Article original : The GraphQL API Handbook – How to Build, Test, Consume and Document GraphQL APIs
Bonjour à tous ! Dans ce tutoriel, nous allons plonger en profondeur dans les API GraphQL.
J'ai récemment écrit cet article où j'ai expliqué les principales différences entre les types d'API courants de nos jours. Et ce tutoriel vise à vous montrer un exemple de la manière dont vous pouvez implémenter pleinement une API GraphQL.
Nous aborderons la configuration de base et l'architecture avec Node et Apollo GraphQL, les tests unitaires avec Supertest, comment nous pouvons consommer l'API à partir d'une application front-end React en utilisant Apollo client et enfin la documentation de l'API en utilisant Apollo sandbox.
Gardez à l'esprit que nous n'irons pas trop en profondeur dans le fonctionnement de chaque technologie. L'objectif ici est de vous donner un aperçu général de la manière dont une API GraphQL fonctionne, comment ses éléments interagissent et ce qu'une implémentation complète pourrait consister.
C'est parti !
Table des matières
Comment construire une API GraphQL avec Node et Apollo GraphQL
Comment consommer une API GraphQL sur une application front-end React
Qu'est-ce que GraphQL ?
GraphQL est un langage de requête et un runtime pour les API qui a été développé par Facebook en 2012. Il a été rendu public en 2015 et a depuis gagné en popularité comme alternative aux API REST.
GraphQL a été développé à l'origine par Facebook comme un moyen de simplifier la récupération de données pour leurs applications mobiles. Ils avaient besoin d'un moyen de faire des requêtes de données complexes auprès du serveur sans causer de problèmes de performance ou de sur-récupération de données. GraphQL est né de la nécessité de résoudre ces problèmes.
GraphQL a été publié en tant que projet open-source en 2015 et a depuis gagné en popularité dans la communauté des développeurs. Il est désormais soutenu par de nombreux outils et frameworks de développement, dont Apollo, Prisma et Hasura.
Caractéristiques principales :
Typage fort : Les API GraphQL sont fortement typées, ce qui signifie que chaque champ a un type de données spécifique. Cela facilite la validation et la gestion des données côté client et serveur.
Langage de requête : GraphQL a son propre langage de requête qui permet aux clients de spécifier exactement les données dont ils ont besoin. Cela réduit la sur-récupération de données et améliore les performances.
Point d'accès unique : Les API GraphQL ont un point d'accès unique, ce qui signifie que les clients peuvent récupérer toutes les données dont ils ont besoin à partir d'une seule requête.
Déclaratif : Les API GraphQL sont déclaratives, ce qui signifie que les clients spécifient ce qu'ils veulent, et non comment l'obtenir. Cela permet une récupération de données plus efficace et flexible.
Basé sur le schéma : Les API GraphQL sont basées sur le schéma, ce qui signifie que le schéma définit la structure des données et les requêtes et mutations disponibles. Cela facilite la compréhension et le travail des développeurs avec l'API.
Avantages :
Récupération de données efficace : Les API GraphQL permettent aux clients de récupérer uniquement les données dont ils ont besoin, réduisant la sur-récupération et améliorant les performances.
Typage fort : Les API GraphQL sont fortement typées, ce qui facilite la validation et la gestion des données.
Point d'accès unique : Les API GraphQL ont un point d'accès unique, réduisant la complexité de l'API et facilitant son utilisation.
Basé sur le schéma : Les API GraphQL sont basées sur le schéma, ce qui facilite la compréhension et le travail des développeurs avec l'API.
Inconvénients :
Complexité : Les API GraphQL peuvent être plus complexes à configurer et à utiliser par rapport aux API REST.
Mise en cache : La mise en cache peut être plus difficile avec les API GraphQL en raison de la nature flexible de l'API.
Courbe d'apprentissage : GraphQL nécessite une courbe d'apprentissage pour les développeurs et les clients, car il a son propre langage de requête et une approche de la récupération de données.
Idéal pour :
Besoins efficaces et flexibles : GraphQL est bien adapté pour construire des applications qui nécessitent une récupération de données efficace et flexible, comme les applications mobiles et web.
Exigences de données complexes : Il est particulièrement utile dans les situations où il y a des exigences de données complexes et où la sur-récupération de données peut causer des problèmes de performance.
Donc, pour résumer, GraphQL est un langage de requête et un runtime pour les API qui fournit des capacités de récupération de données efficaces et flexibles.
Bien qu'il puisse être plus complexe à configurer et à utiliser par rapport aux API REST, il offre des avantages tels que des données fortement typées, des points d'accès uniques et un développement basé sur le schéma. Il est bien adapté pour construire des applications avec des exigences de données complexes et où la récupération de données efficace est importante.
Concepts de base de GraphQL
Avant de nous lancer dans la construction, il y a quelques concepts de base de GraphQL que vous devez comprendre afin de savoir ce que vous faites et comment le code fonctionnera.
Types d'objets
Dans GraphQL, un type d'objet est un type complexe qui représente une collection de champs. Les types d'objets sont utilisés pour définir la structure des données qui peuvent être interrogées et mutées via une API GraphQL.
Chaque type d'objet a un nom unique et un ensemble de champs, où chaque champ a un nom et un type. Le type d'un champ peut être un type scalaire (comme Int, String ou Boolean), un autre type d'objet ou une liste d'un autre type.
Si vous êtes familier avec Typescript et les interfaces, cela pourrait vous rappeler quelque chose.
Voici un exemple de type d'objet qui représente un "User" dans une application de médias sociaux :
type User {
id: ID!
name: String!
email: String!
friends: [User!]!
}
Le signe ! signifie que le champ est obligatoire.
Dans cet exemple, le type d'objet "User" a quatre champs : "id", "name", "email" et "friends". Le champ "id" a un type ID, qui est un type scalaire intégré dans GraphQL qui représente un identifiant unique. Les champs "name" et "email" ont un type String, et le champ "friends" a un type de liste d'objets "User".
Voici un autre exemple de type d'objet qui représente un "Book" dans une application de bibliothèque :
type Book {
id: ID!
title: String!
author: Author!
genre: String!
published: Int!
}
Dans cet exemple, le type d'objet "Book" a cinq champs : "id", "title", "author", "genre" et "published". Le champ "id" a un type ID, les champs "title" et "genre" ont un type String, le champ "published" a un type Int, et le champ "author" a un type d'objet "Author".
Les types d'objets peuvent être utilisés pour définir la structure des données qui sont retournées par une requête ou une mutation dans une API GraphQL. Par exemple, une requête qui retourne une liste d'utilisateurs pourrait ressembler à ceci :
query {
users {
id
name
email
friends {
id
name
}
}
}
Dans cette requête, le champ "users" retourne une liste d'objets "User", et la requête spécifie quels champs inclure dans la réponse.
Requêtes
Dans GraphQL, une requête est une demande de données spécifiques auprès du serveur. La requête spécifie la forme des données que le client souhaite recevoir, et le serveur répond avec les données demandées dans la même forme.
Une requête dans GraphQL suit une structure similaire à la forme des données qu'elle s'attend à recevoir. Elle se compose d'un ensemble de champs qui correspondent aux propriétés des données que le client souhaite récupérer. Chaque champ peut également avoir des arguments qui modifient les données retournées.
Voici un exemple de requête simple dans GraphQL :
query {
user(id: "1") {
name
email
age
}
}
Dans cet exemple, la requête demande des informations sur un utilisateur avec l'ID "1". Les champs spécifiés dans la requête sont "name", "email" et "age", qui correspondent aux propriétés de l'objet utilisateur.
La réponse du serveur serait de la même forme que la requête, avec les données demandées retournées dans les champs correspondants :
{
"data": {
"user": {
"name": "John Doe",
"email": "johndoe@example.com",
"age": 25
}
}
}
Ici, le serveur a retourné les données demandées sur l'utilisateur dans les champs "name", "email" et "age". Les données sont contenues dans un objet "data" pour les différencier des erreurs ou autres métadonnées qui peuvent être incluses dans la réponse.
Mutations
Dans GraphQL, les mutations sont utilisées pour modifier ou créer des données sur le serveur. Comme les requêtes, les mutations spécifient la forme des données envoyées et reçues du serveur. La principale différence est que tandis que les requêtes ne lisent que les données, les mutations peuvent à la fois lire et écrire des données.
Voici un exemple de mutation simple dans GraphQL :
mutation {
createUser(name: "Jane Doe", email: "janedoe@example.com", age: 30) {
id
name
email
age
}
}
Dans cet exemple, la mutation crée un nouvel utilisateur sur le serveur avec le nom "Jane Doe", l'email "janedoe@example.com" et l'âge 30. Les champs spécifiés dans la mutation sont "id", "name", "email" et "age", qui correspondent aux propriétés de l'objet utilisateur.
