

Article original : Backend Software Architecture Checklist: How to Build a Product from Scratch
Par Sajal Sharma
Vous vous réveillez un matin pour prendre votre tasse de café et voilà, le moment Eurêka est arrivé. Vous avez enfin compris votre modèle économique, et tout se met en place. Vous savez que les investisseurs vont l'adorer, et vous n'avez qu'une envie : commencer à construire le produit. L'avantage du premier arrivant est à vous.
Ces moments sont rares, mais lorsqu'ils se produisent, vous devez démarrer au bon moment. Tout ce dont vous avez besoin, c'est du bon guide pour vous aider à déterminer ce que vous devriez faire et ne pas faire. Ce n'est pas le moment d'expérimenter, c'est le moment d'exécuter. C'est VOTRE moment maintenant !
NOTE - Ce qui suit concerne la construction d'architectures logicielles à partir de zéro. Donc, si vous êtes intéressé à connaître les détails des technologies impliquées, alors continuez. Sinon, veuillez partager avec ceux qui vont définitivement adorer cela :P
D'où vient ce guide
J'ai moi-même travaillé sur quelques produits en phase de démarrage, et pour être honnête, j'ai fait des erreurs. J'ai toujours souhaité qu'il y ait une liste de contrôle à suivre lors de la construction d'un produit à partir de zéro.
Il y a tant de choses impliquées dans la construction d'une architecture à partir de zéro que vous allez totalement oublier certains éléments. Et ils vont revenir vous hanter dans les phases ultérieures du cycle de vie du produit.
J'ai finalement décidé de créer cette liste de contrôle des choses que vous devriez considérer avant d'appuyer sur ce bouton de déploiement pour la première fois.
Alors, sans plus attendre, voici la liste de contrôle que vous devriez suivre lors de la construction d'une architecture Backend pour un produit à partir de zéro.
Choisissez le BON langage et framework (pour votre projet)
Choisir le bon langage et framework pour votre produit est délicat, et il n'y a pas de solution miracle pour cela. Mon conseil est de choisir un langage avec lequel vous êtes le plus à l'aise et dont vous connaissez les intrications.
Cela dit, c'est rare, car il y a très peu de personnes qui sont des Ninjas en Javascript, ou des Panthères en Python, ou peu importe les noms farfelus qui existent.
Alors, choisissez un langage qui a un bon support dans l'industrie, comme Javascript, Python, Java, ou Go, pour n'en nommer que quelques-uns. Vous pouvez choisir n'importe quel langage, il suffit de choisir celui avec lequel vous êtes le plus à l'aise.
Et rappelez-vous – vous construisez un MVP (Produit Minimum Viable), et vous serez en train de créer une POC (Preuve de Concept). Alors, sortez votre produit le plus rapidement possible. Vous n'avez pas besoin de vous retrouver bloqué sur des problèmes qui pourraient provenir du nouveau langage à la mode. Pour éviter ces problèmes, choisissez un langage plus largement utilisé et bien documenté.
Enfin, vous pourrez mettre à l'échelle plus tard. Si vous êtes dans la phase de création de POC, construisez et terminez-le. Mais si vous construisez quelque chose de vraiment spécifique, et qu'il existe un langage et un framework construits spécialement pour cela, alors vous devriez définitivement choisir cette technologie.
Mais la plupart du temps, les problèmes que nous essayons de résoudre peuvent être facilement pris en charge avec l'un des langages mentionnés ci-dessus et leurs frameworks respectifs. Alors, choisissez-en un et lancez votre produit.
Une bonne ressource pour vous aider à décider -
Implémentez les microservices d'authentification et d'autorisation
Il existe de nombreuses façons d'authentifier et d'autoriser un utilisateur. Vous pourriez essayer les jetons de session, les JWT (JSON Web Tokens), ou OAuth, pour n'en nommer que quelques-uns. Chaque option a ses propres avantages et inconvénients. Alors, examinons certains d'entre eux de plus près.
JSON Web Tokens
Les JWT sont rapides et faciles à implémenter. Cela est dû au fait que les jetons ne sont jamais stockés nulle part sur votre système. Ils sont simplement encodés, chiffrés et envoyés à l'utilisateur. Ainsi, la validation d'un JWT est plus rapide que toute autre méthode.
Mais alors, puisque ils ne sont pas stockés sur le système, vous ne pouvez pas réellement faire expirer un jeton avant son heure d'expiration réelle, et cela peut être un problème dans certains cas.
Alors, déterminez les avantages et inconvénients de chaque système d'authentification et choisissez celui qui convient le mieux à vos besoins. Je préfère personnellement les JWT (mais c'est mon choix personnel).
Autorisation
N'oubliez jamais d'implémenter l'autorisation des utilisateurs. Vous ne voulez pas que l'utilisateur connecté User1 modifie les détails de User2. Cela peut causer un chaos total dans votre système.
Identifiez les points de terminaison qui nécessitent une autorisation, et implémentez-les immédiatement. Vous ne voulez pas que l'état de votre base de données soit corrompu de cette manière. Rappelez-vous la différence entre 401 et 403.
Les éléments suivants sont certains points de terminaison que vous devriez définitivement considérer lors de la création de votre système d'authentification (j'en ai créé un dans Django en utilisant JWT). Il peut y avoir certaines additions/suppressions pour votre cas d'utilisation, mais ce sont ceux que vous devriez envisager de construire.
De nombreux frameworks les fournissent directement, mais envisagez-les avant de les construire vous-même. Vérifiez _authenticationclasses et _permissionclasses dans le Django Rest Framework pour plus de références.
