

Article original : Essentials of monorepo development
Par Ovidiu Bute
Le mot monorepo est une combinaison entre « mono », comme dans le mot grec mónos (en traduction, seul) et une abréviation du mot dépôt. Un concept simple si pris au pied de la lettre : un dépôt solitaire. Le domaine est l'ingénierie logicielle, donc nous parlons d'un lieu pour le code source, les actifs multimédias, les fichiers binaires, et ainsi de suite. Mais cette définition n'est que la pointe de l'iceberg, car un monorepo en pratique est bien plus.
Dans cet article, je compte distiller les avantages et les inconvénients d'avoir chaque morceau de code que votre entreprise possède dans le même dépôt. À la fin, vous devriez avoir une bonne idée de pourquoi vous devriez envisager de travailler ainsi, quels défis vous rencontrerez, quels problèmes cela résoudra, et combien vous devrez investir.
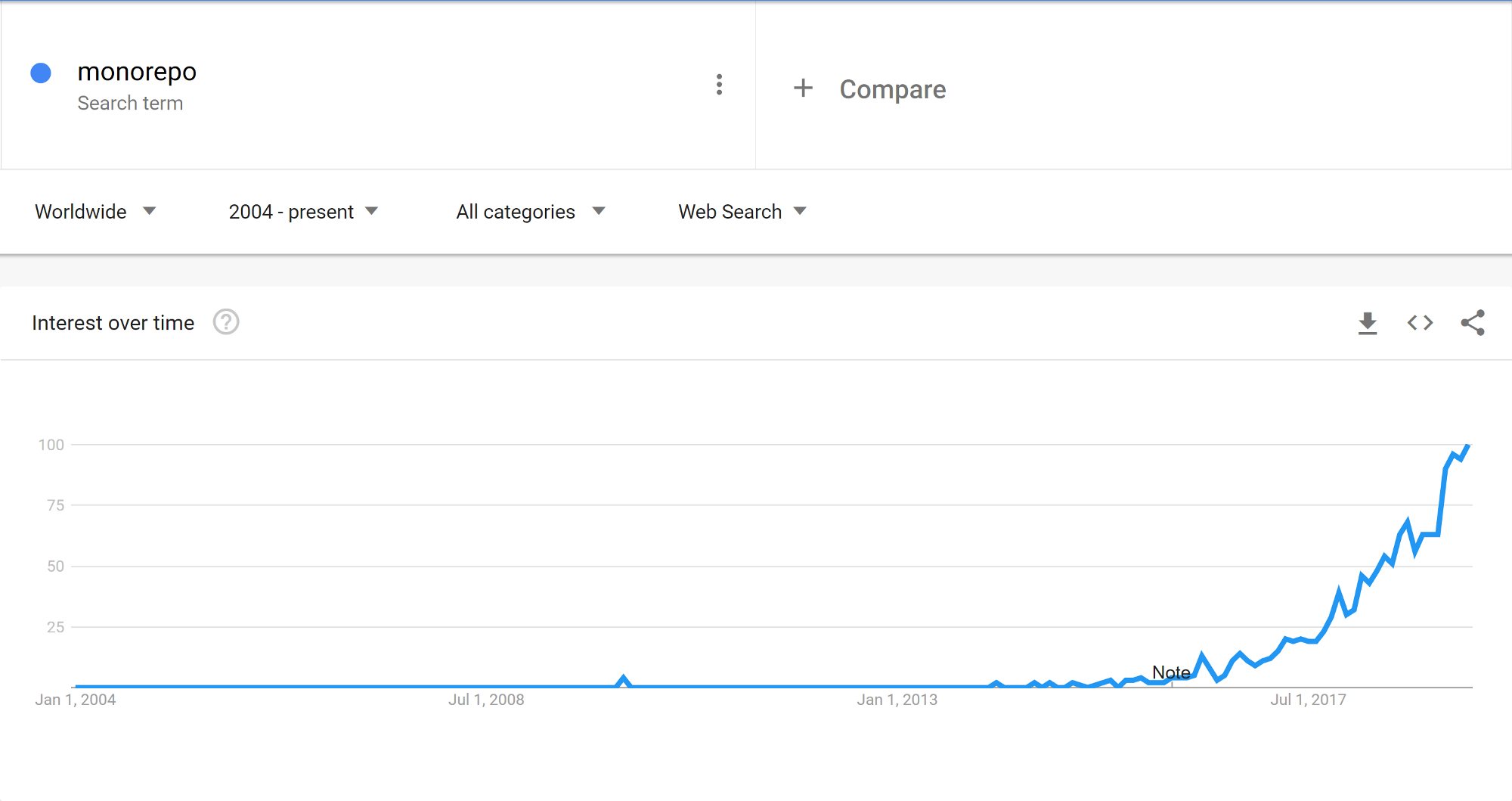 Intérêt relatif pour le terme « monorepo » depuis 2004, source : Google Trends
Intérêt relatif pour le terme « monorepo » depuis 2004, source : Google Trends
Le terme lui-même, comme visible dans le graphique ci-dessus, semble être aussi nouveau que 2017. Cependant, il serait une erreur de penser que personne auparavant ne stockait tout leur code au même endroit. En fait, lors de mon premier emploi en 2009, l'entreprise pour laquelle je travaillais stockait chaque projet dans un seul dépôt SVN, un répertoire par projet. En effet, vous pourriez bien être en mesure de retracer cette pratique encore plus loin. Mais comment pouvons-nous expliquer la popularité explosive récente, alors ?
