
Article original : The Apache Cassandra Beginner Tutorial
Par Sebastian Sigl
Il existe aujourd'hui de nombreuses options de stockage de données. Vous devez choisir entre géré ou non géré, relationnel ou NoSQL, optimisé pour l'écriture ou la lecture, propriétaire ou open-source — et ce n'est pas tout.
Une fois que vous commencez votre recherche, vous vous retrouverez dans l'univers qu'est le marketing des bases de données. Tous les fournisseurs vous expliqueront pourquoi leur base de données est fantastique.
Malheureusement, il est difficile de savoir quand ne pas utiliser une base de données spécifique, car ce n'est pas un argument de vente attrayant.
Si vous savez quelles questions poser, vous comprendrez éventuellement toutes les propriétés essentielles d'un système donné. En fin de compte, votre choix dépendra de votre expertise et de vos exigences.
Dans ce tutoriel, je vais vous présenter Apache Cassandra, une base de données distribuée, évolutive horizontalement et open-source. Ou, comme les utilisateurs de Cassandra aiment à le décrire : « C'est une base de données qui vous met au volant. »
Je vais partager les pièges essentiels et fournir des références à la documentation. Je vais également fournir des informations basées sur mon expérience de l'exécution de Cassandra à grande échelle au travail, avec des exemples exécutables chaque fois que possible.
Voici un aperçu de tout ce que vous allez apprendre :
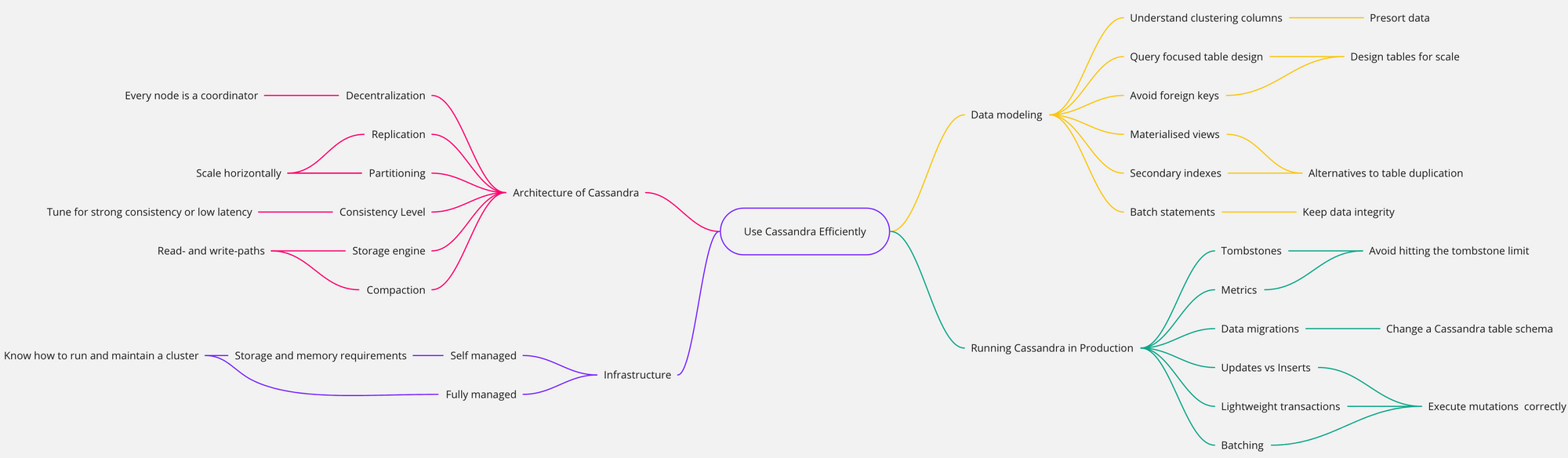
En cours de route, vous apprendrez à poser des questions fondamentales qui vous aideront à choisir une base de données adaptée à vos besoins. Vous en apprendrez également sur d'autres bases de données populaires comme Spanner, Cockroach ou FaunaDB, et comment elles peuvent servir différents cas d'utilisation.
Table des matières
- Comment installer un cluster Cassandra
- Architecture Cassandra
- Décentralisation
- Chaque nœud est un coordinateur
- Partitionnement des données
- Réplication
- Niveau de cohérence
- Optimiser pour la cohérence en configurant une application à forte cohérence
- Optimiser pour la performance en utilisant la cohérence éventuelle
- Comprendre la compaction
- Prétri des données sur les nœuds Cassandra
- Modélisation des données
- Exécution d'un cluster
- Autres apprentissages
- Conclusion
- Références
Comment installer un cluster Cassandra
Pour exécuter les exemples de ce tutoriel, vous aurez besoin d'un cluster Cassandra en cours d'exécution. Vous pouvez le mettre en place rapidement en utilisant Docker.
Paramètres Docker requis
Votre appareil doit avoir un minimum de 8 Go de mémoire et au moins 8 Go d'espace disque libre. Vos paramètres Docker doivent être mis à jour pour pouvoir utiliser au moins 6 Go de mémoire, ou mieux, 8 Go.
Pour appliquer ces suggestions, ouvrez vos préférences Docker, allez dans Ressources et augmentez votre seuil de mémoire.
Cassandra est conçu pour l'échelle, et certaines fonctionnalités ne fonctionnent que sur un cluster Cassandra multi-nœuds, alors commençons par en créer un localement.
Pour Linux et Mac, exécutez les commandes suivantes :
# Exécute le premier nœud et le garde en arrière-plan en cours d'exécution
docker run --name cassandra-1 -p 9042:9042 -d cassandra:3.7
INSTANCE1=$(docker inspect --format="{{ .NetworkSettings.IPAddress }}" cassandra-1)
echo "Instance 1 : ${INSTANCE1}"
# Exécute le deuxième nœud
docker run --name cassandra-2 -p 9043:9042 -d -e CASSANDRA_SEEDS=$INSTANCE1 cassandra:3.7
INSTANCE2=$(docker inspect --format="{{ .NetworkSettings.IPAddress }}" cassandra-2)
echo "Instance 2 : ${INSTANCE2}"
echo "Attendez 60 secondes jusqu'à ce que le deuxième nœud rejoigne le cluster"
sleep 60
# Exécute le troisième nœud
docker run --name cassandra-3 -p 9044:9042 -d -e CASSANDRA_SEEDS=$INSTANCE1,$INSTANCE2 cassandra:3.7
INSTANCE3=$(docker inspect --format="{{ .NetworkSettings.IPAddress }}" cassandra-3)
Pour Windows, exécutez les commandes suivantes dans PowerShell :
# Exécute le premier nœud et le garde en arrière-plan en cours d'exécution
docker run --name cassandra-1 -p 9042:9042 -d cassandra:3.7
$INSTANCE1=$(docker inspect --format="{{ .NetworkSettings.IPAddress }}" cassandra-1)
echo "Instance 1 : ${INSTANCE1}"
# Exécute le deuxième nœud
docker run --name cassandra-2 -p 9043:9042 -d -e CASSANDRA_SEEDS=$INSTANCE1 cassandra:3.7
$INSTANCE2=$(docker inspect --format="{{ .NetworkSettings.IPAddress }}" cassandra-2)
echo "Instance 2 : ${INSTANCE2}"
echo "Attendez 60 secondes jusqu'à ce que le deuxième nœud rejoigne le cluster"
sleep 60
# Exécute le troisième nœud
docker run --name cassandra-3 -p 9044:9042 -d -e CASSANDRA_SEEDS=$INSTANCE1,$INSTANCE2 cassandra:3.7
$INSTANCE3=$(docker inspect --format="{{ .NetworkSettings.IPAddress }}" cassandra-3)
Le processus de démarrage peut prendre quelques minutes.
Vous pouvez vérifier si tout est terminé et prêt en exécutant un outil utilitaire Cassandra appelé nodetool via docker exec sur un nœud :
$ docker exec cassandra-3 nodetool status
Datacenter : datacenter1
=======================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN 172.17.0.3 112.69 KiB 256 68.7% bb5ef231-0dd2-4762-a447-806a45f710ac rack1
UN 172.17.0.2 107.96 KiB 256 68.3% d7392374-8daa-4292-b724-cb790b0ee6ad rack1
UN 172.17.0.4 93.93 KiB 256 63.0% 386d094f-5483-4945-a1a7-2bb3975d6167 rack1
UN signifie Up et Normal. Ici, les 3 nœuds sont en cours d'exécution et en bonne santé.
