


Article original : The Kubernetes Handbook – Learn Kubernetes for Beginners
Kubernetes est une plateforme open-source d'orchestration de conteneurs qui automatise le déploiement, la gestion, la mise à l'échelle et la mise en réseau des conteneurs.
Il a été développé par Google en utilisant le langage de programmation Go, et cette technologie incroyable est open-source depuis 2014.
Selon le Stack Overflow Developer Survey - 2020, Kubernetes est la 3ème plateforme la plus aimée et la 3ème plateforme la plus souhaitée.
En plus d'être très puissant, Kubernetes est connu pour être assez difficile à prendre en main. Je ne dirai pas que c'est facile, mais si vous êtes équipé des prérequis et que vous parcourez ce guide attentivement et avec patience, vous devriez être capable de :
- Obtenir une compréhension solide des fondamentaux.
- Créer et gérer des clusters Kubernetes.
- Déployer (presque) n'importe quelle application sur un cluster Kubernetes.
Prérequis
- Familiarité avec JavaScript
- Familiarité avec le terminal Linux
- Familiarité avec Docker (lecture suggérée : The Docker Handbook)
Code du projet
Le code des projets d'exemple peut être trouvé dans le dépôt suivant :
Vous pouvez trouver le code complet dans la branche completed.
Table des matières
- Introduction à l'orchestration de conteneurs et Kubernetes
- Installation de Kubernetes
- Hello World dans Kubernetes
- Approche de déploiement déclarative
- Travailler avec des applications multi-conteneurs
- Plan de déploiement
- Contrôleurs de réplication, Replica Sets et Deployments
- Créer votre premier déploiement
- Inspecter les ressources Kubernetes
- Obtenir les logs des conteneurs depuis les pods
- Variables d'environnement
- Créer le déploiement de la base de données
- Volumes persistants et Persistent Volume Claims
- Provisionnement dynamique des volumes persistants
- Connecter les volumes avec les pods
- Relier tout ensemble
- Travailler avec les contrôleurs d'entrée
- Dépannage
- Conclusion
Introduction à l'orchestration de conteneurs et Kubernetes
Selon Red Hat —
"L'orchestration de conteneurs est le processus d'automatisation du déploiement, de la gestion, de la mise à l'échelle et des tâches de mise en réseau des conteneurs.
Il peut être utilisé dans tout environnement où vous utilisez des conteneurs et peut vous aider à déployer la même application dans différents environnements sans nécessiter de reconception".
Permettez-moi de vous montrer un exemple. Supposons que vous avez développé une application incroyable qui suggère aux gens ce qu'ils devraient manger en fonction de l'heure de la journée.
Maintenant, supposons que vous avez conteneurisé l'application en utilisant Docker et que vous l'avez déployée sur AWS.

Si l'application tombe en panne pour une raison quelconque, les utilisateurs perdent immédiatement l'accès à votre service.
Pour résoudre ce problème, vous pouvez créer plusieurs copies ou réplicas de la même application et la rendre hautement disponible.

Même si l'une des instances tombe en panne, les deux autres seront disponibles pour les utilisateurs.
Maintenant, supposons que votre application est devenue extrêmement populaire parmi les noctambules et que vos serveurs sont submergés de requêtes la nuit, pendant que vous dormez.
Que se passe-t-il si toutes les instances tombent en panne en raison d'une surcharge ? Qui va faire la mise à l'échelle ? Même si vous mettez à l'échelle et créez 50 réplicas de votre application, qui va vérifier leur état de santé ? Comment allez-vous configurer la mise en réseau pour que les requêtes atteignent le bon point de terminaison ? L'équilibrage de charge va également être un grand problème, n'est-ce pas ?
Kubernetes peut rendre les choses beaucoup plus faciles pour ces types de situations. C'est une plateforme d'orchestration de conteneurs qui se compose de plusieurs composants et qui travaille sans relâche pour maintenir vos serveurs dans l'état que vous souhaitez.
Supposons que vous souhaitez avoir 50 réplicas de votre application en cours d'exécution en continu. Même s'il y a une augmentation soudaine du nombre d'utilisateurs, le serveur doit être mis à l'échelle automatiquement.
Vous dites simplement vos besoins à Kubernetes et il fera le reste du travail pour vous.

Kubernetes ne se contentera pas de mettre en œuvre l'état, il le maintiendra également. Il créera des réplicas supplémentaires si l'un des anciens meurt, gérera la mise en réseau et le stockage, déployera ou annulera les mises à jour, ou même mettra à l'échelle le serveur si nécessaire.
Installation de Kubernetes
Exécuter Kubernetes sur votre machine locale est en fait très différent de l'exécuter sur le cloud. Pour démarrer Kubernetes, vous avez besoin de deux programmes.
- minikube - il exécute un cluster Kubernetes à nœud unique à l'intérieur d'une machine virtuelle (VM) sur votre ordinateur local.
- kubectl - L'outil en ligne de commande Kubernetes, qui vous permet d'exécuter des commandes contre les clusters Kubernetes.
En plus de ces deux programmes, vous aurez également besoin d'un hyperviseur et d'une plateforme de conteneurisation. Docker est le choix évident pour la plateforme de conteneurisation. Les hyperviseurs recommandés sont les suivants :
Hyper-V est intégré à Windows 10 (Pro, Enterprise et Education) en tant que fonctionnalité optionnelle et peut être activé depuis le panneau de configuration.
HyperKit est fourni avec Docker Desktop pour Mac en tant que composant principal.
Et sur Linux, vous pouvez contourner toute la couche hyperviseur en utilisant Docker directement. C'est beaucoup plus rapide que d'utiliser un hyperviseur et c'est la méthode recommandée pour exécuter Kubernetes sur Linux.
Vous pouvez installer l'un des hyperviseurs mentionnés ci-dessus. Ou si vous voulez garder les choses simples, obtenez simplement VirtualBox.
Pour le reste de l'article, je supposerai que vous utilisez VirtualBox. Ne vous inquiétez pas, même si vous utilisez autre chose, il ne devrait pas y avoir beaucoup de différence.
J'utiliserai
minikubeavec le pilote Docker sur une machine Ubuntu tout au long de l'article.
Une fois que vous avez installé l'hyperviseur et la plateforme de conteneurisation, il est temps d'installer les programmes minikube et kubectl.
kubectl est généralement fourni avec Docker Desktop sur Mac et Windows. Les instructions d'installation pour Linux peuvent être trouvées ici.
minikube, en revanche, doit être installé sur les trois systèmes. Vous pouvez utiliser Homebrew sur Mac, et Chocolatey sur Windows pour installer minikube. Les instructions d'installation pour Linux peuvent être trouvées ici.
Une fois que vous les avez installés, vous pouvez tester les deux programmes en exécutant les commandes suivantes :
minikube version
# minikube version: v1.12.1
# commit: 5664228288552de9f3a446ea4f51c6f29bbdd0e0
kubectl version
# Client Version: version.Info{Major:"1", Minor:"18", GitVersion:"v1.18.6", GitCommit:"dff82dc0de47299ab66c83c626e08b245ab19037", GitTreeState:"clean", BuildDate:"2020-07-16T00:04:31Z", GoVersion:"go1.14.4", Compiler:"gc", Platform:"darwin/amd64"}
# Server Version: version.Info{Major:"1", Minor:"18", GitVersion:"v1.18.3", GitCommit:"2e7996e3e2712684bc73f0dec0200d64eec7fe40", GitTreeState:"clean", BuildDate:"2020-05-20T12:43:34Z", GoVersion:"go1.13.9", Compiler:"gc", Platform:"linux/amd64"}
Si vous avez téléchargé les bonnes versions pour votre système d'exploitation et que vous avez correctement configuré les chemins, vous devriez être prêt à partir.
Comme je l'ai déjà mentionné, minikube exécute un cluster Kubernetes à nœud unique à l'intérieur d'une machine virtuelle (VM) sur votre ordinateur local. J'expliquerai les clusters et les nœuds en détail dans une section à venir.
Pour l'instant, comprenez que minikube crée une VM régulière en utilisant votre hyperviseur de choix et traite cela comme un cluster Kubernetes.
Si vous rencontrez des problèmes dans cette section, veuillez consulter la section Dépannage à la fin de cet article.
Avant de démarrer minikube, vous devez définir le bon pilote d'hyperviseur à utiliser. Pour définir VirtualBox comme pilote par défaut, exécutez la commande suivante :
minikube config set driver virtualbox
# ⚡ Ces changements prendront effet après un minikube delete et ensuite un minikube start
Vous pouvez remplacer virtualbox par hyperv, hyperkit, ou docker selon votre préférence. Cette commande est nécessaire uniquement pour la première fois.
Pour démarrer minikube, exécutez la commande suivante :
minikube start
# 😄 minikube v1.12.1 sur Ubuntu 20.04
# ⚡ Utilisation du pilote virtualbox basé sur le profil existant
# 🔥 Démarrage du nœud de plan de contrôle minikube dans le cluster minikube
# 🐳 Mise à jour de la VM virtualbox "minikube" en cours d'exécution...
# 🚀 Préparation de Kubernetes v1.18.3 sur Docker 19.03.12...
# ✅ Vérification des composants Kubernetes...
# 🔗 Addons activés : default-storageclass, storage-provisioner
# 🎉 Terminé ! kubectl est maintenant configuré pour utiliser "minikube"
Vous pouvez arrêter minikube en exécutant la commande minikube stop.
Hello World dans Kubernetes
Maintenant que vous avez Kubernetes sur votre système local, il est temps de mettre les mains dans le cambouis. Dans cet exemple, vous allez déployer une application très simple sur votre cluster local et vous familiariser avec les fondamentaux.
Il y aura des terminologies comme pod, service, load balancer, et ainsi de suite dans cette section. Ne stressez pas si vous ne les comprenez pas tout de suite. Je vais entrer dans les détails en expliquant chacun d'eux dans la sous-section Le tableau complet.
Si vous avez démarré minikube dans la section précédente, vous êtes prêt à partir. Sinon, vous devrez le démarrer maintenant. Une fois que minikube a démarré, exécutez la commande suivante dans votre terminal :
kubectl run hello-kube --image=fhsinchy/hello-kube --port=80
# pod/hello-kube created
Vous verrez le message pod/hello-kube created presque immédiatement. La commande run exécute l'image de conteneur donnée à l'intérieur d'un pod.
Les pods sont comme une boîte qui encapsule un conteneur. Pour vous assurer que le pod a été créé et est en cours d'exécution, exécutez la commande suivante :
kubectl get pod
# NAME READY STATUS RESTARTS AGE
# hello-kube 1/1 Running 0 3m3s
Vous devriez voir Running dans la colonne STATUS. Si vous voyez quelque chose comme ContainerCreating, attendez une minute ou deux et vérifiez à nouveau.
Les pods sont par défaut inaccessibles depuis l'extérieur du cluster. Pour les rendre accessibles, vous devez les exposer en utilisant un service. Donc, une fois que le pod est opérationnel, exécutez la commande suivante pour exposer le pod :
kubectl expose pod hello-kube --type=LoadBalancer --port=80
# service/hello-kube exposed
Pour vous assurer que le service de l'équilibreur de charge a été créé avec succès, exécutez la commande suivante :
kubectl get service
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# hello-kube LoadBalancer 10.109.60.75 <pending> 80:30848/TCP 119s
# kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 7h47m
Assurez-vous de voir le service hello-kube dans la liste. Maintenant que vous avez un pod en cours d'exécution qui est exposé, vous pouvez aller de l'avant et y accéder. Exécutez la commande suivante pour ce faire :
minikube service hello-kube
# |-----------|------------|-------------|-----------------------------|
# | NAMESPACE | NAME | TARGET PORT | URL |
# |-----------|------------|-------------|-----------------------------|
# | default | hello-kube | 80 | http://192.168.99.101:30848 |
# |-----------|------------|-------------|-----------------------------|
# 🎉 Opening service default/hello-kube in default browser...
Votre navigateur web par défaut devrait s'ouvrir automatiquement et vous devriez voir quelque chose comme ceci :

Ceci est une application JavaScript très simple que j'ai assemblée en utilisant vite et un peu de CSS. Pour comprendre ce que vous venez de faire, vous devez acquérir une bonne compréhension de l'architecture Kubernetes.
Architecture de Kubernetes
Dans le monde de Kubernetes, un nœud peut être soit une machine physique, soit une machine virtuelle avec un rôle donné. Une collection de telles machines ou serveurs utilisant un réseau partagé pour communiquer entre eux est appelée un cluster.

Dans votre configuration locale, minikube est un cluster Kubernetes à nœud unique. Au lieu d'avoir plusieurs serveurs comme dans le diagramme ci-dessus, minikube n'en a qu'un seul qui agit à la fois comme serveur principal et comme nœud.