La réalité est que le stockage du code en un seul endroit n'est pas le principal argument de vente. Au cours des dernières années, les grandes entreprises technologiques — Google, Facebook, ou Dropbox — ont montré leur manière de travailler ensemble au sein du même dépôt à grande échelle. Des organisations de dizaines de milliers d'ingénieurs collaborant au sein d'un seul dépôt est un spectacle impressionnant. Et un problème d'ingénierie difficile. Si difficile en fait que ces entreprises investissent beaucoup d'argent dans des outils et des systèmes qui permettent aux développeurs de travailler de manière productive. Ces systèmes ont à leur tour résolu des problèmes que vous ne réalisez peut-être même pas avoir. C'est ce qui fascine les gens lors des conférences techniques. C'est ce qui a stimulé les recherches depuis 2017.
- Développement front-end chez Google, Alex Eagle : https://medium.com/@Jakeherringbone/you-too-can-love-the-monorepo-d95d1d6fcebe
- Présentation du monorepo de Google, Rachel Potvin : https://www.youtube.com/watch?v=W71BTkUbdqE
- Mise à l'échelle de Mercurial à la taille de la base de code de Facebook, Durham Goode : https://code.fb.com/core-data/scaling-mercurial-at-facebook/
J'ai identifié quelques fonctionnalités clés qu'un monorepo validé par Google ou Facebook offre. Ce n'est sûrement pas une liste exhaustive, mais c'est un excellent point de départ. En discutant de chacun de ces points, j'ai pris en considération à quoi ressemble la vie sans eux, et ce qu'ils résolvent exactement. Certes, dans notre domaine de travail, tout est un compromis, rien n'est gratuit. Pour chaque avantage que je liste, quelqu'un trouvera des cas d'utilisation qui me contredisent directement, mais je suis d'accord avec cela.
Tout votre code, indépendamment du langage, est situé dans un seul dépôt
Le premier avantage de stocker tout en un seul endroit peut ne pas être immédiatement évident, mais en tant que développeur, le simple fait de pouvoir naviguer librement à travers tout est d'un grand impact. Cela aide à favoriser un certain esprit d'équipe et est également un moyen très précieux et économique de distribuer des informations. Vous êtes-vous déjà demandé quels projets sont en développement dans votre entreprise ? Passés et présents ? Curieux de savoir ce qu'une certaine équipe fait ? Comment ont-ils résolu un problème d'ingénierie particulier ? Comment écrivent-ils des tests unitaires ?
En opposition directe au monorepo, nous avons la structure multirepo. Chaque projet ou module obtient son propre espace séparé. Dans un tel système, les développeurs peuvent passer beaucoup de temps à obtenir des réponses aux questions que j'ai listées ci-dessus. La nature distribuée du travail signifie qu'il n'y a pas de source unique d'information à laquelle vous pouvez vous abonner.
Il existe des entreprises qui sont passées d'une structure multi à un monorepo en suivant uniquement cette fonctionnalité de ma liste. Une telle structure ne doit pas être confondue avec le sujet de cet article. Je la définirais plutôt comme un multirepo collocalisé. Oui, tout est au même endroit, mais le reste des fonctionnalités de cette liste est bien plus intéressant.
