

Article original : Spotify’s “This Is” playlists: the ultimate song analysis for 50 mainstream artists
Par James Le
Chaque artiste a son propre style musical unique. D'Ed Sheeran qui consacre sa vie à la guitare acoustique, à Drake qui maîtrise l'art du rap. D'Adele qui peut chanter des notes incroyablement hautes sur ses ballades pop, à Kygo qui crée de la magie EDM sur son set de DJ. La musique est une question de créativité, d'originalité, d'inspiration et de sentiments, et c'est la passerelle parfaite pour connecter les gens au-delà des différences.
Spotify est le plus grand service de streaming musical disponible. Avec plus de 35 millions de chansons et 170 millions d'utilisateurs actifs mensuels, c'est la plateforme idéale pour les musiciens afin d'atteindre leur public. Sur l'application, la musique peut être parcourue ou recherchée via divers paramètres — tels que les artistes, l'album, le genre, la playlist ou le label discographique. Les utilisateurs peuvent créer, modifier et partager des playlists, partager des pistes sur les réseaux sociaux et créer des playlists avec d'autres utilisateurs.
En outre, Spotify a lancé une variété de playlists intéressantes sur mesure pour ses utilisateurs, dont j'admire particulièrement ces trois-ci :
- Discover Weekly : une playlist générée chaque semaine (mise à jour le lundi) qui offre aux utilisateurs deux heures de recommandations musicales personnalisées, mélangeant les goûts personnels d'un utilisateur avec des chansons appréciées par des auditeurs similaires.
- Release Radar : une playlist personnalisée qui permet aux utilisateurs de rester à jour sur les nouvelles musiques publiées par les artistes qu'ils écoutent le plus.
- Daily Mix : une série de playlists qui ont une « lecture quasi infinie » et mélange les pistes préférées de l'utilisateur avec de nouvelles chansons recommandées.
J'ai récemment découvert la série de playlists « This Is ». L'une des meilleures fonctionnalités originales de Spotify, « This Is » tient une promesse majeure de la révolution du streaming — la canonisation et la préservation des répertoires des grands artistes pour que les générations futures puissent les découvrir et les apprécier.
Chacune est dédiée à un artiste légendaire différent, retraçant les points forts des discographies iconiques. « This is: Kanye West ». « This is: Maroon 5 ». « This is: Elton John ». Spotify a fourni un raccourci, nous donnant des listes curatées des plus grandes chansons des plus grands artistes.
Ce que nous allons couvrir ici
Le but de ce projet est d'analyser la musique que différents artistes produisent sur Spotify. L'accent sera mis sur la démêler des goûts musicaux de 50 artistes différents issus d'une large gamme de genres. Tout au long du processus, j'identifie également différents groupes d'artistes qui partagent un style musical similaire.
Pour l'étude, j'accéderai à l'API Web Spotify, qui fournit des données du catalogue musical de Spotify. Cela peut être accessible via des requêtes HTTPS standard à un point de terminaison API.
L'API Spotify fournit, entre autres, des informations sur les pistes pour chaque chanson, y compris des statistiques audio telles que la danceabilité, l'instrumentalité, ou le tempo. Chaque caractéristique mesure un aspect d'une chanson. Des informations détaillées sur la manière dont chaque caractéristique est calculée peuvent être trouvées sur le site Web de l'API Spotify. Les extraits de code dans cet article peuvent être un peu difficiles à comprendre, surtout pour les débutants en données, alors restez avec moi.
Voici un bref résumé de mon approche :
- Obtenir les données de l'API Spotify.
- Traiter les données pour extraire les caractéristiques audio de chaque artiste.
- Visualiser les données en utilisant D3.js.
- Appliquer le clustering k-means pour séparer les artistes en différents groupes.
- Analyser chaque caractéristique pour tous les artistes.
Récupérons maintenant les informations sur les caractéristiques audio des playlists « This Is » de 50 artistes différents sur Spotify.
 _Source : [https://blog.prototypr.io/have-you-heard-about-the-spotify-web-api-8e8d1dac9eaf](https://blog.prototypr.io/have-you-heard-about-the-spotify-web-api-8e8d1dac9eaf" rel="noopener" target="blank" title=")
_Source : [https://blog.prototypr.io/have-you-heard-about-the-spotify-web-api-8e8d1dac9eaf](https://blog.prototypr.io/have-you-heard-about-the-spotify-web-api-8e8d1dac9eaf" rel="noopener" target="blank" title=")
Obtention des données
La première étape a été d'enregistrer mon application sur le site Web de l'API et d'obtenir les clés (ID client et secret client) pour les futures requêtes.
L'API Web Spotify dispose de différents URI (identifiants de ressource uniforme) pour accéder aux informations sur les playlists, les artistes ou les pistes. Par conséquent, le processus d'obtention des données doit être divisé en deux étapes clés :
- obtenir la série de playlists « This Is » pour plusieurs musiciens.
- obtenir les caractéristiques audio pour chaque piste de la playlist de chaque artiste.
Identifiants de l'API Web
Tout d'abord, j'ai créé deux variables pour les identifiants Client ID et Client Secret.
spotifyKey <- "VOTRE ID CLIENT"spotifySecret <- "VOTRE SECRET CLIENT"
Après cela, j'ai demandé un jeton d'accès afin d'autoriser mon application à récupérer et gérer les données Spotify.
library(Rspotify)library(httr)library(jsonlite)spotifyEndpoint <- oauth_endpoint(NULL, "https://accounts.spotify.com/authorize","https://accounts.spotify.com/api/token")
spotifyToken <- spotifyOAuth("Spotify Analysis", spotifyKey, spotifySecret)
Série de playlists « This Is »
La première étape consistait à extraire les URI des artistes de la série « This Is ». Voici les 50 musiciens que j'ai choisis, en utilisant leur popularité, leur modernité et leur diversité comme principaux critères :
- Pop : Taylor Swift, Ariana Grande, Shawn Mendes, Maroon 5, Adele, Justin Bieber, Ed Sheeran, Justin Timberlake, Charlie Puth, John Mayer, Lorde, Fifth Harmony, Lana Del Rey, James Arthur, Zara Larsson, Pentatonix.
- Hip-Hop / Rap : Kendrick Lamar, Post Malone, Drake, Kanye West, Eminem, Future, 50 Cent, Lil Wayne, Wiz Khalifa, Snoop Dogg, Macklemore, Jay-Z.
