


Article original : Orchestrating AWS Lambda with GraphQL and Apollo Connectors
AWS Lambda est un service de calcul qui permet d'exécuter des fonctions de code arbitraires sans avoir besoin de provisionner, gérer ou mettre à l'échelle des serveurs. Il est souvent utilisé dans la couche logique d'une architecture multi-niveaux pour gérer des tâches telles que le traitement de fichiers dans S3 ou l'exécution d'opérations CRUD sur une base de données.
AWS propose également une API Gateway, permettant aux développeurs d'invoquer des fonctions AWS Lambda, ce qui offre des fonctionnalités de sécurité et de performance améliorées comme la limitation de débit. Mais même avec l'API Gateway, vous devez coordonner ces microservices, car vos applications client ont probablement chacune des besoins de données uniques. Les données peuvent avoir besoin d'être transformées, filtrées ou combinées avant d'être retournées au client.
Ces tâches d'orchestration peuvent réduire votre productivité et prendre du temps et des efforts loin de la résolution du problème métier que votre application essaie de résoudre.
Apollo GraphQL est une couche d'orchestration d'API qui aide les équipes à livrer de nouvelles fonctionnalités plus rapidement et de manière plus indépendante en composant n'importe quel nombre de services et sources de données sous-jacents en un seul point de terminaison. Cela permet aux clients d'accéder à la demande à précisément ce dont l'expérience a besoin, indépendamment de la source de ces données.
Cet article vous apprendra à orchestrer des fonctions AWS Lambda en utilisant Apollo GraphQL. Plus précisément, voici ce que nous allons couvrir :
Primer GraphQL
Pour ceux qui ne sont pas familiers avec GraphQL, voici un primer qui offre quelques informations sur les défis que GraphQL aborde et comment les données sont typiquement gérées via les API REST dans GraphQL avant l'émergence des Apollo Connectors. Si vous êtes familier avec GraphQL, vous pouvez sauter cette section.
GraphQL est un langage de requête pour les API. Ce langage de requête et son runtime correspondant permettent aux clients de spécifier exactement les données dont ils ont besoin, minimisant ainsi le sur-fetching et le sous-fetching.
Contrairement à REST, qui nécessite plusieurs endpoints pour diverses exigences de données, GraphQL rationalise les requêtes en une seule demande, améliorant les performances et réduisant la latence du réseau.
GraphQL utilise également un schéma fortement typé. Cela améliore la documentation de l'API et facilite la validation, la détection précoce des erreurs et les outils de développement immersifs.
Pour illustrer la différence entre les API REST et GraphQL, considérons l'appel d'API REST suivant : /user/123
Réponse :
{
"id": 123,
"name": "Alice Johnson",
"email": "alice@example.com",
"phone": "555-1234",
"address": {
"street": "123 Main St",
"city": "Springfield",
"state": "IL",
"zip": "62704"
},
"createdAt": "2022-01-01T12:00:00Z",
"updatedAt": "2022-05-15T14:30:00Z",
"isAdmin": false
}
Si vous n'étiez intéressé que par le nom et l'email, utiliser REST serait une perte de données retournées du réseau au client pour aucune raison. En utilisant GraphQL, la requête GraphQL pour retourner le nom et l'email serait la suivante :
query {
user(id: 123) {
name
email
}
}
Le jeu de résultats est simplement les données dont le client a besoin :
{
"data": {
"user": {
"name": "Alice Johnson",
"email": "alice@example.com"
}
}
}
Ceci est un exemple simple montrant l'avantage de ne pas sur-fetcher les données, mais GraphQL a de nombreux autres avantages. L'un d'eux est la séparation entre le client et le serveur. Puisque les deux parties utilisent et respectent le schéma de type GraphQL, les deux équipes peuvent opérer plus indépendamment avec le backend définissant où les données résident et le frontend ne demandant que les données dont il a besoin.
Alors, comment GraphQL sait-il comment remplir les données pour chaque champ de votre schéma ? Il le fait via des resolvers. Les resolvers peuvent récupérer des données à partir de bases de données backend ou d'API tierces telles que les API REST, gRPC, etc. Ces fonctions comprennent du code procédural compilé et maintenu pour chaque champ du schéma. Ainsi, un champ peut avoir un resolver qui interroge une API REST et un autre peut interroger un endpoint gRPC.
Pour illustrer les resolvers, considérons l'exemple ci-dessus. Ajoutons un champ, status, qui interroge une API REST pour déterminer si l'utilisateur est à temps plein, à temps partiel ou licencié.
Tout d'abord, nous avons défini notre schéma comme suit :
type User {
id: ID!
name: String!
email: String!
status: String! # Besoin de cela à partir d'une API REST externe
}
type Query {
user(id: ID!): User
}
La requête user dans ce cas acceptera un id d'utilisateur et retournera un type User. La fonction resolver pour supporter la récupération des données ressemble à ce qui suit :
const resolvers = {
Query: {
user: async (_, { id }) => {
// Récupérer les détails de l'utilisateur à partir d'une API REST
const userResponse = await fetch(`https://api.company.com/users/${id}`);
const userData = await userResponse.json();
// Récupérer le statut de l'employé à partir d'une autre API REST
const statusResponse = await fetch(`https://api.company.com/employees/${id}/status`);
const statusData = await statusResponse.json();
return {
id: userData.id,
name: userData.name,
email: userData.email,
status: statusData.status, // par exemple, "Full-Time", "Part-Time", "Terminated"
};
},
},
};
Remarquez que non seulement deux fetches sont nécessaires pour obtenir les informations que la requête nécessite, mais nous devons également écrire du code procédural et le déployer.
Une meilleure approche serait de spécifier de manière déclarative à GraphQL où se trouve l'API REST et quelles données retourner. Apollo Connectors est la solution à ce défi, simplifiant le processus et permettant d'intégrer les données de l'API REST de manière déclarative sans nécessiter de compilation et de maintenance de code.
Maintenant que vous avez une idée générale de GraphQL et des défis qu'il aborde, plongeons dans l'exemple que nous allons construire.
Aperçu du tutoriel
Dans ce tutoriel, vous allez créer deux fonctions AWS Lambda qui retournent des informations sur les produits, décrites comme suit :
Requête de produits :
POST /2015-03-31/functions/products/invocations
Réponse :
{
"statusCode": 200,
"body": [
{
"id": "RANQi6AZkUXCbZ",
"name": "OG Olive Putter - Blade",
"description": "The traditional Block in a blade shape is made from a solid block of Olive wood. The head weight is approximately 360 grams with the addition of pure tungsten weights. Paired with a walnut center-line and white accents colors.",
"image": "https://keynote-strapi-production.up.railway.app/uploads/thumbnail_IMG_9102_3119483fac.png"
},
{
"id": "RANYrWRy876AA5",
"name": "Butter Knife Olive Putter- Blade",
"description": "The traditional Block in a extremely thin blade shape (~1\") is made from a solid block of Olive wood. The head weight is approximately 330 grams with the addition of pure tungsten weights.",
"image": "https://keynote-strapi-production.up.railway.app/uploads/thumbnail_IMG_9104_97c221e79c.png"
},...
Requête de prix de produit :
POST: /2015-03-31/functions/product-price/invocations
Réponse :
{
"default_price": 49900,
"is_active": true,
"currency": "usd",
"billing_schema": "per_unit",
"recurring": {
"interval": 0,
"interval_count": 3
}
}
Pour exposer ces deux microservices lambda, vous devez créer des déclencheurs API Gateway. Cela implique soit de configurer une API Gateway distincte pour chaque lambda, soit de les consolider sous une ou quelques instances API Gateway avec des routes spécifiées pour chaque lambda.
