
Article original : Communication Design Patterns for Backend Development
Par Chinwendu Enyinna
Lorsque vous construisez le backend d'une application, vous devez déterminer comment les différents composants vont communiquer entre eux.
C'est comme mettre en place un réseau de communication pour le cerveau de votre application, et la manière dont vous le faites peut sérieusement impacter les performances de votre application.
Mais voici la partie amusante : il n'y a pas de réponse universelle. Le modèle de communication que vous choisissez dépend de ce que votre application doit faire.
Alors, dans ce tutoriel, nous allons examiner cinq façons différentes dont les systèmes backend aiment discuter. Nous explorerons leurs points forts et quand vous devriez les inviter à la conversation. Plongeons directement !
Qu'est-ce qu'un Modèle de Conception ?
Avant de nous pencher sur tous ces modèles passionnants, parlons de ce qu'est un modèle de conception, d'accord ?
Les modèles de conception sont des solutions réutilisables, ingénieuses et éprouvées pour des problèmes courants rencontrés lors de la conception et du développement de logiciels. Vous pouvez les appeler les codes de triche de la conception et du développement de logiciels.
Ils peuvent aider à fournir une approche structurée pour résoudre des défis récurrents, offrant un ensemble de directives et de meilleures pratiques qui peuvent être adaptées à divers scénarios.
Maintenant que nous avons compris cela, explorons cinq de ces modèles de conception émergents utilisés pour la communication backend.
Modèle Requête-Réponse
Le modèle requête-réponse est un bloc de construction fondamental pour la manière dont le front-end et le back-end des applications web communiquent entre eux. Ce modèle est comme une conversation entre le client (par exemple votre navigateur) et le serveur, où ils parlent à tour de rôle. Imaginez-le comme un "ping-pong" de données.
Voici un diagramme illustrant à quoi cela ressemble :
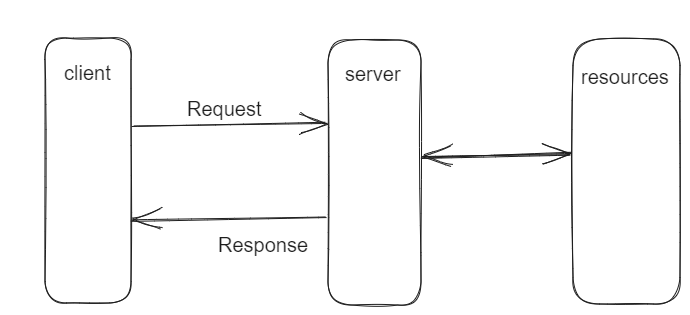 modèle de communication requête/réponse
modèle de communication requête/réponse
Comment fonctionne le modèle Requête-Réponse ?
Ce modèle est tout au sujet de la synchronisation. Le client envoie une requête au serveur, un peu comme lever la main pour poser une question en classe. Ensuite, il attend patiemment que le serveur réponde avant de pouvoir continuer.
C'est comme une conversation polie — l'un parle, l'autre écoute, puis ils échangent les rôles.
Vous avez probablement entendu parler des API RESTful, n'est-ce pas ? Eh bien, elles sont un exemple parfait du modèle requête-réponse en action.
Lorsque votre application a besoin de données ou veut faire quelque chose sur le serveur, elle crée une requête HTTP — par exemple GET, POST, PUT ou DELETE (comme demander gentiment une page), et l'envoie à des endpoints spécifiques (URL) sur le serveur. Le serveur traite ensuite votre requête et répond avec les données dont vous avez besoin ou exécute l'action demandée.
C'est comme commander votre plat préféré dans un menu — vous demandez, et la cuisine (serveur) le prépare pour vous.
Intéressamment, il y a plus d'une façon d'avoir cette conversation. En plus de REST, il y a GraphQL, une alternative qui vous permet de demander exactement les données que vous voulez. C'est comme personnaliser votre commande dans un restaurant — vous pouvez choisir vos ingrédients.
Il est important de noter que ce modèle n'est pas limité aux applications web. Vous le trouverez dans les appels de procédure à distance (RPC), les requêtes de base de données (avec le serveur comme client et la base de données comme serveur), et les protocoles réseau (HTTP, SMTP, FTP) pour n'en nommer que quelques-uns. C'est comme le langage de communication pour le web.
