

Article original : Best Practices for Scaling Your Node.js REST APIs
Par Rishabh Rawat
La scalabilité ne se limite pas à l'utilisation du mode cluster. Dans ce tutoriel, nous explorerons 10 façons de préparer votre API Node.js à l'échelle.
Lorsqu'on travaille sur un projet, nous obtenons souvent quelques pépites ici et là sur la manière de faire quelque chose de mieux. Nous apprenons rétrospectivement, et ensuite nous sommes pleinement préparés à l'appliquer la prochaine fois.
Mais à quelle fréquence cela fonctionne-t-il vraiment ? Parfois, je ne me souviens même pas de ce que j'ai fait hier. Alors j'ai écrit cet article.
Ceci est ma tentative de documenter certaines des meilleures pratiques de scalabilité Node.js qui ne sont pas souvent discutées.
Vous pouvez adopter ces pratiques à n'importe quelle étape de votre projet Node.js. Cela n'a pas à être un correctif de dernière minute.
Cela dit, voici ce que nous allons couvrir dans cet article :
- 🚦 Utiliser la limitation de débit
- 🐢 Optimiser vos requêtes de base de données
- ⚡ Échouer rapidement avec un disjoncteur
- 🔍 Journaliser vos points de contrôle
- ☁️ Utiliser Kafka plutôt que des requêtes HTTP
- 🧹 Surveiller les fuites de mémoire
- 🐿️ Utiliser la mise en cache
- 🎉 Utiliser le pooling de connexions
- 🔼 Mises à l'échelle transparentes
- 📜 Documentation conforme à OpenAPI
Utiliser la limitation de débit
La limitation de débit vous permet de limiter l'accès à vos services pour les empêcher d'être submergés par trop de requêtes. Elle présente certains avantages clairs – vous pouvez protéger votre application, qu'il s'agisse d'une forte affluence d'utilisateurs ou d'une attaque par déni de service.
L'endroit commun pour implémenter un mécanisme de limitation de débit est là où le taux d'entrée et de sortie ne correspondent pas. Particulièrement, lorsqu'il y a plus de trafic entrant que ce qu'un service peut (ou veut) gérer.
Comprenons avec une visualisation.
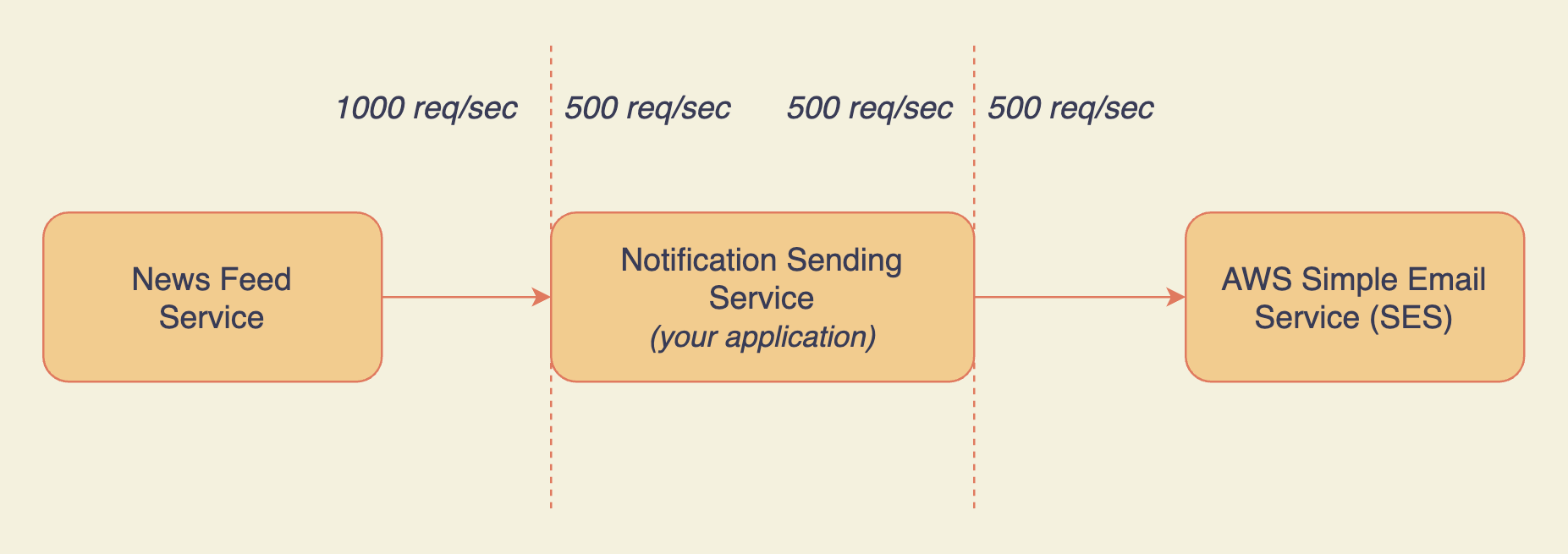 Votre application limite les requêtes du Service de Fil d'Actualité
Votre application limite les requêtes du Service de Fil d'Actualité
Il y a une limitation de débit au premier point de jonction entre votre application et le Service de Fil d'Actualité :
- Service de Fil d'Actualité (NFS) s'abonne à votre application pour envoyer des notifications.
