


Article original : System Design Interview Question Handbook – Concepts You Should Know
Vous avez peut-être entendu les termes "Architecture" ou "Conception de systèmes". Ces termes reviennent souvent lors des entretiens d'embauche pour les développeurs – surtout dans les grandes entreprises technologiques.
J'ai écrit ce guide approfondi lors de ma préparation pour mes entretiens d'ingénierie logicielle chez FAANG. Il couvre les concepts essentiels de la conception de systèmes logiciels dont vous avez besoin pour raisonner sur les systèmes distribués, et il m'a aidé à entrer chez Google en tant qu'ingénieur, après plus de 15 ans en tant qu'avocat d'entreprise.
Ce n'est pas un traitement exhaustif, car la conception de systèmes est un sujet vaste. Mais si vous êtes un développeur junior ou de niveau intermédiaire, cela devrait vous donner une base solide.
À partir de là, vous pouvez approfondir avec d'autres ressources. J'ai listé certaines de mes ressources préférées tout en bas de cet article.
J'ai divisé ce guide en sections par sujet et je vous recommande de le mettre en favoris. J'ai trouvé que l'apprentissage espacé et la répétition sont des outils incroyablement précieux pour apprendre et retenir des informations. Et j'ai conçu ce guide pour être divisé en morceaux faciles à utiliser pour la répétition espacée.
Commençons !
Section 1 : Réseaux et Protocoles
"Protocoles" est un terme sophistiqué qui a une signification en anglais totalement indépendante de l'informatique. Il signifie un système de règles et de réglementations qui régissent quelque chose. Une sorte de "procédure officielle" ou de "manière officielle dont quelque chose doit être fait".
Pour que les personnes se connectent à des machines et à du code qui communiquent entre eux, elles ont besoin d'un réseau sur lequel une telle communication peut avoir lieu. Mais la communication a également besoin de certaines règles, de structure et de procédures convenues.
Ainsi, les protocoles réseau sont des protocoles qui régissent la manière dont les machines et les logiciels communiquent sur un réseau donné. Un exemple de réseau est notre bien-aimé World Wide Web.
Vous avez peut-être entendu parler des protocoles réseau les plus courants de l'ère Internet - des choses comme HTTP, TCP/IP, etc. Décomposons-les en bases.
IP - Protocole Internet
Pensez à cela comme la couche fondamentale des protocoles. C'est le protocole de base qui nous instruit sur la manière dont presque toutes les communications à travers les réseaux Internet doivent être implémentées.
Les messages sur IP sont souvent communiqués en "paquets", qui sont de petits ensembles d'informations (2^16 octets). Chaque paquet a une structure essentielle composée de deux composants : l'en-tête et les données.
L'en-tête contient des "méta" données sur le paquet et ses données. Ces métadonnées incluent des informations telles que l'adresse IP de la source (d'où provient le paquet) et l'adresse IP de destination (destination du paquet). Clairement, cela est fondamental pour pouvoir envoyer des informations d'un point à un autre - vous avez besoin des adresses "de" et "à".
Et une adresse IP est une étiquette numérique attribuée à chaque appareil connecté à un réseau informatique qui utilise le protocole Internet pour la communication. Il existe des adresses IP publiques et privées, et il existe actuellement deux versions. La nouvelle version s'appelle IPv6 et est de plus en plus adoptée car IPv4 manque d'adresses numériques.
Les autres protocoles que nous allons considérer dans cet article sont construits sur IP, tout comme votre langage de programmation préféré a des bibliothèques et des frameworks construits sur lui.
TCP - Protocole de contrôle de transmission
TCP est un utilitaire construit sur IP. Comme vous le savez peut-être en lisant mes articles, je crois fermement que vous devez comprendre pourquoi quelque chose a été inventé afin de vraiment comprendre ce qu'il fait.
TCP a été créé pour résoudre un problème avec IP. Les données sur IP sont généralement envoyées en plusieurs paquets car chaque paquet est assez petit (2^16 octets). Plusieurs paquets peuvent entraîner (A) des paquets perdus ou abandonnés et (B) des paquets désordonnés, corrompant ainsi les données transmises. TCP résout ces deux problèmes en garantissant la transmission des paquets de manière ordonnée.
Étant construit sur IP, le paquet a un en-tête appelé l'en-tête TCP en plus de l'en-tête IP. Cet en-tête TCP contient des informations sur l'ordre des paquets, le nombre de paquets, etc. Cela garantit que les données sont reçues de manière fiable à l'autre extrémité. Il est généralement appelé TCP/IP car il est construit sur IP.
TCP doit établir une connexion entre la source et la destination avant de transmettre les paquets, et il le fait via un "handshake". Cette connexion elle-même est établie en utilisant des paquets où la source informe la destination qu'elle souhaite ouvrir une connexion, et la destination dit OK, puis une connexion est ouverte.
En effet, c'est ce qui se passe lorsqu'un serveur "écoute" à un port - juste avant de commencer à écouter, il y a un handshake, puis la connexion est ouverte (l'écoute commence). De même, l'un envoie à l'autre un message indiquant qu'il est sur le point de fermer la connexion, et cela met fin à la connexion.
HTTP - Protocole de transfert hypertexte
HTTP est un protocole qui est une abstraction construite sur TCP/IP. Il introduit un motif très important appelé le motif requête-réponse, spécifiquement pour les interactions client-serveur.
Un client est simplement une machine ou un système qui demande des informations, et un serveur est la machine ou le système qui répond avec des informations. Un navigateur est un client, et un serveur web est un serveur. Lorsqu'un serveur demande des données à un autre serveur, alors le premier serveur est également un client, et le second serveur est le serveur (je sais, des tautologies).
Ainsi, ce cycle requête-réponse a ses propres règles sous HTTP et cela standardise la manière dont les informations sont transmises sur Internet.
À ce niveau d'abstraction, nous n'avons généralement pas besoin de nous soucier trop de IP et TCP. Cependant, dans HTTP, les requêtes et les réponses ont également des en-têtes et des corps, et ceux-ci contiennent des données qui peuvent être définies par le développeur.
Les requêtes et réponses HTTP peuvent être considérées comme des messages avec des paires clé-valeur, très similaires aux objets en JavaScript et aux dictionnaires en Python, mais pas identiques.
Ci-dessous se trouve une illustration du contenu et des paires clé-valeur dans les messages de requête et de réponse HTTP.
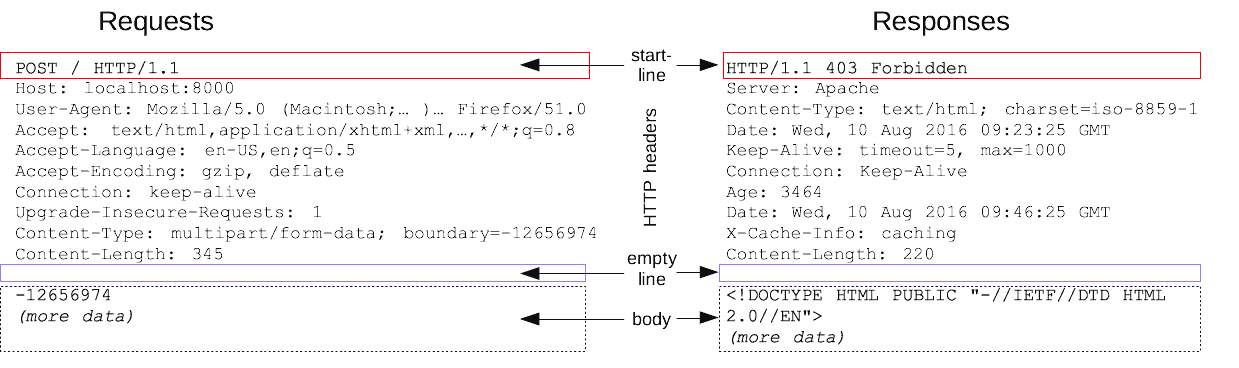
source : https://developer.mozilla.org/en-US/docs/Web/HTTP/Messages
HTTP vient également avec certains "verbes" ou "méthodes" qui sont des commandes qui vous donnent une idée du type d'opération qui est destinée à être effectuée. Par exemple, les méthodes HTTP courantes sont "GET", "POST", "PUT", "DELETE" et "PATCH", mais il y en a d'autres. Dans l'image ci-dessus, recherchez le verbe HTTP dans la ligne de début.
Section 2 : Stockage, Latence et Débit
Stockage
Le stockage consiste à conserver des informations. Toute application, système ou service que vous programmez aura besoin de stocker et de récupérer des données, et ce sont les deux objectifs fondamentaux du stockage.
Mais il ne s'agit pas seulement de stocker des données – il s'agit également de les récupérer. Nous utilisons une base de données pour y parvenir. Une base de données est une couche logicielle qui nous aide à stocker et à récupérer des données.
Ces deux types principaux d'opérations, le stockage et la récupération, sont également diversement appelés 'set, get', 'store, fetch', 'write, read' et ainsi de suite. Pour interagir avec le stockage, vous devrez passer par la base de données, qui agit comme un intermédiaire pour vous permettre de mener à bien ces opérations fondamentales.
Le mot "stockage" peut parfois nous tromper en nous faisant penser à des termes physiques. Si je "stocke" mon vélo dans le hangar, je peux m'attendre à ce qu'il soit là lorsque j'ouvrirai à nouveau le hangar.
Mais cela n'arrive pas toujours dans le monde informatique. Le stockage peut être de deux types : le stockage "Mémoire" et le stockage "Disque".
De ces deux types, le stockage sur disque tend à être plus robuste et "permanent" (pas vraiment permanent, donc nous utilisons souvent le terme "stockage persistant"). Le stockage sur disque est un stockage persistant. Cela signifie que lorsque vous enregistrez quelque chose sur le disque et que vous éteignez l'alimentation, ou redémarrez votre serveur, ces données "persisteront". Elles ne seront pas perdues.