Vous êtes en mesure d'organiser les dépendances entre les modules de manière contrôlée et explicite
La manière traditionnelle et éprouvée de gérer les dépendances consiste à publier des versions dans un système de stockage séparé à partir de systèmes d'intégration continue, ou même manuellement, à partir de machines de développement. Ces versions sont versionnées (ou étiquetées) pour faciliter la recherche ultérieure. Maintenant, dans une configuration multirepo, chaque projet a un ensemble de dépendances d'origines externes (tiers) ou internes, c'est-à-dire publiées depuis l'intérieur de la même entreprise.
Pour qu'une équipe dépende du code d'une autre, tout doit passer par un système de stockage de gestion des dépendances. Des exemples de cela sont npm, MavenCentral, ou PyPi. J'ai dit plus tôt que vous pouvez facilement construire un multirepo collocalisé simplement en stockant tout au même endroit. Un tel système est indirectement observable. Examinons pourquoi c'est important.
En tant que développeurs, notre temps est divisé de manière très inégale entre la lecture et l'écriture de code. Imaginez maintenant devoir déboguer un problème dont la cause racine se trouve à l'intérieur d'une dépendance. Nous pouvons exclure les tiers ici, car c'est déjà un problème difficile. Non, ce problème se produit dans un package publié par une autre équipe dans votre entreprise. Si votre projet dépend de la dernière version, vous avez de la chance ! Il suffit de naviguer vers le répertoire respectif et de prendre un café.
« En effet, le rapport entre le temps passé à lire et à écrire est bien supérieur à 10 contre 1. Nous lisons constamment l'ancien code dans le cadre de l'effort pour écrire du nouveau code. [...] [Par conséquent,] le rendre facile à lire le rend plus facile à écrire. »
— Robert C. Martin, Clean Code: A Handbook of Agile Software Craftsmanship
Plus souvent, cependant, vous pourriez dépendre d'une version plus ancienne. Alors, que faites-vous ? Essayez-vous d'utiliser votre VCS pour lire l'ancien code ? Essayez-vous de lire l'artefact réel au lieu du code original ? Et s'il est minifié, comme c'est généralement le cas avec JavaScript ?
Contrastez cela avec le système de Google, par exemple — puisque les dépendances de code sont directes, c'est-à-dire qu'il n'y a essentiellement aucune version n'importe où, on peut dire que le système est directement observable. Le code que vous regardez est pratiquement tout votre monde. Je dis surtout parce que, bien sûr, il y aura toujours des exceptions mineures à cette règle, comme les dépendances externes qu'il serait prohibitif d'héberger soi-même. Mais cela ne devrait rien enlever à cette discussion.
Pendant que nous sommes sur le sujet de la gestion des dépendances, nous devrions aborder le sujet des restrictions. Imaginez un projet où vous êtes en mesure de dépendre de n'importe quel fichier source dont vous avez besoin. Rien n'est interdit, vous pouvez importer n'importe quoi. Pour ceux d'entre vous qui ont commencé leur carrière il y a au moins 10 ans, cela ressemble à la routine pour l'époque. C'est une définition presque complète d'un monolithe.
Le nom implique grandeur, échelle, mais plus important encore, singularité. Pratiquement chaque fichier source à l'intérieur d'un monolithe ne peut pas vivre en dehors de celui-ci. Il y a une raison fondamentale pour laquelle cela est pertinent pour notre discussion : vous n'avez pas de manière explicite et auditable de gérer les dépendances à l'intérieur d'un monolithe. Tout est à portée de main, et cela semble libre et bon marché. Naturellement, les développeurs finissent par créer un graphe complexe d'imports et d'inclusions.
De nos jours, pratiquement tout le monde fait des microservices, il y a peu de doute à ce sujet. Étant donné une échelle suffisante, une base de code devient une bête, car tout est inexorablement lié les uns aux autres. Je suis sûr que de nombreux développeurs fourniront des contre-arguments selon lesquels les monolithes peuvent être gérés de manière propre et raisonnable sans tomber dans ce piège. Mais les exceptions ne font que renforcer la déclaration initiale. Les microservices résolvent cela en définissant des frontières et des responsabilités claires, et un monorepo est une extension naturelle de cette philosophie. Typiquement, les modules offrent un ensemble d'exports publics, ou d'API, et d'autres modules ne sont capables d'utiliser que ceux-ci dans le cadre de leurs contrats.