La réponse du serveur serait de la même forme que la mutation, avec les données du nouvel utilisateur créé retournées dans les champs correspondants :
{
"data": {
"createUser": {
"id": "123",
"name": "Jane Doe",
"email": "janedoe@example.com",
"age": 30
}
}
}
Ici, le serveur a retourné les données sur le nouvel utilisateur créé dans les champs "id", "name", "email" et "age".
Les mutations peuvent également être utilisées pour mettre à jour ou supprimer des données sur le serveur. Voici un exemple de mutation qui met à jour le nom d'un utilisateur :
mutation {
updateUser(id: "123", name: "Jane Smith") {
id
name
email
age
}
}
Dans cet exemple, la mutation met à jour l'utilisateur avec l'ID "123" pour avoir le nom "Jane Smith". Les champs spécifiés dans la mutation sont les mêmes que dans l'exemple précédent.
La réponse du serveur serait les données de l'utilisateur mises à jour :
{
"data": {
"updateUser": {
"id": "123",
"name": "Jane Smith",
"email": "janedoe@example.com",
"age": 30
}
}
}
Les mutations dans GraphQL sont conçues pour être composables, ce qui signifie que plusieurs mutations peuvent être combinées en une seule requête. Cela permet aux clients d'effectuer des opérations complexes avec un seul aller-retour réseau.
Résolveurs
Dans GraphQL, un résolveur est une fonction responsable de la récupération des données pour un champ spécifique défini dans un schéma GraphQL. Les résolveurs sont le pont entre le schéma et la source de données. La fonction de résolveur reçoit quatre paramètres : parent, args, context et info.
parent: L'objet parent pour le champ actuel. Dans les requêtes imbriquées, il fait référence à la valeur du champ parent.args: Les arguments passés au champ actuel. Il s'agit d'un objet avec des paires clé-valeur des noms d'arguments et de leurs valeurs.context: Un objet partagé entre tous les résolveurs pour une requête particulière. Il contient des informations sur la requête telles que l'utilisateur actuellement authentifié, la connexion à la base de données, etc.info: Contient des informations sur la requête, y compris le nom du champ, l'alias et l'AST du document de requête.
Voici un exemple de fonction de résolveur pour le champ posts d'un type User :
const resolvers = {
User: {
posts: (parent, args, context, info) => {
return getPostsByUserId(parent.id);
},
},
};
Dans cet exemple, User est un type d'objet GraphQL avec un champ posts. Lorsque le champ posts est interrogé, la fonction de résolveur est appelée avec l'objet parent User, les arguments passés, l'objet context et les informations de requête. Dans cet exemple, la fonction de résolveur appelle une fonction getPostsByUserId pour récupérer les posts de l'utilisateur actuel.
Les résolveurs peuvent également être utilisés pour les mutations afin de créer, mettre à jour ou supprimer des données. Voici un exemple de fonction de résolveur pour une mutation createUser :
const resolvers = {
Mutation: {
createUser: (parent, args, context, info) => {
const user = { name: args.name, email: args.email };
const createdUser = createUser(user);
return createdUser;
},
},
};
Dans cet exemple, Mutation est un type d'objet GraphQL avec un champ de mutation createUser. Lorsque la mutation est invoquée, la fonction de résolveur est appelée avec l'objet parent, les arguments passés, l'objet context et les informations de requête. Dans cet exemple, la fonction de résolveur appelle une fonction createUser pour créer un nouvel utilisateur avec le nom et l'email donnés, et retourne le nouvel utilisateur créé.
Schémas
Dans GraphQL, un schéma est un plan qui définit la structure des données qui peuvent être interrogées dans l'API. Il définit les types disponibles, les champs et les opérations qui peuvent être effectuées sur ces types.
Les schémas GraphQL sont écrits dans le langage de définition de schéma GraphQL (SDL), qui utilise une syntaxe simple pour définir les types et les champs disponibles dans l'API. Le schéma est généralement défini dans le code côté serveur et ensuite utilisé pour valider et exécuter les requêtes entrantes.
Voici un exemple de définition de schéma GraphQL simple :
type Book {
id: ID!
title: String!
author: String!
published: Int!
}
type Query {
books: [Book!]!
book(id: ID!): Book
}
type Mutation {
addBook(title: String!, author: String!, published: Int!): Book!
updateBook(id: ID!, title: String, author: String, published: Int): Book
deleteBook(id: ID!): Book
}
Dans ce schéma, nous avons trois types : Book, Query et Mutation. Le type Book a quatre champs : id, title, author et published. Le type Query a deux champs : books et book, qui peuvent être utilisés pour récupérer une liste de livres ou un livre spécifique par ID, respectivement. Le type Mutation a trois champs : addBook, updateBook et deleteBook, qui peuvent être utilisés pour créer, mettre à jour ou supprimer des livres.
Notez que chaque champ a un type, qui peut être un type scalaire intégré comme String ou Int, ou un type personnalisé comme Book. Le ! après un type indique que le champ est non-nullable, ce qui signifie qu'il doit toujours retourner une valeur (c'est-à-dire qu'il ne peut pas être null).
TLDR et comparaison avec les concepts équivalents REST
Types d'objets : Dans GraphQL, les types d'objets sont utilisés pour définir les données qui peuvent être interrogées à partir d'une API, similaire à la manière dont le modèle de données de réponse est défini dans les API REST. Cependant, contrairement à REST, où les modèles de données sont souvent définis dans différents formats (par exemple, JSON ou XML), les types d'objets GraphQL sont définis en utilisant une syntaxe unique et agnostique de langage.
Requêtes : Dans GraphQL, les requêtes sont utilisées pour récupérer des données à partir d'une API, similaire aux requêtes HTTP GET dans les API REST. Cependant, contrairement aux API REST, où plusieurs requêtes peuvent être nécessaires pour récupérer des données imbriquées, les requêtes GraphQL peuvent être utilisées pour récupérer des données imbriquées en une seule requête.
Mutations : Dans GraphQL, les mutations sont utilisées pour modifier des données dans une API, similaire aux requêtes HTTP POST, PUT et DELETE dans les API REST. Cependant, contrairement aux API REST, où différents points de terminaison peuvent être nécessaires pour effectuer différentes modifications, les mutations GraphQL sont effectuées via un seul point de terminaison.
Résolveurs : Dans GraphQL, les résolveurs sont utilisés pour spécifier comment récupérer des données pour un champ particulier dans une requête ou une mutation. Les résolveurs sont similaires aux méthodes de contrôleur dans les API REST, qui sont utilisées pour récupérer des données à partir d'une base de données et les retourner en tant que réponse.
Schémas : Dans GraphQL, un schéma est utilisé pour définir les données qui peuvent être interrogées ou mutées à partir d'une API. Il spécifie les types de données qui peuvent être demandés, comment ils peuvent être interrogés et quelles mutations sont autorisées. Dans les API REST, les schémas sont souvent définis en utilisant OpenAPI ou Swagger, qui spécifient les points de terminaison, les types de requêtes et de réponses, et d'autres métadonnées pour une API.
Dans l'ensemble, GraphQL et les API REST diffèrent dans la manière dont ils gèrent la récupération et la modification des données.
Les API REST s'appuient sur plusieurs points de terminaison et des méthodes HTTP pour récupérer et modifier des données, tandis que GraphQL utilise un seul point de terminaison et des requêtes/mutations pour accomplir la même chose.
L'utilisation par GraphQL d'un seul schéma pour définir le modèle de données d'une API le rend plus facile à comprendre et à maintenir par rapport aux API REST, qui nécessitent souvent plusieurs formats de documentation pour décrire le même modèle de données.
Comment construire une API GraphQL avec Node et Apollo GraphQL
Nos outils
Node.js est un environnement d'exécution JavaScript open-source, multiplateforme et côté serveur qui permet aux développeurs d'exécuter du code JavaScript en dehors d'un navigateur web. Il a été créé par Ryan Dahl en 2009 et est depuis devenu un choix populaire pour construire des applications web, des API et des serveurs.
Node.js fournit un modèle d'E/S piloté par événements et non bloquant qui le rend léger et efficace, lui permettant de gérer de grandes quantités de données avec des performances élevées. Il dispose également d'une grande communauté active, avec de nombreuses bibliothèques et modules disponibles pour aider les développeurs à construire leurs applications plus rapidement et plus facilement.
Apollo GraphQL est une plateforme full-stack pour construire des API GraphQL. Elle fournit des outils et des bibliothèques qui simplifient le processus de construction, de gestion et de consommation des API GraphQL.
Le cœur de la plateforme Apollo GraphQL est le serveur Apollo, un serveur léger et flexible qui facilite la construction d'API GraphQL scalables et performantes. Le serveur Apollo prend en charge une large gamme de sources de données, y compris les bases de données, les API REST et d'autres services, ce qui facilite l'intégration avec les systèmes existants.
Apollo fournit également un certain nombre de bibliothèques client, y compris le client Apollo pour le web et le mobile, qui simplifie le processus de consommation des API GraphQL. Le client Apollo facilite l'interrogation et la mutation des données, et fournit des fonctionnalités avancées comme la mise en cache, l'UI optimiste et les mises à jour en temps réel.