Cependant, si vous laissez des données en "Mémoire", elles seront généralement effacées lorsque vous éteignez ou redémarrez, ou perdez autrement l'alimentation.
L'ordinateur que vous utilisez tous les jours possède ces deux types de stockage. Votre disque dur est un stockage "persistant" sur disque, et votre RAM est un stockage transitoire en mémoire.
Sur les serveurs, si les données que vous suivez ne sont utiles que pendant une session de ce serveur, il est logique de les conserver en mémoire. Cela est beaucoup plus rapide et moins coûteux que d'écrire des choses dans une base de données persistante.
Par exemple, une seule session peut signifier lorsqu'un utilisateur est connecté et utilise votre site. Après s'être déconnecté, vous n'avez peut-être plus besoin de conserver les morceaux de données que vous avez collectés pendant la session.
Mais tout ce que vous souhaitez conserver (comme l'historique du panier d'achat) vous le mettrez dans un stockage persistant sur disque. De cette façon, vous pouvez accéder à ces données la prochaine fois que l'utilisateur se connecte, et il aura une expérience fluide.
D'accord, cela semble assez simple et basique, et c'est fait exprès. C'est une initiation. Le stockage peut devenir très complexe. Si vous regardez la gamme de produits et de solutions de stockage, votre tête va tourner.
C'est parce que différents cas d'utilisation nécessitent différents types de stockage. La clé pour choisir les bons types de stockage pour votre système dépend de nombreux facteurs et des besoins de votre application, et de la manière dont les utilisateurs interagissent avec elle. D'autres facteurs incluent :
la forme (structure) de vos données, ou
le type de disponibilité dont elles ont besoin (quel niveau de temps d'arrêt est acceptable pour votre stockage), ou
la scalabilité (à quelle vitesse vous devez lire et écrire des données, et ces lectures et écritures se feront-elles de manière concurrente (simultanée) ou séquentielle) etc., ou
la cohérence - si vous vous protégez contre les temps d'arrêt en utilisant un stockage distribué, alors à quel point les données sont-elles cohérentes entre vos différents stockages ?
Ces questions et les conclusions qui en découlent vous obligent à considérer soigneusement vos compromis. La cohérence est-elle plus importante que la vitesse ? Avez-vous besoin que la base de données traite des millions d'opérations par minute ou seulement pour des mises à jour nocturnes ? Je vais aborder ces concepts dans les sections suivantes, alors ne vous inquiétez pas si vous n'avez aucune idée de ce qu'ils sont.
Latence
"Latence" et "Débit" sont des termes que vous allez entendre souvent à mesure que vous devenez plus expérimenté dans la conception de systèmes pour soutenir le front-end de votre application. Ils sont très fondamentaux pour l'expérience et la performance de votre application et du système dans son ensemble. Il y a souvent une tendance à utiliser ces termes dans un sens plus large que prévu, ou hors contexte, mais corrigeons cela.
La latence est simplement la mesure d'une durée. Quelle durée ? La durée pour qu'une action accomplisse quelque chose ou produise un résultat. Par exemple : pour que des données se déplacent d'un endroit du système à un autre. Vous pouvez penser à cela comme un décalage, ou simplement le temps nécessaire pour accomplir une opération.
La latence la plus couramment comprise est la requête réseau "aller-retour" - combien de temps faut-il pour que votre site web front-end (client) envoie une requête à votre serveur et obtienne une réponse du serveur.
Lorsque vous chargez un site, vous voulez que cela soit aussi rapide et fluide que possible. En d'autres termes, vous voulez une latence faible. Des recherches rapides signifient une faible latence. Ainsi, trouver une valeur dans un tableau d'éléments est plus lent (latence plus élevée, car vous devez itérer sur chaque élément du tableau pour trouver celui que vous voulez) que de trouver une valeur dans une table de hachage (latence plus faible, car vous recherchez simplement les données en temps "constant", en utilisant la clé. Aucune itération nécessaire.).
De même, la lecture en mémoire est beaucoup plus rapide que la lecture sur un disque (lire plus ici). Mais les deux ont une latence, et vos besoins détermineront quel type de stockage vous choisissez pour quelles données.
En ce sens, la latence est l'inverse de la vitesse. Vous voulez des vitesses plus élevées et une latence plus faible. La vitesse (surtout sur les appels réseau comme via HTTP) est également déterminée par la distance. Ainsi, la latence de Londres à une autre ville, sera impactée par la distance depuis Londres.
Comme vous pouvez l'imaginer, vous voulez concevoir un système pour éviter de pinguer des serveurs distants, mais alors stocker des choses en mémoire peut ne pas être réalisable pour votre système. Ce sont les compromis qui rendent la conception de systèmes complexe, stimulante et extrêmement intéressante !
Par exemple, les sites web qui affichent des articles de presse peuvent préférer le temps de fonctionnement et la disponibilité à la vitesse de chargement, tandis que les jeux en ligne multijoueurs peuvent nécessiter une disponibilité et une latence extrêmement faible. Ces exigences détermineront la conception et l'investissement dans l'infrastructure pour soutenir les besoins spéciaux du système.
Débit
Cela peut être compris comme la capacité maximale d'une machine ou d'un système. Il est souvent utilisé dans les usines pour calculer combien de travail une chaîne de montage peut effectuer en une heure ou un jour, ou une autre unité de mesure du temps.
Par exemple, une chaîne de montage peut assembler 20 voitures par heure, ce qui est son débit. En informatique, ce serait la quantité de données qui peut être transmise dans une unité de temps. Ainsi, une connexion Internet de 512 Mbps est une mesure de débit - 512 Mb (mégaoctets) par seconde.
Imaginez maintenant le serveur web de freeCodeCamp. S'il reçoit 1 million de requêtes par seconde et ne peut en traiter que 800 000, alors son débit est de 800 000 par seconde. Vous pourriez finir par mesurer le débit en termes de bits plutôt que de requêtes, donc ce serait N bits par seconde.
Dans cet exemple, il y a un goulot d'étranglement car le serveur ne peut pas gérer plus de N bits par seconde, mais les requêtes sont plus nombreuses. Un goulot d'étranglement est donc la contrainte d'un système. Un système n'est aussi rapide que son goulot d'étranglement le plus lent.
Si un serveur peut gérer 100 bits par seconde, et un autre peut en gérer 120 bits par seconde et un troisième seulement 50, alors l'ensemble du système fonctionnera à 50 bps car c'est la contrainte - elle retient la vitesse des autres serveurs dans un système donné.
Ainsi, augmenter le débit ailleurs que dans le goulot d'étranglement peut être une perte - vous pouvez simplement augmenter le débit au goulot d'étranglement le plus lent en premier.
Vous pouvez augmenter le débit en achetant plus de matériel (mise à l'échelle horizontale) ou en augmentant la capacité et la performance de votre matériel existant (mise à l'échelle verticale) ou de quelques autres manières.
Augmenter le débit peut parfois être une solution à court terme, et donc un bon concepteur de systèmes réfléchira aux meilleures façons de mettre à l'échelle le débit d'un système donné, y compris en divisant les requêtes (ou toute autre forme de "charge"), et en les distribuant sur d'autres ressources, etc. Le point clé à retenir est ce qu'est le débit, ce qu'est une contrainte ou un goulot d'étranglement, et comment cela impacte un système.
Corriger la latence et le débit ne sont pas des solutions isolées et universelles en elles-mêmes, ni ne sont-elles corrélées l'une à l'autre. Elles ont des impacts et des considérations à travers le système, il est donc important de comprendre le système dans son ensemble, et la nature des demandes qui seront placées sur le système au fil du temps.
Section 3 : Disponibilité du système
Les ingénieurs logiciels visent à construire des systèmes qui sont fiables. Un système fiable est celui qui satisfait constamment les besoins d'un utilisateur, chaque fois que cet utilisateur cherche à avoir ce besoin satisfait. Un composant clé de cette fiabilité est la disponibilité.
Il est utile de penser à la disponibilité comme à la résilience d'un système. Si un système est suffisamment robuste pour gérer les défaillances du réseau, de la base de données, des serveurs, etc., alors il peut généralement être considéré comme un système tolérant aux pannes - ce qui en fait un système disponible.
Bien sûr, un système est la somme de ses parties à bien des égards, et chaque partie doit être hautement disponible si la disponibilité est pertinente pour l'expérience utilisateur finale du site ou de l'application.
Quantification de la disponibilité
Pour quantifier la disponibilité d'un système, nous calculons le pourcentage de temps pendant lequel les fonctionnalités et opérations principales du système sont disponibles (le temps de fonctionnement) dans une fenêtre de temps donnée.
Les systèmes les plus critiques pour l'entreprise devraient avoir une disponibilité quasi parfaite. Les systèmes qui supportent des demandes et des charges très variables avec des pics et des creux marqués peuvent se permettre une disponibilité légèrement inférieure pendant les périodes creuses.
Tout dépend de l'utilisation et de la nature du système. Mais en général, même les choses qui ont des demandes faibles mais constantes ou une garantie implicite que le système est "à la demande" devraient avoir une haute disponibilité.
Pensez à un site où vous sauvegardez vos photos. Vous n'avez pas toujours besoin d'accéder et de récupérer des données depuis celui-ci - il est principalement là pour que vous y stockiez des choses. Vous vous attendriez toujours à ce qu'il soit toujours disponible à chaque fois que vous vous connectez pour télécharger même une seule photo.
Un autre type de disponibilité peut être compris dans le contexte des grandes journées de shopping en ligne comme le Black Friday ou les soldes du Cyber Monday. Ces jours-là, la demande va exploser et des millions de personnes vont essayer d'accéder aux offres simultanément. Cela nécessiterait une conception de système extrêmement fiable et hautement disponible pour supporter ces charges.
