


Article original : The Cryptography Handbook: Exploring RSA PKCSv1.5, OAEP, and PSS
L'algorithme RSA a été introduit en 1978 dans l'article fondateur « A Method for Obtaining Digital Signatures and Public-Key Cryptosystems ». Au fil des décennies, alors que RSA devenait essentiel aux communications sécurisées, diverses vulnérabilités et attaques ont émergé, soulignant l'importance de comprendre et d'implémenter RSA correctement.
Ce guide vous aidera à comprendre le fonctionnement interne de l'algorithme RSA, son évolution au fil des ans et les schémas définis sous diverses RFC. Ces connaissances vous aideront à faire des choix éclairés sur les schémas RSA les plus adaptés en fonction de vos besoins métier.
Dans ce guide, nous commencerons par explorer les principes fondamentaux de l'algorithme RSA. En examinant ses fondements mathématiques et son évolution historique, vous obtiendrez un aperçu de la vaste gamme d'attaques qui ont vu le jour au fil des ans.
Le récit se déroule comme un parcours évolutif : de l'implémentation RSA d'origine, simple (scolaire), à la découverte de vulnérabilités, jusqu'au développement de contre-mesures efficaces et d'affinements supplémentaires à mesure que de nouveaux défis étaient rencontrés. Cette progression illustre comment RSA s'est transformé au fil du temps et démontre également comment les bibliothèques cryptographiques modernes ont intégré ces avancées pour parvenir à des implémentations sécurisées dans les applications d'aujourd'hui.
Vous pouvez également regarder la vidéo associée ici :
Table des matières
Exploitation du déterminisme et de la malléabilité du RSA scolaire (Textbook RSA)
Attaque par diffusion de Håstad : quand l'exposant faible rencontre des destinataires multiples
Adoption dans les bibliothèques cryptographiques (PKCS#1 v1.5 vs OAEP)
Amélioration des signatures numériques : la transition vers PSS
Prérequis
- Algèbre linéaire : Une compréhension fondamentale de l'algèbre linéaire et de l'arithmétique modulaire vous aidera à comprendre certaines sections du guide, bien que ce ne soit pas une exigence absolue. Ce guide fournit des explications complètes sur les expressions mathématiques et leurs concepts sous-jacents au fur et à mesure qu'ils se présentent.
Pour une introduction concise et pertinente au théorème des restes chinois (CRT) dans le contexte de ce guide, vous pourriez trouver cette ressource utile : CRT, RSA et attaques par exposant faible | YouTube.
- Patience (et un sens de l'aventure) : Les RFC peuvent parfois être ennuyeuses à lire, et les articles de recherche peuvent sembler intimidants au premier abord. Ce guide est conçu pour rendre les concepts cryptographiques standards accessibles à tous, en vous guidant à travers chaque étape avec clarté et intuition. Chaque concept est renforcé par des exemples clairs, étape par étape, garantissant non seulement une compréhension approfondie mais aussi une familiarité avec les notations standards largement utilisées. Alors prenez votre temps, respirez profondément et profitez du voyage.
Pour les apprenants visuels, la vidéo associée peut offrir une expérience plus attrayante.
Le paradigme d'Alice et Bob
Tout au long de ce guide, vous rencontrerez de nombreux diagrammes de séquence et preuves mathématiques utilisant le paradigme d'Alice et Bob.
Le paradigme d'Alice et Bob est une convention courante en cryptographie où deux entités génériques, souvent nommées Alice et Bob, sont utilisées pour illustrer divers scénarios, protocoles ou principes cryptographiques.
Ces personnages représentent deux parties engagées dans une communication, Alice représentant généralement l'expéditeur ou l'initiateur, et Bob représentant le destinataire ou le répondant.
Nous introduisons souvent Eve comme une tierce partie, symbolisant un intercepteur ou un attaquant potentiel, ajoutant un élément de risque de sécurité et illustrant des scénarios où des entités externes pourraient tenter d'intercepter ou de manipuler la communication.
La naissance du cryptosystème RSA
L'année 1978 a vu la naissance d'une nouvelle ère de la cryptographie avec l'introduction du cryptosystème RSA, nommé d'après ses inventeurs (Rivest, Shamir et Adleman).
Ce développement, introduit dans l'article « A Method for Obtaining Digital Signatures and Public-Key Cryptosystems », a fourni une méthode pour la communication numérique sécurisée et a jeté les bases de la cryptographie à clé publique moderne.
Au cœur de RSA se trouve la théorie élémentaire des nombres – plus précisément, les propriétés des nombres premiers et de l'arithmétique modulaire. Comprenons d'abord comment ces concepts clés forment ses fondements mathématiques.
Nombres premiers et modules composites
L'algorithme commence par la sélection de deux grands nombres premiers, notés p et q. Leur produit (\(n = p \\times q\)) forme le module pour les clés publique et privée.
La sécurité de RSA repose largement sur le fait que, si la multiplication de ces nombres premiers est simple d'un point de vue calculatoire, la factorisation du grand nombre composite n résultant est considérée comme infaisable pour des nombres premiers suffisamment grands.
À ce stade, il est important de noter que p et q doivent être de grands nombres premiers pour garantir la sécurité de RSA. Heureusement, les bibliothèques modernes gèrent cela automatiquement en utilisant des algorithmes de génération de nombres premiers bien établis. Par conséquent, vous pouvez vous concentrer sur les aspects de haut niveau de vos applications sans avoir à gérer les détails de bas niveau de la sélection des nombres premiers.
Par exemple, examinons la routine de génération de clés RSA d'OpenSSL qui effectue plusieurs vérifications pour s'assurer que le module résultant \(n = p \\times q \) répond aux exigences de longueur de bits souhaitées :
L'extrait ci-dessous décale vers la droite le produit des nombres premiers générés (stocké dans r1) de bitse - 4 bits pour isoler les 4 bits de poids fort, qui sont ensuite vérifiés pour s'assurer que le module répond aux critères de taille souhaités.
if (!BN_rshift(r2, r1, bitse - 4))
goto err;
bitst = BN_get_word(r2);
Les bits extraits (bitst) sont ensuite comparés à une plage prédéfinie (de 0x9 à 0xF). Cette plage garantit que l'octet le plus significatif du module n'est ni trop petit ni trop grand.
if (bitst < 0x9 || bitst > 0xF) {
bitse -= bitsr[i];
Si les bits significatifs ne tombent pas dans la plage souhaitée, la longueur de bits est ajustée et le processus de génération de nombres premiers est réessayé. Si le nombre de tentatives dépasse une limite fixée, le processus complet est redémarré.
if (!BN_GENCB_call(cb, 2, n++))
goto err;
if (primes > 4) {
if (bitst < 0x9)
adj++;
else
adj--;
} else if (retries == 4) {
i = -1;
bitse = 0;
sk_BIGNUM_pop_free(factors, BN_clear_free);
factors = sk_BIGNUM_new_null();
if (factors == NULL)
goto err;
continue;
}
retries++;
goto redo;
Pour s'assurer que les nombres sont nécessairement premiers, ces bibliothèques utilisent une combinaison de tests probabilistes, notamment le test de primalité de Rabin-Miller, et des méthodes de criblage pour éliminer rapidement les candidats non premiers.
L'indicatrice d'Euler
Pour un nombre n qui est le produit de deux nombres premiers, l'indicatrice d'Euler est donnée par :
$$\\varphi(n) = (p-1)(q-1)$$
Cette fonction compte le nombre d'entiers inférieurs à \(n\) qui sont premiers avec \(n\). Le théorème d'Euler, qui stipule que pour tout entier a premier avec n, \( a^{\\varphi(n)} \\equiv 1 \\pmod{n}\), joue un rôle central pour prouver pourquoi les opérations de RSA sont réversibles.
Cependant, la plupart des cryptosystèmes RSA modernes utilisent la fonction de Carmichael au lieu de l'indicatrice d'Euler. Nous examinerons les raisons de ce changement dans les sections suivantes.
Calcul des clés
Nous sélectionnons maintenant un entier \(e\) tel que \(1 < e < \\varphi(n)\) et \(\\gcd(e, \\varphi(n)) = 1\). Cet \(e\) devient l'exposant public que vous voyez comme paramètre dans les appels de fonction RSA que vous effectuez.
Une fois cela fait, déterminons maintenant \(d\) comme l'inverse multiplicatif modulaire de \(e \\, \\, modulo \\, \\varphi(n)\). En d'autres termes, \(d\) est calculé tel que :
$$e \\times d \\equiv 1 \\pmod{\\varphi(n)}$$
Cette étape est le pivot mathématique garantissant que le déchiffrement est l'opération inverse du chiffrement.
Dans l'article de 1978, les auteurs ont explicitement fourni ces formules et étapes. Ils ont montré que si vous chiffrez un message m en utilisant \(c = m^e \\mod n\) puis déchiffrez en utilisant \(m = c^d \\mod n \), le message original est récupéré – grâce aux propriétés de l'exponentiation modulaire et au théorème d'Euler. Ce cadre mathématique était novateur à l'époque et a immédiatement préparé le terrain pour une nouvelle ère de la cryptographie.
Opérations RSA
Maintenant que les fondements mathématiques sont posés, l'algorithme RSA peut être vu comme un ensemble de trois opérations centrales : le chiffrement, le déchiffrement et la signature. Tout au long des prochaines sections de ce guide, nous analyserons ces opérations de manière critique et découvrirons plusieurs pièges dans chacune d'elles. Ensuite, nous examinerons comment ceux-ci ont été évités grâce à la naissance de nouveaux schémas, chacun résolvant un nouveau problème découvert en chemin.
Chiffrement
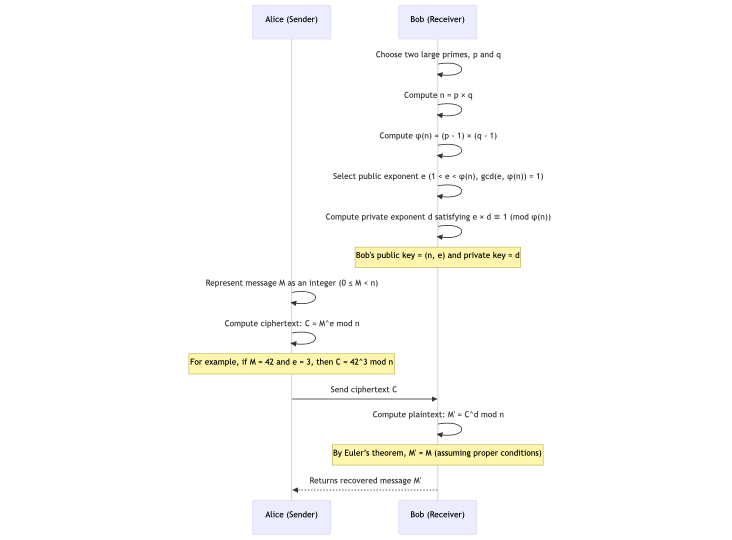
La clé publique \((n, e)\) étant accessible à tous, n'importe quel utilisateur peut chiffrer un message \(m\) (où \(m\) est d'abord encodé sous forme d'entier dans la plage \(0 \\leq m < n\)) en utilisant la formule :
$$c = m^e \\mod n$$
Ici, c est le texte chiffré. Comme l'opération est basée sur l'exponentiation modulaire, même si m est connu, récupérer m à partir de c sans connaître d est calculatoirement difficile.
Déchiffrement
Le destinataire prévu, qui possède la clé privée \(d\), déchiffre le texte chiffré \(c\) en calculant :
$$m = c^d \\bmod n$$
En utilisant la relation (\(e \\times d \\equiv 1 \\pmod{\\varphi(n)}\)) et les propriétés du théorème d'Euler, l'opération ci-dessus inverse exactement l'étape de chiffrement, récupérant le message original \(m\).
Cela garantit que seul le détenteur de la clé privée peut lire le message chiffré. C'est l'épine dorsale de l'utilisation de RSA dans les communications sécurisées.