En plus du serveur Apollo et du client Apollo, Apollo fournit un certain nombre d'autres outils et services, y compris une plateforme de gestion de schéma, un service d'analyse GraphQL et un ensemble d'outils de développement pour construire et déboguer les API GraphQL.
Si vous êtes nouveau dans GraphQL ou dans Apollo lui-même, je vous recommande vraiment de consulter leur documentation. Ce sont parmi les meilleures disponibles, à mon avis.
Notre architecture
Pour ce projet, nous allons suivre une architecture en couches dans notre base de code. L'architecture en couches consiste à diviser les préoccupations et les responsabilités en différents dossiers et fichiers, et à permettre une communication directe uniquement entre certains dossiers et fichiers.
La question de savoir combien de couches votre projet devrait avoir, quels noms chaque couche devrait avoir et quelles actions elle devrait gérer est une question de discussion. Alors voyons ce que je pense être une bonne approche pour notre exemple.
Notre application aura cinq couches différentes, qui seront ordonnées de cette manière :
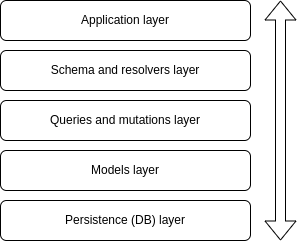
Couches de l'application
La couche application aura la configuration de base de notre serveur et la connexion à notre schéma et résolveurs (la couche suivante).
La couche schéma et résolveurs aura les définitions de types pour nos données et la connexion à nos requêtes et mutations (la couche suivante).
La couche requêtes et mutations aura la logique réelle que nous voulons effectuer dans chacune de nos requêtes et mutations et la connexion à la couche modèle (la couche suivante, vous comprenez l'idée...)
La couche modèle contiendra la logique pour interagir avec notre base de données fictive.
Enfin, la couche de persistance est là où notre base de données sera.
Une chose importante à garder à l'esprit est que dans ces types d'architectures, il y a un flux de communication défini entre les couches qui doit être suivi pour que cela ait du sens.
Cela signifie qu'une requête doit d'abord passer par la première couche, puis la deuxième, puis la troisième et ainsi de suite. Aucune requête ne doit sauter des couches car cela perturberait la logique de l'architecture et les avantages d'organisation et de modularité qu'elle nous offre.
Si vous souhaitez connaître d'autres options d'architecture d'API, je vous recommande cet article sur l'architecture logicielle que j'ai écrit il y a quelque temps.
Le code
Avant de passer au code, mentionnons ce que nous allons réellement construire. Nous allons construire une API pour une entreprise de refuge pour animaux. Ce refuge pour animaux doit enregistrer les animaux qui séjournent dans le refuge, et pour cela nous effectuerons des opérations CRUD de base (créer, lire, mettre à jour et supprimer).
Nous utilisons exactement le même exemple que celui que nous avons utilisé dans mon article sur l'implémentation complète d'une API REST. Si vous êtes intéressé à lire cela aussi, cela devrait aider à comparer les concepts entre REST et GraphQL, et à comprendre ses différences et similitudes. ;)
Maintenant, commençons. Créez un nouveau répertoire, allez-y et démarrez un nouveau projet Node en exécutant npm init -y. Pour notre serveur GraphQL, nous aurons besoin de deux dépendances supplémentaires, alors exécutez npm i @apollo/server et npm i graphql aussi.
App.js
À la racine de votre projet, créez un fichier app.js et mettez ce code dedans :
import { ApolloServer } from '@apollo/server'
import { startStandaloneServer } from '@apollo/server/standalone'
import { typeDefs, resolvers } from './pets/index.js'
// Le constructeur ApolloServer nécessite deux paramètres : votre schéma
// définition et votre ensemble de résolveurs.
const server = new ApolloServer({
typeDefs,
resolvers
})
// Passage d'une instance ApolloServer à la fonction `startStandaloneServer` :
// 1. crée une application Express
// 2. installe votre instance ApolloServer en tant que middleware
// 3. prépare votre application à gérer les requêtes entrantes
const { url } = await startStandaloneServer(server, {
listen: { port: 4000 }
})
console.log(`\ud83d\ude80 Server ready at: ${url}`)
Ici, nous configurons notre serveur Apollo, en lui passant nos typeDefs et résolveurs (nous allons les expliquer dans un instant), puis nous démarrons le serveur sur le port 4000.
Ensuite, allez-y et créez cette structure de dossiers dans votre projet :
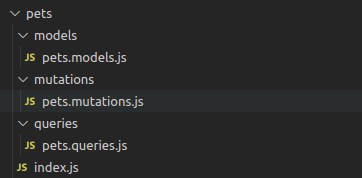
Notre structure de dossiers
index.js
Dans le fichier index.js, mettez ce code :
import { addPet, editPet, deletePet } from './mutations/pets.mutations.js'
import { listPets, getPet } from './queries/pets.queries.js'
// Un schéma est une collection de définitions de types (d'où "typeDefs")
// qui ensemble définissent la "forme" des requêtes exécutées contre vos données.
export const typeDefs = `#graphql
# OBJECT TYPES
# Ce type "Pet" définit les champs interrogeables pour chaque animal dans notre source de données.
type Pet {
id: ID!
name: String!
type: String!
age: Int!
breed: String!
}
# INPUT TYPES
# Définir les objets d'entrée pour les mutations addPet et editPet
input PetToEdit {
id: ID!
name: String!
type: String!
age: Int!
breed: String!
}
input PetToAdd {
name: String!
type: String!
age: Int!
breed: String!
}
# Le type "Query" est spécial : il liste toutes les requêtes disponibles que
# les clients peuvent exécuter, ainsi que le type de retour pour chacune. Dans ce
# cas, la requête "pets" retourne un tableau de zéro ou plusieurs animaux.
# QUERY TYPES
type Query {
pets: [Pet],
pet(id: ID!): Pet
}
# MUTATION TYPES
type Mutation {
addPet(petToAdd: PetToAdd!): Pet,
editPet(petToEdit: PetToEdit!): Pet,
deletePet(id: ID!): [Pet],
}
`
export const resolvers = {
// Résolveurs pour les requêtes
Query: {
pets: () => listPets(),
pet: (_, { id }) => getPet(id)
},
// Résolveurs pour les mutations
Mutation: {
addPet: (_, { petToAdd }) => addPet(petToAdd),
editPet: (_, { petToEdit }) => editPet(petToEdit),
deletePet: (_, { id }) => deletePet(id)
}
}
Ici, nous avons deux choses principales : typeDefs et resolvers.
typeDefs définit les types pour les données qui peuvent être interrogées dans notre API (dans notre cas, c'est l'objet pet), ainsi que l'entrée pour les requêtes/mutations (dans notre cas, c'est PetToEdit et PetToAdd).
Enfin, il définit également les requêtes et mutations disponibles pour notre API, en déclarant leurs noms, ainsi que leurs valeurs d'entrée et de retour. Dans notre cas, nous avons deux requêtes (pets et pet) et trois mutations (addPet, editPet et deletePet).
resolvers contient l'implémentation réelle de nos types de requêtes et mutations. Ici, nous déclarons chaque requête et mutation, et indiquons ce que chacune devrait faire. Dans notre cas, nous les relions aux requêtes/mutations que nous importons de notre couche de requêtes/mutations.
pets.queries.js
Dans votre fichier pets.queries.js, mettez ceci :
import { getItem, listItems } from '../models/pets.models.js'
export const getPet = id => {
try {
const resp = getItem(id)
return resp
} catch (err) {
return err
}
}
export const listPets = () => {
try {
const resp = listItems()
return resp
} catch (err) {
return err
}
}
Comme vous pouvez le voir, ce fichier est très simple. Il déclare les fonctions qui sont importées dans le fichier index.js et les relie aux fonctions déclarées dans la couche des modèles.
pets.mutations.js
Il en va de même pour notre fichier pets.mutations.js, mais avec des mutations cette fois.
import { editItem, addItem, deleteItem } from '../models/pets.models.js'
export const addPet = petToAdd => {
try {
const resp = addItem(petToAdd)
return resp
} catch (err) {
return err
}
}
export const editPet = petToEdit => {
try {
const resp = editItem(petToEdit?.id, petToEdit)
return resp
} catch (err) {
return err
}
}
export const deletePet = id => {
try {
const resp = deleteItem(id)
return resp
} catch (err) {
return err
}
}
pets.models.js
Maintenant, allez dans le dossier des modèles et créez un fichier pets.models.js avec ce code dedans :
import db from '../../db/db.js'
export const getItem = id => {
try {
const pet = db?.pets?.filter(pet => pet?.id === parseInt(id))[0]
return pet
} catch (err) {
console.error('Error', err)
return err
}
}
export const listItems = () => {
try {
return db?.pets
} catch (err) {
console.error('Error', err)
return err
}
}
export const editItem = (id, data) => {
try {
const index = db.pets.findIndex(pet => pet.id === parseInt(id))
if (index === -1) throw new Error('Pet not found')
else {
data.id = parseInt(data.id)
db.pets[index] = data
return db.pets[index]
}
} catch (err) {
console.error('Error', err)
return err
}
}
export const addItem = data => {
try {
const newPet = { id: db.pets.length + 1, ...data }
db.pets.push(newPet)
return newPet
} catch (err) {
console.error('Error', err)
return err
}
}
export const deleteItem = id => {
try {
// supprimer l'élément de la base de données
const index = db.pets.findIndex(pet => pet.id === parseInt(id))
if (index === -1) throw new Error('Pet not found')
else {
db.pets.splice(index, 1)
return db.pets
}
} catch (err) {
console.error('Error', err)
return err
}
}
Ce sont les fonctions responsables de l'interaction avec notre couche de données (base de données) et du retour des informations correspondantes à nos contrôleurs.