Chaque serveur dans un cluster Kubernetes obtient un rôle. Il y a deux rôles possibles :
- control-plane — Prend la plupart des décisions nécessaires et agit comme une sorte de cerveau de l'ensemble du cluster. Cela peut être un seul serveur ou un groupe de serveurs dans des projets plus importants.
- node — Responsable de l'exécution des charges de travail. Ces serveurs sont généralement micro-gérés par le plan de contrôle et exécutent diverses tâches en suivant les instructions fournies.
Chaque serveur de votre cluster aura un ensemble sélectionné de composants. Le nombre et le type de ces composants peuvent varier en fonction du rôle qu'un serveur a dans votre cluster. Cela signifie que les nœuds n'ont pas tous les composants que le plan de contrôle possède.
Dans les sous-sections à venir, vous aurez un aperçu plus détaillé des composants individuels qui constituent un cluster Kubernetes.
Composants du plan de contrôle
Le plan de contrôle dans un cluster Kubernetes se compose de cinq composants. Ils sont les suivants :
- kube-api-server : Cela agit comme l'entrée du plan de contrôle Kubernetes, responsable de la validation et du traitement des requêtes livrées en utilisant des bibliothèques clientes comme le programme
kubectl. - etcd : Il s'agit d'un magasin clé-valeur distribué qui agit comme la seule source de vérité sur votre cluster. Il contient les données de configuration et les informations sur l'état du cluster. etcd est un projet open-source et est développé par les gens derrière Red Hat. Le code source du projet est hébergé sur le dépôt GitHub etcd-io/etcd.
- kube-controller-manager : Les contrôleurs dans Kubernetes sont responsables du contrôle de l'état du cluster. Lorsque vous laissez Kubernetes savoir ce que vous voulez dans votre cluster, les contrôleurs s'assurent que votre demande est satisfaite. Le
kube-controller-managerest l'ensemble des processus de contrôleur regroupés en un seul processus. - kube-scheduler : L'attribution de tâches à un certain nœud en tenant compte de ses ressources disponibles et des exigences de la tâche est connue sous le nom de planification. Le composant
kube-schedulereffectue la tâche de planification dans Kubernetes en s'assurant qu'aucun des serveurs du cluster n'est surchargé. - cloud-controller-manager : Dans un environnement cloud réel, ce composant vous permet de connecter votre cluster à l'API de votre fournisseur cloud (GKE/EKS). De cette manière, les composants qui interagissent avec cette plateforme cloud restent isolés des composants qui interagissent uniquement avec votre cluster. Dans un cluster local comme
minikube, ce composant n'existe pas.
Composants des nœuds
Comparé au plan de contrôle, les nœuds ont un très petit nombre de composants. Ces composants sont les suivants :
- kubelet : Ce service agit comme la passerelle entre le plan de contrôle et chacun des nœuds d'un cluster. Toutes les instructions du plan de contrôle vers les nœuds passent par ce service. Il interagit également avec le magasin
etcdpour maintenir les informations d'état à jour. - kube-proxy : Ce petit service s'exécute sur chaque serveur de nœud et maintient les règles de réseau sur eux. Toute requête réseau qui atteint un service à l'intérieur de votre cluster passe par ce service.
- Container Runtime : Kubernetes est un outil d'orchestration de conteneurs, donc il exécute des applications dans des conteneurs. Cela signifie que chaque nœud doit avoir un runtime de conteneur comme Docker ou rkt ou cri-o.
Objets Kubernetes
Selon la documentation de Kubernetes —
"Les objets sont des entités persistantes dans le système Kubernetes. Kubernetes utilise ces entités pour représenter l'état de votre cluster. Plus précisément, ils peuvent décrire quelles applications conteneurisées sont en cours d'exécution, les ressources disponibles pour elles et les politiques concernant leur comportement."
Lorsque vous créez un objet Kubernetes, vous indiquez effectivement au système Kubernetes que vous voulez que cet objet existe quoi qu'il arrive et le système Kubernetes travaillera constamment pour maintenir l'objet en cours d'exécution.
Pods
Selon la documentation de Kubernetes —
"Les pods sont les plus petites unités déployables de calcul que vous pouvez créer et gérer dans Kubernetes".
Un pod encapsule généralement un ou plusieurs conteneurs qui sont étroitement liés, partageant un cycle de vie et des ressources consommables.

Bien qu'un pod puisse héberger plus d'un conteneur, vous ne devriez pas simplement mettre des conteneurs dans un pod sans réfléchir. Les conteneurs dans un pod doivent être si étroitement liés qu'ils peuvent être traités comme une seule application.
Par exemple, votre API back-end peut dépendre de la base de données, mais cela ne signifie pas que vous mettrez les deux dans le même pod. Tout au long de cet article, vous ne verrez aucun pod qui a plus d'un conteneur en cours d'exécution.
Généralement, vous ne devriez pas gérer un pod directement. Au lieu de cela, vous devriez travailler avec des objets de niveau supérieur qui peuvent vous offrir une bien meilleure gestion. Vous en apprendrez davantage sur ces objets de niveau supérieur dans les sections suivantes.
Services
Selon la documentation de Kubernetes —
"Un service dans Kubernetes est un moyen abstrait d'exposer une application s'exécutant sur un ensemble de pods en tant que service réseau".
Les pods Kubernetes sont éphémères par nature. Ils sont créés et après un certain temps, lorsqu'ils sont détruits, ils ne sont pas recyclés.
Au lieu de cela, de nouveaux pods identiques prennent la place des anciens. Certains objets Kubernetes de niveau supérieur sont même capables de créer et de détruire des pods de manière dynamique.
Une nouvelle adresse IP est attribuée à chaque pod au moment de leur création. Mais dans le cas d'un objet de niveau supérieur qui peut créer, détruire et regrouper un certain nombre de pods, l'ensemble des pods en cours d'exécution à un moment donné peut être différent de l'ensemble des pods exécutant cette application un moment plus tard.
Cela pose un problème : si un ensemble de pods dans votre cluster dépend d'un autre ensemble de pods dans votre cluster, comment font-ils pour se trouver et se suivre mutuellement les adresses IP ?
La documentation de Kubernetes dit —
"un Service est une abstraction qui définit un ensemble logique de Pods et une politique par laquelle y accéder".
Ce qui signifie essentiellement qu'un Service regroupe un certain nombre de pods qui remplissent la même fonction et les présente comme une seule entité.
De cette façon, la confusion de suivre plusieurs pods disparaît car ce Service unique agit désormais comme une sorte de communicateur pour tous.
Dans l'exemple hello-kube, vous avez créé un service de type LoadBalancer qui permet aux requêtes en provenance de l'extérieur du cluster de se connecter aux pods en cours d'exécution à l'intérieur du cluster.

Chaque fois que vous devez donner accès à un ou plusieurs pods à une autre application ou à quelque chose en dehors du cluster, vous devez créer un service.
Par exemple, si vous avez un ensemble de pods exécutant des serveurs web qui doivent être accessibles depuis Internet, un service fournira l'abstraction nécessaire.
Le tableau complet
Maintenant que vous avez une compréhension appropriée des composants individuels de Kubernetes, voici une représentation visuelle de leur fonctionnement ensemble en coulisses :
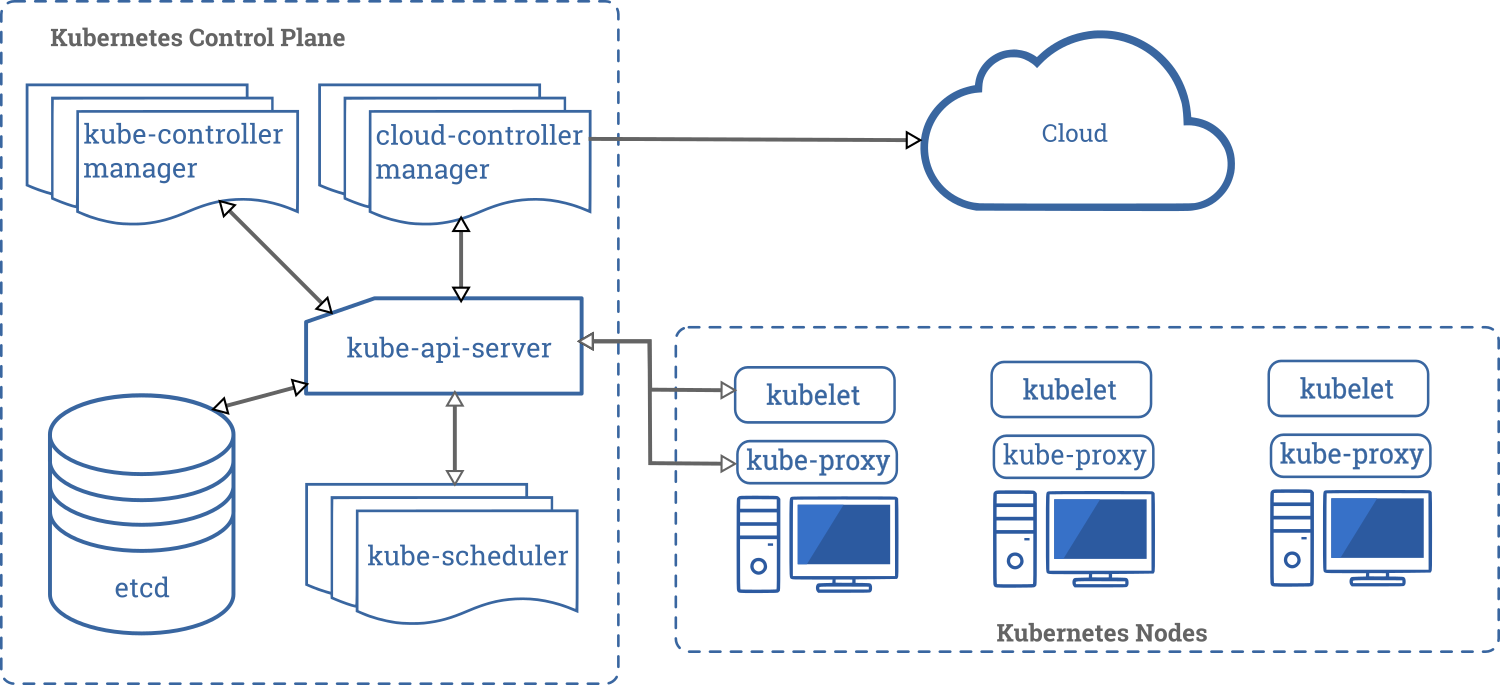 https://kubernetes.io/docs/concepts/overview/components/
https://kubernetes.io/docs/concepts/overview/components/
Avant de me lancer dans l'explication des détails individuels, jetez un coup d'œil à ce que la documentation de Kubernetes a à dire —
"Pour travailler avec des objets Kubernetes — que ce soit pour les créer, les modifier ou les supprimer — vous devrez utiliser l'API Kubernetes. Lorsque vous utilisez l'interface de ligne de commande
kubectl, le CLI effectue les appels nécessaires à l'API Kubernetes pour vous."
La première commande que vous avez exécutée était la commande run. Elle était la suivante :
kubectl run hello-kube --image=fhsinchy/hello-kube --port=80
La commande run est responsable de la création d'un nouveau pod qui exécute l'image donnée. Une fois que vous avez émis cette commande, les ensembles d'événements suivants se produisent à l'intérieur du cluster Kubernetes :
- Le composant
kube-api-serverreçoit la demande, la valide et la traite. - Le
kube-api-servercommunique ensuite avec le composantkubeletsur le nœud et fournit les instructions nécessaires pour créer le pod. - Le composant
kubeletcommence alors à travailler pour faire fonctionner le pod et maintient également les informations d'état à jour dans le magasinetcd.
La syntaxe générique pour la commande run est la suivante :
kubectl run <nom du pod> --image=<nom de l'image> --port=<port à exposer>
Vous pouvez exécuter n'importe quelle image de conteneur valide à l'intérieur d'un pod. L'image Docker fhsinchy/hello-kube contient une application JavaScript très simple qui s'exécute sur le port 80 à l'intérieur du conteneur. L'option --port=80 permet au pod d'exposer le port 80 depuis l'intérieur du conteneur.

Le pod nouvellement créé s'exécute à l'intérieur du cluster minikube et est inaccessible depuis l'extérieur. Pour exposer le pod et le rendre accessible, la deuxième commande que vous avez émise était la suivante :
kubectl expose pod hello-kube --type=LoadBalancer --port=80
La commande expose est responsable de la création d'un service Kubernetes de type LoadBalancer qui permet aux utilisateurs d'accéder à l'application s'exécutant à l'intérieur du pod.
Tout comme la commande run, l'exécution de la commande expose passe par les mêmes étapes à l'intérieur du cluster. Mais au lieu d'un pod, le kube-api-server fournit les instructions nécessaires pour créer un service dans ce cas au composant kubelet.
La syntaxe générique pour la commande expose est la suivante :
kubectl expose <type de ressource à exposer> <nom de la ressource> --type=<type de service à créer> --port=<port à exposer>
Le type d'objet peut être n'importe quel type d'objet Kubernetes valide. Le nom doit correspondre au nom de l'objet que vous essayez d'exposer.
--type indique le type de service que vous souhaitez. Il existe quatre types de services différents disponibles pour la mise en réseau interne ou externe.
Enfin, le --port est le numéro de port que vous souhaitez exposer depuis le conteneur en cours d'exécution.

Une fois le service créé, la dernière pièce du puzzle était d'accéder à l'application s'exécutant à l'intérieur du pod. Pour ce faire, la commande que vous avez exécutée était la suivante :
minikube service hello-kube
Contrairement aux précédentes, cette dernière commande ne va pas au kube-api-server. Elle communique plutôt avec le cluster local en utilisant le programme minikube. La commande service pour minikube retourne une URL complète pour un service donné.
Lorsque vous avez créé le pod hello-kube avec l'option --port=80, vous avez instructé Kubernetes de laisser le pod exposer le port 80 depuis l'intérieur du conteneur, mais il n'était pas accessible depuis l'extérieur du cluster.
Ensuite, lorsque vous avez créé le service LoadBalancer avec l'option --port=80, il a mappé le port 80 de ce conteneur à un port arbitraire dans le système local, le rendant accessible depuis l'extérieur du cluster.
Sur mon système, la commande service retourne l'URL 192.168.99.101:30848 pour le pod. L'IP dans cette URL est en fait l'IP de la machine virtuelle minikube. Vous pouvez vérifier cela en exécutant la commande suivante :
minikube ip
# 192.168.99.101
Pour vérifier que le port 30848 pointe vers le port 80 à l'intérieur du pod, vous pouvez exécuter la commande suivante :
kubectl get service hello-kube
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# hello-kube LoadBalancer 10.109.60.75 <pending> 80:30848/TCP 119s
Dans la colonne PORT(S), vous pouvez voir que le port 80 est effectivement mappé au port 30484 sur le système local. Donc, au lieu d'exécuter la commande service, vous pouvez simplement inspecter l'IP et le port, puis les mettre dans votre navigateur manuellement pour accéder à l'application hello-kube.

