

Article original : The AI Chatbot Handbook – How to Build an AI Chatbot with Redis, Python, and GPT
Par Stephen Sanwo
Afin de construire une application full-stack fonctionnelle, il y a tant de parties mobiles à considérer. Et vous devrez prendre de nombreuses décisions qui seront cruciales pour le succès de votre application.
Par exemple, quel langage allez-vous utiliser et sur quelle plateforme allez-vous déployer ? Allez-vous déployer un logiciel conteneurisé sur un serveur, ou utiliser des fonctions serverless pour gérer le backend ? Prévoyez-vous d'utiliser des API tierces pour gérer les parties complexes de votre application, comme l'authentification ou les paiements ? Où allez-vous stocker les données ?
En plus de tout cela, vous devrez également penser à l'interface utilisateur, au design et à l'utilisabilité de votre application, et bien plus encore.
C'est pourquoi les applications complexes et volumineuses nécessitent une équipe de développement multifonctionnelle collaborant pour construire l'application.
L'une des meilleures façons d'apprendre à développer des applications full stack est de construire des projets qui couvrent le processus de développement de bout en bout. Vous passerez par la conception de l'architecture, le développement des services API, le développement de l'interface utilisateur, et enfin le déploiement de votre application.
Ainsi, ce tutoriel vous guidera à travers le processus de construction d'un chatbot IA pour vous aider à apprendre ces concepts en profondeur.
Certains des sujets que nous aborderons incluent :
- Comment construire des API avec Python, FastAPI et WebSockets
- Comment construire des systèmes en temps réel avec Redis
- Comment construire une interface utilisateur de chat avec React
Note Importante : Il s'agit d'un projet de développement logiciel full stack intermédiaire qui nécessite quelques connaissances de base en Python et JavaScript.
J'ai soigneusement divisé le projet en sections pour m'assurer que vous pouvez facilement sélectionner la phase qui vous intéresse au cas où vous ne souhaiteriez pas coder l'application complète.
Vous pouvez télécharger le dépôt complet sur Mon Github ici.
Table des Matières
Section 1
- Architecture de l'Application
- Comment Configurer l'Environnement de Développement
Section 2
- Comment Construire un Serveur de Chat avec Python, FastAPI et WebSockets
- Comment Construire des Systèmes en Temps Réel avec Redis
- Comment Ajouter de l'Intelligence aux Chatbots avec des Modèles IA
- Comment Commencer avec Huggingface
- Comment Interagir avec le Modèle de Langage
- Comment Simuler la Mémoire à Court Terme pour le Modèle IA
- Consommateur de Stream et Extraction de Données en Temps Réel depuis la File de Messages
- Comment Mettre à Jour le Client de Chat avec la Réponse IA
- Rafraîchir le Jeton
- Comment Tester le Chat avec Plusieurs Clients dans Postman
Architecture de l'Application
Esquisser une architecture de solution vous donne une vue d'ensemble de haut niveau de votre application, des outils que vous prévoyez d'utiliser, et de la manière dont les composants communiqueront entre eux.
J'ai dessiné une architecture simple ci-dessous en utilisant draw.io :
 Architecture du chatbot fullstack
Architecture du chatbot fullstack
Passons en revue les différentes parties de l'architecture plus en détail :
Client/Interface Utilisateur
Nous utiliserons React version 18 pour construire l'interface utilisateur. L'interface utilisateur du chat communiquera avec le backend via WebSockets.
GPT-J-6B et API d'Inférence Huggingface
GPT-J-6B est un modèle de langage génératif qui a été entraîné avec 6 milliards de paramètres et performe de manière proche de GPT-3 d'OpenAI sur certaines tâches.
J'ai choisi d'utiliser GPT-J-6B car il s'agit d'un modèle open-source et ne nécessite pas de jetons payants pour des cas d'utilisation simples.
Huggingface nous fournit également une API à la demande pour nous connecter à ce modèle presque gratuitement. Vous pouvez en savoir plus sur GPT-J-6B et Hugging Face Inference API.
Redis
Lorsque nous envoyons des prompts à GPT, nous avons besoin d'un moyen de stocker les prompts et de récupérer facilement la réponse. Nous utiliserons Redis JSON pour stocker les données de chat et utiliserons également Redis Streams pour gérer la communication en temps réel avec l'API d'inférence Huggingface.
Redis est un magasin clé-valeur en mémoire qui permet une récupération et un stockage ultra-rapides de données de type JSON. Pour ce tutoriel, nous utiliserons un stockage Redis géré et gratuit fourni par Redis Enterprise à des fins de test.
Web Sockets et l'API de Chat
Pour envoyer des messages entre le client et le serveur en temps réel, nous devons ouvrir une connexion socket. Cela est dû au fait qu'une connexion HTTP ne sera pas suffisante pour garantir une communication bidirectionnelle en temps réel entre le client et le serveur.
Nous utiliserons FastAPI pour le serveur de chat, car il fournit un serveur Python rapide et moderne pour notre utilisation. Consultez la documentation FastAPI) pour en savoir plus sur les WebSockets.
Comment Configurer l'Environnement de Développement
Vous pouvez utiliser le système d'exploitation de votre choix pour construire cette application – je suis actuellement sous MacOS, et j'utilise Visual Studio Code. Assurez-vous simplement d'avoir Python et NodeJs installés.
Pour configurer la structure du projet, créez un dossier nommé fullstack-ai-chatbot. Ensuite, créez deux dossiers dans le projet appelés client et server. Le serveur contiendra le code pour le backend, tandis que le client contiendra le code pour le frontend.
Ensuite, dans le répertoire du projet, initialisez un dépôt Git dans la racine du dossier du projet en utilisant la commande "git init". Ensuite, créez un fichier .gitignore en utilisant "touch .gitignore" :
git init
touch .gitignore
Dans la section suivante, nous construirons notre serveur web de chat en utilisant FastAPI et Python.
Comment Construire un Serveur de Chat avec Python, FastAPI et WebSockets
Dans cette section, nous construirons le serveur de chat en utilisant FastAPI pour communiquer avec l'utilisateur. Nous utiliserons WebSockets pour garantir une communication bidirectionnelle entre le client et le serveur afin que nous puissions envoyer des réponses à l'utilisateur en temps réel.
Comment Configurer l'Environnement Python
Pour démarrer notre serveur, nous devons configurer notre environnement Python. Ouvrez le dossier du projet dans VS Code, et ouvrez le terminal.
À partir de la racine du projet, accédez au répertoire server et exécutez python3.8 -m venv env. Cela créera un environnement virtuel pour notre projet Python, qui sera nommé env. Pour activer l'environnement virtuel, exécutez source env/bin/activate
Ensuite, installez quelques bibliothèques dans votre environnement Python.
pip install fastapi uuid uvicorn gunicorn WebSockets python-dotenv aioredis
Ensuite, créez un fichier d'environnement en exécutant touch .env dans le terminal. Nous définirons nos variables d'application et nos variables secrètes dans le fichier .env.
Ajoutez votre variable d'environnement d'application et définissez-la sur "development" comme suit : export APP_ENV=development. Ensuite, nous configurerons un serveur de développement avec un serveur FastAPI.
Configuration du Serveur FastAPI
À la racine du répertoire server, créez un nouveau fichier nommé main.py, puis collez le code ci-dessous pour le serveur de développement :
from fastapi import FastAPI, Request
import uvicorn
import os
from dotenv import load_dotenv
load_dotenv()
api = FastAPI()
@api.get("/test")
async def root():
return {"msg": "API is Online"}
if __name__ == "__main__":
if os.environ.get('APP_ENV') == "development":
uvicorn.run("main:api", host="0.0.0.0", port=3500,
workers=4, reload=True)
else:
pass
Tout d'abord, nous import FastAPI et l'initialisons comme api. Ensuite, nous import load_dotenv de la bibliothèque python-dotenv, et l'initialisons pour charger les variables du fichier .env,
Puis nous créons une simple route de test pour tester l'API. La route de test retournera une simple réponse JSON qui nous indique que l'API est en ligne.
Enfin, nous configurons le serveur de développement en utilisant uvicorn.run et en fournissant les arguments requis. L'API s'exécutera sur le port 3500.
Enfin, exécutez le serveur dans le terminal avec python main.py. Une fois que vous voyez Application startup complete dans le terminal, naviguez vers l'URL http://localhost:3500/test sur votre navigateur, et vous devriez obtenir une page web comme celle-ci :
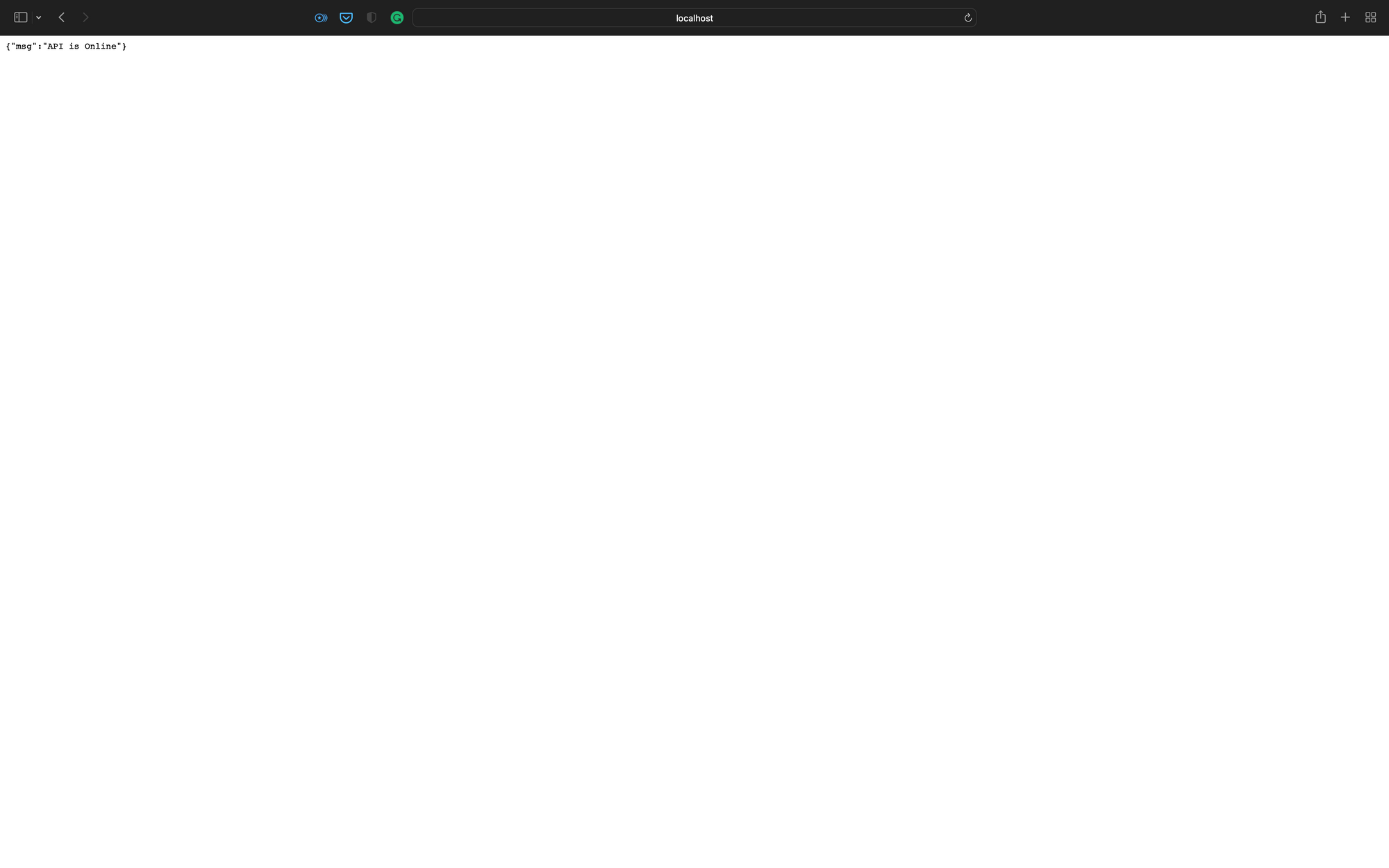 Page de Test de l'API
Page de Test de l'API
Comment Ajouter des Routes à l'API
Dans cette section, nous ajouterons des routes à notre API. Créez un nouveau dossier nommé src. C'est le répertoire où tout notre code API résidera.
