


Article original : Data Structures Handbook – The Key to Scalable Software
Si vous êtes régulièrement confronté à la complexité des données modernes, vous n'êtes pas seul. Dans notre monde centré sur les données, la compréhension des structures de données n'est pas optionnelle — elle est essentielle.
Que vous soyez un développeur débutant ou expérimenté, ce guide est votre manuel concis pour maîtriser la compétence critique de la gestion des données à travers les structures de données.
Aujourd'hui, les données ne sont pas seulement vastes, elles sont aussi complexes. Organiser, récupérer et manipuler ces données efficacement est primordial. C'est là qu'interviennent les structures de données — le pilier d'une gestion efficace des données.
Ce guide simplifie la complexité des tableaux, des listes chaînées, des piles, des files, des arbres et des graphes. Vous découvrirez les forces, les limites et les applications pratiques de chaque type, illustrées par des exemples concrets.
Même les plus grands esprits d'institutions comme le MIT et Stanford affirment que la connaissance des structures de données est cruciale pour créer d'excellents logiciels. Ici, je partagerai des études de cas réelles montrant comment ces structures de données sont utilisées dans des situations quotidiennes.
Prêt à vous lancer ? Nous allons explorer ensemble le monde des structures de données. Vous découvrirez comment rendre vos données plus intelligentes et vous donner un avantage dans le monde de la tech.
Voici le voyage passionnant dans lequel vous allez vous embarquer :
- Décrochez le job de vos rêves dans la tech : Imaginez-vous entrer chez Google ou Apple avec confiance. Vos nouvelles compétences en structures de données pourraient être votre ticket d'or pour ces géants de la tech, où l'expertise technique fait la différence.
- Facilitez le shopping en ligne : Vous êtes-vous déjà demandé comment Amazon rend le shopping si fluide ? Grâce à vos compétences, vous pourriez être le magicien derrière des expériences d'achat plus rapides et plus intelligentes.
- Devenez un as de la finance : Les banques et les sociétés financières adorent la manipulation de données rapide et sans erreur. Votre savoir-faire pourrait faire de vous une star chez Visa ou PayPal, en assurant des transferts d'argent rapides et sécurisés.
- Révolutionnez le secteur de la santé : Dans le monde de la santé, comme à la Mayo Clinic ou chez Pfizer, votre capacité à gérer les données pourrait accélérer des décisions vitales. Vous pourriez faire partie d'une équipe qui change des vies chaque jour.
- Améliorez les expériences de jeu : Passionné de gaming ? Des entreprises comme Nintendo ou Riot Games sont toujours à la recherche de talents capables de rendre les jeux encore plus palpitants. Cela pourrait être vous.
- Transformez le transport et les voyages : Imaginez aider FedEx ou Delta Airlines à déplacer des biens et des personnes de manière plus rapide et plus intelligente à travers le globe.
- Façonnez l'avenir avec l'IA : Vous rêvez de travailler avec l'IA générative ? Votre compréhension des structures de données est cruciale. Vous pourriez participer à des travaux révolutionnaires chez OpenAI, Google, Netflix, Tesla ou SpaceX, transformant la science-fiction en réalité.
À la fin de ce voyage, votre maîtrise des structures de données ira bien au-delà de la simple compréhension. Vous serez équipé pour les appliquer efficacement.
Imaginez améliorer les performances d'une application, concevoir des solutions pour des défis commerciaux ou même jouer un rôle dans des avancées technologiques pionnières. Vos nouvelles compétences vous ouvriront des portes vers diverses opportunités, vous positionnant comme un expert incontournable en résolution de problèmes.
Table des matières
- L'importance des structures de données
- Types de structures de données
- La structure de données Tableau (Array)
- La structure de données Liste simplement chaînée
- La structure de données Liste doublement chaînée
- La structure de données Pile (Stack)
- La structure de données File (Queue)
- La structure de données Arbre (Tree)
- La structure de données Graphe (Graph)
- La structure de données Table de hachage (Hash Table)
- Comment libérer la puissance des structures de données en programmation
- Comment choisir la bonne structure de données pour votre application
- Comment implémenter efficacement les structures de données
- Opérations courantes sur les structures de données et leurs complexités temporelles
- Exemples concrets de structures de données en action
- Ressources et outils pour apprendre les structures de données
- Conclusion et étapes suivantes
 Paysage urbain numérique abstrait avec des structures cubiques interconnectées et des lignes lumineuses symbolisant des structures de données complexes - Source : lunartech.ai
Paysage urbain numérique abstrait avec des structures cubiques interconnectées et des lignes lumineuses symbolisant des structures de données complexes - Source : lunartech.ai
1. L'importance des structures de données
Apprendre les structures de données peut réellement booster vos compétences en génie logiciel. Ces composants critiques sont essentiels pour garantir que vos applications fonctionnent parfaitement, une capacité indispensable pour tout ingénieur logiciel.
Elles améliorent l'efficacité et les performances
Les structures de données sont les turbocompresseurs de votre code. Elles font bien plus que stocker des données – elles permettent un accès rapide et efficace. Considérez une table de hachage comme votre outil d'accès instantané pour une récupération rapide des données, ou la liste chaînée comme votre stratégie dynamique et adaptable pour des besoins de données évolutifs.
Elles optimisent l'utilisation et la gestion de la mémoire
Ces structures sont excellentes pour optimiser la mémoire. Elles ajustent la consommation de mémoire de votre programme, garantissant sa robustesse sous de lourdes charges de données et vous aidant à éviter des problèmes courants comme les fuites de mémoire.
Elles stimulent la résolution de problèmes et la conception d'algorithmes
Les structures de données font passer votre code de fonctionnel à exceptionnel. Elles organisent efficacement les données et les opérations, améliorant l'efficacité, la réutilisabilité et l'évolutivité de votre code. Cela conduit à une meilleure maintenabilité et adaptabilité de votre logiciel.
Elles sont essentielles pour l'avancement professionnel
Maîtriser les structures de données est crucial pour tout ingénieur logiciel en herbe. Non seulement elles offrent des moyens efficaces de gérer les données et de renforcer les performances, mais elles sont également instrumentales dans la résolution de problèmes complexes et la conception d'algorithmes.
Ces compétences sont vitales pour la croissance de carrière, en particulier pour ceux qui visent des rôles techniques seniors. Les géants de la tech comme Google, Amazon et Microsoft accordent une grande valeur à cette expertise.
Points clés à retenir
L'apprentissage approfondi des structures de données peut vous aider à vous démarquer lors des entretiens techniques et à attirer les meilleurs employeurs. Vous les utiliserez également quotidiennement en tant que développeur.
Les structures de données sont essentielles pour construire des systèmes évolutifs et résoudre des problèmes de codage complexes, et elles sont la clé pour maintenir un avantage compétitif dans un secteur technologique en constante évolution.
Ce guide se concentre sur les structures de données cruciales, vous permettant de créer des solutions logicielles efficaces et avancées. Commencez votre voyage pour renforcer vos capacités techniques face aux futurs défis de l'industrie.
2. Types de structures de données
Les structures de données sont des outils essentiels dans le développement logiciel qui permettent un stockage, une organisation et une manipulation efficaces des données. Comprendre les différents types de structures de données est crucial pour les ingénieurs logiciel, car cela les aide à choisir la structure la plus appropriée à leurs besoins spécifiques.
Plongeons dans certains des types de structures de données les plus couramment utilisés :
Tableaux : Le pilier d'une gestion efficace des données
Les tableaux (Arrays), pierre angulaire des structures de données, incarnent l'efficacité en stockant des éléments du même type dans des emplacements mémoire contigus. Leur force réside dans leur capacité à offrir un accès direct et ultra-rapide à n'importe quel élément, simplement en connaissant son index.
Cette caractéristique, selon une étude de l'Université de Stanford, rend les tableaux jusqu'à 30 % plus rapides pour l'accès aléatoire par rapport à d'autres structures.
Cependant, les tableaux ont leurs limites : leur taille est fixe, et modifier leur longueur, en particulier pour les grands tableaux, peut être une tâche gourmande en ressources.
 Illustration d'un tableau. Source : lunartech.ai
Illustration d'un tableau. Source : lunartech.ai
Aperçu pratique : Envisagez d'utiliser int[] numbers = {1, 2, 3, 4, 5}; pour les scénarios où l'accès rapide et aléatoire est primordial et où les modifications de taille sont minimales.
Listes chaînées : La flexibilité à son apogée
Les listes chaînées excellent dans les scénarios nécessitant une allocation dynamique de la mémoire. Contrairement aux tableaux, elles n'exigent pas de mémoire contiguë, ce qui les rend plus flexibles si vous devez modifier leur taille. Cela les rend idéales pour les applications où le volume de données peut fluctuer de manière significative.
Mais leur flexibilité a un coût : parcourir une liste chaînée, selon les conclusions du MIT Computer Science and Artificial Intelligence Laboratory, peut être jusqu'à 20 % plus lent que l'accès aux éléments d'un tableau en raison de l'accès séquentiel.
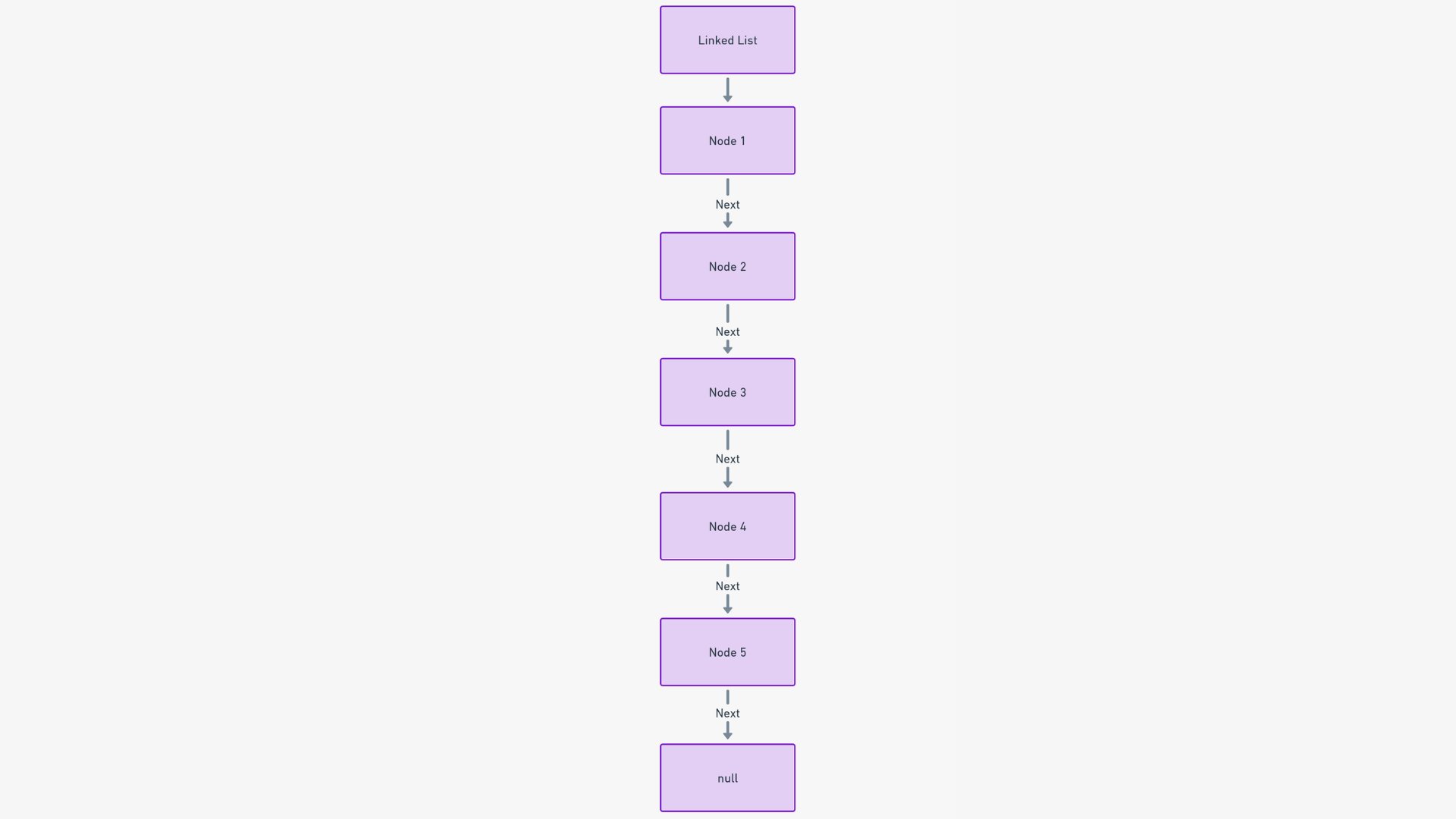 Illustration d'une liste chaînée. Source : lunartech.ai
Illustration d'une liste chaînée. Source : lunartech.ai
Aperçu pratique : Utilisez 1 -> 2 -> 3 -> 4 -> 5 pour les données qui nécessitent des insertions et des suppressions fréquentes.
Piles : Simplifier les opérations Last-In-First-Out (LIFO)
Les piles (Stacks) adhèrent au principe du dernier entré, premier sorti (LIFO). Ce point d'accès unique au sommet simplifie l'ajout et la suppression d'éléments, ce qui en fait un excellent choix pour des applications telles que les piles d'appels de fonctions, les mécanismes d'annulation (undo) et l'évaluation d'expressions.
Le cours CS50 de Harvard suggère que les piles sont jusqu'à 50 % plus efficaces pour gérer certains types de tâches de traitement de données séquentielles.