Les modules logiciels réutilisent une infrastructure commune
C'est un sujet qui me tient très à cœur. Je définirai l'infrastructure dans ce contexte, celui d'une base de code logicielle, comme les outils essentiels nécessaires pour assurer la productivité et la qualité du code.
L'une des raisons pour lesquelles je pense que parier sur des multirepos pour votre entreprise est une erreur a à voir avec un ensemble de exigences de base que tout projet d'ingénierie logicielle devrait satisfaire :
- Un système de construction pour pouvoir produire de manière fiable un artefact livrable.
- Un moyen d'exécuter des tests automatisés.
- Un moyen d'analyser statiquement le code pour détecter les erreurs courantes, les bugs potentiels, et faire respecter les meilleures pratiques.
- Un moyen d'installer et de gérer les dépendances tierces, c'est-à-dire les modules logiciels qui sont externes à votre entreprise.
Si vous avez votre code divisé en plusieurs dépôts, vous devez répliquer ce travail partout. Ne sous-estimez pas la quantité de travail que cela implique ! Toutes les fonctionnalités listées ci-dessus nécessitent au minimum un ensemble de fichiers de configuration qui doivent être maintenus en permanence. Les avoir copiés dans plus de deux endroits garantit pratiquement que vous générerez toujours de la dette technique.
Je sais que certaines entreprises vont à des extrémités pour minimiser l'impact de cela. Elles auront leurs configurations regroupées en échafaudage (a la create-react-app ou yeoman), et les utiliseront pour configurer de nouveaux dépôts. Mais comme nous l'avons vu dans la section précédente, il n'y a aucun moyen de garantir que tout le monde utilise la dernière version de ces dépendances de modèle ! Le temps passé à mettre à jour chaque dépôt individuellement augmente linéairement dans les grandes bases de code. Étant donné une échelle suffisante, pratiquement toutes les versions publiées d'un package interne seront dépendantes en même temps !
Il y a une citation que j'adore et qui est liée à ce dilemme :
À grande échelle, les statistiques ne sont pas vos amies. Plus vous avez d'instances de quoi que ce soit, plus la probabilité qu'une ou plusieurs d'entre elles tombent en panne est élevée. Probablement au même moment.
Si vous pensez que les systèmes distribués ne font référence qu'aux services web, je ne serais pas d'accord. Votre base de code est un système interconnecté et vivant. Des dizaines, des centaines ou des milliers d'ingénieurs se précipitent pour mettre leur code en production chaque jour, tout en luttant pour garder la construction verte et la qualité du code élevée. Si quoi que ce soit, pour moi, cela semble encore plus effrayant qu'un ensemble de microservices :)
Les changements sont toujours reflétés dans l'ensemble du dépôt
Cela dépend fortement du reste des fonctionnalités. C'est l'un des avantages qui est plus facile à comprendre à travers un exemple.
Supposons que je travaille dans une entreprise qui construit des applications web pour des clients du monde entier. Tout est organisé en modules, comme l'exemplifie le projet open-source populaire Babel. Dans cette entreprise, nous utilisons tous ReactJS pour le travail front-end, et par pure coïncidence, tous nos projets sont sur la même version.
 La myriade de modules de Babel : https://github.com/babel/babel/tree/master/packages
La myriade de modules de Babel : https://github.com/babel/babel/tree/master/packages
Mais les gens de Facebook publient la dernière version de React et nous réalisons que la mise à niveau n'est pas triviale. Pour être plus productifs, nous avons construit une bibliothèque de composants réutilisables qui réside en tant que module séparé. Tous les projets en dépendent. Cette nouvelle version de React apporte de nombreux changements majeurs qui l'affectent. Quelles options avons-nous pour effectuer la mise à niveau ?
C'est typiquement là que les adversaires du monorepo rejetteraient tout le concept. Il est facile de dire que nous nous sommes mis dans une impasse et que la structure multirepo aurait été un choix supérieur étant donné les circonstances. En effet, dans ce dernier cas, ce que nous ferions serait simplement adopter progressivement la nouvelle version de React dans nos projets un par un, précédée d'une mise à niveau majeure de notre module de composants de base.