Créez un sous-dossier nommé routes, accédez au dossier, créez un nouveau fichier nommé chat.py et ajoutez ensuite le code ci-dessous :
import os
from fastapi import APIRouter, FastAPI, WebSocket, Request
chat = APIRouter()
# @route POST /token
# @desc Route pour générer un jeton de chat
# @access Public
@chat.post("/token")
async def token_generator(request: Request):
return None
# @route POST /refresh_token
# @desc Route pour rafraîchir le jeton
# @access Public
@chat.post("/refresh_token")
async def refresh_token(request: Request):
return None
# @route Websocket /chat
# @desc Socket pour le chatbot
# @access Public
@chat.websocket("/chat")
async def websocket_endpoint(websocket: WebSocket = WebSocket):
return None
Nous avons créé trois endpoints :
/tokendélivrera à l'utilisateur un jeton de session pour accéder à la session de chat. Puisque l'application de chat sera ouverte au public, nous ne voulons pas nous soucier de l'authentification et garder cela simple – mais nous avons toujours besoin d'un moyen d'identifier chaque session utilisateur unique./refresh_tokenobtiendra l'historique de la session pour l'utilisateur si la connexion est perdue, tant que le jeton est toujours actif et non expiré./chatouvrira un WebSocket pour envoyer des messages entre le client et le serveur.
Ensuite, connectez la route de chat à notre API principale. Tout d'abord, nous devons import chat from src.chat dans notre fichier main.py. Ensuite, nous inclurons le routeur en appelant littéralement une méthode include_router sur la classe FastAPI initialisée et en passant chat comme argument.
Mettez à jour votre code api.py comme indiqué ci-dessous :
from fastapi import FastAPI, Request
import uvicorn
import os
from dotenv import load_dotenv
from routes.chat import chat
load_dotenv()
api = FastAPI()
api.include_router(chat)
@api.get("/test")
async def root():
return {"msg": "API is Online"}
if __name__ == "__main__":
if os.environ.get('APP_ENV') == "development":
uvicorn.run("main:api", host="0.0.0.0", port=3500,
workers=4, reload=True)
else:
pass
Comment Générer un Jeton de Session de Chat avec UUID
Pour générer un jeton utilisateur, nous utiliserons uuid4 pour créer des routes dynamiques pour notre endpoint de chat. Puisque cet endpoint est publiquement disponible, nous n'aurons pas besoin d'entrer dans les détails des JWT et de l'authentification.
Si vous n'avez pas installé uuid initialement, exécutez pip install uuid. Ensuite, dans chat.py, importez UUID et mettez à jour la route /token avec le code ci-dessous :
from fastapi import APIRouter, FastAPI, WebSocket, Request, BackgroundTasks, HTTPException
import uuid
# @route POST /token
# @desc Route générant un jeton de chat
# @access Public
@chat.post("/token")
async def token_generator(name: str, request: Request):
if name == "":
raise HTTPException(status_code=400, detail={
"loc": "name", "msg": "Enter a valid name"})
token = str(uuid.uuid4())
data = {"name": name, "token": token}
return data
Dans le code ci-dessus, le client fournit son nom, ce qui est requis. Nous effectuons une vérification rapide pour nous assurer que le champ de nom n'est pas vide, puis générons un jeton en utilisant uuid4.
Les données de session sont un simple dictionnaire pour le nom et le jeton. Finalement, nous aurons besoin de persister ces données de session et de définir un délai d'expiration, mais pour l'instant, nous les retournons simplement au client.
Comment Tester l'API avec Postman
Parce que nous allons tester un endpoint WebSocket, nous devons utiliser un outil comme Postman qui permet cela (car la documentation swagger par défaut sur FastAPI ne supporte pas les WebSockets).
Dans Postman, créez une collection pour votre environnement de développement et envoyez une requête POST à localhost:3500/token en spécifiant le nom comme paramètre de requête et en lui passant une valeur. Vous devriez obtenir une réponse comme indiqué ci-dessous :
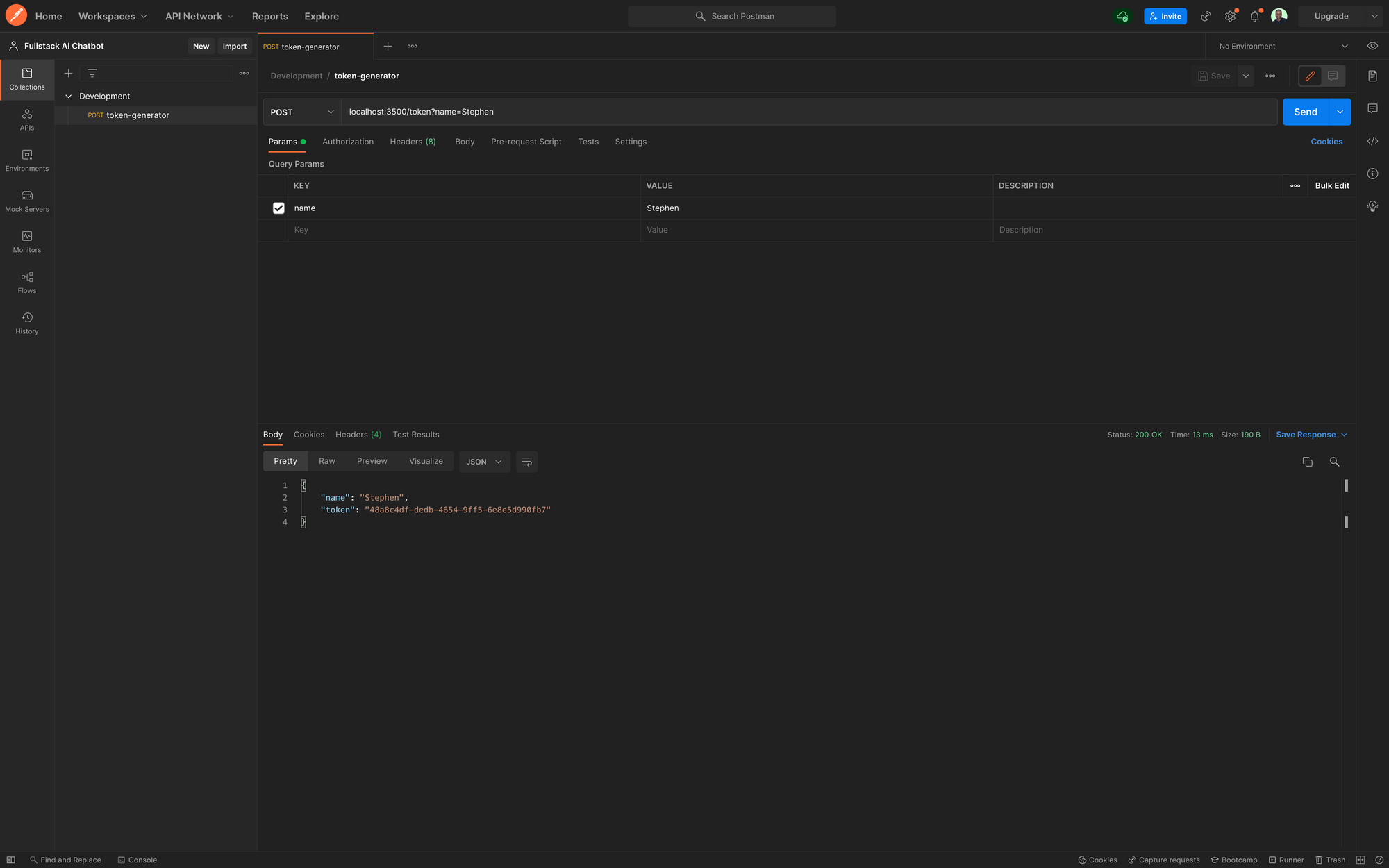 Générateur de Jeton Postman
Générateur de Jeton Postman
Websockets et Gestionnaire de Connexion
Dans la racine src, créez un nouveau dossier nommé socket et ajoutez un fichier nommé connection.py. Dans ce fichier, nous définirons la classe qui contrôle les connexions à nos WebSockets, et toutes les méthodes auxiliaires pour se connecter et se déconnecter.
Dans connection.py, ajoutez le code ci-dessous :
from fastapi import WebSocket
class ConnectionManager:
def __init__(self):
self.active_connections: List[WebSocket] = []
async def connect(self, websocket: WebSocket):
await websocket.accept()
self.active_connections.append(websocket)
def disconnect(self, websocket: WebSocket):
self.active_connections.remove(websocket)
async def send_personal_message(self, message: str, websocket: WebSocket):
await websocket.send_text(message)
La classe ConnectionManager est initialisée avec un attribut active_connections qui est une liste de connexions actives.
Ensuite, la méthode asynchrone connect acceptera un WebSocket et l'ajoutera à la liste des connexions actives, tandis que la méthode disconnect supprimera le Websocket de la liste des connexions actives.
Enfin, la méthode send_personal_message prendra un message et le Websocket auquel nous voulons envoyer le message et enverra le message de manière asynchrone.
Les WebSockets sont un sujet très vaste et nous n'avons fait qu'effleurer la surface ici. Cela devrait cependant être suffisant pour créer plusieurs connexions et gérer les messages vers ces connexions de manière asynchrone.
Vous pouvez en savoir plus sur FastAPI Websockets et Programmation de Sockets.
Pour utiliser le ConnectionManager, importez-le et initialisez-le dans src.routes.chat.py, et mettez à jour la route WebSocket /chat avec le code ci-dessous :
from ..socket.connection import ConnectionManager
manager = ConnectionManager()
@chat.websocket("/chat")
async def websocket_endpoint(websocket: WebSocket):
await manager.connect(websocket)
try:
while True:
data = await websocket.receive_text()
print(data)
await manager.send_personal_message(f"Response: Simulating response from the GPT service", websocket)
except WebSocketDisconnect:
manager.disconnect(websocket)
Dans la fonction websocket_endpoint, qui prend un WebSocket, nous ajoutons le nouveau websocket au gestionnaire de connexion et exécutons une boucle while True, pour nous assurer que le socket reste ouvert. Sauf si le socket se déconnecte.
Pendant que la connexion est ouverte, nous recevons les messages envoyés par le client avec websocket.receive_test() et les imprimons dans le terminal pour l'instant.
Ensuite, nous envoyons une réponse codée en dur au client pour l'instant. Finalement, le message reçu des clients sera envoyé au modèle IA, et la réponse envoyée au client sera la réponse du modèle IA.
Dans Postman, nous pouvons tester cet endpoint en créant une nouvelle requête WebSocket, et en nous connectant à l'endpoint WebSocket localhost:3500/chat.
Lorsque vous cliquez sur connecter, le panneau Messages montrera que le client API est connecté à l'URL, et qu'un socket est ouvert.