Base de données
Nous n'utiliserons pas de base de données réelle pour cet exemple. Au lieu de cela, nous utiliserons simplement un tableau simple qui fonctionnera très bien pour les besoins de l'exemple, bien que nos données seront bien sûr réinitialisées chaque fois que notre serveur le fera.
À la racine de notre projet, créez un dossier db et un fichier db.js avec ce code dedans :
const db = {
pets: [
{
id: 1,
name: 'Rex',
type: 'dog',
age: 3,
breed: 'labrador',
},
{
id: 2,
name: 'Fido',
type: 'dog',
age: 1,
breed: 'poodle',
},
{
id: 3,
name: 'Mittens',
type: 'cat',
age: 2,
breed: 'tabby',
},
]
}
export default db
Comme vous pouvez le voir, notre objet db contient une propriété pets dont la valeur est un tableau d'objets, chaque objet étant un animal. Pour chaque animal, nous stockons un id, un nom, un type, un âge et une race.
Maintenant, allez dans votre terminal et exécutez nodemon app.js. Vous devriez voir ce message confirmant que votre serveur est en vie : \ud83d\ude80 Server ready at: [http://localhost:4000/](http://localhost:4000/).
Comment tester une API GraphQL avec Supertest
Maintenant que notre serveur est opérationnel, implémentons une simple suite de tests pour vérifier si nos requêtes et mutations se comportent comme prévu.
Si vous n'êtes pas familier avec les tests automatisés, je vous recommande de lire cet article d'introduction que j'ai écrit il y a quelque temps.
Nos outils
SuperTest est une bibliothèque JavaScript utilisée pour tester les serveurs HTTP ou les applications web qui effectuent des requêtes HTTP. Elle fournit une abstraction de haut niveau pour tester HTTP, permettant aux développeurs d'envoyer des requêtes HTTP et de faire des assertions sur les réponses reçues, ce qui facilite l'écriture de tests automatisés pour les applications web.
SuperTest fonctionne avec n'importe quel framework de test JavaScript, tel que Mocha ou Jest, et peut être utilisé avec n'importe quel serveur HTTP ou framework d'application web, tel qu'Express.
SuperTest est construit sur la bibliothèque de test populaire Mocha, et utilise la bibliothèque d'assertion Chai pour faire des assertions sur les réponses reçues. Il fournit une API facile à utiliser pour effectuer des requêtes HTTP, y compris la prise en charge de l'authentification, des en-têtes et des corps de requête.
SuperTest permet également aux développeurs de tester l'ensemble du cycle de requête/réponse, y compris le middleware et la gestion des erreurs, ce qui en fait un outil puissant pour tester les applications web.
Dans l'ensemble, SuperTest est un outil précieux pour les développeurs qui souhaitent écrire des tests automatisés pour leurs applications web. Il aide à garantir que leurs applications fonctionnent correctement et que les modifications apportées à la base de code n'introduisent pas de nouveaux bugs ou problèmes.
Le code
Tout d'abord, nous devons installer quelques dépendances. Pour économiser des commandes de terminal, allez dans votre fichier package.json et remplacez votre section devDependencies par le code ci-dessous. Ensuite, exécutez npm install.
"devDependencies": {
"@babel/core": "^7.21.4",
"@babel/preset-env": "^7.21.4",
"babel-jest": "^29.5.0",
"jest": "^29.5.0",
"jest-babel": "^1.0.1",
"nodemon": "^2.0.22",
"supertest": "^6.3.3"
}
Ici, nous installons les bibliothèques supertest et jest, dont nous avons besoin pour exécuter nos tests, ainsi que quelques éléments babel dont nous avons besoin pour que notre projet identifie correctement les fichiers de test.
Toujours dans votre package.json, ajoutez ce script :
"scripts": {
"test": "jest"
},
Pour terminer avec le code standard, à la racine de votre projet, créez un fichier babel.config.cjs et mettez ce code dedans :
//babel.config.cjs
module.exports = {
presets: [
[
'@babel/preset-env',
{
targets: {
node: 'current',
},
},
],
],
};
Maintenant, écrivons quelques tests réels ! Dans votre dossier pets, créez un fichier pets.test.js avec ce code dedans :
import request from 'supertest'
const graphQLEndpoint = 'http://localhost:4000/'
describe('Get all pets', () => {
const postData = {
query: `query Pets {
pets {
id
name
type
age
breed
}
}`
}
test('returns all pets', async () => {
request(graphQLEndpoint)
.post('?')
.send(postData)
.expect(200)
.end((error, response) => {
if (error) console.error(error)
const res = JSON.parse(response.text)
expect(res.data.pets).toEqual([
{
id: '1',
name: 'Rex',
type: 'dog',
age: 3,
breed: 'labrador'
},
{
id: '2',
name: 'Fido',
type: 'dog',
age: 1,
breed: 'poodle'
},
{
id: '3',
name: 'Mittens',
type: 'cat',
age: 2,
breed: 'tabby'
}
])
})
})
})
describe('Get pet detail', () => {
const postData = {
query: `query Pet {
pet(id: 1) {
id
name
type
age
breed
}
}`
}
test('Return pet detail information', async () => {
request(graphQLEndpoint)
.post('?')
.send(postData)
.expect(200)
.end((error, response) => {
if (error) console.error(error)
const res = JSON.parse(response.text)
expect(res.data.pet).toEqual({
id: '1',
name: 'Rex',
type: 'dog',
age: 3,
breed: 'labrador'
})
})
})
})
describe('Edit pet', () => {
const postData = {
query: `mutation EditPet($petToEdit: PetToEdit!) {
editPet(petToEdit: $petToEdit) {
id
name
type
age
breed
}
}`,
variables: {
petToEdit: {
id: 1,
name: 'Rexo',
type: 'dogo',
age: 4,
breed: 'doberman'
}
}
}
test('Updates pet and returns it', async () => {
request(graphQLEndpoint)
.post('?')
.send(postData)
.expect(200)
.end((error, response) => {
if (error) console.error(error)
const res = JSON.parse(response.text)
expect(res.data.editPet).toEqual({
id: '1',
name: 'Rexo',
type: 'dogo',
age: 4,
breed: 'doberman'
})
})
})
})
describe('Add pet', () => {
const postData = {
query: `mutation AddPet($petToAdd: PetToAdd!) {
addPet(petToAdd: $petToAdd) {
id
name
type
age
breed
}
}`,
variables: {
petToAdd: {
name: 'Salame',
type: 'cat',
age: 6,
breed: 'pinky'
}
}
}
test('Adds new pet and returns the added item', async () => {
request(graphQLEndpoint)
.post('?')
.send(postData)
.expect(200)
.end((error, response) => {
if (error) console.error(error)
const res = JSON.parse(response.text)
expect(res.data.addPet).toEqual({
id: '4',
name: 'Salame',
type: 'cat',
age: 6,
breed: 'pinky'
})
})
})
})
describe('Delete pet', () => {
const postData = {
query: `mutation DeletePet {
deletePet(id: 2) {
id,
name,
type,
age,
breed
}
}`
}
test('Deletes given pet and returns updated list', async () => {
request(graphQLEndpoint)
.post('?')
.send(postData)
.expect(200)
.end((error, response) => {
if (error) console.error(error)
const res = JSON.parse(response.text)
expect(res.data.deletePet).toEqual([
{
id: '1',
name: 'Rexo',
type: 'dogo',
age: 4,
breed: 'doberman'
},
{
id: '3',
name: 'Mittens',
type: 'cat',
age: 2,
breed: 'tabby'
},
{
id: '4',
name: 'Salame',
type: 'cat',
age: 6,
breed: 'pinky'
}
])
})
})
})
Ceci est une suite de tests pour notre API GraphQL. Elle utilise la bibliothèque supertest pour faire des requêtes HTTP à l'endpoint de l'API (http://localhost:4000/) et vérifie que l'API répond correctement à diverses requêtes et mutations.
