

Si vous souhaitez vous lancer dans le domaine de l'Intelligence Artificielle (IA), l'un des parcours professionnels les plus demandés ces jours-ci, vous êtes au bon endroit.
Apprendre les Fondamentaux de l'Apprentissage Profond est votre première étape essentielle pour comprendre la Vision par Ordinateur, le Traitement du Langage Naturel (NLP), les Grands Modèles de Langage, l'univers créatif de l'IA Générative, et bien plus encore.
Si vous aspirez à devenir Data Scientist, Chercheur en IA, Ingénieur en IA ou Chercheur en Machine Learning, ce guide est fait pour vous.
L'innovation en IA se produit rapidement. Que vous soyez débutant ou déjà impliqué dans le Machine Learning, vous devriez continuer à consolider votre base de connaissances et apprendre les fondamentaux de l'Apprentissage Profond.
Considérez ce manuel comme votre feuille de route personnelle pour naviguer dans le paysage de l'IA. Que vous soyez un passionné en herbe curieux de savoir comment l'IA transforme notre monde, un étudiant visant à construire une carrière dans la tech, ou un professionnel cherchant à se reconvertir dans ce domaine passionnant, il vous sera utile.
Ce guide peut vous aider à :
Apprendre tous les Fondamentaux de l'Apprentissage Profond en un seul endroit à partir de zéro
Rafraîchir votre mémoire sur tous les fondamentaux de l'Apprentissage Profond
Vous préparer pour vos prochains entretiens en IA.
Table des Matières
Chapitre 2 : Fondements des Réseaux de Neurones
– Architecture des Réseaux de Neurones
– Fonctions d'ActivationChapitre 3 : Comment Entraîner les Réseaux de Neurones
– Passe Avant - dérivation mathématique
– Passe Arrière - dérivation mathématiqueChapitre 4 : Algorithmes d'Optimisation en IA
– Descente de Gradient - avec Python
– SGD - avec Python
– SGD avec Momentum - avec Python
– RMSProp - avec Python
– Adam - avec Python
– AdamW - avec PythonChapitre 5 : Régularisation et Généralisation
– Dropout
– Régularisation Ridge (Régularisation L2)
– Régularisation Lasso (Régularisation L1)
– Normalisation par LotsChapitre 6 : Problème du Gradient Évanescent
– Utiliser des fonctions d'activation appropriées
– Utiliser l'Initialisation de Xavier ou He
– Effectuer la Normalisation par Lots
– Ajouter des Connexions RésiduellesChapitre 8 : Modélisation de Séquences avec les RNN et LSTM
– Architecture des Réseaux de Neurones Récurrents (RNN)
– Pseudocode des Réseaux de Neurones Récurrents
– Limites des Réseaux de Neurones Récurrents
– Architecture de la Mémoire à Long et Court Terme (LSTM)Chapitre 9 : Préparation aux Entretiens en Apprentissage Profond
– Partie 1 : Cours d'Entretien en Apprentissage Profond [50 Q&R]
– Partie 2 : Cours d'Entretien en Apprentissage Profond [100 Q&R]
Prérequis
L'Apprentissage Profond est un domaine d'étude avancé dans les champs de l'Intelligence Artificielle et du Machine Learning. Pour bien comprendre les concepts discutés ici, il est essentiel que vous ayez une solide fondation dans plusieurs domaines clés.
1. Bases du Machine Learning
Comprendre les principes fondamentaux du machine learning est crucial. Si vous n'êtes pas encore familier avec ceux-ci, je vous recommande de consulter mon Manuel des Fondamentaux du Machine Learning, où j'ai exposé tous les travaux préparatoires nécessaires. De plus, mon cours Fondamentaux du Machine Learning offre un enseignement complet sur ces principes.
2. Fondamentaux de la Statistique
La statistique joue un rôle vital dans la compréhension des motifs de données et des inférences en machine learning. Pour ceux qui ont besoin de se rafraîchir la mémoire sur ce sujet, mon cours Fondamentaux de la Statistique est une autre ressource où je couvre tous les concepts statistiques essentiels dont vous aurez besoin.
3. Algèbre Linéaire et Théorie Différentielle
Une compréhension de haut niveau de l'algèbre linéaire et de la théorie différentielle est également importante. Nous couvrirons certains aspects, tels que les règles de différentiation, dans ce manuel. Nous aborderons la multiplication de matrices, les opérations sur les matrices et les vecteurs, les concepts de normalisation et les bases de la théorie de la différentiation.
Mais je vous encourage à renforcer votre compréhension dans ces domaines. Vous pouvez trouver plus de contenu sur freeCodeCamp en recherchant "Linear Algebra" comme ce cours "Full Linear Algebra Course".
Notez que si vous n'avez pas les prérequis tels que les Fondamentaux de la Statistique, du Machine Learning et des Mathématiques, suivre ce manuel sera assez difficile. Nous utiliserons des concepts de tous ces domaines, y compris la moyenne, la variance, les règles de la chaîne, la multiplication de matrices, les dérivées, et ainsi de suite. Alors, assurez-vous de les avoir pour tirer le meilleur parti de ce contenu.
Exemple de Référence – Prédiction du Prix des Maisons
Tout au long de ce livre, nous utiliserons un exemple pratique pour illustrer et clarifier les concepts que vous apprenez. Nous explorerons cette idée de prédire le prix d'une maison en fonction de ses caractéristiques. Cet exemple servira de point de référence pour rendre les concepts abstraits ou complexes plus concrets et plus faciles à comprendre.
Chapitre 1 : Qu'est-ce que l'Apprentissage Profond ?
L'Apprentissage Profond est une série d'algorithmes inspirés par la structure et la fonction du cerveau. L'Apprentissage Profond permet aux modèles quantitatifs composés de plusieurs couches de traitement d'étudier la représentation des données avec plusieurs niveaux d'abstraction.
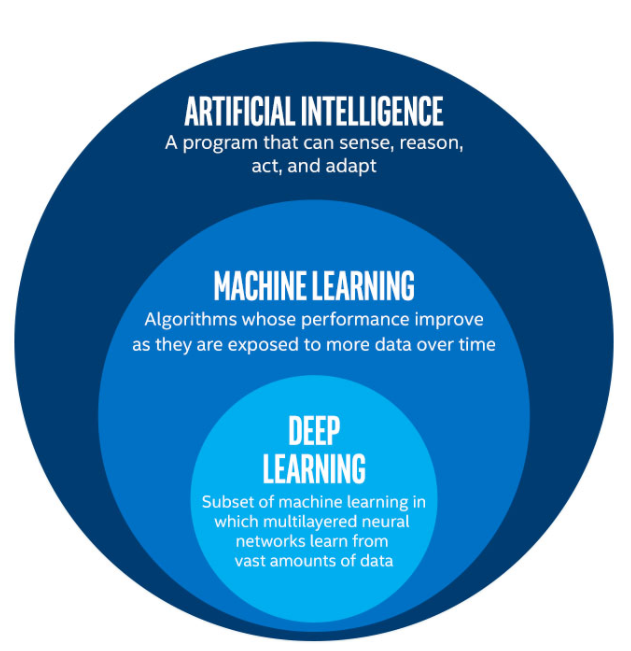
Exploration des Couches de l'IA : De l'Intelligence Artificielle à l'Apprentissage Profond. (Source de l'Image : LunarTech.ai)
L'Apprentissage Profond est une branche du Machine Learning, et il tente d'imiter le fonctionnement du cerveau humain et la prise de décisions basées sur des modèles à base de réseaux de neurones.
En termes plus simples, l'Apprentissage Profond est une version plus avancée et plus complexe du Machine Learning traditionnel. Les modèles d'Apprentissage Profond sont basés sur des Réseaux de Neurones et ils tentent d'imiter la façon dont les humains pensent et prennent des décisions.
Le problème avec les méthodes Statistiques ou ML traditionnelles est qu'elles sont basées sur des règles et des instructions spécifiques. Ainsi, chaque fois que l'ensemble des hypothèses du modèle ne sont pas satisfaites, le modèle peut avoir beaucoup de mal à résoudre le problème et à effectuer des prédictions. Il existe également des types de problèmes tels que la reconnaissance d'images, et d'autres tâches plus avancées, qui ne peuvent pas être résolus avec des modèles Statistiques ou de Machine Learning traditionnels.
C'est précisément là que l'Apprentissage Profond intervient.
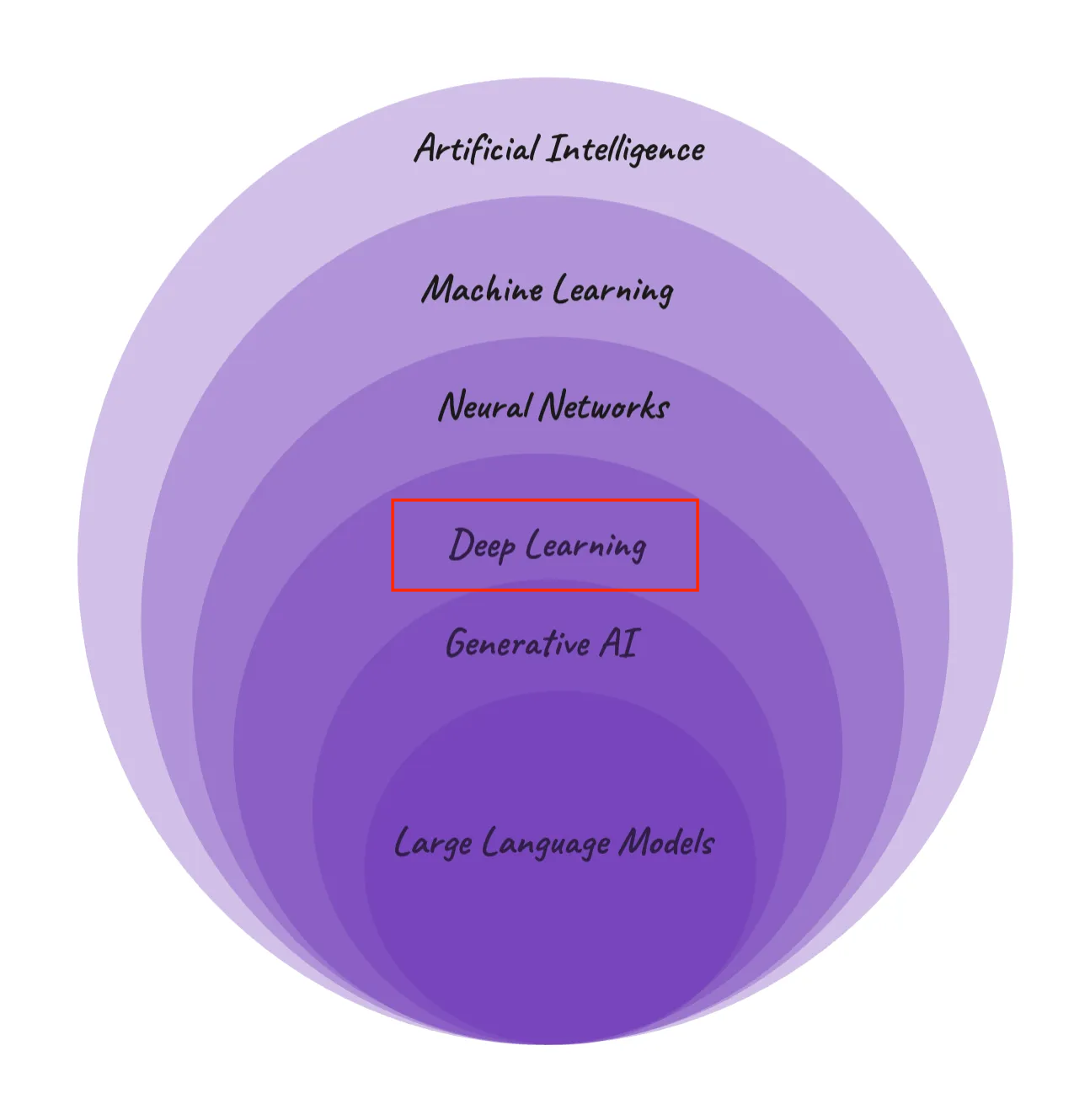
Hiérarchie de l'IA : Navigation des Concepts Généraux de l'IA aux Modèles de Langage Spécialisés (Source de l'Image : Medium)
Applications de l'Apprentissage Profond
Voici quelques exemples où l'Apprentissage Profond est utilisé dans diverses industries et applications :
Santé
Diagnostic et Pronostic des Maladies : Les algorithmes d'apprentissage profond aident à analyser les images médicales comme les radiographies, les IRM et les scanners pour diagnostiquer des maladies telles que le cancer de manière plus précise avec des modèles de vision par ordinateur. Ils le font beaucoup plus rapidement que les méthodes traditionnelles. Ils peuvent également prédire les résultats des patients en analysant les motifs dans les données des patients.
Découverte et Développement de Médicaments : Les modèles d'apprentissage profond aident à identifier les candidats potentiels pour les médicaments et à accélérer le processus de développement des médicaments, réduisant ainsi considérablement le temps et les coûts.
Finance
Trading Algorithme : Les modèles d'apprentissage profond sont utilisés pour prédire les tendances du marché boursier et automatiser les décisions de trading, traitant de vastes quantités de données financières à haute vitesse.
Détection de Fraude : Les banques et les institutions financières utilisent l'apprentissage profond pour détecter les motifs inhabituels indicatifs d'activités frauduleuses, améliorant ainsi la sécurité et la confiance des clients.
Automobile et Transport
Véhicules Autonomes : Les voitures autonomes utilisent également largement l'apprentissage profond pour interpréter les données des capteurs, leur permettant de naviguer en toute sécurité dans des environnements complexes, en utilisant la vision par ordinateur et d'autres méthodes.
Gestion du Trafic : Les modèles d'IA analysent les motifs de trafic pour optimiser le flux de trafic et réduire la congestion dans les villes.
Vente au Détail et E-Commerce
Expérience de Shopping Personnalisée : Les algorithmes d'apprentissage profond aident dans la vente au détail et le e-commerce à analyser les données des clients et à fournir des recommandations de produits personnalisées. Cela améliore l'expérience utilisateur et stimule les ventes.
Optimisation de la Chaîne d'Approvisionnement : Les modèles d'IA prévoient la demande, optimisent les stocks et améliorent les opérations logistiques, améliorant l'efficacité de la chaîne d'approvisionnement.
Divertissement et Médias
Recommandation de Contenu : Des plateformes comme Netflix et Spotify utilisent l'apprentissage profond pour analyser les préférences des utilisateurs et l'historique de visionnage afin de recommander du contenu personnalisé.
Développement de Jeux Vidéo : L'IA est utilisée pour créer des environnements de jeu plus réalistes et interactifs, améliorant l'expérience du joueur.
Technologie et Communications
Assistants Virtuels : Siri, Alexa et autres assistants virtuels utilisent l'apprentissage profond pour le traitement du langage naturel et la reconnaissance vocale, les rendant plus réactifs et conviviaux.
Services de Traduction de Langue : Des services comme Google Translate exploitent l'apprentissage profond pour une traduction de langue en temps réel et précise, brisant les barrières linguistiques.
Fabrication et Production
Maintenance Prédictive : Les modèles d'apprentissage profond prédisent quand les machines nécessitent une maintenance, réduisant les temps d'arrêt et économisant des coûts.
Contrôle de Qualité : Les algorithmes d'IA inspectent et détectent les défauts dans les produits à haute vitesse avec une plus grande précision que les inspecteurs humains.
Agriculture
- Surveillance et Analyse des Récoltes : Les modèles d'IA analysent les images de drones et de satellites pour surveiller la santé des récoltes, optimiser les pratiques agricoles et prédire les rendements.
Sécurité et Surveillance
Reconnaissance Faciale : Utilisée pour améliorer les systèmes de sécurité, les modèles d'apprentissage profond peuvent identifier avec précision les individus même dans des environnements bondés.
Détection d'Anomalies : Les algorithmes d'IA surveillent les images de sécurité pour détecter les activités ou comportements inhabituels, aidant à la prévention de la criminalité.
Recherche et Académie
Découverte Scientifique : L'apprentissage profond aide les chercheurs à analyser des données complexes, conduisant à des découvertes dans des domaines comme l'astronomie, la physique et la biologie.
Outils Éducatifs : Les systèmes de tutorat pilotés par l'IA fournissent des expériences d'apprentissage personnalisées, s'adaptant aux besoins individuels des étudiants.
L'Apprentissage Profond a considérablement affiné l'état de l'art de la reconnaissance vocale, de la reconnaissance d'objets, de la compréhension de la parole, de la traduction automatisée, de la reconnaissance d'images, et de nombreuses autres disciplines telles que la découverte de médicaments et la génomique.
Chapitre 2 : Fondements des Réseaux de Neurones
Maintenant, parlons de certaines caractéristiques et fonctionnalités clés des Réseaux de Neurones :
Structure en Couches : Les modèles d'apprentissage profond, à leur cœur, se composent de plusieurs couches, chacune transformant les données d'entrée en représentations plus abstraites et composites.
Hiérarchie des Caractéristiques : Les caractéristiques simples (comme les bords en reconnaissance d'image) se recombinent d'une couche à l'autre, pour former des caractéristiques plus complexes (comme des objets ou des formes).
Apprentissage de Bout en Bout : Les modèles d'apprentissage profond effectuent des tâches à partir de données brutes jusqu'aux catégories ou décisions finales, s'améliorant souvent avec la quantité de données fournies. Ainsi, les grandes données jouent un rôle clé pour l'Apprentissage Profond.
Voici les composants principaux des modèles d'Apprentissage Profond :
Neurones
Ce sont les éléments de base des réseaux de neurones qui reçoivent des entrées et transmettent leur sortie à la couche suivante après avoir appliqué une fonction d'activation (plus de détails à ce sujet dans les chapitres suivants).
Poids et Biais
Paramètres du réseau de neurones qui sont ajustés au cours du processus d'apprentissage pour aider le modèle à faire des prédictions précises. Ce sont les valeurs que l'algorithme d'optimisation doit optimiser en continu idéalement en peu de temps pour atteindre le modèle le plus optimal et précis (par exemple, couramment référencées par w_ij et b_ij ).
Terme de Biais : En pratique, un terme de biais ( b ) est souvent ajouté au produit somme des poids d'entrée avant d'appliquer la fonction d'activation. C'est un terme qui permet au neurone de décaler la fonction d'activation vers la gauche ou la droite, ce qui peut être crucial pour apprendre des motifs complexes.
Processus d'Apprentissage : Les poids sont ajustés pendant la phase d'entraînement du réseau. Grâce à un processus impliquant souvent la descente de gradient, le réseau met à jour de manière itérative les poids pour minimiser la différence entre sa sortie et les valeurs cibles.
Contexte d'Utilisation : Ce neurone pourrait faire partie d'un réseau plus large, composé de plusieurs couches. Les réseaux de neurones sont utilisés pour résoudre une vaste gamme de problèmes, allant de la reconnaissance d'images et de la parole à la prédiction des tendances du marché boursier.
Correction de la Notation Mathématique : L'équation fournie dans le texte utilise le symbole ( \phi ), qui est inhabituel dans ce contexte. Typiquement, une simple sommation ( \sum ) est utilisée pour désigner l'agrégation des entrées pondérées, suivie de la fonction d'activation ( f ), comme dans
$$f\left(\sum_{i=1}^{n} W_ix_i + b\right)$$
Fonctions d'Activation
Les fonctions qui introduisent des propriétés non linéaires au réseau, lui permettant d'apprendre des motifs de données complexes. Grâce aux fonctions d'activation, au lieu d'agir comme si tous les signaux d'entrée ou unités cachées étaient également importants, les fonctions d'activation aident à transformer ces valeurs, ce qui résulte en un modèle non linéaire beaucoup plus flexible plutôt qu'un modèle de type linéaire.
Chaque neurone dans une couche cachée transforme les entrées de la couche précédente avec une somme pondérée suivie d'une fonction d'activation non linéaire (c'est ce qui différencie votre réseau de neurones non linéaire flexible de la régression linéaire commune). Les sorties de ces neurones sont ensuite transmises à la couche suivante et à la suivante, et ainsi de suite, jusqu'à ce que la couche finale soit atteinte.
Nous discuterons des fonctions d'activation en détail dans ce manuel, ainsi que des exemples des 4 fonctions d'activation les plus populaires pour rendre cela très clair car c'est un concept très important et une partie cruciale du processus d'apprentissage dans les réseaux de neurones.
Ce processus d'entrées passant par des couches cachées en utilisant la ou les fonctions d'activation et résultant en une sortie est connu sous le nom de propagation avant.
Architecture des Réseaux de Neurones
Les réseaux de neurones ont généralement trois types de couches : les couches d'entrée, les couches cachées et les couches de sortie. Apprenons un peu plus sur chacune d'entre elles maintenant.
Nous utiliserons notre exemple de prédiction de prix de maison pour en apprendre davantage sur ces couches. Ci-dessous, vous pouvez voir la figure visualisant une architecture simple de réseau de neurones que nous allons décomposer couche par couche.
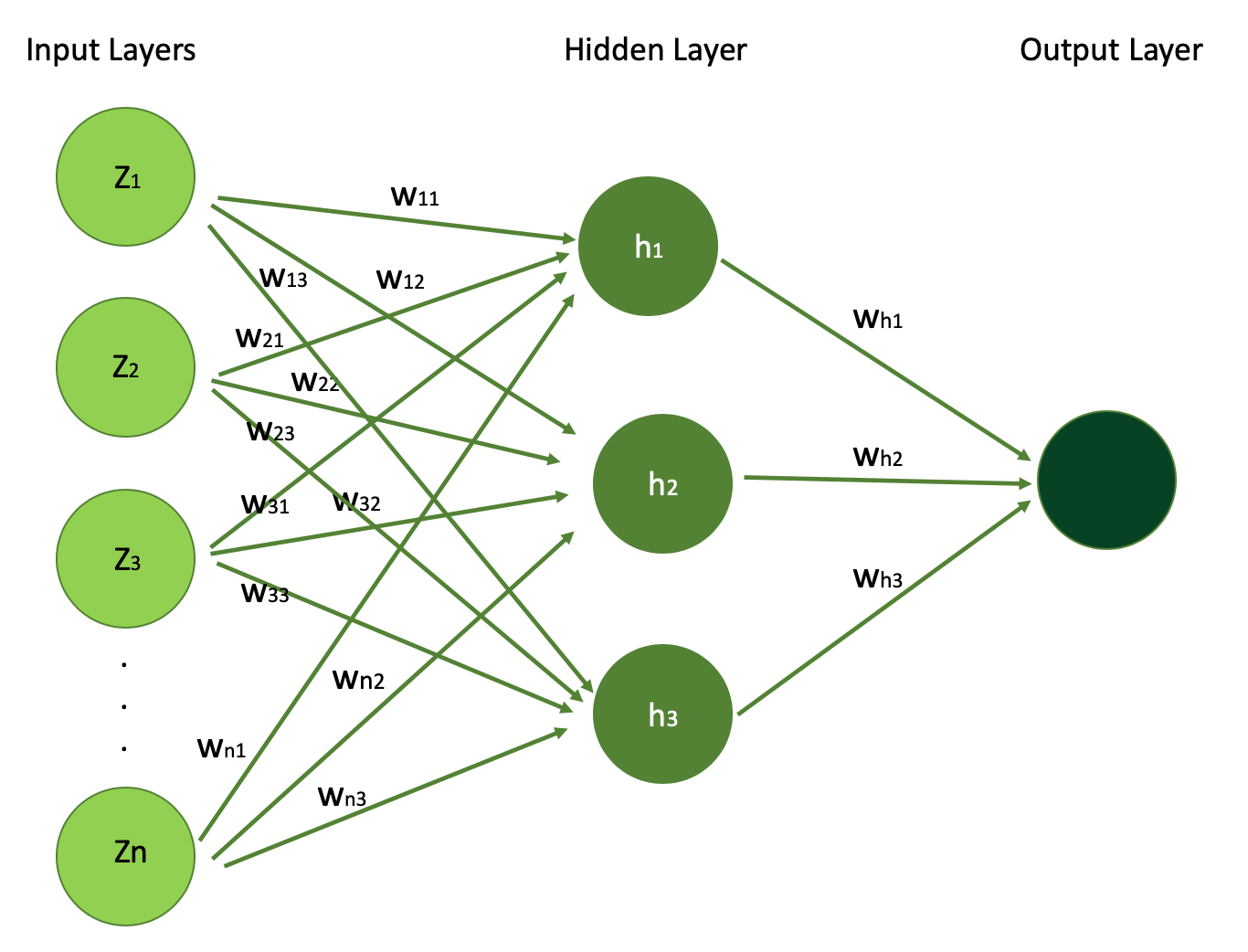
Architecture Simple de Réseau de Neurones : Entrées, Poids et Sorties Expliqués (Source de l'Image : LunarTech.ai)
Couches d'entrée
Les couches d'entrée sont les couches initiales où se trouvent les données. Elles contiennent les caractéristiques que votre modèle prend en entrée pour ensuite entraîner votre modèle.
