


Article original : The Apache Kafka Handbook – How to Get Started Using Kafka
Apache Kafka est une plateforme open-source de diffusion d'événements en continu qui peut transporter d'énormes volumes de données avec une très faible latence.
Des entreprises comme LinkedIn, Uber et Netflix utilisent Kafka pour traiter des billions d'événements et des pétaoctets de données chaque jour.
Kafka a été développé à l'origine chez LinkedIn, pour aider à gérer leurs flux de données en temps réel. Il est maintenant maintenu par la Fondation Apache, et est largement adopté dans l'industrie (étant utilisé par 80 % des entreprises du Fortune 100).
Pourquoi devriez-vous apprendre Apache Kafka ?
Kafka vous permet de :
Publier et vous abonner à des flux d'événements
Stocker des flux d'événements dans l'ordre où ils se sont produits
Traiter des flux d'événements en temps réel
La principale chose que Kafka fait est de vous aider à connecter efficacement des sources de données diverses avec les nombreux systèmes différents qui pourraient avoir besoin d'utiliser ces données.
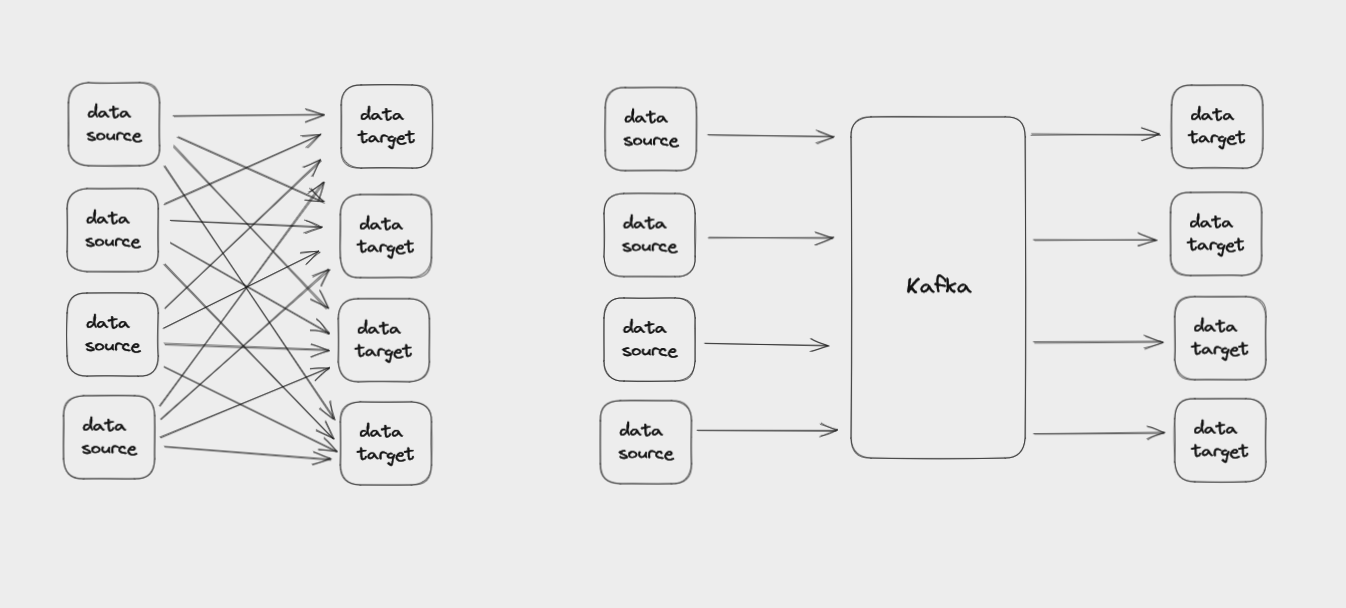
Kafka vous aide à connecter les sources de données aux systèmes utilisant ces données
Certaines des choses pour lesquelles vous pouvez utiliser Kafka incluent :
Personnaliser les recommandations pour les clients
Notifier les passagers des retards de vol
Traitement des paiements en banque
Détection de fraude en ligne
Gestion des stocks et des chaînes d'approvisionnement
Suivi des expéditions de commandes
Collecte de données de télémétrie à partir d'appareils de l'Internet des objets (IoT)
Ce que toutes ces utilisations ont en commun, c'est qu'elles doivent prendre et traiter des données en temps réel, souvent à très grande échelle. C'est quelque chose que Kafka excelle à faire. Pour donner un exemple, Pinterest utilise Kafka pour gérer jusqu'à 40 millions d'événements par seconde.
Kafka est distribué, ce qui signifie qu'il fonctionne comme un cluster de nœuds répartis sur plusieurs serveurs. Il est également répliqué, ce qui signifie que les données sont copiées à plusieurs endroits pour les protéger contre un point de défaillance unique. Cela rend Kafka à la fois scalable et tolérant aux pannes.
Kafka est également rapide. Il est optimisé pour un débit élevé, utilisant efficacement le stockage sur disque et les requêtes réseau groupées.
Cet article va :
Vous introduire aux concepts de base derrière Kafka
Vous montrer comment installer Kafka sur votre propre ordinateur
Vous initier à l'interface de ligne de commande (CLI) de Kafka
Vous aider à construire une simple application Java qui produit et consomme des événements via Kafka
Les sujets que l'article ne couvrira pas :
Des sujets plus avancés sur Kafka, tels que la sécurité, la performance et la surveillance
Déployer un cluster Kafka sur un serveur
Utiliser des services Kafka gérés comme Amazon MSK ou Confluent Cloud
Table des matières
Diffusion d'événements et architectures pilotées par les événements
Concepts de base de Kafka
a. Messages d'événements dans Kafka
b. Topics dans Kafka
c. Partitions dans Kafka
d. Offsets dans Kafka
e. Brokers dans Kafka
f. Réplication dans Kafka
g. Producteurs dans Kafka
h. Consommateurs dans Kafka
i. Groupes de consommateurs dans Kafka
j. Zookeeper de KafkaLa CLI de Kafka
a. Comment lister les topics
b. Comment créer un topic
c. Comment décrire les topics
d. Comment partitionner un topic
e. Comment définir un facteur de réplication
f. Comment supprimer un topic
g. Comment utiliser kafka-console-producer
h. Comment utiliser kafka-console-consumer
i. Comment utiliser kafka-consumer-groupsComment construire une application cliente Kafka avec Java
a. Comment configurer le projet
b. Comment installer les dépendances
c. Comment créer un producteur Kafka
d. Comment envoyer plusieurs messages et utiliser des callbacks
e. Comment créer un consommateur Kafka
f. Comment arrêter le consommateur
Avant de plonger dans Kafka, nous avons besoin de quelques informations sur la diffusion d'événements et les architectures pilotées par les événements.
Diffusion d'événements et architectures pilotées par les événements
Un événement est un enregistrement qu'un événement s'est produit, ainsi que des informations sur ce qui s'est passé. Par exemple : un client a passé une commande, une banque a approuvé une transaction, la gestion des stocks a mis à jour les niveaux de stock.
Les événements peuvent déclencher un ou plusieurs processus pour y répondre. Par exemple : envoyer un reçu par email, transférer des fonds sur un compte, mettre à jour un tableau de bord en temps réel.
La diffusion d'événements est le processus de capture d'événements en temps réel à partir de sources (telles que des applications web, des bases de données ou des capteurs) pour créer des flux d'événements. Ces flux sont des séquences potentiellement sans fin d'enregistrements.
Le flux d'événements peut être stocké, traité et envoyé à différentes destinations, également appelées puits. Les destinations qui consomment les flux pourraient être d'autres applications, des bases de données ou des pipelines de données pour un traitement ultérieur.
À mesure que les applications sont devenues plus complexes, souvent divisées en différents microservices répartis dans plusieurs centres de données, de nombreuses organisations ont adopté une architecture pilotée par les événements pour leurs applications.
Cela signifie que, au lieu que les parties de votre application se demandent directement les unes aux autres des mises à jour sur ce qui s'est passé, chacune publie des événements dans des flux d'événements. D'autres parties de l'application s'abonnent en continu à ces flux et n'agissent que lorsqu'elles reçoivent un événement qui les intéresse.
Cette architecture aide à garantir que si une partie de votre application tombe en panne, les autres parties ne tomberont pas en panne non plus. De plus, vous pouvez ajouter de nouvelles fonctionnalités en ajoutant de nouveaux abonnés au flux d'événements, sans avoir à réécrire la base de code existante.
Concepts de base de Kafka
Kafka est devenu l'un des moyens les plus populaires pour implémenter la diffusion d'événements et les architectures pilotées par les événements. Mais il a une courbe d'apprentissage et vous devez comprendre quelques concepts avant de pouvoir l'utiliser efficacement.
Ces concepts de base sont :
messages d'événements
topics
partitions
offsets
brokers
producteurs
consommateurs
groupes de consommateurs
Zookeeper
Messages d'événements dans Kafka
Lorsque vous écrivez des données dans Kafka, ou lisez des données depuis Kafka, vous le faites sous la forme de messages. Vous les verrez également appelés événements ou enregistrements.
Un message se compose de :
une clé
une valeur
un horodatage
un type de compression
des en-têtes pour les métadonnées (optionnel)
un identifiant de partition et d'offset (une fois le message écrit dans un topic)
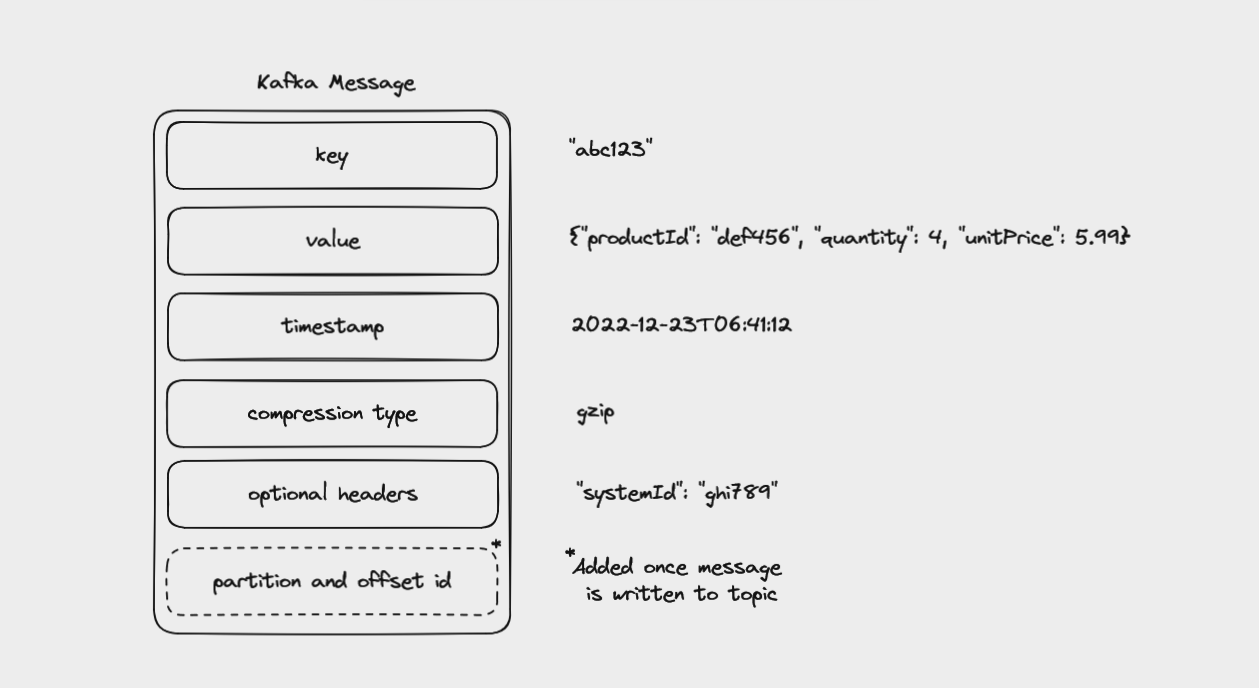
Un message Kafka se composant d'une clé, d'une valeur, d'un horodatage, d'un type de compression et d'en-têtes
Chaque événement dans Kafka est, à sa plus simple expression, une paire clé-valeur. Celles-ci sont sérialisées en binaire, puisque Kafka lui-même gère des tableaux d'octets plutôt que des objets complexes spécifiques à un langage.
Les clés sont généralement des chaînes de caractères ou des entiers et ne sont pas uniques pour chaque message. Au lieu de cela, elles pointent vers une entité particulière dans le système, telle qu'un utilisateur spécifique, une commande ou un appareil. Les clés peuvent être nulles, mais lorsqu'elles sont incluses, elles sont utilisées pour diviser les topics en partitions (plus sur les partitions ci-dessous).
La valeur du message contient des détails sur l'événement qui s'est produit. Cela peut être aussi simple qu'une chaîne de caractères ou aussi complexe qu'un objet avec de nombreuses propriétés imbriquées. Les valeurs peuvent être nulles, mais généralement ne le sont pas.
Par défaut, l'horodatage enregistre le moment où le message a été créé. Vous pouvez le remplacer si votre événement s'est réellement produit plus tôt et que vous souhaitez enregistrer ce moment-là à la place.
Les messages sont généralement petits (moins de 1 Mo) et envoyés dans un format de données standard, tel que JSON, Avro ou Protobuf. Même ainsi, ils peuvent être compressés pour économiser des données. Le type de compression peut être défini sur gzip, lz4, snappy, zstd, ou none.
Les événements peuvent également avoir des en-têtes, qui sont des paires clé-valeur de chaînes contenant des métadonnées, telles que l'origine de l'événement ou l'endroit où vous souhaitez qu'il soit acheminé.
Une fois qu'un message est envoyé dans un topic Kafka, il reçoit également un numéro de partition et un identifiant d'offset (plus d'informations sur ceux-ci plus tard).
Topics dans Kafka
Kafka stocke les messages dans un topic, une séquence ordonnée d'événements, également appelée journal d'événements.
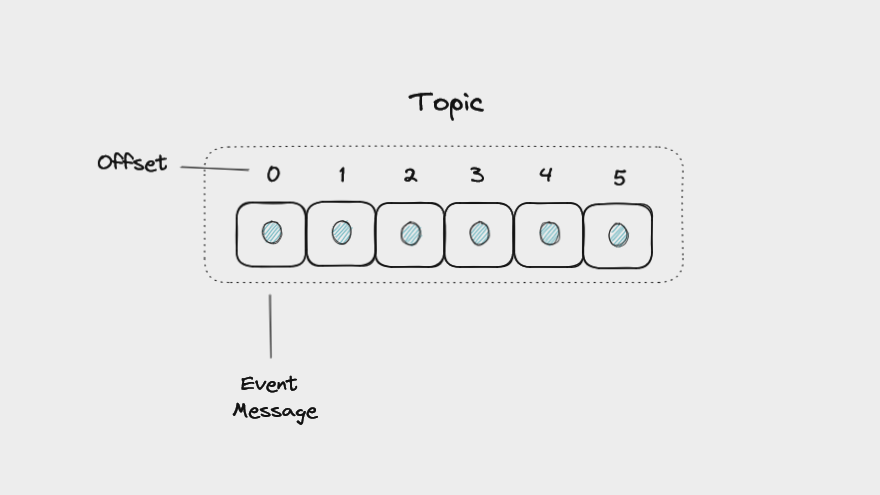
Un topic Kafka contenant des messages, chacun avec un offset unique
Différents topics sont identifiés par leurs noms et stockeront différents types d'événements. Par exemple, une application de médias sociaux pourrait avoir des topics posts, likes et comments pour enregistrer chaque fois qu'un utilisateur crée un post, aime un post ou laisse un commentaire.