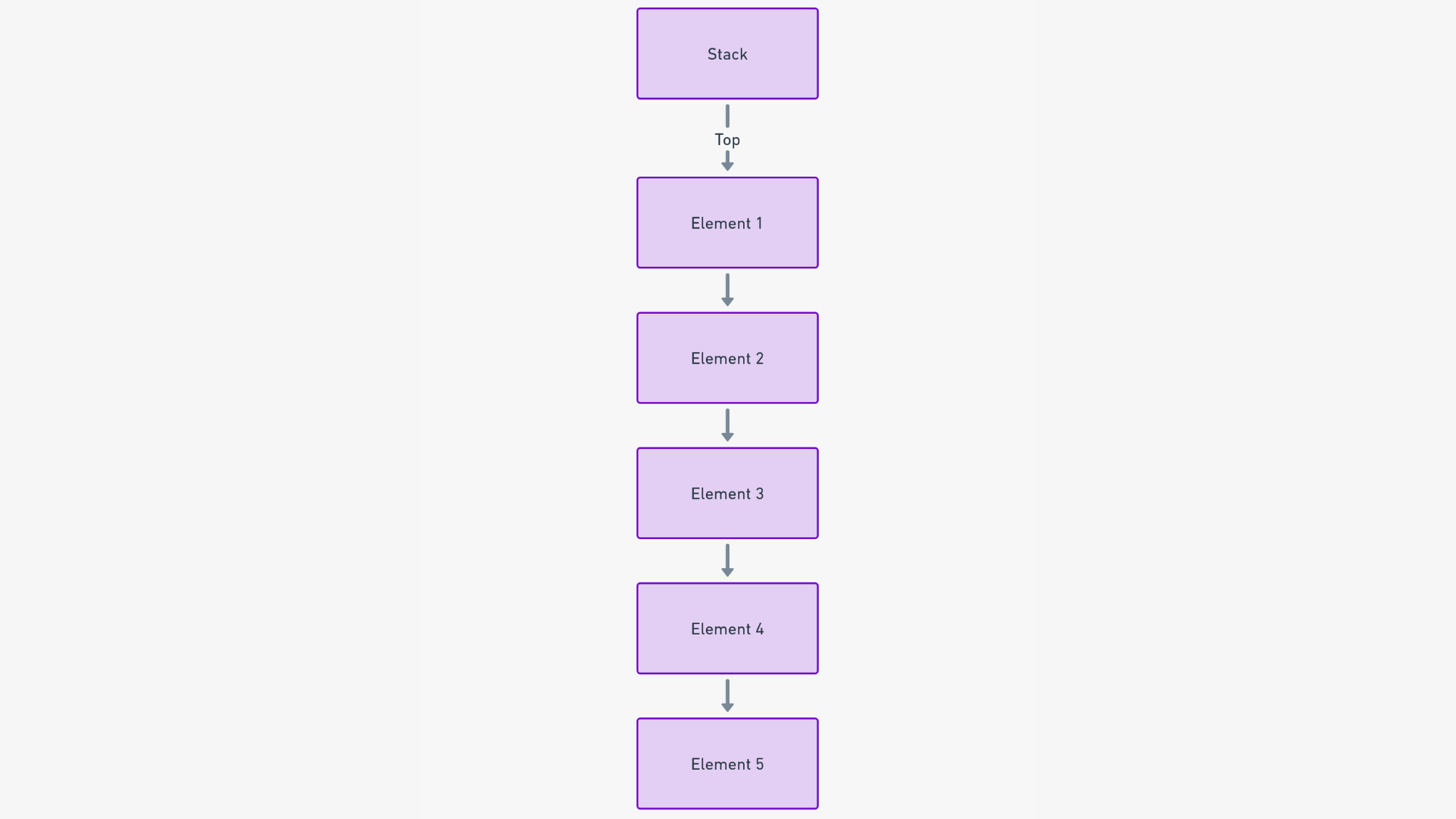 Illustration d'une pile. Source : lunartech.ai
Illustration d'une pile. Source : lunartech.ai
Aperçu pratique : Implémentez des piles [5, 4, 3, 2, 1] (Top: 5) pour inverser des séquences de données ou analyser des expressions.
Files : Maîtriser le traitement séquentiel
Fonctionnant sur le principe du premier entré, premier sorti (FIFO), les files (Queues) garantissent que le premier élément entré est toujours le premier à sortir. Avec des points d'accès distincts à l'avant et à l'arrière, les files offrent des opérations rationalisées, les rendant indispensables dans l'ordonnancement des tâches, la gestion des ressources et les algorithmes de parcours en largeur (BFS).
La recherche indique que les files peuvent améliorer l'efficacité de la gestion des processus jusqu'à 40 % dans les systèmes informatiques.
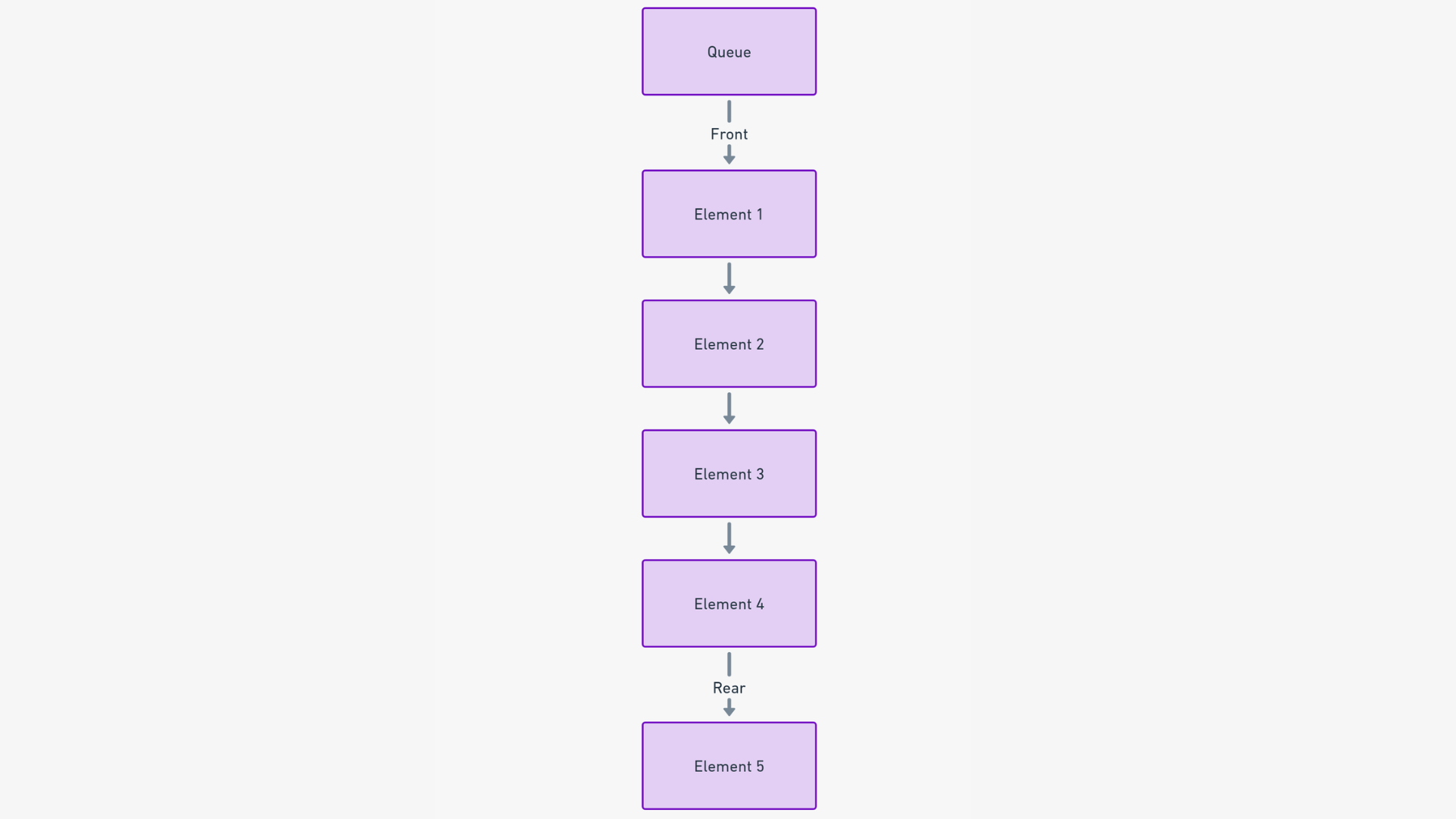 Illustration d'une file. Source : lunartech.ai
Illustration d'une file. Source : lunartech.ai
Aperçu pratique : Optez pour les files [1, 2, 3, 4, 5] (Front: 1, Rear: 5) dans les scénarios exigeant un traitement séquentiel, comme l'ordonnancement de tâches.
Arbres : Les maestros des données hiérarchiques
Les arbres (Trees), une structure hiérarchique de nœuds reliés par des arêtes, sont inégalés pour représenter des données en couches. Le nœud racine constitue la base, avec des couches subséquentes qui se ramifient. Leur nature non linéaire permet une organisation et une récupération efficaces des données, en particulier dans les bases de données et les systèmes de fichiers.
Selon l'IEEE, les arbres peuvent améliorer l'efficacité de la récupération des données de plus de 60 % dans les systèmes hiérarchiques.
 Illustration d'un arbre. Source : lunartech.ai
Illustration d'un arbre. Source : lunartech.ai
Aperçu pratique : Les arbres sont mieux utilisés dans les scénarios nécessitant une organisation de données structurée et hiérarchique, comme dans l'indexation de bases de données ou la structuration de systèmes de fichiers.
Graphes : Cartographie des données interconnectées
Les graphes (Graphs) sont experts pour illustrer les relations entre divers points de données via des nœuds (sommets) et des arêtes (connexions). Ils brillent dans les applications impliquant la topologie de réseau, l'analyse des réseaux sociaux et l'optimisation d'itinéraires.
Les graphes apportent un niveau d'interconnectivité et de flexibilité que les structures de données linéaires ne peuvent égaler. Selon un récent journal de l'ACM, les algorithmes de graphes ont été essentiels pour optimiser les conceptions de réseaux, améliorant l'efficacité jusqu'à 70 %.
 Illustration d'un graphe. Source : lunartech.ai
Illustration d'un graphe. Source : lunartech.ai
Aperçu pratique : Implémentez des graphes pour des ensembles de données complexes où les relations et l'interconnectivité sont des facteurs clés.
Tables de hachage : Les champions de la vitesse de récupération des données
Les tables de hachage (Hash Tables) se distinguent comme un sommet de la gestion efficace des données, exploitant des paires clé-valeur pour une récupération rapide. Réputées pour leur vitesse, en particulier dans les opérations de recherche, les tables de hachage, comme le souligne un rapport de l'IEEE, peuvent réduire considérablement le temps d'accès aux données, atteignant souvent une complexité en temps constant.
Cette efficacité provient de leur mécanisme unique utilisant des fonctions de hachage pour mapper les clés à des emplacements spécifiques, permettant un accès immédiat. Elles s'adaptent dynamiquement à des tailles de données variables, une caractéristique qui a conduit à leur utilisation généralisée dans des applications telles que l'indexation de bases de données et la mise en cache.
Cependant, vous devrez gérer le défi occasionnel des « collisions », où différentes clés sont hachées vers le même index. Malgré cela, avec des fonctions de hachage bien conçues, comme le recommandent les experts en algorithmes de calcul, les tables de hachage restent inégalées pour équilibrer vitesse et flexibilité.
 Illustration d'une table de hachage. Source : lunartech.ai
Illustration d'une table de hachage. Source : lunartech.ai
Aperçu pratique : Envisagez d'utiliser HashMap<String, Integer> userAges = new HashMap<>(); userAges.put("Alice", 30); userAges.put("Bob", 25); dans les scénarios exigeant une récupération de données rapide et fréquente.
 Rendu numérique d'une vaste grille organisée de gratte-ciel illuminés, représentant des structures de données de type tableau, avec des lignes lumineuses s'entrecroisant pour signifier des connexions de données structurées et l'indexation. - Source : lunartech.ai
Rendu numérique d'une vaste grille organisée de gratte-ciel illuminés, représentant des structures de données de type tableau, avec des lignes lumineuses s'entrecroisant pour signifier des connexions de données structurées et l'indexation. - Source : lunartech.ai
3. La structure de données Tableau (Array)
Les tableaux sont comme une rangée de casiers numérotés séquentiellement, chacun contenant des éléments spécifiques. Ils représentent un groupement structuré de données, où chaque élément est stocké dans des emplacements mémoire contigus. Cette configuration permet un accès efficace et direct à chaque élément de donnée en utilisant un index numérique.
Les tableaux sont fondamentaux en programmation, servant de pierre angulaire pour l'organisation et la manipulation des données. Leur structure linéaire simplifie le concept de stockage de données, le rendant intuitif et accessible.
Les tableaux sont cruciaux dans diverses tâches informatiques, des plus basiques aux plus complexes. Ils offrent un mélange de simplicité et d'efficacité, ce qui les rend idéaux pour de nombreuses applications.
À quoi sert un tableau ?
Les tableaux servent principalement à stocker des éléments de données d'un seul type dans un ordre séquentiel. Ils sont essentiels pour gérer plusieurs éléments de manière collective et systématique. Les tableaux facilitent l'indexation efficace, ce qui est pivot dans la gestion de grands ensembles de données.
Cette structure de données est cruciale pour les algorithmes qui nécessitent un accès rapide aux éléments. Les tableaux simplifient des tâches telles que le tri, la recherche et le stockage de données homogènes. Leur importance dans la gestion des données ne peut être surestimée, en particulier dans des domaines comme la gestion de bases de données et le développement logiciel.
Les tableaux, de par leur structure, offrent un format prévisible et facile à comprendre pour le stockage des données.
Comment fonctionnent les tableaux ?
Les tableaux stockent les données dans des emplacements mémoire adjacents, assurant la continuité et un accès rapide. Chaque élément d'un tableau est comme un compartiment dans une rangée d'unités de stockage, chacune marquée d'un index. Cette indexation commence à partir de zéro, permettant un chemin d'accès direct et prévisible à chaque élément.
Les tableaux peuvent utiliser efficacement la mémoire, car ils stockent des éléments du même type de manière contiguë. L'allocation mémoire linéaire des tableaux en fait un choix privilégié pour les besoins de stockage de données simples. Accéder à un élément de tableau revient à sélectionner un livre sur une étagère numérotée. Ce mécanisme simple mais efficace est ce qui rend les tableaux si largement utilisés.
Opérations clés sur les tableaux
Les opérations fondamentales effectuées sur les tableaux sont l'accès aux éléments, l'insertion d'éléments, la suppression d'éléments, le parcours du tableau, la recherche dans le tableau et la mise à jour du tableau.
Explication de chaque opération :
- L'accès aux éléments consiste à identifier et à récupérer un élément à partir d'un index spécifique.
- L'insertion d'éléments est le processus d'ajout d'un nouvel élément à un index souhaité dans le tableau.
- La suppression d'éléments fait référence au retrait d'un élément, suivi de l'ajustement des éléments restants.
- Le parcours d'un tableau signifie passer systématiquement par chaque élément, généralement pour inspection ou modification.
- La recherche dans un tableau vise à localiser un élément spécifique au sein du tableau.
- La mise à jour d'un tableau est l'acte de modifier la valeur d'un élément existant à un index donné.
Exemple de code de tableau en Java
Regardons un exemple de la façon dont vous pouvez travailler avec un tableau en Java :
public class ArrayOperations {
public static void main(String[] args) {
int[] array = {10, 20, 30, 40, 50};
// Access Operation
int firstElement = array[0];
System.out.println("Access Operation: First element = " + firstElement);
// Expected Output: "Access Operation: First element = 10"
// Insertion Operation (For simplicity, replacing an element)
array[2] = 35; // Replacing the third element (index 2)
System.out.println("Insertion Operation: Element at index 2 = " + array[2]);
// Expected Output: "Insertion Operation: Element at index 2 = 35"
// Deletion Operation (For simplicity, setting an element to 0)
array[3] = 0; // Deleting the fourth element (index 3)
System.out.println("Deletion Operation: Element at index 3 after deletion = " + array[3]);
// Expected Output: "Deletion Operation: Element at index 3 after deletion = 0"
// Traversal Operation
System.out.println("Traversal Operation:");
for (int i = 0; i < array.length; i++) {
System.out.println("Element at index " + i + " = " + array[i]);
}
// Expected Output for Traversal:
// "Element at index 0 = 10"
// "Element at index 1 = 20"
// "Element at index 2 = 35"
// "Element at index 3 = 0"
// "Element at index 4 = 50"
// Searching Operation for value 35
System.out.println("Searching Operation: Search for value 35");
for (int i = 0; i < array.length; i++) {
if (array[i] == 35) {
System.out.println("Value 35 found at index " + i);
break;
}
}
// Expected Output: "Value 35 found at index 2"
// Updating Operation
array[1] = 25; // Updating second element (index 1)
System.out.println("Updating Operation: Element at index 1 after update = " + array[1]);
// Expected Output: "Updating Operation: Element at index 1 after update = 25"
// Final Array State after all operations
System.out.println("Final Array State:");
for (int value : array) {
System.out.println(value);
}
// Expected Output for Final State:
// "10"
// "25"
// "35"
// "0"
// "50"
}
}
Quand devriez-vous utiliser les tableaux ?