C'est là que le réseau de neurones reçoit ses données d'entrée. Chaque neurone dans la couche d'entrée de votre réseau de neurones représente une caractéristique des données d'entrée. Si vous avez deux caractéristiques, vous aurez deux couches d'entrée.
Ci-dessous se trouve la visualisation de l'architecture d'un Réseau de Neurones Simple, avec N caractéristiques d'entrée (N signaux d'entrée) que vous pouvez voir dans la couche d'entrée. Vous pouvez également voir la couche cachée unique avec 3 unités cachées h1, h2, et h3 et la couche de sortie.
Commençons par la Couche d'Entrée et comprenons ce que sont ces caractéristiques Z1, Z2, ..., Zn.
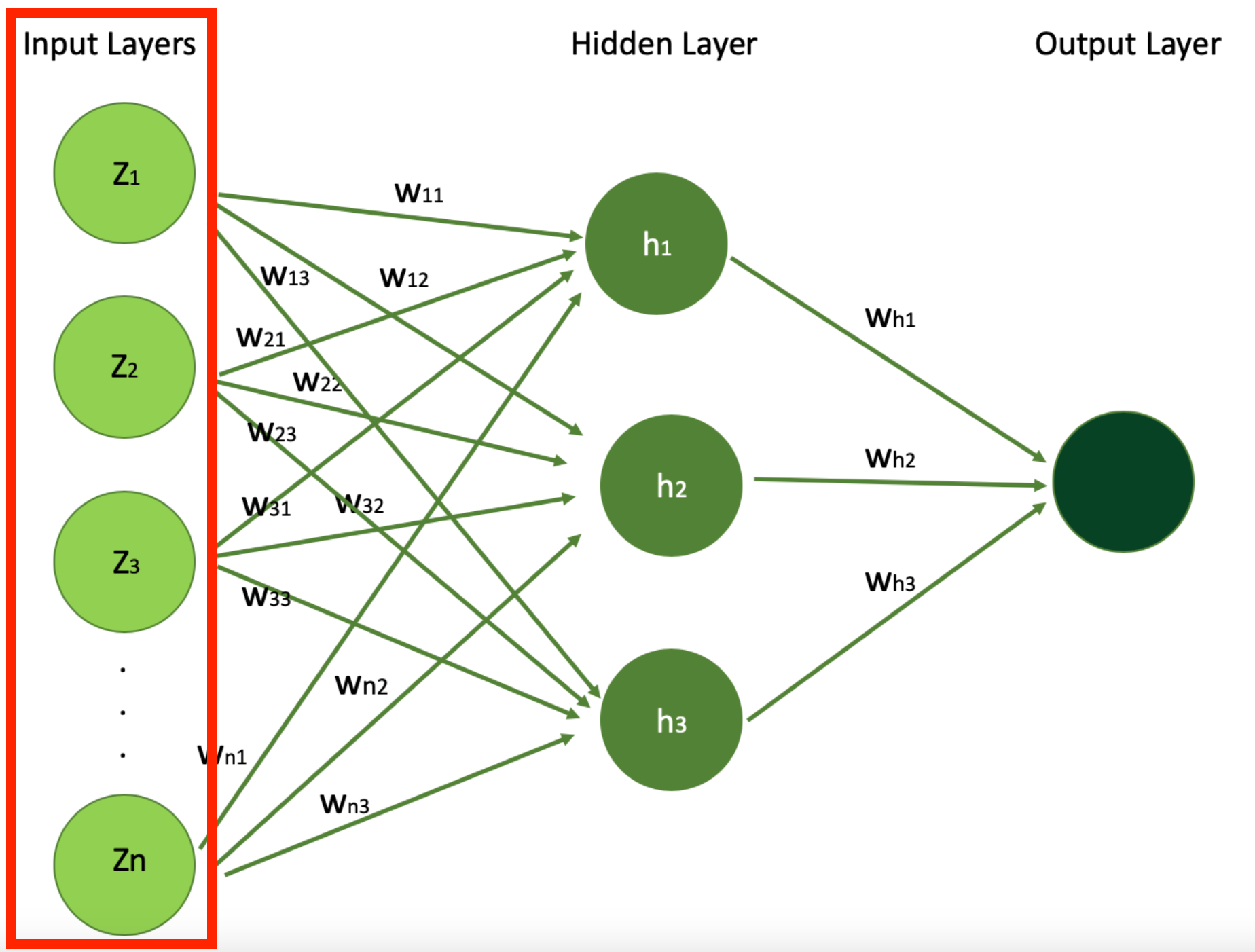
Architecture Simple de Réseau de Neurones Mettant en Évidence les Couches d'Entrée (Source de l'Image : LunarTech.ai)
Dans notre exemple d'utilisation de réseaux de neurones pour prédire le prix d'une maison, la couche d'entrée prendra des caractéristiques de la maison telles que le nombre de chambres, l'âge de la maison, la proximité de l'océan, ou s'il y a une piscine, afin d'apprendre sur la maison. C'est ce qui sera donné à la couche d'entrée du réseau de neurones. Chacune de ces caractéristiques sert de neurone d'entrée, fournissant au modèle des données essentielles.
Mais alors se pose la question de savoir combien chacune de ces caractéristiques devrait contribuer au processus d'apprentissage. Sont-elles toutes également importantes, ou certaines sont-elles plus importantes et devraient contribuer davantage à l'estimation du prix ?
La réponse à cette question réside dans ce que nous appelons les "poids" que nous avons définis précédemment ainsi que les facteurs de biais.
Dans la figure ci-dessus, chaque neurone obtient un poids w_ij où i est l'indice du neurone d'entrée et j est l'indice de l'unité cachée à laquelle ils contribuent dans la Couche Cachée. Ainsi, par exemple, w_11, w_12, w_13 décrivent l'importance de la caractéristique 1 pour l'apprentissage sur la maison pour l'unité cachée h1, h2, et h3 respectivement.
Gardez à l'esprit ces paramètres de poids car ils sont l'une des parties les plus importantes d'un réseau de neurones. Ce sont les poids d'importance que le réseau de neurones mettra à jour pendant le processus d'entraînement, afin d'optimiser le processus d'apprentissage.
Couches cachées
Les couches cachées sont la partie centrale de votre modèle où l'apprentissage se produit. Elles viennent juste après les Couches d'Entrée. Vous pouvez avoir d'une à plusieurs couches cachées.
Simplifions ce concept en regardant notre réseau de neurones simple ainsi que notre exemple de prix de maison.
Ci-dessous, j'ai mis en évidence la Couche Cachée dans notre réseau de neurones simple dont l'architecture nous avons vue précédemment, que vous pouvez considérer comme une partie très importante de votre réseau de neurones pour extraire des motifs et des relations à partir des données qui ne sont pas immédiatement apparents au premier regard.
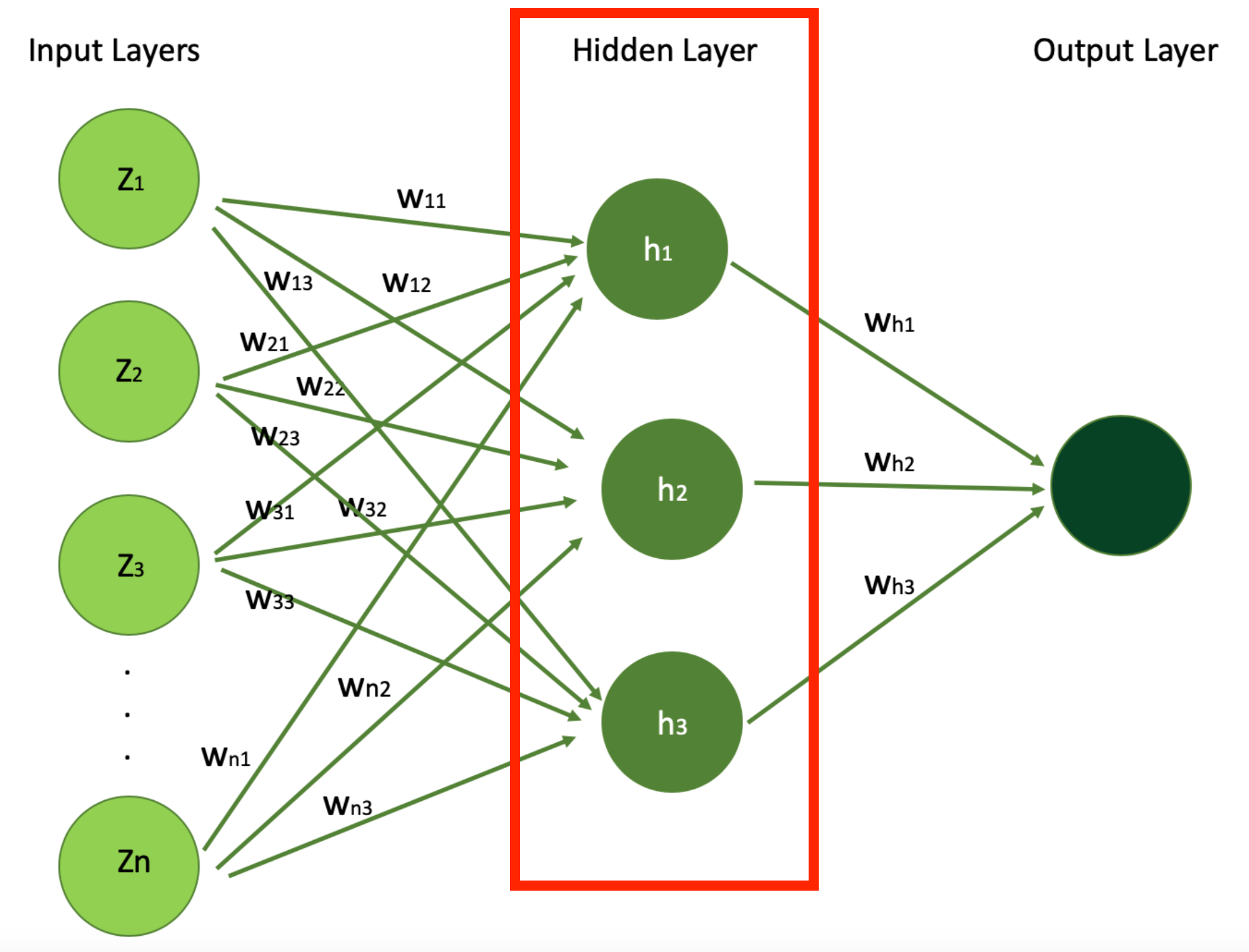
Architecture Simple de Réseau de Neurones Mettant en Évidence la Couche Cachée (Source de l'Image : LunarTech.ai)
Dans notre exemple d'estimation du prix d'une maison avec un réseau de neurones, les couches cachées jouent un rôle crucial dans le traitement et l'interprétation des informations reçues de la couche d'entrée, comme les caractéristiques de la maison que nous venons de mentionner ci-dessus.
Ces couches sont constituées de neurones qui appliquent des poids et des biais aux caractéristiques d'entrée – comme l'âge de la maison, le nombre de chambres, la proximité de l'océan et la présence d'une piscine – pour extraire des motifs et des relations qui ne sont pas immédiatement apparents.
Dans ce contexte, les couches cachées peuvent apprendre des interdépendances complexes entre les caractéristiques de la maison, comme la manière dont la combinaison d'un emplacement de choix, de l'âge de la maison et des équipements modernes augmente considérablement le prix de la maison.
Elles agissent comme le moteur de calcul du réseau de neurones, transformant les données brutes en informations qui conduisent à une estimation précise de la valeur marchande d'une maison. Grâce à l'entraînement, les couches cachées ajustent ces poids et biais (paramètres) pour minimiser les erreurs de prédiction du modèle, améliorant progressivement la précision du modèle dans l'estimation des prix des maisons.
Ces couches effectuent la majorité des calculs grâce à leurs neurones interconnectés. Dans cet exemple simple, nous n'avons qu'une seule couche cachée et 3 unités cachées (par exemple, un autre hyperparamètre à optimiser pendant votre apprentissage en utilisant des techniques telles que Random Search CV ou d'autres).
Mais dans les problèmes du monde réel, les réseaux de neurones sont beaucoup plus profonds et votre nombre de couches cachées, avec les paramètres de poids et de biais, peut dépasser des milliards avec de nombreuses couches cachées.
Couche de sortie
Les couches de sortie sont le composant final d'un réseau de neurones – la couche finale qui fournit la sortie du réseau de neurones après toutes les transformations en sortie pour une tâche spécifique unique. Cette sortie peut être une valeur unique (dans le cas de la régression par exemple) ou un vecteur (comme dans les grands modèles de langage où nous produisons un vecteur de probabilités, ou des embeddings).
Une couche de sortie peut être une étiquette de classe pour un modèle de classification, une valeur numérique continue pour un modèle de régression, ou même un vecteur de nombres, selon la tâche.
Les couches cachées dans un réseau de neurones sont l'endroit où l'apprentissage réel se produit, où le réseau d'apprentissage profond apprend à partir des données en extrayant et en transformant les caractéristiques fournies.
À mesure que les données pénètrent plus profondément dans le réseau, les caractéristiques deviennent plus abstraites et plus composites, chaque couche s'appuyant sur la sortie/valeurs des couches précédentes. La profondeur et la largeur (nombre de neurones) des couches cachées sont des facteurs clés dans la capacité du réseau à apprendre des motifs complexes. Ci-dessous se trouve le diagramme que nous avons vu précédemment montrant l'architecture des réseaux de neurones simples.
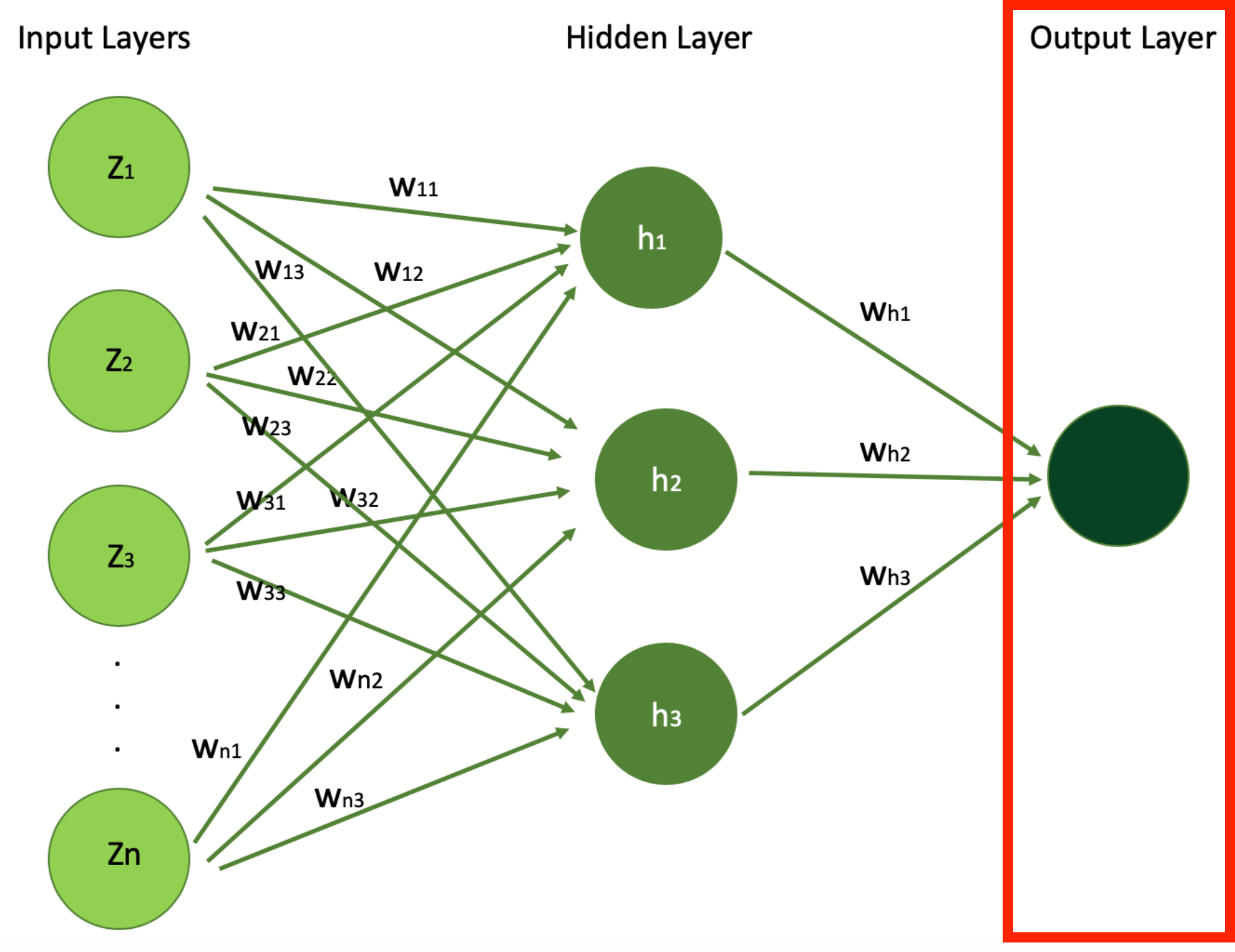
Architecture Simple de Réseau de Neurones Mettant en Évidence la Sortie (Source de l'Image : LunarTech.ai)
Dans notre exemple de prédiction de prix de maison, l'aboutissement du processus d'apprentissage est représenté par la couche de sortie, qui représente notre objectif final : le prix prédit de la maison.
Une fois les caractéristiques d'entrée – comme le nombre de chambres, l'âge de la maison, la distance à l'océan et la présence d'une piscine – alimentées dans le réseau de neurones, elles traversent une ou plusieurs couches cachées du réseau de neurones. C'est au sein de ces couches cachées que le réseau de neurones découvre des motifs complexes et des interconnexions dans les données.
Enfin, cette information traitée atteint la couche de sortie, où le modèle consolide toutes ses découvertes et produit les résultats ou prédictions finaux, dans ce cas, le prix de la maison.
Ainsi, la couche de sortie consolide toutes les informations acquises. Ces transformations sont appliquées tout au long des couches cachées pour produire une seule valeur : le prix prédit de la maison (souvent appelé Y^, prononcé "Y hat").
Cette prédiction est l'estimation par le réseau de neurones de la valeur marchande de la maison, basée sur sa compréhension apprise de la manière dont différentes caractéristiques de la maison affectent le prix de la maison. Elle démontre la capacité du réseau à synthétiser des données complexes en informations exploitables, dans ce cas, en produisant une prédiction de prix précise, grâce à son modèle optimisé.
Fonctions d'activation
Les fonctions d'activation introduisent des propriétés non linéaires dans le modèle de réseau de neurones, ce qui permet au modèle d'apprendre des motifs plus complexes.
Sans non-linéarité, votre réseau profond se comporterait comme un perceptron à une seule couche, qui ne peut apprendre que des fonctions linéairement séparables. Les fonctions d'activation définissent comment les neurones doivent être activés – d'où le nom de fonction d'activation.
Les fonctions d'activation servent de pont entre les signaux d'entrée reçus par le réseau et la sortie qu'il génère. Ces fonctions déterminent comment la somme pondérée des neurones d'entrée – chacun représentant une caractéristique spécifique comme le nombre de chambres, l'âge de la maison, la proximité de l'océan et la présence d'une piscine – doit être transformée ou "activée" pour contribuer au processus d'apprentissage du réseau.
Les fonctions d'activation sont une partie extrêmement importante de l'entraînement des réseaux de neurones. Lorsque le réseau est composé de couches cachées et de couches de sortie, vous devez choisir une fonction d'activation pour les deux (différentes fonctions d'activation peuvent être utilisées dans différentes parties du modèle). Le choix de la fonction d'activation a un impact énorme sur les performances et les capacités du réseau de neurones.
Chacun des signaux entrants ou connexions est dynamiquement renforcé ou affaibli en fonction de leur fréquence d'utilisation (c'est ainsi que nous apprenons de nouvelles idées et concepts). C'est la force de chaque connexion qui détermine la contribution de l'entrée à la sortie des neurones.
Après avoir été pondérés par la force de leurs signaux respectifs, les entrées sont sommées ensemble dans le corps cellulaire. Cela est ensuite transformé en un nouveau signal qui est transmis ou propagé le long de l'axone des cellules et envoyé à d'autres neurones. Ce travail fonctionnel de la fonction d'activation peut être représenté mathématiquement comme suit :
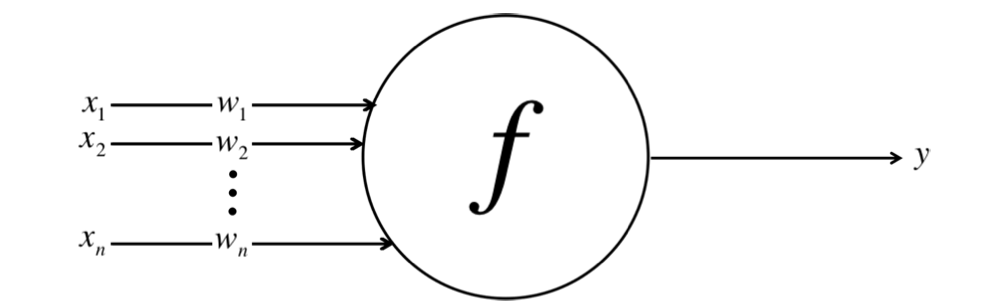
Activation des Neurones : Transformation des Entrées Pondérées en Sorties (Source de l'Image : LunarTech.ai)
Ici, nous avons les entrées x1, x2, ...xn et leurs poids correspondants w1, w2, ... wn, et nous les agrégeons en une seule valeur de Y en utilisant la fonction d'activation f.