Maintenant, l'état final du cluster peut être visualisé comme suit :

Si vous venez de Docker, alors la signification de l'utilisation d'un service afin d'exposer un pod peut sembler un peu trop verbeuse pour vous à l'instant.
Mais à mesure que vous avancerez dans les exemples qui traitent de plus d'un pod, vous commencerez à apprécier tout ce que Kubernetes a à offrir.
Se débarrasser des ressources Kubernetes
Maintenant que vous savez comment créer des ressources Kubernetes comme les pods et les Services, vous devez savoir comment vous en débarrasser. La seule façon de se débarrasser d'une ressource Kubernetes est de la supprimer.
Vous pouvez le faire en utilisant la commande delete pour kubectl. La syntaxe générique de la commande est la suivante :
kubectl delete <type de ressource> <nom de la ressource>
Pour supprimer un pod nommé hello-kube, la commande sera la suivante :
kubectl delete pod hello-kube
# pod "hello-kube" deleted
Et pour supprimer un service nommé hello-kube, la commande sera la suivante :
kubectl delete service hello-kube
# service "hello-kube" deleted
Ou si vous êtes d'humeur destructive, vous pouvez supprimer tous les objets d'un type en une seule fois en utilisant l'option --all pour la commande delete. La syntaxe générique pour l'option est la suivante :
kubectl delete <type d'objet> --all
Ainsi, pour supprimer tous les pods et services, vous devez exécuter kubectl delete pod --all et kubectl delete service --all respectivement.
Approche de déploiement déclarative
Pour être honnête, l'exemple hello-kube que vous venez de voir dans la section précédente n'est pas une manière idéale de procéder au déploiement avec Kubernetes.
L'approche que vous avez prise dans cette section est une approche impérative, ce qui signifie que vous avez dû exécuter chaque commande manuellement l'une après l'autre. Prendre une approche impérative va à l'encontre de tout l'intérêt de Kubernetes.
Une approche idéale pour le déploiement avec Kubernetes est l'approche déclarative. Dans celle-ci, vous, en tant que développeur, faites savoir à Kubernetes l'état dans lequel vous souhaitez que vos serveurs soient, et Kubernetes trouve un moyen de le mettre en œuvre.
Dans cette section, vous allez déployer la même application hello-kube avec une approche déclarative.
Si vous n'avez pas encore cloné le dépôt de code lié ci-dessus, alors allez-y et récupérez-le maintenant.
Une fois que vous l'avez, allez dans le répertoire hello-kube. Ce répertoire contient le code de l'application hello-kube ainsi que le Dockerfile pour construire l'image.
├── Dockerfile
├── index.html
├── package.json
├── public
└── src
2 directories, 3 files
Le code JavaScript se trouve dans le dossier src, mais ce n'est pas ce qui vous intéresse. Le fichier que vous devriez regarder est le Dockerfile car il peut vous donner un aperçu de la manière dont vous devriez planifier votre déploiement. Le contenu du Dockerfile est le suivant :
FROM node as builder
WORKDIR /usr/app
COPY ./package.json ./
RUN npm install
COPY . .
RUN npm run build
EXPOSE 80
FROM nginx
COPY --from=builder /usr/app/dist /usr/share/nginx/html
Comme vous pouvez le voir, il s'agit d'un processus de construction multi-étapes.
- La première étape utilise
nodecomme image de base et compile l'application JavaScript en un ensemble de fichiers prêts pour la production. - La deuxième étape copie les fichiers construits pendant la première étape et les colle à l'intérieur de la racine des documents NGINX par défaut. Étant donné que l'image de base pour la deuxième phase est
nginx, l'image résultante sera une imagenginxservant les fichiers construits pendant la première phase sur le port 80 (port par défaut pour nginx).
Maintenant, pour déployer cette application sur Kubernetes, vous devrez trouver un moyen d'exécuter l'image en tant que conteneur et de rendre le port 80 accessible depuis le monde extérieur.
Écrire votre premier ensemble de configurations
Dans l'approche déclarative, au lieu d'émettre des commandes individuelles dans le terminal, vous écrivez plutôt la configuration nécessaire dans un fichier YAML et vous la fournissez à Kubernetes.
Dans le répertoire du projet hello-kube, créez un autre répertoire nommé k8s. k8s est l'abréviation de k(ubernete = 8 caractères)s.
Vous n'avez pas besoin de nommer le dossier de cette manière, vous pouvez le nommer comme vous le souhaitez.
Il n'est même pas nécessaire de le garder dans le répertoire du projet. Ces fichiers de configuration peuvent vivre n'importe où dans votre ordinateur, car ils n'ont aucun lien avec le code source du projet.
Maintenant, à l'intérieur de ce répertoire k8s, créez un nouveau fichier nommé hello-kube-pod.yaml. Je vais écrire le code pour le fichier d'abord, puis je vais l'expliquer ligne par ligne. Le contenu de ce fichier est le suivant :
apiVersion: v1
kind: Pod
metadata:
name: hello-kube-pod
labels:
component: web
spec:
containers:
- name: hello-kube
image: fhsinchy/hello-kube
ports:
- containerPort: 80
Chaque fichier de configuration Kubernetes valide a quatre champs obligatoires. Ils sont les suivants :
apiVersion: Quelle version de l'API Kubernetes vous utilisez pour créer cet objet. Cette valeur peut changer en fonction du type d'objet que vous créez. Pour créer unPod, la version requise estv1.kind: Quel type d'objet vous voulez créer. Les objets dans Kubernetes peuvent être de nombreux types. Au fur et à mesure que vous parcourez l'article, vous en apprendrez beaucoup sur eux, mais pour l'instant, comprenez simplement que vous créez un objetPod.metadata: Données qui aident à identifier de manière unique l'objet. Sous ce champ, vous pouvez avoir des informations commename,labels,annotation, etc. La chaînemetadata.nameapparaîtra sur le terminal et sera utilisée dans les commandeskubectl. La paire clé-valeur sous le champmetadata.labelsn'a pas besoin d'êtrecomponents: web. Vous pouvez lui donner n'importe quelle étiquette commeapp: hello-kube. Cette valeur sera utilisée comme sélecteur lors de la création du serviceLoadBalancertrès bientôt.spec: contient l'état que vous souhaitez pour l'objet. Le sous-champspec.containerscontient des informations sur les conteneurs qui s'exécuteront à l'intérieur de cePod. La valeurspec.containers.nameest ce que le runtime de conteneur à l'intérieur du nœud attribuera au conteneur nouvellement créé. Lespec.containers.imageest l'image de conteneur à utiliser pour créer ce conteneur. Et le champspec.containers.portscontient la configuration concernant les différentes configurations de ports.containerPort: 80indique que vous souhaitez exposer le port 80 depuis le conteneur.
Si vous êtes sur un Raspberry Pi, utilisez raed667/hello-kube comme image au lieu de fhsinchy/hello-kube. Maintenant, pour fournir ce fichier de configuration à Kubernetes, vous utiliserez la commande apply. La syntaxe générique de la commande est la suivante :
kubectl apply -f <fichier de configuration>
Pour fournir un fichier de configuration nommé hello-kube-pod.yaml, la commande sera la suivante :
kubectl apply -f hello-kube-pod.yaml
# pod/hello-kube-pod created
Pour vous assurer que le Pod est opérationnel, exécutez la commande suivante :
kubectl get pod
# NAME READY STATUS RESTARTS AGE
# hello-kube 1/1 Running 0 3m3s
Vous devriez voir Running dans la colonne STATUS. Si vous voyez quelque chose comme ContainerCreating, attendez une minute ou deux et vérifiez à nouveau.
Une fois que le Pod est opérationnel, il est temps pour vous d'écrire le fichier de configuration pour le service LoadBalancer.
Créez un autre fichier dans le répertoire k8s appelé hello-kube-load-balancer-service.yaml et mettez le code suivant dedans :
apiVersion: v1
kind: Service
metadata:
name: hello-kube-load-balancer-service
spec:
type: LoadBalancer
ports:
- port: 80
targetPort: 80
selector:
component: web
Comme le fichier de configuration précédent, les champs apiVersion, kind et metadata servent le même but ici. Comme vous pouvez le voir, il n'y a pas de champ labels à l'intérieur de metadata ici. C'est parce qu'un service sélectionne d'autres objets en utilisant des labels, d'autres objets ne sélectionnent pas un service.
Rappelez-vous, les services établissent une politique d'accès pour d'autres objets, d'autres objets n'établissent pas une politique d'accès pour un service.
À l'intérieur du champ spec, vous pouvez voir un nouvel ensemble de valeurs. Contrairement à un Pod, les services ont quatre types. Ce sont ClusterIP, NodePort, LoadBalancer, et ExternalName.
Dans cet exemple, vous utilisez le type LoadBalancer, qui est la manière standard d'exposer un service à l'extérieur du cluster. Ce service vous donnera une adresse IP que vous pourrez ensuite utiliser pour vous connecter aux applications s'exécutant à l'intérieur de votre cluster.

Le type LoadBalancer nécessite deux valeurs de port pour fonctionner correctement. Sous le champ ports, la valeur port est pour accéder au pod lui-même et sa valeur peut être n'importe quoi.
La valeur targetPort est celle de l'intérieur du conteneur et doit correspondre au port que vous souhaitez exposer depuis l'intérieur du conteneur.
J'ai déjà dit que l'application hello-kube s'exécute sur le port 80 à l'intérieur du conteneur. Vous avez même exposé ce port dans le fichier de configuration Pod, donc le targetPort sera 80.
Le champ selector est utilisé pour identifier les objets qui seront connectés à ce service. La paire clé-valeur component: web doit correspondre à la paire clé-valeur sous le champ labels dans le fichier de configuration Pod. Si vous avez utilisé une autre paire clé-valeur comme app: hello-kube dans ce fichier de configuration, utilisez celle-ci à la place.
Pour fournir ce fichier à Kubernetes, vous utiliserez à nouveau la commande apply. La commande pour fournir un fichier nommé hello-kube-load-balancer-service.yaml sera la suivante :
kubectl apply -f hello-kube-load-balancer-service.yaml
# service/hello-kube-load-balancer-service created
Pour vous assurer que l'équilibreur de charge a été créé avec succès, exécutez la commande suivante :
kubectl get service
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# hello-kube-load-balancer-service LoadBalancer 10.107.231.120 <pending> 80:30848/TCP 7s
# kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 21h
Assurez-vous de voir le nom hello-kube-load-balancer-service dans la liste. Maintenant que vous avez un pod en cours d'exécution qui est exposé, vous pouvez aller de l'avant et y accéder. Exécutez la commande suivante pour ce faire :
minikube service hello-kube-load-balancer-service
# |-----------|----------------------------------|-------------|-----------------------------|
# | NAMESPACE | NAME | TARGET PORT | URL |
# |-----------|----------------------------------|-------------|-----------------------------|
# | default | hello-kube-load-balancer-service | 80 | http://192.168.99.101:30848 |
# |-----------|----------------------------------|-------------|-----------------------------|
# 🎉 Opening service default/hello-kube-load-balancer in default browser...
Votre navigateur web par défaut devrait s'ouvrir automatiquement et vous devriez voir quelque chose comme ceci :

Vous pouvez également fournir les deux fichiers ensemble au lieu de les fournir individuellement. Pour ce faire, vous pouvez remplacer le nom du fichier par le nom du répertoire comme suit :
kubectl apply -f k8s
# service/hello-kube-load-balancer-service created
# pod/hello-kube-pod created
Dans ce cas, assurez-vous que votre terminal est sur le répertoire parent du répertoire k8s.
Si vous êtes dans le répertoire k8s, vous pouvez utiliser un point (.) pour faire référence au répertoire courant. Lorsque vous appliquez des configurations en masse, il peut être bon de se débarrasser des ressources créées précédemment. De cette façon, la possibilité de conflits devient beaucoup plus faible.
L'approche déclarative est l'approche idéale lorsque vous travaillez avec Kubernetes. Sauf pour quelques cas particuliers, que vous verrez à la fin de l'article.
Le tableau de bord Kubernetes
Dans une section précédente, vous avez utilisé la commande delete pour vous débarrasser d'un objet Kubernetes.
Dans cette section, cependant, j'ai pensé que l'introduction du tableau de bord serait une excellente idée. Le tableau de bord Kubernetes est une interface graphique que vous pouvez utiliser pour gérer vos charges de travail, services, et plus encore.
Pour lancer le tableau de bord Kubernetes, exécutez la commande suivante dans votre terminal :
minikube dashboard
# 🎉 Vérification de la santé du tableau de bord...
# 🎉 Lancement du proxy...
# 🎉 Vérification de la santé du proxy...
# 🎉 Ouverture de http://127.0.0.1:52393/api/v1/namespaces/kubernetes-dashboard/services/http:kubernetes-dashboard:/proxy/ dans votre navigateur par défaut...
Le tableau de bord devrait s'ouvrir automatiquement dans votre navigateur par défaut :