Plusieurs applications peuvent écrire et lire depuis le même topic. Une application peut également lire des messages depuis un topic, filtrer ou transformer les données, puis écrire le résultat dans un autre topic.
Une caractéristique importante des topics est qu'ils sont en ajout uniquement. Lorsque vous écrivez un message dans un topic, il est ajouté à la fin du journal. Les événements dans un topic sont immuables. Une fois qu'ils sont écrits dans un topic, vous ne pouvez pas les modifier.
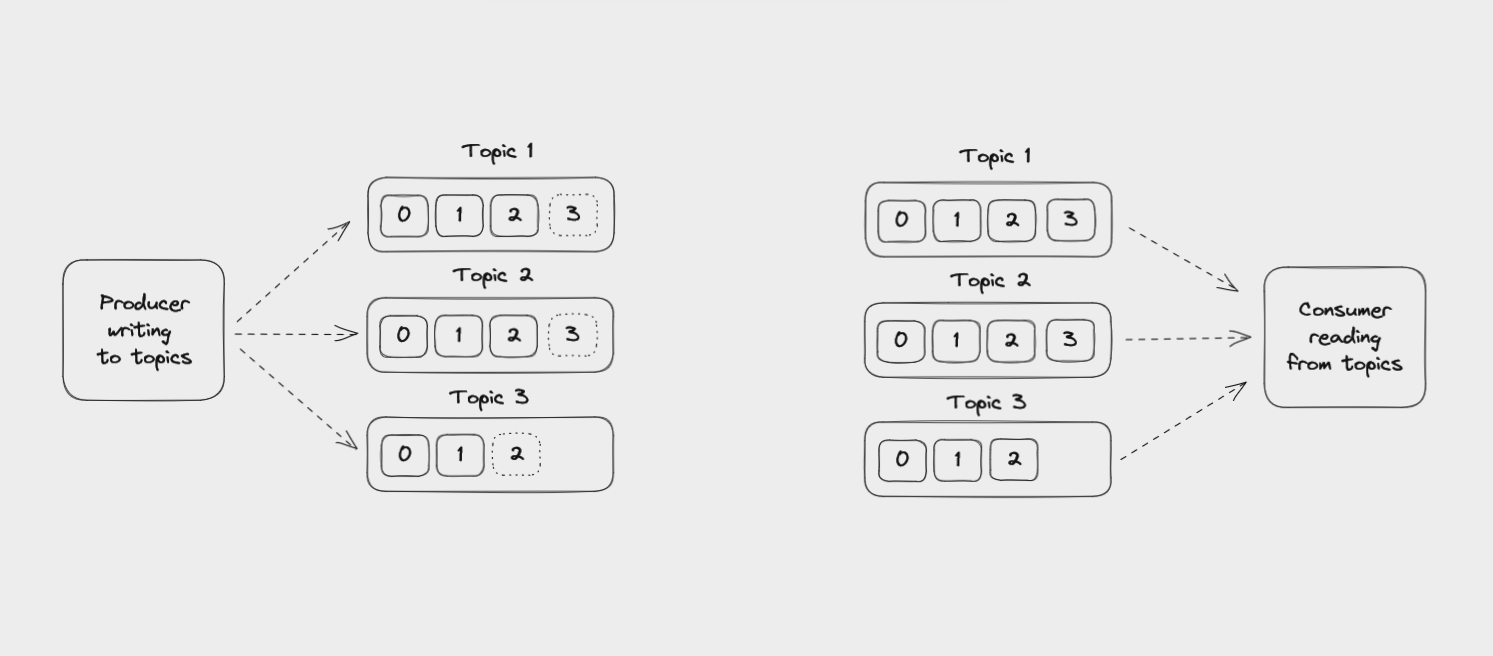
Un Producteur écrivant des événements dans des topics et un Consommateur lisant des événements depuis des topics
Contrairement aux files de messages, la lecture d'un événement depuis un topic ne le supprime pas. Les événements peuvent être lus autant de fois que nécessaire, peut-être plusieurs fois par différentes applications.
Les topics sont également durables, conservant les messages pendant une période spécifique (par défaut 7 jours) en les sauvegardant sur un stockage physique sur disque.
Vous pouvez configurer les topics de sorte que les messages expirent après un certain temps, ou lorsqu'une certaine quantité de stockage est dépassée. Vous pouvez même stocker des messages indéfiniment tant que vous pouvez payer les coûts de stockage.
Partitions dans Kafka
Afin d'aider Kafka à évoluer, les topics peuvent être divisés en partitions. Cela divise le journal d'événements en plusieurs journaux, chacun vivant sur un nœud séparé dans le cluster Kafka. Cela signifie que le travail d'écriture et de stockage des messages peut être réparti sur plusieurs machines.
Lorsque vous créez un topic, vous spécifiez le nombre de partitions qu'il possède. Les partitions sont elles-mêmes numérotées, commençant à 0. Lorsqu'un nouvel événement est écrit dans un topic, il est ajouté à l'une des partitions du topic.
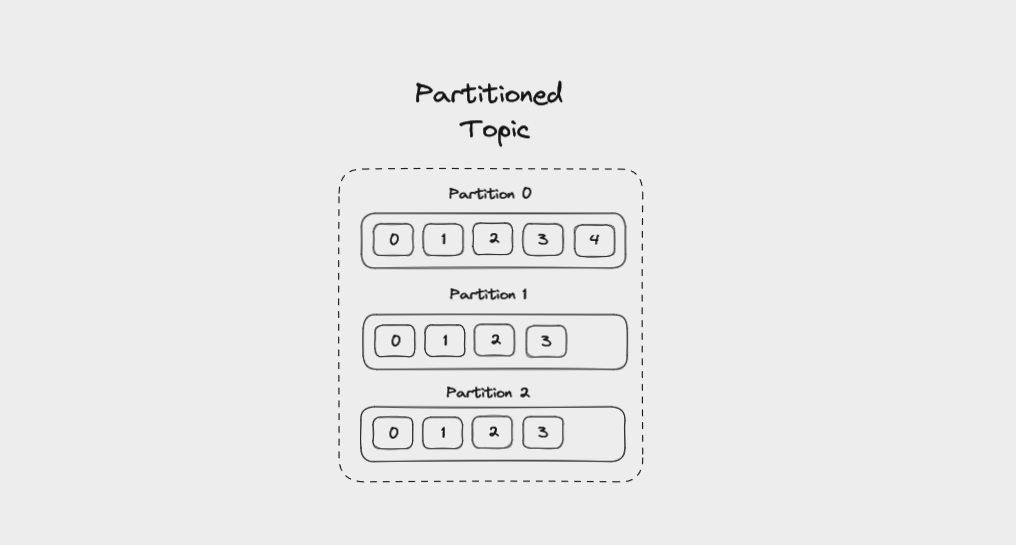
Un topic divisé en trois partitions
Si les messages n'ont pas de clé, ils seront distribués uniformément parmi les partitions de manière round robin : partition 0, puis partition 1, puis partition 2, et ainsi de suite. De cette façon, toutes les partitions obtiennent une part égale des données, mais il n'y a aucune garantie sur l'ordre des messages.
Les messages qui ont la même clé seront toujours envoyés à la même partition, et dans le même ordre. La clé est passée à travers une fonction de hachage qui la transforme en un entier. Cette sortie est ensuite utilisée pour sélectionner une partition.
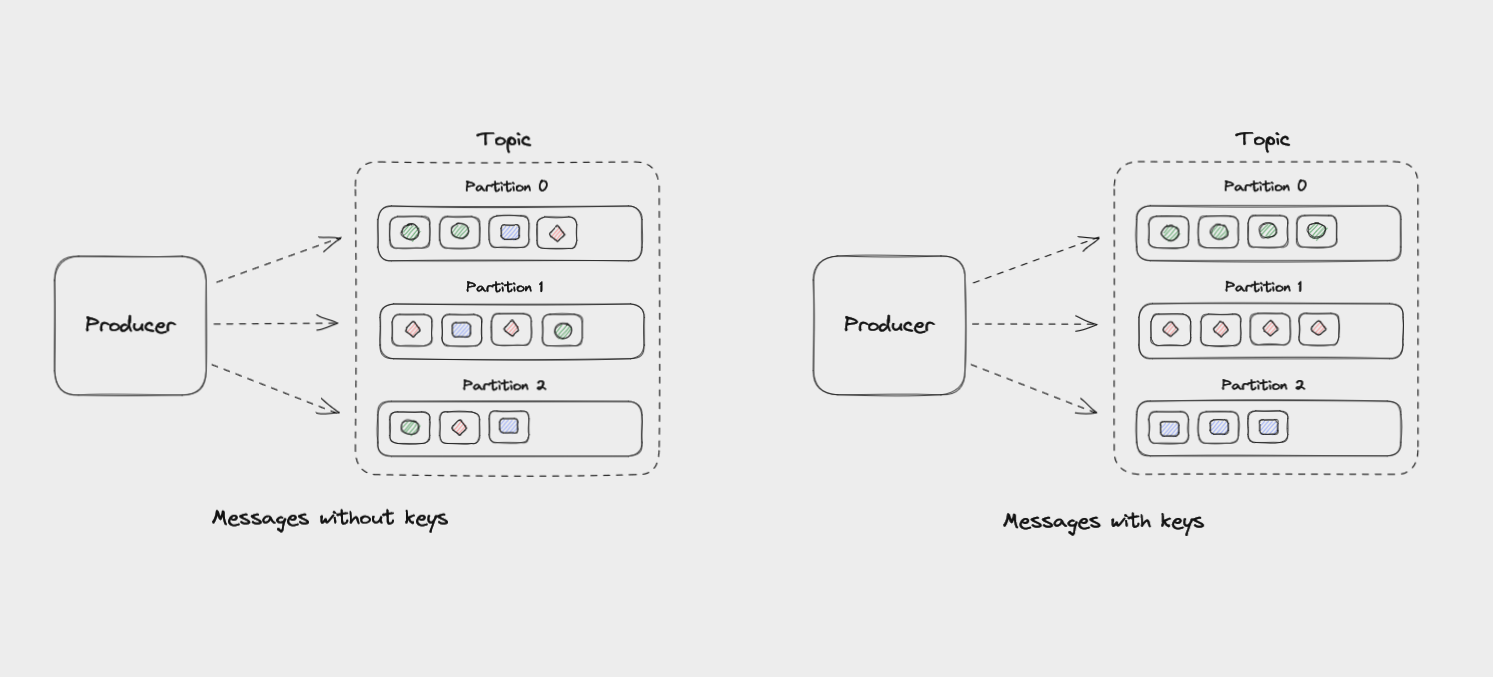
Messages sans clés sont envoyés à travers les partitions, tandis que les messages avec les mêmes clés sont envoyés à la même partition
Les messages au sein de chaque partition sont garantis d'être ordonnés. Par exemple, tous les messages avec le même customer_id comme clé seront envoyés à la même partition dans l'ordre dans lequel Kafka les a reçus.
Offsets dans Kafka
Chaque message dans une partition reçoit un identifiant qui est un entier incrémentiel, appelé offset. Les offsets commencent à 0 et sont incrémentés chaque fois que Kafka écrit un message dans une partition. Cela signifie que chaque message dans une partition donnée a un offset unique.
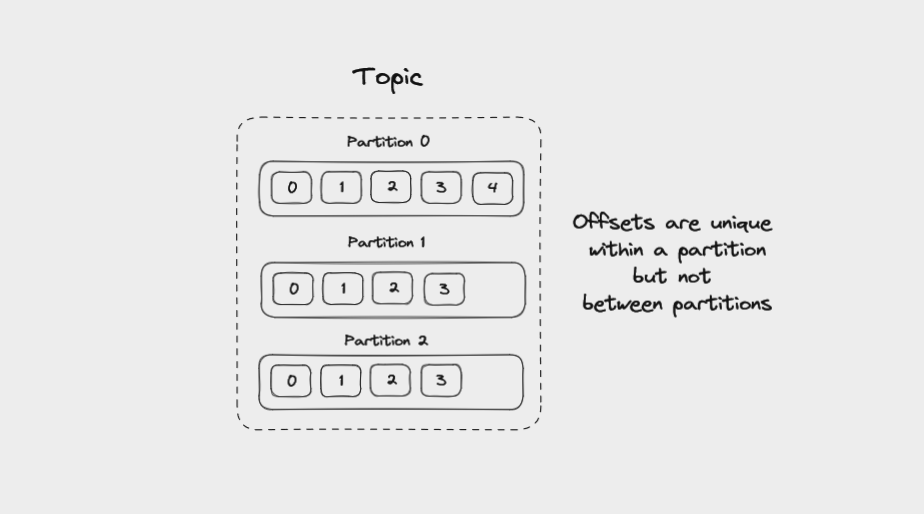
Les offsets sont uniques au sein d'une partition mais pas entre les partitions
Les offsets ne sont pas réutilisés, même lorsque les anciens messages sont supprimés. Ils continuent à s'incrémenter, donnant à chaque nouveau message dans la partition un identifiant unique.
Lorsque les données sont lues depuis une partition, elles sont lues dans l'ordre à partir de l'offset le plus bas existant vers le haut. Nous verrons plus de détails sur les offsets lorsque nous aborderons les consommateurs Kafka.
Brokers dans Kafka
Un seul "serveur" exécutant Kafka est appelé un broker. En réalité, cela pourrait être un conteneur Docker s'exécutant dans une machine virtuelle. Mais cela peut être une image mentale utile de penser aux brokers comme des serveurs individuels.
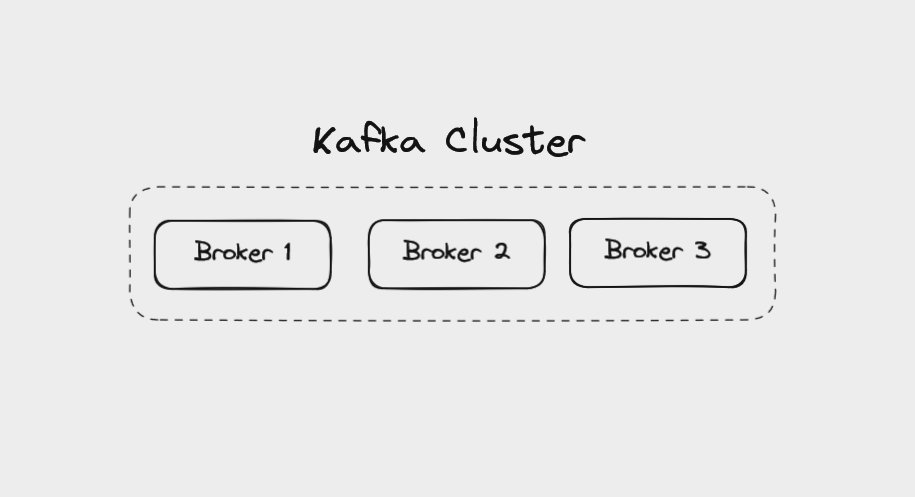
Un cluster Kafka composé de trois brokers
Plusieurs brokers travaillant ensemble constituent un cluster Kafka. Il pourrait y avoir une poignée de brokers dans un cluster, ou plus de 100. Lorsqu'une application cliente se connecte à un broker, Kafka la connecte automatiquement à chaque broker du cluster.
En fonctionnant comme un cluster, Kafka devient plus scalable et tolérant aux pannes. Si un broker tombe en panne, les autres prendront le relais pour garantir qu'il n'y a pas de temps d'arrêt ou de perte de données.
Chaque broker gère un ensemble de partitions et traite les requêtes d'écriture de données ou de lecture de données depuis ces partitions. Les partitions pour un topic donné seront réparties uniformément sur les brokers d'un cluster pour aider à l'équilibrage de charge. Les brokers gèrent également la réplication des partitions pour garder leurs données sauvegardées.