Cette figure est une version simplifiée d'un neurone au sein d'un réseau de neurones artificiels. Chaque entrée ( X_i ) est associée à un poids correspondant ( W_i ), et ces produits sont agrégés pour calculer la sortie ( Y ) du neurone. Le X_i est la valeur d'entrée du signal i (comme le nombre de chambres de la maison, en tant que caractéristique décrivant la maison). Son poids d'importance par w_i correspond à chaque X_i, donc la somme de toutes ces valeurs d'entrée pondérées peut être exprimée comme suit :
$$\phi\left(\sum_{i=1}^{m} w_i x_i\right)$$
Dans cette équation, phi représente la fonction que nous utilisons pour joindre les signaux de différents neurones d'entrée en une seule valeur. Cette fonction est appelée la Fonction d'Activation.
Chaque synapse se voit attribuer un poids, une valeur d'importance. Ces poids et biais constituent la pierre angulaire de l'apprentissage des Réseaux de Neurones. Ces poids et biais déterminent si les signaux sont transmis ou non, ou dans quelle mesure chaque signal est transmis.
Dans le contexte de la prédiction des prix des maisons, après que les caractéristiques d'entrée ont été pondérées selon leur pertinence apprise lors de l'entraînement, la fonction d'activation entre en jeu. Elle prend cette somme pondérée des entrées et applique une opération mathématique spécifique pour produire un score d'activation.
Ce score est une valeur unique qui représente efficacement les informations d'entrée agrégées. Il permet au réseau de prendre des décisions ou des prédictions complexes basées sur les données d'entrée qu'il reçoit.
Essentiellement, les fonctions d'activation sont le mécanisme par lequel les réseaux de neurones convertissent la somme pondérée d'une entrée en une sortie qui a du sens dans le contexte du problème spécifique à résoudre (comme l'estimation du prix d'une maison ici). Elles permettent au réseau d'apprendre des relations non linéaires entre les caractéristiques et les résultats, permettant la prédiction précise de la valeur marchande d'une maison à partir de ses caractéristiques.
La fonction d'activation moderne par défaut ou la plus populaire pour les couches cachées est l'Unité Linéaire Rectifiée (ReLU) ou la fonction Softmax, principalement pour des raisons de précision et de performance. Pour la couche de sortie, la fonction d'activation est principalement choisie en fonction du format des prédictions (probabilité, scalaire, etc.).
Chaque fois que vous envisagez une fonction d'activation, soyez conscient du Problème du Gradient Évanescent (nous reviendrons sur ce sujet plus tard). Cela se produit lorsque les gradients sont trop petits ou trop grands, ce qui peut rendre le processus d'apprentissage difficile.
Certaines fonctions d'activation comme la sigmoïde ou la tanh peuvent provoquer des gradients évanescents dans les réseaux profonds, tandis que certaines d'entre elles peuvent aider à atténuer ce problème.
Examinons maintenant quelques autres types de fonctions d'activation, et quand/comment elles sont utiles.
Fonction d'Activation Linéaire
Une Fonction d'Activation Linéaire peut être exprimée comme suit :
$$f(z) = z$$
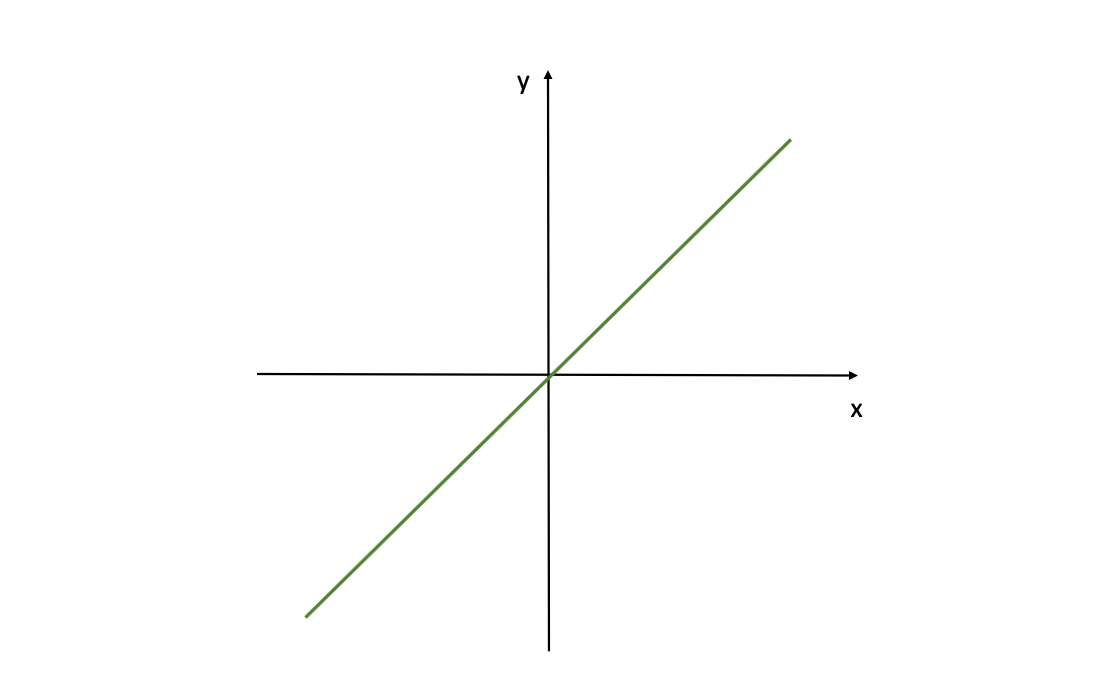
Fonction d'Activation Linéaire (Source de l'Image : LunarTech.ai)
Ce graphique montre une fonction d'activation linéaire pour un réseau de neurones, définie par f(z)=z. Où z est l'entrée (appelée Z-scores comme nous l'avons mentionné précédemment) pour la fonction d'activation f( ). Cela signifie que la sortie est directement proportionnelle à l'entrée.
Les Fonctions d'Activation Linéaires sont les fonctions d'activation les plus simples, et elles sont relativement faciles à calculer. Mais elles ont une limitation importante : les NNs avec seulement des neurones linéaires peuvent être exprimés comme un réseau sans couches cachées – mais les couches cachées dans les NNs sont ce qui leur permet d'apprendre des caractéristiques importantes à partir des signaux d'entrée.
Ainsi, afin d'apprendre des motifs complexes à partir de problèmes complexes, nous avons besoin de Fonctions d'Activation plus avancées plutôt que de Fonctions Linéaires.
Vous pouvez utiliser une fonction linéaire, par exemple, dans la dernière couche de sortie lorsque le résultat brut est suffisant pour vous et que vous ne souhaitez aucune transformation. Mais 99% du temps, cette fonction d'activation est inutile en Apprentissage Profond.
Fonction d'Activation Sigmoïde
L'une des fonctions d'activation les plus populaires est la Fonction d'Activation Sigmoïde, qui peut être exprimée comme suit :
$$f(z) = \frac{1}{1 + e^{-z}}$$
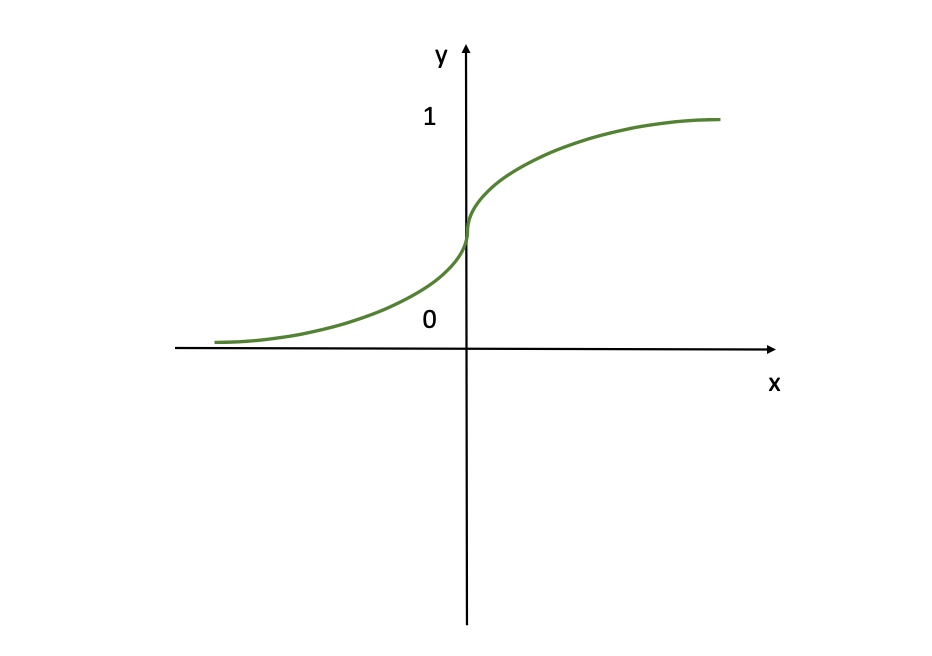
Fonction d'Activation Sigmoïde (Source de l'Image : LunarTech.ai)
Dans cette figure, la fonction d'activation sigmoïde est visualisée, qui est une courbe lisse en forme de S couramment utilisée dans les réseaux de neurones. Si vous êtes familier avec la Régression Logistique, alors cette fonction vous semblera familière également. Cette fonction transforme toutes les valeurs d'entrée en valeurs dans la plage de (0,1) ce qui est très pratique lorsque vous voulez que le modèle fournisse une sortie sous forme de probabilités ou d'un %.
En gros, lorsque le logit est très petit, la sortie d'un neurone logistique est très proche de 0. Lorsque le logit est très grand, la sortie du neurone logistique est plus proche de 1. Entre ces deux valeurs extrêmes, le neurone prend une forme de S. Cette forme de S de la courbe aide également à différencier les sorties qui sont proches de 0 ou proches de 1, fournissant une frontière de décision claire.
Vous utiliserez souvent la Fonction d'Activation Sigmoïde dans la couche de sortie, car elle est idéale pour les cas où l'objectif est d'obtenir une valeur du modèle en sortie entre 0 et 1 (une probabilité par exemple). Donc, si vous avez un problème de classification, envisagez définitivement cette fonction d'activation.
Mais gardez à l'esprit que cette activation est très intensive et qu'un grand nombre de neurones seront activés. C'est aussi pourquoi, pour les unités cachées, l'activation Sigmoïde n'est pas la meilleure option, car elle fixe les grandes valeurs aux limites de 0 et 1, provoquant rapidement la constance des paramètres → pas de gradients (utilisés pour mettre à jour les poids et les facteurs de biais).
C'est le célèbre Problème du Gradient Évanescent (plus de détails à ce sujet dans les prochains chapitres). Cela entraîne l'incapacité du modèle à apprendre avec précision à partir des données et à produire des prédictions précises.
ReLU (Unité Linéaire Rectifiée)
Un type différent de relation non linéaire est découvert lors de l'utilisation de l'Unité Linéaire Rectifiée (ReLU). Cette fonction d'activation est moins stricte et fonctionne bien lorsque votre attention est portée sur les valeurs positives.
La fonction d'activation ReLU active les neurones qui ont des valeurs positives mais désactive les valeurs négatives, contrairement à la fonction Sigmoïde qui active presque tous les neurones. Cette fonction d'activation peut être exprimée comme suit :
$$f(z) = \begin{cases} 0 & \text{si } z < 0 \\ z & \text{si } z \geq 0 \end{cases}$$
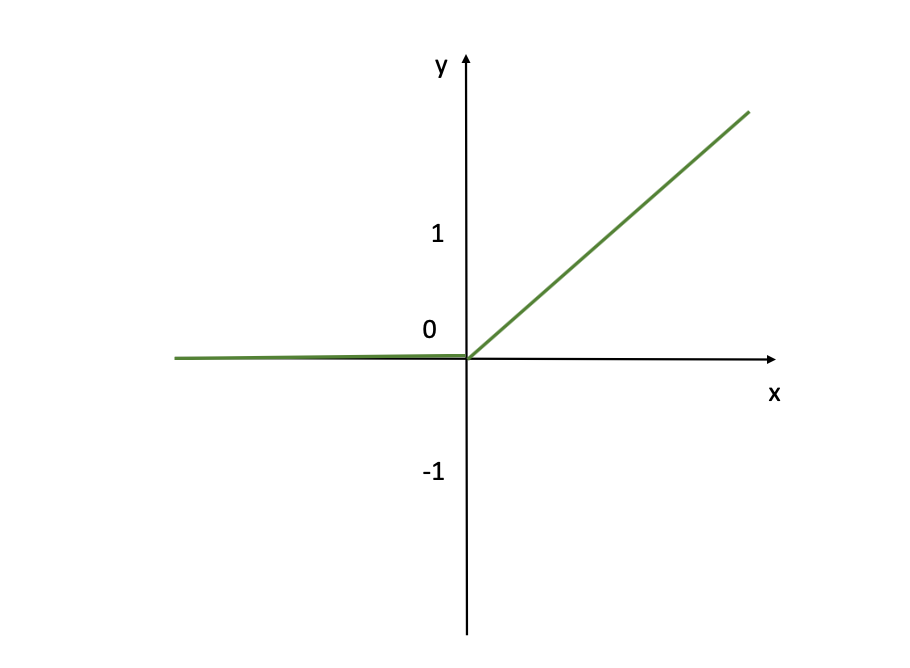
Fonction d'Activation ReLU (Source de l'Image : LunarTech.ai)
Comme vous pouvez le voir ci-dessus à partir de cette visualisation, la fonction d'activation ReLU n'active pas du tout les neurones d'entrée avec des valeurs négatives (vous pouvez voir que pour les x qui sont négatifs, la valeur correspondante de l'axe Y est 0). Alors que pour les entrées positives x, la fonction d'activation retourne la valeur exacte x (Y=X ligne linéaire comme vous le voyez sur la figure). Mais c'est toujours un bon choix par défaut pour les couches cachées. Elle est efficacement calculable et réduit la probabilité de gradients évanescents pendant l'entraînement, surtout pour les réseaux profonds.
Fonction d'Activation Leaky ReLU
Alors que ReLU n'active pas les neurones d'entrée avec des valeurs négatives, Leaky ReLU prend en compte ces valeurs d'entrée négatives. Elle apprend à partir de celles-ci, bien qu'avec un taux plus faible égal à 0,01.
Cette fonction d'activation peut être exprimée comme suit :
$$f(z) = \begin{cases} 0.01z & \text{si } z < 0 \\ z & \text{si } z \geq 0 \end{cases}$$
Ainsi, Leaky ReLU permet un petit gradient non nul lorsque la valeur d'entrée est saturée et non active.
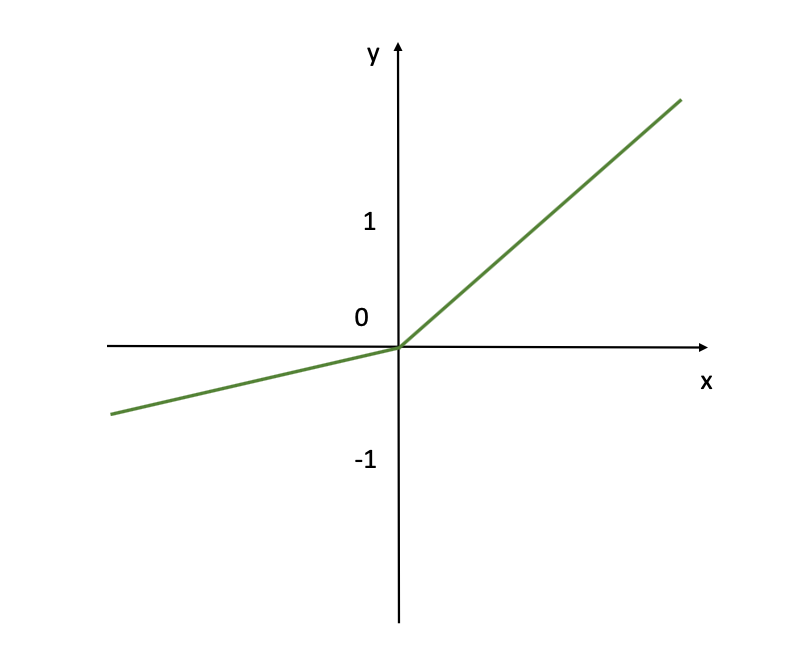
Fonction d'Activation Leaky ReLU (Source de l'Image : LunarTech.ai)
Cette visualisation montre la fonction d'activation Leaky ReLU couramment utilisée dans les réseaux de neurones, en particulier pour les couches cachées et où les activations négatives sont acceptables. Contrairement au ReLU standard, qui donne une sortie de zéro pour toute entrée négative, Leaky ReLU permet une petite sortie non nulle pour les entrées négatives.
Comme ReLU, Leaky ReLU est également un bon choix par défaut pour les couches cachées. Elle est efficacement calculable et réduit la probabilité de gradients évanescents pendant l'entraînement, en particulier pour les réseaux profonds avec plusieurs couches cachées. Nous parlerons davantage de ces fonctions d'activation et des précédentes lors de la discussion sur le Problème du Gradient Évanescent, et si vous souhaitez plus de détails et que le concept soit expliqué dans un tutoriel, consultez les ressources ci-dessous.
Fonction d'Activation Tangente Hyperbolique (Tanh)
La fonction d'activation tangente hyperbolique est souvent simplement appelée fonction Tanh. Elle est très similaire à la fonction d'activation sigmoïde. Elle a même la même représentation en forme de S.
Cette fonction prend n'importe quelle valeur réelle comme valeur d'entrée et produit une valeur dans la plage -1 à 1. Cette fonction d'activation peut être exprimée comme suit :
$$f(z) = \tanh(z) = \frac{e^z - e^{-z}}{e^z + e^{-z}}$$
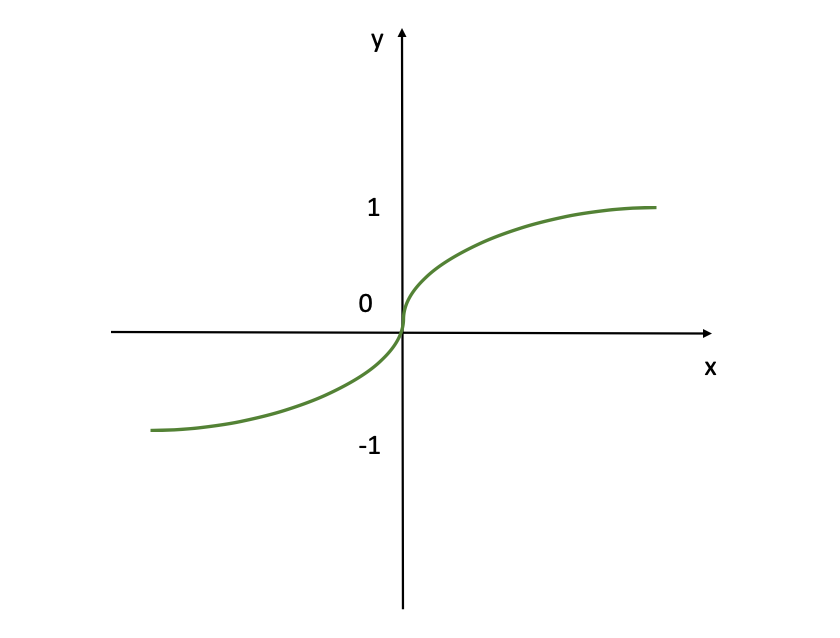
Fonction d'Activation Tanh (Source de l'Image : LunarTech.ai)
La figure montre la fonction d'activation tanh (tangente hyperbolique). Ainsi, cette fonction produit des valeurs allant de -1 à 1, fournissant une sortie normalisée qui peut aider à la convergence des réseaux de neurones pendant l'entraînement. Elle est similaire à la fonction sigmoïde mais est ajustée pour permettre des sorties négatives, ce qui peut être bénéfique pour certains types de réseaux de neurones où la moyenne des sorties doit être centrée autour de zéro.
Note - si vous souhaitez obtenir plus de détails sur ces fonctions d'activation, consultez ce tutoriel où je couvre ce concept plus en détail à l'adresse "Qu'est-ce qu'une Fonction d'Activation" et "Comment Résoudre le Problème du Gradient Évanescent".
Encore une fois, la fonction d'activation par défaut ou la plus populaire pour les couches cachées est l'Unité Linéaire Rectifiée (ReLU) ou la fonction Softmax, principalement pour des raisons de précision/performance. Pour la couche de sortie, la fonction d'activation est principalement choisie en fonction du format des prédictions (probabilité, scalaire, etc.).
Chapitre 3 : Comment Entraîner les Réseaux de Neurones
L'entraînement des réseaux de neurones est un processus systématique qui implique deux processus principaux, effectués de manière répétée, appelés passes avant et arrière.
Tout d'abord, les données passent par la Passe Avant jusqu'à la sortie. Ensuite, elle est suivie par une passe arrière. L'idée derrière ce processus est de parcourir le réseau à plusieurs reprises pour ajuster les poids et minimiser les fonctions de perte ou de coût.