Créer un déclencheur peut sembler fastidieux et répétitif dans une configuration de microservices. Mais il existe une alternative disponible. Vous pourriez invoquer directement ces fonctions via REST en utilisant la permission InvokeFunction assignée à un utilisateur IAM. Cet article vous montrera cette méthode et vous guidera à travers la création de fonctions, les permissions AWS IAM nécessaires et la configuration du connecteur Apollo pour invoquer la fonction.
Prérequis
Pour suivre ce tutoriel, vous devrez avoir une compréhension de base des fonctions AWS Lambda ainsi que de la sécurité AWS. Vous aurez également besoin d'un accès aux éléments suivants :
Un compte AWS avec des permissions pour créer des utilisateurs et des politiques IAM
Un compte Apollo GraphQL, vous pouvez vous inscrire pour un plan gratuit ici.
Nous utiliserons également les outils suivants :
VS Code : Microsoft VS Code est un éditeur de code source gratuit de Microsoft
Apollo Rover CLI : Rover est l'interface de ligne de commande pour gérer et maintenir les graphes
Apollo Studio : Un portail basé sur le web utilisé pour gérer tous les aspects de votre graphe
Apollo Connectors Mapping Playground : Un site web qui prend un document JSON et aide les développeurs à créer le mapping de sélection utilisé avec Apollo Connectors
Section 1 : Créer les ressources AWS
Tout d'abord, configurons notre environnement AWS, en commençant par la sécurité. Dans notre scénario, nous allons créer un utilisateur IAM, "ConnectorUser", avec accès à une politique AWS, "ConnectorLambdaPolicy", avec les permissions minimales nécessaires pour accéder aux fonctions AWS Lambda.
Notez que vous pourriez créer des groupes d'utilisateurs et assigner des politiques de permission à ces groupes dans un environnement de production. Mais pour cet article, nous réduisons le nombre d'étapes administratives pour nous concentrer sur l'intégration principale avec GraphQL.
Étape 1 : Créer une politique AWS
Pour créer une politique, naviguez vers IAM dans la console de gestion AWS, puis sélectionnez "Politiques" sous Gestion des accès. Cliquez sur "Créer une politique". Cela ouvrira la page de l'éditeur de politiques, comme montré ci-dessous :
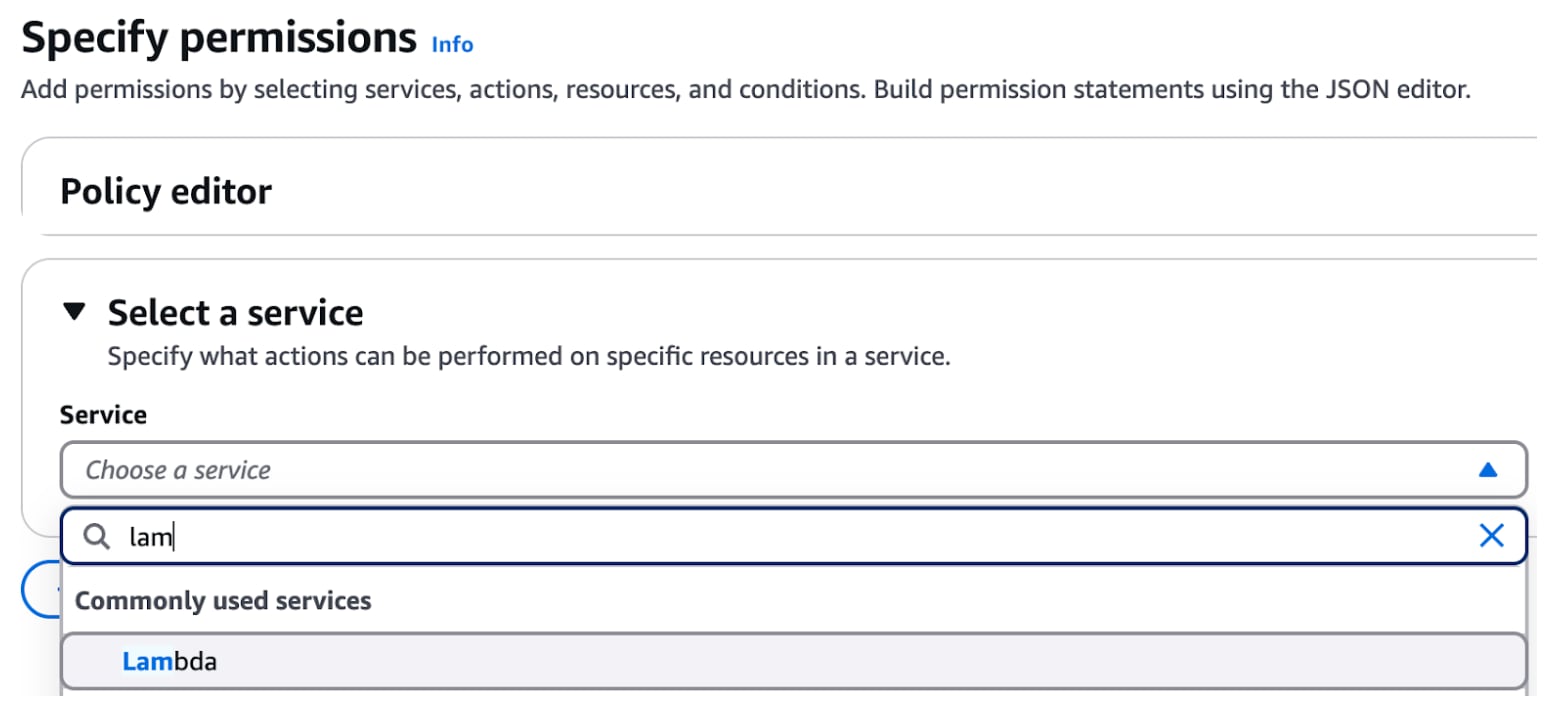
Choisissez le service "Lambda" et sous le niveau d'accès, sélectionnez "InvokeFunction" dans le menu déroulant Write comme montré ci-dessous :
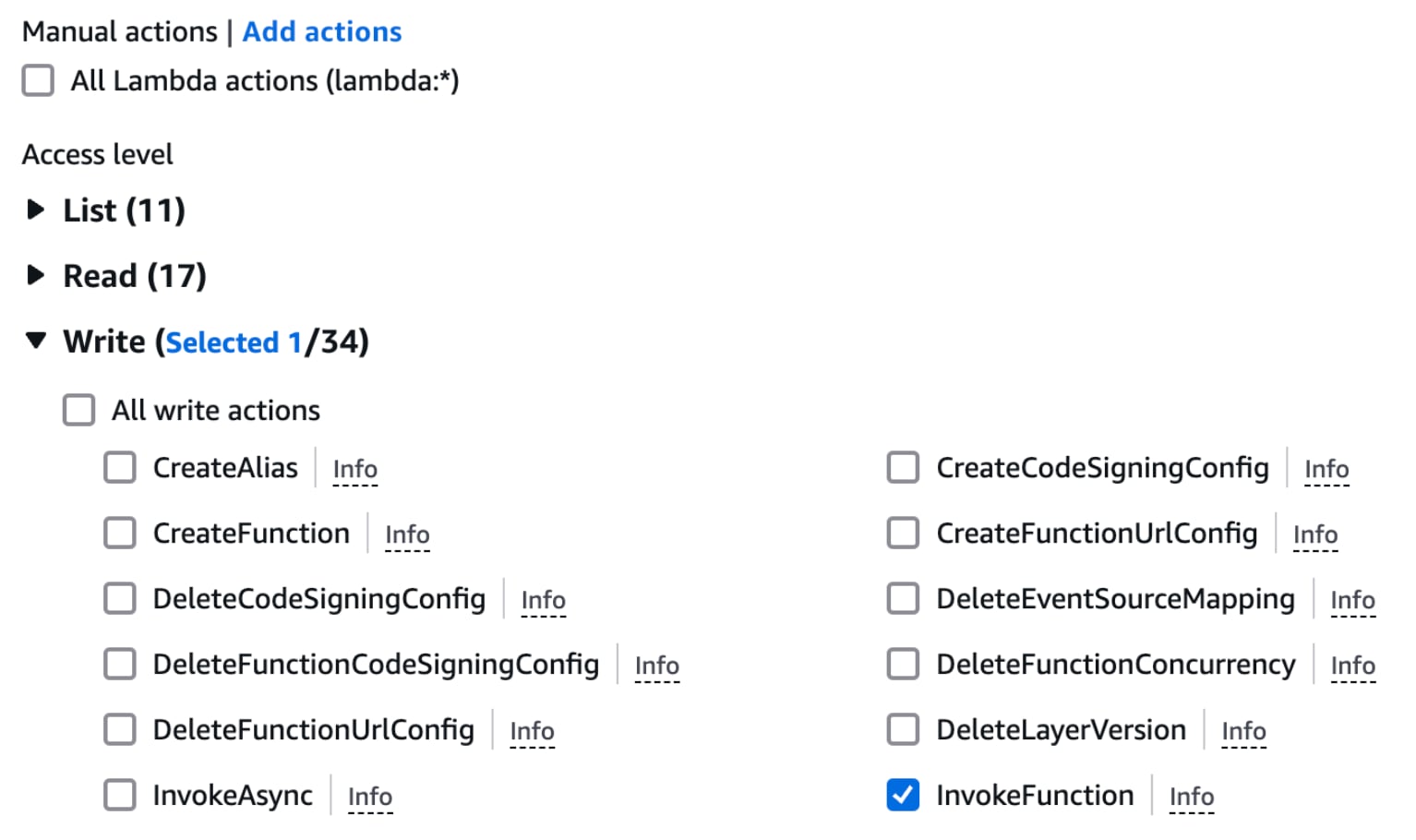
Sous le menu Ressources, vous pouvez choisir soit Tous les ARNs soit une option spécifique. Il est considéré comme une bonne pratique d'être aussi granulaire que possible lors de la définition des configurations de sécurité. Dans cet exemple, limitons notre sélection à la région "us-east-1" en cliquant sur l'option "Spécifique" puis sur "Ajouter des ARNs". Entrez "us-east-1" dans la région de la ressource et sélectionnez "N'importe quel nom de fonction".
