


Article original : The Design Patterns for Distributed Systems Handbook – Key Concepts Every Developer Should Know
Lorsque j'ai commencé ma carrière en tant qu'ingénieur backend, je travaillais toujours avec des systèmes monolithiques.
Le travail était bon, mais j'avais toujours cette pensée au fond de mon esprit :
"Man, je veux travailler sur de grands systèmes comme ceux de Google, Netflix, etc..."
J'avais 19 ans et j'étais un développeur junior, alors soyez indulgent.
Je ne connaissais même pas le terme systèmes distribués jusqu'à ce qu'un de mes collègues commence à en parler.
Puis je l'ai recherché – j'ai beaucoup recherché. Cela semblait très compliqué, et je me sentais très stupide.
Mais j'étais excité.
J'ai étudié ce concept de systèmes distribués pendant un certain temps, mais je ne l'ai pas complètement compris jusqu'à ce que je le voie en action quelques années plus tard.
Maintenant que j'ai quelque expérience, je voudrais partager avec vous ce que je sais sur les systèmes distribués.
Connaissances préalables
Les sujets que je vais aborder ici peuvent être un peu avancés pour les programmeurs débutants. Pour vous aider à vous préparer, voici ce que je suppose que vous connaissez :
- Programmation de niveau intermédiaire (n'importe quel langage fera l'affaire)
- Réseautique informatique de base (TCP/IP, protocoles réseau, etc.)
- Structures de données et algorithmes de base (notation Big O, recherche, tri, etc.)
- Bases de données (relationnelles, NoSQL, etc.)
Si cela semble beaucoup, ne vous découragez pas.
Voici quelques ressources qui peuvent vous aider à vous rafraîchir la mémoire sur certains de ces sujets plus spécifiques :
- Apprenez comment fonctionnent les réseaux informatiques dans ce cours gratuit
- Apprenez les structures de données et les algorithmes dans ce cours gratuit
- Apprenez les bases de données relationnelles ici, et les bases de données NoSQL ici.
Voici ce que nous allons couvrir :
- Qu'est-ce que les systèmes distribués ?
- Défis courants dans les systèmes distribués
- Motif de ségrégation des responsabilités de commande et de requête (CQRS)
- Motif de validation en deux phases (2PC)
- Motif Saga
- Motif de services équilibrés et répliqués (RLBS)
- Motif de services partitionnés
- Motif Sidecar
- Technique de journalisation anticipée
- Motif de scission cérébrale
- Motif de transfert de responsabilité
- Motif de réparation de lecture
- Motif de registre de services
- Motif de disjoncteur
- Motif d'élection de leader
- Motif de cloisonnement
- Motif de nouvelle tentative
- Motif de diffusion-rassemblement
- Structure de données des filtres de Bloom
Qu'est-ce que les systèmes distribués ?
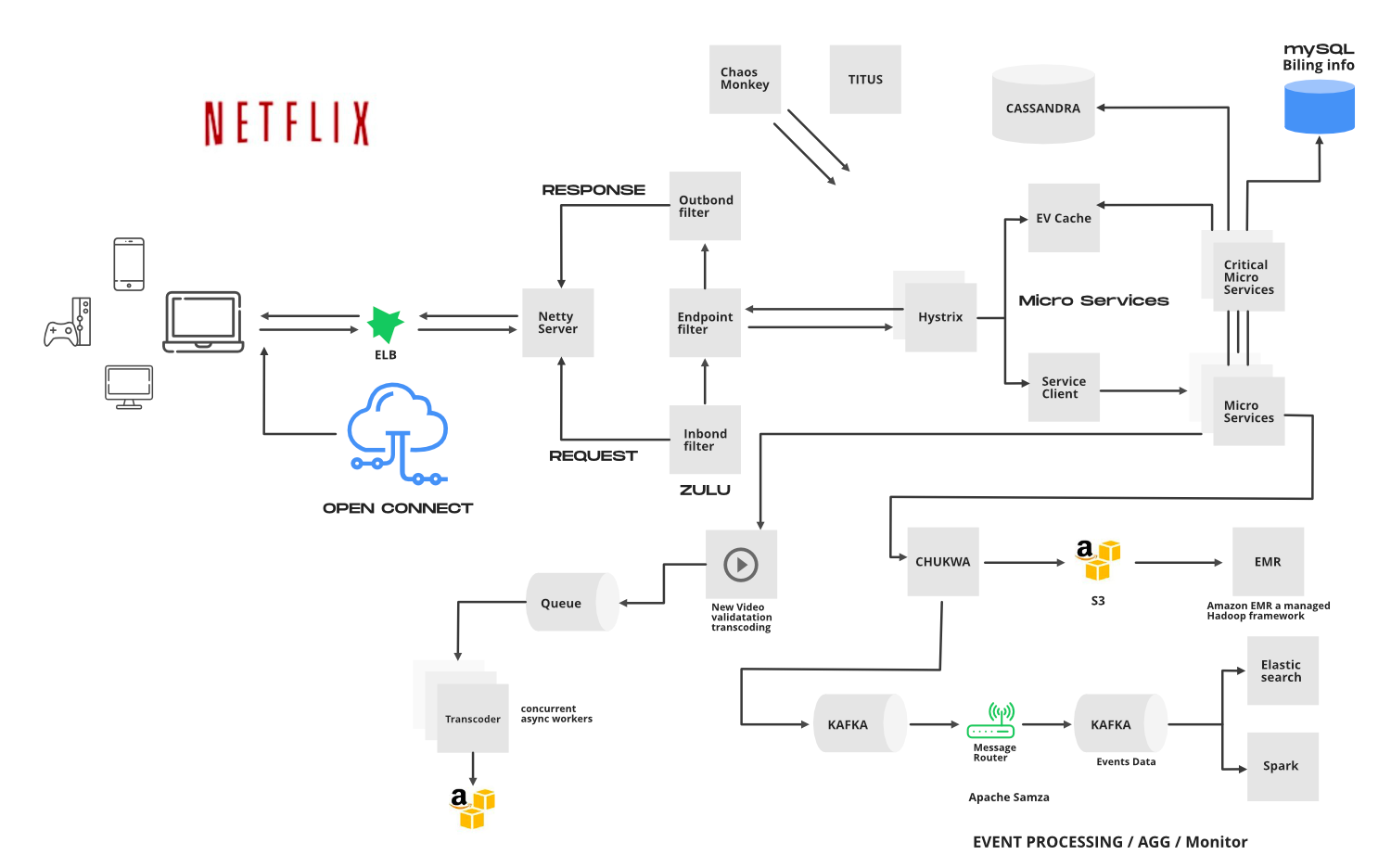 Architecture Netflix. Source
Architecture Netflix. Source
Lorsque j'ai commencé ma carrière, je travaillais en tant que développeur front-end pour une agence.
Nous recevions des demandes de clients et ensuite nous construisions simplement leur site.
À l'époque, je ne comprenais pas complètement l'architecture et l'infrastructure derrière ce que je construisais.
En y repensant maintenant, ce n'était pas compliqué du tout.
Nous avions un service backend écrit en PHP et Yii2 (Framework PHP) et un frontend écrit en JavaScript et React.
Tout cela était déployé sur un serveur hébergé chez ps.kz (fournisseur d'hébergement kazakh) et exposé sur Internet en utilisant NGINX comme serveur web.
Cette architecture fonctionne pour la plupart des projets. Mais une fois que votre application devient plus complexe et populaire, les fissures commencent à apparaître.
Vous rencontrez des problèmes tels que :
- Complexité – La base de code est trop grande et trop complexe pour qu'une seule personne puisse la gérer mentalement. Il est également difficile de créer de nouvelles fonctionnalités et de maintenir les anciennes.
- Problèmes de performance – La popularité de votre application a provoqué un trafic réseau important et cela s'est avéré trop pour votre serveur unique. À cause de cela, l'application a commencé à rencontrer des problèmes de performance.
- Inflexibilité – Avoir une seule base de code signifie que vous êtes coincé avec la pile technologique que vous avez commencée. Si vous voulez la changer, alors vous devrez soit tout réécrire dans un autre langage, soit diviser l'application.
- Système fragile – Le code étant fortement couplé, si une fonctionnalité tombe en panne, toute l'application tombera en panne. Cela entraîne plus de temps d'arrêt, ce qui coûte plus d'argent à l'entreprise.
Il existe de nombreuses façons d'optimiser une application monolithique, et elle peut aller très loin. De nombreuses grandes entreprises technologiques comme Netflix, Google et Facebook (Meta) ont commencé comme des applications monolithiques car elles sont plus faciles à lancer.
Mais elles ont toutes commencé à rencontrer des problèmes avec les monolithes à grande échelle et ont dû trouver un moyen de les résoudre.
Qu'ont-elles fait ? Elles ont restructuré leurs architectures. Ainsi, au lieu d'avoir un super service unique contenant toutes les fonctionnalités de leur entreprise, elles ont maintenant plusieurs services indépendants qui communiquent entre eux.
C'est la base des systèmes distribués.
Certaines personnes confondent les systèmes distribués avec les microservices. Et c'est vrai – les microservices sont un système distribué. Mais les systèmes distribués ne suivent pas toujours l'architecture des microservices.
Avec cela en tête, établissons une définition appropriée pour les systèmes distribués :
Un système distribué est un environnement informatique dans lequel divers composants sont répartis sur plusieurs ordinateurs (ou autres dispositifs informatiques) sur un réseau.
Défis courants dans les systèmes distribués
Les systèmes distribués sont de loin beaucoup plus complexes que les systèmes monolithiques.
C'est pourquoi, avant de migrer ou de commencer un nouveau projet, vous devriez vous poser la question :
En ai-je vraiment besoin ?
Si vous décidez que vous avez besoin d'un système distribué, alors vous rencontrerez certains défis courants :
- Hétérogénéité – Les systèmes distribués nous permettent d'utiliser une large gamme de technologies différentes. Le problème réside dans la manière dont nous maintenons une communication cohérente entre tous les différents services. Ainsi, il est important d'avoir des normes communes convenues et adoptées pour rationaliser le processus.
- Évolutivité – La mise à l'échelle n'est pas une tâche facile. Il y a de nombreux facteurs à garder à l'esprit tels que la taille, la géographie et l'administration. Il y a de nombreux cas particuliers, chacun avec ses propres avantages et inconvénients.
- Ouverture – Les systèmes distribués sont considérés comme ouverts s'ils peuvent être étendus et redéveloppés.
- Transparence – La transparence fait référence à la capacité du système distribué à dissimuler sa complexité et à donner l'apparence d'un système unique.
- Concurence – Les systèmes distribués permettent à plusieurs services d'utiliser des ressources partagées. Des problèmes peuvent survenir lorsque plusieurs services tentent d'accéder aux mêmes ressources en même temps. Nous utilisons le contrôle de concurrence pour garantir que le système reste dans un état stable.
- Sécurité – La sécurité est composée de trois composants clés : la disponibilité, l'intégrité et la confidentialité.
- Gestion des échecs – Il existe de nombreuses raisons pour les erreurs dans un système distribué (par exemple, logiciel, réseau, matériel, etc.). La chose la plus importante est la manière dont nous gérons ces erreurs de manière élégante afin que le système puisse s'auto-réparer.
Oui, concevoir des systèmes distribués robustes et évolutifs n'est pas facile.
Mais vous n'êtes pas seul. D'autres personnes intelligentes ont rencontré des problèmes similaires et offrent des solutions communes appelées motifs de conception.
Couvrons les plus populaires.
PS. Nous ne couvrirons pas seulement les motifs, mais tout ce qui aide dans les systèmes distribués. Cela peut inclure des structures de données, des algorithmes, des scénarios courants, etc...
Motif de ségrégation des responsabilités de commande et de requête (CQRS)
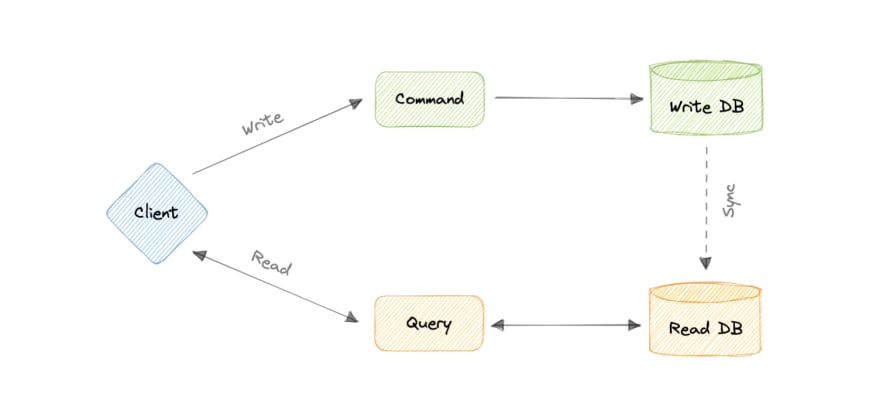
Imaginez que vous avez une application avec des millions d'utilisateurs. Vous avez plusieurs services qui gèrent le backend, mais avec une seule base de données.
Le problème survient lorsque vous effectuez des lectures et des écritures sur cette même base de données. Les écritures sont beaucoup plus coûteuses à calculer que les lectures, et le système commence à souffrir.
C'est ce que le motif CQRS résout.
Il stipule que les écritures (commandes) et les lectures (requêtes) doivent être séparées. En séparant les écritures et les lectures, nous pouvons permettre aux développeurs d'optimiser chaque tâche séparément.
Par exemple, vous pourriez choisir une base de données haute performance pour les opérations d'écriture et un cache ou un moteur de recherche pour les opérations de lecture.
