

![Le Livre des Expressions Régulières – RegEx pour les Développeurs JavaScript [Livre Complet]](https://www.freecodecamp.org/news/content/images/size/w2000/2023/07/Regex-for-JavaScript-Developers-Cover.png)
Article original : The Regular Expressions Book – RegEx for JavaScript Developers [Full Book]
Si vous souhaitez maîtriser les expressions régulières et comprendre comment elles fonctionnent en JavaScript, ce livre est fait pour vous.
Les expressions régulières peuvent être intimidantes lorsque vous les rencontrez pour la première fois. Lorsque j'ai commencé à apprendre à coder, j'ai abandonné les expressions régulières deux fois.
Bien que ce soit en partie parce que j'étais intimidé par les expressions régulières au début, les tutoriels et cours que j'ai utilisés ne les enseignaient jamais de manière à ce que je puisse comprendre.
En fait, avant que certains tutoriels ne commencent à enseigner regex, ils se plaignent de regex et de leur difficulté. Et il n'y a pas de meilleure façon de décourager un apprenant que cela.
Dans ce livre, vous ne verrez pas seulement comment utiliser regex dans un outil de test regex comme regexpal ou regex101. Vous verrez également comment ils fonctionnent en JavaScript. C'est ce que manquent de nombreux cours et tutoriels adaptés pour regex en JavaScript. Alors que vous voyez comment ils fonctionnent en utilisant un testeur regex, vous verrez également comment ils fonctionnent en JavaScript.
Vous pouvez également appliquer ce que vous apprenez dans ce livre à d'autres langages de programmation comme Python, PHP, et ainsi de suite. Tout ce que vous avez à faire est de connaître le fonctionnement du moteur regex de ce langage. Vous devrez également comprendre les méthodes et fonctions que le langage utilise pour travailler avec les expressions régulières.
Pour tirer le meilleur parti de ce livre, assurez-vous de le lire dans l'ordre car chaque chapitre s'appuie sur les précédents. J'ai également organisé les chapitres selon leur niveau de difficulté. Ainsi, vous trouverez des concepts plus simples en premier et des concepts plus avancés plus tard.
Bonne lecture !
Table des Matières
- Chapitre 1 : Introduction aux Expressions Régulières
- Chapitre 2 : Comment Correspondre aux Caractères Littéraux et aux Ensembles de Caractères dans les Expressions Régulières
- Chapitre 3 : Drapeaux des Expressions Régulières
- Chapitre 4 : Comment Utiliser les Expressions Régulières en JavaScript
- Comment Créer des Expressions Régulières en JavaScript
- Méthodes du Constructeur
RegExp() - Propriétés du Constructeur
RegExp() - Méthodes de Chaîne pour Travailler avec les Expressions Régulières
- Comment Correspondre aux Caractères Littéraux dans les Expressions Régulières JavaScript
- Comment Utiliser les Ensembles de Caractères dans les Expressions Régulières JavaScript
- Chapitre 5 : Métacaractères, Quantificateurs, Correspondances Répétées et Correspondances Optionnelles
- Qu'est-ce que les Métacaractères ?
- Les Métacaractères de Mot et de Non-mot
- Les Métacaractères d'Ancre
- Les Métacaractères de Chiffre et de Non-chiffre
- Le Métacaractère de Crochets
- Les Métacaractères de Limite de Mot et de Non-limite de Mot
- Le Métacaractère de Parenthèse
- Les Métacaractères d'Espace et de Non-espace
- Le Métacaractère de Pipe
- Comment Correspondre aux Caractères Répétés avec les Quantificateurs
- Comment Spécifier la Quantité de Correspondance avec le Métacaractère d'Accolades
- Le Métacaractère de Joker
- L'Avarice et la Paresse dans les Expressions Régulières
- Chapitre 6 : Groupement et Capture dans Regex
- Chapitre 7 : Groupes de Recherche : Lookaheads et Lookbehinds
- Chapitre 8 : Bonnes Pratiques et Dépannage des Regex
- Chapitre 9 : Applications des Expressions Régulières
- Glossaire et Références
Chapitre 1 : Introduction aux Expressions Régulières
Qu'est-ce que les Expressions Régulières ?
Vous pourriez voir cela écrit comme expressions régulières, regex, ou RegExp – mais tout cela fait référence à la même chose.
Les regex sont une séquence de caractères pour correspondre à une partie d'une chaîne ou à la chaîne entière. Correspondre aux chaînes avec des expressions régulières peut nécessiter plus que simplement des "caractères". De nombreuses fois, vous devrez utiliser un ensemble spécial de caractères appelés "métacaractères" et "quantificateurs".
Parce que les expressions régulières sont un outil puissant, vous pouvez les utiliser pour faire beaucoup plus que simplement "correspondre aux chaînes" lorsque vous combinez les regex avec les langages de programmation.
Presque tous les principaux langages de programmation de l'ère moderne ont un support intégré pour les expressions régulières. Certains langages de programmation peuvent même avoir des bibliothèques spécifiques qui vous aident à travailler plus facilement avec les regex.
Outre l'utilisation des expressions régulières dans les langages de programmation, d'autres outils qui vous permettent d'utiliser les expressions régulières sont :
Éditeurs de Texte et IDE : pour la recherche et le remplacement dans VS Code, Visual Studio, Notepad++, Sublime Text, et autres.
Outils de Développement du Navigateur : principalement la recherche dans le navigateur (avec des extensions ou des modules complémentaires) et la recherche dans les outils de développement.
Outils de Base de Données : pour l'extraction de données.
Testeurs RegEx : vous pouvez coller du texte et écrire les expressions régulières pour les correspondre – ce qui est une très bonne façon d'apprendre les expressions régulières. Ce livre explore cette option assez largement.
Un Bref Historique des Expressions Régulières
Les expressions régulières ont une histoire riche et fascinante qui s'étend déjà sur plus de sept décennies. Cette histoire continue d'évoluer parallèlement au développement de l'informatique et des langages de programmation.
Le concept des expressions régulières remonte aux années 1950. Le mathématicien américain Stephen Cole Kleene les a introduites comme une notation pour définir des motifs dans les langages formels. Le travail de Kleene a également formé la base de l'informatique théorique.
Au début des années 1960, les premières implémentations des expressions régulières sont apparues. Ken Thompson, un informaticien des Bell Labs, a développé un éditeur de texte nommé QED qui utilisait les expressions régulières pour la correspondance de motifs. Les capacités de QED fournissaient un moyen de rechercher et de manipuler des textes plus efficacement.
Le concept a gagné en popularité lorsque Thompson et Dennis Ritchie ont créé le système d'exploitation Unix au début des années 1970.
Ils ont intégré les expressions régulières dans divers utilitaires Unix, notamment l'éditeur de texte ed et plus tard l'éditeur de flux sed. Ces outils permettaient aux utilisateurs d'effectuer des tâches complexes de manipulation de texte, améliorant considérablement l'efficacité et la puissance du traitement de texte.
En 1973, Thompson a collaboré avec Alfred Aho et Peter Weinberger pour développer un nouvel outil appelé grep (global regular expression print) dans le cadre de la boîte à outils Unix.
Grep permettait aux utilisateurs de rechercher des fichiers pour des motifs spécifiques en utilisant des expressions régulières. La simplicité et l'efficacité de grep en ont fait un outil largement adopté. Il a également établi les expressions régulières comme une fonctionnalité standard dans les systèmes basés sur Unix.
Alors que les systèmes informatiques et les langages de programmation évoluaient, les expressions régulières sont devenues intégrées dans divers environnements de développement logiciel. À la fin des années 1970, le langage de programmation AWK a été créé. AWK a inspiré Larry Wall à créer Perl et à le rendre disponible au public en 1987.
Wall a reconnu la valeur des expressions régulières pour la manipulation de texte et les a intégrées dans Perl.
L'intégration des expressions régulières dans la syntaxe de Perl en a fait un langage populaire pour la correspondance de texte et les tâches d'extraction de données. Cette intégration a formé la base de PCRE (Perl-compatible regular expressions), une variante et une bibliothèque d'expressions régulières que vous pouvez utiliser dans certains langages de programmation tels que Perl, Python, PHP, Java, et autres.
Les expressions régulières ont continué à évoluer et à trouver des applications au-delà d'Unix et de Perl. Dans les années 1980, l'Organisation Internationale de Normalisation (ISO) a développé la norme POSIX, qui incluait une spécification pour les expressions régulières. Cette standardisation a assuré la compatibilité et la cohérence entre différentes implémentations et systèmes.
Avec l'essor de l'internet et du World Wide Web dans les années 1990, les expressions régulières ont trouvé une utilisation généralisée dans le développement web et le traitement des données. Elles sont devenues un composant essentiel de nombreux langages de script, fournissant aux développeurs des outils puissants pour le traitement de texte, la validation de formulaires et l'extraction de données à partir de pages web.
Par exemple, JavaScript a toujours eu une version de PCRE intégrée pour travailler avec les expressions régulières. Mais en 1999, avec la sortie d'ECMAScript, le constructeur RegExp() a été introduit. Cela a donné aux développeurs JavaScript la possibilité de commencer à utiliser les expressions régulières directement dans leur code, à la manière JavaScript.
Au début des années 2000, des outils et des bibliothèques spécifiquement axés sur les expressions régulières sont apparus, facilitant le travail des développeurs avec elles. Des bibliothèques comme PCRE (Perl Compatible Regular Expressions) ont fourni des fonctionnalités améliorées et de meilleures performances, élargissant ainsi l'utilisation et les capacités des expressions régulières.
Aujourd'hui, les expressions régulières sont une partie intégrante des langages de programmation et des outils de traitement de texte comme votre éditeur de code. Elles sont prises en charge par presque tous les principaux langages de programmation, y compris Java, C#, Ruby et PHP.
Les environnements de développement intégrés (IDE) et les éditeurs de code comme Visual Studio, VS Code et Notepad++ incluent également des fonctionnalités de recherche et de remplacement basées sur les regex, simplifiant ainsi le processus de recherche et de manipulation de textes dans le code.
L'histoire des expressions régulières démontre leur évolution de concepts théoriques à des outils pratiques qui ont révolutionné le traitement de texte et la correspondance de motifs.
Des premiers développements chez Bell Labs et Unix à leur intégration dans les langages de programmation populaires, les expressions régulières sont devenues un outil essentiel entre les mains des développeurs et des administrateurs système. Les regex leur permettent de gérer efficacement des tâches basées sur du texte complexe.
Avec les avancées continues en informatique et la demande constante de traitement de texte efficace, les expressions régulières resteront probablement une partie fondamentale du paysage technologique pour les années à venir.
Quelles sont les Utilisations des Expressions Régulières ?
Les expressions régulières sont assez polyvalentes et flexibles. Cela les rend applicables à diverses tâches dans divers domaines tels que la programmation informatique, le traitement des données, l'édition de texte et le développement web.
Ces applications et utilisations incluent, sans s'y limiter, les suivantes :
Correspondance de Chaînes : C'est l'une des façons les plus courantes pour les développeurs d'utiliser les expressions régulières. C'est aussi une bonne façon d'apprendre les expressions régulières.
Vous pouvez coller des textes dans un moteur regex et écrire le regex pour correspondre à une partie du texte ou au texte entier. Vous pouvez également rechercher des chaînes qui contiennent des séquences de caractères spécifiques, commencent ou se terminent par certains caractères, ou correspondent à des motifs complexes.
Cela rend les expressions régulières précieuses pour des tâches comme la recherche de mots-clés, la validation des entrées par rapport à des motifs spécifiques, ou le filtrage des données en fonction des motifs de chaînes.
Validation de la Force des Mots de Passe : Vous pouvez utiliser les expressions régulières pour valider la force des mots de passe sur les sites web et les applications.
En définissant un ensemble de règles à l'aide d'expressions régulières, les développeurs peuvent imposer des exigences spécifiques pour les mots de passe, telles qu'un nombre minimum de caractères, une combinaison de lettres majuscules et minuscules, de chiffres et de caractères spéciaux.
Validation de Formulaires : Valider les entrées d'un formulaire ou des entrées autonomes est une autre façon populaire pour les développeurs d'utiliser les expressions régulières.
Les expressions régulières fournissent un moyen concis et efficace de s'assurer que les données d'entrée suivent des motifs ou des formats spécifiques. Qu'il s'agisse de valider des noms d'utilisateur, des adresses e-mail, des numéros de téléphone, des numéros de carte de crédit, des codes postaux ou d'autres entrées, les expressions régulières peuvent vous aider à imposer des règles de validation et à maintenir l'intégrité des données.
Recherche et Manipulation de Texte : Les expressions régulières excellent dans la recherche de motifs spécifiques dans le texte et l'exécution de manipulations basées sur ces correspondances. Elles sont un outil puissant pour des tâches telles que l'extraction de données, l'analyse de journaux et le traitement de texte.
Que vous ayez besoin de trouver des occurrences de mots ou de phrases particuliers, d'extraire des données structurées du texte, d'analyser du contenu ou d'effectuer une correspondance de chaînes, les expressions régulières offrent des capacités de correspondance de motifs efficaces.
Travail avec les URL et les URI : Puisque les URL et les URI sont une partie intégrante du développement web, les expressions régulières peuvent aider à les valider, les analyser et les manipuler. Cela permet aux développeurs de s'assurer de l'exactitude et de la structure des adresses web, de valider si une chaîne est une URL valide et d'aider à extraire des composants spécifiques tels que le domaine, le chemin, les paramètres de requête ou les fragments.
Cette fonctionnalité est particulièrement utile dans des tâches comme le routage d'URL, la réécriture ou l'extraction de données à partir de paramètres de requête.
Recherche et Remplacement dans les IDE et les Éditeurs de Texte : Les expressions régulières offrent des capacités de recherche sophistiquées. Cela permet aux développeurs de localiser des motifs spécifiques (tels que des mots avec des préfixes spécifiques ou des séquences de caractères) et de remplacer ensuite les correspondances par un texte spécifié. Cela est intégré dans les éditeurs de texte modernes comme VS Code et Notepad++.
Extraction de Données et Scraping : Les expressions régulières jouent un rôle significatif dans l'extraction de données et le scraping web. Elles permettent aux développeurs d'extraire des informations spécifiques à partir de texte non structuré ou semi-structuré en définissant des motifs pour correspondre aux données souhaitées.
Elles sont également précieuses lors de l'extraction de données à partir de sources comme des documents HTML ou XML, car elles permettent une récupération efficace des informations en fonction des motifs définis.
Coloration Syntaxique : Les expressions régulières sont couramment utilisées dans les IDE et les éditeurs de texte pour fournir une coloration syntaxique. Cela aide les utilisateurs à distinguer visuellement différentes parties d'un code ou d'un document en attribuant des couleurs ou des formats aux mots-clés, aux chaînes, aux commentaires et à d'autres constructions spécifiques au langage.
Les expressions régulières sont utilisées pour identifier et correspondre à ces motifs spécifiques au langage, rendant le code plus lisible et améliorant l'expérience globale d'édition.
Variantes des Expressions Régulières
Le terme "variantes des expressions régulières" fait référence aux implémentations spécifiques et aux variations de syntaxe des expressions régulières dans différents langages de programmation, bibliothèques ou outils.
Bien que le concept de base des expressions régulières reste le même, les détails de la manière dont les expressions régulières sont écrites et interprétées peuvent varier entre différents environnements.
Chaque variante des expressions régulières peut avoir son propre ensemble de métacaractères, de règles de syntaxe et de fonctionnalités supplémentaires au-delà de la fonctionnalité de base.
Ces différences peuvent inclure des variations dans la syntaxe des classes de caractères, des métacaractères, des groupes de capture et des assertions, ainsi que des capacités supplémentaires comme les groupes de capture nommés, les lookahead et les lookbehind.
Il existe de nombreuses variantes d'expressions régulières disponibles aujourd'hui. Certaines d'entre elles sont :
Expressions Régulières de Base (BRE) : cette variante est couramment trouvée dans les outils Unix tels que sed et grep. Elle utilise un ensemble limité de métacaractères et de fonctionnalités. Le joker (
.) et zéro ou plus (*) métacaractères sont disponibles dans celle-ci.Expressions Régulières Étendues (ERE) : ERE est une extension de BRE. Elle fournit des métacaractères et des fonctionnalités supplémentaires. En plus des métacaractères disponibles dans BRE, ERE introduit des fonctionnalités comme le regroupement avec des parenthèses (
( )), l'alternance avec le symbole pipe (|), et l'utilisation des accolades ({}) pour spécifier les plages de répétition.Expressions Régulières Compatibles Perl (PCRE) : PCRE est une variante populaire prise en charge par divers langages de programmation tels que Perl, Python, PHP et JavaScript. PCRE étend la syntaxe des expressions régulières de base avec des fonctionnalités puissantes comme les assertions de lookahead et lookbehind, les rétro-références, les groupes non capturants, et l'utilisation de
\bpour les limites de mots.Expressions Régulières JavaScript : JavaScript a sa propre variante d'expressions régulières qui est similaire à PCRE mais avec quelques différences. Elle prend en charge les fonctionnalités de base comme les classes de caractères avec des crochets (
[ ]), les métacaractères (*,+,?, et autres), et les groupes de capture (( )). JavaScript fournit également des fonctionnalités supplémentaires comme le drapeau global/gpour effectuer plusieurs correspondances, et le drapeau ignore case/ipour la correspondance insensible à la casse.Expressions Régulières Python : Le module
rede Python implémente une variante similaire à PCRE mais avec quelques variations. Il prend en charge des fonctionnalités telles que les classes de caractères[ ], les métacaractères (*,+, et?), et les groupes de capture (( )). Le moduleredispose également d'une syntaxe de chaîne brute unique (r' ') pour simplifier le travail avec les barres obliques inverses.
Il est important d'être conscient de la variante des expressions régulières que vous utilisez lorsque vous travaillez avec des expressions régulières dans différents langages de programmation ou outils. Cela garantit que vous utilisez la syntaxe correcte et tirez parti de toutes les fonctionnalités ou capacités uniques fournies par cette variante particulière.
N.B. : Ne vous souciez pas trop des métacaractères (et quantificateurs) mentionnés dans cette partie. Vous les verrez en action dans le chapitre 5 de ce livre.
Outils pour Travailler avec les Expressions Régulières
Les outils d'expressions régulières sont les langages de programmation, les bibliothèques et les frameworks, les utilitaires de ligne de commande, les testeurs regex en ligne, les éditeurs de texte et les IDE, et les applications conçus pour vous aider à créer, tester et appliquer des expressions régulières dans votre vie professionnelle quotidienne.
Il existe de nombreux outils disponibles pour travailler avec les expressions régulières. Laissez-moi vous les présenter sous les catégories de testeurs regex, langages de programmation, bibliothèques, éditeurs de texte et IDE, et outils de ligne de commande.
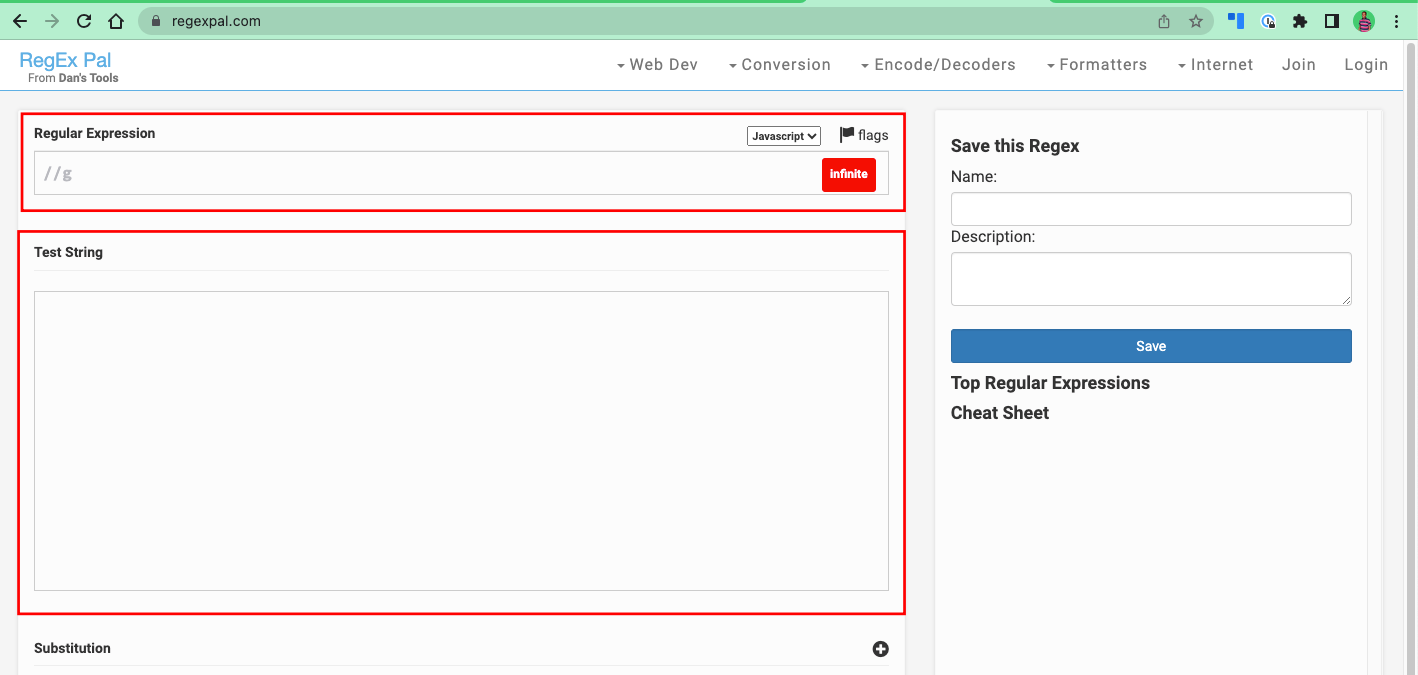
Testeurs RegEx
Les testeurs RegEx sont des environnements de test en ligne spécialement conçus pour créer et tester des expressions régulières contre certaines chaînes de test. Les exemples incluent regex101.com, regexr.com et regexpal.com.
Les interfaces utilisateur de ces testeurs regex ont généralement une entrée pour les expressions régulières que vous souhaitez écrire, et une autre pour le texte que vous souhaitez tester contre le regex.
Voici à quoi ressemble l'interface utilisateur de regexpal.com :
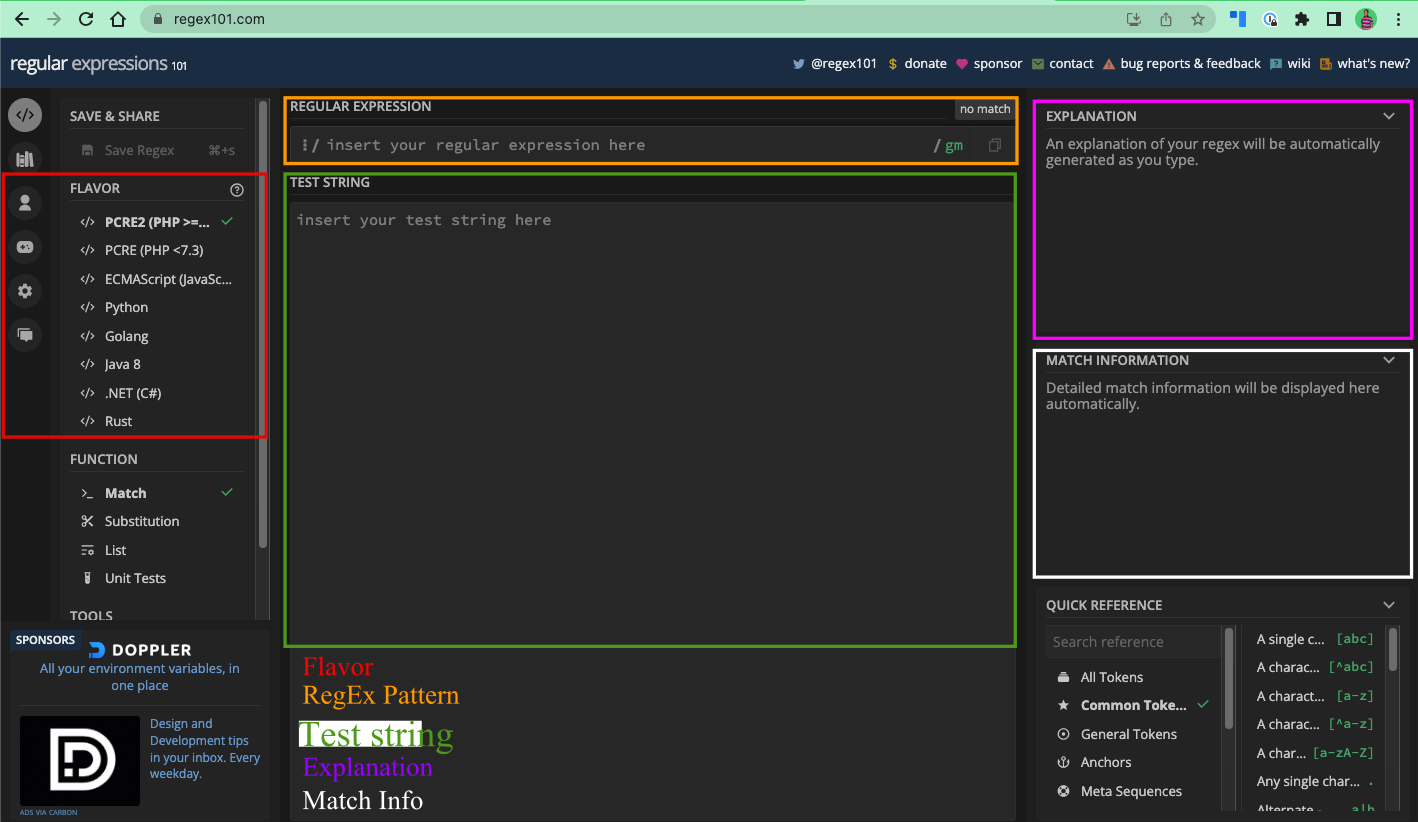
Les plus avancés comme regex101.com vous permettent de sélectionner la variante des expressions régulières avec laquelle vous souhaitez travailler, une explication du regex, et des informations sur les correspondances.
Voici à quoi ressemble l'interface utilisateur de regex101.com :
L'une des bonnes choses à propos de ces testeurs regex en ligne est qu'ils sont utiles pour apprendre les expressions régulières. Beaucoup d'entre eux fournissent des correspondances en temps réel et des aides-mémoire que vous pouvez consulter rapidement. De nombreux développeurs qui utilisent les regex les ont utilisés.
Outre l'apprentissage, vous pouvez également les utiliser en créant votre regex avec eux et en les collant là où vous souhaitez utiliser le regex. C'est ainsi que je crée mes regex.
Langages de Programmation
Presque tous les langages de programmation modernes ont un support intégré pour les expressions régulières. Et donc ils ont tous des méthodes pour créer et tester des expressions régulières.
Par exemple, JavaScript a le constructeur RegExp() pour travailler avec les expressions régulières, Python a le module re, Java a le package java.util.regex, et Perl a les regex intégrées directement.
Bibliothèques et Frameworks
De nombreux langages de programmation ont des bibliothèques et frameworks autonomes qui facilitent la création d'expressions régulières.
Il y a XRegExp pour JavaScript, PCRE (Perl Compatible Regular Expressions) pour Perl, Go-Restructure pour Golang, et Verbal Expressions, une bibliothèque regex multiplateforme.
Éditeurs de Texte et IDE
De nombreux éditeurs de texte et IDE tels que VS Code, Visual Studio, Notpad++, Atom, Sublime Text, IntelliJ IDEA, et autres ont un support intégré pour les expressions régulières.
La chose la plus courante que les développeurs utilisent est la recherche et le remplacement. De plus, la coloration syntaxique dans ces éditeurs de texte et IDE est souvent implémentée avec des expressions régulières.
Outils de Ligne de Commande
Les outils de ligne de commande Unix comme grep et sed vous permettent d'effectuer des opérations regex sur des fichiers texte et des flux. Avec cela, vous pouvez rechercher, filtrer et manipuler plusieurs fichiers.
En utilisant ces outils Unix, des options pour personnaliser les comportements de recherche et personnaliser des transformations de texte complexes sont également disponibles pour vous.
Concepts de Base des Expressions Régulières
Les concepts et la syntaxe de base des expressions régulières sont les éléments de construction impliqués dans la création, le test et l'application de motifs pour la recherche, la correspondance et la manipulation de chaînes.
Cela inclut des concepts comme les caractères littéraux, les métacaractères, les quantificateurs, les classes de caractères, les ancres et limites, et les caractères d'échappement. Les plus avancés sont les groupements, les rétro-références, les assertions de lookahead, et les assertions de lookbehind.
Les utilisateurs d'expressions régulières utilisent beaucoup de ces concepts pour construire des expressions régulières efficaces pour travailler avec du texte. À de nombreuses occasions, les concepts de base suffisent. Mais si vous voulez créer des expressions régulières plus avancées, alors les concepts plus avancés seront également utiles pour vous.
Ce livre ne laissera aucun des concepts de côté. Je vais vous montrer comment vous pouvez les utiliser dans les testeurs regex et comment vous pouvez les utiliser en JavaScript puisque c'est ce pour quoi ce livre est destiné.
Chapitre 2 : Comment Correspondre aux Caractères Littéraux et aux Ensembles de Caractères dans les Expressions Régulières
Qu'est-ce que les Caractères Littéraux dans les Expressions Régulières ?
Les caractères littéraux sont des caractères que vous pouvez correspondre tels qu'ils apparaissent dans une chaîne de test. Ils pourraient être des lettres, des nombres, des espaces, ou même des symboles. En d'autres termes, ce sont des caractères non spéciaux qui se représentent eux-mêmes.
Cela signifie que si vous voulez correspondre à des caractères littéraux, vous devez construire votre motif regex de la même manière que la chaîne de test apparaît.
Par exemple, si vous voulez correspondre au mot hello, votre motif regex peut être hello. Et si vous voulez correspondre au h dans le mot hatch, tout ce dont vous avez besoin comme motif est h.
Ce h correspondrait à la première occurrence de la lettre h dans la chaîne de test hatch. Si vous voulez qu'il corresponde également à l'autre lettre h, vous avez besoin du drapeau "g", ou drapeau global. Vous apprendrez à connaître les drapeaux et modificateurs dans le prochain chapitre de ce livre.
Ce n'est pas le cas pour certains symboles, cependant. C'est parce que certains symboles sont des caractères spéciaux des expressions régulières (métacaractères et quantificateurs). Donc, si vous voulez correspondre à ces caractères, vous devez les échapper avec une barre oblique inverse (\). Ce livre vous enseignera également tout ce que vous devez savoir sur les métacaractères car il y a un chapitre entier qui leur est consacré.
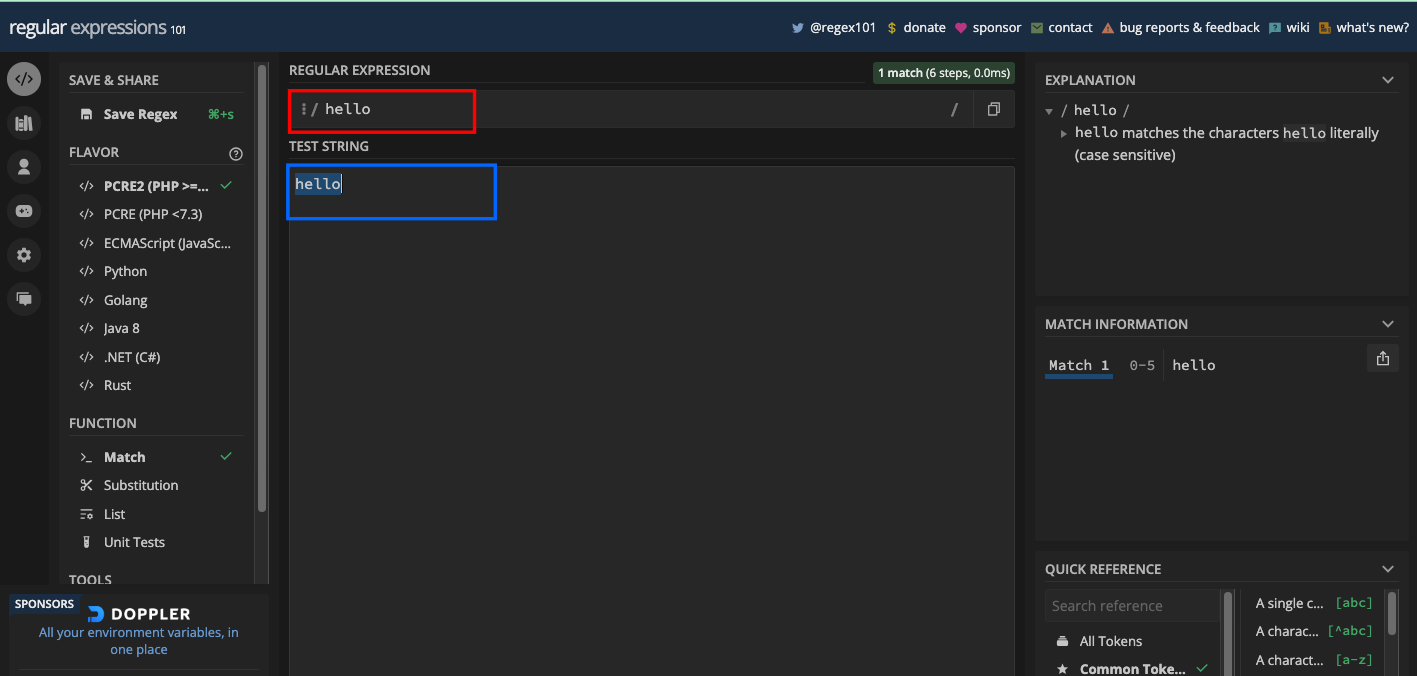
Comment Correspondre aux Caractères Littéraux dans les Testeurs RegEx
À condition que vous souhaitiez correspondre au mot hello, alors hello devrait être votre motif regex :
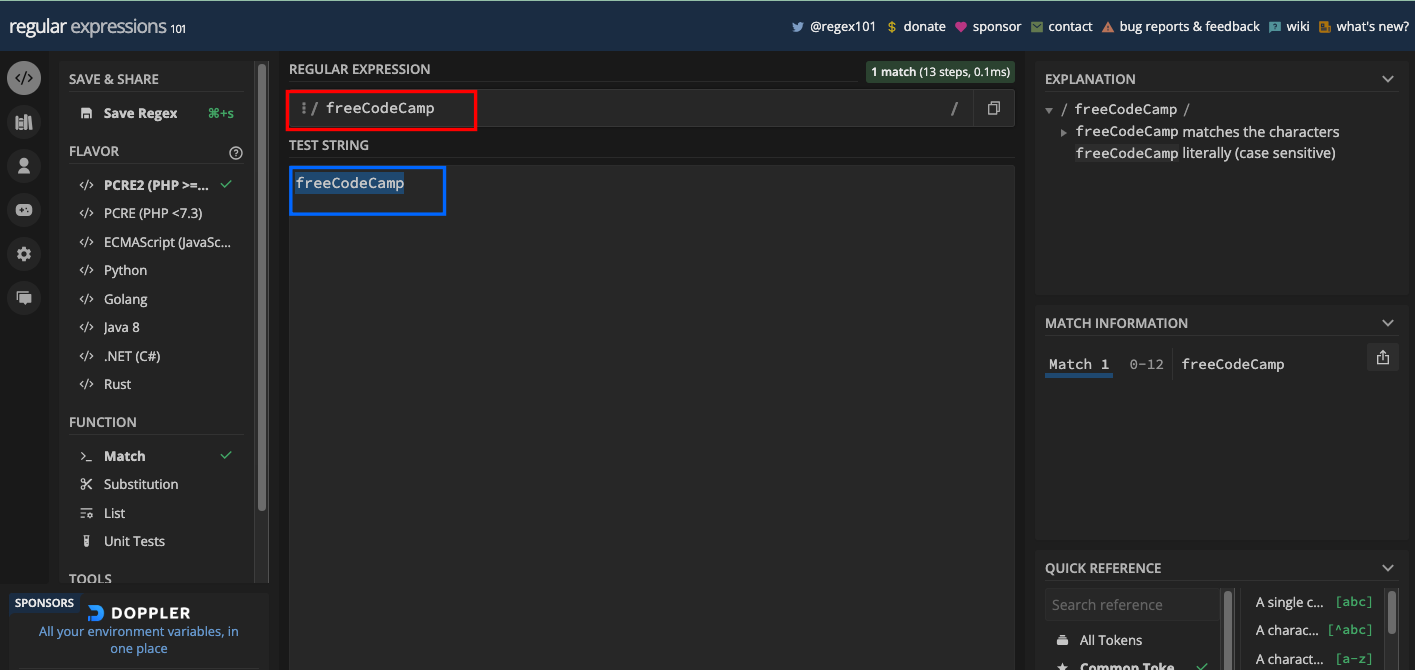
Si vous voulez correspondre au texte freeCodeCamp, vous pouvez construire votre regex pour qu'il soit freeCodeCamp :
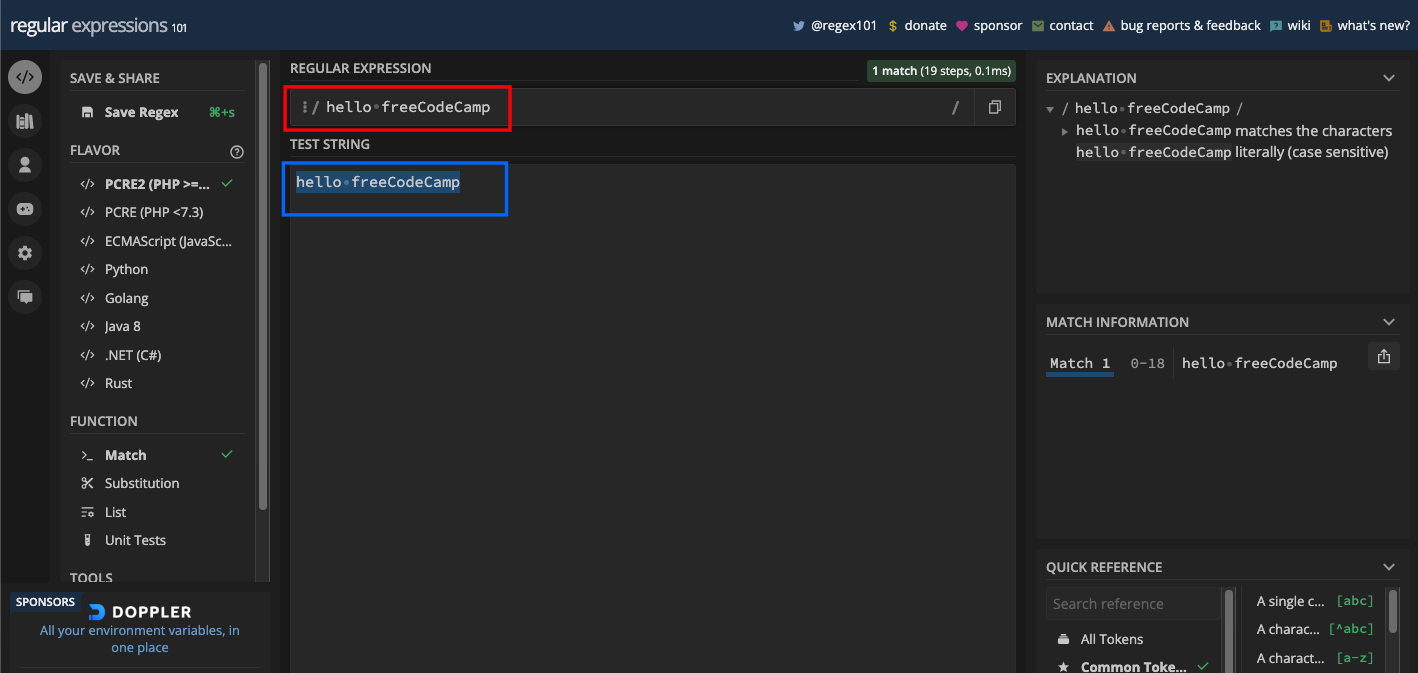
Alors, que faire si vous voulez correspondre à hello freeCodeCamp ? Alors vous utilisez simplement hello freeCodeCamp comme motif :
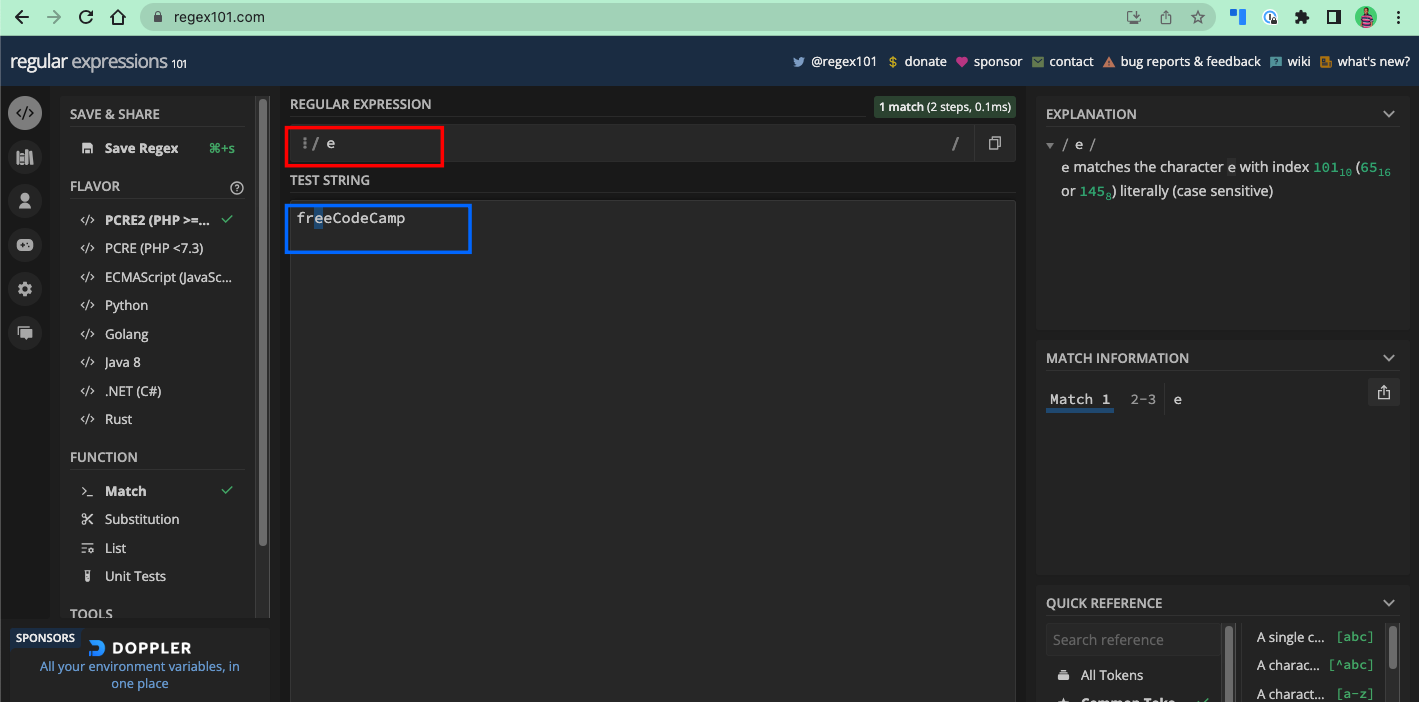
Si vous voulez correspondre à la lettre e dans le texte freeCodeCamp, e est le motif à utiliser :
Et si vous voulez correspondre à h dans le texte hatch, h est le motif que vous devriez utiliser :
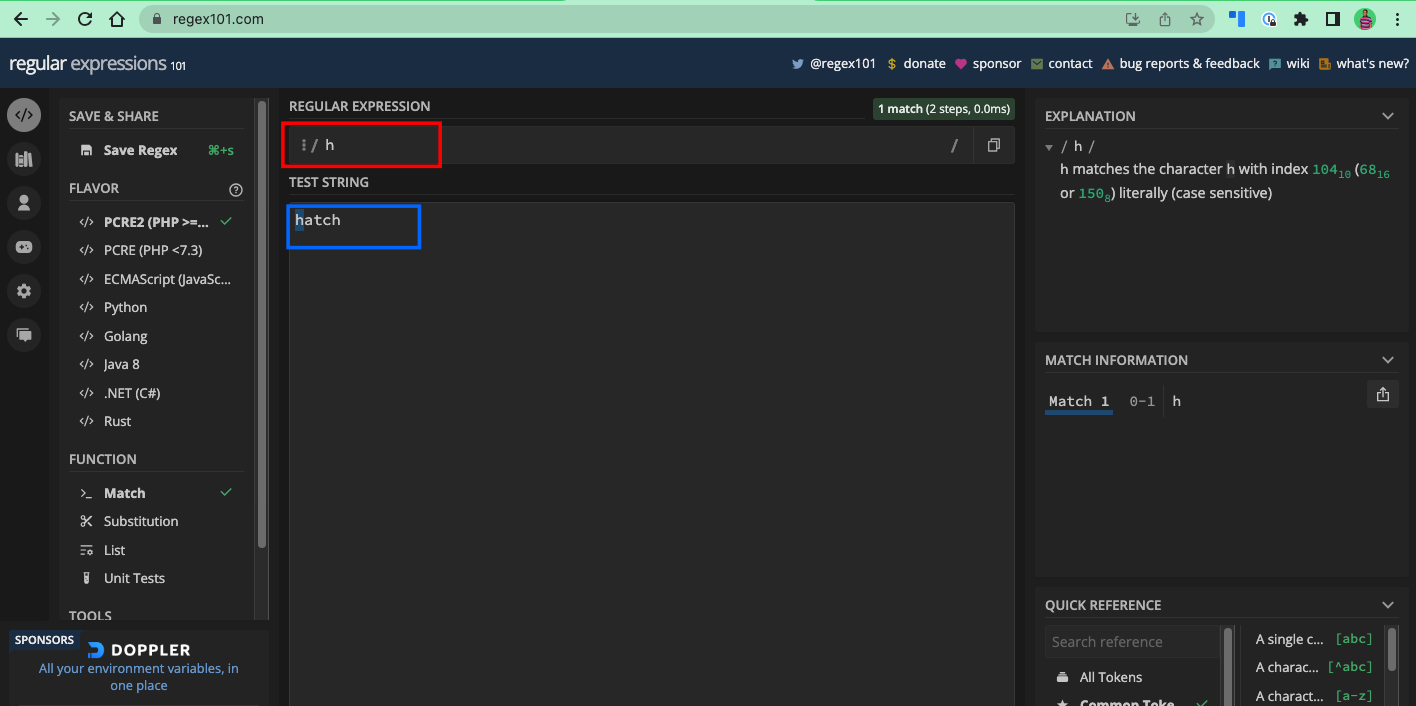
Vous pouvez voir que dans le texte freeCodeCamp, les autres e après la première occurrence n'ont pas été retournés comme correspondances – même chose pour le dernier h dans le mot hatch. Vous apprendrez comment correspondre à chaque occurrence d'une lettre dans un texte dans le prochain chapitre.
Correspondance d'Ensemble de Caractères
Un ensemble de caractères, également appelé classe de caractères, est un ensemble de caractères qui correspondra avec succès à un certain caractère dans une chaîne de test. Cet ensemble de caractères est enfermé dans des crochets.
Par exemple, le motif [abc] correspondra à l'un des caractères a, b, et c, tandis que [xyz] correspondra à l'un des caractères x, y, et z.
Voici quelques exemples d'ensembles de caractères et ce qu'ils font :
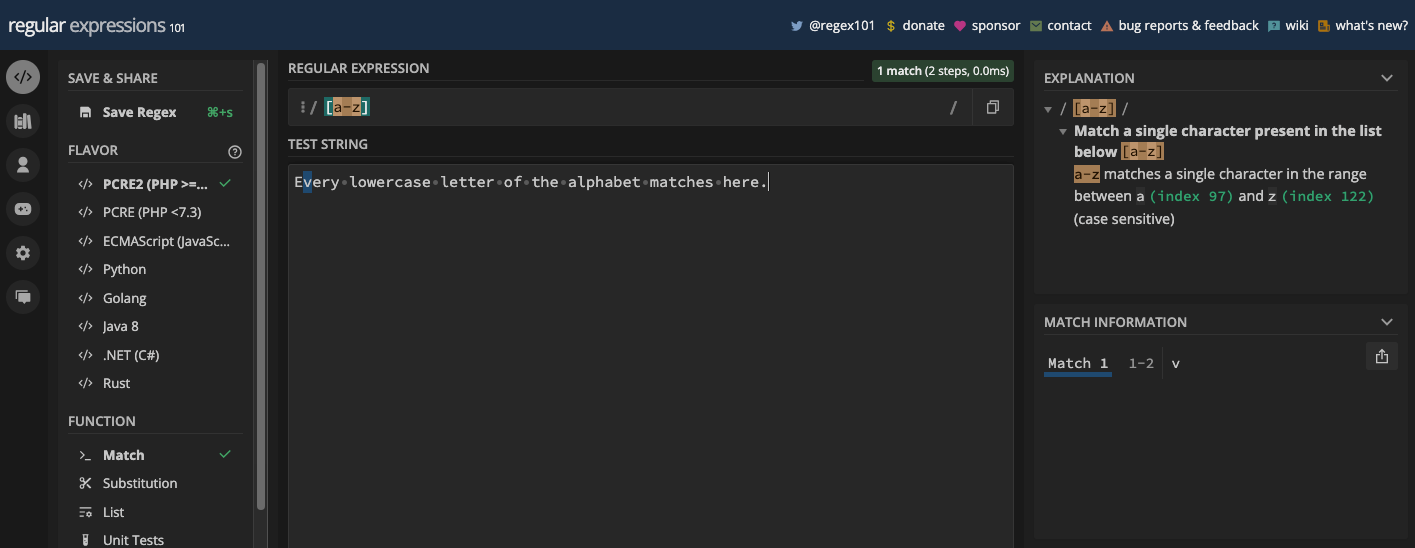
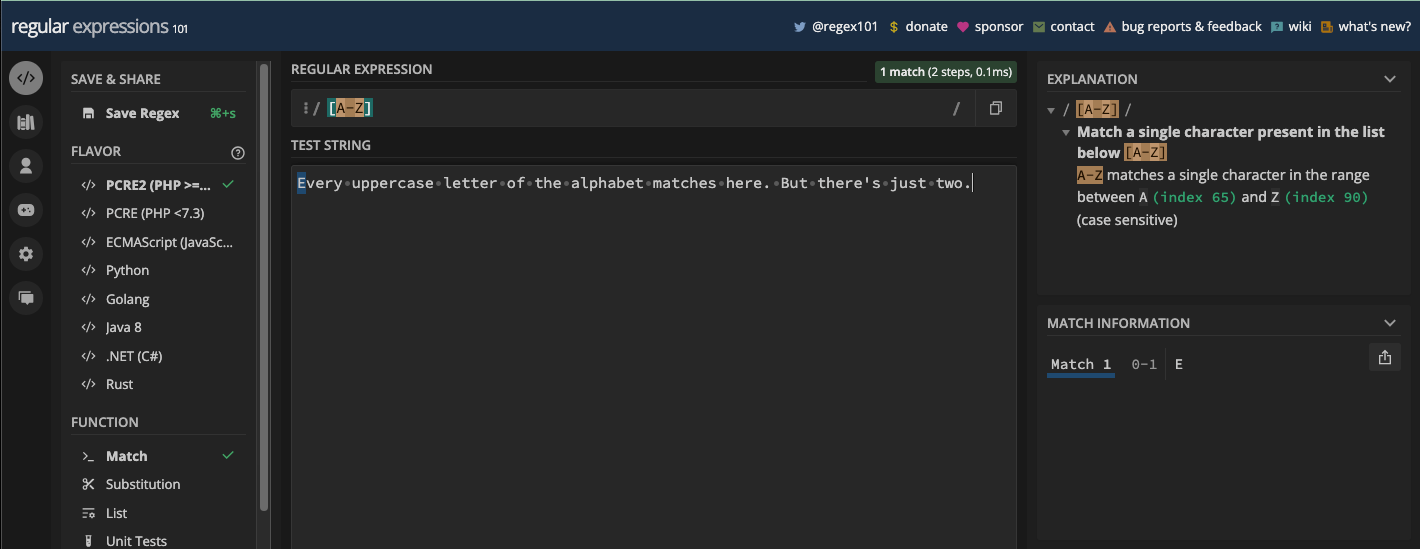
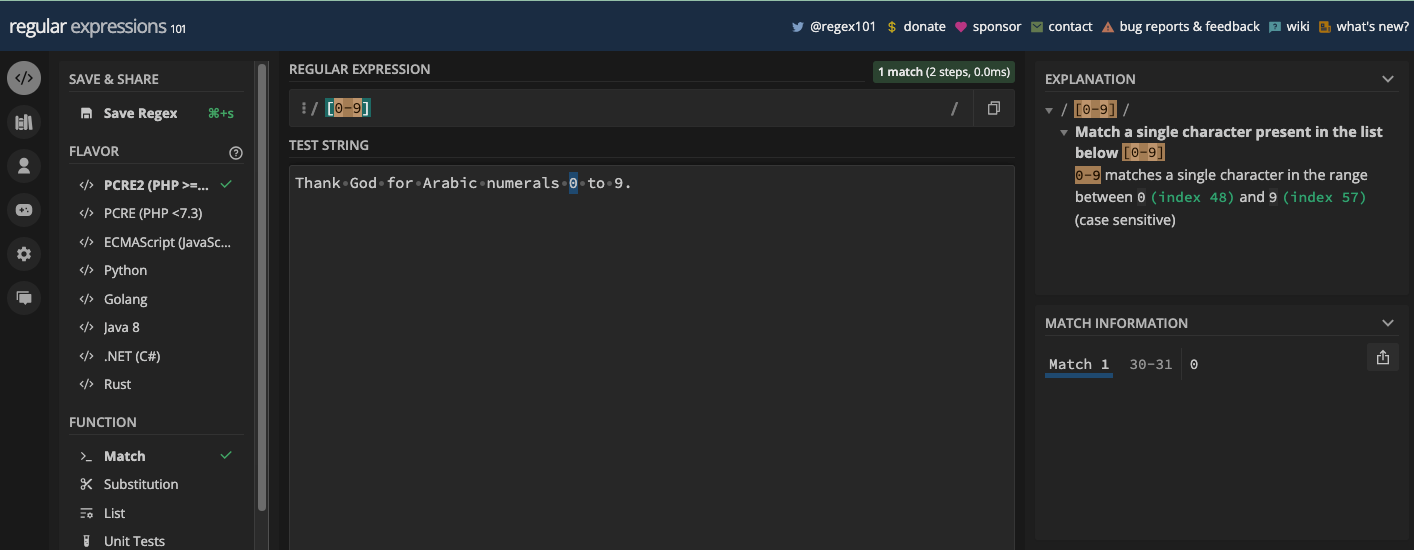
[abc]: correspond àa,b, ouc[aeiou]: correspond à n'importe quel caractère voyelle[a-z]: correspond à n'importe quelle lettre minuscule deaàz[A-Z]: correspond à n'importe quelle lettre majuscule deAàZ[0-9]: correspond à n'importe quel chiffre de 0 à 9
À l'intérieur des crochets, vous n'avez pas besoin d'échapper les métacaractères car ils perdent leur signification spéciale. Le seul symbole qui a une signification dans les crochets est le trait d'union (-), que vous pouvez utiliser pour spécifier des plages, comme je l'ai fait avec certains exemples d'ensembles de caractères.
Vous apprendrez également à propos des plages dans ce livre. À certaines occasions, une barre oblique inverse \ ne perd pas sa signification spéciale dans un ensemble de caractères.
Comme pour la correspondance de caractères littéraux, seule la première occurrence de l'ensemble de caractères sera retournée comme une correspondance, toutes les autres occurrences seront ignorées. Dans le prochain chapitre, vous apprendrez comment correspondre à plusieurs occurrences d'un caractère avec le drapeau g.
Voici comment chacun des ensembles de caractères ci-dessus fonctionne dans un outil de test regex :
[abc] :

