


Article original : Software Deployment Models – Explained for Beginners
Pour planifier efficacement – ou même parler de – le développement d'applications de manière intelligente, vous devez généralement comprendre à laquelle des nombreuses architectures de programmes vous faites référence. En d'autres termes, le code logiciel peut être déployé de bien plus de manières que la simple application web "standard".
Alors, voyons ce que nous avons. Il y a l'informatique client/serveur, les clients légers et lourds, les microservices et diverses variantes d'interfaces de programmation d'applications (API). Explorons ces concepts un par un.
Cet article provient de mon guide d'étude complet pour l'examen LPI Open Source Essentials cours Udemy et livre. Vous pouvez également voir la version vidéo de l'article sur YouTube.
Architectures Client/Serveur
Les architectures informatiques client/serveur sont un type d'architecture informatique distribuée dans laquelle les tâches informatiques sont réparties entre deux types de machines : les clients et les serveurs.
Un client est un appareil ou un programme qui demande des services ou des ressources à un serveur. Les clients peuvent être des ordinateurs de bureau, des ordinateurs portables, des appareils mobiles ou tout autre appareil capable de faire des demandes sur un réseau.
Un serveur est un appareil ou un programme qui fournit des services ou des ressources aux clients. Les serveurs peuvent être des machines dédiées ou des programmes qui s'exécutent sur des machines partagées. Les serveurs sont responsables du traitement des demandes des clients et du retour des données ou services demandés.
L'interaction entre les clients et les serveurs est généralement basée sur un modèle de demande-réponse. Un client envoie une demande à un serveur via un réseau, et le serveur traite la demande et envoie une réponse au client.
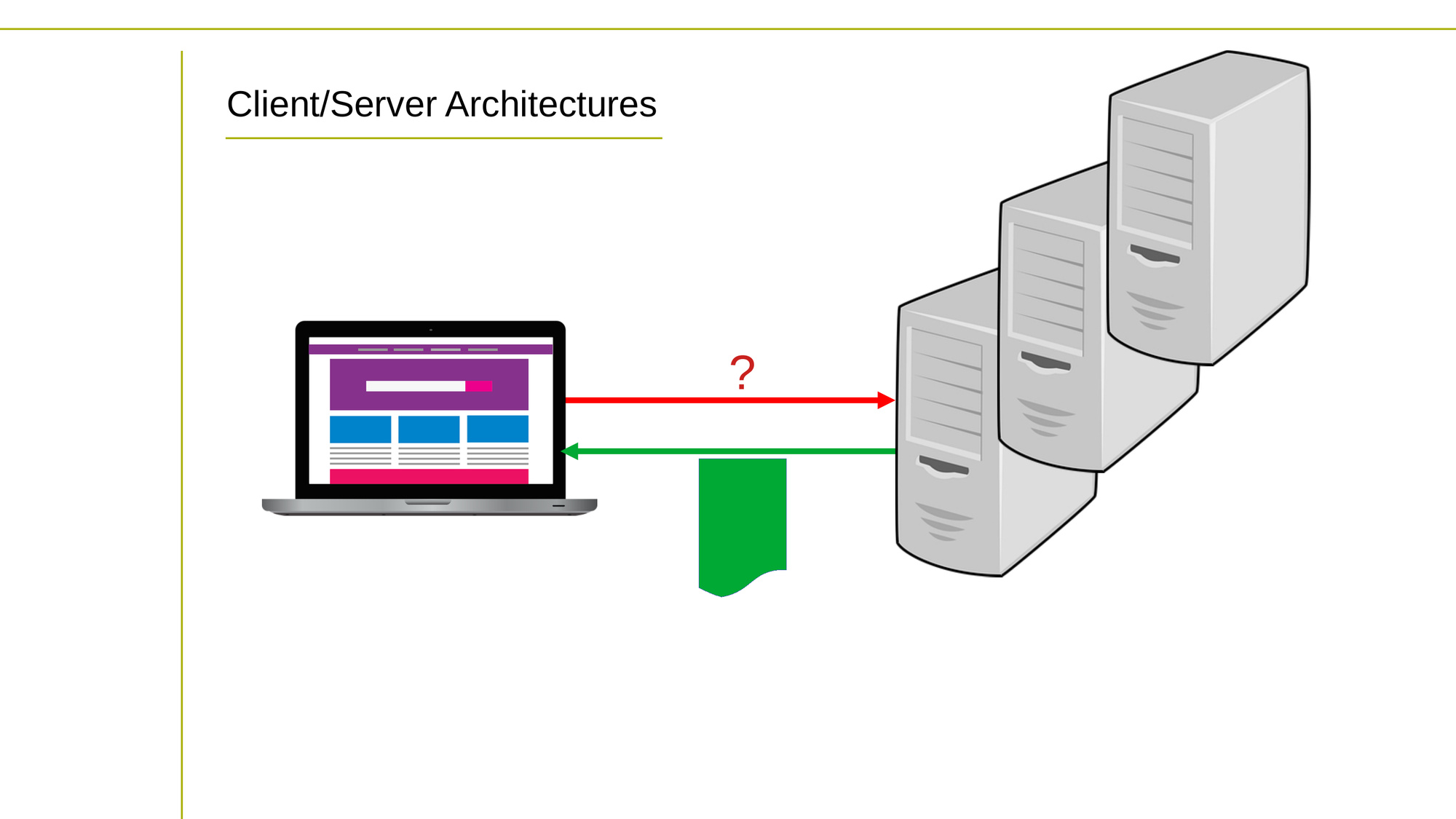 Une configuration client/serveur typique
Une configuration client/serveur typique
L'architecture client/serveur offre plusieurs avantages, notamment :
- L'évolutivité, ce qui signifie que des serveurs peuvent être ajoutés ou retirés du réseau en fonction de la demande. Cela permet au système de monter ou descendre en charge selon les besoins sans avoir à apporter des modifications sur les clients.
- La centralisation, ce qui signifie qu'en centralisant les ressources sur les serveurs, il est plus facile de gérer et de contrôler l'accès à ces ressources, et de faire respecter les politiques de sécurité.