Avantages
- Simplification du code – Réduit la complexité du système en séparant les écritures et les lectures.
- Optimisations des ressources – Optimise l'utilisation des ressources en ayant une base de données séparée pour les écritures et les lectures.
- Évolutivité – Améliore l'évolutivité pour les lectures car vous pouvez simplement ajouter plus de réplicas de base de données.
- Réduction du nombre d'erreurs – En limitant les entités qui peuvent modifier les données partagées, nous pouvons réduire les chances de modifications inattendues des données.
Inconvénients
- Complexité du code – Ajoute de la complexité au code en exigeant que les développeurs gèrent les lectures et les écritures séparément.
- Augmentation du temps de développement – Cela peut augmenter le temps et le coût de développement (au début seulement).
- Infrastructure supplémentaire – Cela peut nécessiter une infrastructure supplémentaire pour supporter des modèles de lecture et d'écriture séparés.
- Latence accrue – Cela peut causer une latence accrue lors de l'envoi de requêtes à haut débit.
Cas d'utilisation
CQRS est mieux utilisé lorsque les écritures et les lectures d'une application ont des exigences de performance différentes. Mais ce n'est pas toujours la meilleure approche, et les développeurs doivent soigneusement considérer les avantages et les inconvénients avant d'adopter le motif.
Voici quelques cas d'utilisation qui utilisent le motif CQRS :
- E-Commerce – Modèles de lecture séparés pour les catalogues de produits et les recommandations, tandis que le côté écriture gère le traitement des commandes et la gestion des stocks.
- Banques – Optimise les modèles de lecture pour les demandes de solde et les rapports, tandis que le côté écriture gère les transactions et les calculs.
- Soins de santé – CQRS peut être utilisé pour optimiser les lectures pour les recherches de patients, la récupération des dossiers médicaux et la génération de rapports, tandis que le côté écriture gère les mises à jour des données, la planification et les plans de traitement.
- Réseaux sociaux – En appliquant CQRS, les modèles de lecture peuvent gérer efficacement la génération de flux, les recommandations de contenu personnalisé et les requêtes de profil utilisateur, tandis que le côté écriture gère la création de contenu, les mises à jour et le suivi de l'engagement.
Motif de validation en deux phases (2PC)
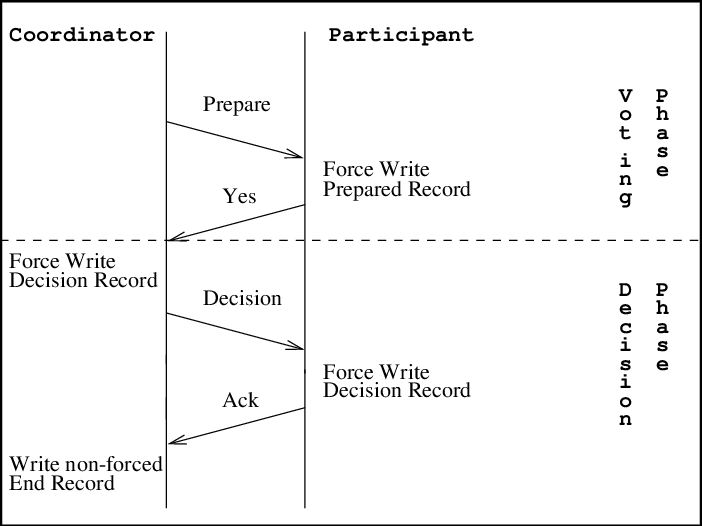 _Source_
_Source_
Le 2PC résout le problème de la cohérence des données. Lorsque vous avez plusieurs services qui communiquent avec une base de données relationnelle, il est difficile de maintenir la cohérence des données car un service peut créer une transaction tandis qu'un autre l'annule.
Le 2PC est un protocole qui garantit que tous les services valident ou annulent une transaction avant qu'elle ne soit terminée.
Il fonctionne en deux phases. La première phase est la phase de préparation dans laquelle le coordinateur de transaction indique au service de préparer les données. Ensuite vient la phase de validation, qui signale au service d'envoyer les données préparées, et la transaction est validée.
Les systèmes 2PC s'assurent que tous les services sont verrouillés par défaut. Cela signifie qu'ils ne peuvent pas simplement écrire dans la base de données.
Pendant le verrouillage, les services terminent l'étape de préparation pour préparer leurs données. Ensuite, le coordinateur de transaction vérifie chaque service un par un pour voir s'ils ont des données préparées.
S'ils en ont, alors le service est déverrouillé et les données sont validées. Sinon, le coordinateur de transaction passe à un autre service.
Le 2PC garantit qu'un seul service peut fonctionner à la fois, ce qui rend le processus plus résistant et cohérent que le CQRS.
Avantages
- Cohérence des données – Garantit la cohérence des données dans un environnement de transaction distribué.
- Tolérance aux pannes – Fournit un mécanisme pour gérer les échecs de transaction et les retours en arrière.
Inconvénients
- Blocage – Le protocole peut introduire des retards ou des blocages dans le système, car il peut devoir attendre des participants non réactifs ou résoudre des problèmes de réseau avant de procéder à la transaction.
- Point unique de défaillance – La dépendance à un seul coordinateur introduit un point potentiel de défaillance. Si le coordinateur échoue, le protocole peut être perturbé, entraînant des échecs ou des retards de transaction.
- Surcoût de performance – Les tours de communication supplémentaires et les étapes de coordination dans le protocole introduisent un surcoût, ce qui peut impacter les performances globales, en particulier dans les scénarios avec de nombreux participants ou une latence réseau élevée.
- Manque d'évolutivité – À mesure que le nombre de participants augmente, le surcoût de coordination et de communication augmente également, limitant potentiellement l'évolutivité du protocole.
- Blocage pendant la récupération – Le protocole peut introduire un blocage pendant la récupération jusqu'à ce que le participant défaillant soit de nouveau en ligne, impactant la disponibilité et la réactivité du système.
Cas d'utilisation
Le 2PC est mieux utilisé pour les systèmes qui traitent des opérations de transaction importantes qui doivent être précises.
Voici quelques cas d'utilisation où le motif 2PC serait bénéfique :
- Bases de données distribuées – Coordination des validations ou annulations de transactions sur plusieurs bases de données dans un système de base de données distribué.
- Systèmes financiers – Assurer un traitement de transaction atomique et cohérent entre les banques, les passerelles de paiement et les institutions financières.
- Plateformes de commerce électronique – Coordination des services comme la gestion des stocks, le traitement des paiements et l'exécution des commandes pour un traitement de transaction fiable et cohérent.
- Systèmes de réservation – Coordination des ressources et participants distribués dans les processus de réservation pour la cohérence et l'atomicité.
- Systèmes de fichiers distribués – Coordination des opérations de fichiers sur plusieurs nœuds ou serveurs dans des systèmes de fichiers distribués pour maintenir la cohérence.
Motif Saga
Imaginez que vous avez une application de commerce électronique qui possède trois services, chacun avec sa propre base de données.
Vous avez une API pour vos marchands appelée /products à laquelle vous pouvez ajouter un produit avec toutes ses informations.
Chaque fois que vous créez un produit, vous devez également créer son prix et ses métadonnées. Les trois sont gérés dans différents services avec différentes bases de données.
Vous implémentez donc l'approche simple suivante :
Créer un produit -> créer un prix -> créer des métadonnées
Mais que se passe-t-il si vous avez créé un produit mais que la création du prix a échoué ? Comment un service peut-il savoir qu'il y a eu une transaction échouée d'un autre service ?
Le motif Saga résout ce problème.
Il existe deux façons d'implémenter les sagas : l'orchestration et la chorégraphie.
Orchestration
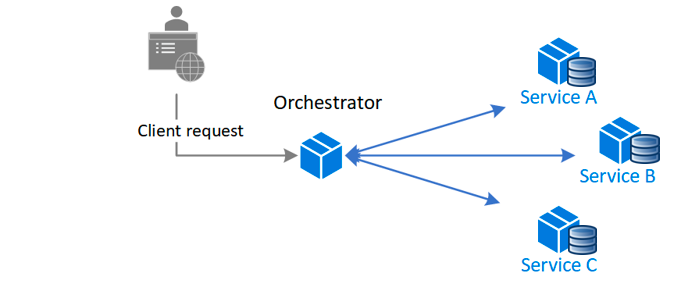
La première méthode s'appelle l'orchestration.
Vous avez un service central qui appelle tous les différents services dans le bon ordre.
Le service central s'assure que s'il y a un échec, il saura comment compenser cela en annulant les transactions ou en journalisant les erreurs.
Avantages
- Convient pour les transactions complexes impliquant plusieurs services ou de nouveaux services ajoutés au fil du temps.
- Convient lorsque vous avez le contrôle sur chaque participant dans le processus et le contrôle sur le flux d'activités.
- N'introduit pas de dépendances cycliques, car l'orchestrateur dépend unilatéralement des participants de la saga.
- Les services n'ont pas besoin de connaître les commandes des autres services. Il y a une séparation claire des préoccupations qui réduit la complexité.
Inconvénients
- La complexité supplémentaire de la conception nécessite la mise en œuvre d'une logique de coordination.
- Si l'orchestrateur échoue, alors tout le système échoue.
Quand utiliser l'orchestration ?
Vous devriez envisager d'utiliser ce motif :
- Si vous avez besoin d'un service centralisé qui coordonne le flux de travail.
- Si vous voulez une vue claire et centralisée du flux de travail, ce qui facilite la compréhension et la gestion du comportement global du système.
- Si vous avez des flux de travail complexes et dynamiques qui nécessitent un haut degré de coordination et de contrôle centralisé.
Chorégraphie
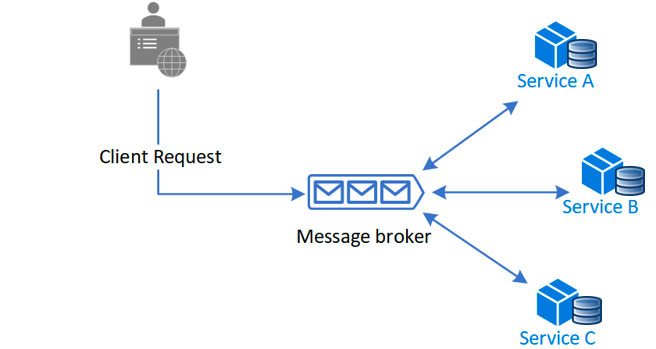
D'autre part, la méthode de chorégraphie n'utilise pas de service central. Au lieu de cela, toute la communication entre les serveurs se fait par des événements.
Les services réagiront aux événements et sauront quoi faire en cas de succès ou d'échec.
Ainsi, pour notre exemple ci-dessus, lorsque l'utilisateur crée un produit, il :
- Crée un événement appelé
product-created-successfully - Ensuite, le service de prix réagit à l'événement en créant un prix pour le produit et crée un autre événement appelé
price-created-successfully - La même logique s'applique au service de métadonnées.
Avantages
- Convient pour les flux de travail simples qui ne nécessitent pas de logique de coordination complexe.
- Simple à implémenter car il ne nécessite pas de service supplémentaire.
- Il n'y a pas de point de défaillance unique car les responsabilités sont distribuées entre les services.
Inconvénients
- Difficile à déboguer car il est difficile de suivre quels services de saga écoutent quelles commandes.
- Il y a un risque de dépendance cyclique entre les services Saga car ils doivent consommer les commandes les uns des autres.
- Les tests d'intégration sont difficiles car tous les services doivent être en cours d'exécution pour simuler une transaction.
Quand utiliser la chorégraphie :
Vous devriez envisager d'utiliser ce motif si :
- L'application doit maintenir la cohérence des données entre plusieurs microservices sans couplage serré.
- Il y a des transactions de longue durée et vous ne voulez pas que d'autres microservices soient bloqués si un microservice s'exécute pendant une longue période.
- Vous devez pouvoir revenir en arrière si une opération échoue dans la séquence.
Motif de services équilibrés et répliqués (RLBS)
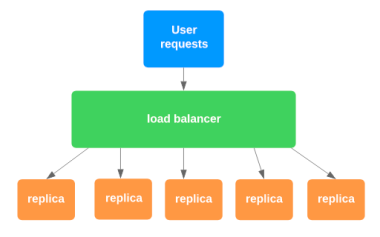
C'est essentiellement un équilibreur de charge – je ne sais pas pourquoi ils l'ont rendu si intimidant.
Un équilibreur de charge est un logiciel ou un matériel qui distribue le trafic réseau de manière égale entre un ensemble de ressources.
Mais ce n'est pas toujours le cas – il peut également router différentes routes vers différents services.
Par exemple :
/frontendva au service front-end./apiva au service back-end.
Avantages
- Performance – L'équilibrage de charge distribue la charge de travail de manière égale sur plusieurs ressources, empêchant toute ressource unique de devenir surchargée. Cela conduit à des temps de réponse améliorés, une latence réduite et de meilleures performances globales pour les utilisateurs ou clients accédant au système.
- Évolutivité – L'équilibrage de charge vous permet de mettre à l'échelle horizontalement, ce qui signifie qu'au lieu d'obtenir des serveurs plus puissants, vous pouvez obtenir plus de serveurs.
- Haute disponibilité – Comme mentionné ci-dessus, l'équilibrage de charge nous permet de mettre à l'échelle verticalement, ce qui signifie que nous avons plusieurs serveurs. Si un serveur tombe en panne, l'équilibreur de charge le détectera et le trafic peut être redirigé vers d'autres serveurs fonctionnels.