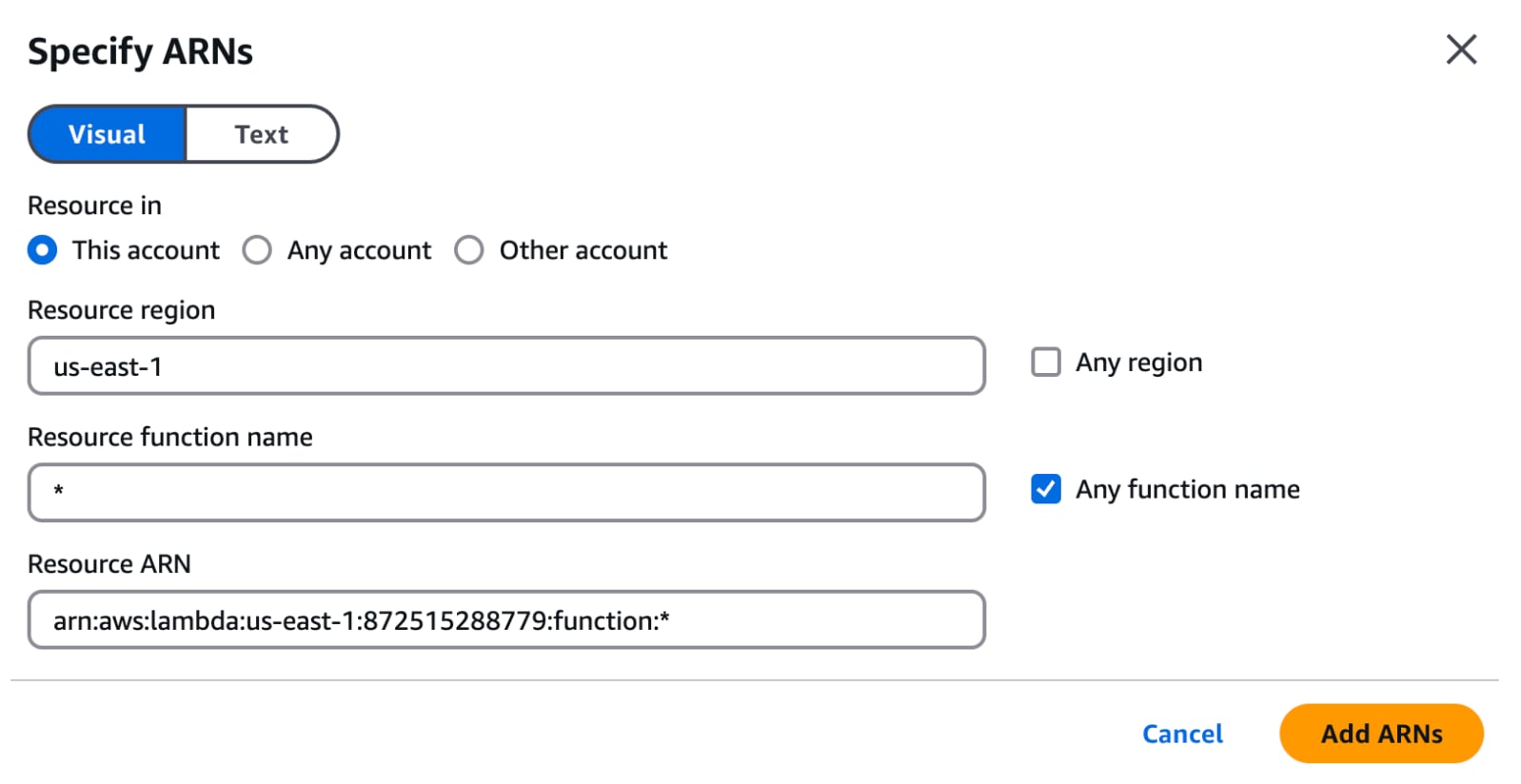
Avec la politique créée, nous pouvons assigner un utilisateur IAM à cette politique.
Étape 2 : Créer l'utilisateur IAM et attacher une politique
Cliquez sur Utilisateurs sous "Gestion des accès" puis Créer un utilisateur. Fournissez un nom pour l'utilisateur, "ConnectorUser".