Pour mieux comprendre, nous allons examiner un Réseau de Neurones simple où nous avons 3 signaux d'entrée, et une seule couche cachée qui a 4 unités cachées. Cela peut être visualisé comme suit :
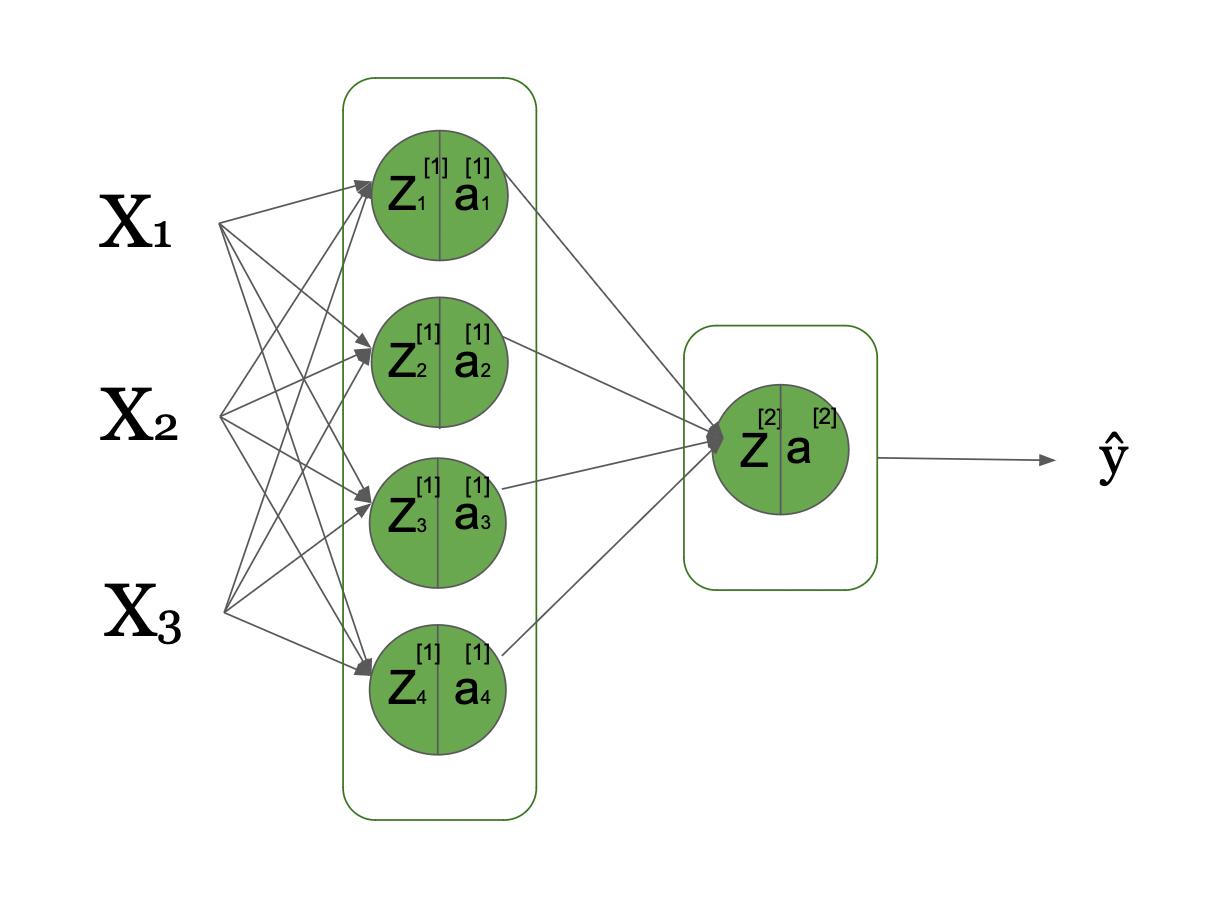
De la Couche d'Entrée à travers les Couches Cachées jusqu'à la Prédiction (Source de l'Image : LunarTech.ai)
Ici, vous pouvez voir que nous avons 3 signaux d'entrée dans notre couche d'entrée, 1 couche cachée avec 4 unités cachées, et 1 couche de sortie. Il s'agit d'un graphe de calcul visualisant ce réseau de neurones de base et la manière dont l'information circule de la gauche, les entrées initiales, vers la droite, jusqu'à la prédiction Y^ (Y hat), après être passée par plusieurs transformations.

Propagation Avant et Arrière dans les Réseaux de Neurones (Source de l'Image : LunarTech.ai)
Maintenant, examinons cette figure qui montre l'idée générale du flux d'informations.
Nous partons de l'entrée X (que nous définissons par A[0] comme les activations initiales)
Ensuite, à chaque étape (indexée par [1]) nous prenons la matrice des poids (W[1] et le vecteur de biais b[1]) et calculons les scores Z (Z[1])
Ensuite, nous appliquons la fonction d'activation pour obtenir les scores d'activation (A[1]) au niveau [1]. Cela se produit à l'étape de temps 1, qui dans notre exemple est la couche cachée 1.
Comme nous obtenons une seule couche, l'étape suivante est la couche de sortie, où les informations de la couche précédente (A[1]) sont utilisées pour calculer les nouveaux scores Z[2] en combinant l'entrée A[1] de la couche précédente et avec W[2] / b[2] de cette couche. Nous appliquons ensuite une autre couche d'activation (notre fonction d'activation de la couche de sortie) sur le Z[2] nouvellement calculé pour calculer le A[2].
Comme le A[2] est dans la couche de sortie, cela nous donne notre prédiction, Y_hat. C'est la Passe Avant ou Propagation Avant.
Ensuite, vous pouvez voir dans la deuxième partie de la figure, nous passons de Y_hat à tous ces termes qui sont en quelque sorte les mêmes que dans la passe avant mais avec une différence cruciale : ils ont tous un "d" devant eux, qui fait référence à la "dérivée".
Ainsi, après que Y_hat est produit, nous obtenons nos prédictions, et le réseau est capable de comparer le Y_hat (valeurs prédites de la variable de réponse y, dans notre exemple le prix de la maison) aux vrais prix des maisons Y et d'obtenir la fonction de perte.
Si vous souhaitez en savoir plus sur les fonctions de perte, consultez ici ou ce tutoriel.
Ensuite, le réseau calcule la dérivée de la fonction de perte par rapport aux activations A et au score Z (dA et dZ). Ensuite, il utilise ceux-ci pour calculer les gradients/dérivées par rapport aux poids W et aux biais b (dW et db).
Cela se produit également par couche et de manière séquentielle, mais comme vous pouvez le voir à partir de la flèche dans la figure ci-dessus, cette fois cela se produit à l'envers de droite à gauche contrairement à la propagation avant.
C'est aussi pourquoi nous appelons ce processus rétropropagation. Les gradients de la couche 2 contribuent au calcul des gradients dans la couche 1, comme vous pouvez également le voir à partir du graphe.
Passe Avant
La propagation avant est le processus d'alimentation des données d'entrée à travers un réseau de neurones pour générer une sortie. Nous définirons les données d'entrée par X qui contient 3 caractéristiques X1, X2, X3 qui peuvent être décrites mathématiquement comme suit :
zi=𝜏Txi+b
𝟓
y^i=ai=𝜹(zi)
𝟓
l(ai,yi)
Où dans ces équations nous passons de l'entrée x_i dans notre réseau de neurones simple, au calcul de la perte.
Décomposons-les :
Étape 1 : Chaque neurone dans les couches suivantes calcule une somme pondérée de ses entrées (x^i) plus un terme de biais b. Nous appelons cela un score z^i. Les entrées sont les sorties des neurones de la couche précédente, et les poids ainsi que le biais sont les paramètres que le réseau de neurones vise à apprendre et à estimer.
Étape 2 : Ensuite, en utilisant une fonction d'activation, que nous désignons par la lettre grecque delta, le réseau transforme les scores Z en une nouvelle valeur que nous définissons par a^i. Notez que la valeur d'activation au passage initial lorsque nous sommes à la couche initiale dans le réseau (couche 0) est égale à x^i. C'est alors la valeur prédite dans ce passage spécifique.
Pour être plus précis, compliquons un peu notre notation. Nous définirons chaque score dans la première couche cachée, couche [1], par unité (car nous avons 4 unités dans cette unité cachée) et généraliserons cela par unité cachée i :
zi[1]=(𝜏i[1])Tx+(bi[1])Tfor𝟶i=1,2,3,4
ai[1]=𝜹(zi[1])
Réécrivons maintenant cela en utilisant l'Algèbre Linéaire et spécifiquement les opérations de matrices et de vecteurs :
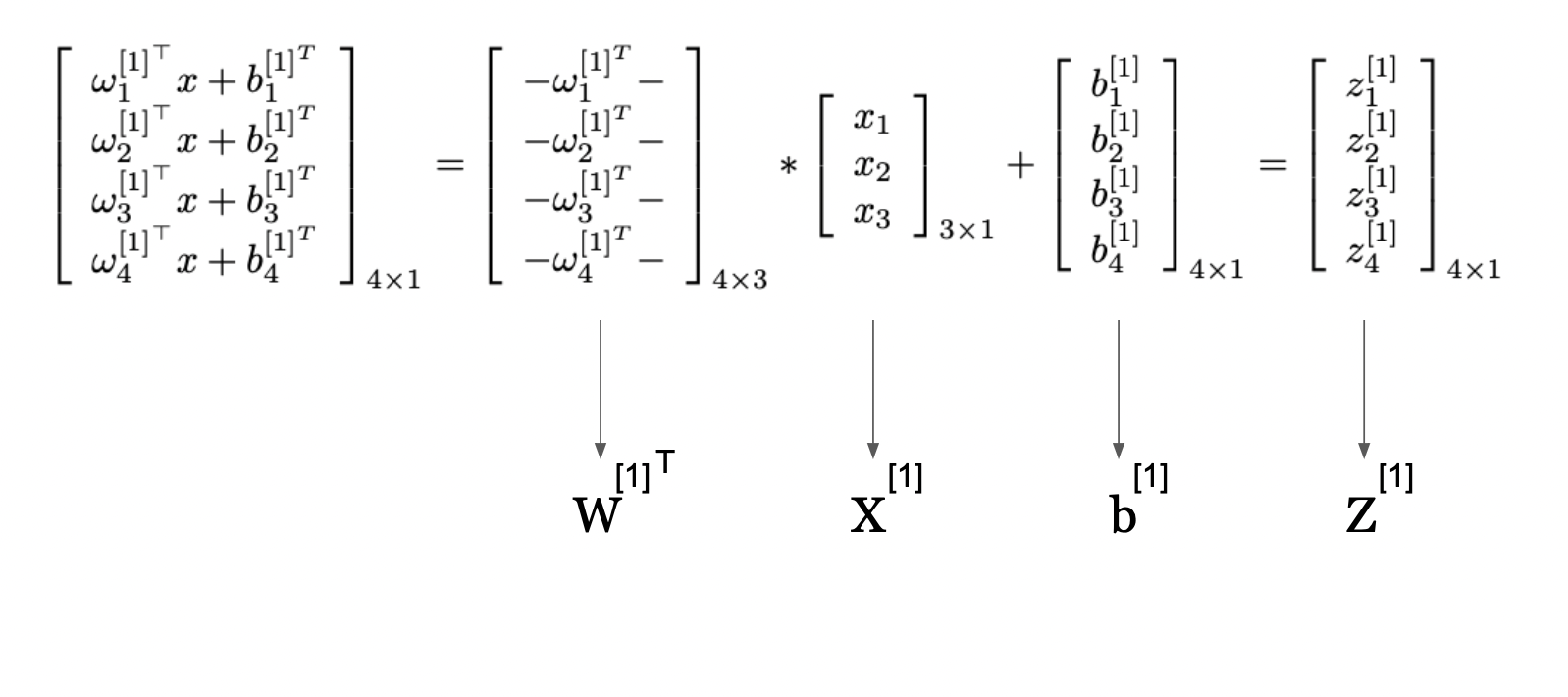
Opérations de Matrices dans les Calculs de Réseaux de Neurones (Source de l'Image : LunarTech.ai)
Cette image présente une manière de représenter les calculs dans une couche de réseau de neurones en utilisant des opérations de matrices de l'Algèbre Linéaire. Elle montre comment les calculs individuels pour chaque neurone dans une couche peuvent être exprimés de manière compacte et effectués simultanément en utilisant la multiplication de matrices et la sommation.
La matrice étiquetée W^[1] contient les poids appliqués aux entrées pour chaque neurone dans la première couche cachée. Le vecteur X[1] est l'entrée de la couche. En multipliant la matrice des poids par le vecteur d'entrée puis en ajoutant le vecteur de biais b[1], nous obtenons le vecteur Z[1], que nous avons également appelé score Z précédemment et qui représente la somme pondérée des entrées plus le biais pour chaque neurone.
Cette forme compacte nous permet d'utiliser des routines efficaces d'algèbre linéaire pour calculer les sorties de tous les neurones de la couche en une seule fois.
Cette approche est fondamentale dans les réseaux de neurones car elle permet le traitement des entrées à travers plusieurs couches de manière efficace, permettant aux réseaux de neurones de s'adapter à un grand nombre de neurones et à des architectures complexes.
Ainsi, nous passons du niveau unitaire à la représentation des transformations dans nos réseaux de neurones simples en utilisant la multiplication de matrices et les sommations de l'Algèbre Linéaire.
Activation de la Première Couche
Maintenant, examinons cette équation qui montre l'idée générale du flux d'informations lorsque nous passons de l'entrée X[1] (que nous définissons par A[0] comme les activations initiales) puis par étape (indexée par [1]) nous prenons la matrice des poids (W[1] et le vecteur de biais b[1]) et calculons les scores Z (Z[1]). Ensuite, nous appliquons la fonction d'activation de la couche 1, g[1] pour obtenir les scores d'activation (A[1]) au niveau [1]. Cela se produit à l'étape de temps 1, qui dans notre exemple est la couche cachée 1.
Activation de la Deuxième Couche (Couche de Sortie)
Comme nous obtenons une seule couche, l'étape suivante est la couche de sortie, où les informations de la couche précédente (A[1]) sont utilisées pour calculer les nouveaux scores Z[2] en combinant l'entrée A[1] de la couche précédente et avec W[2] / b[2] de cette couche. Nous appliquons ensuite une autre fonction d'activation g[2] (notre fonction d'activation de la couche de sortie) sur le Z[2] nouvellement calculé pour calculer le A[2].
Après que la fonction d'activation a été appliquée, elle peut ensuite être alimentée dans la couche suivante du réseau s'il y en a une, ou directement dans la couche de sortie si c'est un réseau à une seule couche cachée. Comme dans notre cas, la couche 2 est notre couche de sortie, nous sommes prêts à passer à Y_hat, nos prédictions.
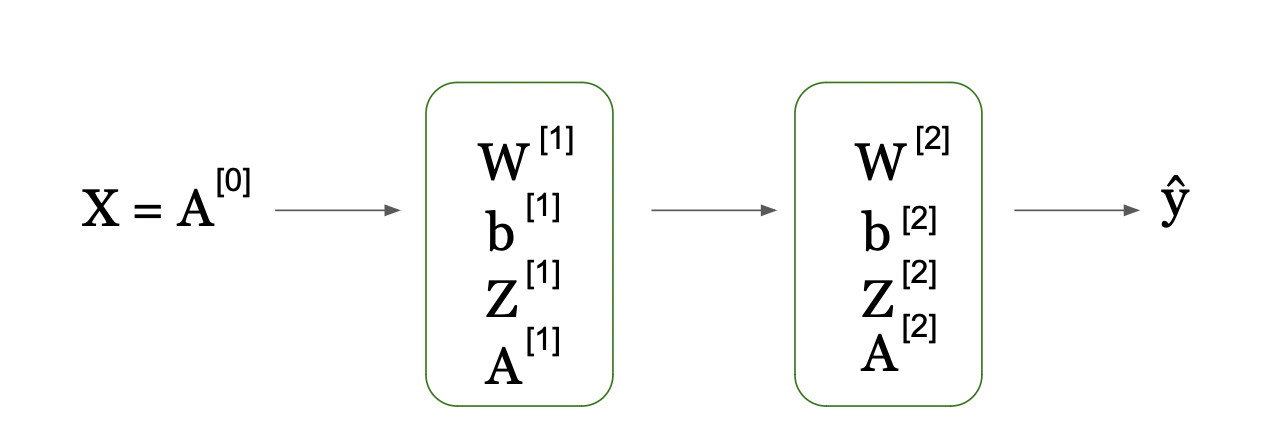
Flux de Données Séquentiel à Travers les Couches du Réseau de Neurones (Source de l'Image : LunarTech.ai)
Cette image montre une manière de représenter les calculs dans une couche de réseau de neurones en utilisant des opérations de matrices. Elle montre comment les calculs individuels pour chaque neurone dans une couche de réseau de neurones peuvent être exprimés de manière compacte, effectués simultanément par multiplication de matrices et addition.
Ici, la matrice étiquetée W[1] contient les poids appliqués aux entrées pour chaque neurone dans la première couche cachée. Le vecteur X[1] est l'entrée de cette couche. En multipliant la matrice des poids par le vecteur d'entrée puis en ajoutant le vecteur de biais b[1], nous obtenons le vecteur Z[1], qui représente la somme pondérée des entrées plus le biais pour chaque neurone.
Cette forme compacte nous permet d'utiliser des routines efficaces d'algèbre linéaire pour calculer les sorties de tous les neurones de la couche en une seule fois. Le vecteur résultant Z[1] est ensuite passé à travers une fonction d'activation (non montrée dans cette partie de l'image), qui effectue une transformation non linéaire sur chaque élément, résultant en la sortie finale de la couche.
Cette approche est fondamentale dans les réseaux de neurones car elle permet le traitement des entrées à travers plusieurs couches de manière efficace, permettant aux réseaux de neurones de s'adapter à un grand nombre de neurones et à des architectures complexes.
Calcul de la Fonction de Perte
Comme le A[2] est dans la couche de sortie, cela nous donne notre prédiction, Y_hat. Après que Y_hat est produit, nous avons nos prédictions, et le réseau est capable de comparer le Y_hat (valeurs prédites de la variable de réponse y, dans notre exemple le prix de la maison) aux vrais prix des maisons Y, et d'obtenir la fonction de perte J. La perte totale peut être calculée comme suit :
où log() est le logarithme utilisé pour calculer cette fonction de perte.
Passe Arrière
La rétropropagation est une partie cruciale du processus d'entraînement d'un réseau de neurones. Combinée avec des algorithmes d'optimisation comme la Descente de Gradient (GD), la Descente de Gradient Stochastique (SGD), ou Adam, ils effectuent la Passe Arrière.
La rétropropagation est un algorithme efficace pour calculer le gradient de la fonction de coût (perte) (J) par rapport à chaque paramètre (poids & biais) dans le réseau.
Ainsi, pour être clair, la rétropropagation est le processus réel de calcul des gradients dans le modèle, et ensuite la Descente de Gradient est l'algorithme qui prend les gradients en entrée et met à jour les paramètres.
Lorsque nous calculons les gradients et les utilisons pour mettre à jour les paramètres dans le modèle, cela nous aide à mettre à jour les paramètres et à les diriger vers une direction plus correcte pour trouver l'optimum global afin de minimiser. Cela aide à minimiser davantage la fonction de perte et à améliorer la précision de prédiction du modèle.
À chaque passe, après que la propagation avant est terminée, les gradients doivent être obtenus. Ensuite, nous les utilisons pour obtenir les paramètres du modèle, tels que les paramètres de poids et de biais.
Regardons un exemple de calculs de gradients pour la rétropropagation dans un réseau de neurones que nous avons vu dans la Propagation Avant avec une seule couche cachée et 4 unités cachées.
La rétropropagation commence toujours par la fin, alors visualisons-la pour vous aider à comprendre ce processus :
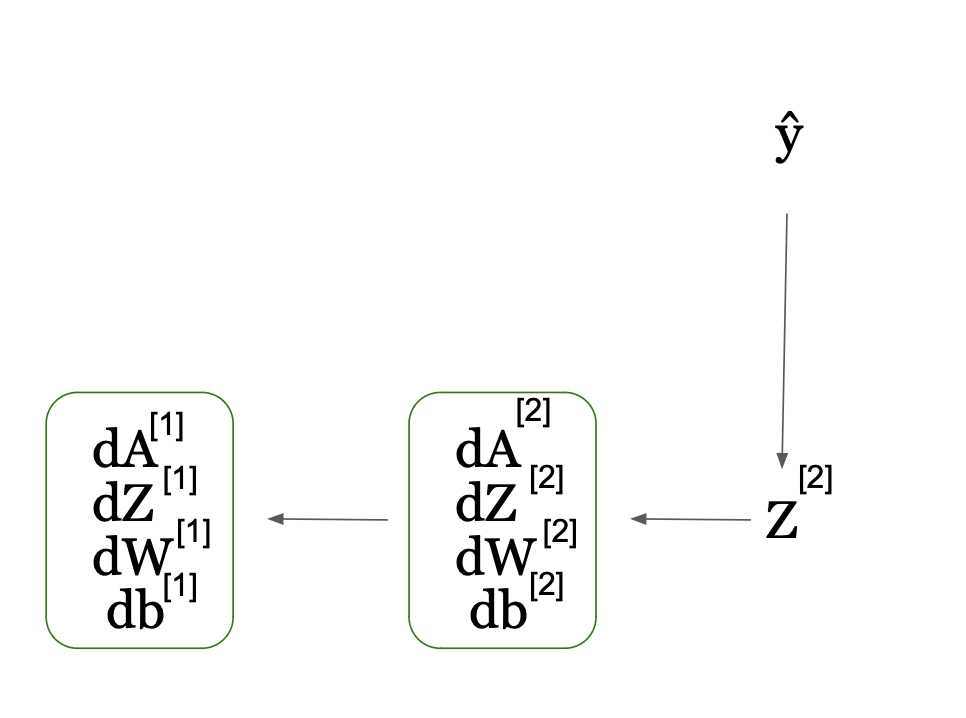
Processus de Rétropropagation dans les Réseaux de Neurones : Calcul des Gradients (Source de l'Image : LunarTech.ai)
Dans cette figure, le réseau calcule la dérivée de la fonction de perte par rapport aux activations A et au score Z (dA et dZ). Il utilise ensuite ceux-ci pour calculer les gradients/dérivées par rapport aux poids W et aux biais b (dW et db). Cela se produit également par couche et de manière séquentielle, mais comme vous pouvez le voir à partir de la flèche dans la figure, cette fois cela se produit à l'envers de droite à gauche contrairement à la propagation avant.
C'est aussi pourquoi nous appelons ce processus rétropropagation. Les gradients de la couche 2 contribuent au calcul des gradients dans la couche 1 comme vous pouvez également le voir à partir du graphe.
Ainsi, l'idée est que nous calculons les gradients par rapport à l'activation (dA[2]), puis par rapport à la pré-activation (dZ[2]), et par rapport aux poids (dW[2]) et au biais (db[2]) de la couche de sortie, en supposant que nous avons une fonction de coût J après avoir calculé le Y^. Assurez-vous de toujours mettre en cache les Z[i] car ils sont nécessaires dans ce processus.
Mathématiquement, les gradients peuvent être calculés en utilisant les règles de différentiation courantes, y compris l'obtention de la dérivée du logarithme, et en utilisant la Règle de la Somme et les Règles de la Chaîne. Le premier gradient dA[2] peut être exprimé comme suit :
Le gradient suivant que nous devons calculer est le gradient de la fonction de coût par rapport à Z[2], c'est-à-dire dZ[2].
