


Article original : The Front-End Performance Optimization Handbook – Tips and Strategies for Devs
Lorsque vous construisez un site web, vous souhaitez qu'il soit réactif, rapide et efficace. Cela signifie s'assurer que le site charge rapidement, fonctionne sans accroc et offre une expérience fluide à vos utilisateurs, entre autres.
Ainsi, lors de la construction, vous devrez garder à l'esprit diverses optimisations de performance – comme la réduction de la taille des fichiers, la diminution des requêtes serveur, l'optimisation des images de différentes manières, et ainsi de suite.
Mais l'optimisation des performances est une arme à double tranchant, avec des aspects positifs et négatifs. Le bon côté est qu'elle peut améliorer les performances du site web, tandis que le mauvais côté est qu'elle est compliquée à configurer, et qu'il y a de nombreuses règles à suivre.
De plus, certaines règles d'optimisation des performances ne conviennent pas à tous les scénarios et doivent être utilisées avec prudence. Assurez-vous donc d'aborder ce guide avec un œil critique. Dans celui-ci, je vais exposer une série de façons d'optimiser les performances de votre site web, et partager des informations pour vous aider à choisir quelles techniques utiliser.
Je vais également fournir les références pour ces suggestions d'optimisation après chacune d'elles et à la fin de l'article.
Table des Matières
Placer le CSS dans le Head et les Fichiers JavaScript en Bas
Utiliser des Icônes de Police (iconfont) au Lieu des Icônes Image
Bien Utiliser la Mise en Cache, Éviter de Recharger les Mêmes Ressources
Utiliser les Effets CSS3 au Lieu des Images Lorsque Possible
Utiliser requestAnimationFrame pour Implémenter les Changements Visuels
Utiliser Flexbox au Lieu des Modèles de Mise en Page Précédents
Utiliser les Propriétés Transform et Opacity pour Implémenter les Animations
Utiliser les Règles de Manière Raisonnable, Éviter la Sur-Optimisation
1. Réduire les Requêtes HTTP
Une requête HTTP complète doit passer par la recherche DNS, la poignée de main TCP, l'envoi de la requête HTTP par le navigateur, la réception de la requête par le serveur, le traitement de la requête par le serveur et l'envoi d'une réponse, la réception de la réponse par le navigateur, et d'autres processus. Examinons un exemple spécifique pour comprendre le fonctionnement de HTTP :
Ceci est une requête HTTP, et la taille du fichier est de 28,4 Ko.
Terminologie expliquée :
Mise en file d'attente : Temps passé dans la file d'attente des requêtes.
Bloqué : La différence de temps entre l'établissement de la connexion TCP et le moment où les données peuvent réellement être transmises, y compris le temps de négociation du proxy.
Négociation du proxy : Temps passé à négocier avec le serveur proxy.
Recherche DNS : Temps passé à effectuer la recherche DNS. Chaque domaine différent sur une page nécessite une recherche DNS.
Connexion initiale / Connexion : Temps passé à établir une connexion, y compris la poignée de main TCP/la nouvelle tentative et la négociation SSL.
SSL : Temps passé à compléter la poignée de main SSL.
Requête envoyée : Temps passé à envoyer la requête réseau, généralement une milliseconde.
Attente (TFFB) : TFFB est le temps écoulé entre le moment où la requête de page est effectuée et le moment où le premier octet de données de réponse est reçu.
Téléchargement du contenu : Temps passé à recevoir les données de réponse.
À partir de cet exemple, nous pouvons voir que le temps de téléchargement réel des données ne représente que 13,05 / 204,16 = 6,39 % du total. Plus le fichier est petit, plus ce ratio est petit – et plus le fichier est grand, plus le ratio est élevé. C'est pourquoi il est recommandé de combiner plusieurs petits fichiers en un seul grand fichier, ce qui réduit le nombre de requêtes HTTP.
Comment combiner plusieurs fichiers
Il existe plusieurs techniques pour réduire le nombre de requêtes HTTP en combinant des fichiers :
1. Regrouper les fichiers JavaScript avec Webpack
// webpack.config.js
module.exports = {
entry: './src/index.js',
output: {
filename: 'bundle.js',
path: path.resolve(__dirname, 'dist'),
},
};
Cela combinera tous les fichiers JavaScript importés dans votre point d'entrée en un seul bundle.
2. Combiner les fichiers CSS En utilisant des préprocesseurs CSS comme Sass :
/* main.scss */
@import 'reset';
@import 'variables';
@import 'typography';
@import 'layout';
@import 'components';
Puis compiler en un seul fichier CSS :
sass main.scss:main.css
Référence :
2. Utiliser HTTP2
Comparé à HTTP1.1, HTTP2 présente plusieurs avantages :
Analyse plus rapide
Lors de l'analyse des requêtes HTTP1.1, le serveur doit lire en continu les octets jusqu'à ce qu'il rencontre le délimiteur CRLF. L'analyse des requêtes HTTP2 n'est pas aussi compliquée car HTTP2 est un protocole basé sur des trames, et chaque trame a un champ indiquant sa longueur.
Multiplexage
Avec HTTP1.1, si vous souhaitez effectuer plusieurs requêtes simultanément, vous devez établir plusieurs connexions TCP car une connexion TCP ne peut gérer qu'une seule requête HTTP1.1 à la fois.
Dans HTTP2, plusieurs requêtes peuvent partager une seule connexion TCP, ce qui est appelé multiplexage. Chaque requête et réponse est représentée par un flux avec un identifiant de flux unique pour l'identifier. Plusieurs requêtes et réponses peuvent être envoyées dans le désordre au sein de la connexion TCP puis réassemblées à la destination en utilisant l'identifiant de flux.
Compression des en-têtes
HTTP2 fournit une fonctionnalité de compression des en-têtes.
Par exemple, considérons les deux requêtes suivantes :
:authority: unpkg.zhimg.com
:method: GET
:path: /za-js-sdk@2.16.0/dist/zap.js
:scheme: https
accept: */*
accept-encoding: gzip, deflate, br
accept-language: zh-CN,zh;q=0.9
cache-control: no-cache
pragma: no-cache
referer: https://www.zhihu.com/
sec-fetch-dest: script
sec-fetch-mode: no-cors
sec-fetch-site: cross-site
user-agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36
:authority: zz.bdstatic.com
:method: GET
:path: /linksubmit/push.js
:scheme: https
accept: */*
accept-encoding: gzip, deflate, br
accept-language: zh-CN,zh;q=0.9
cache-control: no-cache
pragma: no-cache
referer: https://www.zhihu.com/
sec-fetch-dest: script
sec-fetch-mode: no-cors
sec-fetch-site: cross-site
user-agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36
À partir des deux requêtes ci-dessus, vous pouvez voir que beaucoup de données sont répétées. Si nous pouvions stocker les mêmes en-têtes et n'envoyer que les différences entre eux, nous pourrions économiser beaucoup de bande passante et accélérer le temps de requête.
HTTP/2 utilise des "tables d'en-têtes" côté client et serveur pour suivre et stocker les paires clé-valeur précédemment envoyées, et pour les données identiques, elles ne sont plus envoyées à travers chaque requête et réponse.
Voici un exemple simplifié. Supposons que le client envoie les requêtes d'en-tête suivantes en séquence :
Header1:foo
Header2:bar
Header3:bat
Lorsque le client envoie une requête, il crée une table basée sur les valeurs d'en-tête :
| Index | Nom de l'en-tête | Valeur |
| 62 | Header1 | foo |
| 63 | Header2 | bar |
| 64 | Header3 | bat |
Si le serveur reçoit la requête, il créera la même table. Lorsque le client envoie la requête suivante, si les en-têtes sont les mêmes, il peut directement envoyer un bloc d'en-tête comme ceci :
62 63 64
Le serveur recherchera la table précédemment établie et restaurera ces nombres aux en-têtes complets auxquels ils correspondent.
Priorité
HTTP2 peut définir une priorité plus élevée pour les requêtes plus urgentes, et le serveur peut prioriser leur traitement après avoir reçu de telles requêtes.
Contrôle de flux
Puisque la bande passante d'une connexion TCP (selon la bande passante réseau du client au serveur) est fixe, lorsqu'il y a plusieurs requêtes simultanées, si une requête occupe plus de trafic, une autre requête occupera moins. Le contrôle de flux peut contrôler précisément le flux de différents flux.
Push du serveur
Une nouvelle fonctionnalité puissante ajoutée dans HTTP2 est que le serveur peut envoyer plusieurs réponses à une seule requête client. En d'autres termes, en plus de répondre à la requête initiale, le serveur peut également pousser des ressources supplémentaires au client sans que le client les demande explicitement.
Par exemple, lorsqu'un navigateur demande un site web, en plus de retourner la page HTML, le serveur peut également pousser proactivement des ressources basées sur les URL des ressources dans la page HTML.
De nombreux sites web ont déjà commencé à utiliser HTTP2, comme Zhihu :

Où "h2" fait référence au protocole HTTP2, et "http/1.1" fait référence au protocole HTTP1.1.
Références :
3. Utiliser le Rendu Côté Serveur
Dans le rendu côté client, vous obtenez le fichier HTML, téléchargez les fichiers JavaScript selon les besoins, exécutez les fichiers, générez le DOM, puis rendez.
Et dans le rendu côté serveur, le serveur retourne le fichier HTML, et le client n'a besoin que de parser le HTML.
Avantages : Rendu plus rapide de la première page, meilleur référencement.
Inconvénients : Configuration compliquée, augmente la charge de calcul sur le serveur.
Ci-dessous, je vais utiliser Vue SSR comme exemple pour décrire brièvement le processus SSR.
Processus de rendu côté client
Visitez un site web rendu côté client.
Le serveur retourne un fichier HTML contenant des déclarations d'importation de ressources et
<div id="app"></div>.Le client demande des ressources au serveur via HTTP, et lorsque les ressources nécessaires sont chargées, il exécute
new Vue()pour instancier et rendre la page.