Avantages du modèle Requête-Réponse
Facilité d'implémentation et simplicité : La manière dont la communication se déroule dans ce modèle est assez simple, ce qui en fait un choix privilégié pour de nombreux développeurs, surtout lorsqu'ils construisent des applications avec des besoins d'interaction basiques.
Flexibilité et adaptabilité (Une taille convient à plusieurs) : Le modèle requête-réponse s'adapte parfaitement à une large gamme de contextes. Vous pouvez l'utiliser pour faire des appels API, rendre des pages web sur le serveur, récupérer des données à partir de bases de données, et plus encore.
Évolutivité : Chaque requête du client est traitée individuellement, donc le serveur peut facilement gérer plusieurs requêtes à la fois. Cela est très bénéfique pour les sites web à fort trafic, les API qui reçoivent des tonnes d'appels, ou les services basés sur le cloud.
Fiabilité : Puisque le serveur envoie toujours une réponse, le client peut être sûr que sa requête est reçue et traitée. Cela aide à maintenir la cohérence des données et garantit que les actions ont été exécutées comme prévu, même dans des scénarios de fort trafic.
Facilité de débogage : Si quelque chose ne va pas, le serveur envoie gentiment un message d'erreur avec un code d'état indiquant ce qui s'est passé. Cela rend la gestion des erreurs facile.
Limites du modèle Requête-Réponse
Problème de latence : Parce que c'est une conversation aller-retour, il y a souvent une période d'attente. Cela entraîne des périodes d'inactivité et amplifie la latence, surtout lorsque la requête nécessite que le serveur effectue des tâches informatiques chronophages.
Incohérence des données en cas d'échecs : Si un échec se produit après que le serveur a traité la requête mais avant que la réponse ne soit livrée au client, une incohérence des données peut en résulter.
Complexité dans la communication en temps réel : Pour les applications qui nécessitent une communication en temps réel ultra-rapide (comme le streaming en direct, les jeux ou les applications de chat), ce modèle peut introduire des retards et est donc inadapté à ces cas d'utilisation.
Inefficacité dans la diffusion : Dans les scénarios où vous devez envoyer les mêmes données à plusieurs clients à la fois (diffusion), ce modèle peut être un peu inefficace. C'est comme envoyer des lettres individuelles au lieu d'envoyer un message de groupe.
Voici un exemple de code qui montre le modèle requête-réponse en utilisant Node.js.
Tout d'abord, nous avons le fichier server.js. Ici, nous avons configuré le serveur pour écouter les requêtes entrantes du client.
const http = require("http");
const server = http.createServer((req, res) => {
res.statusCode = 200;
res.setHeader("Content-Type", "text/plain");
//vérifier la méthode de requête et recevoir les données du client
if (req.method === "POST") {
let incomingMessage = "";
req.on("data", (chunk) => {
incomingMessage += chunk;
});
//écrire le message reçu du client sur la console
req.on("end", () => {
console.log(`Message du client : ${incomingMessage}`);
res.end(`Bonjour client, message reçu !`);
});
} else {
res.end("Hey, Client !\n");
}
});
const PORT = 3030;
server.listen(PORT, () => {
console.log(
`Le serveur écoute les requêtes entrantes du client sur le port :${PORT}`
);
});
Et voici le fichier client.js :
const http = require("http");
const options = {
method: "POST",
hostname: "localhost",
port: 3030,
path: "/",
};
//message au serveur
let messageToServer = "Hey, serveur !";
//envoyer une requête http au serveur
const req = http.request(options, (res) => {
let incomingData = "";
res.on("data", (chunk) => {
incomingData += chunk;
});
res.on("end", () => {
console.log(`Réponse du serveur : ${incomingData}`);
});
});
req.on("error", (error) => {
console.log(`Message d'erreur : ${error.message}`);
});
//envoyer le message au serveur
req.write(messageToServer);
//terminer votre requête
req.end();
Voici le résultat :
 sortie du code dans le terminal
sortie du code dans le terminal
Le Modèle Publication/Abonnement
La publication/abonnement est un autre modèle de communication de conception que vous pouvez voir dans le backend. Il est utilisé dans les systèmes distribués pour la communication asynchrone entre plusieurs composants (généralement découplés). Il est parfait lorsque vous avez un ensemble de composants qui doivent travailler ensemble mais veulent garder leurs distances.