Une raison commerciale pour une haute disponibilité est simplement qu'un temps d'arrêt sur le site entraînera une perte d'argent pour le site. De plus, cela pourrait être très mauvais pour la réputation, par exemple, lorsque le service est un service utilisé par d'autres entreprises pour offrir des services. Si AWS S3 tombe en panne, de nombreuses entreprises en souffriront, y compris Netflix, et ce n'est pas bon.
Ainsi, les temps de fonctionnement sont extrêmement importants pour le succès. Il est utile de se rappeler que les chiffres de disponibilité commerciale sont calculés sur la base de la disponibilité annuelle, donc un temps d'arrêt de 0,1 % (c'est-à-dire une disponibilité de 99,9 %) représente 8,77 heures par an !
Par conséquent, les temps de fonctionnement sont extrêmement élevés. Il est courant de voir des choses comme 99,99 % de temps de fonctionnement (52,6 minutes de temps d'arrêt par an). C'est pourquoi il est maintenant courant de se référer aux temps de fonctionnement en termes de "nines" - le nombre de nines dans l'assurance de temps de fonctionnement.
Dans le monde d'aujourd'hui, cela est inacceptable pour les services à grande échelle ou critiques. C'est pourquoi ces jours-ci "five nines" est considéré comme le standard de disponibilité idéal car cela se traduit par un peu plus de 5 minutes de temps d'arrêt par an.
SLAs
Afin de rendre les services en ligne compétitifs et de répondre aux attentes du marché, les fournisseurs de services en ligne offrent généralement des accords/niveaux de service garantis. Il s'agit d'un ensemble de métriques de niveau de service garanties. 99,999 % de temps de fonctionnement est une telle métrique et est souvent offerte dans le cadre des abonnements premium.
Dans le cas des fournisseurs de bases de données et de services cloud, cela peut être offert même sur les niveaux d'essai ou gratuits si l'utilisation principale d'un client pour ce produit justifie l'attente d'une telle métrique.
Dans de nombreux cas, le fait de ne pas respecter le SLA donnera au client le droit à des crédits ou à une autre forme de compensation pour l'échec du fournisseur à respecter cette assurance. Voici, à titre d'exemple, le SLA de Google pour l'API Maps.
Les SLA sont donc une partie critique de la considération commerciale et technique globale lors de la conception d'un système. Il est particulièrement important de considérer si la disponibilité est en fait une exigence clé pour une partie d'un système, et quelles parties nécessitent une haute disponibilité.
Conception de HA
Lors de la conception d'un système hautement disponible (HA), vous devez réduire ou éliminer les "points de défaillance uniques". Un point de défaillance unique est un élément du système qui est le seul élément pouvant provoquer cette perte indésirable de disponibilité.
Vous éliminez les points de défaillance uniques en concevant de la 'redondance' dans le système. La redondance consiste essentiellement à créer 1 ou plusieurs alternatives (c'est-à-dire des sauvegardes) à l'élément qui est critique pour la haute disponibilité.
Ainsi, si votre application nécessite que les utilisateurs soient authentifiés pour l'utiliser, et qu'il n'y a qu'un seul service d'authentification et un seul backend, et que celui-ci tombe en panne, alors, parce que c'est le point de défaillance unique, votre système n'est plus utilisable. En ayant deux services ou plus qui peuvent gérer l'authentification, vous avez ajouté de la redondance et éliminé (ou réduit) les points de défaillance uniques.
Par conséquent, vous devez comprendre et décomposer votre système en toutes ses parties. Cartographiez celles qui sont susceptibles de provoquer des points de défaillance uniques, celles qui ne tolèrent pas une telle défaillance, et celles qui peuvent les tolérer. Parce que l'ingénierie HA nécessite des compromis et certains de ces compromis peuvent être coûteux en termes de temps, d'argent et de ressources.
Section 4 : Mise en cache
La mise en cache ! Il s'agit d'une technique très fondamentale et facile à comprendre pour accélérer les performances d'un système. Ainsi, la mise en cache aide à réduire la "latence" dans un système.
Dans notre vie quotidienne, nous utilisons la mise en cache comme une question de bon sens (la plupart du temps...). Si nous vivons à côté d'un supermarché, nous voulons toujours acheter et stocker quelques produits de base dans notre réfrigérateur et notre placard à nourriture. C'est de la mise en cache. Nous pourrions toujours sortir, aller chez le voisin et acheter ces choses chaque fois que nous voulons de la nourriture – mais si c'est dans le garde-manger ou le réfrigérateur, nous réduisons le temps qu'il faut pour préparer notre nourriture. C'est de la mise en cache.
Scénarios courants pour la mise en cache
De même, en termes de logiciels, si nous finissons par dépendre de certaines données souvent, nous pouvons vouloir mettre en cache ces données afin que notre application fonctionne plus rapidement.
Cela est souvent vrai lorsqu'il est plus rapide de récupérer des données de la mémoire plutôt que du disque en raison de la latence dans les requêtes réseau. En fait, de nombreux sites web sont mis en cache (surtout si le contenu ne change pas fréquemment) dans des CDN afin qu'ils puissent être servis à l'utilisateur final beaucoup plus rapidement, et cela réduit la charge sur les serveurs backend.
Un autre contexte dans lequel la mise en cache aide pourrait être lorsque votre backend doit effectuer un travail intensif en calcul et chronophage. La mise en cache des résultats précédents qui convertit votre temps de recherche d'un temps linéaire O(N) à un temps constant O(1) pourrait être très avantageux.
De même, si votre serveur doit effectuer plusieurs requêtes réseau et appels API afin de composer les données qui sont renvoyées au demandeur, alors la mise en cache des données pourrait réduire le nombre d'appels réseau, et ainsi la latence.
Si votre système a un client (front end), un serveur et des bases de données (backend), alors la mise en cache peut être insérée sur le client (par exemple, stockage du navigateur), entre le client et le serveur (par exemple, CDN), ou sur le serveur lui-même. Cela réduirait les appels réseau vers la base de données.
Ainsi, la mise en cache peut se produire à plusieurs points ou niveaux dans le système, y compris au niveau matériel (CPU).
Gestion des données obsolètes
Vous avez peut-être remarqué que les exemples ci-dessus sont implicitement pratiques pour les opérations de "lecture". Les opérations d'écriture ne sont pas si différentes, en principes principaux, avec les considérations supplémentaires suivantes :
les opérations d'écriture nécessitent de maintenir la synchronisation entre le cache et votre base de données
cela peut augmenter la complexité car il y a plus d'opérations à effectuer, et de nouvelles considérations autour de la gestion des données non synchronisées ou "obsolètes" doivent être soigneusement analysées
de nouveaux principes de conception peuvent devoir être mis en œuvre pour gérer cette synchronisation - doit-elle être effectuée de manière synchrone ou asynchrone ? Si asynchrone, alors à quels intervalles ? D'où les données sont-elles servies en attendant ? À quelle fréquence le cache doit-il être rafraîchi, etc...
l'"éviction" des données ou le renouvellement et le rafraîchissement des données, pour maintenir les données en cache fraîches et à jour. Cela inclut des techniques comme LIFO, FIFO, LRU et LFU.
Alors, terminons par quelques conclusions de haut niveau et non contraignantes. En général, la mise en cache fonctionne mieux lorsqu'elle est utilisée pour stocker des données statiques ou rarement modifiées, et lorsque les sources de changement sont susceptibles d'être des opérations uniques plutôt que des opérations générées par l'utilisateur.
Là où la cohérence et la fraîcheur des données sont critiques, la mise en cache peut ne pas être une solution optimale, sauf s'il y a un autre élément dans le système qui rafraîchit efficacement les caches à des intervalles qui n'impactent pas négativement le but et l'expérience utilisateur de l'application.
Section 5 : Proxies
Proxy. Qu'est-ce que c'est ? Beaucoup d'entre nous ont entendu parler des serveurs proxy. Nous avons peut-être vu des options de configuration sur certains de nos logiciels PC ou Mac qui parlent d'ajouter et de configurer des serveurs proxy, ou d'accéder "via un proxy".
Alors, comprenons cette technologie relativement simple, largement utilisée et importante. C'est un mot qui existe dans la langue anglaise complètement indépendamment de l'informatique, alors commençons par cette définition.

Source : https://www.merriam-webster.com/dictionary/proxy
Maintenant, vous pouvez éjecter la plupart de cela de votre esprit, et vous accrocher à un mot clé : "substitut".
En informatique, un proxy est généralement un serveur, et c'est un serveur qui agit comme un intermédiaire entre un client et un autre serveur. C'est littéralement un morceau de code qui se situe entre le client et le serveur. C'est le cœur des proxies.
Au cas où vous auriez besoin d'un rappel, ou ne seriez pas sûr des définitions de client et de serveur, un "client" est un processus (code) ou une machine qui demande des données à un autre processus ou machine (le "serveur"). Le navigateur est un client lorsqu'il demande des données à un serveur backend.
Le serveur sert le client, mais peut également être un client - lorsqu'il récupère des données d'une base de données. Ensuite, la base de données est le serveur, le serveur est le client (de la base de données) et aussi un serveur pour le client front-end (navigateur).

Source : https://teoriadeisegnali.it/appint/html/altro/bgnet/clientserver.html#figure2
Comme vous pouvez le voir ci-dessus, la relation client-serveur est bidirectionnelle. Ainsi, une chose peut être à la fois le client et le serveur. S'il y avait un serveur intermédiaire qui recevait des requêtes, puis les envoyait à un autre service, puis transmettait la réponse qu'il a obtenue de ce service à l'origine du client, ce serait un serveur proxy.
Par la suite, nous ferons référence aux clients en tant que clients, aux serveurs en tant que serveurs et aux proxies en tant que chose entre eux.