Exemple d'application rendue côté client (Vue) :
<!-- index.html -->
<!DOCTYPE html>
<html>
<head>
<title>Exemple de Rendu Côté Client</title>
</head>
<body>
<!-- Conteneur initialement vide -->
<div id="app"></div>
<!-- Bundle JavaScript qui rendra le contenu -->
<script src="/dist/bundle.js"></script>
</body>
</html>
// main.js (compilé en bundle.js)
import Vue from 'vue';
import App from './App.vue';
// Le rendu côté client se produit ici - après le chargement et l'exécution du JS
new Vue({
render: h => h(App)
}).$mount('#app');
// App.vue
<template>
<div>
<h1>{{ title }}</h1>
<p>Ce contenu est rendu côté client.</p>
</div>
</template>
<script>
export default {
data() {
return {
title: 'Bonjour le Monde'
}
},
// Dans le rendu côté client, ce hook de cycle de vie s'exécute dans le navigateur
mounted() {
console.log('Composant monté dans le navigateur');
}
}
</script>
Processus de rendu côté serveur
Visitez un site web rendu côté serveur.
Le serveur vérifie quels fichiers de ressources le composant de la route actuelle nécessite, puis remplit le contenu de ces fichiers dans le fichier HTML. S'il y a des requêtes AJAX, il les exécutera pour la pré-récupération des données et les remplira dans le fichier HTML, et enfin retournera cette page HTML.
Lorsque le client reçoit cette page HTML, il peut commencer à rendre la page immédiatement. En même temps, la page charge également des ressources, et lorsque les ressources nécessaires sont entièrement chargées, elle commence à exécuter
new Vue()pour instancier et prendre le contrôle de la page.
Exemple d'application rendue côté serveur (Vue) :
// server.js
const express = require('express');
const server = express();
const { createBundleRenderer } = require('vue-server-renderer');
// Créer un renderer basé sur le bundle serveur
const renderer = createBundleRenderer('./dist/vue-ssr-server-bundle.json', {
template: require('fs').readFileSync('./index.template.html', 'utf-8'),
clientManifest: require('./dist/vue-ssr-client-manifest.json')
});
// Gérer toutes les routes avec le même renderer
server.get('*', (req, res) => {
const context = { url: req.url };
// Rendre notre application Vue en une chaîne
renderer.renderToString(context, (err, html) => {
if (err) {
// Gérer l'erreur
res.status(500).end('Erreur du Serveur');
return;
}
// Envoyer le HTML rendu au client
res.end(html);
});
});
server.listen(8080);
<!-- index.template.html -->
<!DOCTYPE html>
<html>
<head>
<title>Exemple de Rendu Côté Serveur</title>
<!-- Ressources injectées par le renderer serveur -->
</head>
<body>
<!-- Cela sera remplacé par le HTML de l'application -->
<!--vue-ssr-outlet-->
</body>
</html>
// entry-server.js
import { createApp } from './app';
export default context => {
return new Promise((resolve, reject) => {
const { app, router } = createApp();
// Définir l'emplacement du routeur côté serveur
router.push(context.url);
// Attendre que le routeur ait résolu les composants et hooks asynchrones possibles
router.onReady(() => {
const matchedComponents = router.getMatchedComponents();
// Aucune route correspondante, rejeter avec 404
if (!matchedComponents.length) {
return reject({ code: 404 });
}
// La promesse se résout en l'instance de l'application
resolve(app);
}, reject);
});
}
À partir des deux processus ci-dessus, vous pouvez voir que la différence réside dans la deuxième étape. Un site web rendu côté client retournera directement le fichier HTML, tandis qu'un site web rendu côté serveur rendra complètement la page avant de retourner ce fichier HTML.
Quel est l'avantage de faire cela ? C'est un temps plus rapide pour le contenu.
Supposons que votre site web doit charger quatre fichiers (a, b, c, d) pour être rendu complètement. Et chaque fichier fait 1 Mo de taille.
En calculant de cette manière : un site web rendu côté client doit charger 4 fichiers et un fichier HTML pour compléter le rendu de la page d'accueil, totalisant 4 Mo (en ignorant la taille du fichier HTML). Alors qu'un site web rendu côté serveur n'a besoin que de charger un fichier HTML entièrement rendu pour compléter le rendu de la page d'accueil, totalisant la taille du fichier HTML déjà rendu (qui n'est généralement pas trop grand, généralement quelques centaines de Ko ; mon site web de blog personnel (SSR) charge un fichier HTML de 400 Ko). C'est pourquoi le rendu côté serveur est plus rapide.
Références :
4. Utiliser un CDN pour les Ressources Statiques
Un Content Delivery Network (CDN) est un ensemble de serveurs web répartis dans plusieurs emplacements géographiques. Nous savons tous que plus le serveur est éloigné de l'utilisateur, plus la latence est élevée. Les CDN sont conçus pour résoudre ce problème en déployant des serveurs dans plusieurs emplacements, rapprochant les utilisateurs des serveurs, réduisant ainsi les temps de requête.
Principes du CDN
Lorsque l'utilisateur visite un site web sans CDN, le processus est le suivant :
Le navigateur doit résoudre le nom de domaine en une adresse IP, il fait donc une requête au DNS local.
Le DNS local fait des requêtes successives au serveur racine, au serveur de domaine de premier niveau et au serveur faisant autorité pour obtenir l'adresse IP du serveur du site web.
Le DNS local envoie l'adresse IP au navigateur, et le navigateur fait une requête à l'adresse IP du serveur du site web et reçoit les ressources.

Si l'utilisateur visite un site web qui a déployé un CDN, le processus est le suivant :
Le navigateur doit résoudre le nom de domaine en une adresse IP, il fait donc une requête au DNS local.
Le DNS local fait des requêtes successives au serveur racine, au serveur de domaine de premier niveau et au serveur faisant autorité pour obtenir l'adresse IP du système Global Server Load Balancing (GSLB).
Le DNS local fait ensuite une requête au GSLB. La fonction principale du GSLB est de déterminer l'emplacement de l'utilisateur en fonction de l'adresse IP du DNS local, de filtrer le système local Server Load Balancing (SLB) le plus proche de l'utilisateur, et de retourner l'adresse IP de ce SLB au DNS local.
Le DNS local envoie l'adresse IP du SLB au navigateur, et le navigateur fait une requête au SLB.
Le SLB sélectionne le serveur cache optimal en fonction de la ressource et de l'adresse demandées par le navigateur et le renvoie au navigateur.
Le navigateur redirige ensuite vers le serveur cache en fonction de l'adresse retournée par le SLB.
Si le serveur cache possède la ressource dont le navigateur a besoin, il envoie la ressource au navigateur. Sinon, il demande la ressource au serveur source, l'envoie au navigateur et la met en cache localement.

Références :
5. Placer le CSS dans le Head et les Fichiers JavaScript en Bas
L'exécution du CSS bloque le rendu et empêche l'exécution du JS
Le chargement et l'exécution du JS bloquent l'analyse du HTML et empêchent la construction du CSSOM
Si ces balises CSS et JS sont placées dans la balise HEAD, et qu'elles mettent longtemps à charger et à analyser, alors la page sera blanche. Vous devez donc placer les fichiers JS en bas (ne bloquant pas l'analyse du DOM mais bloquant le rendu) afin que l'analyse du HTML soit terminée avant le chargement des fichiers JS. Cela présente le contenu de la page à l'utilisateur le plus tôt possible.
Alors vous pourriez vous demander – pourquoi les fichiers CSS doivent-ils encore être placés dans le head ?
Parce que charger le HTML en premier puis le CSS fera que les utilisateurs verront une page "laide" et non stylisée au premier regard. Pour éviter cette situation, placez les fichiers CSS dans le head.
Vous pouvez également placer les fichiers JS dans le head tant que la balise script a l'attribut defer, ce qui signifie un téléchargement asynchrone et une exécution différée.
Voici un exemple de placement optimal :
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Chargement Optimisé des Ressources</title>
<!-- CSS dans le head pour un rendu plus rapide -->
<link rel="stylesheet" href="styles.css">
<!-- JS critique qui doit être chargé tôt peut utiliser defer -->
<script defer src="critical.js"></script>
</head>
<body>
<header>
<h1>Mon Site Web</h1>
<!-- Contenu de la page ici -->
</header>
<main>
<p>Contenu que les utilisateurs doivent voir rapidement...</p>
</main>
<footer>
<!-- Contenu du pied de page -->
</footer>
<!-- JavaScript non critique en bas -->
<script src="app.js"></script>
<script src="analytics.js"></script>
</body>
</html>
Explication de cette approche :
CSS dans le
<head>: Assure que la page est stylisée dès qu'elle est rendue, évitant le "flash de contenu non stylisé" (FOUC). Le CSS est bloquant pour le rendu, mais c'est exactement ce que nous voulons dans ce cas.JS critique avec
defer: L'attributdeferindique au navigateur de :Télécharger le script en parallèle pendant l'analyse du HTML
Exécuter le script uniquement après que l'analyse du HTML soit terminée mais avant l'événement
DOMContentLoadedMaintenir l'ordre d'exécution s'il y a plusieurs scripts différés
JS non critique avant la fermeture de
</body>: Les scripts sans attributs spéciaux vont :Bloquer l'analyse du HTML pendant leur téléchargement et leur exécution
En les plaçant en bas, nous assurons que tout le contenu important est analysé et affiché en premier
Cela améliore la performance perçue même si le temps de chargement total est le même
Vous pouvez également utiliser async pour les scripts qui ne dépendent pas du DOM ou d'autres scripts :
<script async src="independent.js"></script>
L'attribut async téléchargera le script en parallèle et l'exécutera dès qu'il sera disponible, ce qui peut interrompre l'analyse du HTML. Utilisez cela uniquement pour les scripts qui ne modifient pas le DOM ou ne dépendent pas d'autres scripts.
Référence :
6. Utiliser des Icônes de Police (iconfont) au Lieu des Icônes Image
Une icône de police est une icône transformée en police. Lorsque vous l'utilisez, c'est comme une police, et vous pouvez définir des attributs tels que la taille de la police, la couleur, etc., ce qui est très pratique. Les icônes de police sont également des graphiques vectoriels et ne perdent pas en clarté. Un autre avantage est que les fichiers générés sont particulièrement petits.
Compresser les Fichiers de Police
Utilisez le plugin fontmin-webpack pour compresser les fichiers de police (merci à Frontend Xiaowei pour avoir fourni cela).