Des exemples d'applications client/serveur incluent les serveurs de messagerie, les serveurs web, les serveurs de fichiers et les serveurs de bases de données. Dans chaque cas, le serveur fournit un service ou une ressource que les clients peuvent accéder via un réseau.
Architectures Client Léger et Client Lourd
Les architectures client léger et client lourd sont différentes approches pour concevoir des systèmes informatiques client/serveur.
Dans une architecture client léger, la machine cliente est responsable uniquement de la couche de présentation, tandis que la logique de l'application et le traitement des données sont gérés côté serveur. Les clients légers ont généralement une puissance de traitement et une mémoire limitées, et dépendent fortement de la connectivité réseau pour fonctionner.
Lorsque l'utilisateur interagit avec un client léger, l'entrée est envoyée via le réseau au serveur, qui traite la demande et renvoie les données nécessaires au client pour l'affichage.
Cette approche peut être plus efficace en termes de ressources matérielles et plus facile à gérer, car le serveur est responsable de la majeure partie du traitement et du stockage. Mais elle peut également être plus dépendante de la connectivité réseau et peut souffrir de problèmes de latence si le réseau est lent ou peu fiable.
Fait amusant (ou, au moins, un fait relativement amusant) : mon tout premier projet d'administration sérieux – et mon introduction à Linux et à l'administration réseau – impliquait le déploiement d'une infrastructure de clients légers pour économiser des coûts et des efforts significatifs. Cela s'est bien passé et a lancé ma carrière d'administrateur.
En revanche, dans une architecture client lourd, la machine cliente est responsable à la fois de la couche de présentation et de la logique de l'application. La machine cliente a généralement plus de puissance de traitement et de mémoire, et peut exécuter du code et traiter des données localement.
Cette approche peut offrir de meilleures performances et une meilleure réactivité, et peut être plus résiliente aux problèmes de connectivité réseau.
Lorsque l'utilisateur interagit avec un client lourd, la machine cliente traite l'entrée et exécute le code et le traitement des données nécessaires localement, sans dépendre du serveur pour chaque demande.