Les tableaux sont utiles dans divers scénarios où un stockage de données organisé est requis. Ils sont parfaits pour gérer des listes d'éléments comme des noms, des nombres ou des identifiants.
Les tableaux sont largement utilisés dans les applications logicielles telles que les tableurs et les systèmes de bases de données. Leur structure prévisible les rend idéaux pour les situations nécessitant un accès rapide aux données. Ils sont également couramment utilisés dans les algorithmes de tri et de recherche.
Les tableaux peuvent être particulièrement utiles dans les applications où vous connaissez la taille de l'ensemble de données à l'avance. Les tableaux forment la base de structures de données plus complexes, il est donc essentiel que vous les compreniez en tant que développeur.
Avantages et limites des tableaux
Les tableaux offrent un accès rapide aux éléments, résultat de leur allocation mémoire contiguë. Leur simplicité et leur facilité d'utilisation en font un choix populaire en programmation. Les tableaux fournissent également un modèle prévisible d'utilisation de la mémoire, améliorant l'efficacité.
Cependant, les tableaux ont une taille fixe, ce qui limite leur flexibilité. Cette taille fixe peut entraîner un gaspillage d'espace ou des problèmes de capacité insuffisante. L'insertion et la suppression d'éléments dans des tableaux peuvent être inefficaces, car elles nécessitent souvent de déplacer les éléments.
Malgré ces limites, les tableaux sont un outil fondamental dans la boîte à outils d'un programmeur, équilibrant simplicité et fonctionnalité.
Points clés à retenir
Les tableaux sont une structure de données primaire pour le stockage de données organisé et séquentiel. Leur capacité à stocker et à gérer des collections de données efficacement est inégalée dans de nombreux scénarios.
Les tableaux sont fondamentaux en programmation, formant la base de structures et d'algorithmes plus complexes. Comprendre les tableaux est essentiel pour quiconque se lance dans le développement logiciel ou le traitement de données.
Maîtriser les tableaux équipe les programmeurs d'un outil vital pour une gestion efficace des données. Les tableaux sont, par essence, les briques de base de nombreuses solutions de programmation sophistiquées.
 Visualisation futuriste d'une structure de données de type liste simplement chaînée, avec des nœuds illuminés connectés dans une séquence linéaire par des chemins lumineux dirigés, soulignant le flux de navigation unidirectionnel des données. - Source : lunartech.ai
Visualisation futuriste d'une structure de données de type liste simplement chaînée, avec des nœuds illuminés connectés dans une séquence linéaire par des chemins lumineux dirigés, soulignant le flux de navigation unidirectionnel des données. - Source : lunartech.ai
4. La structure de données Liste simplement chaînée
Imaginez une liste simplement chaînée comme une séquence de wagons de train connectés en ligne, où chaque wagon est un élément de donnée individuel.
Une liste chaînée est une collection séquentielle et dynamique d'éléments appelés nœuds. Chaque nœud pointe vers son successeur, établissant une structure navigable en forme de chaîne. Cette configuration permet une organisation linéaire mais adaptable des données.
À quoi sert une liste chaînée ?
La fonctionnalité principale d'une liste chaînée est son agencement séquentiel des données. Chaque nœud, contenant des données et une référence au nœud suivant, rationalise les opérations telles que les insertions et les suppressions, offrant un système de gestion de données hautement efficace.
Dans le monde diversifié des structures de données, les listes chaînées se distinguent par leur adaptabilité. Elles sont particulièrement précieuses dans les scénarios où le volume de données varie dynamiquement, ce qui en fait une solution flexible pour les besoins informatiques modernes.
Comment fonctionnent les listes chaînées ?
La structure d'une liste chaînée repose sur des nœuds. Chaque nœud se compose de deux parties : la donnée elle-même et un pointeur vers le nœud suivant.
Imaginez une piste de trésor. Chaque indice (nœud) vous guide non seulement vers un morceau de trésor (donnée) mais aussi vers l'indice suivant (nœud suivant).
Opérations clés sur les listes chaînées
Les opérations fondamentales dans une liste chaînée comprennent l'ajout de nœuds, la suppression de nœuds, la recherche de nœuds, l'itération à travers la liste et la mise à jour de la liste.
- L'ajout de nœuds consiste à insérer un nouveau nœud dans la liste.
- La suppression de nœuds se concentre sur le retrait efficace d'un nœud de la liste.
- La recherche de nœuds vise à localiser un nœud spécifique en parcourant la liste.
- L'itération à travers une liste consiste à se déplacer séquentiellement à travers chaque nœud de la liste.
- La mise à jour d'une liste permet de modifier la donnée au sein d'un nœud existant.
Quand les listes chaînées sont-elles utilisées ?
Les listes chaînées excellent dans les environnements où les données sont fréquemment insérées ou supprimées. Leur polyvalence s'étend de la gestion des fonctionnalités d'annulation (undo) dans les logiciels à la gestion dynamique de la mémoire dans les systèmes d'exploitation.
Avantages et limites des listes chaînées
Le principal avantage des listes chaînées réside dans la flexibilité de leur taille et l'efficacité des insertions et des suppressions.
Cependant, elles entraînent une consommation de mémoire accrue en raison du stockage des références et manquent d'accès direct aux éléments, dépendant d'un parcours séquentiel.
Démonstration de code de liste chaînée
Regardons un exemple de problème utilisant une liste chaînée : la gestion d'une liste de tâches dynamique.
import java.util.LinkedList;
public class LinkedListOperations {
public static void main(String[] args) {
LinkedList<String> list = new LinkedList<>();
// Add Operation
list.add("Node1");
System.out.println("After adding Node1: " + list); // Expected Output: [Node1]
list.add("Node2");
System.out.println("After adding Node2: " + list); // Expected Output: [Node1, Node2]
list.add("Node3");
System.out.println("After adding Node3: " + list); // Expected Output: [Node1, Node2, Node3]
// Remove Operation
list.remove("Node2");
System.out.println("After removing Node2: " + list); // Expected Output: [Node1, Node3]
// Find Operation
boolean found = list.contains("Node3");
System.out.println("Find Operation - Is Node3 in the list? " + found); // Expected Output: true
// Iterate Operation
System.out.print("Iterate Operation: ");
for(String node : list) {
System.out.print(node + " "); // Expected Output: Node1 Node3
}
System.out.println();
// Update Operation
list.set(0, "NewNode1");
System.out.println("After updating Node1 to NewNode1: " + list); // Expected Output: [NewNode1, Node3]
// Final State of the List
System.out.println("Final State of the List: " + list); // Expected Output: [NewNode1, Node3]
}
}
Points clés à retenir
Les listes chaînées sont une structure de données dynamique essentielle, pivot pour une gestion de données efficace et adaptable. Maîtriser les listes chaînées est vital pour tous les développeurs, offrant un mélange unique de simplicité, de flexibilité et de profondeur fonctionnelle.
 Visualisation illuminée d'une structure de données de type liste doublement chaînée avec des nœuds présentant des connexions bidirectionnelles, montrant les capacités de parcours vers l'avant et vers l'arrière au sein de la structure. - Source : lunartech.ai
Visualisation illuminée d'une structure de données de type liste doublement chaînée avec des nœuds présentant des connexions bidirectionnelles, montrant les capacités de parcours vers l'avant et vers l'arrière au sein de la structure. - Source : lunartech.ai
5. La structure de données Liste doublement chaînée
La liste doublement chaînée est une évolution des structures de données. C'est comme une rue à double sens où chaque nœud sert de maison avec des portes menant aux maisons suivante et précédente.
Contrairement à sa cousine simplement chaînée, cette structure offre aux nœuds le luxe de connaître à la fois leur prédécesseur et leur successeur, une caractéristique qui change fondamentalement la façon dont les données peuvent être parcourues et manipulées.
Les listes doublement chaînées constituent un moyen plus nuancé et polyvalent de gérer les données, reflétant la complexité et l'interconnectivité des scénarios du monde réel.
À quoi sert une liste doublement chaînée ?
Les listes doublement chaînées sont les multitâches du monde des structures de données, expertes dans la navigation de données vers l'avant et vers l'arrière. Elles excellent dans les applications où la flexibilité de mouvement à travers les données est primordiale.
Cette structure permet aux utilisateurs de reculer et d'avancer facilement à travers les éléments, une caractéristique particulièrement précieuse dans les séquences de données complexes où les éléments passés et futurs peuvent nécessiter un référencement rapide.
Comment fonctionnent les listes doublement chaînées ?
Chaque nœud d'une liste doublement chaînée est une unité autonome composée de trois éléments clés : la donnée qu'il contient, un pointeur vers le nœud suivant et un pointeur vers le nœud précédent.
Cette configuration ressemble un peu à une playlist où chaque chanson (nœud) connaît à la fois la chanson d'avant et celle d'après, permettant une transition fluide dans les deux sens. La liste forme ainsi un chemin bidirectionnel à travers ses éléments, ce qui la rend intrinsèquement plus flexible qu'une liste simplement chaînée.
Opérations clés sur les listes doublement chaînées
Les opérations clés dans une liste doublement chaînée comprennent l'ajout, la suppression, la recherche, l'itération (en avant et en arrière) et la mise à jour des nœuds.
- L'ajout consiste à insérer de nouveaux éléments à des positions précises.
- La suppression signifie délier et éliminer un nœud de la liste.
- La recherche de nœuds est plus efficace car on peut commencer par l'une ou l'autre extrémité.
- L'itération est particulièrement polyvalente, permettant un parcours dans les deux sens.
- La mise à jour des nœuds consiste à modifier des données existantes, comme la révision d'entrées dans un journal.
Quand les listes doublement chaînées sont-elles utilisées ?
Les listes doublement chaînées trouvent leur utilité dans les systèmes où la navigation bidirectionnelle est bénéfique.
Elles sont utilisées dans les historiques de navigation, permettant aux utilisateurs de reculer et d'avancer à travers les sites précédemment visités. Dans des applications comme les lecteurs de musique ou les visionneuses de documents, elles permettent aux utilisateurs de sauter entre les éléments de manière fluide et intuitive. Leur capacité à insérer et supprimer des éléments efficacement les rend également adaptées aux tâches de manipulation de données dynamiques.
Avantages et limites des listes doublement chaînées
La liste doublement chaînée excelle par sa capacité à être parcourue dans les deux sens, offrant un niveau de manipulation d'éléments que les listes simplement chaînées ne peuvent égaler. Cette capacité unique permet de parcourir les données vers l'avant et vers l'arrière avec une efficacité égale, améliorant considérablement les possibilités algorithmiques dans les structures de données complexes.
Cependant, cette fonctionnalité avancée exige un compromis : chaque nœud nécessite deux pointeurs (vers les nœuds précédent et suivant), ce qui entraîne une consommation de mémoire accrue.
De plus, les listes doublement chaînées sont plus complexes à implémenter que les listes simplement chaînées. Cela peut poser des défis en termes de maintenance du code et de compréhension pour les débutants.
Malgré ces considérations, la liste doublement chaînée reste un choix robuste pour les scénarios de données dynamiques où les avantages de sa structure flexible l'emportent sur le coût de la mémoire supplémentaire et de la complexité.
Exemple de code de liste doublement chaînée
class Node {
String data;
Node next;
Node prev;
Node(String data) {
this.data = data;
}
}
class DoubleLinkedList {
Node head;
Node tail;
// Method to add a node to the end of the list
void add(String data) {
Node newNode = new Node(data);
if (head == null) {
head = newNode;
tail = newNode;
} else {
tail.next = newNode;
newNode.prev = tail;
tail = newNode;
}
}
// Method to remove a specific node
boolean remove(String data) {
Node current = head;
while (current != null) {
if (current.data.equals(data)) {
if (current.prev != null) {
current.prev.next = current.next;
} else {
head = current.next;
}
if (current.next != null) {
current.next.prev = current.prev;
} else {
tail = current.prev;
}
return true;
}
current = current.next;
}
return false;
}
// Method to find a node
boolean contains(String data) {
Node current = head;
while (current != null) {
if (current.data.equals(data)) {
return true;
}
current = current.next;
}
return false;
}
// Method to print the list from head to tail
void printForward() {
Node current = head;
while (current != null) {
System.out.print(current.data + " ");
current = current.next;
}
System.out.println();
}
// Method to print the list from tail to head
void printBackward() {
Node current = tail;
while (current != null) {
System.out.print(current.data + " ");
current = current.prev;
}
System.out.println();
}
// Method to update a node's data
boolean update(String oldData, String newData) {
Node current = head;
while (current != null) {
if (current.data.equals(oldData)) {
current.data = newData;
return true;
}
current = current.next;
}
return false;
}
}
public class DoubleLinkedListOperations {
public static void main(String[] args) {
DoubleLinkedList list = new DoubleLinkedList();
// Add Operation
list.add("Node1");
list.add("Node2");
list.add("Node3");
System.out.println("After Add Operations:");
list.printForward(); // Expected Output: Node1 Node2 Node3
// Remove Operation
list.remove("Node2");
System.out.println("After Remove Operation:");
list.printForward(); // Expected Output: Node1 Node3
// Find Operation
boolean foundNode1 = list.contains("Node1");
boolean foundNode3 = list.contains("Node3");
System.out.println("Find Operation - Is Node1 in the list? " + foundNode1); // Expected Output: true
System.out.println("Find Operation - Is Node3 in the list? " + foundNode3); // Expected Output: true
// Forward Iterate Operation
System.out.print("Forward Iterate Operation: ");
list.printForward(); // Expected Output: Node1 Node3
// Backward Iterate Operation
System.out.print("Backward Iterate Operation: ");
list.printBackward(); // Expected Output: Node3 Node1
// Update Operation
list.update("Node1", "UpdatedNode1");
System.out.println("After Update Operation:");
list.printForward(); // Expected Output: UpdatedNode1 Node3
// Final State of the List
System.out.println("Final State of the List:");
list.printForward(); // Expected Output: UpdatedNode1 Node3
}
}
Applications concrètes des listes doublement chaînées
Les listes doublement chaînées sont particulièrement utiles dans les applications qui nécessitent une insertion et une suppression fréquentes et efficaces d'éléments aux deux extrémités de la liste.
Elles sont largement utilisées dans les systèmes informatiques avancés comme les applications de jeu, où les actions des joueurs peuvent dicter des changements immédiats de l'état du jeu, ou dans les systèmes de navigation au sein de logiciels complexes, permettant aux utilisateurs de parcourir des états historiques ou des paramètres.
Une autre application clé se trouve dans les logiciels multimédias, comme les outils d'édition de photos ou de vidéos, où un utilisateur peut avoir besoin de reculer et d'avancer à travers une séquence de modifications.