Le diagramme de séquence ci-dessous résume notre discussion jusqu'à présent :
Signatures numériques
Les signatures numériques répondent à un objectif de sécurité différent : l'authenticité et l'intégrité plutôt que la confidentialité. Alors que le chiffrement et le déchiffrement utilisent la clé publique pour le « verrouillage » et la clé privée pour le « déverrouillage », les signatures numériques inversent ces rôles.
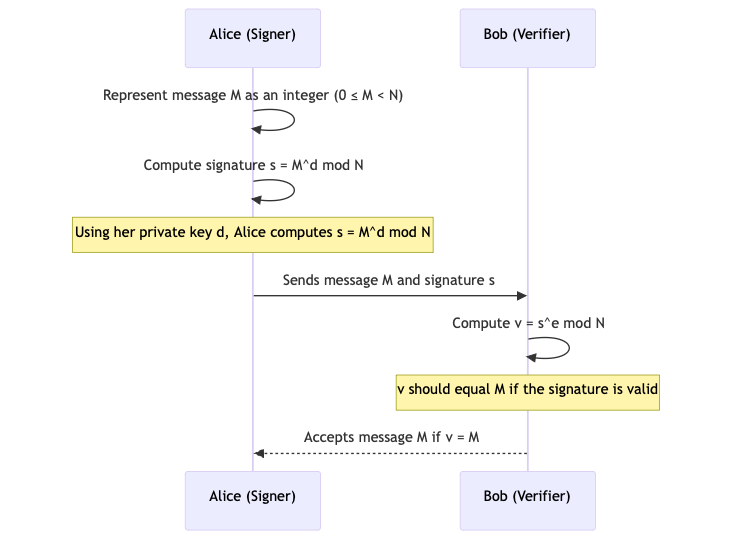
1. Signature
L'auteur d'un message utilise sa clé privée \(d\) pour calculer une signature \(s\) sur le message \(m\), guidé par la formule mentionnée ci-dessous :
$$s = m^d \\bmod n$$
Celle-ci pourra être vérifiée ultérieurement par d'autres en utilisant la clé publique correspondante. Le but ici n'est pas de récupérer un message secret mais de créer une preuve d'authenticité.
2. Vérification :
Toute personne disposant de la clé publique \((n, e)\) peut vérifier que la signature s appartient bien au message \(m\) en calculant :
$$m \\equiv s^e \\bmod n$$
Si l'équivalence est vérifiée, elle confirme deux points clés : que le message n'a pas été altéré (c'est-à-dire l'intégrité), et que la signature a nécessairement été générée à l'aide de la clé privée d (c'est-à-dire l'authenticité).
Tant que \(d\) est gardé secret, seul le signataire légitime peut produire une signature valide. Jetez un œil au diagramme de séquence ci-dessous pour comprendre le processus complet.
Problèmes avec l'indicatrice d'Euler dans RSA
Bien que l'utilisation de l'indicatrice d'Euler fonctionne bien en théorie, les implémenteurs du schéma ont réalisé ses inconvénients pratiques. En termes simples, le problème principal était que l'indicatrice d'Euler peut conduire à un exposant privé \(d\) plus grand que nécessaire.
Pour apprécier pleinement ce fait, prenons un peu de recul pour comprendre pourquoi la taille de l'exposant privé \(d\) est importante dans RSA.
Le déchiffrement RSA (ou la signature) implique le calcul de \(m^d ~~mod ~n\), ce qui se fait via l'exponentiation modulaire. La complexité temporelle des algorithmes d'exponentiation (comme le square-and-multiply) croît avec le nombre de bits de \(d\). Un \(d\) plus grand signifie plus de multiplications et d'élévations au carré, donc un déchiffrement plus lent.
En pratique, si l'utilisation de l'indicatrice d'Euler rend \(d\) environ deux fois plus grand que ce qui est requis, alors le déchiffrement peut être presque deux fois plus lent par rapport à l'utilisation du \(d\) minimal. Cette inefficacité est particulièrement notable lorsque \(e\) est petit (exposants publics courants comme 3 ou 65537). Un petit \(e\) conduit à un \(d\) très grand sous \(φ(n)\).
Au-delà de la performance, avoir un \(d\) inutilement grand peut augmenter légèrement la taille de stockage (quelques octets de plus pour la clé). Cela peut également entraîner des particularités d'interopérabilité, c'est pourquoi les standards et protocoles tels que FIPS 186-4 [1] et RFC 8017 [2] s'attendent à ce que \(d\) soit inférieur à une certaine taille. Nous examinerons cela en détail dans la section suivante.
Pour pallier ces problèmes, les cryptographes ont utilisé la fonction de Carmichael pour générer les clés RSA. Avant de plonger dans la manière dont la fonction de Carmichael aide notre cas, comprenons rapidement ce qu'est réellement la fonction de Carmichael.
La fonction de Carmichael
La fonction de Carmichael, représentée par \(λ(n)\), également connue sous le nom d'indicatrice réduite ou de plus petit exposant universel, est définie comme le plus petit entier positif \(m\) tel que pour tout entier \(a\) premier avec \(n\), \( a^m ≡ 1 (mod n)\).
Pour dire les choses simplement, \(λ(n)\) est l'exposant du groupe multiplicatif modulo \(n\) (le plus petit commun multiple des ordres de tous les éléments). Pour les modules de type RSA (produit de nombres premiers), la fonction de Carmichael est guidée par la formule :
$$\\lambda(n) = \\operatorname{lcm}(p-1,\\,q-1)$$
où \(n = p . q\) avec \(p\) et \(q\) étant les grands nombres premiers.
Vous comprendrez peut-être mieux la fonction de Carmichael si nous la présentons de la manière suivante : \(λ(n)\) est le plus petit commun multiple des \(λ(n)\) de chaque puissance de nombre premier divisant n. Ainsi, pour un nombre premier \(p\), \(λ(p) = φ(p) = p – 1\), et pour deux nombres premiers, nous prenons le \(lcm\) de \(p-1 \) et \(q-1.\)
Implication mathématique de la fonction de Carmichael
La fonction de Carmichael \(λ(n)\) est une borne « plus étroite ». Cela signifie que \(λ(n)\) divise \(φ(n)\) (puisque l'exposant d'un groupe fini divise toujours l'ordre du groupe selon le théorème de Lagrange [3]).
Si \(p\) et \(q\) sont tous deux des nombres premiers impairs, alors \(p–1\) et \(q–1 \) sont pairs, donc leur plus petit commun multiple est environ la moitié de \((p–1)(q–1)\). Mathématiquement :
$$λ(n) = \\dfrac{(p–1)(q–1)} {gcd(p–1, q–1)}$$
Nous pouvons observer que ce \(λ(n)\) est inférieur ou égal à \(φ(n)\) et souvent considérablement plus petit. Cela signifie que \(λ(n)\) fournit l'exposant minimal requis pour la justesse de RSA, alors que \(φ(n)\) pourrait être un nombre plus grand qui fonctionne toujours mais n'est pas nécessaire.
Lorsque vous choisissez deux grands nombres premiers aléatoires \(p\) et \(q\), vous avez :
$$\\varphi(n) = (p-1)(q-1) \\approx n,$$
car pour de grands nombres premiers, les unités soustraites ne font qu'une petite différence par rapport à \(p\) et \(q\) eux-mêmes.
Maintenant, comme \(p-1\) et \(q-1 \) sont tous deux pairs, ils ont chacun un facteur 2. S'il s'agit de leur seul facteur commun (ce qui est souvent le cas pour des nombres premiers aléatoires), alors :
$$\\lambda(n) = \\mathrm{lcm}(p-1, q-1) \\approx \\frac{\\varphi(n)}{2}.$$
Lorsque vous calculez l'exposant privé \(d\) comme l'inverse modulaire de \(e\) (un petit nombre) modulo \( \\varphi(n)\) par rapport à modulo \(\\lambda(n)\), la plage dans laquelle \(d\) est choisi est environ deux fois plus grande dans le premier cas. Cela signifie que le \(d\) typique lorsqu'il est calculé modulo \(\\varphi(n)\) peut être environ deux fois plus grand que lorsqu'il est calculé modulo \(\\lambda(n)\). Un \(d\) plus grand signifie que lors du déchiffrement (ou de la signature), l'exponentiation modulaire \(c^d \\mod n\) prend légèrement plus de temps.
Intuitivement, l'utilisation de \(λ(n)\) garantit que nous ne « dépassons » pas l'exposant requis pour que l'arithmétique modulaire revienne à 1.
Un \(d\) plus petit rend chaque opération de déchiffrement et de signature RSA plus rapide. Par exemple, si \(λ(n)\) est environ la moitié de \(φ(n)\), alors \(d\) aura un bit de moins qu'il n'en aurait autrement, réduisant le travail d'exponentiation d'environ 50 %. C'est un gain de performance gratuit, car nous ne changeons pas les hypothèses de sécurité ni la taille de la clé \(n\), nous utilisons simplement la valeur mathématiquement étroite pour l'exposant. La sécurité de l'algorithme RSA n'en est pas affaiblie et maintenant le \(d\) est différent mais fonctionnellement équivalent.
La fonction de Carmichael dans les implémentations modernes
La propriété critique pour RSA (\(e·d ≡ 1 ~mod ~~λ(n)\)) est à la fois nécessaire et suffisante pour un déchiffrement correct, grâce au théorème de Carmichael. Il n'est donc pas nécessaire que \(d\) satisfasse également la condition plus forte modulo \(φ(n)\).
En passant au calcul de \(d ~ modulo ~~ λ(n)\) (c'est-à-dire \(d = e^{-1} ~mod ~~λ(n)\)), nous obtenons directement le plus petit exposant privé fonctionnel. Ronald Rivest lui-même a noté cette optimisation dans son article fondateur de 1999 [4], déclarant que résoudre pour \(d\) en utilisant \( λ(n)\) au lieu de \(φ(n)\) est légèrement préférable car cela peut donner une valeur plus petite pour d.
Au fil du temps, l'utilisation de \( λ(n)\) dans RSA est passée d'une suggestion académique à un standard de l'industrie. Les standards cryptographiques d'aujourd'hui reconnaissent ou exigent explicitement l'approche \(λ(n)\).
Par exemple, le standard RSA officiel (PKCS #1 v2.2, RFC 8017 [2]) définit la génération de clés RSA en termes de \(λ(n)\). Il spécifie que l'exposant privé \(d\) est choisi tel que \(e·d ≡ 1 (mod λ(n))\) (avec \(λ(n) = lcm(p–1, q–1)\)). En d'autres termes, PKCS #1 s'attend à ce que la fonction de Carmichael soit utilisée pour le module de l'exposant. De même, le FIPS 186-4 du NIST (Digital Signature Standard) exige que \(d\) soit inférieur à \(λ(n)\).
Toute clé RSA où \(d\) est plus grand que \(λ(n)\) est considérée comme non conforme dans ces contextes stricts. Cela force effectivement les implémentations à utiliser le plus petit exposant basé sur \(λ(n)\), car tout \(d\) « surdimensionné » peut être réduit \(mod ~~λ(n)\) pour répondre au critère.
Des standards tels que FIPS 186-4 [1] (le Digital Signature Standard) et RFC 8017 [2] (qui spécifie PKCS#1 v2.2 pour la cryptographie RSA) incluent des exigences ou des recommandations impliquant que l'exposant privé \(d\) devrait être aussi petit que possible et idéalement inférieur à \( \\lambda(n)\). L'utilisation de \(\\lambda(n)\) (le plus petit commun multiple de \(p-1\) et \(q-1\)) produit directement le plus petit \(d\) valide, alors que l'utilisation de \(\\varphi(n)\) donne souvent un \(d\) plus grand que nécessaire. Cela améliore non seulement les performances (en réduisant le nombre de multiplications modulaires nécessaires lors du déchiffrement/signature), mais aide également à maintenir l'interopérabilité avec les protocoles qui s'attendent à ce que d soit inférieur à une certaine taille.
La bibliothèque Python cryptography (PyCA cryptography) documente explicitement [5] qu'elle utilise l'indicatrice de Carmichael pour générer la « plus petite valeur de \(d\) fonctionnelle », notant que les implémentations plus anciennes (y compris l'article RSA original) utilisaient l'indicatrice d'Euler et aboutissaient à des exposants plus grands. OpenSSL utilise également la fonction de Carmichael dans ses API RSA de bas niveau [6].
