

Article original : Will the sun rise tomorrow?
Par Peter Gleeson
Laplace, Bayes et le machine learning aujourd'hui
Ce n'est peut-être pas une question qui vous préoccupait beaucoup. Après tout, cela semble se produire chaque jour sans faille.
Mais quelle est la probabilité que le soleil se lève demain ?
Cela peut sembler surprenant, mais cette question a été considérée par l'un des plus grands mathématiciens de tous les temps, Pierre-Simon Laplace, dans son œuvre pionnière de 1814, « Essai philosophique sur les probabilités ».
Fondamentalement, le traitement de cette question par Laplace était destiné à illustrer un concept plus général. Ce n'était pas une tentative sérieuse d'estimer si le soleil se lèverait effectivement.
Dans son essai, Laplace décrit un cadre de raisonnement probabiliste que nous reconnaissons aujourd'hui comme bayésien.
L'approche bayésienne constitue une pierre angulaire de nombreux algorithmes modernes de machine learning. Mais la puissance de calcul nécessaire pour utiliser ces méthodes n'a été disponible que depuis la seconde moitié du XXe siècle.
(Jusqu'à présent, il semble que l'IA la plus avancée reste silencieuse sur la question du lever du soleil de demain.)
Les idées de Laplace sont toujours pertinentes aujourd'hui, malgré leur développement il y a plus de deux siècles. Cet article passera en revue certaines de ces idées et montrera comment elles sont utilisées dans des applications modernes, peut-être envisagées par les contemporains de Laplace.
Pierre-Simon Laplace
Né dans la petite commune normande de Beaumont-en-Auge en 1749, Pierre-Simon Laplace était initialement destiné à devenir théologien.
Cependant, alors qu'il étudiait à l'Université de Caen, il découvrit une brillante aptitude pour les mathématiques. Il se rendit à Paris, où il impressionna le grand mathématicien et physicien Jean le Rond d'Alembert.
À l'âge de 24 ans, Laplace fut élu à la prestigieuse Académie des Sciences.

Laplace était un scientifique et mathématicien d'une prolificité étonnante. Parmi ses nombreuses contributions, ses travaux sur la probabilité, le mouvement planétaire et la physique mathématique se distinguent. Il comptait parmi ses collaborateurs, conseillers et étudiants des figures telles qu'Antoine Lavoisier, Jean d'Alembert, Siméon Poisson, et même Napoléon Bonaparte.
L'« Essai philosophique sur les probabilités » de Laplace était basé sur une conférence qu'il avait donnée en 1795. Il fournissait un aperçu général des idées contenues dans son œuvre « Théorie analytique des probabilités », publiée deux ans plus tôt en 1812.
Dans l'« Essai philosophique », Laplace présente dix principes de probabilité. Les premiers couvrent les définitions de base et la manière de calculer les probabilités relatives à des événements indépendants et dépendants.
Les principes huit, neuf et dix concernent l'application de la probabilité à ce que nous pourrions décrire aujourd'hui comme une analyse coût-bénéfice.
Le sixième est une généralisation importante du théorème éponyme de Thomas Bayes de 1763.
Il stipule que, pour un événement donné, la probabilité de chaque cause possible est trouvée en multipliant la probabilité a priori de cette cause par une fraction.
Cette fraction est la probabilité que l'événement résulte de cette cause particulière, divisée par la probabilité que l'événement se produise par n'importe quelle cause.
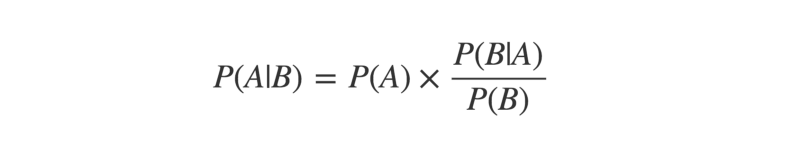
L'influence de ce théorème dans le machine learning ne peut être surestimée.
Le septième principe est celui qui a suscité le plus de controverses depuis sa publication. Cependant, la formulation réelle est assez inoffensive.
En fait, c'est le choix de Laplace de discuter de la probabilité que le soleil se lève le lendemain, à titre d'exemple illustratif, qui a attiré des moqueries et des objections au cours des deux siècles suivants.