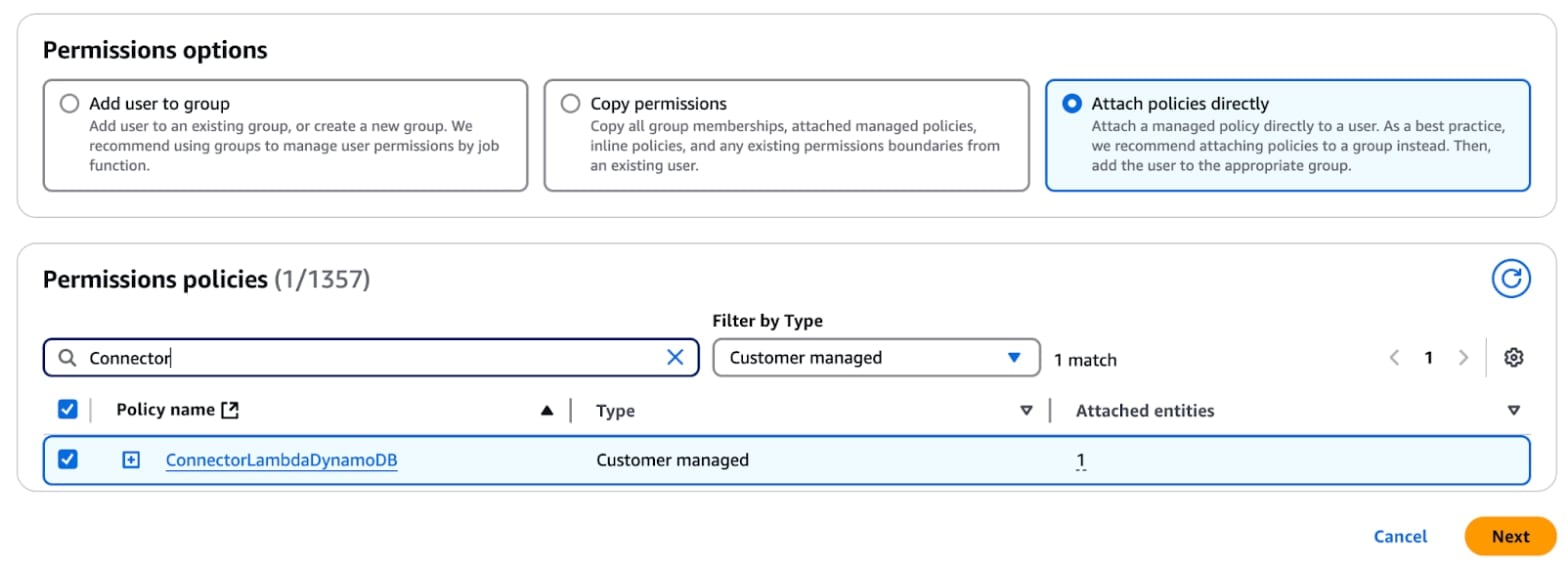
Ensuite, sélectionnez "Attacher des politiques directement", choisissez la politique que nous venons de créer, "ConnectorLambdaPolicy", et cliquez sur "Créer un utilisateur".
Étape 3 : Créer des fonctions AWS Lambda
Dans votre console AWS, créez une nouvelle fonction AWS Lambda NodeJS, "products".
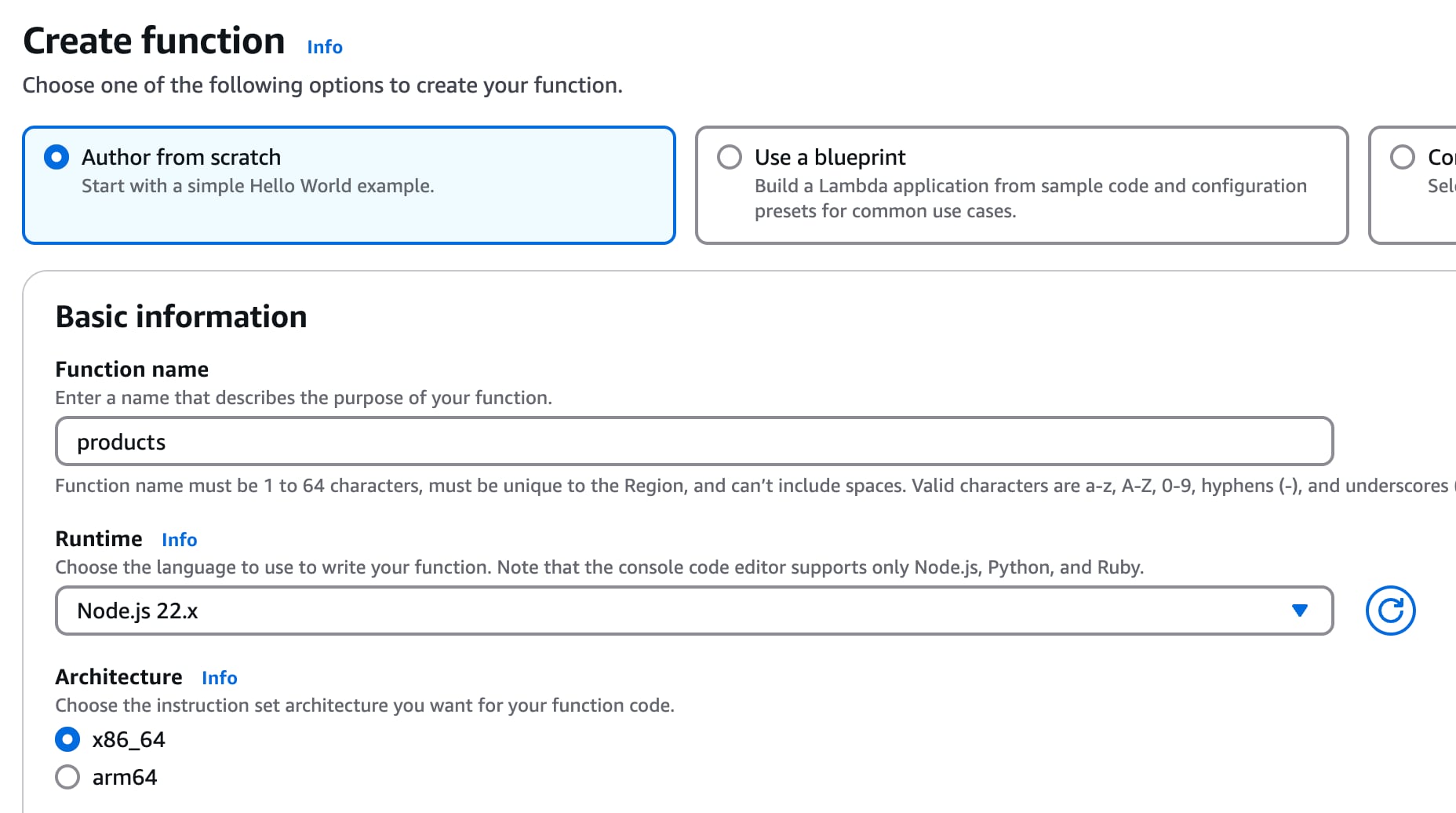
Sélectionnez "Node.JS" pour le runtime puis cliquez sur "Créer une fonction". Une fois créée, collez le code de la fonction à partir de ce Gist.