Jetez un coup d'œil à cette ressource Django REST Framework -
https://www.django-rest-framework.org/tutorial/4-authentication-and-permissions/
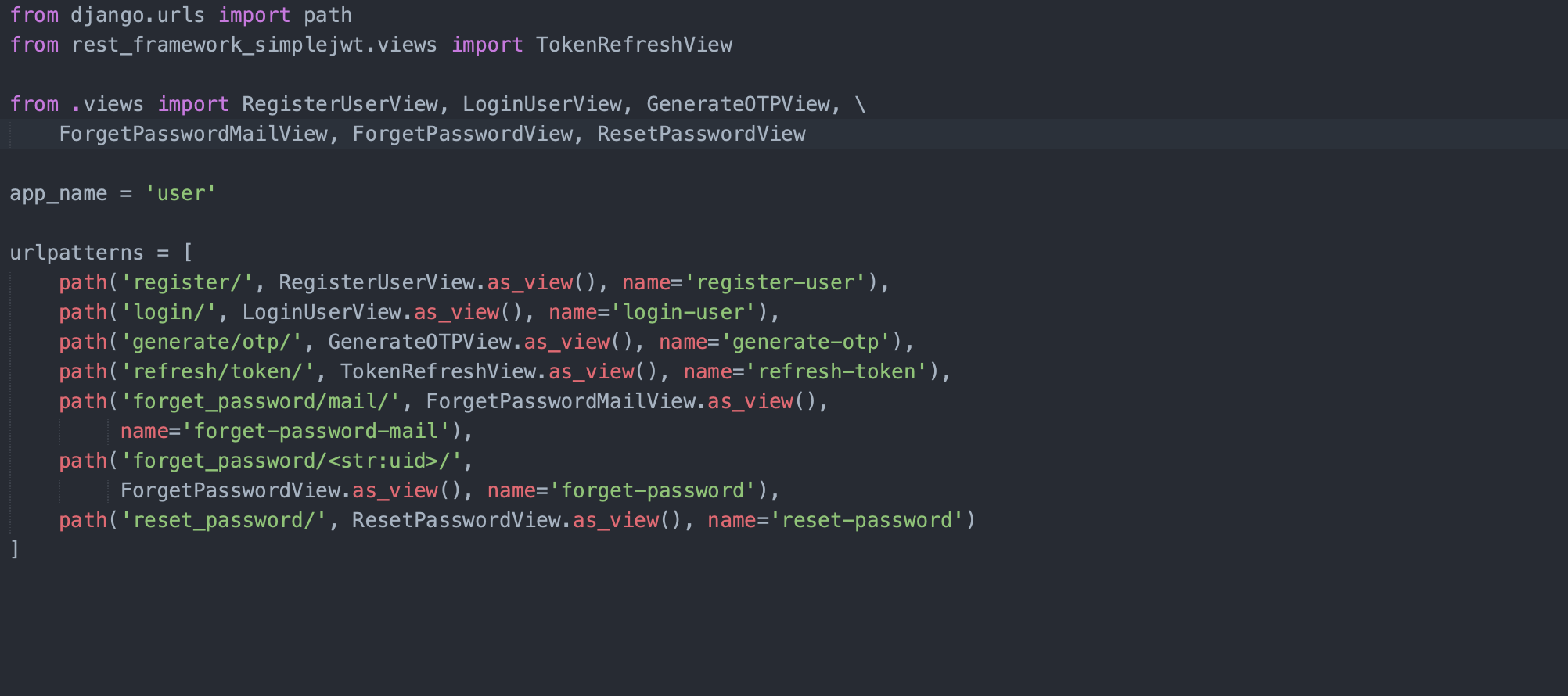
Créez un modèle de base abstrait à hériter par tous les autres modèles dans votre base de données
Rappelez-vous le principe DRY - Don't Repeat Yourself ? Il devrait être suivi à la lettre en ingénierie logicielle.
En construisant sur cette réflexion, il y aura certaines colonnes dans votre base de données qui seront présentes dans chaque table. Il est donc préférable de créer une classe abstraite pour elles afin que d'autres classes de modèles puissent en hériter.
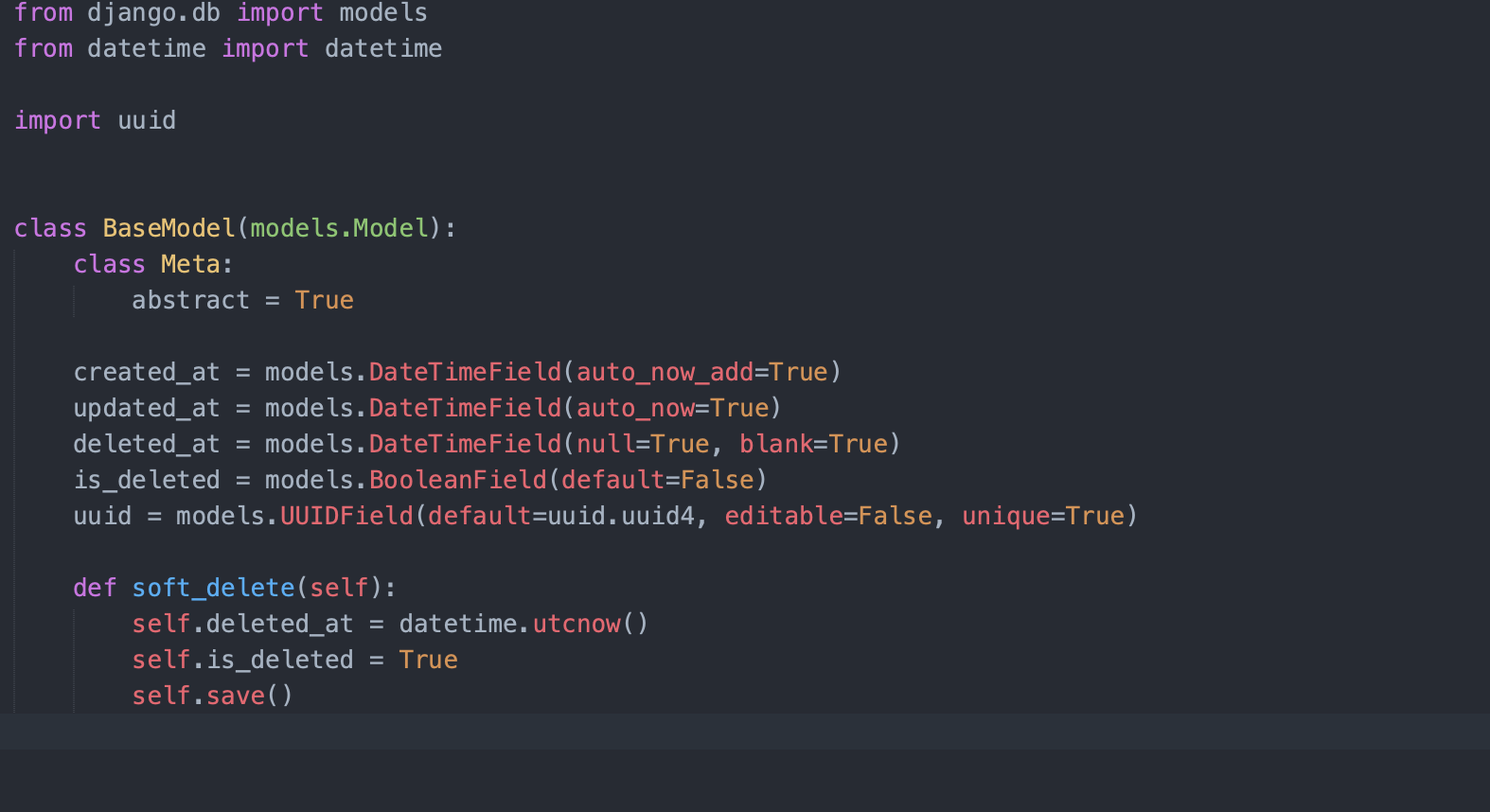
Passons en revue ce code et ce qu'il signifie :
- id - Bien qu'il ne soit pas écrit ici, il est automatiquement créé par le framework Django. Mais s'il n'est pas présent dans le vôtre, écrivez-le dans cette classe. Il s'agit simplement d'un champ auto-incrémenté qui peut être utilisé comme clé primaire dans votre relation de base de données.
- _createdat - Cela implique quand le champ/ligne a été inséré dans votre table, et il est rempli par le framework lui-même. Vous n'avez pas besoin de le définir explicitement.
- _updatedat - Cela implique quand le champ/ligne a été modifié/mis à jour pour la dernière fois dans votre table, et encore une fois, il est rempli par le framework lui-même.
- _deleted_at + isdeleted - Donc, ce champ est controversé. Je n'ai pas de réponse exacte quant à savoir s'il devrait être présent ou non - car, pour être honnête, rien sur Internet n'est jamais supprimé. Ce champ, s'il est rempli, indique que la ligne est supprimée du système (bien que les données restent dans le système pour référence future et peuvent être retirées de la base de données et stockées dans des sauvegardes).