La règle de succession est encore utilisée aujourd'hui sous diverses formes, et parfois sous la forme décrite à l'origine par Laplace.
En fait, la règle de succession représente une étape importante dans l'application de la pensée bayésienne à des systèmes pour lesquels nous avons très peu de données et peu ou pas de connaissances a priori. C'est un point de départ souvent rencontré dans les problèmes modernes de machine learning.
La règle de succession de Laplace
Le septième principe de probabilité donné dans l'« Essai philosophique » de Laplace est, en essence, simple.
Il stipule que la probabilité qu'un événement donné se produise est trouvée en additionnant la probabilité de chacune de ses causes potentielles multipliée par la probabilité que cette cause donne lieu à l'événement en question.
Laplace procède ensuite à un exemple basé sur le tirage de boules dans des urnes. Jusqu'à présent, tout va bien. Rien de controversé encore.
Cependant, il décrit ensuite comment procéder pour estimer la probabilité qu'un événement se produise dans des situations où nous avons peu (ou même aucune) connaissance a priori de ce que pourrait être cette probabilité.
« On trouve ainsi qu'un événement étant arrivé de suite un nombre quelconque de fois, la probabilité qu'il arrivera encore la fois suivante est égale à ce nombre augmenté de l'unité, divisé par le même nombre augmenté de deux unités. »
Ce qui se traduit en anglais par : « Ainsi, pour un événement qui s'est produit un certain nombre de fois jusqu'à présent, la probabilité qu'il se produise à nouveau la prochaine fois est égale à ce nombre augmenté de un, divisé par le même nombre augmenté de deux. »
Ou, en notation mathématique :
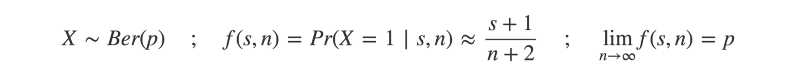
C'est-à-dire, étant donné s succès sur n essais, la probabilité de succès lors du prochain essai est approximativement (s+1)/(n+2).
Pour illustrer son propos, Laplace ne se retient pas :
« ...par exemple, en remontant à la plus ancienne époque de l'histoire, il y a cinq mille ans, ou 1 826 213 jours, et le soleil s'étant levé constamment dans cet intervalle, à chaque révolution de vingt-quatre heures, il y a 1 826 214 à parier contre un qu'il se lèvera encore demain. »
Ce qui se traduit par : « ...par exemple, étant donné que le soleil s'est levé chaque jour depuis les 5000 dernières années — ou 1 826 213 jours — la probabilité qu'il se lève demain est de 1 826 214 / 1 826 215. »
Avec 99,9 %, c'est un pari assez certain. Et il devient encore plus certain chaque jour où le soleil continue de se lever.
Pourtant, Laplace reconnaît que, pour quelqu'un qui comprend le mécanisme par lequel le soleil se lève et ne voit aucune raison pour qu'il cesse de fonctionner, même cette probabilité est déraisonnablement basse.
Et il s'avère que cette qualification est peut-être tout aussi importante que la règle elle-même. Après tout, elle suggère que notre connaissance a priori d'un système est encodée dans les hypothèses que nous faisons lors de l'attribution de probabilités à chacun de ses résultats potentiels.
Cela est vrai dans le machine learning aujourd'hui, surtout lorsque nous essayons d'apprendre à partir de données d'entraînement limitées ou incomplètes.
Mais quelle est la logique derrière la règle de succession de Laplace, et comment se perpétue-t-elle dans certains des algorithmes de machine learning les plus populaires d'aujourd'hui ?
Rien n'est impossible ?
Pour mieux comprendre l'importance de la règle de Laplace, nous devons considérer ce que cela signifie d'avoir très peu de connaissances a priori sur un système.
Supposons que vous avez une des urnes de Laplace, que vous savez contenir au moins une boule rouge. Vous ne savez rien d'autre sur le contenu de l'urne « système ». Peut-être contient-elle de nombreuses couleurs différentes, peut-être ne contient-elle que cette seule boule rouge.
Tirez une boule de l'urne. Vous savez que la probabilité qu'elle soit rouge est supérieure à zéro, et soit inférieure, soit égale à un.