Le code contient cinq cas de test différents :
Get all pets: Ce test interroge l'API pour tous les animaux et vérifie que la réponse correspond à une liste attendue d'animaux.Get pet detail: Ce test interroge l'API pour les détails d'un animal spécifique et vérifie que la réponse correspond aux détails attendus pour cet animal.Edit pet: Ce test effectue une mutation pour modifier les détails d'un animal spécifique et vérifie que la réponse correspond aux détails modifiés attendus pour cet animal.Add pet: Ce test effectue une mutation pour ajouter un nouvel animal et vérifie que la réponse correspond aux détails attendus pour le nouvel animal ajouté.Delete pet: Ce test effectue une mutation pour supprimer un animal spécifique et vérifie que la réponse correspond à la liste attendue d'animaux après la suppression.
Chaque cas de test inclut un objet postData qui contient la requête ou la mutation GraphQL à envoyer à l'endpoint de l'API ainsi que les variables nécessaires.
La requête HTTP réelle est effectuée en utilisant la fonction request de la bibliothèque supertest, qui envoie une requête POST à l'endpoint de l'API avec l'objet postData dans le corps de la requête. La réponse est ensuite analysée en JSON et le cas de test vérifie que la réponse correspond au résultat attendu en utilisant la fonction expect du framework de test Jest.
Maintenant, allez dans votre terminal, exécutez npm test, et vous devriez voir tous vos tests réussir :
> jest
PASS pets/pets.test.js
Get all pets
\u2713 returns all pets (15 ms)
Get pet detail
\u2713 Return pet detail information (2 ms)
Edit pet
\u2713 Updates pet and returns it (1 ms)
Add pet
\u2713 Adds new pet and returns the added item (1 ms)
Delete pet
\u2713 Deletes given pet and returns updated list (1 ms)
Test Suites: 1 passed, 1 total
Tests: 5 passed, 5 total
Snapshots: 0 total
Time: 0.607 s, estimated 1 s
Ran all test suites.
Comment consommer une API GraphQL sur une application front-end React
Maintenant que nous savons que notre serveur est en cours d'exécution et se comporte comme prévu, voyons un exemple plus réaliste de la manière dont notre API pourrait être consommée par une application front-end.
Pour cet exemple, nous utiliserons une application React, et Apollo client pour envoyer et traiter nos requêtes.
Nos outils
React est une bibliothèque JavaScript populaire pour construire des interfaces utilisateur. Elle permet aux développeurs de créer des composants d'interface utilisateur réutilisables et de les mettre à jour et de les rendre efficacement en réponse aux changements d'état de l'application.
En ce qui concerne Apollo client, nous l'avons déjà présenté.
Commentaire à part – nous utilisons Apollo client ici car c'est un outil très populaire et il est logique d'utiliser le même ensemble de bibliothèques à la fois en front-end et en back-end. Si vous êtes intéressé par d'autres façons possibles de consommer une API GraphQL à partir d'une application front-end React, Reed Barger a un article assez cool sur ce sujet.
Le code
Créons notre application React en exécutant yarn create vite et en suivant les invites du terminal. Une fois cela fait, exécutez yarn add react-router-dom (que nous utiliserons pour configurer le routage de base dans notre application).
App.jsx
Mettez ce code dans votre fichier App.jsx :
import { Suspense, lazy, useState } from 'react'
import { BrowserRouter as Router, Routes, Route } from 'react-router-dom'
import './App.css'
const PetList = lazy(() => import('./pages/PetList'))
const PetDetail = lazy(() => import('./pages/PetDetail'))
const EditPet = lazy(() => import('./pages/EditPet'))
const AddPet = lazy(() => import('./pages/AddPet'))
function App() {
const [petToEdit, setPetToEdit] = useState(null)
return (
<div className='App'>
<Router>
<h1>Pet shelter</h1>
<Routes>
<Route
path='/'
element={
<Suspense fallback={<></>}>
<PetList />
</Suspense>
}
/>
<Route
path='/:petId'
element={
<Suspense fallback={<></>}>
<PetDetail setPetToEdit={setPetToEdit} />
</Suspense>
}
/>
<Route
path='/:petId/edit'
element={
<Suspense fallback={<></>}>
<EditPet petToEdit={petToEdit} />
</Suspense>
}
/>
<Route
path='/add'
element={
<Suspense fallback={<></>}>
<AddPet />
</Suspense>
}
/>
</Routes>
</Router>
</div>
)
}
export default App
Ici, nous définissons simplement nos routes. Nous aurons 4 routes principales dans notre application, chacune correspondant à une vue différente :
Une pour voir la liste complète des animaux.
Une pour voir les détails d'un seul animal.
Une pour modifier un seul animal.
Une pour ajouter un nouvel animal à la liste.
En outre, nous avons un bouton pour ajouter un nouvel animal et un état qui stockera les informations de l'animal que nous voulons modifier.
Ensuite, créez un répertoire pages avec ces fichiers dedans :
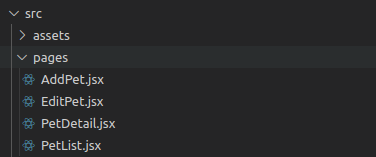
Structure des dossiers
main.js
Avant de plonger dans nos pages, nous devons configurer la bibliothèque Apollo client. Exécutez yarn add @apollo/client et yarn add graphql pour installer les dépendances nécessaires.
Ensuite, allez dans le fichier main.js et mettez ce code dedans :
import React from 'react'
import ReactDOM from 'react-dom/client'
import App from './App'
import './index.css'
import { ApolloClient, InMemoryCache, ApolloProvider } from '@apollo/client'
const client = new ApolloClient({
uri: 'http://localhost:4000/',
cache: new InMemoryCache(),
})
ReactDOM.createRoot(document.getElementById('root')).render(
<ApolloProvider client={client}>
<App />
</ApolloProvider>
)
Ici, nous initialisons le ApolloClient, en passant à son constructeur un objet de configuration avec les champs uri et cache :
urispécifie l'URL de notre serveur GraphQL.cacheest une instance deInMemoryCache, que Apollo Client utilise pour mettre en cache les résultats des requêtes après les avoir récupérés.
Ensuite, nous enveloppons notre composant App avec notre ApolloProvider. Cela permet à n'importe quel composant dans notre arbre de composants d'utiliser les hooks fournis par Apollo client, un peu comme le contexte React fonctionne. ;)
Mutations et requêtes
À la racine de votre projet, créez cette structure de dossiers :

Structure des dossiers
Dans ces deux fichiers, nous déclarerons les corps de requête que nous utiliserons pour nos requêtes et mutations. J'aime séparer cela en différents fichiers car cela nous donne une vue claire des différents types de requêtes que nous avons dans notre application, et cela garde également le code de nos composants plus propre.
Dans le fichier queries.js, mettez ceci :
import { gql } from '@apollo/client'
export const GET_PETS = gql`
query Pets {
pets {
id
name
type
breed
}
}
`
export const GET_PET = gql`
query Pet($petId: ID!) {
pet(id: $petId) {
id
name
type
age
breed
}
}
`
Et dans le fichier mutations.js, mettez ceci :
import { gql } from '@apollo/client'
export const DELETE_PET = gql`
mutation DeletePet($deletePetId: ID!) {
deletePet(id: $deletePetId) {
id
}
}
`
export const ADD_PET = gql`
mutation AddPet($petToAdd: PetToAdd!) {
addPet(petToAdd: $petToAdd) {
id
name
type
age
breed
}
}
`
export const EDIT_PET = gql`
mutation EditPet($petToEdit: PetToEdit!) {
editPet(petToEdit: $petToEdit) {
id
name
type
age
breed
}
}
`
Comme vous pouvez le voir, la syntaxe pour les requêtes et les mutations est assez similaire. Les corps de requête sont écrits en langage de requête GraphQL, qui est utilisé pour définir la structure et les types de données des données qui peuvent être demandées à une API GraphQL.
- Syntaxe de requête GraphQL :
export const GET_PETS = gql`
query Pets {
pets {
id
name
type
breed
}
}
`
Cette requête est nommée Pets et elle demande des données à partir du champ pets. Les champs id, name, type et breed sont demandés pour chaque objet Pet retourné par l'API.
Dans GraphQL, les requêtes commencent toujours par le mot-clé query et sont suivies par le nom de la requête, si fourni. Les champs demandés sont enfermés dans des accolades et peuvent être imbriqués pour demander des données à partir de champs liés.
- Syntaxe de mutation GraphQL :
export const ADD_PET = gql`
mutation AddPet($petToAdd: PetToAdd!) {
addPet(petToAdd: $petToAdd) {
id
name
type
age
breed
}
}
`
Cette mutation est nommée AddPet et envoie un nouvel objet Pet à ajouter à l'API via la mutation addPet. La variable $petToAdd est définie comme une entrée requise de type PetToAdd. Lorsque la mutation est exécutée, la variable d'entrée sera passée en tant qu'argument à la mutation addPet. La mutation retourne ensuite les champs id, name, type, age et breed pour le nouvel objet Pet créé.