- Meilleure utilisation des ressources – L'équilibrage de charge aide à optimiser l'utilisation des ressources en distribuant le trafic de manière égale sur plusieurs serveurs ou ressources. Cela garantit que chaque serveur ou ressource est utilisé efficacement, aidant à réduire les coûts et à maximiser les performances.
Inconvénients
- Complexité – La mise en œuvre et la configuration de l'équilibrage de charge peuvent être compliquées, surtout pour les systèmes à grande échelle.
- Point unique de défaillance – Bien que les équilibreurs de charge améliorent la disponibilité du système, ils peuvent également devenir un point unique de défaillance. Si l'équilibreur de charge lui-même tombe en panne, cela peut provoquer une interruption de service pour toutes les ressources derrière lui.
- Surcoût accru – Les calculs des équilibreurs de charge ne sont pas gratuits, s'ils ne sont pas contrôlés, ils peuvent devenir un goulot d'étranglement pour l'ensemble du système.
- Défis de gestion de session – L'équilibrage de charge des applications avec état est un peu délicat car vous devez maintenir les sessions. Cela nécessite des mécanismes supplémentaires tels que des sessions persistantes ou une synchronisation de session, ce qui ajoute de la complexité.
Quand utiliser l'équilibrage de charge
Un équilibreur de charge est principalement utilisé lorsque :
- Vous avez un site web à fort trafic et vous voulez répartir la charge afin que vos serveurs ne surchauffent pas.
- Vous avez des utilisateurs du monde entier et vous voulez leur servir des données depuis l'emplacement le plus proche. Vous pourriez avoir un serveur en Asie et un autre en Europe. L'équilibreur de charge redirigerait alors tous les utilisateurs d'Asie vers le serveur asiatique et les utilisateurs européens vers le serveur européen.
- Vous avez une architecture orientée services avec des API correspondant à différents services. L'équilibrage de charge peut être utilisé comme une simple passerelle API.
J'ai écrit plusieurs articles sur l'équilibrage de charge, alors n'hésitez pas à les consulter.
- Comment configurer l'équilibrage de charge NGINX : un guide étape par étape
- Équilibrage de charge dans Kubernetes : un guide étape par étape
- Équilibrage de charge 101 : Comment cela fonctionne et pourquoi c'est important pour votre plateforme
Motif de services partitionnés
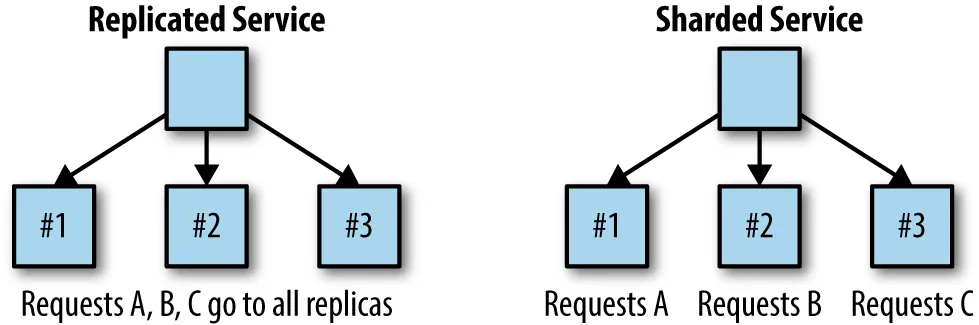
Dans la section précédente, nous avons parlé des services répliqués. Toute demande peut être traitée par l'un des services. Cela est dû au fait qu'ils sont des répliques les uns des autres.
Cela est bon pour les services sans état. Mais que faire si vous avez un service avec état ? Alors une approche partitionnée serait plus appropriée.
Un service partitionné n'accepte que certains types de demandes.
Par exemple, vous pouvez avoir un service partitionné accepter toutes les demandes de mise en cache tandis qu'un autre service partitionné accepte les demandes à haute priorité.
Mais comment implémenter cela ?
Eh bien, si nous parlons strictement des services d'application, vous pourriez opter pour l'approche d'architecture orientée services. Vous pourriez avoir plusieurs services développés et déployés indépendamment.
Ensuite, vous pourriez utiliser un équilibreur de charge pour router les demandes par chemin d'URL vers le service approprié.
PS. Le partitionnement n'est pas seulement utilisé pour les services d'application mais peut être utilisé pour les bases de données, les caches, les CDN, etc...
Avantages :
- Évolutivité – Le partitionnement vous permet de distribuer la charge sur plusieurs nœuds ou serveurs, permettant ainsi une mise à l'échelle horizontale. À mesure que votre charge de travail augmente, vous pouvez simplement ajouter plus de partitions.
- Performance – Un seul nœud n'a pas à gérer toutes les demandes, surtout si elles sont lourdement calculatoires. Chaque nœud peut prendre en charge un sous-ensemble de demandes, améliorant ainsi les performances du système.
- Rentabilité – Le partitionnement peut être une solution rentable pour mettre à l'échelle votre système. Au lieu d'investir dans un serveur unique et hautement performant, vous pouvez utiliser du matériel standard et distribuer la charge de travail sur plusieurs serveurs moins coûteux.
- Isolement des pannes – Le partitionnement offre un niveau d'isolement des pannes. Si une partition ou un nœud tombe en panne, les partitions restantes peuvent continuer à servir les demandes.
Inconvénients :
- Complexité – Le partitionnement n'est pas facile à implémenter. Il nécessite une planification et une conception minutieuses pour gérer la distribution des données, la cohérence et la coordination des requêtes.
- Surcoût opérationnel – La gestion d'un système partitionné implique des tâches opérationnelles supplémentaires telles que la surveillance, la maintenance et la sauvegarde, ce qui peut nécessiter plus de ressources et d'expertise.
Cas d'utilisation
Le motif de services partitionnés est généralement utilisé dans les scénarios suivants :
- Exigences de performance – Si votre système traite de grands volumes de données ou des charges de travail de lecture/écriture élevées qu'un seul serveur ne peut pas gérer, le partitionnement peut distribuer la charge de travail sur plusieurs partitions. Cela permet un traitement parallèle et améliore les performances globales.
- Exigences d'évolutivité – Lorsque vous anticipez le besoin d'une évolutivité horizontale à l'avenir, le partitionnement peut être implémenté dès le début pour fournir la flexibilité d'ajouter plus de partitions et de mettre à l'échelle le système à mesure que la charge de travail augmente.
- Considérations de coût – Si la mise à l'échelle verticale (passage à un matériel plus puissant) devient prohibitivement coûteuse, le partitionnement offre une alternative rentable en distribuant la charge de travail sur plusieurs serveurs ou nœuds moins coûteux.
- Distribution géographique – Le partitionnement peut être bénéfique lorsque vous devez distribuer des données dans différentes localisations géographiques ou centres de données, permettant des performances améliorées et une latence réduite pour les utilisateurs dans différentes régions.
Mais gardez à l'esprit qu'il doit y avoir des considérations attentives lors du partitionnement de vos services, car cela est très complexe et coûteux à implémenter et à inverser.
Motif Sidecar
Dans une architecture orientée services, vous pouvez avoir beaucoup de fonctionnalités communes – des choses comme la gestion des erreurs, la journalisation, la surveillance et la configuration.
Dans le passé, il y avait deux façons de résoudre ce problème :
Implémenter des fonctionnalités communes au sein du service
Le problème avec cette approche est que les utilitaires sont étroitement liés et s'exécutent dans le même processus en utilisant efficacement les ressources partagées. Cela rend les composants interdépendants.
Si une fonctionnalité échoue, cela peut entraîner l'échec d'une autre fonctionnalité ou de l'ensemble du service.
Implémenter des fonctionnalités communes dans un service séparé
Cela peut sembler une bonne approche car les utilitaires peuvent être implémentés dans n'importe quel langage et ne partagent pas de ressources avec d'autres services.
Les inconvénients sont qu'il ajoute de la latence à l'application lorsque nous déployons deux services sur différents conteneurs, et qu'il ajoute de la complexité en termes d'hébergement, de déploiement et de gestion.
Comment pouvons-nous faire mieux ?
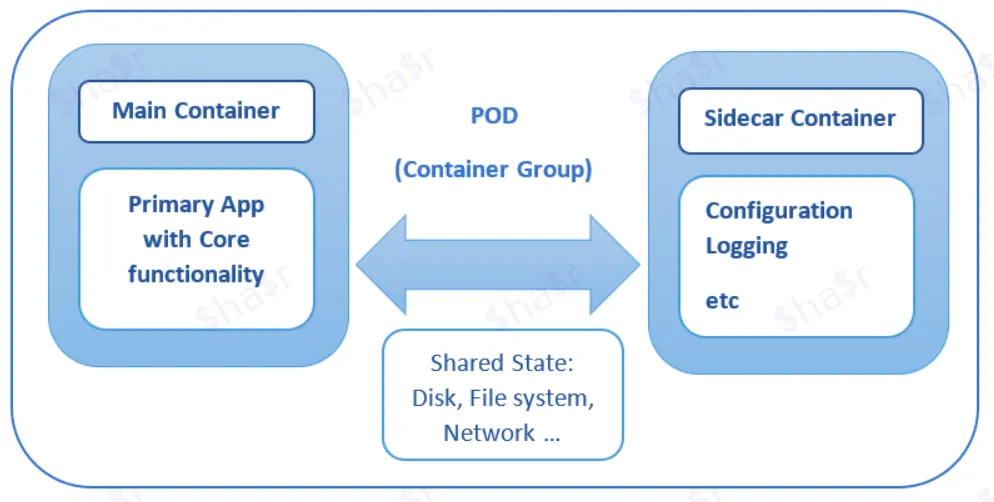
Une méthode consiste à utiliser le motif side-car. Il stipule qu'un conteneur ne doit traiter qu'une seule préoccupation et le faire bien.
Ainsi, pour ce faire, nous avons un seul nœud (machine virtuelle ou physique) avec deux conteneurs.
Le premier est le conteneur d'application qui contient la logique métier. Le second conteneur, généralement appelé sidecar, est utilisé pour étendre/améliorer la fonctionnalité du conteneur d'application.
Maintenant, vous pourriez demander, "Mais, en quoi cela est-il utile ?"
Vous devez garder à l'esprit que le service sidecar s'exécute dans le même nœud que le conteneur d'application. Ainsi, ils partagent les mêmes ressources (comme le système de fichiers, la mémoire, le réseau, etc.)
Un exemple
Disons que vous avez une application héritée qui génère des journaux et les sauvegarde dans un volume (données persistantes) et que vous souhaitez les extraire vers une plateforme externe telle qu'ELK.
Une façon de faire cela est simplement d'étendre l'application principale. Mais cela est difficile en raison du code désordonné.
Vous décidez donc d'opter pour la méthode sidecar et de développer un service utilitaire qui :
- Capture les journaux à partir du volume.
- Transfère les journaux vers Elastic.
L'architecture du nœud ressemblerait à quelque chose comme ceci :
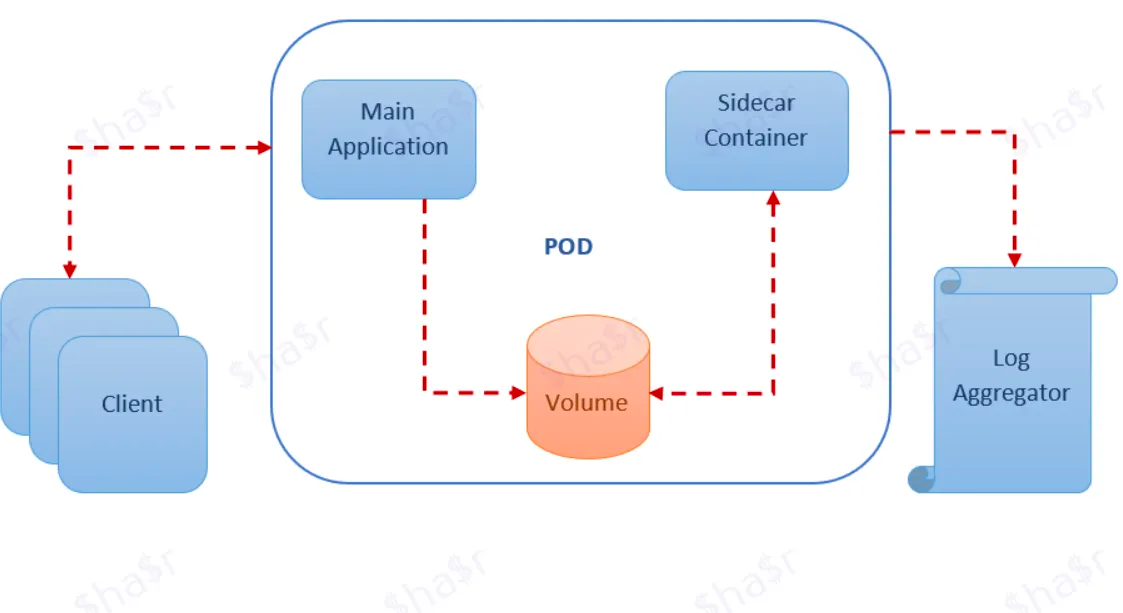
Hourra, vous n'avez changé aucun code dans l'application et vous avez étendu sa fonctionnalité en branchant un sidecar.
En plus, vous pouvez même brancher cet agrégateur de journaux sidecar dans d'autres applications.
Avantages :
- Modularité – Le sidecar vous permet de développer et de maintenir des fonctions utilitaires indépendamment.
- Évolutivité – Si la charge sur le sidecar est trop importante, vous pouvez facilement le mettre à l'échelle horizontalement en ajoutant plus de conteneurs.
- Isolement – Le sidecar est isolé de l'application principale, fournissant une couche supplémentaire de sécurité.