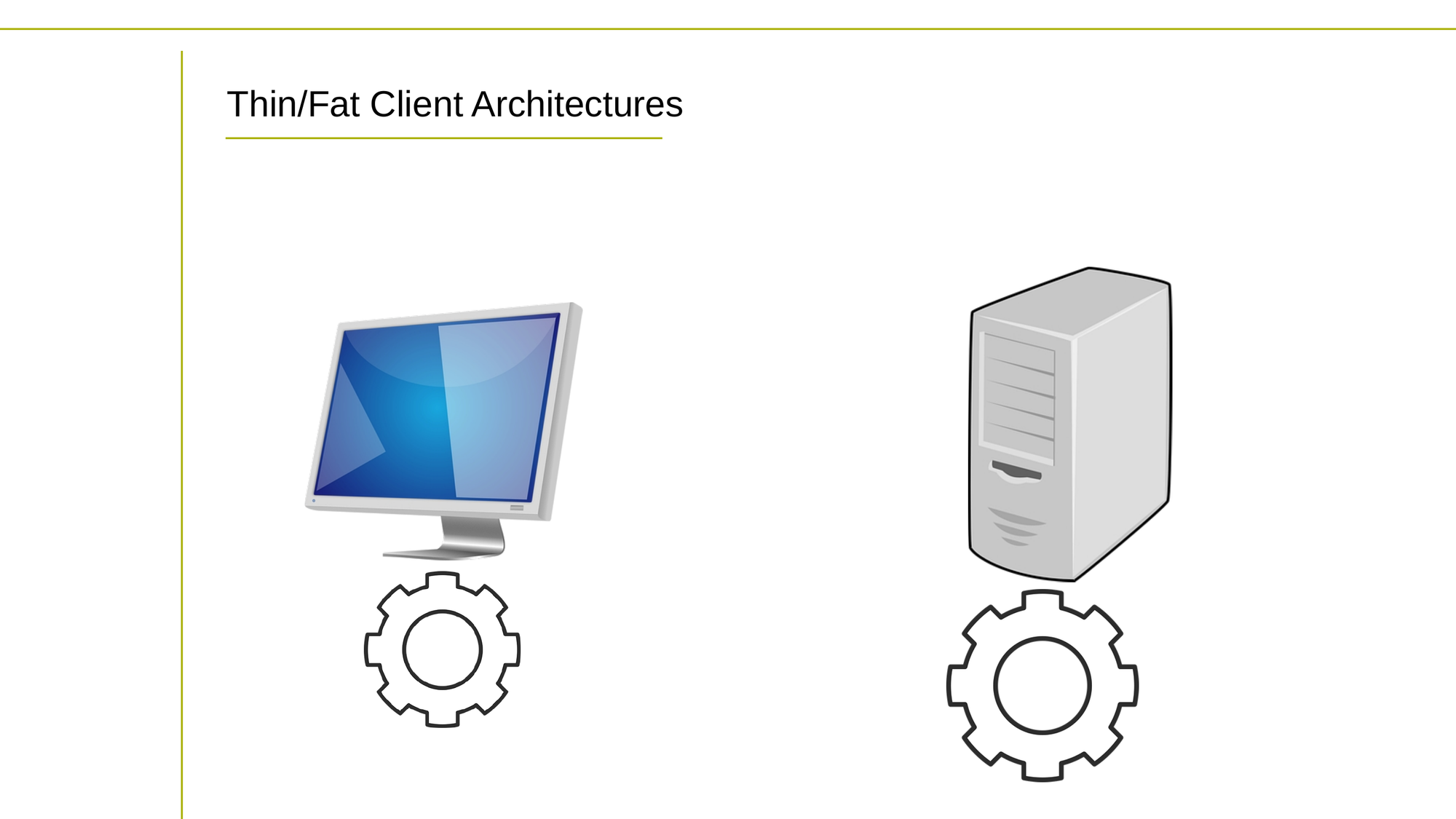 Les clients légers externalisent les opérations de calcul, tandis que les clients lourds traitent les opérations localement
Les clients légers externalisent les opérations de calcul, tandis que les clients lourds traitent les opérations localement
Cette approche peut être plus gourmande en ressources, car la machine cliente doit avoir une puissance de traitement et une mémoire suffisantes pour gérer la charge de travail. Elle peut également être plus complexe à gérer, car les mises à jour et la maintenance doivent être effectuées à la fois sur les clients et les serveurs.
Microservices vs. Architectures Monolithiques
Maintenant, devez-vous concevoir votre logiciel comme une architecture de microservices ou monolithique ? Dans une architecture monolithique, l'ensemble de l'application est construit comme une seule unité autonome. Toutes les fonctionnalités, de l'accès aux données à l'interface utilisateur, sont regroupées dans une seule base de code et déployées comme une seule unité.
Les monolithes sont généralement plus faciles à développer et à déployer, mais peuvent devenir encombrants et difficiles à maintenir à mesure que la base de code grandit en taille et en complexité.