Dans ce tutoriel, nous allons envoyer de nombreuses requêtes à Cassandra. Je recommande de démarrer un nouveau shell et de se connecter à un nœud en utilisant cqlsh. Voici comment démarrer un shell cqlsh dans Docker :
$ docker exec -it cassandra-1 cqlsh
Connected to Test Cluster at 127.0.0.1:9042.
[cqlsh 5.0.1 | Cassandra 3.7 | CQL spec 3.4.2 | Native protocol v4]
Use HELP for help.
cqlsh>
Et pour exécuter votre première requête :
cqlsh> DESCRIBE keyspaces;
system_traces system_schema system_auth system system_distributed
La réponse montre tous les keyspaces existants. Les keyspaces regroupent des tables et sont similaires à une base de données dans un système de base de données relationnelle traditionnelle. Dans d'autres systèmes, des groupes de certains éléments sont également connus sous le nom d'espaces de noms.
Avant de commencer à créer des tables et à insérer des données, créez d'abord un keyspace dans votre centre de données local, qui doit répliquer les données 3 fois :
cqlsh> CREATE KEYSPACE learn_cassandra
WITH REPLICATION = {
'class' : 'NetworkTopologyStrategy',
'datacenter1' : 3
};
Un keyspace avec un facteur de réplication de 3 utilisant la stratégie NetworkTopologyStrategy a été créé. La stratégie définit comment les données sont répliquées dans différents centres de données. Il s'agit de la stratégie recommandée pour tous les keyspaces créés par l'utilisateur.
Pourquoi commencer avec 3 nœuds ?
Il est recommandé d'avoir au moins 3 nœuds ou plus. Une raison est que, si vous avez besoin d'une forte cohérence, vous devez obtenir des données confirmées d'au moins 2 nœuds. Ou si 1 nœud tombe en panne, votre cluster sera toujours disponible car les 2 nœuds restants sont en cours d'exécution.
Vous n'avez pas besoin de tout comprendre pour l'instant. Après avoir lu le reste de ce tutoriel, les choses devraient être plus claires.
Maintenant, tous les nœuds sont en cours d'exécution et en bonne santé. Vous avez une configuration Cassandra à 3 nœuds écoutant sur les ports 9042, 9043 et 9044 pour les requêtes client. Il s'agit d'une configuration réaliste pour un petit cluster.
En production, les instances s'exécuteraient sur différentes machines pour maximiser les performances.
Avant de commencer à créer des tables, à lire et à écrire des données, il est utile de comprendre les bases de la conception de tables pour la scalabilité.
Dans ce tutoriel, vous allez créer des tables avec différents paramètres pour une application de liste de tâches. Si vous souhaitez mettre la main à la pâte immédiatement, vous pouvez sauter directement à l'exemple suivant cqlsh.
Architecture Cassandra
Cassandra est une base de données multi-nœuds décentralisée qui s'étend physiquement sur des emplacements séparés et utilise la réplication et le partitionnement pour mettre à l'échelle de manière infinie les lectures et les écritures.
Décentralisation
Cassandra est décentralisée car aucun nœud n'est supérieur aux autres nœuds, et chaque nœud agit dans différents rôles selon les besoins sans aucun contrôleur central. Nous aborderons des exemples de décentralisation un peu plus tard dans cette section.
La propriété décentralisée de Cassandra est ce qui lui permet de gérer facilement les situations où un nœud devient indisponible ou où un nouveau nœud est ajouté.
Chaque nœud est un coordinateur
Les données sont répliquées sur différents nœuds. Si certaines données sont demandées, une requête peut être traitée à partir de n'importe quel nœud.
Ce récepteur initial de la requête devient le nœud coordinateur pour cette requête. Si d'autres nœuds doivent être vérifiés pour garantir la cohérence, le coordinateur demande les données requises aux nœuds réplicats.
Le coordinateur peut calculer quel nœud contient les données en utilisant un algorithme de hachage cohérent.
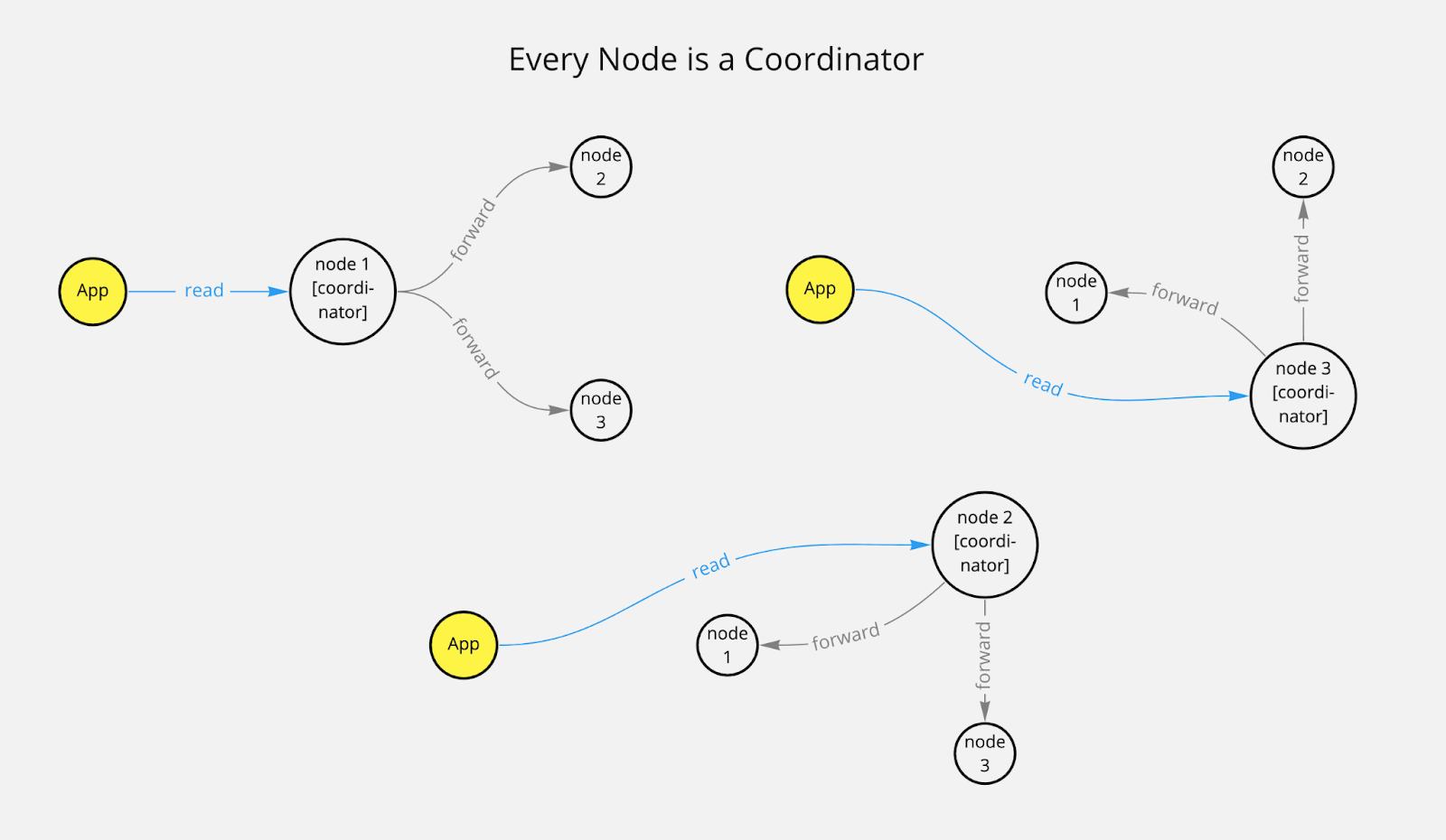
Le coordinateur est responsable de nombreuses choses, telles que le regroupement des requêtes, la réparation des données ou les nouvelles tentatives pour les lectures et les écritures.
Partitionnement des données
[Partitionnement] est une méthode de division et de stockage d'un ensemble de données logique unique dans plusieurs bases de données. En distribuant les données entre plusieurs machines, un cluster de systèmes de bases de données peut stocker des ensembles de données plus importants et gérer des requêtes supplémentaires.
Comme pour de nombreuses autres bases de données, vous stockez des données dans Cassandra dans un schéma prédéfini. Vous devez définir une table avec des colonnes et des types pour chaque colonne.