L'interface est assez conviviale et vous êtes libre de vous promener ici. Bien qu'il soit tout à fait possible de créer, gérer et supprimer des objets à partir de cette interface, je vais utiliser le CLI pour le reste de cet article.
Ici, dans la liste Pods, vous pouvez utiliser le menu à trois points sur le côté droit pour Supprimer le Pod. Vous pouvez faire de même avec le service LoadBalancer. En fait, la liste Services est commodément placée juste après la liste Pods.
Vous pouvez fermer le tableau de bord en appuyant sur la combinaison de touches Ctrl + C ou en fermant la fenêtre du terminal.
Travailler avec des applications multi-conteneurs
Jusqu'à présent, vous avez travaillé avec des applications qui s'exécutent dans un seul conteneur.
Dans cette section, vous allez travailler avec une application composée de deux conteneurs. Vous vous familiariserez également avec Deployment, ClusterIP, PersistentVolume, PersistentVolumeClaim et quelques techniques de débogage.
L'application avec laquelle vous allez travailler est une API de notes express simple avec une fonctionnalité CRUD complète. L'application utilise PostgreSQL comme système de base de données. Vous allez donc non seulement déployer l'application, mais aussi configurer la mise en réseau interne entre l'application et la base de données.
Le code de l'application se trouve dans le répertoire notes-api à l'intérieur du dépôt de projet.
.
├── api
├── docker-compose.yaml
└── postgres
2 directories, 1 file
Le code source de l'application réside dans le répertoire api et le répertoire postgres contient un Dockerfile pour créer l'image postgres personnalisée. Le fichier docker-compose.yaml contient la configuration nécessaire pour exécuter l'application en utilisant docker-compose.
Tout comme avec le projet précédent, vous pouvez consulter le Dockerfile individuel pour chaque service afin de vous faire une idée de la manière dont l'application s'exécute à l'intérieur du conteneur.
Ou vous pouvez simplement inspecter le docker-compose.yaml et planifier votre déploiement Kubernetes en utilisant celui-ci.
version: "3.8"
services:
db:
build:
context: ./postgres
dockerfile: Dockerfile.dev
volumes:
- db-data:/var/lib/postgresql/data
environment:
POSTGRES_PASSWORD: 63eaQB9wtLqmNBpg
POSTGRES_DB: notesdb
api:
build:
context: ./api
dockerfile: Dockerfile.dev
ports:
- 3000:3000
volumes:
- /home/node/app/node_modules
- ./api:/home/node/app
environment:
DB_CONNECTION: pg
DB_HOST: db
DB_PORT: 5432
DB_USER: postgres
DB_DATABASE: notesdb
DB_PASSWORD: 63eaQB9wtLqmNBpg
volumes:
db-data:
name: notes-db-dev-data
En regardant la définition du service api, vous pouvez voir que l'application s'exécute sur le port 3000 à l'intérieur du conteneur. Elle nécessite également un ensemble de variables d'environnement pour fonctionner correctement.
Les volumes peuvent être ignorés car ils étaient nécessaires uniquement à des fins de développement et la configuration de construction est spécifique à Docker. Ainsi, les deux ensembles d'informations que vous pouvez reporter presque inchangés dans vos fichiers de configuration Kubernetes sont les suivants :
- Mappages de ports — car vous devrez exposer le même port depuis le conteneur.
- Variables d'environnement — car ces variables seront les mêmes dans tous les environnements (les valeurs vont changer, cependant).
Le service db est encore plus simple. Il n'a qu'un ensemble de variables d'environnement. Vous pouvez même utiliser l'image officielle postgres au lieu d'une image personnalisée.
Mais la seule raison pour une image personnalisée est si vous voulez que l'instance de la base de données soit livrée avec la table notes pré-créée.
Cette table est nécessaire pour l'application. Si vous regardez dans le répertoire postgres/docker-entrypoint-initdb.d, vous verrez un fichier nommé notes.sql qui est utilisé pour créer la base de données lors de l'initialisation.
Plan de déploiement
Contrairement au projet précédent que vous avez déployé, ce projet va être un peu plus compliqué.
Dans ce projet, vous allez créer non pas une, mais trois instances de l'API de notes. Ces trois instances seront exposées à l'extérieur du cluster en utilisant un service LoadBalancer.

En plus de ces trois instances, il y aura une autre instance du système de base de données PostgreSQL. Les trois instances de l'application API de notes communiqueront avec cette instance de base de données en utilisant un service ClusterIP.
Le service ClusterIP est un autre type de service Kubernetes qui expose une application au sein de votre cluster. Cela signifie qu'aucun trafic externe ne peut atteindre l'application en utilisant un service ClusterIP.

Dans ce projet, la base de données doit être accessible uniquement par l'API de notes, donc exposer le service de base de données au sein du cluster est un choix idéal.
J'ai déjà mentionné dans une section précédente que vous ne devriez pas créer de pods directement. Donc dans ce projet, vous allez utiliser un Deployment au lieu d'un Pod.
Contrôleurs de réplication, Replica Sets et Deployments
Selon la documentation de Kubernetes —
"Dans Kubernetes, les contrôleurs sont des boucles de contrôle qui surveillent l'état de votre cluster, puis effectuent ou demandent des changements là où c'est nécessaire. Chaque contrôleur essaie de rapprocher l'état actuel du cluster de l'état souhaité. Une boucle de contrôle est une boucle non terminante qui régule l'état d'un système."
Un ReplicationController, comme son nom l'indique, permet de créer facilement plusieurs réplicas. Une fois que le nombre souhaité de réplicas est créé, le contrôleur s'assurera que l'état reste ainsi.
Si après un certain temps vous décidez de réduire le nombre de réplicas, alors le ReplicationController prendra des mesures immédiatement et se débarrasser des pods supplémentaires.
Sinon, si le nombre de réplicas devient inférieur à ce que vous vouliez (peut-être que certains des pods ont planté), le ReplicationController en créera de nouveaux pour correspondre à l'état souhaité.
Aussi utiles qu'ils puissent vous sembler, le ReplicationController n'est plus la méthode recommandée pour créer des réplicas de nos jours. Une nouvelle API appelée ReplicaSet a pris sa place.
En plus du fait qu'un ReplicaSet peut vous offrir une gamme plus large d'options de sélection, ReplicationController et ReplicaSet sont plus ou moins la même chose.
Avoir une gamme plus large d'options de sélecteur est bien, mais ce qui est encore mieux, c'est d'avoir plus de flexibilité en termes de déploiement et de retour en arrière des mises à jour. C'est là qu'intervient une autre API Kubernetes appelée Deployment.
Un Deployment est comme une extension de l'API ReplicaSet déjà bien conçue. Deployment ne permet pas seulement de créer des réplicas en un rien de temps, mais permet également de publier des mises à jour ou de revenir à une fonction précédente avec seulement une ou deux commandes kubectl.
| ReplicationController | ReplicaSet | Deployment |
| Permet la création facile de plusieurs pods | Permet la création facile de plusieurs pods | Permet la création facile de plusieurs pods |
| La méthode originale de réplication dans Kubernetes | A des sélecteurs plus flexibles | Étend les ReplicaSets avec des mises à jour et des retours en arrière faciles |
Dans ce projet, vous allez utiliser un Deployment pour maintenir les instances de l'application.
Créer votre premier déploiement
Commençons par écrire le fichier de configuration pour le déploiement de l'API de notes. Créez un répertoire k8s à l'intérieur du répertoire du projet notes-api.
À l'intérieur de ce répertoire, créez un fichier nommé api-deployment.yaml et mettez le contenu suivant dedans :
apiVersion: apps/v1
kind: Deployment
metadata:
name: api-deployment
spec:
replicas: 3
selector:
matchLabels:
component: api
template:
metadata:
labels:
component: api
spec:
containers:
- name: api
image: fhsinchy/notes-api
ports:
- containerPort: 3000
Dans ce fichier, les champs apiVersion, kind, metadata et spec servent le même but que dans le projet précédent. Les changements notables dans ce fichier par rapport au précédent sont les suivants :
- Pour créer un Pod, la
apiVersionrequise étaitv1. Mais pour créer un Deployment, la version requise estapps/v1. Les versions de l'API Kubernetes peuvent être un peu déroutantes à certains moments, mais à mesure que vous continuez à travailler avec Kubernetes, vous vous y habituerez. Vous pouvez également consulter la documentation officielle pour des exemples de fichiers YAML à utiliser comme référence. Le type estDeployment, ce qui est assez explicite. spec.replicasdéfinit le nombre de réplicas en cours d'exécution. Définir cette valeur à3signifie que vous faites savoir à Kubernetes que vous voulez trois instances de votre application en cours d'exécution à tout moment.spec.selectorest l'endroit où vous faites savoir auDeploymentquels pods contrôler. J'ai déjà mentionné qu'unDeploymentest une extension deReplicaSetet peut contrôler un ensemble d'objets Kubernetes. Définirselector.matchLabelsàcomponent: apisignifie que ceDeploymentcontrôlera les pods qui ont une étiquette decomponent: api. Cette ligne indique à Kubernetes que vous voulez que ceDeploymentcontrôle tous les pods ayant l'étiquettecomponent: api.spec.templateest le modèle pour configurer les pods. Il est presque identique au fichier de configuration précédent.
Si vous êtes sur un Raspberry Pi, utilisez raed667/notes-api au lieu de fhsinchy/notes-api comme image. Maintenant, pour voir cette configuration en action, appliquez le fichier comme dans le projet précédent :
kubectl apply -f api-deployment.yaml
# deployment.apps/api-deployment created
Pour vous assurer que le Deployment a été créé, exécutez la commande suivante :
kubectl get deployment
# NAME READY UP-TO-DATE AVAILABLE AGE
# api-deployment 0/3 3 0 2m7s
Si vous regardez la colonne READY, vous verrez 0/3. Cela signifie que les pods n'ont pas encore été créés. Attendez quelques minutes et essayez à nouveau.
kubectl get deployment
# NAME READY UP-TO-DATE AVAILABLE AGE
# api-deployment 0/3 3 0 28m
Comme vous pouvez le voir, j'ai attendu près d'une demi-heure et toujours aucun des pods n'est prêt. L'API elle-même ne fait que quelques centaines de kilo-octets. Un déploiement de cette taille n'aurait pas dû prendre autant de temps. Ce qui signifie qu'il y a un problème et que nous devons le résoudre.
Inspecter les ressources Kubernetes
Avant de pouvoir résoudre un problème, vous devez d'abord en trouver l'origine. Un bon point de départ est la commande get.
Vous connaissez déjà la commande get qui imprime un tableau contenant des informations importantes sur une ou plusieurs ressources Kubernetes. La syntaxe générique de la commande est la suivante :
kubectl get <type de ressource> <nom de la ressource>
Pour exécuter la commande get sur votre api-deployment, exécutez la ligne de code suivante dans votre terminal :
kubectl get deployment api-deployment
# NAME READY UP-TO-DATE AVAILABLE AGE
# api-deployment 0/3 3 0 15m
Vous pouvez omettre le nom api-deployment pour obtenir une liste de tous les déploiements disponibles. Vous pouvez également exécuter la commande get sur un fichier de configuration.
Si vous souhaitez obtenir des informations sur les déploiements décrits dans le fichier api-deployment.yaml, la commande doit être la suivante :
kubectl get -f api-deployment
# NAME READY UP-TO-DATE AVAILABLE AGE
# api-deployment 0/3 3 0 18m
Par défaut, la commande get affiche une très petite quantité d'informations. Vous pouvez en obtenir plus en utilisant l'option -o.
L'option -o définit le format de sortie pour la commande get. Vous pouvez utiliser le format de sortie wide pour voir plus de détails.
kubectl get -f api-deployment.yaml
# NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
# api-deployment 0/3 3 0 19m api fhsinchy/notes-api component=api
Comme vous pouvez le voir, la liste contient maintenant plus d'informations qu'avant. Vous pouvez en apprendre davantage sur les options de la commande get dans la documentation officielle docs.
L'exécution de get sur le Deployment ne donne rien d'intéressant, pour être honnête. Dans de tels cas, vous devez descendre au niveau des ressources de bas niveau.
Jetez un coup d'œil à la liste des pods et voyez si vous pouvez trouver quelque chose d'intéressant là-bas :
kubectl get pod
# NAME READY STATUS RESTARTS AGE
# api-deployment-d59f9c884-88j45 0/1 CrashLoopBackOff 10 30m
# api-deployment-d59f9c884-96hfr 0/1 CrashLoopBackOff 10 30m
# api-deployment-d59f9c884-pzdxg 0/1 CrashLoopBackOff 10 30m
C'est intéressant. Tous les pods ont un STATUS de CrashLoopBackOff, ce qui est nouveau. Auparavant, vous n'aviez vu que les statuts ContainerCreating et Running. Vous pouvez voir Error à la place de CrashLoopBackOff également.
En regardant la colonne RESTARTS, vous pouvez voir que les pods ont déjà été redémarrés 10 fois. Cela signifie que pour une raison quelconque, les pods échouent au démarrage.
Maintenant, pour obtenir une vue plus détaillée de l'un des pods, vous pouvez utiliser une autre commande appelée describe. Elle est très similaire à la commande get. La syntaxe générique de la commande est la suivante :
kubectl get <type de ressource> <nom de la ressource>
Pour obtenir les détails du pod api-deployment-d59f9c884-88j45, vous pouvez exécuter la commande suivante :
kubectl describe pod api-deployment-d59f9c884-88j45
# Name: api-deployment-d59f9c884-88j45
# Namespace: default
# Priority: 0
# Node: minikube/172.28.80.217
# Start Time: Sun, 09 Aug 2020 16:01:28 +0600
# Labels: component=api
# pod-template-hash=d59f9c884
# Annotations: <none>
# Status: Running
# IP: 172.17.0.4
# IPs:
# IP: 172.17.0.4
# Controlled By: ReplicaSet/api-deployment-d59f9c884
# Containers:
# api:
# Container ID: docker://d2bc15bda9bf4e6d08f7ca8ff5d3c8593655f5f398cf8bdd18b71da8807930c1
# Image: fhsinchy/notes-api
# Image ID: docker-pullable://fhsinchy/notes-api@sha256:4c715c7ce3ad3693c002fad5e7e7b70d5c20794a15dbfa27945376af3f3bb78c
# Port: 3000/TCP
# Host Port: 0/TCP
# State: Waiting
# Reason: CrashLoopBackOff
# Last State: Terminated
# Reason: Error
# Exit Code: 1
# Started: Sun, 09 Aug 2020 16:13:12 +0600
# Finished: Sun, 09 Aug 2020 16:13:12 +0600
# Ready: False
# Restart Count: 10
# Environment: <none>
# Mounts:
# /var/run/secrets/kubernetes.io/serviceaccount from default-token-gqfr4 (ro)
# Conditions:
# Type Status
# Initialized True
# Ready False
# ContainersReady False
# PodScheduled True
# Volumes:
# default-token-gqfr4:
# Type: Secret (a volume populated by a Secret)
# SecretName: default-token-gqfr4
# Optional: false
# QoS Class: BestEffort
# Node-Selectors: <none>
# Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
# node.kubernetes.io/unreachable:NoExecute for 300s
# Events:
# Type Reason Age From Message
# ---- ------ ---- ---- -------
# Normal Scheduled <unknown> default-scheduler Successfully assigned default/api-deployment-d59f9c884-88j45 to minikube
# Normal Pulled 2m40s (x4 over 3m47s) kubelet, minikube Successfully pulled image "fhsinchy/notes-api"
# Normal Created 2m40s (x4 over 3m47s) kubelet, minikube Created container api
# Normal Started 2m40s (x4 over 3m47s) kubelet, minikube Started container api
# Normal Pulling 107s (x5 over 3m56s) kubelet, minikube Pulling image "fhsinchy/notes-api"
# Warning BackOff <invalid> (x44 over 3m32s) kubelet, minikube Back-off restarting failed container
La partie la plus intéressante dans tout ce mur de texte est la section Events. Jetez un coup d'œil plus attentif :
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled <unknown> default-scheduler Successfully assigned default/api-deployment-d59f9c884-88j45 to minikube
Normal Pulled 2m40s (x4 over 3m47s) kubelet, minikube Successfully pulled image "fhsinchy/notes-api"
Normal Created 2m40s (x4 over 3m47s) kubelet, minikube Created container api
Normal Started 2m40s (x4 over 3m47s) kubelet, minikube Started container api
Normal Pulling 107s (x5 over 3m56s) kubelet, minikube Pulling image "fhsinchy/notes-api"
Warning BackOff <invalid> (x44 over 3m32s) kubelet, minikube Back-off restarting failed container
À partir de ces événements, vous pouvez voir que l'image du conteneur a été téléchargée avec succès. Le conteneur a également été créé, mais il est évident d'après le Back-off restarting failed container que le conteneur a échoué au démarrage.
La commande describe est très similaire à la commande get et a le même type d'options.
Vous pouvez omettre le nom api-deployment-d59f9c884-88j45 pour obtenir des informations sur tous les pods disponibles. Ou vous pouvez également utiliser l'option -f pour passer un fichier de configuration à la commande. Visitez la documentation officielle docs pour en savoir plus.
Maintenant que vous savez qu'il y a un problème avec le conteneur, vous devez descendre au niveau du conteneur et voir ce qui se passe là.
Obtenir les logs des conteneurs depuis les pods
Il existe une autre commande kubectl appelée logs qui peut vous aider à obtenir les logs des conteneurs à l'intérieur d'un pod. La syntaxe générique de la commande est la suivante :
kubectl logs <pod>
Pour afficher les logs à l'intérieur du pod api-deployment-d59f9c884-88j45, la commande doit être la suivante :
kubectl logs api-deployment-d59f9c884-88j45
# > api@1.0.0 start /usr/app
# > cross-env NODE_ENV=production node bin/www
# /usr/app/node_modules/knex/lib/client.js:55
# throw new Error(`knex: Required configuration option 'client' is missing.`);
^
# Error: knex: Required configuration option 'client' is missing.
# at new Client (/usr/app/node_modules/knex/lib/client.js:55:11)
# at Knex (/usr/app/node_modules/knex/lib/knex.js:53:28)
# at Object.<anonymous> (/usr/app/services/knex.js:5:18)
# at Module._compile (internal/modules/cjs/loader.js:1138:30)
# at Object.Module._extensions..js (internal/modules/cjs/loader.js:1158:10)
# at Module.load (internal/modules/cjs/loader.js:986:32)
# at Function.Module._load (internal/modules/cjs/loader.js:879:14)
# at Module.require (internal/modules/cjs/loader.js:1026:19)
# at require (internal/modules/cjs/helpers.js:72:18)
# at Object.<anonymous> (/usr/app/services/index.js:1:14)
# npm ERR! code ELIFECYCLE
# npm ERR! errno 1
# npm ERR! api@1.0.0 start: `cross-env NODE_ENV=production node bin/www`
# npm ERR! Exit status 1
# npm ERR!
# npm ERR! Failed at the api@1.0.0 start script.
# npm ERR! This is probably not a problem with npm. There is likely additional logging output above.
# npm ERR! A complete log of this run can be found in:
# npm ERR! /root/.npm/_logs/2020-08-09T10_28_52_779Z-debug.log
C'est ce dont vous avez besoin pour déboguer le problème. Il semble que la bibliothèque knex.js manque une valeur requise, ce qui empêche l'application de démarrer. Vous pouvez en apprendre davantage sur la commande logs dans la documentation officielle docs.
Cela se produit parce que vous manquez certaines variables d'environnement requises dans la définition du déploiement.
Si vous jetez un autre coup d'œil à la définition du service api à l'intérieur du fichier docker-compose.yaml, vous devriez voir quelque chose comme ceci :
api:
build:
context: ./api
dockerfile: Dockerfile.dev
ports:
- 3000:3000
volumes:
- /home/node/app/node_modules
- ./api:/home/node/app
environment:
DB_CONNECTION: pg
DB_HOST: db
DB_PORT: 5432
DB_USER: postgres
DB_DATABASE: notesdb
DB_PASSWORD: 63eaQB9wtLqmNBpg
Ces variables d'environnement sont requises pour que l'application communique avec la base de données. Donc, les ajouter à la configuration du déploiement devrait résoudre le problème.
Variables d'environnement
L'ajout de variables d'environnement à un fichier de configuration Kubernetes est très simple. Ouvrez le fichier api-deployment.yaml et mettez à jour son contenu pour qu'il ressemble à ceci :
apiVersion: apps/v1
kind: Deployment
metadata:
name: api-deployment
spec:
replicas: 3
selector:
matchLabels:
component: api
template:
metadata:
labels:
component: api
spec:
containers:
- name: api
image: fhsinchy/notes-api
ports:
- containerPort: 3000
# ce sont les variables d'environnement
env:
- name: DB_CONNECTION
value: pg
Le champ containers.env contient toutes les variables d'environnement. Si vous regardez de près, vous verrez que je n'ai pas ajouté toutes les variables d'environnement du fichier docker-compose.yaml. J'en ai ajouté une seule.
La DB_CONNECTION indique que l'application utilise une base de données PostgreSQL. L'ajout de cette seule variable devrait résoudre le problème.
Maintenant, appliquez à nouveau le fichier de configuration en exécutant la commande suivante :
kubectl apply -f api-deployment.yaml
# deployment.apps/api-deployment configured
Contrairement aux autres fois, la sortie ici indique qu'une ressource a été configurée. C'est la beauté de Kubernetes. Vous pouvez simplement corriger les problèmes et réappliquer immédiatement le même fichier de configuration.
Maintenant, utilisez la commande get une fois de plus pour vous assurer que tout fonctionne correctement.
kubectl get deployment
# NAME READY UP-TO-DATE AVAILABLE AGE
# api-deployment 3/3 3 3 68m
kubectl get pod
# NAME READY STATUS RESTARTS AGE
# api-deployment-66cdd98546-l9x8q 1/1 Running 0 7m26s
# api-deployment-66cdd98546-mbfw9 1/1 Running 0 7m31s
# api-deployment-66cdd98546-pntxv 1/1 Running 0 7m21s
Les trois pods sont en cours d'exécution et le Deployment fonctionne également correctement.
Créer le déploiement de la base de données
Maintenant que l'API est opérationnelle, il est temps d'écrire la configuration pour l'instance de la base de données.
Créez un autre fichier appelé postgres-deployment.yaml à l'intérieur du répertoire k8s et mettez le contenu suivant dedans :
apiVersion: apps/v1
kind: Deployment
metadata:
name: postgres-deployment
spec:
replicas: 1
selector:
matchLabels:
component: postgres
template:
metadata:
labels:
component: postgres
spec:
containers:
- name: postgres
image: fhsinchy/notes-postgres
ports:
- containerPort: 5432
env:
- name: POSTGRES_PASSWORD
value: 63eaQB9wtLqmNBpg
- name: POSTGRES_DB
value: notesdb
Si vous êtes sur un Raspberry Pi, utilisez raed667/notes-postgres au lieu de fhsinchy/notes-postgres comme image. La configuration elle-même est très similaire à la précédente. Je ne vais pas expliquer tout dans ce fichier — espérons que vous le comprenez par vous-même avec les connaissances que vous avez acquises dans cet article jusqu'à présent.
PostgreSQL s'exécute sur le port 5432 par défaut, et la variable POSTGRES_PASSWORD est requise pour exécuter le conteneur postgres. Ce mot de passe sera également utilisé pour se connecter à cette base de données par l'API.
La variable POSTGRES_DB est facultative. Mais en raison de la manière dont ce projet a été structuré, elle est nécessaire ici — sinon l'initialisation échouera.
Vous pouvez en apprendre davantage sur l'image Docker officielle postgres depuis leur page Docker Hub. Pour des raisons de simplicité, je garde le nombre de réplicas à 1 dans ce projet.
Pour appliquer ce fichier, exécutez la commande suivante :
kubectl apply -f postgres-deployment.yaml
# deployment.apps/postgres-deployment created
Utilisez la commande get pour vous assurer que le déploiement et les pods sont en cours d'exécution correctement :
kubectl get deployment
# NAME READY UP-TO-DATE AVAILABLE AGE
# postgres-deployment 1/1 1 1 13m
kubectl get pod
# NAME READY STATUS RESTARTS AGE
# postgres-deployment-76fcc75998-mwnb7 1/1 Running 0 13m
Bien que le déploiement et les pods soient en cours d'exécution correctement, il y a un gros problème avec le déploiement de la base de données.
Si vous avez déjà travaillé avec un système de base de données, vous savez peut-être déjà que les bases de données stockent les données dans le système de fichiers. Actuellement, le déploiement de la base de données ressemble à ceci :