Mais je dirais que cela crée plus de problèmes que cela n'en résout. Une version majeure d'une dépendance de base crée un schisme dans votre équipe d'ingénierie. Vous avez maintenant deux cœurs à maintenir : le nouveau, qui est utilisé par quelques équipes courageuses dans quelques projets, et l'ancien, toujours dépendant de presque toute l'entreprise.
Prenons ce problème à une plus grande échelle pour une analyse plus approfondie. Notre entreprise peut avoir certains projets qui sont toujours en production, mais qui sont simplement en mode maintenance, et n'ont aucune équipe de développement active qui leur est assignée. Ces projets seront probablement les derniers à migrer, prolongeant la fenêtre de temps pendant laquelle vous continuez à travailler sur deux cœurs en même temps. L'ancienne version recevra toujours des corrections de bugs ou de sécurité même si elle est obsolète, car vous ne pouvez pas risquer les activités de vos clients.
Tout cela pour dire qu'une solution multirepo favorise et permet un état constant de dette technique. Il y a beaucoup de migrations en cours, des modules qui dépendent d'anciennes versions d'autres modules, et de nombreuses, nombreuses politiques de dépréciation qui peuvent ou non être applicables.
Considérons maintenant une solution alternative au problème de la mise à niveau de React. En ayant tout le code au même endroit, et dépendant les uns des autres directement, sans versionnement, nous n'avons qu'une seule option : nous devons faire tout le travail en amont, dans tous les modules simultanément.
Si cela semble être une proposition effrayante, je ne vous en blâme pas. C'est terrifiant d'y penser, au début. Cependant, l'avantage est clair : pas de migrations, pas de dette technique, moins de confusion autour de l'état de notre base de code. En termes pratiques, il y a un obstacle à surmonter avec cette solution — il peut y avoir des centaines, des milliers, ou des millions de lignes de code qui doivent être changées en même temps. En ayant des projets séparés, nous évitons le volume de travail en le faisant pièce par pièce. C'est toujours la même quantité totale de changements, mais nous sommes naturellement enclins à penser qu'il serait plus facile de le faire au fil du temps, plutôt que d'un seul coup.
Pour résoudre ce dernier problème, les grandes entreprises se sont tournées vers les codemods — des transformations programmatiques du code source qui peuvent s'exécuter à très grande échelle. Il existe de nombreux tutoriels si vous êtes intéressé, mais l'essentiel est — vous écrivez du code qui détecte d'abord certains motifs dans votre code source, puis applique des changements spécifiques à celui-ci. Pour prendre notre exemple React plus loin, vous pourriez écrire un codemod qui remplace une API obsolète par une plus récente, et même appliquer des changements logiques si nécessaire. En effet, c'est ainsi que Facebook recommande de migrer d'une version de leur bibliothèque à la suivante. C'est ainsi qu'ils le font en interne. Consultez leurs exemples open-source.
Vu sous cet angle, une migration ne semble pas aussi effrayante qu'avant. Vous faites toutes vos recherches en amont, vous définissez comment vous voulez essentiellement réécrire le code affecté, et appliquez les changements plus ou moins tous en même temps. Pour moi, c'est une solution robuste. Je l'ai vue en action, cela peut être fait. C'est en effet impressionnant quand cela fonctionne et de plus en plus d'entreprises l'adoptent.
Inconvénients
Le vieux dicton selon lequel « il n'y a pas de repas gratuit » s'applique certainement ici, aussi. J'ai parlé de nombreux avantages, mais il y a aussi des inconvénients auxquels vous devez penser.
Étant donné que tout le monde travaille au même endroit, et que tout est interconnecté, les tests deviennent le sang du système entier. Essayer de faire un changement qui impacte potentiellement des milliers de lignes de code (ou plus) sans le filet de sécurité des tests automatisés est simplement impossible.
Pourquoi cela est-il différent des manières traditionnelles de stocker le code ? Je dirais que les modules versionnés masquent ce problème particulier, au détriment de la création de dette technique. Si vous possédez un module qui dépend du code d'une autre équipe, par le biais d'un numéro de version strict, alors vous êtes responsable de sa mise à niveau. Si vous n'avez pas une couverture de test suffisante, vous opterez pour la prudence et simplement retarderez la mise à niveau jusqu'à ce que vous soyez sûr que le module n'affecte pas votre propre projet. Comme nous l'avons discuté précédemment, cela a de graves conséquences à long terme, mais c'est une stratégie viable néanmoins. Surtout si votre entreprise ne promeut pas réellement les projets à long terme.