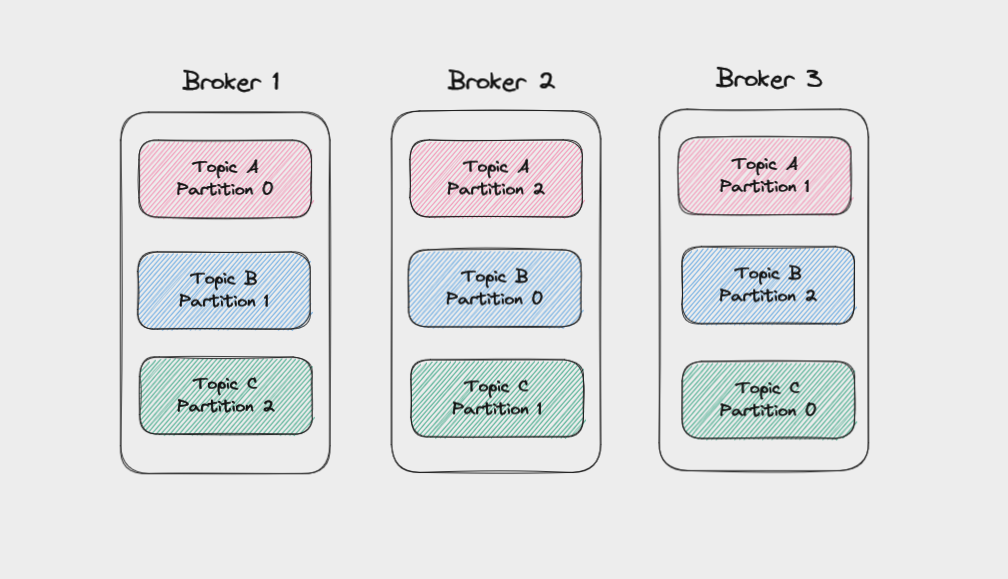
Partitions réparties sur les brokers
Réplication dans Kafka
Pour protéger contre la perte de données si un broker tombe en panne, Kafka écrit les mêmes données dans des copies d'une partition sur plusieurs brokers. Cela s'appelle la réplication.
La copie principale d'une partition est appelée le leader, tandis que les répliques sont appelées followers.
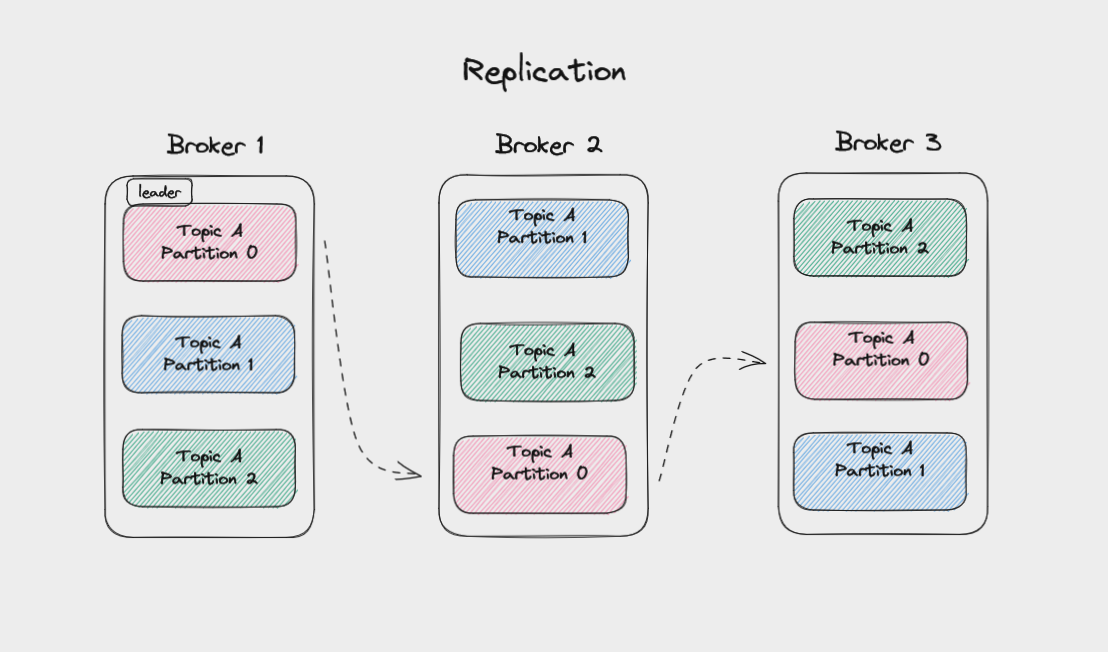
Les données de la partition leader sont copiées vers les partitions followers sur différents brokers
Lorsque vous créez un topic, vous définissez un facteur de réplication pour celui-ci. Cela contrôle combien de répliques sont écrites. Un facteur de réplication de trois est courant, ce qui signifie que les données sont écrites sur un leader et répliquées sur deux followers. Ainsi, même si deux brokers tombaient en panne, vos données seraient toujours en sécurité.
Chaque fois que vous écrivez des messages dans une partition, vous écrivez dans la partition leader. Kafka copie ensuite automatiquement ces messages vers les followers. Ainsi, les journaux sur les followers auront les mêmes messages et offsets que sur le leader.
Les followers qui sont à jour avec le leader sont appelés In-Sync Replicas (ISRs). Kafka considère qu'un message est validé une fois qu'un nombre minimum de répliques l'ont sauvegardé dans leurs journaux. Vous pouvez configurer cela pour obtenir un débit plus élevé au détriment d'une moindre certitude qu'un message a été sauvegardé.
Producteurs dans Kafka
Les producteurs sont des applications clientes qui écrivent des événements dans des topics Kafka. Ces applications ne font pas elles-mêmes partie de Kafka – vous les écrivez.
Généralement, vous utiliserez une bibliothèque pour aider à gérer l'écriture d'événements dans Kafka. Il existe une bibliothèque cliente officielle pour Java ainsi que des dizaines de bibliothèques prises en charge par la communauté pour des langages tels que Scala, JavaScript, Go, Rust, Python, C# et C++.
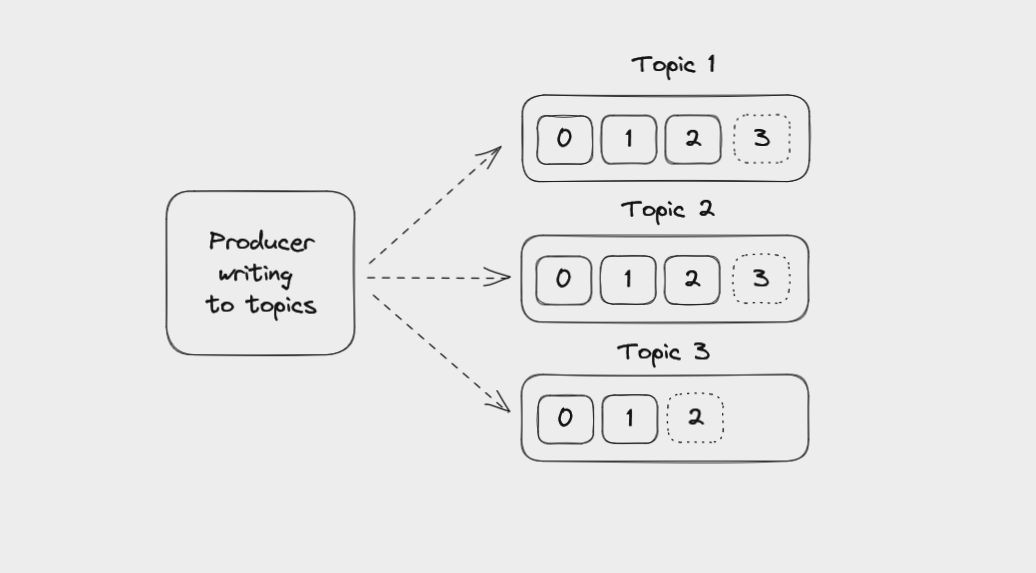
Une application Producteur écrivant dans plusieurs topics
Les producteurs sont totalement découplés des consommateurs, qui lisent depuis Kafka. Ils ne se connaissent pas et leur vitesse n'affecte pas l'autre. Les producteurs ne sont pas affectés si les consommateurs échouent, et la même chose est vraie pour les consommateurs.
Si vous en avez besoin, vous pourriez écrire une application qui écrit certains événements dans Kafka et lit d'autres événements depuis Kafka, en faisant à la fois un producteur et un consommateur.
Les producteurs prennent une paire clé-valeur, génèrent un message Kafka, puis le sérialisent en binaire pour la transmission sur le réseau. Vous pouvez ajuster la configuration des producteurs pour regrouper les messages en fonction de leur taille ou d'une limite de temps fixe afin d'optimiser l'écriture des messages vers les brokers Kafka.
C'est le producteur qui décide dans quelle partition d'un topic envoyer chaque message. Encore une fois, les messages sans clés seront distribués uniformément parmi les partitions, tandis que les messages avec des clés sont tous envoyés à la même partition.
Consommateurs dans Kafka
Les consommateurs sont des applications clientes qui lisent les messages des topics dans un cluster Kafka. Comme pour les producteurs, vous écrivez ces applications vous-même et pouvez utiliser des bibliothèques clientes pour supporter le langage de programmation avec lequel votre application est construite.
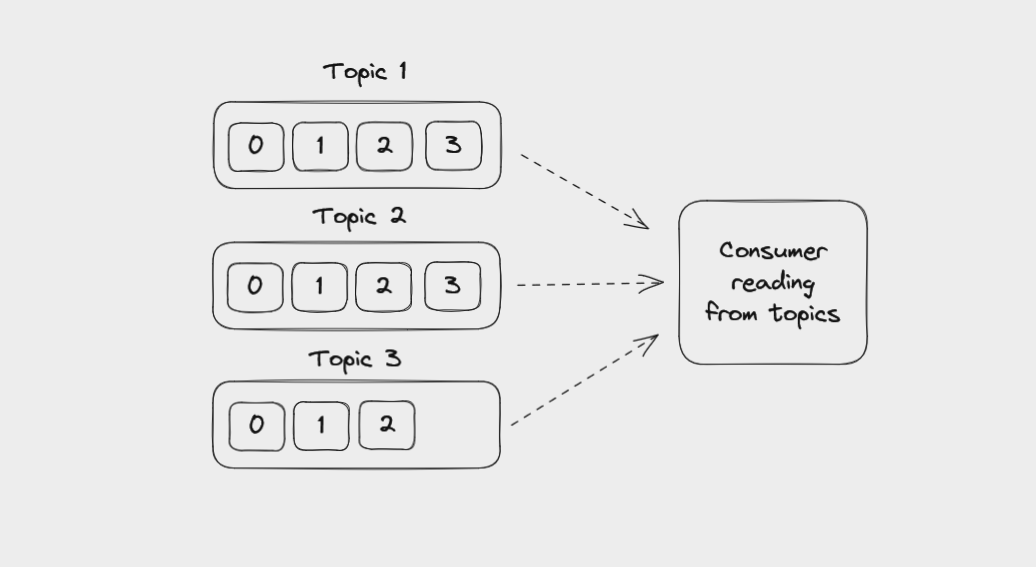
Un consommateur lisant des messages depuis plusieurs topics
Les consommateurs peuvent lire depuis une ou plusieurs partitions au sein d'un topic, et depuis un ou plusieurs topics. Les messages sont lus dans l'ordre au sein d'une partition, de l'offset le plus bas disponible au plus haut. Mais si un consommateur lit des données depuis plusieurs partitions dans le même topic, l'ordre des messages entre ces partitions n'est pas garanti.
Par exemple, un consommateur pourrait lire des messages depuis la partition 0, puis la partition 2, puis la partition 1, puis revenir à la partition 0. Les messages de la partition 0 seront lus dans l'ordre, mais il pourrait y avoir des messages des autres partitions mélangés parmi eux.
Il est important de se rappeler que la lecture d'un message ne le supprime pas. Le message est toujours disponible pour être lu par tout autre consommateur qui doit y accéder. Il est normal que plusieurs consommateurs lisent depuis le même topic s'ils ont chacun des utilisations pour les données qu'il contient.
Par défaut, lorsqu'un consommateur démarre, il lira à partir de l'offset actuel dans une partition. Mais les consommateurs peuvent également être configurés pour revenir en arrière et lire à partir de l'offset le plus ancien existant.
Les consommateurs désérialisent les messages, les convertissant du binaire en une collection de paires clé-valeur que votre application peut ensuite traiter. Le format d'un message ne doit pas changer pendant la durée de vie d'un topic, sinon vos producteurs et consommateurs ne pourront pas le sérialiser et le désérialiser correctement.
Une chose à garder à l'esprit est que les consommateurs demandent des messages à Kafka, qui ne leur envoie pas de messages. Cela protège les consommateurs d'être submergés si Kafka gère un volume élevé de messages. Si vous souhaitez mettre à l'échelle les consommateurs, vous pouvez exécuter plusieurs instances d'un consommateur ensemble dans un groupe de consommateurs.
Groupes de consommateurs dans Kafka
Une application qui lit depuis Kafka peut créer plusieurs instances du même consommateur pour diviser le travail de lecture depuis différentes partitions dans un topic. Ces consommateurs travaillent ensemble en tant que groupe de consommateurs.
Lorsque vous créez un consommateur, vous pouvez lui attribuer un identifiant de groupe. Tous les consommateurs d'un groupe auront le même identifiant de groupe.
Vous pouvez créer des instances de consommateurs dans un groupe jusqu'au nombre de partitions dans un topic. Donc, si vous avez un topic avec 5 partitions, vous pouvez créer jusqu'à 5 instances du même consommateur dans un groupe de consommateurs. Si vous avez plus de consommateurs dans un groupe que de partitions, le consommateur supplémentaire restera inactif.
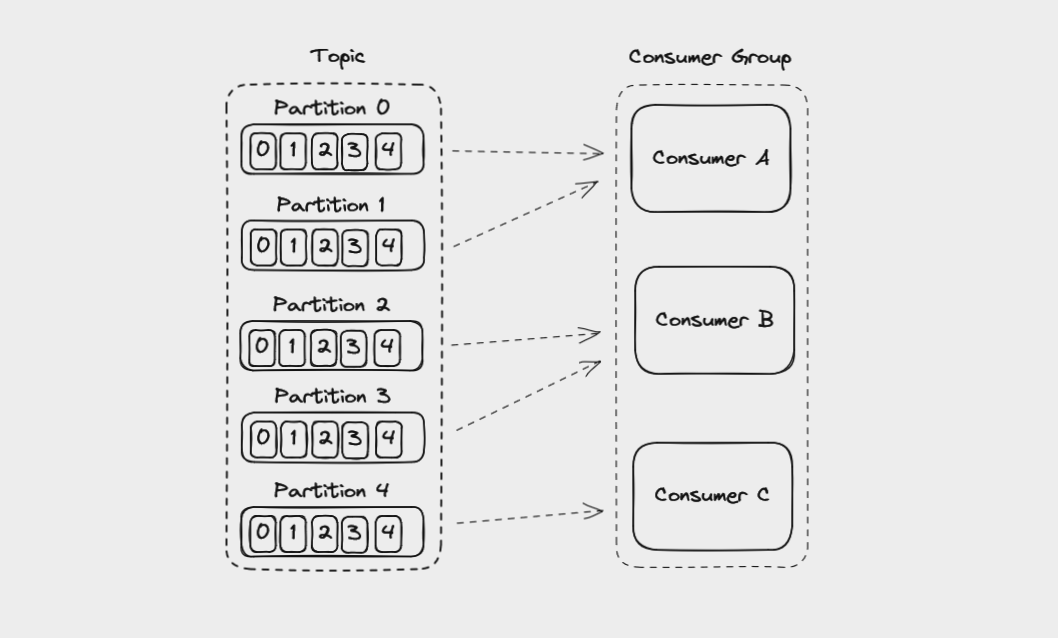
Consommateurs dans un groupe de consommateurs lisant des messages depuis les partitions d'un topic
Si vous ajoutez une autre instance de consommateur à un groupe de consommateurs, Kafka redistribuera automatiquement les partitions parmi les consommateurs dans un processus appelé rééquilibrage.