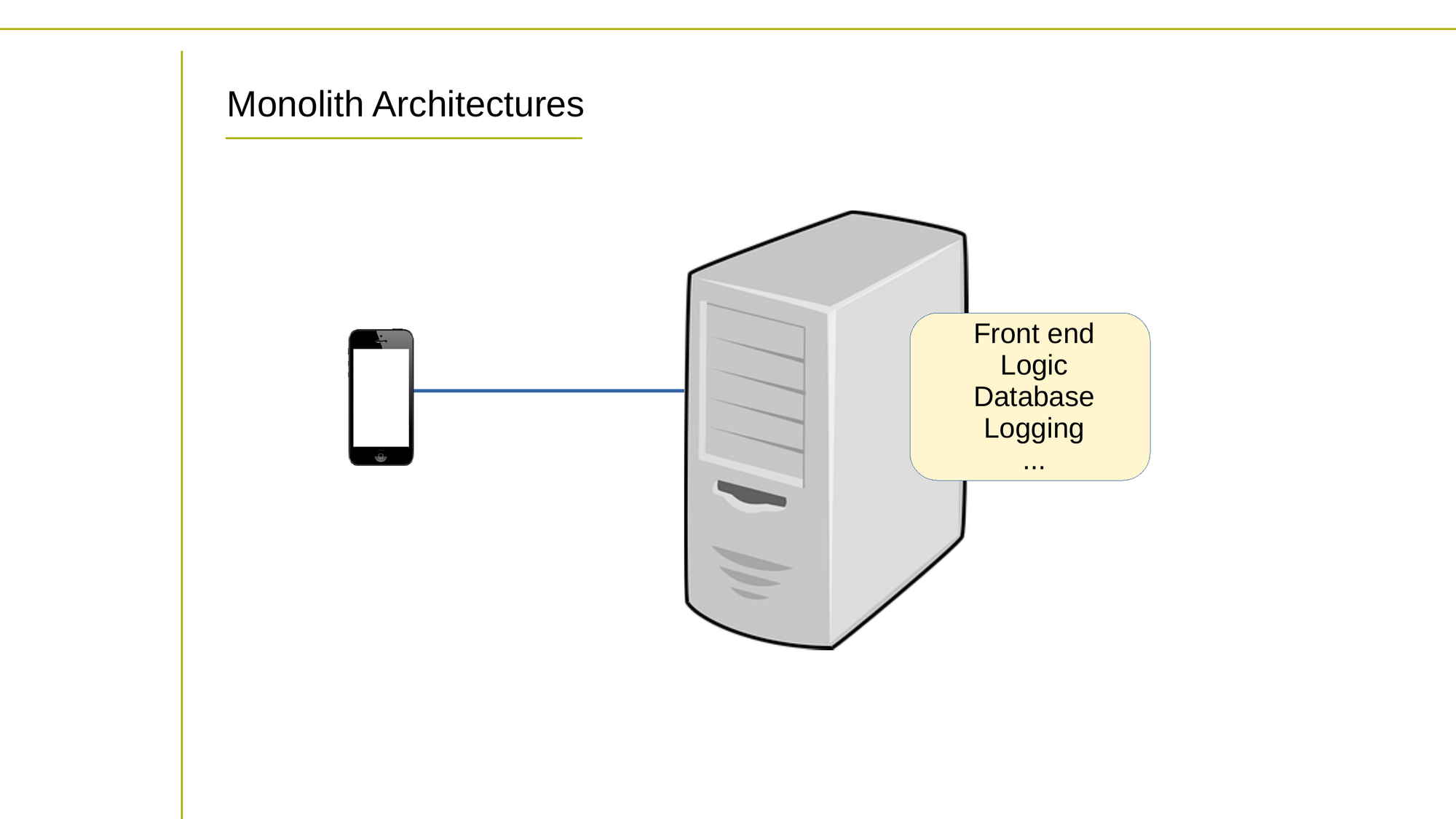 Une charge de travail de serveur multipurpose unique
Une charge de travail de serveur multipurpose unique
Mais dans une architecture de microservices, l'application est divisée en services plus petits et indépendants qui communiquent entre eux via un réseau. Chaque service est conçu pour effectuer une tâche spécifique ou un ensemble de tâches, et peut être développé et déployé indépendamment des autres services.