- R & B : Bruno Mars, Beyoncé, Enrique Iglesias, Stevie Wonder, John Legend, Alicia Keys, Usher, Rihanna.
- EDM / House : Kygo, The Chainsmokers, Avicii, Marshmello, Calvin Harris, Martin Garrix.
- Rock : Coldplay, Elton John, One Republic, The Script, Jason Mraz.
- Jazz : Frank Sinatra, Michael Bublé, Norah Jones.
 _Source : [http://www.thedrum.com/news/2017/11/29/spotify-wraps-up-2017-making-humorous-goals-2018-using-its-data-and-artists](http://www.thedrum.com/news/2017/11/29/spotify-wraps-up-2017-making-humorous-goals-2018-using-its-data-and-artists" rel="noopener" target="blank" title=")
_Source : [http://www.thedrum.com/news/2017/11/29/spotify-wraps-up-2017-making-humorous-goals-2018-using-its-data-and-artists](http://www.thedrum.com/news/2017/11/29/spotify-wraps-up-2017-making-humorous-goals-2018-using-its-data-and-artists" rel="noopener" target="blank" title=")
Je suis essentiellement allé sur la playlist individuelle de chaque musicien, j'ai copié les URI, j'ai stocké chaque URI dans un fichier .csv, et j'ai importé les fichiers .csv dans R.
library(readr)
playlistURI <- read.csv("this-is-playlist-URI.csv", header = T, sep = ";")
Avec chaque URI de playlist, j'ai appliqué la fonction getPlaylistSongs du package « RSpotify », et j'ai stocké les informations de la playlist dans un data.frame vide.
# Dataframe videPlaylistSongs <- data.frame(PlaylistID = character(), Musician = character(), tracks = character(), id = character(), popularity = integer(), artist = character(), artistId = character(), album = character(), albumId = character(), stringsAsFactors=FALSE)
# Obtention de chaque playlistfor (i in 1:nrow(playlistURI)) { i <- cbind(PlaylistID = as.factor(playlistURI[i,2]), Musician = as.factor(playlistURI[i,1]), getPlaylistSongs("spotify", playlistid = as.factor(playlistURI[i,2]), token=spotifyToken)) PlaylistSongs <- rbind(PlaylistSongs, i)}
Caractéristiques audio
Tout d'abord, j'ai écrit une formule (getFeatures) qui extrait les caractéristiques audio pour tout ID spécifique stocké sous forme de vecteur.
getFeatures <- function (vector_id, token) { link <- httr::GET(paste0("https://api.spotify.com/v1/audio-features/?ids=", vector_id), httr::config(token = token)) list <- httr::content(link) return(list)}
Ensuite, j'ai inclus getFeatures dans une autre formule (get_features). Cette dernière formule extrait les caractéristiques audio pour le vecteur d'ID de piste et les retourne dans un data.frame.
get_features <- function (x) { getFeatures2 <- getFeatures(vector_id = x, token = spotifyToken) features_output <- do.call(rbind, lapply(getFeatures2$audio_features, data.frame, stringsAsFactors=FALSE))}
En utilisant la formule créée ci-dessus, j'ai pu extraire les caractéristiques audio pour chaque piste. Pour ce faire, j'avais besoin d'un vecteur contenant chaque ID de piste. La limite de taux pour l'API Spotify est de 100 pistes, j'ai donc décidé de créer un vecteur avec les ID de pistes pour chaque musicien.
Ensuite, j'ai appliqué la formule get_features à chaque vecteur, obtenant les caractéristiques audio pour chaque musicien.
Après cela, j'ai fusionné chaque data.frame des caractéristiques audio des musiciens dans un nouveau, all_features. Il contient les caractéristiques audio de toutes les pistes de chaque playlist « This Is » de chaque musicien.
library(gdata)
all_features <- combine(TaylorSwift,ArianaGrande,KendrickLamar,ShawnMendes,Maroon5,PostMalone,Kygo,TheChainsmokers,Adele,Drake,JustinBieber,Coldplay,KanyeWest,BrunoMars,EdSheeran,Eminem,Beyonce,Avicii,Marshmello,CalvinHarris,JustinTimberlake,FrankSinatra,CharliePuth,MichaelBuble,MartinGarrix,EnriqueIglesias,JohnMayer,Future,EltonJohn,FiftyCent,Lorde,LilWayne,WizKhalifa,FifthHarmony,LanaDelRay,NorahJones,JamesArthur,OneRepublic,TheScript,StevieWonder,JasonMraz,JohnLegend,Pentatonix,AliciaKeys,Usher,SnoopDogg,Macklemore,ZaraLarsson,JayZ,Rihanna)
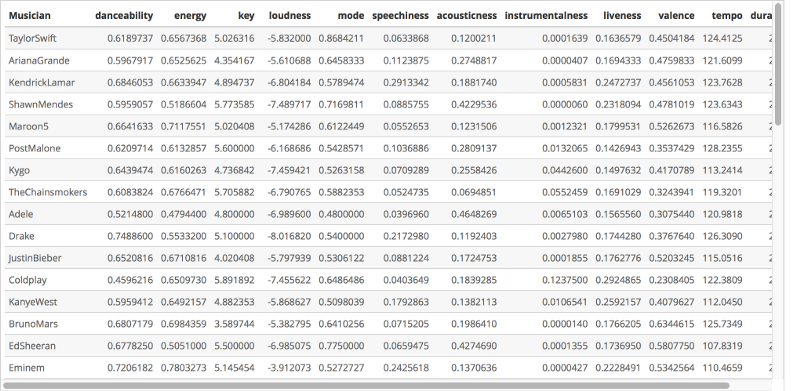
Enfin, j'ai calculé la moyenne des caractéristiques audio de chaque musicien en utilisant la fonction aggregate. Le data.frame résultant contient les caractéristiques audio de chaque musicien, exprimées comme la moyenne des pistes de leurs playlists respectives.
mean_features <- aggregate(all_features[, c(1:11,17)], list(all_features$source), mean)
names(mean_features) <- c("Musician", "danceability", "energy", "key", "loudness", "mode", "speechiness", "acousticness", "instrumentalness", "liveness", "valence", "tempo", "duration_ms")
L'image ci-dessous montre un sous-ensemble du data.frame mean_features, pour votre référence.