De plus, vous devez réfléchir à la clé primaire de votre table. Une clé primaire est obligatoire et garantit que les données sont identifiables de manière unique par une ou plusieurs colonnes.
Le concept de clés primaires est plus complexe dans Cassandra que dans les bases de données traditionnelles comme MySQL. Dans Cassandra, la clé primaire se compose de 2 parties :
- une clé de partition obligatoire et
- un ensemble facultatif de colonnes de regroupement.
Vous en apprendrez plus sur la clé de partition et les colonnes de regroupement dans la section sur la modélisation des données.
Pour l'instant, concentrons-nous sur la clé de partition et son impact sur le partitionnement des données.
Considérons la table suivante :
Table Users | Légende : p - Clé de partition, c - Colonne de regroupement
country (p) | user_email (c) | first_name | last_name | age
----------------------------------------------------------------
US | john@email.com | John | Wick | 55
UK | peter@email.com | Peter | Clark | 65
UK | bob@email.com | Bob | Sandler | 23
UK | alice@email.com | Alice | Brown | 26
Ensemble, les colonnes user_email et country constituent la clé primaire.
La colonne country est la clé de partition (p). L'instruction CREATE pour la table ressemble à ceci :
cqlsh>
CREATE TABLE learn_cassandra.users_by_country (
country text,
user_email text,
first_name text,
last_name text,
age smallint,
PRIMARY KEY ((country), user_email)
);
Le premier groupe de la clé primaire définit la clé de partition. Tous les autres éléments de la clé primaire sont des colonnes de regroupement :

Remplissons la table avec quelques données :
cqlsh>
INSERT INTO learn_cassandra.users_by_country (country,user_email,first_name,last_name,age)
VALUES('US', 'john@email.com', 'John','Wick',55);
INSERT INTO learn_cassandra.users_by_country (country,user_email,first_name,last_name,age)
VALUES('UK', 'peter@email.com', 'Peter','Clark',65);
INSERT INTO learn_cassandra.users_by_country (country,user_email,first_name,last_name,age)
VALUES('UK', 'bob@email.com', 'Bob','Sandler',23);
INSERT INTO learn_cassandra.users_by_country (country,user_email,first_name,last_name,age)
VALUES('UK', 'alice@email.com', 'Alice','Brown',26);
Si vous êtes habitué à concevoir des tables de bases de données relationnelles traditionnelles comme on l'enseigne à l'école ou à l'université, vous pourriez être surpris. Pourquoi utiliser country comme partie essentielle de la clé primaire ?
Cet exemple aura du sens après avoir compris les bases du partitionnement dans Cassandra.
Le partitionnement est la base de la scalabilité, et il est basé sur la clé de partition. Dans cet exemple, les partitions sont créées en fonction du country. Toutes les lignes avec le country US sont placées dans une partition. Toutes les autres lignes avec le pays UK seront stockées dans une autre partition.
Dans le contexte du partitionnement, les mots partition et shard peuvent être utilisés de manière interchangeable.
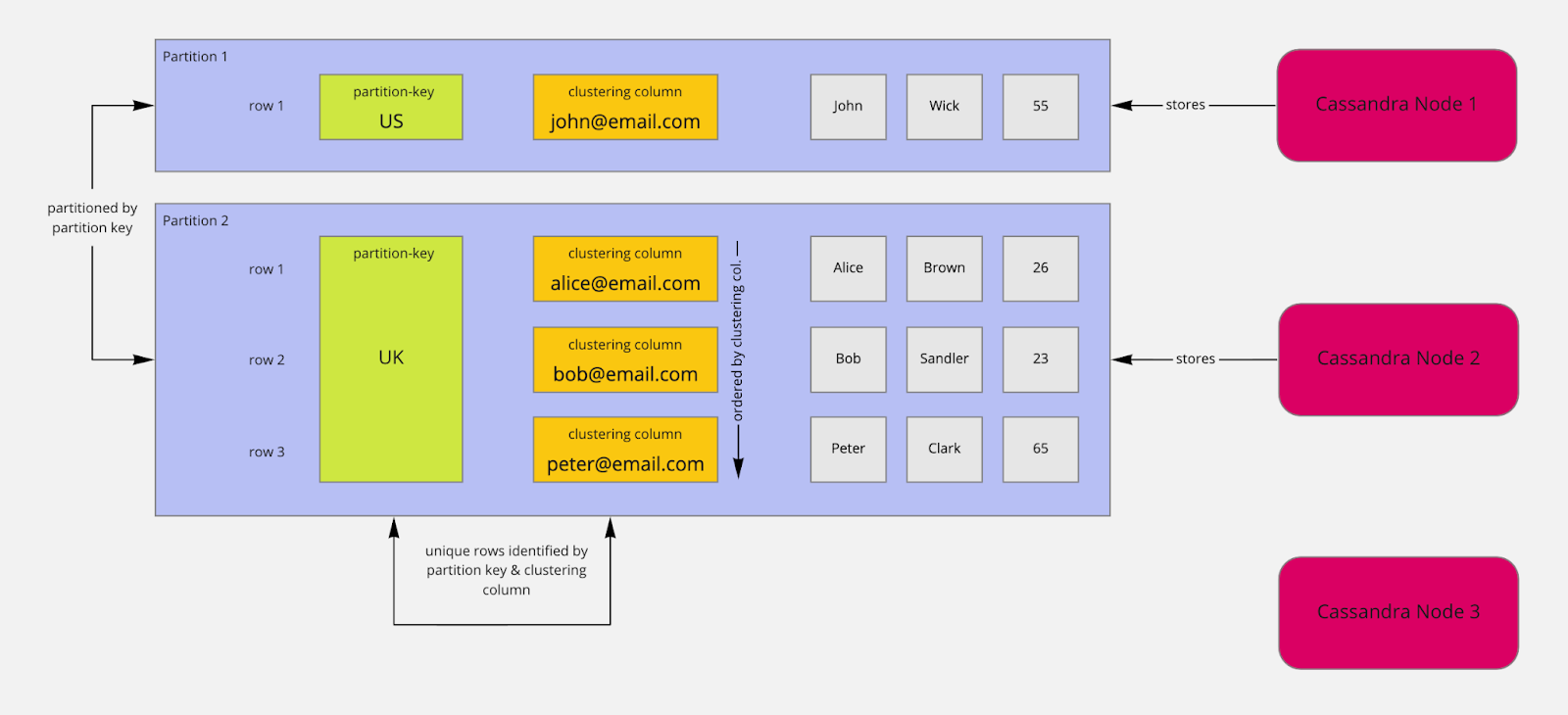
Les partitions sont créées et remplies en fonction des valeurs de la clé de partition. Elles sont utilisées pour distribuer les données à différents nœuds. En distribuant les données à d'autres nœuds, vous obtenez de la scalabilité. Vous lisez et écrivez des données vers et depuis différents nœuds par leur clé de partition.
La distribution des données est un point crucial à comprendre lors de la conception d'applications qui stockent des données basées sur des partitions. Il peut falloir un certain temps pour s'habituer pleinement à ce concept, surtout si vous êtes habitué aux bases de données relationnelles.
Au lieu de cela, réfléchissez à la manière dont vous lisez et écrivez des données et à la manière dont le partitionnement doit être effectué pour évoluer horizontalement.
Que signifie la mise à l'échelle horizontale ?
La mise à l'échelle horizontale signifie que vous pouvez augmenter le débit en ajoutant plus de nœuds. Si vos données sont distribuées sur plus de serveurs, alors plus de CPU, de mémoire et de capacité réseau sont disponibles.
Vous pourriez demander, alors pourquoi avez-vous même besoin de email dans la clé primaire ?
La réponse est que la clé primaire définit quelles colonnes sont utilisées pour identifier les lignes. Vous devez ajouter toutes les colonnes nécessaires pour identifier une ligne de manière unique à la clé primaire. Utiliser uniquement le pays ne permettrait pas d'identifier les lignes de manière unique.
La clé de partition est essentielle pour distribuer les données de manière uniforme entre les nœuds et est essentielle lors de la lecture des données. Le schéma précédemment défini est conçu pour être interrogé par country car country est la clé de partition.
Une requête qui sélectionne des lignes par country fonctionne bien :
cqlsh>
SELECT * FROM learn_cassandra.users_by_country WHERE country='US';
Dans votre shell cqlsh, vous enverrez une requête à un seul nœud Cassandra par défaut. Cela s'appelle un niveau de cohérence de un, qui permet d'excellentes performances et scalabilité.