Pour tester cela, envoyez un message "Hello Bot" au serveur de chat, et vous devriez obtenir une réponse de test immédiate "Response: Simulating response from the GPT service" comme montré ci-dessous :
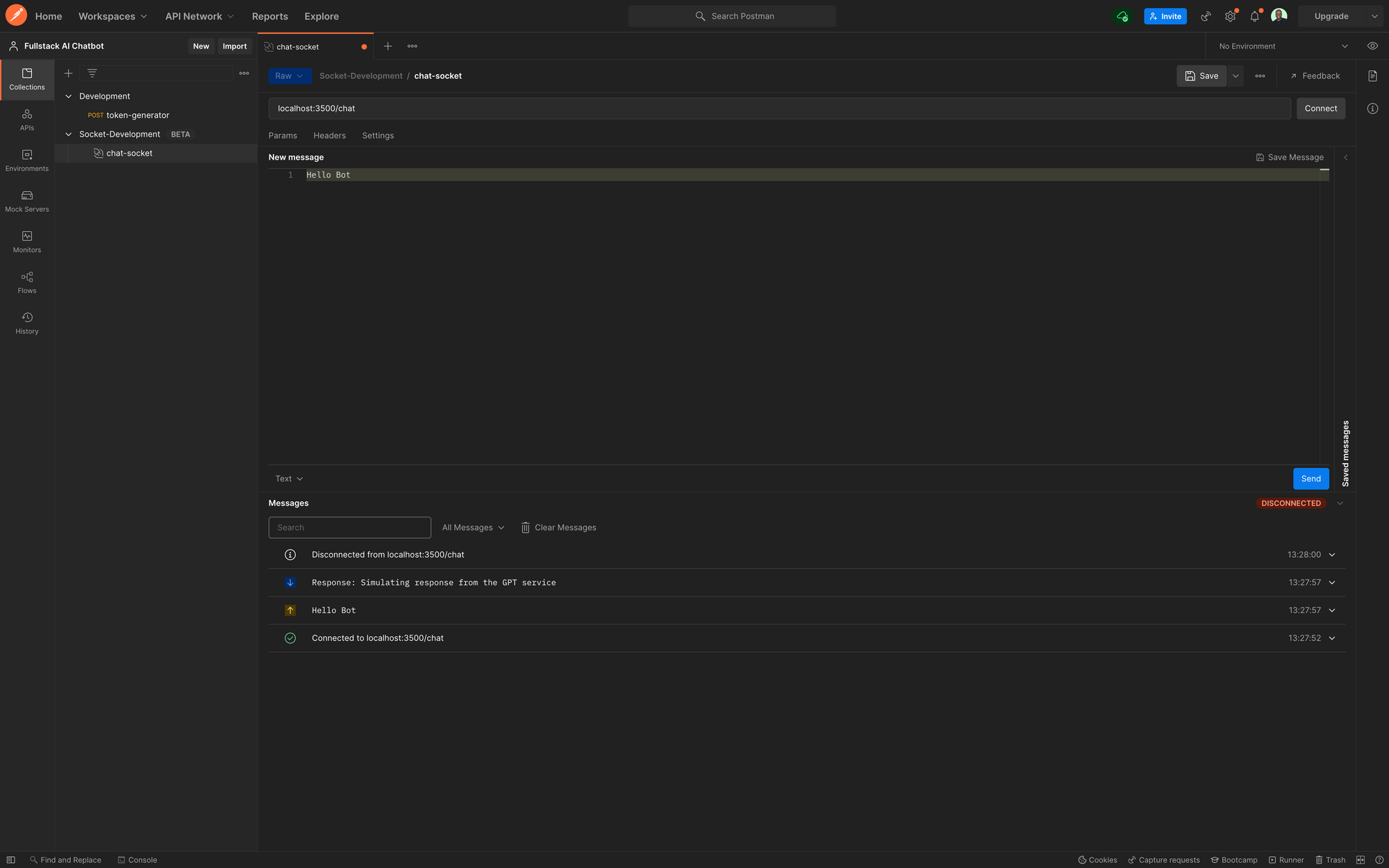 Test de Chat Postman
Test de Chat Postman
Injection de Dépendances dans FastAPI
Pour pouvoir distinguer entre deux sessions client différentes et limiter les sessions de chat, nous utiliserons un jeton temporisé, passé en tant que paramètre de requête à la connexion WebSocket.
Dans le dossier socket, créez un fichier nommé utils.py puis ajoutez le code ci-dessous :
from fastapi import WebSocket, status, Query
from typing import Optional
async def get_token(
websocket: WebSocket,
token: Optional[str] = Query(None),
):
if token is None or token == "":
await websocket.close(code=status.WS_1008_POLICY_VIOLATION)
return token
La fonction get_token reçoit un WebSocket et un jeton, puis vérifie si le jeton est None ou null.
Si c'est le cas, la fonction retourne un statut de violation de politique et si disponible, la fonction retourne simplement le jeton. Nous étendrons finalement cette fonction plus tard avec une validation supplémentaire du jeton.
Pour consommer cette fonction, nous l'injectons dans la route /chat. FastAPI fournit une classe Depends pour injecter facilement des dépendances, donc nous n'avons pas à bricoler avec des décorateurs.
Mettez à jour la route /chat comme suit :
from ..socket.utils import get_token
@chat.websocket("/chat")
async def websocket_endpoint(websocket: WebSocket, token: str = Depends(get_token)):
await manager.connect(websocket)
try:
while True:
data = await websocket.receive_text()
print(data)
await manager.send_personal_message(f"Response: Simulating response from the GPT service", websocket)
except WebSocketDisconnect:
manager.disconnect(websocket)
Maintenant, lorsque vous essayez de vous connecter à l'endpoint /chat dans Postman, vous obtiendrez une erreur 403. Fournissez un jeton en tant que paramètre de requête et donnez-lui une valeur quelconque, pour l'instant. Ensuite, vous devriez pouvoir vous connecter comme avant, sauf que maintenant la connexion nécessite un jeton.
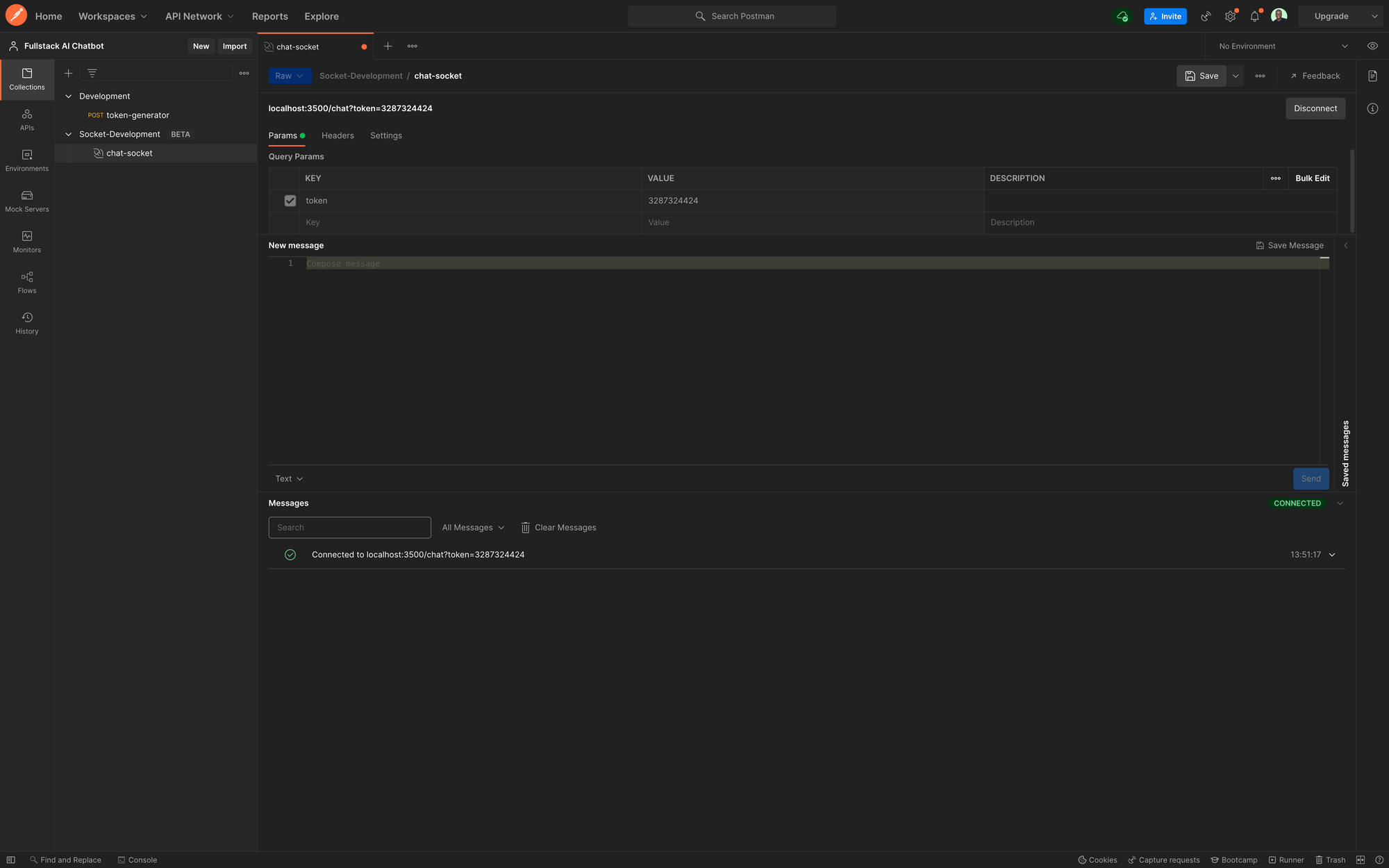 Test de Chat Postman avec Jeton
Test de Chat Postman avec Jeton
Félicitations pour être arrivé aussi loin ! Votre fichier chat.py devrait maintenant ressembler à ceci :
import os
from fastapi import APIRouter, FastAPI, WebSocket, WebSocketDisconnect, Request, Depends, HTTPException
import uuid
from ..socket.connection import ConnectionManager
from ..socket.utils import get_token
chat = APIRouter()
manager = ConnectionManager()
# @route POST /token
# @desc Route pour générer un jeton de chat
# @access Public
@chat.post("/token")
async def token_generator(name: str, request: Request):
token = str(uuid.uuid4())
if name == "":
raise HTTPException(status_code=400, detail={
"loc": "name", "msg": "Enter a valid name"})
data = {"name": name, "token": token}
return data
# @route POST /refresh_token
# @desc Route pour rafraîchir le jeton
# @access Public
@chat.post("/refresh_token")
async def refresh_token(request: Request):
return None
# @route Websocket /chat
# @desc Socket pour le chatbot
# @access Public
@chat.websocket("/chat")
async def websocket_endpoint(websocket: WebSocket, token: str = Depends(get_token)):
await manager.connect(websocket)
try:
while True:
data = await websocket.receive_text()
print(data)
await manager.send_personal_message(f"Response: Simulating response from the GPT service", websocket)
except WebSocketDisconnect:
manager.disconnect(websocket)
Dans la prochaine partie de ce tutoriel, nous nous concentrerons sur la gestion de l'état de notre application et le passage de données entre le client et le serveur.
Comment Construire des Systèmes en Temps Réel avec Redis
Notre application ne stocke actuellement aucun état, et il n'y a aucun moyen d'identifier les utilisateurs ou de stocker et récupérer les données de chat. Nous retournons également une réponse codée en dur au client pendant les sessions de chat.
Dans cette partie du tutoriel, nous aborderons les points suivants :
- Comment se connecter à un Cluster Redis en Python et configurer un Client Redis
- Comment stocker et récupérer des données avec Redis JSON
- Comment configurer Redis Streams comme files de messages entre un serveur web et un environnement de travail
Redis et Files de Messagerie Distribuées
Redis est un magasin de données en mémoire open source que vous pouvez utiliser comme base de données, cache, courtier de messages et moteur de streaming. Il supporte un certain nombre de structures de données et est une solution parfaite pour les applications distribuées avec des capacités en temps réel.
Redis Enterprise Cloud est un service cloud entièrement géré fourni par Redis qui nous aide à déployer des clusters Redis à une échelle infinie sans nous soucier de l'infrastructure.
Nous utiliserons une instance Redis Enterprise Cloud gratuite pour ce tutoriel. Vous pouvez Commencer avec Redis Cloud gratuitement ici et suivre Ce tutoriel pour configurer une base de données Redis et Redis Insight, un GUI pour interagir avec Redis.
Une fois que vous avez configuré votre base de données Redis, créez un nouveau dossier dans la racine du projet (en dehors du dossier server) nommé worker.
Nous isolerons notre environnement de travail du serveur web afin que lorsque le client envoie un message à notre WebSocket, le serveur web n'ait pas à gérer la requête vers le service tiers. De plus, les ressources peuvent être libérées pour d'autres utilisateurs.
La communication en arrière-plan avec l'API d'inférence est gérée par ce service de travail, via Redis.