[aeiou] :
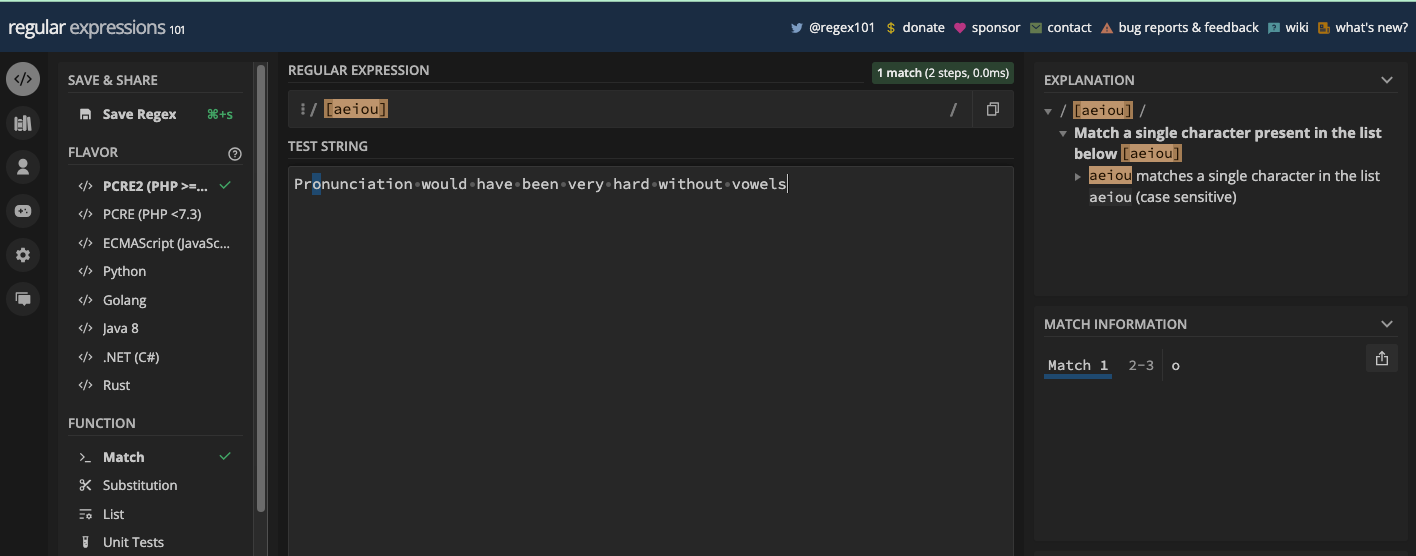
[a-z] :
[A-Z] :
[0-9] :
Vous pouvez également définir votre propre classe de caractères unique en fonction de ce que vous voulez. Les ensembles de caractères sont utiles lorsque vous voulez correspondre à certains caractères dans une position particulière dans un texte.
Par exemple, le motif br[ao]ke correspondra à la fois à brake et broke :

Le motif gr[ae]y correspondra à la fois à gray et grey :

N.B. : J'ai activé le drapeau g pour que vous puissiez voir toutes les correspondances, et à quel point les ensembles de caractères sont puissants. Nous examinerons les drapeaux g et autres dans le prochain chapitre.
Puisqu'il existe toujours plusieurs façons de faire la même chose en programmation, il existe également certains ensembles de caractères appelés "ensembles de caractères raccourcis" que vous pouvez utiliser au lieu des ensembles de caractères.
Puisque ces ensembles de caractères raccourcis sont un sous-ensemble des métacaractères, vous apprendrez à leur sujet dans le chapitre dédié aux métacaractères.
Chapitre 3 : Drapeaux des Expressions Régulières
Également appelés modificateurs, les drapeaux sont des caractères spéciaux que vous pouvez placer à la fin ou au sein d'un motif d'expressions régulières pour en modifier le comportement par défaut.
Les développeurs JavaScript ont tendance à se référer à ces caractères comme des "drapeaux", mais en Python, ils sont utilisés de manière interchangeable.
En Python, vous pouvez placer des drapeaux au sein d'un motif regex, mais en JavaScript, les drapeaux sont toujours placés à la fin du motif regex.
Voici les drapeaux que vous pouvez utiliser dans les expressions régulières :
- drapeau
global - drapeau
case insensitive - drapeau
multi-line - drapeau
single-line - drapeau
unicode - drapeau
sticky
Dans de nombreux moteurs regex, vous pouvez activer n'importe quel drapeau que vous souhaitez utiliser. Dans regex101.com, vous pouvez activer un drapeau en cliquant sur le symbole de barre oblique (/) à droite de l'entrée du motif :
Vous pouvez ensuite sélectionner n'importe quel drapeau que vous souhaitez utiliser :
N.B. : Si la variante de regex que vous avez sélectionnée dans regex101.com n'est pas ECMAScript, l'ensemble des drapeaux présentés peut être différent.
Si vous utilisez regexpal.com, cliquez sur "flags" au-dessus de l'entrée du motif regex :
Sélectionnez n'importe quel drapeau que vous souhaitez en cliquant dessus :
Maintenant, examinons en détail chacun des drapeaux regex et comment ils fonctionnent dans un moteur regex.
Le Drapeau global
Le drapeau global est représenté par la lettre g. Avec lui, vous pouvez effectuer une correspondance globale avec votre motif.
Souvenez-vous, dans le chapitre précédent de ce livre, certains motifs que j'ai définis se sont arrêtés lorsqu'ils ont trouvé la première correspondance, même s'il y en avait d'autres. C'est parce que par défaut, les expressions régulières ne trouvent que la première correspondance dans un texte. Mais avec le drapeau g, toutes les occurrences de la correspondance sont retournées.
Une autre bonne chose à propos de l'utilisation du drapeau g est que vous pouvez itérer sur les correspondances que vous obtenez avec le motif en JavaScript. L'itération continue jusqu'à ce qu'il n'y ait plus rien à correspondre. Vous apprendrez bientôt plusieurs façons d'itérer sur les correspondances.
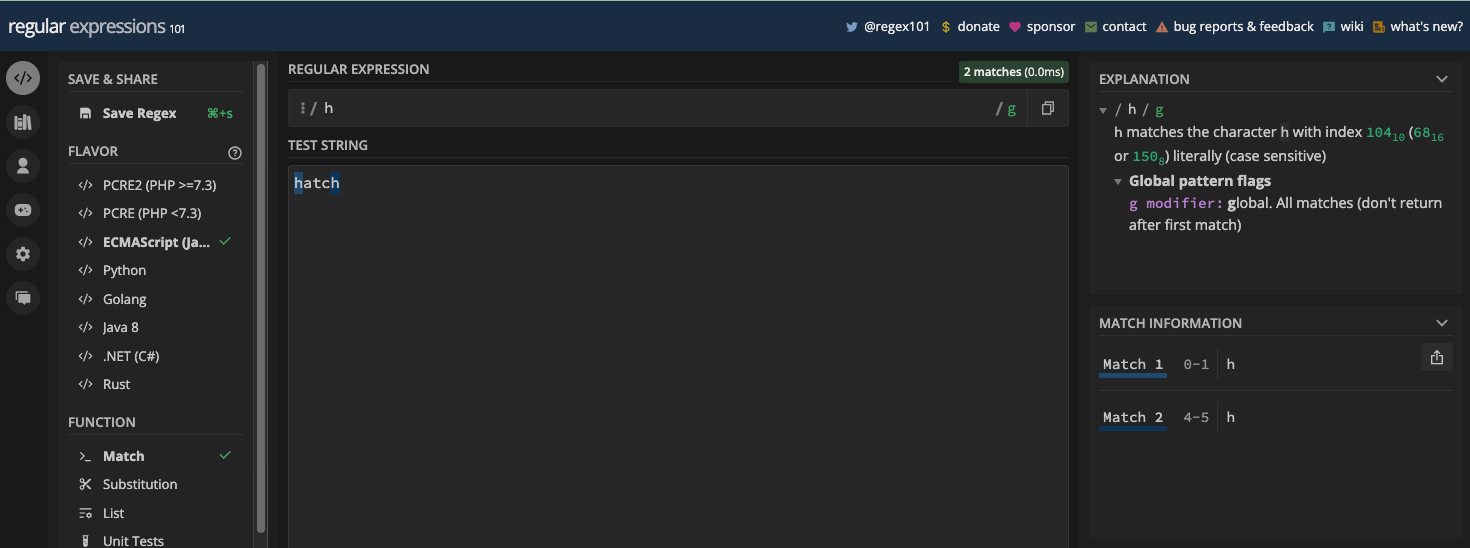
Pour vous montrer comment fonctionne le drapeau g, j'utiliserai les exemples hatch et freeCodeCamp du chapitre précédent.
Si vous voulez correspondre aux lettres h dans le mot hatch avec le motif h, les deux premiers et derniers h seront retournés comme correspondances tant que vous avez le drapeau g activé :
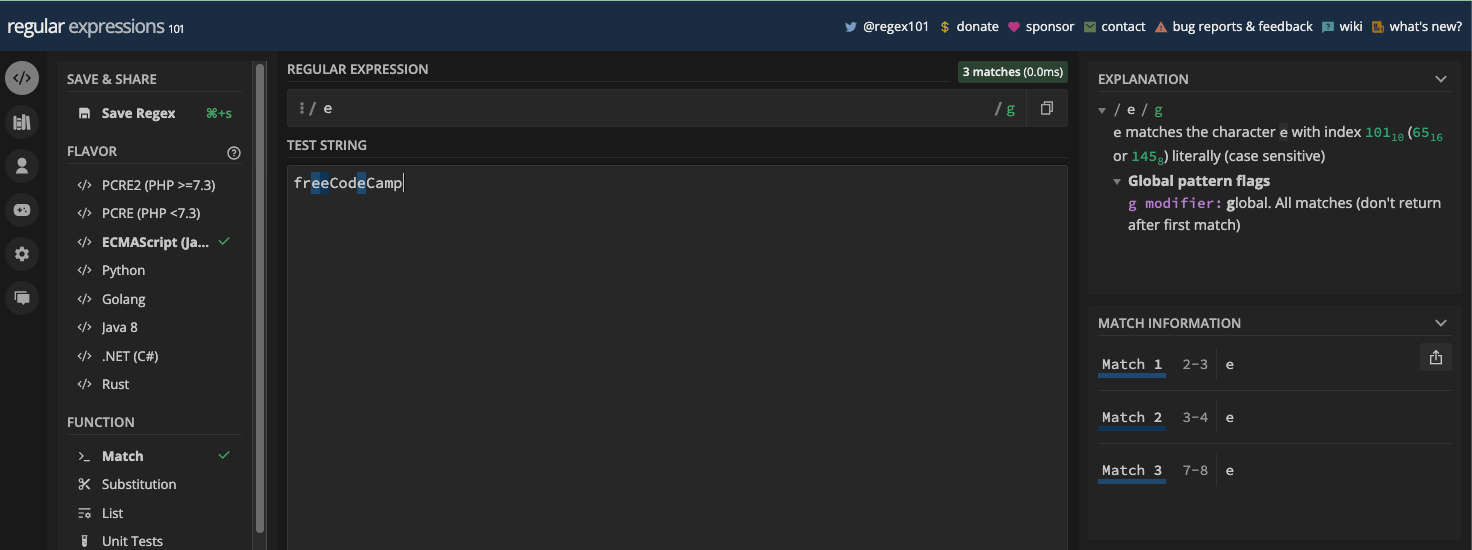
Et si vous voulez correspondre à e dans freeCodeCamp avec le motif e et que vous activez le drapeau g, les deuxième et troisième e sont également retournés comme correspondance :
Le Drapeau case-insensitive
Le drapeau case insensitive est représenté par i. Comme son nom l'indique, il vous permet d'effectuer une correspondance insensible à la casse.
Par défaut, les expressions régulières effectuent une correspondance sensible à la casse. Mais avec le drapeau i, vous pouvez effectuer une correspondance insensible à la casse, donc vous ne vous soucierez pas de la casse dans vos motifs.
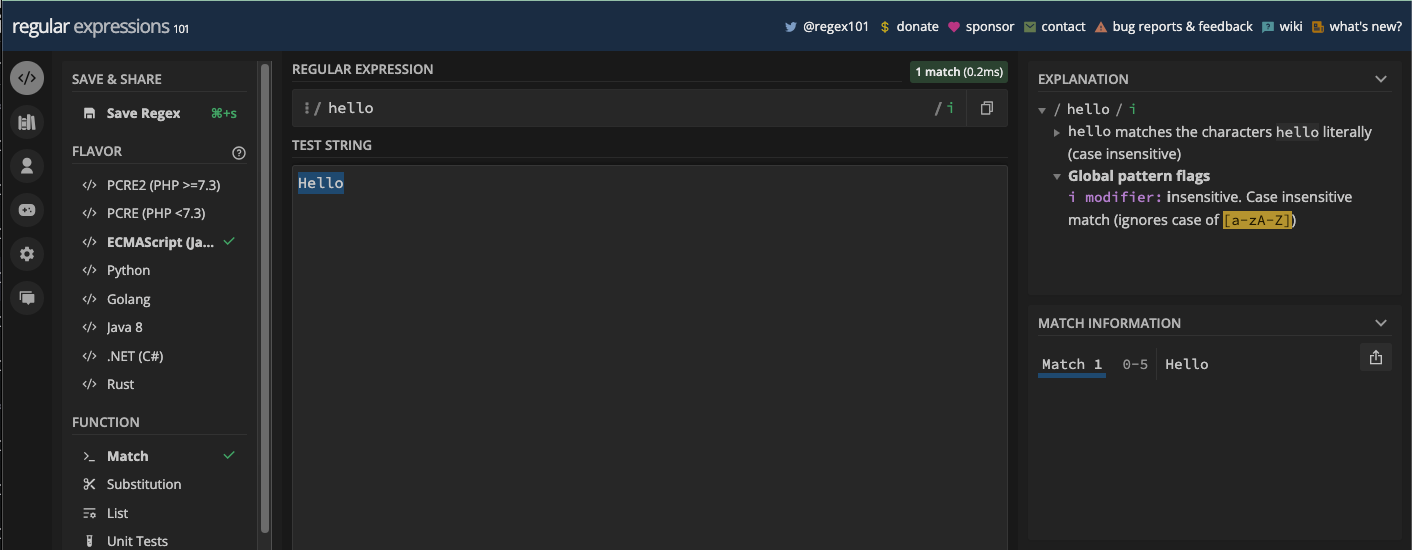
Avec cela, les majuscules ou minuscules seront ignorées. Cela signifie que Hello et hello seront traités de la même manière :
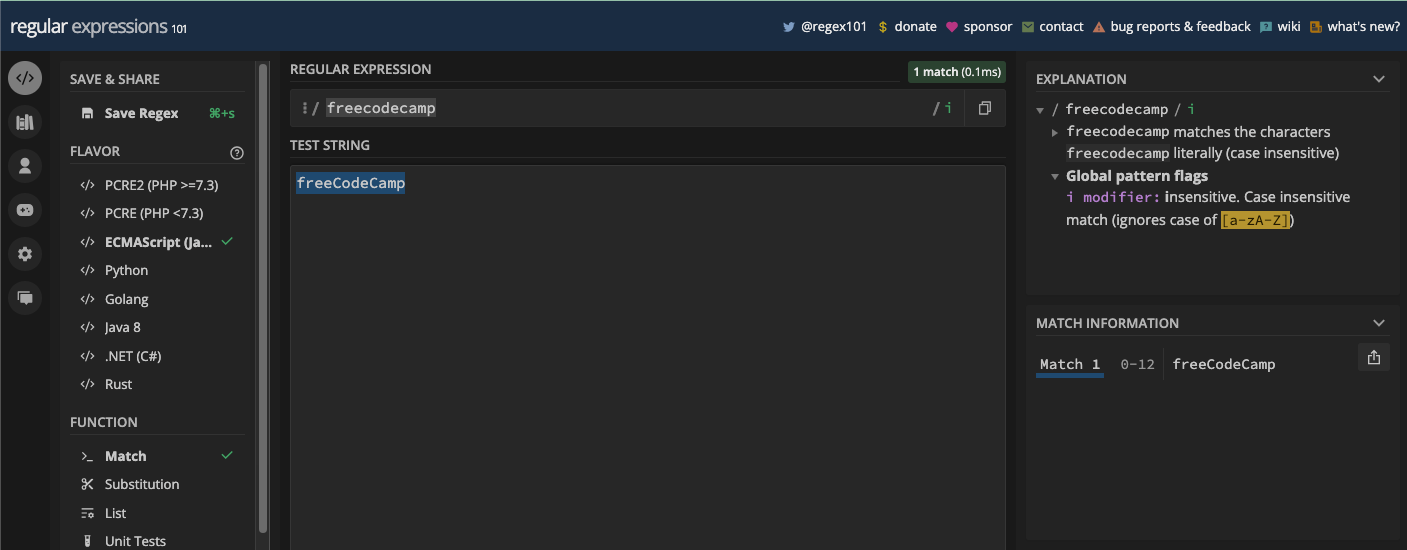
freeCodeCamp et freecodecamp sont également traités de la même manière :
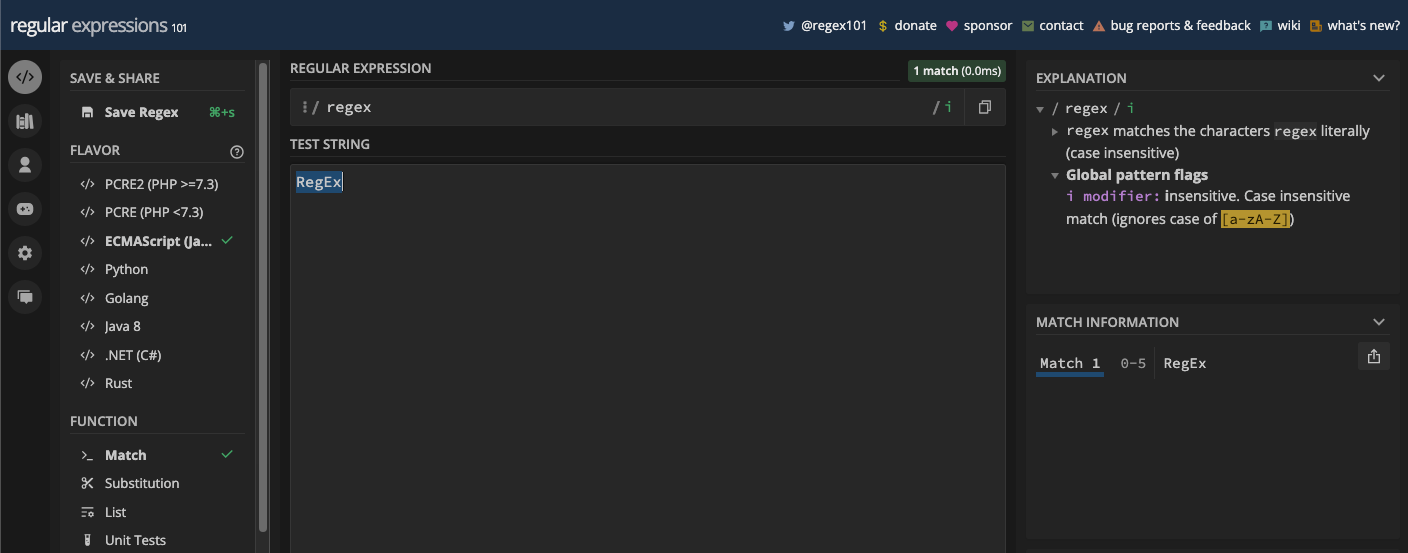
RegEx et regex sont également la même chose :
Une autre chose est que si vous utilisez une classe de caractères, par exemple [a-z], elle correspondra également aux lettres majuscules si vous activez le drapeau case-insensitive.
Ainsi, le motif [a-z] correspond également aux lettres majuscules avec le drapeau case-insensitive activé :

Les Drapeaux multi-line et single-line
Représenté par m, le drapeau multi-line indique au moteur d'expressions régulières que la chaîne de test comporte plus d'une ligne. Puisque le drapeau multi-line influence le comportement des métacaractères d'ancrage de début et de fin (^ et $), vous en apprendrez davantage à ce sujet dans le chapitre sur les ancres et les limites de mots.
Le drapeau single-line est représenté par s. Tout comme le drapeau multi-line, le drapeau single-line fonctionne également avec un métacaractère appelé le joker (.). Vous verrez le drapeau single-line en action dans le chapitre sur les métacaractères.
Le Drapeau Unicode
Le drapeau Unicode permet la correspondance complète Unicode dans le moteur d'expressions régulières qui le supporte. Il est représenté par u.
Par défaut, JavaScript et de nombreux autres langages de programmation traitent les chaînes comme une séquence d'unités de code 16 bits. Avec le drapeau u, les motifs regex peuvent correspondre aux points de code Unicode au lieu des unités de code. Cela permet de gérer des caractères comme les emojis, certains symboles et des caractères de scripts non latins. Ainsi, lorsque vous définissez le drapeau, il modifie le comportement de certaines séquences d'échappement et métacaractères pour fonctionner avec les expressions régulières.
Par exemple, la séquence d'échappement \u{1F602} correspondra au caractère littéral u{1F602} si vous n'activez pas le drapeau u :
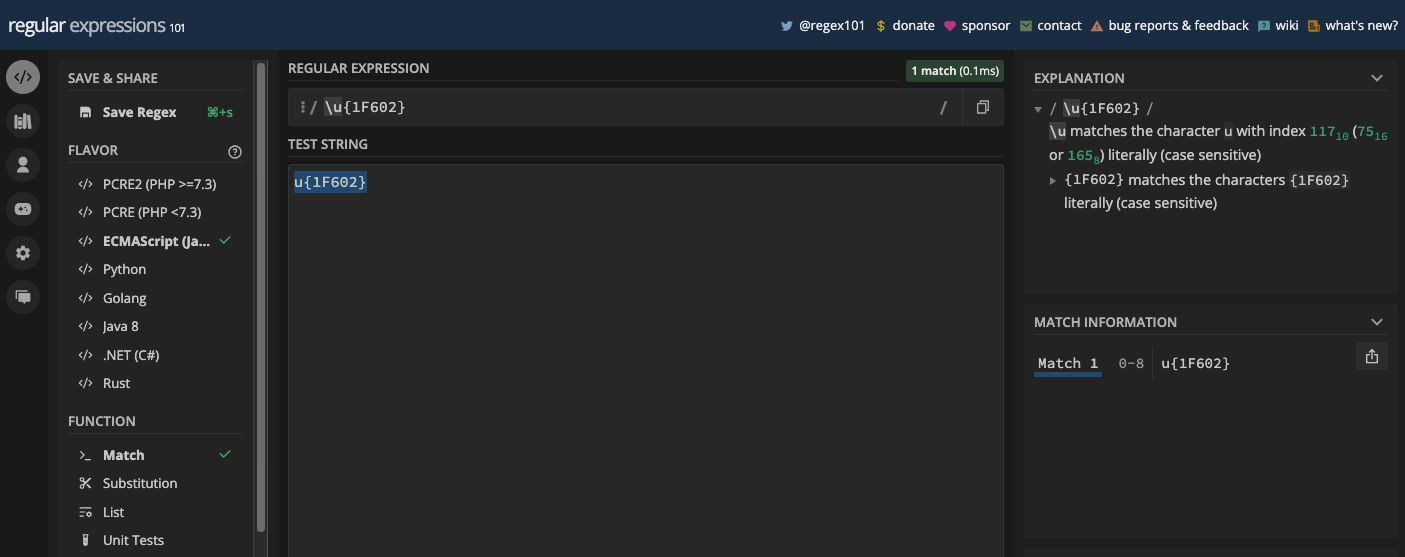
Mais si vous activez le drapeau u, le même motif correspond à l'emoji du visage avec des larmes :

