
setTimeout(() => console.log('tâche2'), 0)
console.log('tâche3')
Ici, nous enregistrons trois chaînes séparées, et sur la deuxième, nous utilisons setTimeout pour la journaliser après 0 millisecondes. Ce qui devrait être, selon la logique commune, instantanément. On pourrait donc s'attendre à ce que la console journalise : "tâche1", puis "tâche2", et enfin "tâche3".
Mais ce n'est pas ce qui se passe :

Et si nous jetions un coup d'œil à notre pile d'appels pendant le programme, elle ressemblerait à ceci :
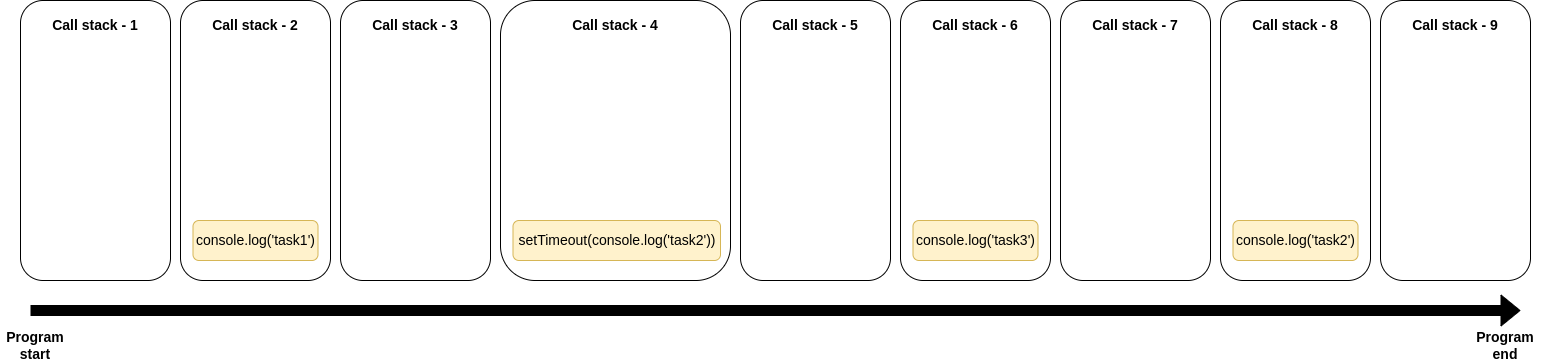
La pile d'appels commence vide au début du programme.
console.log('tâche1')est ajouté à la pile d'appels et exécuté.console.log('tâche1')est supprimé de la pile d'appels une fois terminé.setTimeout(console.log('tâche2'))est ajouté à la pile d'appels, mais il n'est pas exécuté.setTimeout(console.log('tâche2'))"mystérieusement" disparaît de la pile d'appels.console.log('tâche3')est ajouté à la pile d'appels et exécuté.console.log('tâche4')est supprimé de la pile d'appels une fois terminé.console.log('tâche2')"mystérieusement" saute dans la pile d'appels et est exécuté.console.log('tâche2')est supprimé de la pile d'appels une fois terminé.
Pour expliquer cette "mystérieuse" disparition et réapparition de la tâche setTimeout, nous devons introduire trois autres composants qui font partie de l'environnement d'exécution du navigateur : les Web APIs, la file d'attente des callbacks et la boucle d'événements.
Qu'est-ce que les Web APIs ?
Les Web APIs sont un ensemble de fonctionnalités que le navigateur utilise pour permettre à JavaScript de s'exécuter. Ces fonctionnalités incluent la manipulation du DOM, les appels AJAX et setTimeout parmi d'autres choses.
Pour simplifier la compréhension de cela, pensez à cela comme un "lieu d'exécution" différent de la pile d'appels. Lorsque la pile d'appels détecte que la tâche qu'elle traite est liée aux Web APIs, elle demande à l'API web "Hey API, j'ai besoin de faire cela", et l'API web s'en charge, permettant à la pile d'appels de continuer avec la tâche suivante dans la pile.
Qu'est-ce que la file d'attente des callbacks et la boucle d'événements ?
Dans l'exemple de code que nous avons vu précédemment, nous avons vu que setTimeout(console.log('tâche2')) a "mystérieusement" disparu de la pile d'appels. Nous savons maintenant qu'il n'a pas réellement disparu – il a été envoyé à l'API web.
Mais ensuite, il a "mystérieusement" réapparu, alors comment cela fonctionne-t-il ? Eh bien, c'est le travail de la file d'attente des callbacks et de la boucle d'événements.
La file d'attente des callbacks est une file d'attente qui stocke les tâches que les Web APIs retournent. Une fois que l'API web a terminé l'exécution de la tâche donnée (qui dans ce cas était le traitement du setTimeout), elle envoie le callback à la file d'attente des callbacks.
Les files d'attente sont un type de structure de données où les éléments sont ajoutés et supprimés selon un modèle FIFO (premier entré, premier sorti). Encore une fois, si vous n'êtes pas familier avec les structures de données, vous pouvez consulter cet article.
La boucle d'événements est une boucle (woah... vraiment ?) qui vérifie constamment deux choses :
Si la pile d'appels est vide
S'il y a une tâche présente dans la file d'attente des callbacks
Si ces deux conditions sont remplies, alors la tâche présente dans la file d'attente des callbacks est envoyée à la pile d'appels pour terminer son exécution.
Maintenant que nous connaissons les Web APIs, la file d'attente des callbacks et la boucle d'événements, nous pouvons savoir ce qui s'est réellement passé dans notre exemple précédent :