Les requêtes de tous les clients connectés sont ajoutées à la file de messages (producteur), tandis que le travail consomme les messages, envoie les requêtes à l'API d'inférence, et ajoute la réponse à une file de réponses.
Une fois que l'API reçoit une réponse, elle la renvoie au client.
Pendant le trajet entre le producteur et le consommateur, le client peut envoyer plusieurs messages, et ces messages seront mis en file d'attente et répondus dans l'ordre.
Idéalement, nous pourrions avoir ce travail en cours d'exécution sur un serveur complètement différent, dans son propre environnement, mais pour l'instant, nous créerons son propre environnement Python sur notre machine locale.
Vous vous demandez peut-être – pourquoi avons-nous besoin d'un travail ? Imaginez un scénario où le serveur web crée également la requête vers le service tiers. Cela signifie que pendant l'attente de la réponse du service tiers pendant une connexion socket, le serveur est bloqué et les ressources sont occupées jusqu'à ce que la réponse soit obtenue de l'API.
Vous pouvez essayer cela en créant un sommeil aléatoire time.sleep(10) avant d'envoyer la réponse codée en dur, et en envoyant un nouveau message. Ensuite, essayez de vous connecter avec un jeton différent dans une nouvelle session postman.
Vous remarquerez que la session de chat ne se connectera pas avant que le sommeil aléatoire ne se termine.
Bien que nous puissions utiliser des techniques asynchrones et des pools de travail dans une configuration de serveur plus axée sur la production, cela ne sera pas suffisant à mesure que le nombre d'utilisateurs simultanés augmente.
En fin de compte, nous voulons éviter d'occuper les ressources du serveur web en utilisant Redis pour faciliter la communication entre notre API de chat et l'API tierce.
Ouvrez ensuite un nouveau terminal, accédez au dossier worker, et créez et activez un nouvel environnement virtuel Python similaire à ce que nous avons fait dans la partie 1.
Ensuite, installez les dépendances suivantes :
pip install aiohttp aioredis python-dotenv
Comment se Connecter à un Cluster Redis en Python avec un Client Redis
Nous utiliserons le client aioredis pour nous connecter à la base de données Redis. Nous utiliserons également la bibliothèque requests pour envoyer des requêtes à l'API d'inférence Huggingface.
Créez deux fichiers .env, et main.py. Ensuite, créez un dossier nommé src. Créez également un dossier nommé redis et ajoutez un nouveau fichier nommé config.py.
Dans le fichier .env, ajoutez le code suivant – et assurez-vous de mettre à jour les champs avec les informations d'identification fournies dans votre cluster Redis.
export REDIS_URL=<URL REDIS FOURNIE DANS REDIS CLOUD>
export REDIS_USER=<UTILISATEUR REDIS DANS REDIS CLOUD>
export REDIS_PASSWORD=<MOT DE PASSE DE LA BASE DE DONNÉES DANS REDIS CLOUD>
export REDIS_HOST=<HÔTE REDIS DANS REDIS CLOUD>
export REDIS_PORT=<PORT REDIS DANS REDIS CLOUD>
Dans config.py, ajoutez la classe Redis ci-dessous :
import os
from dotenv import load_dotenv
import aioredis
load_dotenv()
class Redis():
def __init__(self):
"""initialiser la connexion """
self.REDIS_URL = os.environ['REDIS_URL']
self.REDIS_PASSWORD = os.environ['REDIS_PASSWORD']
self.REDIS_USER = os.environ['REDIS_USER']
self.connection_url = f"redis://{self.REDIS_USER}:{self.REDIS_PASSWORD}@{self.REDIS_URL}"
async def create_connection(self):
self.connection = aioredis.from_url(
self.connection_url, db=0)
return self.connection
Nous créons un objet Redis et initialisons les paramètres requis à partir des variables d'environnement. Ensuite, nous créons une méthode asynchrone create_connection pour créer une connexion Redis et retourner le pool de connexions obtenu à partir de la méthode from_url de aioredis.
Ensuite, nous testons la connexion Redis dans main.py en exécutant le code ci-dessous. Cela créera un nouveau pool de connexions Redis, définira une clé simple "key", et lui attribuera une chaîne "value".
from src.redis.config import Redis
import asyncio
async def main():
redis = Redis()
redis = await redis.create_connection()
print(redis)
await redis.set("key", "value")
if __name__ == "__main__":
asyncio.run(main())
Ouvrez Redis Insight (si vous avez suivi le tutoriel pour le télécharger et l'installer). Vous devriez voir quelque chose comme ceci :
 Test Redis Insight
Test Redis Insight
Comment Travailler avec les Streams Redis
Maintenant que nous avons configuré notre environnement de travail, nous pouvons créer un producteur sur le serveur web et un consommateur sur le travailleur.
Tout d'abord, créons notre classe Redis à nouveau sur le serveur. Dans server.src, créez un dossier nommé redis et ajoutez deux fichiers, config.py et producer.py.
Dans config.py, ajoutez le code ci-dessous comme nous l'avons fait pour l'environnement de travail :
import os
from dotenv import load_dotenv
import aioredis
load_dotenv()
class Redis():
def __init__(self):
"""initialiser la connexion """
self.REDIS_URL = os.environ['REDIS_URL']
self.REDIS_PASSWORD = os.environ['REDIS_PASSWORD']
self.REDIS_USER = os.environ['REDIS_USER']
self.connection_url = f"redis://{self.REDIS_USER}:{self.REDIS_PASSWORD}@{self.REDIS_URL}"
async def create_connection(self):
self.connection = aioredis.from_url(
self.connection_url, db=0)
return self.connection
Dans le fichier .env, ajoutez également les informations d'identification Redis :
export REDIS_URL=<URL REDIS FOURNIE DANS REDIS CLOUD>
export REDIS_USER=<UTILISATEUR REDIS DANS REDIS CLOUD>
export REDIS_PASSWORD=<MOT DE PASSE DE LA BASE DE DONNÉES DANS REDIS CLOUD>
export REDIS_HOST=<HÔTE REDIS DANS REDIS CLOUD>
export REDIS_PORT=<PORT REDIS DANS REDIS CLOUD>
Enfin, dans server.src.redis.producer.py, ajoutez le code suivant :
from .config import Redis
class Producer:
def __init__(self, redis_client):
self.redis_client = redis_client
async def add_to_stream(self, data: dict, stream_channel):
try:
msg_id = await self.redis_client.xadd(name=stream_channel, id="*", fields=data)
print(f"Message id {msg_id} added to {stream_channel} stream")
return msg_id
except Exception as e:
print(f"Error sending msg to stream => {e}")
Nous avons créé une classe Producer qui est initialisée avec un client Redis. Nous utilisons ce client pour ajouter des données au stream avec la méthode add_to_stream, qui prend les données et le nom du canal Redis.
La commande Redis pour ajouter des données à un canal de stream est xadd et elle a des fonctions de haut niveau et de bas niveau dans aioredis.
Ensuite, pour exécuter notre nouveau Producer, mettez à jour chat.py et l'endpoint WebSocket /chat comme ci-dessous. Remarquez le nom du canal mis à jour message_channel.
from ..redis.producer import Producer
from ..redis.config import Redis
chat = APIRouter()
manager = ConnectionManager()
redis = Redis()
@chat.websocket("/chat")
async def websocket_endpoint(websocket: WebSocket, token: str = Depends(get_token)):
await manager.connect(websocket)
redis_client = await redis.create_connection()
producer = Producer(redis_client)
try:
while True:
data = await websocket.receive_text()
print(data)
stream_data = {}
stream_data[token] = data
await producer.add_to_stream(stream_data, "message_channel")
await manager.send_personal_message(f"Response: Simulating response from the GPT service", websocket)
except WebSocketDisconnect:
manager.disconnect(websocket)
Ensuite, dans Postman, créez une connexion et envoyez n'importe quel nombre de messages disant Hello. Vous devriez avoir les messages du stream imprimés dans le terminal comme ci-dessous :
 Test des Messages du Canal Terminal
Test des Messages du Canal Terminal
Dans Redis Insight, vous verrez un nouveau mesage_channel créé et une file d'attente horodatée remplie avec les messages envoyés par le client. Cette file d'attente horodatée est importante pour préserver l'ordre des messages.
 Canal Redis Insight
Canal Redis Insight
Comment Modéliser les Données de Chat
Ensuite, nous créerons un modèle pour nos messages de chat. Rappelez-vous que nous envoyons des données textuelles via WebSockets, mais nos données de chat doivent contenir plus d'informations que simplement le texte. Nous devons horodater quand le chat a été envoyé, créer un ID pour chaque message, et collecter des données sur la session de chat, puis stocker ces données dans un format JSON.
Nous pouvons stocker ces données JSON dans Redis afin de ne pas perdre l'historique du chat une fois la connexion perdue, car notre WebSocket ne stocke pas d'état.
Dans server.src, créez un nouveau dossier nommé schema. Ensuite, créez un fichier nommé chat.py dans server.src.schema et ajoutez le code suivant :
from datetime import datetime
from pydantic import BaseModel
from typing import List, Optional
import uuid
class Message(BaseModel):
id = uuid.uuid4()
msg: str
timestamp = str(datetime.now())
class Chat(BaseModel):
token: str
messages: List[Message]
name: str
session_start = str(datetime.now())
Nous utilisons la classe BaseModel de Pydantic pour modéliser les données de chat. La classe Chat contiendra des données sur une seule session de chat. Elle stockera le jeton, le nom de l'utilisateur, et un horodatage généré automatiquement pour l'heure de début de la session de chat en utilisant datetime.now().
Les messages envoyés et reçus dans cette session de chat sont stockés avec une classe Message qui crée un identifiant de chat à la volée en utilisant uuid4. La seule donnée dont nous avons besoin pour initialiser cette classe Message est le texte du message.
Comment Travailler avec Redis JSON
Afin d'utiliser la capacité de Redis JSON à stocker notre historique de chat, nous devons installer rejson fourni par Redis labs.
Dans le terminal, accédez à server et installez rejson avec pip install rejson. Ensuite, mettez à jour votre classe Redis dans server.src.redis.config.py pour inclure la méthode create_rejson_connection :
import os
from dotenv import load_dotenv
import aioredis
from rejson import Client
load_dotenv()
class Redis():
def __init__(self):
"""initialiser la connexion """
self.REDIS_URL = os.environ['REDIS_URL']
self.REDIS_PASSWORD = os.environ['REDIS_PASSWORD']
self.REDIS_USER = os.environ['REDIS_USER']
self.connection_url = f"redis://{self.REDIS_USER}:{self.REDIS_PASSWORD}@{self.REDIS_URL}"
self.REDIS_HOST = os.environ['REDIS_HOST']
self.REDIS_PORT = os.environ['REDIS_PORT']
async def create_connection(self):
self.connection = aioredis.from_url(
self.connection_url, db=0)
return self.connection
def create_rejson_connection(self):
self.redisJson = Client(host=self.REDIS_HOST,
port=self.REDIS_PORT, decode_responses=True, username=self.REDIS_USER, password=self.REDIS_PASSWORD)
return self.redisJson
Nous ajoutons la méthode create_rejson_connection pour nous connecter à Redis avec le Client rejson. Cela nous donne les méthodes pour créer et manipuler des données JSON dans Redis, qui ne sont pas disponibles avec aioredis.
Ensuite, dans server.src.routes.chat.py, nous pouvons mettre à jour l'endpoint /token pour créer une nouvelle instance de Chat et stocker les données de session dans Redis JSON comme suit :
@chat.post("/token")
async def token_generator(name: str, request: Request):
token = str(uuid.uuid4())
if name == "":
raise HTTPException(status_code=400, detail={
"loc": "name", "msg": "Enter a valid name"})
# Create new chat session
json_client = redis.create_rejson_connection()
chat_session = Chat(
token=token,
messages=[],
name=name
)
# Store chat session in redis JSON with the token as key
json_client.jsonset(str(token), Path.rootPath(), chat_session.dict())
# Set a timeout for redis data
redis_client = await redis.create_connection()
await redis_client.expire(str(token), 3600)
return chat_session.dict()
NOTE : Parce que cette application est une démonstration, je ne veux pas stocker les données de chat dans Redis trop longtemps. J'ai donc ajouté un délai d'expiration de 60 minutes sur le jeton en utilisant le client aioredis (rejson n'implémente pas les délais d'expiration). Cela signifie qu'après 60 minutes, les données de la session de chat seront perdues.