Chaque partition n'est attribuée qu'à un seul consommateur dans un groupe, mais un consommateur peut lire depuis plusieurs partitions. De plus, plusieurs groupes de consommateurs différents (signifiant différentes applications) peuvent lire depuis le même topic en même temps.
Les brokers Kafka utilisent un topic interne appelé __consumer_offsets pour suivre quels messages un groupe de consommateurs spécifique a traités avec succès.
Lorsqu'un consommateur lit depuis une partition, il sauvegarde régulièrement l'offset qu'il a lu jusqu'à présent et envoie ces données au broker depuis lequel il lit. Cela s'appelle le consumer offset et est géré automatiquement par la plupart des bibliothèques clientes.
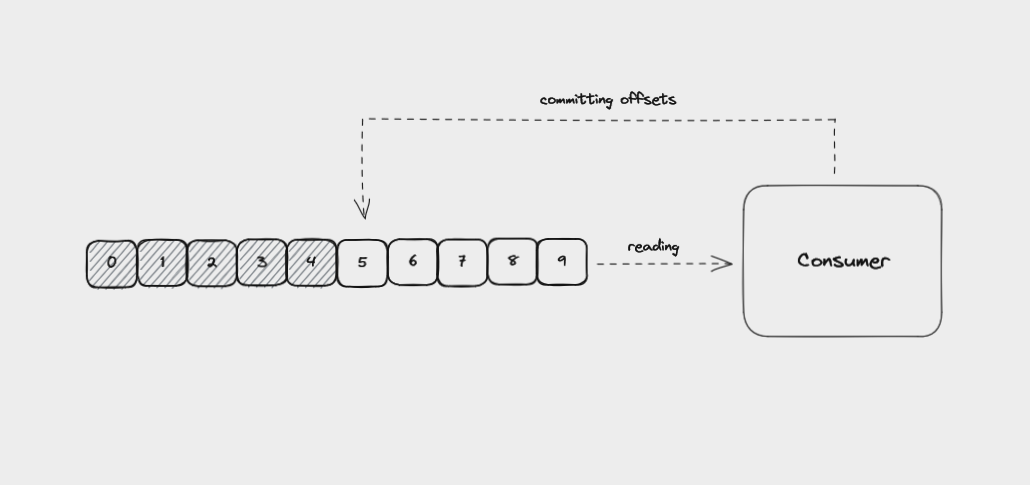
Un consommateur validant les offsets qu'il a lus jusqu'à présent
Si un consommateur plante, le consumer offset aide les consommateurs restants à savoir où commencer lorsqu'ils prennent le relais de la lecture depuis la partition.
La même chose se produit si un nouveau consommateur est ajouté au groupe. Le groupe de consommateurs se rééquilibre, le nouveau consommateur se voit attribuer une partition, et il reprend la lecture depuis le consumer offset de cette partition.
Zookeeper de Kafka
Un autre sujet que nous devons brièvement aborder ici est la gestion des clusters Kafka. Actuellement, cela est généralement fait en utilisant Zookeeper, un service pour gérer et synchroniser les systèmes distribués. Comme Kafka, il est maintenu par la Fondation Apache.
Kafka utilise Zookeeper pour gérer les brokers dans un cluster, et nécessite Zookeeper même si vous exécutez un cluster Kafka avec un seul broker.
Récemment, une proposition a été acceptée pour supprimer Zookeeper et faire en sorte que Kafka se gère lui-même (KIP-500), mais cela n'est pas encore largement utilisé en production.
Zookeeper garde une trace de choses comme :
Quels brokers font partie d'un cluster Kafka
Quel broker est le leader pour une partition donnée
Comment les topics sont configurés, tels que le nombre de partitions et l'emplacement des répliques
Groupes de consommateurs et leurs membres
Listes de contrôle d'accès – qui est autorisé à écrire et à lire depuis chaque topic
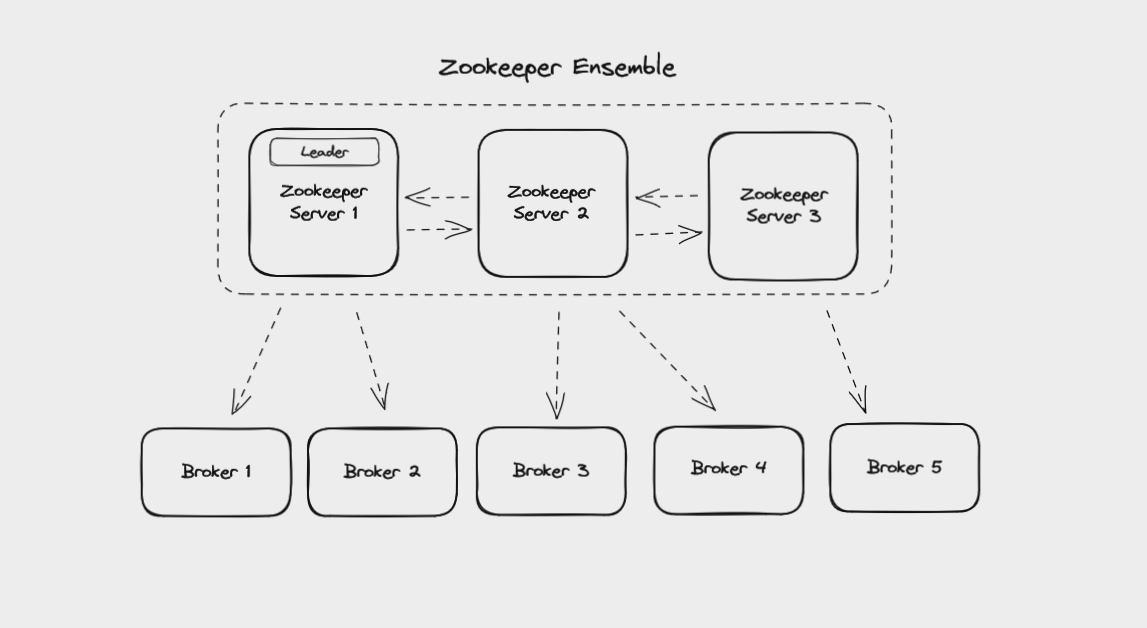
Un ensemble Zookeeper gérant les brokers dans un cluster Kafka
Zookeeper lui-même fonctionne comme un cluster appelé un ensemble. Cela signifie que Zookeeper peut continuer à fonctionner même si un nœud du cluster tombe en panne. Les nouvelles données sont écrites sur le leader de l'ensemble et répliquées sur les followers. Vos brokers Kafka peuvent lire ces données depuis n'importe quel nœud Zookeeper de l'ensemble.
Maintenant que vous comprenez les principaux concepts derrière Kafka, passons à la pratique avec Kafka.
Vous allez installer Kafka sur votre propre ordinateur, pratiquer l'interaction avec les brokers Kafka depuis la ligne de commande, puis construire une simple application de producteur et de consommateur avec Java.
Comment installer Kafka sur votre ordinateur
Au moment de la rédaction de ce guide, la dernière version stable de Kafka est la 3.3.1. Consultez kafka.apache.org/downloads pour voir s'il existe une version stable plus récente. Si c'est le cas, vous pouvez remplacer "3.3.1" par la dernière version stable dans toutes les instructions suivantes.
Installer Kafka sur macOS
Si vous utilisez macOS, je recommande d'utiliser Homebrew pour installer Kafka. Cela garantira que vous avez Java installé avant d'installer Kafka.
Si vous n'avez pas déjà Homebrew installé, installez-le en suivant les instructions sur brew.sh.
Ensuite, exécutez brew install kafka dans un terminal. Cela installera les binaires de Kafka dans usr/local/bin.
Enfin, exécutez kafka-topics --version dans un terminal et vous devriez voir 3.3.1. Si c'est le cas, vous êtes prêt.
Pour faciliter le travail avec Kafka, vous pouvez ajouter Kafka à la variable d'environnement PATH. Ouvrez votre ~/.bashrc (si vous utilisez Bash) ou ~/.zshrc (si vous utilisez Zsh) et ajoutez la ligne suivante, en remplaçant USERNAME par votre nom d'utilisateur :
PATH="$PATH:/Users/USERNAME/kafka_2.13-3.3.1/bin"
Vous devrez fermer votre terminal pour que ce changement prenne effet.
Maintenant, si vous exécutez echo $PATH, vous devriez voir que le répertoire bin de Kafka a été ajouté à votre chemin.
Installer Kafka sur Windows (WSL2) et Linux
Kafka n'est pas nativement pris en charge sur Windows, vous devrez donc utiliser soit WSL2, soit Docker. Je vais vous montrer WSL2 car les étapes sont les mêmes que pour Linux.
Pour configurer WSL2 sur Windows, suivez les instructions dans la documentation officielle.
À partir de là, les instructions sont les mêmes pour WSL2 et Linux.
Tout d'abord, installez Java 11 en exécutant les commandes suivantes :
wget -O- https://apt.corretto.aws/corretto.key | sudo apt-key add -
sudo add-apt-repository 'deb https://apt.corretto.aws stable main'
sudo apt-get update; sudo apt-get install -y java-11-amazon-corretto-jdk
Une fois cela terminé, exécutez java -version et vous devriez voir quelque chose comme :
openjdk version "11.0.17" 2022-10-18 LTS
OpenJDK Runtime Environment Corretto-11.0.17.8.1 (build 11.0.17+8-LTS)
OpenJDK 64-Bit Server VM Corretto-11.0.17.8.1 (build 11.0.17+8-LTS, mixed mode)
Depuis votre répertoire racine, téléchargez Kafka avec la commande suivante :
wget https://archive.apache.org/dist/kafka/3.3.1/kafka_2.13-3.3.1.tgz
Le 2.13 signifie qu'il utilise la version 2.13 de Scala, tandis que 3.3.1 fait référence à la version de Kafka.
Extrayez le contenu du téléchargement avec :
tar xzf kafka_2.13-3.3.1.tgz
Si vous exécutez ls, vous verrez maintenant kafka_2.13-3.3.1 dans votre répertoire racine.
Pour faciliter le travail avec Kafka, vous pouvez ajouter Kafka à la variable d'environnement PATH. Ouvrez votre ~/.bashrc (si vous utilisez Bash) ou ~/.zshrc (si vous utilisez Zsh) et ajoutez la ligne suivante, en remplaçant USERNAME par votre nom d'utilisateur :
PATH="$PATH:home/USERNAME/kafka_2.13-3.3.1/bin"
Vous devrez fermer votre terminal pour que ce changement prenne effet.
Maintenant, si vous exécutez echo $PATH, vous devriez voir que le répertoire bin de Kafka a été ajouté à votre chemin.
Exécutez kafka-topics.sh --version dans un terminal et vous devriez voir 3.3.1. Si c'est le cas, vous êtes prêt.
Comment démarrer Zookeeper et Kafka
Puisque Kafka utilise Zookeeper pour gérer les clusters, vous devez démarrer Zookeeper avant de démarrer Kafka.
Comment démarrer Kafka sur macOS
Dans une fenêtre de terminal, démarrez Zookeeper avec :
/usr/local/bin/zookeeper-server-start /usr/local/etc/zookeeper/zoo.cfg
Dans une autre fenêtre de terminal, démarrez Kafka avec :
/usr/local/bin/kafka-server-start /usr/local/etc/kafka/server.properties
Pendant que vous utilisez Kafka, vous devez garder ces deux fenêtres de terminal ouvertes. Les fermer arrêtera Kafka.
Comment démarrer Kafka sur Windows (WSL2) et Linux
Dans une fenêtre de terminal, démarrez Zookeeper avec :
~/kafka_2.13-3.3.1/bin/zookeeper-server-start.sh ~/kafka_2.13-3.3.1/config/zookeeper.properties
Dans une autre fenêtre de terminal, démarrez Kafka avec :
~/kafka_2.13-3.3.1/bin/kafka-server-start.sh ~/kafka_2.13-3.3.1/config/server.properties
Pendant que vous utilisez Kafka, vous devez garder ces deux fenêtres de terminal ouvertes. Les fermer arrêtera Kafka.
Maintenant que vous avez Kafka installé et en cours d'exécution sur votre machine, il est temps de pratiquer.
La CLI de Kafka
Lorsque vous installez Kafka, il est livré avec une interface de ligne de commande (CLI) qui vous permet de créer et de gérer des topics, ainsi que de produire et de consommer des événements.
Tout d'abord, assurez-vous que Zookeeper et Kafka sont en cours d'exécution dans deux fenêtres de terminal.
Dans une troisième fenêtre de terminal, exécutez kafka-topics.sh (sur WSL2 ou Linux) ou kafka-topics (sur macOS) pour vous assurer que la CLI fonctionne. Vous verrez une liste de toutes les options que vous pouvez passer à la CLI.
options de kafka-topics
Note : Lorsque vous travaillez avec la CLI de Kafka, la commande sera kafka-topics.sh sur WSL2 et Linux. Ce sera kafka-topics.sh sur macOS si vous avez directement installé les binaires de Kafka et kafka-topics si vous avez utilisé Homebrew. Donc, si vous utilisez Homebrew, retirez l'extension .sh des commandes d'exemple dans cette section.
Comment lister les topics
Pour voir les topics disponibles sur le broker Kafka de votre machine locale, utilisez :
kafka-topics.sh --bootstrap-server localhost:9092 --list
Cela signifie "Connectez-vous au broker Kafka en cours d'exécution sur localhost:9092 et listez tous les topics qui s'y trouvent". --bootstrap-server fait référence au broker Kafka auquel vous essayez de vous connecter et localhost:9092 est l'adresse IP à laquelle il est en cours d'exécution. Vous ne verrez aucune sortie puisque vous n'avez pas encore créé de topics.
Comment créer un topic
Pour créer un topic (avec le facteur de réplication et le nombre de partitions par défaut), utilisez les options --create et --topic et passez-leur un nom de topic :
kafka-topics.sh --bootstrap-server localhost:9092 --create --topic my_first_topic
Si vous utilisez un _ ou . dans le nom de votre topic, vous verrez l'avertissement suivant :
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
Puisque Kafka pourrait confondre my.first.topic avec my_first_topic, il est préférable d'utiliser soit des underscores, soit des points lors de la nomination des topics.
Comment décrire les topics
Pour décrire les topics sur un broker, utilisez l'option --describe :
kafka-topics.sh --bootstrap-server localhost:9092 --describe
Cela imprimera les détails de tous les topics sur ce broker, y compris le nombre de partitions et leur facteur de réplication. Par défaut, ceux-ci seront tous les deux définis sur 1.
Si vous ajoutez l'option --topic et le nom d'un topic, il décrira uniquement ce topic :
kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic my_first_topic
Comment partitionner un topic
Pour créer un topic avec plusieurs partitions, utilisez l'option --partitions et passez-lui un nombre :
kafka-topics.sh --bootstrap-server localhost:9092 --create --topic my_second_topic --partitions 3
Comment définir un facteur de réplication
Pour créer un topic avec un facteur de réplication supérieur à la valeur par défaut, utilisez l'option --replication-factor et passez-lui un nombre :
kafka-topics.sh --bootstrap-server localhost:9092 --create --topic my_third_topic --partitions 3 --replication-factor 3
Vous devriez obtenir l'erreur suivante :
ERROR org.apache.kafka.common.errors.InvalidReplicationFactorException: Replication factor: 2 larger than available brokers: 1.