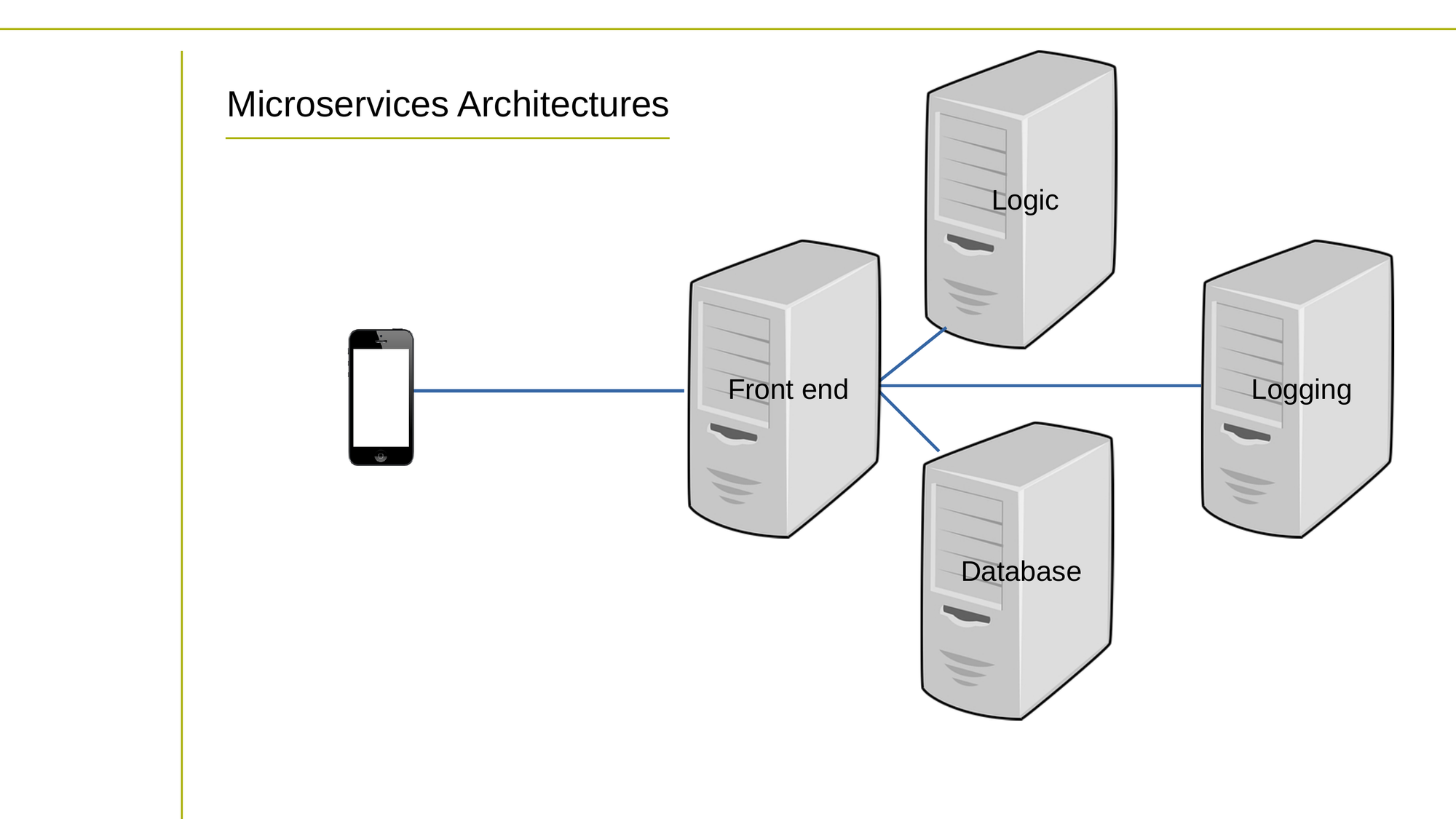 Serveurs spécialisés
Serveurs spécialisés
Les microservices peuvent être plus complexes à développer et à déployer, mais offrent une plus grande flexibilité et évolutivité, car chaque service peut être mis à l'échelle indépendamment pour gérer des charges de travail changeantes.
Dans une architecture monolithique, tous les composants de l'application sont étroitement couplés, ce qui signifie que les modifications apportées à un composant peuvent avoir un effet d'entraînement sur l'ensemble du système. Cela peut rendre difficile la mise à l'échelle ou la modification de composants spécifiques de l'application sans affecter l'ensemble du système.
Les architectures de microservices, en revanche, utilisent des fonctionnalités faiblement couplées, ce qui signifie que les modifications apportées à un service ont un impact minimal sur les autres services. Cela facilite la modification ou la mise à l'échelle de composants spécifiques de l'application sans affecter l'ensemble du système.