- Il envoie 1000 requêtes à votre application chaque seconde.
- Votre application ne gère que 500 requêtes/sec selon le plan de facturation auquel NFS est abonné.
- Les notifications sont envoyées pour les 500 premières requêtes.
Il est très important de noter que toutes les requêtes de NFS qui dépassent le quota de 500 requêtes/sec doivent échouer et être réessayées par NFS.
Pourquoi rejeter les requêtes supplémentaires lorsque vous pouvez les mettre en file d'attente ? Il y a plusieurs raisons :
- Accepter toutes les requêtes entraînera l'accumulation de celles-ci par votre application. Cela deviendra un point de défaillance unique (par épuisement de la RAM/du disque) pour tous les clients abonnés à votre application, y compris NFS.
- Vous ne devez pas accepter les requêtes qui dépassent le cadre du plan d'abonnement de vos clients (dans ce cas, NFS).
Pour la limitation de débit au niveau de l'application, vous pouvez utiliser le middleware express-rate-limit pour votre API Express.js. Pour la limitation de débit au niveau réseau, vous pouvez trouver des solutions comme WAF.
Si vous utilisez un mécanisme de pub-sub, vous pouvez également limiter vos consommateurs ou abonnés. Par exemple, vous pouvez choisir de consommer uniquement un nombre limité d'octets de données lors de la consommation d'un sujet Kafka en définissant l'option maxBytes.
Optimiser vos requêtes de base de données
Il y aura des moments où interroger la base de données sera le seul choix. Vous n'avez peut-être pas mis en cache les données ou elles pourraient être obsolètes.
Lorsque cela se produit, assurez-vous que votre base de données est prête. Avoir suffisamment de RAM et d'IOPS de disque est une bonne première étape.
Deuxièmement, optimisez vos requêtes autant que possible. Pour commencer, voici quelques points qui vous mettront sur la bonne voie :
- Essayez d'utiliser des champs indexés lors des requêtes. Ne surindexez pas vos tables dans l'espoir d'obtenir les meilleures performances. Les index ont un coût.
- Pour les suppressions, restez sur les suppressions logiques. Si la suppression permanente est nécessaire, retardez-la. (histoire intéressante)
- Lors de la lecture des données, ne récupérez que les champs nécessaires en utilisant la projection. Si possible, supprimez les métadonnées et méthodes inutiles (par exemple, Mongoose a lean).
- Essayez de découpler les performances de la base de données de l'expérience utilisateur. Si les opérations CRUD sur la base de données peuvent se faire en arrière-plan (c'est-à-dire non bloquantes), faites-le. Ne laissez pas l'utilisateur attendre.
- Mettez à jour directement les champs souhaités en utilisant des requêtes de mise à jour. Ne récupérez pas le document, ne mettez pas à jour le champ et ne sauvegardez pas le document entier dans la base de données. Cela a un surcoût réseau et de base de données.
Échouer rapidement avec un disjoncteur
Imaginez que vous recevez un trafic intense sur votre application Node.js, et qu'un des services externes nécessaires pour répondre aux requêtes est hors service. Voulez-vous continuer à frapper dans le vide pour chaque requête par la suite ? Définitivement pas. Nous ne voulons pas gaspiller du temps et des ressources sur des requêtes destinées à échouer.
C'est toute l'idée d'un disjoncteur. Échouer tôt. Échouer rapidement.
Par exemple, si 50 des 100 requêtes échouent, il n'autorise plus de requêtes vers ce service externe pendant les X prochaines secondes. Cela empêche l'envoi de requêtes qui sont vouées à l'échec.
Une fois le disjoncteur réinitialisé, il permet aux requêtes de passer. Si elles échouent à nouveau, le disjoncteur se déclenche et le cycle se répète.