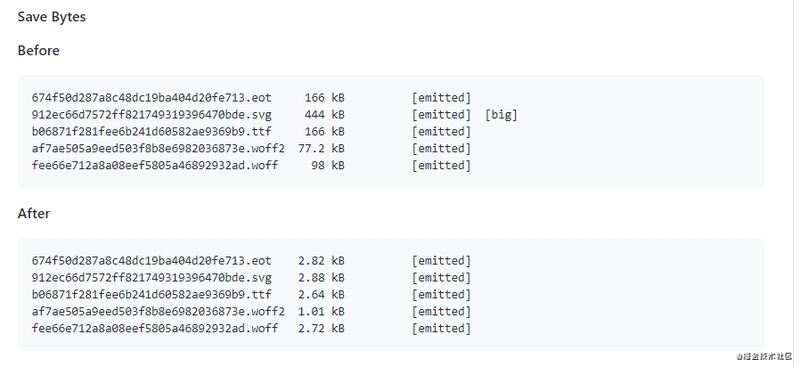
Références :
7. Bien Utiliser la Mise en Cache, Éviter de Recharger les Mêmes Ressources
Pour empêcher les utilisateurs de devoir demander des fichiers chaque fois qu'ils visitent un site web, nous pouvons contrôler ce comportement en ajoutant Expires ou max-age. Expires définit une heure, et tant qu'il est avant cette heure, le navigateur ne demandera pas le fichier mais utilisera directement le cache. Max-age est un temps relatif, et il est recommandé d'utiliser max-age au lieu de Expires.
Mais cela crée un problème : que se passe-t-il lorsque le fichier est mis à jour ? Comment notifier le navigateur pour qu'il demande à nouveau le fichier ?
Cela peut être fait en mettant à jour les adresses de liens de ressources référencées dans la page, faisant en sorte que le navigateur abandonne activement le cache et charge de nouvelles ressources.
L'approche spécifique consiste à associer la modification de l'URL de l'adresse de la ressource au contenu du fichier, ce qui signifie que seule la modification du contenu du fichier entraînera la modification de l'URL correspondante. Cela permet un contrôle précis du cache au niveau du fichier.
Alors, qu'est-ce qui est lié au contenu du fichier ? Nous pensons naturellement à utiliser des algorithmes de hachage pour dériver des informations de hachage pour le fichier. Les informations de hachage correspondent une à une au contenu du fichier, fournissant une base pour le contrôle du cache qui est précise à la granularité des fichiers individuels.
Comment implémenter la mise en cache et le contournement de cache :
1. En-têtes de cache côté serveur (en utilisant Express.js comme exemple) :
// Définir les en-têtes de contrôle de cache pour les ressources statiques
app.use('/static', express.static('public', {
maxAge: '1y', // Cache pour 1 an
etag: true, // Utiliser ETag pour la validation
lastModified: true // Utiliser Last-Modified pour la validation
}));
// Pour les fichiers HTML qui ne doivent pas être mis en cache aussi longtemps
app.get('/*.html', (req, res) => {
res.set({
'Cache-Control': 'public, max-age=300', // Cache pour 5 minutes
'Expires': new Date(Date.now() + 300000).toUTCString()
});
// Envoyer le contenu HTML
});
2. Utilisation de hachages de contenu dans les noms de fichiers (configuration Webpack) :
// webpack.config.js
module.exports = {
output: {
filename: '[name].[contenthash].js', // Utilise le hachage de contenu dans le nom de fichier
path: path.resolve(__dirname, 'dist'),
},
plugins: [
// Extraire le CSS dans des fichiers séparés avec hachage de contenu
new MiniCssExtractPlugin({
filename: '[name].[contenthash].css'
}),
// Générer du HTML avec les bons noms de fichiers hachés
new HtmlWebpackPlugin({
template: 'src/index.html'
})
]
};
Cela produira des fichiers de sortie comme :
main.8e0d62a10c151dad4f8e.jsstyles.f4e3a77c616562b26ca1.css
Lorsque vous changez le contenu d'un fichier, son hachage changera, forçant le navigateur à télécharger le nouveau fichier au lieu d'utiliser la version mise en cache.
3. Exemple de HTML généré avec contournement de cache :
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Exemple de Contournement de Cache</title>
<!-- Notez le hachage de contenu dans le nom de fichier -->
<link rel="stylesheet" href="/static/styles.f4e3a77c616562b26ca1.css">
</head>
<body>
<div id="app"></div>
<!-- Script avec hachage de contenu -->
<script src="/static/main.8e0d62a10c151dad4f8e.js"></script>
</body>
</html>
4. Paramètres de version de requête (approche plus simple mais moins efficace) :
<link rel="stylesheet" href="styles.css?v=1.2.3">
<script src="app.js?v=1.2.3"></script>
Lors de la mise à jour des fichiers, changez manuellement le numéro de version pour forcer un nouveau téléchargement.
Références :
8. Compresser les Fichiers
Compresser les fichiers peut réduire le temps de téléchargement des fichiers, offrant une meilleure expérience utilisateur.
Grâce au développement de Webpack et Node, la compression de fichiers est maintenant très pratique.
Dans Webpack, vous pouvez utiliser les plugins suivants pour la compression :
JavaScript : UglifyPlugin
CSS : MiniCssExtractPlugin
HTML : HtmlWebpackPlugin
En fait, nous pouvons faire encore mieux en utilisant la compression gzip. Cela peut être activé en ajoutant l'identifiant gzip à l'en-tête Accept-Encoding de l'en-tête de requête HTTP. Bien sûr, le serveur doit également supporter cette fonctionnalité.
Gzip est actuellement la méthode de compression la plus populaire et efficace. Par exemple, le fichier app.js généré après la construction d'un projet que j'ai développé avec Vue a une taille de 1,4 Mo, mais après la compression gzip, il n'est plus que de 573 Ko, réduisant le volume de près de 60 %.
Voici les méthodes pour configurer gzip dans webpack et node.
Télécharger les plugins
npm install compression-webpack-plugin --save-dev
npm install compression
Configuration Webpack
const CompressionPlugin = require('compression-webpack-plugin');
module.exports = {
plugins: [new CompressionPlugin()],
}
Configuration Node
const compression = require('compression')
// Utiliser avant les autres middlewares
app.use(compression())
9. Optimisation des Images
1. Chargement Paresseux des Images
Dans une page, ne définissez pas initialement le chemin des images – ne chargez l'image réelle que lorsqu'elle apparaît dans la fenêtre du navigateur. C'est le chargement paresseux. Pour les sites web avec de nombreuses images, le chargement de toutes les images à la fois peut avoir un impact significatif sur l'expérience utilisateur, donc le chargement paresseux des images est nécessaire.
Tout d'abord, configurez les images comme ceci, où les images ne se chargeront pas lorsqu'elles ne sont pas visibles dans la page :
<img data-src="https://avatars0.githubusercontent.com/u/22117876?s=460&u=7bd8f32788df6988833da6bd155c3cfbebc68006&v=4">
Lorsque la page devient visible, utilisez JS pour charger l'image :
const img = document.querySelector('img')
img.src = img.dataset.src
C'est ainsi que l'image est chargée. Pour le code complet, veuillez vous référer aux documents de référence.
Référence :
2. Images Réactives
L'avantage des images réactives est que les navigateurs peuvent automatiquement charger des images appropriées en fonction de la taille de l'écran.
Implémentation via picture :
<picture>
<source srcset="banner_w1000.jpg" media="(min-width: 801px)">
<source srcset="banner_w800.jpg" media="(max-width: 800px)">
<img src="banner_w800.jpg" alt="">
</picture>
Implémentation via @media :
@media (min-width: 769px) {
.bg {
background-image: url(bg1080.jpg);
}
}
@media (max-width: 768px) {
.bg {
background-image: url(bg768.jpg);
}
}
3. Ajuster la Taille des Images
Par exemple, si vous avez une image de taille 1920 * 1080, vous la montrez aux utilisateurs sous forme de miniature, et n'affichez l'image complète que lorsque les utilisateurs passent la souris dessus. Si les utilisateurs ne passent jamais réellement la souris sur la miniature, le temps passé à télécharger l'image est gaspillé.
Nous pouvons donc optimiser cela avec deux images. Initialement, ne chargez que la miniature, et lorsque les utilisateurs passent la souris sur l'image, chargez alors l'image grande. Une autre approche consiste à charger paresseusement l'image grande, en changeant manuellement la src de l'image grande pour la télécharger après que tous les éléments ont été chargés.
Exemple d'implémentation de l'optimisation de la taille des images :
<!-- Structure HTML -->
<div class="image-container">
<img class="thumbnail" src="thumbnail-small.jpg" alt="Petite miniature">
<img class="full-size" data-src="image-large.jpg" alt="Image en taille réelle">
</div>
/* CSS pour le conteneur et les images */
.image-container {
position: relative;
width: 200px;
height: 150px;
overflow: hidden;
}
.thumbnail {
width: 100%;
height: 100%;
object-fit: cover;
display: block;
}
.full-size {
display: none;
position: absolute;
top: 0;
left: 0;
z-index: 2;
max-width: 600px;
max-height: 400px;
}
/* Afficher la taille réelle au survol */
.image-container:hover .full-size {
display: block;
}
// JavaScript pour charger paresseusement l'image en taille réelle
document.addEventListener('DOMContentLoaded', () => {
const containers = document.querySelectorAll('.image-container');
containers.forEach(container => {
const thumbnail = container.querySelector('.thumbnail');
const fullSize = container.querySelector('.full-size');
// Charger l'image en taille réelle lorsque l'utilisateur survole la miniature
container.addEventListener('mouseenter', () => {
if (!fullSize.src && fullSize.dataset.src) {
fullSize.src = fullSize.dataset.src;
}
});
// Alternative : Charger l'image en taille réelle après que la page soit complètement chargée
/*
window.addEventListener('load', () => {
setTimeout(() => {
if (!fullSize.src && fullSize.dataset.src) {
fullSize.src = fullSize.dataset.src;
}
}, 1000); // Délai de chargement d'une seconde après le chargement de la fenêtre
});
*/
});
});
Cette implémentation :
Montre uniquement la miniature initialement
Charge l'image en taille réelle uniquement lorsque l'utilisateur survole la miniature
Fournit une approche alternative pour charger toutes les images en taille réelle avec un délai après le chargement de la page
4. Réduire la Qualité des Images
Par exemple, avec les images au format JPG, il n'y a généralement aucune différence notable entre une qualité de 100 % et une qualité de 90 %, surtout lorsqu'elles sont utilisées comme images de fond. Lorsque je découpe des images de fond dans Adobe Photoshop, je découpe souvent l'image au format JPG et la compresse à une qualité de 60 %, et je ne peux pratiquement voir aucune différence.