Description des caractéristiques audio
La description de chaque caractéristique de l'API Web Spotify peut être trouvée ci-dessous :
- Danceabilité : décrit l'adéquation d'une piste pour la danse. Cela est basé sur une combinaison d'éléments musicaux incluant le tempo, la stabilité rythmique, la force du rythme et la régularité globale. Une valeur de 0,0 est la moins dansable et 1,0 est la plus dansable.
- Énergie : une mesure de 0,0 à 1,0, et représente une mesure perceptuelle de l'intensité et de l'activité. Typiquement, les pistes énergiques semblent rapides, fortes et bruyantes. Par exemple, le death metal a une énergie élevée, tandis qu'un prélude de Bach obtient un score bas sur l'échelle. Les caractéristiques perceptuelles contribuant à cet attribut incluent la plage dynamique, la sonie perçue, le timbre, le taux d'attaque et l'entropie générale.
- Tonalité : la tonalité de la piste. Les entiers sont mappés aux hauteurs en utilisant la notation standard de la classe de hauteur. Par exemple, 0 = C, 1 = C#/D♭, 2 = D, et ainsi de suite.
- Sonorité : la sonorité globale d'une piste en décibels (dB). Les valeurs de sonorité sont moyennées sur toute la piste et sont utiles pour comparer la sonorité relative des pistes. La sonorité est la qualité d'un son qui est le principal corrélat psychologique de la force physique (amplitude). Les valeurs typiques varient entre -60 et 0 dB.
- Mode : indique la modalité (majeure ou mineure) d'une piste, le type de gamme à partir duquel son contenu mélodique est dérivé. Le mode majeur est représenté par 1 et le mode mineur par 0.
- Parole : détecte la présence de mots parlés dans une piste. Plus l'enregistrement est exclusivement de type parole (par exemple, talk-show, livre audio, poésie), plus la valeur de l'attribut est proche de 1,0. Les valeurs supérieures à 0,66 décrivent des pistes qui sont probablement entièrement composées de mots parlés. Les valeurs entre 0,33 et 0,66 décrivent des pistes qui peuvent contenir à la fois de la musique et de la parole, soit en sections soit en couches, incluant des cas tels que la musique rap. Les valeurs inférieures à 0,33 représentent très probablement de la musique instrumentale et d'autres pistes non parlées.
- Acoustique : une mesure de confiance de 0,0 à 1,0 indiquant si la piste est acoustique. 1,0 représente une forte confiance que la piste est acoustique.
- Instrumentalité : prédit si une piste ne contient pas de voix. Les sons « Ooh » et « aah » sont traités comme instrumentaux dans ce contexte. Les pistes de rap ou de spoken word sont clairement « vocales ». Plus la valeur d'instrumentalité est proche de 1,0, plus la probabilité que la piste ne contienne pas de contenu vocal est grande. Les valeurs supérieures à 0,5 sont destinées à représenter des pistes instrumentales, mais la confiance est plus élevée à mesure que la valeur approche 1,0.
- Direct : détecte la présence d'un public dans l'enregistrement. Des valeurs de direct plus élevées représentent une probabilité accrue que la piste ait été interprétée en direct. Une valeur supérieure à 0,8 fournit une forte probabilité que la piste soit en direct.
- Valence : une mesure de 0,0 à 1,0 décrivant la positivité musicale transmise par une piste. Les pistes avec une valence élevée semblent plus positives (par exemple, heureuses, joyeuses, euphoriques), tandis que les pistes avec une valence faible semblent plus négatives (par exemple, tristes, déprimées, en colère).
- Tempo : le tempo global estimé d'une piste en battements par minute (BPM). En terminologie musicale, le tempo est la vitesse ou le rythme d'une pièce donnée, et dérive directement de la durée moyenne des battements.
- Durée_ms : la durée de la piste en millisecondes.
 _Source : [https://www.engadget.com/2018/02/05/spotify-recommendation-tech-nelson-custom-playlists/](https://www.engadget.com/2018/02/05/spotify-recommendation-tech-nelson-custom-playlists/" rel="noopener" target="blank" title=")
_Source : [https://www.engadget.com/2018/02/05/spotify-recommendation-tech-nelson-custom-playlists/](https://www.engadget.com/2018/02/05/spotify-recommendation-tech-nelson-custom-playlists/" rel="noopener" target="blank" title=")
Visualisation des données
Graphiques radar
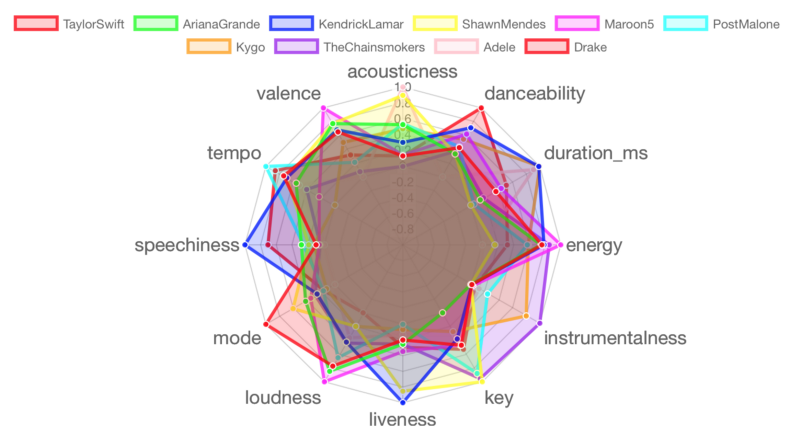
Un graphique radar est utile pour comparer les vibrations musicales de ces musiciens de manière plus visuelle. La première visualisation est une implémentation R du graphique radar de la bibliothèque JavaScript chart.js, et évalue les caractéristiques audio pour dix musiciens sélectionnés.
Pour tracer, j'ai normalisé les valeurs de tonalité, de sonorité, de tempo et de durée_ms pour qu'elles soient comprises entre 0 et 1. Cela aide à rendre le graphique plus clair et lisible.
mean_features_norm <- cbind(mean_features[1], apply(mean_features[-1],2, function(x){(x-min(x))/diff(range(x))}))
D'accord, traçons ces graphiques radar interactifs par lots de dix musiciens. Chaque graphique affiche les étiquettes des ensembles de données lorsque vous survolez chaque ligne radiale, montrant la valeur pour la caractéristique sélectionnée. Le code ci-dessous détaille le processus de création du graphique radar pour le premier lot de dix musiciens. Le code pour les quatre autres lots a été omis, mais les graphiques radar sont affichés.