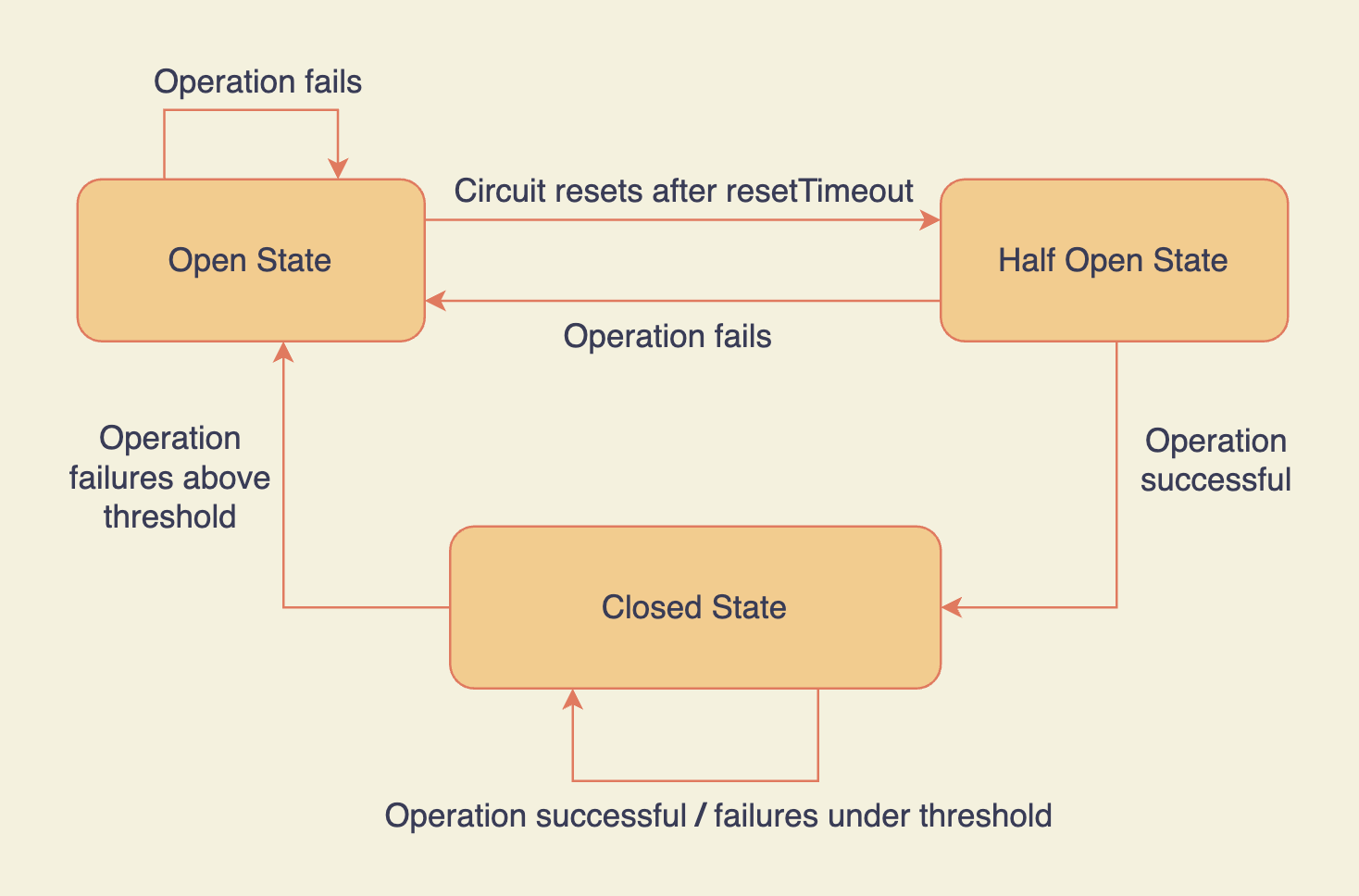 États du disjoncteur Node.js Opposum
États du disjoncteur Node.js Opposum
Pour en savoir plus sur la manière d'ajouter un disjoncteur à votre application Node.js, consultez Opposum. Vous pouvez lire plus sur les disjoncteurs ici.
Journaliser vos points de contrôle
Une bonne configuration de journalisation vous permet de repérer rapidement les erreurs. Vous pouvez créer des visualisations pour comprendre le comportement de votre application, configurer des alertes et déboguer efficacement.