C'est une façon de correspondre aux emojis et autres caractères Unicode. Prenez l'Unicode de l'emoji et mettez l'hexadécimal entre accolades, puis précédez les deux avec \u.
Par exemple, l'Unicode du cœur qui grandit est U+1F497, le motif pour le correspondre serait \u{1F497} :

Vous verrez plus d'exemples de fonctionnement du drapeau dans le chapitre sur l'utilisation des expressions régulières en JavaScript.
Le Drapeau sticky
Le drapeau sticky est représenté par y. C'est une fonctionnalité des expressions régulières JavaScript implémentée dans ECMAScript 6. Le drapeau y limite la correspondance à la position actuelle dans la chaîne, que vous pouvez spécifier avec la propriété lastIndex du constructeur RegExp().
Lorsque vous utilisez le drapeau y, il utilise la propriété lastIndex pour déterminer où la prochaine recherche commencera. Le motif correspond uniquement s'il se produit exactement à la position lastIndex ou au début de la chaîne.
Contrairement au drapeau global (g), le drapeau y ne trouve pas toutes les correspondances mais s'arrête après la première correspondance réussie.
Dans un moteur regex comme regex101.com, le drapeau y s'ancre généralement au début de la chaîne de test et s'arrête là :

Puisque le drapeau y fonctionne généralement avec la propriété lastIndex des expressions régulières JavaScript, nous examinerons plus d'exemples dans le chapitre sur l'utilisation des expressions régulières en JavaScript – spécifiquement lorsque nous examinerons le sticky du constructeur d'expressions régulières.
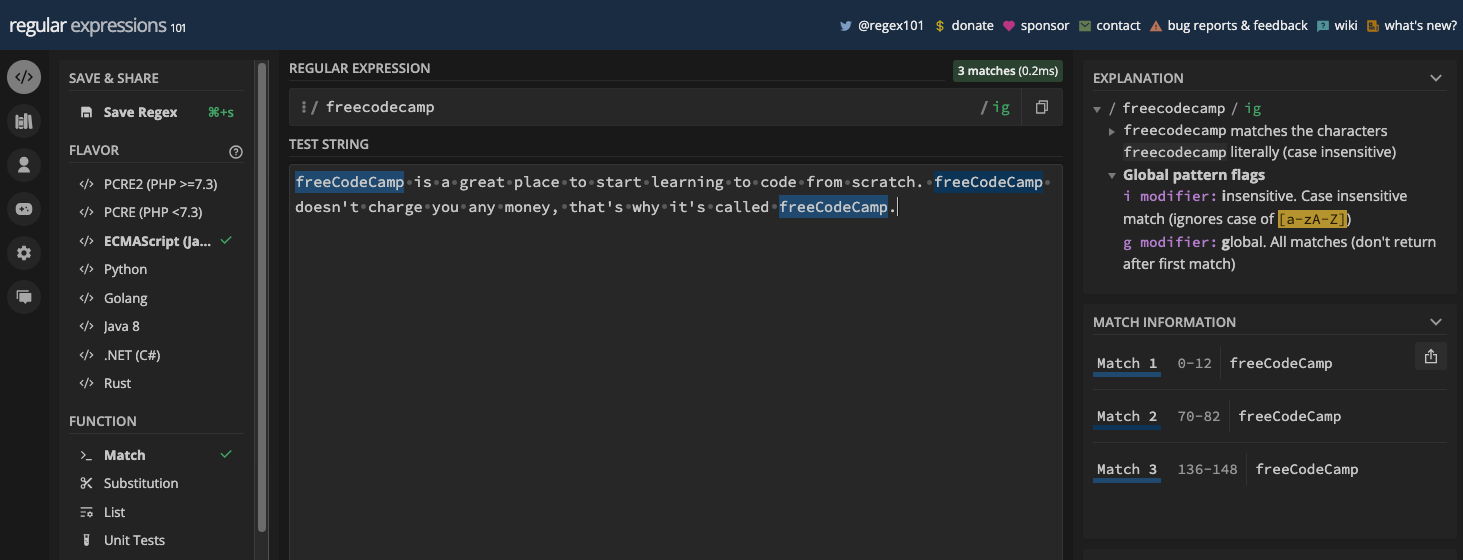
Vous pouvez également combiner plusieurs drapeaux pour écrire une syntaxe plus complexe. Par exemple, vous pouvez utiliser le drapeau g avec le drapeau i pour une correspondance globale et insensible à la casse :
Chapitre 4 : Comment Utiliser les Expressions Régulières en JavaScript
Comment Créer des Expressions Régulières en JavaScript
Il existe deux façons de créer des expressions régulières en JavaScript. La première est avec la syntaxe littérale regex et la seconde est avec le constructeur RegExp().
Pour créer une expression régulière avec la syntaxe littérale regex, vous devez enfermer le motif entre deux barres obliques (/) comme ceci :
/regex pattern/
Si vous souhaitez utiliser un ou plusieurs drapeaux, ils doivent être placés après la deuxième barre oblique :
/regex pattern/flag
Selon votre cas d'utilisation, vous devrez peut-être assigner le regex à une variable :
const regex = /regex pattern/flag
Le drapeau peut être l'un des drapeaux disponibles dans le moteur d'expressions régulières JavaScript.
Si vous souhaitez créer des expressions régulières avec le constructeur RegExp(), vous devez utiliser le mot-clé new, puis mettre le motif et le drapeau à l'intérieur des parenthèses RegExp().
Voici à quoi ressemble la syntaxe :
const regex = new RegExp("regex pattern", "flag");
Puisque RegExp() est un constructeur, il existe certaines méthodes et propriétés disponibles avec lesquelles vous pouvez travailler avec des expressions régulières. Que vous créiez votre motif avec la syntaxe littérale // ou le constructeur RegExp(), les méthodes et propriétés sont disponibles pour celui-ci.
Méthodes du Constructeur RegExp()
Les méthodes du constructeur RegExp() sont définies sur RegExp.prototype. Vous pouvez rapidement vérifier les méthodes (et propriétés) en tapant RegExp().__proto__ et en appuyant sur ENTER dans la console de votre navigateur. Ces méthodes incluent test(), exec(), et toString().
En plus de ces trois, certaines méthodes prennent des expressions régulières comme paramètre. Mais il est préférable de les discuter sous "méthodes de chaîne pour travailler avec des expressions régulières" car, au cœur, ce sont des méthodes de chaîne qui prennent des expressions régulières comme paramètre.
Examinons ce que font test(), exec(), et toString().
La Méthode test()
La méthode test() teste une correspondance entre une expression régulière et la chaîne de test et retourne un booléen comme résultat. Si une correspondance est trouvée, elle retourne true, et si aucune correspondance n'est trouvée, elle retourne false.
Dans l'exemple ci-dessous, il y a une correspondance pour le motif /freeCodeCamp/ :
const re = /freeCodeCamp/;
const testStr =
"freeCodeCamp doesn't charge you any money, that's why it's called freeCodeCamp.";
console.log(re.test(testStr)); //true
Mais dans l'exemple ci-dessous, il n'y a pas de correspondance pour le motif /fcc/, donc la méthode test() retourne false :
const re = /fcc/;
const testStr =
"freeCodeCamp doesn't charge you any money, that's why it's called freeCodeCamp.";
console.log(re.test(testStr)); //false
En plus de tester des motifs aléatoires contre une chaîne, la méthode test() peut être utile dans la validation de formulaires.
La Méthode exec()
La méthode exec() exécute une recherche de correspondance dans une chaîne de test et retourne un tableau contenant des informations détaillées sur la première correspondance. Si aucune correspondance n'est trouvée, elle retourne null.
Ces informations détaillées contiennent la première correspondance, l'index de la correspondance, les groupes capturés (le cas échéant), et la longueur.
Voici un exemple :
const re = /freeCodeCamp/;
const testStr =
"freeCodeCamp doesn't charge you any money, that's why it's called freeCodeCamp.";
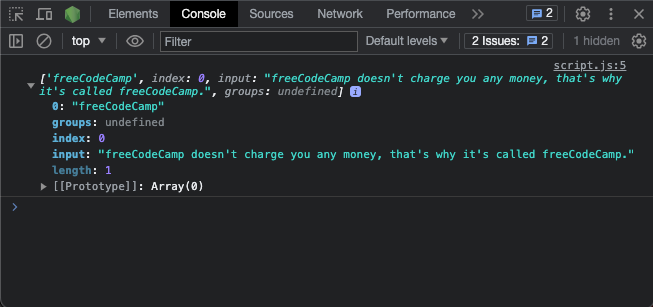
console.log(re.exec(testStr));
Et voici une capture d'écran du résultat :
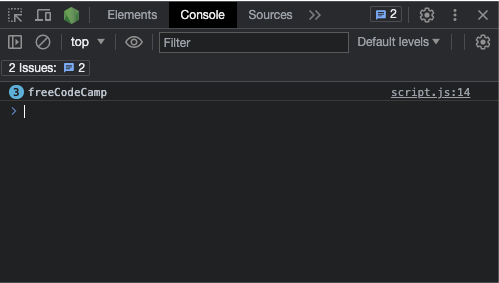
Si vous voulez que la méthode exec() retourne toutes les correspondances, vous pouvez utiliser le drapeau g sur le motif et ensuite boucler avec une boucle while :
const re = /freeCodeCamp/g;
const testStr =
"freeCodeCamp is a great place to start learning to code from scratch. freeCodeCamp doesn't charge you any money, that's why it's called freeCodeCamp.";
let match;
while ((match = re.exec(testStr)) !== null) {
console.log(match[0]);
}
Voici à quoi ressemble le résultat dans la console :
Vous pouvez aller plus loin en accédant à l'index des correspondances de cette manière :
const re = /freeCodeCamp/g;
const testStr =
"freeCodeCamp is a great place to start learning to code from scratch. freeCodeCamp doesn't charge you any money, that's why it's called freeCodeCamp.";
let match;
while ((match = re.exec(testStr)) !== null) {
console.log(match[0]);
// Accéder aux indices des correspondances
console.log(match.index);
}
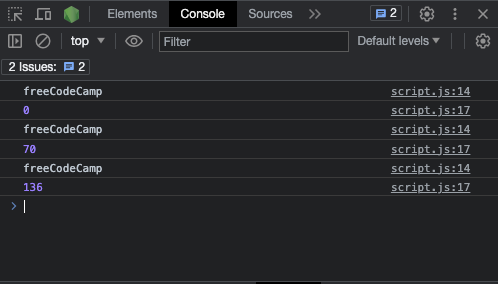
Si aucune correspondance n'est trouvée, exec() retourne null :
const re = /fcc/;
const testStr =
"freeCodeCamp doesn't charge you any money, that's why it's called freeCodeCamp.";
console.log(re.exec(testStr)); //null
La Méthode toString()
La méthode toString() convertit un motif regex en une chaîne. En JavaScript, la méthode toString() est présente dans chaque objet. Les expressions régulières sont traitées comme un objet en arrière-plan, c'est pourquoi vous pouvez les créer avec le mot-clé new.
L'utilisation de cette méthode sur un motif regex convertit le motif en une chaîne :
const pattern = /freeCodeCamp/;
const strPattern = pattern.toString();
console.log(strPattern, typeof strPattern); // /freeCodeCamp/ string
Même si vous créez le motif avec le constructeur RegExp(), vous obtenez le résultat de la même manière :
const pattern = new RegExp('freeCodeCamp');
const strPattern = pattern.toString();
console.log(strPattern, typeof strPattern); // /freeCodeCamp/ string
Et si vous avez un drapeau dans le motif, il serait retourné comme une partie de la chaîne :
const pattern = /freeCodeCamp/gi;
const strPattern = pattern.toString();
console.log(strPattern, typeof strPattern); // /freeCodeCamp/gi string
Propriétés du Constructeur RegExp()
Les propriétés du constructeur RegExp() sont définies sur RegExp.prototype. Elles incluent :
RegExp.prototype.globalRegExp.prototype.sourceRegExp.prototype.flagsRegExp.prototype.multilineRegExp.prototype.ignoreCaseRegExp.prototype.dotAllRegExp.prototype.stickyRegExp.prototype.unicode
En bref, il y a les propriétés global, source, flags, multiline, ignoreCase, dotAll, sticky, et unicode.
La plupart des propriétés vérifient si un certain drapeau est utilisé ou non. Examinons comment chacune des propriétés fonctionne.
La Propriété global
La propriété global vérifie si le drapeau g est utilisé avec un motif regex ou non. Si le motif a le drapeau g, elle retourne true, sinon elle retourne false.
Rappelez-vous que le drapeau global (g) indique que le motif regex ne doit pas seulement retourner la première correspondance mais toutes les correspondances.
Voici comment la propriété global fonctionne en code :
const re1 = /freeCodeCamp/g;
const re2 = /freeCodeCamp/;
const re3 = new RegExp('freeCodeCamp');
const re4 = new RegExp('freeCodeCamp', 'g');
console.log(re1.global); //true
console.log(re2.global); //false
console.log(re3.global); //false
console.log(re4.global); //true
La Propriété flag
La propriété flag retourne les drapeaux que vous utilisez dans le motif regex dans l'ordre alphabétique. C'est-à-dire, g avant i, i avant m, m avant y, et ainsi de suite.
Dans le code ci-dessous, vous pouvez voir que le drapeau g vient avant i, et m vient avant y :
const re1 = /freeCodeCamp/gi;
const re2 = new RegExp('freeCodeCamp', 'my');
console.log(re1.flags); //gi
console.log(re2.flags); //my
La Propriété source
La propriété source retourne le motif regex sous forme de chaîne. Elle agit donc comme la méthode toString().
La différence entre la propriété source et la méthode toString() est que la propriété source exclut le drapeau que vous utilisez avec le motif. De plus, la propriété source ne montre pas les barres obliques littérales que vous utilisez pour créer le regex.
Dans le code ci-dessous, vous pouvez voir que les barres obliques ne sont pas imprimées, les drapeaux sont omis également, et le type est une chaîne :
const re1 = /freeCodeCamp/gi;
const re2 = new RegExp('freeCodeCamp', 'my');
const re1Source = re1.source;
const re2Source = re2.source;
console.log(re1Source, typeof re1Source); // freeCodeCamp string
console.log(re2Source, typeof re2Source); // freeCodeCamp string
La Propriété multiline
Le drapeau multiline est une autre propriété booléenne du constructeur RegExp(). Il spécifie si le drapeau multiline est utilisé avec le motif ou non en retournant true ou false.
Rappelez-vous que le drapeau multiline (m) indique que la chaîne de test doit être traitée comme un texte qui a plus d'une ligne.
Voici comment la propriété multiline fonctionne en action :
const re1 = /freeCodeCamp/gi;
const re2 = new RegExp('freeCodeCamp', 'my');
const re1Source = re1.multiline;
const re2Source = re2.multiline;
console.log(re1Source); //false
console.log(re2Source); // true
La Propriété ignoreCase
La propriété ignoreCase spécifie si le drapeau insensible à la casse (i) est utilisé dans le motif regex. Elle retourne true si vous utilisez le drapeau i et false si vous ne l'utilisez pas.
const re1 = /freeCodeCamp/i;
const re2 = /freeCodeCamp/;
const re3 = new RegExp('freeCodeCamp', 'i');
const re4 = new RegExp('freeCodeCamp');
console.log(re1.ignoreCase); //true
console.log(re2.ignoreCase); // false
console.log(re3.ignoreCase); // true
console.log(re4.ignoreCase); // false
La Propriété Unicode
La propriété unicode vous aide à vérifier si le drapeau Unicode (u) est utilisé dans le motif regex ou non. Si elle trouve le drapeau u, elle retourne true, sinon elle retourne false.
const re1 = /\u{1F1F3}\u{1F1EC}/u; // correspond à l'emoji du drapeau nigérian
const re2 = /\u{1F1F3}\u{1F1EC}/;
const re3 = new RegExp('\u{1F1F3}\u{1F1EC}', 'u');
const re4 = new RegExp('\u{1F1F3}\u{1F1EC}');
console.log(re1.unicode); //true
console.log(re2.unicode); // false
console.log(re3.unicode); // true
console.log(re4.unicode); // false
La Propriété sticky
La propriété sticky indique si le drapeau sticky (y) est défini dans l'expression régulière ou non. Même si c'est ce qu'elle fait, elle reste un peu difficile à comprendre à cause de la propriété lastIndex.
Lorsque le drapeau y est défini, le moteur regex utilisé tentera de faire correspondre le motif en commençant à la position exacte spécifiée par la propriété lastIndex (sans utiliser le drapeau g). Si une correspondance est trouvée, la propriété lastIndex est mise à jour à la position immédiatement après la fin de la correspondance.
Pour vous aider à mieux comprendre cela, voici un extrait de code avec des commentaires :
const re = /xyz/y;
const str = 'xyzxyz';
re.lastIndex = 0;
console.log(re.test(str)); // true – il y a une correspondance à l'index 0 à 2
console.log(re.lastIndex); // 3
re.lastIndex = 1;
console.log(re.test(str)); // false – aucune correspondance à l'index spécifié
console.log(re.lastIndex); // 0 – réinitialise à 0 car il n'y a pas de correspondance à l'index spécifié
re.lastIndex = 3;
console.log(re.test(str)); // true – il y a une correspondance à l'index 3 à 5
console.log(re.lastIndex); // 6
re.lastIndex = 6;
console.log(re.test(str)); // false
console.log(re.lastIndex); // 0 – réinitialise à 0 car il n'y a pas de correspondance à l'index spécifié
N.B. : La propriété dotAll fonctionne avec le métacaractère joker (.). En raison de cela, vous verrez comment elle fonctionne en détail dans le chapitre sur les métacaractères. De plus, hasIndices fonctionne avec les captures. Vous verrez donc comment l'utiliser dans le chapitre sur le groupement et la capture.
Méthodes de Chaîne pour Travailler avec les Expressions Régulières
JavaScript fournit certaines méthodes intégrées pour travailler avec des chaînes. Certaines de ces méthodes prennent des expressions régulières comme paramètre. Ces méthodes incluent match(), matchAll(), replace(), replaceAll(), split(), et search().
Examinons chacune d'entre elles une par une.
La Méthode search()
La méthode search() recherche la correspondance d'une expression régulière dans une chaîne et retourne l'index de la correspondance.
const myStr =
"fCC est l'abréviation de freeCodeCamp. freeCodeCamp ne vous facture aucun argent, c'est pourquoi il s'appelle freeCodeCamp. Apprenez à coder gratuitement aujourd'hui.";
const re = /freeCodeCamp/;
const searchFCC = myStr.search(re);
console.log(searchFCC); //28
Si la méthode search() ne trouve aucune correspondance, elle retourne -1 :
const myStr =
"fCC est l'abréviation de freeCodeCamp. freeCodeCamp ne vous facture aucun argent, c'est pourquoi il s'appelle freeCodeCamp. Apprenez à coder gratuitement aujourd'hui.";
const re = /FCC/;
const searchFCC = myStr.search(re);
console.log(searchFCC); //-1
Vous pourriez penser que l'utilisation du drapeau g avec le motif retournerait les indices de toutes les correspondances, mais ce n'est pas le cas. Le drapeau g n'affecte pas la méthode search() :
const myStr =
"fCC est l'abréviation de freeCodeCamp. freeCodeCamp ne vous facture aucun argent, c'est pourquoi il s'appelle freeCodeCamp. Apprenez à coder gratuitement aujourd'hui.";
const re = /freeCodeCamp/g; // motif avec le drapeau g
const searchFCC = myStr.search(re);
console.log(searchFCC); //28
Si vous souhaitez obtenir les indices de toutes les correspondances, vous devez utiliser la méthode match() ou matchAll().
La Méthode match()
La méthode match() vous permet de spécifier un motif regex comme paramètre, puis elle parcourt la chaîne que vous utilisez et retourne un tableau contenant la ou les sous-chaînes qui correspondent au motif regex.
const my_str = 'freeCodeCamp';
match = my_str.match(/free/);
console.log(match); // [ 'free', index: 0, input: 'freeCodeCamp', groups: undefined ]
Vous pouvez également séparer le motif regex dans une variable distincte :
const my_str = 'freeCodeCamp';
const re = /free/;
const match = my_str.match(re);
console.log(match); // [ 'free', index: 0, input: 'freeCodeCamp', groups: undefined ]
Si match() trouve plusieurs correspondances, il les retourne toutes dans le tableau, à condition que vous utilisiez le drapeau g dans le motif :
const my_str =
"freeCodeCamp ne vous facture aucun argent, c'est pourquoi il s'appelle freeCodeCamp. Apprenez à coder gratuitement aujourd'hui.";
const re = /free/g;
const match = my_str.match(re);
console.log(match); // ['free', 'free', 'free']
Si vous développez le tableau, voici à quoi il ressemble :

Puisque le résultat est un tableau, vous devriez probablement utiliser console.table() au lieu de console.log() pour voir les indices des correspondances :
const my_str =
"freeCodeCamp ne vous facture aucun argent, c'est pourquoi il s'appelle freeCodeCamp. Apprenez à coder gratuitement aujourd'hui.";
const re = /free/g;
const match = my_str.match(re);
console.table(match);
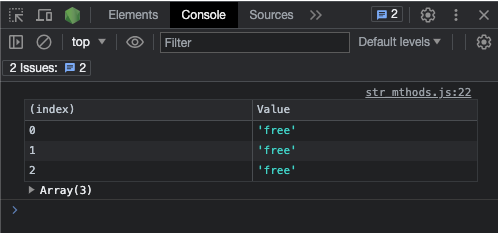
Si la méthode match() ne trouve aucune correspondance, elle retourne null :
const my_str = 'freeCodeCamp';
const re = /ref/;
const match = my_str.match(re);
console.log(match); // null
La Méthode matchAll()
matchAll() est un hybride de la méthode match(). Elle retourne un itérateur de toutes les sous-chaînes qui correspondent aux expressions régulières que vous fournissez. Cela signifie que vous devez l'utiliser avec le drapeau global (g).
Parce qu'elle retourne l'itérateur de toutes les correspondances, matchAll() est une excellente option pour parcourir les correspondances des expressions régulières.
Une alternative à l'itération des correspondances d'une expression régulière est l'utilisation de la méthode exec() et du drapeau g, puis la boucle avec une boucle while de cette manière :
const my_str =
"freeCodeCamp ne vous facture aucun argent, c'est pourquoi il s'appelle freeCodeCamp. Apprenez à coder gratuitement aujourd'hui.";
const re = /free/g;
let match;
while ((match = re.exec(my_str))) {
console.log(match[0]); //
}
// free
// free
// free
Avec la méthode matchAll(), vous n'avez pas besoin de exec() et de la boucle while. Tout ce dont vous avez besoin est une boucle for...of pour obtenir les correspondances :
const my_str =
"freeCodeCamp ne vous facture aucun argent, c'est pourquoi il s'appelle freeCodeCamp. Apprenez à coder gratuitement aujourd'hui.";
const re = /free/g;
const matches = my_str.matchAll(re);
console.log(matches); // RegExpStringIterator {}
// parcourir les correspondances avec une boucle for...of
for (const match of matches) {
console.log(match);
}
Cela retourne chaque match, leurs index, la chaîne de test, la longueur et les groupes dans leurs tableaux respectifs :

Vous pouvez modifier le journal de la console pour obtenir uniquement les correspondances et leur index de cette manière :
const my_str =
"freeCodeCamp ne vous facture aucun argent, c'est pourquoi il s'appelle freeCodeCamp. Apprenez à coder gratuitement aujourd'hui.";
const re = /free/g;
const matches = my_str.matchAll(re);
console.log(matches); // RegExpStringIterator {}
// parcourir les correspondances avec une boucle for...of
for (const match of matches) {
console.log(`Trouvé une correspondance ${match[0]} à l'index ${match.index}`);
}
/*
Sortie :
Trouvé une correspondance free à l'index 0
Trouvé une correspondance free à l'index 66
Trouvé une correspondance free à l'index 98
*/
Vous pouvez également utiliser la méthode Array.from() pour faire la même chose :
const my_str =
"freeCodeCamp ne vous facture aucun argent, c'est pourquoi il s'appelle freeCodeCamp. Apprenez à coder gratuitement aujourd'hui.";
const re = /free/g;
Array.from(my_str.matchAll(re), (match) =>
console.log(`Trouvé une correspondance ${match[0]} à l'index ${match.index}`)
);
/*
Sortie :
Trouvé une correspondance free à l'index 0
Trouvé une correspondance free à l'index 66
Trouvé une correspondance free à l'index 98
*/
Si la méthode matchAll() ne trouve aucune correspondance, elle retourne un itérateur vide. Et si vous décidez de parcourir cet itérateur vide, il n'y aura rien à voir dans la console.
La Méthode replace()
La méthode replace() fait ce que son nom implique. Elle recherche les correspondances d'une chaîne ou d'une expression régulière spécifiée dans une chaîne et les remplace par la chaîne de remplacement spécifiée. Elle retourne une nouvelle chaîne avec les remplacements appliqués.
La méthode replace() n'est pas aussi simple que match() et matchAll() car elle accepte deux paramètres – une expression régulière et la chaîne de remplacement. Toute sous-chaîne de la chaîne de test qui correspond aux expressions régulières est ensuite remplacée par la chaîne de remplacement.
Si l'expression régulière n'inclut pas le drapeau global (g), seule la première correspondance est remplacée :
const myStr =
'Les éléphants sont de très grands animaux. Ils sont si grands qu'ils peuvent déraciner un grand arbre.';
const re = /large/;
const replaceLarge = myStr.replace(re, 'massif');
console.log(replaceLarge); // Les éléphants sont de très massifs animaux. Ils sont grands au point de pouvoir déraciner un grand arbre.
Si vous utilisez le drapeau g dans le motif, toutes les correspondances sont remplacées :
const myStr =
'Les éléphants sont de très grands animaux. Ils sont si grands qu'ils peuvent déraciner un grand arbre.';
const re = /large/g;
const replaceLarge = myStr.replace(re, 'massif');
console.log(replaceLarge); // Les éléphants sont de très massifs animaux. Ils sont massifs au point de pouvoir déraciner un massif arbre.
La Méthode replaceAll()
La méthode replaceAll() est relativement nouvelle car elle est devenue disponible dans ECMAScript 2021. C'est un hybride de replace().
replace() et replaceAll() font la même chose en prenant une expression régulière et une chaîne de remplacement comme paramètres, et en remplaçant toutes les correspondances par la chaîne de remplacement spécifiée.
Mais contrairement à replace() qui ne remplacera que la première correspondance si vous n'utilisez pas le drapeau g, replaceAll() remplace toutes les correspondances par défaut :
const myStr =
'Les éléphants sont de très grands animaux. Ils sont si grands qu'ils peuvent déraciner un grand arbre.';
const re = /large/g;
const replaceLarge = myStr.replaceAll(re, 'massif');
console.log(replaceLarge); // Les éléphants sont de très massifs animaux. Ils sont massifs au point de pouvoir déraciner un massif arbre.
Si vous n'utilisez pas le drapeau g avec replaceAll(), cela génère une TypeError :
const myStr =
'Les éléphants sont de très grands animaux. Ils sont si grands qu'ils peuvent déraciner un grand arbre.';
const re = /large/;
const replaceLarge = myStr.replaceAll(re, 'massif');
console.log(replaceLarge); // Uncaught TypeError: String.prototype.replaceAll called with a non-global RegExp argument
// at String.replaceAll (<anonymous>)
La Méthode split()
La méthode split() prend une chaîne ou une regex et divise la chaîne que vous utilisez contre elle en un tableau basé sur la chaîne ou la regex que vous passez. La méthode split() prend également un paramètre limit optionnel, un nombre positif. Lorsque vous spécifiez le limit, la division s'arrête à cette limite.
Là où split() trouve une correspondance, il crée un nouvel élément dans le tableau. Voici comment cela fonctionne :
const myStr = "Les codes ne mentent pas. C'est vous qui faites quelque chose de mal.";
const re = /\s/; // "\s" signifie espace blanc - espace, retour arrière, tabulation, ENTER.
const splitedStr = myStr.split(re);
console.log(splitedStr);
/*
Sortie :
[
'Les', "codes",
'ne', "mentent",
'pas.', "C'est",
'vous', 'qui',
'faites', 'quelque',
'chose', 'de',
'mal.'
]
*/
Voici comment utiliser la méthode split() avec le paramètre limit :
const myStr = "Les codes ne mentent pas. C'est vous qui faites quelque chose de mal.";
const re = /\s/; // "\s" signifie espace blanc - espace, retour arrière, tabulation, ENTER.
const splitedStr = myStr.split(re, 5); // 5 est la limite ici
console.log(splitedStr);
/*
sortie : [ 'Les', "codes", 'ne', "mentent", 'pas.' ]
*/
Comment Correspondre aux Caractères Littéraux dans les Expressions Régulières JavaScript
Comme je l'ai souligné précédemment, les caractères littéraux sont des textes ou des chaînes pour lesquels vous écriverez des motifs tels quels.
Si vous voulez correspondre au texte hello, /hello/ devrait être votre motif. Vous pouvez ensuite utiliser le drapeau i avec lui pour correspondre à la fois à hello et Hello :
const testString = 'hello';
const re = /hello/;
const re2 = /hello/i;
console.log(re.test(testString)); // true
console.log(re2.test(testString)); // true
Si vous voulez correspondre à freeCodeCamp, le motif devrait être exactement cela. Vous pouvez également créer un motif qui correspond à freeCodeCamp dans n'importe quelle casse :
const testString = 'freeCodeCamp';
const re = /freeCodeCamp/;
const re2 = /freeCodeCamp/i; // correspond à freeCodeCamp dans n'importe quelle casse
console.log(re.test(testString)); // true
console.log(re2.test(testString)); // true
Vous pouvez également correspondre aux chiffres en utilisant des caractères littéraux :
const num = 10234;
const re = /2/;
console.log(re.test(num)); //true
Comment Utiliser les Ensembles de Caractères dans les Expressions Régulières JavaScript
Pour rappel, un ensemble de caractères est un groupe de caractères enfermés dans des crochets. Ils fournissent un moyen de spécifier un ensemble de caractères à partir duquel le moteur regex peut correspondre à un seul caractère à une position spécifique dans une chaîne de test.
Les ensembles de caractères vous permettent de spécifier une plage de caractères, des caractères individuels, ou une combinaison des deux.
Voici des exemples courants d'ensembles de caractères populaires dans les expressions régulières :
[abc]: correspond àa,b, ouc[aeiou]: correspond à n'importe quel caractère voyelle[a-z]: correspond à n'importe quelle lettre minuscule deaàz[A-Z]: correspond à n'importe quelle lettre majuscule deAàZ[0-9]: correspond à n'importe quel chiffre de 0 à 9
Examinons comment correspondre à chacun des ensembles de caractères ci-dessus dans les expressions régulières JavaScript :
// ensemble de caractères majuscules
const hcaseRe = /[A-Z]/;
const hcaseStr = 'freeCodeCamp est cool';
console.log(hcaseRe.test(hcaseStr)); //true
// ensemble de caractères voyelles
const vowelsRe = /[aeiou]/;
const vowelsStr = 'Imaginez comment la prononciation aurait été sans les voyelles';
console.log(vowelsRe.test(vowelsStr)); //true
// ensemble de caractères [abc]
const abcSetRe = /[abc]/;
const abcSetStr = 'freeCodeCamp est totalement gratuit';
console.log(abcSetRe.test(abcSetStr)); //true
// ensemble de caractères numériques
const numRe = /[0-9]/;
const numStr = 'Merci à Dieu pour les chiffres arabes de 0 à 9.';
console.log(numRe.test(numStr)); //true
Chapitre 5 : Métacaractères, Quantificateurs, Correspondances Répétées et Correspondances Optionnelles
Qu'est-ce que les Métacaractères ?
Dans les expressions régulières, les métacaractères sont des caractères qui ont des significations spéciales au-delà de leur signification littérale.
Les métacaractères sont l'épine dorsale des expressions régulières. Ils servent de blocs de construction pour construire de meilleurs motifs regex et définir le comportement du moteur d'expressions régulières que vous utilisez, mais avec une courbe d'apprentissage supplémentaire.
Cette partie du livre est celle où vous apprendrez des sujets tels que :
- Les ancres
- Les limites de mots
- Comment spécifier des plages de caractères
- Comment correspondre à chaque occurrence avec le joker
- L'alternance
- L'avidité et la paresse des expressions régulières et comment prévenir l'avidité
Et bien plus encore.
Si vous souhaitez correspondre à un métacaractère en tant que caractère littéral, vous devez l'échapper avec une barre oblique inverse (\). Et s'il y a un métacaractère représenté par un mot, vous devez également l'échapper avec la barre oblique inverse. Ainsi, la barre oblique inverse est également un métacaractère séparé.
Il existe un métacaractère pour nier la plupart des métacaractères. Par exemple, \b et \s représentent les métacaractères de limite de mot et d'espace. Si vous souhaitez les nier, vous pouvez utiliser \B et \S respectivement. C'est le schéma que suivent la plupart des métacaractères – la lettre minuscule est le métacaractère et la lettre majuscule le nie.
Les métacaractères sont catégorisés en métacaractères simples et doubles. Comme leur nom l'indique, les métacaractères simples ont un caractère "simple" et les métacaractères doubles ont un caractère "double".
La plupart des métacaractères sont également appelés classes de caractères raccourcies. Alors que nous examinons chaque métacaractère, vous verrez s'il s'agit d'un métacaractère simple ou double.
Les Métacaractères de Mot et de Non-mot
Représenté par \w, le métacaractère de mot est une classe de caractères raccourcie qui correspond à tous les caractères de mot. Les caractères de mot sont des caractères alphanumériques et des traits de soulignement. Ils sont donc a-z, A-Z, 0-9, et le trait de soulignement (_).
Voici ce qui se passe lorsque vous utilisez \w dans un testeur regex :

Et voici comment cela fonctionne en JavaScript :
const testStr =
'Chaque caractère alphanumérique (de a à z et de 0 à 9) et le trait de soulignement (_) est un caractère de mot';
const wordCharacterRe = /\w/g;
console.log(testStr.match(wordCharacterRe));
Puisque les caractères de mot sont des caractères alphanumériques et des traits de soulignement, vous pouvez simuler le métacaractère \w en mettant tous les exemples dans un ensemble de caractères :
const testStr =
'Chaque caractère alphanumérique (de a à z et de 0 à 9) et le trait de soulignement (_) est un caractère de mot';
const wordCharacterRe = /[a-z A-Z 0-9_]/g;
console.log(testStr.match(wordCharacterRe));
Le métacaractère de non-mot est l'opposé du métacaractère de mot et il est représenté par une lettre majuscule W échappée (\W).
Le métacaractère de non-mot correspond à tous les autres caractères à part les caractères alphanumériques et le trait de soulignement. Cela inclut les espaces, les marques de ponctuation et les symboles :

Le voici en action dans du code JavaScript :
const testStr =
'Chaque caractère autre que les caractères alphanumériques (de a à z et de 0 à 9) et le trait de soulignement (_) est un caractère de non-mot';
const nonWordCharacterRe = /\W/g;
console.log(testStr.match(nonWordCharacterRe));
Puisque vous pouvez représenter le métacaractère de mot en mettant tous les caractères dans un ensemble de caractères, vous vous demandez peut-être comment faire de même pour le métacaractère de non-mot.
C'est là que l'ensemble de caractères négatif intervient. Le circonflexe (^) est utilisé pour la négation. C'est l'un des deux métacaractères d'ancrage, que nous examinerons ensuite.
Les Métacaractères d'Ancre
Le circonflexe (^) et le signe dollar ($) sont les deux métacaractères d'ancrage. Ils sont tous deux des métacaractères simples.
Le circonflexe ancre le motif regex au début d'une ligne ou d'une chaîne, vous pouvez donc l'appeler une "ancre de début de ligne".
Par exemple, si vous voulez correspondre au texte "freeCodeCamp" et que vous voulez vous assurer qu'il est au début de la ligne ou d'une chaîne, vous pouvez utiliser le circonflexe de cette manière :

Si le texte "freeCodeCamp" n'est pas au début de la ligne, il n'y aura pas de correspondance :
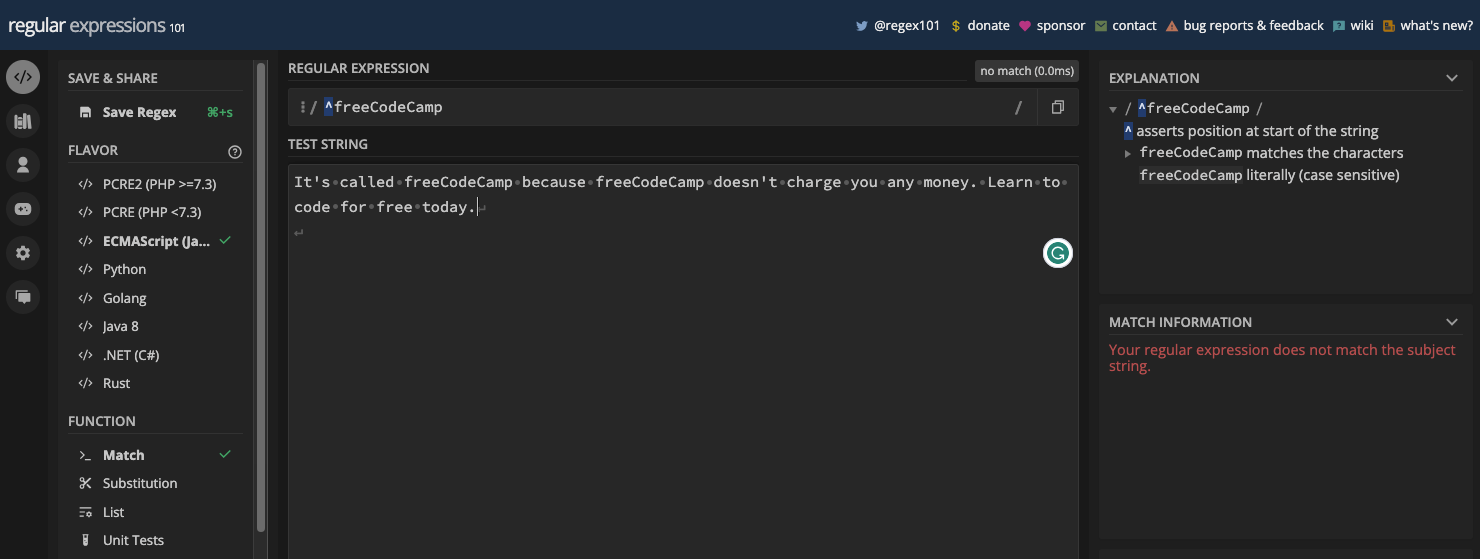
Voici les deux cas en code JavaScript :
const testStr =
"freeCodeCamp ne vous facture aucun argent. C'est pourquoi il s'appelle freeCodeCamp parce que. Apprenez à coder gratuitement aujourd'hui."; // a "freeCodeCamp" au début de la ligne
const testStr2 =
"Il s'appelle freeCodeCamp parce que freeCodeCamp ne vous facture aucun argent. Apprenez à coder gratuitement aujourd'hui."; // n'a pas "freeCodeCamp" au début de la ligne
const startAnchorRe = /^freeCodeCamp/;
console.log(startAnchorRe.test(testStr)); //true
console.log(startAnchorRe.test(testStr2)); //false
Le métacaractère du signe dollar est l'opposé du circonflexe. Il ancre le motif regex à la fin de la ligne ou de la chaîne. Donc, il n'y aura une correspondance que si le texte cible est à la fin de la ligne.
Pour utiliser le métacaractère $, il doit être le dernier caractère de votre motif :