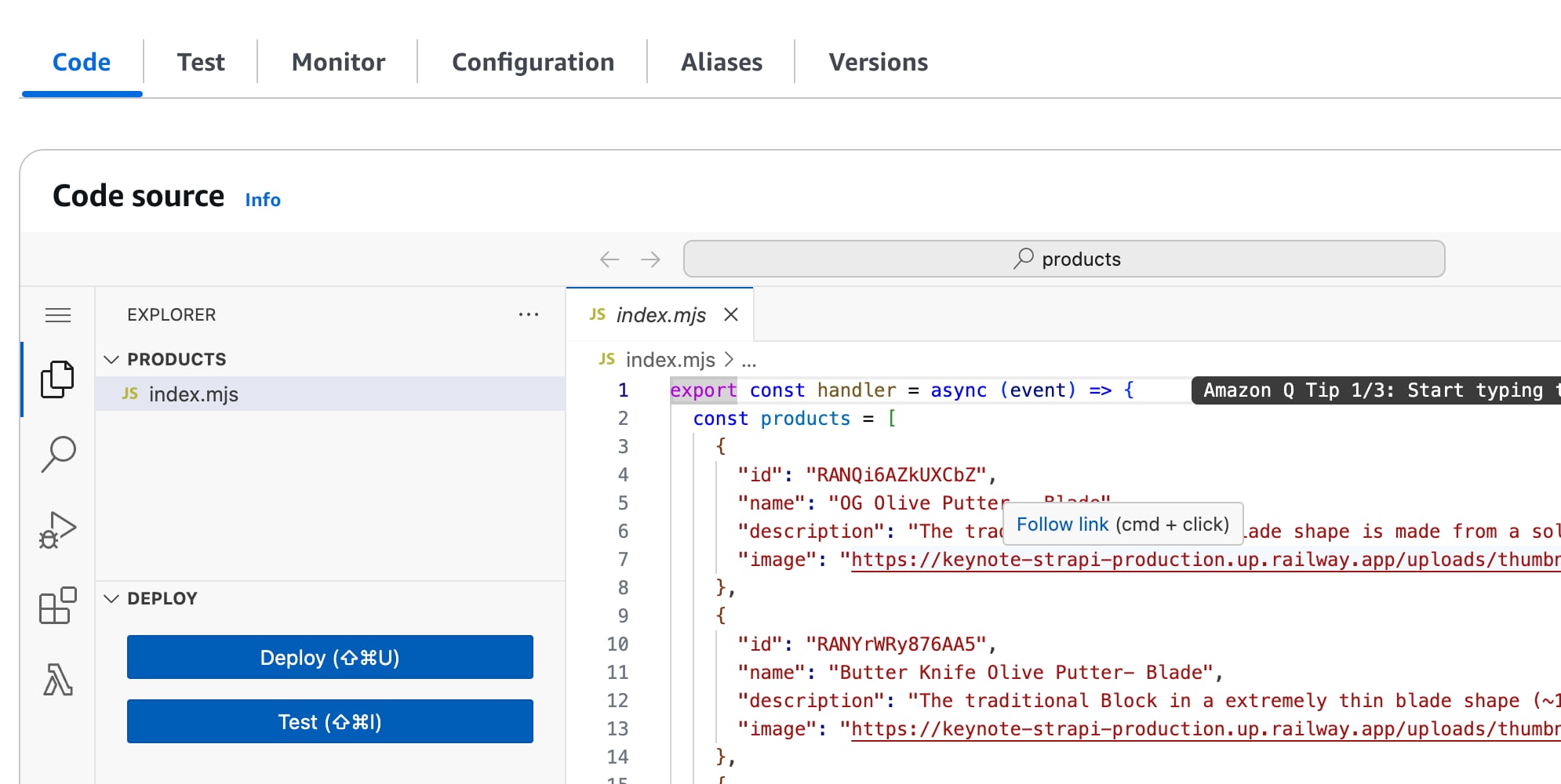
Répétez ce processus, en créant une autre fonction pour "product-price" et utilisez le code de la fonction à partir de ce Gist.
Section 2 : Créer un connecteur Apollo
Dans cette section, nous allons installer l'outil de ligne de commande Apollo Rover CLI, créer un compte Apollo Studio gratuit et cloner le dépôt Apollo Connectors. Si vous avez déjà un environnement Apollo disponible, vous pouvez sauter les étapes 1 et 2.
Étape 1 : Installer Rover
Rover est l'interface de ligne de commande pour gérer et maintenir les graphes. Il fournit également une expérience moderne de rechargement à chaud pour développer et exécuter vos connecteurs localement. Si vous n'avez pas Rover installé, installez-le en suivant les étapes ici.
Étape 2 : Créer un compte Apollo Studio gratuit
Apollo Studio est une plateforme de gestion basée sur le cloud conçue pour explorer, livrer et collaborer sur des graphes. Si vous n'avez pas de compte Apollo Studio, créez-en un sur un plan gratuit en naviguant ici.
Étape 3 : Cloner le dépôt Apollo Connectors
Pour vous aider à démarrer votre premier connecteur Apollo, un dépôt GitHub fournit des connecteurs d'exemple et un script de modèle. Lorsque vous l'exécutez, ce script créera tous les fichiers et configurations nécessaires pour commencer.
Allez-y et clonez le dépôt à partir d'ici.
Note : Bien que ce ne soit pas obligatoire, je recommande d'utiliser VS Code, car ce dépôt utilise des fichiers de configuration spécifiques à VS Code.
Étape 4 : Créer un fichier .env
Avant d'exécuter le script de modèle Create Connectors, créez un fichier .env localement avec une clé API utilisateur de votre Apollo Studio. Vous pouvez créer et obtenir cette clé ici. Remplir ce fichier .env ajoutera cette clé API au modèle de connecteur que vous créez à l'étape suivante.

Étape 5 : Créer votre nouveau connecteur à partir d'un modèle
Exécutez npm start et fournissez un emplacement pour créer le modèle de connecteur. Vous pouvez utiliser les valeurs par défaut pour les questions restantes.
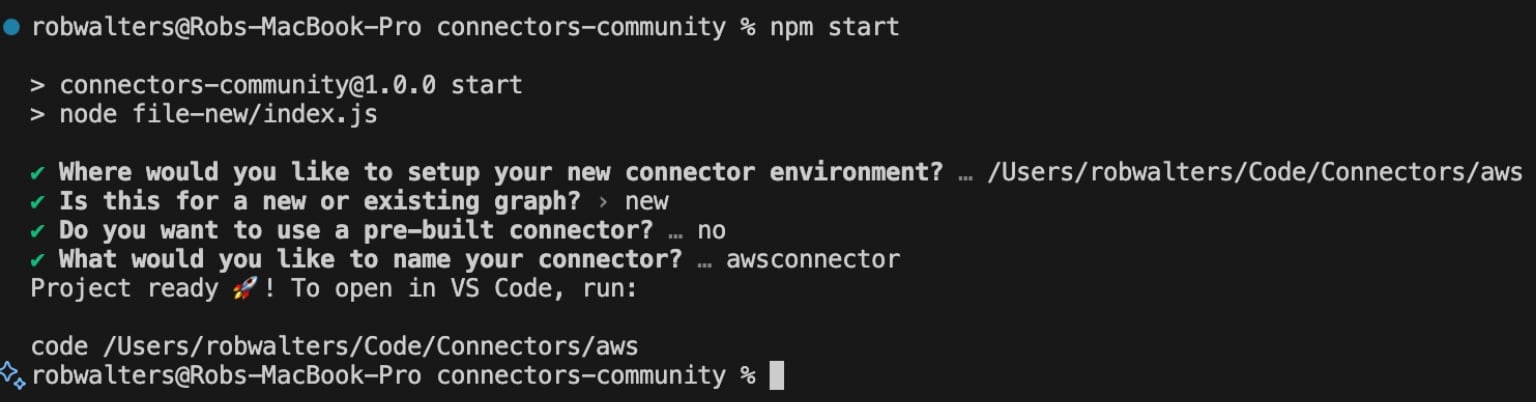
Ce script créera tous les fichiers nécessaires pour exécuter une instance locale Apollo GraphQL dans le répertoire spécifié. Chargez le connecteur nouvellement créé en utilisant VS Code ou votre éditeur de code préféré. Vous reviendrez à cet éditeur bientôt, mais d'abord, nous devons obtenir quelques clés d'accès d'AWS.
Étape 6 : Créer une clé d'accès AWS
Puisque nous nous connectons à AWS en utilisant SigV4, nous devons créer une clé d'accès AWS et entrer les valeurs de la clé dans le fichier settings.json. Retournez à la console IAM AWS et sélectionnez l'utilisateur ConnectorUser que vous avez créé à l'étape 1. Créez une nouvelle clé d'accès en cliquant sur "Créer une clé d'accès".