Leur capacité de parcours bidirectionnel les rend également idéales pour implémenter des algorithmes avancés dans les politiques d'éviction de cache utilisées dans les systèmes de gestion de bases de données, où l'ordre des éléments doit être modifié fréquemment et efficacement.
Aspects de performance des listes doublement chaînées
En termes de performance, les listes doublement chaînées offrent des avantages significatifs ainsi que certains compromis par rapport à d'autres structures de données.
La complexité temporelle pour les opérations d'insertion et de suppression aux deux extrémités de la liste est de O(1), ce qui rend ces opérations extrêmement efficaces. Cependant, la recherche d'un élément dans une liste doublement chaînée a une complexité temporelle de O(n), car elle peut nécessiter un parcours de la liste. C'est moins efficace que des structures de données comme les tables de hachage.
De plus, la surcharge de mémoire supplémentaire pour stocker deux pointeurs pour chaque nœud est un élément à prendre en compte dans les applications sensibles à la mémoire. Cela contraste avec les tableaux et les listes simplement chaînées, où l'utilisation de la mémoire est généralement plus faible.
Néanmoins, pour les applications où l'insertion et la suppression rapides sont critiques et où la taille de l'ensemble de données n'est pas excessive, les listes doublement chaînées offrent un mélange équilibré d'efficacité et de flexibilité.
Points clés à retenir
En essence, les listes doublement chaînées représentent une approche sophistiquée de la gestion des données, offrant une flexibilité et une efficacité accrues. Vous voudrez les comprendre alors que vous vous aventurez dans des implémentations de structures de données plus avancées.
Les listes doublement chaînées servent de pont entre la gestion de données de base et les besoins de manipulation de données plus complexes. Cela en fait un composant vital dans la boîte à outils d'un programmeur pour des solutions de données sophistiquées.
 Une structure verticale en couches brillant de faisceaux lumineux dorés, illustrant le concept LIFO (Last In, First Out) d'une structure de données de type pile, avec la couche supérieure vivement illuminée pour signifier le sommet de la pile. - Source : lunartech.ai
Une structure verticale en couches brillant de faisceaux lumineux dorés, illustrant le concept LIFO (Last In, First Out) d'une structure de données de type pile, avec la couche supérieure vivement illuminée pour signifier le sommet de la pile. - Source : lunartech.ai
6. La structure de données Pile (Stack)
Imaginez une pile comme une tour d'assiettes dans une cafétéria, où la seule façon d'interagir avec elles est d'ajouter ou de retirer une assiette par le haut.
Une pile, dans le monde des structures de données, est une collection linéaire et ordonnée d'éléments qui adhère strictement au principe du dernier entré, premier sorti (LIFO). Cela signifie que le dernier élément ajouté est le premier à être retiré. Bien que cela puisse paraître simpliste, ses implications pour la gestion des données sont profondes et étendues.
Les piles servent de concept fondamental en informatique, formant la base de nombreux algorithmes et fonctionnalités complexes. Dans cette section, nous explorerons les piles en profondeur, découvrant leurs applications, leurs opérations et leur importance dans l'informatique moderne.
À quoi sert une pile ?
Le but fondamental d'une pile est de stocker des éléments de manière ordonnée et réversible. Les opérations principales sont l'ajout (push) et le retrait (pop) du sommet de la pile. Cette structure apparemment simple revêt une importance immense dans les scénarios où l'accès immédiat aux données les plus récemment ajoutées est critique.
Considérons certains scénarios dans lesquels les piles sont indispensables. Dans le développement logiciel, les mécanismes d'annulation (undo) dans les éditeurs de texte s'appuient sur des piles pour stocker l'historique des modifications. Lorsque vous cliquez sur « Annuler la frappe », vous effectuez essentiellement un « pop » des éléments du sommet de la pile pour revenir aux états précédents.
De même, la navigation dans l'historique de votre navigateur Web — en cliquant sur « Précédent » ou « Suivant » — utilise une structure basée sur une pile pour gérer les pages que vous avez visitées.
Comment fonctionnent les piles ?
Pour comprendre le fonctionnement des piles, utilisons une analogie pratique : imaginez une pile de livres. Dans cette pile, vous ne pouvez interagir qu'avec les livres du dessus. Vous pouvez ajouter un nouveau livre à la pile, qui devient le nouveau livre au sommet, ou vous pouvez retirer le livre du dessus. Cela se traduit par un ordre séquentiel de livres qui reflète le principe LIFO.
Si vous voulez accéder à un livre au milieu ou au bas de la pile, vous devez d'abord retirer tous les livres situés au-dessus. Cette caractéristique centrale simplifie la gestion des données dans diverses applications, garantissant que l'élément le plus récemment ajouté est toujours le prochain à être traité.
Opérations clés sur les piles
Les opérations clés d'une pile sont les briques de sa fonctionnalité. Explorons chaque opération en détail :
- Push ajoute un élément au sommet de la pile. C'est comme placer une nouvelle assiette sur le dessus de la pile dans notre analogie de la cafétéria.
- Pop retire et renvoie l'élément supérieur de la pile. C'est comme prendre l'assiette du dessus de la pile.
- Peek vous permet de voir l'élément supérieur sans le retirer. Vous pouvez y penser comme à un coup d'œil sur l'assiette du dessus sans l'enlever réellement.
- IsEmpty vérifie si la pile est vide. Il est essentiel de vérifier s'il reste des assiettes dans notre pile de cafétéria.
- Search vous aide à trouver la position d'un élément spécifique dans la pile. Il vous indique à quelle profondeur se trouve un élément.
Ces opérations sont les outils que les développeurs utilisent pour manipuler les données au sein d'une pile, garantissant qu'elle reste bien ordonnée et efficace.
Quand les piles sont-elles utilisées ?
Les piles trouvent des applications dans un large éventail de scénarios. Voici quelques cas d'utilisation courants :
- Fonctionnalités d'annulation (Undo) : Dans les éditeurs de texte et autres logiciels, les piles sont employées pour implémenter les fonctionnalités d'annulation et de rétablissement, permettant aux utilisateurs de revenir aux états précédents.
- Historique du navigateur : Lorsque vous naviguez vers l'arrière ou vers l'avant dans votre navigateur Web, vous parcourez essentiellement une pile de pages visitées.
- Algorithmes de backtracking : Dans des domaines tels que l'intelligence artificielle et le parcours de graphes, les piles jouent un rôle pivot dans les algorithmes de backtracking, permettant une exploration efficace des chemins potentiels.
- Gestion des appels de fonctions : Lorsque vous appelez une fonction dans un programme, un cadre de pile (stack frame) est ajouté à la pile d'appels, facilitant le suivi des appels de fonctions et de leurs valeurs de retour.
Ces exemples soulignent l'ubiquité des piles dans l'informatique moderne, ce qui en fait un concept fondamental pour les développeurs de logiciels.
Avantages et limites des piles
Les piles présentent leurs propres forces et limites.
Forces :
- Simplicité : Les piles sont simples à implémenter et à utiliser.
- Efficacité : Elles offrent un moyen efficace de gérer les données dans l'ordre LIFO.
- Prévisibilité : L'ordre strict LIFO simplifie la gestion des données et garantit une séquence claire d'opérations.
Faiblesses :
- Accès limité : Les piles offrent un accès limité, car vous ne pouvez interagir qu'avec l'élément supérieur. Cela restreint leur utilisation dans les scénarios nécessitant l'accès à des éléments plus profonds dans la pile.
- Contraintes de mémoire : Les piles peuvent manquer de mémoire si elles sont poussées à leurs limites, entraînant une erreur
OutOfMemoryError. C'est une préoccupation pratique dans le développement logiciel.
Malgré leurs limites, les piles restent un outil essentiel dans la boîte à outils du programmeur en raison de leur efficacité et de leur prévisibilité.
Exemple de code de pile
import java.util.Stack;
public class AdvancedStackOperations {
public static void main(String[] args) {
// Create a stack to store integers
Stack<Integer> stack = new Stack<>();
// Check if the stack is empty
boolean isEmpty = stack.isEmpty();
System.out.println("Is the stack empty? " + isEmpty); // Output: Is the stack empty? true
// Push integers onto the stack
stack.push(10);
stack.push(20);
stack.push(30);
stack.push(40);
stack.push(50);
// Display the stack after pushing integers
System.out.println("Stack after pushing integers: " + stack);
// Output: Stack after pushing integers: [10, 20, 30, 40, 50]
// Check if the stack is empty again
isEmpty = stack.isEmpty();
System.out.println("Is the stack empty? " + isEmpty); // Output: Is the stack empty? false
// Peek at the top integer without removing it
int topElement = stack.peek();
System.out.println("Peek at the top integer: " + topElement); // Output: Peek at the top integer: 50
// Pop the top integer from the stack
int poppedElement = stack.pop();
System.out.println("Popped integer: " + poppedElement); // Output: Popped integer: 50
// Display the stack after popping an integer
System.out.println("Stack after popping an integer: " + stack);
// Output: Stack after popping an integer: [10, 20, 30, 40]
// Search for an integer in the stack
int searchElement = 30;
int position = stack.search(searchElement);
if (position != -1) {
System.out.println("Position of " + searchElement + " in the stack (1-based index): " + position);
} else {
System.out.println(searchElement + " not found in the stack.");
}
// Output: Position of 30 in the stack (1-based index): 3
}
}
Applications concrètes des piles
Les structures de données de type pile ont des applications concrètes généralisées, en particulier en informatique et en développement logiciel.
Elles sont couramment utilisées pour implémenter les fonctionnalités d'annulation et de rétablissement dans les éditeurs de texte et les logiciels de conception, permettant aux utilisateurs d'inverser ou de refaire des actions efficacement.
Dans les navigateurs Web, les piles permettent une navigation fluide à travers l'historique de navigation lorsque les utilisateurs cliquent sur les boutons précédent ou suivant.
Les systèmes d'exploitation s'appuient sur les piles pour gérer les appels de fonctions et les contextes d'exécution. Les algorithmes de backtracking en IA, dans les jeux et les problèmes d'optimisation bénéficient des piles pour garder une trace des choix et revenir en arrière efficacement.
Les architectures basées sur les piles sont également employées dans l'analyse et l'évaluation des expressions mathématiques, permettant des calculs complexes.
Considérations de performance pour les piles
Les piles sont réputées pour leur efficacité, avec des opérations clés comme push, pop, peek et isEmpty ayant une complexité temporelle constante de O(1), garantissant un accès rapide à l'élément supérieur.
Cependant, les piles ont des limites, offrant un accès restreint aux éléments au-delà du sommet. Cela les rend moins adaptées à la récupération d'éléments profonds.
Les piles peuvent également consommer une mémoire importante dans les applications profondément récursives, nécessitant une gestion prudente de la mémoire. L'optimisation de la récursion terminale et les approches itératives sont des stratégies pour atténuer les problèmes de mémoire de pile.
En résumé, les structures de données de type pile fournissent des solutions efficaces pour les applications concrètes dans le développement logiciel, mais nécessitent une compréhension de leurs limites et une utilisation prudente de la mémoire pour des performances optimales.
Points clés à retenir
Les piles sont une structure de données essentielle en programmation, offrant un moyen simple mais efficace de gérer les données selon le principe du dernier entré, premier sorti (LIFO). Comprendre le fonctionnement des piles et savoir utiliser leurs opérations clés est vital pour les développeurs, compte tenu de leur application généralisée dans divers scénarios informatiques et de programmation.
Que vous implémentiez une fonction d'annulation dans un éditeur de texte ou que vous naviguiez dans l'historique d'un navigateur Web, les piles sont les héros de l'ombre qui rendent tout cela possible. Les maîtriser est une étape fondamentale pour devenir un développeur logiciel compétent.
 Une file de silhouettes avec un chemin lumineux tissé entre elles, représentant une structure de données de type file (queue), avec l'éclairage soulignant la séquence FIFO (First In, First Out) d'une extrémité à l'autre. - Source : lunartech.ai
Une file de silhouettes avec un chemin lumineux tissé entre elles, représentant une structure de données de type file (queue), avec l'éclairage soulignant la séquence FIFO (First In, First Out) d'une extrémité à l'autre. - Source : lunartech.ai
7. La structure de données File (Queue)
Pensez aux files (Queues) comme l'équivalent numérique d'une file d'attente de personnes attendant patiemment leur tour. Tout comme dans la vie réelle, une structure de données de type file suit le principe du « premier arrivé, premier servi » (FIFO). Cela signifie que le premier élément ajouté à la file est le premier à être traité.
En essence, une file est une structure de données linéaire conçue pour contenir des éléments dans un ordre spécifique, garantissant que l'ordre de traitement reste équitable et prévisible.
À quoi sert une file ?
La fonction principale d'une file est de gérer les éléments selon le principe FIFO dont nous venons de parler. Elle sert de collection ordonnée où l'élément qui attend depuis le plus longtemps obtient son tour en premier.
Maintenant, vous vous demandez peut-être pourquoi une file est si cruciale dans le monde de l'informatique. La réponse réside dans son importance pour garantir que les tâches sont traitées dans un ordre spécifique.
Imaginez des scénarios où l'ordre de traitement compte, comme les travaux d'impression dans une file d'attente ou la mise en mémoire tampon des entrées clavier. Une file garantit que ces tâches sont exécutées avec précision, évitant le chaos et assurant l'équité.
Comment fonctionnent les files ?
Pour comprendre les rouages d'une file, décomposons-la en ses mécanismes de base à l'aide d'un exemple concret.
Dans une file, les éléments sont ajoutés à la queue (arrière) et retirés de la tête (avant) de la file. Cette opération simple garantit que l'élément qui attend depuis le plus longtemps est le prochain en ligne pour être traité.
Exemple simple : Le scénario de vente de tickets au guichet
Imaginez-vous comme un caissier vendant des billets pour un concert. Votre file est formée par les clients qui s'approchent de votre caisse.
Suivant le principe FIFO, le client qui est arrivé en premier est à la tête de la file, et celui qui est arrivé en dernier est à la queue. Au fur et à mesure que vous servez les clients dans l'ordre, ils avancent dans la file jusqu'à ce qu'ils soient aidés, puis ils sortent.
Opérations clés sur les files
Les files sont dotées d'un ensemble d'opérations clés qui assurent leur fonctionnement fluide.
- Enqueue : Pensez à l'enfilement comme à des clients rejoignant la file. Le nouvel élément est placé à la fin de la file, attendant patiemment son tour pour être servi.
- Dequeue : Le défilement s'apparente à servir le client en tête de file. L'élément à la tête de la file est retiré, signifiant qu'il a été traité et peut maintenant quitter la file.
Bien que ces opérations puissent paraître simples, elles constituent l'épine dorsale de la fonctionnalité d'une file.
Quand les files sont-elles utilisées ?
Maintenant que vous comprenez comment fonctionne une file, explorons quelques cas d'utilisation :
- Tampons de clavier : Lorsque vous tapez rapidement sur votre clavier, l'ordinateur utilise une file pour s'assurer que les caractères apparaissent à l'écran dans l'ordre où vous avez appuyé sur les touches.