Voici un diagramme montrant comment cela fonctionne :
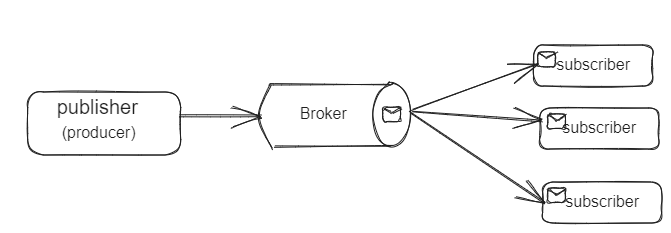 modèle de communication Pub/Sub
modèle de communication Pub/Sub
Comment fonctionne le modèle Publication/Abonnement ?
Ce modèle implique l'utilisation de files d'attente de messages (souvent appelées courtier de messages) qui servent d'intermédiaires entre les éditeurs et les abonnés. Ces courtier de messages regroupent les messages dans ce que l'on appelle des canaux (ou sujets).
Les éditeurs sont les composants qui créent et envoient des messages tandis que les abonnés sont les composants qui reçoivent et consomment les messages.
Les éditeurs envoient simplement des messages (ou événements) dans des canaux/sujets spécifiques au sein du courtier de messages. Ces canaux agissent comme le point de distribution pour les messages. Les abonnés indiquent ensuite leur intérêt en s'abonnant à ces canaux au sein du courtier de messages et chaque fois qu'un message ou un événement est publié sur ce canal, ils reçoivent une copie.
Des outils de mise en file d'attente de messages comme Apache Kafka et MQTT utilisent le modèle de communication publication/abonnement sous le capot.
Avantages du modèle Publication/Abonnement
Communication Asynchrone : Contrairement au modèle requête-réponse, pub/sub est conçu pour être asynchrone par nature. Cela le rend idéal pour construire des applications en temps réel avec des goulots d'étranglement de latence réduits.
Couplage lâche des composants : Les composants dans un modèle publication/abonnement sont faiblement couplés. Cela signifie qu'ils ne sont pas liés ensemble et peuvent interagir librement en déclenchant et en répondant à des événements.
Hautement évolutif : Il n'y a pas de limite au nombre d'abonnés auxquels un éditeur peut publier des événements. De plus, il n'y a pas de limite au nombre d'éditeurs auxquels les abonnés peuvent s'abonner.
Indépendant du langage et du protocole : Le modèle Pub/Sub peut être facilement intégré dans n'importe quelle stack technologique car il est agnostique en termes de langage. De plus, il supporte souvent une large gamme d'environnements et de plateformes, ce qui le rend compatible multiplateforme.
Équilibrage de charge : Dans les cas où plusieurs abonnés s'abonnent à un événement particulier, le modèle pub/sub peut distribuer les événements de manière égale parmi les abonnés, offrant des capacités d'équilibrage de charge dès la sortie de la boîte.
Limites du modèle Publication/Abonnement
Complexité de l'implémentation : La mise en place d'un système Pub/Sub peut être plus complexe que des modèles de communication plus simples comme le modèle requête-réponse. Vous devez configurer et gérer des courtier de messages, des canaux et des abonnements, ce qui peut ajouter des frais généraux à votre système.
Duplication de messages : Selon la configuration et les problèmes de réseau, les messages peuvent être dupliqués. Les abonnés peuvent recevoir le même message plus d'une fois, ce qui peut entraîner de la redondance et un traitement supplémentaire.
Défis d'évolutivité : Bien que Pub/Sub soit hautement évolutif, la gestion de volumes extrêmement élevés de messages et d'abonnés peut devenir complexe. Vous devrez peut-être considérer comment distribuer les messages efficacement et gérer un nombre massif d'abonnés.
Gestion des erreurs complexe : Traiter les erreurs dans un système Pub/Sub peut être difficile. Gérer des situations comme les échecs de livraison de messages ou les erreurs d'abonnés nécessite une considération et une conception minutieuses.
Quand l'utiliser ?