Ce passage à la fonction de Carmichael garantit que, sous le capot, votre clé RSA est un peu plus efficace que celles de la fin des années 1970 tout en offrant le même niveau de sécurité.
Problèmes avec le RSA brut (Raw RSA)
Le RSA brut ou « scolaire » s'est vite avéré non sécurisé lorsque deux faiblesses majeures ont été découvertes.
Les opérations impliquées dans RSA sont entièrement déterministes, ce qui signifie que pour un texte en clair \(m\) donné, le chiffrement produit toujours le même texte chiffré \(C = m^e \\mod n\).
Un intercepteur ou un attaquant, appelons-le Eve, peut deviner ou déduire des textes en clair en exploitant la prévisibilité des sorties. Comme le chiffrement RSA est une opération publique, un attaquant peut chiffrer des messages probables et comparer les résultats à un texte chiffré cible – une attaque à texte clair choisi triviale.
En plus de cela, le RSA scolaire est également malléable. Cela signifie que sa structure algébrique permet aux attaquants de manipuler les textes chiffrés de manière significative. Par exemple, étant donné un texte chiffré \(C = RSA(M)\), un attaquant peut le multiplier par le chiffrement d'une valeur connue (disons, r) pour produire un nouveau texte chiffré \(C’ = C · r^e ~~mod ~n\), qui se déchiffre en le texte en clair \(M·r\). Lorsque le destinataire légitime déchiffre \(C'\), le résultat est \(M·r\), à partir duquel l'attaquant peut souvent récupérer \(M\).
Comprenons ces vulnérabilités avec un petit exemple pratique.
Exploitation du déterminisme et de la malléabilité du RSA scolaire (Textbook RSA)
Génération de clés (Configuration)
Pour notre exemple simplifié, nous choisirons de petits nombres premiers et générerons une paire de clés RSA :
Sélectionnons les valeurs \(p =3\) et \(q=11\). Ces deux valeurs sont premières. Maintenant, calculons le module et l'indicatrice comme suit :
$$\\begin{gather} \\begin{split} n = p × q = 3 × 11 = 33 \\\\ φ(n) = (p – 1) × (q – 1) = 2 × 10 = 20 \\end{split} \\end{gather}$$
Choisissez maintenant l'exposant public. Considérons \(e=3\) puisqu'il est premier avec \( φ(n) = 20\), et \(gcd(3, 20) = 1\).
Calculons maintenant l'exposant privé. Nous savons que d est l'inverse modulaire de \(e ~~mod ~φ(n)\). Nous devons trouver d tel que \((d × e) ≡ 1~~ (mod ~20)\). Grâce à cela, nous pouvons calculer \(d = 7\) car \(3 × 7 = 21 ≡ 1 ~~ (mod~ 20)\).
Enfin, la clé publique est \((n = 33, ~ e = 3)\) et la clé privée (secrète) est \(d = 7\).
Processus de chiffrement
Chiffrons maintenant un message simple à l'aide de la clé ci-dessus. Sélectionnons notre texte en clair \(M = 4\). Le texte chiffré dans ce cas serait :
$$\\begin{gather} \\begin{split} C = 4^3 ~~mod ~33 \\\\ C = 64 ~~mod ~33 \\\\ C = 64 – 33×1 = 31 \\end{split} \\end{gather}$$
Pour consolider les résultats jusqu'à présent, si nous chiffrons le message \(4\) avec la clé publique \((e=3, n=33)\), nous produirons le texte chiffré \(31\). Maintenant, essayons les exploitations.
Exploitation du déterminisme (Attaque par devinette de texte chiffré)
Le RSA scolaire est déterministe – le même texte en clair donne toujours le même texte chiffré (sans aucun aléa). Un attaquant qui intercepte le texte chiffré \(C=31\) peut exploiter cela en chiffrant des suppositions de texte en clair probables et en comparant les résultats :
L'adversaire, appelons-le Eve, essaiera de chiffrer des textes en clair candidats avec la clé publique et verra lequel produit \(31\). Ils peuvent choisir des valeurs aléatoires pour augmenter leur efficacité :
$$\\begin{gather} \\begin{aligned} Supposition~ M = 1 ⇒ 1^3~~ mod ~33 = 1 \\\\ Supposition~ M = 2 ⇒ 2^3~~ mod ~33 = 8 \\\\ Supposition~ M = 3 ⇒ 3^3~~ mod ~33 = 27 \\\\ Supposition~ M = 4 ⇒ 4^3~~ mod ~33 = 31 \\\\ \\end{aligned} \\end{gather}$$
En comparant simplement les textes chiffrés, l'attaquant découvre que le chiffrement de \(4\) donne 31, ce qui correspond au texte chiffré intercepté. Ainsi, l'attaquant apprend que le texte en clair original \(M\) était \(4\). Cela est possible car il n'y a pas d'aléa dans le RSA scolaire – un intercepteur peut identifier un message par chiffrement d'essai de suppositions, brisant la confidentialité si l'espace des messages est petit ou devinable.
Exploitation de la malléabilité (Attaque par manipulation de texte chiffré)
Le RSA brut est également malléable. Cela signifie qu'un attaquant peut prendre un texte chiffré et le modifier d'une manière qui entraîne un changement prévisible dans le texte en clair déchiffré. Comprenons comment cela fonctionne.
RSA possède une propriété multiplicative, c'est-à-dire que multiplier deux textes chiffrés correspond à multiplier leurs textes en clair avant le chiffrement :
$$E(M\_1) \\cdot E(M\_2) \\mod n = (M\_1^e \\mod n)\\times(M\_2^e \\mod n) \\mod n = (M\_1 \\cdot M\_2)^e \\mod n$$
Le diagramme de séquence ci-dessous explique comment l'exploitation de la malléabilité fonctionne dans le RSA naïf.
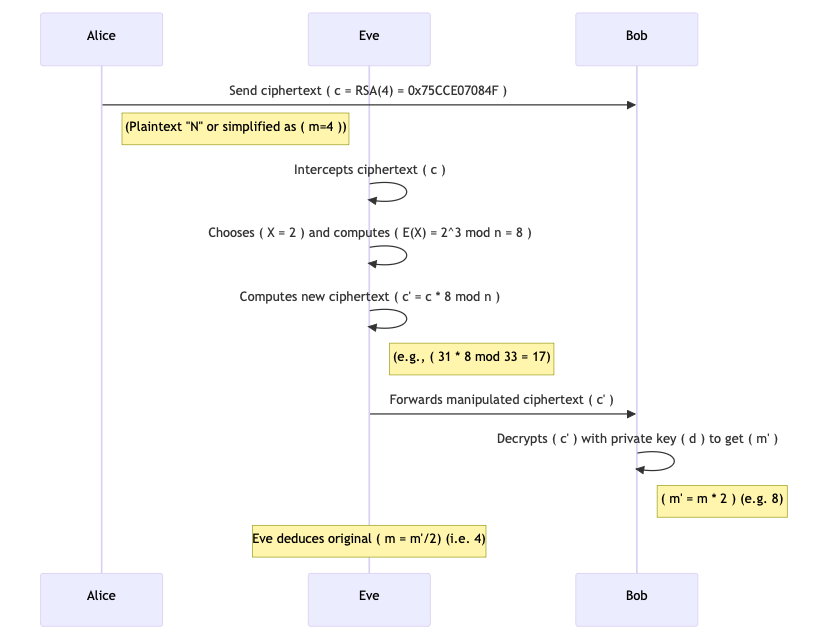
Alice envoie un texte chiffré à Bob après la phase d'initialisation. Notez qu'à ce stade, n et e sont de connaissance publique. Eve intercepte ce texte chiffré en utilisant des mécanismes tels qu'une attaque MiTM (Man in the Middle).
Maintenant, Eve choisit une valeur connue pour manipuler le message. Disons que l'attaquant choisit \(X = 2\) (dans l'intention de doubler le texte en clair original).
Ensuite, ils calculent le chiffrement de X à l'aide de la clé publique :
$$E(X) = 2^3 \\mod 33 = 8.$$
Maintenant, Eve multiplie le texte chiffré original par cette valeur (mod n) pour obtenir un nouveau texte chiffré :
$$\\begin{gather} \\begin{split} C{\\prime} = C \\times E(X) \\mod n = 31 \\times 8 \\mod 33 \\\\ C{\\prime} = 248~~ mod~ 33 = 248 – 33×7 = 248 – 231 = 17 \\end{split} \\end{gather}$$
Ce nouveau texte chiffré \(C{\\prime}\) est le chiffrement du produit du texte en clair original et de \(2\). Si nous chiffrions directement \(M \\times X = 4 \\times 2 = 8\) avec RSA, nous obtiendrions \(8^3 \\mod 33 = 512 \\mod 33 = 17\). Cela signifie que \(C′\) correspond au texte en clair \(8\), qui est le message original \(4\) multiplié par \(2\).
Dans une attaque à texte chiffré choisi en conditions réelles, l'attaquant peut avoir accès à un oracle de déchiffrement ou observer une réponse du système qui révèle des informations sur \(M{\\prime}\). Le résultat du déchiffrement \(8\) est exactement \(M \\times 2\) (le message original multiplié par le facteur choisi par l'attaquant). Connaissant le facteur \(X = 2\), l'attaquant peut déduire le message original en divisant : \(8/ 2 = 4\).
Notez qu'Eve n'a pas brisé les fondements mathématiques de RSA ici. Ils ont seulement utilisé la clé publique pour calculer un chiffrement de \(2\), puis l'ont combiné avec le texte chiffré intercepté. Ils ne connaissent pas encore le texte en clair original, mais ils ont manipulé le texte chiffré de manière à savoir que le nouveau texte en clair est le double du message original.
Attaques par exposant faible
Au-delà des exploitations du déterminisme et de la malléabilité, le RSA scolaire est également vulnérable aux attaques par exposant faible. L'utilisation d'un petit exposant public comme \(e = 3\) (ou parfois \(17\)) était populaire car elle permettait d'accélérer le chiffrement et la vérification de signature. Mais cela s'est vite avéré être une préoccupation de sécurité.
Lorsque RSA utilise un petit exposant public (disons, \(e = 3\)) et que le texte en clair est très court (de sorte que \(M^3\) est plus petit que le module \(n\)), le chiffrement ne « boucle » pas modulo \(n\). Mathématiquement :
$$c = M^3 \\mod n = M^3 \\quad \\text{(si \\( M^3 < n \\))}$$
Comprenons cela avec un exemple simple :
Considérons notre texte en clair : \(M = 5\). Nous calculons \(M^3\) comme \(M^3 = 5^3 = 125\).
Supposons maintenant que \(n\) soit un nombre de \(4096\) bits, ce qui est grand par rapport à \(125\). Dans ce cas, le texte chiffré est simplement \(c = 125\). Eve interceptant \(c = 125\) peut calculer la racine cubique de \(125\) pour obtenir le texte en clair : \(\\sqrt\[3\]{125} = 5\), récupérant ainsi \(M\) directement.
Cela montre que si \(M\) est suffisamment petit, le texte chiffré laisse fuiter le texte en clair lorsque \(e\) est faible.
Attaque par diffusion de Håstad : quand l'exposant faible rencontre des destinataires multiples
En 1985, Johan Håstad a mis en évidence l'attaque par diffusion qui illustre le danger d'un exposant faible, \(e\), lorsque le même message est envoyé à plusieurs parties sous forme de diffusion (broadcast).
Imaginez qu'Alice veuille envoyer le même message en clair M à trois destinataires différents. Chaque destinataire possède sa propre clé publique RSA avec les modules \(N\_1, N\_2, N\_3,\) mais pour la vitesse, tous utilisent \(e = 3\) (une pratique courante historiquement). Alice chiffre \(M\) avec chaque clé publique, produisant les textes chiffrés :
$$\\begin{gather} \\begin{split} C\_1 = M^3 \\bmod N\_1 \\\\ C\_2 = M^3 \\bmod N\_2 \\\\ C\_3 = M^3 \\bmod N\_3 \\end{split} \\end{gather}$$
Eve, qui intercepte les trois \(C\_1, C\_2, C\_3\), peut récupérer M sans briser aucune clé RSA individuelle.