Vous pouvez consulter la pile ELK pour configurer une bonne pipeline de journalisation et d'alerte.
Bien que la journalisation soit un outil essentiel, il est très facile d'en abuser. Si vous commencez à tout journaliser, vous pouvez finir par épuiser vos IOPS de disque, ce qui nuira à votre application.
En règle générale, ne journalisez que les points de contrôle.
Les points de contrôle peuvent être :
- Les requêtes, lorsqu'elles entrent dans le flux de contrôle principal de votre application et après avoir été validées et assainies.
- La requête et la réponse lors de l'interaction avec un service/SDK/API externe.
- La réponse finale à cette requête.
- Des messages d'erreur utiles pour vos gestionnaires de catch (avec des valeurs par défaut sensées pour les messages d'erreur).
PS : Si une requête passe par plusieurs services pendant son cycle de vie, vous pouvez transmettre un identifiant unique dans les journaux pour capturer une requête particulière à travers tous les services.
Utiliser Kafka plutôt que des requêtes HTTP
Bien que HTTP ait ses cas d'utilisation, il est facile d'en abuser. Évitez d'utiliser des requêtes HTTP lorsque ce n'est pas nécessaire.
Comprenons cela à l'aide d'un exemple.
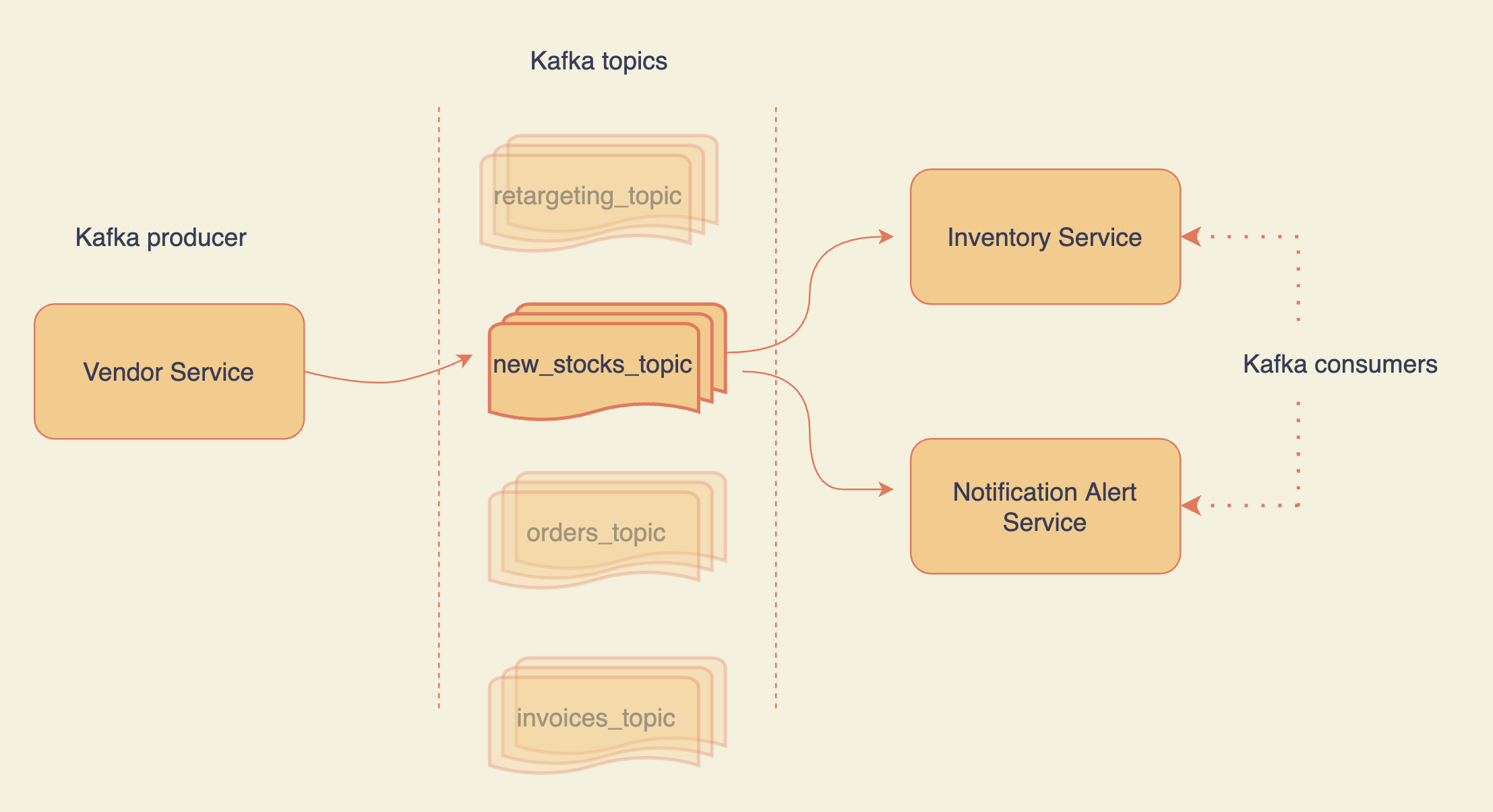 Aperçu de Kafka pub-sub utilisant des sujets
Aperçu de Kafka pub-sub utilisant des sujets
Disons que vous construisez un produit comme Amazon et qu'il y a deux services :
- Service fournisseur
- Service d'inventaire
Chaque fois que vous recevez un nouveau stock du service fournisseur, vous poussez les détails du stock vers un sujet Kafka. Le service d'inventaire écoute ce sujet et met à jour la base de données en reconnaissant le réapprovisionnement.