Ainsi, lorsqu'un client envoie une requête à un serveur via le proxy, le proxy peut parfois masquer l'identité du client - pour le serveur, l'adresse IP qui apparaît dans la requête peut être celle du proxy et non celle du client d'origine.
Pour ceux d'entre vous qui accèdent à des sites ou téléchargez des choses qui sont autrement restreintes (par exemple, depuis le réseau torrent, ou des sites interdits dans votre pays), vous pouvez reconnaître ce schéma - c'est le principe sur lequel les VPN sont construits.
Avant d'aller plus loin, je veux souligner quelque chose - lorsque le terme proxy est généralement utilisé, il fait référence à un proxy "direct". Un proxy direct est celui où le proxy agit au nom du client (substitut du client) dans l'interaction entre le client et le serveur.
Cela se distingue d'un proxy inverse - où le proxy agit au nom d'un serveur. Sur un diagramme, cela aurait la même apparence - le proxy se situe entre le client et le serveur, et les flux de données sont les mêmes client <-> proxy <-> serveur.
La différence clé est qu'un proxy inverse est conçu pour substituer le serveur. Souvent, les clients ne sauront même pas que la requête réseau a été acheminée via un proxy et que le proxy l'a transmise au serveur prévu (et a fait de même avec la réponse du serveur).
Ainsi, dans un proxy direct, le serveur ne saura pas que la requête du client et sa réponse voyagent via un proxy, et dans un proxy inverse, le client ne saura pas que la requête et la réponse sont acheminées via un proxy.
Les proxies semblent un peu sournois :)
Mais dans la conception de systèmes, surtout pour les systèmes complexes, les proxies sont utiles et les proxies inverses sont particulièrement utiles. Votre proxy inverse peut être délégué à de nombreuses tâches que vous ne voulez pas que votre serveur principal gère - il peut être un gardien, un filtre, un équilibreur de charge et un assistant polyvalent.
Ainsi, les proxies peuvent être utiles mais vous ne savez peut-être pas pourquoi. Encore une fois, si vous avez lu mes autres articles, vous sauriez que je crois fermement que vous ne pouvez comprendre les choses correctement que lorsque vous savez pourquoi elles existent - savoir ce qu'elles font n'est pas suffisant.
Section 6 : Équilibrage de charge
Si vous pensez aux deux mots, charge et équilibre, vous allez commencer à avoir une intuition de ce que cela fait dans le monde de l'informatique. Lorsqu'un serveur reçoit simultanément beaucoup de requêtes, il peut ralentir (le débit diminue, la latence augmente). Après un certain point, il peut même échouer (pas de disponibilité).
Vous pouvez donner plus de puissance au serveur (mise à l'échelle verticale) ou vous pouvez ajouter plus de serveurs (mise à l'échelle horizontale). Mais maintenant, vous devez déterminer comment les requêtes entrantes sont distribuées aux différents serveurs - quelles requêtes sont acheminées vers quels serveurs et comment s'assurer qu'ils ne sont pas surchargés ? En d'autres termes, comment équilibrer et allouer la charge des requêtes ?
Entrez les équilibreurs de charge. Puisque cet article est une introduction aux principes et concepts, ils sont, par nécessité, des explications très simplifiées. Le travail d'un équilibreur de charge est de se situer entre le client et le serveur (mais il peut être inséré à d'autres endroits) et de déterminer comment distribuer les charges de requêtes entrantes sur plusieurs serveurs, de sorte que l'expérience de l'utilisateur final (client) soit constamment rapide, fluide et fiable.
Ainsi, les équilibreurs de charge sont comme des gestionnaires de trafic qui dirigent le trafic. Et ils le font pour maintenir la disponibilité et le débit.
Lorsqu'on comprend où un équilibreur de charge est inséré dans l'architecture du système, on peut voir que les équilibreurs de charge peuvent être considérés comme des proxies inverses. Mais un équilibreur de charge peut être inséré à d'autres endroits également - entre d'autres échanges - par exemple, entre votre serveur et votre base de données.
L'acte d'équilibrage - Stratégies de sélection de serveur
Alors, comment l'équilibreur de charge décide-t-il comment router et allouer le trafic des requêtes ? Pour commencer, chaque fois que vous ajoutez un serveur, vous devez informer votre équilibreur de charge qu'il y a un candidat de plus auquel router le trafic.
Si vous retirez un serveur, l'équilibreur de charge doit également le savoir. La configuration garantit que l'équilibreur de charge sait combien de serveurs il a dans sa liste de référence et lesquels sont disponibles. Il est même possible pour l'équilibreur de charge d'être informé des niveaux de charge, de l'état, de la disponibilité, de la tâche actuelle, etc., de chaque serveur.
Une fois que l'équilibreur de charge est configuré pour savoir vers quels serveurs il peut rediriger, nous devons déterminer la meilleure stratégie de routage pour garantir une distribution appropriée parmi les serveurs disponibles.
Une approche naïve à cela est que l'équilibreur de charge choisisse simplement un serveur au hasard et dirige chaque requête entrante de cette manière. Mais comme vous pouvez l'imaginer, le hasard peut causer des problèmes et des allocations "déséquilibrées" où certains serveurs sont plus chargés que d'autres, ce qui pourrait affecter négativement les performances de l'ensemble du système.
Round Robin et Round Robin pondéré
Une autre méthode qui peut être intuitivement comprise s'appelle "round robin". C'est la manière dont de nombreux humains traitent les listes qui bouclent. Vous commencez par le premier élément de la liste, descendez en séquence, et lorsque vous avez terminé avec le dernier élément, vous revenez en haut et recommencez à descendre la liste.
L'équilibreur de charge peut faire de même, en bouclant simplement à travers les serveurs disponibles dans une séquence fixe. De cette manière, la charge est assez uniformément répartie sur vos serveurs selon un motif simple à comprendre et prévisible.
Vous pouvez obtenir un peu plus "fancy" avec le round robin en "pondérant" certains services par rapport à d'autres. Dans le round robin normal et standard, chaque serveur est donné un poids égal (disons que tous sont donnés une pondération de 1). Mais lorsque vous pondérez différemment les serveurs, vous pouvez avoir certains serveurs avec une pondération plus faible (disons 0,5, s'ils sont moins puissants), et d'autres peuvent être plus élevés comme 0,7 ou 0,9 ou même 1.
Ensuite, le trafic total sera divisé en proportion de ces poids et alloué en conséquence aux serveurs qui ont une puissance proportionnelle au volume des requêtes.
Sélection de serveur basée sur la charge
Les équilibreurs de charge plus sophistiqués peuvent déterminer la capacité actuelle, les performances et les charges des serveurs dans leur liste de référence et allouer dynamiquement en fonction des charges actuelles et des calculs quant à ceux qui auront le débit le plus élevé, la latence la plus faible, etc. Il le ferait en surveillant les performances de chaque serveur et en décidant lesquels peuvent et ne peuvent pas gérer les nouvelles requêtes.
Sélection basée sur le hachage IP
Vous pouvez configurer votre équilibreur de charge pour hacher l'adresse IP des requêtes entrantes, et utiliser la valeur de hachage pour déterminer vers quel serveur diriger la requête. Si j'avais 5 serveurs disponibles, alors la fonction de hachage serait conçue pour retourner l'une des cinq valeurs de hachage, donc l'un des serveurs est définitivement nommé pour traiter la requête.
Le routage basé sur le hachage IP peut être très utile lorsque vous souhaitez que les requêtes provenant d'un certain pays ou région obtiennent des données d'un serveur qui est le mieux adapté pour répondre aux besoins de cette région, ou lorsque vos serveurs mettent en cache les requêtes afin qu'elles puissent être traitées rapidement.
Dans ce dernier scénario, vous souhaitez vous assurer que la requête est envoyée à un serveur qui a précédemment mis en cache la même requête, car cela améliorera la vitesse et les performances de traitement et de réponse à cette requête.
Si vos serveurs maintiennent chacun des caches indépendants et que votre équilibreur de charge n'envoie pas systématiquement des requêtes identiques au même serveur, vous finirez par avoir des serveurs qui refont un travail qui a déjà été fait dans une requête précédente à un autre serveur, et vous perdez l'optimisation qui accompagne la mise en cache des données.
Sélection basée sur le chemin ou le service
Vous pouvez également faire en sorte que l'équilibreur de charge route les requêtes en fonction de leur "chemin" ou de la fonction ou du service fourni. Par exemple, si vous achetez des fleurs chez un fleuriste en ligne, les requêtes pour charger les "Bouquets en promotion" peuvent être envoyées à un serveur et les paiements par carte de crédit peuvent être envoyés à un autre serveur.
Si seulement un visiteur sur vingt achetait effectivement des fleurs, alors vous pourriez avoir un serveur plus petit traitant les paiements et un plus grand gérant tout le trafic de navigation.
Sac mélangé
Et comme pour toutes les choses, vous pouvez atteindre des niveaux de complexité plus élevés et plus détaillés. Vous pouvez avoir plusieurs équilibreurs de charge qui ont chacun des stratégies de sélection de serveur différentes ! Et si le vôtre est un système très grand et très fréquenté, alors vous pourriez avoir besoin d'équilibreurs de charge pour les équilibreurs de charge...
En fin de compte, vous ajoutez des pièces au système jusqu'à ce que vos performances soient ajustées à vos besoins (vos besoins peuvent sembler plats, ou augmenter légèrement au fil du temps, ou être sujets à des pics !).
Nous avons parlé des VPN (pour les proxies directs) et de l'équilibrage de charge (pour les proxies inverses), mais il y a plus d'exemples ici.
Section 7 : Hachage cohérent
L'un des concepts un peu plus délicats à comprendre est le hachage dans le contexte de l'équilibrage de charge. Il a donc sa propre section.