Si la chaîne cible a plus d'une ligne et que le texte cible est à la fin de chaque ligne, la dernière correspond :

Pour corriger ce comportement, vous devez utiliser à la fois les drapeaux g et m :
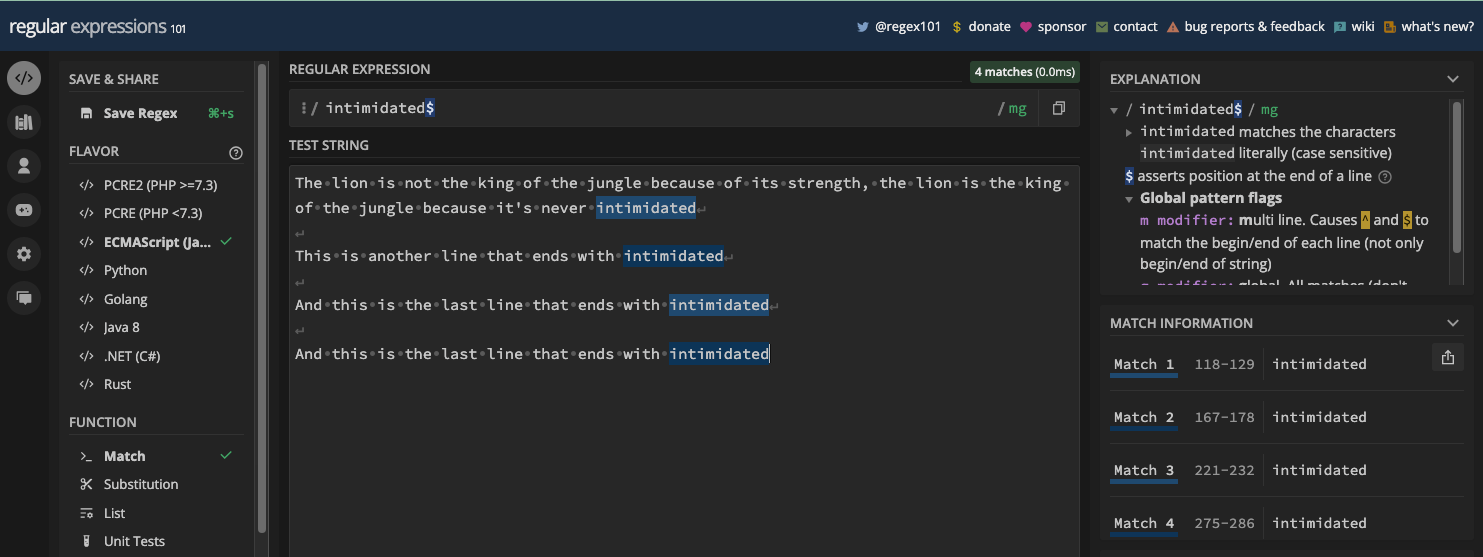
Voici tous les cas en code JavaScript :
const testStr =
"Le lion n'est pas le roi de la jungle à cause de sa force, le lion est le roi de la jungle parce qu'il n'est jamais intimidé";
const testStr2 = `Le lion n'est pas le roi de la jungle à cause de sa force, le lion est le roi de la jungle parce qu'il n'est jamais intimidé
C'est une autre ligne qui se termine par intimidé
Et c'est la dernière ligne qui se termine par intimidé
Et c'est la dernière ligne qui se termine par intimidé`;
const re = /intimidé$/;
const re2 = /intimidé$/gm;
console.log(re.test(testStr)); // true
console.log(re.test(testStr2)); // true
console.log(re2.test(testStr2)); // true
Si le texte cible n'est pas à la fin de la ligne, il n'y aura aucune correspondance :
const testStr =
"Un lion ne peut jamais être intimidé parce qu'il est le roi de la jungle";
const re = /intimidé$/;
console.log(re.test(testStr)); // false
Lorsque vous utilisez à la fois les métacaractères dollar et circonflexe avec les drapeaux g et m, ils ne correspondent pas seulement au début et à la fin d'une ligne, ils trouvent les correspondances au début et à la fin de chaque ligne :
// dollar avec les drapeaux g et m
const testStr1 = `Le lion n'est pas le roi de la jungle à cause de sa force, le lion est le roi de la jungle parce qu'il n'est jamais intimidé
Une autre ligne avec intimidé
Et une autre ligne avec intimidé`;
const re1 = /intimidé$/gm;
const matches1 = testStr1.match(re1);
console.log(matches1); // [ 'intimidé', 'intimidé', 'intimidé' ]
// circonflexe avec les drapeaux g et m
const testStr = `freeCodeCamp ne vous facture aucun argent. C'est pourquoi il s'appelle freeCodeCamp parce que. Apprenez à coder gratuitement aujourd'hui.
freeCodeCamp commence cette ligne
freeCodeCamp commence cette ligne aussi
`;
const re2 = /^freeCodeCamp/gm;
const matches2 = testStr.match(re2);
console.log(matches2); // [ 'freeCodeCamp', 'freeCodeCamp', 'freeCodeCamp' ]
Comme je l'ai souligné précédemment, le métacaractère circonflexe est généralement utilisé pour nier un ensemble de caractères ou tout autre caractère. Avec cela, vous dites au moteur regex utilisé de ne pas correspondre à ce caractère ou à chacun des ensembles de caractères.
Par exemple, si vous avez le motif [^a], alors toutes les lettres "a" dans la chaîne de test ne seront pas retournées comme correspondances :
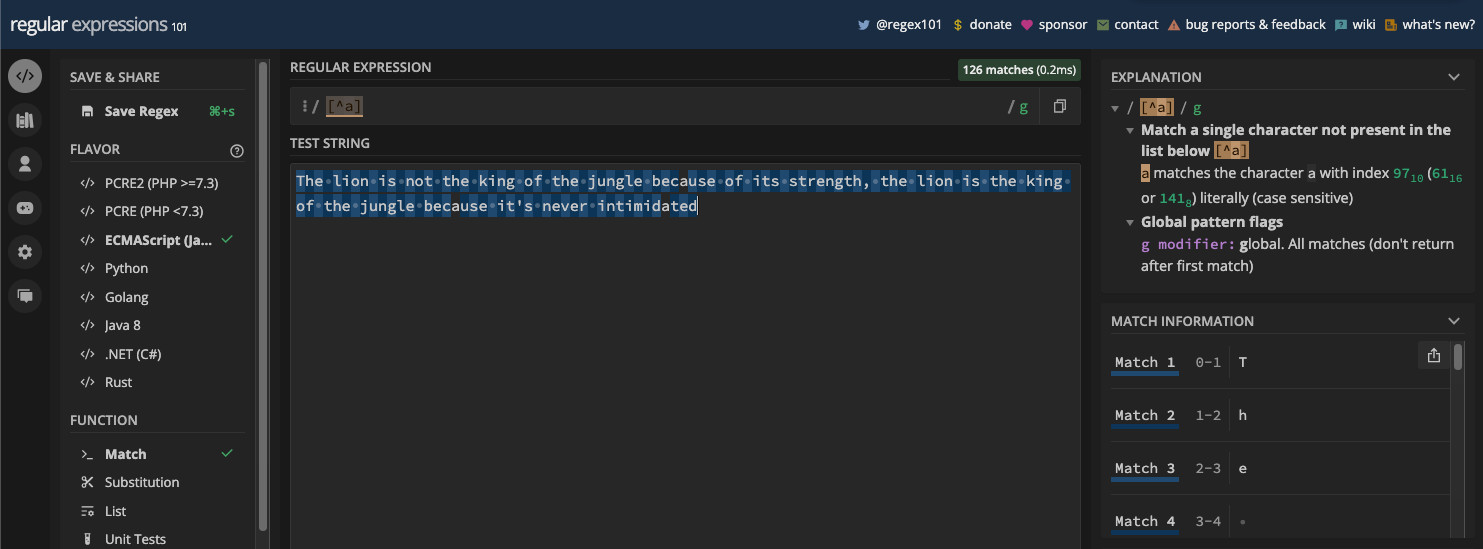
Si vous avez le motif [^aeiou], toutes les voyelles dans la chaîne de test ne seront pas retournées comme correspondances :
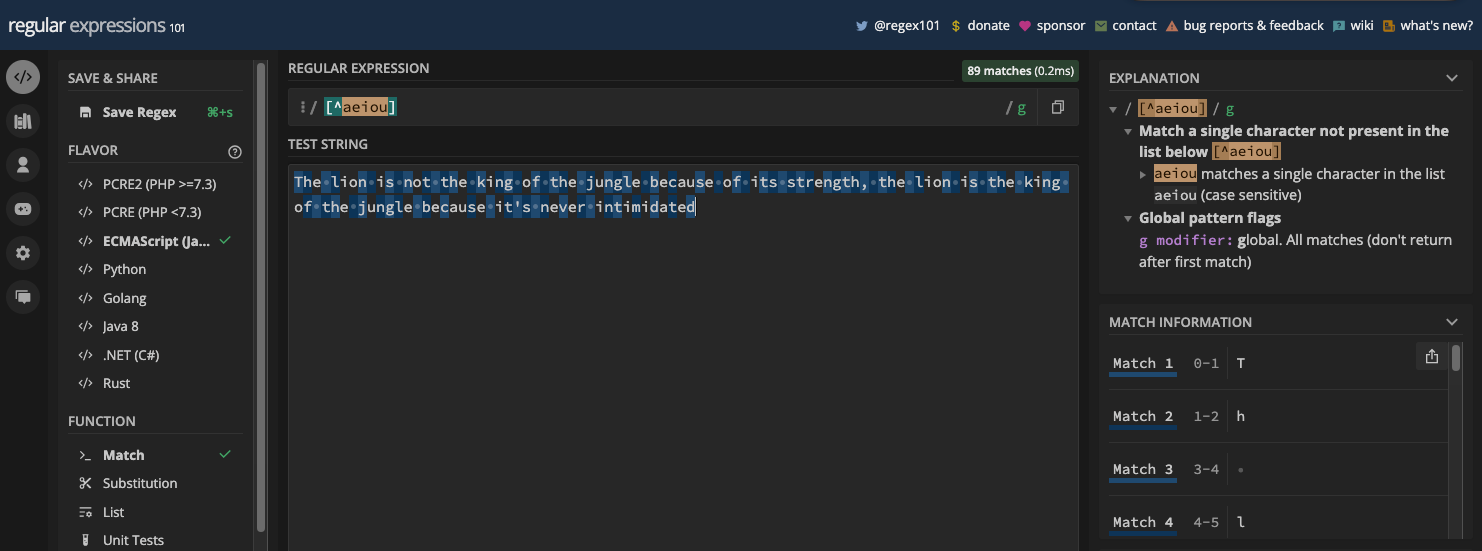
Si vous avez le motif [^a-zA-Z0-9_], cela équivaut au métacaractère de non-mot (\W) :
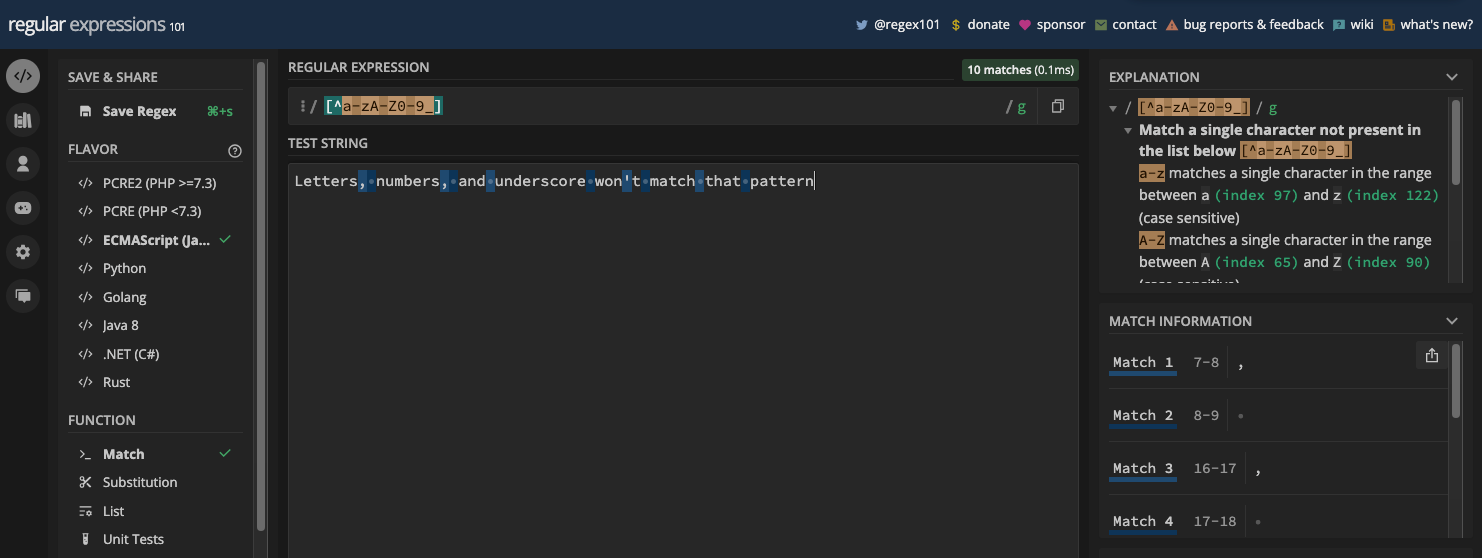
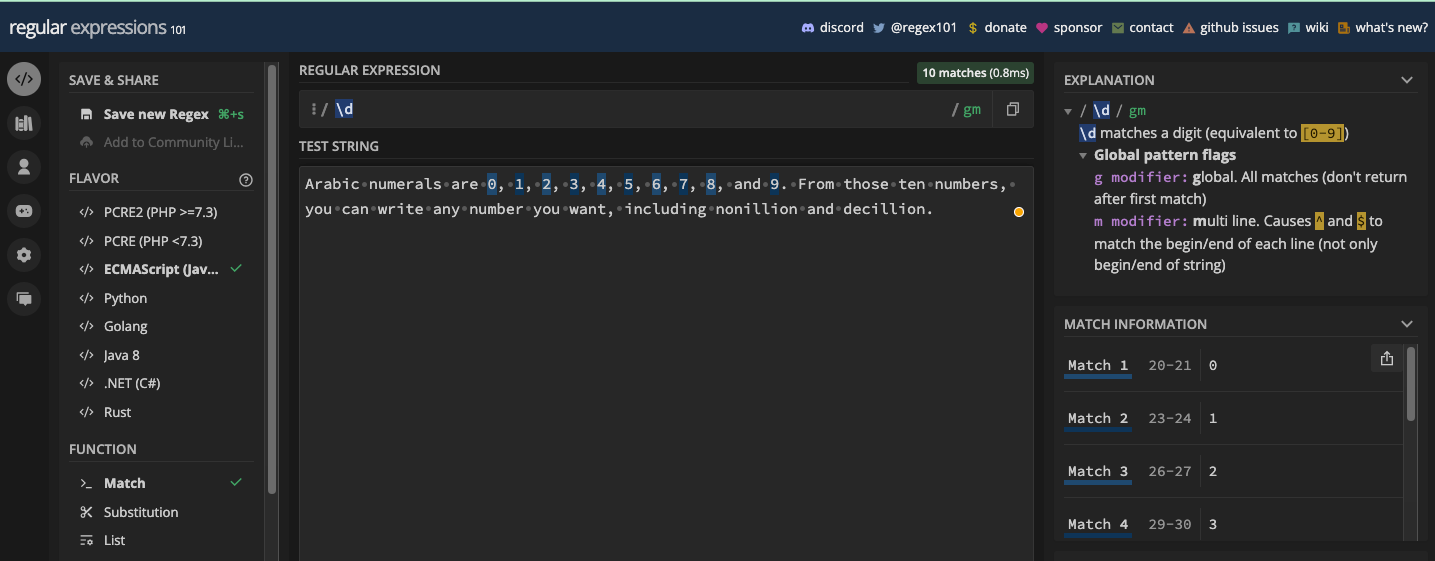
Les Métacaractères de Chiffre et de Non-chiffre
Le métacaractère de chiffre est représenté par \d. Vous pouvez le nier avec \D, donc \D est le métacaractère de non-chiffre.
\d correspond à tous les nombres (0 à 9), donc c'est une classe de caractères raccourcie pour [0-9]. Donc, si vous avez une chaîne et que vous voulez extraire les nombres, vous pouvez utiliser le métacaractère \d. Mais vous devez l'utiliser avec le drapeau g pour qu'il corresponde à chaque nombre dans la chaîne de test :
Vous pouvez utiliser la méthode match() pour extraire les nombres en JavaScript aussi :
const testStr =
'Les chiffres arabes sont 0, 1, 2, 3, 4, 5, 6, 7, 8, et 9. À partir de ces dix nombres, vous pouvez écrire n'importe quel nombre que vous voulez, y compris nonillion et décillion.';
const re = /\d/g;
console.log(testStr.match(re));
/* sortie
[
'0', '1', '2', '3',
'4', '5', '6', '7',
'8', '9'
]
*/
Un exemple plus simple est la correspondance des dates puisque les dates sont principalement en chiffres. Par exemple, si vous voulez correspondre à une date au format jj/mm/aaaa, vous pouvez la correspondre avec le motif /\d\d\/\d\d\/\d\d\d\d/ :
const date = '22/04/2023';
const re = /\d\d\/\d\d\/\d\d\d\d/;
console.log(re.test(date)); // true
Puisque vous pouvez également avoir un point ou un trait d'union comme séparateur de date, vous pouvez en tenir compte également en mettant tous les séparateurs possibles dans un ensemble de caractères :
const slashSeparatedSate = '22/04/2023';
const hyphenSeparatedDate = '22-04-2023';
const periodSeparatedDate = '22.04.2023';
const re = /\d\d[/.-]\d\d[/.-]\d\d\d\d/;
console.log(re.test(slashSeparatedSate)); // true
console.log(re.test(hyphenSeparatedDate)); // true
console.log(re.test(periodSeparatedDate)); // true
N.B. : Le motif ci-dessus correspond à une date mais aussi à une date invalide comme 99/45/2022. Une meilleure façon de correspondre aux dates est fournie dans le chapitre des applications de regex.
Un autre exemple est la correspondance des numéros de téléphone. Par exemple, les numéros de téléphone américains sont au format (123) 456-7890. Vous pouvez utiliser le motif /\(\d\d\d\) \d\d\d-\d\d\d\d/ :
const USPhone = '(123) 456-7890';
const re = /\(\d\d\d\) \d\d\d-\d\d\d\d/;
console.log(re.test(USPhone)); // true
Le métacaractère de non-chiffre est l'opposé du métacaractère de chiffre. Il correspond à tous les caractères non-chiffres. C'est-à-dire, les alphabets, les espaces et les symboles. En d'autres termes, c'est la classe de caractères raccourcie pour [^0-9].
Si vous voulez extraire tous les caractères non-chiffres dans une chaîne, vous pouvez utiliser le métacaractère \D :

Voici comment cela fonctionne en code JavaScript :
const testStr =
'Les chiffres arabes sont 0, 1, 2, 3, 4, 5, 6, 7, 8, et 9. À partir de ces dix nombres, vous pouvez écrire n'importe quel nombre que vous voulez, y compris nonillion et décillion.';
const re = /\D/g;
console.log(testStr.match(re));
/* sortie
Un total de 137 correspondances est trop long à afficher ici, mais vous pouvez le tester vous-même.
*/
Le Métacaractère de Crochets
Vous avez déjà vu le métacaractère de crochets ([]) en action. Les crochets sont utilisés pour spécifier une classe de caractères, ou un ensemble de caractères. Et si vous voulez les correspondre en tant que caractère littéral, alors vous devez les échapper.
Une chose à garder à l'esprit est que certains métacaractères perdent leur signification à l'intérieur de l'ensemble de caractères. Les exceptions à cela sont :
- Le circonflexe (
^) que vous pouvez utiliser pour nier un ensemble de caractères - Le trait d'union (
-) que vous pouvez utiliser pour spécifier des plages
N.B. : Parfois, vous pourriez rencontrer une situation où vous devez échapper certains métacaractères à l'intérieur d'un ensemble de caractères.
Si vous voulez correspondre à l'un de ces caractères dans un ensemble de caractères, vous devez l'échapper. Si vous passez simplement les trois de ces caractères directement, vous n'avez pas besoin de les échapper si le circonflexe n'est pas le premier caractère.
const testStr =
'Si vous voulez correspondre au circonflexe (^), au trait d'union et (-) aux symboles dans un ensemble de caractères, vous n'avez peut-être pas besoin de les échapper.';
const re = /[-^]/g;
console.log(testStr.match(re)); // [ '^', '-' ]
Mais si le circonflexe est le premier caractère dans l'ensemble de caractères avec certains caractères de mot et de non-mot, vous devez l'échapper, sinon il niera tous les autres caractères :
![]()
Les Métacaractères de Limite de Mot et de Non-limite de Mot
Le métacaractère de limite de mot est représenté par \b et le métacaractère de non-limite de mot est représenté par \B. Les deux vous permettent de correspondre à une partie spécifique d'une chaîne où un caractère de mot et un caractère de non-mot existent.
La limite de mot (\b) correspond à une position entre un caractère de mot (\w) et un caractère de non-mot (\W), et vice versa. Elle peut être utile lorsque vous voulez correspondre à un certain mot dans une chaîne, ou si vous voulez vous assurer qu'un mot ou un caractère particulier est dans une chaîne.
Voici un exemple dans un testeur regex :
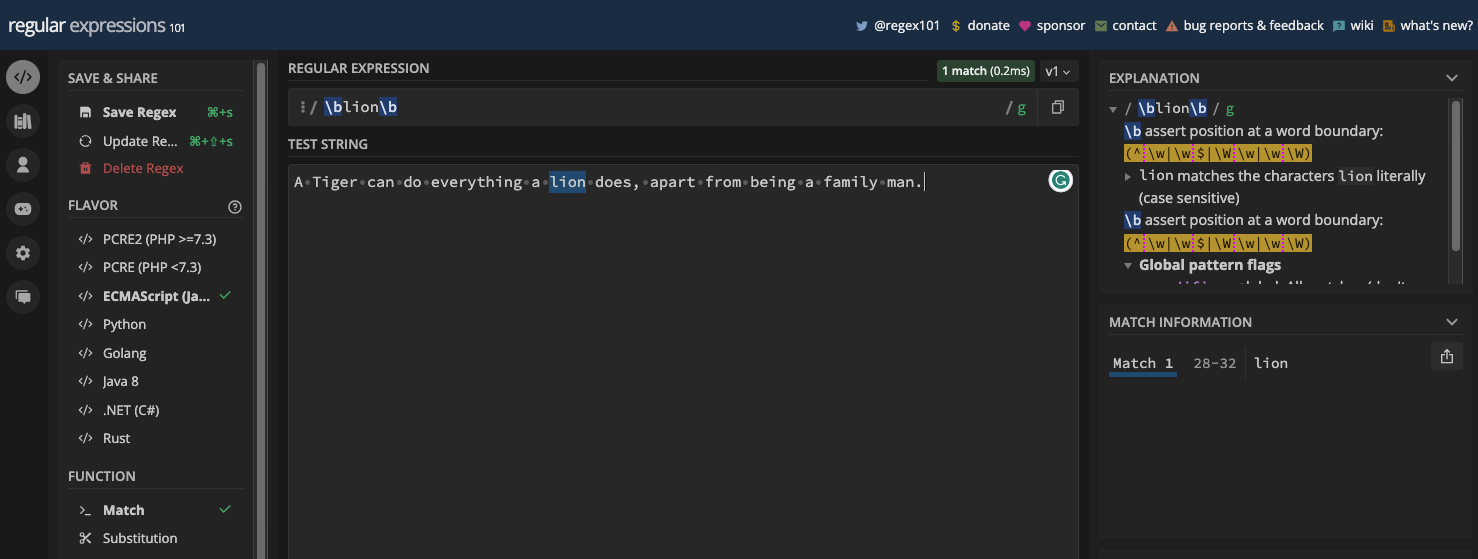
Et le même exemple en code JavaScript :
const myStr =
'Un tigre peut faire tout ce qu'un lion fait, à part être un homme de famille.';
const re = /\blion\b/;
console.log(myStr.match(re));
/*
Sortie :
[
'lion',
index: 28,
input: 'Un tigre peut faire tout ce qu'un lion fait, à part être un homme de famille.',
groups: undefined
]
*/
Si vous utilisez un drapeau g avec le motif et utilisez la méthode match(), toutes les correspondances seront retournées – comme prévu :
const myStr =
'Un tigre peut faire tout ce qu'un lion fait, à part être un homme de famille. Même un tigre ne peut pas intimider un lion au sein de sa famille.';
const re = /\blion\b/g;
console.log(myStr.match(re)); // [ 'lion', 'lion' ]
D'autre part, la non-limite de mot (\B) est l'opposé de la limite de mot (\b). Donc, elle correspond partout où une limite de mot ne retournera pas de correspondance. Par exemple, "thin" dans "everything" :
Et aussi "code" dans "freeCodeCamp" lorsque vous utilisez le drapeau insensible à la casse (i) :
Vous pouvez voir que le premier "code" dans le texte n'était pas la correspondance retournée. C'est le pouvoir des métacaractères de limite de mot et de non-limite de mot.
Voici ce que les deux révèlent en code JavaScript :
const myStr1 =
'Un tigre peut faire tout ce qu'un lion fait, à part être un homme de famille.';
const myStr2 = 'Apprenez à coder gratuitement sur freeCodeCamp.';
const re1 = /\Bthin\B/;
const re2 = /\Bcode\B/i;
console.log(myStr1.match(re1));
console.log(myStr2.match(re2));
/*
Sortie :
[
'thin',
index: 20,
input: 'Un tigre peut faire tout ce qu'un lion fait, à part être un homme de famille.',
groups: undefined
]
[
'Code',
index: 30,
input: 'Apprenez à coder gratuitement sur freeCodeCamp.',
groups: undefined
]
*/
Le Métacaractère de Parenthèse
Les métacaractères de parenthèse (( et )) vous permettent de créer des groupements et des captures. Avec eux, vous pouvez traiter n'importe quel groupe de caractères comme une seule unité et appliquer un modificateur ou un quantificateur commun à eux.
Les parenthèses sont également utilisées pour créer des assertions de lookahead et de lookbehind.
Lorsque vous créez le groupe et les assertions, vous pouvez y faire référence plus tard dans le même motif avec une barre oblique inverse et l'ordre dans lequel ils apparaissent. Par exemple, vous pouvez faire référence au premier groupe en spécifiant \1 dans le motif.
Dans ce livre, un chapitre entier est dédié au groupement et à la capture. Là, vous en apprendrez davantage sur le groupement et la capture afin de voir les métacaractères de parenthèse en action.
Les Métacaractères d'Espace et de Non-espace
Il est impossible pour un texte d'avoir du sens sans espaces. Pas seulement un "espace", mais aussi d'autres caractères d'espace comme les tabulations, les retours chariot et les nouvelles lignes. C'est pourquoi les métacaractères d'espace et de non-espace sont disponibles dans les expressions régulières.
Le métacaractère d'espace est représenté par \s et le métacaractère de non-espace est représenté par \S.
\s correspond à tous les caractères d'espace :
Et \S correspond à tous les métacaractères de non-espace :

Voici comment les métacaractères \s et \S fonctionnent en code JavaScript :
const myStr = 'Apprenez à coder gratuitement sur freeCodeCamp';
const spaceRe = /\s/g;
const nonSpaceRe = /\S/g;
console.log(myStr.match(spaceRe)); // [' ', ' ', ' ', ' ', ' ', ' '];
console.log(myStr.match(nonSpaceRe));
// [
// 'A', 'p', 'p', 'r', 'e', 'n',
// 'e', 'z', 'à', 'c', 'o', 'd', 'e', 'r',
// 'g', 'r', 'a', 't', 'u', 'i', 't', 'e', 'm', 'e', 'n', 't',
// 's', 'u', 'r', 'f', 'r', 'e', 'e', 'C', 'o', 'd', 'e', 'C', 'a',
// 'm', 'p'
// ]
Une chose cool que vous pouvez faire avec \s en JavaScript est de remplacer tous les espaces par, par exemple, un trait d'union, ou toute autre chose que vous voulez :
const myStr = 'Apprenez à coder gratuitement sur freeCodeCamp';
const replaceHyphen = myStr.replace(spaceRe, '-');
console.log(replaceHyphen); // Apprenez-à-coder-gratuitement-sur-freeCodeCamp
Le métacaractère d'espace ne correspond pas seulement à la barre d'espace que vous appuyez sur le clavier de votre appareil. Il correspond également à :
- Un caractère de tabulation
- Un caractère de retour chariot
- Un caractère de nouvelle ligne
- Un caractère de tabulation verticale
- Et un caractère de saut de page
Voici un exemple :
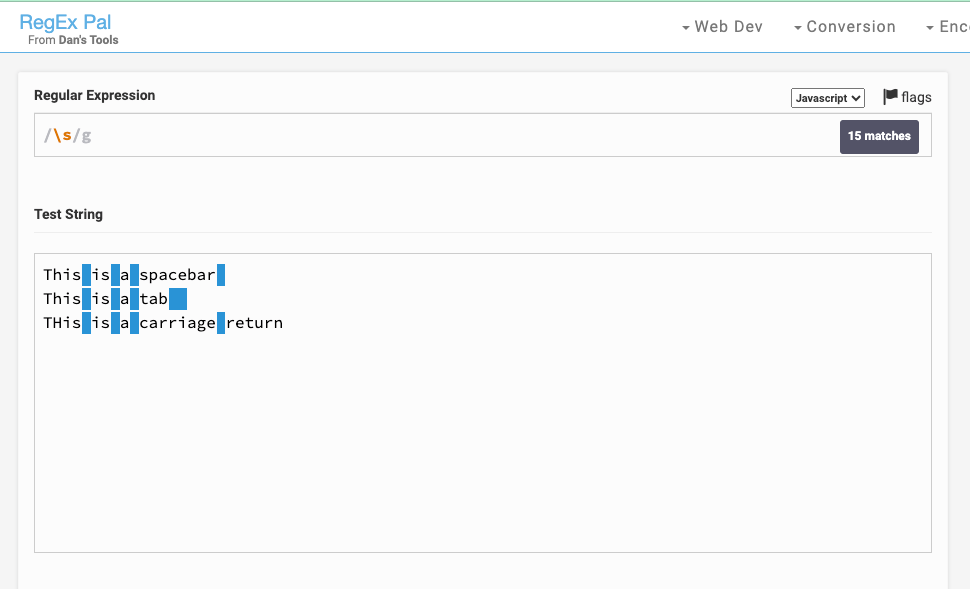
Vous ne pouvez pas voir la correspondance pour le retour chariot mais elle est là :
Si vous voulez correspondre à chacun de ces caractères d'espace, ils ont également leurs métacaractères uniques :
\tpour la tabulation\rpour le retour chariot\npour la nouvelle ligne\vpour la tabulation verticale\fpour le saut de page.
Vous devez être conscient que la plupart du temps, \s est tout ce dont vous avez besoin car il peut effectuer la correspondance pour n'importe quel caractère d'espace.
Le Métacaractère de Pipe
Également connu sous le nom d'opérateur OR, le métacaractère de pipe est représenté par le symbole de pipe (|). Il vous permet de spécifier plusieurs alternatives pour la correspondance.
Le pipe correspond au caractère qui le précède, ou au caractère qui le suit. Par exemple, si vous avez website|web\sapp comme motif, alors l'un ou les deux de website et web app seront retournés comme correspondance :
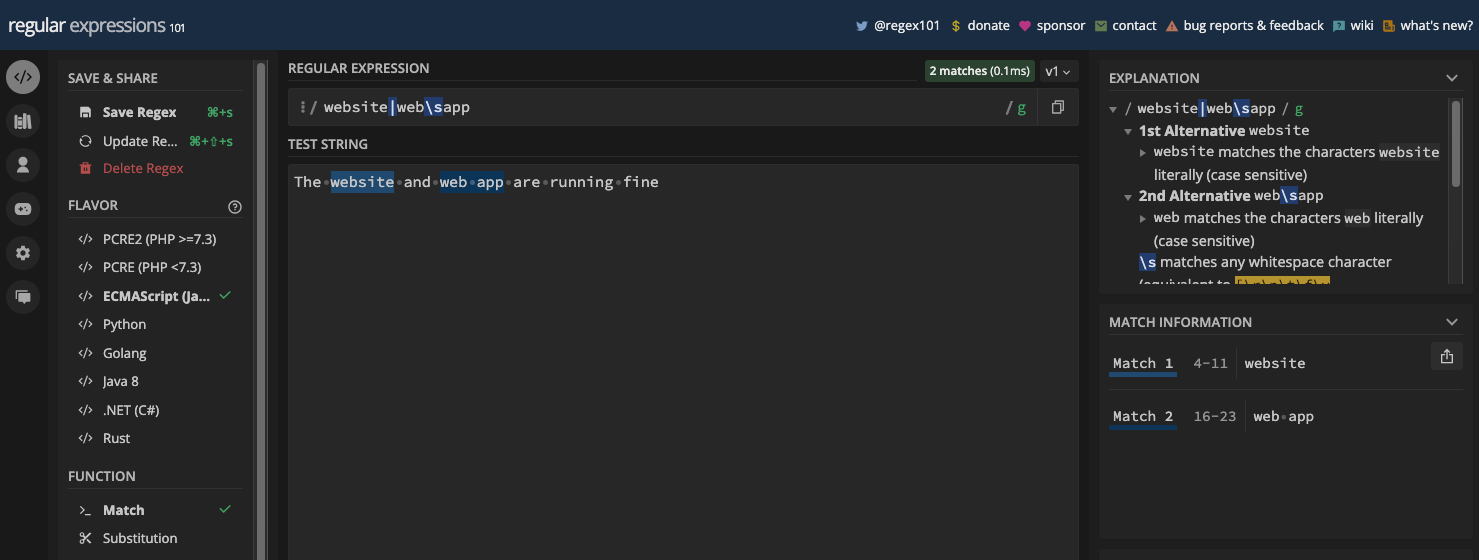
L'évaluation se fait de gauche à droite. Si une correspondance est trouvée à gauche, elle retourne la correspondance. Et s'il n'y a pas de correspondance à gauche, le caractère du côté droit est évalué pour une éventuelle correspondance. Si les deux caractères de gauche et de droite sont dans la chaîne de test, alors les deux sont retournés comme correspondances.
Vous pouvez également avoir plus de deux caractères séparés par les symboles de pipe. Par exemple, le motif /o|a|i|re/ correspondrait à o, a, i, et re :
Il n'y a pas de limite aux caractères que vous pouvez séparer avec lui.
Vous pouvez voir que j'ai utilisé le drapeau g dans ces exemples. Si vous n'utilisez pas le drapeau g et que les deux caractères de gauche et de droite sont des correspondances, seule la première correspondance dans la chaîne de test sera retournée :
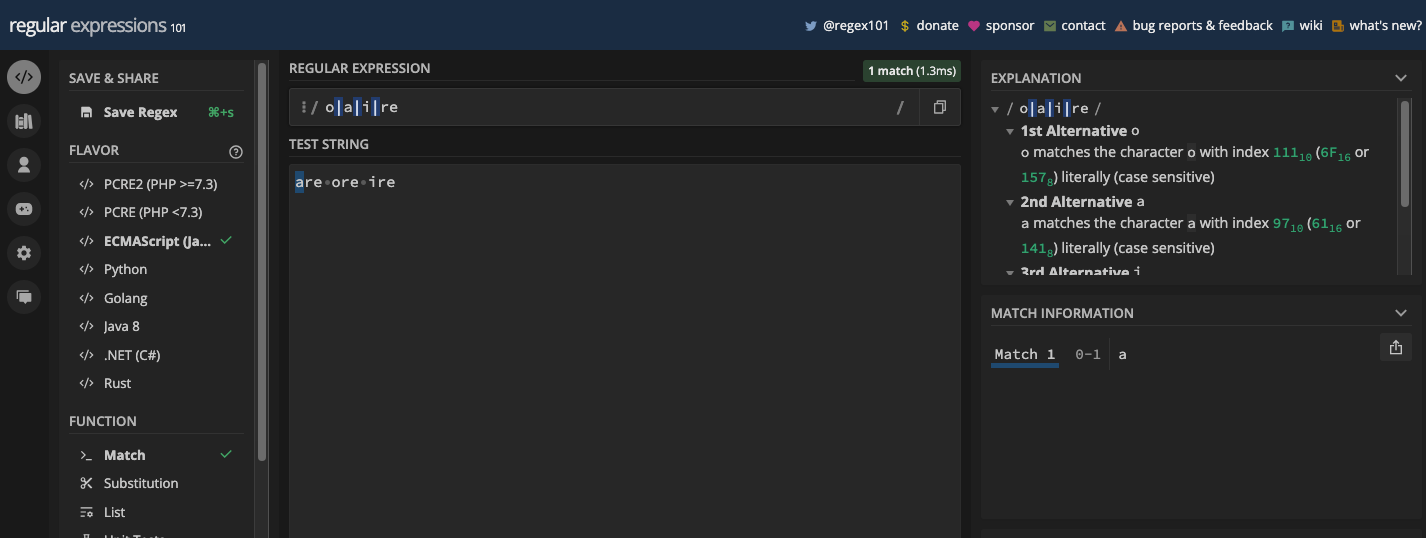
Voici un exemple plus clair :
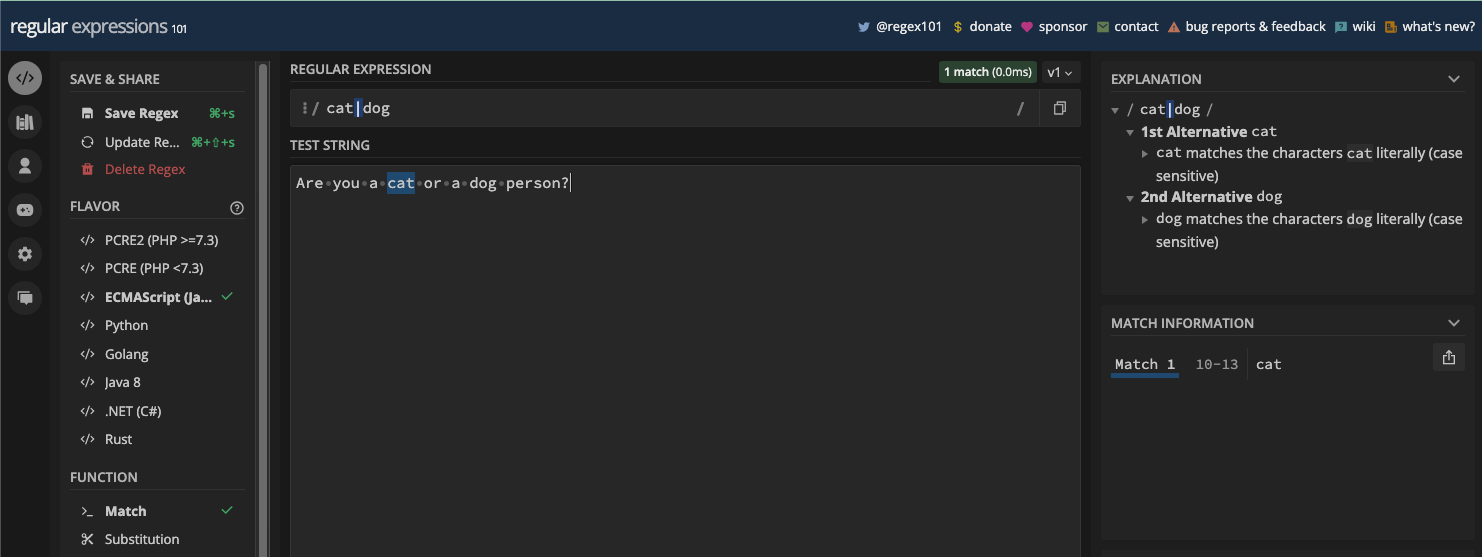
Voici comment l'utilisation de l'opérateur OR fonctionne avec le drapeau g en code :
const myStr = 'Le site web et l'application web fonctionnent bien';
const re = /website|web\sapp/g;
console.log(myStr.match(re)); // retourne [ 'website', 'web app' ] grâce au drapeau g
Et voici comment cela fonctionne sans le drapeau g :
const myStr = 'Le site web et l'application web fonctionnent bien';
const re = /website|web\sapp/;
const matches = myStr.match(re);
for (const match of matches) {
console.log(match); // retourne "website" et ignore web app car il n'y a pas de drapeau g
}
Comment Correspondre aux Caractères Répétés avec les Quantificateurs
Les caractères répétés se produisent lorsque le même caractère existe en plusieurs nombres consécutifs.
Lorsque vous avez un caractère répété dans votre chaîne de test, vous n'avez pas besoin de répéter un caractère particulier dans votre motif pour le correspondre. C'est parce qu'il existe des métacaractères disponibles pour une ou plusieurs correspondances, zéro ou plusieurs correspondances, et zéro ou une correspondance, alias correspondances optionnelles.
Une ou Plusieurs Correspondances avec le Métacaractère de Signe Plus
Comme vous pouvez le deviner, le métacaractère de signe plus est représenté par un plus (+). Vous pouvez également l'appeler le "quantificateur une ou plusieurs".
Si vous voulez qu'un caractère particulier soit répété une ou plusieurs fois, c'est ce que fait le métacaractère de signe plus.
Par exemple, le motif /fe+d/ correspondra à tout mot avec une lettre e ou plusieurs lettres e qui se produisent consécutivement. Par exemple, fed et feed :
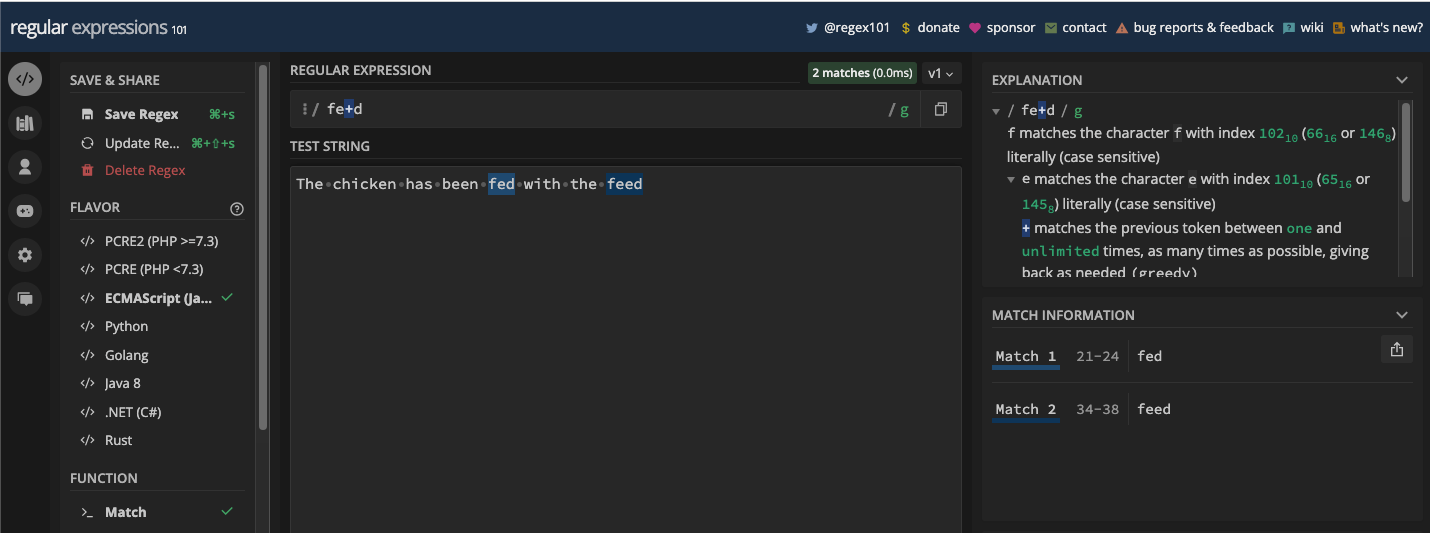
Un exemple pratique en JavaScript est l'extraction des voyelles dans une chaîne de test tout en limitant les occurrences en s'assurant que plusieurs voyelles qui se suivent sont également retournées :
const myStr = 'Vous devriez planter des arbres pour sauver la terre mère';
const re = /[aeiou]+/gi;
console.log(myStr.match(re));
/*
Sortie :
[
'ou', 'ou', 'a',
'ee', 'o', 'a',
'e', 'o', 'e',
'ea'
]
*/
Vous pouvez également ajouter le métacaractère de signe plus à d'autres métacaractères. Par exemple, /\d+/ correspondrait à un ou plusieurs chiffres :