Pour noter cela, vous poussez les nouvelles données de stock dans le pipeline et passez à autre chose. Elles sont consommées par le service d'inventaire à son propre rythme. Kafka vous permet de découpler les services.
Maintenant, que se passe-t-il si votre service d'inventaire tombe en panne ? Ce n'est pas simple avec les requêtes HTTP. Alors qu'avec Kafka, vous pouvez rejouer les messages prévus (par exemple en utilisant kcat). Avec Kafka, vous ne perdez pas de données après consommation.
Lorsque qu'un article revient en stock, vous pouvez vouloir envoyer des notifications aux utilisateurs qui l'ont ajouté à leur liste de souhaits. Pour cela, votre service de notification peut écouter le même sujet que le service d'inventaire. De cette façon, un seul bus de messages est consommé à divers endroits sans surcharge HTTP.
La page Getting Started de KafkaJS partage le code exact pour commencer avec une configuration de base dans votre application Node.js. Je vous recommande vivement de la consulter, car il y a beaucoup à explorer.
Surveiller les fuites de mémoire
Si vous n'écrivez pas de code sécurisé en mémoire et ne profilez pas souvent votre application, vous pourriez finir avec un serveur planté.
Vous ne voulez pas que vos résultats de profilage ressemblent à ceci :
 setTimeout retenant 98% de mémoire après la fin de l'exécution
setTimeout retenant 98% de mémoire après la fin de l'exécution
Pour commencer, je recommanderais ce qui suit :
- Exécutez votre API Node.js avec le drapeau
--inspect. - Ouvrez
chrome://inspect/#devicesdans votre navigateur Chrome. - Cliquez sur inspecter > onglet
Memory>Allocation instrumentation on timeline. - Effectuez quelques opérations sur votre application. Vous pouvez utiliser apache bench sur macOS pour envoyer plusieurs requêtes. Exécutez
curl cheat.sh/abdans votre terminal pour apprendre à l'utiliser. - Arrêtez l'enregistrement et analysez les retenues de mémoire.
Si vous trouvez de grands blocs de mémoire retenue, essayez de les minimiser. Il existe de nombreuses ressources sur ce sujet. Commencez par rechercher "comment prévenir les fuites de mémoire dans Node.js".
Le profilage de votre application Node.js et la recherche de modèles d'utilisation de la mémoire devraient être une pratique régulière. Faisons du "Profiling Driven Refactor" (PDR) une chose ?
Utiliser la mise en cache pour éviter les recherches excessives dans la base de données
L'objectif est de ne pas frapper la base de données pour chaque requête que votre application reçoit. Stocker les résultats en cache diminue la charge sur votre base de données et améliore les performances.
Il existe deux stratégies lors de l'utilisation de la mise en cache.
La mise en cache write through s'assure que les données sont insérées dans la base de données et le cache lorsqu'une opération d'écriture se produit. Cela garde le cache pertinent et conduit à de meilleures performances. Inconvénients ? Cache coûteux car vous stockez également des données rarement utilisées dans le cache.
Alors que dans le chargement paresseux, les données ne sont écrites dans le cache que lorsqu'elles sont lues pour la première fois. La première requête sert les données à partir de la base de données, mais les requêtes suivantes utilisent le cache. Cela a un coût moindre mais un temps de réponse accru pour la première requête.