Il existe deux méthodes de compression : l'une via le plugin Webpack image-webpack-loader, et l'autre via des sites web de compression en ligne.
Voici comment utiliser le plugin Webpack image-webpack-loader :
npm i -D image-webpack-loader
Configuration Webpack :
{
test: /\.(png|jpe?g|gif|svg)(\?.*)?$/,
use:[
{
loader: 'url-loader',
options: {
limit: 10000, /* Les images plus petites que 1000 octets seront automatiquement converties en références de code base64 */
name: utils.assetsPath('img/[name].[hash:7].[ext]')
}
},
/* Compresser les images */
{
loader: 'image-webpack-loader',
options: {
bypassOnDebug: true,
}
}
]
}
5. Utiliser les Effets CSS3 au Lieu des Images Lorsque Possible
De nombreuses images peuvent être dessinées avec des effets CSS (dégradés, ombres, etc.). Dans ces cas, les effets CSS3 sont meilleurs. Cela est dû au fait que la taille du code est généralement une fraction ou même un dixième de la taille de l'image.
Référence :
6. Utiliser le Format WebP pour les Images
L'avantage de WebP réside dans son meilleur algorithme de compression des données d'image, qui apporte un volume d'image plus petit tout en maintenant une qualité d'image indiscernable à l'œil nu. Il dispose également de modes de compression avec et sans perte, de la transparence Alpha et de fonctionnalités d'animation. Ses effets de conversion sur JPEG et PNG sont excellents, stables et uniformes.
Exemple d'implémentation de WebP avec des solutions de repli :
<!-- Utilisation de l'élément picture pour WebP avec solution de repli -->
<picture>
<source srcset="image.webp" type="image/webp">
<source srcset="image.jpg" type="image/jpeg">
<img src="image.jpg" alt="Description de l'image">
</picture>
Détection et service WebP côté serveur :
// Exemple Express.js
app.get('/images/:imageName', (req, res) => {
const supportsWebP = req.headers.accept && req.headers.accept.includes('image/webp');
const imagePath = supportsWebP
? `public/images/${req.params.imageName}.webp`
: `public/images/${req.params.imageName}.jpg`;
res.sendFile(path.resolve(__dirname, imagePath));
});
Référence :
10. Charger le Code à la Demande via Webpack, Extraire les Bibliothèques Tierces, Réduire le Code Redondant lors de la Conversion de ES6 vers ES5
La citation suivante de la documentation officielle de Webpack explique le concept de chargement paresseux :
"Le chargement paresseux ou à la demande est un excellent moyen d'optimiser un site web ou une application. Cette approche sépare en réalité votre code à certains points de rupture logiques, puis fait immédiatement référence ou est sur le point de faire référence à certains nouveaux blocs de code après avoir terminé certaines opérations dans certains blocs de code. Cela accélère le chargement initial de l'application et allège son volume global car certains blocs de code peuvent ne jamais être chargés." Source : Chargement Paresseux
Note : Bien que le chargement paresseux des images (discuté dans la section 9.1) retarde le chargement des ressources d'image jusqu'à ce qu'elles soient visibles dans la fenêtre, le chargement paresseux du code divise les bundles JavaScript et charge les fragments de code uniquement lorsqu'ils sont nécessaires pour une fonctionnalité spécifique. Les deux améliorent le temps de chargement initial, mais ils travaillent à différents niveaux d'optimisation des ressources.
Générer des Noms de Fichiers Basés sur le Contenu du Fichier, Combiné avec l'Importation Dynamique des Composants pour Réaliser le Chargement à la Demande
Cette exigence peut être réalisée en configurant la propriété filename de output. L'une des options de valeur dans la propriété filename est [contenthash], qui crée un hachage unique basé sur le contenu du fichier. Lorsque le contenu du fichier change, [contenthash] change également.
output: {
filename: '[name].[contenthash].js',
chunkFilename: '[name].[contenthash].js',
path: path.resolve(__dirname, '../dist'),
},
Exemple de chargement paresseux de code dans une application Vue :
// Au lieu d'importer de manière synchrone comme ceci :
// import UserProfile from './components/UserProfile.vue'
// Utiliser l'importation dynamique pour les composants de route :
const UserProfile = () => import('./components/UserProfile.vue')
// Puis l'utiliser dans vos routes
const router = new VueRouter({
routes: [
{ path: '/user/:id', component: UserProfile }
]
})
Cela garantit que le composant UserProfile n'est chargé que lorsque l'utilisateur navigue vers cette route, et non au chargement initial de la page.
Extraire les Bibliothèques Tierces
Puisque les bibliothèques tierces importées sont généralement stables et ne changent pas fréquemment, les extraire séparément en tant que caches à long terme est un meilleur choix. Cela nécessite l'utilisation de l'option cacheGroups du plugin splitChunk de Webpack4.
optimization: {
runtimeChunk: {
name: 'manifest' // Diviser le code d'exécution de webpack en un chunk séparé.
},
splitChunks: {
cacheGroups: {
vendor: {
name: 'chunk-vendors',
test: /[\\/]node_modules[\\/]/,
priority: -10,
chunks: 'initial'
},
common: {
name: 'chunk-common',
minChunks: 2,
priority: -20,
chunks: 'initial',
reuseExistingChunk: true
}
},
}
},
test: Utilisé pour contrôler quels modules sont appariés par ce groupe de cache. Si passé inchangé, il sélectionne par défaut tous les modules. Types de valeurs qui peuvent être passés :RegExp,String, etFunction.priority: Indique le poids d'extraction, les nombres plus élevés indiquant une priorité plus élevée. Puisqu'un module pourrait répondre aux conditions de plusieurscacheGroups, l'extraction est déterminée par le poids le plus élevé.reuseExistingChunk: Indique s'il faut utiliser les chunks existants. Si vrai, cela signifie que si le chunk actuel contient des modules qui ont déjà été extraits, de nouveaux ne seront pas générés.minChunks(par défaut 1) : Le nombre minimum de fois où ce bloc de code doit être référencé avant d'être divisé (note : pour assurer la réutilisabilité du bloc de code, la stratégie par défaut ne nécessite pas de références multiples pour être divisé).chunks(par défaut async) : initial, async, et all.name(nom des chunks packagés) : String ou fonction (les fonctions peuvent personnaliser les noms en fonction des conditions).
Réduire le Code Redondant lors de la Conversion de ES6 vers ES5
Pour atteindre la même fonctionnalité que le code original après la conversion Babel, certaines fonctions d'assistance sont nécessaires. Par exemple ceci :
class Person {}
sera converti en ceci :
"use strict";
function _classCallCheck(instance, Constructor) {
if (!(instance instanceof Constructor)) {
throw new TypeError("Cannot call a class as a function");
}
}
var Person = function Person() {
_classCallCheck(this, Person);
};
Ici, _classCallCheck est une fonction helper. Si des classes sont déclarées dans de nombreux fichiers, alors de nombreuses fonctions helper seront générées.
Le package @babel/runtime déclare toutes les fonctions d'assistance nécessaires, et le rôle de @babel/plugin-transform-runtime est d'importer tous les fichiers qui ont besoin de fonctions helper depuis le package @babel/runtime :
"use strict";
var _classCallCheck2 = require("@babel/runtime/helpers/classCallCheck");
var _classCallCheck3 = _interopRequireDefault(_classCallCheck2);
function _interopRequireDefault(obj) {
return obj && obj.__esModule ? obj : { default: obj };
}
var Person = function Person() {
(0, _classCallCheck3.default)(this, Person);
};
Ici, la fonction helper classCallCheck n'est plus compilée, mais fait plutôt référence à helpers/classCallCheck depuis @babel/runtime.
Installation :
npm i -D @babel/plugin-transform-runtime @babel/runtime
Utilisation :
Dans le fichier .babelrc,
"plugins": [
"@babel/plugin-transform-runtime"
]
Références :
11. Réduire les Reflows et Repaints
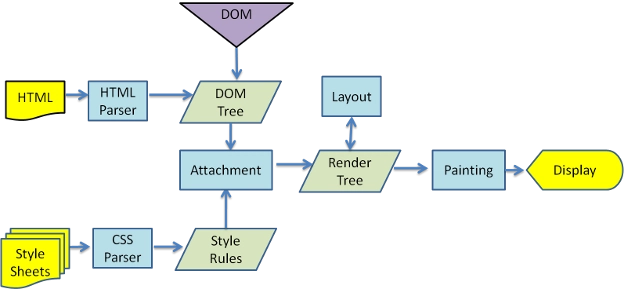
Processus de Rendu du Navigateur
Analyser le HTML pour générer l'arbre DOM.
Analyser le CSS pour générer l'arbre des règles CSSOM.
Combiner l'arbre DOM et l'arbre des règles CSSOM pour générer l'arbre de rendu.
Parcourir l'arbre de rendu pour commencer la mise en page, en calculant les informations de position et de taille de chaque nœud.
Peindre chaque nœud de l'arbre de rendu à l'écran.
Reflow
Lorsque la position ou la taille des éléments DOM est modifiée, le navigateur doit régénérer l'arbre de rendu, un processus appelé reflow.
Repaint
Après avoir régénéré l'arbre de rendu, chaque nœud de l'arbre de rendu doit être peint à l'écran, un processus appelé repaint. Toutes les actions ne provoqueront pas un reflow – par exemple, changer la couleur de la police ne provoquera qu'un repaint. Rappelez-vous, le reflow provoquera un repaint, mais le repaint ne provoquera pas de reflow.
Les opérations de reflow et de repaint sont très coûteuses car le thread du moteur JavaScript et le thread de rendu GUI sont mutuellement exclusifs, et un seul peut travailler à la fois.