Vous pouvez également ajouter le métacaractère + à un ensemble de caractères pour le répéter une ou plusieurs fois. Dans la capture d'écran ci-dessous, le motif /f[a-z]+/ correspondrait à une ou plusieurs lettres f suivies de n'importe quel ensemble de lettres minuscules :
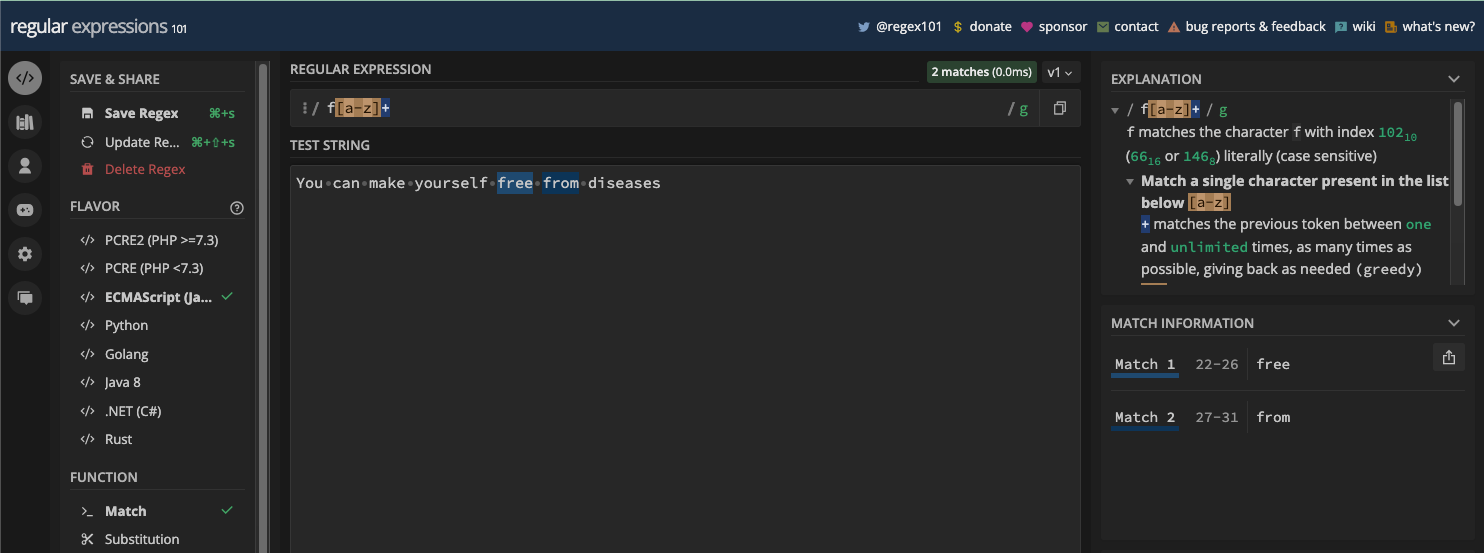
Zéro ou Plusieurs Correspondances avec le Métacaractère Astérisque
Le métacaractère astérisque (*) correspond à zéro ou plusieurs occurrences du caractère qui le précède. Vous pouvez également l'appeler un "quantificateur zéro ou plusieurs".
Ainsi, si vous voulez qu'un caractère soit répété zéro ou plus d'une fois, vous pouvez utiliser le métacaractère astérisque. Un exemple de base est l'utilisation du motif /go*d/ qui correspondrait à tout mot commençant par la lettre g suivie de n'importe quel nombre de la lettre o, et se terminant par la lettre d :
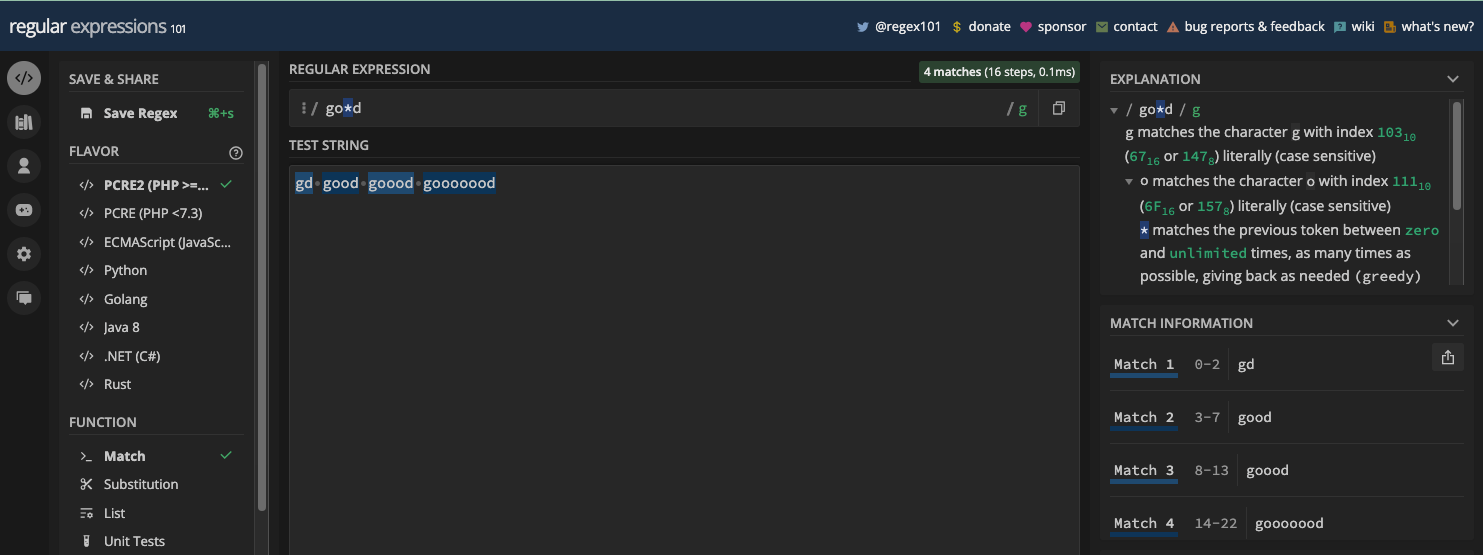
Tout comme vous pouvez le faire avec le métacaractère plus, vous pouvez également ajouter le métacaractère astérisque à tout autre métacaractère. Par exemple, vous pouvez correspondre à des chaînes vides avec le motif /\s*/ :
Vous doutez de cela ? Voici comment cela fonctionne en code JavaScript :
const re = /\s*/;
const emptyString = '';
console.log(re.test(emptyString)); // true
Je ne savais pas que correspondre à des chaînes vides était aussi simple que cela jusqu'à ce que j'arrive à ce point dans le livre !
Encore une fois, comme le métacaractère plus, vous pouvez également ajouter le métacaractère * à un ensemble de caractères pour le répéter zéro ou plusieurs fois :
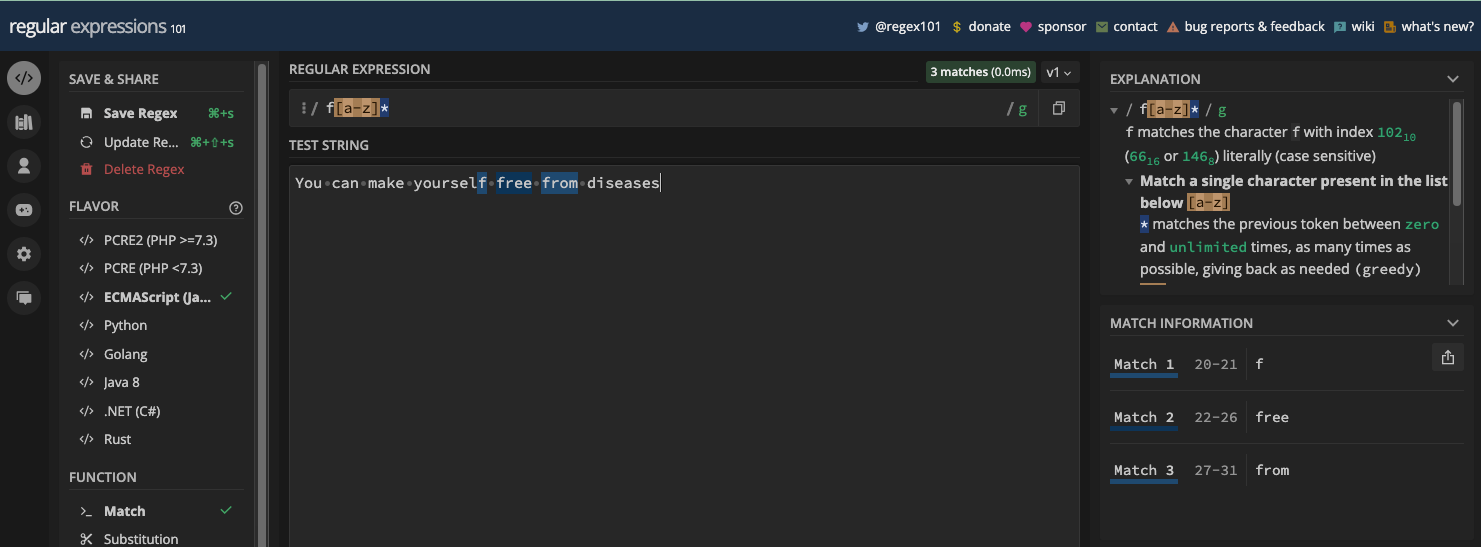
Voici la même chose en code JavaScript :
const myStr = 'Vous pouvez vous libérer des maladies';
const re = /f[a-z]*/g;
console.log(myStr.match(re)); // [ 'f', 'free', 'from' ]
Vous pouvez voir que le f dans le mot yourself est également une correspondance. C'est une façon de déduire que l'astérisque (*) retourne plus de correspondances que le métacaractère de signe plus (+) car il est plus gourmand. Vous apprendrez à propos de la gourmandise d'une expression régulière dans la partie finale de ce chapitre.
Zéro ou Une Correspondance avec le Métacaractère Point d'Interrogation
Le métacaractère point d'interrogation (?) est également connu sous le nom de quantificateur zéro ou un. Il vous permet de rendre le caractère qui le précède optionnel, donc il joue un rôle important dans la prévention de la gourmandise.
Par exemple, le motif /ab?c/ correspondra à abc et ac, mais jamais à abbbc ou à tout autre nombre de b entre le a et le c :
Ce n'est pas le cas avec les deux autres métacaractères pour correspondre aux caractères répétés (+ et *). Le motif /ab*c/ correspondra à tous les abc, ac, abbbc, et abbbbbbbc tandis que /ab+c/ laissera de côté ac :
const myStr = 'abc ac abbbc abbbbbbbc';
const re1 = /ab*c/g;
const re2 = /ab+c/g;
const re3 = /ab?c/g;
console.log(myStr.match(re1)); // [ 'abc', 'ac', 'abbbc', 'abbbbbbbc' ]
console.log(myStr.match(re2)); // [ 'abc', 'abbbc', 'abbbbbbbc' ]
console.log(myStr.match(re3)); // [ 'abc', 'ac' ]
Un meilleur exemple est d'adapter un motif regex pour correspondre à des mots qui ont des orthographes différentes en raison des petites variations entre l'anglais britannique et américain. Par exemple, color et colour :
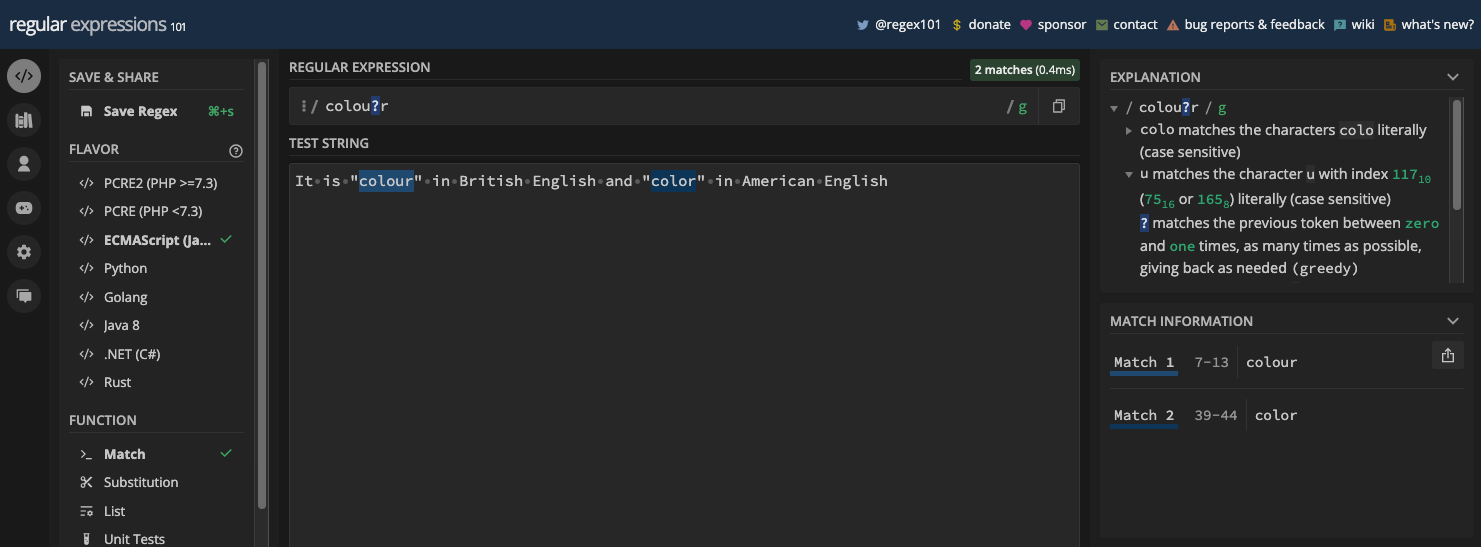
Il y a aussi centre et center :
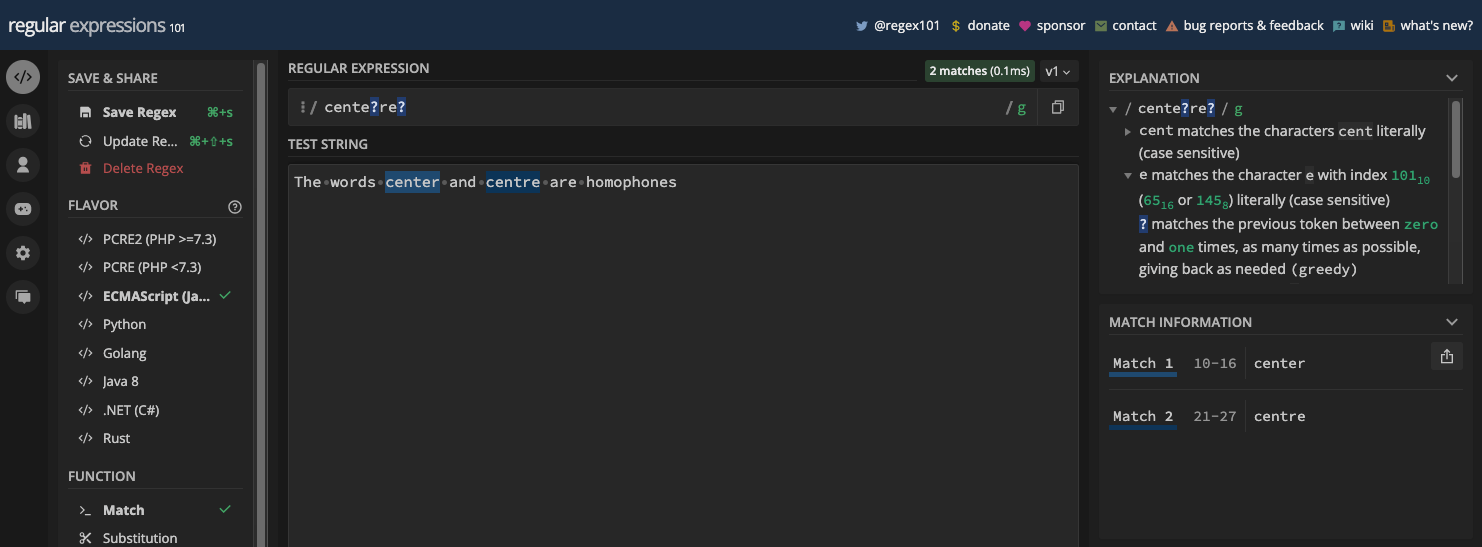
Vous pouvez extraire ces mots en JavaScript. Vous ne pouvez pas utiliser la méthode match() pour cela car elle provoque certains comportements inattendus lorsqu'elle est utilisée avec le métacaractère ?.
Voici comment j'ai pu le faire pour color et colour :
const myStr = 'Les mots center et centre sont des homophones';
const re = /cente?re?/g;
let match;
const matches = [];
while ((match = re.exec(myStr)) !== null) {
matches.push(match[0]);
}
console.log(matches); // ["center", "centre"]
J'ai utilisé la même approche pour extraire center et centre :
const myStr =
'C'est "colour" en anglais britannique et "color" en anglais américain';
const re = /colou?r/g;
let match;
const matches = [];
while ((match = re.exec(myStr)) !== null) {
matches.push(match[0]);
}
console.log(matches); // [ 'colour', 'color' ]
De nombreuses fois, il est difficile de savoir lequel utiliser pour la répétition de caractères entre ces trois métacaractères – *, +, et ?. Il peut même être difficile de s'habituer à ce que chacun d'eux fait si vous débutez avec les expressions régulières.
Soyez conscient que les identifier et savoir lequel utiliser entre eux n'est pas une tâche herculéenne. Voici quelques points à noter sur les trois :
- Astérisque (
*) signifie "zéro ou plusieurs" : utilisez-le si vous ne voulez pas qu'un caractère apparaisse dans la chaîne cible ou si vous voulez que le même caractère soit plus d'un - Plus (
+) signifie "un ou plusieurs" : utilisez-le si vous voulez qu'un caractère apparaisse une fois ou plus d'une fois dans la chaîne cible - Point d'interrogation (
?) signifie "zéro ou un" : utilisez-le si vous voulez qu'un caractère soit optionnel dans la chaîne cible.
Comment Spécifier la Quantité de Correspondance avec le Métacaractère d'Accolades
Les quantificateurs vous permettent d'indiquer la quantité ou la fréquence d'un caractère précédent dans un motif avec des accolades ({}}. Avec ces accolades, vous pouvez spécifier un quantificateur exact, un quantificateur minimum et un quantificateur de plage.
Le Quantificateur de Plage
La syntaxe générale du quantificateur de plage ressemble à ceci :
char{n1,n2}
chaest n'importe quel caractère auquel vous appliquez le quantificateurn1est le nombre minimum de fois que vous voulez que le caractère se répèten2est le nombre maximum de fois que vous voulez que le caractère se répète
Un exemple est le motif /a{3,6}/. Cela signifie que vous voulez correspondre entre trois et six lettres a :
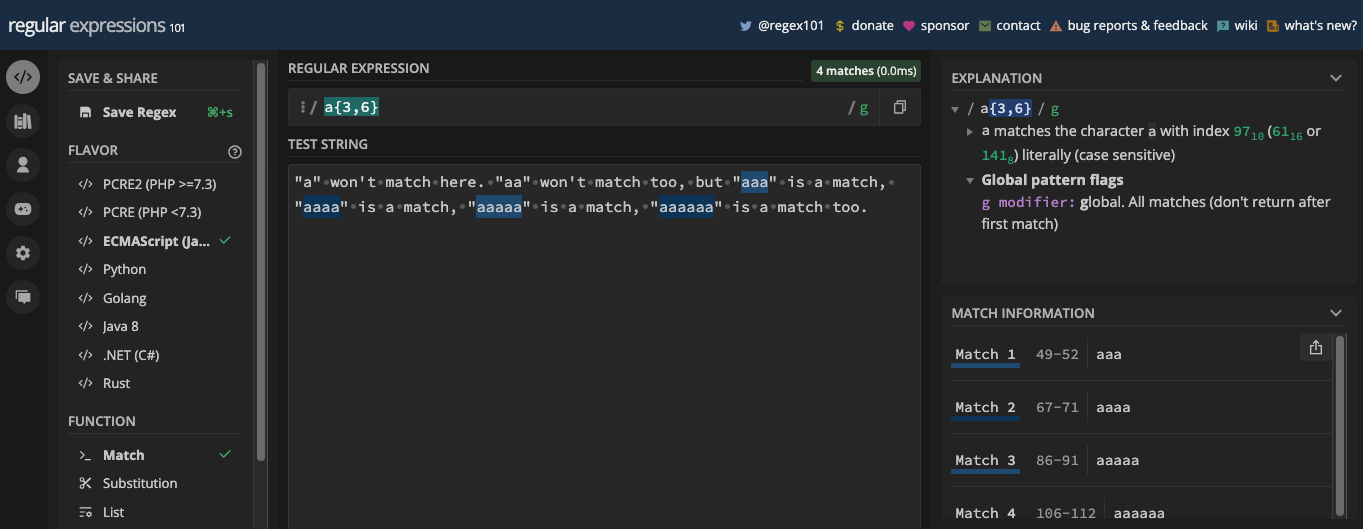
Si vous avez plus de six lettres a dans la chaîne de test, les six premières correspondront :
Pour corriger cela, vous pouvez entourer le motif dans une limite de mot :
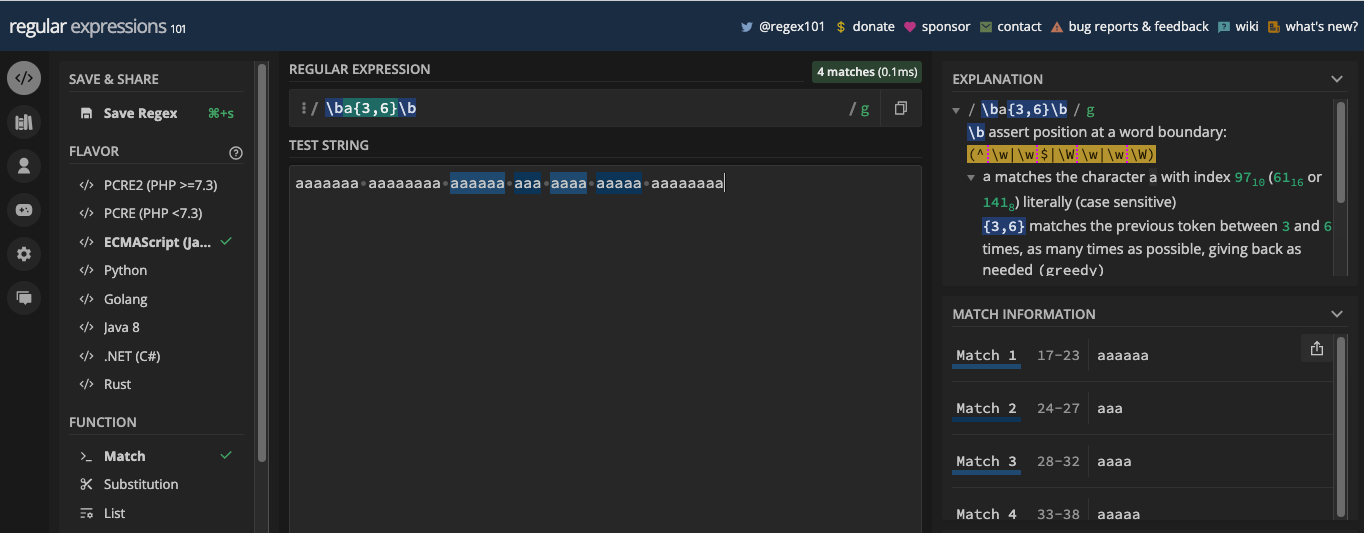
Vous pouvez également attacher le quantificateur de plage aux métacaractères. Par exemple, vous pouvez extraire n'importe quel nombre qui est au moins en centaines de cette manière :
const myStr =
'Le marathon comptait 500 participants, avec 251 terminant en moins de 3 heures, et le gagnant a franchi la ligne en 4800 secondes.';
const re = /\b\d{3,6}\b/g;
console.log(myStr.match(re)); // [ '500', '251', '4800' ]
Le Quantificateur Minimum
Le quantificateur minimum vous permet de spécifier le nombre minimum de fois que vous voulez que le caractère qui le précède corresponde. Vous pouvez faire cela en mettant une virgule juste après le nombre dans l'accolade. La syntaxe générale ressemble à ceci : {n,}.
Par exemple, le motif /a{3,}/ signifie que vous voulez un minimum de trois lettres a. Dans ce cas, une lettre a et deux lettres a ne seront pas une correspondance, mais trois lettres a et plus seront retournées comme correspondances :
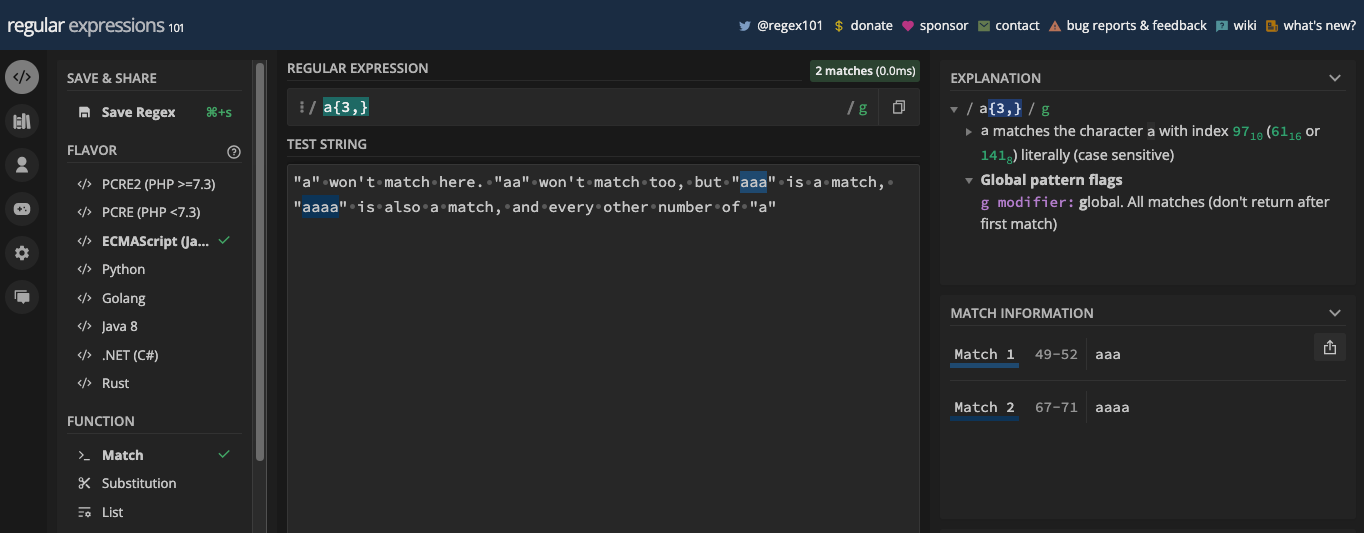
Extrayons ces correspondances avec la méthode match() :
const myStr =
'"a" ne correspondra pas ici. "aa" ne correspondra pas non plus, mais "aaa" est une correspondance, "aaaa" est aussi une correspondance, et tout autre nombre de "a"';
const re = /a{3,}/g;
console.log(myStr.match(re)); // [ 'aaa', 'aaaa' ]
Le Quantificateur Exact
Le spécificateur exact est représenté par {n}. Dans ce cas, n représente le nombre exact de fois que vous voulez que ce caractère soit répété. Par exemple, le motif /a{3}/ signifie que vous voulez que a soit répété trois fois.
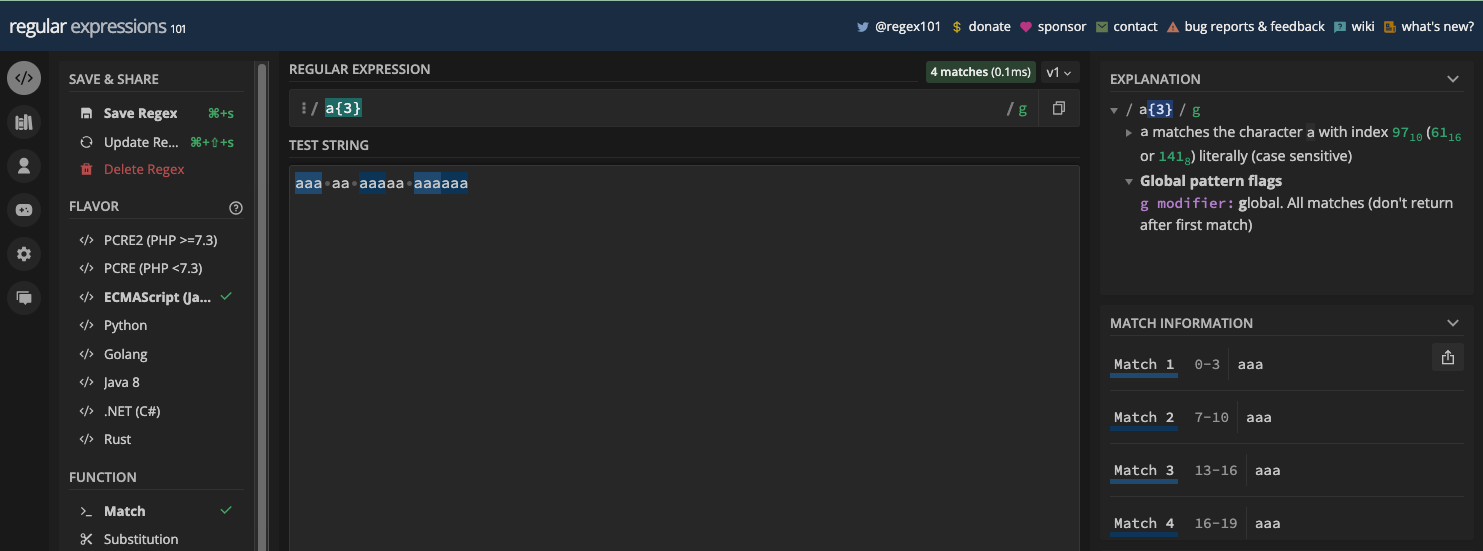
Malheureusement, une correspondance est retournée partout où il y a trois lettres a qui se suivent. Vous pouvez prévenir ce comportement avec une limite de mot (\b) :
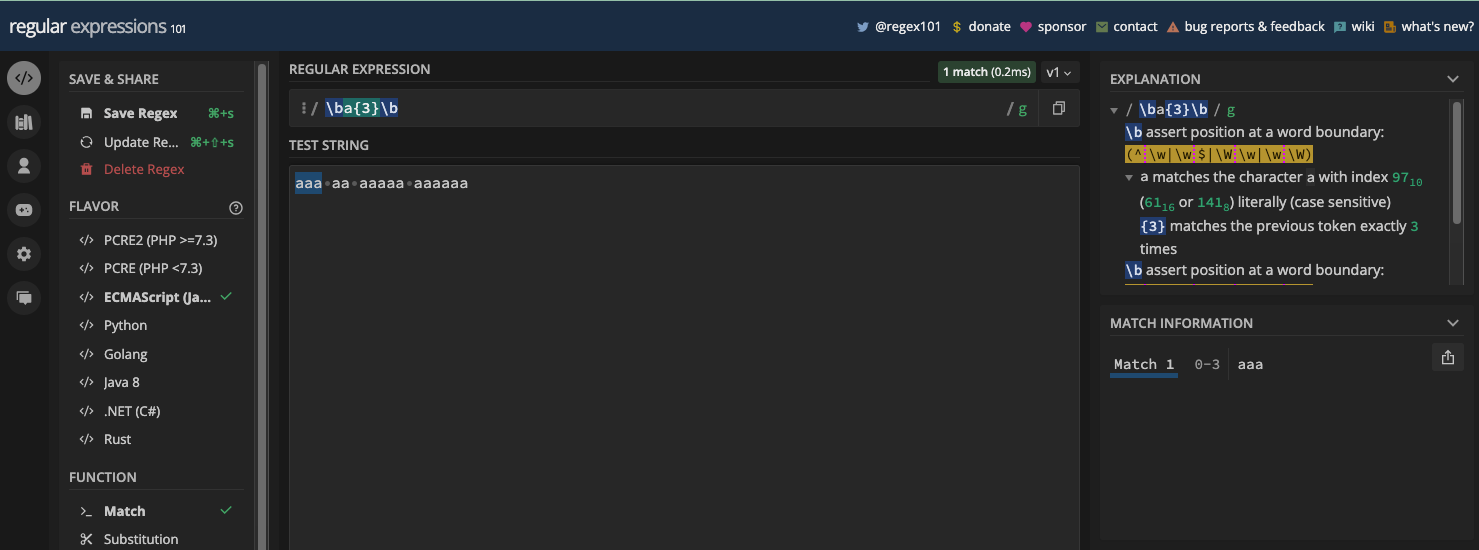
De cette façon, vous pouvez extraire les abréviations, AAA d'une chaîne en utilisant la méthode match(). Voici un exemple :
const myStr =
"Il y a l'American Automobile Association (AAA) et il y a l'Australian Automobile Association (AAA). Ce que je n'ai jamais vu, c'est AAAA ou AAAAAA.";
const re = /\ba{3}\b/gi;
console.log(myStr.match(re)); // [ 'AAA', 'AAA' ]
Vous vous souvenez du motif que j'ai écrit pour correspondre aux dates au format jj/mm/aaaa ? Vous pouvez le rendre meilleur et plus facile à lire avec le quantificateur exact comme ceci :
\d{2}[/.-]\d{2}[/.-]\d{4}
Tout fonctionne toujours bien :
const slashSeparatedSate = '22/04/2023';
const hyphenSeparatedDate = '22-04-2023';
const periodSeparatedDate = '22.04.2023';
const re = /\d{2}[/.-]\d{2}[/.-]\d{4}/;
console.log(re.test(slashSeparatedSate)); // true
console.log(re.test(hyphenSeparatedDate)); // true
console.log(re.test(periodSeparatedDate)); // true
Vous pouvez également rendre le motif qui correspond au numéro de téléphone américain meilleur et plus court avec la même approche :
\(\d{3}\) \d{3}-\d{4}
Tout fonctionne toujours bien aussi :
const USPhone = '(123) 456-7890';
const re = /\(\d{3}\) \d{3}-\d{4}/;
console.log(re.test(USPhone)); // true
Le Métacaractère de Joker
Le métacaractère de joker est représenté par un point (.), donc vous pouvez également l'appeler le métacaractère de point.
Le joker vous permet de correspondre à n'importe quel caractère à part une nouvelle ligne (\n). Cela signifie que vous pouvez l'utiliser pour correspondre à des caractères alphanumériques, des espaces et des symboles.
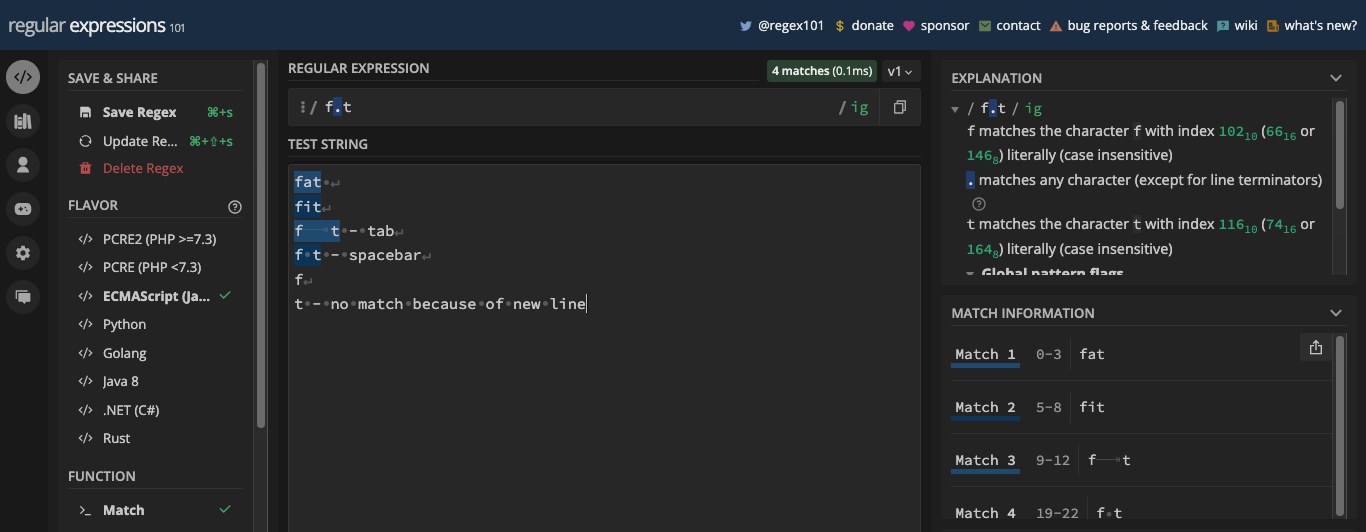
Vous pouvez également attacher le métacaractère de joker à un autre métacaractère. Par exemple, le motif /\d./g devrait correspondre à au moins un nombre et à tout ce qui le suit :
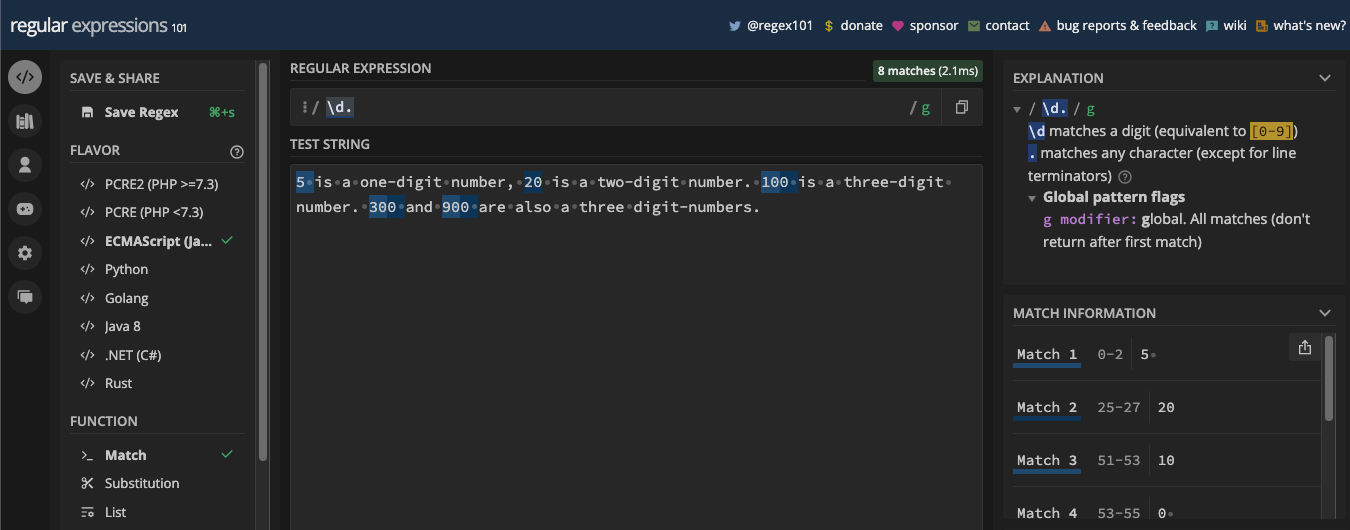
Vous pouvez voir que le motif dépasse les chiffres en correspondant aux espaces qui les suivent. C'est ce qu'on appelle l'avidité.
Le motif /\d.*/g est encore plus gourmand car il correspondra à tout ce qui suit après avoir rencontré le premier nombre :
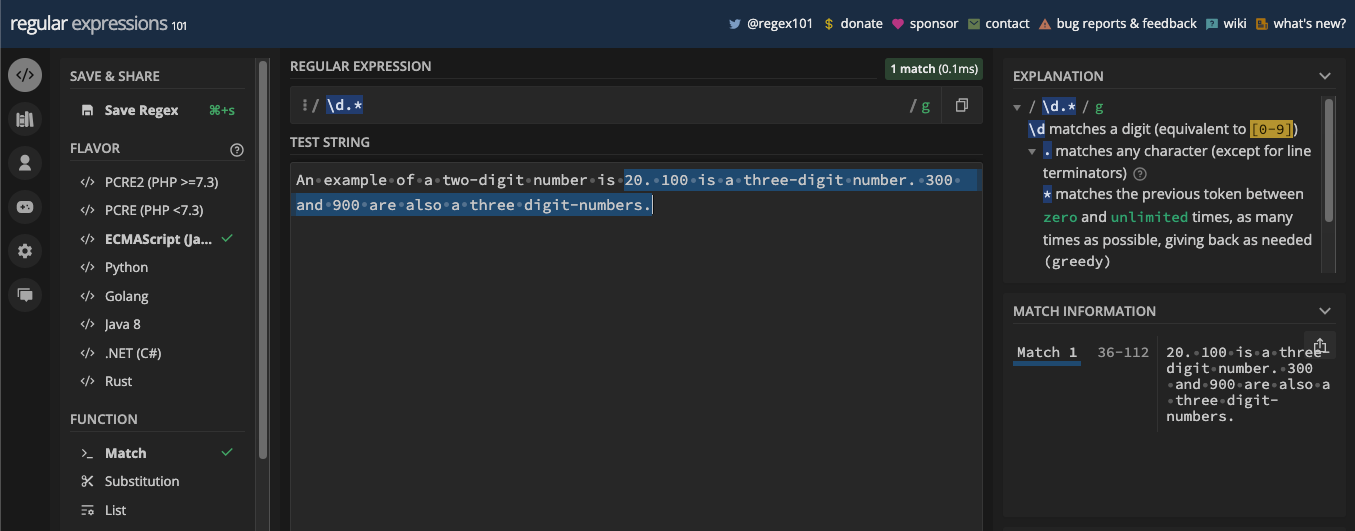
C'est la même chose en code :
const myStr =
'Un exemple de nombre à deux chiffres est 20. 100 est un nombre à trois chiffres. 300 et 900 sont également des nombres à trois chiffres.';
const re = /\d.*/g;
console.log(myStr.match(re)); // [ '20. 100 est un nombre à trois chiffres. 300 et 900 sont également des nombres à trois chiffres.']
Si vous voulez que le joker corresponde également à une nouvelle ligne, vous pouvez utiliser le drapeau s. Voici un exemple :
let codeBlock = `
function add(x, y) {
/* C'est une fonction
qui prend deux nombres
et les additionne. */
return x + y;
}
`;
let commentRegex = /\/\*(.*)\*\//s; // obtient tout entre /* et */
const match = codeBlock.match(commentRegex);
console.log(match);
Voici le résultat :
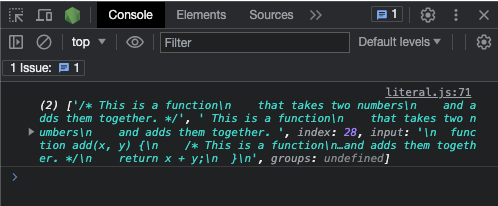
Vous pouvez utiliser la propriété dotAll pour vérifier si le drapeau s est utilisé dans le motif :
let codeBlock = `
function add(x, y) {
/* C'est une fonction
qui prend deux nombres
et les additionne. */
return x + y;
}
`;
let commentRegex = /\/\*(.*)\*\//s; // obtient tout entre /* et */
const match = codeBlock.match(commentRegex);
console.log(commentRegex.dotAll) // true;
Vous pouvez extraire la correspondance avec une instruction if :
let codeBlock = `
function add(x, y) {
/* C'est une fonction
qui prend deux nombres
et les additionne. */
return x + y;
}
`;
let commentRegex = /\/\*(.*)\*\//s; // obtient tout entre /* et */
const match = codeBlock.match(commentRegex);
if (match) {
console.log(match[1]);
}
/*
Sortie :
C'est une fonction
qui prend deux nombres
et les additionne.
*/
Parce que le joker correspond toujours à n'importe quel caractère qu'il rencontre à part une nouvelle ligne, il est préférable de ne pas l'utiliser sauf si c'est absolument nécessaire. Pour chaque caractère que le joker correspond, il existe toujours une autre façon de le correspondre.
L'Avarice et la Paresse dans les Expressions Régulières
Par défaut, les motifs d'expressions régulières sont gourmands, ce qui signifie qu'ils essaient toujours de correspondre à autant de caractères que possible. Mais le concept d'avidité est principalement applicable aux quantificateurs (*, +, ?, et {}) et au joker (.).
Par exemple, le motif /f.*h/gi correspondra à autant de caractères que possible après avoir rencontré un f dans la chaîne cible :
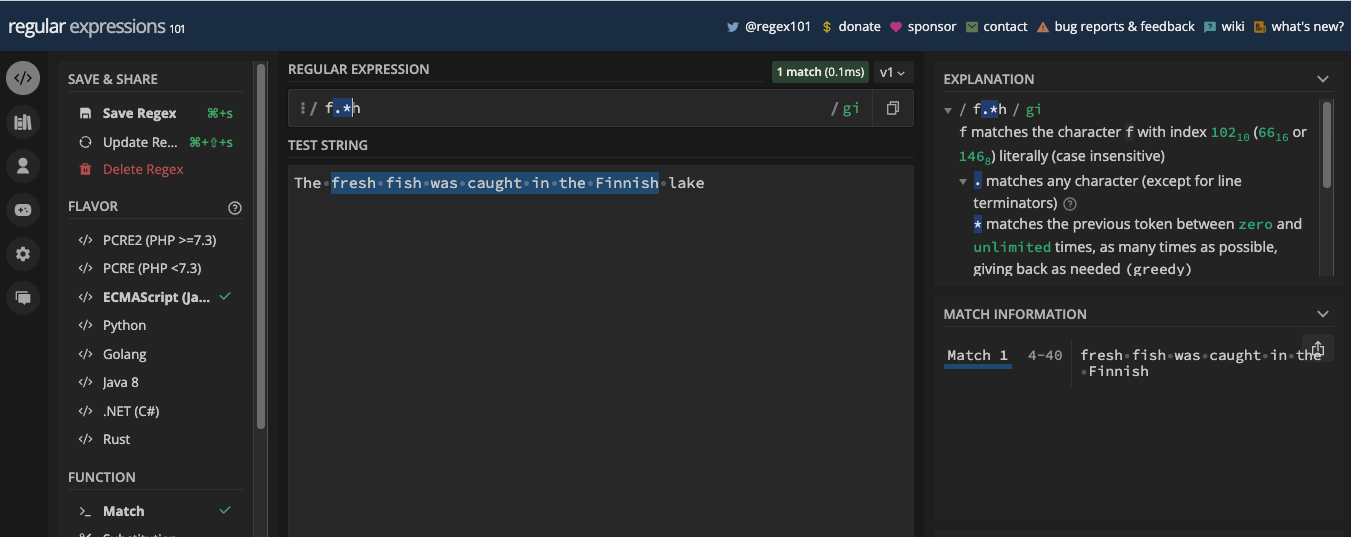
De même pour le motif /f.*h/gi :
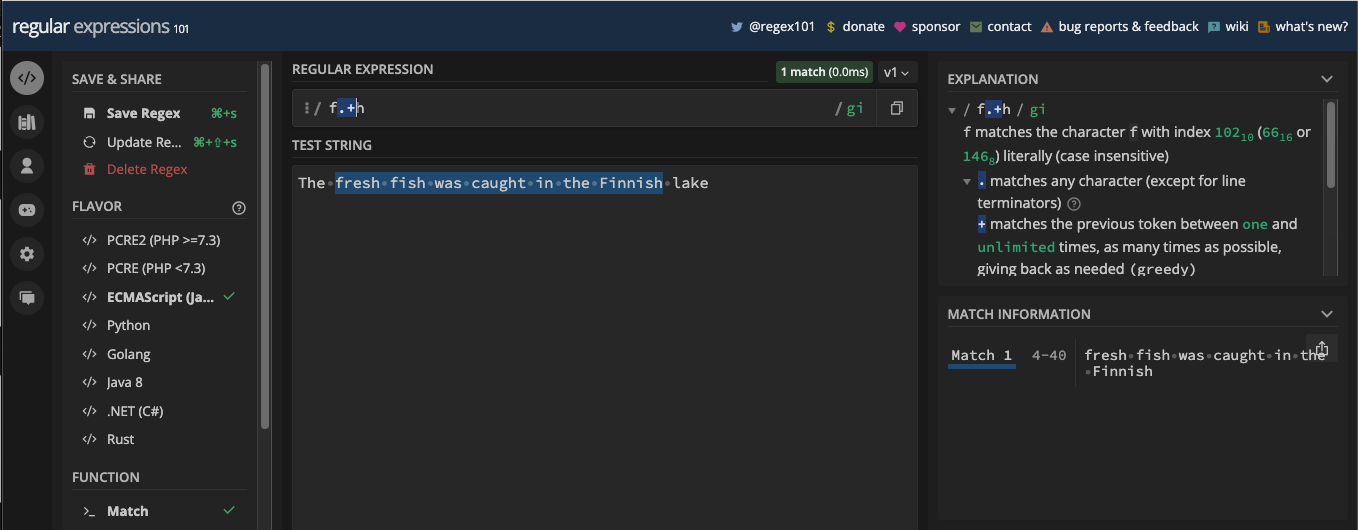
C'est la même chose en code :
const myStr = 'Le poisson frais a été pêché dans le lac finlandais';
const re = /f.*h/gi;
console.log(myStr.match(re)); // [ 'fresh fish was caught in the Finnish' ]
La paresse est l'opposé de l'avidité et c'est la façon dont vous arrêtez l'avidité. À de nombreuses occasions, si vous voulez arrêter l'avidité, tout ce dont vous avez besoin est d'appliquer le quantificateur zéro ou un (?) au métacaractère qui cause l'avidité.
Voici comment j'ai arrêté l'avidité du métacaractère astérisque :
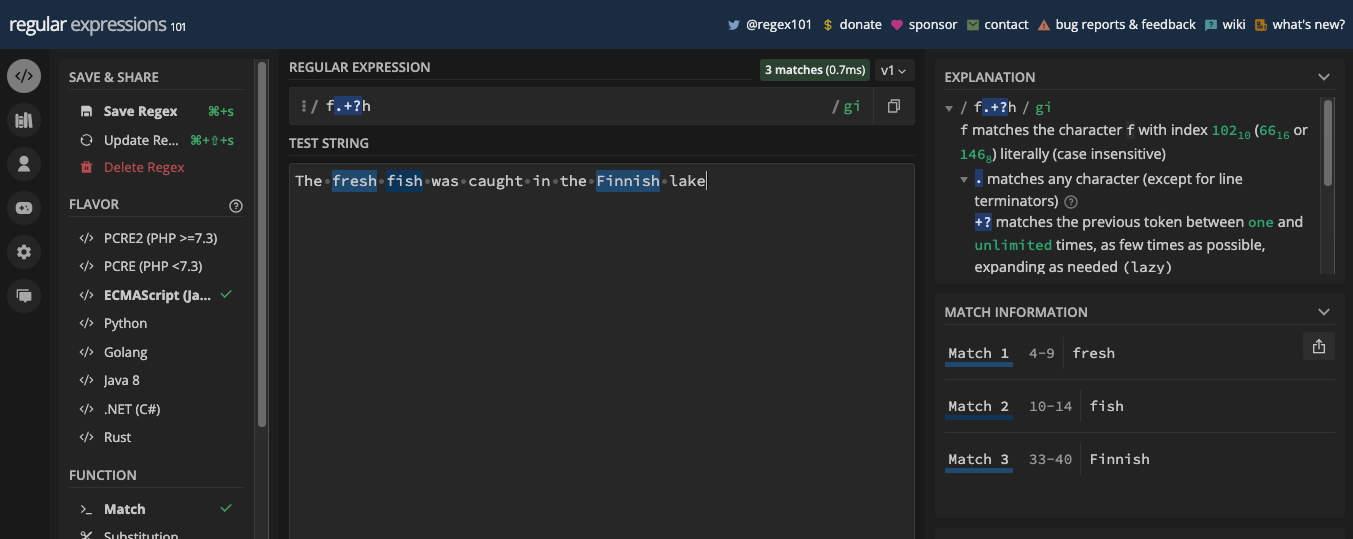
Je l'ai arrêté pour le métacaractère plus de la même manière :
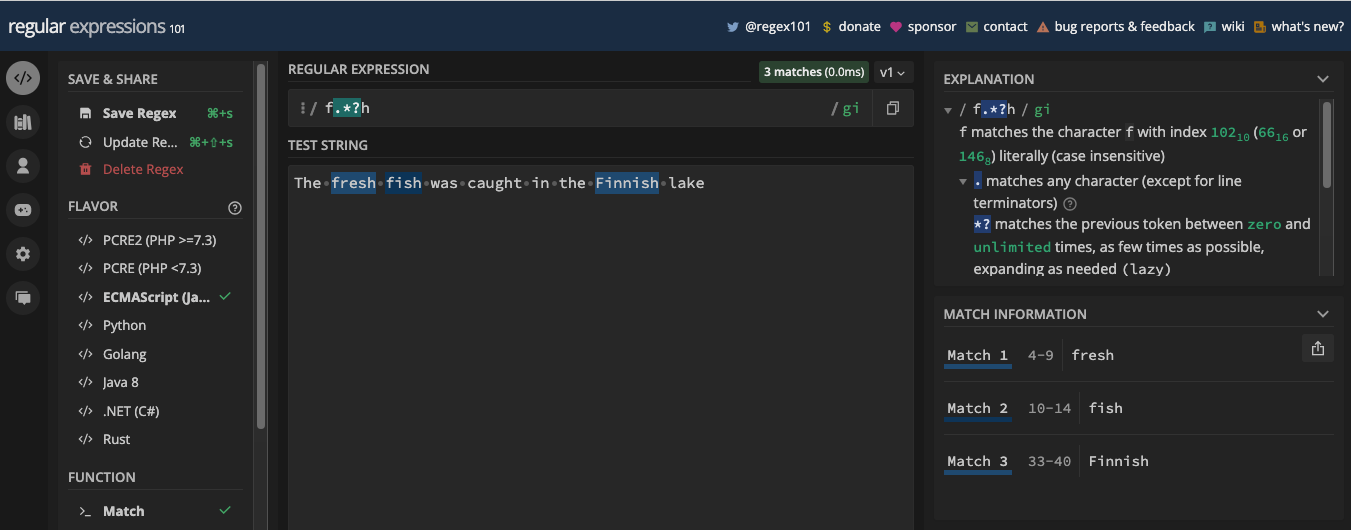
Je peux maintenant extraire en toute sécurité chaque mot qui commence par f et se termine par h :
const myStr = 'Le poisson frais a été pêché dans le lac finlandais';
const re = /f.*?h/gi;
console.log(myStr.match(re)); // [ 'fresh', 'fish', 'Finnish' ]
Chapitre 6 : Groupement et Capture dans Regex
Qu'est-ce que le Groupement ?
Le groupement signifie traiter un motif regex ou une partie d'un motif regex comme une seule unité. Pour réaliser le groupement, vous entourez le motif ou la partie du motif que vous souhaitez grouper de parenthèses (( et )).
Après avoir groupé la partie du motif que vous souhaitez, vous pouvez ensuite y faire référence par un processus que nous appelons "rétro-référencement" dans les expressions régulières.
Les groupes que vous définissez dans un motif font référence à la chaîne ou au texte cible et non au motif lui-même. Vous verrez cela en action lorsqu'il sera temps de discuter du rétro-référencement.
Après le groupement, vous pouvez ensuite appliquer un quantificateur à ce groupe puisque tous les motifs qu'il contient sont une unité.
Disons que vous avez un groupe d'identifiants z8g4g4 ga1v4g f4k7f9 bb3b2b d6b4t5 d4cm3d e9f5y6 ggj64 mgtyqg m0foh9 et que vous voulez savoir lesquels d'entre eux suivent le motif lettre chiffre lettre chiffre lettre chiffre. Le motif [a-z]\d[a-z]\d[a-z]\d peut le faire pour vous :
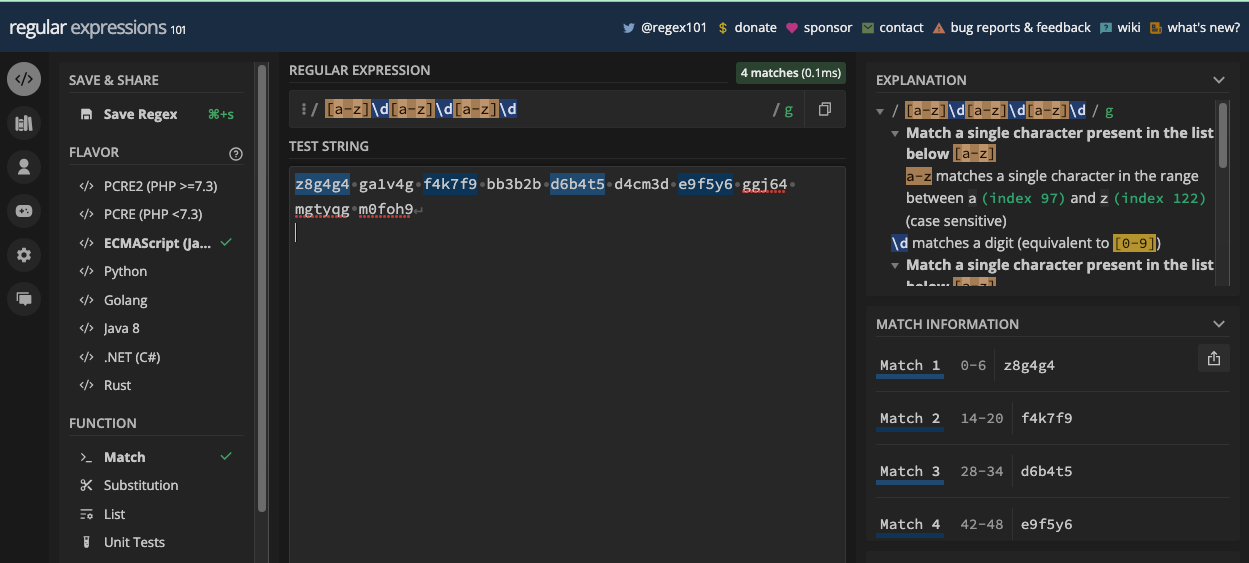
En utilisant le groupement, vous pouvez rendre le motif plus court en groupant la séquence [a-z]\d et en appliquant un quantificateur exact de 3 :
([a-z]\d){3}
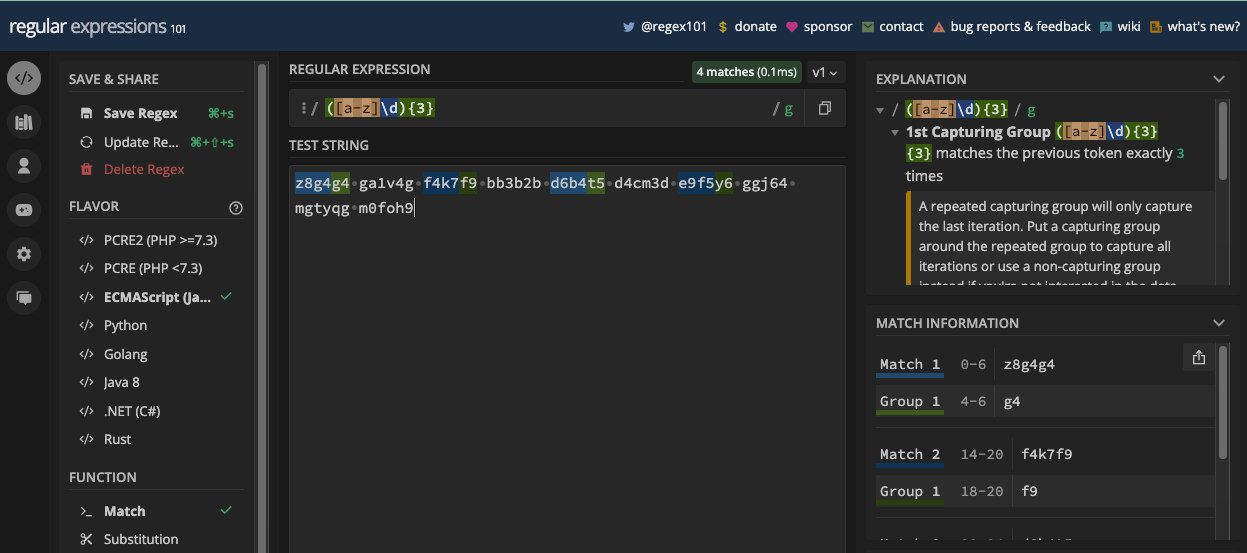
Lorsque vous utilisez le groupement dans un motif, surtout si vous avez plusieurs groupes dans le même motif, vous pouvez utiliser la méthode exec() pour extraire chacun des groupes.
Un bon exemple pour illustrer cela est une date dans n'importe quel format acceptable, par exemple jj/mm/aaaa.
Voici comment je groupe le motif \d\d[/.-]\d\d[/.-]\d\d\d\d en jj, mm, et aaaa :
(\d\d)[/.-](\d\d)[/.-](\d\d\d\d)
J'ai utilisé la méthode exec() de cette manière :
const re = /(\d\d)[/.-](\d\d)[/.-](\d\d\d\d)/;
const date = '22-03-2023';
const execRes = re.exec(date);
console.log(execRes);
Voici à quoi ressemble le résultat dans la console :
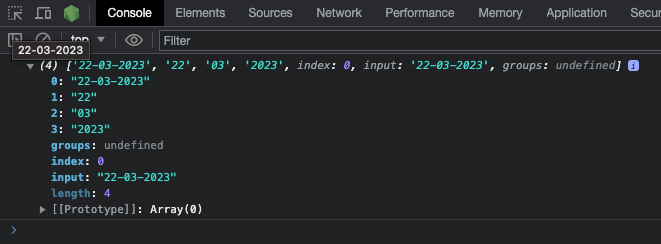
Dans le tableau, vous pouvez voir que :
- il y a la date complète à l'index
0 - l'index
1contient lejour - l'index
2contient lemois - et l'index
3contient l'année
Vous pouvez ensuite utiliser la référence de tableau pour obtenir toutes ces valeurs :
const re = /(\d\d)[/.-](\d\d)[/.-](\d\d\d\d)/;
const date = '22-03-2023';
const execRes = re.exec(date);
console.log(`La date complète est ${execRes[0]}`); // La date complète est 22-03-2023
console.log(`Le jour est ${execRes[1]}`); // Le jour est 22
console.log(`Le mois est ${execRes[2]}`); // Le mois est 03
console.log(`L'année est ${execRes[3]}`); // L'année est 2023
Vous pouvez également utiliser cette approche pour extraire un nom d'utilisateur et un domaine d'un email :
function extractUsernameAndDomain(email) {
const re = /([a-z]{2,})@([a-z]{3,}\.com)/;
const result = re.exec(email);
console.log(`Le nom d'utilisateur est ${result[1]}`);
console.log(`Le domaine est ${result[2]}`);
console.log(`L'email complet est ${result[0]}`);
}
extractUsernameAndDomain('janedoe@gmail.com');
/*
Sortie :
Le nom d'utilisateur est janedoe
Le domaine est gmail.com
L'email complet est janedoe@gmail.com
*/
Ce comportement de groupement dans lequel chaque correspondance du motif est séparée dans un tableau selon les groupes est la raison pour laquelle les groupes sont également appelés groupes "capturants". Ainsi, vous n'avez pas besoin de la méthode split() de JavaScript ou d'autres astuces de programmation pour obtenir chacun des groupes sur ces dates.
Comment Référencer les Groupes Capturés avec les Rétro-références
Puisque les groupes sont capturés par défaut, vous pouvez y faire référence. Pour ce faire, vous utilisez une barre oblique inverse (\) puis l'ordre du groupe dans le motif. Par exemple, vous pouvez référencer le premier groupe avec \1 et le troisième groupe avec \3. Pas d'indentation zéro.
Disons que vous voulez correspondre à "tsetse" fly dans le texte Il y a beaucoup de mouches tsetse dans les tropiques. Si vous groupez d'abord le texte "tse" et utilisez le drapeau g, vous obtiendrez deux correspondances :
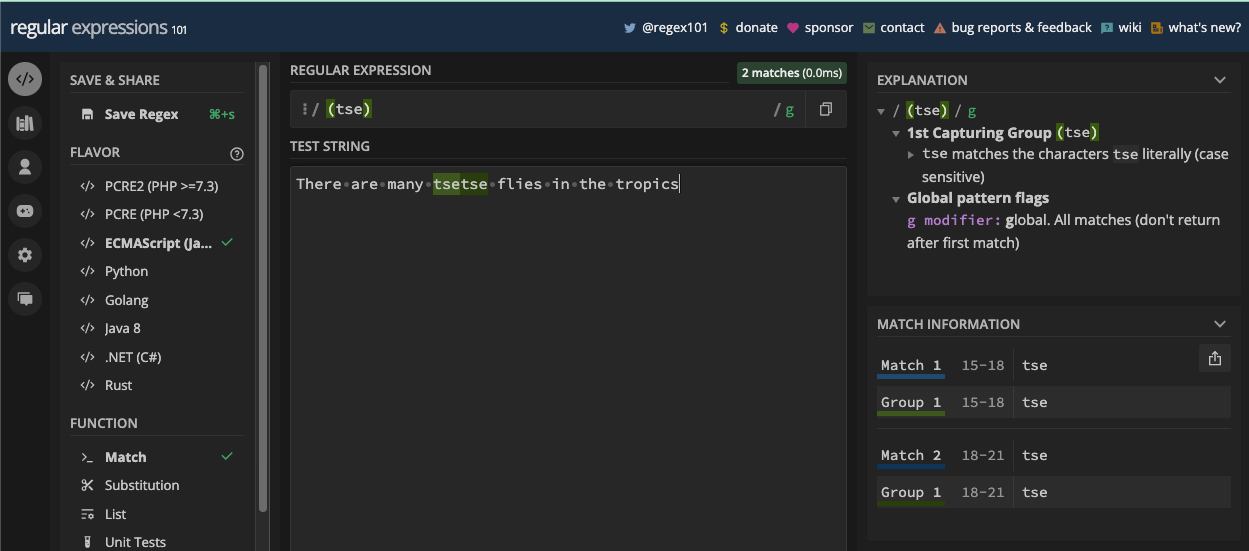
Vous pouvez faire référence à ce groupe tse avec \1 et vous aurez une seule correspondance :
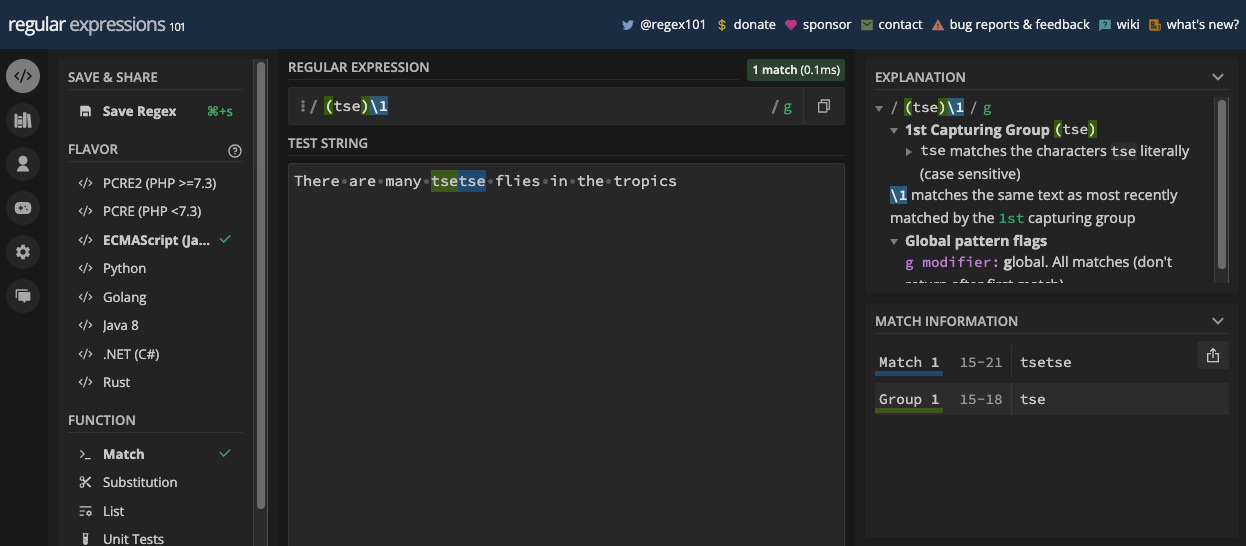
Il est très important de noter que lorsque vous utilisez un groupe capturant, le groupement fait référence à la chaîne cible (ou texte) et non au motif lui-même. La raison pour laquelle le motif /(tse)\1/ retourne une correspondance dans le dernier exemple est à cause du "tse" dans le texte et non du "tse" dans le motif.
Pour illustrer cela, utilisons à nouveau une date, puisque le mois ou la date et les séparateurs peuvent se répéter et peuvent être différents. J'utiliserai le motif (\d\d)([/.-])\1\2(\d\d\d\d) pour correspondre aux dates que j'ai groupées dans l'un des exemples précédents. Rappelez-vous que le motif correspond avec succès à une date :
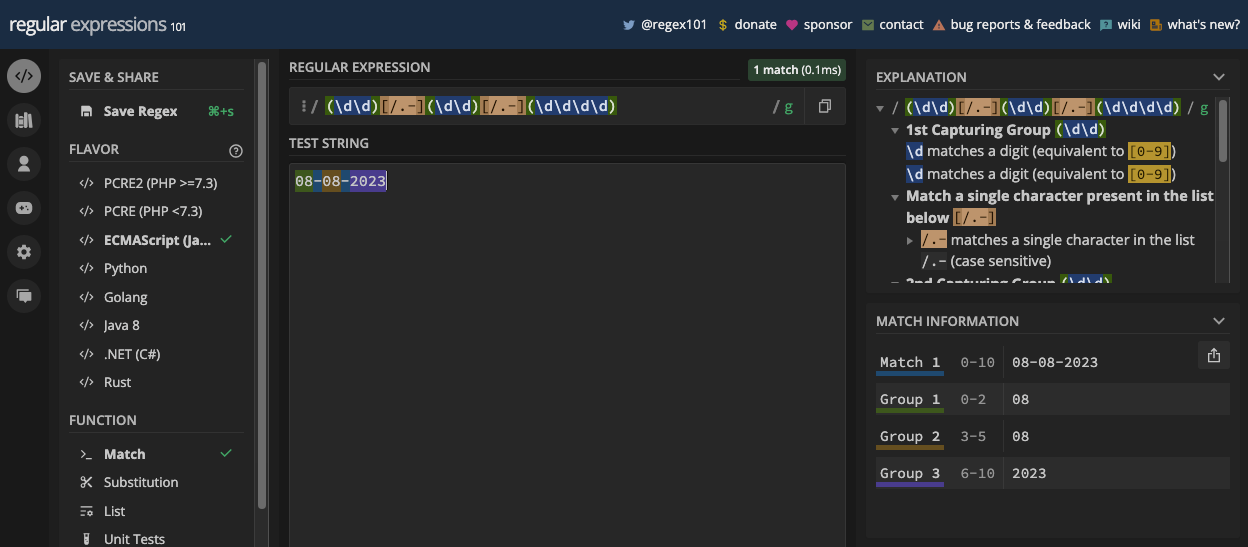
Je peux également regrouper le séparateur et y faire référence pour le deuxième séparateur. Je peux également faire référence à la partie jour de la date pour correspondre au mois, puisque les deux recherchent deux chiffres.
Voici le nouveau motif maintenant :
(\d\d)([/.-])\1\2(\d\d\d\d)
Je peux rendre le motif plus court avec un quantificateur exact :
(\d{2})([/.-])\1\2(\d{4})
Le nouveau motif correspond avec succès à la même date :
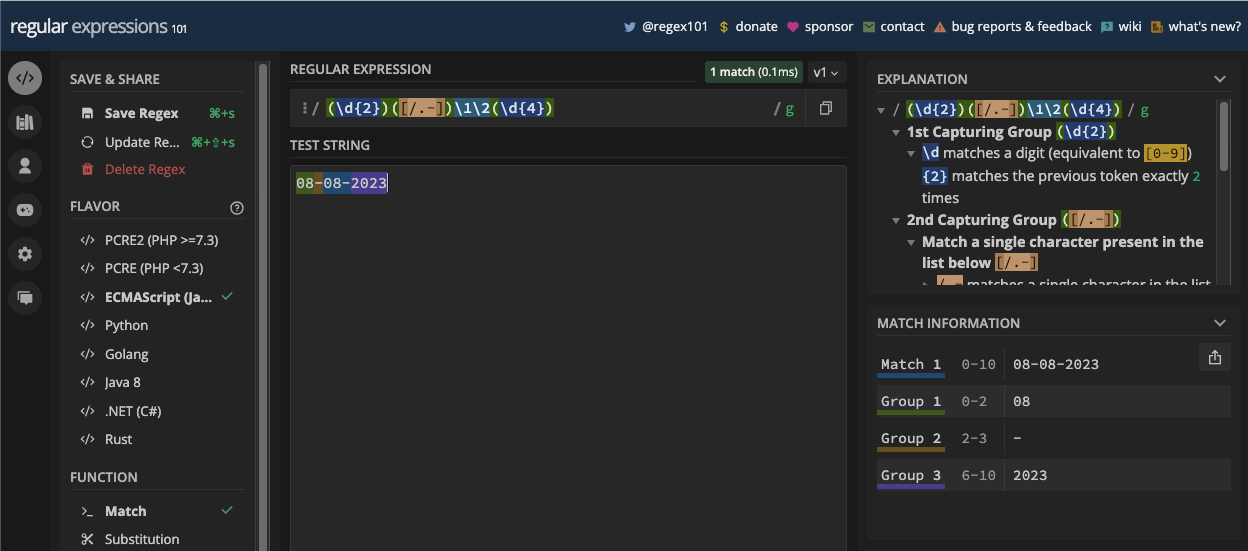
Mais la raison pour laquelle il y a une correspondance dans l'exemple ci-dessus est que les séparateurs sont les mêmes et que le jour et le mois sont les mêmes.
Si le jour est différent du mois, il n'y aura pas de correspondance :
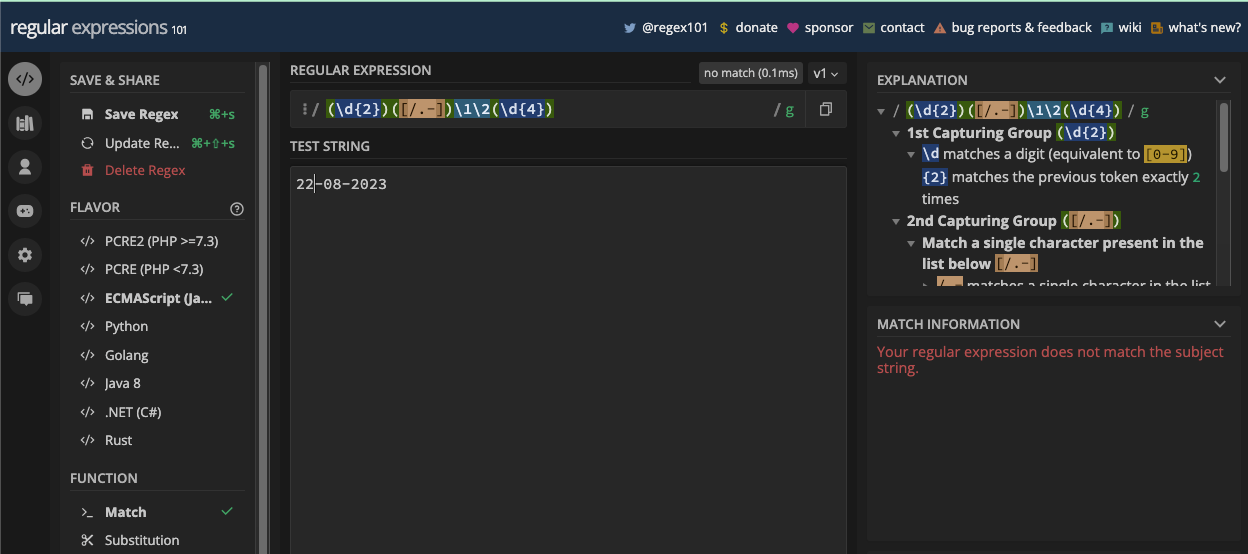
Si les séparateurs sont également différents, il n'y aura pas non plus de correspondance :
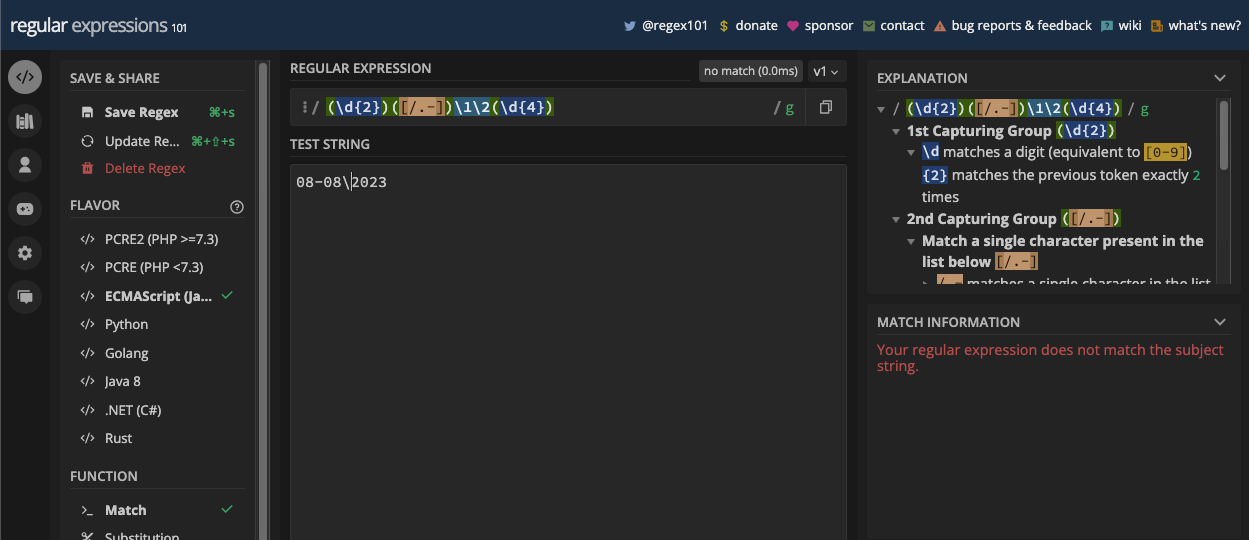
Mais rappelez-vous que si les deux sont identiques, il y aura une correspondance :
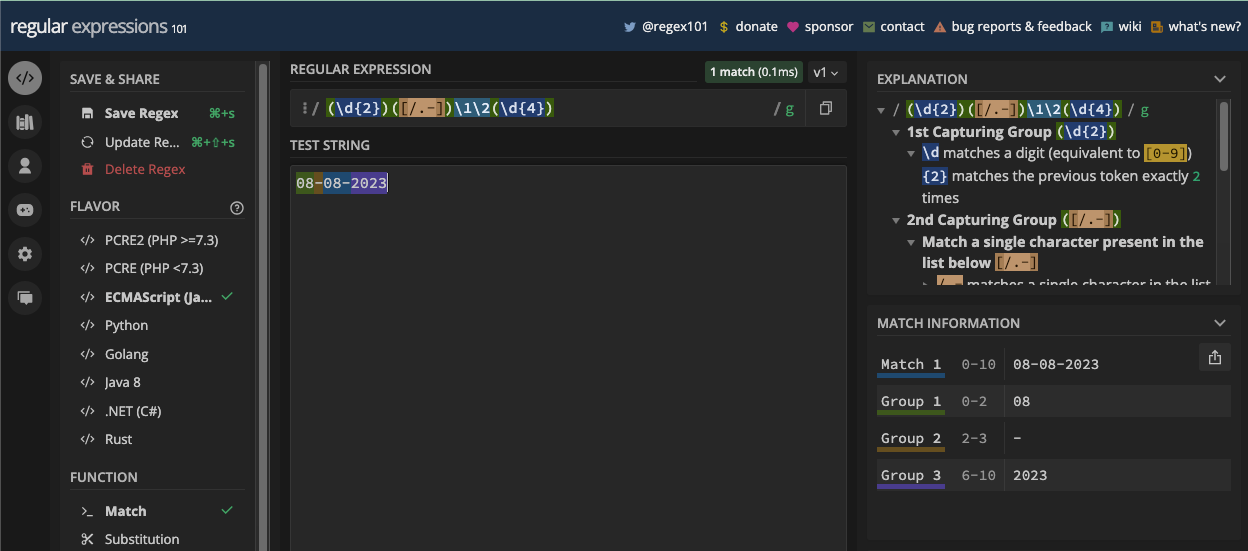
C'est la raison pour laquelle les groupes dans un motif font référence à la chaîne cible (ou texte) et non au motif lui-même.
Il est également possible de rendre un groupe non capturant. Ainsi, vous ne pourrez pas y faire référence dans le motif. Pour créer un groupe non capturant, vous utilisez un point d'interrogation et un deux-points juste après la parenthèse ouvrante.
La syntaxe pour cela ressemble à ceci :
(?: chars)
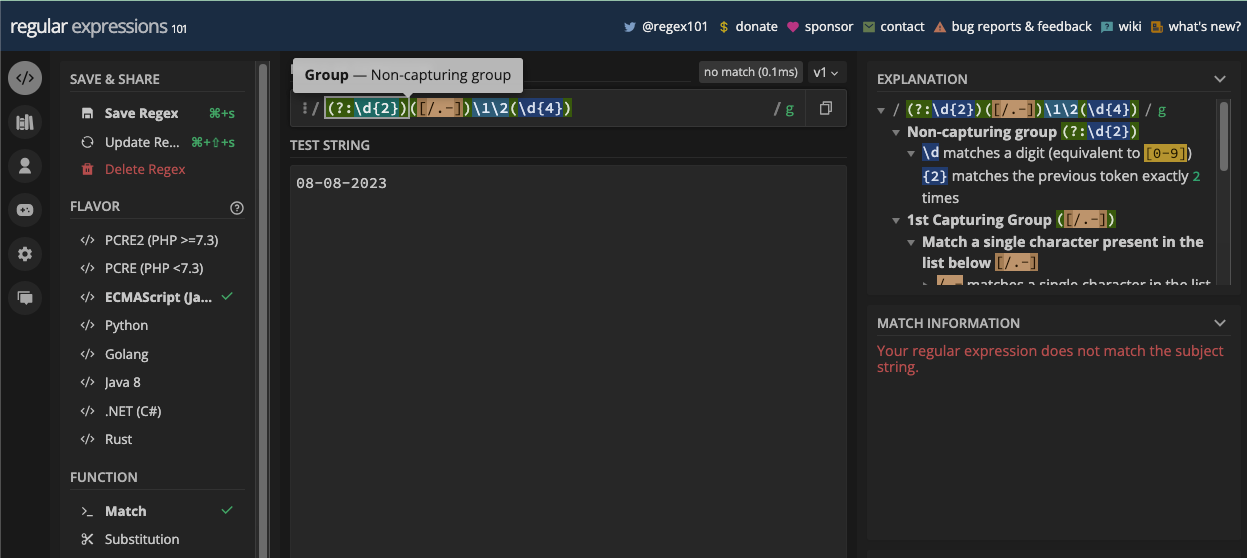
À cause de cela, le texte ne correspond plus au motif. Pour le faire correspondre à nouveau, je dois :
- supprimer la première rétro-référence (
\1) - définir
\d{2}pour la date - changer la référence au séparateur de
\2à\1
Voici le nouveau motif :
(?:\d{2})([/.-])\d{2}\1(\d{4})
Et maintenant la date correspond au motif :
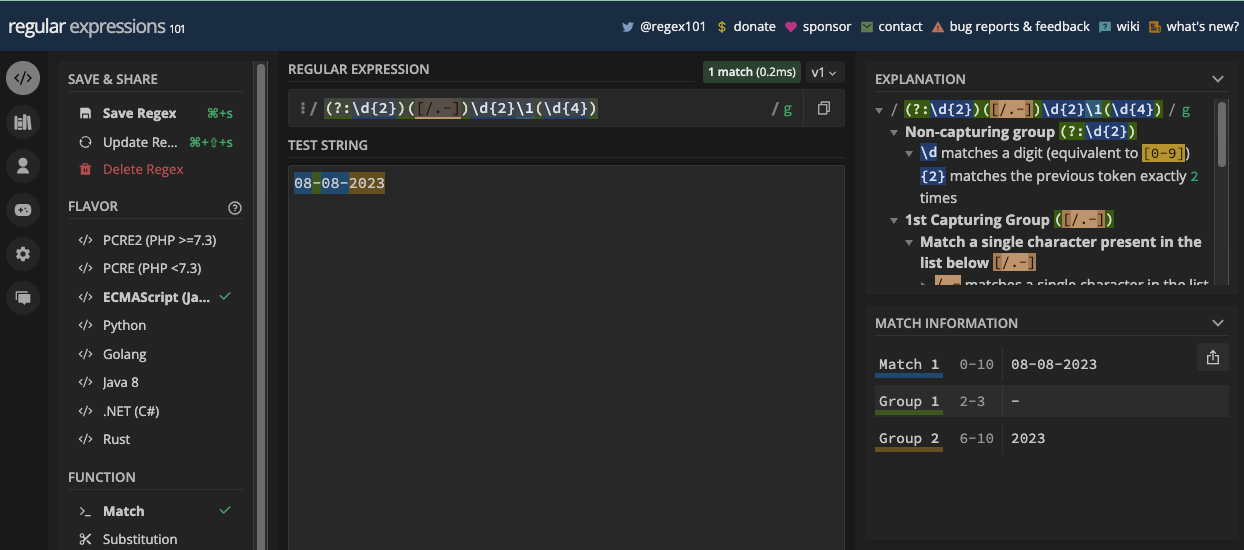
Comment Utiliser le Drapeau d et la Propriété hasIndices avec les Groupes
Le drapeau d ajoute des informations d'index aux objets de correspondance pour les groupes de capture. Ainsi, vous ne saurez pas seulement ce qui a été correspondre par chaque groupe de capture, mais aussi où cette correspondance a été trouvée dans la chaîne d'entrée.
Examinons comment cela fonctionne avec le groupement pour correspondre aux dates :
const re = /(\d\d)[/.-](\d\d)[/.-](\d\d\d\d)/d;
const date = '22-03-2023';
const match = re.exec(date);
console.log(match);
Le résultat contient un tableau d'objets détaillant la position totale de toutes les correspondances, et la position de chaque correspondance :
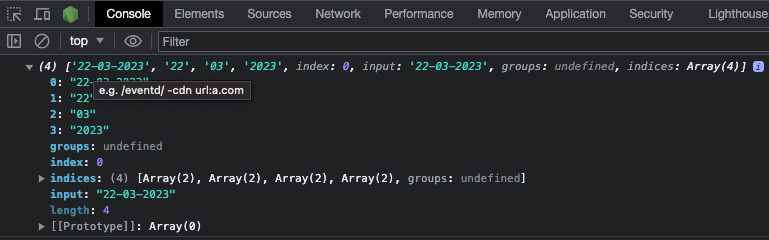
Si vous voulez voir ces indices, vous pouvez utiliser .indices pour les voir :
const re = /(\d\d)[/.-](\d\d)[/.-](\d\d\d\d)/d;
const date = '22-03-2023';
const match = re.exec(date);
console.log(match.indices);
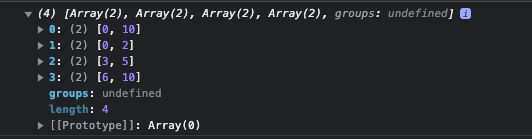
Vous pouvez également extraire ces indices séparément :
const re = /(\d\d)[/.-](\d\d)[/.-](\d\d\d\d)/d;
const date = '22-03-2023';
const match = re.exec(date);
console.log(`La plage d'index complète est ${match.indices[0]}`); //La plage d'index complète est 0,10
console.log(`La plage d'index du jour est ${match.indices[1]}`); // La plage d'index du jour est 0,2
console.log(`La plage d'index du mois est ${match.indices[2]}`); // La plage d'index du mois est 3,5
console.log(`La plage d'index de l'année est ${match.indices[3]}`); // La plage d'index de l'année est 6,10
Et enfin, vous pouvez vérifier si le drapeau d est vraiment utilisé avec la propriété hasIndices :
const re = /(\d\d)[/.-](\d\d)[/.-](\d\d\d\d)/d;
const date = '22-03-2023';
console.log(re.hasIndices); // true
Chapitre 7 : Groupes de Recherche : Lookaheads et Lookbehinds
Qu'est-ce que les Groupes de Recherche ?
Les assertions de recherche sont des groupes non capturants qui retournent des correspondances uniquement si la chaîne cible est suivie ou précédée d'un caractère particulier.
Les assertions de recherche ne consomment pas les caractères dans la chaîne ou le texte d'entrée. Cela en fait une "assertion de largeur nulle", et c'est pourquoi les groupes de recherche sont également appelés "assertions de lookahead".
Il existe deux types de groupes de recherche : lookahead et lookbehind. Les deux ont également leurs formes positives et négatives, donc il y a des groupes positive lookahead, negative lookahead, positive lookbehind, et negative lookbehind.
Qu'est-ce qu'un Groupe de Lookahead ?
Un groupe de lookahead est un groupe non capturant qui vous permet de correspondre à une partie d'une chaîne uniquement si elle est suivie d'un autre caractère dans la chaîne, sans inclure cette chaîne ou ce texte à correspondre dans le motif.
Un groupe de lookahead est utile lorsque vous souhaitez correspondre à une chaîne en fonction d'une condition. Vous pouvez donc le considérer comme une instruction if dans un langage de programmation.
Il existe deux types de lookaheads, à savoir positive lookahead et negative lookahead.
Parce que vous traitez toujours avec des groupements, un positive lookahead est spécifié par une parenthèse ouvrante suivie d'un point d'interrogation, d'un signe égal, des caractères, et d'une parenthèse fermante :
(?=chars)
Par exemple, le motif x(?=y) signifie correspondre à x uniquement s'il est suivi de y.
Dans la syntaxe du negative lookahead, vous remplacez le signe égal par un point d'exclamation :
(?!chars)
Par exemple, le motif x(?!y) signifie ne pas correspondre à x s'il est suivi de y.
Examinons un exemple d'assertion de positive lookahead.
Disons que vous voulez correspondre au nom de domaine des domaines qui n'ont que l'extension .org dans une chaîne de domaines avec d'autres extensions. Ce motif le ferait :
[a-zA-Z]+(?=\.org)
Dans le motif, [a-zA-Z]+ représente un ou plusieurs caractères de mot, et (?=\.org) vérifie si le domaine contient une extension .org.
Dans la capture d'écran ci-dessous, vous pouvez voir que les noms de domaine qui ont une extension .org ont été correspondus :