Nous savons ce qui suit :
A[2]=𝜹(Z[2])𝟰
dJdA[2]=dA[2]dZ[2]𝟰
dA[2]dZ[2]=𝜹𝟲(Z[2])
Ainsi, A[2] = 𝜹(Z[2]), nous pouvons alors utiliser ces dérivées de la fonction sigmoïde 𝜹'(Z[2]) = 𝜹(Z[2]) * (1 - 𝜹(Z[2])). Cela peut être dérivé mathématiquement comme suit :
$$\begin{align*} \frac{dZ^{[2]}}{dJ} &= \frac{dJ}{dZ^{[2]}} \\ \downarrow \\ \frac{dZ^{[2]}}{dJ} &= \frac{dJ}{dA^{[2]}} \cdot \frac{dA^{[2]}}{dZ^{[2]}} \quad \text{en utilisant la règle de la chaîne} \\ \downarrow \\ \frac{dZ^{[2]}}{dJ} &= dA^{[2]} \cdot \sigma'(Z^{[2]}) \\ \downarrow \\ \frac{dZ^{[2]}}{dJ} &= dA^{[2]} \cdot A^{[2]} \cdot (1 - A^{[2]}) \end{align*}$$
$$\begin{align*} \sigma(Z^{[2]}) &= \frac{1}{1 - e^{Z^{[2]}}} = (1 - e^{-Z^{[2]}})^{-1} \\ \downarrow \\ \sigma'(Z^{[2]}) &= \frac{d\sigma(Z^{[2]})}{dZ^{[2]}} \\ \downarrow \\ \sigma'(Z^{[2]}) &= -\frac{-1}{(1 - e^{Z^{[2]}})^2} \cdot (-1) \cdot e^{Z^{[2]}} \\ \downarrow \\ \sigma'(Z^{[2]}) &= \frac{1}{1 - e^{Z^{[2]}}} \cdot \frac{e^{Z^{[2]}}}{1 - e^{Z^{[2]}}} \\ \downarrow \\ \sigma'(Z^{[2]}) &= \sigma(Z^{[2]}) \cdot (1 - \sigma(Z^{[2]})) = A^{[2]} \cdot (1 - A^{[2]}) \end{align*}$$
Maintenant que nous savons le comment et le pourquoi derrière le calcul du gradient par rapport au score Z, nous pouvons calculer le gradient par rapport au poids W. Cela est très important pour la mise à jour de la valeur du paramètre de poids (par exemple, la direction).
$$\begin{align*} Z^{[2]} &= W^{[2]T} \cdot A^{[1]} + b^{[2]} \\ \downarrow \\ \frac{db^{[2]}}{dZ^{[2]}} &= \frac{dJ}{dZ^{[2]}} \cdot \frac{dZ^{[2]}}{db^{[2]}} \quad \text{en utilisant la règle de la chaîne} \\ \downarrow \\ db^{[2]} &= dZ^{[2]} \cdot 1 + 0 \quad \text{en utilisant la règle de la constante} \\ \downarrow \\ db^{[2]} &= dZ^{[2]} \end{align*}$$
Maintenant, dans cette étape, la seule chose restante est de calculer le gradient par rapport au biais, notre deuxième paramètre b, dans la couche cachée, couche 2.
$$\begin{align*} Z^{[2]} = W^{[2]T} \cdot A^{[1]} + b^{[2]} \\ \frac{db^{[2]}}{dJ} = \frac{dJ}{dZ^{[2]}} \cdot \frac{dZ^{[2]}}{db^{[2]}} \quad \text{en utilisant la règle de la chaîne} \\ db^{[2]} = dZ^{[2]} \cdot 1 + 0 \quad \text{en utilisant la règle de la constante} \\ db^{[2]} = dZ^{[2]} \end{align*}$$
Puisque b[2] est un terme de biais, sa dérivée est simplement la somme des gradients dZ[2] sur tous les exemples d'entraînement (ce qui, dans une implémentation vectorisée, est souvent fait en sommant dZ[2] sur les m observations).
Une fois la rétropropagation terminée, l'étape suivante est d'utiliser ces gradients comme entrée pour un algorithme d'optimisation comme GD, SGD, ou d'autres pour déterminer comment les paramètres doivent être mis à jour.
Ainsi, nous sommes enfin prêts à mettre à jour les paramètres de Poids et de Biais du modèle dans cette passe.
Voici un exemple utilisant l'algorithme GD :
$$W^{[2]} = W^{[2]} - \eta \cdot dW^{[2]}$$
$$b^{[2]} = b^{[2]} - \eta \cdot db^{[2]}$$
Ici, le 𝜇 représente le paramètre d'apprentissage en supposant l'algorithme d'optimisation GD simple (plus sur les algorithmes d'optimisation dans les chapitres suivants).
Dans la section suivante, nous entrerons dans plus de détails sur la manière dont vous pouvez utiliser divers algorithmes d'optimisation pour entraîner des modèles d'Apprentissage Profond.
Chapitre 4 : Algorithmes d'Optimisation en IA
Une fois le gradient calculé via la rétropropagation, l'étape suivante consiste à utiliser un algorithme d'optimisation pour ajuster les poids afin de minimiser la fonction de coût.
Pour être clair, l'algorithme d'optimisation prend en entrée les gradients calculés et utilise ceux-ci pour mettre à jour les paramètres du modèle.
Ce sont les algorithmes d'optimisation les plus populaires utilisés lors de l'entraînement des Réseaux de Neurones :
Descente de Gradient (GD)
Descente de Gradient Stochastique (SGD)
SGD avec Momentum
RMSProp
Optimiseur Adam
Connaître les fondamentaux des modèles d'Apprentissage Profond et apprendre à entraîner ces modèles est définitivement une grande partie de l'Apprentissage Profond. Si vous avez lu jusqu'ici et que les mathématiques ne vous ont pas fatigué, félicitations ! Vous avez saisi certains sujets difficiles. Mais ce n'est qu'une partie du travail.
Pour utiliser votre modèle d'Apprentissage Profond pour résoudre des problèmes réels, vous devrez l'optimiser après avoir établi sa base. C'est-à-dire que vous devez optimiser l'ensemble des paramètres dans votre modèle de Machine Learning pour trouver l'ensemble des paramètres optimaux qui donnent le modèle le plus performant (toutes choses étant égales par ailleurs).
Ainsi, pour optimiser ou ajuster votre modèle de Machine Learning, vous devez effectuer une optimisation des hyperparamètres. En trouvant la combinaison optimale des valeurs des hyperparamètres, nous pouvons diminuer les erreurs que le modèle produit et construire le réseau de neurones le plus précis.
Un hyperparamètre d'un modèle est une constante dans le modèle. Il est externe au modèle, et sa valeur ne peut pas être estimée à partir des données (mais doit plutôt être spécifiée à l'avance avant que le modèle ne soit entraîné). Par exemple, les paramètres de poids et de biais dans un réseau de neurones sont des paramètres que nous voulons optimiser.
NOTE : Comme les algorithmes d'optimisation sont utilisés dans tous les réseaux de neurones, j'ai pensé qu'il serait utile de vous fournir le code Python que vous pouvez implémenter pour effectuer manuellement l'optimisation des réseaux de neurones.
Gardez simplement à l'esprit que ce n'est pas ce que vous ferez en pratique, car il existe des bibliothèques à cet effet. Néanmoins, voir le code Python vous aidera à comprendre le fonctionnement réel de ces algorithmes comme GD, SGD, SGD avec Momentum, Adam, AdamW beaucoup mieux.
Je vous fournirai les formules, les explications, ainsi que le code Python afin que vous puissiez voir le code Python derrière les fonctions réelles des bibliothèques qui implémentent ces algorithmes d'optimisation.
Descente de Gradient (GD)
L'algorithme de Descente de Gradient par Lots (souvent appelé simplement Descente de Gradient ou GD), calcule le gradient de la Fonction de Perte J(𝜇) par rapport au paramètre cible en utilisant l'ensemble des données d'entraînement.
Nous faisons cela en prédisant d'abord les valeurs pour toutes les observations à chaque itération, et en les comparant à la valeur donnée dans les données d'entraînement.
Ces deux valeurs sont utilisées pour calculer le terme d'erreur de prédiction par observation qui est ensuite utilisé pour mettre à jour les paramètres du modèle. Ce processus se poursuit jusqu'à ce que le modèle converge.
Le gradient ou la première dérivée de la fonction de perte peut être exprimé comme suit :
$$\nabla_{\theta} J(\theta)$$
Ensuite, ce gradient est utilisé pour mettre à jour la valeur des itérations précédentes du paramètre cible. C'est-à-dire :
$$\theta = \theta - \eta \cdot \nabla_{\theta} J(\theta)$$
Dans cette équation :
𝜇 représente le(s) paramètre(s) ou le(s) poids(s) d'un modèle que vous essayez d'optimiser. Dans de nombreux contextes, en particulier dans les réseaux de neurones, 𝜇 peut être un vecteur contenant de nombreux poids individuels.
𝜇 est le taux d'apprentissage. C'est un hyperparamètre qui dicte la taille du pas à chaque itération tout en se déplaçant vers un minimum de la fonction de coût. Un taux d'apprentissage plus petit peut rendre l'optimisation plus précise, mais pourrait également ralentir le processus de convergence. Un taux d'apprentissage plus grand peut accélérer la convergence, mais risque de dépasser le minimum. Cela peut être [0,1] mais est généralement un nombre entre (0,001 et 0,04)
𝜵_J_(𝜇) est le gradient de la fonction de coût J par rapport au paramètre 𝜇. Il indique la direction et l'amplitude de l'augmentation la plus raide de J. En soustrayant cela de la valeur actuelle du paramètre (multipliée par le taux d'apprentissage), nous ajustons 𝜇 dans la direction de la diminution la plus raide de J.
En termes de Réseaux de Neurones, dans la section précédente nous avons vu l'utilisation de cette technique d'optimisation simple.
Il y a deux inconvénients majeurs à la GD qui rendent cette technique d'optimisation peu populaire, surtout lorsqu'il s'agit de grands ensembles de données complexes.
Puisque dans chaque itération l'ensemble des données d'entraînement doit être utilisé et stocké, le temps de calcul peut être très long, ce qui entraîne un processus incroyablement lent. En plus de cela, le stockage de cette grande quantité de données entraîne des problèmes de mémoire, rendant la GD lourde et lente en termes de calcul.
Vous pouvez en apprendre plus dans ce Tutoriel d'Entretien sur la Descente de Gradient.
Descente de Gradient en Python
Regardons un exemple de l'utilisation de la Descente de Gradient en Python :
def update_parameters_with_gd(parameters, grads, learning_rate):
"""
Met à jour les paramètres en utilisant une règle de mise à jour simple de descente de gradient.
Arguments :
parameters -- dictionnaire python contenant vos paramètres
(par exemple, {"W1": W1, "b1": b1, "W2": W2, "b2": b2, ..., "WL": WL, "bL": bL})
grads -- dictionnaire python contenant vos gradients pour mettre à jour chaque paramètre
(par exemple, {"dW1": dW1, "db1": db1, "dW2": dW2, "db2": db2, ..., "dWL": dWL, "dbL": dbL})
learning_rate -- le taux d'apprentissage, scalaire.
Retourne :
parameters -- dictionnaire python contenant vos paramètres mis à jour
"""
L = len(parameters) // 2 # nombre de couches dans les réseaux de neurones
# Règle de mise à jour pour chaque paramètre
for l in range(L):
parameters["W" + str(l+1)] -= learning_rate * grads["dW" + str(l+1)]
parameters["b" + str(l+1)] -= learning_rate * grads["db" + str(l+1)]
return parameters
Il s'agit d'un extrait de code Python implémentant l'algorithme de descente de gradient (GD) pour la mise à jour des paramètres dans un réseau de neurones qui prend ces trois arguments :
parameters : dictionnaire contenant les paramètres actuels du réseau de neurones (par exemple, poids et biais pour chaque couche du réseau de neurones)
grads : dictionnaire contenant les gradients des paramètres, calculés pendant la rétropropagation
learning_rate : valeur scalaire représentant le taux d'apprentissage, qui contrôle la taille du pas des mises à jour des paramètres.
Ce code parcourt les couches du réseau de neurones et met à jour les poids (W) et les biais (b) pour chaque couche en utilisant la règle de mise à jour suivante pour chaque paramètre :
Après avoir parcouru toutes les couches du réseau de neurones, il retourne les paramètres mis à jour. Ce processus aide le réseau de neurones à apprendre et à ajuster ses paramètres pour minimiser la perte pendant l'entraînement, améliorant finalement ses performances et résultant en des prédictions très précises.
Descente de Gradient Stochastique (SGD)
La méthode de Descente de Gradient Stochastique (SGD), également connue sous le nom de Descente de Gradient Incrémentale, est une approche itérative pour résoudre les problèmes d'optimisation avec une fonction objectif différentielle, exactement comme la GD.
Mais contrairement à la GD, la SGD n'utilise pas l'ensemble du lot de données d'entraînement pour mettre à jour la valeur du paramètre à chaque itération. La méthode SGD est souvent appelée approximation stochastique de la descente de gradient. Elle vise à trouver les points extrêmes ou zéro de la fonction stochastique contenant des paramètres qui ne peuvent pas être estimés directement.
La SGD minimise cette fonction de coût en parcourant les données de l'ensemble de données d'entraînement et en mettant à jour les valeurs des paramètres à chaque itération.
Dans la SGD, tous les paramètres du modèle sont améliorés à chaque étape d'itération avec un seul échantillon d'entraînement ou un mini-lot. Ainsi, au lieu de parcourir tous les échantillons d'entraînement à la fois pour modifier les paramètres du modèle, l'algorithme SGD améliore les paramètres en regardant un seul ensemble d'entraînement aléatoirement échantillonné (d'où le nom Stochastique, qui signifie "impliquant le hasard ou la probabilité").
Il ajuste les paramètres dans la direction opposée du gradient par un pas proportionnel au taux d'apprentissage. La mise à jour à l'étape de temps t peut être donnée par la formule suivante :
$$\theta_{t+1} = \theta_t - \eta \nabla_{\theta} J(\theta_t)$$
Dans cette équation :
𝜇 représente le(s) paramètre(s) ou le(s) poids(s) d'un modèle que vous essayez d'optimiser. Dans de nombreux contextes, en particulier dans les réseaux de neurones, 𝜇 peut être un vecteur contenant de nombreux poids individuels.
𝜇 est le taux d'apprentissage. C'est un hyperparamètre qui dicte la taille du pas à chaque itération tout en se déplaçant vers un minimum de la fonction de coût. Un taux d'apprentissage plus petit peut rendre l'optimisation plus précise mais pourrait également ralentir le processus de convergence. Un taux d'apprentissage plus grand peut accélérer la convergence mais risque de dépasser le minimum.
𝜵_J_(𝜇t) est le gradient de la fonction de coût J par rapport au paramètre 𝜇 pour une entrée donnée x(i) et sa sortie cible correspondante y(i) à l'étape t. Il indique la direction et l'amplitude de l'augmentation la plus raide de J. En soustrayant cela de la valeur actuelle du paramètre (multipliée par le taux d'apprentissage), nous ajustons 𝜇 dans la direction de la diminution la plus raide de J.
x(i) représente le ième échantillon de données d'entrée de votre ensemble de données.
y(i) est la vraie sortie cible pour le ième échantillon de données d'entrée.
Dans le contexte de la Descente de Gradient Stochastique (SGD), la règle de mise à jour s'applique aux échantillons de données individuels x(i) et y(i) plutôt qu'à l'ensemble de données, ce qui serait le cas pour la Descente de Gradient par lots.
Cette seule étape améliore la vitesse du processus de recherche des minima globaux du problème d'optimisation et c'est ce qui différencie la SGD de la GD. Ainsi, la SGD ajuste de manière cohérente les paramètres en tentant de se déplacer dans la direction du minimum global de la fonction objectif.
Dans la SGD, tous les paramètres du modèle sont améliorés à chaque étape d'itération avec un seul échantillon d'entraînement. Ainsi, au lieu de parcourir tous les échantillons d'entraînement à la fois pour modifier les paramètres du modèle, la SGD améliore les paramètres en regardant un seul échantillon d'entraînement.
Bien que la SGD aborde le problème du temps de calcul lent de la GD, car elle s'adapte bien aux grandes données et à la taille du modèle, elle est connue comme un "mauvais optimiseur" car elle est sujette à trouver un optimum local au lieu d'un optimum global.
La SGD peut être bruyante en raison de cette nature stochastique, car elle utilise des gradients calculés à partir d'un sous-ensemble des données (un mini-lot ou un point unique). Cela peut entraîner une variance dans les mises à jour des paramètres.
Pour plus de détails sur la SGD, vous pouvez consulter ce tutoriel.
Exemple de SGD en Python
Maintenant, voyons comment l'implémenter en Python :
def update_parameters_with_sgd(parameters, grads, learning_rate):
"""
Met à jour les paramètres en utilisant SGD
Arguments d'entrée :
parameters -- dictionnaire contenant vos paramètres (par exemple, poids, biais)
grads -- dictionnaire contenant les gradients pour mettre à jour chaque paramètre
learning_rate -- le taux d'apprentissage, scalaire.
Sortie :
parameters -- dictionnaire contenant vos paramètres mis à jour
"""
for key in parameters:
# Règle de mise à jour pour chaque paramètre
parameters[key] = parameters[key] - learning_rate * grads['d' + key]
return parameters
Voici ce qui se passe dans ce code :
parametersest un dictionnaire qui contient les poids et les biais de votre réseau (par exemple,parameters['W1'],parameters['b1'], et ainsi de suite)gradscontient les gradients des poids et des biais (par exemple,grads['dW1'],grads['db1'], et ainsi de suite).La fonction
initialize_velocity()est utilisée pour créer le dictionnaire de vitesse avant de commencer à entraîner le réseau avec le momentum.La fonction
update_parameters_with_momentum()utilise ensuite cette vitesse en conjonction avec les gradients pour mettre à jour les paramètres.
SGD avec Momentum
Lorsque la fonction d'erreur est complexe et non convexe, au lieu de trouver l'optimum global, l'algorithme SGD se déplace par erreur dans la direction de nombreux minima locaux.
Afin de résoudre ce problème et d'améliorer davantage l'algorithme SGD, diverses méthodes ont été introduites. Une méthode populaire pour échapper à un minimum local et se déplacer dans la bonne direction d'un minimum global est le SGD avec Momentum.
L'objectif de la méthode SGD avec momentum est d'accélérer les vecteurs de gradient dans la direction du minimum global, ce qui entraîne une convergence plus rapide.
L'idée derrière le momentum est que les paramètres du modèle sont appris en utilisant les directions et les valeurs des ajustements de paramètres précédents. De plus, les valeurs d'ajustement sont calculées de manière à ce que les ajustements plus récents soient pondérés plus lourdement (ils obtiennent des poids plus grands) par rapport aux ajustements très précoces (ils obtiennent des poids plus petits).
En gros, le SGD avec momentum est conçu pour accélérer la convergence du SGD et réduire ses oscillations. Il introduit donc un terme de vitesse, qui est une fraction de la mise à jour précédente. Cette étape exacte aide l'optimiseur à accumuler de la vitesse dans les directions avec des gradients persistants et cohérents, et à amortir les mises à jour dans les directions fluctuantes.
Les règles de mise à jour pour le momentum sont les suivantes, où vous devez d'abord calculer le gradient (comme avec le SGD simple) puis mettre à jour la vitesse et le paramètre theta.
$$v_{t+1} = \gamma v_t + \eta \nabla_{\theta} J(\theta_t)$$
$$\theta_{t+1} = \theta_t - v_{t+1}$$
Le momentum 𝜃 qui est typiquement une valeur entre 0,5 & 0,9, détermine combien des gradients passés seront conservés et utilisés dans la mise à jour.
La raison de cette différence est que, avec la méthode SGD, nous ne déterminons pas la dérivée exacte de la fonction de perte, mais nous l'estimons sur un petit lot. Puisque le gradient est bruyant, il est probable qu'il ne se déplace pas toujours dans la direction optimale.
Le momentum aide alors à estimer ces dérivées plus précisément, ce qui entraîne de meilleurs choix de direction lors du déplacement vers le minimum global.
Une autre raison de la différence de performance entre le SGD classique et le SGD avec momentum réside dans la zone appelée Courbure Pathologique, également appelée la zone de ravin.
La Courbure Pathologique ou la Zone de Ravin peut être représentée par le graphique suivant. La ligne orange représente le chemin pris par la méthode basée sur le gradient tandis que la ligne bleue foncée représente le chemin idéal vers la direction de fin du minimum global.
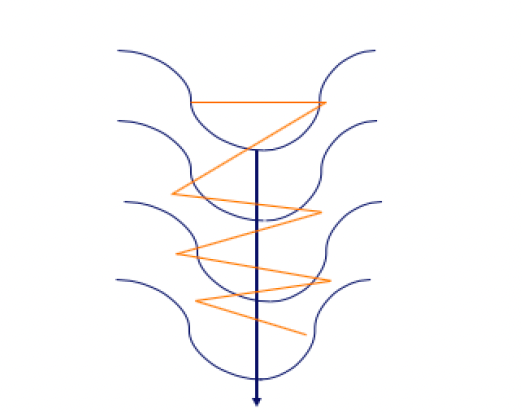
Chemins d'Optimisation : Descente de Gradient vs. Trajectoire Idéale vers le Minimum Global
Pour visualiser la différence entre le SGD et le SGD Momentum, regardons la figure suivante :

Comparaison des Chemins de Descente de Gradient dans Différents Paysages d'Optimisation
Sur le côté gauche se trouve la méthode SGD sans Momentum. Sur le côté droit se trouve le SGD avec Momentum. Le motif orange représente le chemin du gradient dans une recherche du minimum global. Comme vous pouvez le voir, dans la figure de gauche, nous avons plus de ces oscillations par rapport à celle de droite, et c'est l'impact du Momentum, où nous accélérons l'entraînement et l'algorithme fait alors moins de ces mouvements.
L'idée derrière le momentum est que les paramètres du modèle sont appris en utilisant les directions et les valeurs des ajustements de paramètres précédents. De plus, les valeurs d'ajustement sont calculées de manière à ce que les ajustements plus récents soient pondérés plus lourdement (ils obtiennent des poids plus grands) par rapport aux ajustements très précoces (ils obtiennent des poids plus petits).
Exemple de SGD avec Momentum en Python
Voyons à quoi cela ressemble en code :
def initialize_velocity(parameters):
"""
Initialise la vitesse en tant que dictionnaire python avec :
- clés : "dW1", "db1", ..., "dWL", "dbL"
- valeurs : tableaux numpy de zéros de la même forme que les gradients/paramètres correspondants.
"""
L = len(parameters) // 2 # nombre de couches dans les réseaux de neurones
v = {}
for l in range(L):
v["dW" + str(l+1)] = np.zeros_like(parameters["W" + str(l+1)])
v["db" + str(l+1)] = np.zeros_like(parameters["b" + str(l+1)])
return v
def update_parameters_with_momentum(parameters, grads, v, beta, learning_rate):
"""
Met à jour les paramètres en utilisant le Momentum
Arguments :
parameters -- dictionnaire python contenant vos paramètres
grads -- dictionnaire python contenant vos gradients pour chaque paramètre
v -- dictionnaire python contenant la vitesse actuelle
beta -- l'hyperparamètre de momentum, scalaire
learning_rate -- le taux d'apprentissage, scalaire
Retourne :
parameters -- dictionnaire python contenant vos paramètres mis à jour
v -- dictionnaire python contenant vos vitesses mises à jour
"""
L = len(parameters) // 2 # nombre de couches dans les réseaux de neurones
# Mise à jour du momentum pour chaque paramètre
for l in range(L):
# calculer les vitesses
v["dW" + str(l+1)] = beta * v["dW" + str(l+1)] + (1 - beta) * grads["dW" + str(l+1)]
v["db" + str(l+1)] = beta * v["db" + str(l+1)] + (1 - beta) * grads["db" + str(l+1)]
# mettre à jour les paramètres
parameters["W" + str(l+1)] = parameters["W" + str(l+1)] - learning_rate * v["dW" + str(l+1)]
parameters["b" + str(l+1)] = parameters["b" + str(l+1)] - learning_rate * v["db" + str(l+1)]
return parameters, v
Dans ce code, nous avons deux fonctions pour implémenter l'algorithme de descente de gradient basé sur le momentum (SGD avec momentum) :
initialize_velocity(parameters) : Cette fonction initialise la vitesse pour chaque paramètre dans le réseau de neurones. Elle prend les paramètres actuels en entrée et retourne un dictionnaire (v) avec des clés pour les gradients ("dW1", "db1", ..., "dWL", "dbL") et initialise les valeurs correspondantes en tant que tableaux numpy remplis de zéros.
update_parameters_with_momentum(parameters, grads, v, beta, learning_rate) : Cette fonction met à jour les paramètres en utilisant la technique d'optimisation Momentum. Elle prend les arguments suivants :
parameters : dictionnaire contenant les paramètres actuels du réseau de neurones.
grads : dictionnaire contenant les gradients des paramètres.
v : dictionnaire contenant les vitesses actuelles des paramètres (initialisé en utilisant la fonction initialize_velocity).
beta : hyperparamètre de momentum, un scalaire qui contrôle l'influence des gradients passés sur les mises à jour.
learning_rate : taux d'apprentissage, un scalaire contrôlant la taille du pas des mises à jour des paramètres.