Mais, comme vous ne savez pas si l'urne contient d'autres couleurs, vous ne pouvez pas dire que la probabilité de tirer une boule rouge est certainement égale à un. Vous ne pouvez simplement pas exclure toute autre possibilité.
Alors, comment estimez-vous la probabilité de tirer une boule rouge de l'urne ?
Eh bien, selon la règle de succession de Laplace, vous pouvez modéliser le tirage d'une boule de l'urne comme un essai de Bernoulli avec deux résultats possibles : « rouge » et « non-rouge ».
Avant d'avoir tiré quoi que ce soit de l'urne, nous avons déjà permis à deux résultats potentiels d'exister. En faisant cela, nous avons effectivement « pseudo-compté » deux tirages imaginaires de l'urne, observant chaque résultat une fois.
Cela donne à chaque résultat (« rouge » et « non-rouge ») une probabilité de 1/2.
À mesure que le nombre de tirages de l'urne augmente, l'effet de ces pseudo-comptes devient de moins en moins important. Si la première boule tirée est rouge, vous mettez à jour la probabilité que la suivante soit rouge à (1+1)/(1+2) = 2/3.
Si la boule suivante est rouge, la probabilité est mise à jour à 3/4. Si vous continuez à tirer des boules rouges, la probabilité se rapproche de plus en plus de 1.
Dans le langage d'aujourd'hui, la probabilité concerne un espace d'échantillonnage. Il s'agit d'un ensemble mathématique de tous les résultats possibles pour une « expérience » donnée (un processus qui sélectionne l'un des résultats).
La probabilité a été placée sur une base axiomatique formelle par Andrey Kolmogorov dans les années 1930. Les axiomes de Kolmogorov rendent facile la preuve qu'un espace d'échantillonnage doit contenir au moins un élément.
Kolmogorov définit également la probabilité comme une mesure qui retourne un nombre réel compris entre zéro et un pour tous les éléments de l'espace d'échantillonnage.
Naturellement, la probabilité offre un moyen utile de modéliser les systèmes du monde réel, surtout lorsque vous supposez une connaissance complète du contenu de l'espace d'échantillonnage.
Mais lorsque nous ne comprenons pas le système en question, nous ne connaissons pas l'espace d'échantillonnage — à part le fait qu'il doit contenir au moins un élément. C'est un point de départ courant dans de nombreux contextes de machine learning. Nous devons apprendre le contenu de l'espace d'échantillonnage au fur et à mesure.
Par conséquent, nous devons permettre à l'espace d'échantillonnage de contenir au moins un élément supplémentaire, un élément « fourre-tout » — ou, si vous préférez, l'« inconnu inconnu ». La règle de succession de Laplace nous dit d'attribuer à l'« inconnu inconnu » une probabilité de 1/n+2, après n observations répétées d'événements connus.
Bien que dans de nombreux cas, il soit pratique d'ignorer la possibilité des inconnus inconnus, il existe des raisons épistémologiques de toujours permettre de telles éventualités.
Un tel argument est connu sous le nom de règle de Cromwell, inventé par le regretté Dennis Lindley. Citant Oliver Cromwell du XVIIe siècle :
« Je vous en supplie, au nom des entrailles du Christ, pensez qu'il est possible que vous vous trompiez. »
Cette déclaration plutôt dramatique nous demande de permettre une possibilité lointaine pour que l'inattendu se produise. En langage de probabilité bayésienne, cela revient à exiger que nous considérions toujours un a priori non nul.
Car si votre probabilité a priori est fixée à zéro, aucune quantité de preuves ne vous convaincra du contraire. Après tout, même les preuves les plus solides du contraire donneront toujours une probabilité a posteriori de zéro, lorsqu'elles sont multipliées par zéro.
Objections et une défense de Laplace
Il n'est peut-être pas surprenant d'apprendre que l'exemple du lever du soleil de Laplace a attiré de nombreuses critiques de la part de ses contemporains.
Les gens contestaient la simplicité perçue — la naïveté, même — des hypothèses de Laplace. L'idée qu'il y avait une probabilité de 1/1 826 215 que le soleil ne se lève pas le lendemain semblait absurde.