Quelles opérations provoqueront un reflow ?
Ajout ou suppression d'éléments DOM visibles
Changements de position des éléments
Changements de taille des éléments
Changements de contenu
Changements de taille de la fenêtre du navigateur
Comment réduire les reflows et les repaints ?
Lorsque vous modifiez les styles avec JavaScript, il est préférable de ne pas écrire les styles directement, mais de remplacer les classes pour changer les styles.
Si vous devez effectuer une série d'opérations sur un élément DOM, vous pouvez sortir l'élément DOM du flux du document, apporter des modifications, puis le ramener dans le document. Il est recommandé d'utiliser des éléments cachés (display:none) ou des fragments de document (DocumentFragement), qui peuvent tous deux implémenter cette approche efficacement.
Exemple provoquant des reflows inutiles (inefficace) :
// Cela provoque plusieurs reflows car chaque changement de style déclenche un reflow
const element = document.getElementById('myElement');
element.style.width = '100px';
element.style.height = '200px';
element.style.margin = '10px';
element.style.padding = '20px';
element.style.borderRadius = '5px';
Version optimisée 1 – utilisant les classes CSS :
/* style.css */
.my-modified-element {
width: 100px;
height: 200px;
margin: 10px;
padding: 20px;
border-radius: 5px;
}
// Un seul reflow se produit lorsque la classe est ajoutée
document.getElementById('myElement').classList.add('my-modified-element');
Version optimisée 2 – regroupement des changements de style :
// Regroupement des changements de style en utilisant cssText
const element = document.getElementById('myElement');
element.style.cssText = 'width: 100px; height: 200px; margin: 10px; padding: 20px; border-radius: 5px;';
Version optimisée 3 – utilisant des fragments de document (pour plusieurs éléments) :
// Au lieu d'ajouter des éléments un par un
const list = document.getElementById('myList');
const fragment = document.createDocumentFragment();
for (let i = 0; i < 100; i++) {
const item = document.createElement('li');
item.textContent = `Item ${i}`;
fragment.appendChild(item);
}
// Un seul reflow se produit lorsque le fragment est ajouté
list.appendChild(fragment);
Version optimisée 4 – sortir l'élément du flux, modifier, puis réinsérer :
// Retirer du DOM, apporter des modifications, puis réinsérer
const element = document.getElementById('myElement');
const parent = element.parentNode;
const nextSibling = element.nextSibling;
// Retirer (provoque un reflow)
parent.removeChild(element);
// Apporter plusieurs modifications (aucun reflow pendant le détachement)
element.style.width = '100px';
element.style.height = '200px';
element.style.margin = '10px';
element.style.padding = '20px';
element.style.borderRadius = '5px';
// Réinsérer (provoque un autre reflow)
if (nextSibling) {
parent.insertBefore(element, nextSibling);
} else {
parent.appendChild(element);
}
Version optimisée 5 – utiliser display:none temporairement :
const element = document.getElementById('myElement');
// Masquer l'élément (un reflow)
element.style.display = 'none';
// Apporter plusieurs modifications (aucun reflow pendant le masquage)
element.style.width = '100px';
element.style.height = '200px';
element.style.margin = '10px';
element.style.padding = '20px';
element.style.borderRadius = '5px';
// Afficher à nouveau l'élément (un autre reflow)
element.style.display = 'block';
En utilisant ces techniques d'optimisation, vous pouvez réduire considérablement le nombre de reflows et de repaints, conduisant à des performances plus fluides, en particulier pour les animations et les mises à jour de contenu dynamique.
12. Utiliser la Délégation d'Événements
La délégation d'événements tire parti de la remontée d'événements, vous permettant de spécifier un seul gestionnaire d'événements pour gérer tous les événements d'un type particulier. Tous les événements qui utilisent des boutons (la plupart des événements de souris et de clavier) conviennent à la technique de délégation d'événements. L'utilisation de la délégation d'événements peut économiser de la mémoire.
<ul>
<li>Pomme</li>
<li>Banane</li>
<li>Ananas</li>
</ul>
// bien
document.querySelector('ul').onclick = (event) => {
const target = event.target
if (target.nodeName === 'LI') {
console.log(target.innerHTML)
}
}
// mal
document.querySelectorAll('li').forEach((e) => {
e.onclick = function() {
console.log(this.innerHTML)
}
})
13. Prêter Attention à la Localité du Programme
Un programme informatique bien écrit a souvent une bonne localité – il tend à référencer des éléments de données proches des éléments de données récemment référencés ou les éléments de données eux-mêmes récemment référencés. Cette tendance est connue sous le nom de principe de localité. Les programmes avec une bonne localité s'exécutent plus rapidement que ceux avec une mauvaise localité.
La localité prend généralement deux formes différentes :
Localité temporelle : Dans un programme avec une bonne localité temporelle, les emplacements mémoire qui ont été référencés une fois sont susceptibles d'être référencés plusieurs fois dans un avenir proche.
Localité spatiale : Dans un programme avec une bonne localité spatiale, si un emplacement mémoire a été référencé une fois, le programme est susceptible de référencer un emplacement mémoire à proximité dans un avenir proche.
Exemple de localité temporelle :
function sum(arry) {
let i, sum = 0
let len = arry.length
for (i = 0; i < len; i++) {
sum += arry[i]
}
return sum
}
Dans cet exemple, la variable sum est référencée une fois à chaque itération de la boucle, donc elle a une bonne localité temporelle.
Exemple de localité spatiale :
Programme avec une bonne localité spatiale :
// Tableau à deux dimensions
function sum1(arry, rows, cols) {
let i, j, sum = 0
for (i = 0; i < rows; i++) {
for (j = 0; j < cols; j++) {
sum += arry[i][j]
}
}
return sum
}
Programme avec une mauvaise localité spatiale :
// Tableau à deux dimensions
function sum2(arry, rows, cols) {
let i, j, sum = 0
for (j = 0; j < cols; j++) {
for (i = 0; i < rows; i++) {
sum += arry[i][j]
}
}
return sum
}
En regardant les deux exemples de localité spatiale ci-dessus, la méthode d'accès à chaque élément du tableau séquentiellement en commençant par chaque ligne, comme montré dans les exemples, est appelée un motif de référence avec un pas de 1.
Si dans un tableau, chaque k éléments sont accessibles, il est appelé un motif de référence avec un pas de k. Généralement, à mesure que le pas augmente, la localité spatiale diminue.
Quelle est la différence entre ces deux exemples ? Eh bien, le premier exemple parcourt le tableau par ligne, en parcourant complètement une ligne avant de passer à la suivante. Le deuxième exemple parcourt le tableau par colonne, en parcourant un élément dans une ligne et en passant immédiatement à l'élément de la même colonne dans la ligne suivante.
Les tableaux sont stockés en mémoire dans l'ordre des lignes, ce qui fait que l'exemple de parcours du tableau ligne par ligne obtient un motif de référence avec un pas de 1 avec une bonne localité spatiale. L'autre exemple a un pas de lignes, avec une localité spatiale extrêmement mauvaise.
Test de Performance
Environnement d'exécution :
CPU : i5-7400
Navigateur : Chrome 70.0.3538.110
Test de la localité spatiale sur un tableau à deux dimensions de longueur 9000 (longueur du sous-tableau également 9000) 10 fois, en prenant le temps moyen (millisecondes), les résultats sont les suivants :
Les exemples utilisés sont les deux exemples de localité spatiale mentionnés ci-dessus.
| Pas 1 | Pas 9000 |
| 124 | 2316 |
À partir des résultats des tests ci-dessus, le tableau avec un pas de 1 s'exécute un ordre de grandeur plus rapidement que le tableau avec un pas de 9000.
Donc, pour résumer :
Les programmes qui référencent à plusieurs reprises les mêmes variables ont une bonne localité temporelle
Pour les programmes avec un motif de référence avec un pas de k, plus le pas est petit, meilleure est la localité spatiale ; tandis que les programmes qui sautent dans la mémoire avec de grands pas auront une très mauvaise localité spatiale
Référence :
14. if-else vs switch
À mesure que le nombre de conditions de jugement augmente, il devient préférable d'utiliser switch plutôt que if-else.
if (color == 'blue') {
} else if (color == 'yellow') {
} else if (color == 'white') {
} else if (color == 'black') {
} else if (color == 'green') {
} else if (color == 'orange') {
} else if (color == 'pink') {
}
switch (color) {
case 'blue':
break
case 'yellow':
break
case 'white':
break
case 'black':
break
case 'green':
break
case 'orange':
break
case 'pink':
break
}
Dans des situations comme celle ci-dessus, du point de vue de la lisibilité, utiliser switch est meilleur (l'instruction switch de JavaScript n'est pas basée sur une implémentation de hachage mais sur un jugement de boucle, donc du point de vue des performances, if-else et switch sont identiques).
Pourquoi switch est meilleur pour plusieurs conditions :
Lisibilité améliorée : Les instructions switch présentent une structure visuelle plus claire lorsqu'elles traitent de plusieurs conditions sur la même variable. Les instructions case créent un format plus organisé et tabulaire qui est plus facile à parcourir et à comprendre.
Maintenance du code plus propre : Ajouter ou supprimer des conditions dans une instruction switch est plus simple et moins sujet aux erreurs. Avec les chaînes if-else, il est facile d'interrompre accidentellement la chaîne ou d'oublier un mot-clé "else".
Moins de répétition : Dans l'exemple if-else, nous répétons la vérification de la même variable (
color) plusieurs fois, tandis que dans switch, nous la spécifions une fois en haut.Meilleur pour le débogage : Lors du débogage, il est plus facile de définir des points d'arrêt sur des cas spécifiques dans une instruction switch que d'essayer d'identifier quelle partie d'une longue chaîne if-else vous devez cibler.
Signalisation de l'intention : L'utilisation de switch communique aux autres développeurs que vous vérifiez plusieurs valeurs possibles de la même variable, plutôt que des conditions potentiellement non liées.