Comme chaque \(N\_i \) est différent (et nous supposons qu'ils sont premiers entre eux deux à deux, comme les clés RSA devraient l'être), l'attaquant peut utiliser le théorème des restes chinois (CRT) pour combiner les trois congruences \(x \\equiv C\_i \\pmod{N\_i}\). Notez qu'à ce stade, Eve n'a que \(C\_1\), \(C\_2\) et \(C\_3\). Ils n'ont pas le texte en clair \(M\) ou \(M^3\) et pourtant ils peuvent reconstruire \(M^3\) avec les données interceptées. Pour comprendre le théorème des restes chinois et cette reconstruction, vous pouvez suivre ceci : CRT, RSA et attaques par exposant faible | Youtube.
Il existe une solution unique modulo \(N\_1N\_2N\_3\) pour \(x\), et cette solution s'avère être un entier, \(x = M^3\) (car l'entier réel \(M^3\) est plus petit que le produit \(N\_1N\_2N\_3\) de chaque \(M < N\_i \)). En substance, le CRT permet à Eve de reconstruire exactement \(M^3\). Une fois qu'ils ont \(M^3\) sous forme d'entier ordinaire, ils prennent simplement la racine cubique pour trouver \(M\). Il n'est pas nécessaire de factoriser un module ou d'inverser la fonction RSA – les mathématiques s'en chargent grâce à l'exposant faible.
Le diagramme de séquence ci-dessous vise à fournir une compréhension de haut niveau de l'attaque :

Voyons maintenant cette attaque en action avec un exemple :
Supposons que trois clés publiques RSA différentes utilisent toutes l'exposant \(e=3\), avec les modules \( n\_b = 187\) (pour Bob),
\(n\_c = 115 \) (pour Carol) et \(n\_d = 87\) (pour Dave).
Ces \(n\_i\) sont premiers entre eux deux à deux (le \(gcd\) de chaque paire est \(1\)). Supposons maintenant que le même message en clair \(M\) soit chiffré avec chaque clé publique. Prenons un \(M\) concret. Par exemple avec \(M=42\), nous aurons :
$$\\begin{gather} \\begin{split} c\_b = M^3 \\bmod n\_b \\\\ c\_c = M^3 \\bmod n\_c \\\\ c\_d = M^3 \\bmod n\_d \\\\ \\end{split} \\end{gather}$$
En calculant ceux-ci, nous avons :
$$\\begin{gather} \\begin{split} c\_b = 42^3 \\bmod 187 = 36 \\\\ c\_c = 42^3 \\bmod 115 = 28 \\\\ c\_d = 42^3 \\bmod 87 = 51 \\\\ \\end{split} \\end{gather}$$
Les trois textes chiffrés observés sont donc \(36\), \(28\) et \(51\), respectivement. Eve qui connaît \(n\_b, n\_c, n\_d\) et ces textes chiffrés peut maintenant récupérer \(M\) comme suit :
Eve calculera le module total \(N = n\_b \\cdot n\_c \\cdot n\_d = 187 \\times 115 \\times 87 = 1\,870\,935.\) (C'est le module du système combiné de congruences).
Maintenant, Eve calculera les produits partiels pour chaque congruence :
$$\\begin{gather} \\begin{split} N\_b = \\frac{N}{n\_b} = \\frac{1,870,935}{187} = 10,005 \\\\ N\_c = \\frac{N}{n\_c} = \\frac{1,870,935}{115} = 16,269 \\\\ N\_d = \\frac{N}{n\_d} = \\frac{1,870,935}{87} = 21,505 \end{split} \\end{gather}$$
À ce stade, Eve a besoin des inverses de chaque \(N\_i\) modulo son \(n\_i\) correspondant :
D'abord, Eve calcule \(M\_b = (N\_b)^{-1} \\bmod n\_b\), c'est-à-dire le nombre \(M\_b\) tel que \(N\_b \\cdot M\_b \\equiv 1 \\pmod{187}\). Dans ce cas, \(N\_b = 10005\). En utilisant l'algorithme d'Euclide étendu, Eve peut trouver \(M\_b = 2\) (puisque \(10005 \\times 2 = 20010 \\equiv 1 \\pmod{187}\)).
Ensuite, Eve calcule \(M\_c = (N\_c)^{-1} \\bmod n\_c\). Ici \(N\_c = 16269\). L'inverse mod \(115\) s'avère être \(M\_c = 49\) (Pour vérification : \(16269 \\times 49 \\equiv 1 \\pmod{115}\)).
Ensuite, Eve calcule \(M\_d = (N\_d)^{-1} \\bmod n\_d\). Pour \(N\_d = 21505\), l'inverse mod \(87\) est également \(M\_d = 49\) (coïncidence dans ce cas, puisque \(21505 \\times 49 \\equiv 1 \\pmod{87}\)).
Maintenant, Eve reconstruit la valeur combinée en utilisant le théorème des restes chinois pour trois congruences. La construction de cette formule dépasse la portée de ce guide, mais pour comprendre complètement comment cela fonctionne, vous pouvez consulter cette vidéo : CRT, RSA et attaques par exposant faible | Youtube.
$$C \\;=\\; c\_b \\cdot N\_b \\cdot M\_b \\;+\\; c\_c \\cdot N\_c \\cdot M\_c \\;+\\; c\_d \\cdot N\_d \\cdot M\_d \\pmod{N}$$
En remplaçant par les nombres :
$$C = 36 \\cdot 10005 \\cdot 2 \\;+\\; 28 \\cdot 16269 \\cdot 49 \\;+\\; 51 \\cdot 21505 \\cdot 49 \\pmod{1\,870\,935}$$
Évaluons soigneusement chaque terme :
$$\\begin{gather} \\begin{split} 36 \\cdot 10005 \\cdot 2 = 720\,360 \\\\ 28 \\cdot 16269 \\cdot 49 = 22\,341\,348 \\\\ 51 \\cdot 21505 \\cdot 49 = 53\,740\,995 \\\\ \\end{split} \\end{gather}$$
La somme donne un total brut de \(720\,360 + 22\,321\,068 + 53\,740\,995 = 76\,782\,423\). Réduisons maintenant cela modulo \(N = 1\,870\,935\) :
$$\\begin{align} \\begin{split} C \\equiv 76\,782\,423 \\pmod{1\,870\,935}\\\\ C = 74\,088 \\\\ \\end{split} \\end{align}$$
Maintenant, Eve prendra simplement la racine cubique de \(C : \\sqrt\[3\]{74088} = 42\), qui est le texte en clair original.
Eve a réussi à récupérer \(M\).
Le point clé à retenir de ces attaques est que sans défenses appropriées, RSA seul ne répond pas aux définitions modernes de la sécurité. Il n'est pas résistant aux attaques à texte clair choisi ou à texte chiffré choisi. Cet écart entre la fonction à sens unique théorique (la permutation à trappe de RSA) et un schéma de chiffrement sécurisé est devenu évident lorsque les implémenteurs ont découvert que le RSA naïf pouvait être « brisé » par diverses astuces ingénieuses.
Pour contrer ces faiblesses, les organismes de normalisation ont introduit des schémas de remplissage (padding) pour renforcer le chiffrement RSA. Dans les sections suivantes, vous découvrirez chacun de ces schémas de remplissage et comment ils ont été exploités au fil des ans.
Introduction aux schémas de remplissage (padding) dans RSA
Avant de plonger dans les schémas de remplissage et la manière dont ils aident notre cas, récapitulons rapidement la nécessité du remplissage dans RSA.
Le chiffrement RSA scolaire est déterministe. Le même texte en clair produit toujours le même texte chiffré sous une clé publique donnée. Ce déterminisme rend le RSA brut non sécurisé. Un attaquant peut deviner des messages possibles, les chiffrer avec la clé publique et les comparer avec le texte chiffré cible pour voir quelle supposition correspond.
Au-delà du déterminisme, les attaques par exposant faible illustrent pourquoi le remplissage est critique. Si le message \(m\) est trop petit par rapport au module, l'élever à un petit exposant public (comme \(e=3\)) pourrait ne pas boucler autour de \(N\). Remplir le texte en clair avec des données aléatoires avant le chiffrement remédie à ces problèmes en rendant le texte chiffré imprévisible et en garantissant que \(m^e\) couvre toute la plage du module.
Standards de cryptographie à clé publique (PKCS#1 v1.5)
En 1998, Kaliski et les laboratoires RSA ont présenté PKCS#1 v1.5 au monde dans une publication publique [7]. Dans PKCS#1 v1.5, chaque message chiffré par RSA est enveloppé dans un « bloc de chiffrement » spécial \(EB\). Ce bloc garantit que le message brut est à la fois de la bonne taille pour RSA et rempli d'une manière difficile à altérer.
Dans ce schéma, le texte en clair est rempli à la taille du module \(N\) (en octets) comme suit :
$$EB = 00 ~||~ BT ~||~ PS ~||~ 00 ~||~ M$$
Ici, \(0x00\) (octet de tête nul) est toujours placé à l'avant. Il garantit que, lorsque la chaîne concaténée \(EB\) est convertie en un entier big-endian, la valeur est inférieure au module RSA (c'est-à-dire que nous ne nous retrouvons pas avec un nombre trop grand pour être traité par RSA). Vous apprécierez mieux ce fait lorsque nous plongerons dans les mathématiques derrière cela.
L'octet suivant est le type de bloc, \(BT\), qui nous indique le « type » de remplissage utilisé. Le standard définit trois valeurs \(BT\) possibles : \(00, 01, \) et \(02\) - pour prendre en charge différentes opérations. Par exemple, \(BT=00\) et \(BT = 01\) sont utilisés pour les opérations de clé privée (telles que les signatures numériques) et \(BT = 02\) est utilisé pour les opérations de clé publique. Pour le chiffrement sous PKCS#1 v1.5, c'est toujours \(0x02\). C'est essentiellement une étiquette qui dit : « Ceci est un bloc de chiffrement, pas autre chose ».
Le bloc suivant est la chaîne de remplissage \(PS\). Il s'agit d'une chaîne d'octets aléatoires non nuls. C'est crucial pour la sécurité car cela introduit de l'aléa dans chaque chiffrement. Si le même message est chiffré plusieurs fois, ces octets aléatoires garantissent que chaque texte chiffré semble différent, déjouant de nombreuses attaques simples qui reposent sur l'observation de motifs répétés.
L'octet suivant, \(0x00\), est un délimiteur. Cet octet nul unique marque la fin du remplissage. Lors du déchiffrement, cela aide le destinataire à identifier rapidement où s'arrête le remplissage et où commence le message réel.
Enfin, nous avons les données réelles que vous souhaitez protéger – \(M\). Une fois que le destinataire a vérifié le remplissage, il sait exactement où trouver ce message.
Ce mécanisme a aidé à résoudre le problème déterministe du RSA naïf. Dans les sections suivantes, comprenons les mathématiques impliquées dans le remplissage PKCS#1 v1.5 et ses implications en matière de sécurité.
Les mathématiques derrière PKCS#1 v1.5
Avant de commencer, précisons nos symboles et abréviations. Nous utiliserons des symboles en majuscules (tels que \(EB\)) pour désigner les chaînes d'octets et les chaînes de bits. Nous utiliserons des symboles en minuscules (tels que \(n\)) pour désigner les entiers.