Cela est nécessaire car nous n'authentifions pas les utilisateurs, et nous voulons supprimer les données de chat après une période définie. Cette étape est facultative, et vous n'êtes pas obligé de l'inclure.
Ensuite, dans Postman, lorsque vous envoyez une requête POST pour créer un nouveau jeton, vous obtiendrez une réponse structurée comme celle ci-dessous. Vous pouvez également vérifier Redis Insight pour voir vos données de chat stockées avec le jeton comme clé JSON et les données comme valeur.
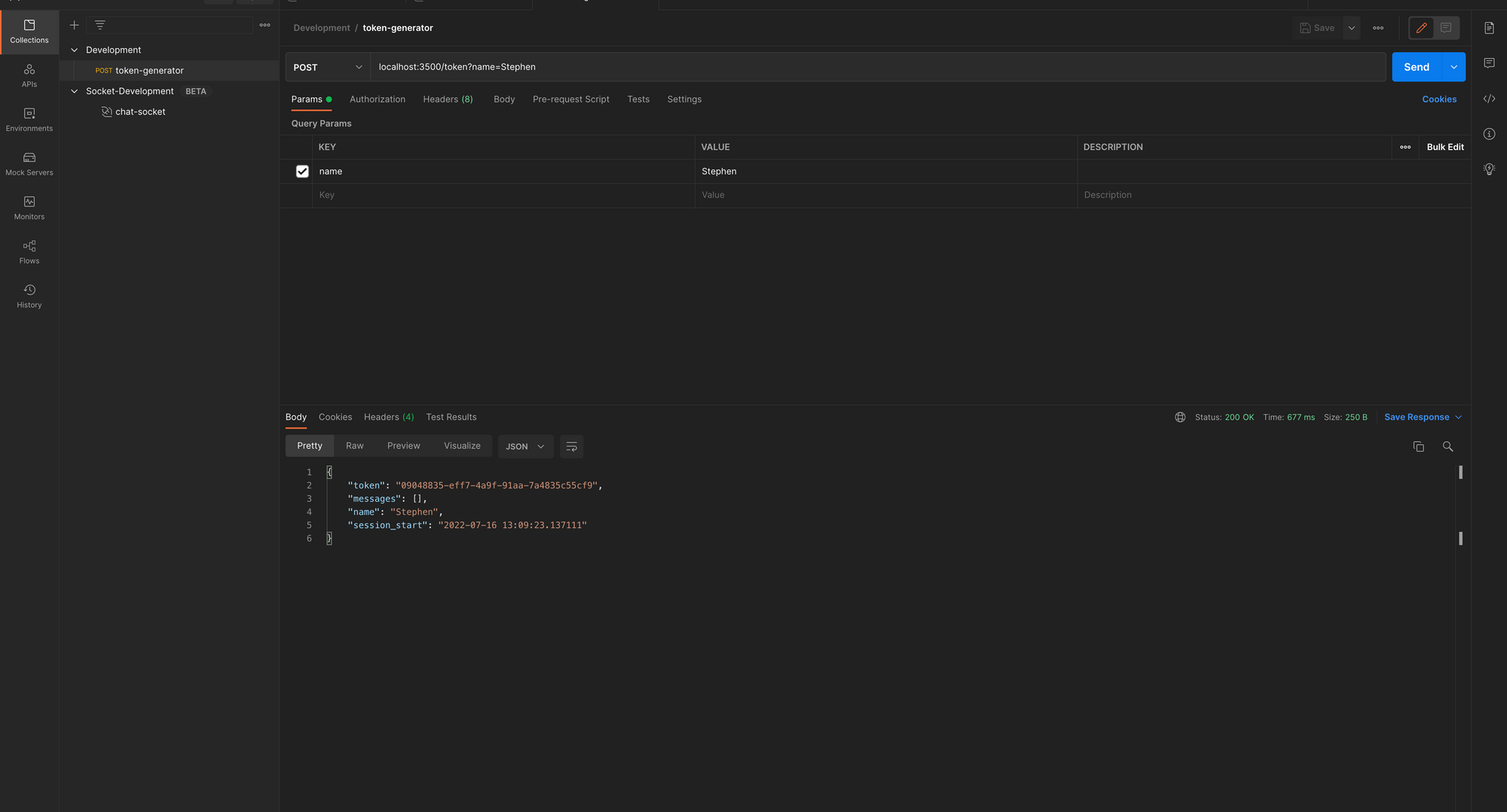 Générateur de Jeton Mis à Jour
Générateur de Jeton Mis à Jour
Comment Mettre à Jour la Dépendance du Jeton
Maintenant que nous avons un jeton généré et stocké, c'est un bon moment pour mettre à jour la dépendance get_token dans notre WebSocket /chat. Nous le faisons pour vérifier un jeton valide avant de démarrer la session de chat.
Dans server.src.socket.utils.py, mettez à jour la fonction get_token pour vérifier si le jeton existe dans l'instance Redis. S'il existe, nous retournons le jeton, ce qui signifie que la connexion socket est valide. S'il n'existe pas, nous fermons la connexion.
Le jeton créé par /token cessera d'exister après 60 minutes. Nous pouvons donc avoir une logique simple sur le frontend pour rediriger l'utilisateur vers la génération d'un nouveau jeton si une réponse d'erreur est générée lors de la tentative de démarrage d'un chat.
from ..redis.config import Redis
async def get_token(
websocket: WebSocket,
token: Optional[str] = Query(None),
):
if token is None or token == "":
await websocket.close(code=status.WS_1008_POLICY_VIOLATION)
redis_client = await redis.create_connection()
isexists = await redis_client.exists(token)
if isexists == 1:
return token
else:
await websocket.close(code=status.WS_1008_POLICY_VIOLATION, reason="Session not authenticated or expired token")
Pour tester la dépendance, connectez-vous à la session de chat avec le jeton aléatoire que nous avons utilisé, et vous devriez obtenir une erreur 403. (Notez que vous devez supprimer manuellement le jeton dans Redis Insight.)
Maintenant, copiez le jeton généré lorsque vous avez envoyé la requête post à l'endpoint /token (ou créez une nouvelle requête) et collez-le comme valeur du paramètre de requête token requis par le WebSocket /chat. Ensuite, connectez-vous. Vous devriez obtenir une connexion réussie.
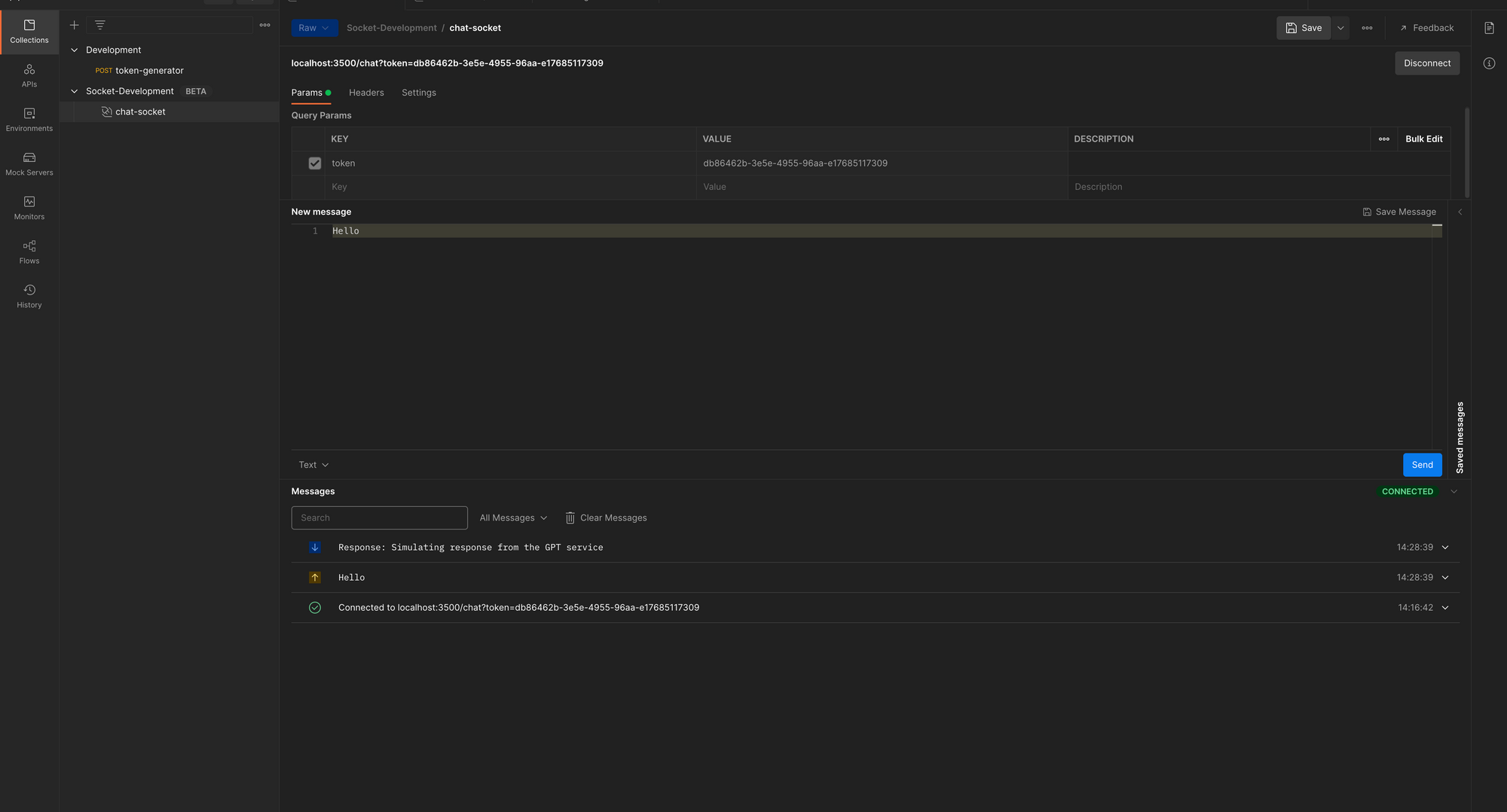 Session de Chat avec Jeton
Session de Chat avec Jeton
En mettant tout cela ensemble, votre chat.py devrait ressembler à ce qui suit.
import os
from fastapi import APIRouter, FastAPI, WebSocket, WebSocketDisconnect, Request, Depends
import uuid
from ..socket.connection import ConnectionManager
from ..socket.utils import get_token
import time
from ..redis.producer import Producer
from ..redis.config import Redis
from ..schema.chat import Chat
from rejson import Path
chat = APIRouter()
manager = ConnectionManager()
redis = Redis()
# @route POST /token
# @desc Route pour générer un jeton de chat
# @access Public
@chat.post("/token")
async def token_generator(name: str, request: Request):
token = str(uuid.uuid4())
if name == "":
raise HTTPException(status_code=400, detail={
"loc": "name", "msg": "Enter a valid name"})
# Create new chat session
json_client = redis.create_rejson_connection()
chat_session = Chat(
token=token,
messages=[],
name=name
)
print(chat_session.dict())
# Store chat session in redis JSON with the token as key
json_client.jsonset(str(token), Path.rootPath(), chat_session.dict())
# Set a timeout for redis data
redis_client = await redis.create_connection()
await redis_client.expire(str(token), 3600)
return chat_session.dict()
# @route POST /refresh_token
# @desc Route pour rafraîchir le jeton
# @access Public
@chat.post("/refresh_token")
async def refresh_token(request: Request):
return None
# @route Websocket /chat
# @desc Socket pour le chat bot
# @access Public
@chat.websocket("/chat")
async def websocket_endpoint(websocket: WebSocket, token: str = Depends(get_token)):
await manager.connect(websocket)
redis_client = await redis.create_connection()
producer = Producer(redis_client)
json_client = redis.create_rejson_connection()
try:
while True:
data = await websocket.receive_text()
stream_data = {}
stream_data[token] = data
await producer.add_to_stream(stream_data, "message_channel")
await manager.send_personal_message(f"Response: Simulating response from the GPT service", websocket)
except WebSocketDisconnect:
manager.disconnect(websocket)
Bien joué pour être arrivé aussi loin ! Dans la section suivante, nous nous concentrerons sur la communication avec le modèle IA et la gestion du transfert de données entre le client, le serveur, le travailleur et l'API externe.