Si vous accédez à Cassandra différemment, le niveau de cohérence par défaut peut ne pas être un.
Que signifie un niveau de cohérence de un ?
Un niveau de cohérence de un signifie qu'un seul nœud est interrogé pour retourner les données. Avec cette approche, vous perdrez les garanties de forte cohérence et expérimenterez plutôt une cohérence éventuelle.
Nous approfondirons les niveaux de cohérence plus tard.
Créons une autre table. Celle-ci a une partition définie uniquement par la colonne user_email :
cqlsh>
CREATE TABLE learn_cassandra.users_by_email (
user_email text,
country text,
first_name text,
last_name text,
age smallint,
PRIMARY KEY (user_email)
);
Maintenant, remplissons cette table avec quelques enregistrements :
cqlsh>
INSERT INTO learn_cassandra.users_by_email (user_email, country,first_name,last_name,age)
VALUES('john@email.com', 'US', 'John','Wick',55);
INSERT INTO learn_cassandra.users_by_email (user_email,country,first_name,last_name,age)
VALUES('peter@email.com', 'UK', 'Peter','Clark',65);
INSERT INTO learn_cassandra.users_by_email (user_email,country,first_name,last_name,age)
VALUES('bob@email.com', 'UK', 'Bob','Sandler',23);
INSERT INTO learn_cassandra.users_by_email (user_email,country,first_name,last_name,age)
VALUES('alice@email.com', 'UK', 'Alice','Brown',26);
Cette fois, chaque ligne est placée dans sa propre partition.

Ce n'est pas mauvais en soi. Si vous souhaitez optimiser l'obtention de données par email uniquement, c'est une bonne idée :
cqlsh>
SELECT * FROM learn_cassandra.users_by_email WHERE user_email='alice@email.com';
Si vous configurez votre table avec une clé de partition pour user_email et souhaitez obtenir tous les utilisateurs par age, vous devrez obtenir les données de toutes les partitions car les partitions ont été créées par user_email.
Parler à tous les nœuds est coûteux et peut causer des problèmes de performance sur un grand cluster.
Cassandra essaie d'éviter les requêtes nuisibles. Si vous souhaitez filtrer par une colonne qui n'est pas une clé de partition, vous devez dire explicitement à Cassandra que vous souhaitez filtrer par une colonne non clé de partition :
cqlsh>
SELECT * FROM learn_cassandra.users_by_email WHERE age=26 ALLOW FILTERING;
Sans ALLOW FILTERING, la requête ne serait pas exécutée pour éviter de nuire au cluster en exécutant accidentellement des requêtes coûteuses. Exécuter des requêtes sans conditions (comme sans clause WHERE) ou avec des conditions qui n'utilisent pas la clé de partition est coûteux et doit être évité pour prévenir les goulots d'étranglement de performance.
Mais comment obtenir toutes les lignes de la table de manière scalable ?
Si vous le pouvez, partitionnez par une valeur comme country. Si vous connaissez tous les pays, vous pouvez alors itérer sur tous les pays disponibles, envoyer une requête pour chacun et collecter les résultats dans votre application.
En termes de scalabilité, il est pire de simplement sélectionner toutes les lignes, car lorsque vous utilisez une table partitionnée par user_email, toutes les données sont collectées en 1 requête dans un seul coordinateur.
Cela est acceptable tant que vous n'avez pas de problèmes de performance.
En comparaison, envoyer plusieurs requêtes par country distribue l'effort à différents nœuds coordinateurs, ce qui est beaucoup plus scalable.
Si vous avez encore besoin d'accéder à toutes les données, il existe une excellente intégration entre Spark et Cassandra qui permet des lectures et écritures efficaces pour des ensembles de données massifs. Le connecteur Spark pour Cassandra regroupe vos données par clé de partition et peut exécuter des requêtes très efficacement.
Réplication
La scalabilité utilisant uniquement le partitionnement est limitée.
Considérons de nombreuses requêtes d'écriture arrivant pour une seule partition. Toutes les requêtes seraient envoyées à un seul nœud avec des limitations techniques telles que le CPU, la mémoire et la bande passante. De plus, vous souhaitez gérer les requêtes de lecture et d'écriture si ce nœud n'est pas disponible.
C'est là qu'intervient le concept de réplication. En dupliquant les données sur différents nœuds, appelés réplicas, vous pouvez servir plus de données simultanément à partir d'autres nœuds pour améliorer la latence et le débit. Cela permet également à votre cluster d'effectuer des lectures et des écritures au cas où un réplica n'est pas disponible.
Dans Cassandra, vous devez définir un facteur de réplication pour chaque keyspace. Au début de notre exemple, vous avez créé un keyspace avec un facteur de réplication de 3 pour notre centre de données par défaut :
cqlsh> CREATE KEYSPACE learn_cassandra
WITH REPLICATION = {
'class' : 'NetworkTopologyStrategy',
'datacenter1' : 3
};
Un facteur de réplication de un signifie qu'il n'y a qu'une seule copie de chaque ligne dans le cluster. Si le nœud contenant la ligne tombe en panne, la ligne ne peut pas être récupérée.
Un facteur de réplication de deux signifie deux copies de chaque ligne, où chaque copie se trouve sur un nœud différent. Tous les réplicas sont également importants ; il n'y a pas de réplica primaire ou maître.
En règle générale, le facteur de réplication ne doit pas dépasser le nombre de nœuds dans le cluster. Cependant, vous pouvez augmenter le facteur de réplication et ajouter ensuite le nombre souhaité de nœuds plus tard.
Généralement, il est recommandé d'utiliser un facteur de réplication de 3 pour les cas d'utilisation en production. Cela garantit que vos données sont très peu susceptibles d'être perdues ou de devenir inaccessibles car trois copies sont disponibles. De plus, si les données ne sont pas cohérentes entre les réplicas à un moment donné, vous pouvez demander quel état d'information est détenu par la majorité.
Dans votre configuration de cluster local, la majorité signifie 2 réplicas sur 3. Cela nous permet d'utiliser certaines options de requête puissantes que vous verrez dans la section suivante.
Niveau de cohérence
Maintenant que vous connaissez le partitionnement et la réplication, vous êtes prêt à réfléchir aux niveaux de cohérence. Cassandra possède une fonctionnalité vraiment exceptionnelle appelée cohérence réglable.
Vous pouvez définir le niveau de cohérence de vos requêtes de lecture et d'écriture. Vous pouvez consulter la documentation Cassandra pour tous les paramètres disponibles.
Concentrons-nous sur les paramètres les plus populaires et essayons de comprendre quand choisir chaque niveau de cohérence.
Supposons que vous avez 3 réplicas définis.
La première question à laquelle vous devez répondre est : avez-vous besoin d'une forte cohérence ?
Que signifie une forte cohérence ?
Contrairement à la cohérence éventuelle, la forte cohérence signifie qu'un seul état de vos données peut être observé à tout moment et en tout lieu.
Par exemple, lorsque la cohérence est critique, comme dans un domaine bancaire, vous voulez être sûr que tout est correct. Vous préféreriez accepter une diminution de la disponibilité et une augmentation de la latence pour garantir la correction.
Tout se résume au théorème CAP. Vous ne pouvez pas être disponible et cohérent en même temps en cas de problèmes de connexion entre les nœuds de votre cluster.
Réfléchissons à l'exemple suivant :
Vous souhaitez écrire une seule valeur dans une table. Les données sont répliquées sur 2 nœuds, et la connexion entre les nœuds est interrompue. Tout d'abord, une requête d'écriture est envoyée au nœud 1. Ensuite, les données sont lues à partir du nœud 2.
Comment gérez-vous cette situation ?

- Devez-vous interdire les écritures sur tous les nœuds pour garantir la cohérence ? Cela signifie que la disponibilité serait sacrifiée pour garantir la cohérence et la correction.
- Accepter l'écriture sur le nœud 1 et continuer à servir les lectures à partir des deux nœuds. Cela maintiendrait le système disponible, mais selon le nœud à partir duquel vous lisez, la réponse sera différente, ce qui signifie sacrifier la cohérence au profit de la disponibilité.
Vous pouvez simplifier le problème pour prendre des décisions cruciales pour votre application : voulez-vous la cohérence ou la disponibilité ?
Un autre facteur est la latence. En parlant à plus de nœuds pour garantir la cohérence, vous devez attendre plus longtemps pour recevoir toutes les réponses des nœuds.