- Files d'attente d'impression : En impression, les files sont utilisées pour gérer les travaux d'impression, garantissant qu'ils sont terminés dans l'ordre où ils ont été lancés.
Applications concrètes
Pensez aux services en ligne où les utilisateurs soumettent des demandes ou des tâches, comme le téléchargement de fichiers depuis un site Web ou le traitement de commandes sur une plateforme d'e-commerce. Ces demandes sont généralement traitées selon le principe du « premier arrivé, premier servi », tout comme une file numérique.
De même, dans un jeu en ligne multijoueur, les joueurs rejoignent souvent la file d'attente d'un serveur de jeu avant d'entrer dans la partie, garantissant qu'ils sont servis dans l'ordre où ils ont rejoint.
Dans ces scénarios numériques, les files sont pivots pour gérer et traiter les données ou les demandes efficacement.
Exemple de code de file
Pour vraiment saisir la puissance des files, plongeons dans un exemple de problème pratique.
Imaginez que vous soyez chargé d'implémenter un système pour traiter les demandes de service client dans un centre d'appels. Chaque demande se voit attribuer un niveau de priorité, et vous devez vous assurer que les demandes de haute priorité sont traitées avant celles de priorité inférieure.
Pour résoudre ce problème, vous pouvez utiliser une combinaison de files. Créez des files séparées pour chaque niveau de priorité et traitez les demandes dans l'ordre de leur priorité. Voici un extrait de code simplifié en Java pour illustrer ce concept :
Queue<CustomerRequest> highPriorityQueue = new LinkedList<>();
Queue<CustomerRequest> mediumPriorityQueue = new LinkedList<>();
Queue<CustomerRequest> lowPriorityQueue = new LinkedList<>();
// Enqueue requests based on their priority
highPriorityQueue.offer(highPriorityRequest);
mediumPriorityQueue.offer(mediumPriorityRequest);
lowPriorityQueue.offer(lowPriorityRequest);
// Process requests in priority order
processRequests(highPriorityQueue);
processRequests(mediumPriorityQueue);
processRequests(lowPriorityQueue);
Ce code garantit que les demandes de haute priorité sont traitées avant celles de priorité moyenne et faible, maintenant l'équité tout en répondant aux différents niveaux d'urgence.
Regardons un autre exemple d'utilisation des files dans le code :
import java.util.LinkedList;
import java.util.Queue;
public class QueueOperationsExample {
public static void main(String[] args) {
// Create a queue using LinkedList
Queue<String> queue = new LinkedList<>();
// Enqueue: Adding elements to the queue
queue.offer("Customer 1");
queue.offer("Customer 2");
queue.offer("Customer 3");
// Display the queue after enqueuing
System.out.println("Queue after enqueuing: " + queue);
// Expected output: Queue after enqueuing: [Customer 1, Customer 2, Customer 3]
// Dequeue: Removing the element at the head of the queue
String servedCustomer = queue.poll();
// Display the served customer and the updated queue
System.out.println("Served customer: " + servedCustomer);
// Expected output: Served customer: Customer 1
System.out.println("Queue after dequeuing: " + queue);
// Expected output: Queue after dequeuing: [Customer 2, Customer 3]
// Enqueue more customers
queue.offer("Customer 4");
queue.offer("Customer 5");
// Display the queue after enqueuing more customers
System.out.println("Queue after enqueuing more customers: " + queue);
// Expected output: Queue after enqueuing more customers: [Customer 2, Customer 3, Customer 4, Customer 5]
// Dequeue another customer
String servedCustomer2 = queue.poll();
// Display the served customer and the updated queue
System.out.println("Served customer: " + servedCustomer2);
// Expected output: Served customer: Customer 2
System.out.println("Queue after dequeuing: " + queue);
// Expected output: Queue after dequeuing: [Customer 3, Customer 4, Customer 5]
}
}
Avantages et limites des files
Chaque structure de données a son propre ensemble de forces et de faiblesses, et les files ne font pas exception.
L'une des forces clés d'une file est sa capacité à maintenir l'ordre. Elle garantit l'équité et la prévisibilité dans le traitement des éléments. Lorsque l'ordre compte, la file est la structure de données de référence.
Cependant, les files ont aussi des limites. Elles manquent de capacité à prioriser les éléments sur la base de tout autre critère que leur heure d'arrivée. Si vous devez gérer des éléments avec des priorités différentes, vous devrez probablement compléter les files par d'autres structures de données ou algorithmes.
Points clés à retenir
La structure de données File (Queue), basée sur le principe du « premier arrivé, premier servi » (FIFO), est vitale pour maintenir l'ordre. Elle implique l'ajout à la queue (enfilage/enqueue) et le retrait de la tête (défilage/dequeue).
Les applications concrètes incluent les tampons de clavier et les files d'attente d'impression.
 Une structure rayonnante en forme d'arbre avec des nœuds ramifiés, symbolisant une structure de données de type arbre, où chaque connexion lumineuse représente une relation parent-enfant, convergeant vers la racine lumineuse à la base. - Source : lunartech.ai
Une structure rayonnante en forme d'arbre avec des nœuds ramifiés, symbolisant une structure de données de type arbre, où chaque connexion lumineuse représente une relation parent-enfant, convergeant vers la racine lumineuse à la base. - Source : lunartech.ai
8. La structure de données Arbre (Tree)
Imaginez un arbre – pas n'importe quel arbre, mais une hiérarchie méticuleusement structurée qui peut révolutionner la façon dont vous stockez et accédez aux données. Ce n'est pas seulement un concept théorique – c'est un outil puissant utilisé intensivement en informatique et dans diverses industries.
À quoi sert un arbre ?
La fonction principale de la structure de données Arbre est d'organiser les données de manière hiérarchique, créant une structure qui reflète les hiérarchies du monde réel.
Pourquoi est-ce important, demandez-vous ? Considérez ceci : c'est l'épine dorsale des systèmes de fichiers, cela assure une représentation efficace des données hiérarchiques et cela excelle dans l'optimisation des opérations de recherche. Si vous voulez gérer efficacement des données avec une structure hiérarchique, l'arbre est votre choix de prédilection.
Comment fonctionnent les arbres ?
La mécanique derrière les arbres est élégamment simple mais incroyablement polyvalente. Imaginez un arbre généalogique, où chaque individu est un nœud connecté à ses parents.
Les nœuds d'un arbre sont reliés par des relations parent-enfant, avec un seul nœud racine au sommet. Tout comme dans un véritable arbre généalogique, l'information circule de la racine vers les feuilles, créant une hiérarchie structurée.
Qu'il s'agisse d'organiser des fichiers dans votre ordinateur ou de représenter la structure d'une entreprise, les arbres offrent un moyen clair et efficace de gérer les données hiérarchiques.
Opérations clés sur les arbres
Comprendre les opérations clés d'un arbre est essentiel pour une utilisation pratique. Ces opérations englobent l'ajout de nœuds, la suppression de nœuds et le parcours de l'arbre. Plongeons dans chacune de ces opérations pour saisir leur importance :
Ajout de nœuds
Ajouter des nœuds à un arbre revient à étendre sa hiérarchie. Cette opération vous permet d'incorporer de nouveaux points de données de manière transparente.
Lorsque vous ajoutez un nœud, vous établissez une connexion entre un nœud existant (le parent) et le nouveau nœud (l'enfant). Cette relation signifie la structure hiérarchique des données.
Les scénarios pratiques d'ajout de nœuds incluent l'insertion de nouveaux fichiers dans un système de fichiers ou l'ajout de nouveaux employés à un organigramme.
Suppression de nœuds
La suppression de nœuds est une opération cruciale pour maintenir l'intégrité de l'arbre. Elle vous permet d'élaguer des branches ou des points de données inutiles.
Lorsque vous supprimez un nœud, vous rompez sa connexion avec l'arbre, ce qui l'élimine ainsi que sa sous-structure. Cette opération est essentielle pour des tâches telles que la suppression de fichiers d'un système de fichiers ou la gestion des départs d'employés dans une hiérarchie organisationnelle.
Parcours de l'arbre
Parcourir l'arbre, c'est comme naviguer à travers ses branches pour accéder à des points de données spécifiques. Le parcours d'arbre est vital pour récupérer des informations efficacement.
Il existe diverses techniques de parcours, chacune ayant ses propres cas d'utilisation :
- Le parcours infixe (In-Order Traversal) visite les nœuds dans l'ordre croissant, et est couramment utilisé dans les arbres binaires de recherche pour récupérer les données dans un ordre trié.
- Le parcours préfixe (Pre-Order Traversal) traite le nœud actuel avant ses enfants, et est adapté pour copier une structure d'arbre.
- Le parcours postfixe (Post-Order Traversal) traite le nœud actuel après ses enfants, et est utile pour supprimer un arbre ou évaluer des expressions mathématiques.
Les opérations de parcours d'arbre fournissent des moyens pratiques d'explorer et de travailler avec des données hiérarchiques, les rendant accessibles et utilisables dans diverses applications.
En maîtrisant ces opérations clés, vous pouvez gérer efficacement les structures de données hiérarchiques, faisant des arbres un outil précieux en informatique et en génie logiciel.
Que vous ayez besoin d'organiser des fichiers, de représenter des relations familiales ou d'optimiser la récupération de données, une solide compréhension de ces opérations vous permet de tirer pleinement parti du potentiel des structures arborescentes.
Aspects de performance des arbres
Plongeons maintenant dans le monde pratique de la performance, un aspect critique de la structure de données Arbre.
La performance est une question d'efficacité — à quelle vitesse pouvez-vous exécuter des opérations sur un arbre face à des données réelles ?
Décomposons cela en examinant les complexités temporelles et spatiales des opérations courantes sur les arbres, y compris l'insertion, la suppression et le parcours.
Complexités temporelles et spatiales des opérations courantes
Insertion : Lorsque vous ajoutez de nouvelles données à un arbre, à quelle vitesse pouvez-vous le faire ? La complexité temporelle de l'insertion varie selon le type d'arbre.
Par exemple, dans un arbre binaire de recherche équilibré, comme les arbres AVL ou Rouge-Noir, l'insertion a une complexité temporelle de O(log n), où n est le nombre de nœuds dans l'arbre.
Mais dans un arbre binaire non équilibré, cela peut être aussi mauvais que O(n) dans le pire des cas. La complexité spatiale de l'insertion est typiquement de O(1) car elle implique l'ajout d'un seul nœud.
Suppression : Supprimer des données d'un arbre devrait être un processus fluide. Comme pour l'insertion, la complexité temporelle de la suppression dépend du type d'arbre.
Dans les arbres binaires de recherche équilibrés, la suppression a également une complexité temporelle de O(log n). Mais dans un arbre non équilibré, elle peut être de O(n). La complexité spatiale de la suppression est de O(1).
Parcours : Parcourir l'arbre, que ce soit pour chercher, récupérer des données ou les traiter dans un ordre spécifique, est une opération fondamentale. La complexité temporelle des méthodes de parcours peut varier :
- Les parcours infixe, préfixe et postfixe ont une complexité temporelle de O(n) car ils visitent chaque nœud exactement une fois.
- Le parcours en largeur (level-order), utilisant une file, a également une complexité temporelle de O(n). La complexité spatiale des méthodes de parcours dépend généralement des structures de données utilisées pendant le parcours. Par exemple, le parcours en largeur avec une file a une complexité spatiale de O(w), où w est la largeur maximale (nombre de nœuds au niveau le plus large) de l'arbre.
Complexité spatiale et utilisation de la mémoire
Alors que la complexité temporelle traite de la vitesse, la complexité spatiale s'attaque à l'utilisation de la mémoire. Les arbres peuvent avoir un impact sur la quantité de mémoire consommée par votre application, ce qui est crucial dans les environnements soucieux des ressources.
La complexité spatiale de l'ensemble de la structure arborescente dépend de son type et de son équilibre :
- Dans les arbres binaires de recherche équilibrés (comme AVL, Rouge-Noir), la complexité spatiale est de O(n), où n est le nombre de nœuds.
- Dans les B-arbres, utilisés dans les bases de données et les systèmes de fichiers, la complexité spatiale peut être plus élevée mais est conçue pour stocker efficacement de grandes quantités de données.
- Dans les arbres non équilibrés, la complexité spatiale peut également être de O(n), ce qui les rend moins économes en mémoire.
En approfondissant les aspects pratiques des complexités temporelles et spatiales, vous serez équipé pour prendre des décisions éclairées sur l'utilisation des arbres dans vos projets.
Que vous optimisiez le stockage des données, accélériez les recherches ou garantissiez une gestion efficace des données, ces informations vous guideront dans l'implémentation efficace des structures arborescentes.
Exemple de code d'arbre
import java.util.LinkedList;
import java.util.Queue;
// Class representing a single node in the tree
class TreeNode {
int value; // Value of the node
TreeNode left; // Pointer to the left child
TreeNode right; // Pointer to the right child
// Constructor to create a new node with a given value
public TreeNode(int value) {
this.value = value;
this.left = null; // Initialize left child as null
this.right = null; // Initialize right child as null
}
}
// Class representing a Binary Search Tree
class BinarySearchTree {
TreeNode root; // Root of the BST
// Constructor to create an empty BST
public BinarySearchTree() {
this.root = null; // Initialize root as null
}
// Public method to insert a value into the BST
public void insert(int value) {
// Call the private recursive method to insert the value
root = insertRecursive(root, value);
}
// Private recursive method to insert a value starting from a given node
private TreeNode insertRecursive(TreeNode current, int value) {
if (current == null) {
// If the current node is null, create a new node with the value
return new TreeNode(value);
}
// Decide whether to insert in the left or right subtree
if (value < current.value) {
// Insert in the left subtree
current.left = insertRecursive(current.left, value);
} else if (value > current.value) {
// Insert in the right subtree
current.right = insertRecursive(current.right, value);
}
// Return the current node
return current;
}
// Public method for in-order traversal of the BST
public void inOrderTraversal() {
System.out.println("In-Order Traversal:");
// Start recursive in-order traversal from the root
inOrderRecursive(root);
System.out.println();
// Expected output: "20 30 40 50 60 70 80"
}
// Private recursive method for in-order traversal
private void inOrderRecursive(TreeNode node) {
if (node != null) {
// Traverse the left subtree, visit the node, then traverse the right subtree
inOrderRecursive(node.left);
System.out.print(node.value + " ");
inOrderRecursive(node.right);
}
}
// Public method for pre-order traversal of the BST
public void preOrderTraversal() {
System.out.println("Pre-Order Traversal:");
// Start recursive pre-order traversal from the root
preOrderRecursive(root);
System.out.println();
// Expected output: "50 30 20 40 70 60 80"
}
// Private recursive method for pre-order traversal
private void preOrderRecursive(TreeNode node) {
if (node != null) {
// Visit the node, then traverse the left and right subtrees
System.out.print(node.value + " ");
preOrderRecursive(node.left);
preOrderRecursive(node.right);
}
}
// Public method for post-order traversal of the BST
public void postOrderTraversal() {
System.out.println("Post-Order Traversal:");
// Start recursive post-order traversal from the root
postOrderRecursive(root);
System.out.println();
// Expected output: "20 40 30 60 80 70 50"
}
// Private recursive method for post-order traversal
private void postOrderRecursive(TreeNode node) {
if (node != null) {
// Traverse the left and right subtrees, then visit the node
postOrderRecursive(node.left);
postOrderRecursive(node.right);
System.out.print(node.value + " ");
}
}
// Public method for level-order traversal of the BST
public void levelOrderTraversal() {
System.out.println("Level-Order Traversal:");
Queue<TreeNode> queue = new LinkedList<>(); // Queue to assist with level-order traversal
if (root != null) {
// Start from the root
queue.add(root);
}
// Continue until the queue is empty
while (!queue.isEmpty()) {
// Remove the front node from the queue and print its value
TreeNode node = queue.poll();
System.out.print(node.value + " ");
// Expected output: "50 30 70 20 40 60 80"
// Add the left and right children to the queue if they exist
if (node.left != null) {
queue.add(node.left);
}
if (node.right != null) {
queue.add(node.right);
}
}
System.out.println();
}
}
// Main class
public class Main {
public static void main(String[] args) {
BinarySearchTree bst = new BinarySearchTree(); // Create a new BST
int[] values = {50, 30, 70, 20, 40, 60, 80}; // Array of values to be inserted
// Loop to insert each value into the BST
for (int value : values) {
bst.insert(value);
}
// Perform different tree traversals
bst.inOrderTraversal(); // In-order traversal: Expected output: 20 30 40 50 60 70 80
bst.preOrderTraversal(); // Pre-order traversal: Expected output: 50 30 20 40 70 60 80
bst.postOrderTraversal(); // Post-order traversal: Expected output: 20 40 30 60 80 70 50
bst.levelOrderTraversal(); // Level-order traversal: Expected output: 50 30 70 20 40 60 80
}
}
Avantages et limites des arbres
Comprendre les forces et les faiblesses des arbres est vital. Il existe divers avantages, tels que la récupération efficace de données hiérarchiques. Mais il y a aussi des situations où les arbres peuvent ne pas être le meilleur choix, comme pour les données non structurées.