Inconvénients :
- Complexité – Cela nécessite une gestion supplémentaire de plusieurs conteneurs et de leurs dépendances.
- Surcoût de ressources – Parce que nous avons un conteneur supplémentaire, cela peut augmenter l'utilisation globale des ressources de l'application.
- Coordination – Le sidecar doit être coordonné de manière à ce qu'il fonctionne correctement avec l'application principale, ce qui augmente la complexité.
- Débogage – Le débogage est plus difficile avec le motif sidecar, car il nécessite de tracer les interactions entre l'application principale et le sidecar.
Cas d'utilisation
Le motif sidecar est utile lorsque vous souhaitez ajouter des fonctionnalités supplémentaires à l'application sans toucher au code de la logique métier principale.
En déployant le sidecar, la logique principale peut rester légère et se concentrer sur sa tâche principale tandis que le sidecar peut gérer des fonctionnalités supplémentaires.
Si nécessaire, vous pouvez réutiliser le sidecar pour d'autres applications également.
Maintenant que nous savons quand utiliser ce motif, examinons quelques cas d'utilisation où il est bénéfique :
- Journalisation et surveillance – Le conteneur sidecar collecte les journaux et les métriques du conteneur principal, fournissant un stockage centralisé et une surveillance en temps réel pour une meilleure observabilité.
- Mise en cache – Le conteneur sidecar met en cache les données ou les réponses fréquemment consultées, améliorant les performances en réduisant le besoin de demandes répétées aux services externes.
- Découverte de services et équilibrage de charge – Le conteneur sidecar enregistre le conteneur principal auprès d'un système de découverte de services, permettant l'équilibrage de charge et la tolérance aux pannes sur plusieurs instances du conteneur principal.
- Sécurité et authentification – Le conteneur sidecar gère les tâches d'authentification, déchargeant les responsabilités telles que OAuth, la vérification JWT ou la gestion des certificats du conteneur principal.
- Transformation et intégration des données – Le conteneur sidecar effectue des tâches de transformation et d'intégration des données, facilitant la communication et la synchronisation transparentes entre le conteneur principal et les systèmes externes.
- Proxy et passerelle – Le conteneur sidecar agit comme un proxy ou une passerelle, fournissant des fonctionnalités telles que la limitation du débit, la terminaison SSL ou la traduction de protocole pour des capacités de communication améliorées.
- Optimisation des performances – Le conteneur sidecar gère les tâches intensives en CPU ou les processus en arrière-plan, optimisant l'utilisation des ressources et améliorant les performances du conteneur principal.
Technique de journalisation anticipée
Imaginez ceci : vous travaillez sur un service qui est connecté à une base de données contenant des informations sensibles sur les utilisateurs.
Un jour, le serveur tombe en panne. Votre base de données tombe en panne. Toutes les données sont perdues, à l'exception des sauvegardes.
Vous synchronisez la base de données avec la sauvegarde, mais la sauvegarde n'est pas à jour. Elle a un jour de retard. Vous vous asseyez et pleurez dans un coin.
Heureusement, cela n'arrivera probablement jamais.
Car la plupart des bases de données ont quelque chose appelé un journal anticipé (WAL).
Qu'est-ce qu'un journal anticipé ?
Un journal anticipé est une technique populaire utilisée pour préserver :
- Atomicité – Chaque transaction est traitée comme une seule unité. Soit la transaction entière est exécutée, soit aucune partie ne l'est. Cela garantit que les données ne sont pas corrompues ou perdues.
- Durabilité – Garantit que les données ne seront pas perdues, même en cas de défaillance du système.
Mais comment cela fonctionne-t-il ?
Un WAL stocke chaque changement que vous avez apporté dans un fichier sur un disque dur.
Par exemple, supposons que vous avez créé votre propre base de données en mémoire appelée KVStore. En cas de défaillance du système, vous voulez :
- Que les données ne soient pas perdues.
- Que les données soient récupérées en mémoire.
Vous décidez donc d'implémenter un journal anticipé.
Chaque fois que vous effectuez une transaction (SET ou REMOVE), la commande sera journalisée dans un fichier sur le disque dur. Cela nous permet de récupérer les données en cas de défaillance du système. La mémoire sera vidée, mais le journal est toujours stocké sur le disque dur.
L'architecture globale ressemblerait à quelque chose comme ceci :
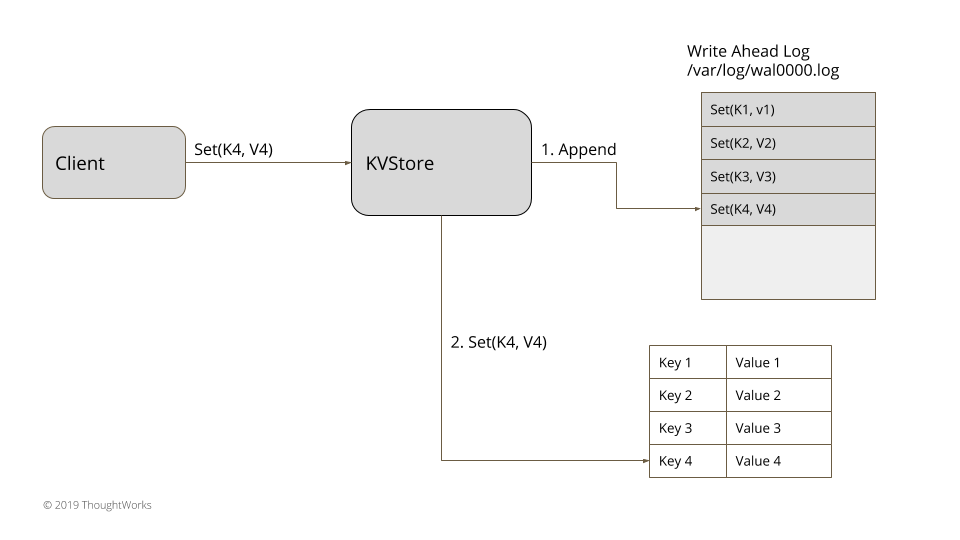
Ce n'est pas toujours un ciel bleu et des arcs-en-ciel
Aussi utile soit-il, le WAL n'est pas facile à implémenter. Il y a de nombreuses nuances, mais les plus courantes sont :
Performance
Si vous utilisez des bibliothèques de gestion de fichiers standard dans la plupart des langages de programmation, vous "flusherez" probablement le fichier sur le disque dur.
Flusher chaque journal donnera une forte garantie de durabilité. Mais cela limite sévèrement les performances et peut rapidement devenir un goulot d'étranglement.
Vous pourriez demander, "pourquoi ne pas retarder le flush ou le faire de manière asynchrone ?"
Eh bien, cela pourrait améliorer les performances mais au risque de perdre des entrées du journal si le serveur tombe en panne avant que les entrées ne soient flushées.
La meilleure pratique ici est d'implémenter des techniques comme le batching, pour limiter l'impact de l'opération de flush.
Corruption des données
L'autre considération est que nous devons nous assurer que les fichiers de journal corrompus sont détectés.
Pour gérer cela, sauvegardez les fichiers de journal via des enregistrements CRC (Cyclic Redundancy Check), qui valident les fichiers lors de la lecture.
Stockage
Les fichiers de journal uniques peuvent être difficiles à gérer et peuvent consommer tout l'espace de stockage disponible.
Pour gérer ce problème, utilisez des techniques comme :
- Journal segmenté – Divisez le journal unique en plusieurs segments.
- Marque de bas niveau – Cette technique nous indique quelle partie des journaux peut être supprimée en toute sécurité.
Ces deux techniques sont utilisées ensemble car elles se complètent mutuellement.
Entrées en double
Les WAL sont en mode ajout uniquement, ce qui signifie que vous ne pouvez ajouter que des données. En raison de ce comportement, nous pouvons avoir des entrées en double. Ainsi, lorsque le journal est appliqué, il doit s'assurer que les doublons sont ignorés.
Une façon de résoudre ce problème est d'utiliser une table de hachage, où les mises à jour de la même clé sont idempotentes. Sinon, il doit y avoir un mécanisme pour marquer chaque transaction avec un identifiant unique et détecter les doublons.
Cas d'utilisation
Globalement, les WAL sont principalement utilisés dans les bases de données mais peuvent être bénéfiques dans d'autres domaines :
Les journaux anticipés (WAL) sont largement utilisés dans divers systèmes et bases de données. Voici quelques cas d'utilisation courants pour les journaux anticipés :
- Systèmes de fichiers – Les systèmes de fichiers peuvent employer la journalisation anticipée pour maintenir la cohérence des données. En journalisant les modifications avant de les appliquer au système de fichiers, les WAL permettent la récupération après un crash et aident à prévenir la corruption des données en cas de défaillance du système.
- Files d'attente de messages et sourçage d'événements – Les journaux anticipés sont souvent utilisés dans les architectures de files d'attente de messages et de sourçage d'événements. Les journaux servent d'enregistrement fiable et ordonné des événements, permettant une livraison de messages fiable, une relecture d'événements et une restauration de l'état du système.
- Systèmes distribués – Les systèmes distribués qui doivent maintenir la cohérence sur plusieurs nœuds peuvent bénéficier des journaux anticipés. En coordonnant la réplication et la relecture des journaux, les WAL aident à synchroniser les mises à jour des données et à assurer la cohérence dans les environnements distribués.
Motif de scission cérébrale
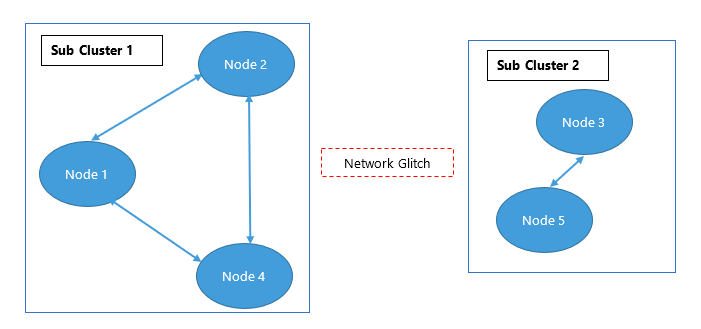
C'est définitivement un nom intéressant, n'est-ce pas ? Cela pourrait vous faire penser aux deux moitiés du cerveau.
Eh bien, c'est en fait quelque peu similaire.
Une scission cérébrale dans les systèmes distribués se produit lorsque les nœuds d'un système distribué deviennent déconnectés les uns des autres mais continuent à fonctionner.
Scission cérébrale ? Nœuds travaillant indépendamment alors qu'ils devraient travailler ensemble ? Cela semble similaire ? Je l'espère.
Quoi qu'il en soit, le plus gros problème avec cela est qu'il provoque :
- Incohérence des données
- Concurrence pour les ressources
Cela fermera généralement le cluster pendant que les développeurs tentent de réparer les choses. Cela provoque des temps d'arrêt qui font perdre de l'argent à l'entreprise.
Quelle est la solution ?
Une solution consiste à utiliser un numéro de génération. Chaque fois qu'un leader est élu, le numéro de génération est incrémenté.
Par exemple, si l'ancien leader avait un numéro de génération de un, alors le deuxième leader aura un numéro de génération de deux.
Le numéro de génération est inclus dans chaque demande, et maintenant les clients peuvent simplement faire confiance au leader avec le numéro le plus élevé.
Mais gardez à l'esprit que le numéro de génération doit être persistant sur le disque.
Une façon de faire cela est d'utiliser un Write Ahead Log. Voyez, les choses sont connectées les unes aux autres.
Cette solution est catégorisée comme une élection de leader, mais il en existe d'autres :
- Consensus basé sur le quorum – Utilisez des algorithmes comme Raft ou Paxos pour garantir qu'une majorité de nœuds seulement peut prendre des décisions, empêchant les décisions conflictuelles dans un scénario de scission cérébrale.
- Détection de partition réseau – Utilisez des techniques de surveillance ou des détecteurs de défaillance distribués pour identifier les partitions réseau et prendre des mesures appropriées.
- Réconciliation automatique – Implémentez des mécanismes pour résoudre automatiquement les conflits et garantir la cohérence des données une fois qu'une scission cérébrale est résolue, comme la fusion des modifications conflictuelles ou l'utilisation de timestamps ou d'horloges vectorielles.
- Solutions au niveau de l'application – Concevez l'application pour tolérer les scénarios de scission cérébrale en employant des modèles de cohérence éventuelle, des structures de données sans conflit ou des CRDT.
- Intervention manuelle – Dans certains cas, une intervention manuelle peut être nécessaire pour résoudre les scénarios de scission cérébrale, impliquant une prise de décision humaine ou des actions administratives pour déterminer l'état correct du système et effectuer la réconciliation des données.
Avantages
- Cohérence des données – La mise en œuvre d'une solution garantit que les données partagées restent cohérentes dans le système distribué.
- Stabilité du système – La résolution des scénarios de scission cérébrale favorise la stabilité du système en évitant les opérations conflictuelles et en maintenant un comportement cohérent.
Inconvénients
- Complexité accrue – La résolution des scénarios de scission cérébrale ajoute de la complexité au système en raison de la logique et des mécanismes complexes requis.
- Surcoût de performance – Les mécanismes de résolution de scission cérébrale peuvent impacter les performances et la latence du système en raison des exigences supplémentaires de traitement et de communication.
- Utilisation accrue des ressources – La résolution des scénarios de scission cérébrale peut nécessiter l'allocation de plus de ressources, augmentant potentiellement les coûts.
- Surface de défaillance accrue – L'introduction de mécanismes de résolution de scission cérébrale peut involontairement introduire de nouveaux modes de défaillance ou vulnérabilités.