Pour décider du TTL (ou Time To Live) pour les données en cache, demandez-vous :
- À quelle fréquence les données sous-jacentes changent-elles ?
- Quel est le risque de retourner des données obsolètes à l'utilisateur final ?
Si c'est acceptable, avoir plus de TTL vous aidera à obtenir de meilleures performances.
Importamment, ajoutez un léger delta à vos TTL. Si votre application reçoit un grand pic de trafic et que toutes vos données en cache expirent en même temps, cela peut entraîner une charge insupportable sur la base de données, affectant l'expérience utilisateur.
final TTL = estimated value of TTL + small random delta
Il existe un certain nombre de politiques pour effectuer l'éviction de cache. Mais laisser les paramètres par défaut est une approche valide et acceptée.
Utiliser le pooling de connexions
Ouvrir une connexion autonome à la base de données est coûteux. Cela implique un handshake TCP, SSL, des vérifications d'authentification et d'autorisation, et ainsi de suite.
Au lieu de cela, vous pouvez tirer parti du pooling de connexions.
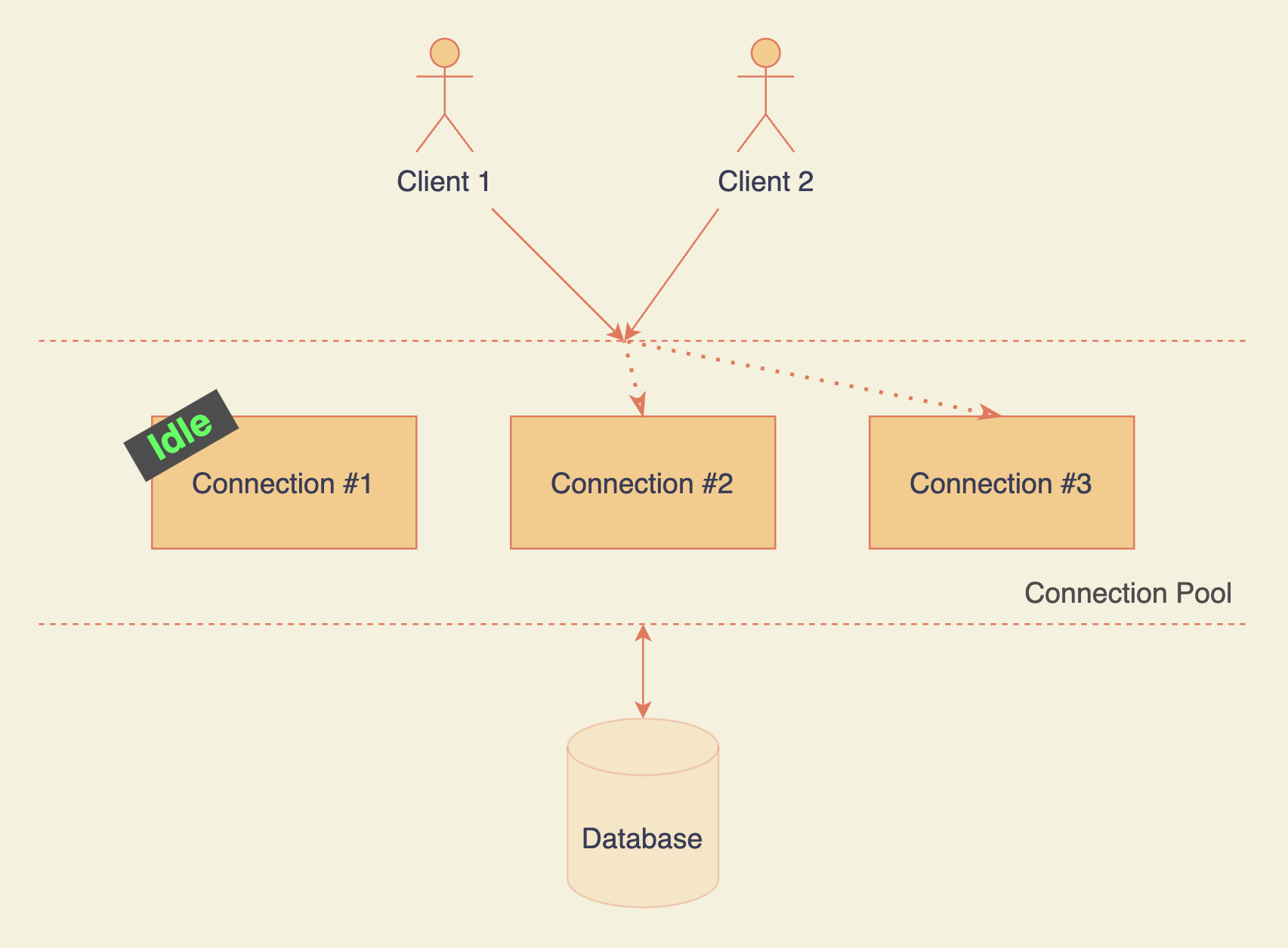 Pool de connexions de base de données
Pool de connexions de base de données
Un pool de connexions contient plusieurs connexions à tout moment. Chaque fois que vous en avez besoin, le gestionnaire de pool attribue toute connexion disponible/inactive. Vous pouvez sauter la phase de démarrage à froid d'une toute nouvelle connexion.