Il est tentant de croire que, étant donné un grand nombre d'essais, un événement de probabilité non nulle doit se produire. Et donc, observer autant de levers de soleil consécutifs sans un seul échec implique sûrement que l'estimation de Laplace est une surestimation ?
Par exemple, vous pourriez vous attendre à ce qu'après un million d'essais, vous ayez observé un événement d'une chance sur un million — presque garanti par définition ! Quelle est la probabilité de faire autrement ?
Eh bien, vous ne seriez pas surpris si vous lanciez une pièce équilibrée deux fois sans obtenir de face. Ni ne serait-ce une source d'inquiétude si vous lanciez un dé six fois et ne voyiez jamais le nombre six. Ce sont des événements avec des probabilités de 1/2 et 1/6 respectivement, mais cela ne garantit absolument pas leur occurrence dans les deux et six premiers essais.
Un résultat attribué à Bernoulli au XVIIe siècle trouve la limite lorsque la probabilité 1/n et le nombre d'essais n deviennent très grands :
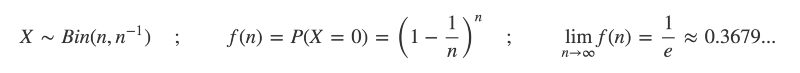
Bien qu'en moyenne vous aurez observé au moins une occurrence d'un événement avec une probabilité de 1/n après n essais, il y a encore plus d'1/3 de chance que vous ne l'ayez pas observé.
De même, si la véritable probabilité que le soleil ne se lève pas était effectivement de 1/1 826 215, alors nous ne devrions peut-être pas être si surpris qu'un tel événement n'ait jamais été enregistré dans l'histoire.
Et, on peut dire que la qualification de Laplace est trop généreuse.
Il est vrai que, pour une personne qui prétend comprendre le mécanisme par lequel le soleil se lève chaque jour, la probabilité qu'il ne le fasse pas doit être beaucoup plus proche de zéro.
Pourtant, supposer une compréhension d'un tel mécanisme nous oblige à posséder une connaissance a priori du système, au-delà de ce que nous avons observé. Cela est dû au fait qu'un tel mécanisme est implicitement supposé constant — en d'autres termes, vrai pour tout le temps.
Cette supposition nous permet, en un sens, de « conjurer » un nombre illimité d'observations — en plus de celles que nous avons réellement observées. C'est une supposition demandée par nul autre qu'Isaac Newton, au début du troisième livre de son célèbre « Philosophiae Naturalis Principia Mathematica ».
Newton expose quatre « Règles de raisonnement en philosophie ». La quatrième règle affirme que nous pouvons considérer les propositions dérivées d'observations précédentes comme « très près de la vérité », jusqu'à ce qu'elles soient contredites par des observations futures.

Une telle supposition était cruciale pour la révolution scientifique, malgré un coup dur pour les philosophes comme David Hume, qui a famously argumenté pour le problème de l'induction.
C'est ce compromis épistémologique qui nous permet de faire de la science utile et, à son tour, d'inventer la technologie. Quelque part en cours de route, alors que nous voyons la probabilité estimée que le soleil ne se lève pas diminuer de plus en plus près de zéro, nous nous permettons de « arrondir à la baisse » et de revendiquer une vérité scientifique à part entière.
Mais tout cela dépasse probablement le cadre du point que Laplace cherchait à faire à l'origine.
En effet, son choix d'un exemple de lever de soleil est malheureux. La règle de succession se révèle vraiment lorsqu'elle est appliquée à des systèmes « boîte noire » complètement inconnus pour lesquels nous avons zéro (ou très peu) d'observations.
C'est parce que la règle de succession offre un exemple précoce d'un a priori non informatif.
Comment supposer le moins possible
La probabilité bayésienne est un concept clé dans le machine learning moderne. Des algorithmes tels que la classification Naive Bayes, l'Expectation Maximisation, l'Inférence Variationnelle et les Chaînes de Markov Monte Carlo sont parmi les plus populaires utilisés aujourd'hui.
La probabilité bayésienne fait généralement référence à une interprétation de la probabilité où vous mettez à jour votre croyance (souvent subjective) à la lumière de nouvelles preuves.