- Complexité de configuration et de réglage – La mise en œuvre d'une solution nécessite une configuration minutieuse et une maintenance continue pour garantir un comportement optimal dans différents scénarios.
Motif de transfert de responsabilité
 _Source_
_Source_
La technique de transfert de responsabilité garantit que vous avez :
- Tolérance aux pannes – La capacité du système à continuer de fonctionner même si un ou plusieurs composants tombent en panne.
- Disponibilité des données – Capacité à accéder et à modifier les données à tout moment.
Quel problème résout-elle ?
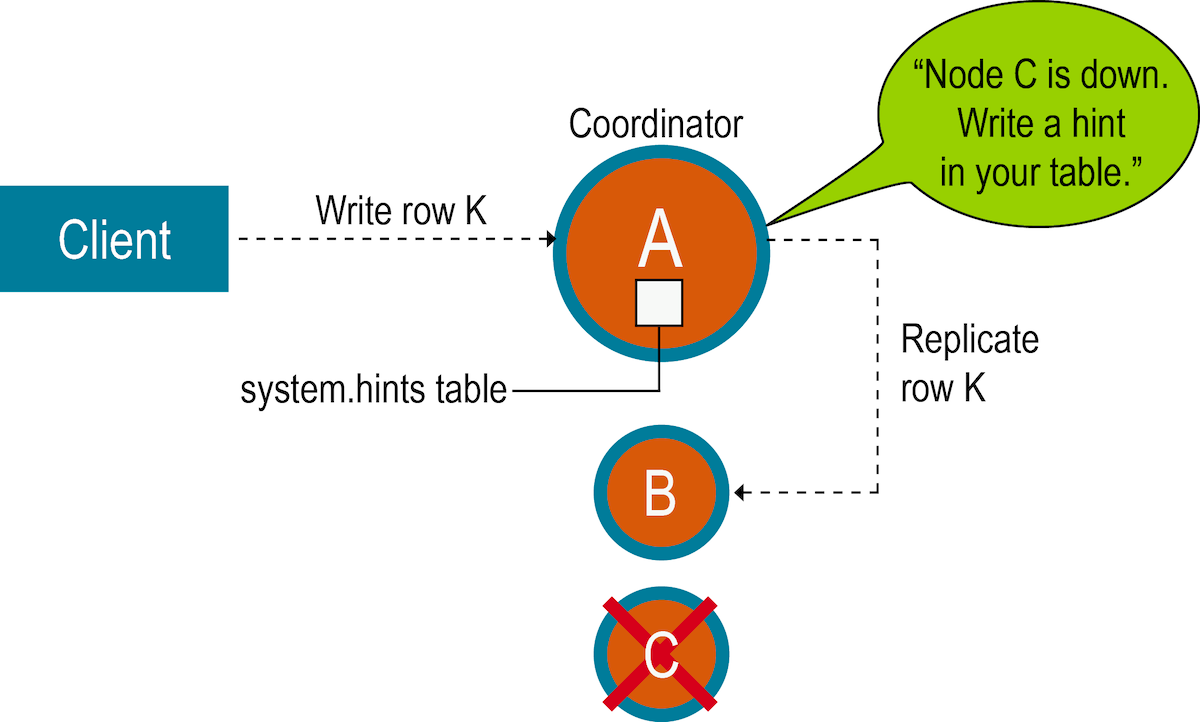
Imaginez que vous avez un service bancaire qui communique avec un nœud ayant trois répliques. Aucun des nœuds n'est leader, donc l'architecture est sans leader.
Vous envoyez une demande pour mettre à jour le solde du client à 100 $. Vous envoyez cela à toutes les répliques.
La demande est réussie pour les deux premières répliques, mais la dernière est hors ligne. Après quelques secondes, la réplique qui était hors ligne est revenue en ligne, mais elle a les anciennes données.
Comment résoudre ce problème ?
La technique de transfert de responsabilité indique que lorsqu'un nœud pour des données particulières est hors ligne, les autres nœuds du système stockeront temporairement les mises à jour ou modifications destinées au nœud indisponible.
D'où le nom "hints".
Ainsi, lorsque le nœud indisponible revient en ligne, il peut récupérer les hints et les appliquer.
Le processus se déroule comme suit :
- Détection – Lorsqu'un nœud tombe en panne, les autres nœuds détectent cette panne et marquent ce nœud comme indisponible.
- Génération de hints – Lorsqu'un nœud reçoit une demande à envoyer au nœud indisponible, il la stockera localement, généralement dans un fichier sur le disque.
- Livraison de hints – Lorsque le nœud disponible revient en ligne, il envoie un message aux autres nœuds demandant tout hint qui a été fait pendant qu'il était hors ligne. Les autres nœuds envoient les hints et le nœud les applique.
En utilisant cette technique, nous garantissons que nos données sont cohérentes et disponibles même lorsque des nœuds tombent en panne ou deviennent temporairement indisponibles.
Avantages
- Amélioration de la disponibilité des données – Le transfert de responsabilité garantit que les données restent accessibles pendant les pannes temporaires de nœuds en transférant les responsabilités à d'autres nœuds.
- Cohérence des données – Le transfert de responsabilité aide à maintenir la cohérence des données en synchronisant le nœud défaillant avec les autres lorsqu'il se rétablit.
- Latence réduite – Le transfert de responsabilité minimise l'impact des pannes de nœuds sur les performances du système, en routant les demandes vers des nœuds alternatifs et en réduisant la latence.
- Évolutivité – Le transfert de responsabilité permet une redistribution dynamique des responsabilités de données, permettant au système de gérer des charges de travail accrues et des changements de nœuds.
Inconvénients
- Complexité accrue – La mise en œuvre du transfert de responsabilité ajoute de la complexité au système, rendant le développement, le débogage et la maintenance plus difficiles.
- Surcoût de stockage – Le transfert de responsabilité nécessite le stockage de métadonnées supplémentaires, entraînant un surcoût de stockage pour suivre l'état du transfert.
- Risque de données obsolètes – Après une panne, les nœuds rétablis peuvent avoir des données temporairement obsolètes jusqu'à ce que la synchronisation se produise, entraînant des incohérences potentielles.
- Trafic réseau accru – Le transfert de responsabilité implique le transfert des responsabilités de données, entraînant une augmentation du trafic réseau et un impact potentiel sur les performances du réseau.
Cas d'utilisation
Le transfert de responsabilité est généralement implémenté dans les systèmes de bases de données distribuées ou les systèmes de stockage distribués où la disponibilité et la cohérence des données sont cruciales.
Voici quelques scénarios où l'implémentation du transfert de responsabilité est bénéfique :
- Systèmes de stockage cloud – Le transfert de responsabilité permet une redirection transparente des demandes des clients vers des nœuds disponibles dans les systèmes de stockage cloud lorsqu'un nœud devient temporairement indisponible.
- Systèmes de messagerie – Le transfert de responsabilité permet aux systèmes de messagerie distribués de router les messages vers d'autres courtiers actifs lorsqu'un nœud courtier tombe en panne, garantissant la livraison des messages et le fonctionnement du système.
- Systèmes de fichiers distribués – Le transfert de responsabilité dans les systèmes de fichiers distribués permet le transfert temporaire des responsabilités de données vers d'autres nœuds lorsqu'un nœud de données tombe en panne, garantissant la disponibilité des données et des opérations de lecture/écriture ininterrompues.
- Réseaux de diffusion de contenu (CDN) – Le transfert de responsabilité dans les CDN facilite la redirection des demandes de diffusion de contenu vers d'autres serveurs du réseau lorsqu'un serveur devient temporairement indisponible, garantissant une diffusion continue de contenu aux utilisateurs.
Motif de réparation de lecture
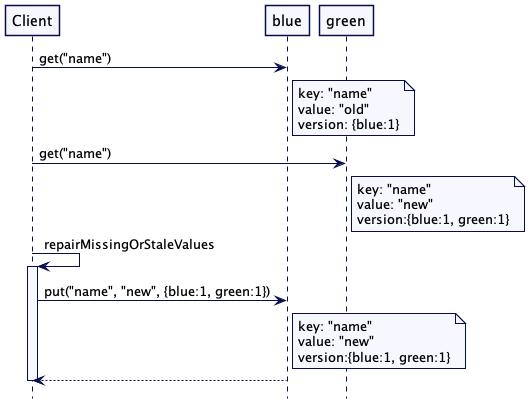
Dans un système distribué, vous pouvez avoir des données partitionnées en plusieurs nœuds.
Cela introduit un nouveau défi où nous devons maintenir la cohérence des données dans tous les nœuds.
Par exemple, si vous mettez à jour des données sur le nœud A, les modifications peuvent ne pas être immédiatement propagées aux autres nœuds pour toutes sortes de raisons.
Nous utilisons donc le motif de "réparation de lecture"
Lorsque qu'un client lit une donnée depuis un nœud, ce nœud vérifie si la donnée est la plus récente. Si ce n'est pas le cas, il reçoit les données les plus récentes depuis un autre nœud.
Une fois qu'il reçoit les données les plus récentes, il mettra à jour le nœud avec les anciennes données avec les nouvelles données. D'où le terme "réparation".
Mais cela est fait du côté de l'application
Faire les choses du côté de l'application est assez flexible car vous pouvez avoir votre propre logique personnalisée par service, mais cela augmente la complexité et le temps de développement.
Heureusement, il existe trois autres méthodes pour implémenter la réparation de lecture :
- Réparation de lecture basée sur l'écriture – Mettre à jour de manière proactive plusieurs répliques ou nœuds avec les dernières données lors des opérations d'écriture.
- Réparation en arrière-plan – Planifier des processus de réparation en arrière-plan périodiques pour scanner et réparer les incohérences dans la base de données.
- Réparation de lecture spécifique à la base de données – Tirer parti des mécanismes de réparation de lecture intégrés ou des fonctionnalités de résolution de conflits fournies par la base de données.
Avantages
- Cohérence des données – La réparation de lecture maintient la cohérence des données en détectant et en corrigeant automatiquement les incohérences entre les répliques ou les nœuds.
- Expérience utilisateur améliorée – La réparation de lecture fournit des données fiables et précises, améliorant l'expérience utilisateur en réduisant les informations conflictuelles ou obsolètes.
- Tolérance aux pannes – La réparation de lecture augmente la résilience du système en traitant les incohérences de données et en réduisant le risque de pannes en cascade.
- Optimisation des performances – La réparation de lecture améliore les performances en minimisant le besoin de processus de réparation séparés et en distribuant la charge de travail de réparation.
- Développement simplifié – La réparation de lecture automatise les vérifications de cohérence, simplifiant le développement de l'application.
Inconvénients
- Complexité accrue – La mise en œuvre de la réparation de lecture ajoute de la complexité à la conception, au développement et à la maintenance du système.
- Surcoût de performance – La réparation de lecture peut introduire une latence supplémentaire et un surcoût de calcul, impactant les performances globales du système.
- Risque d'amplification des pannes – Une mise en œuvre incorrecte de la réparation de lecture peut propager des incohérences ou amplifier les pannes.
- Défis d'évolutivité – La coordination des réparations dans les systèmes à grande échelle peut être difficile, impactant les performances et l'évolutivité.
- Compatibilité et portabilité – Les mécanismes de réparation de lecture peuvent être spécifiques à certaines bases de données ou technologies, limitant la compatibilité et la portabilité.
Cas d'utilisation
La réparation de lecture peut être bénéfique dans divers scénarios où le maintien de la cohérence des données entre les répliques ou les nœuds est crucial.
Voici quelques situations où vous devriez envisager d'utiliser la réparation de lecture :
- Systèmes de bases de données distribuées – Utilisez la réparation de lecture dans les systèmes de bases de données distribuées où les données sont répliquées sur plusieurs nœuds ou répliques pour garantir la cohérence des données.
- Exigences élevées de cohérence des données – Implémentez la réparation de lecture lorsque votre application nécessite un niveau élevé de cohérence des données, comme dans les systèmes financiers, les plateformes de collaboration ou l'analyse en temps réel.
- Charges de travail intensives en lecture – Envisagez la réparation de lecture pour les charges de travail intensives en lecture afin de détecter et de réconcilier les incohérences lors des opérations de lecture, améliorant les performances en réduisant le besoin de processus de réparation séparés.
- Systèmes avec retards réseau ou pannes – Utilisez la réparation de lecture dans les environnements avec des retards réseau ou des pannes occasionnelles de nœuds pour détecter et corriger automatiquement les incohérences de données causées par ces problèmes.
Motif de registre de services
Lorsque vous travaillez avec un système distribué, vous aurez des services qui ont des instances pouvant être mises à l'échelle ou réduites.
Un service peut avoir dix instances à un moment donné et deux à un autre moment.
Les adresses IP de ces instances sont créées dynamiquement. Des problèmes surviennent ici.
Imaginez que vous avez un client et qu'il veut parler à un service. Comment saura-t-il l'adresse IP du service si les adresses IP sont créées dynamiquement ?
La réponse est un registre de services.
Qu'est-ce que c'est ?
Un registre de services est généralement un service séparé qui s'exécute et conserve des informations sur les instances disponibles et leurs emplacements.
Mais comment le registre de services connaît-il toutes ces informations ?
Lorsque nous créons une instance de l'un de nos services, nous nous enregistrons auprès du registre de services avec notre nom, notre adresse IP et notre numéro de port.
Le registre de services stocke ensuite ces informations dans son magasin de données.
Lorsque qu'un client doit se connecter à un service, il interroge le registre de services pour obtenir les informations nécessaires à la connexion au service.
Maintenant que nous savons ce qu'est un registre de services, parlons des motifs de découverte de services.