Dans GraphQL, les mutations commencent toujours par le mot-clé mutation et sont suivies par le nom de la mutation, si fourni. Les champs demandés dans la réponse de la mutation sont également enfermés dans des accolades.
Notez que les requêtes et les mutations dans GraphQL peuvent accepter des variables en entrée, qui sont définies dans le corps de la requête ou de la mutation en utilisant une syntaxe spéciale ($variableName: variableType!). Ces variables peuvent être passées lors de l'exécution de la requête ou de la mutation, permettant des requêtes et des mutations plus dynamiques et réutilisables.
PetList.jsx
Commençons par le fichier responsable du rendu de la liste complète des animaux :
import { Link } from 'react-router-dom'
import { useQuery } from '@apollo/client'
import { GET_PETS } from '../api/queries'
function PetList() {
const { loading, error, data } = useQuery(GET_PETS)
return (
<>
<h2>Pet List</h2>
<Link to='/add'>
<button>Add new pet</button>
</Link>
{loading && <p>Loading...</p>}
{error && <p>Error: {error.message}</p>}
{data?.pets?.map(pet => {
return (
<div key={pet?.id}>
<p>
{pet?.name} - {pet?.type} - {pet?.breed}
</p>
<Link to={`/${pet?.id}`}>
<button>Pet detail</button>
</Link>
</div>
)
})}
</>
)
}
export default PetList
Ce code définit un composant fonctionnel React appelé PetList qui récupère une liste d'animaux à partir d'une API GraphQL en utilisant le hook useQuery fourni par la bibliothèque @apollo/client. La requête utilisée pour récupérer les animaux est définie dans un fichier séparé appelé queries.js, qui exporte une requête GraphQL appelée GET_PETS.
Le hook useQuery retourne un objet avec trois propriétés : loading, error et data. Ces propriétés sont déstructurées à partir de l'objet et utilisées pour rendre conditionnellement différents éléments d'interface utilisateur en fonction du statut de la requête API.
Si loading est vrai, un message de chargement est affiché à l'écran. Si error est défini, un message d'erreur est affiché avec le message d'erreur spécifique retourné par l'API. Si data est défini et contient un tableau de pets, chaque pet est affiché dans un div avec leur name, type et breed. Chaque div de pet contient également un lien pour voir plus de détails sur le pet.
Le hook useQuery fonctionne en exécutant la requête GET_PETS et en retournant le résultat sous forme d'objet avec les propriétés loading, error et data. Lorsque le composant est rendu pour la première fois, loading est vrai pendant que la requête est en cours d'exécution. Si la requête réussit, loading est faux et data est rempli avec les résultats. Si la requête rencontre une erreur, error est rempli avec le message d'erreur spécifique.
Comme vous pouvez le voir, la gestion des requêtes avec Apollo client est vraiment agréable et simple. Et les hooks qu'il fournit nous font économiser pas mal de code normalement utilisé pour exécuter des requêtes, stocker leur réponse et gérer les erreurs.
N'oubliez pas que pour faire des appels à notre serveur, nous devons l'avoir en cours d'exécution en exécutant nodemon app.js dans le terminal de notre projet serveur.
Juste pour montrer qu'il n'y a pas de magie étrange ici, si nous allons dans notre navigateur, ouvrons les outils de développement et allons dans l'onglet réseau, nous pourrions voir que notre application fait une requête POST à notre endpoint de serveur. Et que la charge utile est notre corps de requête sous la forme d'une chaîne.
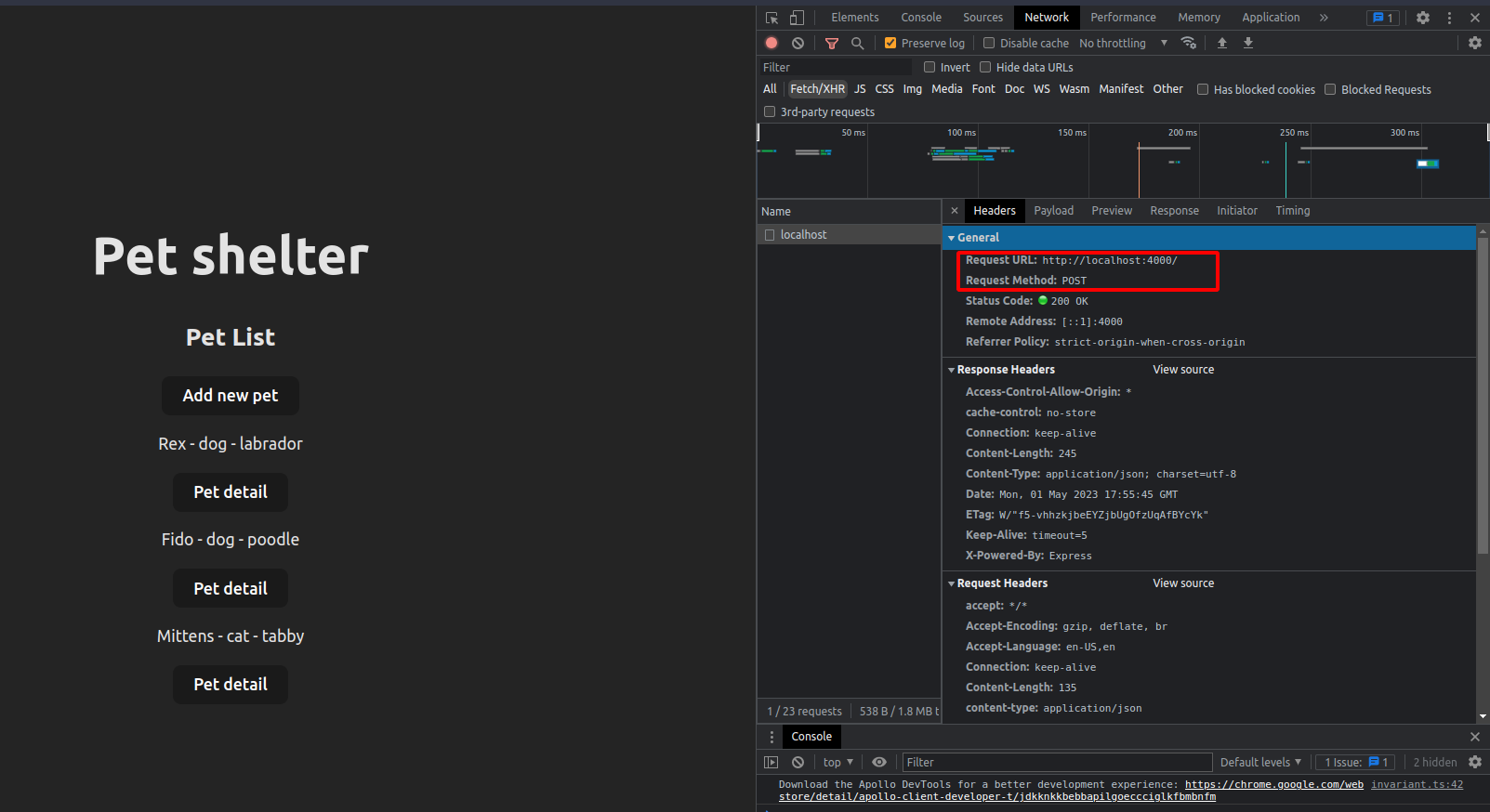
La requête POST

Corps de la requête
Cela signifie que si nous le voulions, nous pourrions également consommer notre API GraphQL en utilisant fetch, comme suit :
import { Link } from 'react-router-dom'
import { useEffect, useState } from 'react'
function PetList() {
const [pets, setPets] = useState([])
const getPets = () => {
fetch('http://localhost:4000/', {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify({
query: `
query Pets {
pets {
id
name
type
breed
}
}
`
})
})
.then(response => response.json())
.then(data => setPets(data?.data?.pets))
.catch(error => console.error(error))
}
useEffect(() => {
getPets()
}, [])
return (
<>
<h2>Pet List</h2>
<Link to='/add'>
<button>Add new pet</button>
</Link>
{pets?.map(pet => {
return (
<div key={pet?.id}>
<p>
{pet?.name} - {pet?.type} - {pet?.breed}
</p>
<Link to={`/${pet?.id}`}>
<button>Pet detail</button>
</Link>
</div>
)
})}
</>
)
}
export default PetList
Si vous vérifiez à nouveau votre onglet réseau, vous devriez voir toujours la même requête POST avec le même corps de requête.
Bien sûr, cette approche n'est pas très pratique car elle nécessite plus de lignes de code pour effectuer la même chose. Mais il est important de savoir que des bibliothèques comme Apollo nous donnent simplement une API déclarative pour travailler et simplifier notre code. Sous tout cela, nous travaillons toujours avec des requêtes HTTP régulières.