Pour comprendre cela, veuillez d'abord comprendre comment fonctionne le hachage à un niveau conceptuel. Le TL;DR est que le hachage convertit une entrée en une valeur de taille fixe, souvent une valeur entière (le hachage).
L'un des principes clés pour un bon algorithme ou fonction de hachage est que la fonction doit être déterministe, ce qui est une manière sophistiquée de dire que des entrées identiques généreront des sorties identiques lorsqu'elles sont passées dans la fonction. Donc, déterministe signifie - si je passe la chaîne "Code" (sensible à la casse) et que la fonction génère un hachage de 11002, alors chaque fois que je passe "Code" elle doit générer "11002" comme entier. Et si je passe "code" elle générera un nombre différent (de manière cohérente).
Parfois, la fonction de hachage peut générer le même hachage pour plus d'une entrée - ce n'est pas la fin du monde et il existe des moyens de le gérer. En fait, cela devient plus probable à mesure que la plage d'entrées uniques augmente. Mais lorsque plus d'une entrée génère de manière déterministe la même sortie, cela s'appelle une "collision".
Avec cela bien en tête, appliquons-le au routage et aux requêtes dirigées vers les serveurs. Supposons que vous avez 5 serveurs pour répartir les charges. Une méthode facile à comprendre serait de hacher les requêtes entrantes (peut-être par adresse IP, ou un détail client), puis de générer des hachages pour chaque requête. Ensuite, vous appliquez l'opérateur modulo à ce hachage, où l'opérande de droite est le nombre de serveurs.
Par exemple, voici à quoi pourrait ressembler le pseudo-code de vos équilibreurs de charge :
request#1 => hashes to 34
request#2 => hashes to 23
request#3 => hashes to 30
request#4 => hashes to 14
// You have 5 servers => [Server A, Server B ,Server C ,Server D ,Server E]
// so modulo 5 for each request...
request#1 => hashes to 34 => 34 % 5 = 4 => send this request to servers[4] => Server E
request#2 => hashes to 23 => 23 % 5 = 3 => send this request to servers[3] => Server D
request#3 => hashes to 30 => 30 % 5 = 0 => send this request to servers[0] => Server A
request#4 => hashes to 14 => 14 % 5 = 4 => send this request to servers[4] => Server E
Comme vous pouvez le voir, la fonction de hachage génère une répartition des valeurs possibles, et lorsque l'opérateur modulo est appliqué, il en résulte une plage plus petite de nombres qui correspondent au numéro du serveur.
Vous obtiendrez définitivement différentes requêtes qui correspondent au même serveur, et c'est bien, tant qu'il y a "uniformité" dans l'allocation globale à tous les serveurs.
Ajout de serveurs et gestion des serveurs en panne
Alors - que se passe-t-il si l'un des serveurs auxquels nous envoyons du trafic tombe en panne ? La fonction de hachage (voir l'extrait de pseudo-code ci-dessus) pense toujours qu'il y a 5 serveurs, et l'opérateur mod génère une plage de 0-4. Mais nous n'avons plus que 4 serveurs maintenant que l'un d'eux est en panne, et nous continuons à lui envoyer du trafic. Oups.
Inversement, nous pourrions ajouter un sixième serveur, mais celui-ci ne recevrait jamais de trafic car notre opérateur mod est 5, et il ne générera jamais un nombre qui inclurait le nouveau sixième serveur. Double oups.
// Let's add a 6th server
servers => [Server A, Server B ,Server C ,Server D ,Server E, Server F]
// let's change the modulo operand to 6
request#1 => hashes to 34 => 34 % 6 = 4 => send this request to servers[4] => Server E
request#2 => hashes to 23 => 23 % 6 = 5 => send this request to servers[5] => Server F
request#3 => hashes to 30 => 30 % 6 = 0 => send this request to servers[0] => Server A
request#4 => hashes to 14 => 14 % 6 = 2 => send this request to servers[2] => Server C
Nous notons que le numéro du serveur après l'application du mod change (bien que, dans cet exemple, pas pour request#1 et request#3 - mais c'est juste parce que dans ce cas spécifique, les nombres ont fonctionné de cette manière).
En effet, le résultat est que la moitié des requêtes (cela pourrait être plus dans d'autres exemples !) sont maintenant acheminées vers des serveurs complètement nouveaux, et nous perdons les avantages des données précédemment mises en cache sur les serveurs.
Par exemple, request#4 allait auparavant à Server E, mais va maintenant à Server C. Toutes les données mises en cache relatives à request#4 se trouvant sur Server E ne sont d'aucune utilité puisque la requête va maintenant à Server C. Vous pouvez calculer un problème similaire pour le cas où l'un de vos serveurs tombe en panne, mais la fonction mod continue à lui envoyer des requêtes.
Cela semble mineur dans ce petit système. Mais sur un système à très grande échelle, c'est un résultat médiocre. #SystemDesignFail.
Ainsi, clairement, un système simple de hachage pour l'allocation ne se met pas à l'échelle ou ne gère pas bien les pannes.
Une solution populaire - le hachage cohérent
Malheureusement, c'est la partie où je sens que les descriptions textuelles ne suffiront pas. Le hachage cohérent est mieux compris visuellement. Mais le but de cet article jusqu'à présent est de vous donner une intuition autour du problème, ce qu'il est, pourquoi il survient, et quels pourraient être les inconvénients d'une solution de base. Gardez cela fermement à l'esprit.
Le problème clé avec le hachage naïf, comme nous l'avons discuté, est que lorsque (A) un serveur tombe en panne, le trafic continue d'être acheminé vers lui, et (B) vous ajoutez un nouveau serveur, les allocations peuvent être considérablement modifiées, perdant ainsi les avantages des caches précédents.
Il y a deux choses très importantes à garder à l'esprit lorsque vous approfondissez le hachage cohérent :
Le hachage cohérent ne résout pas les problèmes, surtout le problème B. Mais il réduit beaucoup les problèmes. Au début, vous pourriez vous demander en quoi le hachage cohérent est important, puisque l'inconvénient sous-jacent existe toujours - oui, mais dans une bien moindre mesure, et cela constitue en soi une amélioration précieuse dans les systèmes à très grande échelle.
Le hachage cohérent applique une fonction de hachage aux requêtes entrantes et aux serveurs. Les résultats obtenus tombent donc dans une plage de valeurs continue. Ce détail est très important.
Veuillez garder ces points à l'esprit lorsque vous regardez la vidéo recommandée ci-dessous qui explique le hachage cohérent, sinon ses avantages peuvent ne pas être évidents.
Je recommande vivement cette vidéo car elle intègre ces principes sans vous surcharger de trop de détails.
Si vous avez un peu de mal à vraiment comprendre pourquoi cette stratégie est importante dans l'équilibrage de charge, je vous suggère de faire une pause, puis de revenir à la section sur l'équilibrage de charge et de relire cela. Il n'est pas rare que tout cela semble très abstrait à moins que vous n'ayez directement rencontré le problème dans votre travail !
Section 8 : Bases de données
Nous avons brièvement considéré qu'il existe différents types de solutions de stockage (bases de données) conçues pour répondre à un certain nombre de cas d'utilisation différents, et certaines sont plus spécialisées pour certaines tâches que d'autres. À un niveau très élevé, les bases de données peuvent être catégorisées en deux types : Relationnelles et Non-Relationnelles.
Bases de données relationnelles
Une base de données relationnelle est une base de données qui impose strictement des relations entre les éléments stockés dans la base de données. Ces relations sont généralement rendues possibles en exigeant que la base de données représente chaque élément (appelé "entité") sous forme de tableau structuré - avec zéro ou plusieurs lignes ("enregistrements", "entrées") et une ou plusieurs colonnes ("attributs", "champs").
En imposant une telle structure à une entité, nous pouvons nous assurer que chaque élément/entrée/enregistrement a les bonnes données qui l'accompagnent. Cela permet une meilleure cohérence et la capacité à établir des relations étroites entre les entités.
Vous pouvez voir cette structure dans le tableau enregistrant les données "Bébé" (entité) ci-dessous. Chaque enregistrement ("entrée") dans le tableau a 4 champs, qui représentent les données relatives à ce bébé. Il s'agit d'une structure classique de base de données relationnelle (et une structure d'entité formalisée est appelée un schéma).

source : https://web.stanford.edu/class/cs101/table-1-data.html
Ainsi, la caractéristique clé à comprendre sur les bases de données relationnelles est qu'elles sont très structurées et imposent une structure à toutes les entités. Cette structure est renforcée en s'assurant que les données ajoutées au tableau se conforment à cette structure. L'ajout d'un champ de hauteur au tableau lorsque son schéma ne le permet pas ne sera pas autorisé.
La plupart des bases de données relationnelles supportent un langage de requête de base de données appelé SQL - Structured Query Language. Il s'agit d'un langage spécifiquement conçu pour interagir avec le contenu d'une base de données structurée (relationnelle). Les deux concepts sont assez étroitement liés, au point que les gens se réfèrent souvent à une base de données relationnelle comme une "base de données SQL" (et parfois prononcée comme une base de données "sequel").
En général, il est considéré que les bases de données SQL (relationnelles) supportent des requêtes plus complexes (combinant différents champs, filtres et conditions) que les bases de données non relationnelles. La base de données elle-même gère ces requêtes et envoie les résultats correspondants.
De nombreuses personnes qui sont fans des bases de données SQL soutiennent que sans cette fonction, vous devriez récupérer toutes les données et ensuite faire en sorte que le serveur ou le client charge ces données "en mémoire" et applique les conditions de filtrage - ce qui est acceptable pour de petits ensembles de données mais pour un grand ensemble de données complexe, avec des millions d'enregistrements et de lignes, cela affecterait gravement les performances. Cependant, ce n'est pas toujours le cas, comme nous le verrons lorsque nous apprendrons sur les bases de données NoSQL.