Le conteneur postgres est encapsulé par un pod. Toutes les données sauvegardées restent dans le système de fichiers interne du conteneur.
Maintenant, si pour une raison quelconque, le conteneur plante ou si le pod encapsulant le conteneur tombe en panne, toutes les données persistantes à l'intérieur du système de fichiers seront perdues.
Lors d'un crash, Kubernetes créera un nouveau pod pour maintenir l'état souhaité, mais il n'existe aucun mécanisme de transfert de données entre les deux pods.
Pour résoudre ce problème, vous pouvez stocker les données dans un espace séparé à l'extérieur du pod dans le cluster.

La gestion d'un tel stockage est un problème distinct de la gestion des instances de calcul. Le sous-système PersistentVolume dans Kubernetes fournit une API pour les utilisateurs et les administrateurs qui abstrait les détails de la manière dont le stockage est fourni de la manière dont il est consommé.
Volumes persistants et Persistent Volume Claims
Selon la documentation de Kubernetes —
"Un
PersistentVolume(PV) est une partie du stockage dans le cluster qui a été provisionnée par un administrateur ou provisionnée dynamiquement en utilisant uneStorageClass. C'est une ressource dans le cluster, tout comme un nœud est une ressource du cluster."
Ce qui signifie essentiellement qu'un PersistentVolume est un moyen de prendre une tranche de votre espace de stockage et de la réserver pour un certain pod. Les volumes sont toujours consommés par des pods et non par un objet de haut niveau comme un déploiement.
Si vous souhaitez utiliser un volume avec un déploiement qui a plusieurs pods, vous devrez suivre quelques étapes supplémentaires.
Créez un nouveau fichier appelé database-persistent-volume.yaml à l'intérieur du répertoire k8s et mettez le contenu suivant dans ce fichier :
apiVersion: v1
kind: PersistentVolume
metadata:
name: database-persistent-volume
spec:
storageClassName: manual
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/mnt/data"
Les champs apiVersion, kind et metadata servent le même but que tout autre fichier de configuration. Le champ spec, cependant, contient certains nouveaux champs.
spec.storageClassNameindique le nom de la classe pour ce volume. Supposons qu'un fournisseur de cloud ait trois types de stockage disponibles. Ceux-ci peuvent être lent, rapide et très rapide. Le type de stockage que vous obtenez du fournisseur dépendra du montant d'argent que vous payez. Si vous demandez un stockage très rapide, vous devrez payer plus. Ces différents types de stockage sont les classes. J'utilisemanualcomme exemple ici. Vous pouvez utiliser ce que vous voulez dans votre cluster local.spec.capacity.storageest la quantité de stockage que ce volume aura. Je lui donne 5 gigaoctets de stockage dans ce projet.spec.accessModesdéfinit le mode d'accès pour le volume. Il existe trois modes d'accès possibles.ReadWriteOncesignifie que le volume peut être monté en lecture-écriture par un seul nœud.ReadWriteManysignifie que le volume peut être monté en lecture-écriture par plusieurs nœuds.ReadOnlyManysignifie que le volume peut être monté en lecture seule par plusieurs nœuds.spec.hostPathest quelque chose de spécifique au développement. Il indique le répertoire dans votre cluster local à nœud unique qui sera traité comme un volume persistant./mnt/datasignifie que les données sauvegardées dans ce volume persistant vivront à l'intérieur du répertoire/mnt/datadans le cluster.
Pour appliquer ce fichier, exécutez la commande suivante :
kubectl apply -f database-persistent-volume.yaml
# persistentvolume/database-persistent-volume created
Maintenant, utilisez la commande get pour vérifier que le volume a été créé :
kubectl get persistentvolume
# NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
# database-persistent-volume 5Gi RWO Retain Available manual 58s
Maintenant que le volume persistant a été créé, vous avez besoin d'un moyen pour permettre au pod postgres d'y accéder. C'est là qu'intervient un PersistentVolumeClaim (PVC).
Un PersistentVolumeClaim est une demande de stockage par un pod. Supposons que dans un cluster, vous avez beaucoup de volumes. Cette revendication définira les caractéristiques qu'un volume doit remplir pour pouvoir satisfaire les nécessités d'un pod.
Un exemple concret peut être que vous achetez un SSD dans un magasin. Vous allez au magasin et le vendeur vous montre les modèles suivants :
| Modèle 1 | Modèle 2 | Modèle 3 |
| 128GB | 256GB | 512GB |
| SATA | NVME | SATA |
Maintenant, vous demandez un modèle qui a au moins 200 Go de capacité de stockage et est un lecteur NVME.
Le premier a moins de 200 Go et est SATA, donc il ne correspond pas à votre demande. Le troisième a plus de 200 Go, mais n'est pas NVME. Le deuxième, cependant, a plus de 200 Go et est également un NVME. C'est donc celui que vous obtenez.
Les modèles de SSD que le vendeur vous a montrés sont équivalents aux volumes persistants et vos exigences sont équivalentes aux revendications de volumes persistants.
Créez un autre nouveau fichier appelé database-persistent-volume-claim.yaml à l'intérieur du répertoire k8s et mettez le contenu suivant dans ce fichier :
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: database-persistent-volume-claim
spec:
storageClassName: manual
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2Gi
Encore une fois, les champs apiVersion, kind et metadata servent le même but que tout autre fichier de configuration.
spec.storageClassdans un fichier de configuration de revendication indique le type de stockage que cette revendication souhaite. Cela signifie que toutPersistentVolumequi aspec.storageClassdéfini surmanualest adapté pour être consommé par cette revendication. Si vous avez plusieurs volumes avec la classemanual, la revendication obtiendra l'un d'eux et si vous n'avez aucun volume avec la classemanual— un volume sera provisionné dynamiquement.spec.accessModesdéfinit à nouveau le mode d'accès ici. Cela indique que cette revendication souhaite un stockage qui a unaccessModedeReadWriteOnce. Supposons que vous avez deux volumes avec la classe définie surmanual. L'un d'eux a sonaccessModesdéfini surReadWriteOnceet l'autre surReadWriteMany. Cette revendication obtiendra celui avecReadWriteOnce.resources.requests.storageest la quantité de stockage que cette revendication souhaite.2Gine signifie pas que le volume donné doit avoir exactement 2 gigaoctets de capacité de stockage. Cela signifie qu'il doit avoir au moins 2 gigaoctets. J'espère que vous vous souvenez que vous avez défini la capacité du volume persistant à 5 gigaoctets, ce qui est plus que 2 gigaoctets.
Pour appliquer ce fichier, exécutez la commande suivante :
kubectl apply -f database-persistent-volume-claim.yaml
# persistentvolumeclaim/database-persistent-volume-claim created
Maintenant, utilisez la commande get pour vérifier que le volume a été créé :
kubectl get persistentvolumeclaim
# NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
# database-persistent-volume-claim Bound database-persistent-volume 5Gi RWO manual 37s
Regardez la colonne VOLUME. Cette revendication est liée au volume persistant database-persistent-volume que vous avez créé précédemment. Regardez également la colonne CAPACITY. Elle est de 5Gi, car la revendication a demandé un volume avec au moins 2 gigaoctets de capacité de stockage.
Provisionnement dynamique des volumes persistants
Dans la sous-section précédente, vous avez créé un volume persistant puis créé une revendication. Mais, que se passe-t-il s'il n'y a aucun volume persistant provisionné au préalable ?
Dans de tels cas, un volume persistant compatible avec la revendication sera provisionné automatiquement.
Pour commencer cette démonstration, supprimez le volume persistant et la revendication de volume persistant précédemment créés avec les commandes suivantes :
kubectl delete persistentvolumeclaim --all
# persistentvolumeclaim "database-persistent-volume-claim" deleted
kubectl delete persistentvolumeclaim --all
# persistentvolume "database-persistent-volume" deleted
Ouvrez le fichier database-persistent-volume-claim.yaml et mettez à jour son contenu pour qu'il soit comme suit :
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: database-persistent-volume-claim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2Gi
J'ai supprimé le champ spec.storageClass du fichier. Maintenant, réappliquez le fichier database-persistent-volume-claim.yaml sans appliquer le fichier database-persistent-volume.yaml :
kubectl apply -f database-persistent-volume-claim.yaml
# persistentvolumeclaim/database-persistent-volume-claim created
Maintenant, utilisez la commande get pour regarder les informations de la revendication :
kubectl get persistentvolumeclaim
# NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
# database-persistent-volume-claim Bound pvc-525ae8af-00d3-4cc7-ae47-866aa13dffd5 2Gi RWO standard 2s
Comme vous pouvez le voir, un volume avec le nom pvc-525ae8af-00d3-4cc7-ae47-866aa13dffd5 et une capacité de stockage de 2Gi a été provisionné et lié à la revendication de manière dynamique.
Vous pouvez utiliser un volume persistant provisionné de manière statique ou dynamique pour le reste de ce projet. J'utiliserai un volume provisionné de manière dynamique.
Connecter les volumes avec les pods
Maintenant que vous avez créé un volume persistant et une revendication, il est temps de permettre au pod de base de données d'utiliser ce volume.
Vous faites cela en connectant le pod à la revendication de volume persistant que vous avez faite dans la sous-section précédente. Ouvrez le fichier postgres-deployment.yaml et mettez à jour son contenu pour qu'il soit comme suit :
apiVersion: apps/v1
kind: Deployment
metadata:
name: postgres-deployment
spec:
replicas: 1
selector:
matchLabels:
component: postgres
template:
metadata:
labels:
component: postgres
spec:
# configuration du volume pour le pod
volumes:
- name: postgres-storage
persistentVolumeClaim:
claimName: database-persistent-volume-claim
containers:
- name: postgres
image: fhsinchy/notes-postgres
ports:
- containerPort: 5432
# configuration du montage du volume pour le conteneur
volumeMounts:
- name: postgres-storage
mountPath: /var/lib/postgresql/data
subPath: postgres
env:
- name: POSTGRES_PASSWORD
value: 63eaQB9wtLqmNBpg
- name: POSTGRES_DB
value: notesdb
J'ai ajouté deux nouveaux champs dans ce fichier de configuration.
- Le champ
spec.volumescontient les informations nécessaires pour que le pod trouve la revendication de volume persistant.spec.volumes.namepeut être n'importe quoi que vous voulez.spec.volumes.persistentVolumeClaim.claimNamedoit correspondre à la valeurmetadata.namedu fichierdatabase-persistent-volume-claim.yaml. containers.volumeMountscontient les informations nécessaires pour monter le volume à l'intérieur du conteneur.containers.volumeMounts.namedoit correspondre à la valeur despec.volumes.name.containers.volumeMounts.mountPathindique le répertoire où ce volume sera monté./var/lib/postgresql/dataest le répertoire de données par défaut pour PostgreSQL.containers.volumeMounts.subPathindique un répertoire qui sera créé à l'intérieur du volume. Supposons que vous utilisez le même volume avec d'autres pods également. Dans ce cas, vous pouvez mettre des données spécifiques au pod à l'intérieur d'un autre répertoire à l'intérieur de ce volume. Toutes les données sauvegardées à l'intérieur du répertoire/var/lib/postgresql/datairont à l'intérieur d'un répertoirepostgresdans le volume.
Maintenant, réappliquez le fichier postgres-deployment.yaml en exécutant la commande suivante :
kubectl apply -f postgres-deployment.yaml
# deployment.apps/postgres-deployment configured
Maintenant, vous avez un déploiement de base de données approprié avec un risque beaucoup plus faible de perte de données.
Une chose que je voudrais mentionner ici est que le déploiement de la base de données dans ce projet n'a qu'un seul réplica. S'il y avait plus d'un réplica, les choses auraient été différentes.
Plusieurs pods accédant au même volume sans qu'ils ne connaissent l'existence des autres peuvent entraîner des résultats catastrophiques. Dans de tels cas, la création de sous-répertoires pour les pods à l'intérieur de ce volume peut être une bonne idée.
Relier tout ensemble
Maintenant que vous avez à la fois l'API et la base de données en cours d'exécution, il est temps de terminer certaines affaires inachevées et de configurer la mise en réseau.
Vous avez déjà appris dans les sections précédentes que pour configurer la mise en réseau dans Kubernetes, vous utilisez des services. Avant de commencer à écrire les services, jetez un coup d'œil au plan de mise en réseau que j'ai pour ce projet.

- La base de données ne sera exposée qu'à l'intérieur du cluster en utilisant un service
ClusterIP. Aucun trafic externe ne sera autorisé. - Le déploiement de l'API, cependant, sera exposé au monde extérieur. Les utilisateurs communiqueront avec l'API et l'API communiquera avec la base de données.
Vous avez précédemment travaillé avec un service LoadBalancer qui expose une application au monde extérieur. Le ClusterIP, en revanche, expose une application à l'intérieur du cluster et n'autorise aucun trafic extérieur.

Étant donné que le service de base de données doit être disponible uniquement à l'intérieur du cluster, un service ClusterIP est le choix parfait pour ce scénario.
Créez un nouveau fichier appelé postgres-cluster-ip-service.yaml à l'intérieur du répertoire k8s et mettez le contenu suivant dedans :
apiVersion: v1
kind: Service
metadata:
name: postgres-cluster-ip-service
spec:
type: ClusterIP
selector:
component: postgres
ports:
- port: 5432
targetPort: 5432
Comme vous pouvez le voir, le fichier de configuration pour un ClusterIP est identique à celui pour un LoadBalancer. La seule chose qui diffère est la valeur spec.type.
Vous devriez être capable d'interpréter ce fichier sans aucun problème maintenant. 5432 est le port par défaut sur lequel PostgreSQL s'exécute. C'est pourquoi ce port doit être exposé.
Le fichier de configuration suivant est pour le service LoadBalancer, responsable de l'exposition de l'API au monde extérieur. Créez un autre fichier appelé api-load-balancer-service.yaml et mettez le contenu suivant dedans :
apiVersion: v1
kind: Service
metadata:
name: api-load-balancer-service
spec:
type: LoadBalancer
ports:
- port: 3000
targetPort: 3000
selector:
component: api
Cette configuration est identique à celle que vous avez écrite dans une section précédente. L'API s'exécute sur le port 3000 à l'intérieur du conteneur et c'est pourquoi ce port doit être exposé.
La dernière chose à faire est d'ajouter le reste des variables d'environnement au déploiement de l'API. Donc, ouvrez le fichier api-deployment.yaml et mettez à jour son contenu comme ceci :
apiVersion: apps/v1
kind: Deployment
metadata:
name: api-deployment
spec:
replicas: 3
selector:
matchLabels:
component: api
template:
metadata:
labels:
component: api
spec:
containers:
- name: api
image: fhsinchy/notes-api
ports:
- containerPort: 3000
env:
- name: DB_CONNECTION
value: pg
- name: DB_HOST
value: postgres-cluster-ip-service
- name: DB_PORT
value: '5432'
- name: DB_USER
value: postgres
- name: DB_DATABASE
value: notesdb
- name: DB_PASSWORD
value: 63eaQB9wtLqmNBpg
Auparavant, il n'y avait que la variable DB_CONNECTION sous spec.containers.env. Les nouvelles variables sont les suivantes :
DB_HOSTindique l'adresse hôte pour le service de base de données. Dans un environnement non conteneurisé, la valeur est généralement127.0.0.1. Mais dans un environnement Kubernetes, vous ne connaissez pas l'adresse IP du pod de la base de données. Vous utilisez donc simplement le nom du service qui expose la base de données.DB_PORTest le port exposé par le service de base de données, qui est 5432.DB_USERest l'utilisateur pour se connecter à la base de données.postgresest le nom d'utilisateur par défaut.DB_DATABASEest la base de données à laquelle l'API se connectera. Cela doit correspondre à la valeurspec.containers.env.DB_DATABASEdu fichierpostgres-deployment.yaml.DB_PASSWORDest le mot de passe pour se connecter à la base de données. Cela doit correspondre à la valeurspec.containers.env.DB_PASSWORDdu fichierpostgres-deployment.yaml.
Avec cela fait, vous êtes maintenant prêt à tester l'API. Avant de le faire, je vous suggère d'appliquer tous les fichiers de configuration une fois de plus en exécutant la commande suivante :
kubectl apply -f k8s
# deployment.apps/api-deployment created
# service/api-load-balancer-service created
# persistentvolumeclaim/database-persistent-volume-claim created
# service/postgres-cluster-ip-service created
# deployment.apps/postgres-deployment created
Si vous rencontrez des erreurs, supprimez simplement toutes les ressources et réappliquez les fichiers. Les services, les volumes persistants et les revendications de volumes persistants doivent être créés instantanément.
Utilisez la commande get pour vous assurer que les déploiements sont tous opérationnels :
kubectl get deployment
# NAME READY UP-TO-DATE AVAILABLE AGE
# api-deployment 3/3 3 3 106s
# postgres-deployment 1/1 1 1 106s
Comme vous pouvez le voir dans la colonne READY, tous les pods sont opérationnels. Pour accéder à l'API, utilisez la commande service pour minikube.
minikube service api-load-balancer-service
# |-----------|---------------------------|-------------|-----------------------------|
# | NAMESPACE | NAME | TARGET PORT | URL |
# |-----------|---------------------------|-------------|-----------------------------|
# | default | api-load-balancer-service | 3000 | http://172.19.186.112:31546 |
# |-----------|---------------------------|-------------|-----------------------------|
# 🎉 Opening service default/api-load-balancer-service in default browser...
L'API devrait s'ouvrir automatiquement dans votre navigateur par défaut :

C'est la réponse par défaut pour l'API. Vous pouvez également utiliser http://172.19.186.112:31546/ avec un outil de test d'API comme Insomnia ou Postman pour tester l'API. L'API a une fonctionnalité CRUD complète.
Vous pouvez voir les tests qui accompagnent le code source de l'API comme documentation. Il suffit d'ouvrir le fichier api/tests/e2e/api/routes/notes.test.js. Vous devriez être capable de comprendre le fichier sans trop de difficulté si vous avez de l'expérience avec JavaScript et express.
Travailler avec les contrôleurs d'entrée
Jusqu'à présent dans cet article, vous avez utilisé ClusterIP pour exposer une application au sein du cluster et LoadBalancer pour exposer une application à l'extérieur du cluster.
Bien que j'aie cité LoadBalancer comme le type de service standard pour exposer une application à l'extérieur du cluster, il présente certains inconvénients.
Lorsque vous utilisez des services LoadBalancer pour exposer des applications dans un environnement cloud, vous devrez payer pour chaque service exposé individuellement, ce qui peut être coûteux dans le cas de grands projets.
Il existe un autre type de service appelé NodePort qui peut être utilisé comme alternative aux services de type LoadBalancer.