- uuid - Cela dépend si vous voulez mettre cela dans votre table ou non. Si vous devez exposer la clé primaire de votre table à un système externe, il est préférable d'exposer celle-ci plutôt que le champ entier auto-incrémenté. Vous pourriez vous demander pourquoi...? Eh bien, pourquoi voudriez-vous dire à un système externe que vous avez 10378 commandes dans votre table ? Mais encore une fois, c'est un choix personnel.
Configurez un microservice de notification
Chaque produit doit envoyer des rappels et des notifications à l'utilisateur à des fins d'engagement et de transaction. Donc, chaque produit en aura besoin.
Vous devriez définitivement envisager de construire un microservice qui fournit des services de notification (comme les notifications push, les e-mails et les SMS) à vos utilisateurs finaux.
Cela devrait être un microservice séparé. Ne construisez pas cela à l'intérieur de votre microservice d'authentification ou de votre service d'application (la logique métier réelle).
Il existe de nombreuses bibliothèques/services tiers qui peuvent être utilisés pour le construire pour votre application. Utilisez-les et construisez-le par-dessus.
N'oubliez pas de construire toutes les 3 fonctionnalités :
- Notifications push (APNS + FCM),
- E-mails (intégrez simplement un client SMTP pour commencer)
- et SMS
NOTE - Ayez deux canaux pour envoyer des SMS, transactionnel et promotionnel. Ne envoyez jamais un SMS promotionnel sur un canal transactionnel, car il y a des chances que vous soyez poursuivi par un utilisateur bien informé et motivé.
Une façon facile de configurer votre client SMTP dans votre application est d'utiliser ceci dans vos paramètres :
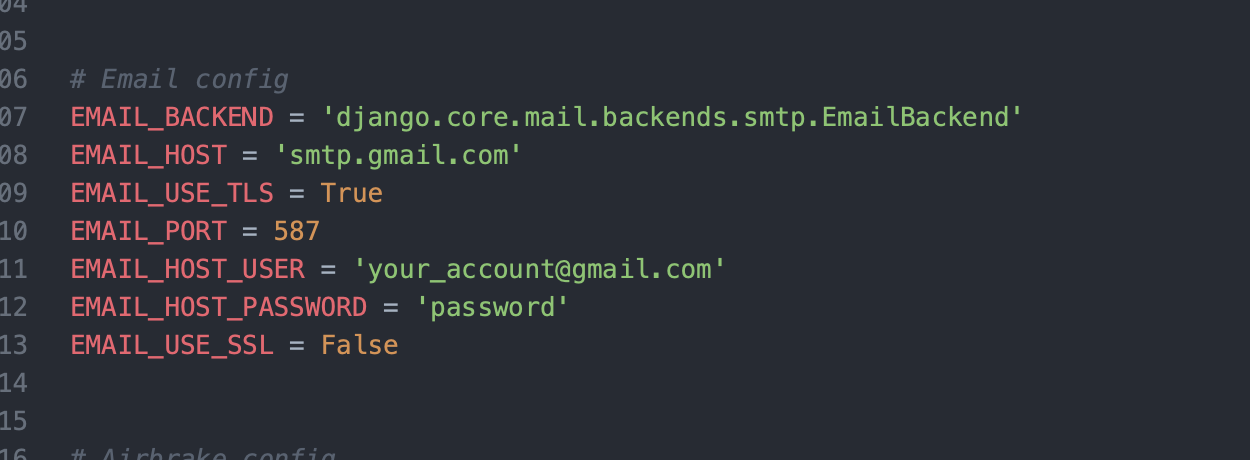
J'ai fait cela dans Django, mais vous pouvez faire de même dans votre langage et framework choisi.