En suivant les lignes rouges, nous pouvons voir que lorsque la pile d'appels a identifié que la tâche impliquait setTimeout, elle l'a envoyée aux Web APIs pour la traiter.
Une fois que les Web APIs ont traité la tâche, elles ont inséré le callback dans la file d'attente des callbacks.
Et une fois que la boucle d'événements a détecté que la pile d'appels était vide et qu'il y avait un callback présent dans la file d'attente des callbacks, elle a inséré le callback dans la pile d'appels pour terminer son exécution.
C'est ainsi que JavaScript rend l'asynchronisme possible. Les tâches asynchrones sont traitées par les Web APIs au lieu de la pile d'appels, qui ne gère que les tâches synchrones.
De cette manière, la pile d'appels peut simplement dériver les tâches asynchrones vers les Web APIs et continuer à exécuter ce qui est présent sur la pile. Et grâce à la file d'attente des callbacks et à la boucle d'événements, une fois que la tâche asynchrone a été traitée par les Web APIs, le callback est réinséré dans la pile d'appels.
Il est important de se rappeler que JavaScript n'exécute toujours qu'une seule tâche à la fois. La "magie" de l'asynchronisme est rendue possible par l'existence des Web APIs, de la file d'attente des callbacks et de la boucle d'événements, qui sont responsables de la gestion des tâches asynchrones.
Commentaire : Si vous vous demandez comment tout cela fonctionne sur Node au lieu d'un navigateur, c'est assez similaire. Au lieu des Web APIs, vous avez des APIs C++. La pile d'appels, la file d'attente des callbacks et la boucle d'événements fonctionnent exactement de la même manière.
Si vous voulez une explication plus détaillée de tous ces sujets, je vous recommande de consulter cette conférence très connue de Philip Roberts.
Alors, comment codons-nous tout cela... ?
Maintenant que nous avons la base théorique de la manière dont JavaScript rend l'asynchronisme possible, voyons comment tout cela s'implémente en code.
Il existe principalement trois façons de coder l'asynchronisme en JavaScript : les fonctions de callback, les promesses et async-await.
Je vais les présenter dans l'ordre chronologique où JavaScript a fourni ces fonctionnalités (d'abord il n'y avait que les fonctions de callback, puis sont venues les promesses, et enfin async-await). Mais gardez à l'esprit que la pratique la plus courante et recommandée de nos jours est d'utiliser async-await. ;)
Comment fonctionnent les fonctions de callback
Les callbacks sont des fonctions qui sont passées en tant qu'arguments à d'autres fonctions. La fonction qui prend l'argument est appelée une "fonction d'ordre supérieur", et la fonction qui est passée en tant qu'argument est appelée un "callback".
Nous pouvons voir cela en pratique dans l'exemple suivant :
const callbackFunc = () => console.log('Je suis le callback')
const higherOrderFunction = callback => callback()
higherOrderFunction(callbackFunc)
Commentaire : la possibilité de passer des fonctions en tant que paramètres à d'autres fonctions est l'une des fonctionnalités qui font des fonctions des citoyens de première classe en JavaScript.
La différence entre les callbacks synchrones et asynchrones repose sur le type de tâche que la fonction exécute. Il n'y a pas de différence syntaxique entre chaque type. Voyons cela en code.
const arr = [1,2,3]
console.log('journalisation...')
arr.map(e => console.log('élément sync', e)) // Ceci est un callback synchrone
arr.map(e => setTimeout(() => console.log('élément async', e), 0)) // Ceci est un callback asynchrone
console.log('les trucs')
Ici, nous avons un tableau de trois éléments, quelques console.log, et deux fonctions map. Ce que map fait est d'itérer sur chaque élément du tableau et d'exécuter une fonction pour chaque élément du tableau. Cette fonction est définie comme un callback.
Dans le premier map, nous journalisons l'élément avec console.log. Dans le second, nous faisons la même chose mais en utilisant setTimeout (qui, comme nous l'avons vu précédemment, est une tâche asynchrone effectuée par les Web APIs).
En conséquence, notre console ressemblera à ceci :