Découverte côté client
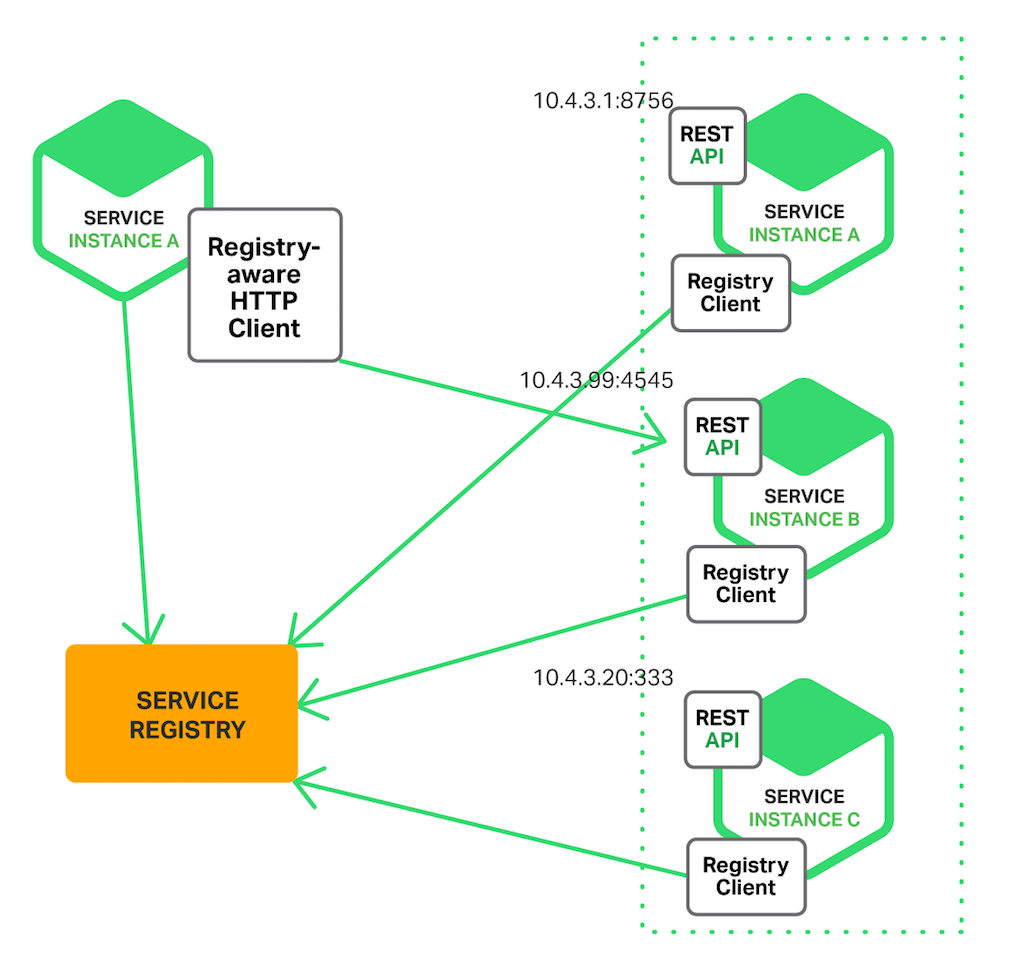
La première et la plus simple façon est que le client appelle le registre de services et obtienne des informations sur toutes les instances disponibles d'un service.
Cette approche fonctionne bien lorsque vous voulez :
- Avoir quelque chose de simple et direct.
- Laisser le côté client prendre les décisions sur les instances à appeler.
Mais l'inconvénient majeur ici est qu'il couple le client avec le registre de services.
Ainsi, vous devez implémenter une logique de découverte côté client pour chaque langage de programmation et framework que votre service utilise.
Découverte côté serveur
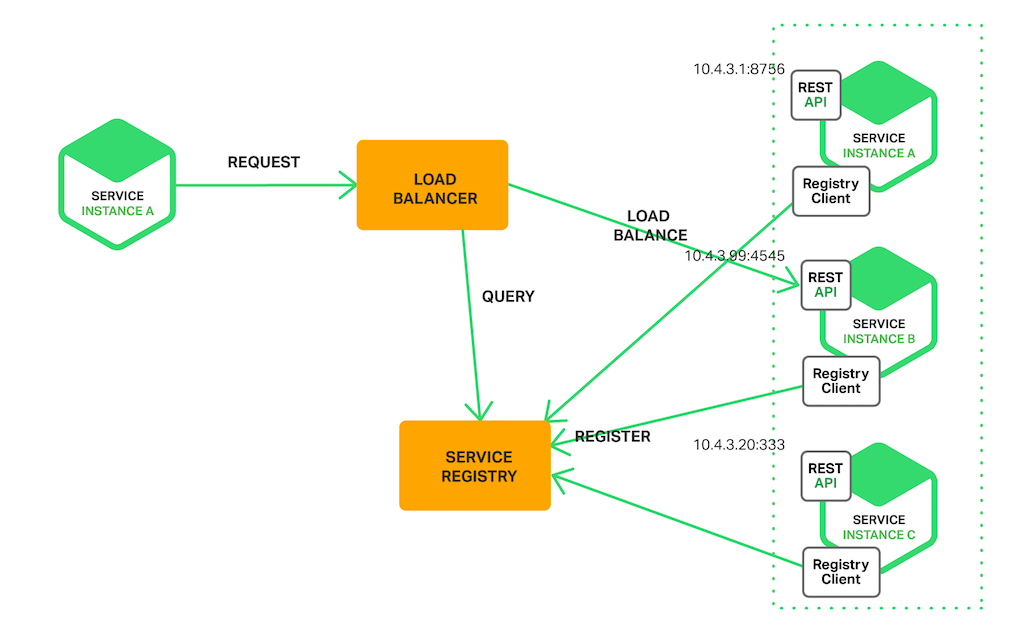
D'autre part, la découverte côté serveur force le client à faire la demande via un équilibreur de charge.
Si vous ne savez pas ce qu'est un équilibreur de charge, n'hésitez pas à consulter mon autre article complet à ce sujet.
L'équilibreur de charge appellera le registre de services et acheminera la demande vers l'instance spécifique.
La découverte côté serveur présente les avantages suivants :
- Abstraire les détails du registre de services à l'équilibreur de charge signifie que le client peut simplement faire une demande à l'équilibreur de charge.
- Elle est intégrée dans la plupart des fournisseurs populaires tels que AWS ELB (Elastic Load Balancer).
Le seul inconvénient est que vous avez un autre composant (registre de services) dans votre infrastructure que vous devez maintenir.
Motif de disjoncteur
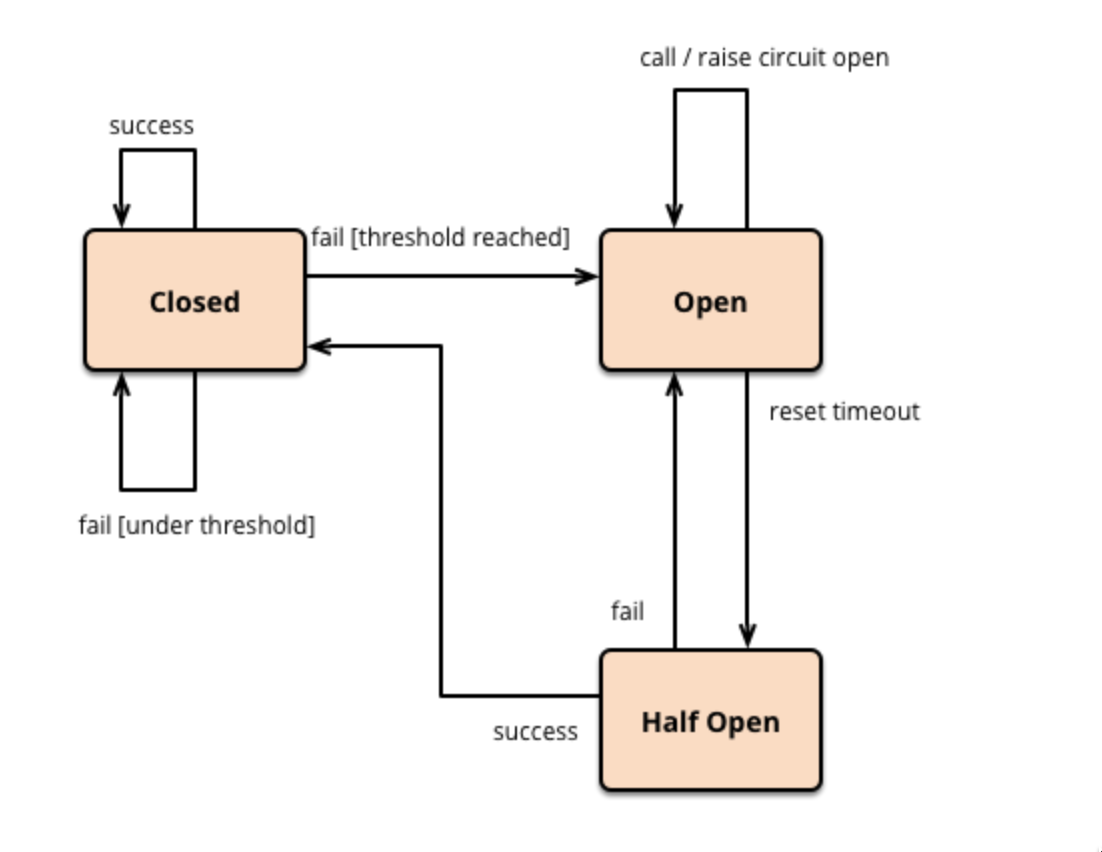
Disons que vous avez trois services, A, B et C. Ils s'appellent tous séquentiellement – A appelle B, qui appelle C.
Tout se passe bien tant que les services fonctionnent. Mais que se passe-t-il si l'un des services est en panne ? Alors les autres services échoueraient. Si le service C est en panne, alors B et A seraient également en panne.
Comment résoudre ce problème ?
Nous utilisons le motif de disjoncteur qui agit comme un middleware entre deux services.
Il surveille l'état du deuxième service et, en cas de défaillance ou de non-réponse, arrête les requêtes vers le service et retourne une réponse de repli ou un message d'erreur au composant.
Le middleware a trois états :
- Fermé – Le service peut communiquer avec le deuxième service normalement.
- Ouvert – Lorsque le middleware détecte un certain nombre d'échecs consécutifs, il passe à l'état ouvert, et toutes les requêtes vers le service sont immédiatement bloquées.
- Demi-ouvert – Après une certaine période de temps, le middleware passe à un état demi-ouvert qui permet un nombre limité de requêtes à être envoyées au deuxième service. Si elles réussissent, alors le middleware passe à un état fermé, sinon il passera à un état ouvert.
Globalement, le motif de disjoncteur augmente la résilience en fournissant un mécanisme de repli et en réduisant la charge sur un service défaillant.
Il fournit également des informations sur l'état d'un service, ce qui nous aide à identifier les défaillances plus rapidement.
Avantages
- Tolérance aux pannes – Les disjoncteurs améliorent la stabilité du système en protégeant contre les pannes en cascade et en réduisant l'impact des dépendances indisponibles ou sujettes aux erreurs.
- Mécanisme de défaillance rapide – Les disjoncteurs détectent rapidement les défaillances, permettant une récupération plus rapide et réduisant la latence en évitant d'attendre que les requêtes défaillantes se terminent.
- Dégradation élégante – Les disjoncteurs permettent au système de dégrader élégamment les fonctionnalités en fournissant des réponses alternatives ou des mécanismes de repli pendant les défaillances.
- Distribution de charge – Les disjoncteurs peuvent équilibrer la charge sur les ressources disponibles pendant les périodes de trafic élevé ou lorsqu'un service rencontre des problèmes.
Inconvénients
- Complexité accrue – La mise en œuvre d'un disjoncteur ajoute de la complexité au système, impactant les efforts de développement, de test et de maintenance.
- Surcoût et latence – Les disjoncteurs introduisent un surcoût de traitement et de la latence lorsque les requêtes sont interceptées et évaluées par rapport aux états du circuit.
- Faux positifs – Les disjoncteurs peuvent bloquer à tort des requêtes même lorsque la dépendance est disponible, entraînant des faux positifs et impactant la disponibilité et les performances du système.
- Dépendance à la surveillance – Les disjoncteurs dépendent d'une surveillance et de vérifications de santé précises, et si celles-ci sont peu fiables, l'efficacité du disjoncteur peut être compromise.
- Contrôle limité sur les services distants – Les disjoncteurs offrent une protection mais manquent de contrôle direct sur les services sous-jacents, nécessitant une intervention externe pour résoudre certains problèmes.
Cas d'utilisation
Le motif de disjoncteur est bénéfique dans des scénarios spécifiques où un système dépend de services distants ou de dépendances externes.
Voici quelques situations où il est recommandé d'utiliser le motif de disjoncteur :
- Systèmes distribués – Lors de la construction de systèmes distribués qui communiquent avec plusieurs services ou API externes, le motif de disjoncteur aide à améliorer la tolérance aux pannes et la résilience en atténuant l'impact des défaillances dans ces dépendances.
- Services ou dépendances peu fiables ou intermittents – Si vous intégrez des services ou dépendances connus pour être peu fiables ou avoir une disponibilité intermittente, la mise en œuvre d'un disjoncteur peut protéger votre système contre les retards prolongés ou les défaillances causées par ces dépendances.
- Architecture de microservices – Dans une architecture de microservices, où les services individuels ont leurs propres dépendances, la mise en œuvre de disjoncteurs peut prévenir les défaillances en cascade entre les services et permettre une dégradation élégante des fonctionnalités pendant les défaillances.