Configurez la journalisation des erreurs
Utilisez un middleware pour journaliser les erreurs qui se produisent sur votre système de production. Votre système de production ne sera pas surveillé par des humains assis là pour voir les journaux de l'application 24/7. Vous aurez donc besoin d'un système qui journalisera ces erreurs internes du serveur dans un endroit central. Ensuite, vous pourrez aller les vérifier quotidiennement ou créer un webhook afin de pouvoir être alerté au bon moment et vous en occuper.
Il existe de nombreux outils de journalisation des erreurs tiers sur le marché. Choisissez simplement celui qui convient à vos besoins. J'utilise principalement Sentry/Airbrake.
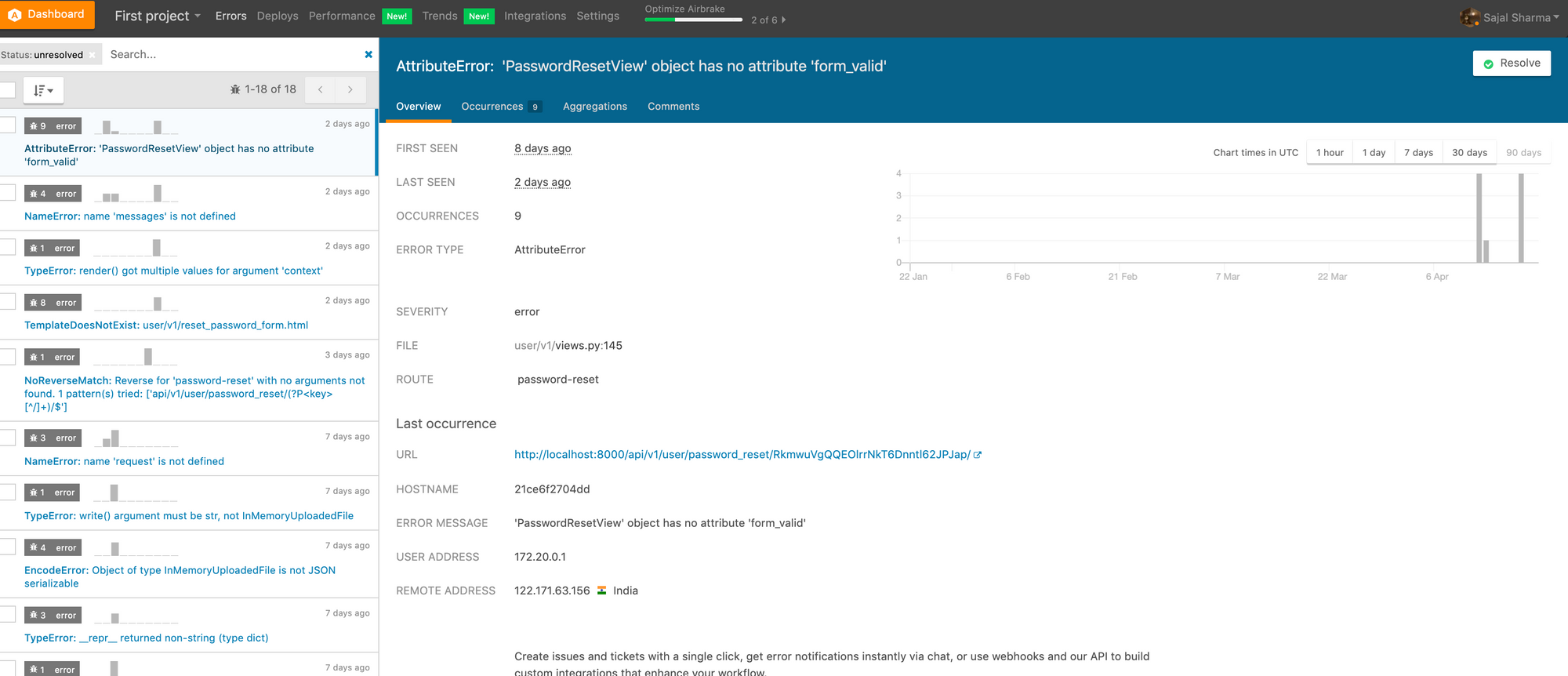
Envisagez de configurer des webhooks, comme je l'ai mentionné ci-dessus. Ils informeront vos utilisateurs des erreurs et, par exemple, vous pourrez publier ces erreurs au fur et à mesure qu'elles se produisent sur certains canaux Slack. Ensuite, vous pourrez vérifier ces canaux régulièrement et les rectifier en fonction de leur gravité.
Page d'accueil officielle d'Airbrake - https://airbrake.io/
Page d'accueil officielle de Sentry - https://sentry.io/welcome/
Implémentez la journalisation des requêtes - réponses et de l'application
Scénario - Un utilisateur vient sur votre support et dit qu'il n'a pas reçu le reçu transactionnel pour l'achat qu'il a effectué sur votre site web. Que ferez-vous ?