Applications Web
Les applications web sont des logiciels accessibles via un navigateur web sur un réseau tel qu'Internet. Le but des applications web est de fournir aux utilisateurs un moyen pratique et accessible d'effectuer diverses tâches et d'accéder à des services sur le web.
Les applications web peuvent être utilisées pour une large gamme de fins, telles que le commerce électronique, la banque en ligne, les réseaux sociaux, les emails, le partage de fichiers et les outils de productivité en ligne. Elles peuvent être conçues pour être accessibles depuis n'importe quel appareil disposant d'un navigateur web, y compris les ordinateurs de bureau, les ordinateurs portables, les tablettes et les smartphones.
Les applications web sont généralement construites en utilisant des technologies de développement web telles que HTML, CSS et JavaScript, et peuvent être hébergées sur un serveur web qui communique avec les navigateurs côté client en utilisant divers protocoles web tels que HTTP et HTTPS.
Applications à Page Unique (SPA)
Une SPA est une application web qui charge une seule page HTML et met dynamiquement à jour le contenu de cette page à mesure que l'utilisateur interagit avec elle. Cela contraste avec les applications web traditionnelles, qui nécessitent un rafraîchissement complet de la page chaque fois que l'utilisateur interagit avec l'application.
Dans une SPA, le HTML, CSS et JavaScript initiaux sont téléchargés vers le navigateur côté client, et les interactions ultérieures avec l'application sont gérées via des requêtes asynchrones vers l'API côté serveur. Le serveur renvoie les données dans un format léger, tel que JSON, que le JavaScript côté client utilise ensuite pour mettre à jour le contenu de la page sans rafraîchir l'ensemble de la page.
Les SPA sont souvent construites en utilisant des frameworks et bibliothèques JavaScript modernes, tels que React, Angular et Vue.js. Elles offrent plusieurs avantages par rapport aux applications web traditionnelles, tels que des temps de chargement plus rapides, une meilleure expérience utilisateur et une charge serveur réduite. Mais les SPA peuvent également présenter certains défis, tels que l'optimisation pour les moteurs de recherche, l'accessibilité et la gestion de l'état de l'application côté client.
Interfaces de Programmation d'Applications (API)
Une API est un ensemble de règles, de protocoles et d'outils que les développeurs utilisent pour construire des applications logicielles. Le but d'une API est de permettre la communication et l'intégration entre différentes applications logicielles, leur permettant d'échanger des données et des fonctionnalités.
Ou, en d'autres termes, les API sont un outil pour exposer de manière sécurisée et efficace les fonctionnalités de calcul et les données aux réseaux publics. Ce qui est simplement une autre manière de réaliser un déploiement de logiciel.
Les API peuvent être classées en plusieurs catégories, en fonction de leur fonction et de leur niveau d'accès :
- Les API ouvertes, également connues sous le nom d'API publiques, sont accessibles aux développeurs en dehors de l'organisation qui possède l'API, et nécessitent souvent aucune authentification ou autorisation pour y accéder.
- Les API internes, également connues sous le nom d'API privées, sont destinées à être utilisées au sein d'une organisation et ne sont pas accessibles aux développeurs externes.
- Les API composites sont des API qui combinent les fonctionnalités de plusieurs API en une seule interface, simplifiant ainsi le processus de développement pour les développeurs.
- Les API REST sont des API qui utilisent le protocole HTTP pour accéder et manipuler des données, et sont largement utilisées pour construire des applications web et mobiles. Elles facilitent pour les développeurs l'exposition programmatique des ressources locales aux utilisateurs distants de manière contrôlée. REST signifie Representational State Transfer Application Programming Interface.
- Les API SOAP, où SOAP signifie Simple Object Access Protocol, sont des API qui utilisent le protocole SOAP pour échanger des données entre différents systèmes, et sont couramment utilisées pour des applications de niveau entreprise. De nos jours, SOAP est un protocole beaucoup moins populaire que REST.
Conclusion
Nous avons passé en revue certaines des alternatives les plus populaires en matière de plateformes de déploiement de logiciels. Maintenant, avec une meilleure idée de ce qui est disponible, c'est à vous de sortir et de créer !
Cet article provient de mon cours Complete LPI Open Source Essentials Study Guide. Et il y a beaucoup plus de bonnes choses technologiques disponibles sur bootstrap-it.com