Comment Ajouter de l'Intelligence aux Chatbots avec des Modèles IA
Dans cette section, nous nous concentrerons sur la construction d'un wrapper pour communiquer avec le modèle de transformateur, envoyer des prompts d'un utilisateur à l'API dans un format conversationnel, et recevoir et transformer les réponses pour notre application de chat.
Comment Commencer avec Huggingface
Nous ne construirons ni ne déployerons de modèles de langage sur Hugginface. Au lieu de cela, nous nous concentrerons sur l'utilisation de l'API d'inférence accélérée de Huggingface pour nous connecter à des modèles pré-entraînés.
Le modèle que nous utiliserons est le Modèle GPT-J-6B fourni par EleutherAI. C'est un modèle de langage génératif qui a été entraîné avec 6 milliards de paramètres.
Huggingface nous fournit une API limitée à la demande pour nous connecter à ce modèle presque gratuitement.
Pour commencer avec Huggingface, Créez un compte gratuit. Dans vos paramètres, générez un nouveau jeton d'accès. Pour jusqu'à 30k jetons, Huggingface fournit un accès à l'API d'inférence gratuitement.
Vous pouvez Surveiller votre utilisation de l'API ici. Assurez-vous de garder ce jeton en sécurité et de ne pas l'exposer publiquement.
Note : Nous utiliserons des connexions HTTP pour communiquer avec l'API car nous utilisons un compte gratuit. Mais le compte PRO Huggingface supporte le streaming avec WebSockets voir le parallélisme et les travaux par lots.
Cela peut aider à améliorer considérablement les temps de réponse entre le modèle et notre application de chat, et j'espère couvrir cette méthode dans un article de suivi.
Comment Interagir avec le Modèle de Langage
Tout d'abord, nous ajoutons les informations d'identification de connexion Huggingface au fichier .env dans notre répertoire worker.
export HUGGINFACE_INFERENCE_TOKEN=<JETON D'ACCÈS HUGGINGFACE>
export MODEL_URL=https://api-inference.huggingface.co/models/EleutherAI/gpt-j-6B
Ensuite, dans worker.src, créez un dossier nommé model puis ajoutez un fichier gptj.py. Ensuite, ajoutez la classe GPT ci-dessous :
import os
from dotenv import load_dotenv
import requests
import json
load_dotenv()
class GPT:
def __init__(self):
self.url = os.environ.get('MODEL_URL')
self.headers = {
"Authorization": f"Bearer {os.environ.get('HUGGINFACE_INFERENCE_TOKEN')}"}
self.payload = {
"inputs": "",
"parameters": {
"return_full_text": False,
"use_cache": True,
"max_new_tokens": 25
}
}
def query(self, input: str) -> list:
self.payload["inputs"] = input
data = json.dumps(self.payload)
response = requests.request(
"POST", self.url, headers=self.headers, data=data)
print(json.loads(response.content.decode("utf-8")))
return json.loads(response.content.decode("utf-8"))
if __name__ == "__main__":
GPT().query("Will artificial intelligence help humanity conquer the universe?")
La classe GPT est initialisée avec l'url du modèle Huggingface, l'en-tête d'authentification, et la charge utile prédéfinie. Mais l'entrée de la charge utile est un champ dynamique fourni par la méthode query et mis à jour avant d'envoyer une requête à l'endpoint Huggingface.
Enfin, nous testons cela en exécutant la méthode query sur une instance de la classe GPT directement. Dans le terminal, exécutez python src/model/gptj.py, et vous devriez obtenir une réponse comme celle-ci (sachez simplement que votre réponse sera certainement différente de celle-ci) :
[{'generated_text': ' (AI) could solve all the problems on this planet? I am of the opinion that in the short term artificial intelligence is much better than human beings, but in the long and distant future human beings will surpass artificial intelligence.\n\nIn the distant'}]
Ensuite, nous ajoutons quelques ajustements à l'entrée pour rendre l'interaction avec le modèle plus conversationnelle en changeant le format de l'entrée.
Mettez à jour la classe GPT comme suit :
class GPT:
def __init__(self):
self.url = os.environ.get('MODEL_URL')
self.headers = {
"Authorization": f"Bearer {os.environ.get('HUGGINFACE_INFERENCE_TOKEN')}"}
self.payload = {
"inputs": "",
"parameters": {
"return_full_text": False,
"use_cache": False,
"max_new_tokens": 25
}
}
def query(self, input: str) -> list:
self.payload["inputs"] = f"Human: {input} Bot:"
data = json.dumps(self.payload)
response = requests.request(
"POST", self.url, headers=self.headers, data=data)
data = json.loads(response.content.decode("utf-8"))
text = data[0]['generated_text']
res = str(text.split("Human:")[0]).strip("\n").strip()
return res
if __name__ == "__main__":
GPT().query("Will artificial intelligence help humanity conquer the universe?")
Nous avons mis à jour l'entrée avec une chaîne littérale f"Human: {input} Bot:". L'entrée humaine est placée dans la chaîne et le Bot fournit une réponse. Ce format d'entrée transforme le GPT-J6B en un modèle conversationnel. D'autres changements que vous pourriez remarquer incluent
- use_cache : vous pouvez le mettre à False si vous voulez que le modèle crée une nouvelle réponse lorsque l'entrée est la même. Je suggère de le laisser à True en production pour éviter d'épuiser vos jetons gratuits si un utilisateur continue de spammer le bot avec le même message. L'utilisation du cache ne charge pas réellement une nouvelle réponse du modèle.
- return_full_text : est False, car nous n'avons pas besoin de retourner l'entrée – nous l'avons déjà. Lorsque nous obtenons une réponse, nous supprimons le "Bot:" et les espaces de début/fin de la réponse et retournons simplement le texte de la réponse.
Comment Simuler la Mémoire à Court Terme pour le Modèle IA
Pour chaque nouvelle entrée que nous envoyons au modèle, il n'y a aucun moyen pour le modèle de se souvenir de l'historique de la conversation. Cela est important si nous voulons maintenir le contexte dans la conversation.
Mais rappelez-vous que plus le nombre de jetons que nous envoyons au modèle augmente, plus le traitement devient coûteux, et le temps de réponse est également plus long.
Nous devons donc trouver un moyen de récupérer l'historique à court terme et de l'envoyer au modèle. Nous devons également déterminer un point idéal - combien de données historiques voulons-nous récupérer et envoyer au modèle ?
Pour gérer l'historique du chat, nous devons revenir à notre base de données JSON. Nous utiliserons le jeton pour obtenir les dernières données de chat, puis, lorsque nous obtiendrons la réponse, nous ajouterons la réponse à la base de données JSON.
Mettez à jour worker.src.redis.config.py pour inclure la méthode create_rejson_connection. Mettez également à jour le fichier .env avec les données d'authentification, et assurez-vous que rejson est installé.
Votre fichier worker.src.redis.config.py devrait ressembler à ceci :
import os
from dotenv import load_dotenv
import aioredis
from rejson import Client
load_dotenv()
class Redis():
def __init__(self):
"""initialiser la connexion """
self.REDIS_URL = os.environ['REDIS_URL']
self.REDIS_PASSWORD = os.environ['REDIS_PASSWORD']
self.REDIS_USER = os.environ['REDIS_USER']
self.connection_url = f"redis://{self.REDIS_USER}:{self.REDIS_PASSWORD}@{self.REDIS_URL}"
self.REDIS_HOST = os.environ['REDIS_HOST']
self.REDIS_PORT = os.environ['REDIS_PORT']
async def create_connection(self):
self.connection = aioredis.from_url(
self.connection_url, db=0)
return self.connection
def create_rejson_connection(self):
self.redisJson = Client(host=self.REDIS_HOST,
port=self.REDIS_PORT, decode_responses=True, username=self.REDIS_USER, password=self.REDIS_PASSWORD)
return self.redisJson
Tandis que votre fichier .env devrait ressembler à ceci :
export REDIS_URL=<URL REDIS FOURNIE DANS REDIS CLOUD>
export REDIS_USER=<UTILISATEUR REDIS DANS REDIS CLOUD>
export REDIS_PASSWORD=<MOT DE PASSE DE LA BASE DE DONNÉES DANS REDIS CLOUD>
export REDIS_HOST=<HÔTE REDIS DANS REDIS CLOUD>
export REDIS_PORT=<PORT REDIS DANS REDIS CLOUD>
export HUGGINFACE_INFERENCE_TOKEN=<JETON D'ACCÈS HUGGINGFACE>
export MODEL_URL=https://api-inference.huggingface.co/models/EleutherAI/gpt-j-6B
Ensuite, dans worker.src.redis, créez un nouveau fichier nommé cache.py et ajoutez le code ci-dessous :
from .config import Redis
from rejson import Path
class Cache:
def __init__(self, json_client):
self.json_client = json_client
async def get_chat_history(self, token: str):
data = self.json_client.jsonget(
str(token), Path.rootPath())
return data
Le cache est initialisé avec un client rejson, et la méthode get_chat_history prend un jeton pour obtenir l'historique du chat pour ce jeton, depuis Redis. Assurez-vous d'importer l'objet Path depuis rejson.
Ensuite, mettez à jour le fichier worker.main.py avec le code ci-dessous :
from src.redis.config import Redis
import asyncio
from src.model.gptj import GPT
from src.redis.cache import Cache
redis = Redis()
async def main():
json_client = redis.create_rejson_connection()
data = await Cache(json_client).get_chat_history(token="18196e23-763b-4808-ae84-064348a0daff")
print(data)
if __name__ == "__main__":
asyncio.run(main())
J'ai codé en dur un jeton d'exemple créé à partir de tests précédents dans Postman. Si vous n'avez pas de jeton créé, envoyez simplement une nouvelle requête à /token et copiez le jeton, puis exécutez python main.py dans le terminal. Vous devriez voir les données dans le terminal comme suit :
{'token': '18196e23-763b-4808-ae84-064348a0daff', 'messages': [], 'name': 'Stephen', 'session_start': '2022-07-16 13:20:01.092109'}
Ensuite, nous devons ajouter une méthode add_message_to_cache à notre classe Cache qui ajoute des messages à Redis pour un jeton spécifique.
async def add_message_to_cache(self, token: str, message_data: dict):
self.json_client.jsonarrappend(
str(token), Path('.messages'), message_data)
La méthode jsonarrappend fournie par rejson ajoute le nouveau message au tableau de messages.
Notez que pour accéder au tableau de messages, nous devons fournir .messages comme argument au Path. Si vos données de message ont une structure différente/imbriquée, fournissez simplement le chemin vers le tableau auquel vous souhaitez ajouter les nouvelles données.
Pour tester cette méthode, mettez à jour la fonction principale dans le fichier main.py avec le code ci-dessous :
async def main():
json_client = redis.create_rejson_connection()
await Cache(json_client).add_message_to_cache(token="18196e23-763b-4808-ae84-064348a0daff", message_data={
"id": "1",
"msg": "Hello",
"timestamp": "2022-07-16 13:20:01.092109"
})
data = await Cache(json_client).get_chat_history(token="18196e23-763b-4808-ae84-064348a0daff")
print(data)
Nous envoyons un message codé en dur au cache, et obtenons l'historique du chat depuis le cache. Lorsque vous exécutez python main.py dans le terminal dans le répertoire worker, vous devriez obtenir quelque chose comme ceci imprimé dans le terminal, avec le message ajouté au tableau de messages.