Pourquoi ne pas maximiser le nombre de connexions dans le pool, alors ? Parce que cela dépend fortement de vos ressources matérielles. Si vous l'ignorez, les performances peuvent en prendre un coup.
Plus il y a de connexions, moins chaque connexion a de RAM, et plus les requêtes qui utilisent la RAM sont lentes (par exemple, le tri). Le même principe s'applique à votre disque et à votre CPU. Avec chaque nouvelle connexion, vous étalez vos ressources de manière mince à travers les connexions.
Vous pouvez ajuster le nombre de connexions jusqu'à ce qu'il corresponde à vos besoins. Pour commencer, vous pouvez obtenir une estimation de la taille dont vous avez besoin ici.
Lisez à propos du pool de connexions MongoDB ici. Pour PostgreSQL, vous pouvez utiliser le package node-postgres. Il a un support intégré pour le pooling de connexions.
Mises à l'échelle transparentes
Lorsque la base d'utilisateurs de votre application commence à croître et que vous avez déjà atteint le plafond de la mise à l'échelle verticale, que faites-vous ? Vous mettez à l'échelle horizontalement.
La mise à l'échelle verticale signifie augmenter les ressources d'un nœud (CPU, mémoire, etc.) alors que la mise à l'échelle horizontale implique l'ajout de plus de nœuds pour équilibrer la charge sur chaque nœud.
Si vous utilisez AWS, vous pouvez tirer parti des groupes de mise à l'échelle automatique (ASG) qui mettent à l'échelle horizontalement le nombre de serveurs en fonction d'une règle prédéfinie (par exemple, lorsque l'utilisation du CPU est supérieure à 50%).
Vous pouvez même pré-planifier la mise à l'échelle et la réduction à l'aide d'actions planifiées en cas de schémas de trafic prévisibles (par exemple, pendant les finales de la Coupe du Monde pour un service de streaming).
Une fois que vous avez votre ASG en place, l'ajout d'un équilibreur de charge devant s'assurera que le trafic est routé vers toutes les instances en fonction d'une stratégie choisie (comme round robin, par exemple).
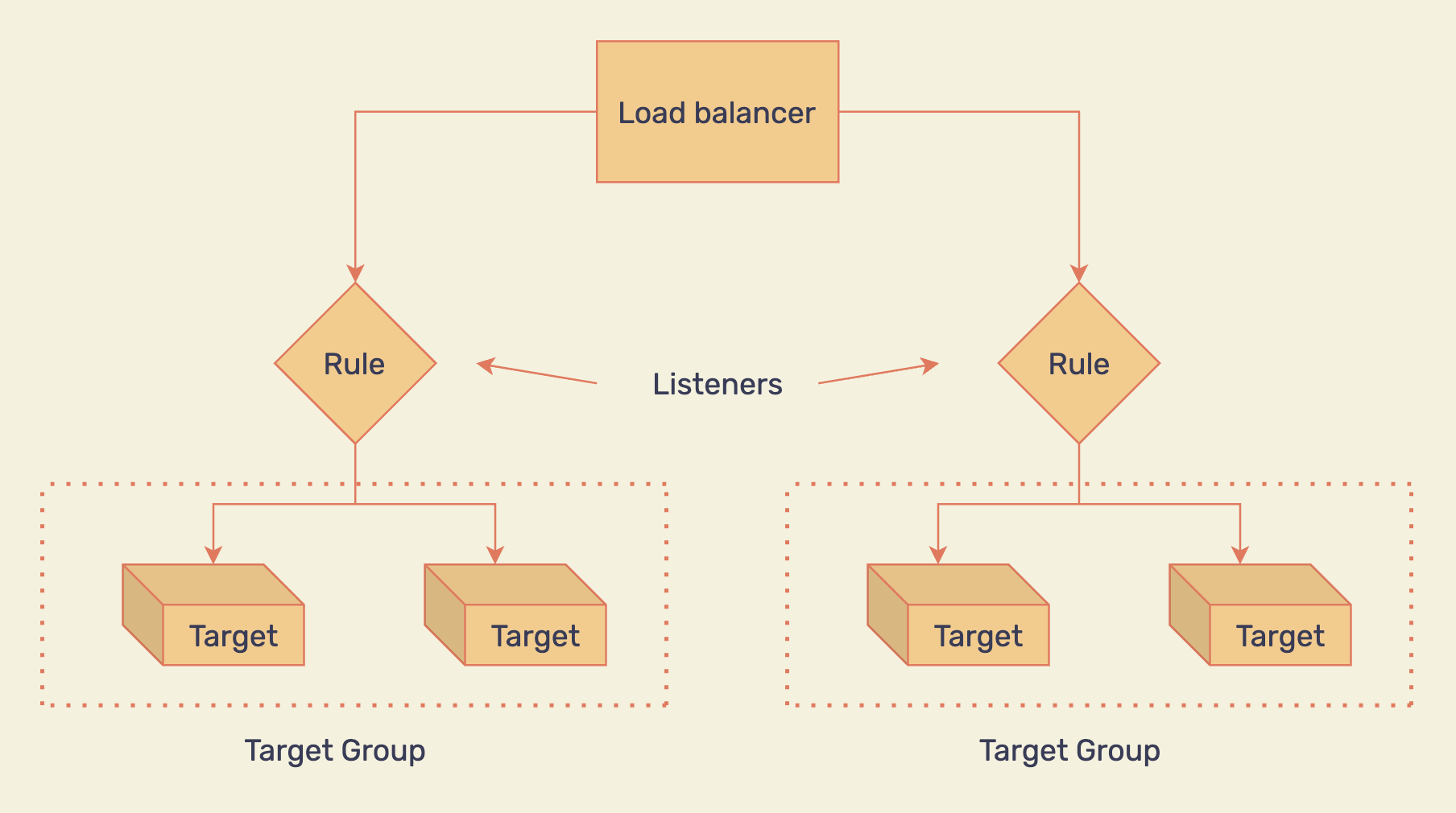 Équilibrage de charge de plusieurs cibles en fonction de règles prédéfinies