Un exemple commun et très apprécié de base de données relationnelle est la base de données PostgreSQL (souvent appelée "Postgres").
ACID
Les transactions ACID sont un ensemble de fonctionnalités qui décrivent les transactions qu'une bonne base de données relationnelle prendra en charge. ACID = "Atomicité, Cohérence, Isolation, Durabilité". Une transaction est une interaction avec une base de données, généralement des opérations de lecture ou d'écriture.
L'atomicité exige que lorsqu'une seule transaction comprend plus d'une opération, la base de données doit garantir que si une opération échoue, l'ensemble de la transaction (toutes les opérations) échoue également. C'est "tout ou rien". Ainsi, si la transaction réussit, alors à la fin, vous savez que toutes les sous-opérations ont été complétées avec succès, et si une opération échoue, alors vous savez que toutes les opérations qui l'accompagnaient ont échoué.
Par exemple, si une seule transaction impliquait la lecture de deux tables et l'écriture dans trois, alors si l'une de ces opérations individuelles échoue, l'ensemble de la transaction échoue. Cela signifie qu'aucune de ces opérations individuelles ne doit être complétée. Vous ne voudriez pas que même 1 des 3 transactions d'écriture fonctionne - cela "salerait" les données dans vos bases de données !
La cohérence exige que chaque transaction dans une base de données soit valide selon les règles définies par la base de données, et lorsque la base de données change d'état (certaines informations ont changé), un tel changement est valide et ne corrompt pas les données. Chaque transaction fait passer la base de données d'un état valide à un autre état valide. La cohérence peut être considérée comme suit : chaque opération de "lecture" reçoit les résultats les plus récents de l'opération d'"écriture".
L'isolation signifie que vous pouvez exécuter "concurremment" (en même temps) plusieurs transactions sur une base de données, mais la base de données finira par avoir un état qui semble comme si chaque opération avait été exécutée en série (dans une séquence, comme une file d'attente d'opérations). Personnellement, je pense que "Isolation" n'est pas un terme très descriptif pour le concept, mais je suppose que ACCD est moins facile à dire que ACID...
La durabilité est la promesse que, une fois les données stockées dans la base de données, elles y resteront. Elles seront "persistantes" - stockées sur disque et non en "mémoire".
Bases de données non relationnelles
En revanche, une base de données non relationnelle a une structure moins rigide, ou, en d'autres termes, une structure plus flexible pour ses données. Les données sont généralement présentées sous forme de paires "clé-valeur". Une manière simple de représenter cela serait sous forme de tableau (liste) d'objets de paires "clé-valeur", par exemple :
// baby names
[
{
name: "Jacob",
rank: ##,
gender: "M",
year: ####
},
{
name: "Isabella",
rank: ##,
gender: "F",
year: ####
},
{
//...
},
// ...
]
Les bases de données non relationnelles sont également appelées bases de données "NoSQL", et offrent des avantages lorsque vous ne voulez pas ou n'avez pas besoin d'avoir des données structurées de manière cohérente.
Similaires aux propriétés ACID, les propriétés des bases de données NoSQL sont parfois appelées BASE :
Disponibilité de base qui stipule que le système garantit la disponibilité
État souple signifie que l'état du système peut changer au fil du temps, même sans entrée
Cohérence éventuelle stipule que le système deviendra cohérent sur une période de temps (très courte) à moins que d'autres entrées ne soient reçues.
Puisque, au cœur, ces bases de données stockent les données dans une structure de type table de hachage, elles sont extrêmement rapides, simples et faciles à utiliser, et sont parfaites pour des cas d'utilisation comme la mise en cache, les variables d'environnement, les fichiers de configuration et l'état de session, etc. Cette flexibilité les rend parfaites pour une utilisation en mémoire (par exemple, Memcached) et également dans le stockage persistant (par exemple, DynamoDb).
Il existe d'autres bases de données "de type JSON" appelées bases de données de documents comme la bien-aimée MongoDb, et au cœur, ce sont également des magasins "clé-valeur".
Indexation des bases de données
C'est un sujet compliqué, donc je vais simplement effleurer la surface dans le but de vous donner un aperçu de haut niveau de ce dont vous avez besoin pour les entretiens de conception de systèmes.
Imaginez une table de base de données avec 100 millions de lignes. Cette table est principalement utilisée pour rechercher une ou deux valeurs dans chaque enregistrement. Pour récupérer les valeurs d'une ligne spécifique, vous devriez itérer sur la table. Si c'est le tout dernier enregistrement, cela prendrait beaucoup de temps !
L'indexation est un moyen de raccourcir le chemin vers l'enregistrement qui a des valeurs correspondantes de manière plus efficace que de passer par chaque ligne. Les index sont généralement une structure de données qui est ajoutée à la base de données et qui est conçue pour faciliter la recherche rapide dans la base de données pour ces attributs spécifiques (champs).
Ainsi, si le bureau du recensement a 120 millions d'enregistrements avec des noms et des âges, et que vous devez le plus souvent récupérer des listes de personnes appartenant à un groupe d'âge, alors vous indexeriez cette base de données sur l'attribut âge.
L'indexation est au cœur des bases de données relationnelles et est également largement offerte sur les bases de données non relationnelles. Les avantages de l'indexation sont donc disponibles en théorie pour les deux types de bases de données, et cela est extrêmement bénéfique pour optimiser les temps de recherche.
Réplication et Sharding
Bien que cela puisse sembler sortir d'un film de bioterrorisme, vous êtes plus susceptible de les entendre quotidiennement dans le contexte de la mise à l'échelle des bases de données.
La réplication signifie dupliquer (faire des copies, répliquer) votre base de données. Vous vous souvenez peut-être que lorsque nous avons discuté de la disponibilité.
Nous avions considéré les avantages d'avoir de la redondance dans un système pour maintenir une haute disponibilité. La réplication garantit la redondance dans la base de données si l'une tombe en panne. Mais cela soulève également la question de la synchronisation des données entre les répliques, puisqu'elles sont censées avoir les mêmes données. La réplication des opérations d'écriture et de mise à jour sur une base de données peut se faire de manière synchrone (en même temps que les modifications apportées à la base de données principale) ou de manière asynchrone.
L'intervalle de temps acceptable entre la synchronisation de la base de données principale et d'une base de données réplique dépend vraiment de vos besoins - si vous avez vraiment besoin que l'état entre les deux bases de données soit cohérent, alors la réplication doit être rapide. Vous voulez également vous assurer que si l'opération d'écriture sur la réplique échoue, l'opération d'écriture sur la base de données principale échoue également (atomicité).
Mais que faire lorsque vous avez tellement de données que la simple réplication peut résoudre les problèmes de disponibilité mais ne résout pas les problèmes de débit et de latence (vitesse) ?
À ce stade, vous pouvez envisager de "diviser" vos données en "shards". Certaines personnes appellent également cela le partitionnement de vos données (ce qui est différent du partitionnement de votre disque dur !).
Le sharding des données divise votre énorme base de données en bases de données plus petites. Vous pouvez déterminer comment vous souhaitez sharder vos données en fonction de leur structure. Cela peut être aussi simple que chaque 5 millions de lignes sont enregistrées dans un shard différent, ou opter pour d'autres stratégies qui conviennent le mieux à vos données, besoins et emplacements desservis.
Section 9 : Élection du leader
Revenons aux serveurs pour un sujet légèrement plus avancé. Nous comprenons déjà le principe de la Disponibilité, et comment la redondance est un moyen d'augmenter la disponibilité. Nous avons également passé en revue certaines considérations pratiques lors de la gestion du routage des requêtes vers des clusters de serveurs redondants.
Mais parfois, avec ce type de configuration où plusieurs serveurs font à peu près la même chose, il peut arriver que vous ayez besoin qu'un seul serveur prenne les devants.
Par exemple, vous voulez vous assurer qu'un seul serveur est responsable de la mise à jour d'une API tierce, car plusieurs mises à jour provenant de différents serveurs pourraient causer des problèmes ou engendrer des coûts pour la partie tierce.
Dans ce cas, vous devez choisir ce serveur principal pour lui déléguer cette responsabilité de mise à jour. Ce processus est appelé élection du leader.
Lorsque plusieurs serveurs sont dans un cluster pour fournir de la redondance, ils peuvent, entre eux, être configurés pour avoir un et un seul leader. Ils détecteraient également lorsque ce serveur leader a échoué, et en nommeraient un autre pour prendre sa place.
Le principe est très simple, mais le diable est dans les détails. La partie vraiment délicate est de s'assurer que les serveurs sont "synchronisés" en termes de leurs données, état et opérations.
Il y a toujours le risque que certaines pannes puissent entraîner la déconnexion d'un ou deux serveurs des autres, par exemple. Dans ce cas, les ingénieurs finissent par utiliser certaines des idées sous-jacentes qui sont utilisées dans la blockchain pour dériver des valeurs de consensus pour le cluster de serveurs.
En d'autres termes, un algorithme de consensus est utilisé pour donner à tous les serveurs une valeur "convenue" sur laquelle ils peuvent tous compter dans leur logique lorsqu'ils identifient quel serveur est le leader.
L'élection du leader est couramment mise en œuvre avec des logiciels comme etcd, qui est un magasin de paires clé-valeur offrant à la fois une haute disponibilité et une forte cohérence (ce qui est précieux et une combinaison inhabituelle) en utilisant l'élection du leader elle-même et en utilisant un algorithme de consensus.
Ainsi, les ingénieurs peuvent compter sur l'architecture d'élection du leader d'etcd pour produire l'élection du leader dans leurs systèmes. Cela est fait en stockant dans un service comme etcd, une paire clé-valeur qui représente le leader actuel.