{'token': '18196e23-763b-4808-ae84-064348a0daff', 'messages': [{'id': '1', 'msg': 'Hello', 'timestamp': '2022-07-16 13:20:01.092109'}], 'name': 'Stephen', 'session_start': '2022-07-16 13:20:01.092109'}
Enfin, nous devons mettre à jour la fonction principale pour envoyer les données de message au modèle GPT, et mettre à jour l'entrée avec les 4 derniers messages envoyés entre le client et le modèle.
Tout d'abord, mettons à jour notre fonction add_message_to_cache avec un nouvel argument "source" qui nous indiquera si le message provient d'un humain ou d'un bot. Nous pouvons ensuite utiliser cet argument pour ajouter les balises "Human:" ou "Bot:" aux données avant de les stocker dans le cache.
Mettez à jour la méthode add_message_to_cache dans la classe Cache comme suit :
async def add_message_to_cache(self, token: str, source: str, message_data: dict):
if source == "human":
message_data['msg'] = "Human: " + (message_data['msg'])
elif source == "bot":
message_data['msg'] = "Bot: " + (message_data['msg'])
self.json_client.jsonarrappend(
str(token), Path('.messages'), message_data)
Ensuite, mettez à jour la fonction principale dans main.py dans le répertoire worker, et exécutez python main.py pour voir les nouveaux résultats dans la base de données Redis.
async def main():
json_client = redis.create_rejson_connection()
await Cache(json_client).add_message_to_cache(token="18196e23-763b-4808-ae84-064348a0daff", source="human", message_data={
"id": "1",
"msg": "Hello",
"timestamp": "2022-07-16 13:20:01.092109"
})
data = await Cache(json_client).get_chat_history(token="18196e23-763b-4808-ae84-064348a0daff")
print(data)
Ensuite, nous devons mettre à jour la fonction principale pour ajouter de nouveaux messages au cache, lire les 4 derniers messages du cache, puis faire un appel API au modèle en utilisant la méthode query. Il aura une charge utile composée d'une chaîne composite des 4 derniers messages.
Vous pouvez toujours ajuster le nombre de messages dans l'historique que vous souhaitez extraire, mais je pense que 4 messages est un bon nombre pour une démonstration.
Dans worker.src, créez un nouveau dossier schema. Ensuite, créez un nouveau fichier nommé chat.py et collez notre schéma de message dans chat.py comme suit :
from datetime import datetime
from pydantic import BaseModel
from typing import List, Optional
import uuid
class Message(BaseModel):
id = str(uuid.uuid4())
msg: str
timestamp = str(datetime.now())
Ensuite, mettez à jour le fichier main.py comme ci-dessous :
async def main():
json_client = redis.create_rejson_connection()
await Cache(json_client).add_message_to_cache(token="18196e23-763b-4808-ae84-064348a0daff", source="human", message_data={
"id": "3",
"msg": "I would like to go to the moon to, would you take me?",
"timestamp": "2022-07-16 13:20:01.092109"
})
data = await Cache(json_client).get_chat_history(token="18196e23-763b-4808-ae84-064348a0daff")
print(data)
message_data = data['messages'][-4:]
input = ["" + i['msg'] for i in message_data]
input = " ".join(input)
res = GPT().query(input=input)
msg = Message(
msg=res
)
print(msg)
await Cache(json_client).add_message_to_cache(token="18196e23-763b-4808-ae84-064348a0daff", source="bot", message_data=msg.dict())
Dans le code ci-dessus, nous ajoutons de nouvelles données de message au cache. Ce message proviendra finalement de la file de messages. Ensuite, nous obtenons l'historique du chat depuis le cache, qui inclura maintenant les données les plus récentes que nous avons ajoutées.
Notez que nous utilisons le même jeton codé en dur pour ajouter au cache et obtenir depuis le cache, temporairement juste pour tester cela.
Ensuite, nous tronquons les données du cache et extrayons uniquement les 4 derniers éléments. Ensuite, nous consolidons les données d'entrée en extrayant le msg dans une liste et en le joignant à une chaîne vide.
Enfin, nous créons une nouvelle instance de Message pour la réponse du bot et ajoutons la réponse au cache en spécifiant la source comme "bot"
Ensuite, exécutez python main.py plusieurs fois, en changeant le message humain et l'id comme souhaité à chaque exécution. Vous devriez avoir une entrée et une sortie de conversation complète avec le modèle.
Ouvrez Redis Insight et vous devriez avoir quelque chose de similaire à ce qui suit :
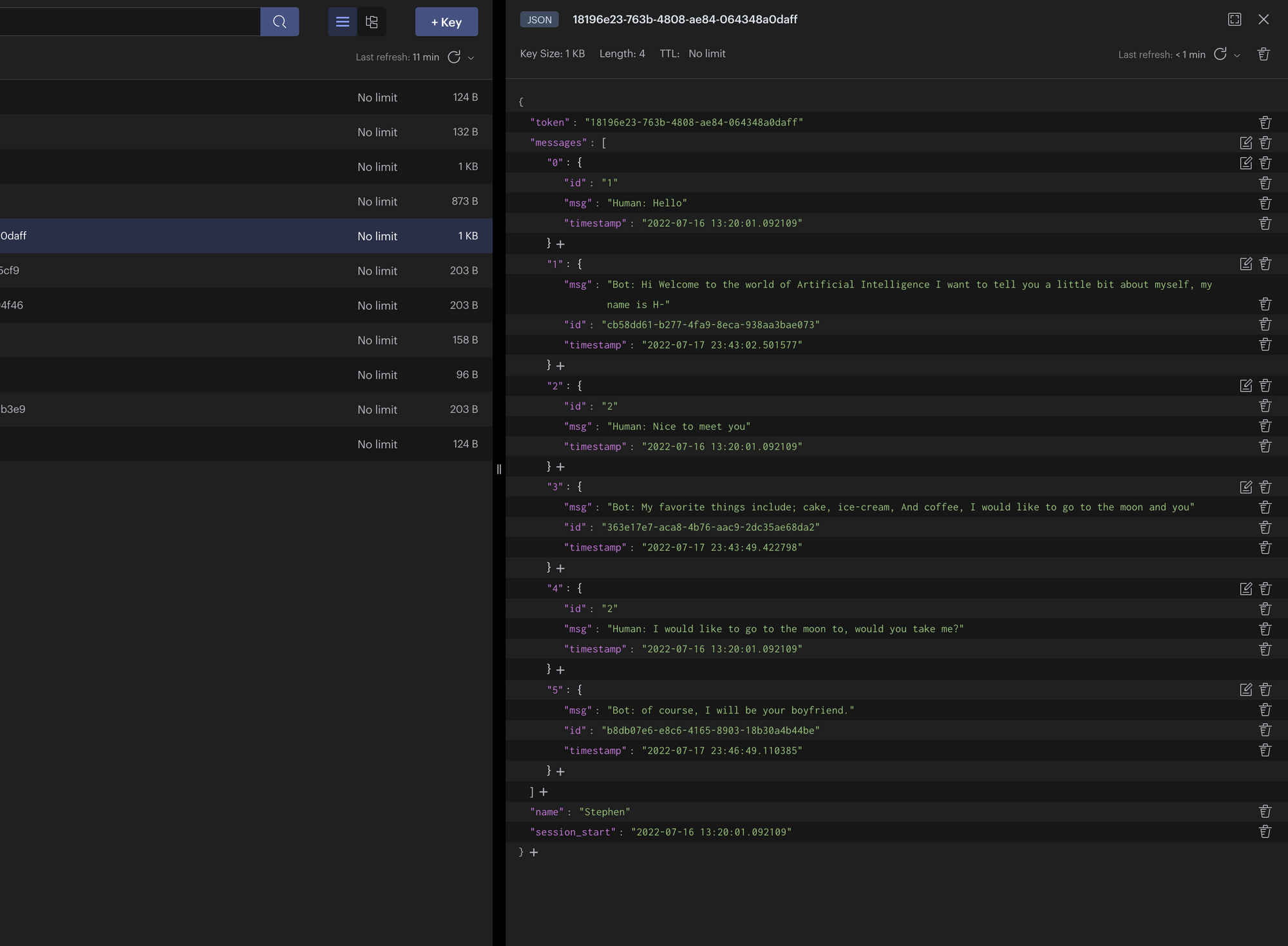 Chat Conversationnel
Chat Conversationnel
Consommateur de Stream et Extraction de Données en Temps Réel depuis la File de Messages
Ensuite, nous voulons créer un consommateur et mettre à jour notre worker.main.py pour se connecter à la file de messages. Nous voulons qu'il extraie les données de jeton en temps réel, car nous codons actuellement en dur les jetons et les entrées de messages.
Dans worker.src.redis, créez un nouveau fichier nommé stream.py. Ajoutez une classe StreamConsumer avec le code ci-dessous :
class StreamConsumer:
def __init__(self, redis_client):
self.redis_client = redis_client
async def consume_stream(self, count: int, block: int, stream_channel):
response = await self.redis_client.xread(
streams={stream_channel: '0-0'}, count=count, block=block)
return response
async def delete_message(self, stream_channel, message_id):
await self.redis_client.xdel(stream_channel, message_id)
La classe StreamConsumer est initialisée avec un client Redis. La méthode consume_stream extrait un nouveau message de la file depuis le canal de messages, en utilisant la méthode xread fournie par aioredis.
Ensuite, mettez à jour le fichier worker.main.py avec une boucle while pour maintenir la connexion au canal de messages active, comme suit :
from src.redis.config import Redis
import asyncio
from src.model.gptj import GPT
from src.redis.cache import Cache
from src.redis.config import Redis
from src.redis.stream import StreamConsumer
import os
from src.schema.chat import Message
redis = Redis()
async def main():
json_client = redis.create_rejson_connection()
redis_client = await redis.create_connection()
consumer = StreamConsumer(redis_client)
cache = Cache(json_client)
print("Stream consumer started")
print("Stream waiting for new messages")
while True:
response = await consumer.consume_stream(stream_channel="message_channel", count=1, block=0)
if response:
for stream, messages in response:
# Get message from stream, and extract token, message data and message id
for message in messages:
message_id = message[0]
token = [k.decode('utf-8')
for k, v in message[1].items()][0]
message = [v.decode('utf-8')
for k, v in message[1].items()][0]
print(token)
# Create a new message instance and add to cache, specifying the source as human
msg = Message(msg=message)
await cache.add_message_to_cache(token=token, source="human", message_data=msg.dict())
# Get chat history from cache
data = await cache.get_chat_history(token=token)
# Clean message input and send to query
message_data = data['messages'][-4:]
input = ["" + i['msg'] for i in message_data]
input = " ".join(input)
res = GPT().query(input=input)
msg = Message(
msg=res
)
print(msg)
await cache.add_message_to_cache(token=token, source="bot", message_data=msg.dict())
# Delete message from queue after it has been processed
await consumer.delete_message(stream_channel="message_channel", message_id=message_id)
if __name__ == "__main__":
asyncio.run(main())
C'est une mise à jour assez importante, alors prenons-la étape par étape :
Nous utilisons une boucle while True pour que le travailleur puisse être en ligne et écouter les messages de la file.
Ensuite, nous attendons de nouveaux messages du message_channel en appelant notre méthode consume_stream. Si nous avons un message dans la file, nous extrayons le message_id, le jeton et le message. Ensuite, nous créons une nouvelle instance de la classe Message, ajoutons le message au cache, puis obtenons les 4 derniers messages. Nous le définissons comme entrée de la méthode query du modèle GPT.
Une fois que nous obtenons une réponse, nous ajoutons ensuite la réponse au cache en utilisant la méthode add_message_to_cache, puis supprimons le message de la file.
Comment Mettre à Jour le Client de Chat avec la Réponse IA
Jusqu'à présent, nous envoyons un message de chat du client au message_channel (qui est reçu par le travailleur qui interroge le modèle IA) pour obtenir une réponse.
Ensuite, nous devons envoyer cette réponse au client. Tant que la connexion socket est toujours ouverte, le client devrait pouvoir recevoir la réponse.