Deux concepts clés sont les probabilités a priori et a posteriori.
Les probabilités a posteriori sont celles que nous attribuons après avoir mis à jour nos croyances face à de nouvelles preuves.
Les probabilités a priori (ou « priors ») sont celles que nous considérons comme vraies avant de voir de nouvelles preuves.
Les scientifiques des données s'intéressent à la manière dont nous attribuons des probabilités a priori aux événements en l'absence de toute connaissance préalable. C'est un point de départ typique pour de nombreux problèmes en machine learning et en analyse prédictive.
Les a priori peuvent être informatifs, dans le sens où ils viennent avec des « opinions » sur la probabilité de différents événements. Ces « opinions » peuvent être fortes ou faibles, et sont généralement basées sur des observations passées ou d'autres hypothèses raisonnables. Elles sont inestimables dans les situations où nous voulons entraîner notre modèle de machine learning rapidement.
Cependant, les a priori peuvent également être non informatifs. Cela signifie qu'ils supposent le moins possible sur les probabilités respectives d'un événement. Ceux-ci sont utiles dans les situations où nous voulons que notre modèle de machine learning apprenne à partir d'un état vierge.
Nous devons donc nous demander : comment mesure-t-on à quel point une distribution de probabilité a priori est « informative » ?
La théorie de l'information fournit une réponse. Il s'agit d'une branche des mathématiques qui concerne la manière dont l'information est mesurée et communiquée.
L'information peut être pensée en termes de certitude, ou de manque de celle-ci.
Après tout, dans un sens quotidien, plus vous avez d'informations sur un événement, plus vous êtes certain de son résultat. Moins d'informations équivaut à moins de certitude. Cela signifie que la théorie de l'information et la théorie des probabilités sont inextricablement liées.
L'entropie de l'information est un concept fondamental en théorie de l'information. Elle sert de mesure de l'incertitude inhérente à une distribution de probabilité donnée. Une distribution de probabilité avec une entropie élevée est celle pour laquelle le résultat est plus incertain.
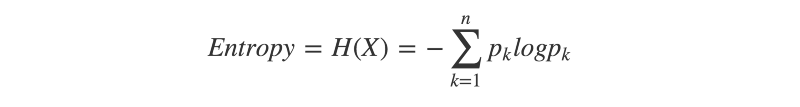
Peut-être de manière intuitive, vous pouvez raisonner qu'une distribution de probabilité uniforme — une distribution pour laquelle chaque événement est également probable — a l'entropie la plus élevée possible. Par exemple, si vous lanciez une pièce équilibrée et une pièce biaisée, quel résultat vous rendrait le moins certain ?
L'entropie de l'information fournit un moyen formel de quantifier cela, et si vous connaissez un peu de calcul, vous pouvez consulter la preuve ici.
Ainsi, la distribution uniforme est, dans un sens très réel, la distribution la moins informative possible. Et pour cette raison, elle fait un choix évident pour un a priori non informatif.
Peut-être avez-vous remarqué comment la règle de succession de Laplace revient effectivement à utiliser un a priori uniforme ? En ajoutant un succès et un échec avant même d'avoir observé des résultats, nous utilisons une distribution de probabilité uniforme pour représenter notre croyance « a priori » sur le système.
Ensuite, à mesure que nous observons de plus en plus de résultats, le poids des preuves domine de plus en plus l'a priori.
Étude de cas : Classification Naive Bayes
Aujourd'hui, la règle de succession de Laplace est généralisée en lissage additif et pseudo-comptage.
Ce sont des techniques qui nous permettent d'utiliser des probabilités non nulles pour des événements non observés dans les données d'entraînement. C'est une partie essentielle de la manière dont les algorithmes de machine learning sont capables de généraliser lorsqu'ils sont confrontés à des entrées jamais vues auparavant.
Par exemple, prenons la classification Naive Bayes.
Il s'agit d'un algorithme simple mais efficace qui peut classer des données textuelles et autres données correctement tokenisées, en utilisant le théorème de Bayes.
L'algorithme est entraîné sur un corpus de données pré-classifiées, dans lequel chaque document se compose d'un ensemble de mots ou de « caractéristiques ». L'algorithme commence par estimer la probabilité de chaque caractéristique, étant donné une certaine classe.