Optimiser pour la cohérence en configurant une application à forte cohérence
Il existe une formule très importante qui, si elle est vraie, garantit une forte cohérence :
[niveau-de-cohérence-de-lecture] + [niveau-de-cohérence-d'écriture] > [facteur-de-réplication]
Que signifie le niveau de cohérence ?
Le niveau de cohérence signifie combien de nœuds doivent accuser réception d'une requête de lecture ou d'écriture.
Vous pouvez ajuster les niveaux de cohérence de lecture et d'écriture en votre faveur si vous souhaitez maintenir une forte cohérence. Ou vous pouvez même renoncer à une forte cohérence pour de meilleures performances, ce qui est également appelé cohérence éventuelle :

Pour un système à lecture intensive, il est recommandé de maintenir une cohérence de lecture faible car les lectures se produisent plus souvent que les écritures. Supposons que vous avez un facteur de réplication de 3. La formule serait la suivante :
1 + [niveau-de-cohérence-d'écriture] > 3
Par conséquent, la cohérence d'écriture doit être définie à 3 pour avoir un système fortement cohérent.
Pour un système à écriture intensive, vous pouvez faire de même. Définissez le niveau de cohérence d'écriture à 1 et le niveau de cohérence de lecture à 3.
Vous vérifiez soit chaque nœud pour une lecture afin de vous assurer que tous les nœuds ont reçu le dernier état mis à jour, soit, pour une écriture, vous vous assurez que tous les nœuds ont écrit la mise à jour dans leur stockage local. Les deux garantiront que les données pour la lecture et l'écriture sont correctes.
Cette décision doit être réfléchie dans toutes les applications qui accèdent à vos données Cassandra car, au niveau d'une requête, vous devez définir le niveau de cohérence requis.
Vous avez défini le facteur de réplication à 3. Par conséquent, vous pouvez utiliser un niveau de cohérence de ALL ou THREE :
cqlsh>
CONSISTENCY ALL;
SELECT * FROM learn_cassandra.users_by_country WHERE country='US';
Si une seule de vos applications viole la stratégie de cohérence requise, vous risquez rapidement soit de perdre la cohérence, soit de mettre sous pression le cluster plus que nécessaire.
Optimiser pour la performance en utilisant la cohérence éventuelle
Si vous n'avez pas besoin d'une forte cohérence, vous pouvez réduire le niveau de cohérence des requêtes à 1 pour gagner en performance :
cqlsh>
CONSISTENCY ONE;
SELECT * FROM learn_cassandra.users_by_country WHERE country='US';
Éventuellement, les données seront propagées à tous les réplicas et cela garantira une cohérence éventuelle. La rapidité avec laquelle les données seront rendues cohérentes dépend de différents mécanismes qui synchronisent les données entre les nœuds.
Diverses fonctionnalités peuvent être ajustées dans Cassandra, comme les réparations de lecture et les processus externes qui réparent les données en continu.
Optimiser le stockage des données pour la lecture ou l'écriture
Les écritures sont moins coûteuses que les lectures dans Cassandra en raison de son moteur de stockage. Écrire des données signifie simplement ajouter quelque chose à un journal de validation.
Les journaux de validation sont des journaux en ajout uniquement de toutes les mutations locales à un nœud Cassandra et réduisent les E/S requises au minimum.
La lecture est plus coûteuse, car elle peut nécessiter de vérifier différents emplacements de disque jusqu'à ce que toutes les données de la requête soient finalement trouvées.
Mais cela ne signifie pas que Cassandra est mauvais en lecture. Au lieu de cela, le moteur de stockage de Cassandra peut être optimisé pour les performances de lecture ou d'écriture.
Comprendre la compaction
Pour chaque opération d'écriture, les données sont écrites sur le disque pour assurer la durabilité. Cela signifie que si quelque chose ne va pas, comme une panne de courant, les données ne sont pas perdues.
La base pour le stockage des données est ce que l'on appelle les SSTables. Les SSTables sont des fichiers de données immuables que Cassandra utilise pour persister les données sur le disque.
Vous pouvez définir diverses stratégies pour une table qui définissent comment les données doivent être fusionnées et compactées. Ces stratégies affectent les performances de lecture et d'écriture :
SizeTieredCompactionStrategyest la stratégie par défaut, et est particulièrement performante si vous avez plus d'écritures que de lectures,LeveledCompactionStrategyoptimise les lectures par rapport aux écritures. Cette optimisation peut être coûteuse et doit être testée en production avec soinTimeWindowCompactionStrategyest pour les données de séries temporelles
Par défaut, les tables utilisent la stratégie SizeTieredCompactionStrategy :
cqlsh>
DESCRIBE TABLE learn_cassandra.users_by_country;
CREATE TABLE learn_cassandra.users_by_country (
country text,
user_email text,
age smallint,
first_name text,
last_name text,
PRIMARY KEY (country, user_email)
) WITH CLUSTERING ORDER BY (user_email ASC)
AND bloom_filter_fp_chance = 0.01
AND caching = {'keys': 'ALL', 'rows_per_partition': 'NONE'}
AND comment = ''
AND compaction = {'class': 'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy', 'max_threshold': '32', 'min_threshold': '4'}
AND compression = {'chunk_length_in_kb': '64', 'class': 'org.apache.cassandra.io.compress.LZ4Compressor'}
AND crc_check_chance = 1.0
AND dclocal_read_repair_chance = 0.1
AND default_time_to_live = 0
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair_chance = 0.0
AND speculative_retry = '99PERCENTILE';
Bien que vous puissiez modifier la stratégie de compaction d'une table existante, je ne le recommande pas, car tous les nœuds Cassandra commencent cette migration simultanément. Cela entraînera des problèmes de performance significatifs dans un système de production.
Au lieu de cela, définissez explicitement la stratégie de compaction lors de la création de votre nouvelle table :
cqlsh>
CREATE TABLE learn_cassandra.users_by_country_with_leveled_compaction (
country text,
user_email text,
first_name text,
last_name text,
age smallint,
PRIMARY KEY ((country), user_email)
) WITH
compaction = { 'class' : 'LeveledCompactionStrategy' };
Vérifions le résultat :
cqlsh>
DESCRIBE TABLE learn_cassandra.users_by_country_with_leveled_compaction;
CREATE TABLE learn_cassandra.users_by_country_with_leveled_compaction (
country text,
user_email text,
age smallint,
first_name text,
last_name text,
PRIMARY KEY (country, user_email)
) WITH CLUSTERING ORDER BY (user_email ASC)
AND bloom_filter_fp_chance = 0.1
AND caching = {'keys': 'ALL', 'rows_per_partition': 'NONE'}
AND comment = ''
AND compaction = {'class': 'org.apache.cassandra.db.compaction.LeveledCompactionStrategy'}
AND compression = {'chunk_length_in_kb': '64', 'class': 'org.apache.cassandra.io.compress.LZ4Compressor'}
AND crc_check_chance = 1.0
AND dclocal_read_repair_chance = 0.1
AND default_time_to_live = 0
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair_chance = 0.0
AND speculative_retry = '99PERCENTILE';
Les stratégies définissent quand et comment la compaction est exécutée. La compaction signifie réorganiser les données sur le disque pour supprimer les anciennes données et maintenir les performances aussi bonnes que possible lorsque plus de données doivent être stockées.
Consultez l'excellente documentation DataStax sur la compaction pour plus de détails. Il pourrait même y avoir de meilleures stratégies à l'avenir pour la performance de votre cas d'utilisation.
Prétri des données sur les nœuds Cassandra
Une table nécessite toujours une clé primaire. Une clé primaire se compose de 2 parties :
- Au moins 1 colonne(s) comme clé de partition et
- Zéro ou plusieurs colonnes de regroupement pour imbriquer les lignes de données.
Toutes les colonnes de la clé de partition ensemble sont utilisées pour identifier les partitions. Toutes les colonnes de la clé primaire, c'est-à-dire la clé de partition et les colonnes de regroupement, identifient une ligne spécifique au sein d'une partition.
Dans Cassandra, les données sont déjà triées sur le disque. Donc, si vous souhaitez éviter de trier les données plus tard, vous pouvez vous assurer que le tri est appliqué comme nécessaire. Cela peut être garanti au niveau de la table et évite d'avoir à trier les données dans les applications clientes qui interrogent Cassandra.