NodePort ouvre un port spécifique sur tous les nœuds de votre cluster et gère tout le trafic qui passe par ce port ouvert.
Comme vous le savez déjà, les services regroupent un certain nombre de pods et contrôlent la manière dont ils peuvent être accessibles. Ainsi, toute requête qui atteint le service via le port exposé aboutira dans le pod correct.
Un exemple de fichier de configuration pour créer un NodePort peut être le suivant :
apiVersion: v1
kind: Service
metadata:
name: hello-kube-node-port
spec:
type: NodePort
ports:
- port: 8080
targetPort: 8080
nodePort: 31515
selector:
component: web
Le champ spec.ports.nodePort ici doit avoir une valeur comprise entre 30000 et 32767. Cette plage est en dehors des ports bien connus généralement utilisés par divers services mais est également inhabituelle. Je veux dire, combien de fois voyez-vous un port avec autant de chiffres ?
Vous pouvez essayer de remplacer les services
LoadBalancerque vous avez créés dans les sections précédentes par un serviceNodePort. Cela ne devrait pas être difficile et peut être traité comme un test pour ce que vous avez appris jusqu'à présent.
Pour résoudre les problèmes que j'ai mentionnés, l'API Ingress a été créée. Pour être très clair, Ingress n'est en fait pas un type de service. Au lieu de cela, il se place devant plusieurs services et agit comme une sorte de routeur.
Un IngressController est nécessaire pour travailler avec les ressources Ingress dans votre cluster. Une liste des contrôleurs d'entrée disponibles peut être trouvée dans la documentation de Kubernetes.
Configuration du contrôleur d'entrée NGINX
Dans cet exemple, vous allez étendre l'API de notes en ajoutant un front-end. Et au lieu d'utiliser un service comme LoadBalancer ou NodePort, vous allez utiliser Ingress pour exposer l'application.
Le contrôleur que vous allez utiliser est le NGINX Ingress Controller car NGINX sera utilisé pour router les requêtes vers différents services ici. Le NGINX Ingress Controller facilite grandement le travail avec les configurations NGINX dans un cluster Kubernetes.
Le code du projet se trouve dans le répertoire fullstack-notes-application.
.
├── api
├── client
├── docker-compose.yaml
├── k8s
│ ├── api-deployment.yaml
│ ├── database-persistent-volume-claim.yaml
│ ├── postgres-cluster-ip-service.yaml
│ └── postgres-deployment.yaml
├── nginx
└── postgres
5 directories, 1 file
Vous verrez un répertoire k8s là. Il contient tous les fichiers de configuration que vous avez écrits dans la dernière sous-section, à l'exception du fichier api-load-balancer-service.yaml.
La raison en est que, dans ce projet, l'ancien service LoadBalancer sera remplacé par un Ingress. De plus, au lieu d'exposer l'API, vous allez exposer l'application front-end au monde.
Avant de commencer à écrire les nouveaux fichiers de configuration, jetez un coup d'œil à la manière dont les choses vont fonctionner en coulisses.

Un utilisateur visite l'application front-end et soumet les données nécessaires. L'application front-end transmet ensuite les données soumises à l'API back-end.
L'API persiste ensuite les données dans la base de données et les renvoie également à l'application front-end. Ensuite, le routage des requêtes est réalisé en utilisant NGINX.
Vous pouvez consulter le fichier nginx/production.conf pour comprendre comment ce routage a été configuré.
Maintenant, la mise en réseau nécessaire pour que cela se produise est la suivante :

Ce diagramme peut être expliqué comme suit :
- L'
Ingressagira comme le point d'entrée et le routeur pour cette application. Il s'agit d'unIngressde typeNGINX, donc le port sera le port nginx par défaut, qui est 80. - Chaque requête qui arrive à
/sera routée vers l'application front-end (le service de gauche). Donc si l'URL de cette application esthttps://kube-notes.test, alors toute requête venant àhttps://kube-notes.test/fooouhttps://kube-notes.test/barsera gérée par l'application front-end. - Chaque requête qui arrive à
/apisera routée vers l'API back-end (le service de droite). Donc si l'URL est à nouveauhttps://kube-notes.test, alors toute requête venant àhttps://kube-notes.test/api/fooouhttps://kube-notes.test/api/barsera gérée par l'API back-end.
Il était tout à fait possible de configurer le service Ingress pour qu'il fonctionne avec des sous-domaines au lieu de chemins comme celui-ci, mais j'ai choisi l'approche basée sur les chemins car c'est ainsi que mon application est conçue.
Dans cette sous-section, vous devrez écrire quatre nouveaux fichiers de configuration.
- Configuration
ClusterIPpour le déploiement de l'API. - Configuration
Deploymentpour l'application front-end. - Configuration
ClusterIPpour l'application front-end. - Configuration
Ingresspour le routage.
Je vais passer rapidement les trois premiers fichiers sans passer beaucoup de temps à les expliquer.
Le premier est la configuration api-cluster-ip-service.yaml et le contenu du fichier est le suivant :
apiVersion: v1
kind: Service
metadata:
name: api-cluster-ip-service
spec:
type: ClusterIP
selector:
component: api
ports:
- port: 3000
targetPort: 3000
Bien que dans la sous-section précédente vous ayez exposé l'API directement au monde extérieur, dans celle-ci, vous allez laisser l'Ingress faire le gros du travail tout en exposant l'API en interne en utilisant un bon vieux service ClusterIP.
La configuration elle-même devrait être assez explicite à ce stade, donc je ne vais pas passer de temps à l'expliquer.
Ensuite, créez un fichier nommé client-deployment.yaml responsable de l'exécution de l'application front-end. Le contenu du fichier est le suivant :
apiVersion: apps/v1
kind: Deployment
metadata:
name: client-deployment
spec:
replicas: 3
selector:
matchLabels:
component: client
template:
metadata:
labels:
component: client
spec:
containers:
- name: client
image: fhsinchy/notes-client
ports:
- containerPort: 8080
env:
- name: VUE_APP_API_URL
value: /api
Il est presque identique au fichier api-deployment.yaml et j'espère que vous serez capable d'interpréter ce fichier de configuration par vous-même.
La variable d'environnement VUE_APP_API_URL ici indique le chemin vers lequel les requêtes API doivent être transférées. Ces requêtes transférées seront à leur tour gérées par l'Ingress.
Pour exposer cette application client en interne, un autre service ClusterIP est nécessaire. Créez un nouveau fichier appelé client-cluster-ip-service.yaml et mettez le contenu suivant dedans :
apiVersion: v1
kind: Service
metadata:
name: client-cluster-ip-service
spec:
type: ClusterIP
selector:
component: client
ports:
- port: 8080
targetPort: 8080
Tout ce que cela fait est d'exposer le port 8080 à l'intérieur du cluster sur lequel l'application front-end s'exécute par défaut.
Maintenant que les anciennes configurations ennuyeuses sont terminées, la configuration suivante est le fichier ingress-service.yaml et le contenu du fichier est le suivant :
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-service
annotations:
kubernetes.io/ingress.class: nginx
nginx.ingress.kubernetes.io/rewrite-target: /$1
spec:
rules:
- http:
paths:
- pathType: Prefix
path: "/?(.*)"
backend:
service:
name: client-cluster-ip-service
port:
number: 8080
- pathType: Prefix
path: "/api/?(.*)"
backend:
service:
name: api-cluster-ip-service
port:
number: 3000
Ce fichier de configuration peut sembler assez inhabituel pour vous, mais il est en fait assez simple.
- L'API
Ingressest encore en phase bêta, donc laapiVersionestextensions/v1. - Les champs
kindetmetadata.nameservent le même but que n'importe laquelle des configurations que vous avez écrites précédemment. metadata.annotationspeut contenir des informations concernant la configurationIngress. Lekubernetes.io/ingress.class: nginxindique que l'objetIngressdoit être contrôlé par le contrôleuringress-nginx.nginx.ingress.kubernetes.io/rewrite-targetindique que vous souhaitez réécrire la cible de l'URL à certains endroits.spec.rules.http.pathscontient la configuration concernant les routages de chemins individuels que vous avez précédemment vus à l'intérieur du fichiernginx/production.conf. Lepaths.pathTypecorrespond au type de chemin. Par défaut, il estPrefixdans NGINX. Le champpaths.pathindique le chemin qui doit être routé.backend.serviceNameest le service vers lequel le chemin mentionné ci-dessus doit être routé etbackend.servicePortest le port cible à l'intérieur de ce service./?(.*)et/api/?(.*)sont des regex simples qui signifient que la partie?(.*)sera routée vers les services désignés.
La manière dont vous configurez les réécritures peut changer de temps en temps, donc consulter la documentation officielle docs serait une bonne idée.
Avant d'appliquer les nouvelles configurations, vous devrez activer l'addon ingress pour minikube en utilisant la commande addons. La syntaxe générique est la suivante :
minikube addons <option> <nom de l'addon>
Pour activer l'addon ingress, exécutez la commande suivante :
minikube addons enable ingress
# 🎉 Vérification de l'addon ingress...
# 🎉 L'addon 'ingress' est activé
Vous pouvez utiliser l'option disable pour la commande addon pour désactiver n'importe quel addon. Vous pouvez en apprendre davantage sur la commande addon dans la documentation officielle docs.
Une fois que l'addon a été activé, vous pouvez appliquer les fichiers de configuration. Je vous suggère de supprimer toutes les ressources (services, déploiements et revendications de volumes persistants) avant d'appliquer les nouvelles.
kubectl delete ingress --all
# ingress.extensions "ingress-service" deleted
kubectl delete service --all
# service "api-cluster-ip-service" deleted
# service "client-cluster-ip-service" deleted
# service "kubernetes" deleted
# service "postgres-cluster-ip-service" deleted
kubectl delete deployment --all
# deployment.apps "api-deployment" deleted
# deployment.apps "client-deployment" deleted
# deployment.apps "postgres-deployment" deleted
kubectl delete persistentvolumeclaim --all
# persistentvolumeclaim "database-persistent-volume-claim" deleted
kubectl apply -f k8s
# service/api-cluster-ip-service created
# deployment.apps/api-deployment created
# service/client-cluster-ip-service created
# deployment.apps/client-deployment created
# persistentvolumeclaim/database-persistent-volume-claim created
# ingress.extensions/ingress-service created
# service/postgres-cluster-ip-service created
# deployment.apps/postgres-deployment created
Attendez que toutes les ressources aient été créées. Vous pouvez utiliser la commande get pour vous en assurer. Une fois qu'elles sont toutes en cours d'exécution, vous pouvez accéder à l'application à l'adresse IP du cluster minikube. Pour obtenir l'IP, vous pouvez exécuter la commande suivante :
minikube ip
# 172.17.0.2
Vous pouvez également obtenir cette adresse IP en inspectant l'Ingress :
kubectl get ingress
# NAME CLASS HOSTS ADDRESS PORTS AGE
# ingress-service <none> * 172.17.0.2 80 2m33s
Comme vous pouvez le voir, l'IP et le port sont visibles sous les colonnes ADDRESS et PORTS. En accédant à 127.17.0.2:80, vous devriez atterrir directement sur l'application de notes.