Dans PKCS#1 v1.5, nous utiliserons \(k\) pour représenter la longueur du module RSA \(n\) en octets. Par exemple, si vous avez une clé RSA de \(1024\) bits, alors le module RSA \(n\) est un nombre de \(1024\) bits. Comme il y a \(8\) bits dans un octet, si votre module RSA a une longueur de \(L\) bits, alors :
$$k = \\left\\lceil \\frac{L}{8} \\right\\rceil = \\frac{1024}{8} = 128 \\text{ octets}$$
La longueur totale du bloc de chiffrement sera égale à cette longueur de clé RSA \(k\) (en octets). Ici, la longueur des données \(M\) ne doit pas dépasser \(k-11\) octets, car les 11 octets sont consommés par les blocs – \(0x00 ~||~ 0x02 ~||~ PS ~||~ 0x00\). Cette limitation garantit que la longueur de la chaîne de remplissage \(PS\) est d'au moins huit octets, ce qui est une condition de sécurité dans PKCS#1v1.5 :
$$∣PS∣=k~−∣M∣−~3$$
Par exemple, avec un module RSA de \(1024\) bits, la valeur de \(k\) est de \(128\). Ici, Alice pourrait chiffrer jusqu'à \(128 - 11 = 117\) octets de données. Les \(11\) octets sont utilisés pour la structure \(0x00 ~||~ 0x02 ~||~ PS ~||~ 0x00\). Le \(PS \) aléatoire garantit que chaque chiffrement du même message produit un texte chiffré différent, évitant ainsi le problème du chiffrement déterministe.
RSA n'opère pas directement sur les octets. Une fois que la chaîne remplie \(EB\) est prête, elle doit être convertie en un entier guidé par la formule Octet String to Integer Primitive (OS2IP) :
$$x = \\sum\_{i=1}^{k} 2^{8(k - i)} \\,\\mathrm{EB}\_i$$
où \(EB\_i\) sont les octets de \(EB\) du premier au dernier. En d'autres termes, \(EB\_1\) (le premier octet) est l'octet le plus significatif, et \(EB\_k\) (le dernier octet) est le moins significatif. Alice peut maintenant simplement chiffrer ce bloc en utilisant \(C = x^c \\mod n\).
Pour solidifier nos acquis, appliquons cela à un exemple de texte en clair et trouvons les blocs remplis.
Supposons que le module RSA ait une longueur de \(8\) octets (\(k=8\)). Supposons que nous voulions chiffrer un message \(M\) de \(2\) octets de long. Alors la chaîne de remplissage \(PS\) doit remplir l'espace restant :
$$Total ~ octets=k=8=1(0x00)+1(BT)+∣PS∣+1(délimiteur)+∣M∣$$
Comme \(∣M∣=2\) et qu'il y a \(∣M∣=2∣\) octets fixes, nous pouvons trouver la longueur requise de la chaîne de remplissage :
$$∣PS∣=8−3−2=3 ~ octets$$
Choisissons 3 octets arbitraires non nuls pour \(PS\), disons - \(0xA3, ~0x5F, ~0xC2\). Et disons que le message est le texte ASCII « Hi ». En hexadécimal, c'est : \(0x48\) pour 'H' et \(0x69\) for 'i'.
Ainsi, le bloc de chiffrement complet devient :
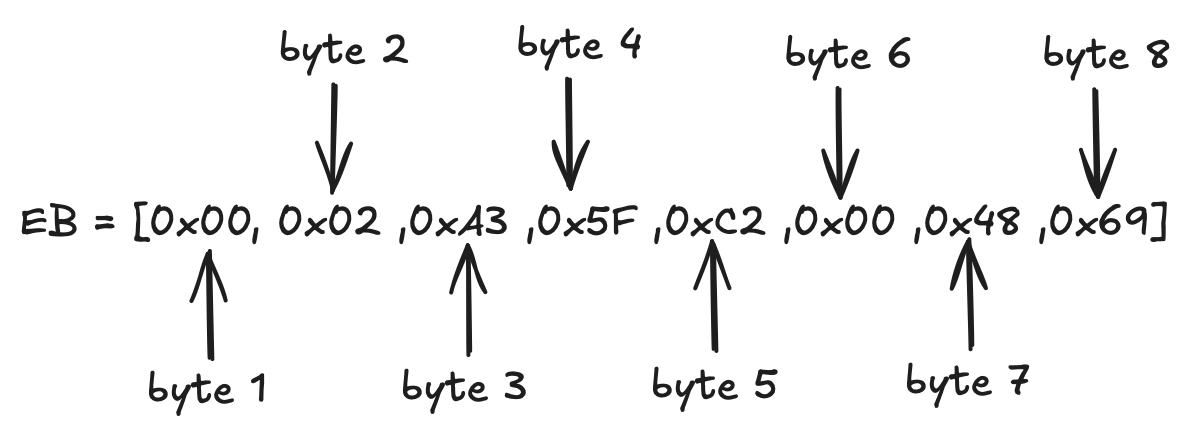
Nous allons maintenant convertir cette chaîne d'octets en un entier à l'aide de la formule OS2IP discutée ci-dessus :
$$x = \\sum\_{i=1}^{k} 2^{8(k - i)} \\,\\mathrm{EB}\_i$$
Pour notre exemple, avec \(k=8\), la conversion est :
$$x= 0x00×256^7+0x02×256^6+0xA3×256^5+0x5F×256^4+0xC2×256^3+0x00×256^2+0x48×256^1+0x69×256^0$$
Notez que les valeurs hexadécimales peuvent être converties en décimales si nécessaire. Par exemple, \(0xA3 = 163, 0x5F = 95, 0xC2 = 194, 0x48 = 72,\) et \(0x69 = 105\).
Il y a une observation intéressante dans l'application de cette formule. Comme les deux premiers octets sont fixes (\(0x00\) et \(0x02\)), l'entier \(x\) a une borne inférieure connue. La contribution des deux premiers octets est :
$$0×256^ 7 +2×256^ 6 =2×256^ 6$$
Le reste des octets (\(PS\), le délimiteur et \(M\)) ajoute une valeur qui est au moins \(0\) et au plus juste inférieure à \(256^6\) (puisque le deuxième octet est fixé à \(0x02\) et ne peut pas être \(0x03\)). Ainsi, \(x\) est dans la plage :
$$2×256 ^ 6 ≤x<3×256 ^ 6$$
Cette propriété qui rend la plage prévisible a ouvert la voie à l'attaque de Bleichenbacher (également connue sous le nom d'attaque par « oracle de remplissage »). Si un système révèle si un bloc déchiffré est « correctement rempli », un attaquant peut sonder systématiquement différents textes chiffrés et réduire les possibilités du texte en clair – car l'attaquant sait qu'il doit se situer dans cette plage étroite. Examinons en détail l'attaque de Bleichenbacher dans les sections suivantes et comprenons comment l'exploitation fonctionne.
L'attaque de Bleichenbacher
En 1998, Daniel Bleichenbacher a publié un article fondateur [8] démontrant une attaque à texte chiffré choisi adaptative contre RSA avec remplissage PKCS#1 v1.5. L'attaque de Bleichenbacher, également surnommée l'attaque du « million de messages », a démontré que si un attaquant a accès à un oracle qui indique si un texte chiffré soumis se déchiffre en un texte en clair correctement rempli (c'est-à-dire si le formatage PKCS#1 v1.5 est correct), l'attaquant peut progressivement récupérer le texte en clair complet. Décomposons le fonctionnement de cette attaque :
Premièrement, Eve a besoin d'un oracle. L'attaque suppose que l'attaquant peut interroger un système, tel qu'un serveur SSL/TLS, et découvrir si un texte chiffré \(C\) donné est conforme à PKCS#1 v1.5. Dans l'article de 1998, Bleichenbacher a exploité le fait qu'un serveur TLS, lorsqu'il était confronté à un secret pré-maître (premaster secret) chiffré par RSA mal rempli, répondait par une alerte d'erreur spécifique si le remplissage était incorrect. Essentiellement, le serveur agissait comme un oracle : il déchiffrait \(C\) avec sa clé privée et indiquait simplement à l'attaquant « remplissage OK » ou « erreur de remplissage » (l'erreur pouvait être basée sur le temps ou être une alerte explicite).
Notez que l'oracle ne révèle pas le texte en clair. Il ne révèle qu'un seul bit d'information à la fois : « remplissage valide ou non ». Cela peut sembler inoffensif, mais Bleichenbacher a montré que c'est suffisant pour finalement récupérer le texte en clair.
Pour récapituler rapidement, l'objectif de l'attaquant est de trouver l'entier de message inconnu \(m\) (le texte en clair rempli selon PKCS#1 sous forme d'entier) étant donné son texte chiffré \(C = m^e \\bmod N\), en utilisant l'oracle. Nous savons que si \(m\) est correctement rempli, il se situe dans une plage numérique spécifique : \(2B \\le m < 3B\) où \(B = 2^{8\*(k-2)}\), comme défini précédemment.
Si \(k=128\) octets, alors \(B=2^{8\*126}\), et un \(m\) correctement rempli commencera par \(0x00 ~||~0x02\), il est donc compris entre \(2B\) et \(3B\). L'attaquant, Eve, sait initialement seulement que \(m\) est dans la plage \(\[2B, 3B)\).
Dans l'attaque de Bleichenbacher, Eve exploitera la propriété multiplicative de RSA. Ils choisiront un nombre \(s\) (appelé multiplicateur) et calculeront un nouveau texte chiffré \(C' = (C s^e) \\bmod N\). Ce \(C'\) correspond ici à un nouveau texte en clair : \(m' = m s \\bmod N\) (car \(C' \\equiv m^e \* s^e \\equiv (ms)^e \\pmod{N}\)).
Pour commencer l'attaque, Eve trouve un certain \(s\_0\) tel que \(C\_0 = C \* (s\_0)^e \\mod N\) donne un remplissage valide. C'est ce qu'on appelle l'étape d'aveuglement (blinding). C'est généralement facile – par exemple, \(s\_0\) peut être choisi de sorte que \(m \* s\_0\) soit juste légèrement au-dessus de \(N\), ce qui bouclera presque certainement et atterrira dans \(\[2B,3B)\). L'attaquant ne connaît pas \(m\) pour vérifier cela directement. Ils s'appuient sur la réponse oui/non de l'oracle de remplissage pour déduire que le texte en clair aveuglé \((m×s\_0)\\mod N\) tombe dans la bonne plage.
Si l'oracle renvoie « remplissage valide » pour un \( s\_0\) donné, cela indique à l'attaquant que \(s\_0 \\mod N\) se situe entre \(2B\) et \(3B\). Mathématiquement :
$$2B≤(m×s\_0)~mod N<3B$$
Maintenant, Eve essaiera de réduire cette plage dans une boucle, ce que l'on appelle souvent l'étape de division de l'intervalle. Initialement, Eve avait un large intervalle \(\[a, b\] = \[2B, 3B)\) contenant \(m\). À chaque itération, Eve essaie des valeurs croissantes de \(s\) (en partant d'un certain minimum) jusqu'à ce que l'oracle renvoie « remplissage OK » pour \(C' = C\_0 \* s^e\). Supposons que cela se produise à un certain \(s = s\_i\). Étant donné ce retour, Eve sait maintenant :
$$2𝐵 ≤ (𝑚 × 𝑠\_i) ~ mod 𝑁 < 3𝐵$$
Cette congruence implique qu'il existe un entier \(r\) tel que :
$$2B ≤ ( m×s\_i)−rN < 3B$$
En réarrangeant, nous obtenons une contrainte sur \(m\) :
$$\\frac{2B+rN}{s\_i} ≤ m < \\frac{3B+rN}{s\_i}$$
Eve ne connaît pas \(r\) d'emblée, mais ils peuvent résoudre pour la plage possible de \(r\) en considérant l'intervalle actuel \(\[a,b\]\) pour \(m\). Essentiellement, Eve utilise les bornes précédentes sur \(m\) pour deviner quel \(r\) rendrait l'inégalité vraie, puis met à jour les nouvelles bornes \(\[a, b\]\) comme l'intersection de toutes les solutions possibles pour \(m\). Cela réduit considérablement l'intervalle.
Chaque requête à l'oracle produit une telle contrainte. Finalement, l'intervalle \(\[a,b\]\) s'effondre sur une seule valeur, \(\[a,a\]\). Maintenant, Eve peut trouver le texte en clair en utilisant :
$$m = (a × s\_i^{-1}) ~ mod N$$
À ce stade, Eve a récupéré l'intégralité du texte en clair rempli \(m\), et en retirant le remplissage, le message original lui-même.