Dans notre table users_by_country, vous pouvez définir age comme une autre colonne de regroupement pour trier les données stockées :
cqlsh>
CREATE TABLE learn_cassandra.users_by_country_sorted_by_age_asc (
country text,
user_email text,
first_name text,
last_name text,
age smallint,
PRIMARY KEY ((country), age, user_email)
) WITH CLUSTERING ORDER BY (age ASC);
Ajoutons les mêmes données à nouveau :
cqlsh>
INSERT INTO learn_cassandra.users_by_country_sorted_by_age_asc (country,user_email,first_name,last_name,age)
VALUES('US','john@email.com', 'John','Wick',10);
INSERT INTO learn_cassandra.users_by_country_sorted_by_age_asc (country,user_email,first_name,last_name,age)
VALUES('UK', 'peter@email.com', 'Peter','Clark',30);
INSERT INTO learn_cassandra.users_by_country_sorted_by_age_asc (country,user_email,first_name,last_name,age)
VALUES('UK', 'bob@email.com', 'Bob','Sandler',20);
INSERT INTO learn_cassandra.users_by_country_sorted_by_age_asc (country,user_email,first_name,last_name,age)
VALUES('UK', 'alice@email.com', 'Alice','Brown',40);
Et obtenons les données par pays :
cqlsh>
SELECT * FROM learn_cassandra.users_by_country_sorted_by_age_asc WHERE country='UK';
country | age | user_email | first_name | last_name
---------+-----+------------------+------------+-----------
UK | 20 | bob@email.com | Bob | Sandler
UK | 30 | peter@email.com | Peter | Clark
UK | 40 | alice@email.com | Alice | Brown
(3 rows)
Dans cet exemple, les colonnes de regroupement sont age et user_email. Donc les données sont d'abord triées par âge puis par user_email. Au cœur, Cassandra est toujours comme un magasin clé-valeur. Par conséquent, vous ne pouvez interroger la table que par :
countrycountryetagecountry,age, etuser_email
Mais jamais par country et user_email.
Après avoir appris le partitionnement, la réplication et les niveaux de cohérence, passons à la modélisation des données et amusons-nous davantage avec le cluster Cassandra.
Modélisation des données
Vous avez déjà appris beaucoup de choses sur les fondamentaux de Cassandra.
Mettons vos connaissances en pratique et concevons une application de liste de tâches qui reçoit beaucoup plus de lectures que d'écritures.
La meilleure approche est d'analyser certaines histoires d'utilisateurs que vous souhaitez réaliser avec la conception de votre table :
- En tant qu'utilisateur, je veux créer un élément de liste de tâches
Note : Cela ne concerne que la création de données. Pour l'instant, vous pouvez retarder certaines décisions car vous souhaitez vous concentrer sur la manière dont les données sont lues.
- En tant qu'utilisateur, je veux lister tous mes éléments de liste de tâches dans l'ordre ascendant
Tout d'abord, vous devez interroger par user_email. Créez une table appelée todos_by_user_email.
Vous avez besoin d'une table qui contient toutes les informations d'un élément de liste de tâches d'un utilisateur. Les données doivent être partitionnées par user_email pour des lectures et écritures efficaces par user_email.
De plus, les enregistrements les plus anciens doivent être affichés en premier, ce qui signifie utiliser la date de création comme colonne de regroupement. La creation_date garantit également l'unicité. :
cqlsh>
CREATE TABLE learn_cassandra.todo_by_user_email (
user_email text,
name text,
creation_date timestamp,
PRIMARY KEY ((user_email), creation_date)
) WITH CLUSTERING ORDER BY (creation_date DESC)
AND compaction = { 'class' : 'LeveledCompactionStrategy' };
- En tant qu'utilisateur, je veux partager un élément de liste de tâches avec un autre utilisateur
Pour obtenir toutes les tâches partagées avec un utilisateur, vous devez créer une table appelée todos_shared_by_target_user_email pour afficher toutes les tâches partagées pour l'utilisateur cible.
La table contient le nom de la tâche à afficher.
Mais l'utilisateur veut également voir les tâches qu'il a partagées avec d'autres utilisateurs. Il s'agit d'une autre table, todos_shared_by_source_user_email.
Les deux tables ont, selon le cas d'utilisation, la user_email requise comme clés de partition pour permettre des requêtes efficaces. De plus, creation_date est ajoutée comme colonne de regroupement pour le tri et l'unicité :
cqlsh>
CREATE TABLE learn_cassandra.todos_shared_by_target_user_email (
target_user_email text,
source_user_email text,
creation_date timestamp,
name text,
PRIMARY KEY ((target_user_email), creation_date)
) WITH CLUSTERING ORDER BY (creation_date DESC)
AND compaction = { 'class' : 'LeveledCompactionStrategy' };
CREATE TABLE learn_cassandra.todos_shared_by_source_user_email (
target_user_email text,
source_user_email text,
creation_date timestamp,
name text,
PRIMARY KEY ((source_user_email), creation_date)
) WITH CLUSTERING ORDER BY (creation_date DESC)
AND compaction = { 'class' : 'LeveledCompactionStrategy' };
Ce type de modélisation est différent de la réflexion sur les clés étrangères et les clés primaires que vous pourriez connaître des bases de données traditionnelles. Au début, il s'agit de définir des tables et de réfléchir aux valeurs que vous souhaitez filtrer et afficher.
Vous devez définir une clé de partition pour garantir que les données sont organisées pour des opérations de lecture et d'écriture efficaces. De plus, vous devez définir des colonnes de regroupement pour garantir l'unicité, l'ordre de tri et les paramètres de requête facultatifs.
Maintenir les données synchronisées en utilisant les instructions BATCH
En raison de la duplication, vous devez veiller à maintenir la cohérence des données. Dans Cassandra, vous pouvez le faire en utilisant des instructions BATCH qui vous offrent une garantie tout-en-un, également appelée atomicité.
Cela peut sembler beaucoup de travail, et oui, c'en est beaucoup ! Si vous avez un schéma de table avec de nombreuses relations, vous aurez plus de travail par rapport à un schéma de table normalisé.
Qu'est-ce qu'un schéma de table normalisé ?
Un schéma de table normalisé est optimisé pour ne contenir aucune duplication. Au lieu de cela, les données sont référencées par ID et doivent être jointes plus tard.
Dans Cassandra, vous essayez d'éviter les tables normalisées. Il n'est même pas possible d'écrire une requête qui contient une jointure.
Les instructions de lot sont peu coûteuses sur une seule partition, mais dangereuses lorsque vous les exécutez sur différentes partitions, car :
- Les mutations de données ne seront pas appliquées en même temps à toutes les partitions, sans isolation
- C'est coûteux pour le nœud coordinateur, car vous devez parler à plusieurs nœuds et préparer un retour en arrière si quelque chose ne va pas
- Il existe une limite de taille de requête de lot de 50 ko pour éviter de surcharger le coordinateur. Cette limite peut être augmentée, mais ce n'est pas recommandé
En général, les lots sont coûteux.
Il existe d'autres moyens d'appliquer des changements éventuellement. Si vous devez les exécuter très souvent, envisagez d'utiliser des requêtes asynchrones avec un mécanisme de nouvelle tentative approprié.
Selon la manière dont vous accédez à votre Cassandra, le pilote peut déjà vous offrir des capacités de nouvelle tentative.
Néanmoins, cette approche nécessite de réfléchir à ce qui se passera si une requête n'est jamais exécutée. Si chaque requête doit vraiment être exécutée éventuellement, comment pouvez-vous vous assurer qu'elle ne se perd pas si votre service tombe en panne ?
Le sujet lui-même nécessite beaucoup plus de temps pour être expliqué, et pourrait être le sujet principal d'un autre tutoriel Cassandra.
L'apprentissage clé ici est :
- Les lots de partition unique sont peu coûteux et doivent être utilisés
- Les lots qui incluent différentes partitions sont coûteux, et s'il y a beaucoup de lectures/écritures, cela pourrait être la raison pour laquelle un cluster Cassandra est épuisé.