Si vous avez mis en place la journalisation de l'application dans votre système, alors ne vous inquiétez pas. Maintenant, que veux-je dire par là ? Il est toujours préférable de montrer un exemple plutôt que d'essayer d'expliquer avec des mots. Alors, le voici :
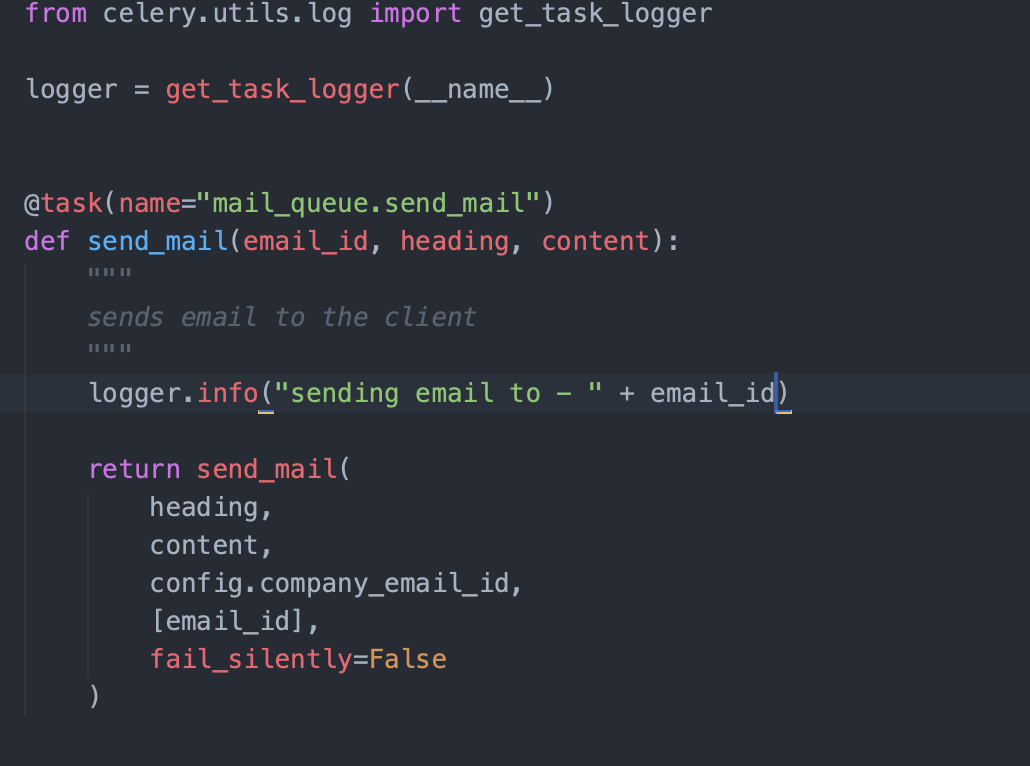
J'ai journalisé que je suis sur le point d'envoyer l'e-mail à l'email_id mentionné. Je peux vérifier dans les journaux de l'application si l'e-mail a été envoyé au client en vérifiant si un tel journal existe dans le système. Assurez-vous de mettre des journaux complets dans votre système afin de pouvoir tracer le parcours de la requête.
De plus, il est bon de mettre en place un système asynchrone qui extraira ces journaux de requêtes-réponses et d'application de votre système et les déversera dans un endroit central. Là, ils pourront être traités pour être plus facilement interprétables.
La pile ELK est une bonne option pour cela : ElasticSearch - Logstash - Kibana.
Plus d'informations sur la pile ELK - https://www.elastic.co/what-is/elk-stack
NOTE - Lors de la journalisation des requêtes et des réponses, prenez soin des éléments suivants :
- Ne journalisez pas les mots de passe.
- Ne journalisez pas les jetons (les jetons d'accès utilisés pour l'authentification)
- Ne journalisez pas les OTP
Introduisez la limitation de débit dans vos API et la limitation de taux sur vos serveurs d'application
Scénario - Vous venez de lancer votre service et avez fait la promotion du produit sur les plateformes de médias sociaux. Un pirate informatique black hat l'a découvert et a simplement voulu jouer avec votre système. Il a donc planifié une attaque DOS (Denial of Service) sur votre système.
Pour lutter contre cela, vous pouvez définir une limitation de taux basée sur divers facteurs au-dessus de vos équilibreurs de charge pour vos serveurs d'application. Cela prendra en charge les attaques DOS et empêchera l'utilisateur malveillant d'attaquer vos serveurs.
Scénario - Le point de terminaison de l'API /otp/validate qui prend des OTP à 4 chiffres pour authentifier l'utilisateur et renvoie des jetons à utiliser pour les API authentifiées. Un utilisateur malveillant obtient le numéro de mobile de l'un de vos clients et commence à frapper le point de terminaison de l'API avec une attaque par force brute en changeant les adresses IP, une attaque DDOS (Distributed Denial of Service). Le limiteur de taux n'est pas en mesure d'arrêter l'utilisateur, car l'IP change à chaque requête.
Pour arrêter cela, vous pouvez mettre en place une limitation de débit sur les API basée sur l'utilisateur également. Vous pouvez configurer combien de requêtes peuvent être faites par un utilisateur particulier à un point de terminaison de l'API. Pour la validation des OTP, un bon nombre est de 5 requêtes par 10 minutes. Cela empêchera l'utilisateur malveillant d'effectuer une attaque par force brute DDOS sur l'API ci-dessus.