Le diagramme de séquence ci-dessous consolide notre apprentissage de l'attaque :
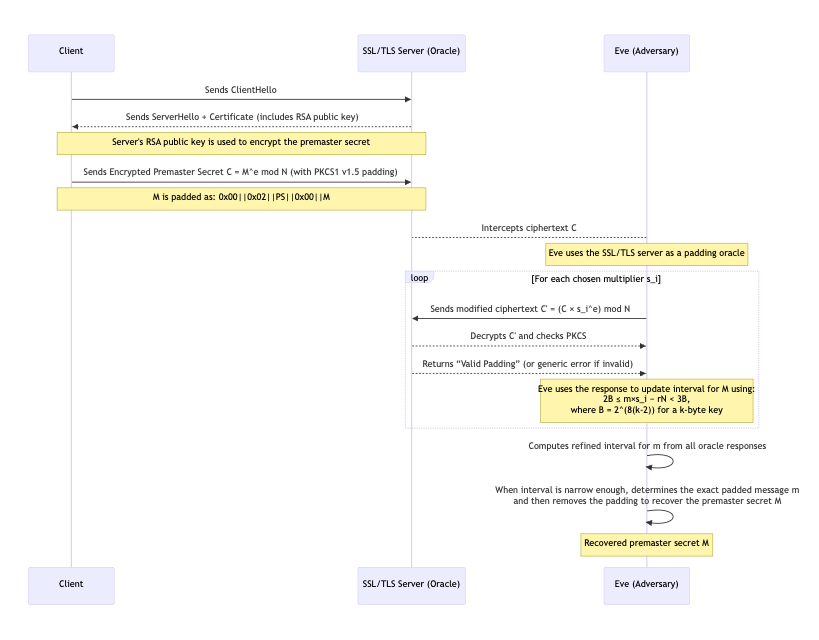
L'attaque de Bleichenbacher a montré que le format du remplissage dans PKCS#1 v1.5 faisait fuiter juste assez d'informations pour permettre une opération complète par clé privée (déchiffrement du message) sans jamais factoriser N. L'attaque a exploité le fait qu'il est possible de concevoir des textes chiffrés qui se déchiffreront en un texte en clair semblant valide sans connaître le texte en clair. En substance, le remplissage PKCS#1 v1.5 permettait environ \(1\) chance sur \(2^{16}\) (environ) pour qu'un bloc aléatoire apparaisse comme un « remplissage valide ». C'était suffisant pour qu'une attaque adaptative réussisse avec des requêtes réalisables.
C'est précisément ce que les conceptions de remplissage ultérieures comme OAEP ont corrigé. La conception d'OAEP rend de tels textes chiffrés valides aléatoires astronomiquement improbables (conscient du texte en clair - plaintext aware). Nous découvrirons RSA-OAEP dans les sections suivantes.
Pour atténuer l'attaque de Bleichenbacher sans changer immédiatement le schéma de remplissage, les praticiens ont mis en œuvre des mesures défensives. Par exemple, TLS doit traiter tous les échecs de déchiffrement de la même manière (afin qu'un attaquant ne puisse pas distinguer le remplissage des autres erreurs), et les serveurs généreraient un faux secret pré-maître en cas d'échec de remplissage pour continuer la poignée de main (handshake) et éviter les fuites temporelles. Néanmoins, l'option la plus sûre a été de désapprouver le chiffrement PKCS#1 v1.5 au profit de schémas comme RSA-OAEP.
Optimal Asymmetric Encryption Padding (OAEP)
À la fin de 1995, Bellare et Rogaway ont proposé l'Optimal Asymmetric Encryption Padding (OAEP) dans le but d'atteindre une sécurité prouvable. Ce remplissage visait à rendre le chiffrement RSA résistant non seulement aux attaques passives mais aussi aux attaques à texte chiffré choisi adaptatives. En d'autres termes, même si un attaquant peut piéger un système pour qu'il déchiffre des textes chiffrés choisis (en tant qu'« oracle »), il ne devrait rien apprendre d'utile sur le texte en clair. OAEP a ensuite été standardisé dans PKCS#1 v2.0 (publié sous le nom de RFC 2437 en 1998) et les versions ultérieures.
Comparé à PKCS#1 v1.5, OAEP a un encodage plus complexe qui utilise des fonctions de hachage et une fonction de génération de masque (MGF) pour rendre aléatoire de manière approfondie le texte en clair avant le chiffrement RSA, offrant des garanties plus fortes.
La conception d'OAEP peut être vue comme un réseau de type Feistel à deux couches utilisant une graine aléatoire. Il prend le message d'entrée et le rend aléatoire d'une manière qui n'est réversible qu'avec la bonne graine. Le schéma a été prouvé conscient du texte en clair (plaintext-aware) dans le modèle de l'oracle aléatoire, ce qui signifie qu'un adversaire ne peut pas concocter un texte chiffré valide sans connaître le texte en clair correspondant. Si un attaquant tente de forger ou d'altérer des textes chiffrés, il produit presque certainement un remplissage invalide qui sera rejeté. Cette propriété contre directement les attaques par oracle de remplissage.
OAEP (avec une fonction de hachage/MGF appropriée) est sémantiquement sûr contre les attaques à texte chiffré choisi adaptatives, en supposant que RSA est difficile à inverser et en traitant les fonctions de hachage comme des oracles aléatoires. Contrairement à PKCS#1 v1.5, qui manquait d'une preuve formelle, OAEP est accompagné d'une esquisse de preuve montrant que briser RSA-OAEP est aussi difficile que de briser RSA lui-même.
En pratique, cela signifie qu'OAEP réduit considérablement le risque de tout oracle de remplissage : un attaquant ne peut plus facilement trouver des textes chiffrés qui passent le contrôle de remplissage, sauf par force brute, ce qui a une probabilité de réussite de \(2^{-hLen\*8}\). Par exemple, la probabilité de réussite avec SHA-1 serait de \(2^{-160}\).
Le schéma fonctionnel ci-dessous est une représentation visuelle du schéma d'encodage OAEP :
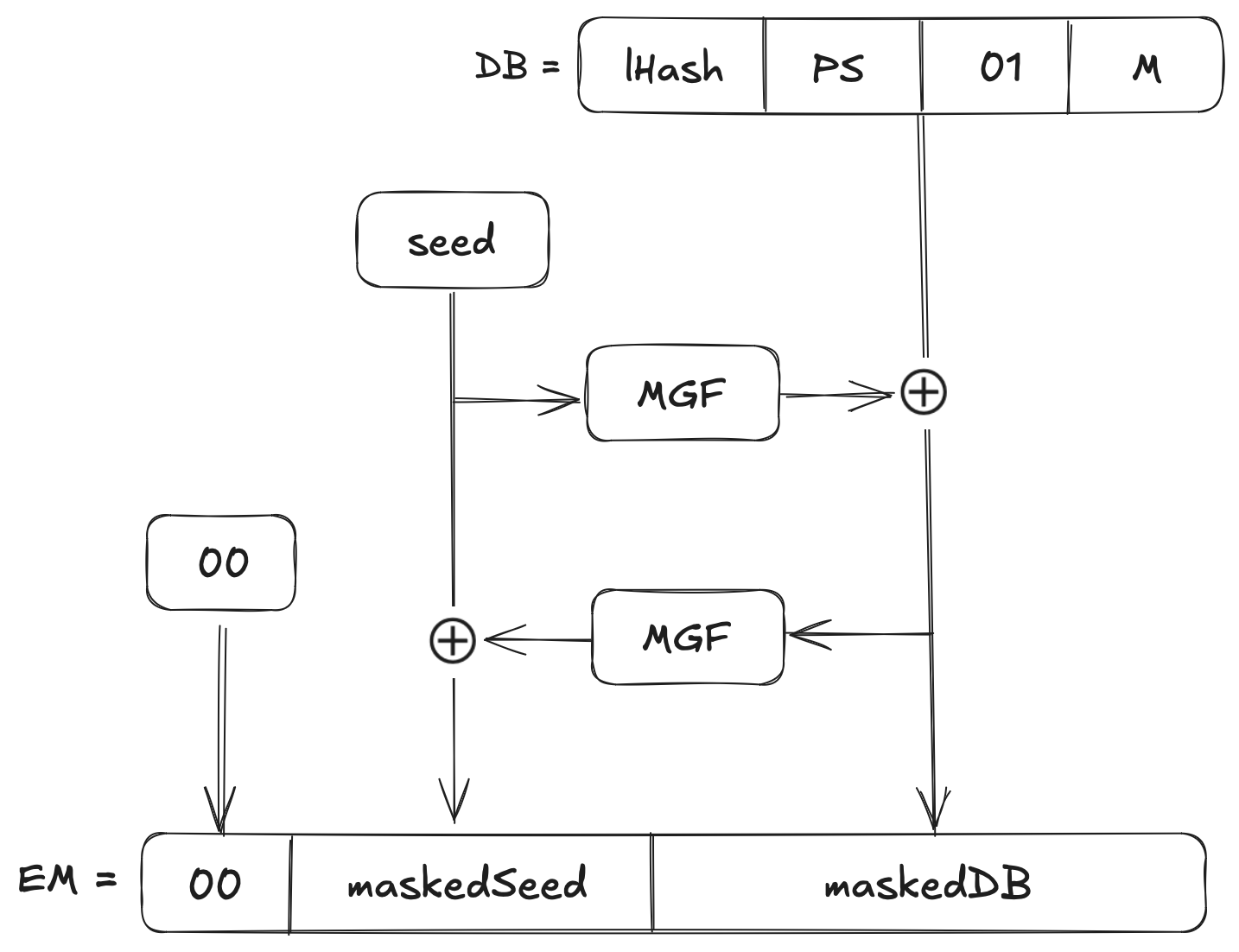
Comprenons ce que signifient ces notions mathématiques et le fonctionnement de RSA-OAEP dans ce qui suit.
Les mathématiques derrière OAEP
L'Optimal Asymmetric Encryption Padding nécessite une fonction de hachage pour deux opérations que nous aborderons dans cette section. Nous choisirons SHA-1 comme fonction de hachage dans OAEP et \(hLen\) désigne la longueur en octets de la sortie de la fonction de hachage. Nous démontrerons plus tard pourquoi même MD5 ou SHA-1 est un choix sûr pour OAEP même s'il n'est pas résistant aux collisions.
Avant de plonger dans les mathématiques, récapitulons quelques notations et définissons les éléments principaux que nous utiliserons :
Dans RSA, \(N\) est le module, et \(k\) est la taille de \(N\) en octets. Pour un module de \(2048\) bits, \(k=256\) octets.
\(M \) est le message ou le texte en clair à chiffrer. Ce texte en clair doit être suffisamment court pour tenir dans le bloc rempli (au plus \(k−2⋅hLen−2\) octets). Dans notre notation, \(Hash\) fait référence à la fonction de hachage cryptographique (par exemple, SHA-1, SHA-256) de longueur de sortie \(hLen\). Par exemple : si vous utilisez SHA-1, \(hLen=20\) octets.
Nous utiliserons également une chaîne facultative associée au message (souvent vide). Il s'agit de l'étiquette (label) \(L\). Si cette étiquette est vide, son hachage est une valeur fixe. (Par exemple : le SHA-1 d'une chaîne vide).
Le hachage de cette étiquette \(L\) est représenté par \(lHash\), où \(lHash=Hash(L)\). Comme mentionné précédemment, si \(L\) est vide, \(lHash\) est simplement \(Hash('')\). Cela signifie que dans tous les cas, \(lHash\) contiendra une valeur.
Nous utiliserons également une fonction de génération de masque, \(MGF\), qui est souvent mentionnée comme \(MGF1\). Cette fonction prend une entrée (graine ou données masquées) et produit une sortie d'une longueur spécifiée en itérant la fonction de hachage sous-jacente. Nous écrirons \(MGF(entrée, longueur)\) pour indiquer « générer un masque de \(longueur\) octets à partir de \(entrée\) ».
Maintenant que vous êtes familier avec toutes les notations nécessaires, nous sommes prêts à commencer l'étape d'encodage.
Étape 1 : Construction du bloc de données (Data Block - DB)
Nous calculerons \(lHash=Hash(L)\). Si \(L\) est vide, \(lHash\) est une constante (par exemple, le SHA-1 de la chaîne vide).