Créons une instruction BATCH qui contient un élément de liste de tâches partagé avec un utilisateur :
cqlsh>
BEGIN BATCH
INSERT INTO learn_cassandra.todo_by_user_email (user_email,creation_date,name) VALUES('alice@email.com', toTimestamp(now()), 'My first todo entry')
INSERT INTO learn_cassandra.todos_shared_by_target_user_email (target_user_email, source_user_email,creation_date,name) VALUES('bob@email.com', 'alice@email.com',toTimestamp(now()), 'My first todo entry')
INSERT INTO learn_cassandra.todos_shared_by_source_user_email (target_user_email, source_user_email,creation_date,name) VALUES('alice@email.com', 'bob@email.com', toTimestamp(now()), 'My first todo entry')
APPLY BATCH;
Regardons l'une des tables :
cqlsh>
SELECT * FROM learn_cassandra.todos_shared_by_target_user_email WHERE target_user_email='bob@email.com';
target_user_email | creation_date | name | source_user_email
-------------------+-----------------+--------+-------------------
bob@email.com | 2021-05-24 ...| My first todo entry | alice@email.com
Toutes les données existent et peuvent être consultées de manière performante en utilisant toutes les tables définies.
Utiliser des clés étrangères au lieu de dupliquer les données dans Cassandra
Vous pourriez envisager d'utiliser des clés étrangères au lieu de dupliquer les données.
Traditionnellement, les clés étrangères sont des références d'ID d'une entité qui se trouvent dans une autre table et dans une base de données relationnelle. Elles garantissent que l'ID référencé existe.
Dans Cassandra, cela peut sembler bien car vous avez moins de données dupliquées. À ce stade, réfléchissez à nouveau à la raison pour laquelle vous utilisez Cassandra. Habituellement, la réponse est un trafic élevé et une scalabilité.
Cassandra peut évoluer énormément et offre des performances de haut niveau lorsqu'elle est utilisée correctement.
Normaliser les tables va à l'encontre de nombreux principes de Cassandra. Vous pouvez référencer des données par ID, mais gardez à l'esprit que cela signifie que vous devez joindre les données vous-même. Cela signifie également lire et écrire des données vers plusieurs partitions à la fois.
Cassandra est conçu pour évoluer. Si vous commencez à normaliser votre schéma pour réduire la duplication, vous sacrifiez alors la scalabilité horizontale.
Si vous souhaitez toujours utiliser des clés étrangères au lieu de la duplication de données, vous pourriez vouloir utiliser une autre base de données. Mais tout a des compromis.
Au lieu d'utiliser Cassandra, vous pourriez utiliser une base de données qui sacrifie la performance et la disponibilité, et offre plus de garanties de cohérence. Dans des cas comme celui-ci, je peux recommander Cloud Spanner ou Cockroach DB pour une base de données relationnelle évolutive.
Index dans Cassandra
Il existe des fonctionnalités similaires à des index dans Cassandra qui peuvent réduire le nombre de tables que vous devez maintenir vous-même. Une fonctionnalité est appelée index secondaires.
Je ne peux pas les recommander car ils ne fonctionnent que localement sur un nœud.
L'utilisation d'un index secondaire signifie parler à tous les nœuds car le coordinateur ne sait pas quels nœuds contiennent les données si vous utilisez d'autres colonnes pour interroger les données que la clé de partition réelle.
Vues matérialisées
Les vues matérialisées ont été conçues en gardant à l'esprit la scalabilité.
Elles facilitent la duplication de tables avec différentes clés de partition afin que vous puissiez interroger les données par différentes combinaisons de colonnes. Elles simplifient également le processus de création d'une nouvelle table et garantissent l'intégrité des données pour les mutations.
Il n'y a qu'un seul inconvénient — la clé primaire complète de la table source doit faire partie de la clé primaire de la vue matérialisée, et éventuellement, une autre colonne.
Les colonnes qui agissent comme clés de partition peuvent être différentes.
Exécution d'un cluster
L'exécution d'un cluster Cassandra peut être intense. Il contient vos données critiques pour l'entreprise et est généralement sous forte pression.
Je ne vais pas entrer dans les détails car je suis plus un utilisateur de Cassandra qu'un expert en maintenance de cluster. Néanmoins, je souhaite partager mes connaissances.
Cassandra entièrement gérée
Datastax a lancé un produit Cassandra entièrement géré appelé Astra. Ils promettent beaucoup :
- Commencez en quelques minutes avec un niveau gratuit, aucune carte de crédit requise.
- Éliminez les frais généraux pour installer, exploiter et mettre à l'échelle les clusters Cassandra.
- Construisez plus rapidement avec REST, GraphQL, CQL et les API JSON/Document.
- Basé sur Apache Cassandra open-source, utilisé par les meilleurs de l'internet.
- Mise à l'échelle élastique — les applications sont prêtes pour le viral dès le premier jour.
- Déployez multi-cloud, multi-locataire ou des clusters dédiés sur AWS, Azure ou GCP.
- Assurez une fiabilité, une sécurité et une gestion de niveau entreprise.
Cité de la documentation Astra
Je n'ai aucune expérience avec leur offre. Mais je serais prêt à l'essayer ! Leur tarification semble raisonnable.
Cassandra auto-gérée
Cassandra est construit avec Java. Connaître les bases de l'exécution des applications JVM est donc très bénéfique.
Si vous utilisez Kubernetes, alors vérifiez définitivement K8ssandra. Il regroupe tous les outils utiles autour de Cassandra comme :
- Stargate.io pour REST, Graphql et la documentation API
- Reaper pour une gestion plus facile des réparations
- Medusa pour les sauvegardes
- Collecteur de métriques pour la surveillance
- Traefik pour l'ingress
Cette pile d'outils est entièrement open source et peut être utilisée sans aucun coût monétaire supplémentaire.
Pour les développeurs, il existe un outil très bénéfique appelé nodetool. Il peut inspecter et fournir des informations sur le nombre de nœuds en cours d'exécution, la taille de certaines tables, le nombre de SSTables et de tombstones. Nodetool peut également réparer vos données pour imposer une cohérence éventuelle.
Autres apprentissages
Même après des années d'utilisation de Cassandra, il y a encore des choses à apprendre qui vous permettent d'utiliser Cassandra plus efficacement. Dans cette section, je souhaite partager divers sujets que vous rencontrerez éventuellement.
Migrations de données
Si vous avez travaillé avec d'autres bases de données auparavant, vous connaissez peut-être des outils de migration de bases de données comme flyway ou liquibase. Depuis la version 4.0 RC-1, il existe un support de base pour liquibase.
De plus, la communauté a travaillé sur quelque chose de similaire avec Cassandra-migration. Il supporte déjà des fonctionnalités avancées telles que l'élection de leader, pour lorsque plusieurs services démarrent en même temps.
Tout type d'exportation et d'importation peut être effectué en utilisant DSBulk qui permet de charger et de décharger des données depuis et vers Cassandra au format CSV et JSON.
Tombstones
Cassandra est un cluster multi-nœuds qui contient des données répliquées sur différents nœuds. Par conséquent, une suppression ne peut pas simplement supprimer un enregistrement particulier.
Pour une opération de suppression, une nouvelle entrée est ajoutée au journal de validation comme pour toute autre mutation d'insertion et de mise à jour. Ces suppressions sont appelées tombstones, et elles marquent une valeur spécifique pour suppression.
Les tombstones n'existent que sur le disque et peuvent être analysées et traçées comme décrit dans cet article de blog : À propos des suppressions et des tombstones dans Cassandra.
Dans Cassandra, vous pouvez définir une durée de vie sur les données insérées. Après le temps écoulé, l'enregistrement sera automatiquement supprimé. Lorsque vous définissez une durée de vie (TTL), une tombstone est créée avec une date dans le futur.
En comparaison, une requête de suppression régulière est la même avec la différence que la date de la tombstone est définie au moment où la suppression est exécutée.
Créons une tombstone en définissant un TTL en secondes qui fonctionne essentiellement comme une suppression différée :
cqlsh>
INSERT INTO learn_cassandra.todo_by_user_email (user_email,creation_date,name) VALUES('john@email.com', toTimestamp(now()), 'This entry should be removed soon') USING TTL 60;
Et les données sont stockées comme des données régulières :
cqlsh>
SELECT * FROM learn_cassandra.todo_by_user_email WHERE user_email='john@email.com';
user_email | creation_date | name
----------------+---------------+--------------------
john@email.com | 2021-05-30... | This entry should be removed soon
(1 rows)
Vous pouvez également lire le TTL depuis la base de données pour une colonne donnée :
cqlsh>
SELECT TTL(name) FROM learn_cassandra.todo_by_user_email WHERE user_email='john@email.com';
ttl(name)
-----------
43
(1 rows)
Après 60 secondes, la ligne a disparu.
cqlsh>
SELECT * FROM learn_cassandra.todo_by_user_email WHERE user_email='john@email.com';
user_email | creation_date | todo_uuid | name
-----------+---------------+-----------+------
(0 rows)
Définir un TTL est l'une des nombreuses façons de créer et d'exécuter des tombstones.