Tout d'abord, tous les callbacks synchrones sont exécutés, puis les callbacks asynchrones entrent en jeu.
Comme nous pouvons le voir, le fait que les fonctions s'exécutent de manière asynchrone n'est pas lié au fait qu'elles soient des callbacks ou non, mais plutôt au type de tâche que la fonction exécute. Comme setTimeout est une tâche asynchrone, ces callbacks sont exécutés de manière asynchrone.
Comment fonctionnent les promesses
Une approche plus moderne pour gérer l'asynchronisme consiste à utiliser des promesses. Une promesse est un type spécial d'objet en JavaScript qui a 3 états possibles :
En attente : C'est l'état initial, et il signifie que la tâche correspondante n'a pas encore été résolue.
Tenue : Signifie que la tâche a été terminée avec succès.
Rompu : Signifie que la tâche a produit une sorte d'erreur.
Pour voir cela en pratique, nous allons utiliser un cas réaliste dans lequel nous récupérons des données à partir d'un point de terminaison d'API et journalisons ces données dans notre console. Nous allons utiliser l'API fetch fournie par les navigateurs et une API publique qui retourne des blagues de Chuck Norris.
Ici, notre fonction exécute une requête HTTP GET vers le point de terminaison, et nous utilisons les méthodes then et catch que l'objet promesse possède pour traiter la réponse de la promesse.
const fetchJokeWithPromises = () => {
console.log('récupération avec des promesses...')
fetch('https://api.chucknorris.io/jokes/random')
.then(res => res.json())
.then(res => console.log('res', res))
.catch(error => console.error('Il y a eu une erreur !', error))
}
fetchJokeWithPromises()
Mais examinons cela étape par étape.
- Si nous journalisons simplement la ligne fetch, comme ceci :
console.log('fetch', fetch('https://api.chucknorris.io/jokes/random'))
Nous voyons que nous obtenons une promesse avec un état en attente :

- Ensuite, si nous exécutons la première méthode
thenet journalisons son résultat, nous obtenons ce qui suit :
fetch('https://api.chucknorris.io/jokes/random')
.then(res => console.log('res', res))
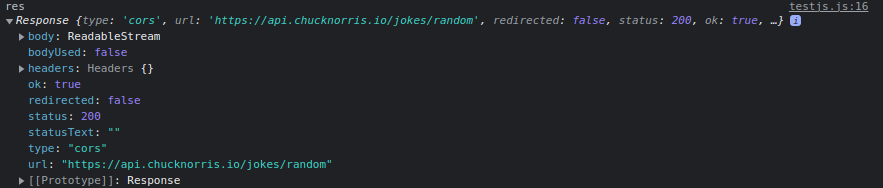
Nous voyons ici que nous n'avons plus une promesse, mais la réponse réelle du point de terminaison. La méthode then attend que la promesse soit complétée, puis nous fournit le résultat, qui est présent en tant que paramètre pour la méthode.
- Mais pour lire le corps de la réponse réelle (que dans notre console nous pouvons voir est un
ReadableStream), nous devons appeler la méthode.json()sur celui-ci. Cela retourne une autre promesse. C'est pourquoi nous avons besoin d'un autre.then().
fetch('https://api.chucknorris.io/jokes/random')
.then(res => res.json())
.then(responseBody => console.log('responseBody', responseBody))