- Scénarios à fort trafic – Dans les situations où le système subit un trafic ou une charge élevée, les disjoncteurs peuvent aider à distribuer la charge efficacement en redirigeant les requêtes vers des services alternatifs ou en fournissant des réponses de repli, maintenant ainsi la stabilité et les performances du système.
- Systèmes résilients et réactifs – Le motif de disjoncteur est utile lorsque vous souhaitez construire des systèmes qui sont résilients et réactifs aux défaillances. Il permet au système de détecter et de récupérer rapidement des problèmes, réduisant l'impact sur les utilisateurs et assurant une meilleure expérience utilisateur.
Motif d'élection de leader
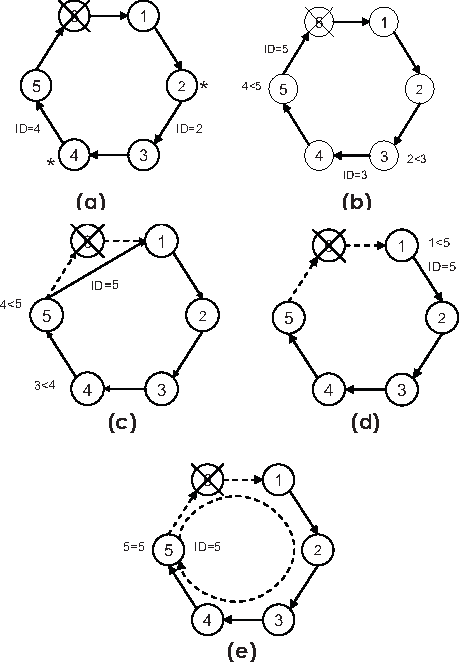 _Source_
_Source_
Le motif d'élection de leader est un motif qui donne à une seule chose (processus, nœud, thread, objet) des superpouvoirs dans un système distribué.
Ce motif est utilisé pour garantir qu'un groupe de nœuds peut coordonner efficacement et efficacement.
Ainsi, lorsque vous avez trois ou cinq nœuds effectuant des tâches similaires telles que le traitement de données ou la maintenance d'une ressource partagée, vous ne voulez pas qu'ils entrent en conflit les uns avec les autres (c'est-à-dire qu'ils se disputent les ressources ou interfèrent avec le travail des autres).
Élire un leader qui coordonne tout
Le leader sera responsable des décisions critiques ou de la distribution des charges de travail parmi les autres processus.
N'importe quel nœud peut être un leader, donc nous devons être prudents lorsque nous les élisons. Nous ne voulons pas deux leaders en même temps.
Ainsi, nous devons avoir un bon système pour sélectionner un leader. Il doit être robuste, ce qui signifie qu'il doit faire face aux pannes de réseau ou aux défaillances de nœuds.
Comment sélectionner un leader
Un algorithme nommé Bully assigne à chaque nœud un identifiant unique. Le nœud avec l'identifiant le plus élevé est initialement considéré comme le leader.
Si un nœud de rang inférieur détecte que le leader a échoué, il envoie un signal à tous les autres nœuds de rang supérieur pour prendre le relais. Si aucun d'eux ne répond, alors le nœud se déclarera lui-même leader.
Un autre algorithme populaire s'appelle l'algorithme Ring. Chaque nœud est disposé en un anneau logique. Le nœud avec l'identifiant le plus élevé est initialisé comme un anneau.
Si un nœud de rang inférieur détecte que l'anneau a échoué, alors il demandera à tous les autres nœuds de mettre à jour leur leader vers le nœud suivant le plus élevé.
Les deux algorithmes ci-dessus supposent que chaque nœud peut être identifié de manière unique.
Avantages
- Coordination – L'élection de leader permet une meilleure organisation et coordination dans les systèmes distribués en établissant un point de contrôle centralisé.
- Attribution des tâches – Le leader peut allouer et distribuer efficacement les tâches parmi les nœuds, optimisant l'utilisation des ressources et l'équilibrage de la charge de travail.
- Tolérance aux pannes – L'élection de leader garantit la résilience du système en élisant rapidement un nouveau leader si le leader actuel échoue, minimisant les perturbations.
- Cohérence et ordre – Le leader maintient des opérations cohérentes et impose l'ordre approprié des tâches dans les systèmes distribués, assurant la cohérence.
Inconvénients
- Surcoût et complexité – L'élection de leader introduit une complexité supplémentaire et un surcoût de communication, augmentant le trafic réseau et les exigences de calcul.
- Point unique de défaillance – La dépendance à un seul leader peut entraîner des perturbations du système si le leader échoue ou devient indisponible.
- Algorithmes d'élection – La mise en œuvre et la sélection d'algorithmes d'élection de leader appropriés peuvent être difficiles en raison des différents compromis en matière de performance, de tolérance aux pannes et d'évolutivité.
- Sensibilité aux conditions réseau – Les algorithmes d'élection de leader peuvent être sensibles aux conditions réseau, impactant potentiellement la précision et l'efficacité en cas de latence, de perte de paquets ou de partitions réseau.
Cas d'utilisation
- Informatique distribuée – Dans les systèmes informatiques distribués, l'élection de leader est cruciale pour coordonner et synchroniser les activités de plusieurs nœuds. Elle permet la sélection d'un leader responsable de la distribution des tâches, du maintien de la cohérence et de l'utilisation efficace des ressources.
- Algorithmes de consensus – L'élection de leader est un composant fondamental des algorithmes de consensus tels que Paxos et Raft. Ces algorithmes s'appuient sur l'élection d'un leader pour atteindre un accord parmi les nœuds distribués sur l'état ou l'ordre des opérations.
- Systèmes à haute disponibilité – L'élection de leader est utilisée dans les systèmes nécessitant une haute disponibilité et une tolérance aux pannes. En élisant rapidement un nouveau leader lorsque le leader actuel échoue, ces systèmes peuvent assurer des opérations ininterrompues et atténuer l'impact des pannes.
- Équilibrage de charge – Dans les scénarios d'équilibrage de charge, l'élection de leader peut être utilisée pour sélectionner un nœud leader responsable de la distribution des requêtes entrantes parmi plusieurs nœuds serveurs. Cela aide à optimiser l'utilisation des ressources et à répartir uniformément la charge de travail.
- Réplication de base de données maître-esclave – Dans les configurations de réplication de base de données, l'élection de leader est utilisée pour déterminer le nœud maître responsable de l'acceptation des opérations d'écriture. Le maître élu coordonne la synchronisation des données avec les nœuds esclaves, assurant la cohérence de l'ensemble des répliques.
- Systèmes de fichiers distribués – L'élection de leader est souvent utilisée dans les systèmes de fichiers distribués, tels que le HDFS d'Apache Hadoop. Elle aide à maintenir la cohérence des métadonnées et permet une gestion efficace de l'accès et du stockage des fichiers sur un cluster de nœuds.
Motif de cloisonnement
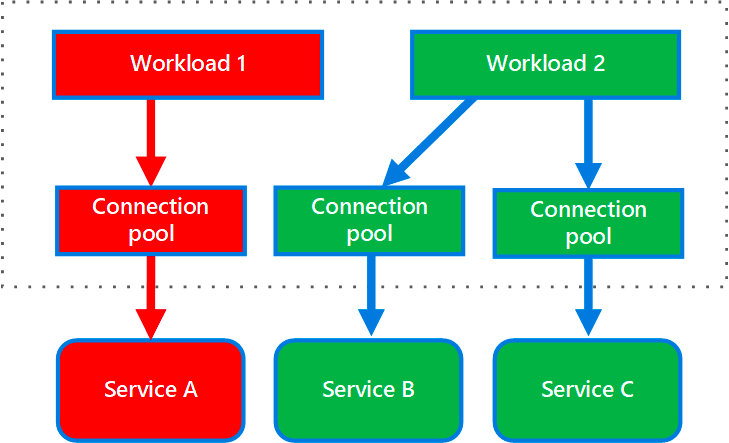
Les choses échouent pour toutes sortes de raisons dans un système distribué. C'est pourquoi nous devons nous assurer que nos systèmes sont résilients en cas de défaillances.
Une façon d'améliorer cela est d'utiliser le motif de cloisonnement.
Supposons que nous avons deux services, A et B.
Certaines requêtes de A dépendent de B. Mais le problème est que le service B est assez lent, ce qui rend A lent et bloque ses threads. Cela rend toutes les requêtes vers A lentes, même celles qui ne dépendent pas de B.
Le motif de cloisonnement résout cela en allouant une quantité spécifique de threads pour les requêtes vers B. Cela empêche A de consommer tous les threads à cause de B.
Avantages
- Isolement des pannes – Le motif de cloisonnement contient les pannes au sein des services individuels, minimisant leur impact sur l'ensemble du système.
- Évolutivité – Les services peuvent être mis à l'échelle indépendamment, permettant l'allocation de ressources là où c'est nécessaire sans affecter l'ensemble du système.
- Optimisation des performances – Des services spécifiques peuvent recevoir des optimisations de performance indépendamment, assurant un fonctionnement efficace.
- Agilité de développement – La modularité du code et la séparation des préoccupations facilitent les efforts de développement parallèle.
Inconvénients
- Complexité – La mise en œuvre du motif de cloisonnement ajoute une complexité architecturale au système.
- Utilisation accrue des ressources – La duplication des ressources entre les composants peut augmenter la consommation des ressources.
- Défis d'intégration – La coordination et l'intégration des services peuvent être difficiles et introduire des points de défaillance potentiels.
Cas d'utilisation
Voici quelques scénarios courants où le motif de cloisonnement est bénéfique :
- Architecture de microservices – Le motif de cloisonnement est utilisé pour isoler les microservices individuels, assurant la tolérance aux pannes et l'évolutivité dans un système distribué.
- Applications gourmandes en ressources – En partitionnant le système en composants, le motif de cloisonnement optimise l'allocation des ressources, permettant un traitement efficace des tâches gourmandes en ressources sans impacter les autres composants.
- Traitement concurrent – Le motif de cloisonnement aide à gérer le traitement concurrent en attribuant des ressources dédiées à chaque unité de traitement, empêchant les pannes d'affecter les autres unités.
- Systèmes à fort trafic ou à forte demande – Dans les systèmes subissant un fort trafic ou une forte demande, le motif de cloisonnement distribue la charge entre les composants, évitant les goulots d'étranglement et permettant une gestion évolutive du trafic accru.
- Systèmes modulaires et extensibles – Le motif de cloisonnement facilite le développement et la maintenance modulaires, permettant des mises à jour et des déploiements indépendants de composants spécifiques dans un système.
Motif de nouvelle tentative
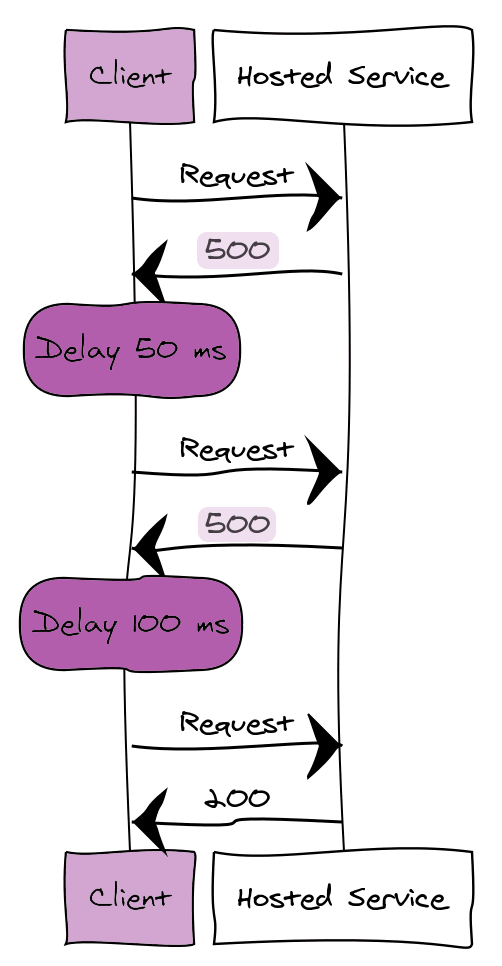
Le motif de nouvelle tentative est utilisé pour gérer les échecs temporaires.
Les requêtes échouent pour toutes sortes de raisons, des connexions défectueuses au rechargement du site après un déploiement.
Supposons que nous avons un client et un service. Le client envoie une requête au service et reçoit un code de réponse 500.
Il existe plusieurs façons de gérer cela selon le motif de nouvelle tentative.
- Si le problème est rare, alors réessayez immédiatement.
- Si le problème est plus courant, alors réessayez après un certain délai (par exemple 50ms, 100ms, etc.)
- Si le problème n'est pas temporaire (identifiants invalides, etc.), alors annulez la requête.
Mais parfois, le client pense que la requête a échoué
Parfois, l'opération a réussi mais la requête a échoué à retourner quelque chose. Cela se produit lorsque les requêtes ne sont pas sans état, ce qui signifie qu'elles changent l'état du système d'une certaine manière (comme les opérations CRUD sur une base de données).
Ce que nous faisons, c'est envoyer une requête en double, ce qui peut causer des problèmes dans le système.
Pour cela, nous avons besoin d'un système de suivi. Nous pouvons utiliser le motif de disjoncteur pour limiter l'impact de la nouvelle tentative répétée d'un service défaillant/en récupération.
Avantages
- Résilience et fiabilité – En réessayant automatiquement les requêtes échouées, vous augmentez les chances que le système se remette d'une défaillance (résilience) et augmentez les chances d'une requête réussie (fiabilité).
- Gestion des erreurs – Réessayer une opération masque transparemment l'erreur pour l'utilisateur final, rendant le système plus robuste.