Limitation de débit dans le framework Django REST -
https://www.django-rest-framework.org/api-guide/throttling/
Établissez et configurez la communication asynchrone dès le premier jour
Scénario - Vous devez envoyer un e-mail de bienvenue à l'utilisateur lorsqu'il s'inscrit sur votre application. Le client frontal frappe l'API d'inscription, vous créez l'utilisateur dans le backend après les validations, et cela commence le processus d'envoi d'un e-mail de bienvenue.
L'envoi de cet e-mail de bienvenue prendra du temps, peut-être quelques secondes. Mais pourquoi voudriez-vous que le client mobile soit bloqué pour un tel processus ? Cela peut se faire en arrière-plan sans que l'utilisateur soit bloqué pour aucune raison particulière sur la page d'inscription. Chaque seconde est précieuse et vous ne voulez pas que l'utilisateur perde ces secondes précieuses.
Alors, envoyez simplement l'e-mail via une tâche asynchrone. Utilisez des workers, des tâches, des brokers de messages et des backends de résultats pour effectuer cela.
Un bon exemple de cela dans le monde Python est Celery worker. Il suffit de mettre la tâche à effectuer dans un broker de messages (Rabbit MQ/SQS, etc). Celery écoutera cela et enverra la tâche au worker désigné. Ce worker traitera ensuite la requête et mettra le résultat dans un backend de résultats qui peut être un système de cache/système de base de données. (Redis/PostgreSQL par exemple).
Vous pouvez surveiller ces tâches et files d'attente avec de nombreuses bibliothèques tierces. Un bon exemple de cela est Celery Flower qui surveille tout cela.
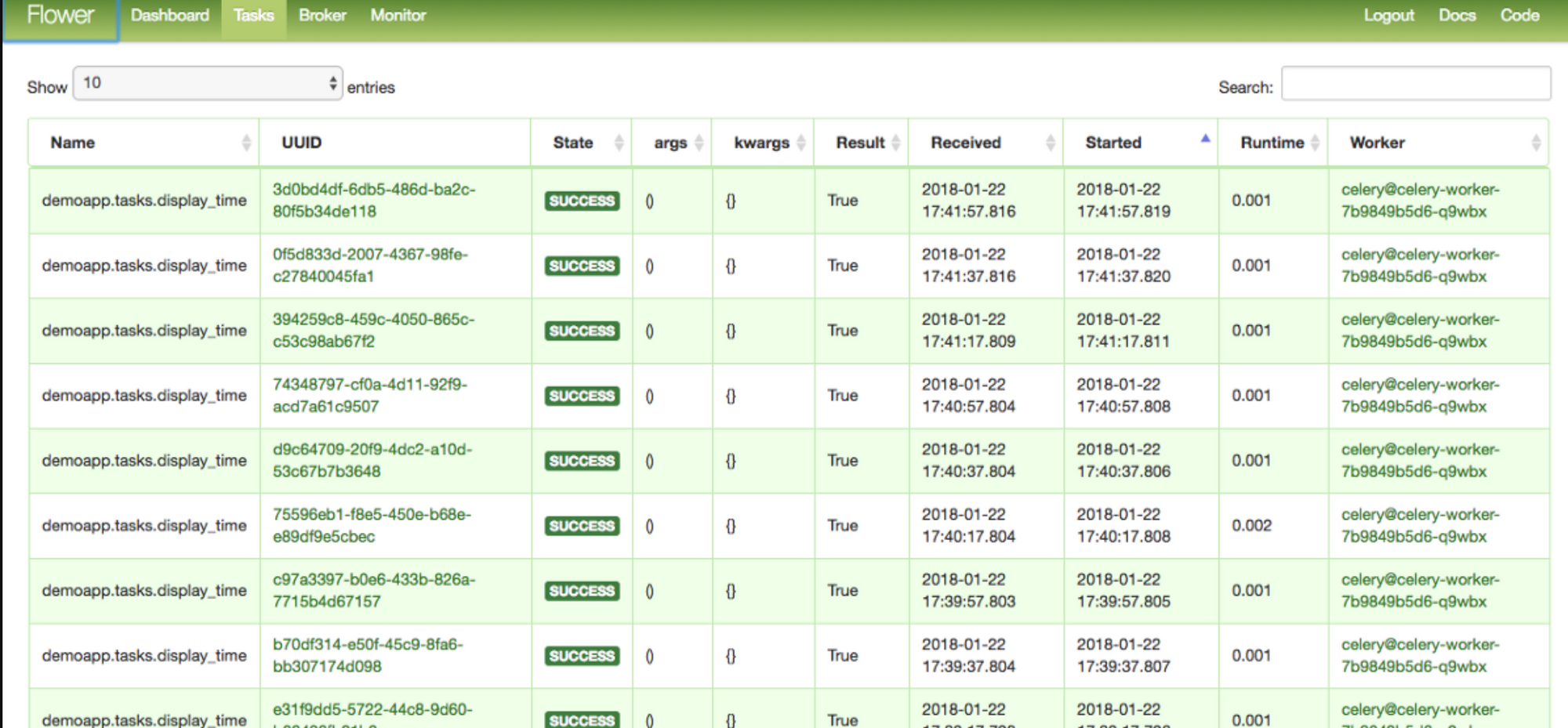
Vous pouvez lire plus sur RabbitMQ ici - https://www.rabbitmq.com/
Et Celery - https://docs.celeryproject.org/en/stable/django/first-steps-with-django.html
Et enfin, Celery Flower - https://flower.readthedocs.io/en/latest/
Configurez des tâches cron
Scénario - Vous venez de lancer votre produit et vous devez envoyer des recommandations à vos utilisateurs concernant de nouveaux produits sur votre plateforme. Vous les enverrez en fonction de leur historique d'achat chaque week-end.