Puisque vous n'exécutez qu'un seul broker Kafka sur votre machine, vous ne pouvez pas définir un facteur de réplication supérieur à un. Si vous exécutiez un cluster avec plusieurs brokers, vous pourriez définir un facteur de réplication aussi élevé que le nombre total de brokers.
Comment supprimer un topic
Pour supprimer un topic, utilisez l'option --delete et spécifiez un topic avec l'option --topic :
kafka-topics.sh --bootstrap-server localhost:9092 --delete --topic my_first_topic
Vous n'obtiendrez aucune sortie pour indiquer que le topic a été supprimé, mais vous pouvez vérifier en utilisant --list ou --describe.
Comment utiliser kafka-console-producer
Vous pouvez produire des messages vers un topic à partir de la ligne de commande en utilisant kafka-console-producer.
Exécutez kafka-console-producer.sh pour voir les options que vous pouvez lui passer.
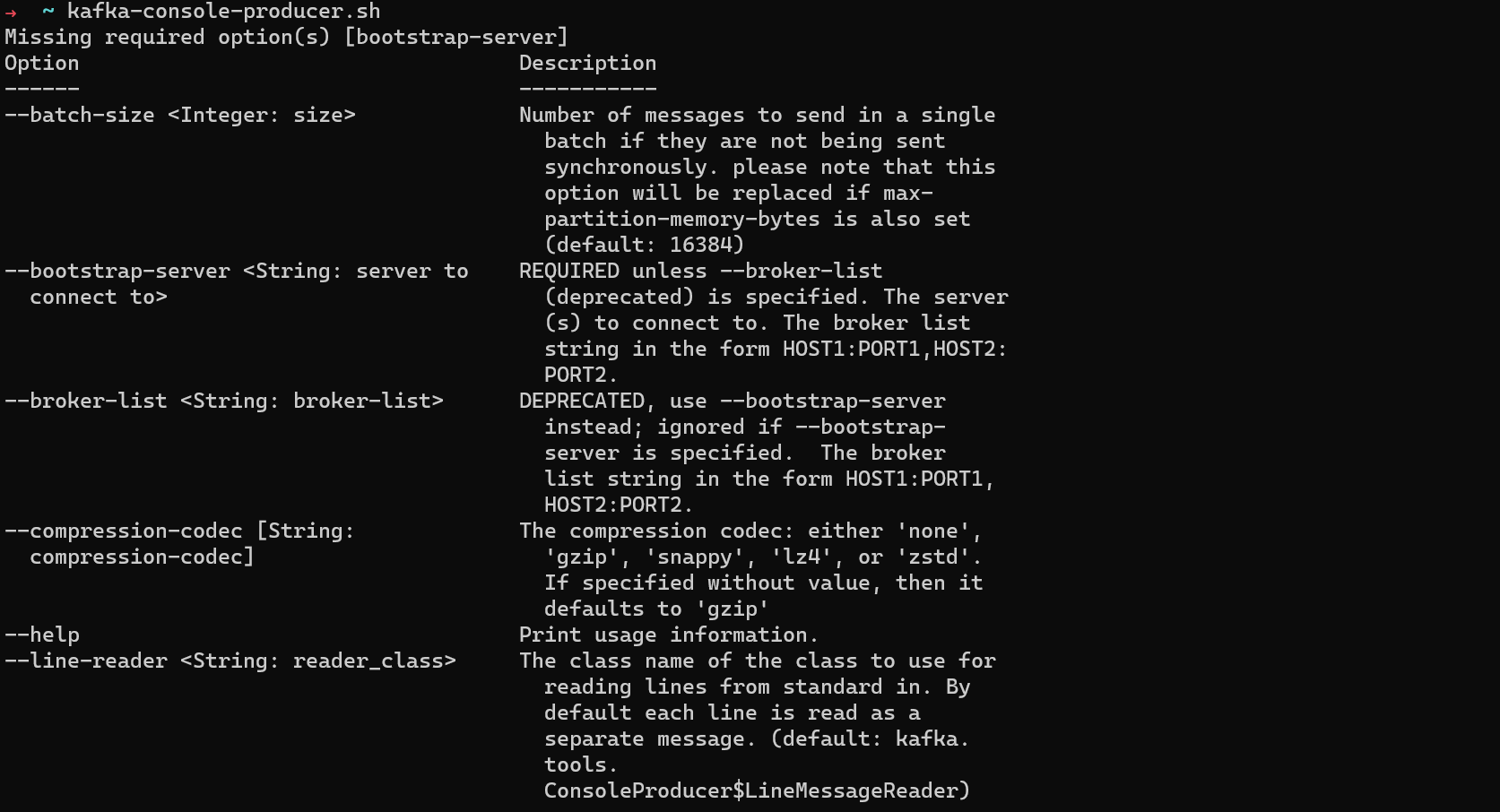
options de kafka-console-producer
Pour créer un producteur connecté à un topic spécifique, exécutez :
kafka-console-producer.sh --bootstrap-server localhost:9092 --topic TOPIC_NAME
Produisons des messages vers le topic my_first_topic.
kafka-console-producer.sh --bootstrap-server localhost:9092 --topic my_first_topic
Votre prompt changera et vous pourrez taper du texte. Appuyez sur enter pour envoyer ce message. Vous pouvez continuer à envoyer des messages jusqu'à ce que vous appuyiez sur ctrl + c.
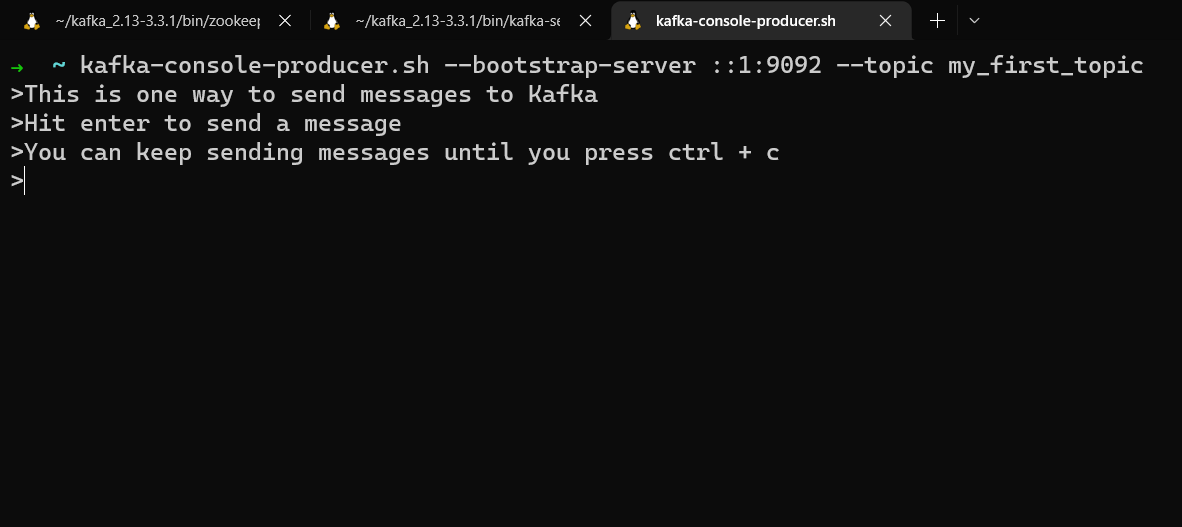
Envoyer des messages en utilisant kafka-console-producer
Si vous produisez des messages vers un topic qui n'existe pas, vous recevrez un avertissement, mais le topic sera créé et les messages seront toujours envoyés. Il est préférable de créer un topic à l'avance, cependant, afin que vous puissiez spécifier des partitions et une réplication.
Par défaut, les messages envoyés depuis kafka-console-producer ont leurs clés définies sur null, et sont donc distribués uniformément à toutes les partitions.
Vous pouvez définir une clé en utilisant l'option --property pour définir parse.key sur true et en fournissant un séparateur de clé, tel que :
Par exemple, nous pouvons créer un topic books et utiliser le genre des livres comme clé.
kafka-topics.sh --bootstrap-server localhost:9092 --topic books --create
kafka-console-producer.sh --bootstrap-server localhost:9092 --topic books --property parse.key=true --property key.separator=:
Vous pouvez maintenant entrer des clés et des valeurs au format key:value. Tout ce qui se trouve à gauche du séparateur de clé sera interprété comme une clé de message, tout ce qui se trouve à droite comme une valeur de message.
science_fiction:All Systems Red
fantasy:Uprooted
horror:Mexican Gothic
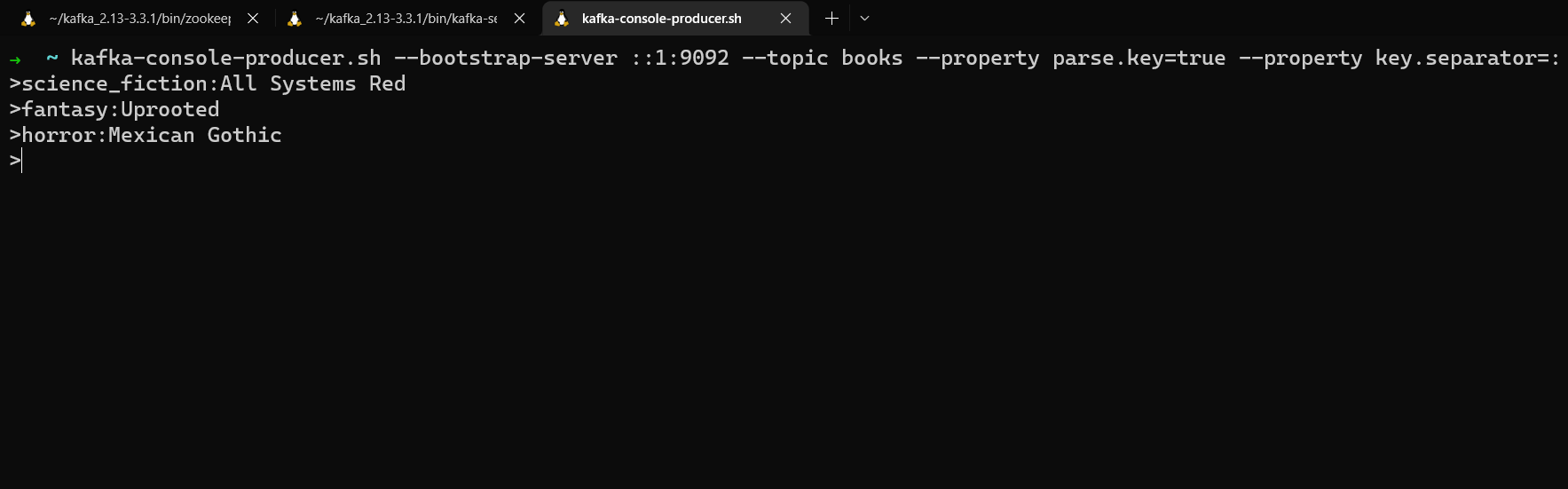
Production de messages avec des clés et des valeurs
Maintenant que vous avez produit des messages vers un topic à partir de la ligne de commande, il est temps de consommer ces messages à partir de la ligne de commande.
Comment utiliser kafka-console-consumer
Vous pouvez consommer des messages à partir d'un topic à partir de la ligne de commande en utilisant kafka-console-consumer.
Exécutez kafka-console-consumer.sh pour voir les options que vous pouvez lui passer.
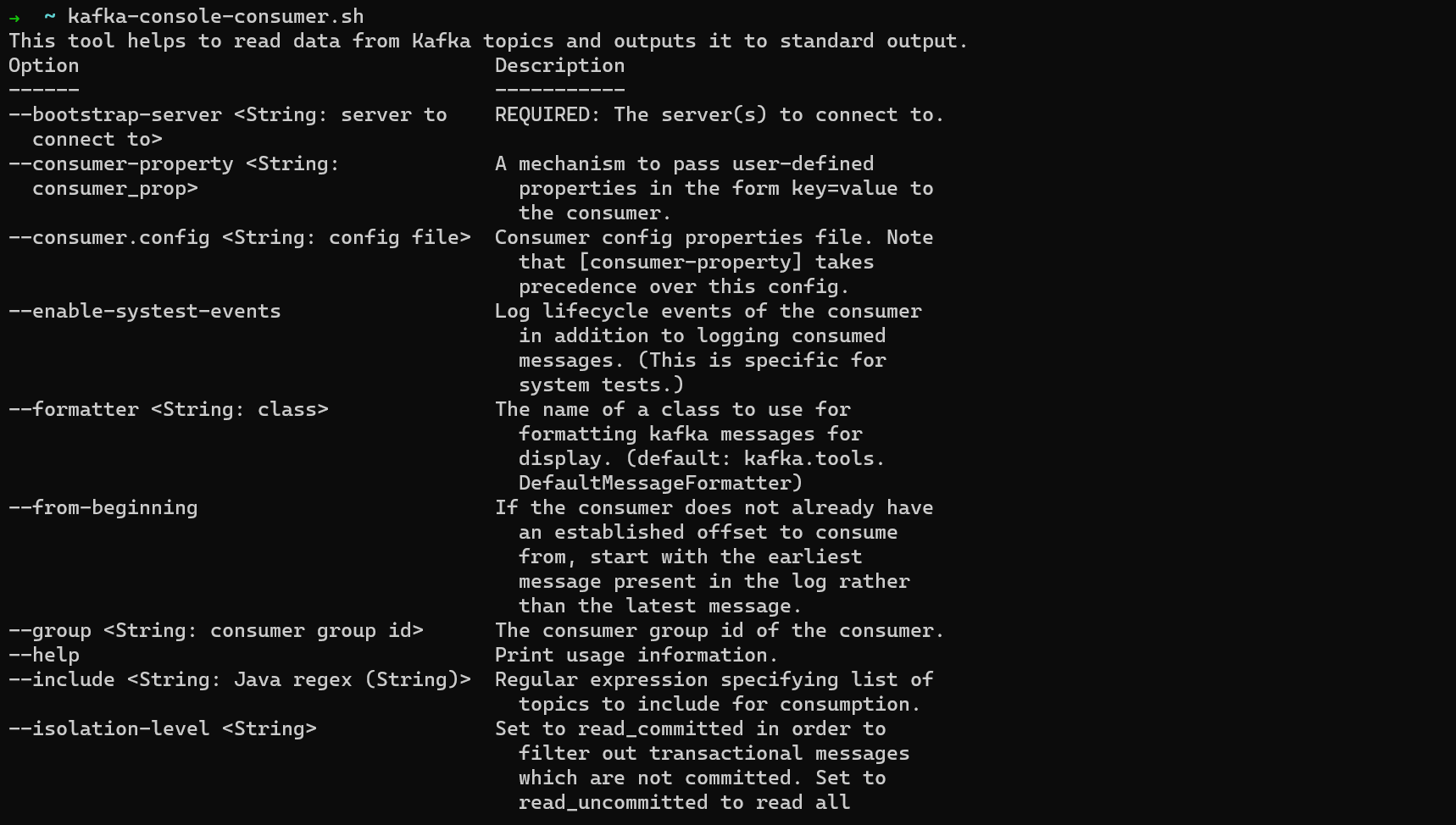
options de kafka-console-consumer
Pour créer un consommateur, exécutez :
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic TOPIC_NAME
Lorsque vous démarrez un consommateur, par défaut, il lira les messages au fur et à mesure qu'ils sont écrits à la fin du topic. Il ne lira pas les messages qui ont été précédemment envoyés au topic.