- Implémentation simplifiée – Le motif de nouvelle tentative est simple à implémenter. Au lieu d'avoir une logique de gestion des erreurs personnalisée pour toutes vos requêtes, vous pouvez toutes les envelopper avec une
classe de motif de nouvelle tentative. - Optimisation des performances – Dans certains cas, les erreurs temporaires peuvent être résolues rapidement, et les nouvelles tentatives ultérieures peuvent réussir sans retards significatifs. Cela peut aider à optimiser les performances en évitant les échecs inutiles et en réduisant l'impact sur l'utilisateur final.
Inconvénients
- Latence accrue – Lorsque des nouvelles tentatives sont effectuées, un retard inhérent est introduit dans le système. Si les nouvelles tentatives sont fréquentes ou si les opérations prennent beaucoup de temps à se terminer, la latence globale du système peut augmenter.
- Risque de boucles infinies – Sans précautions appropriées, les nouvelles tentatives peuvent potentiellement conduire à des boucles infinies si la condition d'erreur sous-jacente persiste.
- Utilisation accrue du réseau et des ressources – Réessayer les opérations échouées peut entraîner un trafic réseau supplémentaire et une utilisation accrue des ressources.
- Potentiel de défaillances en cascade – Si la cause sous-jacente de la défaillance n'est pas résolue, réessayer l'opération peut entraîner des défaillances en cascade dans tout le système.
- Difficulté à gérer les opérations idempotentes – Réessayer des requêtes avec état peut entraîner des conséquences non intentionnelles si la requête est exécutée plusieurs fois.
Cas d'utilisation
L'applicabilité du motif de nouvelle tentative dépend des exigences et des caractéristiques spécifiques du système en cours de développement.
Le motif est le plus utile pour gérer les erreurs temporaires. Mais vous devez également garder à l'esprit les scénarios impliquant de longs retards, des requêtes avec état ou des cas où une intervention manuelle est nécessaire.
Maintenant, examinons quelques cas d'utilisation où la nouvelle tentative des requêtes aide :
- Communication réseau – Lorsque vous travaillez avec des services ou API tiers sur un réseau, toutes sortes d'erreurs peuvent se produire.
- Opérations de base de données – Les bases de données rencontrent également les mêmes problèmes en raison de l'indisponibilité temporaire, des délais d'attente ou des situations de blocage.
- Accès aux fichiers ou aux ressources – Lorsque vous accédez à des fichiers, des ressources externes ou des dépendances, des échecs peuvent se produire en raison de verrous, de permissions ou d'indisponibilité temporaire.
- Traitement des files d'attente – Les systèmes qui dépendent des files d'attente de messages ou des architectures basées sur les événements peuvent rencontrer des problèmes temporaires tels que la congestion des files d'attente, les échecs de livraison de messages ou les fluctuations de disponibilité des services.
- Transactions distribuées – Dans les systèmes distribués, l'exécution de transactions coordonnées sur plusieurs services ou composants peut rencontrer des défis tels que les partitions réseau ou les défaillances temporaires des services.
- Synchronisation des données – Lorsque vous synchronisez des données entre différents systèmes ou bases de données, des erreurs temporaires peuvent perturber le processus de synchronisation.
Motif de diffusion-rassemblement
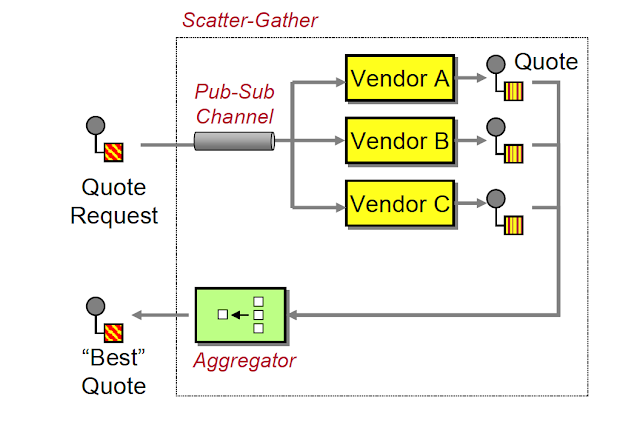
Disons que nous avons une tâche lourde en termes de processus comme la compression vidéo.
Nous obtenons une vidéo et devons la compresser en 5 résolutions différentes telles que 240p, 360p, 480, 720p et 1080p.
Nous avons un seul service de compression d'images qui prend la vidéo et traite chaque résolution séquentiellement. Le problème ici est que c'est très lent.
Le motif de diffusion-rassemblement nous conseille d'exécuter plusieurs de ces processus simultanément et de rassembler tous les résultats en un seul endroit.
Ainsi, pour notre exemple de traitement vidéo, voici comment cela se présentera :
- Diffusion – Nous diviserons la tâche en plusieurs nœuds, donc un nœud s'occupera de compresser la vidéo en 240p, un autre en 360p, et ainsi de suite.
- Traitement – Chaque nœud compressera sa vidéo individuellement et simultanément.
- Rassemblement – Une fois que tous les nœuds ont terminé de compresser les vidéos, les vidéos seront stockées sur un serveur et nous collecterons les liens pour toutes les différentes versions.
Au lieu d'attendre que chacune de nos vidéos soit compressée séquentiellement, nous pouvons maintenant paralléliser l'ensemble de ce processus et augmenter considérablement les performances.
Avantages
- Traitement parallèle – Le motif de diffusion-rassemblement améliore les performances en permettant le traitement parallèle des sous-tâches. Les tâches peuvent s'exécuter simultanément sur plusieurs nœuds ou processeurs.
- Évolutivité – Le motif de diffusion-rassemblement nous permet de mettre à l'échelle horizontalement, plus notre charge de travail est élevée, plus nous provisionnons de nœuds.
- Tolérance aux pannes – Ce motif améliore la tolérance aux pannes en redistribuant les sous-tâches échouées à d'autres nœuds disponibles, garantissant que la tâche globale peut toujours être terminée avec succès.
- Utilisation des ressources – Le motif de diffusion-rassemblement optimise l'utilisation des ressources en exploitant efficacement les ressources de calcul disponibles sur plusieurs nœuds ou processeurs.
Inconvénients
- Surcoût de communication – Ce motif implique la communication entre les nœuds, ce qui introduit une latence potentielle et une congestion du réseau qui peuvent impacter les performances globales, en particulier avec de grands volumes de données.
- Équilibrage de charge – Équilibrer la charge de travail de manière égale entre les nœuds peut être difficile, conduisant à des inefficacités potentielles et à des goulots d'étranglement de performance si certains nœuds sont inactifs tandis que d'autres sont surchargés.
- Complexité – Ce motif n'est pas facile à implémenter et ajoute une couche supplémentaire de complexité au système. Il nécessite une planification minutieuse et des mécanismes de synchronisation pour coordonner les sous-tâches.
- Dépendance des données – Gérer les dépendances entre les sous-tâches, où la sortie d'une sous-tâche est nécessaire comme entrée pour une autre, peut être plus complexe dans le motif de diffusion-rassemblement par rapport à d'autres motifs.
Cas d'utilisation
Le motif de diffusion-rassemblement est utile dans les systèmes distribués et les scénarios de calcul parallèle où vous pouvez diviser les tâches en sous-tâches plus petites qui peuvent être effectuées simultanément sur plusieurs nœuds et processeurs.
Voici quelques cas d'utilisation où le motif de diffusion-rassemblement peut être utilisé :
- Crawling Web – Vous pouvez utiliser le motif de diffusion-rassemblement pour récupérer et crawler plusieurs pages web simultanément.
- Analyse de données – Appliquez la diffusion-rassemblement pour diviser de grands ensembles de données en morceaux pour un traitement parallèle dans les tâches d'analyse de données, combinant les résultats individuels pour des insights finaux.
- Traitement d'images/vidéos – Utilisez la diffusion-rassemblement pour le traitement distribué d'images/vidéos, comme l'encodage de frames en parallèle et le rassemblement des résultats pour la sortie finale.
- Recherche distribuée – Implémentez la diffusion-rassemblement dans les systèmes de recherche distribués pour distribuer les requêtes de recherche sur les nœuds, rassembler et classer les résultats pour la sortie de recherche finale.
- Apprentissage automatique – Appliquez la diffusion-rassemblement dans l'apprentissage automatique distribué pour l'entraînement parallèle de modèles sur des données dispersées et la combinaison de modèles pour le modèle entraîné final.
- MapReduce – Incorporez la diffusion-rassemblement dans le modèle MapReduce pour le traitement de grandes données, la diffusion de l'entrée, le traitement parallèle des résultats intermédiaires et le rassemblement pour la sortie finale.
Filtres de Bloom (Structure de données)
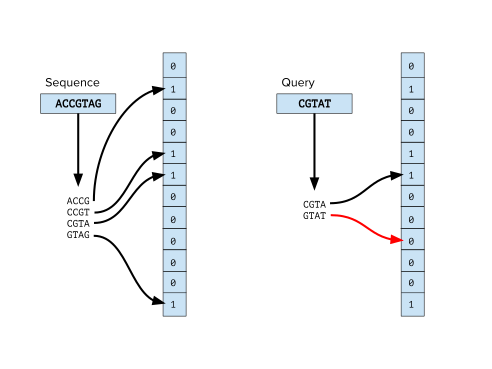 _Source_
_Source_
Les filtres de Bloom sont une structure de données conçue pour vous indiquer efficacement, à la fois en mémoire et en vitesse, si un élément se trouve dans un ensemble.
Mais le coût de cette efficacité est qu'elle est probabiliste. Elle peut vous indiquer qu'un élément est soit :
- Définitivement pas dans un ensemble.
- Peut-être dans un ensemble.
Avantages
- Efficacité d'espace – Les filtres de Bloom nécessitent généralement une quantité de mémoire plus faible pour stocker le même nombre d'éléments par rapport aux tables de hachage ou à d'autres structures de données similaires.
- Recherches rapides – Vérifier si un élément est dans un filtre de Bloom a une complexité de temps constante, indépendamment de la taille du filtre ou du nombre d'éléments qu'il contient.
- Pas de faux négatifs – Les filtres de Bloom fournissent une réponse définitive "non" si un élément n'est pas dans le filtre. Il n'y a pas de faux négatifs, ce qui signifie que si le filtre affirme qu'un élément n'est pas présent, il est garanti qu'il est absent.
- Parallelisable – Les filtres de Bloom peuvent être facilement parallélisés, permettant une implémentation efficace sur des systèmes multi-cœurs ou des environnements distribués.
Inconvénients
- Faux positifs – En raison de leur nature probabiliste, il existe une faible probabilité que le filtre affirme à tort qu'un élément est présent alors qu'il ne l'est pas. La probabilité de faux positifs augmente à mesure que le filtre devient plus encombré ou que le nombre d'éléments augmente.
- Opérations limitées – Les filtres de Bloom ne prennent en charge que l'insertion et les tests d'appartenance. Ils ne permettent pas la suppression d'éléments ni ne fournissent un mécanisme pour récupérer les éléments originaux stockés dans le filtre. Une fois qu'un élément est inséré, il ne peut pas être supprimé individuellement.
- Taille fixe – La taille du filtre de Bloom doit être déterminée à l'avance et ne peut pas être redimensionnée dynamiquement. Si ces paramètres ne sont pas estimés avec précision, le filtre peut devenir inefficace ou gaspiller de la mémoire.
- Données non ordonnées – Les filtres de Bloom ne maintiennent pas l'ordre ni ne fournissent aucune information sur les éléments stockés. Ils ne sont pas adaptés aux scénarios qui nécessitent un ordonnancement ou une récupération d'éléments basée sur certains critères.
Cas d'utilisation
Les filtres de Bloom sont les plus utiles dans les situations où les tests d'appartenance approximatifs avec un faible taux de faux positifs sont acceptables et où l'efficacité de la mémoire est une priorité.
Voici quelques scénarios où les filtres de Bloom sont particulièrement bénéfiques :
- Systèmes de cache – Les filtres de Bloom peuvent être utilisés pour vérifier rapidement si un élément est susceptible d'être présent dans le cache ou non. En vérifiant le filtre de Bloom, le système peut éviter l'opération coûteuse de récupérer l'élément du cache ou du stockage sous-jacent s'il n'est pas susceptible d'y être, améliorant ainsi les performances globales.
- Systèmes de diffusion de contenu – Les CDN utilisent des filtres de Bloom pour gérer l'invalidation du cache. Au lieu de vérifier chaque serveur de bordure, nous utilisons un filtre de Bloom pour identifier si le serveur de bordure possède potentiellement une ressource spécifique.
- Systèmes anti-spam – Les systèmes anti-spam vérifient les e-mails par rapport aux bases de données de spam courantes. Au lieu de vérifier directement les bases de données, ce qui est coûteux, nous utilisons des filtres de Bloom qui sont beaucoup plus efficaces.
- Traitement de données distribuées – Dans un cadre de traitement de données distribuées tel que Hadoop ou Spark. Nous utilisons des filtres de Bloom pour optimiser les opérations de jointure en préfiltrant les données et en supprimant les mélanges inutiles.
Conclusion
Vous n'avez pas besoin d'être un expert dans toutes ces choses – je ne le suis pas. Et même si vous n'utilisez jamais directement ou ne travaillez pas avec certains de ces concepts, ils sont toujours bons à connaître.
Essayez de les implémenter dans des projets simples. C'est une bonne idée de garder les projets suffisamment simples pour ne pas vous laisser distraire.
Ci-dessous, je partage avec vous mes ressources préférées que j'ai utilisées pour apprendre les systèmes distribués.
Merci d'avoir lu.