En utilisant le théorème de Bayes (et quelques hypothèses très naïves sur l'indépendance des caractéristiques), l'algorithme peut alors approximer les probabilités relatives de chaque classe, étant donné les caractéristiques observées dans un document précédemment non vu.
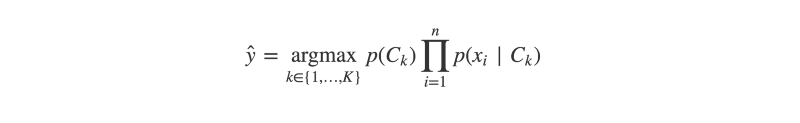
Une étape importante dans la classification Naive Bayes est l'estimation de la probabilité qu'une caractéristique soit observée dans une classe donnée. Cela peut être fait en calculant la fréquence à laquelle la caractéristique est observée dans chacun des enregistrements de cette classe dans les données d'entraînement.
Par exemple, le mot « Python » pourrait apparaître dans 12 % de tous les documents classés comme « programmation », contre 1 % de tous les documents classés comme « start-up ». Le mot « apprendre » pourrait apparaître dans 10 % des documents de programmation et 20 % de tous les documents de start-up.
Prenons la phrase « apprendre Python ».
En utilisant ces fréquences, nous trouvons que la probabilité que la phrase soit classée comme « programmation » est égale à 0,12 × 0,10 = 0,012, et la probabilité qu'elle soit classée comme « start-up » est de 0,01 × 0,20 = 0,002.
Par conséquent, « programmation » est la plus probable de ces deux classes.
Mais cette approche basée sur la fréquence rencontre des problèmes chaque fois que nous considérons une caractéristique qui ne se produit jamais dans une classe donnée. Cela signifierait qu'elle a une fréquence de zéro.
La classification Naive Bayes nous oblige à multiplier les probabilités, mais multiplier quoi que ce soit par zéro donnera, bien sûr, toujours zéro.
Alors, que se passe-t-il si un document précédemment non vu contient un mot jamais observé dans une classe donnée dans les données d'entraînement ? Cette classe sera jugée impossible — peu importe la fréquence à laquelle tous les autres mots du document se produisent dans cette classe.
Lissage additif
Une approche appelée lissage additif offre une solution. Au lieu de permettre des fréquences nulles, nous ajoutons une petite constante au numérateur. Cela empêche les combinaisons de classes/caractéristiques non vues de faire dérailler le classificateur.
Lorsque cette constante est égale à un, le lissage additif est le même que l'application de la règle de succession de Laplace.
En plus de la classification Naive Bayes, le lissage additif est utilisé dans d'autres contextes de machine learning probabilistes. Les exemples incluent des problèmes de modélisation du langage, de réseaux de neurones et de modèles de Markov cachés.
En termes mathématiques, le lissage additif revient à utiliser une distribution bêta comme a priori conjugué pour effectuer une inférence bayésienne avec des distributions binomiales et géométriques.
La distribution bêta est une famille de distributions de probabilité définies sur l'intervalle [0,1]. Elle prend deux paramètres de forme, α et β. La règle de succession de Laplace correspond à définir α = 1 et β = 1.
Comme discuté ci-dessus, la distribution bêta(1,1) est celle pour laquelle l'entropie de l'information est maximisée. Cependant, il existe des a priori alternatifs pour les cas où l'hypothèse d'un succès et d'un échec ne sont pas valides.
Par exemple, l'a priori de Haldane est défini comme une distribution bêta(0,0). Il s'applique dans les cas où nous ne sommes même pas sûrs de pouvoir permettre un résultat binaire. L'a priori de Haldane place une quantité infinie de « poids » sur zéro et un.
L'a priori de Jeffrey, la distribution bêta(0,5, 0,5), est un autre a priori non informatif. Il a la propriété utile de rester invariant sous reparamétrisation. Sa dérivation dépasse le cadre de cet article, mais si vous êtes intéressé, consultez ce fil de discussion.
L'héritage des idées
Personnellement, je trouve fascinant de voir comment certaines des premières idées en probabilité et en statistique ont survécu à des années de controverse et trouvent encore une utilisation généralisée dans le machine learning moderne.