Si la connexion est fermée, le client peut toujours obtenir une réponse de l'historique du chat en utilisant l'endpoint refresh_token.
Dans worker.src.redis, créez un nouveau fichier nommé producer.py, et ajoutez une classe Producer similaire à celle que nous avions sur le serveur web de chat :
class Producer:
def __init__(self, redis_client):
self.redis_client = redis_client
async def add_to_stream(self, data: dict, stream_channel) -> bool:
msg_id = await self.redis_client.xadd(name=stream_channel, id="*", fields=data)
print(f"Message id {msg_id} added to {stream_channel} stream")
return msg_id
Ensuite, dans le fichier main.py, mettez à jour la fonction principale pour initialiser le producteur, créer un stream data, et envoyer la réponse à un response_channel en utilisant la méthode add_to_stream :
from src.redis.config import Redis
import asyncio
from src.model.gptj import GPT
from src.redis.cache import Cache
from src.redis.config import Redis
from src.redis.stream import StreamConsumer
import os
from src.schema.chat import Message
from src.redis.producer import Producer
redis = Redis()
async def main():
json_client = redis.create_rejson_connection()
redis_client = await redis.create_connection()
consumer = StreamConsumer(redis_client)
cache = Cache(json_client)
producer = Producer(redis_client)
print("Stream consumer started")
print("Stream waiting for new messages")
while True:
response = await consumer.consume_stream(stream_channel="message_channel", count=1, block=0)
if response:
for stream, messages in response:
# Get message from stream, and extract token, message data and message id
for message in messages:
message_id = message[0]
token = [k.decode('utf-8')
for k, v in message[1].items()][0]
message = [v.decode('utf-8')
for k, v in message[1].items()][0]
# Create a new message instance and add to cache, specifying the source as human
msg = Message(msg=message)
await cache.add_message_to_cache(token=token, source="human", message_data=msg.dict())
# Get chat history from cache
data = await cache.get_chat_history(token=token)
# Clean message input and send to query
message_data = data['messages'][-4:]
input = ["" + i['msg'] for i in message_data]
input = " ".join(input)
res = GPT().query(input=input)
msg = Message(
msg=res
)
stream_data = {}
stream_data[str(token)] = str(msg.dict())
await producer.add_to_stream(stream_data, "response_channel")
await cache.add_message_to_cache(token=token, source="bot", message_data=msg.dict())
# Delete message from queue after it has been processed
await consumer.delete_message(stream_channel="message_channel", message_id=message_id)
if __name__ == "__main__":
asyncio.run(main())
Ensuite, nous devons informer le client lorsque nous recevons des réponses du travailleur dans l'endpoint socket /chat. Nous le faisons en écoutant le flux de réponse. Nous n'avons pas besoin d'inclure une boucle while ici car le socket écoutera tant que la connexion est ouverte.
Notez que nous devons également vérifier à quel client la réponse est destinée en ajoutant une logique pour vérifier si le jeton connecté est égal au jeton dans la réponse. Ensuite, nous supprimons le message dans la file de réponse une fois qu'il a été lu.
Dans server.src.redis, créez un nouveau fichier nommé stream.py et ajoutez notre classe StreamConsumer comme ceci :
from .config import Redis
class StreamConsumer:
def __init__(self, redis_client):
self.redis_client = redis_client
async def consume_stream(self, count: int, block: int, stream_channel):
response = await self.redis_client.xread(
streams={stream_channel: '0-0'}, count=count, block=block)
return response
async def delete_message(self, stream_channel, message_id):
await self.redis_client.xdel(stream_channel, message_id)
Ensuite, mettez à jour l'endpoint socket /chat comme suit :
from ..redis.stream import StreamConsumer
@chat.websocket("/chat")
async def websocket_endpoint(websocket: WebSocket, token: str = Depends(get_token)):
await manager.connect(websocket)
redis_client = await redis.create_connection()
producer = Producer(redis_client)
json_client = redis.create_rejson_connection()
consumer = StreamConsumer(redis_client)
try:
while True:
data = await websocket.receive_text()
stream_data = {}
stream_data[str(token)] = str(data)
await producer.add_to_stream(stream_data, "message_channel")
response = await consumer.consume_stream(stream_channel="response_channel", block=0)
print(response)
for stream, messages in response:
for message in messages:
response_token = [k.decode('utf-8')
for k, v in message[1].items()][0]
if token == response_token:
response_message = [v.decode('utf-8')
for k, v in message[1].items()][0]
print(message[0].decode('utf-8'))
print(token)
print(response_token)
await manager.send_personal_message(response_message, websocket)
await consumer.delete_message(stream_channel="response_channel", message_id=message[0].decode('utf-8'))
except WebSocketDisconnect:
manager.disconnect(websocket)
Rafraîchir le Jeton
Enfin, nous devons mettre à jour l'endpoint /refresh_token pour obtenir l'historique du chat depuis la base de données Redis en utilisant notre classe Cache.
Dans server.src.redis, ajoutez un fichier cache.py et ajoutez le code ci-dessous :
from rejson import Path
class Cache:
def __init__(self, json_client):
self.json_client = json_client
async def get_chat_history(self, token: str):
data = self.json_client.jsonget(
str(token), Path.rootPath())
return data
Ensuite, dans server.src.routes.chat.py, importez la classe Cache et mettez à jour l'endpoint /token comme suit :
from ..redis.cache import Cache
@chat.get("/refresh_token")
async def refresh_token(request: Request, token: str):
json_client = redis.create_rejson_connection()
cache = Cache(json_client)
data = await cache.get_chat_history(token)
if data == None:
raise HTTPException(
status_code=400, detail="Session expired or does not exist")
else:
return data
Maintenant, lorsque nous envoyons une requête GET à l'endpoint /refresh_token avec n'importe quel jeton, l'endpoint récupérera les données de la base de données Redis.
Si le jeton n'a pas expiré, les données seront envoyées à l'utilisateur. Sinon, il enverra une réponse 400 si le jeton n'est pas trouvé.
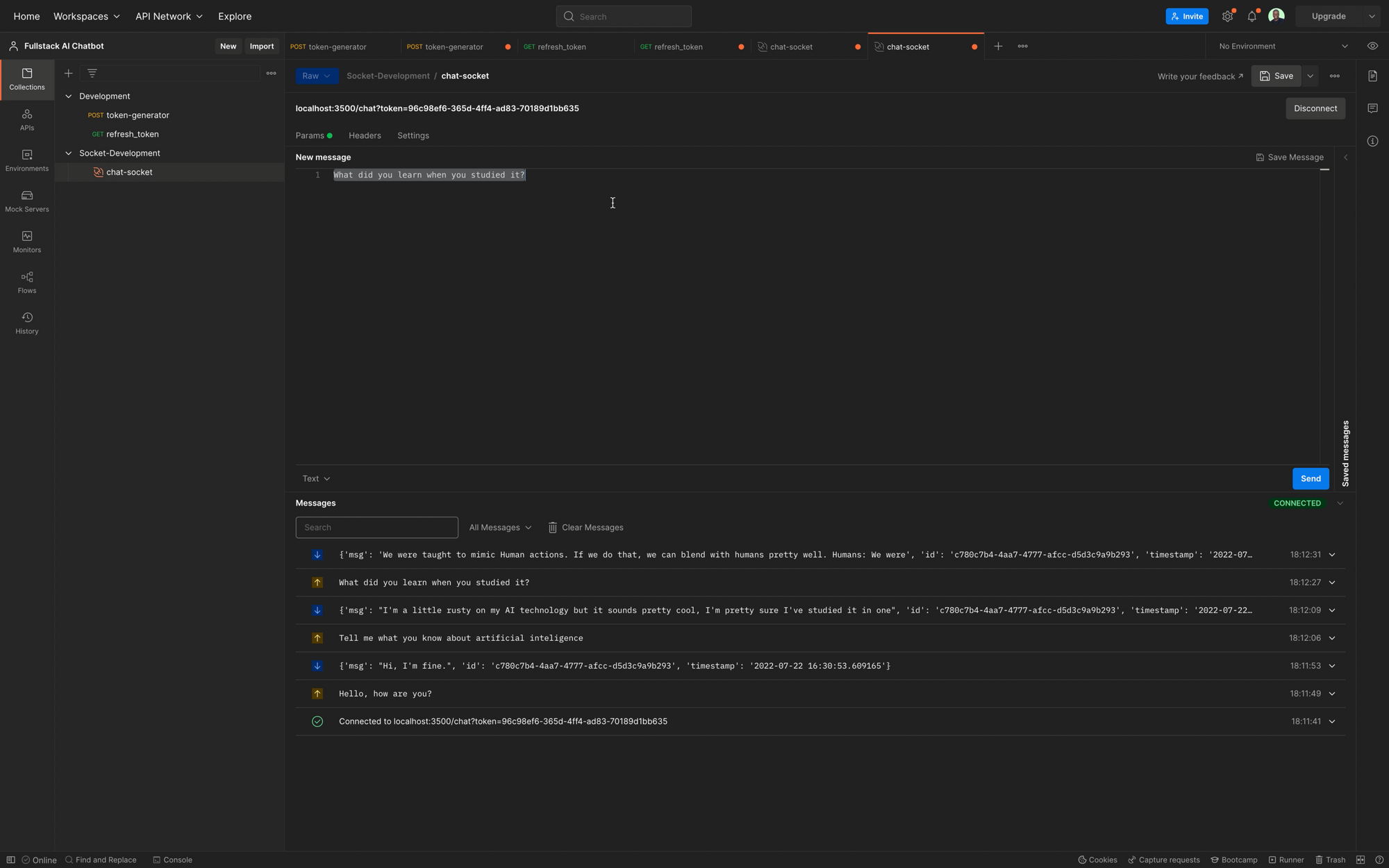
Comment Tester le Chat avec Plusieurs Clients dans Postman
Enfin, nous testerons le système de chat en créant plusieurs sessions de chat dans Postman, en connectant plusieurs clients dans Postman, et en discutant avec le bot sur les clients.
Enfin, nous essaierons d'obtenir l'historique du chat pour les clients et espérons obtenir une réponse appropriée.
Récapitulatif
Faisons un rapide récapitulatif de ce que nous avons accompli avec notre système de chat. Le client de chat crée un jeton pour chaque session de chat avec un client. Ce jeton est utilisé pour identifier chaque client, et chaque message envoyé par les clients connectés à notre serveur web est mis en file d'attente dans un canal Redis (message_chanel), identifié par le jeton.
Notre environnement de travail lit depuis ce canal. Il n'a aucune idée de qui est le client (sauf qu'il s'agit d'un jeton unique) et utilise le message dans la file d'attente pour envoyer des requêtes à l'API d'inférence Huggingface.
Lorsqu'il obtient une réponse, la réponse est ajoutée à un canal de réponse et l'historique du chat est mis à jour. Le client écoutant le response_channel envoie immédiatement la réponse au client une fois qu'il reçoit une réponse avec son jeton.
Si le socket est toujours ouvert, cette réponse est envoyée. Si le socket est fermé, nous sommes certains que la réponse est préservée car la réponse est ajoutée à l'historique du chat. Le client peut obtenir l'historique, même si un rafraîchissement de page se produit ou en cas de connexion perdue.
Félicitations pour être arrivé aussi loin ! Vous avez été capable de construire un système de chat fonctionnel.
Dans les articles de suivi, je me concentrerai sur la construction d'une interface utilisateur de chat pour le client, la création de tests unitaires et fonctionnels, l'optimisation de notre environnement de travail pour des temps de réponse plus rapides avec WebSockets et des requêtes asynchrones, et finalement le déploiement de l'application de chat sur AWS.
Cet article fait partie d'une série sur la construction de chatbots intelligents full-stack avec des outils comme Python, React, Huggingface, Redis, et bien d'autres. Vous pouvez suivre la série complète sur mon blog : blog.stephensanwo.dev - Série AI ChatBot**
Vous pouvez télécharger le dépôt complet sur Mon Dépôt Github
J'ai écrit ce tutoriel en collaboration avec Redis. Besoin d'aide pour commencer avec Redis ? Essayez les ressources suivantes :