Pour le JavaScript moderne, il existe une autre alternative à considérer pour le mappage simple de valeurs – les littéraux d'objet :
const colorActions = {
'blue': () => { /* action bleue */ },
'yellow': () => { /* action jaune */ },
'white': () => { /* action blanche */ },
'black': () => { /* action noire */ },
'green': () => { /* action verte */ },
'orange': () => { /* action orange */ },
'pink': () => { /* action rose */ }
};
// Exécuter l'action si elle existe
if (colorActions[color]) {
colorActions[color]();
}
Cette approche offre encore de meilleures performances (temps de recherche O(1)) par rapport aux approches if-else et switch.
15. Tables de Recherche
Lorsque vous avez de nombreuses instructions conditionnelles, utiliser switch et if-else n'est pas le meilleur choix. Dans de tels cas, vous pourriez vouloir essayer les tables de recherche. Les tables de recherche peuvent être construites en utilisant des tableaux et des objets.
switch (index) {
case '0':
return result0
case '1':
return result1
case '2':
return result2
case '3':
return result3
case '4':
return result4
case '5':
return result5
case '6':
return result6
case '7':
return result7
case '8':
return result8
case '9':
return result9
case '10':
return result10
case '11':
return result11
}
Cette instruction switch peut être convertie en une table de recherche :
const results = [result0,result1,result2,result3,result4,result5,result6,result7,result8,result9,result10,result11]
return results[index]
Si les instructions conditionnelles ne sont pas des valeurs numériques mais des chaînes, vous pouvez utiliser un objet pour construire une table de recherche :
const map = {
red: result0,
green: result1,
}
return map[color]
Pourquoi les tables de recherche sont meilleures pour de nombreuses conditions :
Complexité temporelle constante (O(1)) : Les tables de recherche fournissent un accès direct au résultat basé sur l'index/clé, rendant le temps d'opération constant indépendamment du nombre d'options disponibles. En revanche, les chaînes if-else et les instructions switch ont une complexité temporelle linéaire (O(n)) car dans le pire des cas, elles pourraient avoir besoin de vérifier toutes les conditions.
Gains de performance avec de nombreuses conditions : À mesure que le nombre de conditions augmente, l'avantage de performance des tables de recherche devient plus significatif. Pour un petit nombre de cas (2-5), la différence est négligeable, mais avec des dizaines ou des centaines de cas, les tables de recherche sont substantiellement plus rapides.
Brièveté du code : Comme le montrent les exemples, les tables de recherche nécessitent généralement moins de code, rendant votre base de code plus maintenable.
Configuration dynamique : Les tables de recherche peuvent être facilement peuplées dynamiquement :
const actionMap = {};
// Peupler dynamiquement la map
function registerAction(key, handler) {
actionMap[key] = handler;
}
// Enregistrer différents handlers
registerAction('save', saveDocument);
registerAction('delete', deleteDocument);
// L'utiliser
if (actionMap[userAction]) {
actionMap[userAction]();
}
- Charge cognitive réduite : Lorsque vous avez de nombreuses conditions, les tables de recherche éliminent la surcharge mentale de suivre de longues chaînes de logique.
Quand utiliser chaque approche :
If-else : Meilleur pour quelques conditions (2-3) avec une logique complexe ou différentes variables vérifiées
Switch : Bon pour un nombre modéré de conditions (4-10) vérifiant la même variable
Tables de recherche : Idéal pour de nombreuses conditions (10+) ou lorsque vous avez besoin d'un temps d'accès O(1)
Dans les applications réelles, les tables de recherche peuvent être peuplées à partir de sources externes comme des bases de données ou des fichiers de configuration, les rendant flexibles pour les scénarios où la logique de mappage pourrait changer sans nécessiter de modifications de code.
16. Éviter le Bégaiement de la Page
60fps et Taux de Rafraîchissement de l'Écran
Actuellement, la plupart des appareils ont un taux de rafraîchissement d'écran de 60 fois/seconde. Par conséquent, s'il y a une animation ou un effet de dégradé sur la page, ou si l'utilisateur fait défiler la page, le navigateur doit rendre les animations ou les pages à un rythme qui correspond au taux de rafraîchissement de l'écran de l'appareil.
Le temps budgété pour chaque image est juste supérieur à 16 millisecondes (1 seconde / 60 = 16,66 millisecondes). Mais en réalité, le navigateur a des tâches de maintenance à effectuer, donc tout votre travail doit être terminé en 10 millisecondes. Si vous ne pouvez pas respecter ce budget, le taux d'images par seconde chutera, et le contenu scintillera à l'écran.
Ce phénomène est communément appelé le bégaiement et a un impact négatif sur l'expérience utilisateur. Source : Google Web Fundamentals - Performance de Rendu

Supposons que vous utilisez JavaScript pour modifier le DOM, déclencher des changements de style, passer par le reflow et le repaint, et enfin peindre à l'écran. Si l'une de ces étapes prend trop de temps, cela provoquera un temps de rendu trop long pour cette image, et le taux d'images par seconde moyen chutera. Supposons que cette image a pris 50 ms, alors le taux d'images par seconde serait de 1s / 50ms = 20fps, et la page semblerait bégayer.
Pour certains scripts JavaScript de longue durée, nous pouvons utiliser des temporisateurs pour diviser et retarder l'exécution.
for (let i = 0, len = arry.length; i < len; i++) {
process(arry[i])
}
Supposons que la structure de boucle ci-dessus prend trop de temps en raison soit de la haute complexité de process(), soit de trop d'éléments de tableau, soit des deux, vous pourriez vouloir essayer de diviser.
const todo = arry.concat()
setTimeout(function() {
process(todo.shift())
if (todo.length) {
setTimeout(arguments.callee, 25)
} else {
callback(arry)
}
}, 25)
Si vous êtes intéressé à en apprendre davantage, consultez High Performance JavaScript Chapitre 6.
Référence :
17. Utiliser requestAnimationFrame pour Implémenter les Changements Visuels
Du point 16, nous savons que la plupart des appareils ont un taux de rafraîchissement d'écran de 60 fois/seconde, ce qui signifie que le temps moyen par image est de 16,66 millisecondes. Lorsque vous utilisez JavaScript pour implémenter des effets d'animation, le meilleur cas est que le code commence à s'exécuter au début de chaque image. La seule façon de garantir que JavaScript s'exécute au début d'une image est d'utiliser requestAnimationFrame.
/**
* Si exécuté en tant que rappel requestAnimationFrame, ceci
* sera exécuté au début de l'image.
*/
function updateScreen(time) {
// Faire des mises à jour visuelles ici.
}
requestAnimationFrame(updateScreen);
Si vous utilisez setTimeout ou setInterval pour implémenter des animations, la fonction de rappel s'exécutera à un moment donné dans l'image, éventuellement tout à la fin, ce qui peut souvent nous faire manquer des images, entraînant des saccades.
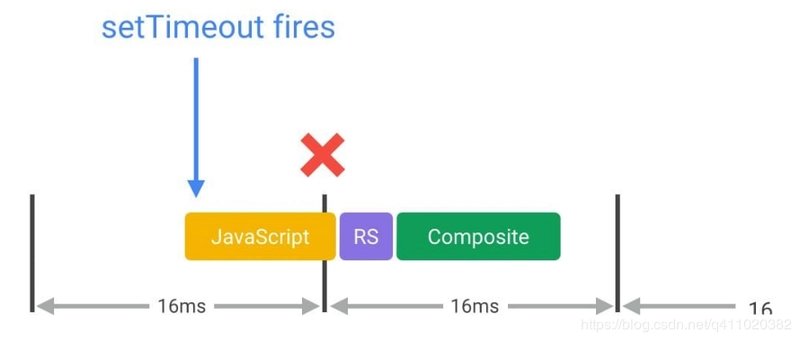
Référence :
18. Utiliser les Web Workers
Les Web Workers utilisent d'autres threads de travail pour fonctionner indépendamment du thread principal. Ils peuvent effectuer des tâches sans interférer avec l'interface utilisateur. Un worker peut envoyer des messages au code JavaScript qui l'a créé en envoyant des messages au gestionnaire d'événements spécifié par ce code (et vice versa).
Les Web Workers sont adaptés pour traiter des données pures ou des scripts de longue durée non liés à l'interface utilisateur du navigateur.
Créer un nouveau worker est simple – il suffit de spécifier un URI de script pour exécuter le thread de travail (main.js) :
var myWorker = new Worker('worker.js');
// Vous pouvez envoyer des messages au worker via la méthode postMessage() et l'événement onmessage
first.onchange = function() {
myWorker.postMessage([first.value, second.value]);
console.log('Message posté au worker');
}
second.onchange = function() {
myWorker.postMessage([first.value, second.value]);
console.log('Message posté au worker');
}
Dans le worker, après avoir reçu le message, vous pouvez écrire une fonction de gestionnaire d'événements de code en tant que réponse (worker.js) :
onmessage = function(e) {
console.log('Message reçu du script principal');
var workerResult = 'Résultat : ' + (e.data[0] * e.data[1]);
console.log('Postage du message de retour au script principal');
postMessage(workerResult);
}
La fonction de gestionnaire onmessage s'exécute immédiatement après la réception du message, et le message lui-même est utilisé comme propriété de données de l'événement. Ici, nous multiplions simplement les deux nombres et utilisons à nouveau la méthode postMessage() pour renvoyer le résultat au thread principal.
De retour dans le thread principal, nous utilisons à nouveau onmessage pour répondre au message renvoyé par le worker :
myWorker.onmessage = function(e) {
result.textContent = e.data;
console.log('Message reçu du worker');
}
Ici, nous obtenons les données de l'événement de message et les définissons comme le textContent de result, afin que l'utilisateur puisse voir directement le résultat du calcul.
Notez que dans le worker, vous ne pouvez pas manipuler directement les nœuds DOM, ni utiliser les méthodes et propriétés par défaut de l'objet window. Mais vous pouvez utiliser de nombreuses choses sous l'objet window, y compris les mécanismes de stockage de données tels que WebSockets, IndexedDB, et l'API Data Store spécifique à Firefox OS.
Référence :
19. Utiliser les Opérations Binaires
Les nombres en JavaScript sont stockés au format 64 bits en utilisant la norme IEEE-754. Mais dans les opérations binaires, les nombres sont convertis au format signé 32 bits. Même avec la conversion, les opérations binaires sont beaucoup plus rapides que les autres opérations mathématiques et booléennes.