PetDetail.jsx
Maintenant, allons dans le fichier PetDetail.jsx :
import { useEffect } from 'react'
import { useParams, Link } from 'react-router-dom'
import { useQuery, useMutation } from '@apollo/client'
import { GET_PET } from '../api/queries'
import { DELETE_PET } from '../api/mutations'
function PetDetail({ setPetToEdit }) {
const { petId } = useParams()
const { loading, error, data } = useQuery(GET_PET, {
variables: { petId }
})
useEffect(() => {
if (data && data?.pet) setPetToEdit(data?.pet)
}, [data])
const [deletePet, { loading: deleteLoading, error: deleteError, data: deleteData }] = useMutation(DELETE_PET, {
variables: { deletePetId: petId }
})
useEffect(() => {
if (deleteData && deleteData?.deletePet) window.location.href = '/'
}, [deleteData])
return (
<div style={{ display: 'flex', flexDirection: 'column', justifyContent: 'center', aligniItems: 'center' }}>
<h2>Pet Detail</h2>
<Link to='/'>
<button>Back to list</button>
</Link>
{(loading || deleteLoading) && <p>Loading...</p>}
{error && <p>Error: {error.message}</p>}
{deleteError && <p>deleteError: {deleteError.message}</p>}
{data?.pet && (
<>
<p>Pet name: {data?.pet?.name}</p>
<p>Pet type: {data?.pet?.type}</p>
<p>Pet age: {data?.pet?.age}</p>
<p>Pet breed: {data?.pet?.breed}</p>
<div style={{ display: 'flex', justifyContent: 'center', aligniItems: 'center' }}>
<Link to={`/${data?.pet?.id}/edit`}>
<button style={{ marginRight: 10 }}>Edit pet</button>
</Link>
<button style={{ marginLeft: 10 }} onClick={() => deletePet()}>
Delete pet
</button>
</div>
</>
)}
</div>
)
}
export default PetDetail
Ce composant charge les informations détaillées de l'animal en exécutant une requête de manière très similaire au composant précédent.
De plus, il exécute la mutation nécessaire pour supprimer l'enregistrement de l'animal. Vous pouvez voir que pour cela, nous utilisons le hook useMutation. Il est assez similaire à useQuery, mais en plus des valeurs loading, error et data, il fournit également une fonction pour exécuter notre requête après un événement donné.
Vous pouvez voir que pour ce hook de mutation, nous passons un objet en tant que deuxième paramètre, contenant les variables requises par cette mutation. Dans ce cas, il s'agit de l'ID de l'enregistrement de l'animal que nous voulons supprimer.
const [deletePet, { loading: deleteLoading, error: deleteError, data: deleteData }] = useMutation(DELETE_PET, {
variables: { deletePetId: petId }
})
Rappelez-vous que lorsque nous avons déclaré notre mutation dans mutations.js, nous avions déjà déclaré les variables que cette mutation utiliserait.
export const DELETE_PET = gql`
mutation DeletePet($deletePetId: ID!) {
deletePet(id: $deletePetId) {
id
}
}
`
AddPet.jsx
Ce fichier est responsable de l'ajout d'un nouvel animal à notre registre :
import React, { useState, useEffect } from 'react'
import { Link } from 'react-router-dom'
import { useMutation } from '@apollo/client'
import { ADD_PET } from '../api/mutations'
function AddPet() {
const [petName, setPetName] = useState()
const [petType, setPetType] = useState()
const [petAge, setPetAge] = useState()
const [petBreed, setPetBreed] = useState()
const [addPet, { loading, error, data }] = useMutation(ADD_PET, {
variables: {
petToAdd: {
name: petName,
type: petType,
age: parseInt(petAge),
breed: petBreed
}
}
})
useEffect(() => {
if (data && data?.addPet) window.location.href = `/${data?.addPet?.id}`
}, [data])
return (
<div style={{ display: 'flex', flexDirection: 'column', justifyContent: 'center', aligniItems: 'center' }}>
<h2>Add Pet</h2>
<Link to='/'>
<button>Back to list</button>
</Link>
{loading || error ? (
<>
{loading && <p>Loading...</p>}
{error && <p>Error: {error.message}</p>}
</>
) : (
<>
<div style={{ display: 'flex', flexDirection: 'column', margin: 20 }}>
<label>Pet name</label>
<input type='text' value={petName} onChange={e => setPetName(e.target.value)} />
</div>
<div style={{ display: 'flex', flexDirection: 'column', margin: 20 }}>
<label>Pet type</label>
<input type='text' value={petType} onChange={e => setPetType(e.target.value)} />
</div>
<div style={{ display: 'flex', flexDirection: 'column', margin: 20 }}>
<label>Pet age</label>
<input type='text' value={petAge} onChange={e => setPetAge(e.target.value)} />
</div>
<div style={{ display: 'flex', flexDirection: 'column', margin: 20 }}>
<label>Pet breed</label>
<input type='text' value={petBreed} onChange={e => setPetBreed(e.target.value)} />
</div>
<button
style={{ marginTop: 30 }}
disabled={!petName || !petType || !petAge || !petBreed}
onClick={() => addPet()}
>
Add pet
</button>
</>
)}
</div>
)
}
export default AddPet
Ici, nous avons un composant qui charge un formulaire pour ajouter un nouvel animal et effectue une mutation lorsque les données sont envoyées. Il accepte les nouvelles informations sur l'animal en tant que paramètre, de manière similaire à la mutation deletePet qui acceptait l'ID de l'animal.
EditPet.jsx
Enfin, le fichier responsable de la modification d'un enregistrement d'animal :
import React, { useState, useEffect } from 'react'
import { Link } from 'react-router-dom'
import { useMutation } from '@apollo/client'
import { EDIT_PET } from '../api/mutations'
function EditPet({ petToEdit }) {
const [petName, setPetName] = useState(petToEdit?.name)
const [petType, setPetType] = useState(petToEdit?.type)
const [petAge, setPetAge] = useState(petToEdit?.age)
const [petBreed, setPetBreed] = useState(petToEdit?.breed)
const [editPet, { loading, error, data }] = useMutation(EDIT_PET, {
variables: {
petToEdit: {
id: parseInt(petToEdit.id),
name: petName,
type: petType,
age: parseInt(petAge),
breed: petBreed
}
}
})
useEffect(() => {
if (data && data?.editPet?.id) window.location.href = `/${data?.editPet?.id}`
}, [data])
return (
<div style={{ display: 'flex', flexDirection: 'column', justifyContent: 'center', aligniItems: 'center' }}>
<h2>Edit Pet</h2>
<Link to='/'>
<button>Back to list</button>
</Link>
{loading || error ? (
<>
{loading && <p>Loading...</p>}
{error && <p>Error: {error.message}</p>}
</>
) : (
<>
<div style={{ display: 'flex', flexDirection: 'column', margin: 20 }}>
<label>Pet name</label>
<input type='text' value={petName} onChange={e => setPetName(e.target.value)} />
</div>
<div style={{ display: 'flex', flexDirection: 'column', margin: 20 }}>
<label>Pet type</label>
<input type='text' value={petType} onChange={e => setPetType(e.target.value)} />
</div>
<div style={{ display: 'flex', flexDirection: 'column', margin: 20 }}>
<label>Pet age</label>
<input type='text' value={petAge} onChange={e => setPetAge(e.target.value)} />
</div>
<div style={{ display: 'flex', flexDirection: 'column', margin: 20 }}>
<label>Pet breed</label>
<input type='text' value={petBreed} onChange={e => setPetBreed(e.target.value)} />
</div>
<button
style={{ marginTop: 30 }}
disabled={!petName || !petType || !petAge || !petBreed}
onClick={() => editPet()}
>
Save changes
</button>
</>
)}
</div>
)
}
export default EditPet
Enfin, nous avons un composant pour modifier un enregistrement d'animal via un formulaire. Il effectue une mutation lorsque les données sont envoyées, et en tant que paramètres, il accepte les nouvelles informations sur l'animal.
Et c'est tout ! Nous utilisons toutes nos requêtes et mutations d'API dans notre application front-end. =)
Comment documenter une API GraphQL avec Apollo Sandbox
L'une des fonctionnalités les plus cool d'Apollo est qu'il est livré avec un bac à sable intégré que vous pouvez utiliser pour tester et documenter votre API.
Apollo Sandbox est un IDE GraphQL basé sur le web qui fournit un environnement de bac à sable pour tester les requêtes, mutations et abonnements GraphQL. C'est un outil gratuit en ligne fourni par Apollo qui vous permet d'interagir avec votre API GraphQL et d'explorer son schéma, ses données et ses capacités.
Voici quelques-unes des principales fonctionnalités d'Apollo Sandbox :
Éditeur de requêtes : Un éditeur de requêtes GraphQL riche en fonctionnalités qui fournit la coloration syntaxique, l'autocomplétion, la validation et la mise en évidence des erreurs.
Explorateur de schéma : Une interface graphique qui vous permet d'explorer votre schéma GraphQL et de voir ses types, champs et relations.
Mocking : Apollo Sandbox vous permet de générer facilement des données fictives basées sur votre schéma, ce qui est utile pour tester vos requêtes et mutations sans vous connecter à une source de données réelle.