Puisque etcd est hautement disponible et fortement cohérent, cette paire clé-valeur peut toujours être fiable par votre système pour contenir le serveur "source de vérité" final dans votre cluster est le leader élu actuel.
Section 10 : Polling, Streaming, Sockets
À l'ère moderne des mises à jour continues, des notifications push, du contenu en streaming et des données en temps réel, il est important de saisir les principes de base qui sous-tendent ces technologies. Pour que les données de votre application soient mises à jour régulièrement ou instantanément, il est nécessaire d'utiliser l'une des deux approches suivantes.
Polling
Cela est simple. Si vous regardez l'entrée wikipedia, vous pouvez la trouver un peu intense. Alors, au lieu de cela, regardez sa signification dans le dictionnaire, surtout dans le contexte de l'informatique. Gardez ce simple fondamental à l'esprit.
Le polling consiste simplement à faire en sorte que votre client vérifie auprès d'un serveur en lui envoyant une requête réseau et en demandant des données mises à jour. Ces requêtes sont généralement effectuées à intervalles réguliers comme 5 secondes, 15 secondes, 1 minute ou tout autre intervalle requis par votre cas d'utilisation.
Le polling toutes les quelques secondes n'est toujours pas tout à fait la même chose que le temps réel, et comporte également les inconvénients suivants, surtout si vous avez plus d'un million d'utilisateurs simultanés :
des requêtes réseau presque constantes (pas génial pour le client)
des requêtes entrantes presque constantes (pas génial pour les charges du serveur - 1 million+ de requêtes par seconde !)
Ainsi, le polling rapide n'est pas vraiment efficace ou performant, et le polling est mieux utilisé dans des circonstances où de petits écarts dans les mises à jour des données ne posent pas de problème pour votre application.
Par exemple, si vous avez construit un clone d'Uber, vous pouvez faire en sorte que l'application côté conducteur envoie les données de localisation du conducteur toutes les 5 secondes, et que votre application côté passager interroge la localisation du conducteur toutes les 5 secondes.
Streaming
Le streaming résout le problème du polling constant. Si le fait de frapper constamment le serveur est nécessaire, il est préférable d'utiliser quelque chose appelé web-sockets.
Il s'agit d'un protocole de communication réseau conçu pour fonctionner sur TCP. Il ouvre un canal dédié bidirectionnel (socket) entre un client et un serveur, un peu comme une ligne directe ouverte entre deux points de terminaison.
Contrairement à la communication TCP/IP habituelle, ces sockets sont "long-lived" de sorte qu'il s'agit d'une seule requête au serveur qui ouvre cette ligne directe pour le transfert bidirectionnel de données, plutôt que de multiples requêtes séparées. Par "long-lived", nous entendons que la connexion socket entre les machines durera jusqu'à ce que l'une ou l'autre des parties la ferme, ou que le réseau tombe.
Vous vous souvenez peut-être de notre discussion sur IP, TCP et HTTP qu'ils fonctionnent en envoyant des "paquets" de données, pour chaque cycle requête-réponse. Les web-sockets signifient qu'il y a une seule interaction requête-réponse (pas vraiment un cycle si vous y réfléchissez !) et cela ouvre le canal à travers lequel les données sont envoyées en "stream".
La grande différence avec le polling et toutes les communications IP "régulières" est que, alors que le polling a le client faisant des requêtes au serveur pour des données à intervalles réguliers ("pulling" des données), dans le streaming, le client est "en standby" attendant que le serveur "pousse" des données vers lui. Le serveur enverra des données lorsqu'elles changeront, et le client écoute toujours cela. Par conséquent, si le changement de données est constant, cela devient un "stream", ce qui peut être mieux pour ce dont l'utilisateur a besoin.
Par exemple, lors de l'utilisation d'IDEs de codage collaboratif, lorsque l'un ou l'autre utilisateur tape quelque chose, cela peut apparaître chez l'autre, et cela est fait via des web-sockets car vous voulez avoir une collaboration en temps réel. Ce serait nul si ce que j'ai tapé apparaissait sur votre écran après que vous ayez essayé de taper la même chose ou après 3 minutes d'attente en vous demandant ce que je faisais !
Ou pensez aux jeux en ligne multijoueurs - c'est un cas d'utilisation parfait pour le streaming des données de jeu entre les joueurs !
Pour conclure, le cas d'utilisation détermine le choix entre le polling et le streaming. En général, vous voulez streamer si vos données sont "en temps réel", et si c'est acceptable d'avoir un décalage (même aussi peu que 15 secondes est encore un décalage), alors le polling peut être une bonne option. Mais tout dépend du nombre d'utilisateurs simultanés que vous avez et s'ils s'attendent à ce que les données soient instantanées. Un exemple couramment utilisé de service de streaming est Apache Kafka.
Section 11 : Protection des points de terminaison
Lorsque vous construisez des systèmes à grande échelle, il devient important de protéger votre système contre trop d'opérations, où de telles opérations ne sont pas réellement nécessaires pour utiliser le système. Cela semble très abstrait. Mais pensez à ceci - combien de fois avez-vous cliqué frénétiquement sur un bouton en pensant que cela rendrait le système plus réactif ? Imaginez si chacun de ces clics sur le bouton envoyait un ping à un serveur et que le serveur essayait de tous les traiter ! Si le débit du système est faible pour une raison quelconque (par exemple, un serveur avait du mal sous une charge inhabituelle), alors chacun de ces clics aurait rendu le système encore plus lent car il doit tous les traiter !
Parfois, ce n'est même pas une question de protéger le système. Parfois, vous voulez limiter les opérations car cela fait partie de votre service. Par exemple, vous avez peut-être utilisé des niveaux gratuits sur des services d'API tiers où vous n'êtes autorisé à faire que 20 requêtes par intervalle de 30 minutes. Si vous faites 21 ou 300 requêtes dans un intervalle de 30 minutes, après les 20 premières, ce serveur cessera de traiter vos requêtes.
Cela s'appelle la limitation de débit. En utilisant la limitation de débit, un serveur peut limiter le nombre d'opérations tentées par un client dans une fenêtre de temps donnée. Une limite de débit peut être calculée sur les utilisateurs, les requêtes, les temps, les charges utiles, ou d'autres choses. Typiquement, une fois la limite dépassée dans une fenêtre de temps, pour le reste de cette fenêtre, le serveur retournera une erreur.
D'accord, maintenant vous pourriez penser que la "protection" des points de terminaison est une exagération. Vous limitez simplement la capacité de l'utilisateur à obtenir quelque chose du point de terminaison. Vrai, mais c'est aussi une protection lorsque l'utilisateur (client) est malveillant - comme un bot qui frappe votre point de terminaison. Pourquoi cela se produirait-il ? Parce qu'inonder un serveur avec plus de requêtes qu'il ne peut en gérer est une stratégie utilisée par des personnes malveillantes pour faire tomber ce serveur, ce qui fait effectivement tomber ce service. C'est exactement ce qu'est une attaque par déni de service (DoS).
Bien que les attaques DoS puissent être défendues de cette manière, la limitation de débit seule ne vous protégera pas contre une version sophistiquée d'une attaque DoS - une attaque DoS distribuée. Ici, la distribution signifie simplement que l'attaque provient de plusieurs clients qui semblent sans rapport et qu'il n'y a aucun moyen réel de les identifier comme étant contrôlés par le même agent malveillant. D'autres méthodes doivent être utilisées pour se protéger contre de telles attaques coordonnées et distribuées.
Mais la limitation de débit est utile et populaire de toute façon, pour des cas d'utilisation moins effrayants, comme la restriction d'API que j'ai mentionnée. Étant donné le fonctionnement de la limitation de débit, puisque le serveur doit d'abord vérifier les conditions de limite et les appliquer si nécessaire, vous devez réfléchir au type de structure de données et de base de données que vous souhaitez utiliser pour effectuer ces vérifications très rapidement, afin de ne pas ralentir le traitement de la requête si elle est dans les limites autorisées. De plus, si vous l'avez en mémoire dans le serveur lui-même, vous devez pouvoir garantir que toutes les requêtes d'un client donné viendront à ce serveur afin qu'il puisse appliquer correctement les limites. Pour gérer des situations comme celle-ci, il est populaire d'utiliser un service Redis séparé qui se trouve en dehors du serveur, mais qui conserve les détails de l'utilisateur en mémoire, et peut rapidement déterminer si un utilisateur est dans ses limites autorisées.
La limitation de débit peut être rendue aussi compliquée que les règles que vous souhaitez appliquer, mais la section ci-dessus devrait couvrir les fondamentaux et les cas d'utilisation les plus courants.
Section 12 : Messagerie et Pub-Sub
Lorsque vous concevez et construisez des systèmes à grande échelle et distribués, pour que le système fonctionne de manière cohésive et fluide, il est important d'échanger des informations entre les composants et services qui constituent le système. Mais comme nous l'avons vu auparavant, les systèmes qui dépendent des réseaux souffrent de la même faiblesse que les réseaux - ils sont fragiles. Les réseaux échouent et ce n'est pas un événement rare. Lorsque les réseaux échouent, les composants du système ne peuvent pas communiquer et peuvent dégrader le système (meilleur cas) ou faire échouer complètement le système (pire cas). Ainsi, les systèmes distribués ont besoin de mécanismes robustes pour garantir que la communication continue ou se rétablit là où elle s'est arrêtée, même s'il y a une "partition arbitraire" (c'est-à-dire une défaillance) entre les composants du système.