Modulo
Puisque le bit le plus bas des nombres pairs est 0 et celui des nombres impairs est 1, les opérations modulo peuvent être remplacées par des opérations binaires.
if (value % 2) {
// Nombre impair
} else {
// Nombre pair
}
// Opération binaire
if (value & 1) {
// Nombre impair
} else {
// Nombre pair
}
Comment cela fonctionne : L'opérateur & (ET binaire) compare chaque bit du premier opérande au bit correspondant du second opérande. Si les deux bits sont 1, le bit de résultat correspondant est défini à 1 ; sinon, il est défini à 0.
Lorsque nous faisons value & 1, nous vérifions uniquement le dernier bit du nombre :
Pour les nombres pairs (par exemple, 4 =
100en binaire), le dernier bit est 0 :100 & 001 = 000(0)Pour les nombres impairs (par exemple, 5 =
101en binaire), le dernier bit est 1 :101 & 001 = 001(1)
Floor
~~10.12 // 10
~~10 // 10
~~'1.5' // 1
~~undefined // 0
~~null // 0
Comment cela fonctionne : L'opérateur ~ (NON binaire) inverse tous les bits dans l'opérande. Pour un nombre n, ~n est égal à -(n+1). Lorsqu'il est appliqué deux fois (~~n), il tronque effectivement la partie décimale d'un nombre, similaire à Math.floor() pour les nombres positifs et Math.ceil() pour les nombres négatifs.
Le processus :
Premier
~: Convertit le nombre en un entier 32 bits et inverse tous les bitsSecond
~: Inverse tous les bits à nouveau, résultant en le nombre original mais avec la partie décimale supprimée
Par exemple :
~10.12 → ~10 → -(10+1) → -11
~(-11) → -(-11+1) → -(-10) → 10
Bitmask
const a = 1
const b = 2
const c = 4
const options = a | b | c
En définissant ces options, vous pouvez utiliser l'opération ET binaire pour déterminer si a/b/c est dans les options.
// L'option b est-elle dans les options ?
if (b & options) {
...
}
Comment cela fonctionne : Dans les bitmasks, chaque bit représente un drapeau booléen. Les valeurs sont généralement des puissances de 2 de sorte que chacune a exactement un bit défini.
a = 1: Binaire001b = 2: Binaire010c = 4: Binaire100options = a | b | c: Le|(OU binaire) les combine :001 | 010 | 100 = 111(binaire) = 7 (décimal)
Lorsque vous vérifiez si un drapeau est défini avec if (b & options) :
b & options=010 & 111=010= 2 (décimal)Puisque cela est non nul, la condition est évaluée à vrai
Cette technique est extrêmement efficace pour stocker et vérifier plusieurs valeurs booléennes dans un seul nombre, et est couramment utilisée dans la programmation système, la programmation graphique et les systèmes de permissions.
20. Ne Pas Remplacer les Méthodes Natives
Peu importe à quel point votre code JavaScript est optimisé, il ne peut pas égaler les méthodes natives. Cela est dû au fait que les méthodes natives sont écrites en langages de bas niveau (C/C++) et compilées en code machine, devenant partie intégrante du navigateur. Lorsque des méthodes natives sont disponibles, essayez de les utiliser, surtout pour les opérations mathématiques et les manipulations du DOM.
Exemple : Remplacement de Chaîne (Native vs. Personnalisée)
Un piège courant est de réécrire des méthodes natives de chaîne comme replaceAll(). Voici une implémentation personnalisée inefficace par rapport à la méthode native, avec des benchmarks de performance :
// Remplacement global personnalisé inefficace (boucle manuelle)
function customReplaceAll(str, oldSubstr, newSubstr) {
let result = '';
let index = 0;
while (index < str.length) {
if (str.slice(index, index + oldSubstr.length) === oldSubstr) {
result += newSubstr;
index += oldSubstr.length;
} else {
result += str[index];
index++;
}
}
return result;
}
// Méthode native efficace (optimisée par le navigateur)
function nativeReplaceAll(str, oldSubstr, newSubstr) {
return str.replaceAll(oldSubstr, newSubstr);
}
// Test avec une grande chaîne (100 000 répétitions de "abc ")
const largeString = 'abc '.repeat(100000);
// Benchmark : Implémentation personnalisée
console.time('customReplaceAll');
customReplaceAll(largeString, 'abc', 'xyz');
console.timeEnd('customReplaceAll'); // Sortie : ~5ms (varie selon le navigateur)
// Benchmark : Méthode native
console.time('nativeReplaceAll');
nativeReplaceAll(largeString, 'abc', 'xyz');
console.timeEnd('nativeReplaceAll'); // Sortie : ~2ms (généralement 2-3x plus rapide)
Points clés à retenir :
Performance : Les méthodes natives comme
replaceAll()sont optimisées au niveau du navigateur, surpassant souvent le code écrit à la main (comme le montre le benchmark ci-dessus).Maintenabilité : Les méthodes natives sont standardisées, bien documentées et moins sujettes aux erreurs que la logique personnalisée (par exemple, la gestion des cas limites comme les sous-chaînes qui se chevauchent).
Compatibilité avec l'écosystème : L'utilisation de méthodes natives garantit la cohérence avec les bibliothèques et les outils qui dépendent du comportement intégré de JavaScript.
Quand Utiliser du Code Personnalisé
Bien que les méthodes natives soient généralement supérieures, il existe des cas rares où vous pourriez avoir besoin d'une logique personnalisée :
Lorsque la méthode native n'existe pas (par exemple, polyfilling pour les anciens navigateurs).
Pour des cas limites très spécialisés non couverts par les API natives.
Lorsque vous devez éviter le surcoût des appels de fonction dans des boucles extrêmement critiques en termes de performance (par exemple, des calculs numériques serrés).
Rappelez-vous : Les fournisseurs de navigateurs passent des millions d'heures à optimiser les méthodes natives. En les utilisant, vous obtenez des boosts de performance gratuits et réduisez le risque de réinventer des solutions défectueuses.
21. Réduire la Complexité des Sélecteurs CSS
1. Lorsque les navigateurs lisent les sélecteurs, ils suivent le principe de lecture de droite à gauche.
Prenons un exemple :
#block .text p {
color: red;
}
Trouver tous les éléments P.
Vérifier si les éléments trouvés dans le résultat 1 ont des éléments parents avec le nom de classe "text"
Vérifier si les éléments trouvés dans le résultat 2 ont des éléments parents avec l'ID "block"
Pourquoi est-ce inefficace ? Ce processus d'évaluation de droite à gauche peut être très coûteux dans des documents complexes. Prenons le sélecteur #block .text p comme exemple :
Le navigateur trouve d'abord tous les éléments
pdans le document (potentiellement des centaines)Pour chacun de ces éléments de paragraphe, il doit vérifier si l'un de leurs ancêtres a la classe
textPour ceux qui passent l'étape 2, il doit vérifier si l'un de leurs ancêtres a l'ID
block
Cela crée un goulot d'étranglement de performance significatif car :
La sélection initiale (
p) est très largeChaque étape suivante nécessite de vérifier plusieurs ancêtres dans l'arbre DOM
Ce processus se répète pour chaque élément de paragraphe
Une alternative plus efficace serait :
#block p.specific-text {
color: red;
}
Cela est plus efficace car il cible directement uniquement les paragraphes avec une classe spécifique, évitant de vérifier tous les paragraphes
2. Priorité des sélecteurs CSS
Inline > Sélecteur d'ID > Sélecteur de classe > Sélecteur de balise
Sur la base des deux informations ci-dessus, nous pouvons tirer des conclusions :
Plus le sélecteur est court, mieux c'est.
Essayez d'utiliser des sélecteurs de haute priorité, tels que les sélecteurs d'ID et de classe.
Évitez d'utiliser le sélecteur universel *.
Conseils pratiques pour des sélecteurs CSS optimaux :
/* ❌ Inefficace : Trop profond, commence par un sélecteur de balise */
body div.container ul li a.link {
color: blue;
}
/* ✅ Meilleur : Plus court, commence par un sélecteur de classe */
.container .link {
color: blue;
}
/* ✅ Meilleur : Direct, sélecteur de classe unique */
.nav-link {
color: blue;
}
Enfin, je devrais dire que selon les documents que j'ai trouvés, il n'est pas nécessaire d'optimiser les sélecteurs CSS car la différence de performance entre les sélecteurs les plus lents et les plus rapides est très faible.
Référence :
22. Utiliser Flexbox au Lieu des Modèles de Mise en Page Précédents
Dans les premières méthodes de mise en page CSS, nous pouvions positionner les éléments de manière absolue, relative ou en utilisant des flottants. Maintenant, nous avons une nouvelle méthode de mise en page appelée Flexbox, qui présente un avantage par rapport aux méthodes de mise en page précédentes : de meilleures performances.