Nous avons mentionné l'avantage que chaque contributeur puisse accéder à tout le code source de votre organisation. Si nous retournons cela, cela peut aussi être un problème pour certains types de travail. Il n'y a pas de moyen facile de restreindre l'accès aux projets. Cela est important si vous considérez les contrats gouvernementaux ou militaires, car ils ont généralement des exigences de sécurité strictes.
Enfin, considérons l'intégration continue. Vous pourriez utiliser un système tel que Jenkins, Travis, ou CircleCI, pour gérer la façon dont votre code est testé et livré aux clients. Lorsque vous avez plus d'un dépôt, vous configurez généralement un pipeline pour chacun. Certaines équipes vont même plus loin et ont une instance CI dédiée par projet. C'est un système flexible qui peut s'adapter aux besoins de chaque équipe. Votre équipe de facturation peut déployer en production une fois par semaine, tandis que votre équipe web pourrait avancer plus vite et déployer plusieurs fois par jour.
Si vous envisagez de passer à un monorepo, méfiez-vous des capacités de votre système CI. Il devra faire beaucoup de travail. Des tâches simples telles que la récupération du code, ou la construction d'un artefact peuvent devenir des tâches longues qui impactent la productivité. Google a développé et exécute sa propre solution CI personnalisée, et pour de bonnes raisons. Rien de disponible sur le marché n'était assez bon.
Maintenant, avant de conclure que c'est un blocage, je vous recommande d'analyser soigneusement votre projet et les outils que vous utilisez. Si vous utilisez git, par exemple, il y a un mythe qui circule selon lequel il ne peut pas gérer les grands dépôts. Cela est démontré comme étant inexact, comme en témoigne le projet qui a inspiré git en premier lieu, le noyau Linux.
Faites vos propres recherches et voyez combien de fichiers et de lignes de code vous avez, et essayez de prédire combien votre projet va croître. Si vous êtes loin de l'échelle du noyau, alors vous êtes en sécurité. Vous pourriez aussi faire valoir que git n'est pas très bon pour stocker les binaires. LFS vise à résoudre cela. Vous pouvez également réécrire votre historique pour supprimer les anciens binaires afin d'optimiser les performances.
Dans le même ordre d'idées, les systèmes CI open-source sont beaucoup plus puissants que vous ne le pensez. Jenkins, par exemple, peut évoluer vers des centaines de jobs, des dizaines de workers, et peut servir les besoins d'une grande équipe avec facilité. Peut-il faire l'échelle de Google ? Absolument pas ! Mais avez-vous des dizaines de milliers d'ingénieurs qui poussent en production chaque jour ? Le plateau auquel ces outils cessent de performer est si élevé qu'il ne vaut pas la peine d'y penser jusqu'à ce que vous soyez proche. Et les chances sont, vous saurez quand vous vous approchez.
Et enfin, il y a le coût. Vous aurez besoin d'au moins une équipe dédiée pour y parvenir. Parce que la quantité de travail n'est certainement pas triviale, et elle demande de la passion et de la concentration. Cette équipe devra, et je résume ici, construire et maintenir en permanence ce qui est essentiellement une plateforme qui stocke le code, les actifs, les artefacts de construction, l'infrastructure de développement réutilisable pour exécuter des tests ou des analyses statiques, et un système CI capable de supporter de grandes charges de travail et du trafic. Si cela semble effrayant, c'est parce que c'est le cas. Mais vous n'aurez aucun problème à convaincre les développeurs de rejoindre une telle équipe, c'est le type d'expérience qui est difficile à accumuler en faisant des projets secondaires à la maison.
En conclusion
J'ai parlé des nombreux avantages de travailler dans un monorepo, des inconvénients, et j'ai abordé les coûts. Cette configuration n'est pas pour tout le monde. Je ne vous encouragerais pas à l'essayer sans avoir d'abord évalué exactement à quoi ressemblent vos problèmes et vos exigences commerciales. Et bien sûr, passez en revue toutes les alternatives possibles avant de décider.