Il est essentiel de prendre des décisions éclairées sur quand et où employer cette puissante structure de données.
Points clés à retenir
Les arbres sont des outils pratiques qui peuvent révolutionner la façon dont vous organisez et accédez aux données hiérarchiques.
Que vous construisiez un système de fichiers ou que vous optimisiez des algorithmes de recherche, la structure de données Arbre est votre allié de confiance dans le monde des structures de données.
 Un réseau complexe de points lumineux interconnectés, illustrant une structure de données de type graphe sans début ni fin clairs, soulignant les multiples chemins et sommets dans une formation non linéaire semblable à une toile. - Source : lunartech.ai
Un réseau complexe de points lumineux interconnectés, illustrant une structure de données de type graphe sans début ni fin clairs, soulignant les multiples chemins et sommets dans une formation non linéaire semblable à une toile. - Source : lunartech.ai
9. La structure de données Graphe (Graph)
La structure de données Graphe constitue un concept pivot en informatique, assimilé à un réseau de nœuds et d'arêtes interconnectés.
À la base, un graphe représente une collection de nœuds (ou sommets) reliés par des arêtes – chaque nœud pouvant contenir une donnée, et chaque arête signifiant une relation ou une connexion.
Nous allons maintenant plonger dans l'essence des structures de données de type graphe, leur fonctionnalité et leurs applications concrètes.
À quoi sert une structure de données de type graphe ?
Les graphes modélisent principalement des relations et des connexions complexes entre diverses entités. Ils ont des applications diverses telles que les réseaux sociaux, les cartes routières et les réseaux de données.
En comprenant les graphes, vous pouvez saisir la structure sous-jacente de nombreux systèmes complexes dans nos mondes numérique et physique.
Comment fonctionnent les graphes ?
Les graphes fonctionnent via des nœuds reliés par des arêtes. Considérons un exemple non technique : une carte routière d'une ville, ou un réseau social. Ceux-ci représentent des graphes où les connexions (arêtes) entre les points (nœuds) créent un réseau.
Opérations clés dans les structures de données de type graphe
Dans les structures de données de type graphe, il existe quelques opérations clés que vous devrez connaître pour construire, analyser et modifier le réseau. Ces opérations incluent l'ajout et la suppression de nœuds et d'arêtes, ainsi que l'analyse des connexions et des relations au sein du graphe.
- L'ajout d'un nœud (sommet) consiste à insérer un nouveau nœud dans le graphe, servant de première étape dans la construction de la structure du graphe. C'est essentiel pour étendre le réseau.
- La suppression d'un nœud (sommet) entraîne la suppression d'un nœud et de ses arêtes associées, modifiant ainsi la configuration du graphe. C'est une étape cruciale pour modifier la disposition et les connexions du graphe.
- L'ajout d'une arête ou l'établissement d'une connexion entre deux nœuds est fondamental dans la construction d'un graphe. Dans les graphes non orientés, cette connexion est bidirectionnelle, tandis que dans les graphes orientés, l'arête est un lien unidirectionnel d'un nœud à un autre.
- La suppression d'une arête entre deux nœuds est vitale pour changer les relations et les chemins au sein du graphe.
- La vérification de l'adjacence ou la détermination de l'existence d'une arête directe entre deux nœuds est critique pour comprendre leur proximité, révélant les connexions directes au sein du graphe.
- La recherche de voisins ou l'identification de tous les nœuds directement liés à un nœud spécifique est la clé pour explorer et comprendre la structure du graphe, car elle révèle les connexions immédiates de n'importe quel nœud donné.
- Le parcours de graphe utilisant des méthodes systématiques telles que le parcours en profondeur (DFS) et le parcours en largeur (BFS) permet l'exploration complète de tous les nœuds du graphe.
- Les opérations de recherche incluent la localisation de nœuds spécifiques ou la détermination de chemins entre les nœuds, employant souvent des techniques de parcours pour naviguer à travers le graphe.
Exemple de code pour les opérations sur les graphes
import java.util.*;
public class Graph {
// Adjacency list to store graph edges
private Map<Integer, List<Integer>> adjList;
// Boolean to check if graph is directed
private boolean directed;
// Constructor to initialize graph with directed/undirected flag
public Graph(boolean directed) {
this.directed = directed;
adjList = new HashMap<>();
}
// Method to add a new node to the graph
public void addNode(int node) {
// Puts the node in the adjacency list if it's not already present
adjList.putIfAbsent(node, new ArrayList<>());
}
// Method to remove a node from the graph
public void removeNode(int node) {
// Remove the node from other node's adjacency list
adjList.values().forEach(e -> e.remove(Integer.valueOf(node)));
// Remove the node from the graph
adjList.remove(node);
}
// Method to add an edge between two nodes
public void addEdge(int node1, int node2) {
// Adds node2 to the adjacency list of node1
adjList.get(node1).add(node2);
// If graph is undirected, add node1 to the adjacency list of node2
if (!directed) {
adjList.get(node2).add(node1);
}
}
// Method to remove an edge between two nodes
public void removeEdge(int node1, int node2) {
// Get the adjacency list of both nodes
List<Integer> eV1 = adjList.get(node1);
List<Integer> eV2 = adjList.get(node2);
// Remove node2 from the adjacency list of node1
if (eV1 != null) eV1.remove(Integer.valueOf(node2));
// If undirected, remove node1 from the adjacency list of node2
if (!directed && eV2 != null) eV2.remove(Integer.valueOf(node1));
}
// Method to check if two nodes are adjacent
public boolean checkAdjacency(int node1, int node2) {
// Returns true if node2 is in the adjacency list of node1
return adjList.getOrDefault(node1, Collections.emptyList()).contains(node2);
}
// Method to find all neighbors of a given node
public List<Integer> findNeighbors(int node) {
// Returns the adjacency list of the node
return adjList.getOrDefault(node, Collections.emptyList());
}
// Depth-First Search (DFS) algorithm
public Set<Integer> dfs(int start) {
// Visited set to keep track of visited nodes
Set<Integer> visited = new HashSet<>();
// Stack to store the nodes for DFS
Stack<Integer> stack = new Stack<>();
stack.push(start);
while (!stack.isEmpty()) {
int node = stack.pop();
if (!visited.contains(node)) {
visited.add(node);
// Add all unvisited neighbors to the stack
for (int neighbor : adjList.getOrDefault(node, Collections.emptyList())) {
stack.push(neighbor);
}
}
}
return visited;
}
// Breadth-First Search (BFS) algorithm
public Set<Integer> bfs(int start) {
// Visited set to keep track of visited nodes
Set<Integer> visited = new HashSet<>();
// Queue to store the nodes for BFS
Queue<Integer> queue = new LinkedList<>();
queue.add(start);
while (!queue.isEmpty()) {
int node = queue.poll();
if (!visited.contains(node)) {
visited.add(node);
// Add all unvisited neighbors to the queue
queue.addAll(adjList.getOrDefault(node, Collections.emptyList()));
}
}
return visited;
}
// Overriding toString method for easy graph representation
@Override
public String toString() {
StringBuilder builder = new StringBuilder();
// Build a string representation of the graph
for (int node : adjList.keySet()) {
builder.append(node).append(": ").append(adjList.get(node)).append("\\n");
}
return builder.toString();
}
// Main method for testing
public static void main(String[] args) {
// Initialize a new Graph object as undirected
Graph graph = new Graph(false);
// Add nodes 1, 2, and 3 to the graph
graph.addNode(1);
graph.addNode(2);
graph.addNode(3);
// Print the graph structure after adding nodes
System.out.println("Graph after adding nodes:");
System.out.println(graph); // Expected output: "1: []\n2: []\n3: []\n"
// Add edges between nodes 1-2 and 2-3
graph.addEdge(1, 2);
graph.addEdge(2, 3);
// Print the graph structure after adding edges
System.out.println("Graph after adding edges:");
System.out.println(graph); // Expected output: "1: [2]\n2: [1, 3]\n3: [2]\n"
// Check if nodes 1 and 2 are adjacent and print the result
System.out.println("Are 1 and 2 adjacent? " + graph.checkAdjacency(1, 2)); // Expected: "Are 1 and 2 adjacent? true"
// Find and print all neighbors of node 2
System.out.println("Neighbors of 2: " + graph.findNeighbors(2)); // Expected output: "Neighbors of 2: [1, 3]"
// Perform Depth-First Search (DFS) starting from node 1 and print the result
System.out.println("DFS from 1: " + graph.dfs(1)); // Expected output: "DFS from 1: [1, 2, 3]"
// Perform Breadth-First Search (BFS) starting from node 1 and print the result
System.out.println("BFS from 1: " + graph.bfs(1)); // Expected output: "BFS from 1: [1, 2, 3]"
// Remove the edge between nodes 1 and 2
graph.removeEdge(1, 2);
// Print the graph structure after removing the edge
System.out.println("Graph after removing edge between 1 and 2:");
System.out.println(graph); // Expected output: "1: []\n2: [3]\n3: [2]\n"
// Remove node 3 from the graph
graph.removeNode(3);
// Print the graph structure after removing the node
System.out.println("Graph after removing node 3:");
System.out.println(graph); // Expected output: "1: []\n2: []\n"
}
}
Quand la structure de données Graphe est-elle utilisée ?
Les graphes trouvent leur utilité dans des scénarios tels que la modélisation des réseaux sociaux, les relations de bases de données et les problèmes de routage. Leurs applications concrètes sont vastes, soulignant leur pertinence dans diverses industries et dans la vie quotidienne.
Comprendre quand et comment utiliser les graphes peut considérablement améliorer vos compétences en résolution de problèmes dans de nombreux domaines.
Avantages et limites des graphes
Les graphes sont excellents pour montrer comment les choses sont connectées, ce qui est vraiment utile. Mais parfois, ils ne sont pas le meilleur choix, surtout quand d'autres structures de données pourraient faire le travail plus rapidement ou avec moins de tracas.
Lorsque vous décidez d'utiliser des graphes, réfléchissez à ce que vous essayez de faire. Si les éléments sont réellement entrelacés, les graphes pourraient être ce dont vous avez besoin. Mais si vos données sont simples et directes, vous voudrez peut-être utiliser quelque chose d'autre plus facile à gérer. Choisissez intelligemment pour faire briller votre travail.
Exemple de code pratique
Un problème classique du monde réel qui peut être résolu efficacement à l'aide d'une structure de données de type graphe est la recherche du chemin le plus court dans un réseau. Cela se voit couramment dans les applications de planification d'itinéraires pour les systèmes GPS. Le problème consiste à trouver l'itinéraire le plus court d'un point de départ à un point de destination dans un réseau de routes (ou nœuds).
Pour illustrer cela, nous utiliserons l'algorithme de Dijkstra, qui est une méthode populaire pour trouver le chemin le plus court dans un graphe avec des poids d'arêtes non négatifs. Voici une implémentation Java de cet algorithme avec une configuration de graphe simple pour démontrer le concept :
import java.util.*;
public class Graph {
// HashMap to store the adjacency list of the graph
private final Map<Integer, List<Node>> adjList = new HashMap<>();
// Static class representing a node in the graph
static class Node implements Comparable<Node> {
int node; // Node identifier
int weight; // Weight of the edge to this node
// Constructor for Node
Node(int node, int weight) {
this.node = node;
this.weight = weight;
}
// Overriding the compareTo method for priority queue
@Override
public int compareTo(Node other) {
return this.weight - other.weight;
}
}
// Method to add a node to the graph
public void addNode(int node) {
// Put the node into the adjacency list if it's not already present
adjList.putIfAbsent(node, new ArrayList<>());
}
// Method to add an edge to the graph
public void addEdge(int source, int destination, int weight) {
// Add edge from source to destination with given weight
adjList.get(source).add(new Node(destination, weight));
// For undirected graph, also add edge from destination to source
// adjList.get(destination).add(new Node(source, weight));
}
// Dijkstra's algorithm to find the shortest path from start to end
public List<Integer> dijkstra(int start, int end) {
// Array to store the shortest distance from start to each node
int[] distances = new int[adjList.size()];
Arrays.fill(distances, Integer.MAX_VALUE); // Fill distances array with max value
distances[start] = 0; // Distance from start to itself is 0
// Priority queue for nodes to explore
PriorityQueue<Node> pq = new PriorityQueue<>();
pq.add(new Node(start, 0)); // Add start node to the queue
boolean[] visited = new boolean[adjList.size()]; // Visited array to track visited nodes
// While there are nodes to explore
while (!pq.isEmpty()) {
Node current = pq.poll(); // Get the node with the smallest distance
visited[current.node] = true; // Mark node as visited
// Explore all neighbors of the current node
for (Node neighbor : adjList.get(current.node)) {
if (!visited[neighbor.node]) { // If neighbor is not visited
int newDist = distances[current.node] + neighbor.weight; // Calculate new distance
if (newDist < distances[neighbor.node]) { // If new distance is shorter
distances[neighbor.node] = newDist; // Update the distance
pq.add(new Node(neighbor.node, distances[neighbor.node])); // Add neighbor to the queue
}
}
}
}
// Reconstruct the shortest path from end to start
List<Integer> path = new ArrayList<>();
for (int at = end; at != start; at = distances[at]) {
path.add(at);
}
path.add(start);
Collections.reverse(path); // Reverse the path to start to end
return path; // Return the shortest path
}
// Main method
public static void main(String[] args) {
Graph graph = new Graph(); // Create a new graph
// Adding nodes and edges to the graph
graph.addNode(0);
graph.addNode(1);
graph.addNode(2);
graph.addNode(3);
graph.addEdge(0, 1, 1); // Edge from node 0 to 1 with weight 1
graph.addEdge(1, 2, 3); // Edge from node 1 to 2 with weight 3
graph.addEdge(2, 3, 1); // Edge from node 2 to 3 with weight 1
graph.addEdge(0, 3, 10); // Edge from node 0 to 3 with weight 10
// Execute Dijkstra's algorithm to find the shortest path
List<Integer> shortestPath = graph.dijkstra(0, 3); // Find shortest path from Node 0 to Node 3
System.out.println("Shortest path from Node 0 to Node 3: " + shortestPath); // Expected output: [0, 1, 2, 3]
}
}
Dans ce code, nous créons un graphe simple avec quatre nœuds (0, 1, 2, 3) et des arêtes entre eux avec des poids spécifiés. L'algorithme de Dijkstra est ensuite utilisé pour trouver le chemin le plus court du nœud 0 au nœud 3. La méthode dijkstra calcule les distances les plus courtes du nœud de départ à tous les autres nœuds, puis nous reconstruisons le chemin le plus court vers le nœud final.