À l'intérieur de la fonction, elle parcourt les couches du réseau de neurones et effectue les étapes suivantes pour chaque paramètre :
Calcule la nouvelle vitesse en utilisant la formule de momentum.
Met à jour le paramètre en utilisant la nouvelle vitesse et le taux d'apprentissage.
Enfin, elle retourne les paramètres mis à jour et les vitesses.
RMSProp
La Propagation de la Moyenne Quadratique, communément appelée RMSprop, est une méthode d'optimisation avec un taux d'apprentissage adaptatif. Elle a été proposée par Geoff Hinton dans son cours Coursera.
RMSprop ajuste le taux d'apprentissage pour chaque paramètre en divisant le taux d'apprentissage pour un poids par une moyenne mobile des magnitudes des gradients récents pour ce poids.
RMSprop peut être défini mathématiquement comme suit :
$$v_t = \beta v_{t-1} + (1 - \beta) g_t^2$$
$$\theta_{t+1} = \theta_t - \frac{\eta}{\sqrt{v_t + \epsilon}} \cdot g_t$$
_vt_𝟰 est la moyenne mobile des gradients au carré.
𝜂 est le taux de décroissance qui contrôle la moyenne mobile (généralement fixé à 0,9).
𝜇 est le taux d'apprentissage.
𝜹 est un petit scalaire utilisé pour éviter la division par zéro (généralement autour de 10^-8).
_gt_𝟰 est le gradient à l'étape de temps t, et _𝜇t_𝟰 est le vecteur de paramètres à l'étape de temps t.
L'algorithme calcule d'abord la moyenne mobile des gradients au carré (le hessien) pour chaque paramètre : v_t à l'étape t.
Ensuite, il divise le taux d'apprentissage eta par la racine carrée de cette vitesse moyenne (division élément par élément si les paramètres sont des vecteurs ou des matrices). Ensuite, il utilise cela dans la même étape pour mettre à jour les paramètres.
Exemple de RMSProp en Python
Voici un exemple de son fonctionnement en Python :
def update_parameters_with_rmsprop(parameters, grads, s, learning_rate, beta, epsilon):
"""
Met à jour les paramètres en utilisant RMSprop.
Arguments :
parameters -- dictionnaire python contenant vos paramètres
(par exemple, {"W1": W1, "b1": b1, "W2": W2, "b2": b2})
grads -- dictionnaire python contenant vos gradients pour mettre à jour chaque paramètre
(par exemple, {"dW1": dW1, "db1": db1, "dW2": dW2, "db2": db2})
s -- dictionnaire python contenant la moyenne mobile des gradients au carré
(par exemple, {"dW1": s_dW1, "db1": s_db1, "dW2": s_dW2, "db2": s_db2})
learning_rate -- le taux d'apprentissage, scalaire.
beta -- l'hyperparamètre de momentum, scalaire.
epsilon -- petit nombre pour éviter la division par zéro, scalaire.
Retourne :
parameters -- dictionnaire python contenant vos paramètres mis à jour
s -- dictionnaire python contenant la moyenne mobile mise à jour des gradients au carré
"""
L = len(parameters) // 2 # nombre de couches dans les réseaux de neurones
# Règle de mise à jour pour chaque paramètre
for l in range(L):
# Calculer la moyenne mobile des gradients au carré
s["dW" + str(l+1)] = beta * s["dW" + str(l+1)] + (1 - beta) * np.square(grads["dW" + str(l+1)])
s["db" + str(l+1)] = beta * s["db" + str(l+1)] + (1 - beta) * np.square(grads["db" + str(l+1)])
# Mettre à jour les paramètres
parameters["W" + str(l+1)] -= learning_rate * grads["dW" + str(l+1)] / (np.sqrt(s["dW" + str(l+1)]) + epsilon)
parameters["b" + str(l+1)] -= learning_rate * grads["db" + str(l+1)] / (np.sqrt(s["db" + str(l+1)]) + epsilon)
return parameters, s
Ce code définit une fonction pour mettre à jour les paramètres d'un réseau de neurones en utilisant la technique d'optimisation RMSprop. Voici un résumé de la fonction :
- update_parameters_with_rmsprop(parameters, grads, s, learning_rate, beta, epsilon) : fonction met à jour les paramètres d'un réseau de neurones en utilisant RMSprop.
Elle prend les arguments suivants :
parameters : dictionnaire contenant les paramètres actuels du réseau de neurones.
grads : dictionnaire contenant les gradients des paramètres.
s : dictionnaire contenant la moyenne mobile des gradients au carré pour chaque paramètre.
learning_rate : taux d'apprentissage, un scalaire.
beta : hyperparamètre de momentum, un scalaire.
epsilon : Un petit nombre ajouté pour éviter la division par zéro, un scalaire.
À l'intérieur de cette fonction, le code parcourt les couches du réseau de neurones et effectue les étapes suivantes pour chaque paramètre :
Calcule la moyenne mobile des gradients au carré pour les poids (W) et les biais (b) en utilisant la formule RMSprop.
Met à jour les paramètres en utilisant les moyennes mobiles calculées et le taux d'apprentissage, avec un terme epsilon supplémentaire au dénominateur pour éviter la division par zéro.
Enfin, le code retourne les paramètres mis à jour et la moyenne mobile mise à jour des gradients au carré (s).
RMSprop est une technique d'optimisation qui adapte le taux d'apprentissage pour chaque paramètre en fonction de l'historique des gradients au carré. Elle aide à stabiliser et à accélérer l'entraînement, en particulier lorsqu'on traite avec des gradients clairsemés ou bruyants.
Optimiseur Adam
Une autre technique populaire pour améliorer la procédure d'optimisation SGD est l'Estimation Adaptative des Moments (Adam) introduite par Kingma et Ba (2015). Adam combine essentiellement le momentum SGD avec RMSProp.
La principale différence par rapport au SGD avec momentum, qui utilise un seul taux d'apprentissage pour toutes les mises à jour de paramètres, est que l'algorithme Adam définit différents taux d'apprentissage pour différents paramètres.
L'algorithme calcule les taux d'apprentissage adaptatifs individuels pour chaque paramètre en fonction des estimations des deux premiers moments des gradients (première et deuxième dérivée de la fonction de perte).
Ainsi, chaque paramètre a un taux d'apprentissage unique, qui est mis à jour en utilisant la moyenne décroissante exponentielle des premiers moments (la moyenne) et des deuxièmes moments (la variance) des gradients.
En gros, Adam calcule des taux d'apprentissage adaptatifs individuels pour différents paramètres à partir des estimations des 1er et 2ème moments des gradients.
Les règles de mise à jour pour l'optimiseur Adam peuvent être exprimées comme suit :
Calculer les moyennes mobiles des gradients et des gradients au carré
Ajuster ces moyennes mobiles pour un facteur de biais
Utiliser ces moyennes mobiles pour mettre à jour le taux d'apprentissage pour chaque paramètre individuellement
Mathématiquement, ces étapes sont représentées comme suit :
$$m_t = \beta_1 m_{t-1} + (1 - \beta_1) g_t$$
$$v_t = \beta_2 v_{t-1} + (1 - \beta_2) g_t^2$$
$$\hat{m}_t = \frac{m_t}{1 - \beta_1^t}$$
$$\hat{v}t = \frac{v_t}{1 - \beta_2^t}$$
$$\theta{t+1} = \theta_t - \alpha \cdot \frac{\hat{m}_t}{\sqrt{\hat{v}_t} + \epsilon}$$
_mt_𝟰 et vt sont des estimations du premier moment (la moyenne) et du deuxième moment (la variance non centrée) des gradients, respectivement.
m_hat et v_hat sont des versions corrigées du biais de ces estimations.
_𝜂_1𝟰 et _𝜂_2𝟰 sont les taux de décroissance exponentielle pour ces estimations de moments (généralement fixés à 0,9 & 0,999, respectivement).
𝜁 est le taux d'apprentissage.
𝜹 est un petit scalaire utilisé pour éviter la division par zéro (généralement autour de 10^(𝟰8)).
Exemple de Adam en Python
Voici un exemple de l'utilisation de Adam en Python :
def initialize_adam(parameters) :
"""
Initialise v et s en tant que deux dictionnaires python avec :
- clés : "dW1", "db1", ..., "dWL", "dbL"
- valeurs : tableaux numpy de zéros de la même forme que les gradients/paramètres correspondants.
"""
L = len(parameters) // 2 # nombre de couches dans les réseaux de neurones
v = {}
s = {}
for l in range(L):
v["dW" + str(l+1)] = np.zeros_like(parameters["W" + str(l+1)])
v["db" + str(l+1)] = np.zeros_like(parameters["b" + str(l+1)])
s["dW" + str(l+1)] = np.zeros_like(parameters["W" + str(l+1)])
s["db" + str(l+1)] = np.zeros_like(parameters["b" + str(l+1)])
return v, s
def update_parameters_with_adam(parameters, grads, v, s, t, learning_rate=0.01,
beta1=0.9, beta2=0.999, epsilon=1e-8):
"""
Met à jour les paramètres en utilisant Adam
Arguments :
parameters -- dictionnaire python contenant vos paramètres :
parameters['W' + str(l)] = Wl
parameters['b' + str(l)] = bl
grads -- dictionnaire python contenant vos gradients pour chaque paramètre :
grads['dW' + str(l)] = dWl
grads['db' + str(l)] = dbl
v -- variable Adam, moyenne mobile du premier gradient, dictionnaire python
s -- variable Adam, moyenne mobile du gradient au carré, dictionnaire python
learning_rate -- le taux d'apprentissage, scalaire.
beta1 -- Hyperparamètre de décroissance exponentielle pour les estimations du premier moment
beta2 -- Hyperparamètre de décroissance exponentielle pour les estimations du deuxième moment
epsilon -- hyperparamètre empêchant la division par zéro dans les mises à jour Adam
Retourne :
parameters -- dictionnaire python contenant vos paramètres mis à jour
v -- variable Adam, moyenne mobile du premier gradient, dictionnaire python
s -- variable Adam, moyenne mobile du gradient au carré, dictionnaire python
"""
L = len(parameters) // 2 # nombre de couches dans les réseaux de neurones
v_corrected = {} # Initialisation de l'estimation du premier moment, dictionnaire python
s_corrected = {} # Initialisation de l'estimation du deuxième moment, dictionnaire python
# Effectuer la mise à jour Adam sur tous les paramètres
for l in range(L):
# Moyenne mobile des gradients.
v["dW" + str(l+1)] = beta1 * v["dW" + str(l+1)] + (1 - beta1) * grads["dW
Dans ce code, nous implémentons l'algorithme Adam, composé de deux fonctions :
initialize_adam(parameters) : Cette fonction initialise les variables de l'optimiseur Adam
vetsen tant que deux dictionnaires Python. Elle prend les paramètres actuels en entrée et retournevets, tous deux étant des dictionnaires avec des clés pour les gradients ("dW1", "db1", ..., "dWL", "dbL"). Les valeurs sont des tableaux numpy remplis de zéros et ont la même forme que les gradients/paramètres correspondants.update_parameters_with_adam(parameters, grads, v, s, t, learning_rate=0.01, beta1=0.9, beta2=0.999, epsilon=1e-8) : Cette fonction met à jour les paramètres d'un réseau de neurones en utilisant la technique d'optimisation Adam. Elle prend les arguments suivants :
parameters : Un dictionnaire contenant les paramètres actuels du réseau de neurones.
grads : Un dictionnaire contenant les gradients des paramètres.
v : Un dictionnaire représentant la moyenne mobile des premiers moments de gradient.
s : Un dictionnaire représentant la moyenne mobile des deuxièmes moments de gradient.
t : Un scalaire représentant l'étape de temps actuelle (utilisé pour la correction de biais).
learning_rate : Le taux d'apprentissage, un scalaire.
beta1 : L'hyperparamètre de décroissance exponentielle pour les estimations du premier moment.
beta2 : L'hyperparamètre de décroissance exponentielle pour les estimations du deuxième moment.
epsilon : Un petit nombre ajouté pour éviter la division par zéro dans les mises à jour Adam.
À l'intérieur de cette fonction, le code parcourt les couches du réseau de neurones et effectue les mises à jour Adam pour chaque paramètre. Cela inclut le calcul des moyennes mobiles des gradients et des gradients au carré, et l'utilisation de ces valeurs pour mettre à jour les paramètres. Il effectue également une correction de biais pour ajuster les moyennes mobiles.
Enfin, le code retourne les paramètres mis à jour, v (estimations du premier moment), et s (estimations du deuxième moment).
AdamW
AdamW (le 'W' signifie 'Weight Decay') est un algorithme d'optimisation qui modifie la manière dont le decay des poids est intégré dans l'algorithme Adam original. Ce changement apparemment mineur a des implications significatives pour le processus d'entraînement, en particulier dans la manière dont il gère la régularisation pour prévenir le surapprentissage.
Cette étape a un impact crucial dans la généralisation des modèles d'apprentissage profond, pour construire des modèles qui se généralisent bien aux nouvelles données non vues.
Dans les optimiseurs traditionnels comme SGD, le decay des poids régularise directement les paramètres de poids du modèle. Mais dans Adam, ce processus est quelque peu confondu avec les taux d'apprentissage adaptatifs de l'optimiseur.
AdamW découple le decay des poids des taux d'apprentissage, rétablissant l'effet de régularisation directe vu dans SGD. Cela entraîne une régularisation plus efficace et, souvent, de meilleures performances dans l'entraînement des réseaux de neurones profonds.
Si vous souhaitez voir la représentation mathématique réelle où je compare Adam et AdamW, vous pouvez consulter ce Tutoriel sur YouTube.
En choisissant AdamW, vous pouvez profiter des avantages des taux d'apprentissage adaptatifs tout en maintenant un mécanisme de régularisation plus robuste.
Cet algorithme d'optimisation a rapidement gagné en popularité dans la communauté du machine learning, en particulier parmi ceux qui travaillent sur des modèles à grande échelle et des ensembles de données complexes où chaque bit d'efficacité d'optimisation compte.
AdamW en Python
import numpy as np
def initialize_adamw(parameters):
"""
Initialise v, s et w en tant que trois dictionnaires python avec :
- clés : "dW1", "db1", ..., "dWL", "dbL"
- valeurs : tableaux numpy de zéros de la même forme que les gradients/paramètres correspondants.
"""
L = len(parameters) // 2 # nombre de couches dans le réseau de neurones
v = {}
s = {}
w = {}
for l in range(L):
v["dW" + str(l+1)] = np.zeros_like(parameters["W" + str(l+1)])
v["db" + str(l+1)] = np.zeros_like(parameters["b" + str(l+1)])
s["dW" + str(l+1)] = np.zeros_like(parameters["W" + str(l+1)])
s["db" + str(l+1)] = np.zeros_like(parameters["b" + str(l+1)])
w["W" + str(l+1)] = np.copy(parameters["W" + str(l+1)])
return v, s, w
def update_parameters_with_adamw(parameters, grads, v, s, w, t, learning_rate=0.01,
beta1=0.9, beta2=0.999, epsilon=1e-8, weight_decay=0.01):
"""
Met à jour les paramètres en utilisant AdamW (Adam avec decay des poids)
Arguments :
parameters -- dictionnaire python contenant vos paramètres :
parameters['W' + str(l)] = Wl
parameters['b' + str(l)] = bl
grads -- dictionnaire python contenant vos gradients pour chaque paramètre :
grads['dW' + str(l)] = dWl
grads['db' + str(l)] = dbl
v -- variable Adam, moyenne mobile du premier gradient, dictionnaire python
s -- variable Adam, moyenne mobile du gradient au carré, dictionnaire python
w -- paramètres de poids pour le decay des poids, dictionnaire python
t -- étape de temps actuelle (utilisée pour la correction de biais), scalaire
learning_rate -- le taux d'apprentissage, scalaire
beta1 -- hyperparamètre de décroissance exponentielle pour les estimations du premier moment
beta2 -- hyperparamètre de décroissance exponentielle pour les estimations du deuxième moment
epsilon -- hyperparamètre empêchant la division par zéro dans les mises à jour Adam
weight_decay -- hyperparamètre de decay des poids, scalaire
Retourne :
parameters -- dictionnaire python contenant vos paramètres mis à jour
v -- variable Adam, moyenne mobile du premier gradient, dictionnaire python
s -- variable Adam, moyenne mobile du gradient au carré, dictionnaire python
"""
L = len(parameters) // 2 # nombre de couches dans le réseau de neurones
v_corrected = {} # Initialisation de l'estimation du premier moment, dictionnaire python
s_corrected = {} # Initialisation de l'estimation du deuxième moment, dictionnaire python
# Effectuer la mise à jour AdamW sur tous les paramètres
for l in range(L):
# Moyenne mobile des gradients
v["dW" + str(l+1)] = beta1 * v["dW" + str(l+1)] + (1 - beta1) * grads["dW" + str(l+1)]
v["db" + str(l+1)] = beta1 * v["db" + str(l+1)] + (1 - beta1) * grads["db" + str(l+1)]
# Moyenne mobile des gradients au carré
s["dW" + str(l+1)] = beta2 * s["dW" + str(l+1)] + (1 - beta2) * np.square(grads["dW" + str(l+1)])
s["db" + str(l+1)] = beta2 * s["db" + str(l+1)] + (1 - beta2) * np.square(grads["db" + str(l+1)])
# Correction de biais pour les moyennes mobiles
v_corrected["dW" + str(l+1)] = v["dW" + str(l+1)] / (1 - np.power(beta1, t))
v_corrected["db" + str(l+1)] = v["db" + str(l+1)] / (1 - np.power(beta1, t))
s_corrected["dW" + str(l+1)] = s["dW" + str(l+1)] / (1 - np.power(beta2, t))
s_corrected["db" + str(l+1)] = s["db" + str(l+1)] / (1 - np.power(beta2, t))
# Mettre à jour les paramètres avec le decay des poids
parameters["W" + str(l+1)] -= learning_rate * (v_corrected["dW" + str(l+1)] / (np.sqrt(s_corrected["dW" + str(l+1)]) + epsilon) + weight_decay * w["W" + str(l+1)])
parameters["b" + str(l+1)] -= learning_rate * (v_corrected["db" + str(l+1)] / (np.sqrt(s_corrected["db" + str(l+1)]) + epsilon) + weight_decay * w["W" + str(l+1)])
return parameters, v, s
Dans ce code, nous implémentons l'algorithme d'optimisation AdamW, qui est une extension de l'optimiseur Adam avec une régularisation de decay des poids ajoutée. Passons en revue chaque partie du code :
- initialize_adamw(parameters) : Cette fonction initialise les variables de l'optimiseur AdamW. Elle prend tous les paramètres actuels d'un réseau de neurones en entrée et retourne trois dictionnaires :
v,s, etw.
Voici ce que représente chacun de ces dictionnaires :
v : Un dictionnaire pour la moyenne mobile des premiers moments de gradient. Il a des clés comme "dW1", "db1", ..., "dWL", "dbL", et les valeurs sont initialisées en tant que tableaux numpy remplis de zéros de la même forme que les gradients/paramètres correspondants.
s : Un dictionnaire pour la moyenne mobile des deuxièmes moments de gradient, similaire à
v.w : Un dictionnaire pour les paramètres de poids utilisés pour le decay des poids. Il est initialisé avec une copie des paramètres de poids actuels.
update_parameters_with_adamw(parameters, grads, v, s, w, t, learning_rate=0.01, beta1=0.9, beta2=0.999, epsilon=1e-8, weight_decay=0.01) : Cette fonction effectue la mise à jour AdamW comme nous l'avons vu dans les équations, pour mettre à jour les paramètres du réseau de neurones. Elle prend plusieurs arguments :
parameters : Un dictionnaire contenant les paramètres actuels du réseau de neurones.
grads : Un dictionnaire contenant les gradients des paramètres, calculés pendant la rétropropagation.
v : dictionnaire représentant la moyenne mobile des premiers moments de gradient.
s : dictionnaire représentant la moyenne mobile des deuxièmes moments de gradient.
w : dictionnaire contenant les paramètres de poids pour le decay des poids.
t : scalaire représentant l'étape de temps actuelle (utilisée pour la correction de biais).
learning_rate : Le taux d'apprentissage, un scalaire.
beta1 : hyperparamètre de décroissance exponentielle pour les estimations du premier moment (généralement proche de 1).
beta2 : hyperparamètre de décroissance exponentielle pour les estimations du deuxième moment (généralement proche de 1).
epsilon : petit nombre ajouté pour éviter la division par zéro dans les mises à jour Adam.
weight_decay : hyperparamètre de decay des poids, qui contrôle la force de la régularisation L2.
À l'intérieur de la fonction, les étapes suivantes sont effectuées pour chaque paramètre :
Mettre à jour
vetsen utilisant les gradients, similaire à la mise à jour standard d'Adam.Effectuer la correction de biais sur
vetspour tenir compte du fait qu'ils sont initialisés avec des zéros et peuvent être biaisés vers zéro.Mettre à jour les paramètres avec la régularisation de decay des poids. Le decay des poids encourage des valeurs de paramètres plus petites en soustrayant une fraction du poids actuel de la mise à jour.
Retourner les paramètres mis à jour,
v, ets.
Chapitre 5 : Régularisation et Généralisation
Dans ce chapitre, nous allons plonger dans certains concepts importants de l'Apprentissage Profond, comme :
Le surapprentissage et le sous-apprentissage dans les réseaux de neurones
Les techniques de régularisation : Dropout, régularisation L1/L2, normalisation par lots
L'augmentation des données et son rôle dans l'amélioration de la robustesse du modèle
Commençons.
La Technique de Régularisation Dropout
Le Dropout est l'une des techniques de régularisation les plus populaires utilisées pour prévenir le surapprentissage dans les réseaux de neurones. La manière dont l'algorithme fonctionne est qu'il "supprime" aléatoirement (c'est-à-dire qu'il met à zéro) un certain nombre de caractéristiques de sortie de la couche pendant l'entraînement.
Pendant le processus d'entraînement, après avoir calculé les activations, l'algorithme met aléatoirement à zéro une fraction p (le taux de dropout) des activations. Ces caractéristiques ne sont alors pas utilisées pendant le processus d'entraînement dans cette passe. Ce taux de dropout p est un hyperparamètre généralement fixé entre 0,2 et 0,5. Notez que ce taux de dropout n'est utilisé que pendant l'entraînement.