- Dans la construction de fonctionnalités qui nécessitent une réactivité en temps réel et à faible latence pour les utilisateurs finaux, par exemple des applications de chat en direct ou de jeu pour plusieurs joueurs.
- Dans les systèmes de notification d'événements
- Dans la construction de systèmes distribués qui reposent sur la journalisation et la mise en cache
Voici un extrait de code montrant une implémentation simple de pub/sub en utilisant le package npm pubsub-js.
Voici le contenu du fichier pubsub.js :
const PubSub = require("pubsub-js");
/*
crée un sujet de votre choix.
Tout abonné qui s'abonne à ce sujet
reçoit les messages publiés
*/
const TOPIC = "chat";
//une fonction pour publier un message aux abonnés
function publishMessageToSubscribers(message) {
PubSub.publish(TOPIC, message);
console.log(`Message publié : ${message}`);
}
let subscriber1 = function (msg, data) {
console.log(msg, data);
console.log("subscriber1 reçu : ", data);
};
let subscriber2 = function (msg, data) {
console.log(msg, data);
console.log("subscriber2 reçu : ", data);
};
// Subscriber1 s'abonne au sujet
PubSub.subscribe(TOPIC, subscriber1);
//subscriber2 s'abonne au sujet
PubSub.subscribe(TOPIC, subscriber2);
publishMessageToSubscribers("Bonjour abonné !");
console.log("Subscriber 1 écoute....");
console.log("Subscriber 2 écoute....");
Voici le résultat :
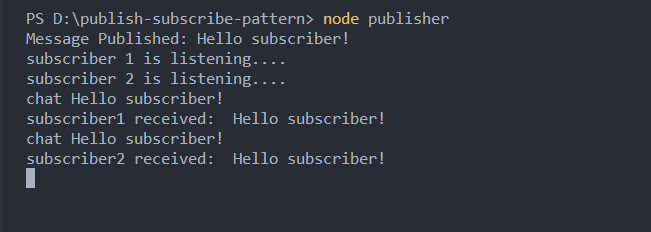
Le Modèle de Sondage Courte
Le sondage court est un autre modèle de communication qui facilite l'échange de données entre le client et le serveur. Il utilise le mécanisme de communication basé sur la récupération (qui est essentiellement le client qui récupère les données du backend) pour interroger continuellement le serveur pour de nouvelles mises à jour.
Comment fonctionne le Sondage Court ?
Imaginez que vous attendez un message d'un ami, et vous ne voulez pas le manquer. Que faites-vous ? Vous continuez à demander, "As-tu un message pour moi ?"
Ainsi, le client envoie une requête au serveur à des intervalles réguliers (fixes) (par exemple toutes les x unités de temps) pour vérifier les nouvelles données ou mises à jour. Le serveur envoie une réponse et si de nouvelles données ou une mise à jour sont disponibles, le serveur inclut les données dans la réponse.
Voici à quoi ressemblerait la communication client-serveur :
- Client : "Hey, serveur, des nouveaux messages ?"
- Serveur : "Non, rien pour l'instant."
- Client : "D'accord, je vérifierai plus tard."
- [Un certain temps passe...]
- Client : "Hey, serveur, des nouveaux messages ?"
- Serveur : "Bingo ! Les voici !"
Bien que le sondage ait certaines similitudes avec le modèle requête-réponse que nous avons discuté précédemment, une différence clé entre eux est le timing.
Alors que le sondage se produit à des intervalles réguliers et prédéfinis, indépendamment du fait que des mises à jour soient disponibles, le modèle requête-réponse permet aux clients de demander des données ou des actions à la demande lorsque cela est nécessaire, réduisant ainsi la communication inutile.
Avantages du Sondage
Simplicité : Le sondage est facile à comprendre et à implémenter et il est complètement sans état entre le client et le serveur. Cela le rend parfait pour les scénarios où les complexités doivent être minimisées.
Compatibilité : Il peut être utilisé avec une large gamme de technologies et de protocoles, ce qui le rend hautement compatible avec un certain nombre de plateformes et d'environnements.
Certains cas d'utilisation du modèle de sondage incluent des tableaux de bord simples, des applications météo qui nécessitent des mises à jour périodiques, la surveillance des ressources, ou dans les cas où vous envisagez la compatibilité multiplateforme.