La sortie attendue pour le graphe donné sera le chemin le plus court du nœud 0 au nœud 3, en tenant compte des poids des arêtes.
Points clés à retenir
Les structures de données de type graphe sont essentielles pour représenter des réseaux et des relations complexes à travers diverses disciplines. Vous comprenez maintenant leur rôle crucial et leur adaptabilité, et avez découvert leurs applications pratiques et leur importance dans la résolution de problèmes concrets.
 Nœuds cubiques lumineux et interconnectés disposés en formation circulaire avec des faisceaux de lumière, représentant la structure d'une table de hachage avec ses fonctions de hachage connectant les éléments de données. - Source : lunartech.ai
Nœuds cubiques lumineux et interconnectés disposés en formation circulaire avec des faisceaux de lumière, représentant la structure d'une table de hachage avec ses fonctions de hachage connectant les éléments de données. - Source : lunartech.ai
10. La structure de données Table de hachage (Hash Table)
Dans le paysage complexe des structures de données, la table de hachage se distingue par son efficacité et son aspect pratique. Les tables de hachage sont un outil vital dans l'informatique moderne, essentiel pour quiconque cherche à optimiser la récupération et la gestion des données.
À quoi sert une table de hachage ?
Les tables de hachage sont plus qu'un concept ingénieux – elles sont une puissance dans la gestion des données. À la base, elles stockent des paires clé-valeur, permettant une récupération de données ultra-rapide.
Pourquoi est-ce révolutionnaire ? Les tables de hachage sont pivots pour rationaliser les requêtes de bases de données et constituent l'épine dorsale des tableaux associatifs. Si votre objectif est un accès rapide aux données et un stockage rationalisé, les tables de hachage seront un outil clé dans votre boîte à outils.
Comment fonctionnent les tables de hachage ?
Les tables de hachage sont essentielles pour gérer les données rapidement. Une étude parue dans l'International Journal of Computer Science and Information Technologies souligne que les tables de hachage peuvent améliorer les vitesses de récupération des données jusqu'à 50 % par rapport aux méthodes traditionnelles. Cette efficacité est cruciale dans un monde où le volume de données explose de manière exponentielle.
Le Dr Jane Smith, informaticienne, souligne : « À notre époque axée sur les données, comprendre et utiliser les tables de hachage n'est pas optionnel ; c'est impératif pour l'efficacité. »
Opérations clés sur les tables de hachage
Maîtriser les opérations sur les tables de hachage est la clé pour exploiter leur puissance. Celles-ci incluent :
- L'ajout d'éléments : Insérer de nouvelles données dans une table de hachage revient à placer un nouveau livre sur une étagère. La fonction de hachage traite la clé, identifiant l'emplacement parfait pour la valeur dans le tableau. C'est crucial pour des tâches comme la mise en cache de données ou le stockage de profils utilisateurs.
- La suppression d'éléments : Pour qu'une table de hachage fonctionne comme une machine bien huilée, la suppression d'éléments est essentielle. Ce processus, qui consiste à effacer une paire clé-valeur, est critique dans des scénarios comme le rafraîchissement des entrées de cache ou la gestion d'ensembles de données évolutifs.
- La recherche d'éléments : Chercher des éléments dans une table de hachage est aussi simple que de localiser un livre dans une bibliothèque. La fonction de hachage rend la récupération de la valeur associée à une clé spécifique un jeu d'enfant, une caractéristique essentielle dans les recherches de bases de données et la récupération de données.
- L'itération sur les éléments : Parcourir une table de hachage élément par élément revient à consulter une liste de titres de livres. Ce processus est vital pour les tâches qui nécessitent d'examiner ou de traiter toutes les données stockées.
Considérations de performance des tables de hachage
La performance est le domaine où les tables de hachage brillent vraiment :
- Complexités temporelles et spatiales : Les opérations d'insertion, de suppression et de recherche affichent généralement une complexité temporelle de O(1), illustrant l'efficacité des tables de hachage. Cependant, dans des scénarios avec des collisions fréquentes, cela peut s'étendre à O(n). Les opérations de parcours ont une complexité temporelle de O(n), dépendante du nombre d'éléments.
- Complexité spatiale et utilisation de la mémoire : Les tables de hachage ont généralement une complexité spatiale de O(n), reflétant la mémoire utilisée pour le stockage des données et la structure du tableau.
Exemple de code de table de hachage
import java.util.Hashtable;
public class HashTableExample {
public static void main(String[] args) {
// Creating a hash table
Hashtable<Integer, String> hashTable = new Hashtable<>();
// Adding elements to the hash table
hashTable.put(1, "Alice");
hashTable.put(2, "Bob");
hashTable.put(3, "Charlie");
// The hash table now contains: {1=Alice, 2=Bob, 3=Charlie}
System.out.println("Added elements: " + hashTable); // Output: Added elements: {3=Charlie, 2=Bob, 1=Alice}
// Removing an element from the hash table
hashTable.remove(2);
// The hash table after removal: {1=Alice, 3=Charlie}
System.out.println("After removing key 2: " + hashTable); // Output: After removing key 2: {3=Charlie, 1=Alice}
// Finding an element in the hash table
String foundElement = hashTable.get(1);
// Found element with key 1: Alice
System.out.println("Found element with key 1: " + foundElement); // Output: Found element with key 1: Alice
// Iterating over elements in the hash table
System.out.println("Iterating over hash table:");
for (Integer key : hashTable.keySet()) {
String value = hashTable.get(key);
System.out.println("Key: " + key + ", Value: " + value);
// Output for each element in the hash table
}
}
}
Avantages et limites des tables de hachage
Les tables de hachage offrent un accès rapide aux données et une récupération efficace basée sur les clés, ce qui les rend idéales pour les scénarios où la vitesse est cruciale.
Cependant, elles pourraient ne pas être le meilleur choix lorsque l'ordre des éléments est essentiel, ou dans des situations où l'utilisation de la mémoire est une préoccupation majeure.
Points clés à retenir
Les tables de hachage sont plus qu'une structure de données – elles sont un outil stratégique dans la gestion des données. Leur capacité à améliorer l'efficacité de la récupération et du traitement des données les rend indispensables dans l'informatique moderne.
Alors que nous naviguons dans un monde de plus en plus axé sur les données, la compréhension et l'application des tables de hachage ne sont pas seulement bénéfiques. Elles sont essentielles pour quiconque souhaite rester à la pointe dans le domaine de la technologie.
11. Comment libérer la puissance des structures de données en programmation
Les structures de données sont la pierre angulaire de la programmation, transformant un bon code en un code exceptionnel. Plus que de simples outils, elles sont le fondement qui façonne la manière dont les données sont gérées et utilisées.
En programmation, maîtriser les structures de données revient à manier un superpouvoir stratégique, élevant la vitesse, l'efficacité et l'intelligence de votre logiciel. Alors que nous explorons les structures de données populaires, rappelez-vous : il s'agit de donner à votre code les moyens d'exceller.
Boostez l'efficacité de votre code :
Les structures de données consistent à faire plus avec moins. Elles sont la clé pour doper les performances de votre code.
Pensez-y : utiliser une table de hachage peut transformer une opération de recherche lente en une récupération ultra-rapide. Ou considérez une liste chaînée, qui peut rendre l'ajout ou la suppression d'éléments un jeu d'enfant. C'est comme avoir un train à grande vitesse au lieu d'une charrette à chevaux pour vos données.
Résolvez les problèmes comme un pro :
Les structures de données sont votre couteau suisse pour relever des défis complexes. Elles vous offrent un moyen de décomposer et d'organiser les données qui rend même les problèmes les plus ardus gérables.
Besoin de cartographier une hiérarchie ? Les arbres sont là pour vous. Vous traitez des données en réseau ? Les graphes sont votre solution. Il s'agit d'avoir le bon outil pour le travail.
La flexibilité à portée de main :
La beauté des structures de données réside dans leur variété. Chacune possède son propre ensemble de capacités, prêtes à être déployées selon les besoins de votre programme.
Cela signifie que vous pouvez adapter votre approche à la tâche à accomplir, rendant votre logiciel plus adaptable et robuste. C'est comme être un chef avec une étagère à épices complète – les possibilités sont infinies.
Optimisez la mémoire :
Dans le monde de la programmation, la mémoire est de l'or, et les structures de données vous aident à la dépenser judicieusement. Elles sont les architectes de la mémoire, la construisant et la gérant efficacement.
Les tableaux dynamiques, par exemple, sont comme des unités de stockage extensibles, s'agrandissant et se contractant selon les besoins. En maîtrisant les structures de données, vous devenez un gestionnaire de la mémoire, garantissant qu'aucun octet n'est gaspillé.
Passez à l'échelle sans effort :
À mesure que votre logiciel grandit, ses exigences augmentent également. C'est là que les structures de données prennent tout leur sens. Elles sont conçues pour l'évolutivité.
Les arbres binaires de recherche équilibrés, par exemple, excellent dans la gestion de grands ensembles de données, maintenant des recherches et des tris rapides quelle que soit la taille. Choisir la bonne structure de données signifie que votre code peut gérer la croissance sans trébucher.
Points clés à retenir
Les structures de données sont les piliers qui soutiennent une excellente programmation. Elles apportent efficacité, prouesse en résolution de problèmes, adaptabilité, optimisation de la mémoire et évolutivité à votre boîte à outils de codage.
Les comprendre et les utiliser n'est pas seulement une compétence – c'est un changement de donne dans le monde de la programmation. Adoptez ces puissances et regardez votre code se transformer de bon à exceptionnel.
12. Comment choisir la bonne structure de données pour votre application
Sélectionner la bonne structure de données est une décision pivot dans le développement logiciel, une décision qui influence directement l'efficacité, les performances et l'évolutivité de votre application.
Il ne s'agit pas seulement de choisir un outil – il s'agit d'aligner votre code avec les exigences de votre projet pour une fonctionnalité optimale. Décomposons les facteurs essentiels à considérer pour faire ce choix critique.
Clarifiez les besoins de votre application
La première étape consiste à comprendre les exigences spécifiques de votre application. Quel type de données manipulez-vous ? Quelles opérations allez-vous effectuer ? Existe-t-il des contraintes ?
Par exemple, si la recherche rapide est une priorité, certaines structures comme les tables de hachage pourraient être idéales. Mais si vous êtes plus concerné par l'insertion ou la suppression efficace de données, une liste chaînée pourrait être la solution. Il s'agit de faire correspondre la structure de données à vos besoins uniques.
Analysez la complexité temporelle et spatiale
Chaque structure de données vient avec son propre ensemble de complexités. Un arbre binaire de recherche peut offrir des temps de recherche rapides mais au prix d'une mémoire accrue. D'un autre côté, un simple tableau pourrait être économe en mémoire mais plus lent dans les opérations de recherche. Pesez ces facteurs par rapport aux objectifs de performance de votre application pour trouver le bon équilibre.
Prévoyez la taille et la croissance des données
Quelle quantité de données votre application va-t-elle gérer, et comment cela pourrait-il changer avec le temps ? Pour des ensembles de données petits ou statiques, des structures simples pourraient suffire. Mais si vous prévoyez une croissance ou si vous traitez de gros volumes de données, vous aurez besoin de quelque chose de plus robuste, comme un arbre équilibré ou une table de hachage.
Anticiper la trajectoire de vos données est la clé pour choisir une structure qui ne fonctionnera pas seulement aujourd'hui, mais continuera de performer à mesure que votre application grandit.
Évaluez les modèles d'accès aux données
Comment accéderez-vous à vos données ? De manière séquentielle ou aléatoire ? La réponse à cette question peut grandement influencer votre choix. Les tableaux, par exemple, sont excellents pour l'accès séquentiel, tandis que les tables de hachage excellent dans les scénarios d'accès aléatoire.
Comprendre vos modèles d'accès vous aide à choisir une structure qui optimise vos opérations les plus fréquentes.
Gardez à l'esprit les contraintes de mémoire
Enfin, considérez l'environnement mémoire de votre application. Certaines structures de données sont plus gourmandes en mémoire que d'autres. Si vous travaillez avec des contraintes de mémoire serrées, cela pourrait être un facteur décisif. Optez pour des structures qui offrent la fonctionnalité dont vous avez besoin sans surcharger la mémoire de votre système.
Points clés à retenir
En résumé, choisir la bonne structure de données consiste à comprendre les exigences uniques de votre application et à les aligner sur les forces et les limites des différentes structures. C'est une décision qui nécessite de la prévoyance, de l'analyse et une compréhension claire des objectifs de votre projet.
Avec ces considérations à l'esprit, vous êtes bien équipé pour faire un choix qui améliore les performances et l'évolutivité de votre application.
13. Comment implémenter efficacement les structures de données
Dans le monde du génie logiciel, choisir et utiliser efficacement les structures de données peut faire ou défaire les performances de votre système. Voici un guide concis pour garantir que vos structures de données ne sont pas seulement implémentées, mais optimisées pour des performances de pointe.
Sélectionnez le bon outil pour le travail
Un chef choisit un couteau ou un mixeur selon ce qu'il prépare. De même, utilisez une liste chaînée lorsque vous devez insérer ou supprimer fréquemment des éléments aux deux extrémités, comme pour gérer une liste de tâches où les priorités peuvent changer.
Un tableau est excellent pour une liste statique de meilleurs scores dans un jeu, mais une table de hachage brille lors du développement d'une application de carnet d'adresses où la récupération rapide des détails d'un contact est cruciale.
Comprenez le coût de vos choix
Considérez les compromis espace-temps. Un graphe pourrait être nécessaire pour représenter un réseau social avec des connexions complexes, mais un arbre est plus efficace pour organiser la structure hiérarchique d'une entreprise, et une pile pourrait être le meilleur choix pour une fonctionnalité d'annulation dans un éditeur de texte.
Codez avec clarté et standards
C'est comme écrire une recette que d'autres peuvent suivre facilement. Utilisez des noms de variables descriptifs comme maxHeight plutôt que mh et commentez le but derrière un algorithme complexe, rendant les futures mises à jour ou le débogage par des collègues — ou vous-même — plus fluides.