Vous serez présenté avec plusieurs options quant à l'origine de l'utilisation de cette clé. Puisque nous exécutons d'abord localement, sélectionnez "Service tiers" puis continuez l'assistant jusqu'à ce que vous soyez présenté avec la clé et la clé secrète comme montré ci-dessous :
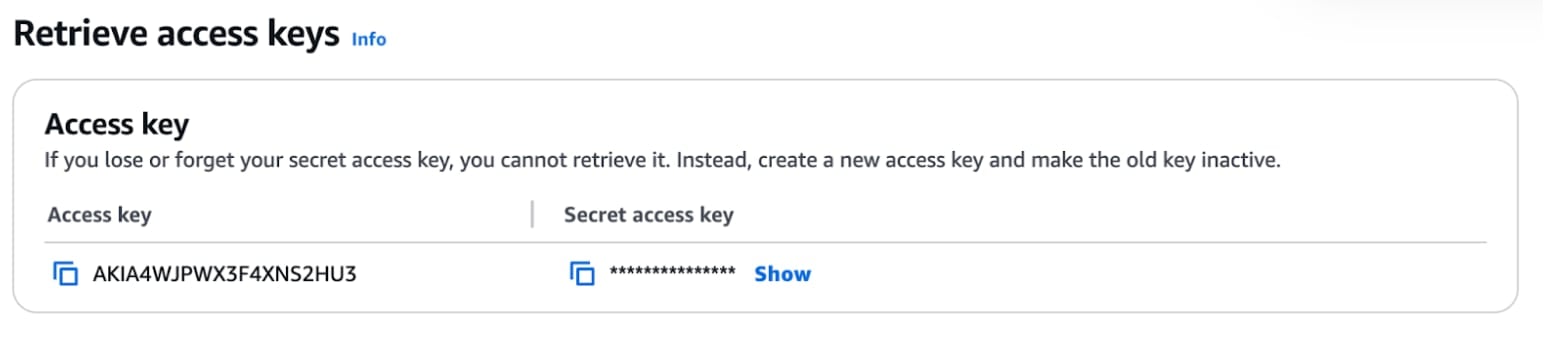
Ajoutez la clé d'accès et la clé d'accès secrète au fichier settings.json en tant que "AWS_ACCESS_KEY_ID" et "AWS_SECRET_ACCESS_KEY" respectivement.
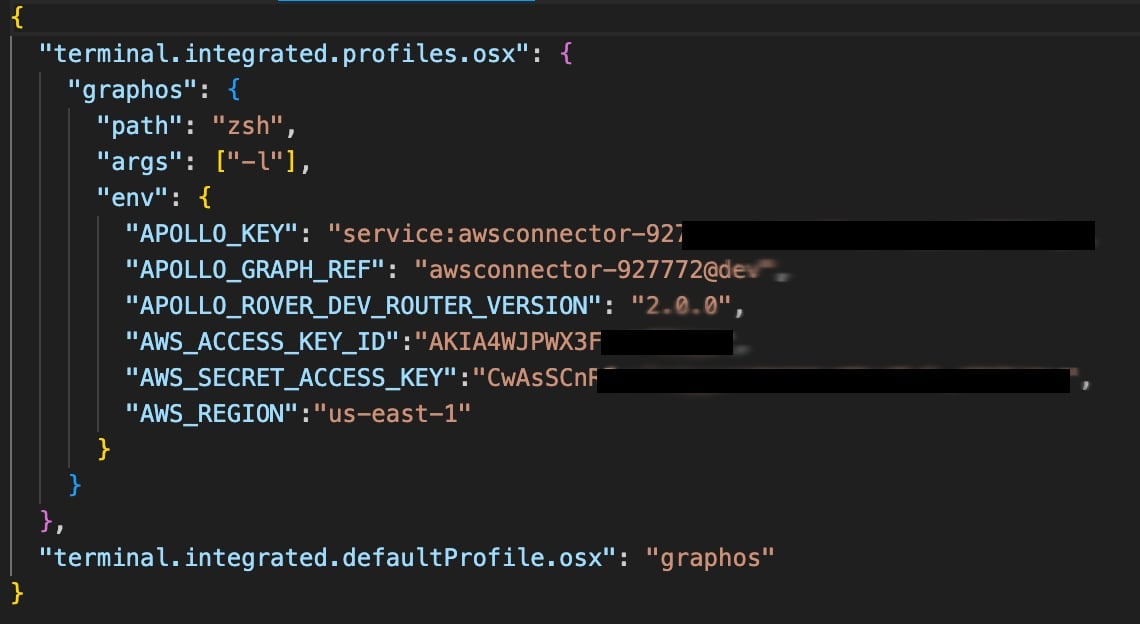
Vous devrez recharger la fenêtre puisque VS Code ne charge ces fichiers sous le répertoire .vscode qu'une seule fois.

Note : Dans cette étape, nous avons sauvegardé la clé dans le fichier settings.json. Bien que cela soit acceptable pour le développement, envisagez de sauvegarder les variables d'environnement dans des fichiers .env.
Étape 7 : Configurer le graphe
Le fichier supergraph.yaml est utilisé pour définir tous les sous-graphes qui font partie de cette fédération. Modifiez le fichier supergraph.yaml comme suit :
federation_version: =2.10.0
subgraphs:
awsconnector:
routing_url: http://lambda
schema:
file: connector.graphql
Étape 8 : Configurer Apollo Router
Apollo Router prend en charge l'authentification AWS SigV4. Pour configurer le connecteur pour utiliser cela, modifiez le fichier router.yaml et ajoutez une section d'authentification comme suit :
authentication:
connector:
sources:
awsconnector.lambda: # nom du sous-graphe . nom de la source du connecteur
aws_sig_v4:
default_chain:
region: "us-east-1"
service_name: "lambda"
Il existe d'autres options de configuration de sécurité AWS disponibles, y compris l'utilisation de l'assumption de rôle. La documentation complète pour l'authentification des sous-graphes est disponible ici.
Étape 9 : Construire le connecteur
Maintenant que nous avons configuré les variables d'environnement et les informations d'authentification, nous sommes prêts à construire le connecteur. Ouvrez le fichier connector.graphql et effacez le contenu. Ensuite, copiez le schéma d'extension suivant :
extend schema
@link(
url: "https://specs.apollo.dev/federation/v2.10"
import: ["@key"]
)
@link(
url: "https://specs.apollo.dev/connect/v0.1"
import: ["@source", "@connect"]
)
@source(
name: "lambda"
http: { baseURL: "https://lambda.us-east-1.amazonaws.com" }
)
Extend schema est utilisé pour lier les directives Apollo Connectors dans le schéma actuel. Dans cet article, nous définissons l'URL de base de notre fonction lambda. Si votre API REST a des en-têtes HTTP qui s'appliquent à toutes les références de cette source, comme des restrictions de Content-Length, vous pouvez les ajouter ici dans la déclaration @source. Ensuite, définissons le schéma Product :
type Product {
id: ID!
name: String
description: String
image: String
price: Price
@connect(
source: "lambda"
http: {
POST: "/2015-03-31/functions/product-price/invocations"
body: """
product_id: $this.id
"""
}
selection: """
amount: default_price
isActive: is_active
currency
recurringInterval: recurring.interval -> match(
[0,"ONE_TIME"],
[1,"DAILY"],
[2,"MONTHLY"],
[3,"ANNUALLY"],
)
recurringCount: recurring.interval_count
"""
)
}
Remarquez que notre requête Products a une directive @connect qui définit, au minimum, le nom de la source. Ici, vous pouvez ajouter la configuration spécifique HTTP dont vous avez besoin pour ce champ, comme les en-têtes d'autorisation. Dans ce scénario, puisque nous n'avons défini qu'une baseUrl dans la section extend schema, nous devons mettre l'URL spécifique pour InvokeFunction, qui est /2015-03-31/functions/product-price/invocations.
Le champ selection vous permet de transformer et mapper les valeurs retournées par l'API REST en utilisant la définition de mapping définie dans le champ selection. Bien qu'une discussion complète sur le mapping de sélection soit hors de portée de cet article, consultez la documentation pour un regard détaillé sur Mapping GraphQL Responses. Apollo fournit un outil en ligne gratuit qui rend la construction de mappings intuitive et rapide.