Vous pouvez effectuer des opérations CRUD simples dans cette application. Le port 80 est le port par défaut pour NGINX, donc vous n'avez pas besoin d'écrire le numéro de port dans l'URL.
Vous pouvez faire beaucoup de choses avec ce contrôleur d'entrée si vous savez comment configurer NGINX. Après tout, c'est à cela que sert ce contrôleur — stocker les configurations NGINX sur une ConfigMap Kubernetes, que vous apprendrez dans la prochaine sous-section.
Secrets et Config Maps dans Kubernetes
Jusqu'à présent dans vos déploiements, vous avez stocké des informations sensibles telles que POSTGRES_PASSWORD en texte brut, ce qui n'est pas une très bonne idée.
Pour stocker de telles valeurs dans votre cluster, vous pouvez utiliser un Secret, qui est une méthode beaucoup plus sécurisée pour stocker des mots de passe, des jetons, etc.
L'étape suivante peut ne pas fonctionner de la même manière dans la ligne de commande Windows. Vous pouvez utiliser git bash ou cmder pour la tâche.
Pour stocker des informations dans un Secret, vous devez d'abord passer vos données par base64. Si le mot de passe en texte brut est 63eaQB9wtLqmNBpg, exécutez la commande suivante pour obtenir une version encodée en base64 :
echo -n "63eaQB9wtLqmNBpg" | base64
# NjNlYVFCOXd0THFtTkJwZw==
Cette étape n'est pas optionnelle, vous devez passer la chaîne de texte brut par base64. Maintenant, créez un fichier nommé postgres-secret.yaml à l'intérieur du répertoire k8s et mettez le contenu suivant dedans :
apiVersion: v1
kind: Secret
metadata:
name: postgres-secret
data:
password: NjNlYVFCOXd0THFtTkJwZw==
Les champs apiVersion, kind et metadata sont assez explicites. Le champ data contient le secret réel.
Comme vous pouvez le voir, j'ai créé une paire clé-valeur où la clé est password et la valeur est NjNlYVFCOXd0THFtTkJwZw==. Vous utiliserez la valeur metadata.name pour identifier ce Secret dans d'autres fichiers de configuration et la clé pour accéder à la valeur du mot de passe.
Maintenant, pour utiliser ce secret à l'intérieur de votre configuration de base de données, mettez à jour le fichier postgres-deployment.yaml comme suit :
apiVersion: apps/v1
kind: Deployment
metadata:
name: postgres-deployment
spec:
replicas: 1
selector:
matchLabels:
component: postgres
template:
metadata:
labels:
component: postgres
spec:
volumes:
- name: postgres-storage
persistentVolumeClaim:
claimName: database-persistent-volume-claim
containers:
- name: postgres
image: fhsinchy/notes-postgres
ports:
- containerPort: 5432
volumeMounts:
- name: postgres-storage
mountPath: /var/lib/postgresql/data
subPath: postgres
env:
# ne mettant plus le mot de passe directement
- name: POSTGRES_PASSWORD
valueFrom:
secretKeyRef:
name: postgres-secret
key: password
- name: POSTGRES_DB
value: notesdb
Comme vous pouvez le voir, l'ensemble du fichier est le même sauf le champ spec.template.spec.continers.env.
La variable d'environnement name utilisée pour stocker la valeur du mot de passe était en texte brut auparavant. Mais maintenant, il y a un nouveau champ valueFrom.secretKeyRef.
Le champ name ici fait référence au nom du Secret que vous avez créé il y a quelques instants, et la valeur key fait référence à la clé de la paire clé-valeur dans ce fichier de configuration Secret. La valeur encodée sera décodée en texte brut en interne par Kubernetes.
En plus de la configuration de la base de données, vous devrez également mettre à jour le fichier api-deployment.yaml comme suit :
apiVersion: apps/v1
kind: Deployment
metadata:
name: api-deployment
spec:
replicas: 3
selector:
matchLabels:
component: api
template:
metadata:
labels:
component: api
spec:
containers:
- name: api
image: fhsinchy/notes-api
ports:
- containerPort: 3000
env:
- name: DB_CONNECTION
value: pg
- name: DB_HOST
value: postgres-cluster-ip-service
- name: DB_PORT
value: '5432'
- name: DB_USER
value: postgres
- name: DB_DATABASE
value: notesdb
# ne mettant plus le mot de passe directement
- name: DB_PASSWORD
valueFrom:
secretKeyRef:
name: postgres-secret
key: password
Maintenant, appliquez toutes ces nouvelles configurations en exécutant la commande suivante :
kubectl apply -f k8s
# service/api-cluster-ip-service created
# deployment.apps/api-deployment created
# service/client-cluster-ip-service created
# deployment.apps/client-deployment created
# persistentvolumeclaim/database-persistent-volume-claim created
# secret/postgres-secret created
# ingress.extensions/ingress-service created
# service/postgres-cluster-ip-service created
# deployment.apps/postgres-deployment created
Selon l'état de votre cluster, vous pouvez voir un ensemble de sortie différent.
En cas de problème, supprimez toutes les ressources Kubernetes et recréez-les en appliquant les configurations.
Utilisez la commande get pour inspecter et vous assurer que tous les pods sont opérationnels.
Maintenant, pour tester la nouvelle configuration, accédez à l'application de notes en utilisant l'IP de minikube et essayez de créer de nouvelles notes. Pour obtenir l'IP, vous pouvez exécuter la commande suivante :
minikube ip
# 172.17.0.2
En accédant à 127.17.0.2:80, vous devriez atterrir directement sur l'application de notes.

Il existe une autre façon de créer des secrets sans aucun fichier de configuration. Pour créer le même Secret en utilisant kubectl, exécutez la commande suivante :
kubectl create secret generic postgres-secret --from-literal=password=63eaQB9wtLqmNBpg
# secret/postgres-secret created
C'est une approche plus pratique car vous pouvez sauter toute l'étape de codage en base64. Le secret dans ce cas sera codé automatiquement.
Un ConfigMap est similaire à un Secret mais est destiné à être utilisé avec des informations non sensibles.
Pour mettre toutes les autres variables d'environnement dans le déploiement de l'API à l'intérieur d'un ConfigMap, créez un nouveau fichier appelé api-config-map.yaml à l'intérieur du répertoire k8s et mettez le contenu suivant dedans :
apiVersion: v1
kind: ConfigMap
metadata:
name: api-config-map
data:
DB_CONNECTION: pg
DB_HOST: postgres-cluster-ip-service
DB_PORT: '5432'
DB_USER: postgres
DB_DATABASE: notesdb
apiVersion, kind et metadata sont à nouveau explicites. Le champ data peut contenir les variables d'environnement sous forme de paires clé-valeur.
Contrairement au Secret, les clés ici doivent correspondre exactement à la clé requise par l'API. Ainsi, j'ai en quelque sorte copié les variables du fichier api-deployment.yaml et les ai collées ici avec une légère modification de la syntaxe.
Pour utiliser ce secret dans le déploiement de l'API, ouvrez le fichier api-deployment.yaml et mettez à jour son contenu comme suit :
apiVersion: apps/v1
kind: Deployment
metadata:
name: api-deployment
spec:
replicas: 3
selector:
matchLabels:
component: api
template:
metadata:
labels:
component: api
spec:
containers:
- name: api
image: fhsinchy/notes-api
ports:
- containerPort: 3000
# ne mettant plus les variables d'environnement directement
envFrom:
- configMapRef:
name: api-config-map
env:
- name: DB_PASSWORD
valueFrom:
secretKeyRef:
name: postgres-secret
key: password
L'ensemble du fichier est presque inchangé sauf le champ spec.template.spec.containers.env.
J'ai déplacé les variables d'environnement vers le ConfigMap. spec.template.spec.containers.envFrom est utilisé pour obtenir des données à partir d'un ConfigMap. configMapRef.name ici indique le ConfigMap à partir duquel les variables d'environnement seront extraites.
Maintenant, appliquez toutes ces nouvelles configurations en exécutant la commande suivante :
kubectl apply -f k8s
# service/api-cluster-ip-service created
# configmap/api-config-map created
# deployment.apps/api-deployment created
# service/client-cluster-ip-service created
# deployment.apps/client-deployment created
# persistentvolumeclaim/database-persistent-volume-claim created
# ingress.extensions/ingress-service configured
# service/postgres-cluster-ip-service created
# deployment.apps/postgres-deployment created
# secret/postgres-secret created
Selon l'état de votre cluster, vous pouvez voir un ensemble de sortie différent.
En cas de problème, supprimez toutes les ressources Kubernetes et recréez-les en appliquant les configurations.
Une fois que vous vous êtes assuré que les pods sont opérationnels en utilisant la commande get, accédez à l'application de notes en utilisant l'IP de minikube et essayez de créer de nouvelles notes.
Pour obtenir l'IP, vous pouvez exécuter la commande suivante :
minikube ip
# 172.17.0.2
En accédant à 127.17.0.2:80, vous devriez atterrir directement sur l'application de notes.
Secret et ConfigMap ont encore quelques tours dans leur manche que je ne vais pas aborder pour l'instant. Mais si vous êtes curieux, vous pouvez consulter la documentation officielle docs.
Effectuer des déploiements de mises à jour dans Kubernetes
Maintenant que vous avez déployé avec succès une application composée de plusieurs conteneurs sur Kubernetes, il est temps d'apprendre à effectuer des mises à jour.
Aussi magique que Kubernetes puisse vous sembler, la mise à jour d'un conteneur vers une version d'image plus récente est un peu fastidieuse. Il existe plusieurs approches que les gens prennent souvent pour mettre à jour un conteneur, mais je ne vais pas toutes les aborder.
Au lieu de cela, je vais passer directement à l'approche que je prends le plus souvent pour mettre à jour mes conteneurs. Si vous ouvrez le fichier client-deployment.yaml et regardez le champ spec.template.spec.containers, vous trouverez quelque chose qui ressemble à ceci :
containers:
- name: client
image: fhsinchy/notes-client
Comme vous pouvez le voir, dans le champ image, je n'ai pas utilisé de tag d'image. Maintenant, si vous pensez qu'ajouter :latest à la fin du nom de l'image garantira que le déploiement tire toujours la dernière image disponible, vous vous trompez complètement.
L'approche que j'utilise généralement est une approche impérative. J'ai déjà mentionné dans une section précédente que, dans quelques cas, utiliser une approche impérative au lieu d'une approche déclarative est une bonne idée. Créer un Secret ou mettre à jour un conteneur est un tel cas.
La commande que vous pouvez utiliser pour effectuer la mise à jour est la commande set, et la syntaxe générique est la suivante :
kubectl set image <type de ressource>/<nom de la ressource> <nom du conteneur>=<nom de l'image avec tag>
Le type de ressource est deployment et le nom de la ressource est client-deployment. Le nom du conteneur peut être trouvé sous le champ containers à l'intérieur du fichier client-deployment.yaml, qui est client dans ce cas.
J'ai déjà construit une version de l'image fhsinchy/notes-client avec un tag edge que j'utiliserai pour mettre à jour ce déploiement.
Donc, la commande finale devrait être la suivante :
kubectl set image deployment/client-deployment client=fhsinchy/notes-client:edge
# deployment.apps/client-deployment image updated
Le processus de mise à jour peut prendre un certain temps, car Kubernetes va recréer tous les pods. Vous pouvez exécuter la commande get pour savoir si tous les pods sont à nouveau opérationnels.
Une fois qu'ils ont tous été recréés, accédez à l'application de notes en utilisant l'IP de minikube et essayez de créer de nouvelles notes. Pour obtenir l'IP, vous pouvez exécuter la commande suivante :
minikube ip
# 172.17.0.2
En accédant à 127.17.0.2:80, vous devriez atterrir directement sur l'application de notes.
Étant donné que je n'ai apporté aucune modification réelle au code de l'application, tout restera le même. Vous pouvez vous assurer que les pods utilisent la nouvelle image en utilisant la commande describe.
kubectl describe pod client-deployment-849bc58bcc-gz26b | grep 'Image'
# Image: fhsinchy/notes-client:edge
# Image ID: docker-pullable://fhsinchy/notes-client@sha256:58bce38c16376df0f6d1320554a56df772e30a568d251b007506fd3b5eb8d7c2
La commande grep est disponible sur Mac et Linux. Si vous êtes sur Windows, utilisez git bash au lieu de la ligne de commande Windows.
Bien que le processus de mise à jour impérative soit un peu fastidieux, il peut être grandement simplifié en utilisant un bon flux de travail CI/CD.
Combiner les configurations
Comme vous l'avez déjà vu, le nombre de fichiers de configuration dans ce projet est assez élevé malgré le fait qu'il ne contient que trois conteneurs.
Vous pouvez en fait combiner des fichiers de configuration comme suit :
apiVersion: apps/v1
kind: Deployment
metadata:
name: client-deployment
spec:
replicas: 3
selector:
matchLabels:
component: client
template:
metadata:
labels:
component: client
spec:
containers:
- name: client
image: fhsinchy/notes-client
ports:
- containerPort: 8080
env:
- name: VUE_APP_API_URL
value: /api
---
apiVersion: v1
kind: Service
metadata:
name: client-cluster-ip-service
spec:
type: ClusterIP
selector:
component: client
ports:
- port: 8080
targetPort: 8080
Comme vous pouvez le voir, j'ai combiné le contenu des fichiers client-deployment.yaml et client-cluster-ip-service.yaml en utilisant un délimiteur (---). Bien que ce soit possible et puisse aider dans les projets où le nombre de conteneurs est très élevé, je recommande de les garder séparés, propres et concis.
Dépannage
Dans cette section, je vais lister certains problèmes courants que vous pourriez rencontrer lors de votre utilisation de Kubernetes.
- Si vous êtes sur Windows ou Mac et utilisez le pilote Docker pour
minikube, le pluginIngressne fonctionnera pas. - Si vous avez Laravel Valet en cours d'exécution sur Mac et utilisez le pilote HyperKit pour
minikube, il échouera à se connecter à Internet. Désactiver le servicednsmasqrésoudra le problème. - Si vous avez un PC Ryzen (le mien est R5 1600) et exécutez Windows 10, le pilote VirtualBox peut échouer à démarrer en raison du manque de support pour la virtualisation imbriquée. Vous devrez utiliser le pilote Hyper-V sur Windows 10 (Pro, Enterprise et Education). Pour les utilisateurs de l'édition Home, malheureusement, il n'y a pas d'option sûre sur ce matériel.
- Si vous exécutez Windows 10 (Pro, Enterprise et Education) avec le pilote Hyper-V pour
minikube, la VM peut échouer à démarrer avec un message concernant une mémoire insuffisante. Ne paniquez pas, et exécutez la commandeminikube startune fois de plus pour démarrer correctement la VM. - Si vous voyez certaines des commandes exécutées dans cet article manquantes ou mal comportées dans la ligne de commande Windows, utilisez git bash ou cmder à la place.
- Si vous êtes sur un Raspberry Pi, mes images ne fonctionneront pas. Utilisez les images construites par Raed Chammam. Les trois images peuvent être trouvées sur son profil Docker Hub. Les instructions concernant la construction d'images pour Raspberry Pi peuvent être trouvées dans ce problème GitHub.
Je vous suggérerais d'installer une bonne distribution Linux sur votre système et d'utiliser le pilote Docker pour minikube. C'est de loin la configuration la plus rapide et la plus fiable.
Conclusion
Je tiens à vous remercier du fond du cœur pour le temps que vous avez passé à lire cet article. J'espère que vous avez apprécié votre temps et que vous avez appris toutes les bases de Kubernetes.
En plus de celui-ci, j'ai écrit des manuels complets sur d'autres sujets compliqués disponibles gratuitement sur freeCodeCamp.
Ces manuels font partie de ma mission de simplifier les technologies difficiles à comprendre pour tout le monde. Chacun de ces manuels prend beaucoup de temps et d'efforts à écrire.
Si vous avez apprécié mon écriture et souhaitez me motiver, envisagez de laisser des étoiles sur GitHub et de m'endosser pour des compétences pertinentes sur LinkedIn. J'accepte également les parrainages, vous pouvez donc envisager de m'offrir un café si vous le souhaitez.
Je suis toujours ouvert aux suggestions et aux discussions sur Twitter ou LinkedIn. Envoyez-moi des messages directs.
Enfin, envisagez de partager les ressources avec les autres, car
Partager les connaissances est l'acte le plus fondamental d'amitié. Parce que c'est une façon de donner quelque chose sans perdre quelque chose. — Richard Stallman
Jusqu'au prochain, restez en sécurité et continuez à apprendre.