Malheureusement, il y en a aussi d'autres.
Par exemple, lorsque vous insérez une valeur nulle, une tombstone est créée pour la cellule donnée. Et comme mentionné pour les requêtes de suppression, différents types de tombstones sont stockés.
Par défaut, après 10 jours, les données marquées par une tombstone sont libérées avec une exécution de compaction. Ce temps peut être configuré et réduit en utilisant l'option gc_grace_seconds dans la configuration de Cassandra.
Quand une compaction est-elle exécutée ?
Lorsque l'opération est exécutée dépend principalement de la stratégie sélectionnée. En général, une exécution de compaction prend des
SSTableset crée de nouvellesSSTablesà partir de celles-ci.Les exécutions les plus courantes sont :
- Lorsque les conditions pour une compaction sont vraies, cela déclenche l'exécution de la compaction lorsque les données sont insérées
- Une compaction majeure exécutée manuellement en utilisant le nodetool
Parfois, les tombstones ne sont pas supprimées pour les raisons suivantes :
- Les valeurs nulles marquent les valeurs à supprimer et sont stockées comme des tombstones. Cela peut être évité en remplaçant null par une valeur statique, ou en ne définissant pas la valeur du tout si la valeur est nulle
- Les listes et ensembles vides sont similaires à null pour Cassandra et créent une tombstone, donc ne les insérez pas s'ils sont vides. Prenez soin d'éviter les exceptions de pointeur null lors du stockage et de la récupération des données dans votre application
- Les listes et ensembles mis à jour créent des tombstones. Si vous mettez à jour une entité et que la liste ou l'ensemble ne change pas, il crée toujours une tombstone pour vider la liste et définir les mêmes valeurs. Par conséquent, ne mettez à jour que les champs nécessaires pour éviter les problèmes. Le bon côté est qu'ils sont compactés en raison des nouvelles valeurs
Si vous avez beaucoup de tombstones, vous pourriez rencontrer un autre problème de Cassandra qui empêche une requête d'être exécutée.
Cela se produit lorsque le tombstone_failure_threshold est atteint, qui est défini par défaut à 100 000 tombstones. Cela signifie que, lorsqu'une requête a itéré sur plus de 100 000 tombstones, elle sera abandonnée.
Le problème ici est, une fois qu'une requête arrête de s'exécuter, il n'est pas facile de tout nettoyer car Cassandra s'arrêtera même lorsque vous exécutez une suppression, car elle a atteint la limite de tombstones.
Habituellement, vous n'auriez jamais autant de tombstones. Mais des erreurs se produisent, et vous devez prendre soin d'éviter ce cas.
Il existe une métrique d'opération pratique que vous devriez observer appelée TombstoneScannedHistogram pour éviter des problèmes inattendus en production.
Les UPDATE sont simplement des INSERT, et vice versa
Dans Cassandra, tout est en ajout uniquement. Il n'y a pas de différence entre une mise à jour et une insertion.
Vous avez déjà appris qu'une clé primaire définit l'unicité d'une ligne. Si aucune entrée n'existe encore, une nouvelle ligne apparaîtra, et si une entrée existe déjà, l'entrée sera mise à jour. Peu importe si vous exécutez une mise à jour ou insérez une requête.
La clé primaire dans notre exemple est définie sur user_email et creation_date qui définit l'unicité de l'enregistrement.
Insérons un nouvel enregistrement :
cqlsh>
INSERT INTO learn_cassandra.todo_by_user_email (user_email, creation_date, name) VALUES('john@email.com', '2021-03-14 16:07:19.622+0000', 'Insert query');
Et exécutons une mise à jour avec un nouveau todo_uuid :
cqlsh>
UPDATE learn_cassandra.todo_by_user_email SET
name = 'Update query'
WHERE user_email = 'john@email.com' AND creation_date = '2021-03-14 16:10:19.622+0000';
2 nouvelles lignes apparaissent dans notre table :
cqlsh>
SELECT * FROM learn_cassandra.todo_by_user_email WHERE user_email='john@email.com';
user_email | creation_date | name
----------------+---------------------------------+--------------
john@email.com | 2021-03-14 16:10:19.622000+0000 | Update query
john@email.com | 2021-03-14 16:07:19.622000+0000 | Insert query
(2 rows)
Ainsi, vous avez inséré une ligne en utilisant une mise à jour, et vous pouvez également utiliser une insertion pour mettre à jour :
cqlsh>
INSERT INTO learn_cassandra.todo_by_user_email (user_email,creation_date,name) VALUES('john@email.com', '2021-03-14 16:07:19.622+0000', 'Insert query updated');
Vérifions notre ligne mise à jour :
cqlsh>
SELECT * FROM learn_cassandra.todo_by_user_email WHERE user_email='john@email.com';
user_email | creation_date | name
----------------+--------------------------+----------------------
john@email.com | 2021-03-14 16:10:19.62 | Update query
john@email.com | 2021-03-14 16:07:19.62 | Insert query updated
(2 rows)
Ainsi, UPDATE et INSERT sont techniquement identiques. Ne pensez pas qu'un INSERT échoue s'il existe déjà une ligne avec la même clé primaire.
Le même principe s'applique à un UPDATE — il sera exécuté, même si la ligne n'existe pas.
La raison en est que, par conception, Cassandra lit rarement avant d'écrire pour maintenir des performances élevées. Les seules exceptions sont décrites dans la section suivante sur les transactions légères.
Mais il existe des restrictions sur les actions que vous pouvez exécuter en fonction d'une mise à jour ou d'une insertion :
- Les compteurs ne peuvent être modifiés qu'avec
UPDATE, et non avecInsert IF NOT EXISTSne peut être utilisé qu'en combinaison avec unINSERTIF EXISTSne peut être utilisé qu'en combinaison avec unUPDATE
Vous en apprendrez plus sur les conditions dans les requêtes dans la section suivante.
Transactions légères
Vous pouvez utiliser des conditions dans les requêtes en utilisant une fonctionnalité appelée transactions légères (LWT), qui exécute une lecture pour vérifier une certaine condition avant d'exécuter l'écriture.
Mettons à jour uniquement si une entrée existe déjà, en utilisant IF EXISTS :
cqlsh>
UPDATE learn_cassandra.todo_by_user_email SET
name = 'Update query with LWT'
WHERE user_email = 'john@email.com' AND creation_date = '2021-03-14 16:07:19.622+0000' IF EXISTS;
[applied]
-----------
True
Le même principe fonctionne pour une requête d'insertion en utilisant IF NOT EXISTS :
cqlsh>
INSERT INTO learn_cassandra.todo_by_user_email (user_email,creation_date,name) VALUES('john@email.com', toTimestamp(now()), 'Yet another entry') IF NOT EXISTS;
[applied]
-----------
True
Ces exécutions sont coûteuses par rapport aux simples requêtes UPDATE et INSERT. Néanmoins, si c'est critique pour l'entreprise, elles sont un excellent moyen d'atteindre la sécurité transactionnelle.
Conclusion
J'espère que vous avez apprécié l'article.
Si vous l'avez aimé et ressentez le besoin de m'applaudir, ou souhaitez simplement entrer en contact, suivez-moi sur Twitter.
Je travaille chez eBay Kleinanzeigen, l'une des plus grandes entreprises de petites annonces au monde. Au fait, nous recrutons !
Un remerciement spécial à Roger Sheen, Michael de la Fontaine, Christian Baer, Thomas Uebel et Swen Fuhrmann pour leurs excellents commentaires et relectures.
Références
- Documentation Cassandra sur la réplication
- Documentation Cassandra sur la cohérence
- Aperçu des stratégies de compaction
- Détails sur la stratégie de compaction par niveaux
- Comment fonctionnent les vues matérialisées
- Bogues connus avec les vues matérialisées
- Démarrer un cluster Cassandra multi-nœuds
- Métriques d'opération Cassandra
- Comment les données sont supprimées dans Cassandra
- Comment fonctionne le connecteur Spark Cassandra
- Comment fonctionne le sharding
- UUIDs en Java
- Définition, histoire et définition des UUIDs
- Suppressions et Tombstones dans Cassandra
- Règles de base de la modélisation Cassandra
- Data Stax