Limites du Sondage
Latence : Le sondage introduit de la latence, car les clients doivent attendre des intervalles prédéfinis avant de recevoir des mises à jour. Cela peut entraîner des retards dans l'accès aux données en temps réel ou la réception de notifications.
Inefficacité : Interroger constamment le serveur pour des mises à jour peut être inefficace et peut entraîner une surcharge inutile du réseau et du serveur.
Évolutivité : Gérer un grand nombre de clients simultanés utilisant le sondage peut être intensif en ressources pour le serveur. Il peut nécessiter des ressources serveurs significatives pour gérer de nombreuses requêtes de sondage concurrentes.
Voici un extrait de code pour illustrer le sondage court. Ici, le client envoie une requête périodique (sondage) au serveur pour vérifier la progression du téléchargement.
Le fichier app.js :
const express = require("express");
const app = express();
//créer un dictionnaire pour stocker la progression du téléchargement
const uploadStatus = {};
//simuler le téléchargement d'un fichier
app.post("/upload", (req, res) => {
//créer un identifiant de requête unique pour la requête entrante
const requestId = Math.floor(Math.random() * 1000000);
uploadStatus[requestId] = 0;
simulateUploadProgress(requestId);
res.json({ requestId });
});
//endpoint pour vérifier la progression du téléchargement
app.get("/status/:requestId", (req, res) => {
const requestId = parseInt(req.params.requestId);
if (!isNaN(requestId) && uploadStatus[requestId] !== undefined) {
if (uploadStatus[requestId] === 100) {
//téléchargement terminé
res.json({ progress: 100, message: "TÉLÉCHARGEMENT TERMINÉ !" });
} else {
// téléchargement toujours en cours
res.json({ progress: uploadStatus[requestId] });
}
} else {
res.status(404).json({ error: "Identifiant de requête introuvable" });
}
});
//mettre à jour la progression du téléchargement de 10% toutes les 5 secondes
function simulateUploadProgress(requestId) {
if (uploadStatus[requestId] < 100) {
setTimeout(() => {
uploadStatus[requestId] += 10;
simulateUploadProgress(requestId);
}, 5000);
}
}
const PORT = 4000;
app.listen(PORT, () => {
console.log(`Le serveur est en cours d'exécution sur le port ${PORT}`);
});
Voici la sortie dans le terminal

Le Modèle de Sondage Long
Le sondage long est similaire au sondage mais utilise un mécanisme de communication basé sur la poussée. Dans le sondage long, au lieu que le client demande au serveur, "Des mises à jour ?" tout le temps, il dit, "Préviens-moi quand quelque chose se passe."
Voici comment fonctionne le Sondage Long :
Le client interroge le serveur, tout comme dans le sondage régulier, mais cette fois, le serveur ne répond pas immédiatement. Il maintient la connexion ouverte, comme garder une ligne téléphonique en attente. Lorsqu'il y a quelque chose à partager, il répond. C'est comme si le serveur disait, "Hey, je t'appellerai quand j'aurai des nouvelles."
Il est utilisé dans les applications web pour obtenir des mises à jour en temps réel ou quasi en temps réel entre un client et un serveur.
Avantages du Modèle de Sondage Long
Faible Latence : Le sondage long offre une faible latence par rapport au sondage traditionnel car les données sont immédiatement renvoyées aux clients dès qu'elles sont disponibles.
Mises à Jour en Temps Réel : Avec la technique de sondage long, les applications peuvent obtenir des mises à jour en temps réel sans avoir besoin de sonder constamment le serveur.
Limites du Modèle de Sondage Long
Intensif en Ressources : Le sondage long nécessite de maintenir de nombreuses connexions ouvertes. Par conséquent, il peut être consommateur de ressources à la fois du côté serveur et du côté client.
Latence Accrue : Bien que le sondage long aide à réduire les sondages fréquents, il peut encore introduire de la latence par rapport à d'autres protocoles de communication en temps réel comme Web Socket. Les clients peuvent subir des retards entre les mises à jour puisqu'ils doivent attendre que le serveur réponde.
Difficile à Scaler : Lorsque l'on traite avec un grand nombre de clients simultanés, le sondage long peut solliciter les ressources du serveur. À mesure que plus de clients établissent des connexions de sondage long, le serveur peut avoir du mal à gérer et à répondre à toutes ces connexions efficacement.