Formons la chaîne de remplissage \(PS\), la longueur de \(PS\) est choisie de sorte que le bloc entier \(DB\) ait une longueur de \((k−hLen−1)\) octets. Numériquement, \(PS\) contient \((k−mLen−2⋅hLen−2)\) octets de \(0x00\), où \(mLen\) est la longueur du message \(M\).
Maintenant, nous concaténons simplement les blocs pour générer la chaîne d'octets pour le bloc de données (\(DB\)) :
$$DB=lHash~∣∣~PS~∣∣~0x01~∣∣~M$$
Ici, l'octet unique \(0x01\) agit comme un délimiteur qui marque où s'arrête le remplissage de zéros et où commence le message réel \(M\). \(DB\) finit par faire \((k−hLen−1)\) octets.
Étape 2 : Génération d'un masque pour le bloc de données
Tout d'abord, nous choisissons une chaîne aléatoire appelée graine (\(seed\)) d'une longueur de \(hLen\) octets. Par exemple, lors de l'utilisation de SHA-1 où \(hLen=20\), nous disons que la graine se compose de \(20\) octets aléatoires.
Nous utilisons maintenant la fonction de génération de masque, \(MGF\), sur la graine (\(seed\)) pour créer un masque de la même longueur que \(DB\) :
$$dbMask=MGF(seed, k−hLen−1)$$
L'idée est de propager l'aléa de la graine sur l'ensemble du \(DB\).
Étape 3 : Masquer le bloc de données
Maintenant, nous allons combiner \(DB\) et \(dbMask\) avec l'opération XOR bit à bit :
$$maskedDB=DB \\oplus dbMask$$
Cette étape « brouille » \(DB\) avec la graine aléatoire.
Étape 4 : Génération d'un masque pour la graine
Ensuite, nous produirons un masque pour la graine elle-même, basé sur \(maskedDB\) :
$$seedMask=MGF(maskedDB, hLen)$$
Cette étape garantit simplement que la graine n'est pas laissée en clair.
Étape 5 : Masquer la graine
Maintenant, nous allons combiner la graine originale et le nouveau masque avec une opération XOR :
$$maskedSeed=seed \\oplus seedMask$$
Désormais, la graine est également « brouillée » par le bloc de données.
Étape 6 : Formation du message encodé final (EM)
Nous sommes maintenant prêts à construire notre bloc final. Concaténez simplement le tout dans une chaîne de \(k\) octets :
$$EM=0x00~∣∣~maskedSeed~∣∣~maskedDB$$
L'octet de tête \(0x00\) garantit que lorsque \(EM\) est interprété comme un entier, il est inférieur au module RSA \(N\). À ce stade, \(EM\) est votre message rempli par OAEP de longueur \(k\).
Étape 7 : Conversion de la chaîne concaténée en entier
Rappelez-vous de notre discussion précédente sur PKCS#1v1.5 que RSA ne peut pas opérer directement sur cette chaîne concaténée d'octets. Nous devons convertir le bloc \(EM\) en un entier non négatif à l'aide de la formule OS2IP :
$$x = \\sum\_{i=1}^{k} 2^{8(k - i)} \\,\\mathrm{EB}\_i$$
Étape 8 : Exécution du chiffrement RSA
Maintenant que nous avons le message encodé (\(EM\)) sous forme d'entier \(x\), nous sommes prêts à effectuer le RSA guidé par la formule :
$$C =x^e \\bmod N$$
où \((e,N)\) est la clé publique. Le \(C\) ainsi calculé est notre texte chiffré généré à l'aide de RSA-OAEP.
Lors du déchiffrement, le processus est inversé : le destinataire utilise sa clé privée \(d\) pour calculer \(m = c^d \\bmod N\), récupère l'\(EM\), puis le divise en \(0x00\), \(maskedSeed\) et \(maskedDB\), et utilise la même \(MGF\) et la même fonction de hachage pour démêler les XOR dans l'ordre inverse. Enfin, ils vérifient que le \(lHash'\) récupéré correspond au hachage attendu et que le bloc contient la structure appropriée (\(...||0x01||...\)).
Si une vérification échoue, le remplissage est invalide. Le message \(M\) n'est renvoyé que si tout est vérifié. Le résultat est qu'un texte chiffré invalide sera presque toujours détecté et rejeté sans donner à un attaquant d'informations utiles.
Par conception, OAEP a efficacement déjoué le problème de l'oracle de remplissage. La chance qu'une supposition aléatoire produise un encodage OAEP valide est négligeable : de l'ordre de \(2^{-hLen\*8}\). En fait, Daniel Bleichenbacher (après avoir brisé PKCS#1 v1.5) a préconisé exactement un tel remplissage « conscient du texte en clair » où forger un remplissage valide est infaisable.
Pourquoi SHA-1 ou MD5 sont sûrs dans RSA-OAEP
Plus tôt dans la section ci-dessus, nous avons mentionné que nous utiliserions SHA-1 pour notre formulation mathématique et nos exemples. Lorsque vous voyez SHA-1 ou MD5 utilisés dans le contexte de RSA-OAEP, ne soyez pas alarmé par le fait que ces fonctions de hachage sont considérées comme brisées pour la résistance aux collisions. Si vous remarquez attentivement dans la section précédente, les fonctions de hachage servent deux rôles très spécifiques qui ne reposent pas sur leur résistance aux collisions. Décomposons-les un par un :
Hachage d'étiquette (Label Hashing)
La fonction de hachage est utilisée pour calculer un hachage de longueur fixe d'une étiquette (label) facultative \(L\) (souvent vide).
Voyons maintenant pourquoi cela est sûr dans ce contexte. Ce hachage, appelé \(lHash\), agit comme un séparateur de domaine. Son rôle est simplement de s'assurer que l'étiquette est correctement associée au texte chiffré lors du déchiffrement. Tant que l'étiquette est choisie judicieusement (c'est-à-dire qu'elle n'est pas construite à partir de parties contrôlées par l'adversaire), la résistance aux collisions n'est pas critique ici.
Fonction de génération de masque (MGF1)
La fonction de hachage est également utilisée à l'intérieur de \(MGF1\) pour créer un masque pseudonyme. Ce masque est appliqué à la fois au bloc de données \(DB\) et à la graine aléatoire utilisée dans le processus d'encodage.
Dans ce contexte, la fonction de hachage est traitée comme un oracle aléatoire. Le rôle est de propager l'aléa de la graine sur un bloc de données plus grand. À cette fin, des propriétés telles que l'extension de longueur ou la résistance aux collisions ne sont pas pertinentes. Ce qui importe, c'est que la sortie semble aléatoire, et même SHA-1 ou MD5 peuvent fournir cela lorsqu'ils sont utilisés dans ce scénario contrôlé à entrée fixe.
Adoption dans les bibliothèques cryptographiques (PKCS#1 v1.5 vs OAEP)
Après l'attaque de Bleichenbacher, les standards et les bibliothèques ont migré vers OAEP ou ont au moins ajouté sa prise en charge, tout en traitant PKCS#1 v1.5 comme une option héritée (legacy). Les bibliothèques et protocoles cryptographiques modernes reflètent ces leçons.
En 1998, le standard RSA a été mis à jour. PKCS#1 v2.0 a introduit RSAES-OAEP comme nouveau schéma de chiffrement recommandé, et depuis PKCS#1 v2.1 et v2.2 (RFC 3447 et RFC 8017), OAEP est requis pour les nouvelles applications, PKCS#1 v1.5 n'étant inclus que pour la compatibilité ascendante.
OpenSSL décourage les utilisateurs d'utiliser PKCS#1 v1.5 car il laisse fuiter des informations qui peuvent potentiellement être utilisées pour monter une attaque par oracle de remplissage de Bleichenbacher [10]. La documentation mentionne clairement qu'il est fortement recommandé d'utiliser RSA_PKCS1_OAEP_PADDING dans les nouvelles applications.
La bibliothèque Python cryptography (PyCA cryptography) demande également aux développeurs d'utiliser OAEP pour le chiffrement au lieu de PKCS#1 v1.5 [11].
Après l'attaque de Bleichenbacher en 1998, il était impraticable de remplacer instantanément PKCS#1 v1.5 partout. Au lieu de cela, les concepteurs de protocoles ont publié des contre-mesures.
TLS, par exemple, a répondu en modifiant la gestion des erreurs : le serveur ne révélait pas distinctement un échec de remplissage. Il générait un faux secret pré-maître et continuait pour éviter les indices temporels, et renvoyait toujours un échec générique de poignée de main à une étape ultérieure, ce qui rendait plus difficile pour l'attaquant de distinguer pourquoi le déchiffrement avait échoué.
Ces contre-mesures ont réduit la fidélité de l'oracle mais étaient difficiles à implémenter correctement dans les différentes versions. En fait, tout le monde n'y est pas parvenu – l'attaque de Bleichenbacher a continué à refaire surface sous diverses formes lorsque les implémentations faisaient des erreurs dans la gestion des erreurs.
En 2018, des chercheurs ont découvert l'attaque ROBOT (Return Of Bleichenbacher’s Oracle Threat) : plusieurs implémentations TLS présentaient des bugs subtils qui recréaient un oracle de remplissage, permettant à l'attaque de réussir 19 ans plus tard. L'article ROBOT a montré que même avec des directives de contre-mesures, la complexité de la gestion uniforme des erreurs entraînait des dérapages dans des produits populaires.
Cela souligne que corriger un schéma non sécurisé est souvent source d'erreurs – une conception sécurisée par construction (comme OAEP) est préférable.
PKCS#1 v1.5 continue d'exister en raison de ces mesures de sécurité de fortune et du fait qu'il ne peut pas être supprimé brusquement de tous les systèmes existants. Il est généralement considéré comme « hérité » ou maintenu à des fins de « compatibilité ». La sagesse collective est claire : utilisez OAEP pour le chiffrement RSA chaque fois que possible.
Amélioration des signatures numériques : la transition vers PSS
Maintenant que vous comprenez comment OAEP a transformé le chiffrement RSA en atténuant les vulnérabilités du remplissage déterministe, il est temps de porter notre attention sur les signatures numériques RSA – une fonction critique pour garantir l'intégrité et l'authenticité des messages.
Les premiers schémas de signature RSA souffraient de problèmes similaires au chiffrement brut : leur nature déterministe les rendait sujets aux attaques par forge et par rejeu. Cette vulnérabilité a ouvert la voie à une amélioration : le Probabilistic Signature Scheme (PSS).
Avant de plonger dans PSS lui-même, comprenons rapidement les points sensibles des premières signatures RSA.
Problèmes avec les premiers schémas de signature RSA
Les signatures RSA traditionnelles étaient générées en appliquant simplement la fonction de déchiffrement RSA sur une empreinte de message (digest), souvent avec un formatage minimal :
$$s=m^d \\bmod N$$
où \(m\) est le hachage (ou le hachage encodé) du message. Cette approche était déterministe, ce qui signifiait que chaque fois que le même message était signé, la signature exacte était produite. Un tel déterminisme présentait deux inconvénients majeurs :
Prévisibilité et rejeu
Comme la signature pour un message donné était toujours identique, un attaquant pouvait rejouer une signature capturée en toute impunité ou forger des signatures s'il pouvait déduire des motifs dans le schéma de signature.
Risques de forge
Dans un cadre déterministe, si un attaquant trouve une structure ou une relation mathématique dans la signature, il pourrait être capable de forger une signature valide pour un nouveau message. Dans certains scénarios, un formatage faible pourrait permettre à un adversaire de créer une « transformation de signature » qui produit une signature valide sans avoir accès à la clé privée.
Ces problèmes ont souligné qu'un schéma de signature doit être probabiliste pour être sécurisé contre les tentatives de forge adaptatives et pour garantir la non-répudiation. Cela signifie que le signataire ne devrait pas pouvoir répudier une signature car elle est liée à une valeur aléatoire connue uniquement au moment de la signature.
Naissance du Probabilistic Signature Scheme (PSS)
Vers la fin de 1998, Bellare et Rogaway ont également proposé un schéma pour surmonter les limitations inhérentes aux signatures RSA déterministes [12]. L'idée centrale était d'introduire de l'aléa dans le processus de génération de signature afin que, même en signant deux fois le même message, les signatures résultantes soient différentes. Cet aléa provient d'une valeur de sel (salt) et d'un processus d'encodage soigneusement conçu. Le résultat est une méthode de signature avec des garanties de sécurité fortes et prouvables.