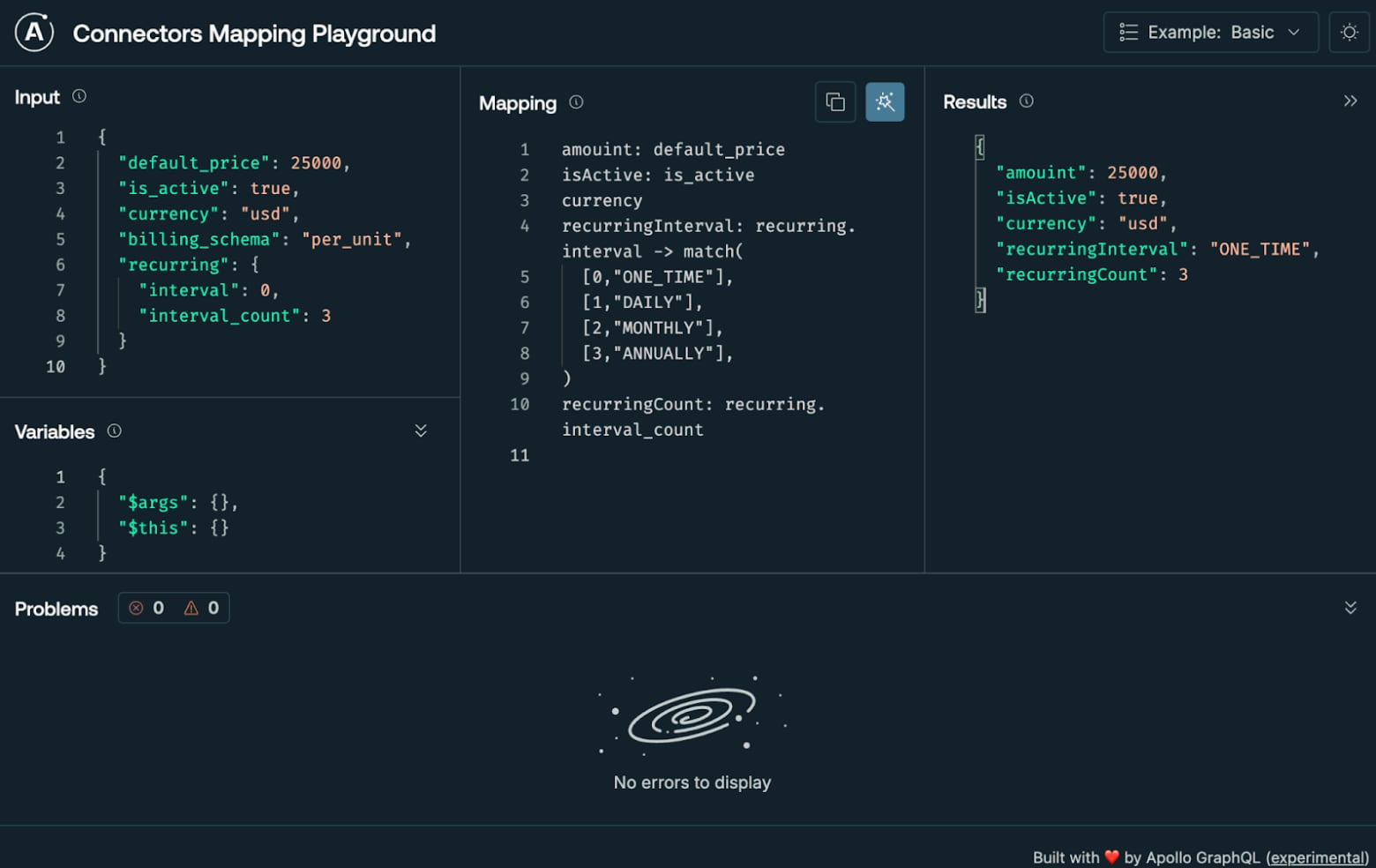
Ensuite, définissons le schéma Price et la requête products.
type Price {
amount: Float
isActive: Boolean
currency: String
recurringInterval: RecurringInterval
recurringCount: Int
}
enum RecurringInterval {
ONE_TIME
DAILY
MONTHLY
ANNUALLY
}
type Query {
products: [Product]
# https://docs.aws.amazon.com/lambda/latest/api/API_Invoke.html
@connect(
source: "lambda"
http: { POST: "/2015-03-31/functions/products/invocations" }
selection: """
$.body {
id
name
description
image
}
"""
)
}
Maintenant, nous sommes prêts à exécuter notre connecteur et à émettre des requêtes à notre graphe ! Le script de configuration complet est disponible à ce Gist.
Étape 10 : Exécuter le connecteur
Si vous utilisez VS Code, le dépôt inclut un fichier tasks.json qui ajoute une tâche "rover dev", qui lance Rover localement.
{
"version": "2.0.0",
"tasks": [{
"label": "rover dev",
"command": "rover", // Peut être n'importe quelle autre commande shell
"args": ["dev", "--supergraph-config","supergraph.yaml", "--router-config","router.yaml"],
"type": "shell",
"problemMatcher": [],
}]
}
Si vous n'utilisez pas VS Code, vous pouvez démarrer votre graphe en exécutant rover dev --supergraph-config supergraph.yaml --router-config router.yaml à partir d'une fenêtre de terminal.
Si tout est configuré correctement, vous verrez ce qui suit :
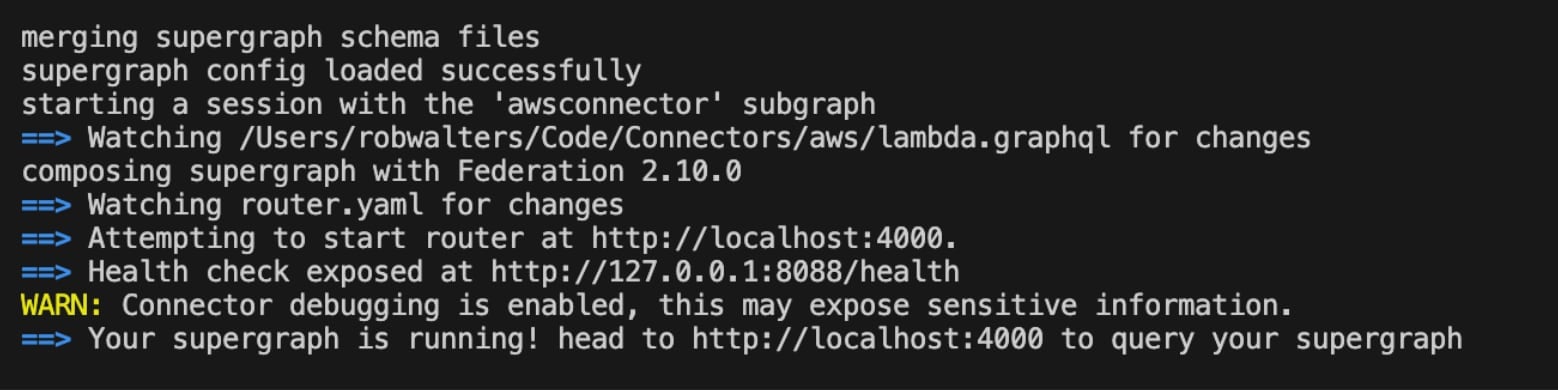
Section 3 : Comment utiliser Apollo Sandbox
La commande rover dev que vous avez lancée à l'étape précédente configure une instance locale d'Apollo Router pour le mode développement. Ce mode facilite la création, l'exécution et le débogage de requêtes GraphQL ad-hoc par les développeurs en utilisant le portail web Apollo Sandbox. Ce portail est situé à http://localhost:4000 par défaut.
Lancez le portail et cliquez sur le champ products. Cela remplira le panneau Operation avec tous les champs disponibles dans le schéma. Dans le panneau operation, vous pouvez modifier et construire votre requête GraphQL. Cliquer sur le bouton Run (qui affiche le nom de la requête, Products, dans notre exemple) exécutera la requête et affichera les résultats dans le panneau Response, comme illustré dans la figure ci-dessus.