Lot 1 : Taylor Swift, Ariana Grande, Kendrick Lamar, Shawn Mendes, Maroon 5, Post Malone, Kygo, The Chainsmokers, Adele, Drake
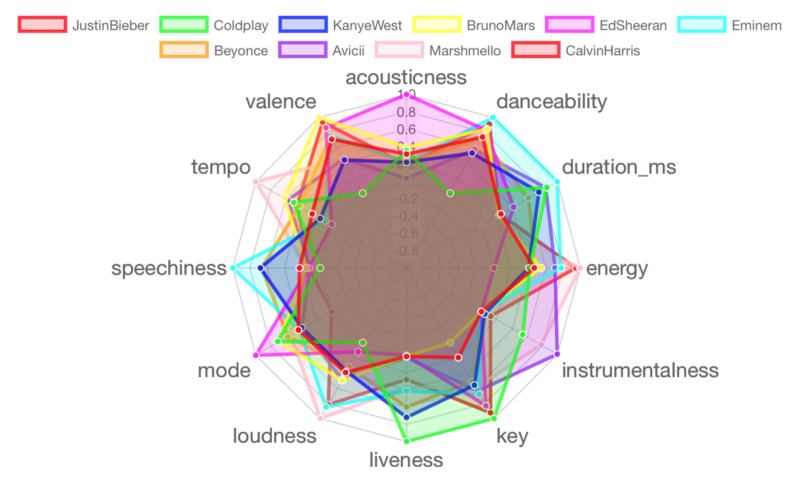
Lot 2 : Justin Bieber, Coldplay, Kanye West, Bruno Mars, Ed Sheeran, Eminem, Beyoncé, Avicii, Marshmello, Calvin Harris
Lot 3 : Justin Timberlake, Frank Sinatra, Charlie Puth, Michael Bublé, Martin Garrix, Enrique Iglesias, John Mayer, Future, Elton John, 50 Cent
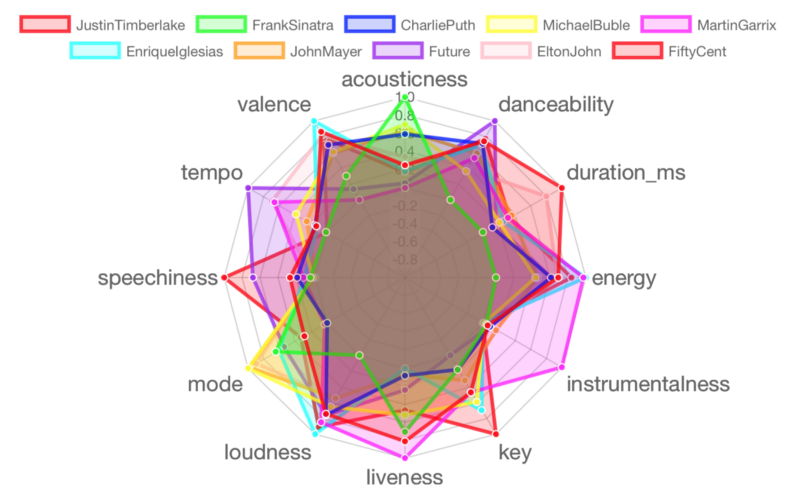
Lot 4 : Lorde, Lil Wayne, Wiz Khalifa, Fifth Harmony, Lana Del Rey, Norah Jones, James Arthur, One Republic, The Script, Stevie Wonder
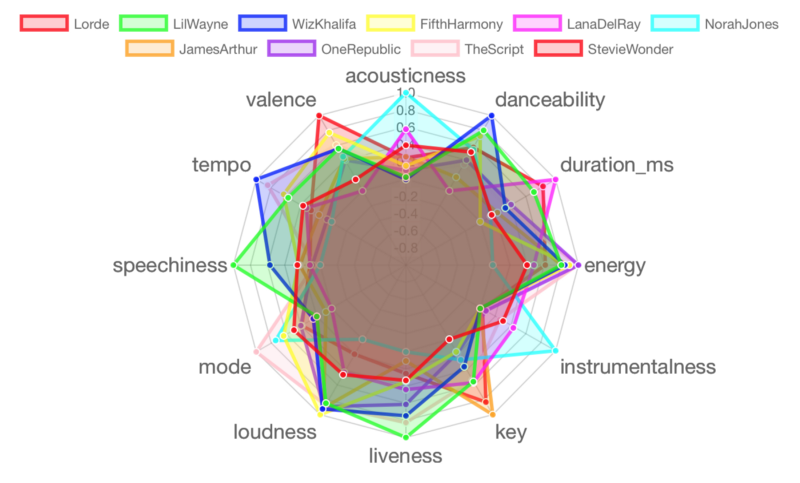
Lot 5 : Jason Mraz, John Legend, Pentatonix, Alicia Keys, Usher, Snoop Dogg, Macklemore, Zara Larsson, Jay-Z, Rihanna
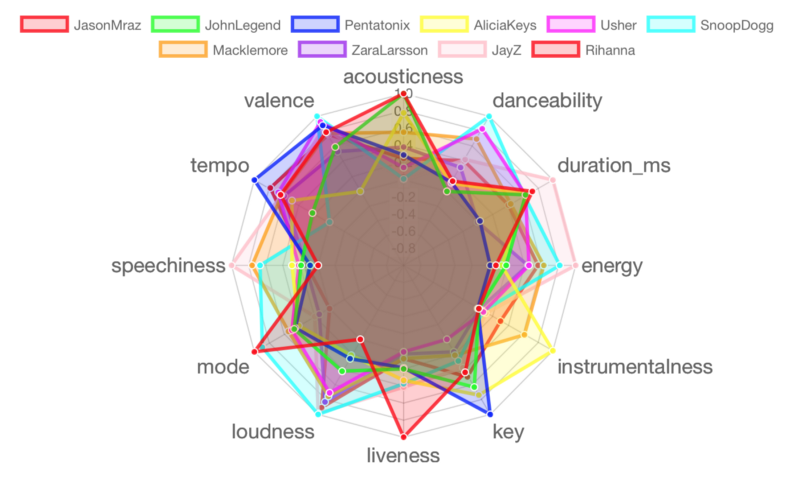
Analyse par clusters
Une autre façon de découvrir les différences entre ces musiciens dans leur répertoire musical est de les regrouper en clusters. L'idée générale d'un algorithme de clustering est de diviser un ensemble de données donné en plusieurs groupes sur la base de la similarité des données.