Vous pouvez également voir que les mots "freeCodeCamp" et "catholic" n'étaient pas inclus dans le motif, mais ils correspondent toujours au motif parce qu'ils ont l'extension .org.
S'il n'y a pas de domaines avec l'extension .org dans la chaîne cible, il n'y aura aucune correspondance. C'est vrai pour les domaines sans l'extension .org.
De cette façon, vous pouvez extraire du texte comme celui-ci en JavaScript et en faire ce que vous voulez :
const domains = 'koladechris.com freeCodeCamp.org mdn.com catholic.org';
const re = /[a-zA-Z]+(?=\.org)/g;
const charityWebsitesArr = domains.match(re);
const charityWebsites = charityWebsitesArr.join(',').replace(/,/, ' et ');
console.log(charityWebsites, 'sont des exemples d'organisations caritatives.'); //freeCodeCamp et catholic sont des exemples d'organisations caritatives.
Si vous voulez correspondre au .org également pour que le domaine entier soit correspondre, vous devez inclure le .org dans le motif :
Puisque les groupes de lookahead ne consomment pas de caractères, vous verrez beaucoup de développeurs utiliser des positive lookaheads pour valider les mots de passe.
Disons que vous voulez que le mot de passe soit au moins six caractères incluant une lettre minuscule, une lettre majuscule, un chiffre et un symbole. Vous pouvez utiliser des lookaheads pour définir toutes ces conditions :
(?=.{6,})– au moins 6 caractères(?=.*[a-z])– au moins un caractère minuscule, mais vérifiez s'il y a zéro ou plusieurs caractères avant(?=.*[A-Z])– au moins un caractère minuscule, mais vérifiez s'il y a zéro ou plusieurs caractères avant(?=.*[0-9])– au moins un chiffre, mais vérifiez s'il y a zéro ou plusieurs caractères avant(?=.*[!@#$%%^&*()+=-])– symboles acceptés, mais vérifiez s'il y a zéro ou plusieurs caractères avant chacun.*– vérifiez s'il y a zéro ou plusieurs caractères après les groupes
Voici l'expression régulière complète :
(?=.{6,})(?=.*[a-z])(?=.*[A-Z])(?=.*[0-9])(?=.*[!@#$%%^&*()+=-]).*
Et voici ce qui correspond au motif et ce qui ne correspond pas :