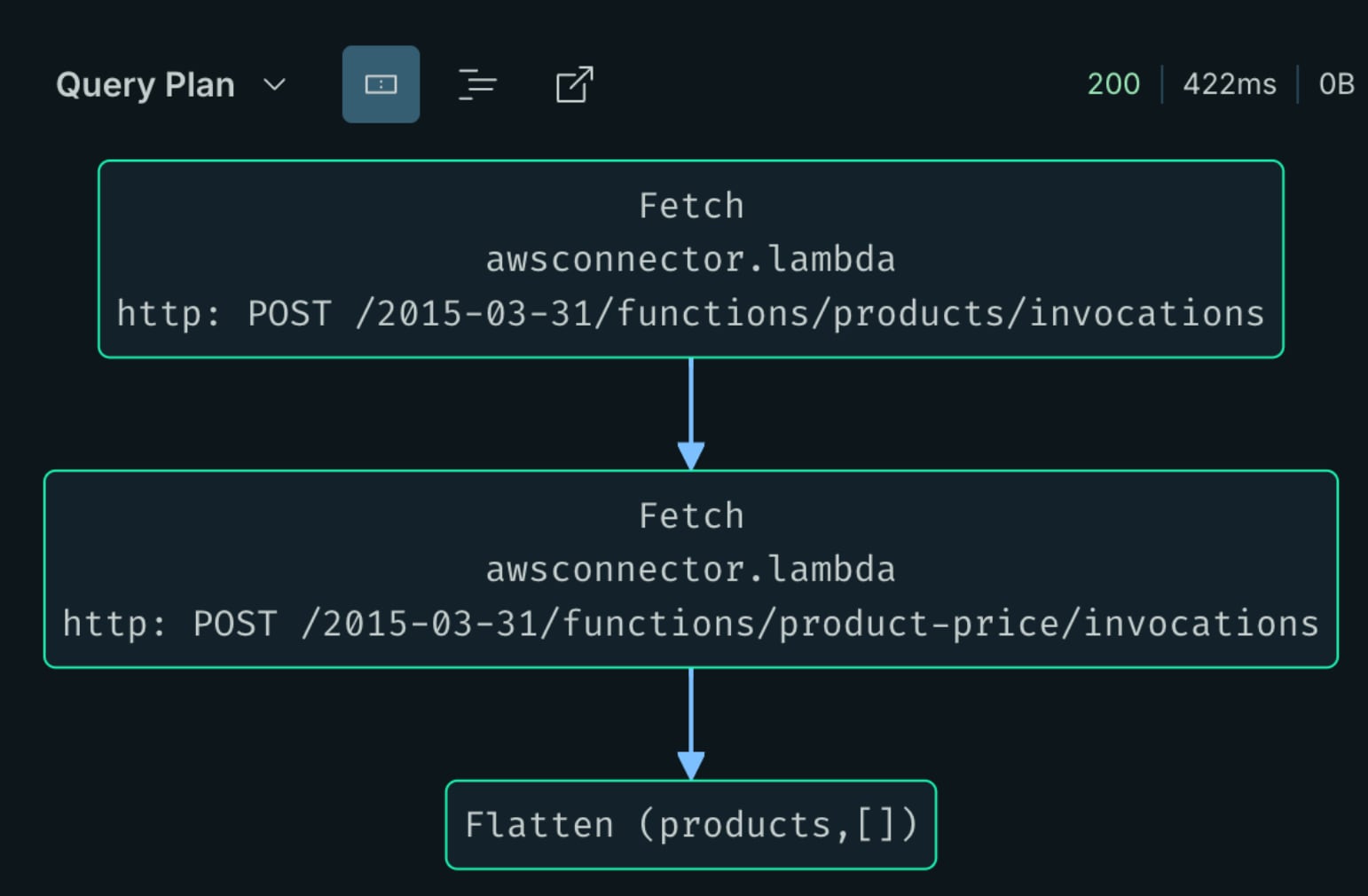
Dans cet exemple, vous pouvez voir que les données ont été retournées par notre fonction AWS Lambda. Pour confirmer, vous pouvez afficher le plan de requête en sélectionnant "Query Plan" dans le menu déroulant Response.
Le plan de requête illustre l'orchestration de nos deux fonctions AWS Lambda qui récupèrent les données de produit et de prix de produit.
Une fonctionnalité de débogage utile est le débogueur de connecteurs, disponible dans le menu déroulant comme montré dans la figure précédente.
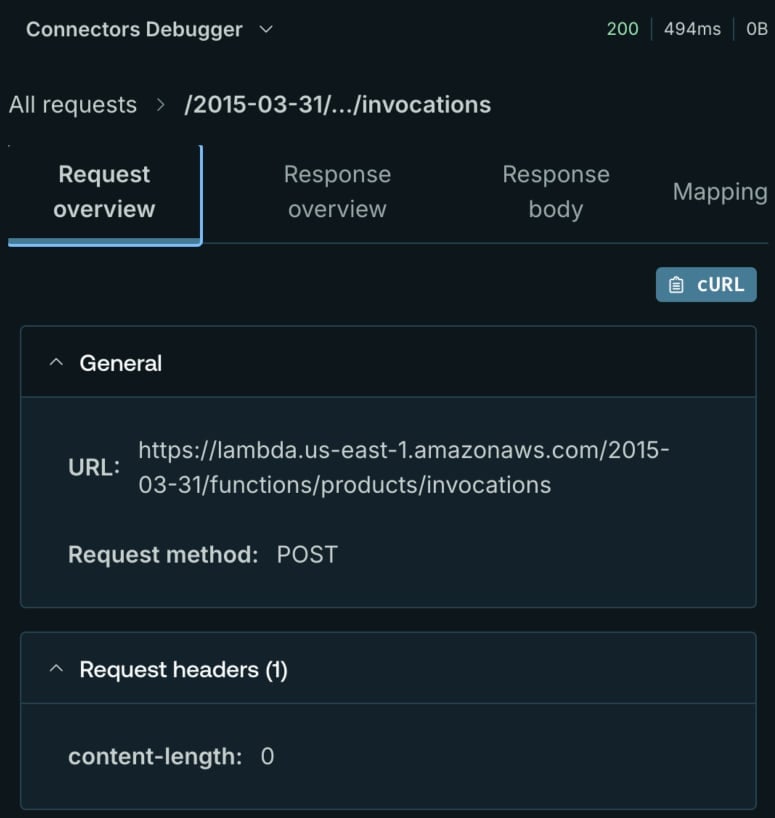
Le débogueur de connexion fournit une vue complète de la requête HTTP, y compris les en-têtes, le corps, le code de réponse et le mapping de sélection utilisé dans la requête. Si vous rencontrez des difficultés à exécuter des requêtes, utilisez ce débogueur, il vous fera gagner beaucoup de temps.
Résumé
Dans cet article, vous avez appris à :
Configurer un utilisateur IAM AWS, des politiques et des fonctions Lambda
Créer un connecteur Apollo pour obtenir des données à partir d'une fonction AWS Lambda
Configurer le routeur Apollo
Exécuter et déboguer des requêtes en utilisant Apollo Sandbox
L'intégration d'AWS Lambda avec Apollo Connectors offre une méthode simplifiée, sans resolver, pour incorporer des fonctions cloud dans votre API GraphQL. En utilisant Apollo Connectors, vous pouvez lier de manière déclarative des fonctions Lambda basées sur REST à votre supergraphe tout en assurant une authentification sécurisée avec AWS SigV4.
Vous pouvez en apprendre davantage sur Apollo Connectors à partir des ressources suivantes :
Blog : Découvrez comment Apollo Connectors s'intègre avec Apollo Federation à travers les insights du fondateur et CTO d'Apollo : Orchestration d'API REST avec GraphQL.
Blog : Plongez dans le voyage d'ingénierie derrière Apollo Connectors et le processus de leur création : Notre voyage vers Apollo Connectors
Webinaire : Webinaire de lancement GA d'Apollo Connectors