La tâche ci-dessus peut être facilement effectuée à l'aide d'une tâche cron. Elle est facilement configurable dans chaque framework. L'important est de garder à l'esprit que vous ne devez pas mettre les tâches cron directement dans le fichier crontab de votre serveur. Vous devez laisser le framework s'en charger.
Cela est dû au fait que l'ingénieur de déploiement/Devops doit être la seule personne à avoir accès au système de cette manière pour des raisons de sécurité. Bien que vous n'ayez pas à l'implémenter de cette manière, c'est une bonne chose à avoir dès le début.
Dans le monde Django, vous pouvez utiliser celerybeat pour configurer vos crons en utilisant des workers Celery.
En savoir plus sur Celery Beat ici -https://docs.celeryproject.org/en/latest/userguide/periodic-tasks.html
Gérez vos secrets correctement (fichier de paramètres)
Il existe de nombreuses façons de gérer les secrets de paramètres dans vos serveurs de production. Certaines d'entre elles sont :
- Créer un fichier de secrets et le stocker dans un bucket s3 privé, et le récupérer lors du déploiement de votre application.
- Définir les paramètres dans les variables d'environnement lors du déploiement de votre application (en les stockant à nouveau dans s3)
- Placer les secrets dans un service de gestion des secrets (par exemple, https://aws.amazon.com/secrets-manager/), et les utiliser pour obtenir les secrets dans votre application.
Vous pouvez choisir l'une de ces méthodes selon votre confort et votre cas d'utilisation. (Vous pouvez choisir de garder différents fichiers de secrets pour les environnements local, de staging et de production également.)
Versionnez vos API dès le premier jour
Cela est quelque chose que vous devriez définitivement considérer dès le premier jour. Vous ne saurez jamais à quelle fréquence vos modèles économiques pourraient changer, et vous devez avoir une compatibilité ascendante et descendante dans votre application. Vous devez donc versionner vos API pour vous assurer que tout fonctionne bien pour tout le monde.
Vous pouvez avoir différentes applications pour différentes versions et laisser nginx s'en charger pour votre application. Ou vous pouvez avoir un versionnage dans l'application elle-même, et laisser les routes dans votre serveur d'application s'en charger. Vous pouvez choisir n'importe quelle méthode pour l'implémenter – le point principal est d'avoir le versionnage activé dès le départ.
Décidez des vérifications de version de mise à jour dure et douce pour vos clients frontaux
Alors, quelle est la différence entre les mises à jour dures et douces ?
Mises à jour dures font référence au moment où l'utilisateur est forcé de mettre à jour la version du client vers un numéro de version supérieur à celui installé sur son mobile.
Mises à jour douces font référence au moment où l'utilisateur voit une invite indiquant qu'une nouvelle version est disponible et qu'il peut mettre à jour son application vers la nouvelle version s'il le souhaite.
Les mises à jour dures ne sont pas encouragées, mais il y a des moments où vous devez les imposer. Quel que soit le cas, vous devriez définitivement considérer comment vous allez implémenter cela pour vos applications.
Vous pouvez le faire en l'implémentant ou en le configurant dans le Play Store ou l'App Store. Une autre façon est de créer une API dans votre application backend qui sera appelée chaque fois que l'application mobile est lancée. Cela enverra deux clés : hard_update -> true/false et soft_update -> true/false, en fonction de la version de l'utilisateur et des versions de mise à jour dure et douce définies dans votre système backend.
Un bon endroit pour stocker ces versions est dans votre cache (Redis/Memcache), que vous pouvez changer à la volée sans avoir besoin de déployer votre application.
Introduisez l'intégration continue (CI) dès le premier jour
Scénario - l'un des stagiaires travaillant sur votre projet n'est pas suffisamment compétent pour écrire du code de niveau production. Il a peut-être changé quelque chose qui pourrait casser un composant critique de votre projet. Comment pouvez-vous vous assurer que tout est correct dans de tels cas ?
Introduisez l'intégration continue. Elle exécutera des linters et des cas de test à chaque commit, et échouera si des règles sont violées. Cela bloquera à son tour la demande de pull request jusqu'à ce que toutes les règles de linting et les cas de test passent. C'est une bonne chose à avoir, et cela aide vraiment à long terme, alors gardez cela à l'esprit.
Il existe de nombreuses options disponibles sur le marché. Vous pouvez choisir d'implémenter l'une d'entre elles vous-même (Jenkins CI/CD), ou vous pouvez utiliser TravisCI, CircleCI, etc. pour la même chose.
Lisez sur TravisCI ici - https://travis-ci.org/
Et CircleCI - https://circleci.com/
Activez la prise en charge de Docker (préférence personnelle)
Créez un Dockerfile et un docker-compose.yml pour votre application afin que tout le monde exécute l'application en utilisant Docker dès le départ. L'une des principales raisons d'utiliser une telle approche est d'avoir une cohérence entre vos environnements local/staging/production, afin qu'aucun développeur ne puisse jamais dire cela à nouveau :
Mais ça marchait sur ma machine.
Ce n'est pas difficile à mettre en œuvre dès le premier jour. Au début, utilisez simplement Docker pour votre environnement local afin que la configuration de votre application puisse être vraiment fluide. Mais gardez à l'esprit comment vous pouvez l'exécuter avec et sans Docker en production.