Pour chaque couche l, pour chaque exemple d'entraînement i, et pour chaque neurone/unité j, le dropout peut être représenté mathématiquement comme suit :
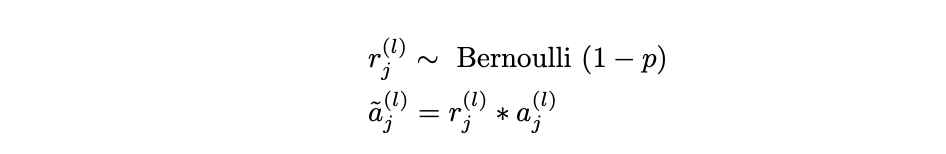
Où :
rj(l)𝟰 est une variable aléatoire qui suit une distribution de Bernoulli, où la probabilité de ne pas être supprimé (succès : 1) est 1𝟰_p_.
aj(l)𝟰 est l'activation du neurone j dans la couche l.
a~j(l)𝟰 est l'activation du neurone j après l'application du dropout.
Pendant la rétropropagation dans le processus d'entraînement, les gradients ne sont transmis que par les neurones qui n'ont pas été supprimés (lorsqu'il y a eu un succès dans l'essai de Bernoulli). N'oubliez pas que ce taux de dropout n'est utilisé que pendant l'entraînement.
Ajustement de Test : Pendant le processus de test, le dropout n'est pas appliqué. Au lieu de cela, les activations sont réduites d'un facteur de p pour tenir compte de l'effet du dropout pendant le processus d'entraînement. Cela est nécessaire car pendant l'entraînement, en moyenne, chaque unité n'est active qu'avec une probabilité de 1𝟰_p_.
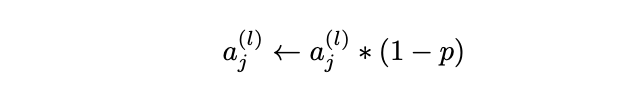
Cela garantit que la somme attendue des activations est la même pendant l'entraînement et le test.
Le Dropout crée effectivement un réseau "aminci" avec une architecture différente pour chaque étape d'entraînement. Parce que l'architecture du réseau est différente pour chaque échantillon d'entraînement, car nous éteignons aléatoirement certains des neurones, cela peut être vu comme l'entraînement d'une collection de réseaux avec des poids partagés.
Pendant le test, vous obtenez l'avantage de moyenner les effets de ces différents réseaux, ce qui tend à réduire le surapprentissage. Cela est dû au fait qu'il introduit un biais, mais plus important encore, il réduit considérablement la variance lorsque le modèle est utilisé pour la prédiction. Voici pourquoi :
Introduction de Biais
En supprimant différents sous-ensembles de neurones avec un taux p, le réseau est alors contraint d'apprendre des caractéristiques plus robustes qui sont utiles en conjonction avec de nombreux sous-ensembles aléatoires différents des autres neurones.
Cet ajustement peut conduire à un biais légèrement plus élevé pendant l'entraînement car le réseau est moins susceptible d'apprendre des motifs qui sont très spécifiques aux données d'entraînement (qui peuvent être considérés comme du bruit).
Diminution de la Variance
Le Dropout réduit la variance en empêchant le réseau de devenir trop adapté aux données d'entraînement. Il réduit le risque que le réseau dépende d'une caractéristique particulière, garantissant ainsi que le modèle se généralise mieux aux données non vues.
Cela est courant dans les méthodes d'ensemble en apprentissage automatique comme le Boosting, la Forêt Aléatoire, où la moyenne des prédictions de différents modèles conduit à une réduction de la variance.
Régularisation Ridge (Régularisation L2)
Les régularisations Lasso et Ridge sont des techniques initialement développées pour les modèles linéaires, mais elles peuvent également être appliquées à l'apprentissage profond. Dans l'apprentissage profond, ces méthodes de régularisation fonctionnent de manière similaire en ajoutant une pénalité à la fonction de perte, mais elles doivent être adaptées au contexte des réseaux de neurones. Voici comment elles fonctionnent dans l'apprentissage profond :
La régularisation Ridge, également appelée régularisation L2, ajoute une pénalité égale au carré de l'amplitude des coefficients comme indiqué ci-dessous. Ce L_L2 montre le terme de pénalisation qui est ajouté à la fonction de perte du réseau de neurones. Pour les réseaux de neurones, cela signifie que la pénalité est la somme des carrés de tous les poids dans le réseau.
$$L2 = \lambda \sum w_i^2$$
où lambda est le paramètre de pénalisation, w_i sont les poids du réseau de neurones.
L'effet de cela est qu'il encourage les poids à être petits mais ne les force pas à zéro.
Cela est utile pour les modèles d'apprentissage profond où nous ne voulons pas nécessairement effectuer une sélection de caractéristiques (réduire la dimension du modèle) mais simplement vouloir prévenir le surapprentissage en décourageant les modèles trop complexes qui mémorisent les données d'entraînement et ne sont pas généralisables.
Ce terme de régularisation est contrôlé par un hyperparamètre, souvent désigné par la lettre grecque 𝜆, qui détermine la force de cette pénalité. À mesure que 𝜆 augmente, la pénalité pour les poids plus grands augmente, et le modèle est poussé vers des poids plus petits.
Régularisation Lasso (Régularisation L1)
Lasso signifie Least Absolute Shrinkage and Selection Operator Regularization, également connue sous le nom de régularisation L1 basée sur la norme L1.
La régularisation L1 ajoute une pénalité égale à la valeur absolue de l'amplitude des coefficients (la somme de ceux-ci). La formule ci-dessous montre le terme de pénalisation L_L1 ajouté à la fonction de perte du réseau de neurones. Les notions sont les mêmes que dans le cas de la Régularisation Ridge. Cela se traduit pour les réseaux de neurones en apprentissage profond comme la somme des valeurs absolues de tous les poids.
$$L1 = \lambda \sum |w_i|$$
La régularisation L1 pousse certains poids à être exactement zéro, réalisant ainsi des modèles clairsemés. Dans l'apprentissage profond, cela peut conduire à une clairsemance au sein des poids, effectuant ainsi une forme de sélection de caractéristiques en permettant au modèle d'ignorer certaines entrées.
Similaire à la régularisation L2, la force de la régularisation L1 est contrôlée par un hyperparamètre, qui, lorsqu'il est augmenté, peut conduire à plus de poids étant mis à zéro.
Les régularisations L1 et L2 peuvent être utilisées individuellement ou combinées dans ce qu'on appelle la régularisation Elastic Net comme moyen de régulariser le réseau.
L'utilisation de ces techniques de régularisation peut améliorer la généralisation des modèles d'apprentissage profond. Mais il est également important de considérer d'autres techniques plus courantes en apprentissage profond, telles que le dropout et la normalisation par lots – ou d'utiliser toutes ces techniques ensemble (ce qui peut parfois être plus efficace pour prévenir le surapprentissage dans les grands réseaux de neurones profonds).
Si vous souhaitez en savoir plus sur la régularisation L1/L2, assurez-vous de consulter cette vidéo et ce tutoriel pour voir comment ces techniques de régularisation pénalisent les poids dans le réseau de neurones, qui font partie de mon cours gratuit Préparation aux Entretiens en Apprentissage Profond.
Normalisation par Lots
La Normalisation par Lots est une autre technique importante utilisée en Apprentissage Profond qui, bien que n'étant pas une méthode de régularisation au sens traditionnel, a un effet de régularisation indirect.
Cette technique normalise les entrées de chaque couche de manière à ce qu'elles aient une moyenne d'activation de sortie de zéro et un écart-type de un. En gros comme une Distribution Gaussienne – ce qui est la raison pour laquelle elle est appelée Normalisation, car nous normalisons un lot.
Normalisation par Lots : Source de l'Image
La figure ci-dessus visualise l'idée derrière la Normalisation par Lots, qui montre que la normalisation est effectuée pour chaque lot, où toutes les observations N sont dans 1 lot, et C représente le nombre de Canaux ou de caractéristiques dans vos données. En gros, cette figure montre que la normalisation par lots normalise les données par 1 caractéristique (à travers un seul canal) et pour toutes les observations N dans 1 lot.
Cela est réalisé en ajustant et en mettant à l'échelle les activations pendant l'entraînement. La normalisation par lots permet à chaque couche d'un réseau d'apprendre par elle-même un peu plus indépendamment des autres couches. Voyons comment cela fonctionne en détail.
Étape 1 : Moyenne et Variance du Mini-Lot :
Calculer la moyenne des activations pour un mini-lot en utilisant l'équation suivante :
$$\mu_B = \frac{1}{m} \sum_{i=1}^{m} x_i$$
Dans cette équation,
_𝜆_beta_𝟰 est la moyenne du mini-lot
m est le nombre d'exemples d'entraînement dans le mini-lot, et
_xi_𝟰 est l'activation de la couche actuelle avant la normalisation par lots.
Maintenant, vous devrez calculer la variance des activations pour un mini-lot. Vous pouvez le faire en utilisant l'équation suivante :
$$\sigma_B^2 = \frac{1}{m} \sum_{i=1}^{m} (x_i - \mu_B)^2$$
Étape 2 : Normaliser les activations du mini-lot
Ensuite, la normalisation se produit :
$$\hat{x}_i = \frac{x_i - \mu_B}{\sqrt{\sigma_B^2 + \epsilon}}$$
Dans cette équation,
x^_i_𝟰 est l'activation normalisée
𝜹 est une petite constante ajoutée pour la stabilité numérique (pour éviter la division par zéro).
Étape 3 : Appliquer les paramètres apprenables pour l'échelle et le décalage
$$y_i = \gamma \hat{x}_i + \beta$$
Bien que l'objectif principal de la normalisation par lots soit de stabiliser et d'accélérer le processus d'entraînement des réseaux de neurones profonds en réduisant le décalage covariant interne, elle a également un effet de régularisation qui est une manière de réduire le surapprentissage.
En ajoutant un certain niveau de bruit aux activations (puisque la moyenne et la variance sont estimées à partir des données), elle peut rendre le modèle moins sensible aux poids spécifiques des neurones, ce qui a un effet similaire au dropout car cela peut prévenir le surapprentissage.
La normalisation par lots peut être particulièrement bénéfique dans les réseaux de neurones profonds, où elle peut permettre l'utilisation de taux d'apprentissage plus élevés, rendre le réseau moins sensible à l'initialisation, et peut réduire le besoin d'autres techniques de régularisation telles que le dropout.
En pratique, la normalisation par lots est appliquée avant la fonction d'activation d'une couche, et elle nécessite le maintien d'une moyenne mobile de la moyenne et de la variance à utiliser pendant l'inférence pour le processus de normalisation.
Chapitre 6 : Problème du Gradient Évanescent
Lorsque le gradient de la perte est propagé en arrière à travers le temps et les couches, il peut diminuer vers 0 (devenir très petit). Cela conduit à des mises à jour très petites des poids.
Cela rend difficile pour le réseau de neurones d'apprendre les dépendances à long terme, ce qui peut entraîner aucune mise à jour dans les couches précédentes du réseau dans les paramètres lorsque les gradients s'évanouissent (deviennent très petits, proches de zéro).
Ainsi, lorsque les gradients s'évanouissent, les couches initiales du réseau s'entraînent très lentement ou pas du tout, ce qui conduit à des performances sous-optimales.
Utiliser des fonctions d'activation appropriées
Une façon de résoudre le problème du gradient évanescent est d'utiliser une fonction d'activation appropriée qui ne souffre pas de saturation.
La saturation se produit lorsque, pour la valeur d'entrée x qui est un grand nombre positif ou un petit nombre négatif, le gradient de la fonction est proche de 0 car la valeur de la fonction est dans le voisinage des valeurs extrêmes statiques de celle-ci. Cela ralentit la mise à jour des paramètres. Ce phénomène est appelé le problème de saturation.
Les fonctions d'activation ReLU (Unité Linéaire Rectifiée) et Leaky ReLU ne saturent pas dans la direction positive, contrairement aux fonctions Sigmoïde ou tanh. Cela peut aider à atténuer le problème du gradient évanescent.
Leaky ReLU peut aider davantage en permettant un petit gradient non nul lorsque l'unité n'est pas active. Cela est important pour les cas où les entrées négatives doivent également être prises en compte et où obtenir une valeur négative en sortie est acceptable.
Vous pouvez trouver plus de détails sur cette fonction d'activation dans la section sur les Fonctions d'Activation du Chapitre 2.
Utiliser l'Initialisation de Xavier ou He
L'initialisation soigneuse des poids est importante. Une bonne initialisation telle que l'initialisation de Xavier peut aider à empêcher les gradients de devenir trop petits tôt dans l'entraînement.
L'initialisation de Xavier, également connue sous le nom d'initialisation de Glorot, est une technique d'initialisation pour les paramètres de poids dans un réseau de neurones. Elle est conçue pour résoudre le problème des gradients évanescents ou explosifs dans les réseaux de neurones profonds lorsque les fonctions d'activation Sigmoïde et tanh sont utilisées.
Elle porte le nom de Xavier Glorot qui a formulé cette stratégie basée sur la compréhension du flux des variances à travers un réseau de neurones pour maintenir les gradients à une échelle raisonnable et les empêcher de devenir trop petits pour s'évanouir ou trop grands pour exploser.
Voici l'idée principale derrière l'Initialisation de Xavier :
Pour une couche donnée, les poids sont initialisés aléatoirement à partir d'une distribution avec une moyenne de 0 et une variance spécifique (peut également être 1 comme dans la distribution gaussienne) qui dépend du nombre de neurones d'entrée et du nombre de neurones de sortie.
L'objectif de l'Initialisation de Xavier est d'avoir la variance des sorties de chaque couche égale à la variance de ses entrées, et les gradients d'avoir une variance égale avant et après avoir traversé une couche dans la propagation arrière.
Si c'est une Distribution Uniforme, les poids sont généralement initialisés avec des valeurs tirées de ce calcul :
$$W \sim \text{Uniform}\left(-\sqrt{\frac{6}{n_{\text{in}} + n_{\text{out}}}}, \sqrt{\frac{6}{n_{\text{in}} + n_{\text{out}}}}\right)\$$
$$\text{Var}(W) = \frac{2}{\sqrt{n_{\text{in}} + n_{\text{out}}}}$$
Cette variance pour l'initialisation des poids dans le Réseau de Neurones est généralement définie à cette valeur ci-dessus, désignée par Var(W) - comme dans la Variance de la matrice de Poids W, où :
_n__in𝟰 est le nombre de neurones alimentant la couche
_n__out𝟰 est le nombre de neurones auxquels les résultats sont alimentés (c'est-à-dire le nombre de neurones dans la couche suivante)
Si une Distribution Normale est utilisée à la place, alors les poids sont tirés de celle-ci :
$$W \sim \text{Normal}\left(0, \sqrt{\frac{2}{n_{\text{in}} + n_{\text{out}}}}\right)\$$
$$\text{Var}(W) = \frac{2}{\sqrt{n_{\text{in}} + n_{\text{out}}}}$$
Effectuer la Normalisation par Lots
La normalisation par lots sur la couche d'entrée peut aider à maintenir une moyenne de sortie proche de 0 et un écart-type proche de 1 comme la Distribution Normale Standard. Cela empêche les gradients de devenir trop petits.
En normalisant les activations, vous stabilisez directement le réseau mais contrôlez indirectement le changement des poids de votre réseau. Cela signifie que les gradients restent plus constants, et en conséquence indirecte, les gradients de BatchNorm ne s'évanouiront ni n'exploseront.
Ajouter des Connexions Résiduelles (surtout aux RNN ou LSTM)
Les connexions résiduelles offrent des résultats d'optimisation innovants pour l'entraînement des réseaux de neurones profonds, en particulier lorsqu'il s'agit de combattre le problème des gradients évanescents.
Cela est particulièrement un problème lors de la manipulation des réseaux de neurones récurrents (RNN) ou des réseaux de mémoire à long et court terme (LSTM), qui sont intrinsèquement profonds en raison de leur nature séquentielle. L'incorporation de connexions résiduelles dans les RNN ou LSTM peut améliorer considérablement leurs capacités d'apprentissage.
Les RNN et LSTM sont spécialisés pour gérer des séquences de données, ce qui les rend idéaux pour des tâches comme la modélisation du langage et l'analyse des séries temporelles. Mais à mesure que la longueur de la séquence augmente, ces réseaux tendent à souffrir du problème des gradients évanescents.
Pour résoudre ce problème, des connexions résiduelles sont souvent utilisées pour les RNN et LSTM. En ajoutant un raccourci qui contourne une ou plusieurs couches, une connexion résiduelle permet au gradient de circuler à travers le réseau de manière plus directe. Dans le contexte des RNN et LSTM, cela signifie connecter la sortie d'un pas de temps non seulement au pas de temps suivant, mais aussi à un ou plusieurs pas de temps ultérieurs.
Comment Implémenter les Connexions Résiduelles dans les RNN et LSTM
La stratégie d'implémentation des connexions résiduelles dans les RNN et LSTM est simple. Pour chaque pas de temps, nous modifions le réseau de sorte que la sortie ne soit pas seulement une fonction de l'entrée actuelle et de l'état caché précédent, mais qu'elle inclue également l'entrée directement.
Ce processus peut être décrit comme suit où nous ajoutons x à la sortie F(x). Vous pouvez également voir le chemin direct pour que le gradient circule dans le réseau et la dérivation mathématique basée sur ce processus d'ajout de l'entrée à la sortie :
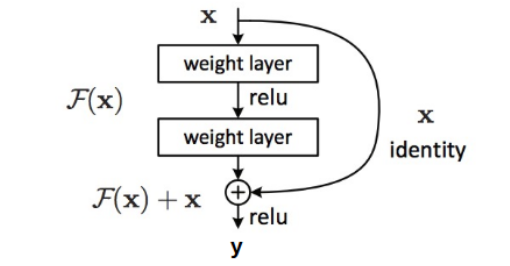
Écrêtage du Gradient (Source de l'Image : LunarTech.ai)
$$y = x + F(x)\$$
$$\frac{\partial E}{\partial x} = \frac{\partial E}{\partial y} \cdot \frac{\partial y}{\partial x}\$$
$$\frac{\partial E}{\partial x} = \frac{\partial E}{\partial y} \cdot (1 + F'(x))\$$
$$\frac{\partial E}{\partial x} = \frac{\partial E}{\partial y} \cdot F'(x)$$
Ici, vous pouvez voir les mathématiques derrière les Connexions Résiduelles et comment le gradient obtient le raccourci. Lorsque nous ajoutons x à F(x) pour obtenir y, au lieu de simplement y=F(x), vous pouvez voir que lorsque nous prenons la dérivée d'une fonction E (disons notre fonction de perte) par rapport à x. Ensuite, nous utilisons la règle de la chaîne des mathématiques différentielles.
Après ces transformations, vous pouvez voir que nous finissons par avoir la somme de deux valeurs :
Gradient de la fonction de perte par rapport à y
Gradient de la fonction de perte par rapport à y multiplié par la dérivée partielle de F(x) par rapport à x
Ainsi, vous pouvez voir ici que dans le cas où la connexion résiduelle est faite, et nous ajoutons un x supplémentaire au y simple = F(x), cela finit par ajouter un Gradient supplémentaire de la fonction de perte par rapport à y sans aucun autre facteur de multiplication à ajouter au gradient final.
Pour une explication intuitive et détaillée, consultez cette réponse de tutoriel-entretien sur les Connexions Résiduelles.
Flux de Gradient Direct : En fournissant un raccourci pour le flux de gradient, il est moins susceptible de s'évanouir lorsqu'il est propagé en arrière à travers le temps. Cela garantit que même les couches les plus anciennes de la séquence peuvent être efficacement entraînées.
Apprentissage des Mappages d'Identité : Si la fonction optimale pour un pas de temps est de copier son entrée vers la sortie, le réseau peut apprendre plus facilement ce mappage d'identité avec des connexions résiduelles. Le réseau peut ainsi se concentrer sur l'affinement des écarts par rapport à l'identité plutôt que de l'apprendre à partir de zéro.
Facilitation des Architectures Plus Profondes : Avec l'intégration de connexions résiduelles, il devient réalisable de construire des RNN ou LSTM plus profonds. Cette profondeur permet au réseau d'apprendre des motifs et des relations plus complexes au sein des données.
Chapitre 7 : Combattre les Gradients Explosifs
Les gradients explosifs sont le problème opposé des Gradients Évanescents. Les Gradients Explosifs se produisent lors de l'entraînement de modèles d'apprentissage profond, en particulier ceux impliquant des réseaux de neurones pendant la phase de rétropropagation, lorsque les gradients deviennent trop grands et explosent.
Mais dans les réseaux profonds avec de nombreuses couches, ces gradients peuvent s'accumuler et croître de manière exponentielle à travers chaque couche. Cette augmentation exponentielle est due à la multiplication répétitive des gradients à travers la profondeur du réseau, surtout lorsque les gradients sont trop grands en magnitude.
Cela entrave le processus d'apprentissage et rend le réseau de neurones moins efficace pour apprendre les informations importantes dans les couches.
Examinons comment nous pouvons résoudre ce problème.
Écrêtage des Gradients
Une façon de résoudre le problème des gradients explosifs est d'utiliser l'Écrêtage des Gradients. L'écrêtage des gradients est une technique pratique utilisée pour empêcher les gradients d'exploser pendant l'entraînement des réseaux de neurones.
Lorsque les gradients calculés sont trop grands, l'écrêtage des gradients les réduit à un seuil prédéterminé. Cela garantit des mises à jour stables et cohérentes des paramètres du modèle.
Ce processus implique :
Étape 1 : Calculer le gradient (g) : Obtenir le gradient de la fonction de perte par rapport aux paramètres du modèle.
Étape 2 : Mettre à l'échelle le gradient : Si la norme de ce gradient 𝟰_g_𝟰 est plus grande qu'un seuil spécifié c, nous réduisons le gradient g pour qu'il ait la norme c, en maintenant sa direction. Cela est fait en définissant g à c_𝟰_g/𝟰_g_𝟰
Étape 3 : Mettre à jour les paramètres : Nous utilisons le gradient écrêté pour une mise à jour contrôlée et plus modérée.
L'écrêtage des gradients garantit que le processus d'apprentissage du modèle ne déraille pas en raison de ces grandes mises à jour résultant de gradients explosifs, qui peuvent se produire en présence de pentes raides dans le paysage de perte lorsque l'optimisation devrait se produire après la rétropropagation.
En maintenant ces mises à jour des paramètres de poids et de biais dans une taille "sûre", cette méthode aide à naviguer dans le paysage de perte plus doucement, contribuant à une meilleure convergence de l'entraînement. Le seuil c_c_ est un hyperparamètre qui nécessite un réglage pour équilibrer entre une vitesse d'apprentissage adéquate et la stabilité.
Chapitre 8 : Modélisation de Séquences avec les RNN et LSTM
Dans ce chapitre, vous apprendrez à connaître l'un des types de modèles de Réseaux de Neurones les plus populaires, les Réseaux de Neurones Récurrents (RNN).