Il est extraordinaire de réaliser que l'influence des idées développées il y a plus de deux siècles se fait encore sentir aujourd'hui. Le machine learning et la science des données ont gagné un véritable élan grand public au cours de la dernière décennie ou plus. Mais les fondations sur lesquelles ils sont construits ont été posées bien avant que les premiers ordinateurs ne soient même proches de la réalisation.
Il n'est pas surprenant que de telles idées touchent à la philosophie de la connaissance. Cela devient particulièrement pertinent à mesure que les machines deviennent de plus en plus intelligentes. À quel moment l'accent pourrait-il se déplacer vers notre philosophie de la conscience ?
Enfin, que penseraient Laplace et ses contemporains du machine learning aujourd'hui ? Il est tentant de suggérer qu'ils seraient stupéfaits par les progrès qui ont été réalisés.
Mais cela serait probablement un déservice à leur clairvoyance. Après tout, le philosophe français René Descartes avait écrit sur une philosophie mécaniste dès le XVIIe siècle. Décrire une machine hypothétique :
« Je désire que vous considériez... toutes les fonctions que j'ai attribuées à cette machine, comme... la réception de la lumière, des sons, des odeurs, des goûts... l'empreinte de ces idées dans la mémoire... et enfin les mouvements extérieurs... qu'ils imitent le plus parfaitement possible ceux d'un vrai homme... considériez que ces fonctions... ne dépendent que de la disposition de ses organes, ni plus ni moins que les mouvements d'une horloge... de celle de ses contrepoids et de ses roues. »
Ce qui se traduit par : « Je désire que vous considériez que toutes les fonctions que j'ai attribuées à cette machine telles que... la réception de la lumière, du son, de l'odeur et du goût... l'empreinte de ces idées dans la mémoire... et enfin les mouvements extérieurs qui imitent le plus parfaitement possible ceux d'un vrai humain... Considérez que ces fonctions ne sont que sous le contrôle des organes, ni plus ni moins que les mouvements d'une horloge le sont de ses contrepoids et de ses roues. »
Le passage ci-dessus décrit une machine hypothétique capable de répondre aux stimuli et de se comporter comme un « vrai humain ». Il a été publié dans l'œuvre de Descartes de 1664 « Traité de l'homme » — un plein 150 ans avant l'« Essai philosophique sur les probabilités » de Laplace.
En effet, les XVIIIe et début XIXe siècles ont vu la construction d'automates incroyablement sophistiqués par des inventeurs tels que Pierre Jaquet-Droz et Henri Maillardet. Ces androïdes mécaniques pouvaient être « programmés » pour écrire, dessiner, et jouer de la musique.

Il n'y a donc aucun doute que Laplace et ses contemporains pouvaient concevoir la notion d'une machine intelligente. Et il ne leur aurait certainement pas échappé comment les progrès réalisés dans le domaine de la probabilité pourraient être appliqués à l'intelligence des machines.
Dès le début de l'« Essai philosophique », Laplace écrit sur une intelligence surhumaine hypothétique, rétrospectivement nommée « le Démon de Laplace » :
« Une intelligence qui, pour un instant donné, connaîtrait toutes les forces dont la nature est animée, et la situation respective des êtres qui la composent, si d'ailleurs elle était assez vaste pour soumettre ces données à l'analyse... rien ne serait incertain pour elle, et l'avenir comme le passé, serait présent à ses yeux. »
Ce qui se traduit par : « Une intelligence, qui à un moment donné, connaît toutes les forces par lesquelles la nature est animée, et la situation respective des êtres qui la composent, et si elle était assez vaste pour soumettre ces données à l'analyse... rien ne serait incertain pour elle, et l'avenir comme le passé, serait présent à ses yeux. »
Le Démon de Laplace pourrait-il être réalisé comme l'une des machines intelligentes de Descartes ? Les sensibilités modernes suggèrent massivement non.
Pourtant, la prémisse de Laplace envisagée à plus petite échelle pourrait bientôt devenir une réalité, grâce en grande partie à son propre travail pionnier dans le domaine de la probabilité.
Pendant ce temps, le soleil continuera (probablement) de se lever.