Dans ce cas, les musiciens seront regroupés dans différents clusters selon leurs préférences musicales. Plutôt que de définir des groupes avant de regarder les données, le clustering me permet de trouver et d'analyser les regroupements de musiciens qui se sont formés organiquement.
Avant de clusteriser les données, il est important de redimensionner les variables numériques du jeu de données. Puisque j'ai des données numériques mixtes, où chaque caractéristique audio est différente d'une autre et a des mesures différentes, exécuter la fonction d'échelle (aka les standardiser) est une bonne pratique pour leur donner un poids égal. Après cela, j'ai conservé les musiciens comme noms de lignes pour pouvoir les afficher comme étiquettes dans le graphique.
scaled.features <- scale(mean_features[-1])rownames(scaled.features) <- mean_features$Musician
J'ai appliqué la méthode de Clustering K-Means, qui est l'une des techniques les plus populaires des méthodes d'apprentissage statistique non supervisé. Elle est utilisée pour des données non étiquetées. L'algorithme trouve des groupes dans les données, avec le nombre de groupes représenté par la variable K. L'algorithme fonctionne de manière itérative pour assigner chaque point de données à l'un des K groupes en fonction des variables fournies. Les points de données sont clusterisés en fonction de la similarité.
Dans ce cas, j'ai choisi K = 6 — les clusters peuvent être formés sur la base des six genres différents que j'ai utilisés pour choisir les artistes (Pop, Hip-Hop, R&B, EDM, Rock et Jazz).
Après avoir appliqué l'algorithme K-Means pour chaque musicien, je peux tracer une vue bidimensionnelle des données. Dans le premier graphique, l'axe x et l'axe y correspondent respectivement aux première et deuxième composantes principales. Les vecteurs propres (représentés par des flèches rouges) indiquent l'influence directionnelle que chaque variable a sur les composantes principales.
Examinons les clusters qui résultent de l'application de l'algorithme K-Means à mon jeu de données.
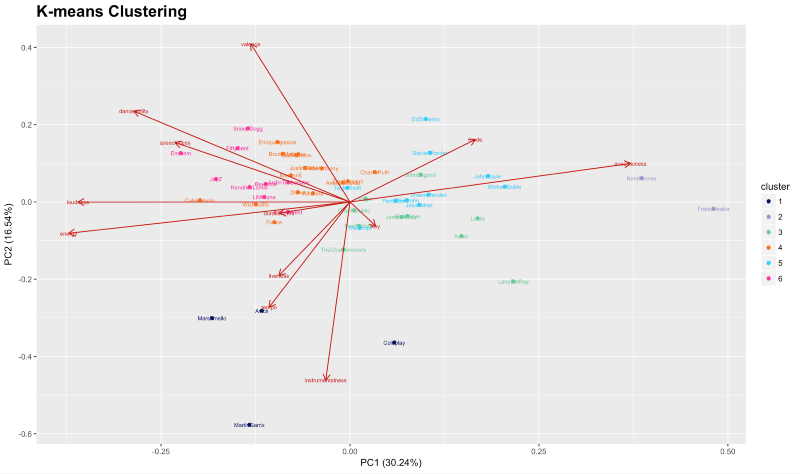
Comme vous pouvez le voir sur le graphique ci-dessus, l'axe x est PC1 (30,24%) et l'axe y est PC2 (16,54%). Ce sont les deux premières composantes principales. Le graphique PCA montre que PC1 sépare les artistes par sonorité/énergie vs acoustique/douceur, tandis que PC2 semble séparer les artistes sur une échelle de valence vs tonalité, tempo et instrumentalité.
Étant donné que mes données sont multivariées, il est fastidieux d'inspecter tous les nombreux graphiques de dispersion bivariés. Au lieu de cela, un seul graphique de dispersion « résumé » est plus pratique. Le graphique de dispersion des deux premières composantes principales dérivées des données a été montré dans le graphique. Le pourcentage, de même, est la variance expliquée par chaque composante de la variabilité globale : la première composante a capturé 30,24 % et la deuxième composante a capturé 16,54 % des informations sur les données multivariées.
Si vous êtes intéressé à en apprendre davantage sur les mathématiques derrière cet algorithme, je vous recommande de vous rafraîchir la mémoire sur l'Analyse en Composantes Principales.
Voyons quels artistes appartiennent à quels clusters :
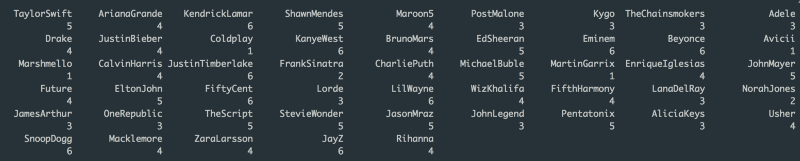
k_means$cluster
J'ai également tracé un autre graphique radar contenant les caractéristiques de chaque cluster. Il est utile de comparer les attributs des chansons que chaque cluster crée.