La modélisation de séquences est une pierre angulaire de l'apprentissage profond pour les données séquentielles telles que les séries temporelles, la parole et le texte. Nous examinerons les mécanismes des RNN, leurs limites inhérentes et l'évolution des architectures avancées telles que la Mémoire à Long et Court Terme (LSTM).
Architecture des Réseaux de Neurones Récurrents (RNN)
Les RNN se distinguent par leur capacité unique à former un graphe dirigé le long d'une séquence, leur permettant d'exhiber un comportement dynamique temporel. Contrairement aux réseaux de neurones feedforward habituels, les RNN peuvent utiliser leur état interne (mémoire) pour traiter des séquences d'entrées.
Au cœur du RNN se trouve le concept de cellule, qui est l'unité répétitive formant la base de la capacité du RNN à maintenir une mémoire à travers les séquences d'entrée (l'élément de temps et de séquence). À un niveau élevé, un RNN peut être visualisé comme suit :
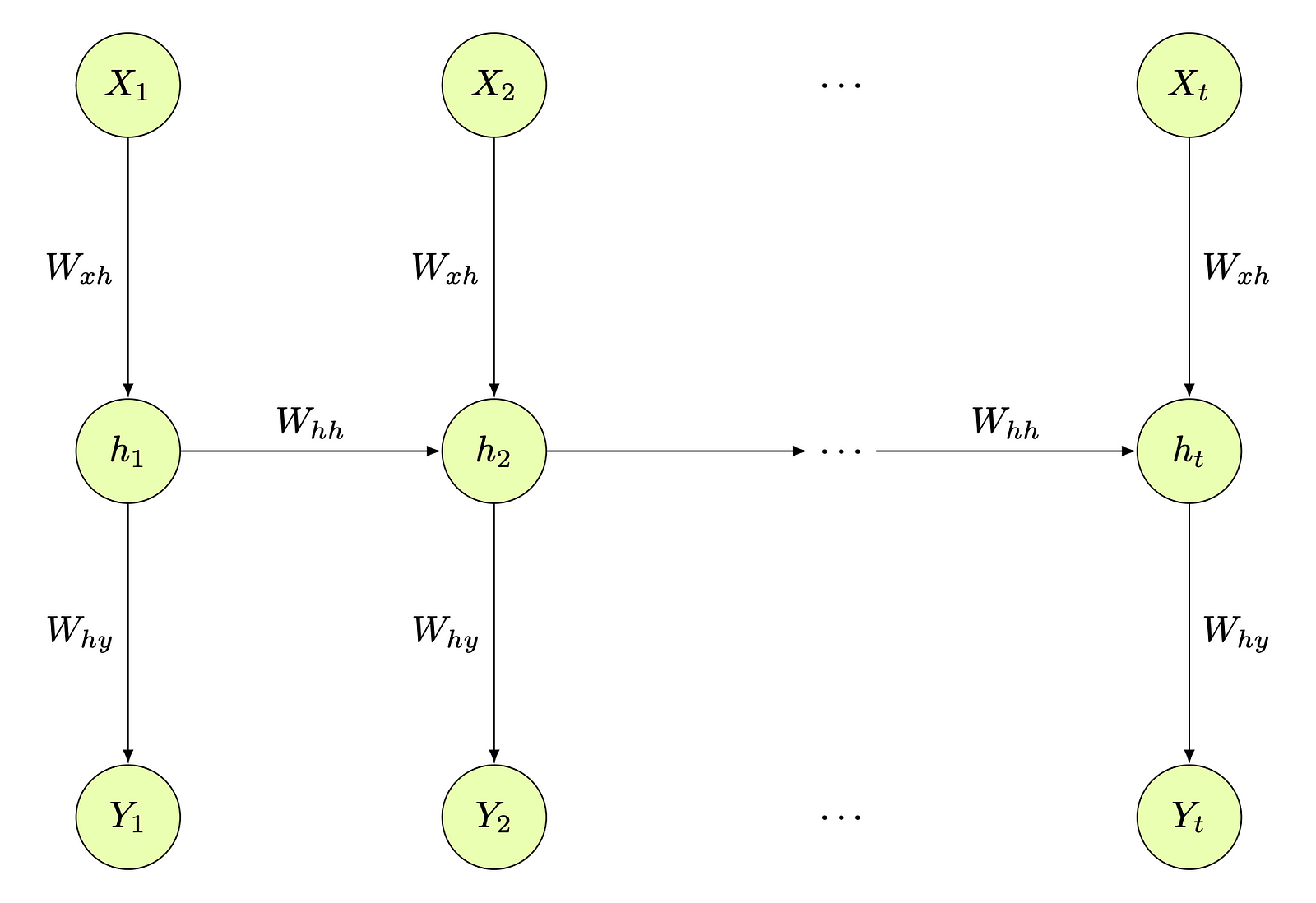
Architecture RNN (Source de l'Image : LunarTech.ai)
Cette visualisation facilite la compréhension de cette architecture plus complexe. Comme vous pouvez le voir sur l'image, la couche cachée utilisée sur une observation spécifique d'un ensemble de données n'est pas seulement utilisée pour générer une sortie pour cette observation (sortie y utilisant h_t), mais elle est également utilisée pour entraîner la couche cachée de l'observation suivante (h_t est utilisé avec x_(t+1) pour obtenir h_(t+1)).
Contrairement aux Réseaux de Neurones de base qui ont une seule entrée, plusieurs couches cachées indépendantes, puis une seule sortie Y, les RNN ont une architecture différente.
Outre le fait d'avoir une structure différente pour l'entrée et la sortie (c'est-à-dire, plusieurs entrées et sorties), la chose la plus importante à remarquer ici est que dans les couches cachées d'un RNN, les états cachés sont interconnectés.
Cette propriété "dépendante" d'une observation aidant à prédire l'observation suivante est la raison pour laquelle les réseaux de neurones récurrents sont si pratiques lorsqu'il s'agit de problèmes avec des éléments de temps ou de séquence (comme les problèmes d'analyse de séries temporelles ou de prédiction du mot suivant en NLP).
Pseudocode des Réseaux de Neurones Récurrents
Pour commencer, regardons par exemple le premier pas de temps. L'état caché au pas de temps 1 est calculé comme suit :
$$h_1 = f(W_{xh} \cdot X_1 + W_{hh} \cdot h_0 + b_h)$$
où :
f est une fonction d'activation (comme ReLU ou Tanh)
W_xh est la matrice de poids d'entrée à cachée
W_hh est la matrice de poids de cachée à cachée
h_0 est l'état caché initial (précédent)
b_h est le biais de la couche cachée
W_hh est souvent appelé la matrice de poids récurrente. C'est la matrice qui définit combien chacun de ces états cachés précédents contribuera au calcul de l'état caché présent.
Ensuite, la sortie à ce premier pas de temps est la suivante :
$$Y_1 = W_{hy} \cdot h_1 + b_y$$
où :
_W_hy_𝟰 est la matrice de poids de cachée à couche de sortie
_b_y_𝟰 est le biais pour la couche de sortie
L'algorithme RNN pour tous les pas de temps de 1 à T peut être décrit avec le pseudocode suivant :
Algorithme 1 Pas de Temps des Réseaux de Neurones Récurrents
1: pour chaque pas de temps t = 1 à T faire
2: Entrée : Xt
3: Initialiser : h0 à un vecteur de zéros
4: Paramètres :
5: Wxh : Matrice de poids de l'entrée à la couche cachée
6: Whh : Matrice de poids récurrente pour la couche cachée
7: Why : Matrice de poids de la couche cachée à la couche de sortie
8: bh : Biais pour la couche cachée
9: by : Biais pour la couche de sortie
10: Fonction d'activation : f (par exemple, tanh, ReLU)
11: Mise à jour de l'État Caché :
12: ht = f(Wxh . Xt + Whh . ht𝟰1 + bh)
13: Sortie :
14: Yt = Why . ht + by
15: fin pour
Limitations des Réseaux de Neurones Récurrents
Maintenant, discutons des limitations des RNN et pourquoi les LSTM sont entrés en jeu ainsi que plus tard les Transformers ! Voici les limitations du Réseau de Neurones Récurrent :
Problème du Gradient Évanescent
Problème du Gradient Explosif
Calcul Séquentiel
Difficulté à Gérer les Longues Séquences
Informations Contextuelles Limitées
Puisque nous avons déjà discuté des problèmes de Gradient Évanescent et Explosif et comment les résoudre, nous passerons aux limitations restantes des RNN avant de discuter des variations des RNN qui abordent ces défis.
Mais d'abord, notons simplement : surtout dans le cas des RNN, le Gradient Évanescent peut entraîner un apprentissage très lent des couches initiales du réseau, voire pas du tout, ce qui rend les RNN mal adaptés à l'apprentissage des dépendances à long terme au sein d'une séquence. Et dans le cas des Gradients Explosifs, ils peuvent entraîner de grandes mises à jour des paramètres du réseau et, par conséquent, un Réseau de Neurones Récurrent instable.
Limitation du Calcul Séquentiel
La nature séquentielle des RNN ne permet pas de parallélisation pendant l'entraînement car le calcul de l'étape suivante dépend de l'étape précédente. Cela peut entraîner des processus d'entraînement beaucoup plus lents par rapport aux réseaux de neurones qui permettent une parallélisation complète.
Limitation de la Gestion des Longues Séquences
Les RNN peuvent avoir des difficultés à traiter les longues séquences car les informations du début de la séquence peuvent être perdues au moment où elles atteignent la fin en cas de problème de Gradient Évanescent.
Limitation des Informations Contextuelles
C'est l'une des limitations les plus importantes des RNN qui a motivé l'invention des Transformers. Les RNN standard n'ont pas de mécanisme pour se souvenir ou oublier sélectivement les informations, ce qui peut être une limitation lors du traitement de séquences où seules certaines parties sont pertinentes pour la prédiction.
Architecture de la Mémoire à Long et Court Terme (LSTM)
Les réseaux de mémoire à long et court terme ou LSTM sont un type spécial de RNN conçu pour atténuer la plupart des limitations des RNN traditionnels. Ils intègrent des mécanismes que nous appelons Cellules qui permettent au réseau de réguler les informations qui le traversent.
Ces portes sont :
Porte d'Oubli : Porte qui détermine quelles informations doivent être supprimées de l'état de la cellule
Porte d'Entrée : Porte qui met à jour l'état de la cellule avec de nouvelles informations
Porte de Sortie : Porte qui détermine quel doit être le prochain état caché
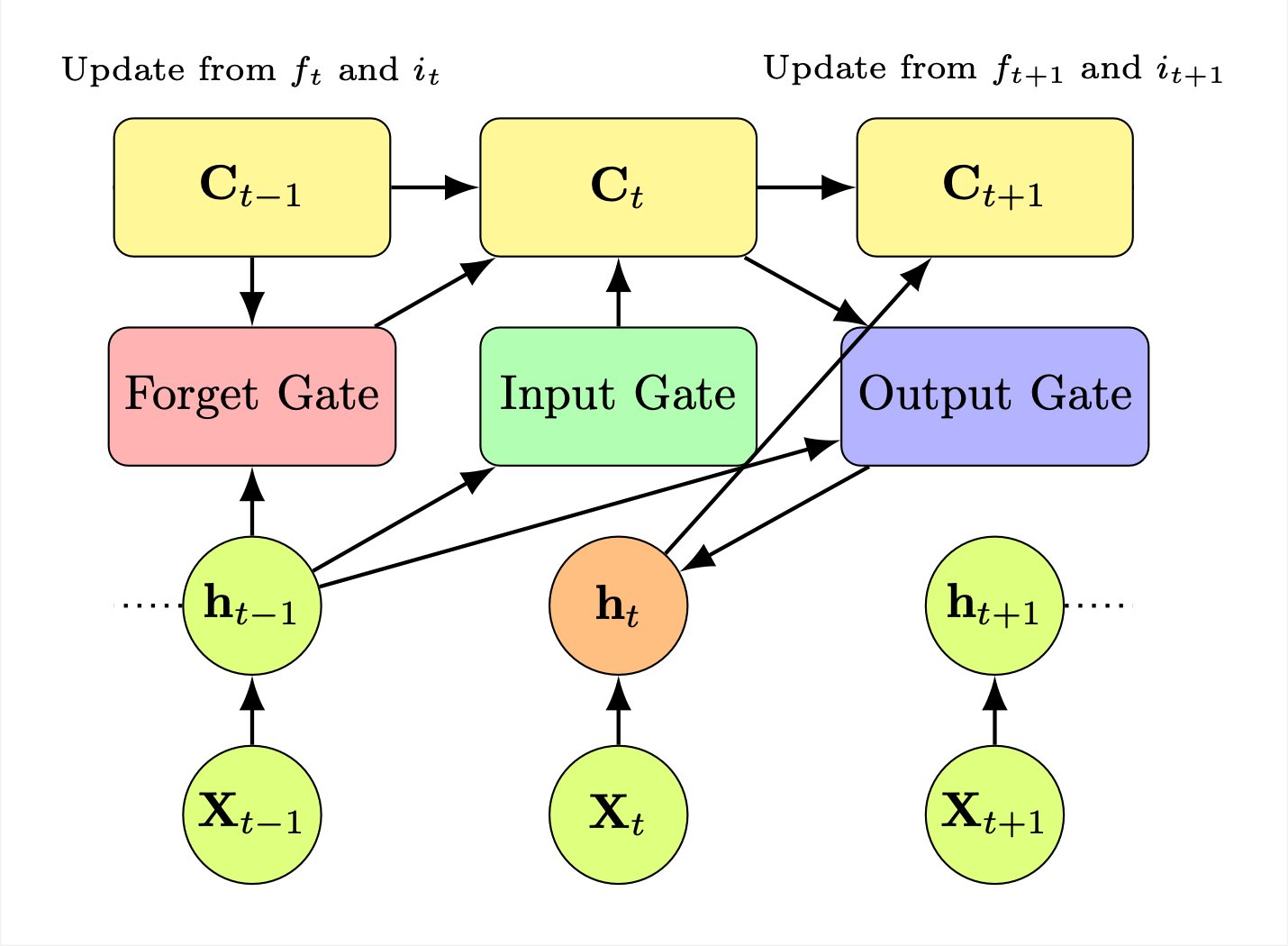
Architecture LSTM (Source de l'Image : LunarTech.ai)
Ce diagramme représente l'architecture d'un réseau LSTM (Long Short-Term Memory), visualisant le flux de données à travers ses composants à différents pas de temps. Plongeons plus profondément dans chacun de ces états et le processus qui les sous-tend :
États de Cellule : En haut, nous avons des rectangles en jaune étiquetés C_(t𝟰1), C(t)𝟰_, 𝟰 C(t+1)_𝟰. Ceux-ci représentent les états de cellule du LSTM à des pas de temps consécutifs.
Ces états de cellule sont un composant clé du LSTM car ils transportent les informations pertinentes tout au long du traitement de la séquence. Ils contiennent les informations sur quelles informations utiliser, quelles informations oublier et quelles informations produire.
Les flèches indiquent le flux et les transformations de l'état de cellule d'un pas de temps à l'autre.
Portes : Au milieu, vous pouvez voir les 3 portes, des blocs colorés représentant les portes du LSTM :
Porte d'Oubli (Rose) : Détermine quelles parties de l'état de cellule C(t𝟰1)_𝟰 doivent être oubliées et quelles parties doivent être retenues, pour produire l'état de cellule suivant C(t)_𝟰.
Porte d'Entrée (Verte) : Décide quelles valeurs seront mises à jour dans l'état de cellule en fonction de l'entrée au pas de temps actuel.
Porte de Sortie (Violette) : Détermine quelle partie de l'état de cellule sera utilisée pour générer l'état caché de sortie _h_t_𝟰.
Ces 3 portes contrôlent le flux d'informations et leur quantité, avec des lignes reliant l'état caché précédent h(t𝟰1) 𝟰_et l'état de cellule à chacune de ces portes, illustrant comment chacune d'elles contribue à l'état actuel.
Différence entre Cellule et Portes : Notez que les cellules et les portes sont des concepts différents, où, comme vous pouvez le voir sur le diagramme, la cellule est à un niveau supérieur à celui des portes, et pour chaque pas de temps, il y a un seul état de cellule mais 3 portes. L'état de la cellule utilise essentiellement 3 portes pour réguler le flux d'informations. C'est comme une fonction qui utilise 3 valeurs d'entrée pour générer une sortie, pour le dire simplement.
Commun à l'architecture originale des RNN, l'état caché à chaque pas de temps est influencé par l'état caché précédent et l'entrée actuelle, ainsi que les opérations internes des portes communes aux LSTM.
Ces portes au sein des LSTM lui permettent d'apprendre quelles informations conserver ou supprimer au fil du temps, ce qui rend possible la capture de dépendances à long terme dans les données.
Comment les LSTM abordent les limitations des RNN
Résolution des Gradients Évanescents et Explosifs : Les LSTM sont conçus pour avoir des changements de poids plus constants, ce qui signifie que les gradients sont plus constants. Cela leur permet d'apprendre sur de nombreux pas de temps, résolvant ainsi les problèmes de gradients évanescents/explosifs grâce à leur mécanisme de gating et en maintenant un état de cellule séparé.
Dépendances à Long Terme : En apprenant ce qu'il faut stocker et ce qu'il faut supprimer/oublier de l'état de cellule, les LSTM peuvent maintenir des dépendances ou des relations à long terme dans les données. Cela les rend plus efficaces pour les tâches impliquant de longues séquences telles que celles des modèles de langage.
Mémoire Sélective : Les LSTM peuvent apprendre à ne conserver que les informations pertinentes pour faire des prédictions en utilisant la porte d'oubli. Oublier les données non pertinentes, ce qui les rend meilleurs pour modéliser des séquences complexes où la pertinence de l'information varie avec le temps, aide à faire exactement cela.
Limites des LSTM
Bien que les LSTM représentent une amélioration significative par rapport aux RNN originaux, ils présentent encore certains inconvénients majeurs, tels que d'être plus intensifs en calcul en raison de leur architecture complexe. Les LSTM ont un nombre plus élevé de paramètres, ce qui peut entraîner des temps d'entraînement plus longs et nécessiter plus de données pour généraliser efficacement.
De plus, similaire aux RNN, les LSTM traitent également les données de manière séquentielle, ce qui signifie qu'ils ne peuvent pas être entièrement parallélisés.
Ainsi, la parallélisation et le temps d'entraînement plus long en raison du nombre plus élevé de paramètres restent deux inconvénients majeurs pour les RNN et les LSTM.
Chapitre 9 : Préparation aux Entretiens en Apprentissage Profond
Alors que nous atteignons le point culminant de ce manuel complet, il est temps de se concentrer sur la traduction de vos nouvelles connaissances en succès dans le monde réel.
Que vous visiez à entrer dans l'industrie de l'IA ou que vous ayez en vue un poste convoité de Chercheur en IA ou d'Ingénieur en IA dans les entreprises FAANG, le dernier obstacle est souvent le plus difficile mais aussi le plus gratifiant : l'entretien d'embauche.
Vous devrez connaître les détails et être capable de répondre à des questions pièges qui vont au-delà des informations théoriques de surface.
Vous devrez connaître :
Les Réseaux de Neurones Convolutifs (pooling, padding, noyaux)
Les Réseaux de Neurones Récurrents (RNN), LSTM, GRU
La Normalisation par Lots/Couche
Les Réseaux Adverses Génératifs (GAN)
Les Auto-Encodeurs (Architectures Encodeur-Décodeur)
Les Auto-Encodeurs Variationnels (Divergence KL, ELBO)
Les Embeddings
Le Mécanisme d'Attention Multi-Têtes
Les Transformers
Et ce ne sont là que quelques sujets que vous pouvez attendre pour vos entretiens plus avancés/FAANG. Consultez la liste complète des 100 questions de ce programme à l'adresse suivante : ici.
Comprenant l'importance de cette étape cruciale, je suis ravi de vous présenter mon cours spécialement conçu de Préparation aux Entretiens en Apprentissage Profond, sponsorisé par LunarTech, disponible sur LunarTech.ai et Udemy. Ce cours est méticuleusement conçu pour vous assurer d'être non seulement prêt pour l'entretien, mais aussi prêt à exceller dans le marché du travail en IA hautement compétitif.
Voici ce que couvre le cours :
Partie 1 – Les Essentiels (Cours Gratuit de 4 Heures) : Je crois en l'autonomisation de chaque passionné de Data Science et d'IA. Je propose donc la première partie de mon cours d'entretien absolument gratuit. Cette section comprend le premier ensemble de 50 questions d'entretien qui couvrent l'étendue des fondamentaux de l'apprentissage profond.
Cours Complet – [Cours Complet de Préparation aux Entretiens en Apprentissage Profond - 100 Q&R 7.5 heures ]** : Pour ceux qui sont déterminés à ne laisser aucune pierre non retournée, notre cours complet sur LunarTech.ai est l'outil ultime de préparation pour les entretiens faciles mais aussi complexes en Apprentissage Profond. S'étendant à 100 questions d'entretien approfondies, ce cours complet explore les nuances de l'apprentissage profond, garantissant que vous vous démarquez même dans les entretiens les plus exigeants, y compris ceux des entreprises comme FAANG.
C'est votre opportunité de dépasser le statut de candidat – pour devenir un leader dans le domaine de l'IA.
À Propos de l'Auteur
Je suis Tatev Aslanyan, Chercheur Senior en Machine Learning et IA. J'ai eu le privilège de travailler dans le domaine de la Data Science dans de nombreux pays, dont les États-Unis, le Royaume-Uni, le Canada et les Pays-Bas. Je suis Co-fondateur de LunarTech où nous rendons la Data Science et l'IA plus accessibles à tous !
Avec un MSc et un BSc en Économétrie à mon actif, mon parcours dans le domaine du Machine Learning et de l'IA a été tout simplement incroyable. Tirant parti de mes études techniques pendant mon Bachelor & Master, ainsi que de plus de 5 ans d'expérience pratique dans l'industrie de la Data Science, du Machine Learning et de l'IA.
Connectez-vous avec Moi et LunarTech

Source de l'Image : [LunarTech](https://lunartech.ai" style="box-sizing: inherit; margin: 0px; padding: 0px; border: 0px; font-style: inherit; font-variant-caps: inherit; font-weight: inherit; font-stretch: inherit; line-height: inherit; font-family: inherit; font-size-adjust: inherit; font-kerning: inherit; font-variant-alternates: inherit; font-variant-ligatures: inherit; font-variant-numeric: inherit; font-variant-east-asian: inherit; font-variant-position: inherit; font-feature-settings: inherit; font-optical-sizing: inherit; font-variation-settings: inherit; font-size: 17.6px; vertical-align: baseline; background-color: transparent; color: var(--gray90); text-decoration: underline; cursor: pointer; word-break: break-word;)
Visitez mon Site Web Personnel pour des Ressources Gratuites
Abonnez-vous à La Newsletter sur la Data Science et l'IA
Si vous souhaitez commencer une carrière dans la Data Science ou l'IA, téléchargez mon guide gratuit Data Science and AI Handbook ou Fondamentaux du Machine Learning Handbook
Meilleurs vœux dans toutes vos futures entreprises !