Les cas d'utilisation typiques du sondage long incluent les mises à jour en temps réel, les applications pilotées par événements et les systèmes de notification d'événements.
Voici un extrait de code pour illustrer le concept de sondage long où le client attend les mises à jour du serveur.
const express = require("express");
const app = express();
const uploadStatus = {};
app.post("/upload", (req, res) => {
const requestId = Math.floor(Math.random() * 1000000);
uploadStatus[requestId] = 0;
updateUploadProgress(requestId, uploadStatus[requestId]);
res.json({ requestId });
});
app.get("/status/:requestId", async (req, res) => {
const requestId = parseInt(req.params.requestId);
//simuler le sondage long (le serveur ne répondra pas avant la fin)
while ((await checkUploadComplete(requestId)) === false);
res.end("\n\n Statut du téléchargement : terminé " + uploadStatus[requestId]);
});
//mettre à jour la progression de 20% toutes les 5 secondes
function updateUploadProgress(requestId, progress) {
uploadStatus[requestId] = progress;
console.log(`Progression mise à jour à ${progress}`);
if (progress === 100) return;
this.setTimeout(() => updateUploadProgress(requestId, progress + 20), 5000);
}
//vérifier le statut du téléchargement
function checkUploadComplete(requestId) {
return new Promise((resolve, reject) => {
if (uploadStatus[requestId] < 100) {
this.setTimeout(() => resolve(false), 1000);
} else {
resolve(true);
}
});
}
const PORT = 4000;
app.listen(PORT, () => {
console.log(`Le serveur est en cours d'exécution sur le port ${PORT}`);
});
Et voici la sortie dans le terminal.
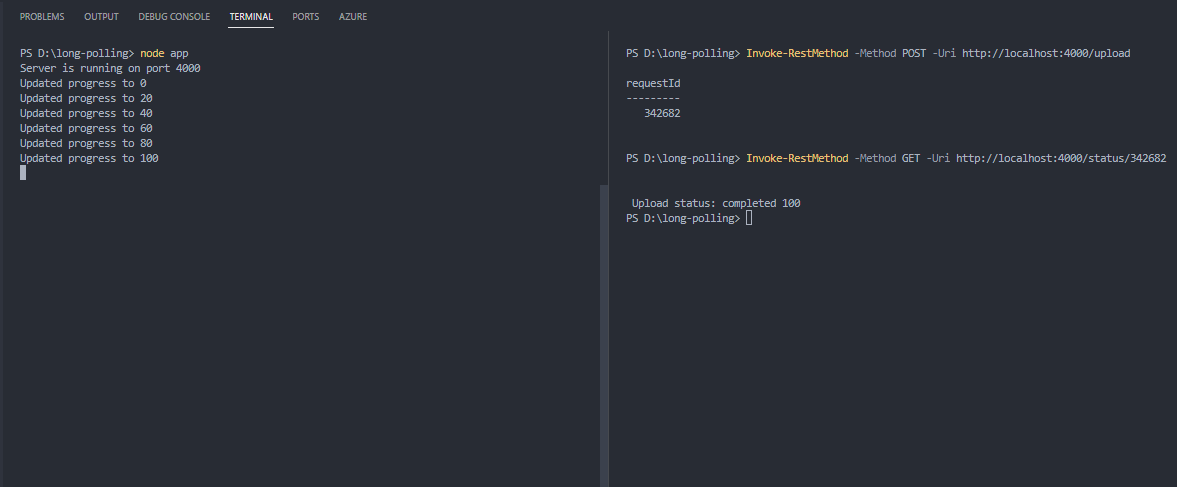 sortie du code
sortie du code
Le Modèle de Poussée
La poussée est un modèle de communication utilisé pour fournir des mises à jour en temps réel aux clients connectés.
Dans ce modèle, le client ouvre une connexion au serveur et attend des messages ou des mises à jour du serveur. Chaque fois qu'il y a une nouvelle mise à jour ou un message, le serveur pousse immédiatement cette mise à jour au client sans que le client ne la demande explicitement — tant qu'il est connecté.