Voici plus d'informations sur Docker Hub - https://hub.docker.com/
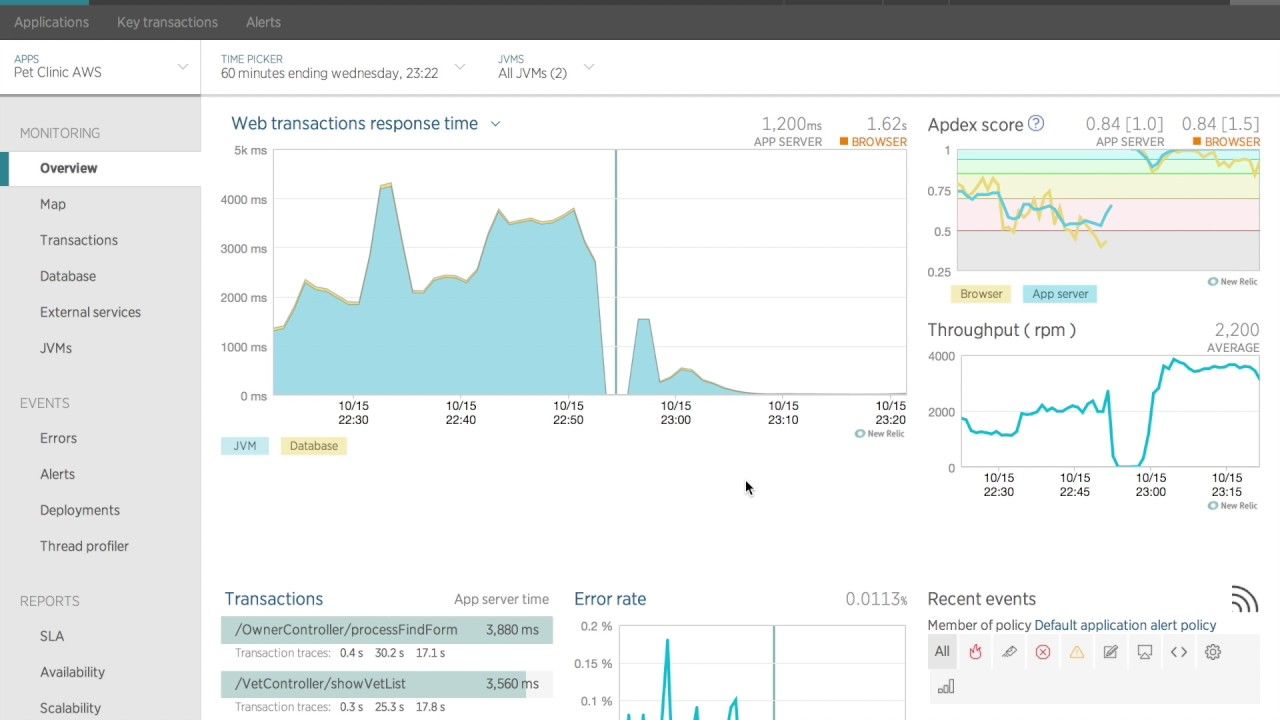
Utilisez un outil APM
Un outil de surveillance d'application est un must si vous voulez surveiller les API de votre application, les transactions, les connexions à la base de données, etc.
Scénario - le disque dur de votre serveur cron est presque plein et il n'est pas en mesure d'exécuter les tâches cron. Comme il ne trouve pas d'espace sur le disque, vos crons ne s'exécutent pas. Alors, comment pouvez-vous être notifié lorsque cela se produit ?
Il existe de nombreux outils APM que vous pouvez utiliser pour surveiller cela. Vous pouvez les configurer selon vos besoins de notification. Vous recevrez des notifications sur le support de votre choix lorsque de tels chaos se produisent sur votre système – et croyez-moi, cela arrive tout le temps. Alors, mieux vaut être préparé. New Relic est une bonne option.
Lisez plus sur New Relic ici - https://newrelic.com/
Utilisez ElasticSearch pour alimenter les recherches dans l'ensemble de l'application dans vos applications clientes
Selon Wikipedia,
Elasticsearch est un moteur de recherche basé sur la bibliothèque Lucene. Il fournit un moteur de recherche de texte intégral distribué, capable de gérer plusieurs locataires, avec une interface web HTTP et des documents JSON sans schéma. Elasticsearch est développé en Java.
Au début, vous serez tenté d'utiliser des requêtes de base de données traditionnelles pour obtenir des résultats dans cette barre de recherche pour l'application cliente. Pourquoi ? Parce que c'est facile.
Mais les bases de données traditionnelles ne sont pas conçues pour de telles requêtes performantes. Trouvez un bon moment pour migrer votre recherche vers ElasticSearch et introduisez un pipeline de données dans votre système. Il alimente la recherche élastique avec des données et connecte ensuite la recherche d'ElasticSearch au serveur d'application.
Voici un bon aperçu d'Elasticsearch pour vous aider à démarrer.
Et la documentation d'ElasticSearch - https://www.elastic.co/guide/index.html
Mettez un pare-feu dans votre serveur de production
Vous devriez définitivement faire cela - c'est un must. Mettez un pare-feu dans votre serveur de production et fermez tous les ports sauf ceux à utiliser pour les API (connexions https). Acheminez les points de terminaison de l'API à l'aide d'un serveur web proxy inverse, comme NGiNX ou Apache. Aucun port ne doit être accessible au monde extérieur autre que ceux autorisés par NGiNX.
Pourquoi vous devriez utiliser NGiNX :
- https://www.nginx.com/resources/wiki/community/why_use_it/
- https://blog.serverdensity.com/why-we-use-nginx/
- https://www.freecodecamp.org/news/an-introduction-to-nginx-for-developers-62179b6a458f/
Conclusion
Les points mentionnés ci-dessus sont basés sur mes propres préférences et je les ai développés au fil des ans. Il y aura de légères différences ici et là, mais les concepts restent les mêmes.
Et à la fin, nous faisons tout cela pour avoir un système fluide construit à partir de zéro, fonctionnant en production dès que possible après avoir eu l'idée.
J'ai essayé de coucher sur papier toutes mes connaissances que j'ai acquises au fil des ans, et je pourrais avoir tort à quelques endroits. Si vous pensez pouvoir offrir de meilleures informations, n'hésitez pas à commenter. Et comme toujours, veuillez partager si vous pensez que cela est utile.