Pour utiliser ce motif en JavaScript, vous pouvez le tester contre une chaîne de mot de passe et faire quelque chose à partir de là :
const password = 'Tse23*';
const passwordRe =
/(?=.{6,})(?=.*[a-z])(?=.*[A-Z])(?=.*[0-9])(?=.*[!@#$%%^&*()+=-]).*/;
if (passwordRe.test(password)) {
console.log('Bienvenue sur votre tableau de bord !');
} else {
throw new Error('Mot de passe incorrect !');
}
/**
sortie : Bienvenue sur votre tableau de bord !
*/
Pour l'application du negative lookahead, il est utile lorsque vous ne voulez pas d'un certain caractère avant le ou les caractères que vous recherchez dans une chaîne.
Disons que vous voulez extraire tous les éléments d'un tableau qui n'ont pas l'article "the" avant eux. Dans ce cas, vous pouvez utiliser le motif ci-dessous :
/^(?!.*\bThe\b).*$/
Dans le motif ci-dessus :
^garantit que le motif regex correspond à partir du début de la ligne(?!.*\bThe\b)est le negative lookbehind qui garantit que l'article "the" n'est pas dans la chaîne cible\bThe\best une limite de mot qui correspond à "The" et rien d'autre.*le joker qui correspond à n'importe quel caractère à part une nouvelle ligne
let docTitles = [
'The Incredible Dr. Poll',
'Born in Africa',
"America's Funniest Home Videos",
'The Lion Queen',
'Snake in the City',
];
let re = /^(?!.*\bThe\b).*$/;
for (let title of docTitles) {
if (re.test(title)) {
console.log(`Un titre sans "The" : ${title}`);
}
}
/*
Sortie :
Un titre sans "The" : Born in Africa
Un titre sans "The" : America's funniest home videos
Un titre sans "The" : Snake in the City
*/
Qu'est-ce qu'un Groupe de Lookbehind ?
Un groupe de lookbehind est similaire à un groupe de lookahead. Mais au lieu de vérifier si un certain caractère(s) suit ce que vous essayez de correspondre, il vérifie si le caractère(s) précède ce que vous essayez de correspondre.
Ainsi, un groupe de lookbehind est un groupe non capturant qui vous permet de correspondre à une partie d'une chaîne uniquement si elle est précédée d'un autre caractère dans la chaîne, sans inclure cette chaîne ou ce texte à correspondre dans le motif.
Comme les lookaheads, il existe également des assertions de lookbehind positives et négatives. Un lookbehind positif retourne une correspondance uniquement si le caractère que vous souhaitez correspondre est précédé d'un autre caractère que vous spécifiez dans votre motif. D'autre part, un lookbehind négatif retourne une correspondance uniquement si le caractère que vous souhaitez correspondre n'est pas précédé d'un autre caractère.
Un lookbehind positif est représenté par une parenthèse ouvrante, un point d'interrogation, un symbole inférieur à, un signe égal, le ou les caractères, et une parenthèse fermante :
(?<=chars)
Par exemple, le motif (?<=x)y indique que vous voulez correspondre à y uniquement s'il y a x avant. Dans ce cas, xx ou yx ne correspondront pas, mais xy correspondrait.

Pour un lookbehind négatif, un point d'exclamation remplace le signe égal :
(?<!chars)
Par exemple, le motif (?<!x)y signifie ne pas correspondre à y s'il y a x avant. Dans ce cas, by correspondrait, my correspondrait, mais jamais xy.
Les groupes de lookbehind positifs peuvent être utiles pour correspondre aux nombres précédés uniquement d'un certain symbole de devise, par exemple les nombres précédés du signe dollar.
L'expression régulière ci-dessous a un lookbehind positif qui correspond à un nombre uniquement s'il est précédé d'un signe dollar :
(?<=\$)\d+(\.\d*)?
Dans le motif ci-dessus, le lookbehind ((?<=\$)) vérifie s'il y a un signe dollar avant un ou plusieurs chiffres (représentés par \d+). L'autre groupe, (\.\d*), et le quantificateur zéro ou un (?) vérifient si le nombre contient des points flottants.
Voici ce qui correspond et ce qui ne correspond pas :

En JavaScript, ce que vous pouvez faire avec les nombres qui correspondent est de calculer le total avec la méthode reduce() :
const myStr =
'10 pièces de l'article coûtent $102.99, mais vous pouvez obtenir 15 pour une réduction de $2, et 20 pour une réduction de $3.99';
const re = /(?<=\$)\d+(\.\d*)?/g;
// mettre tous les prix dans un tableau
const allPrices = myStr.match(re); // [ '102.99', '2', '3.99' ]
// convertir chacun des prix en un nombre avec map() et unaire plus
const allPricesToNum = allPrices.map((price) => +price); // [ 102.99, 2, 3.99 ]
// additionner tous les nombres avec reduce()
const sumOfAllPrices = allPricesToNum.reduce((acc, curr) => acc + curr, 0); // 108.97999999999999
// ajouter un signe dollar au nombre et utiliser toFixed() pour l'arrondir
console.log(`$${sumOfAllPrices.toFixed(2)}`); // $108.98
Pour l'exemple de lookbehind négatif, disons que vous voulez correspondre à un chiffre tant qu'il n'est pas précédé du signe dollar. Ce motif le fait :
(?<!\$)\d+
Mais malheureusement, il recherche toujours un nombre à l'intérieur d'un autre nombre et le correspond même s'il y a un signe dollar avant le nombre entier :
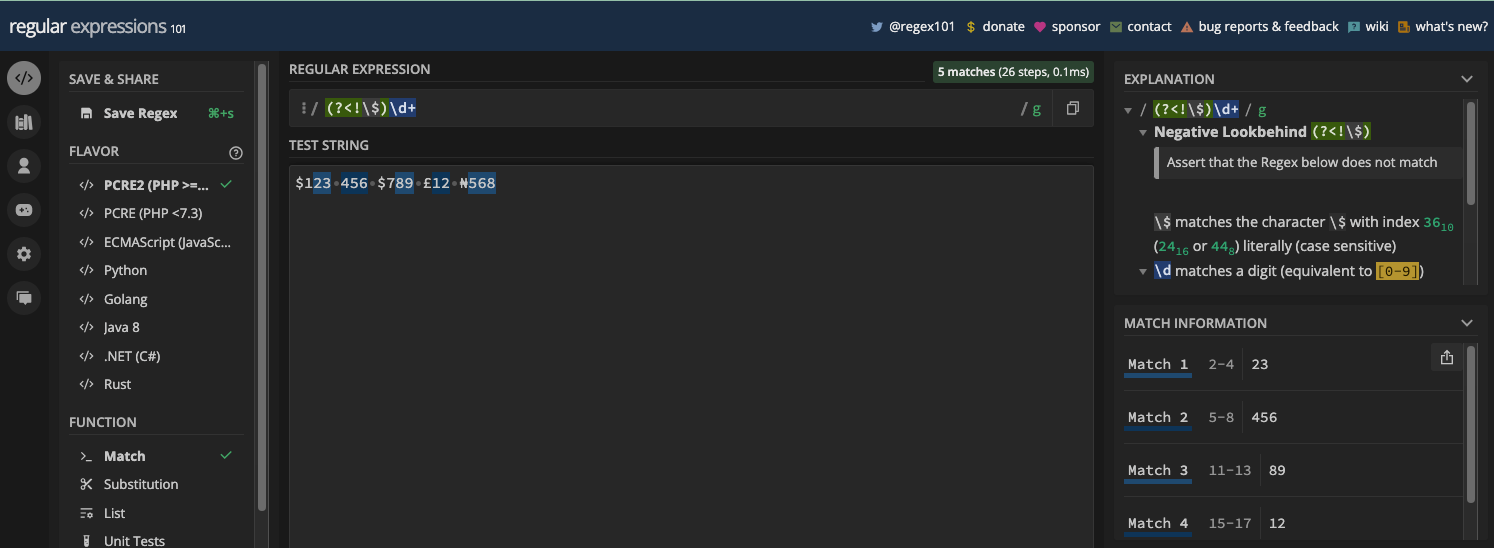
Pour corriger ce comportement, vous pouvez entourer le motif entier avec une limite de mot (\b) :
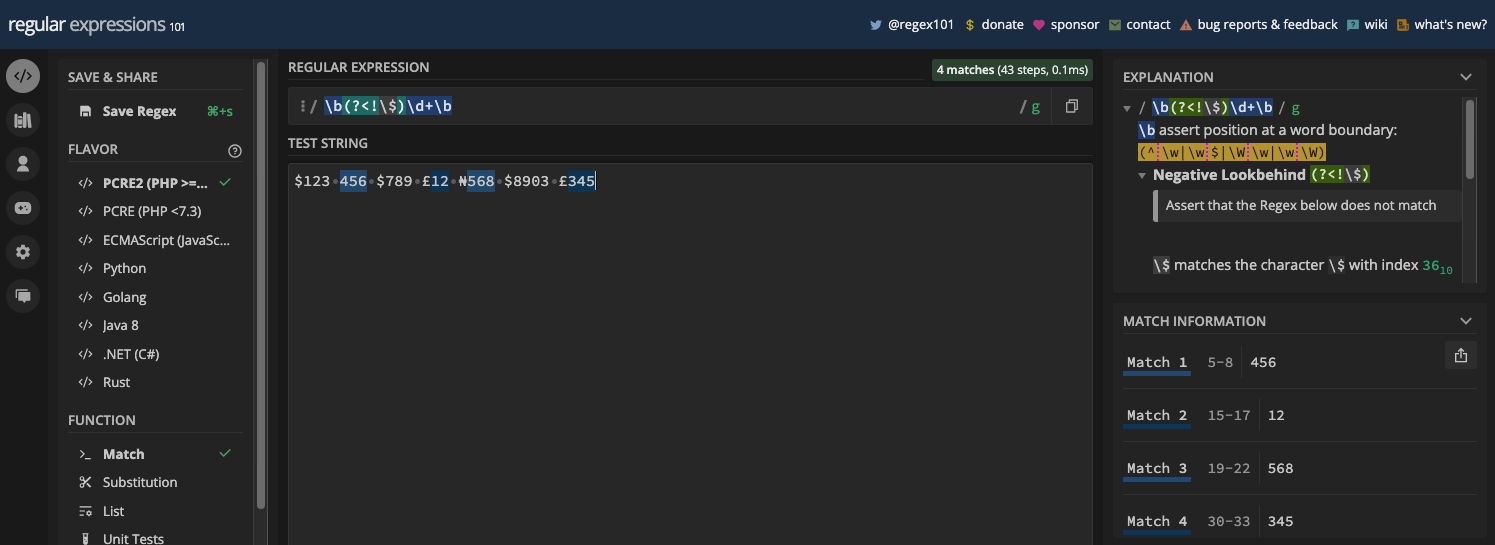
Les groupes de lookbehind négatifs sont également pris en charge en JavaScript :
const monies = '$123 456 $789
312
568 $8903
345';
const re = /\b(?<!\$)\d+\b/g;
console.log('Monies sans signe dollar :', monies.match(re)); // Monies sans signe dollar : [ '456', '12', '568', '345' ]
Chapitre 8 : Bonnes Pratiques et Dépannage des Regex
Bonnes Pratiques à Considérer lors de l'Écriture d'Expressions Régulières
Avec le temps, les expressions régulières peuvent devenir complexes et difficiles à comprendre, selon le cas d'utilisation et le but. Les choses peuvent devenir plus compliquées si cela vous prend beaucoup de temps pour revenir à elles ou si vous travaillez en équipe.
Heureusement, il existe quelques bonnes pratiques à considérer lors de l'écriture d'expressions régulières afin de faciliter les choses pour vous-même et vos collègues.
Voici ces bonnes pratiques :
Gardez-le simple et lisible : une regex simple, facile à lire et efficace est meilleure qu'une regex complexe et efficace. Si vous pouvez rendre la regex efficace sans utiliser le concept complexe des groupes non capturants comme les lookarounds (lookaheads et lookbehinds), alors ne les utilisez pas.
Évitez les correspondances gourmandes : les métacaractères comme
*et+et le joker (.) sont gourmands par défaut. Il est difficile de s'en passer, mais lorsque vous les utilisez et qu'ils provoquent de la gourmandise, assurez-vous d'utiliser le quantificateur zéro ou un (?) sur eux. De plus, évitez d'utiliser le joker lorsque c'est nécessaire.Utilisez des commentaires pour décrire ce que fait une regex : si vous travaillez en équipe, essayez d'expliquer ce que font les regex que vous écrivez afin que les autres puissent les comprendre sans perdre de temps.
Utilisez des testeurs regex en ligne : au lieu d'écrire vos expressions régulières dans votre éditeur de code, écrivez-les dans des testeurs regex où vous pouvez tester ce qu'elles correspondent sans écrire plus de code. Des testeurs regex en ligne gratuits comme regex101 et regexpal.com jouent également un rôle dans le débogage car ils peuvent mettre en évidence les erreurs et vous dire ce qui ne va pas.
Échappez les caractères spéciaux : si vous souhaitez effectuer une correspondance littérale sur des métacaractères comme
.,*,+,{,}, et autres, n'oubliez pas de les échapper sauf si vous les utilisez à l'intérieur d'un ensemble de caractères. Parfois, vous devez même échapper les traits d'union dans un ensemble de caractères.
Comment Écrire des Expressions Régulières Précises
Écrire des expressions régulières précises avec précision nécessite de comprendre ce que vous voulez correspondre, le motif à utiliser, l'attention aux détails et une compréhension de la syntaxe et du comportement sous-jacents des expressions régulières en général.
Cela est crucial afin de s'assurer qu'il n'y a pas d'erreurs évitables et de s'assurer que les regex que vous écrivez correspondent efficacement à la chaîne souhaitée.
Voici quelques conseils pour vous aider à écrire des expressions régulières précises :
Comprenez la chaîne que vous voulez correspondre : avant d'écrire le motif regex pour correspondre à une chaîne, examinez la chaîne de près. Déterminez si vous ciblez toute la chaîne ou une partie particulière de la chaîne. Si vous ciblez une partie de la chaîne ou si vous voulez en extraire certaines, recherchez le motif que vous voulez suivre. Si vous vous familiarisez avec la chaîne, vous pouvez écrire une regex plus précise.
Soyez spécifique : évitez d'utiliser le joker lorsque c'est nécessaire. Par exemple, n'utilisez pas le joker pour correspondre à un nombre puisque vous pouvez utiliser
\dou[0-9], ou des lettres majuscules puisque vous pouvez utiliser[A-Z].Utilisez des quantificateurs pour raccourcir les motifs : si vous voulez qu'une partie particulière de votre regex corresponde à des occurrences répétées, essayez d'utiliser des quantificateurs comme
+,*,{n,m},{n,}, et{n}. Par exemple, si vous voulez correspondre à une date avec/comme séparateur, vous pouvez utiliser le motif\d{1,2}\/\d{1,2}\/\d{4}au lieu de\d\d\/\d\d\/\d\d\d\d.Utilisez des testeurs regex en ligne : des testeurs regex en ligne comme regexpal.com et regex101.com vous aident à écrire des regex plus précises en vous donnant un aperçu en direct des correspondances, en mettant en évidence les correspondances et en vous montrant les erreurs que leurs moteurs rencontrent lors du traitement des regex.
Utilisez des limites de mot pour prévenir les correspondances indésirables : entourer votre motif avec la limite de mot (
\b) peut vous aider à prévenir les correspondances inutiles et indésirables. Par exemple, si vous voulez correspondre à un code postal à 6 chiffres,\d{6}peut le faire pour vous mais correspondra également à toute partie de la chaîne qui a 6 chiffres qui se suivent. Ce qui le ferait mieux est\b\d{6}\b.
Les ancres (^ et $) peuvent également aider à prévenir les correspondances indésirables puisqu'elles "ancrent" un motif au début ou à la fin de la ligne. Vous pouvez les utiliser pour vous assurer que la correspondance est trouvée à la fin ou au début de la ligne, ou les deux.
Par exemple :
/^Hello/icorrespondrait uniquement àHelloouhelloau début d'une ligne/Hello$/icorrespondrait uniquement àHelloouhelloà la fin d'une ligne/^Hello$/icorrespondrait uniquement àHelloouhellos'il s'agit de la seule chaîne cible sauf si vous avez le drapeau multiline activé et qu'il y aHelloouhellosur une autre ligne.
Si vous avez des problèmes pour obtenir les choses correctement avec un motif regex, des outils de test en ligne comme regex101.com et regexpal.com peuvent également vous aider à parcourir le motif bit par bit. Il existe également des visualiseurs regex que vous pouvez utiliser pour vérifier ce qui ne va pas avec vos motifs regex.
L'un de ces outils que je trouve incroyable est Regulex (jex.im/regulex). Il vous aide à mettre vos expressions régulières dans une perspective visuelle que vous pouvez exporter
Et il peut vous montrer ce qui ne va pas avec votre motif :
Chapitre 9 : Applications des Expressions Régulières
Une Meilleure Façon de Correspondre aux Dates
Vous avez vu plusieurs motifs que vous pouvez utiliser pour correspondre aux dates au format jj/mm/aaaa tels que \d\d\/\d\d\/\d\d\d\d, \d\d[/.-]\d\d[/.-]\d\d\d\d/;, et \d{1,2}\/\d{1,2}\/\d{4}.
Le problème est que ces trois motifs vérifient simplement l'occurrence d'un nombre, et non une date valide. Par exemple, des dates invalides comme 99/89/2022 ou 42/32/1909 correspondraient toujours à ces motifs :

La solution est que vous devez tenir compte du jour, du mois et de l'année acceptables :
- le jour peut être de 1 ou 2 chiffres
- le jour ne peut pas dépasser 31
- le mois ne peut pas dépasser 12
- l'année pourrait être de 2 ou 4 chiffres, mais jamais 1, 3, ou plus de 4 chiffres
Vous devez également tenir compte de :
- un jour qui pourrait commencer par 0, 1, 2, ou 3, mais jamais 4 ou plus
- un mois qui pourrait commencer par 0, ou 1, mais jamais 2 ou plus
Voici le motif regex qui satisfait ces conditions :
/^(3[01]|[12][0-9]|0?[1-9])[-./](1[0-2]|0?[1-9])[-./](20[0-9]{2}|[0-9]{4}|[0-9]{2})$/gm
L'image ci-dessous est une illustration qui étiquette chaque partie du motif et explique ce qu'elles font :
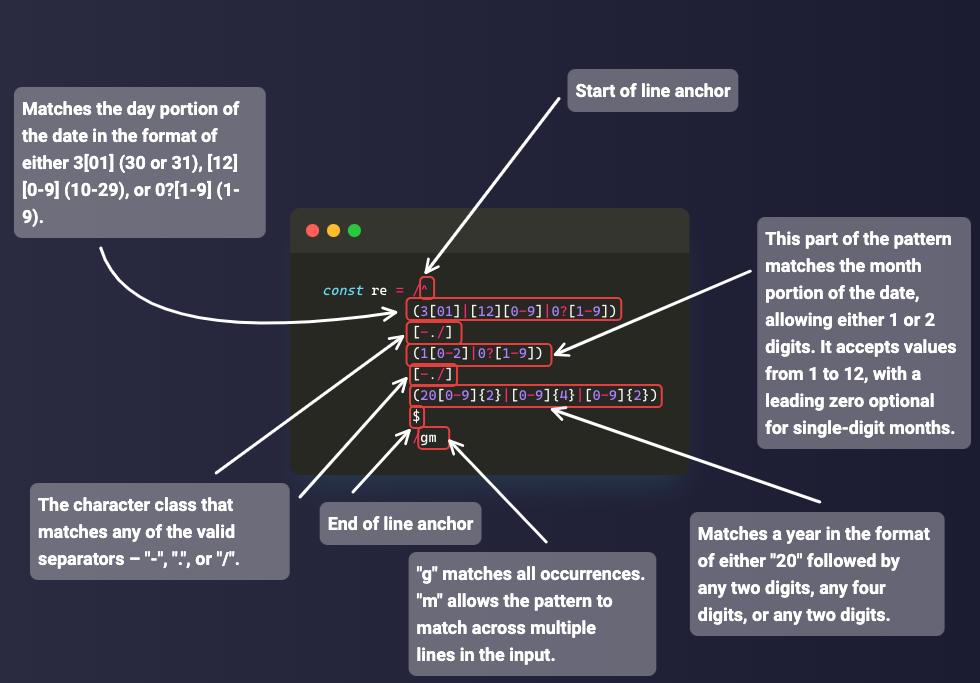
Voici les dates qui correspondent au motif et celles qui ne correspondent pas :