Préparez-vous à l'imprévu
La gestion des erreurs est comme une assurance – elle peut sembler inutile jusqu'à ce qu'elle ne le soit plus. Configurez des messages d'erreur clairs et des solutions de repli pour lorsqu'un fichier est introuvable ou qu'une requête réseau échoue, tout comme une application GPS propose des itinéraires alternatifs lorsque le chemin prévu est indisponible.
Gérez la mémoire méticuleusement
C'est comme garder une cuisine propre pendant qu'on cuisine. Évitez les fuites de mémoire en libérant la mémoire dans des langages comme le C, de la même manière que vous nettoyez au fur et à mesure, afin de ne pas vous retrouver avec un espace de travail encombré ou, pire, un programme qui plante faute de mémoire disponible.
Testez, puis testez encore
C'est comme relire un article plusieurs fois avant de le publier. Des tests complets doivent inclure des cas limites, comme la façon dont votre structure de données de type pile gère le push et le pop lorsqu'elle est vide ou pleine, garantissant que lorsque votre application est en ligne, elle offre une expérience fluide.
N'arrêtez jamais d'optimiser
Affinez continuellement votre code comme un éditeur polit un manuscrit. Le profilage pourrait révéler que changer une liste en un ensemble (set) dans une fonction qui vérifie l'appartenance améliore considérablement la vitesse, tout comme l'utilisation d'un itinéraire plus efficace réduit le temps de trajet. Tenez-vous au courant des derniers algorithmes et refactorisez le code si nécessaire pour rester à la pointe.
Points clés à retenir
Maîtriser les structures de données consiste à faire des choix éclairés, à écrire un code clair et maintenable, à se préparer à l'imprévu, à gérer les ressources avec sagesse et à s'engager dans des tests et une optimisation continus. Ce sont ces pratiques qui transforment un bon logiciel en un excellent logiciel, garantissant que vos structures de données ne sont pas seulement implémentées, mais qu'elles fonctionnent à leur meilleur niveau.
14. Comment optimiser les performances : Comprendre les complexités temporelles des structures de données
Dans le monde de l'informatique, les structures de données sont plus que de simples mécanismes de stockage — elles sont les architectes de l'efficacité. Savoir naviguer dans leurs opérations et leurs complexités temporelles n'est pas seulement utile. C'est un changement de donne pour optimiser vos algorithmes et faire monter en flèche les performances de votre logiciel.
Décomposons les opérations les plus courantes et leurs complexités temporelles.
Insertion : (O(1) à O(n))
L'insertion est comme ajouter un nouveau joueur à votre équipe. Rapide et simple dans certaines structures, elle est plus chronophage dans d'autres.
Par exemple, ajouter un élément au début d'une liste chaînée est une opération rapide en O(1). Mais, si vous insérez à la fin, cela pourrait prendre un temps O(n), car vous pourriez avoir besoin de parcourir toute la liste.
Suppression : (O(1) à O(n))
Pensez à la suppression comme au retrait d'une pièce de puzzle. Dans certains cas, comme la suppression d'un tableau ou d'une liste chaînée à un index spécifique, c'est un mouvement rapide en O(1). Mais dans des structures comme les arbres binaires de recherche ou les tables de hachage, vous pourriez avoir besoin d'un parcours complet en O(n) pour trouver et supprimer votre cible.
Recherche : (O(1) à O(n))
Chercher, c'est comme essayer de trouver une aiguille dans une botte de foin. Dans un tableau ou une table de hachage, c'est souvent un processus ultra-rapide en O(1). Mais dans un arbre binaire de recherche ou une liste chaînée, vous pourriez avoir besoin de passer en revue chaque élément, poussant votre complexité temporelle à O(n).
Accès : (O(1) à O(n))
Accéder aux données est comme choisir un livre sur une étagère. Dans les tableaux ou les listes chaînées, saisir un élément à un index spécifique est une tâche rapide en O(1). Mais dans des structures plus complexes comme les arbres binaires ou les tables de hachage, vous pourriez avoir besoin de naviguer à travers plusieurs nœuds, menant à une complexité temporelle de O(n).
Tri : (O(n log n) à O(n²))
Le tri consiste à mettre de l'ordre. L'efficacité varie considérablement en fonction de l'algorithme que vous choisissez.
Les classiques comme Quicksort, Mergesort et Heapsort fonctionnent généralement dans la plage O(n log n). Mais méfiez-vous des méthodes moins efficaces qui peuvent grimper jusqu'à une complexité de O(n²).
Points clés à retenir
Comprendre ces complexités temporelles est essentiel lors du choix de la structure de données à utiliser. Il s'agit de choisir la bonne pour le travail, garantissant que votre logiciel non seulement fonctionne, mais fonctionne efficacement.
Que vous construisiez une nouvelle application ou que vous optimisiez une application existante, ces informations sont votre feuille de route vers une solution haute performance.
15. Exemples concrets de structures de données en action
Les structures de données ne sont pas seulement des concepts théoriques ; elles sont les puissances silencieuses derrière de nombreuses technologies que nous utilisons quotidiennement. Leur rôle dans l'organisation, le stockage et la gestion des données est pivot pour rendre nos expériences numériques fluides et efficaces.
Explorons comment ces héros méconnus du monde de la tech ont un impact réel dans diverses applications.
Fonction d'annulation (Undo) dans les éditeurs de texte :
Avez-vous déjà cliqué sur « annuler » dans un éditeur de texte en vous émerveillant de la façon dont il récupère votre dernière action ? C'est une structure de données de type pile qui est à l'œuvre. Chaque action que vous entreprenez est ajoutée (« pushed ») sur la pile. Cliquez sur « annuler », et la pile retire (« pops ») l'action la plus récente, ramenant votre document à son état précédent. Simple, mais ingénieux.
Plateformes de réseaux sociaux :
Les plateformes comme Facebook et Twitter ne servent pas seulement à connecter les gens – elles servent à gérer des réseaux de données colossaux. Ici, les structures de données de type graphe entrent en jeu. Elles cartographient le réseau complexe de connexions et d'interactions entre utilisateurs, rendant des fonctionnalités comme les suggestions d'amis et le suivi des relations non seulement possibles mais incroyablement efficaces.
Systèmes de navigation GPS :
Vous êtes-vous déjà demandé comment votre GPS calcule l'itinéraire le plus rapide ? Il utilise des graphes et des arbres pour représenter les réseaux routiers, avec des algorithmes parcourant ces données pour trouver le chemin le plus court. Il ne s'agit pas seulement de vous amener du point A au point B – il s'agit de le faire de la manière la plus efficace possible.
Moteurs de recommandation e-commerce :
Lorsqu'une boutique en ligne semble lire dans vos pensées avec des suggestions de produits parfaites, remerciez les structures de données comme les tables de hachage et les arbres. Elles analysent vos habitudes d'achat, vos préférences et votre historique, utilisant ces données pour adapter des recommandations qui semblent souvent étrangement précises.
Organisation du système de fichiers :
La capacité de votre ordinateur à stocker et à récupérer des fichiers rapidement est due aux structures de données. Les arbres aident à organiser les répertoires, rendant la navigation dans les fichiers un jeu d'enfant. Pendant ce temps, des méthodes comme les listes chaînées et les bitmaps gardent une trace de l'espace de stockage, assurant une gestion efficace des fichiers.
Indexation des moteurs de recherche :
La vitesse à laquelle les moteurs de recherche comme Google fournissent des résultats pertinents est due aux structures de données. Des index inversés relient les mots-clés aux pages Web qui les contiennent, tandis que des arbres et des tables de hachage stockent ces informations pour une récupération rapide. Ce n'est pas seulement chercher – c'est trouver des aiguilles dans des bottes de foin numériques à la vitesse de la lumière.
16. Boîte à outils essentielle pour apprendre les structures de données
Naviguer dans le monde des structures de données peut être intimidant, mais les bons outils et ressources peuvent transformer ce voyage en une expérience enrichissante.
Que vous débutiez ou que vous cherchiez à approfondir votre expertise, les ressources sélectionnées suivantes sont vos alliés pour maîtriser l'art des structures de données.
- freeCodeCamp : Une communauté open-source où vous pouvez apprendre à coder gratuitement. Elle propose des défis de codage interactifs et des projets, ainsi que des articles et des vidéos pour renforcer vos connaissances en algorithmes et structures de données. Bingo !
- "Introduction to Algorithms" par Cormen, Leiserson, Rivest et Stein : Ce livre séminal est une mine d'or de sagesse algorithmique, offrant une plongée profonde dans les principes et techniques des structures de données.
- "Data Structures and Algorithms: Annotated Reference with Examples" par Granville Barnett et Luca Del Tongo : Un guide pratique qui démystifie les structures de données avec des explications claires et des exemples concrets, parfait pour les autodidactes.
- Coursera : Une plateforme proposant des cours en ligne de haut niveau provenant d'universités renommées, offrant des parcours d'apprentissage structurés et des devoirs pratiques pour consolider votre compréhension des structures de données et des algorithmes.
- VisuAlgo : Donnant vie aux structures de données grâce à des visualisations animées, cet outil simplifie les concepts complexes, les rendant plus accessibles et compréhensibles.
- Data Structure Visualizations : Une plateforme qui propose des représentations visuelles interactives, vous permettant d'explorer et de comprendre la mécanique des structures de données courantes.
- LeetCode : Un vaste répertoire de défis de codage, incluant des problèmes spécifiques aux structures de données, pour affiner vos compétences en codage dans un contexte réel.
- HackerRank : Avec son large éventail de défis, cette plateforme est une excellente arène pour appliquer et perfectionner vos compétences en implémentation de structures de données.
- Stack Overflow : Puisez dans la sagesse collective d'une vaste communauté de programmeurs, une ressource précieuse pour le dépannage et pour obtenir des conseils de développeurs chevronnés.
- Reddit : Découvrez des communautés de programmation où les discussions sur les structures de données prospèrent, offrant des opportunités de groupes d'étude et des recommandations de ressources.
Ces ressources sont plus que de simples aides à l'apprentissage – elles sont des portes d'entrée vers une compréhension plus profonde et une application pratique des structures de données. Rappelez-vous, la meilleure approche de l'apprentissage est celle qui s'aligne sur votre style et votre rythme personnels. Utilisez ces outils pour élever vos connaissances en structures de données vers de nouveaux sommets.
17. Conclusion et étapes suivantes
Armé d'une compréhension complète des structures de données, vous êtes maintenant prêt à exploiter tout leur potentiel. Voici les points clés à retenir et les étapes concrètes pour guider la suite de votre voyage :
Pratiquez et expérimentez
Appliquez vos connaissances en implémentant diverses structures de données dans différents langages de programmation. Cette approche pratique consolide votre compréhension et améliore vos compétences en résolution de problèmes.
Explorez les structures avancées :
Aventurez-vous au-delà des bases vers des structures de données plus complexes comme les arbres, les graphes et les tables de hachage. Comprendre leurs nuances boostera considérablement votre capacité à relever des défis de programmation sophistiqués.
Plongez au cœur des algorithmes :
Associez vos connaissances des structures de données à l'étude des algorithmes. Familiarisez-vous avec les techniques de tri, de recherche et de parcours de graphes pour optimiser votre code et résoudre efficacement des problèmes informatiques complexes.
Restez informé et engagé :
Tenez-vous au courant du paysage en constante évolution du génie logiciel. Suivez les blogs de l'industrie, assistez à des conférences tech et engagez-vous dans des communautés de programmation pour rester à la pointe.
Collaborez et partagez :
Joignez vos forces à celles de vos pairs dans les communautés de développement. Travailler ensemble sur des projets de codage offre de nouvelles perspectives et aiguise vos compétences. Contribuer à des projets open-source est également un excellent moyen de redonner et de cimenter votre expertise.
Valorisez vos compétences :
Construisez un portfolio qui met en avant votre maîtrise de l'utilisation des structures de données pour résoudre des problèmes concrets. Cette présentation tangible de vos compétences est inestimable pour impressionner des employeurs ou des clients potentiels.
Embrassez le voyage vers la maîtrise des structures de données. C'est un chemin qui mène à un codage optimisé, à une résolution de problèmes efficace et à une présence remarquée dans le monde du génie logiciel. Continuez à apprendre, à expérimenter et à partager vos connaissances, et regardez les portes s'ouvrir sur de nouvelles opportunités et avancées dans votre carrière.
18. Conclusion
En résumé, apprendre à utiliser les structures de données est une pierre angulaire pour tout ingénieur logiciel en herbe. En comprenant ces structures, vous pouvez améliorer les performances de votre code, garantir l'évolutivité et construire des applications robustes.
Des tableaux fondamentaux et listes chaînées aux arbres et graphes complexes, chaque structure offre des avantages et des applications uniques.
Continuez votre exploration en approfondissant les algorithmes et leurs implémentations pratiques. Restez curieux, pratiquez avec diligence et rejoignez notre communauté de professionnels engagés vers l'excellence en génie logiciel. Nous offrons une multitude de ressources, de cours et d'opportunités de réseautage pour soutenir votre croissance et votre succès dans ce domaine dynamique.
Ressources
Si vous souhaitez maîtriser les structures de données, consultez le Data Structures Mastery Bootcamp de LunarTech.AI. C'est parfait pour ceux qui s'intéressent à l'IA et au machine learning, en se concentrant sur l'utilisation efficace des structures de données dans le codage. Ce programme complet couvre les structures de données essentielles, les algorithmes et la programmation Python, et inclut un mentorat et un soutien à la carrière.
De plus, pour plus de pratique sur les structures de données, explorez ces ressources sur notre site Web :
- Java Data Structures Mastery - Ace the Coding Interview : Un eBook gratuit pour perfectionner vos compétences en Java, axé sur les structures de données pour améliorer vos compétences en entretien et professionnelles.
- Foundations of Java Data Structures - Your Coding Catalyst : Un autre eBook gratuit, plongeant dans les essentiels de Java, la programmation orientée objet et les applications d'IA.
Visitez notre site Web pour ces ressources et plus d'informations sur le bootcamp.
Connectez-vous avec moi :
- Suivez-moi sur LinkedIn pour une multitude de ressources gratuites en CS, ML et IA
- Visitez mon site personnel
- Abonnez-vous à ma Newsletter The Data Science and AI
À propos de l'auteur
Ici Vahe Aslanyan, au carrefour de l'informatique, de la science des données et de l'IA. Visitez vaheaslanyan.com pour voir un portfolio qui témoigne de précision et de progrès. Mon expérience comble le fossé entre le développement full-stack et l'optimisation de produits d'IA, portée par la résolution de problèmes de manière innovante.
Avec un parcours incluant le lancement d'un bootcamp de science des données de premier plan et la collaboration avec les meilleurs spécialistes de l'industrie, mon objectif reste d'élever l'éducation technologique aux standards universels.
Alors que nous terminons ce « Manuel des structures de données », je vous exprime ma gratitude pour votre temps. Ce voyage consistant à distiller des années de connaissances professionnelles et académiques dans ce manuel a été une entreprise enrichissante. Merci de m'avoir rejoint dans cette quête, et j'ai hâte de voir votre croissance dans la sphère technologique.