Cet aléa empêche les attaquants d'exploiter des motifs dans le processus de signature. Le Probabilistic Signature Scheme a été conçu pour être prouvablement sûr dans le modèle de l'oracle aléatoire, ce qui signifie que forger une signature serait aussi difficile que de briser RSA lui-même sous certaines hypothèses [13].
Le schéma fonctionnel ci-dessous est une représentation visuelle du schéma d'encodage PSS :
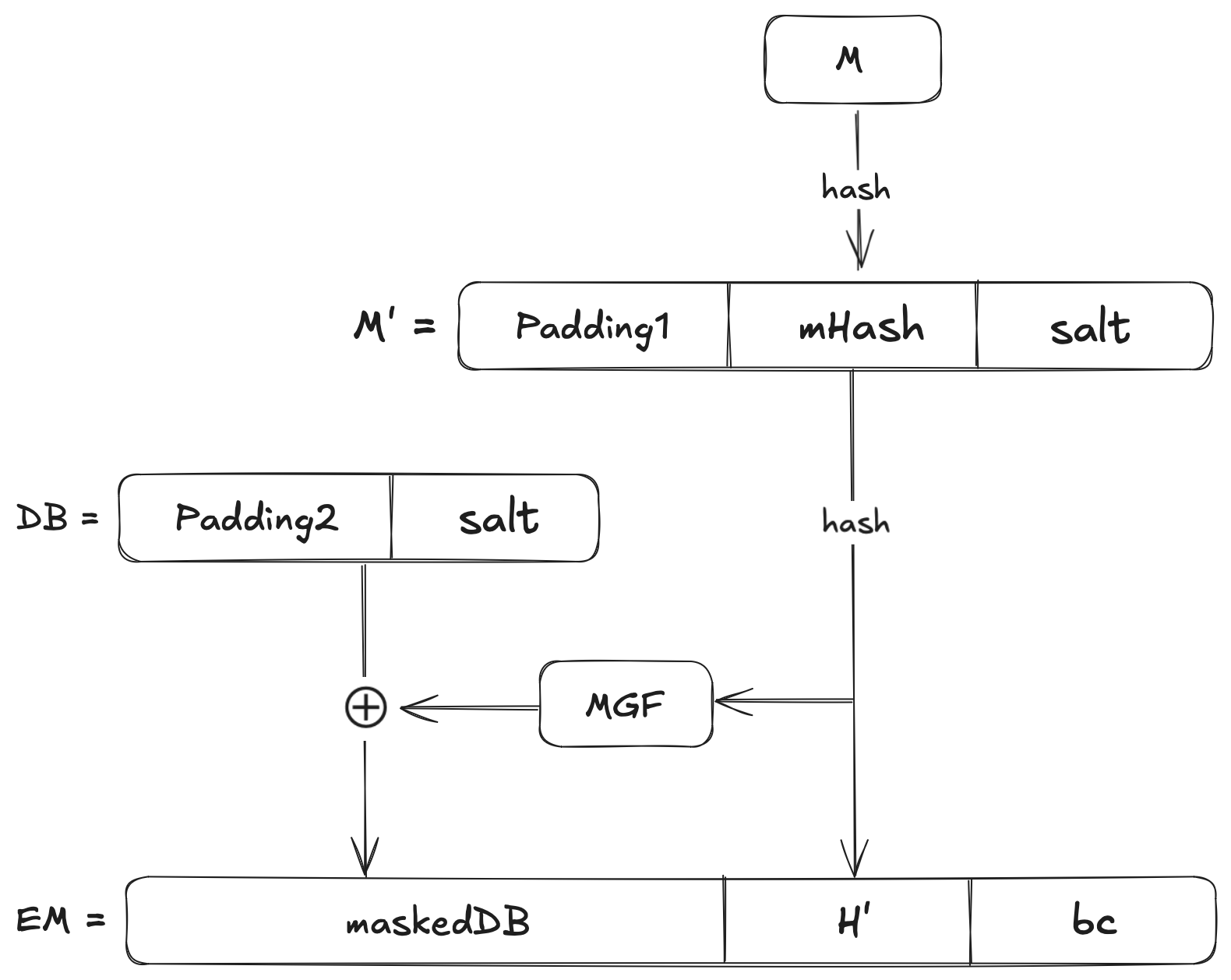
Comprenons ce que signifient ces notions mathématiques ainsi que le fonctionnement de RSA-PSS dans ce qui suit.
Les mathématiques derrière PSS
Avant de plonger dans la mécanique de RSA-PSS, il est utile de définir les notations et les termes que vous verrez dans les étapes à venir.
Dans RSA, \(N\) est le module, un grand entier qui est le produit de deux nombres premiers. \(k\) est la longueur de \(N\) en octets. Pour une clé de \(2048\) bits, \(k=256\) octets.
\(M\) représente les données du message ou le document que vous souhaitez signer. Dans RSA-PSS, vous calculerez généralement d'abord un hachage de \(M\). \(Hash\) fait référence à une fonction de hachage cryptographique (par exemple, SHA-256) qui mappe les données à une sortie de taille fixe. La longueur de sortie est notée \(hLen\). Pour SHA-256, \(hLen=32\) octets.
Nous utiliserons un sel, \(S\), une chaîne générée aléatoirement de longueur fixe (souvent la même que \(hLen\)). Cet aléa est essentiel pour garantir que chaque signature est unique, même pour le même message.
\(H\) ou \(mHash\) est le hachage du message \(M\) et \(H'\) est un hachage secondaire qui inclut à la fois \(M\) et le sel \(S\). Cela apparaît dans l'étape d'encodage PSS.
La fonction de génération de masque, \(MGF\), est une fonction qui utilise le hachage en interne pour produire une sortie pseudonyme de longueur arbitraire. Dans PSS, elle est utilisée pour « masquer » des parties du bloc de données afin que la signature soit difficile à forger.
Un octet fixe, \(0xbc\) (en hexadécimal) est ajouté à la fin du message encodé pour marquer la limite de la structure PSS. Cela sert de simple vérification d'intégrité lors du décodage. Après un encodage réussi, nous recevons un message encodé \(EM\) qui est une chaîne d'octets de longueur \(emLen = \\left\\lceil{\\frac{emBits}{8}}\\right\\rceil\).
Maintenant que vous êtes familier avec toutes les notations nécessaires, nous sommes prêts à commencer l'étape d'encodage.
Étape 1 : Hachage du message et génération du sel
Nous calculons le hachage du message comme \(H~( mHash)=Hash(M)\) où \(M\) est notre message. Nous créerons également un sel aléatoire \(S\) (de longueur fixe, disons 20 octets si vous utilisez SHA-1).
Étape 2 : Encodage du hachage avec le sel (PSS-Encode)
Nous allons construire un bloc de données, \(DB\), en combinant un remplissage avec le hachage et le sel. Le remplissage est une séquence de \(0\) qui remplit l'espace et garantit une longueur fixe. Mathématiquement :
$$M' = (0x)~00 ~00 ~00 ~00 ~00 ~00 ~00 ~00 ~||~ mHash ~||~ salt$$
Maintenant, nous calculons le hachage de ce bloc comme \(H' = Hash(M')\). Nous allons générer une autre chaîne d'octets \(PS\) et la concaténer avec le sel et \(0x01\) comme délimiteur :
$$DB = PS ~||~ 0x01 ~||~ salt$$
Notez que DB est une chaîne d'octets de longueur \(emLen - hLen - 1\). Le masque que vous voyez dans la représentation visuelle ci-dessus doit être de cette longueur. Mathématiquement :
$$dbMask = MGF(H, emLen - hLen - 1)$$
Nous appliquerons ensuite ce masque sur le bloc \(DB\) à l'aide d'une opération XOR pour produire notre \(maskedDB\) :
$$maskedDB = DB \\oplus dbMask$$
Rappelez-vous que \(emLen\) est la longueur prévue du message encodé \(EM\) et \(hLen\) est la longueur de la sortie du hachage. Nous ajoutons maintenant un champ de fin (trailer) fixe \(0xbc\) et produisons le message encodé dans sa représentation en chaîne d'octets :
$$EM = maskedDB ~||~ H ~||~ 0xbc$$
Ce processus d'encodage garantit que le sel et le hachage sont mélangés de manière non réversible et pseudonyme. L'aléa du sel est « propagé » sur le bloc de données par la \(MGF\), ce qui rend extrêmement difficile pour tout adversaire de manipuler la signature.
Étape 3 : Génération de la signature RSA
Une fois que vous avez le message encodé \(EM\), la signature RSA est produite en utilisant la clé privée RSA. Tout d'abord, convertissez la chaîne d'octets en sa représentation entière à l'aide de la méthode OS2IP dont nous avons discuté précédemment. Appliquez ensuite l'opération de clé privée RSA :
$$s=m^d \\bmod N$$
où \(d\) est l'exposant privé et \(N\) est le module RSA.
Étape 4 : Vérification de la signature
À l'extrémité réceptrice, lorsqu'un destinataire souhaite vérifier une signature, il inverse le processus :
$$m′= s^e \\bmod N$$
et convertit \(m'\) en un message encodé \(EM\). Le vérificateur extrait ensuite les composants \((MaskedDB, H′, trailer)\) et recalcule \(H'\) à partir du message et du sel. Le vérificateur confirme que le hachage et le sel intégrés dans \(EM\) correspondent à ce qui est attendu. Si tout est vérifié, la signature est valide.
L'avenir : évaluer la viabilité à long terme de RSA
En 1994, l'algorithme de Peter Shor [14] a démontré qu'un ordinateur quantique peut factoriser de grands entiers en temps polynomial, brisant ainsi efficacement le problème difficile sous-jacent de RSA – la difficulté de factoriser \(N = p \\times q\).
Bien que les ordinateurs quantiques expérimentaux aient progressé, ils sont encore loin d'avoir le nombre de qubits stables requis pour briser les clés RSA de tailles pratiques (2048 ou 4096 bits).
En prévision des ordinateurs quantiques à grande échelle, la communauté cryptographique développe et standardise activement des algorithmes que l'on croit résistants aux attaques quantiques. Ceux-ci incluent des schémas à base de réseaux (tels que CRYSTALS-Kyber et NTRU), la cryptographie à base de codes (telle que le cryptosystème de McEliece), les signatures à base de hachage (telles que XMSS) et les cryptosystèmes à polynômes multivariés.
Il est important de noter que si OAEP et PSS améliorent la sécurité de RSA contre les attaques classiques, ils ne protègent pas RSA des attaques quantiques. Dans un monde post-quantique, même le remplissage classique le plus sûr n'empêchera pas un ordinateur quantique de briser RSA en utilisant l'algorithme de Shor.
À court terme, RSA reste largement utilisé et, lorsqu'il est implémenté avec des schémas de remplissage tels qu'OAEP et PSS, continue de fournir une sécurité robuste contre les adversaires classiques. Mais à l'avenir, on s'attend à ce que les organisations migrent progressivement vers des algorithmes post-quantiques à mesure qu'ils mûrissent et deviennent standardisés.
Références
[1] FIPS 186-5: Standard de signature numérique (DSS)
[2] RFC 8017 PKCS #1: Spécifications de la cryptographie RSA
[4] Ronald L. Rivest, Robert D. Silverman: Les nombres premiers forts sont-ils nécessaires pour RSA?
[6] OpenSSL Github: rsa_chk.c
[7] RFC 2313: PKCS #1: Chiffrement RSA
[8 ] Daniel Bleichenbacher: Attaques à texte chiffré choisi contre les protocoles basés sur le standard de chiffrement RSA PKCS #1
[9] RFC 8017: Spécifications de la cryptographie RSA PKCS #1 Version 2.2
[10] RSA_public_encrypt: Avertissements
[11] pyca/PKCS1v1
[12] Probabilistic signature scheme
[13] RFC 8017: RSASSA-PSS
[14] Algorithmes pour le calcul quantique : logarithmes discrets et factorisation