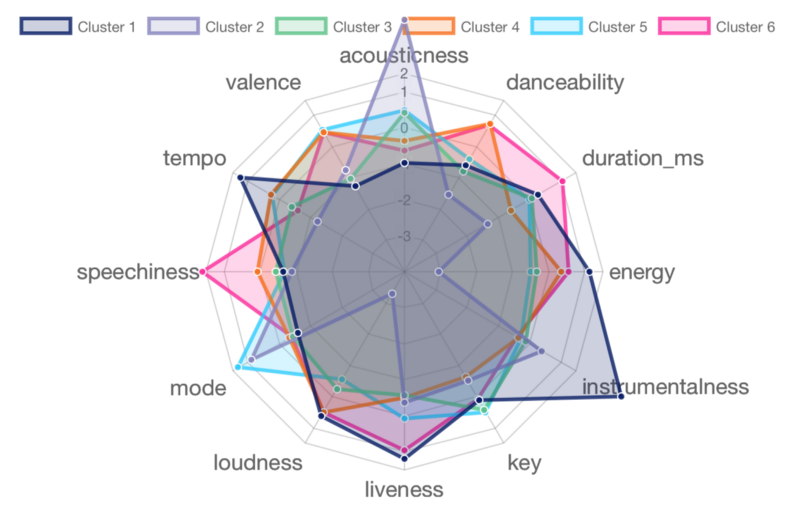
Cluster 1 contient quatre artistes : Coldplay, Avicii, Marshmello et Martin Garrix. Leur musique est principalement interprétée en direct et instrumentale, généralement forte et pleine d'énergie avec un tempo élevé. Ce n'est pas trop surprenant, car trois des quatre artistes jouent de la musique EDM / House, et Coldplay est connu pour ses concerts en direct.
Cluster 2 contient 2 artistes : Frank Sinatra et Norah Jones (des fans de jazz par ici ?). Leur musique obtient un score élevé en acoustique et en mode de gamme majeure. Cependant, ils obtiennent un score faible dans tous les autres attributs. Des airs de jazz typiques.
Cluster 3 contient dix artistes : Post Malone, Kygo, The Chainsmokers, Adele, Lorde, Lana Del Rey, James Arthur, One Republic, John Legend et Alicia Keys. Ce cluster obtient une moyenne dans presque tous les attributs. Cela suggère que ce groupe d'artistes est bien équilibré et polyvalent en style et en création, d'où la diversité des genres présentés dans ce cluster (EDM, Pop, R&B).
Cluster 4 contient 15 artistes : Ariana Grande, Maroon 5, Drake, Justin Bieber, Bruno Mars, Calvin Harris, Charlie Puth, Enrique Iglesias, Future, Wiz Khalifa, Fifth Harmony, Usher, Macklemore, Zara Larsson et Rihanna. Leur musique est dansable, forte, à tempo élevé et énergique. Ce groupe compte de nombreux jeunes artistes grand public des genres Pop et Hip-Hop.
Cluster 5 contient 10 artistes : Taylor Swift, Shawn Mendes, Ed Sheeran, Michael Bublé, John Mayer, Elton John, The Script, Stevie Wonder, Jason Mraz et Pentatonix. C'est mon groupe préféré ! Taylor Swift ? Ed Sheeran ? John Mayer ? Jason Mraz ? Elton John ? Je suppose que j'écoute beaucoup d'artistes auteurs-compositeurs-interprètes. Leur musique est principalement en gamme majeure, tout en atteignant un équilibre parfait (score moyen) dans tous les autres attributs.
Cluster 6 contient neuf artistes : Kendrick Lamar, Kanye West, Eminem, Beyoncé, Justin Timberlake, 50 Cent, Lil Wayne, Snoop Dogg et Jay-Z. Vous voyez déjà la tendance ici : sept d'entre eux sont des rappeurs, et même Beyoncé et JT collaborent régulièrement avec des rappeurs. Leurs chansons contiennent un grand nombre de mots parlés et de sections de type parole, sont longues en durée et souvent interprétées en direct. Une meilleure description de la musique rap ?
Analyse par caractéristique
Les graphiques suivants montrent les valeurs de chaque caractéristique pour chaque musicien. Le code ci-dessous détaille le processus de création du graphique à barres divergentes pour la danceabilité. Le code pour les autres caractéristiques a été omis, mais le graphique de chaque caractéristique est affiché ensuite.
Danceabilité
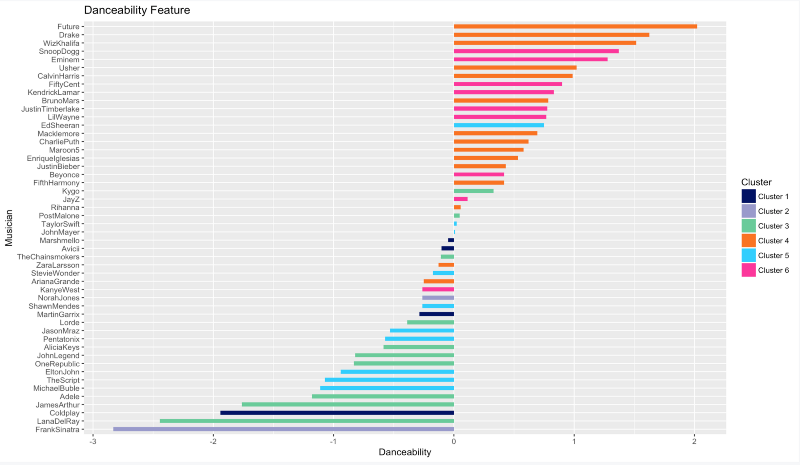
Si vous voulez impressionner votre crush avec vos mouvements de danse, essayez d'écouter plus Future, Drake, Wiz Khalifa, Snoop Dogg et Eminem. En revanche, n'essayez même pas de danser sur les mélodies de Frank Sinatra ou de Lana Del Rey.
Énergie
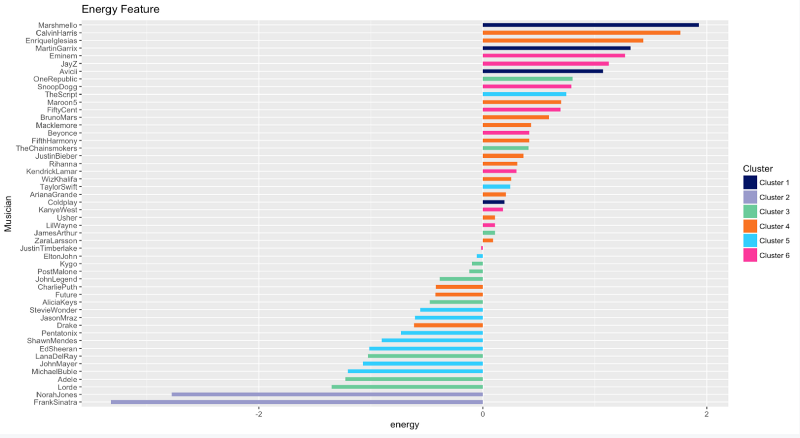
Vous êtes une personne plutôt énergique si vous écoutez beaucoup de Marshmello, Calvin Harris, Enrique Iglesias, Martin Garrix, Eminem et Jay-Z. L'inverse est vrai si vous êtes fan de Frank Sinatra et Norah Jones.