Équilibrage de charge de plusieurs cibles en fonction de règles prédéfinies
PS : Il est toujours bon d'estimer les requêtes que votre serveur unique peut gérer (CPU, mémoire, disque, etc.) et d'allouer au moins 30% de plus.
Documentation conforme à OpenAPI
Cela peut ne pas affecter directement votre capacité à mettre à l'échelle une application Node.js, mais je devais inclure cela dans la liste. Si vous avez déjà fait une intégration d'API, vous le savez.
Il est crucial de tout savoir sur l'API avant de faire un seul pas en avant. Cela facilite l'intégration, l'itération et la réflexion sur la conception. Sans parler des gains en vitesse de développement.
Assurez-vous de créer une spécification OpenAPI (OAS) pour votre API Node.js.
Cela vous permet de créer une documentation d'API de manière standardisée dans l'industrie. Elle sert de source unique de vérité. Lorsqu'elle est définie correctement, elle rend l'interaction avec l'API beaucoup plus productive.
J'ai créé et publié une documentation d'API exemple ici. Vous pouvez même inspecter n'importe quelle API en utilisant swagger inspector.
Vous pouvez trouver toutes vos documentations d'API et en créer de nouvelles à partir du tableau de bord Swagger Hub.
À vous de jouer, capitaine !
Nous avons examiné dix pratiques moins connues pour préparer Node.js à l'échelle et comment vous pouvez faire vos premiers pas avec chacune d'entre elles.
Maintenant, c'est à vous de parcourir la liste de contrôle et d'explorer celles que vous trouvez manquantes dans votre application Node.js.
J'espère que vous avez trouvé cela utile et que cela vous a donné quelques pistes pour avancer dans votre entreprise de scalabilité. Ce n'est pas une liste exhaustive de toutes les meilleures pratiques – j'ai simplement inclus celles que j'ai trouvées moins discutées en fonction de mon expérience.
N'hésitez pas à me contacter sur Twitter. J'adorerais avoir vos retours et suggestions sur d'autres meilleures pratiques que vous utilisez.
Vous avez aimé l'article ? Obtenez les pilules d'amélioration sur le développement web backend 💌.