Si vous souhaitez lire les messages que vous avez déjà envoyés à un topic, utilisez l'option --from-beginning pour lire depuis le début du topic :
kafka-console-consumer --bootstrap-server localhost:9092 --topic my_first_topic --from-beginning
Les messages peuvent apparaître "hors d'ordre". Rappelez-vous, les messages sont ordonnés au sein d'une partition, mais l'ordre ne peut pas être garanti entre les partitions. Si vous ne définissez pas de clé, ils seront envoyés en round robin entre les partitions et l'ordre n'est pas garanti.
Vous pouvez afficher des informations supplémentaires sur les messages, telles que leur clé et leur horodatage, en utilisant l'option --property et en définissant la propriété print sur true.
Utilisez l'option --formatter pour définir le formateur de message et l'option --property pour sélectionner les propriétés de message à imprimer.
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic my_first_topic --from-beginning --formatter kafka.tools.DefaultMessageFormatter --property print.timestamp=true --property print.key=true --property print.value=true
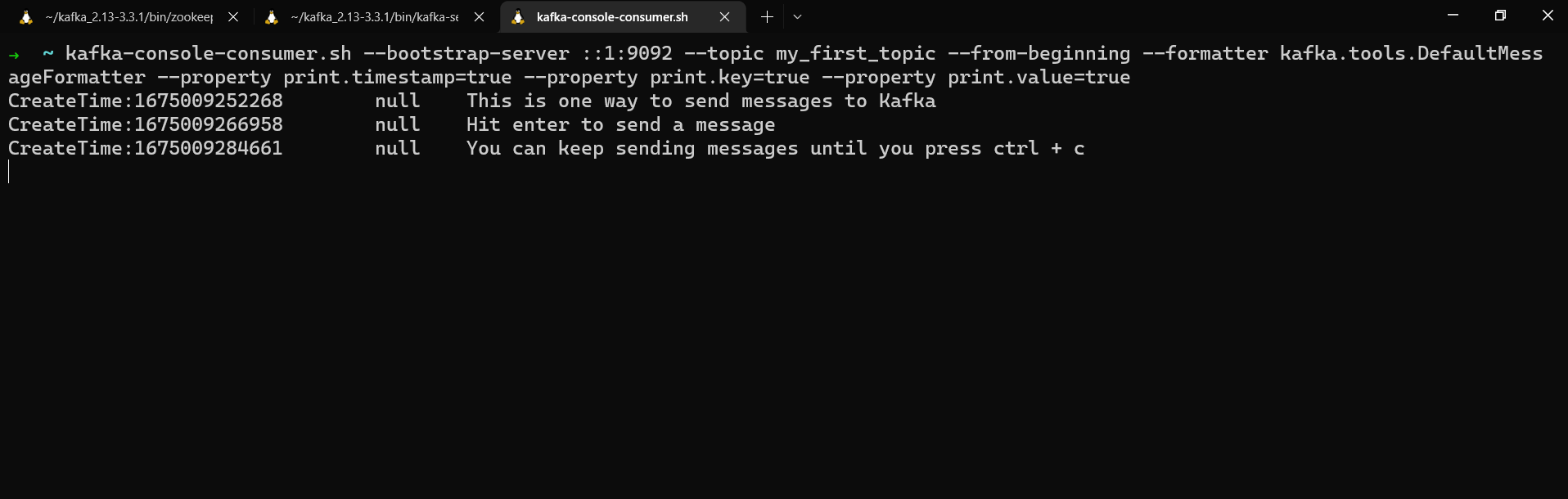
Consommation de messages à partir d'un topic
Nous obtenons l'horodatage, la clé et la valeur des messages. Puisque nous n'avons attribué aucune clé lors de l'envoi de ces messages à my_first_topic, leur key est null.
Comment utiliser kafka-consumer-groups
Vous pouvez exécuter des consommateurs dans un groupe de consommateurs en utilisant la CLI de Kafka. Pour afficher la documentation de ceci, exécutez :
kafka-consumer-groups.sh
options de kafka-consumer-groups
Tout d'abord, créez un topic avec trois partitions. Chaque consommateur dans un groupe consommera à partir d'une partition. S'il y a plus de consommateurs que de partitions, tout consommateur supplémentaire restera inactif.
kafka-topics.sh --bootstrap-server localhost:9092 --topic fantasy_novels --create --partitions 3
Vous ajoutez un consommateur à un groupe lors de sa création en utilisant l'option --group. Si vous exécutez la même commande plusieurs fois avec le même nom de groupe, chaque nouveau consommateur sera ajouté au groupe.
Pour créer le premier consommateur dans votre groupe de consommateurs, exécutez :
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic fantasy_novels --group fantasy_consumer_group
Ensuite, ouvrez deux nouvelles fenêtres de terminal et exécutez à nouveau la même commande pour ajouter un deuxième et un troisième consommateur au groupe de consommateurs.
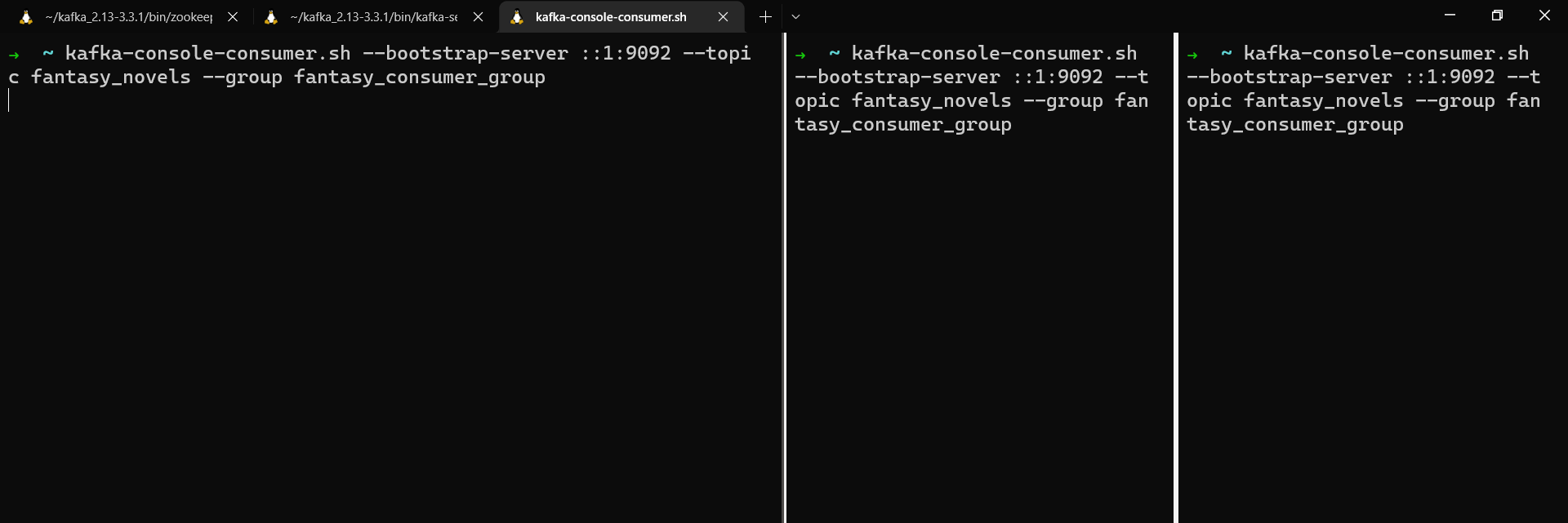
Trois consommateurs s'exécutant dans un groupe de consommateurs
Dans une fenêtre de terminal différente, créez un producteur et envoyez quelques messages avec des clés au topic.
Note : Depuis Kafka 2.4, Kafka envoie des messages par lots à une partition "sticky" pour de meilleures performances. Afin de démontrer les messages envoyés en round robin entre les partitions (sans envoyer un grand volume de messages), nous pouvons définir le partitionneur sur RoundRobinPartitioner.
kafka-console-producer.sh --bootstrap-server localhost:9092 --topic fantasy_novels --property parse.key=true --property key.separator=: --property partitioner.class=org.apache.kafka.clients.producer.RoundRobinPartitioner
tolkien:The Lord of the Rings
le_guin:A Wizard of Earthsea
leckie:The Raven Tower
de_bodard:The House of Shattered Wings
okorafor:Who Fears Death
liu:The Grace of Kings
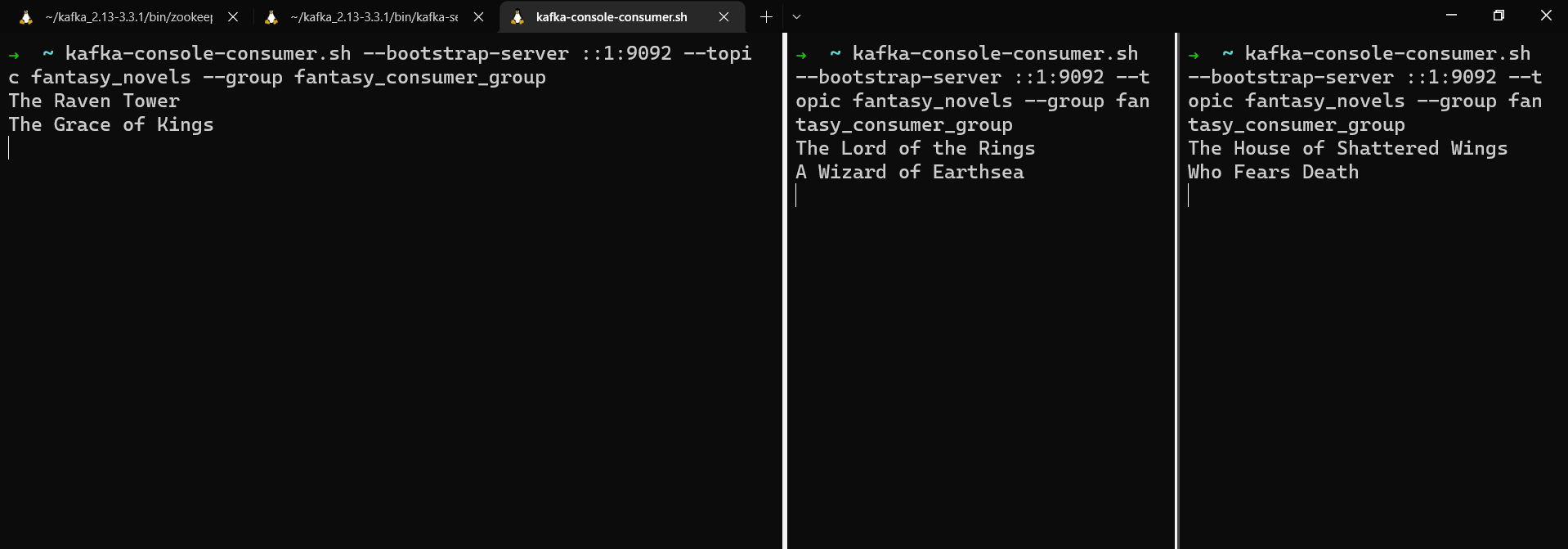
Messages répartis entre les consommateurs dans un groupe de consommateurs
Si vous arrêtez l'un des consommateurs, le groupe de consommateurs se rééquilibrera et les messages futurs seront envoyés aux consommateurs restants.
Maintenant que vous avez une certaine expérience de travail avec Kafka depuis la ligne de commande, l'étape suivante est de construire une petite application qui se connecte à Kafka.
Comment construire une application cliente Kafka avec Java
Nous allons construire une simple application Java qui produit des messages vers Kafka et consomme des messages depuis Kafka. Pour cela, nous utiliserons le client Java officiel de Kafka.
Si à un moment donné vous êtes bloqué, le code complet de ce projet est disponible sur GitHub.
Préliminaires
Tout d'abord, assurez-vous d'avoir Java (au moins JDK 11) et Kafka installés.
Nous allons envoyer des messages sur des personnages de Le Seigneur des Anneaux. Donc, créons un topic pour ces messages avec trois partitions.
Depuis la ligne de commande, exécutez :
kafka-topics.sh --bootstrap-server localhost:9092 --create --topic lotr_characters --partitions 3
Comment configurer le projet
Je recommande d'utiliser IntelliJ pour les projets Java, alors allez-y et installez la Community Edition si vous ne l'avez pas déjà. Vous pouvez la télécharger depuis jetbrains.com/idea
Dans IntelliJ, sélectionnez File, New, et Project.
Donnez un nom à votre projet et sélectionnez un emplacement pour celui-ci sur votre ordinateur. Assurez-vous d'avoir sélectionné Java comme langage, Maven comme système de construction, et que le JDK est au moins Java 11. Ensuite, cliquez sur Create.
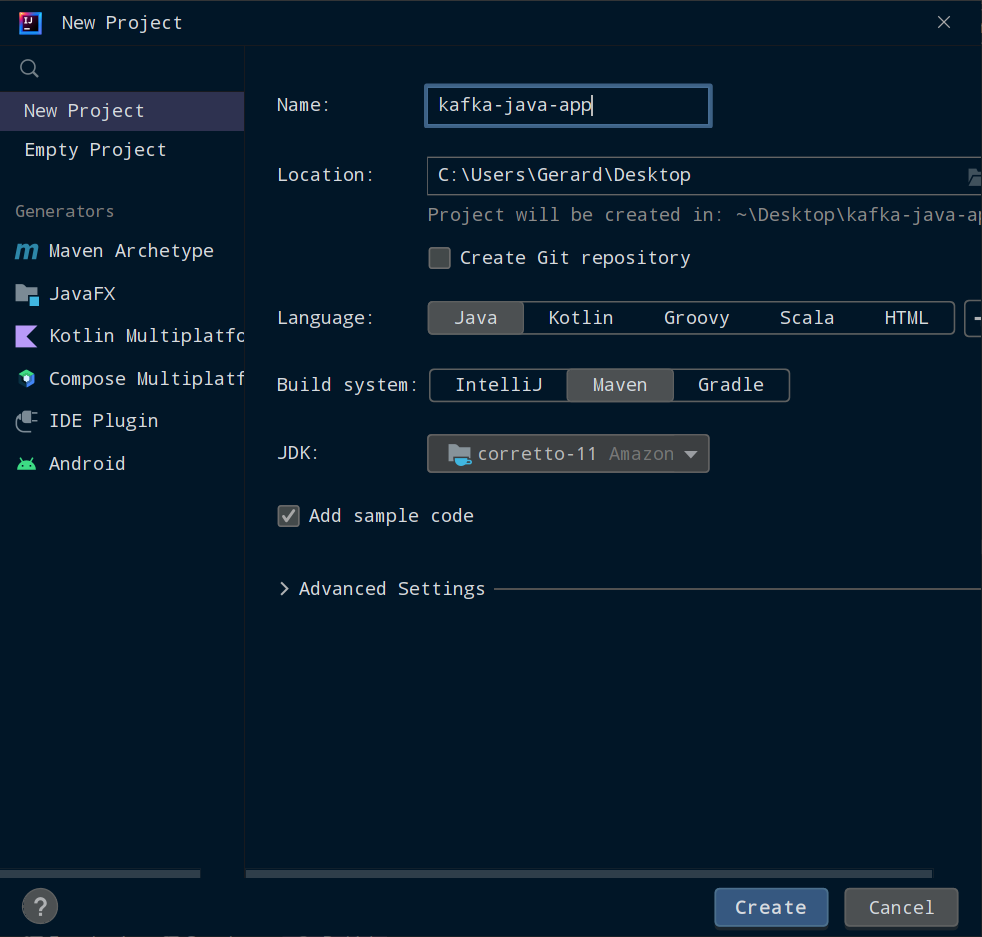
Configuration d'un projet Maven dans IntelliJ
Note : Si vous êtes sur Windows, IntelliJ ne peut pas utiliser un JDK installé sur WSL. Pour installer Java du côté Windows, allez sur docs.aws.amazon.com/corretto/latest/corretto-11-ug/downloads-list et téléchargez l'installateur Windows. Suivez les étapes d'installation, ouvrez une invite de commande et exécutez java -version. Vous devriez voir quelque chose comme :
openjdk version "11.0.18" 2023-01-17 LTS
OpenJDK Runtime Environment Corretto-11.0.18.10.1 (build 11.0.18+10-LTS)
OpenJDK 64-Bit Server VM Corretto-11.0.18.10.1 (build 11.0.18+10-LTS, mixed mode)
Une fois que votre projet Maven a fini de se configurer, exécutez la classe Main pour voir "Hello world!" et assurez-vous que tout a fonctionné.