Sonorité
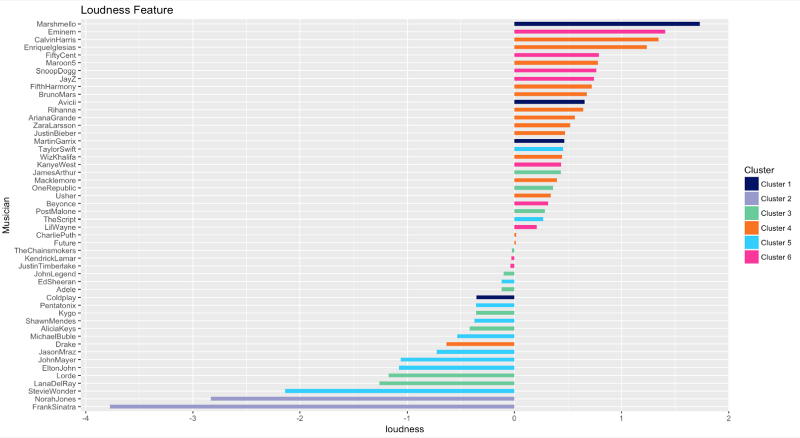
Le classement de la sonorité est presque le même que celui de l'énergie.
Parole
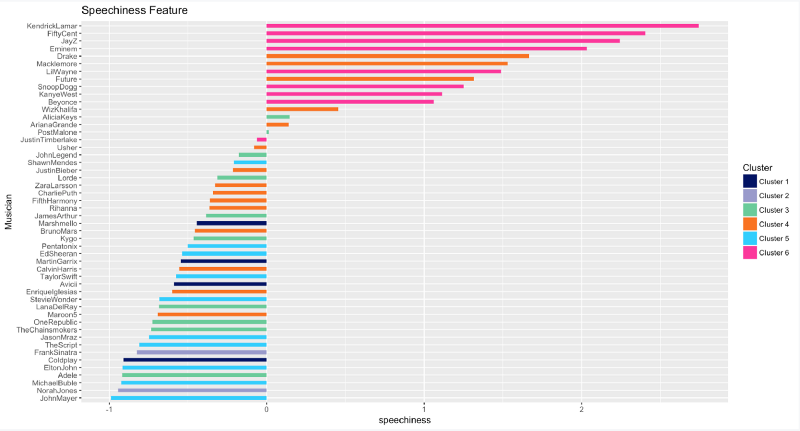
Tous les fans de rap ici : quelles sont vos chansons préférées de Kendrick Lamar ? ou de 50 Cent ? ou de Jay-Z ? Hmm, je suis surpris qu'Eminem ne soit pas mieux classé, car je pense personnellement qu'il est le GOAT de tous les rappeurs.
Acoustique
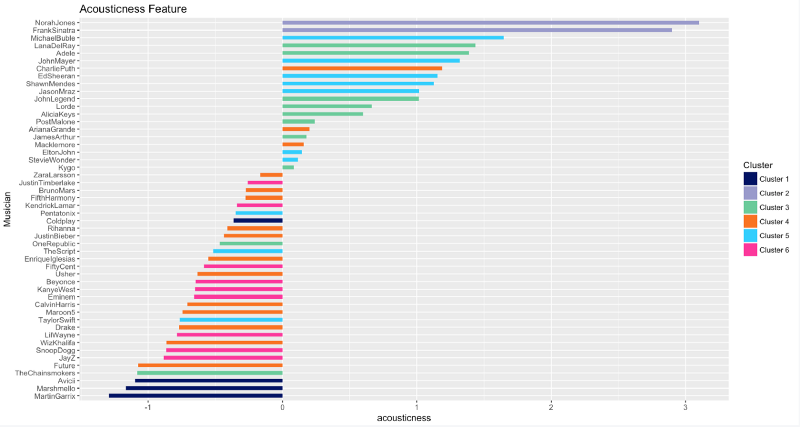
L'acoustique est l'exact opposé de la sonorité et de l'énergie. M. Sinatra et Mme Jones ont sorti des morceaux acoustiques puissants tout au long de leur carrière.
Instrumentalité
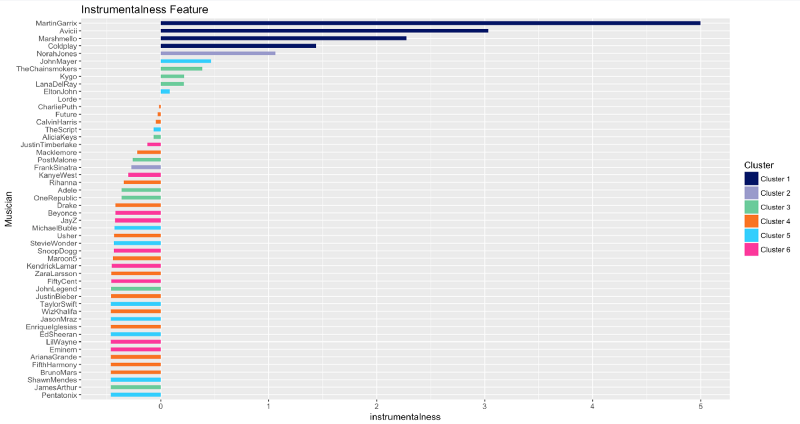
L'EDM pour la victoire ! Martin Garrix, Avicii et Marshmello produisent des morceaux qui contiennent presque aucune voix.