Et ici, enfin, nous pouvons voir la réponse complète et notre blague dans la propriété value. ;)
- Ce que fait la méthode
catchest de s'exécuter chaque fois qu'une promesse est rompue. Normalement,catchest utilisé pour gérer une erreur, comme afficher un certain message à l'utilisateur lorsqu'une API échoue à répondre.
Pour voir cela en action, utilisons un point de terminaison aléatoire comme celui-ci :
fetch('https://asdadsasdasd/')
.then(res => res.json())
.then(resp => console.log('resp', resp))
.catch(error => console.error('Il y a eu une erreur !', error))
Et dans notre console, nous pouvons voir la méthode catch exécutée :

Une chose importante à noter est que dans des situations comme celle-ci, où nous avons plusieurs méthodes .then enchaînées, nous n'avons besoin d'utiliser qu'une seule méthode .catch. Cela est dû au fait que ce seul .catch traitera les erreurs dans toutes les promesses enchaînées.
Encore une fois, pour voir cela en action maintenant, revenons à notre point de terminaison précédent et modifions l'appel .json(), en le mal orthographiant maintenant.
fetch('https://api.chucknorris.io/jokes/random')
.then(res => res.jon())
.then(resp => console.log('resp', resp))
.catch(error => console.error('Il y a eu une erreur !', error))

Pour conclure sur les promesses, il existe une méthode supplémentaire fournie par les promesses qui est .finally. Cela s'exécutera toujours une fois que la promesse aura été résolue, avec succès ou non.
fetch('https://api.chucknorris.io/jokes/random')
.then(res => res.json())
.then(resp => console.log('resp', resp))
.catch(error => console.error('Il y a eu une erreur !', error))
.finally(() => console.log('Promesse résolue !'))
Comment fonctionne Async-Await
Async-await est la dernière façon de gérer l'asynchronisme fournie par JavaScript. Fondamentalement, ce n'est que du sucre syntaxique qui nous permet de gérer les promesses de manière plus concise que l'utilisation des méthodes .then.
Voyons cela en action en suivant le même exemple précédent.
const fetchJokeWithAsyncAwait = async () => {
try {
const res = await fetch('https://api.chucknorris.io/jokes/random')
const data = await res.json()
console.log('async-await data', data)
} catch (error) {
console.error('Il y a eu une erreur !', error)
}
}
fetchJokeWithAsyncAwait()
Ici, nous avons une fonction qui exécute le fetch et journalise la réponse. Voyez que nous commençons par utiliser le mot-clé async lorsque nous déclarons la fonction. C'est une exigence pour toutes les fonctions qui utilisent async-await.
Ensuite, nous enfermons notre appel fetch dans une instruction try-catch. Cela est requis car avec async-await, nous n'utiliserons pas la méthode .catch. Mais nous devons toujours traiter les erreurs possibles.
Nous y parvenons avec l'utilisation de try-catch. Si quelque chose contenu dans l'instruction try retourne une erreur, alors l'instruction catch s'exécute, obtenant l'erreur en tant que paramètre.
Comme vous pouvez le voir, nous attribuons le résultat de l'appel fetch à une variable appelée res. Et avant le fetch, nous utilisons le mot-clé await.
const res = await fetch('https://api.chucknorris.io/jokes/random')
Cela signifie que JavaScript attendra que la promesse soit résolue avant d'attribuer sa valeur à la variable. Et toute opération effectuée sur cette variable ne s'exécutera que lorsque sa valeur aura été attribuée.
Dans la ligne suivante, nous appelons la méthode .json() sur la variable res, et utilisons à nouveau le mot-clé await avant celle-ci afin que le résultat de la promesse soit ensuite attribué à la variable data.
Et enfin, nous journalisons notre data.

Comme mentionné, async-await n'est que du sucre syntaxique. Il ne fait rien de différent des méthodes .then et .catch. C'est simplement plus facile à écrire et à lire.
Conclusion
Eh bien, tout le monde, comme toujours, j'espère que vous avez apprécié l'article et appris quelque chose de nouveau.
Si vous le souhaitez, vous pouvez également me suivre sur LinkedIn ou Twitter. À la prochaine !