Comment installer les dépendances
Ensuite, nous allons installer nos dépendances. Ouvrez pom.xml et à l'intérieur de l'élément <project>, créez un élément <dependencies>.
Nous allons utiliser le client Java Kafka pour interagir avec Kafka et SLF4J pour la journalisation, alors ajoutez ce qui suit à l'intérieur de votre élément <dependencies> :
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka-clients -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.3.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.slf4j/slf4j-api -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>2.0.6</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.slf4j/slf4j-simple -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>2.0.6</version>
</dependency>
Les noms de package et les numéros de version peuvent être en rouge, ce qui signifie que vous ne les avez pas encore téléchargés. Si cela se produit, cliquez sur View, Tool Windows, et Maven pour ouvrir le menu Maven. Cliquez sur l'icône Reload All Maven Projects et Maven installera ces dépendances.
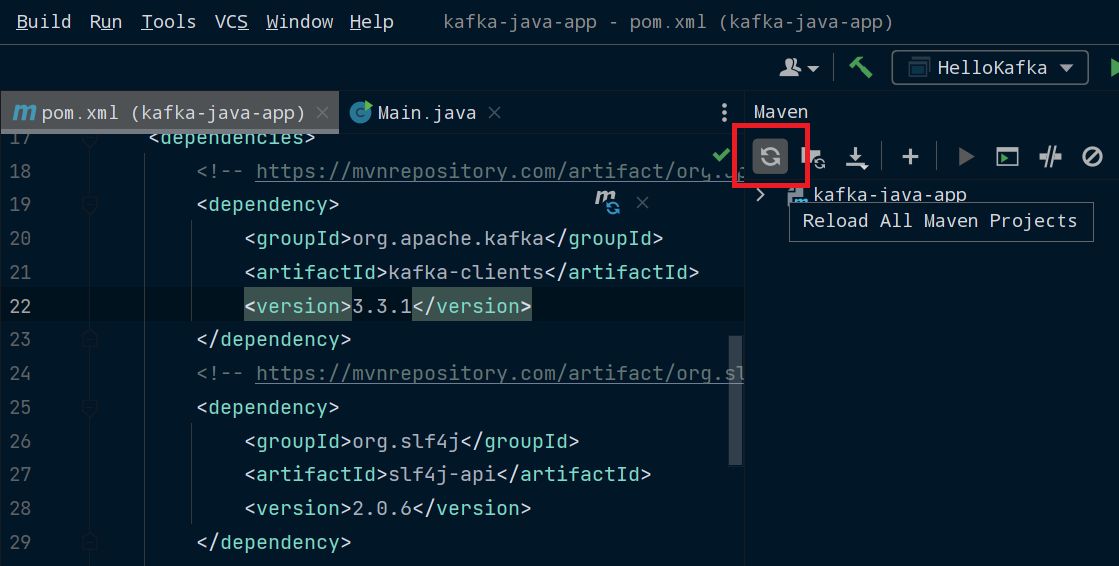
Rechargement des dépendances Maven dans IntelliJ
Créez une classe HelloKafka dans le même répertoire que votre classe Main et donnez-lui le contenu suivant :
package org.example;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class HelloKafka {
private static final Logger log = LoggerFactory.getLogger(HelloKafka.class);
public static void main(String[] args) {
log.info("Hello Kafka");
}
}
Pour vous assurer que vos dépendances sont installées, exécutez cette classe et vous devriez voir [main] INFO org.example.HelloKafka - Hello Kafka imprimé dans la console IntelliJ.
Comment créer un producteur Kafka
Ensuite, nous allons créer une classe Producer. Vous pouvez l'appeler comme vous voulez tant qu'elle n'entre pas en conflit avec une autre classe. Donc, n'utilisez pas KafkaProducer car vous aurez besoin de cette classe dans une minute.
package org.example;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class Producer {
private static final Logger log = LoggerFactory.getLogger(KafkaProducer.class);
public static void main(String[] args) {
log.info("This class will produce messages to Kafka");
}
}
Tout notre code spécifique à Kafka va aller à l'intérieur de la méthode main() de cette classe.
La première chose que nous devons faire est de configurer quelques propriétés pour le producteur. Ajoutez ce qui suit à l'intérieur de la méthode main() :
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
Properties stocke un ensemble de propriétés sous forme de paires de chaînes. Celles que nous utilisons sont :
ProducerConfig.BOOTSTRAP_SERVERS_CONFIGqui spécifie l'adresse IP à utiliser pour accéder au cluster KafkaProducerConfig.KEY_SERIALIZER_CLASS_CONFIGqui spécifie le sérialiseur à utiliser pour les clés des messagesProducerConfig.VALUE_SERIALIZER_CLASS_CONFIGqui spécifie le sérialiseur à utiliser pour les valeurs des messages
Nous allons nous connecter à notre cluster Kafka local en cours d'exécution sur localhost:9092, et utiliser le StringSerializer puisque nos clés et valeurs seront des chaînes.
Nous pouvons maintenant créer notre producteur et lui passer les propriétés de configuration.
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
Pour envoyer un message, nous devons créer un ProducerRecord et le passer à notre producteur. ProducerRecord contient un nom de topic, et optionnellement une clé, une valeur et un numéro de partition.
Nous allons créer le ProducerRecord avec le topic à utiliser, la clé du message et la valeur du message.
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("lotr_characters", "hobbits", "Bilbo");
Nous pouvons maintenant utiliser la méthode send() du producteur pour envoyer le message à Kafka.
producer.send(producerRecord);
Enfin, nous devons appeler la méthode close() pour arrêter le producteur. Cette méthode gère tous les messages actuellement traités par send() puis ferme le producteur.
producer.close();
Il est maintenant temps d'exécuter notre producteur. Assurez-vous que Zookeeper et Kafka sont en cours d'exécution. Ensuite, exécutez la méthode main() de la classe Producer.
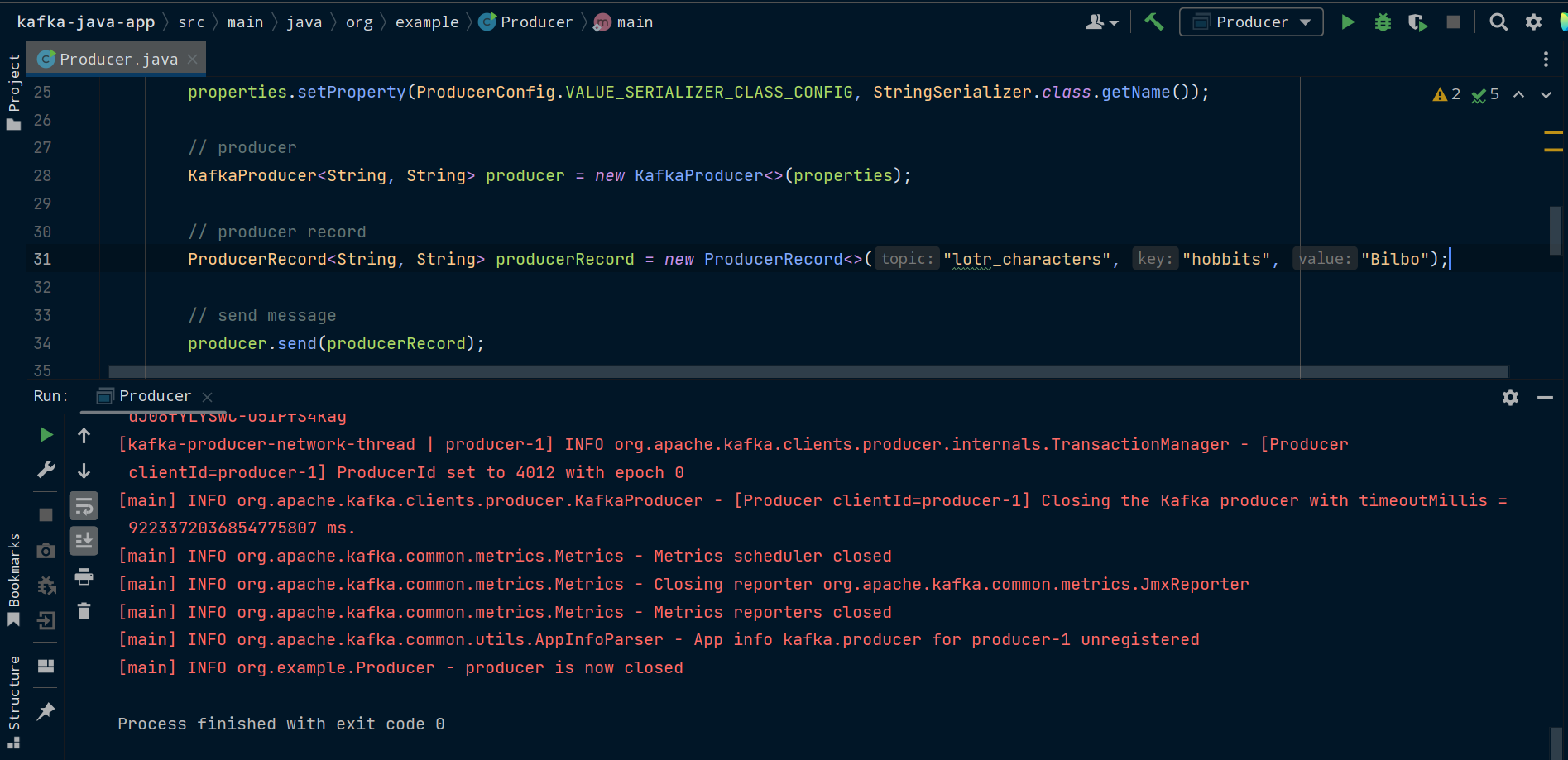
Envoi d'un message à partir d'un producteur dans une application cliente Kafka Java
Note : Sur Windows, votre producteur pourrait ne pas pouvoir se connecter à un broker Kafka en cours d'exécution sur WSL. Pour corriger cela, vous devrez faire ce qui suit :
Dans un terminal WSL, naviguez jusqu'au dossier de configuration de Kafka :
cd ~/kafka_2.13-3.3.1/config/Ouvrez
server.properties, par exemple avec Nano :nano server.propertiesDécommentez
#listeners=PLAINTEXT//:9092Remplacez-le par
listeners=PLAINTEXT//[::1]:9092Dans votre classe
Producer, remplacez"localhost:9092"par"[::1]:9092"
[::1], ou 0:0:0:0:0:0:0:1, fait référence à l'adresse de rebouclage (ou localhost) en IPv6. Cela est équivalent à 127.0.0.1 en IPv4.
Si vous changez listeners, lorsque vous essayez d'accéder au broker Kafka depuis la ligne de commande, vous devrez également utiliser la nouvelle adresse IP, donc utilisez --bootstrap-server ::1:9092 au lieu de --bootstrap-server localhost:9092 et cela devrait fonctionner.
Nous pouvons maintenant vérifier que Producer a fonctionné en utilisant kafka-console-consumer dans une autre fenêtre de terminal pour lire depuis le topic lotr_characters et voir le message imprimé dans la console.
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic lotr_characters --from-beginning
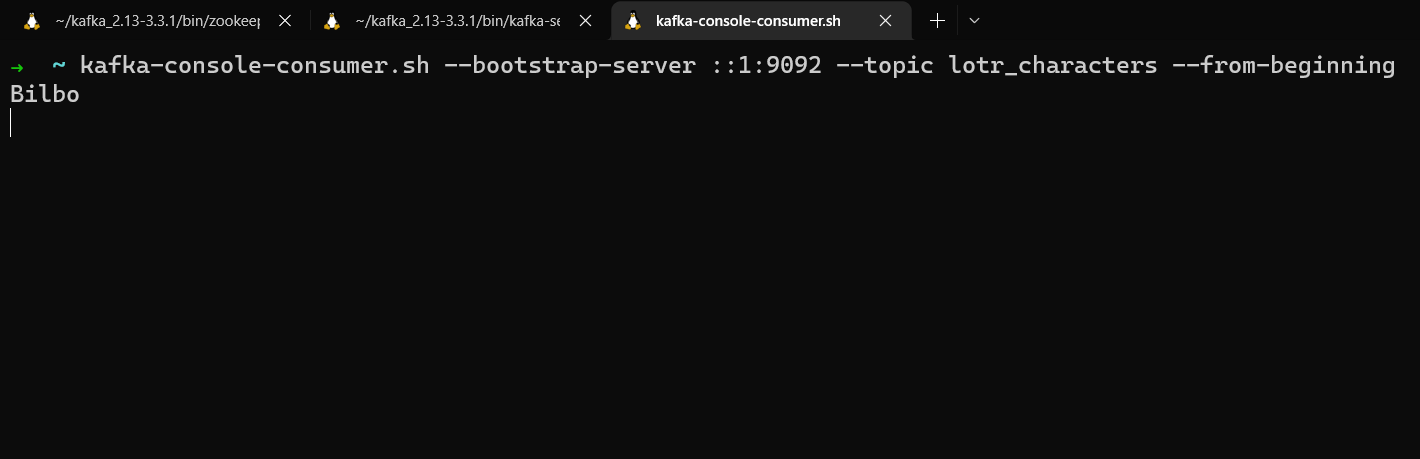
kafka-console-consumer lisant le message envoyé par le producteur dans notre application Java
Comment envoyer plusieurs messages et utiliser des callbacks
Jusqu'à présent, nous n'envoyons qu'un seul message. Si nous mettons à jour Producer pour envoyer plusieurs messages, nous pourrons voir comment les clés sont utilisées pour diviser les messages entre les partitions. Nous pouvons également profiter de cette opportunité pour utiliser un callback afin de visualiser les métadonnées du message envoyé.
Pour ce faire, nous allons parcourir une collection de personnages pour générer nos messages.
Remplacez donc ceci :
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("lotr_characters", "hobbits", "Bilbo");
producer.send(producerRecord);
par ceci :
HashMap<String, String> characters = new HashMap<String, String>();
characters.put("hobbits", "Frodo");
characters.put("hobbits", "Sam");
characters.put("elves", "Galadriel");
characters.put("elves", "Arwen");
characters.put("humans", "c9owyn");
characters.put("humans", "Faramir");
for (HashMap.Entry<String, String> character : characters.entrySet()) {
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("lotr_characters", character.getKey(), character.getValue());
producer.send(producerRecord, (RecordMetadata recordMetadata, Exception err) -> {
if (err == null) {
log.info("Message received. \n" +
"topic [" + recordMetadata.topic() + "]\n" +
"partition [" + recordMetadata.partition() + "]\n" +
"offset [" + recordMetadata.offset() + "]\n" +
"timestamp [" + recordMetadata.timestamp() + "]");
} else {
log.error("An error occurred while producing messages", err);
}
});
}
Ici, nous parcourons la collection, créons un ProducerRecord pour chaque entrée et passons l'enregistrement à send(). En arrière-plan, Kafka regroupera ces messages pour effectuer moins de requêtes réseau. send() peut également prendre un callback comme deuxième argument. Nous allons lui passer une lambda qui exécutera du code lorsque la requête send() sera terminée.
Si la requête s'est terminée avec succès, nous obtenons un objet RecordMetadata avec des métadonnées sur le message, que nous pouvons utiliser pour voir des choses comme la partition et l'offset dans lesquels le message a abouti.