Vous pouvez prendre le motif et le tester contre certaines dates en JavaScript :
const re =
/^(3[01]|[12][0-9]|0?[1-9])[-./](1[0-2]|0?[1-9])[-./](20[0-9]{2}|[0-9]{4}|[0-9]{2})$/;
function testDate(date) {
const dateTester = re.test(date);
console.log(dateTester);
}
testDate('12-01-2022'); // true
testDate('31.11.1999'); // true
testDate('02-01-21'); // true
testDate('42-01-2021'); // false
testDate('22-91-23'); // false
Vous pouvez voir que les parties jour, mois, année et séparateur du motif sont dans leurs groupes respectifs. Si vous voulez correspondre à d'autres formats comme mm/jj/aaaa ou aaaa/mm/jj, vous pouvez modifier le motif.
Vous pouvez même rendre le motif un peu plus court en mettant le premier séparateur dans un groupe et en y faisant référence pour le deuxième séparateur :
^(3[01]|[12][0-9]|0?[1-9])([-./])(1[0-2]|0?[1-9])\2(20[0-9]{2}|[0-9]{4}|[0-9]{2})$
Comment Correspondre aux Codes Postaux US
Les codes postaux aux États-Unis sont un nombre à 5 chiffres, mais ils peuvent également avoir une extension à 4 chiffres, par exemple, 56893 ou 56893-9232.
Le motif \b\d{5}\b correspondrait à un code postal à 5 chiffres :
Vous devez également tenir compte des 4 autres chiffres et du trait d'union entre les deux ensembles de nombres. Le motif \b\d{5}(\-\d{4})?\b le ferait pour vous.
Voici une image qui étiquette chaque partie du motif et explique ce qu'elles font :
Vous pouvez également prendre le regex et extraire tous les codes postaux qui sont des correspondances :
const re = /\b\d{5}(\-\d{4})?\b/g;
const zipCodes = [
'56893',
'ca58392bn',
'29043',
'90342-9014',
'89435',
'75034',
'90453-3056',
'12345-6789',
'b458923',
'589323',
];
const matchedZipCodes = [];
for (const zipCode of zipCodes) {
const matches = zipCode.match(re);
if (matches) {
matchedZipCodes.push(matches[0]);
}
}
console.log(matchedZipCodes);
/*
Sortie :
[
'56893',
'29043',
'90342-9014',
'89435',
'75034',
'90453-3056',
'12345-6789'
]
*/
Et si vous voulez les codes postaux qui sont invalides, vous pouvez utiliser la méthode de tableau filter() pour supprimer ceux qui ne correspondent pas au motif :
const re = /\b\d{5}(\-\d{4})?\b/g;
const zipCodes = [
'56893',
'ca58392bn',
'29043',
'90342-9014',
'89435',
'75034',
'90453-3056',
'12345-6789',
'b458923',
'589323',
];
const invalidZipCodes = zipCodes.filter((zipCode) => !zipCode.match(re));
console.log(invalidZipCodes); // [ 'ca58392bn', 'b458923', '589323' ]
Comment Correspondre aux Adresses Email
Les adresses email peuvent être aussi simples que john@email.com, et aussi complexes que vous pouvez l'imaginer. Il n'y a donc pas de "motif unique" pour valider les adresses email. Cela rend également la validation des emails une tâche complexe.
Valider les emails avec regex peut également être un peu discutable car vous ne pouvez pas empêcher quiconque de fabriquer un email. Mais il y a toujours un format que vous voulez généralement que l'adresse email suive, qu'elle soit fabriquée ou non. C'est pourquoi vous pourriez vouloir utiliser des expressions régulières pour valider un email.
Un motif comme ^/\w{4,}@\w{3,}\.\w{3,}$/ pourrait suffire pour valider des adresses email simples et directes comme john@example.com.
Voici une image qui étiquette chaque partie du motif et explique ce qu'elles font :
Et voici les emails qui correspondent :
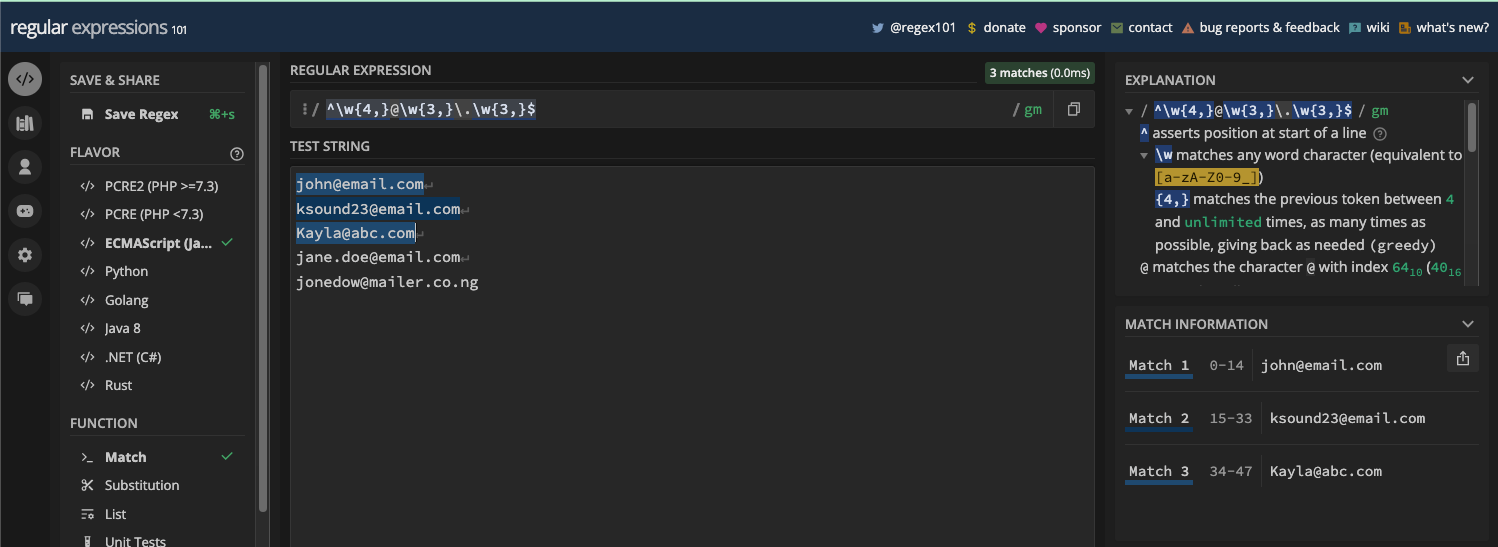
Comme vous pouvez le voir, le motif n'a même pas correspondre à tous les emails fournis. C'est parce que le motif ne tient pas compte de :
- les emails avec un point dans les noms d'utilisateur comme
jane.doe@email.com - les extensions de domaine de second niveau (SLD) comme
john@example.abc.com - et les domaines de second niveau de code de pays (ccSLDs) comme
jane@email.co.uk
En fait, un seul email peut même combiner tous les critères listés ci-dessus.
Un meilleur motif pour correspondre aux emails est /^[\w.-]+@[a-zA-Z\d.-]+\.[a-zA-Z]{2,}$/.
J'ai également préparé une illustration qui étiquette chaque partie du motif et montre ce qu'elles font :
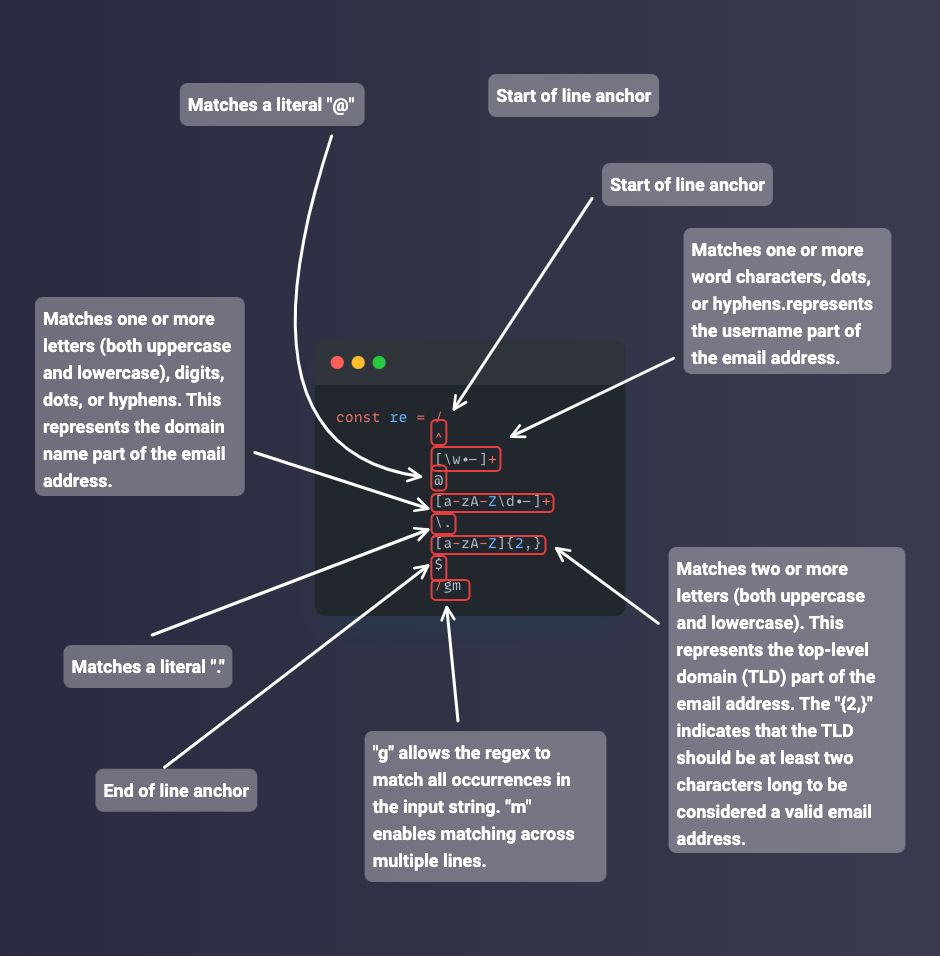
Ce motif correspond mieux à une adresse email que le premier :
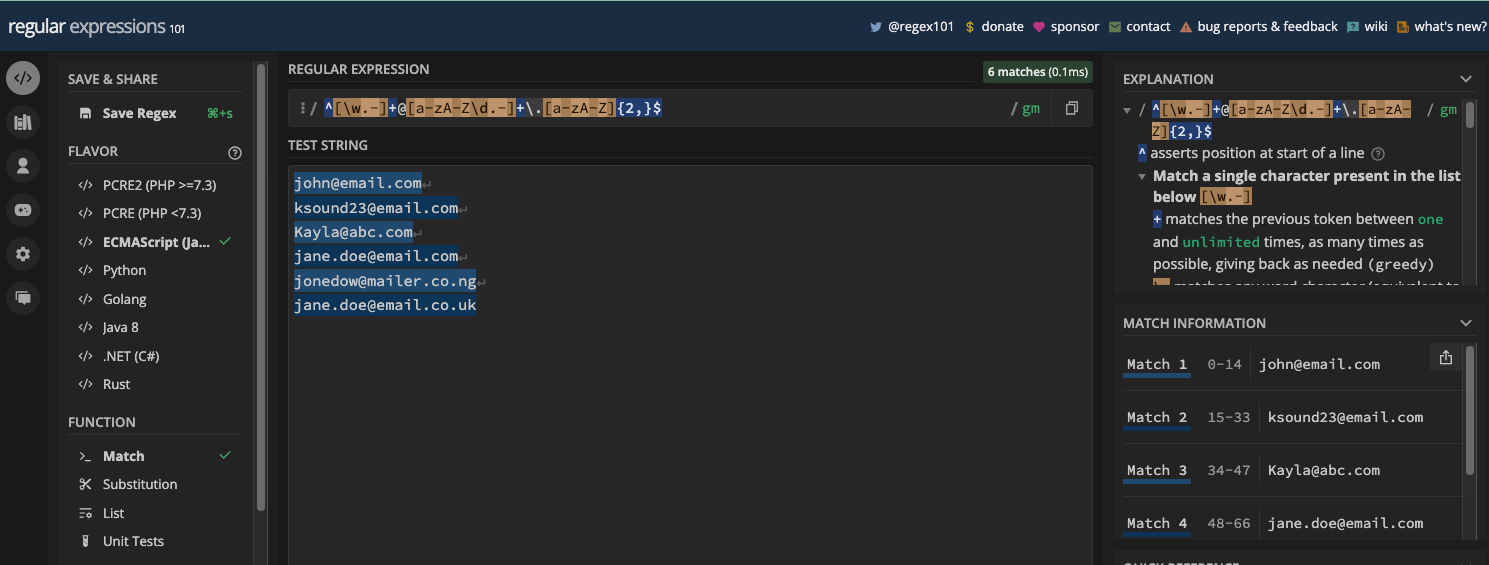
Selon la spécification RFC 5322, le motif qui fonctionne 99% du temps pour valider les emails est le suivant :
(?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:\.[a-z0-9!#$%&'*+/=?^_`{|}~-]+)*|"(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21\x23-\x5b\x5d-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])*")@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|\[(?:(?:(2(5[0-5]|[0-4][0-9])|1[0-9][0-9]|[1-9]?[0-9]))\.){3}(?:(2(5[0-5]|[0-4][0-9])|1[0-9][0-9]|[1-9]?[0-9])|[a-z0-9-]*[a-z0-9]:(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21-\x5a\x53-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])+)\])
N.B. : Vous devez entourer le motif d'ancres pour qu'il ne laisse pas de côté une partie d'un email possible et ne corresponde qu'aux autres.
C'est ce que j'essaie de souligner :

Vous pouvez prendre ce motif en JavaScript et le tester contre certaines adresses email :
const emailRe =
/^(?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:\.[a-z0-9!#$%&'*+/=?^_`{|}~-]+)*|"(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21\x23-\x5b\x5d-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])*")@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|\[(?:(?:(2(5[0-5]|[0-4][0-9])|1[0-9][0-9]|[1-9]?[0-9]))\.){3}(?:(2(5[0-5]|[0-4][0-9])|1[0-9][0-9]|[1-9]?[0-9])|[a-z0-9-]*[a-z0-9]:(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21-\x5a\x53-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])+)\])$/;
function matchEmail(email) {
if (emailRe.test(email)) {
console.log('Email valide !');
} else {
console.log('Email invalide');
}
}
matchEmail('janedoe@email.com');
matchEmail('john.doe@email.com');
matchEmail('7@koala@email.com!');
matchEmail('kayla.simpson@email.co.uk');
matchEmail('kayla.simpson@email.co..uk');
Comme je l'ai souligné précédemment, correspondre aux adresses email avec regex est une tâche complexe. Si vous savez quel type d'email vous allez utiliser, il est préférable d'adapter votre regex pour eux.
Parfois, pour correspondre à un email, tout ce dont vous avez besoin est une regex simple. D'autres fois, le motif dont vous avez besoin peut être aussi complexe que celui ci-dessus.
Comment Correspondre aux Mots de Passe
Pour correspondre aux mots de passe, vous pouvez utiliser un lookahead – puisque les groupes de lookaround ne consomment généralement pas de caractères. Mais il existe toujours plusieurs façons de faire la même chose dans les expressions régulières, et en programmation en général bien sûr.
Vous avez déjà vu un lookahead pour correspondre aux mots de passe à 6 chiffres. Cette fois-ci, disons que le mot de passe ne doit pas être inférieur à 8 caractères avec au moins une majuscule, une minuscule, un chiffre et un symbole.
Voici le motif regex qui fait exactement cela :
^(?=.{8,})(?=.*[a-z])(?=.*[A-Z])(?=.*[0-9])(?=.*[!@#$?%"';^}{&:*()
221e+=-]).*$
Voici les mots de passe qu'il correspond :

Vous pouvez prendre cela en JavaScript et le tester contre des mots de passe possibles :
const passwordRe =
/^(?=.{8,})(?=.*[a-z])(?=.*[A-Z])(?=.*[0-9])(?=.*[!@#$?%"';^}{&:*()
221e+=-]).*$/gm;
function matchPassWord(password) {
if (passwordRe.test(password)) {
console.log(true);
} else {
console.log(false);
}
}
matchPassWord('johnDoe21^');
matchPassWord('Strong@123');
matchPassWord('weakpassword');
matchPassWord('ABcd12$');
matchPassWord('Longpassword1234!');
matchPassWord('Short@1');
matchPassWord('janEdoe34$');
Vous pouvez également extraire chacun de ces groupes dans sa variable et tester un mot de passe contre lui. Cela vous permettrait de montrer une erreur pour cette condition particulière que le mot de passe essaie de correspondre :
const passwordLength = /(?=.{8,})/,
lowercaseChar = /(?=.*[a-z])/,
uppercaseChar = /(?=.*[A-Z])/,
numberChar = /(?=.*[0-9])/,
specialChar = /(?=.*[!@#$?%"';^}{&:*()
221e+=-])/;
function validatePassword(password) {
if (
passwordLength.test(password) &&
lowercaseChar.test(password) &&
uppercaseChar.test(password) &&
numberChar.test(password) &&
specialChar.test(password)
) {
console.log('Mot de passe valide !');
} else {
console.log('Mot de passe invalide');
}
}
validatePassword('johnDoe21^');
validatePassword('Strong@123');
validatePassword('weakpassword');
validatePassword('ABcd12$');
validatePassword('Longpassword1234!');
validatePassword('Short@1');
validatePassword('janEdoe34$');
Validation de Formulaire avec Regex
L'une des façons les plus populaires pour les développeurs d'utiliser les expressions régulières est la validation de formulaires. Puisqu'un formulaire contient généralement des champs de saisie comme le nom, l'email, le mot de passe et autres, vous pouvez écrire une expression régulière pour ce que vous attendez de l'utilisateur dans ces champs de saisie.
J'ai préparé un petit site web où je vous montre comment valider les champs de nom, de nom d'utilisateur, d'email et de mot de passe d'un formulaire avec regex.
Voici le HTML :
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<link rel="stylesheet" href="styles.css">
<script src="form-validate.js" defer></script>
<title>Validation de Formulaire avec RegEx</title>
</head>
<body>
<div id="error-message"></div>
<form action="">
<h1>Inscription</h1>
<p>Remplissez les champs du formulaire</p>
<div class="form-control">
<label for="name">Nom</label>
<input type="text" name="name" id="name">
</div>
<div class="form-control">
<label for="username">Nom d'utilisateur</label>
<input type="text" name="username" id="username">
</div>
<div class="form-control">
<label for="email">Email</label>
<input type="email" name="email" id="email">
</div>
<div class="form-control">
<label for="email">Mot de passe</label>
<input type="password" name="password" id="password">
</div>
<input type="submit" value="Soumettre" id="submit">
</form>
</body>
</html>
Le CSS :
@import url('https://fonts.googleapis.com/css2?family=Roboto&display=swap');
* {
margin: 0;
padding: 0;
box-sizing: border-box;
}
body {
background-color: #d0d0d5;
color: #fff;
font-family: 'Roboto', sans-serif;
}
form {
position: absolute;
top: 50%;
left: 50%;
transform: translate(-50%, -50%);
background-color: #3b3b4f;
padding: 0.4rem 3rem 1rem;
border-radius: 2px;
}
p {
margin: 0.5rem 0;
}
#error-message {
background-color: crimson;
color: #fff;
max-width: 80%;
margin: 0.5rem auto 0;
padding: 0.2rem 0.5rem;
border-radius: 4px;
}
#error-message p {
font-size: 14px;
text-align: center;
}
.form-control {
display: flex;
flex-direction: column;
}
.form-control label {
margin-bottom: 0.2rem;
}
.form-control input {
width: 14rem;
margin-bottom: 1.2rem;
padding: 0.2rem;
border: 2px solid #d0d0d5;
border-radius: 2px;
}
.form-control input:focus {
outline: none;
}
input[type='submit'] {
background-color: #fecc4c;
border-color: #f1a02a;
font-family: 'Roboto', sans-serif;
padding: 0.3rem;
border-width: 1px;
cursor: pointer;
}
input[type='submit']:hover {
background-color: #e3bd53;
}
.hide {
display: none;
}
.show {
display: block;
}
@media screen and (max-width: 768px) {
#error-message {
margin: 0.5rem auto 0;
padding: 0.1rem 0.2rem;
}
}
@media screen and (max-width: 667px) {
form {
top: 61%;
}
#error-message {
margin: 0.2rem auto 0;
padding: 0.1rem 0.4rem;
}
}
Le JavaScript bien commenté qui contient les motifs que j'ai utilisés, et comment j'ai testé chaque motif contre les champs respectifs auxquels ils sont corrélés :
// Obtenir l'élément de formulaire
const form = document.querySelector('form');
// Obtenir l'élément div qui affiche l'erreur(s)
const errorMessageDiv = document.querySelector('#error-message');
// Les motifs RegEx dans un objet "patterns"
const patterns = {
nameRe: /^[a-zA-Z]{2,35}\s[a-zA-Z]{2,35}$/, // valide le champ de nom
usernameRe: /^[a-zA-Z]{3,30}(\d{1,4})?$/, // valide le champ de nom d'utilisateur
emailRe: /^[\w.-]+@[a-zA-Z\d.-]+\.[a-zA-Z]{2,}$/, // valide le champ d'email
passwordRe:
/^(?=.{8,})(?=.*[a-z])(?=.*[A-Z])(?=.*[0-9])(?=.*[!@#$?%"';^}{&:*()
221e+=-]).*$/, // valide le champ de mot de passe
};
// Masquer le div de message d'erreur lorsque la page se charge
errorMessageDiv.style.display = 'none';
// Ajouter un événement de soumission au formulaire
form.addEventListener('submit', validateAndSubmitForm);
// Fonction de validation et de soumission du formulaire
function validateAndSubmitForm(e) {
e.preventDefault();
// Effacer les messages d'erreur précédents
errorMessageDiv.innerHTML = '';
let nameInputValue = document.querySelector('#name').value;
let usernameInputValue = document.querySelector('#username').value;
let emailInputValue = document.querySelector('#email').value;
let passwordInputValue = document.querySelector('#password').value;
// Valider le Nom
if (!patterns.nameRe.test(nameInputValue)) {
showError('Le nom doit avoir un prénom et un nom de famille séparés par un espace');
}
// Valider le Nom d'utilisateur
if (!patterns.usernameRe.test(usernameInputValue)) {
showError(
'Le nom d'utilisateur doit avoir entre 3 et 30 caractères et peut inclure jusqu'à 4 chiffres à la fin'
);
}
// Valider l'Email
if (!patterns.emailRe.test(emailInputValue)) {
showError('Entrez une adresse email valide');
}
// Valider le Mot de passe
if (!patterns.passwordRe.test(passwordInputValue)) {
showError(
'Le mot de passe doit contenir au moins 8 caractères, une lettre minuscule, une lettre majuscule, un chiffre et un caractère spécial.'
);
}
// Si aucun message d'erreur n'est présent, le formulaire est valide, vous pouvez donc le soumettre
if (errorMessageDiv.innerHTML === '') {
console.log(nameInputValue);
console.log(usernameInputValue);
console.log(emailInputValue);
console.log(passwordInputValue);
// Masquer l'élément errorMessageDiv puisque aucune erreur n'est présente
errorMessageDiv.style.display = 'none';
// Saluer l'utilisateur
alert(`Salut ${usernameInputValue}
d83d
dc4b
d83c
dffd \nMerci d'avoir rempli ce formulaire`);
// Effacer les champs de saisie avec la méthode reset()
document.forms[0].reset();
} else {
// Afficher l'élément errorMessageDiv s'il y a des erreurs
errorMessageDiv.style.display = 'block';
}
}
// La fonction responsable de l'affichage de l'erreur(s)
function showError(message) {
const errorMessageElement = document.createElement('p');
errorMessageElement.innerText = message;
errorMessageDiv.appendChild(errorMessageElement);
}
Voici ce que fait le formulaire :
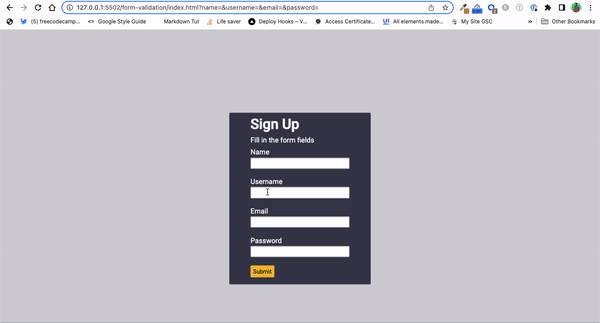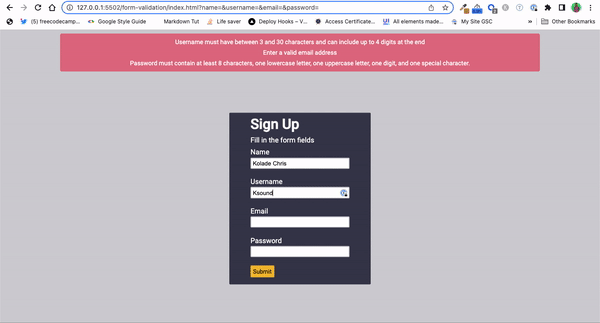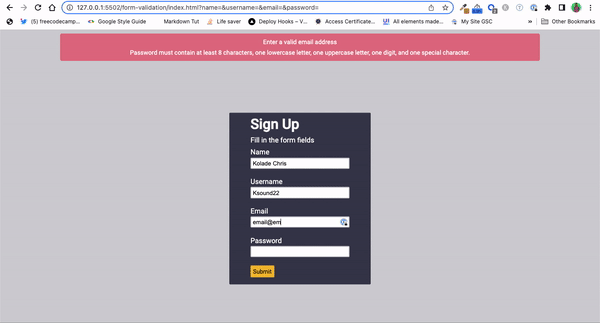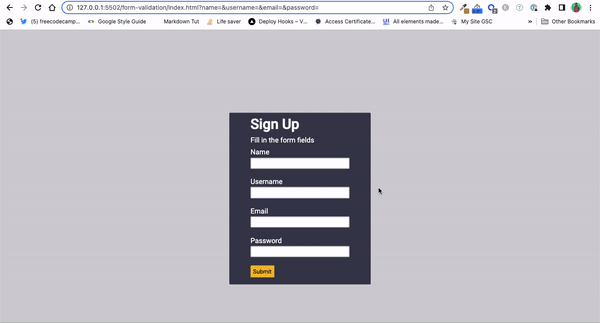
Vous pouvez récupérer tout le code dans ce dépôt GitHub.
Générateur de Table des Matières d'Article
Vous pouvez tirer parti de la puissance des expressions régulières pour créer un générateur de table des matières en markdown.
Les tables des matières en markdown sont composées de titres h2 au niveau supérieur. Ces titres h2 ont un attribut id que vous pouvez utiliser comme lien. Si vous regardez ces attributs id, ils sont au format suivant :
[Comment Faire ABC sur XYZ!!!](##commentfaireabcsurxyz)
Cela signifie que vous devez :
- utiliser le texte tel quel comme texte du lien et les entourer d'accolades
- remplacer tous les espaces par une chaîne vide
- remplacer tous les symboles par une chaîne vide
- convertir toutes les lettres en minuscules
- entourer le nouveau lien de parenthèses
Les méthodes de chaîne replace() et lowerCase() vous aideront à réaliser ces choses.
Voici le HTML pour l'application :
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<link rel="stylesheet" href="styles.css">
<script src="toc.js" defer></script>
<title>Générateur de TOC</title>
</head>
<body>
<div class="alert" id="alert">
Veuillez entrer des textes de titre !
</div>
<h1>Générateur de Table des Matières Markdown pour votre Prochain Article</h1>
<h2>Collez vos titres pour générer la table des matières</h2>
<form action="">
<div class="form">
<div class="form-control">
<textarea name="toc" id="toc" cols="40" rows="15"></textarea>
</div>
<div class="form-control">
<input type="submit" value="Générer" id="submit">
</div>
</div>
</form>
<div id="generated-toc">
<!-- <p>Lorem ipsum dolor sit amet consectetur.</p>
<p>Lorem ipsum dolor sit amet consectetur.</p>
<p>Lorem ipsum dolor sit amet consectetur.</p>
<p>Lorem ipsum dolor sit amet consectetur.</p>
<p>Lorem ipsum dolor sit amet consectetur.</p>
<p>Lorem ipsum dolor sit amet consectetur.</p>
<p>Lorem ipsum dolor sit amet consectetur.</p> -->
</div>
</body>
</html>
Le CSS :
@import url('https://fonts.googleapis.com/css2?family=Poppins&family=Roboto&display=swap');
* {
margin: 0;
padding: 0;
box-sizing: border-box;
}
body {
font-family: 'Poppins' sans-serif;
background-color: #3b3b4f;
color: #fff;
}
h1 {
margin-top: 2rem;
}
h1,
h2 {
text-align: center;
color: black;
margin-bottom: 1rem;
color: white;
}
form {
max-width: 90%;
margin: 0 auto;
background-color: #d0d0d5;
padding: 2rem;
border-radius: 2px;
}
.form-control {
text-align: center;
}
textarea {
padding: 0.2rem 2rem 1rem 0.2rem;
}
textarea:focus {
outline: 1px solid #3b3b4f;
}
input[type='submit'] {
font-family: 'Poppins', sans-serif;
font-size: 1.1rem;
border: none;
background-color: #03732e;
color: #fff;
padding: 0.5rem 1rem;
border-radius: 4px;
margin-top: 1rem;
transition: 0.3s;
}
input[type='submit']:hover {
cursor: pointer;
background-color: #00471b;
}
#generated-toc {
max-width: 60%;
margin: 1rem auto;
background-color: #d0d0d5;
color: black;
padding: 2rem;
border-radius: 2px;
text-align: left;
font-size: 1.1rem;
display: none;
}
.alert {
display: none;
margin: 1rem auto;
max-width: 20%;
text-align: center;
padding: 1rem 0;
border-radius: 2px;
background-color: #eb7189;
color: black;
}
@media screen and (max-width: 768px) {
textarea {
width: 16rem;
}
.alert {
max-width: 50%;
}
}
Et le JavaScript bien commenté :
const form = document.querySelector('form');
const generatedToc = document.querySelector('#generated-toc');
const alert = document.querySelector('.alert');
// Expressions régulières pour supprimer les espaces et les caractères spéciaux
const spaceRe = /\s+/g;
const symRe = /[
b0?+*$
221e^%$#@!.,
a9:&;"=%'_\[\]
2013\/\\<>|
f7
2122
ae)
a3(}{
20ac
a5
a2
2014
201c
201d
2018
2022~]/g;
function generateToc(e) {
e.preventDefault();
// Obtenir les textes de titre de la zone de texte
const headingTexts = document.querySelector('#toc').value;
if (headingTexts === '') {
// Alerter l'utilisateur pour entrer des textes de titre
alert.style.display = 'block';
// masquer l'alerte après 3 secondes
setTimeout(() => {
alert.style.display = 'none';
}, 3000);
// masquer la table des matières générée (si elle existe) puisque l'utilisateur essaie de coller une autre
generatedToc.style.display = 'none';
return;
}
// Diviser les textes de titre en un tableau de lignes
const headingLines = headingTexts.split('\n');
// Créer une variable initiale vide pour sauvegarder la table des matières plus tard
let tocContent = '';
// Parcourir chaque ligne et générer les éléments de la table des matières
headingLines.forEach((headingLine) => {
// Supprimer les espaces de début et/ou de fin de la ligne
headingLine = headingLine.trim();
// sauter les lignes vides
if (headingLine === '') {
return;
}
// Générer le lien TOC basé sur le(s) texte(s) de titre
const markdownLink = headingLine
.replace(spaceRe, '') // remplacer les espaces par une chaîne vide
.replace(symRe, '') // remplacer les caractères spéciaux (symboles)
.toLowerCase(); // convertir les textes de lien en caractères minuscules
// Créer l'élément de la table des matières et l'ajouter à la variable tocContent
tocContent += `<p>
2022 [${headingLine}](#${markdownLink})</p>`;
});
// Insérer la table des matières générée dans l'élément div "generated-toc"
generatedToc.innerHTML = tocContent;
// masquer l'alerte puisque actuellement il n'y a pas d'erreur à ce stade
alert.style.display = 'none';
// afficher le div "generated-toc"
generatedToc.style.display = 'block';
// effacer les textes de titre dans la zone de texte
document.querySelector('#toc').value = '';
}
// Ajouter un événement de soumission au formulaire
form.addEventListener('submit', generateToc);
/*
Qu'est-ce que le HTML ?
Comment Contribuer$ À l'Open Source Comme un Boss!!
Pourquoi vous devriez Apprendre à C$oder en Java ?
Pourquoi vous devriez vous lancer dans le Web3 !
Ne pas Attacher de Point d'Interrogation(?) aux Hows !
Arrêtez de Faire Peur aux Nouveaux !
Pourquoi êtes-vous trop froid&
*/
Voici ce qui se passe dans l'application :
Vous pouvez consulter le code pour avoir une meilleure compréhension de la manière dont j'ai pu le faire. Le code est disponible sur ce dépôt GitHub et l'application est en ligne ici.
Glossaire et Références
Glossaire des Termes
Expression RégulièreouRegEx: Un outil que vous pouvez utiliser pour correspondre, rechercher et manipuler du texte.Motifoumotif regex: Une séquence de caractères qui définit un critère de recherche dans une expression régulière.Caractère Littéral: Un caractère qui correspond à lui-même dans une expression régulière (par exemple, "a" correspond au caractère "a").Drapeau: Modificateurs ajoutés après le délimiteur de fermeture d'une regex pour changer le comportement de correspondance, tels quei(insensible à la casse) oug(global).Métacaractère: Un caractère avec une signification spéciale dans une expression régulière. Exemples incluent.(n'importe quel caractère),*(zéro ou plus), et|(alternance).Quantificateur: Un métacaractère qui spécifie le nombre de répétitions de l'élément précédent. Par exemple,*correspond à zéro ou plusieurs occurrences, et{n}correspond àncaractère(s).Ancres: Métacaractères qui représentent des positions dans la chaîne d'entrée, tels que^(début de ligne) et$(fin de ligne).Groupement: Utilisation de parenthèses()pour créer une sous-expression que vous pouvez répéter ou référencer comme une seule unité.Groupe de Capture: Un groupe dans une expression régulière qui capture et stocke le texte correspondre pour une utilisation ultérieure.Groupe Non-Capturant: Un groupe dans une expression régulière qui correspond au motif mais ne capture pas le texte correspondre.Gourmand: Un comportement de correspondance où les quantificateurs essaient de correspondre autant que possible.Paresseux: Un autre comportement de correspondance où les quantificateurs correspondent le moins possible. C'est l'opposé degourmand.Lookahead: Une assertion de largeur nulle qui regarde devant pour voir si un motif existe sans l'inclure dans la correspondance.Lookbehind: Une assertion de largeur nulle qui regarde derrière pour voir si un motif existe sans l'inclure dans la correspondance.Séquence d'Échappement et Caractère: Utilisation d'une barre oblique inverse\pour échapper un métacaractère afin de le traiter comme un caractère littéral. Ou l'utiliser avant un caractère pour correspondre à sa signification spéciale au lieu du caractère littéral. Par exemple,\d.Limite de Mot: Une assertion de largeur nulle qui correspond à la position entre un caractère de mot et un caractère non-mot.Classe de Caractères Négative: Une classe de caractères avec^comme premier caractère, correspondant à n'importe quel caractère non dans la classe.Moteur Regex: Le composant logiciel sous-jacent qui traite les expressions régulières et effectue la correspondance.Sensible à la Casse: Un comportement de correspondance où les cas des lettres doivent correspondre exactement dans le motif regex et la chaîne d'entrée.Insensible à la Casse: Un drapeau (i) qui active la correspondance insensible à la casse dans l'expression régulière.Classe de Caractères Raccourcie: Raccourcis pour les classes de caractères courantes, tels que\d(chiffre),\w(caractère de mot), et\s(espace blanc).- Rétro-référence : Faire référence au contenu d'un groupe capturé dans le motif regex. Par exemple,
\1. - Alternance : Utilisation du métacaractère
|pour correspondre à l'un ou l'autre des deux motifs. - Objet RegExp JavaScript : L'objet JavaScript intégré qui représente une expression régulière. Il a des méthodes comme
test()etexec()pour travailler avec des expressions régulières. Littéraux d'Expression Régulière: Expressions régulières définies en utilisant des barres obliques/.../, par exemple,/regex-pattern/.- Constructeur RegExp : Le constructeur RegExp pour créer des expressions régulières dynamiquement.
Référence Rapide des Métacaractères et Quantificateurs
\d: correspond à n'importe quel chiffre (0-9).\D: correspond à n'importe quel caractère non-chiffre.\w: correspond à n'importe quel caractère de mot (caractères alphanumériques et trait de soulignement).\W: correspond à n'importe quel caractère non-mot.\s: correspond à n'importe quel caractère d'espace blanc (espace, tabulation, nouvelle ligne, retour chariot).\S: correspond à n'importe quel caractère non-espace blanc.\b: correspond à une position de limite de mot.\B: correspond à une position de non-limite de mot.^: correspond au début de la ligne.$: correspond à la fin de la ligne..: correspond à n'importe quel caractère sauf nouvelle ligne.*: correspond à zéro ou plusieurs occurrences.+: correspond à une ou plusieurs occurrences.?: correspond à zéro ou une occurrence.{n}: correspond exactement àn(nombre) occurrences.{n,}: correspond ànou plusieurs occurrences.{n,m}correspond à au moinsnet au plusm(un autre nombre) occurrences.|: correspond soit à l'expression de gauche soit à celle de droite.(...): groupe de capture.(?:...): groupe non-capturant.\: échappe un métacaractère afin de le correspondre littéralement, ou échappe un métacaractère qui est également un caractère littéral. Par exemple,\d.[...]: classe de caractères.[^...]: classe de caractères négative.(?=...): lookahead positif.(?!...): lookahead négatif.(?<=...)lookbehind positif.(?<!...): lookbehind négatif.
Merci d'avoir lu !