Direct
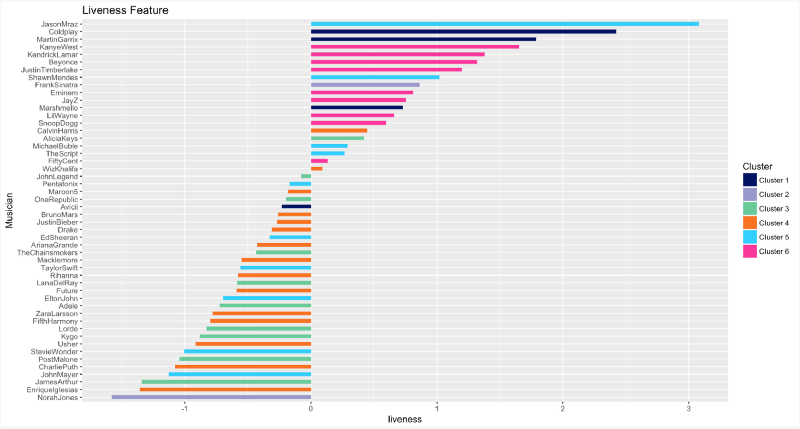
Alors, qui sont les 5 artistes ayant réalisé le plus d'enregistrements audio en direct ? Jason Mraz, Coldplay, Martin Garrix, Kanye West et Kendrick Lamar, dans cet ordre.
Valence
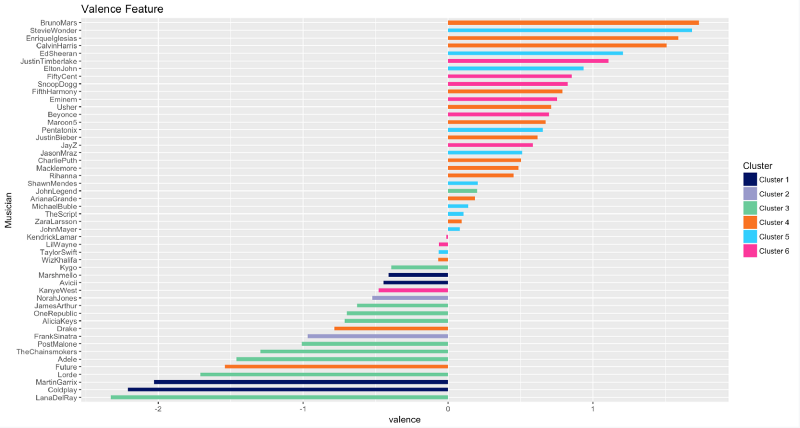
La valence est la caractéristique qui décrit la positivité musicale transmise par une piste. La musique de Bruno Mars, Stevie Wonder et Enrique Iglesias est très positive, tandis que la musique de Lana Del Rey, Coldplay et Martin Garrix semble assez négative.
Tempo
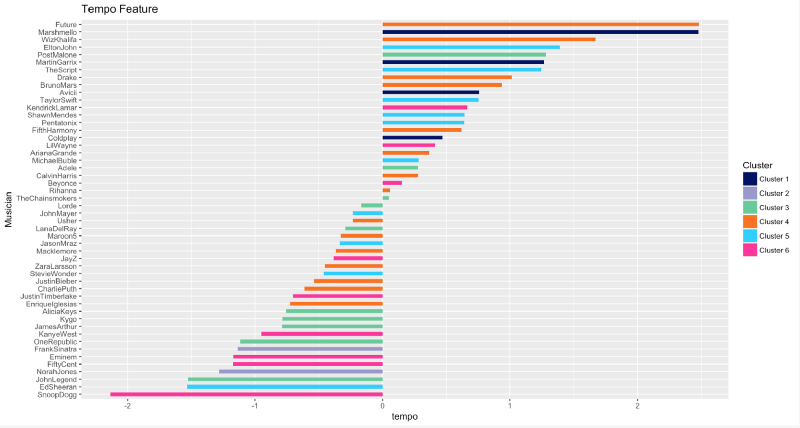
Future, Marshmello et Wiz Khalifa sont les rois de la vitesse. Ils produisent des morceaux avec le tempo le plus élevé en battements par minute. Et Snoop Dogg, lol ? Il a tendance à prendre son temps pour prononcer ses mots magiques.
Durée
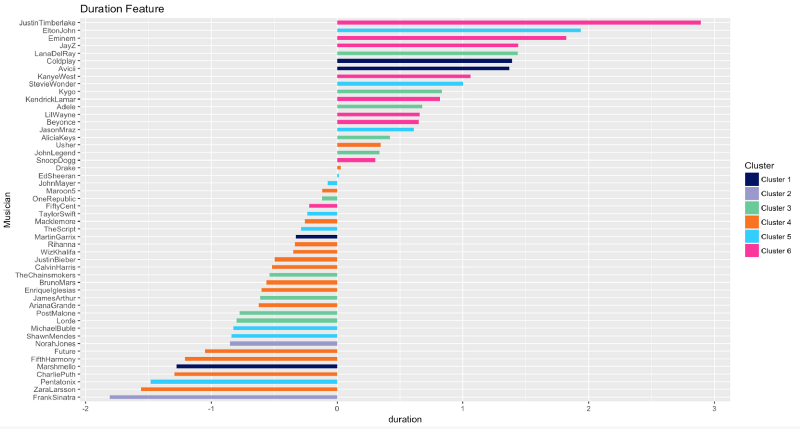
Enfin, les chansons de Justin Timberlake, suivies par Elton John et Eminem, sont, parfois de manière atroce, longues. En revanche, Frank Sinatra, Zara Larsson et Pentatonix privilégient une musique plus courte.
Conclusion
Waouh, je me suis beaucoup amusé à faire cette analyse et ce projet de visualisation sur les données de Spotify. Qui aurait pensé que James Arthur et Post Malone sont dans le même cluster ? Ou que Kendrick Lamar est le rappeur le plus rapide du jeu ? Ou que Marshmello battrait Martin Garrix dans la production de morceaux énergiques ?
En tout cas, vous pouvez consulter le R Markdown complet, le code R séparé pour le traitement et la visualisation des données, ainsi que le jeu de données original dans mon dépôt GitHub ici. De mon point de vue, R est bien meilleur en visualisation de données que Python, avec des bibliothèques comme ggplot et plot.ly. Je vous encourage vivement à essayer R !
— —
Si vous avez apprécié cet article, j'adorerais que vous cliquiez sur le bouton d'applaudissements 👏 afin que d'autres puissent le découvrir. Vous pouvez trouver mon propre code sur GitHub, et plus de mes écrits et projets sur https://jameskle.com/. _Vous pouvez également me suivre sur Twitter, me contacter directement par email ou me trouver sur LinkedIn. Inscrivez-vous à ma newsletter pour recevoir mes dernières réflexions sur la science des données, l'apprentissage automatique et l'intelligence artificielle directement dans votre boîte de réception !_