La capture d'écran ci-dessous montre le coût de mise en page de l'utilisation de flottants sur 1300 boîtes :
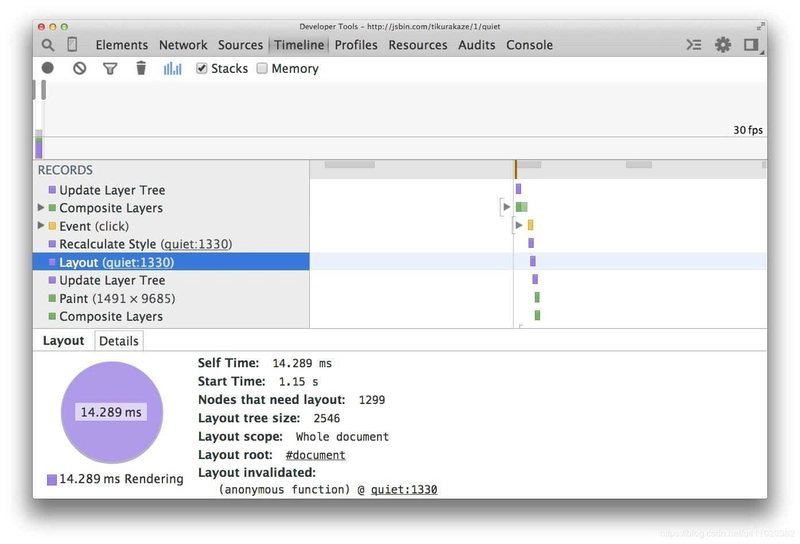
Ensuite, nous recréons cet exemple en utilisant Flexbox :
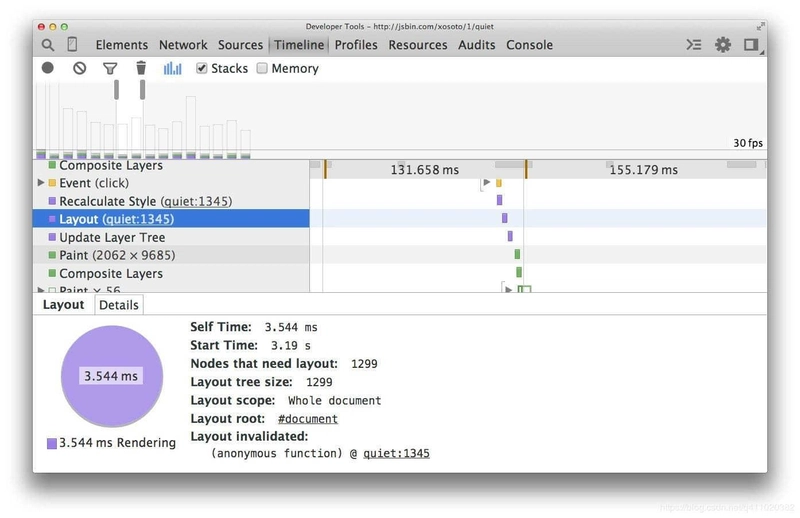
Maintenant, pour le même nombre d'éléments et la même apparence visuelle, le temps de mise en page est beaucoup moins (3,5 millisecondes contre 14 millisecondes dans cet exemple).
Mais la compatibilité de Flexbox reste un problème, car tous les navigateurs ne le supportent pas, alors utilisez-le avec prudence.
Compatibilité des navigateurs :
Chrome 29+
Firefox 28+
Internet Explorer 11
Opera 17+
Safari 6.1+ (préfixé avec -webkit-)
Android 4.4+
iOS 7.1+ (préfixé avec -webkit-)
Référence :
23. Utiliser les Propriétés Transform et Opacity pour Implémenter les Animations
En CSS, les transformations et les changements de propriété d'opacité ne déclenchent pas de reflow et de repaint. Ce sont des propriétés qui peuvent être traitées par le compositeur seul.

Exemple : Animation Inefficace vs. Efficace
❌ Animation inefficace utilisant des propriétés qui déclenchent le reflow et le repaint :
/* CSS */
.box-inefficient {
position: absolute;
left: 0;
top: 0;
width: 100px;
height: 100px;
background-color: #3498db;
animation: move-inefficient 2s infinite alternate;
}
@keyframes move-inefficient {
to {
left: 300px;
top: 200px;
width: 150px;
height: 150px;
}
}
Cette animation déclenche constamment des recalculs de mise en page (reflow) car elle anime les propriétés de position (left/top) et de taille (width/height).
✅ Animation efficace utilisant transform et opacity :
/* CSS */
.box-efficient {
position: absolute;
width: 100px;
height: 100px;
background-color: #3498db;
animation: move-efficient 2s infinite alternate;
}
@keyframes move-efficient {
to {
transform: translate(300px, 200px) scale(1.5);
opacity: 0.7;
}
}
Pourquoi c'est mieux :
transform: translate(300px, 200px)remplaceleft: 300px; top: 200pxtransform: scale(1.5)remplacewidth: 150px; height: 150pxCes opérations de transformation et les changements d'opacité peuvent être gérés directement par le GPU sans déclencher d'opérations de mise en page ou de peinture
Comparaison de performance :
La version inefficace peut perdre des images sur les appareils bas de gamme car chaque image nécessite :
JavaScript → Calculs de style → Mise en page → Peinture → Composition
La version efficace maintient généralement 60fps car elle ne nécessite que :
JavaScript → Calculs de style → Composition
Implémentation HTML :
<div class="box-inefficient">Inefficace</div>
<div class="box-efficient">Efficace</div>
Pour les animations complexes, vous pouvez utiliser le panneau Performance des outils de développement Chrome pour visualiser la différence. L'animation inefficace montrera beaucoup plus d'événements de mise en page et de peinture par rapport à l'efficace.
Référence :
24. Utiliser les Règles de Manière Raisonnable, Éviter la Sur-Optimisation
L'optimisation des performances est principalement divisée en deux catégories :
Optimisation du temps de chargement
Optimisation du temps d'exécution
Sur les 23 suggestions ci-dessus, les 10 premières appartiennent à l'optimisation du temps de chargement, et les 13 dernières appartiennent à l'optimisation du temps d'exécution. Habituellement, il n'est pas nécessaire d'appliquer les 23 règles d'optimisation des performances. Il est préférable d'apporter des ajustements ciblés en fonction du groupe d'utilisateurs du site web, économisant ainsi des efforts et du temps.
Avant de résoudre un problème, vous devez d'abord identifier le problème, sinon vous ne saurez pas par où commencer. Donc, avant de faire de l'optimisation des performances, il est préférable d'enquêter sur les performances de chargement et d'exécution du site web.
Vérifier les Performances de Chargement
Les performances de chargement d'un site web dépendent principalement du temps d'écran blanc et du temps de première page.
Temps d'écran blanc : Le temps écoulé entre l'entrée de l'URL et le moment où la page commence à afficher du contenu.
Temps de première page : Le temps écoulé entre l'entrée de l'URL et le moment où la page est complètement rendue.
Vous pouvez obtenir le temps d'écran blanc en plaçant le script suivant avant </head>.
<script>
new Date() - performance.timing.navigationStart
// Vous pouvez également utiliser domLoading et navigationStart
performance.timing.domLoading - performance.timing.navigationStart
</script>
Vous pouvez obtenir le temps de première page en exécutant new Date() - performance.timing.navigationStart dans l'événement window.onload.
Vérifier les Performances d'Exécution
Avec les outils de développement de Chrome, nous pouvons vérifier les performances du site web pendant l'exécution.
Ouvrez le site web, appuyez sur F12 et sélectionnez performance, cliquez sur le point gris en haut à gauche, il devient rouge pour indiquer qu'il a commencé l'enregistrement. À ce stade, vous pouvez simuler les utilisateurs utilisant le site web, et une fois terminé, cliquez sur stop, puis vous verrez le rapport de performance du site web pendant l'exécution.
Si des blocs rouges apparaissent, cela signifie qu'il y a des baisses de frames. Si c'est vert, cela signifie que le FPS est bon. Pour une utilisation détaillée des performances, vous pouvez rechercher en utilisant un moteur de recherche, car le champ est limité.
En vérifiant les performances de chargement et d'exécution, je crois que vous avez déjà une compréhension générale des performances du site web. Donc, ce que vous devez faire maintenant est d'utiliser les 23 suggestions ci-dessus pour optimiser votre site web. Allez-y !
Références :
Conclusion
L'optimisation des performances est un aspect critique du développement web moderne qui impacte directement l'expérience utilisateur, l'engagement et, en fin de compte, les résultats commerciaux. Tout au long de cet article, nous avons exploré 24 techniques diverses couvrant divers niveaux d'applications web – de l'optimisation du réseau à la performance de rendu et à l'exécution de JavaScript.
Points Clés à Retenir
Commencez par la mesure, pas par l'optimisation. Comme discuté au point #24, identifiez toujours vos goulots d'étranglement de performance spécifiques avant d'appliquer des techniques d'optimisation. Des outils comme le panneau Performance de Chrome DevTools, Lighthouse et WebPageTest peuvent aider à identifier exactement où votre application rencontre des difficultés.
Concentrez-vous sur le chemin de rendu critique. De nombreuses techniques (placer le CSS dans le head, JavaScript en bas, réduire les requêtes HTTP, rendu côté serveur) sont centrées sur l'accélération du temps jusqu'au premier rendu significatif – le moment où les utilisateurs voient et peuvent interagir avec votre contenu.
Comprenez le processus de rendu du navigateur. La connaissance de la manière dont les navigateurs analysent le HTML, exécutent le JavaScript et rendent les pixels à l'écran est essentielle pour prendre des décisions d'optimisation éclairées, en particulier lors de la gestion des animations et du contenu dynamique.
Équilibrez le coût de mise en œuvre par rapport au gain de performance. Toutes les techniques d'optimisation ne valent pas la peine d'être mises en œuvre pour chaque projet. Par exemple, le rendu côté serveur ajoute une complexité qui peut ne pas être justifiée pour des applications simples, et les opérations binaires offrent des gains de performance uniquement dans des scénarios de calcul lourds spécifiques.
Tenez compte des conditions de l'appareil et du réseau de vos utilisateurs. Si vous développez pour des utilisateurs dans des régions avec des connexions Internet plus lentes ou des appareils moins puissants, des techniques comme l'optimisation des images, le fractionnement du code et la réduction des charges utiles JavaScript deviennent encore plus importantes.
Stratégie de Mise en Œuvre Pratique
Au lieu d'essayer de mettre en œuvre les 24 techniques à la fois, envisagez une approche par phases :
Première passe : Implémentez les gains faciles avec un impact élevé
Optimisation des images
HTTP/2
Mise en cache de base
Placement CSS/JS
Deuxième passe : Résolvez les goulots d'étranglement mesurés spécifiques
Utilisez le profilage des performances pour identifier les zones problématiques
Appliquez des optimisations ciblées en fonction des résultats
Maintenance continue : Faites de la performance une partie de votre flux de travail de développement
Définissez des budgets de performance
Mettez en œuvre des tests de performance automatisés
Examinez les nouvelles fonctionnalités pour leur impact sur les performances
En traitant la performance comme une fonctionnalité essentielle plutôt qu'une réflexion après coup, vous créerez des applications web qui non seulement ont une belle apparence et fonctionnent bien, mais offrent également la vitesse et la réactivité que les utilisateurs modernes attendent.
Rappelez-vous que la performance web est un voyage continu, pas une destination. Les navigateurs évoluent, les meilleures pratiques changent et les attentes des utilisateurs augmentent. Les techniques de cet article fournissent une base solide, mais rester à jour avec les tendances de performance web garantira que vos applications restent rapides et efficaces pendant des années.