Collaboration : Vous pouvez partager votre bac à sable avec d'autres personnes, collaborer sur des requêtes et voir les changements en temps réel.
Documentation : Vous pouvez ajouter de la documentation à votre schéma et aux résultats de vos requêtes pour aider les autres à comprendre votre API.
Pour utiliser notre bac à sable, ouvrez simplement votre navigateur à l'adresse http://localhost:4000/. Vous devriez voir quelque chose comme ceci :
Apollo sandbox
À partir de là, vous pouvez voir le schéma de données de l'API et les mutations et requêtes disponibles, et également les exécuter et voir comment votre API répond. Par exemple, en exécutant la requête pets, nous pouvons voir la réponse dans le panneau latéral droit.
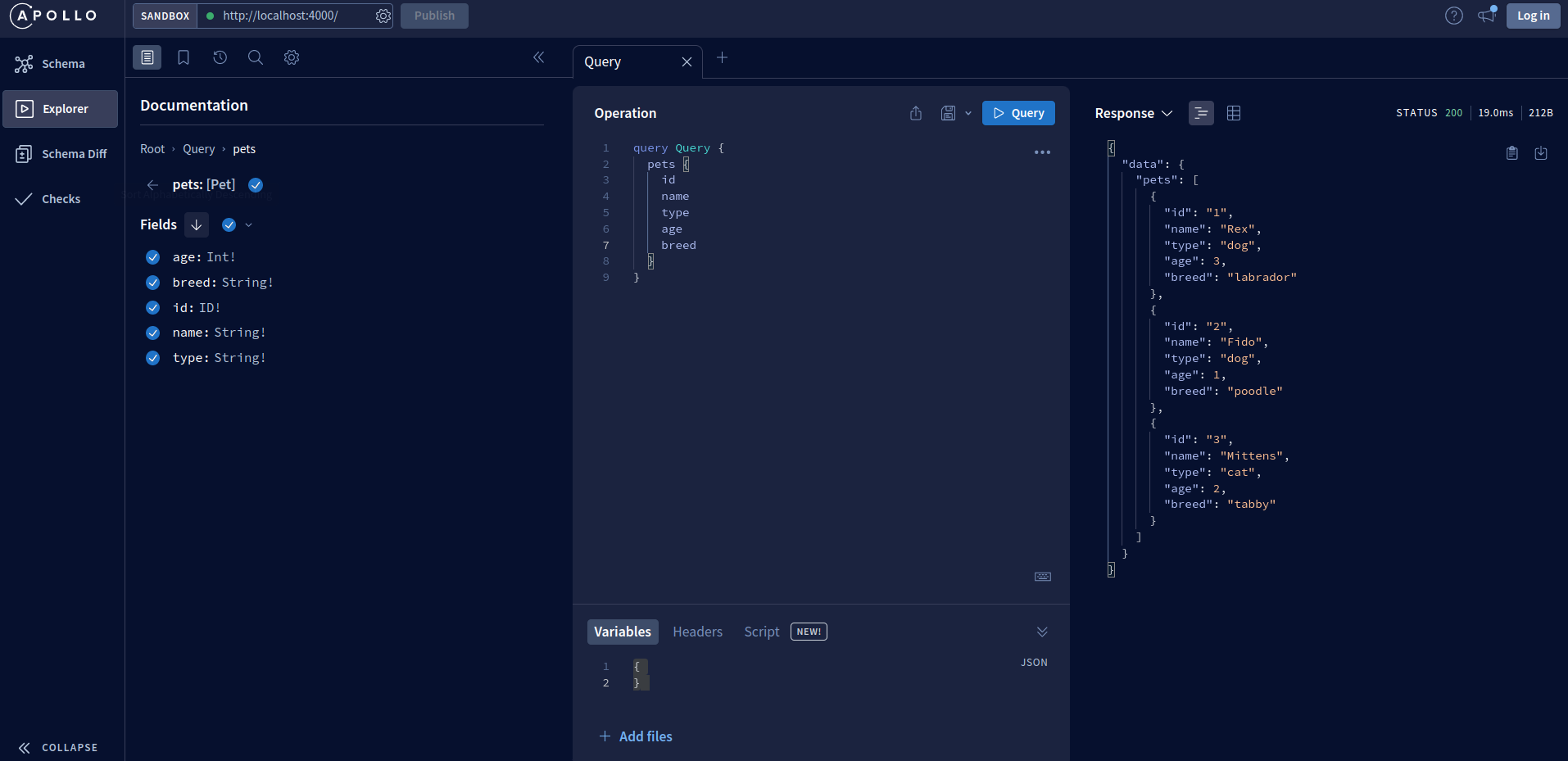
Exécution d'une requête
Si vous allez dans la section schéma, vous pourriez voir un détail complet des requêtes disponibles, des mutations, des objets et des types d'entrée dans notre API.
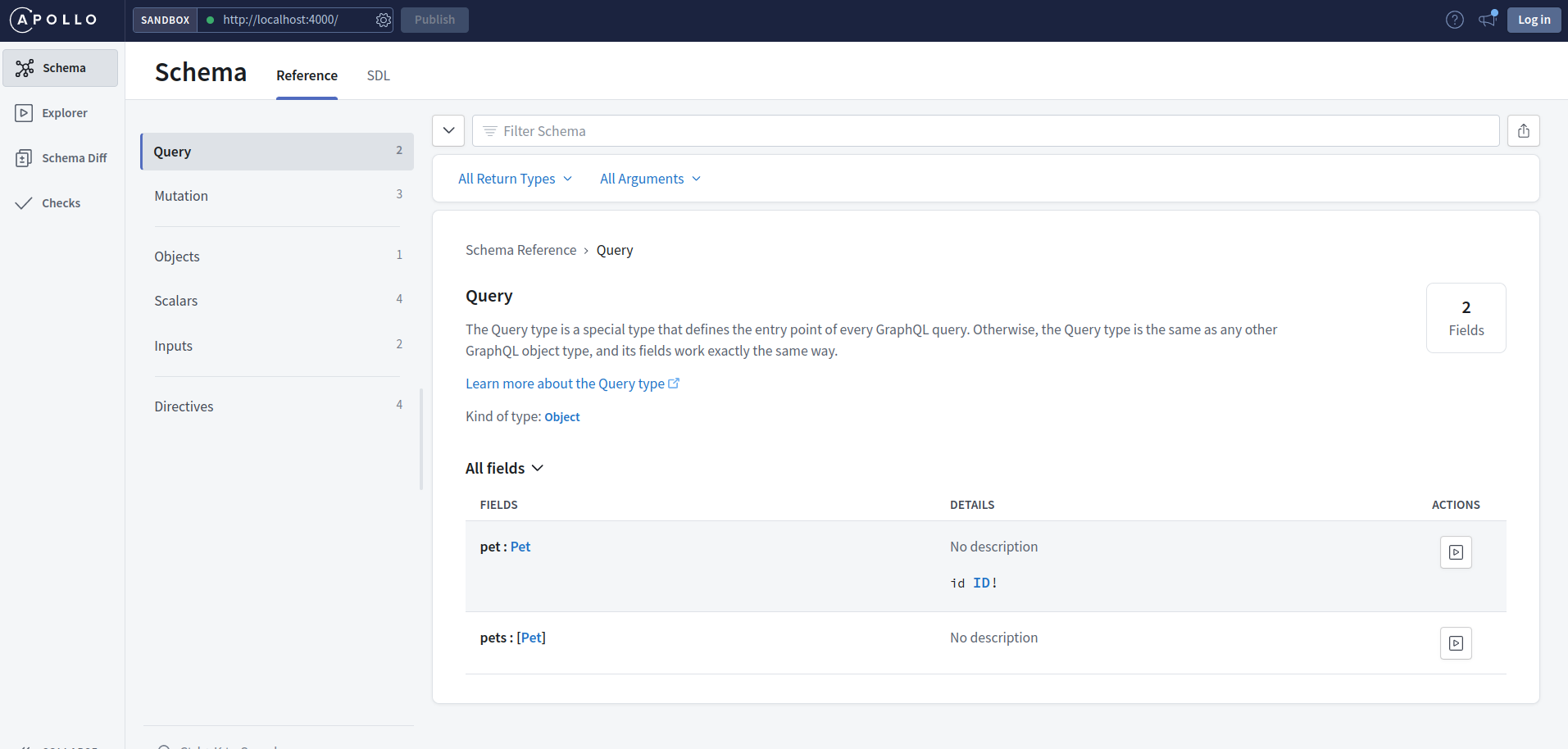
La section schéma
Apollo sandbox est un excellent outil qui peut être utilisé à la fois comme auto-documentation pour notre API et comme un excellent outil de développement et de test.
Conclusion
Eh bien, tout le monde, comme toujours, j'espère que vous avez apprécié l'article et appris quelque chose de nouveau.
Si vous le souhaitez, vous pouvez également me suivre sur LinkedIn ou Twitter. À la prochaine !