Imaginez, par exemple, que vous réservez des billets d'avion. Vous obtenez un bon prix, choisissez vos sièges, confirmez la réservation et vous avez même payé avec votre carte de crédit. Maintenant, vous attendez que votre PDF de billet arrive dans votre boîte de réception. Vous attendez, et attendez, et il n'arrive jamais. Quelque part, il y a eu une défaillance du système qui n'a pas été gérée ou récupérée correctement. Un système de réservation se connectera souvent aux API des compagnies aériennes et des prix pour gérer la sélection réelle des vols, le résumé des tarifs, la date et l'heure du vol, etc. Tout cela est fait pendant que vous cliquez sur l'interface utilisateur de réservation du site. Mais il n'a pas besoin de vous envoyer le PDF des billets avant quelques minutes. Au lieu de cela, l'interface utilisateur peut simplement confirmer que votre réservation est faite, et vous pouvez vous attendre à recevoir les billets dans votre boîte de réception sous peu. C'est une expérience utilisateur raisonnable et courante pour les réservations car le moment du paiement et la réception des billets n'ont pas besoin d'être simultanés - les deux événements peuvent être asynchrones. Un tel système aurait besoin de messagerie pour garantir que le service (point de terminaison du serveur) qui génère de manière asynchrone le PDF est informé d'une réservation confirmée et payée, et de tous les détails, puis le PDF peut être généré automatiquement et envoyé par e-mail. Mais si ce système de messagerie échoue, le service de messagerie ne saura jamais rien de votre réservation et aucun billet ne sera généré.
Messagerie Éditeur / Abonné
Il s'agit d'un paradigme (modèle) très populaire pour la messagerie. Le concept clé est que les éditeurs 'publient' un message et un abonné s'abonne aux messages. Pour une granularité plus fine, les messages peuvent appartenir à un certain "sujet" qui est comme une catégorie. Ces sujets sont comme des "canaux" ou des tuyaux dédiés, où chaque tuyau gère exclusivement les messages appartenant à un sujet spécifique. Les abonnés choisissent le sujet auquel ils veulent s'abonner et sont informés des messages dans ce sujet. L'avantage de ce système est que l'éditeur et l'abonné peuvent être complètement découplés - c'est-à-dire qu'ils n'ont pas besoin de se connaître. L'éditeur annonce, et l'abonné écoute les annonces pour les sujets qu'il recherche.
Un serveur est souvent l'éditeur de messages et il y a généralement plusieurs sujets (canaux) qui sont publiés. Le consommateur d'un sujet spécifique s'abonne à ces sujets. Il n'y a pas de communication directe entre le serveur (éditeur) et l'abonné (qui peut être un autre serveur). La seule interaction est entre l'éditeur et le sujet, et le sujet et l'abonné.
Les messages dans le sujet sont simplement des données qui doivent être communiquées, et peuvent prendre les formes dont vous avez besoin. Cela vous donne quatre acteurs dans Pub/Sub : Éditeur, Abonné, Sujets et Messages.
Mieux qu'une base de données
Alors pourquoi s'embêter avec cela ? Pourquoi ne pas simplement persister toutes les données dans une base de données et les consommer directement à partir de là ? Eh bien, vous avez besoin d'un système pour mettre en file d'attente les messages car chaque message correspond à une tâche qui doit être effectuée en fonction des données de ce message. Donc dans notre exemple de billetterie, si 100 personnes font une réservation en 35 minutes, mettre tout cela dans la base de données ne résout pas le problème d'envoyer des e-mails à ces 100 personnes. Cela stocke simplement 100 transactions. Les systèmes Pub/Sub gèrent la communication, la séquence des tâches et les messages sont persistés dans une base de données. Ainsi, le système peut offrir des fonctionnalités utiles comme la livraison "au moins une fois" (les messages ne seront pas perdus), le stockage persistant, l'ordre des messages, "réessayer", la "rejouabilité" des messages, etc. Sans ce système, le simple stockage des messages dans la base de données ne vous aidera pas à garantir que le message est livré (consommé) et agi pour compléter avec succès la tâche.
Parfois, le même message peut être consommé plus d'une fois par un abonné - généralement parce que le réseau a momentanément coupé, et bien que l'abonné ait consommé le message, il n'a pas informé l'éditeur. Ainsi, l'éditeur le renverra simplement à l'abonné. C'est pourquoi la garantie est "au moins une fois" et non "une fois et une seule". Cela est inévitable dans les systèmes distribués car les réseaux sont intrinsèquement peu fiables. Cela peut soulever des complications, où le message déclenche une opération du côté de l'abonné, et cette opération pourrait changer les choses dans la base de données (changer l'état dans l'application globale). Et si une seule opération est répétée plusieurs fois, et chaque fois l'état de l'application change ?
Contrôle des résultats - un ou plusieurs résultats ?
La solution à ce nouveau problème s'appelle l'idempotence - un concept qui est important mais pas intuitif à saisir les premières fois que vous l'examinez. C'est un concept qui peut sembler complexe (surtout si vous lisez l'entrée wikipedia), donc pour le but actuel, voici une simplification conviviale de StackOverflow :
En informatique, une opération idempotente est une opération qui n'a aucun effet supplémentaire si elle est appelée plus d'une fois avec les mêmes paramètres d'entrée.
Ainsi, lorsqu'un abonné traite un message deux ou trois fois, l'état global de l'application est exactement ce qu'il était après que le message a été traité la première fois. Par exemple, à la fin de la réservation de vos billets d'avion et après avoir entré les détails de votre carte de crédit, vous avez cliqué sur "Payer maintenant" trois fois parce que le système était lent... vous ne voudriez pas payer 3X le prix du billet, n'est-ce pas ? Vous avez besoin de l'idempotence pour vous assurer que chaque clic après le premier ne fait pas un autre achat et ne facture pas votre carte de crédit plus d'une fois. En revanche, vous pouvez poster un commentaire identique sur le fil d'actualité de votre meilleur ami N fois. Ils apparaîtront tous comme des commentaires séparés, et en plus d'être ennuyeux, ce n'est pas vraiment faux. Un autre exemple est d'offrir des "applaudissements" sur les articles de Medium - chaque applaudissement est censé incrémenter le nombre d'applaudissements, et non être un seul et unique applaudissement. Ces deux derniers exemples ne nécessitent pas d'idempotence, mais l'exemple de paiement en a besoin.
Il existe de nombreuses variantes de systèmes de messagerie, et le choix du système est déterminé par le cas d'utilisation à résoudre. Souvent, les gens feront référence à une architecture "basée sur les événements", ce qui signifie que le système repose sur des messages concernant des "événements" (comme le paiement des billets) pour traiter les opérations (comme l'envoi du billet par e-mail). Les services dont on parle vraiment couramment sont Apache Kafka, RabbitMQ, Google Cloud Pub/Sub, AWS SNS/SQS.
Section 13 : Petits essentiels
Journalisation
Avec le temps, votre système collectera beaucoup de données. La plupart de ces données sont extrêmement utiles. Elles peuvent vous donner une vue de la santé de votre système, de ses performances et de ses problèmes. Elles peuvent également vous donner des informations précieuses sur qui utilise votre système, comment ils l'utilisent, à quelle fréquence, quelles parties sont plus ou moins utilisées, et ainsi de suite.
Ces données sont précieuses pour l'analyse, l'optimisation des performances et l'amélioration des produits. Elles sont également extrêmement précieuses pour le débogage, non seulement lorsque vous journalisez dans votre console pendant le développement, mais aussi pour traquer les bugs dans vos environnements de test et de production. Ainsi, les journaux aident à la traçabilité et aux audits également.
Le truc clé à retenir lors de la journalisation est de la considérer comme une séquence d'événements consécutifs, ce qui signifie que les données deviennent des données de séries temporelles, et les outils et bases de données que vous utilisez doivent être spécifiquement conçus pour aider à travailler avec ce type de données.
Surveillance
C'est l'étape suivante après la journalisation. Elle répond à la question "Que faire avec toutes ces données de journalisation ?". Vous les surveillez et les analysez. Vous construisez ou utilisez des outils et services qui analysent ces données et vous présentent des tableaux de bord ou des graphiques ou d'autres moyens de donner un sens à ces données de manière lisible par l'homme.
En stockant les données dans une base de données spécialisée conçue pour gérer ce type de données (données de séries temporelles), vous pouvez brancher d'autres outils qui sont construits avec cette structure de données et cette intention à l'esprit.
Alertes
Lorsque vous surveillez activement, vous devez également mettre en place un système pour vous alerter des événements significatifs. Tout comme avoir une alerte pour les prix des actions dépassant un certain plafond ou descendant en dessous d'un certain seuil, certaines métriques que vous surveillez peuvent justifier l'envoi d'une alerte si elles deviennent trop élevées ou trop basses. Les temps de réponse (latence) ou les erreurs et les échecs sont de bons candidats pour configurer des alertes si elles dépassent un niveau "acceptable".
La clé d'une bonne journalisation et surveillance est de s'assurer que vos données sont assez cohérentes dans le temps, car travailler avec des données incohérentes pourrait entraîner des champs manquants qui brisent ensuite les outils analytiques ou réduisent les avantages de la journalisation.
Ressources
Comme promis, voici quelques ressources utiles :
Un fantastique dépôt Github rempli de concepts, de diagrammes et de préparation d'études
L'introduction de Tushar Roy à la Conception de Systèmes
La playlist YouTube de Gaurav Sen
J'espère que vous avez apprécié ce guide long format !
Si vous souhaitez en savoir plus sur mon parcours d'avocat à ingénieur logiciel, consultez l'épisode 53 du podcast freeCodeCamp ainsi que l'épisode 207 de "Lessons from a Quitter". Ces épisodes fournissent le plan de ma reconversion professionnelle.
Si vous êtes intéressé par l'auto-apprentissage de la programmation, le changement de carrière et devenir un codeur professionnel, ou devenir votre propre cofondateur technique, n'hésitez pas à me contacter ici. Vous pouvez également consulter mon webinaire gratuit sur le changement de carrière vers le code si c'est ce dont vous rêvez.