Ce modèle permet une communication bidirectionnelle entre le client et le serveur. Les WebSockets, un protocole populaire, utilisent le modèle de poussée comme méthode d'échange de données sous-jacente.
Le modèle de poussée offre l'expérience utilisateur finale la plus en temps réel ou quasi en temps réel par rapport à d'autres paradigmes étroitement liés tels que le sondage et le sondage long.
Pour expliquer comment fonctionne le modèle de poussée, imaginez une salle de chat avec plusieurs utilisateurs connectés comme exemple. La conversation entre le client et le serveur ressemblera à ceci :
- utilisateur1 (client) : "Bonjour..."
- Serveur : "Oh, utilisateur1 a un message !" L'envoie instantanément à tout le monde dans la salle.
- Utilisateur2 (client) : Reçoit le message de l'utilisateur1 sans rien faire.
- Utilisateur3 (client) : Reçoit également le message de l'utilisateur1 — pas besoin de rafraîchir ou de le demander.
Dans l'exemple ci-dessus, le modèle de poussée permet une communication en temps réel de sorte que chaque fois qu'il y a un message d'un client dans la salle de chat, il pousse le message à tous les autres clients connectés dans cette salle sans qu'ils aient à sonder continuellement ou à demander des mises à jour.
Les technologies populaires qui utilisent le modèle de poussée sont RabbitMQ et WebSocket.
Avantages du Modèle de Poussée
Mises à Jour en Temps Réel : Le modèle de poussée permet aux clients de recevoir des mises à jour du serveur dès qu'elles sont disponibles. Cela est clé, surtout dans les applications où les mises à jour en temps réel sont cruciales.
Latence Réduite : Puisque le serveur pousse les mises à jour au client dès qu'elles sont disponibles, cela réduit potentiellement la latence.
Efficacité : Parce qu'il n'y a pas besoin de sondage continu ou de requêtes fréquentes du client, il y a une utilisation efficace des ressources réseau et une charge serveur réduite.
Bien que le modèle de poussée soit largement adopté comme le mieux adapté pour fournir des mises à jour en temps réel, il a ses propres inconvénients.
Limites du Modèle de Poussée
Évolutivité : Il peut devenir difficile à scaler à mesure que le nombre de clients connectés augmente. À ce stade, cela devient intensif en ressources, surtout du côté serveur puisque le serveur doit maintenir des connexions ouvertes avec plusieurs clients.
Support Client : Certains clients peuvent ne pas être en mesure de gérer les messages poussés car toutes les plateformes clientes ne supportent pas les technologies de poussée. Cela peut entraîner des problèmes de compatibilité et peut nécessiter un mécanisme de repli pour les clients non supportés.
Certains cas d'utilisation du modèle de poussée incluent les applications de chat et de messagerie, les systèmes de notification, le streaming de données IoT et les jeux en ligne, pour n'en nommer que quelques-uns.
Voici un exemple de code Node.js simple pour illustrer le modèle de poussée en utilisant les WebSockets. Pour exécuter le code, vous devez installer la bibliothèque ws en utilisant npm.
//créer un serveur - ce serveur poussera les mises à jour aux clients à intervalles
const WebSocket = require("ws");
const server = new WebSocket.Server({ port: 8080 });
server.on("connection", (client) => {
console.log("Client connecté au serveur");
//Simuler la réception de mises à jour en temps réel du serveur toutes les 2 secondes
const interval = setInterval(() => {
const message = `Message reçu à : ${new Date().toLocaleTimeString()}`;
client.send(message);
}, 2000);
// Gérer la déconnexion du client
client.on("close", () => {
clearInterval(interval);
console.log("Client déconnecté");
});
});
// Client (écoute les mises à jour du serveur)
const clientSocket = new WebSocket("ws://localhost:8080");
clientSocket.onmessage = (event) => {
console.log(`Message du serveur : "${event.data}"`);
};
Conclusion
Dans ce tutoriel, nous avons exploré cinq modèles de conception de communication clés : Requête-Réponse, Publication/Abonnement, Sondage Court, Sondage Long et Poussée.
Chaque modèle a ses propres forces et limites uniques qui les rendent adaptés à divers cas d'utilisation.
En fonction de l'objectif de votre application, comprendre ces modèles vous aidera à concevoir des systèmes backend efficaces.