Si nous obtenons une exception, nous pourrions la gérer en réessayant d'envoyer le message ou en alertant notre application. Dans ce cas, nous allons simplement journaliser l'exception.
Exécutez la méthode main() de la classe Producer et vous devriez voir les métadonnées du message journalisées.
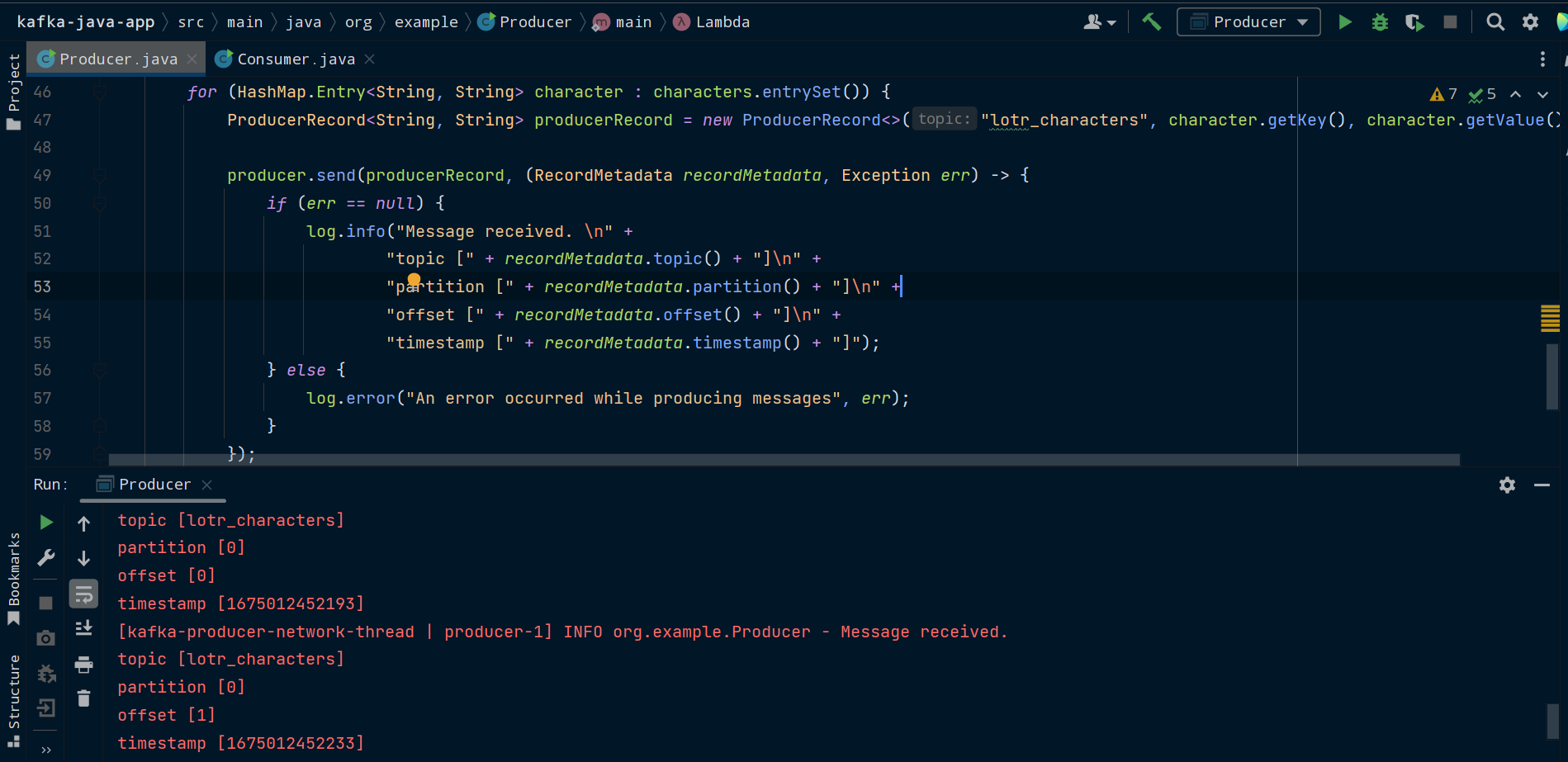
Le code complet de la classe Producer devrait maintenant être :
package org.example;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.HashMap;
import java.util.Properties;
public class Producer {
private static final Logger log = LoggerFactory.getLogger(Producer.class);
public static void main(String[] args) {
log.info("This class produces messages to Kafka");
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
HashMap<String, String> characters = new HashMap<String, String>();
characters.put("hobbits", "Frodo");
characters.put("hobbits", "Sam");
characters.put("elves", "Galadriel");
characters.put("elves", "Arwen");
characters.put("humans", "c9owyn");
characters.put("humans", "Faramir");
for (HashMap.Entry<String, String> character : characters.entrySet()) {
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("lotr_characters", character.getKey(), character.getValue());
producer.send(producerRecord, (RecordMetadata recordMetadata, Exception err) -> {
if (err == null) {
log.info("Message received. \n" +
"topic [" + recordMetadata.topic() + "]\n" +
"partition [" + recordMetadata.partition() + "]\n" +
"offset [" + recordMetadata.offset() + "]\n" +
"timestamp [" + recordMetadata.timestamp() + "]");
} else {
log.error("An error occurred while producing messages", err);
}
});
}
producer.close();
}
}
Ensuite, nous allons créer un consommateur pour lire ces messages depuis Kafka.
Comment créer un consommateur Kafka
Tout d'abord, créez une classe Consumer. Encore une fois, vous pouvez l'appeler comme vous voulez, mais ne l'appeler pas KafkaConsumer car vous aurez besoin de cette classe dans un instant.
Tout le code spécifique à Kafka ira dans la méthode main() de Consumer.
package org.example;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class Consumer {
private static final Logger log = LoggerFactory.getLogger(Consumer.class);
public static void main(String[] args) {
log.info("This class consumes messages from Kafka");
}
}
Ensuite, configurez les propriétés du consommateur.
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "lotr_consumer_group");
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
Tout comme avec Producer, ces propriétés sont un ensemble de paires de chaînes. Celles que nous utilisons sont :
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIGqui spécifie l'adresse IP à utiliser pour accéder au cluster KafkaConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIGqui spécifie le désérialiseur à utiliser pour les clés des messagesConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIGqui spécifie le désérialiseur à utiliser pour les valeurs des messagesConsumerConfig.GROUP_ID_CONFIGqui spécifie le groupe de consommateurs auquel ce consommateur appartientConsumerConfig.AUTO_OFFSET_RESET_CONFIGqui spécifie l'offset à partir duquel commencer la lecture
Nous nous connectons au cluster Kafka sur localhost:9092, utilisons des désérialiseurs de chaînes puisque nos clés et valeurs sont des chaînes, définissons un identifiant de groupe pour notre consommateur et disons au consommateur de lire depuis le début du topic.
Note : Si vous exécutez le consommateur sur Windows et accédez à un broker Kafka en cours d'exécution sur WSL, vous devrez changer "localhost:9091" en "[::1]:9092" ou "0:0:0:0:0:0:0:1:9092", comme vous l'avez fait dans Producer.
Ensuite, nous créons un KafkaConsumer et lui passons les propriétés de configuration.
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
Nous devons dire au consommateur à quel topic, ou topics, s'abonner. La méthode subscribe() prend en entrée une collection d'une ou plusieurs chaînes, nommant les topics que vous souhaitez lire. Rappelez-vous, les consommateurs peuvent s'abonner à plus d'un topic en même temps. Pour cet exemple, nous utiliserons un topic, le topic lotr_characters.
String topic = "lotr_characters";
consumer.subscribe(Arrays.asList(topic));
Le consommateur est maintenant prêt à commencer à lire les messages du topic. Il le fait en interrogeant régulièrement de nouveaux messages.
Nous allons utiliser une boucle while pour appeler de manière répétée la méthode poll() afin de vérifier de nouveaux messages.
poll() prend en entrée une durée pour laquelle il doit lire à la fois. Il regroupe ensuite ces messages dans un itérable appelé ConsumerRecords. Nous pouvons ensuite parcourir ConsumerRecords et faire quelque chose avec chaque ConsumerRecord individuel.
Dans une application réelle, nous traiterions ces données ou les enverrions à une destination ultérieure, comme une base de données ou un pipeline de données. Ici, nous allons simplement journaliser la clé, la valeur, la partition et l'offset pour chaque message que nous recevons.
while(true){
ConsumerRecords<String, String> messages = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> message : messages){
log.info("key [" + message.key() + "] value [" + message.value() +"]");
log.info("partition [" + message.partition() + "] offset [" + message.offset() + "]");
}
}
Il est maintenant temps d'exécuter notre consommateur. Assurez-vous que Zookeeper et Kafka sont en cours d'exécution. Exécutez la classe Consumer et vous verrez les messages que Producer a précédemment envoyés au topic lotr_characters dans Kafka.
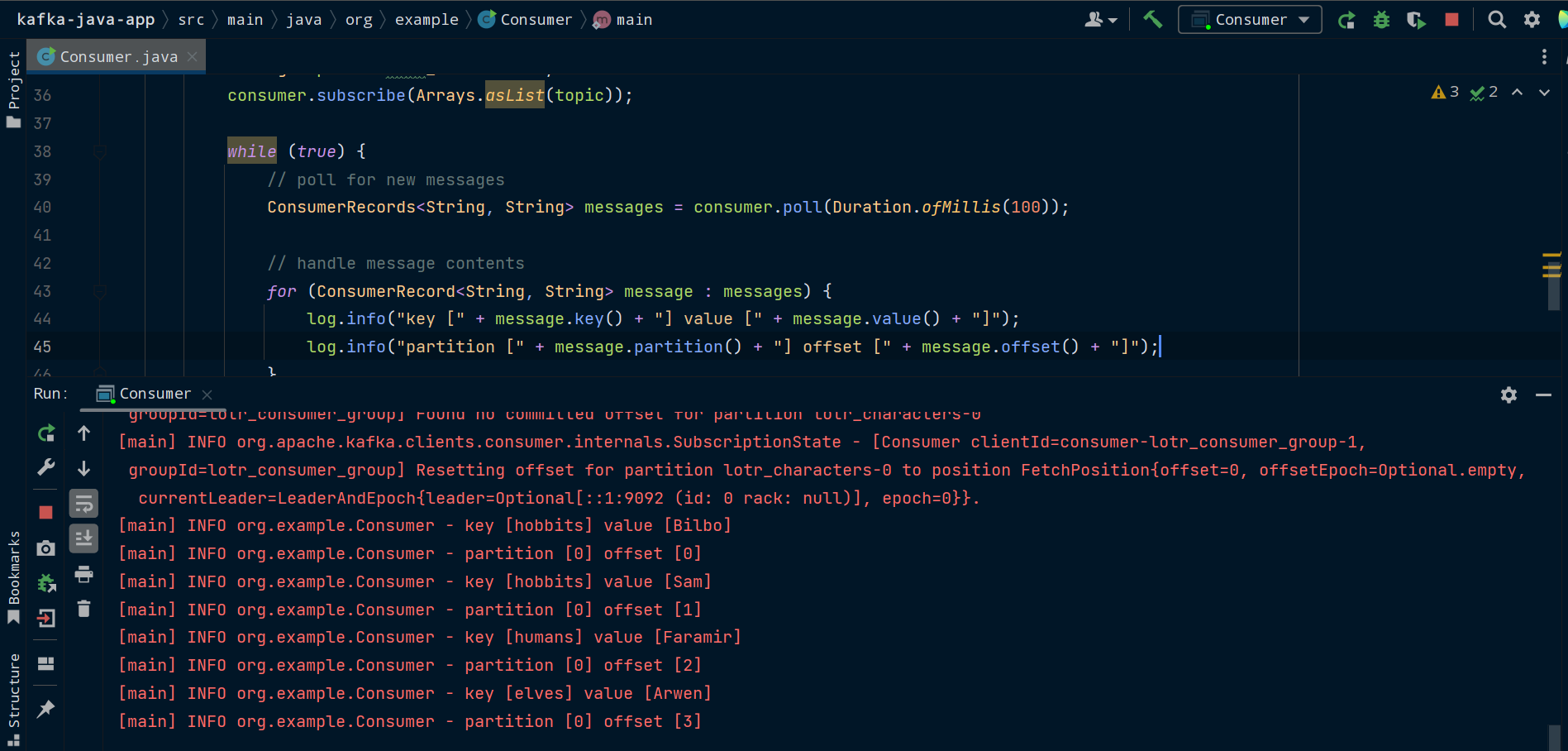
L'application cliente Kafka consommant des messages qui ont été précédemment produits vers Kafka
Comment arrêter le consommateur
Actuellement, notre consommateur s'exécute dans une boucle infinie et interroge de nouveaux messages toutes les 100 ms. Ce n'est pas un problème, mais nous devrions ajouter des garde-fous pour gérer l'arrêt du consommateur si une exception se produit.
Nous allons envelopper notre code dans un bloc try-catch-finally. Si une exception se produit, nous pouvons la gérer dans le bloc catch.
Le bloc finally appellera ensuite la méthode close() du consommateur. Cela fermera la socket utilisée par le consommateur, validera les offsets qu'il a traités et déclenchera un rééquilibrage du groupe de consommateurs afin que tout autre consommateur du groupe puisse reprendre la lecture des partitions que ce consommateur gérait.
try {
// subscribe to topic(s)
String topic = "lotr_characters";
consumer.subscribe(Arrays.asList(topic));
while (true) {
// poll for new messages
ConsumerRecords<String, String> messages = consumer.poll(Duration.ofMillis(100));
// handle message contents
for (ConsumerRecord<String, String> message : messages) {
log.info("key [" + message.key() + "] value [" + message.value() + "]");
log.info("partition [" + message.partition() + "] offset [" + message.offset() + "]");
}
}
} catch (Exception err) {
// catch and handle exceptions
log.error("Error: ", err);
} finally {
// close consumer and commit offsets
consumer.close();
log.info("consumer is now closed");
}
Consumer interrogera en continu ses topics assignés pour de nouveaux messages et s'arrêtera en toute sécurité s'il rencontre une exception.
Le code complet de la classe Consumer devrait maintenant être :
package org.example;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
public class Consumer {
private static final Logger log = LoggerFactory.getLogger(Consumer.class);
public static void main(String[] args) {
log.info("This class consumes messages from Kafka");
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "lotr_consumer_group");
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
try {
String topic = "lotr_characters";
consumer.subscribe(Arrays.asList(topic));
while (true) {
ConsumerRecords<String, String> messages = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> message : messages) {
log.info("key [" + message.key() + "] value [" + message.value() + "]");
log.info("partition [" + message.partition() + "] offset [" + message.offset() + "]");
}
}
} catch (Exception err) {
log.error("Error: ", err);
} finally {
consumer.close();
log.info("The consumer is now closed");
}
}
}
Vous avez maintenant une application Java de base qui peut envoyer des messages à Kafka et lire des messages depuis Kafka. Si vous avez été bloqué à un moment donné, le code complet est disponible sur GitHub.
Où aller à partir de là
Félicitations pour être arrivé jusqu'ici. Vous avez appris :
les concepts principaux derrière Kafka
comment communiquer avec Kafka depuis la ligne de commande
comment construire une application Java qui produit et consomme depuis Kafka
Il y a beaucoup plus à apprendre sur Kafka, que ce soit Kafka Connect pour connecter Kafka aux systèmes de données courants ou l'API Kafka Streams pour traiter et transformer vos données.
Certaines ressources que vous pourriez trouver utiles alors que vous continuez votre voyage avec Kafka sont :
J'espère que ce guide a été utile et vous a donné envie d'en apprendre davantage sur Kafka, la diffusion d'événements et le traitement de données en temps réel.